Publiée une fois par année, la Revue électronique suisse de science de l'information (RESSI) a pour but principal le développement scientifique de cette discipline en Suisse.
Publié par Ressi
S'applique aux numéros publiés et contenus disponibles au public.
N°8 décembre 2008
Ressi — 9 décembre 2008
Sommaire - N°8, Décembre 2008
Comptes-rendus d'expériences :
- La théorie sur la "voie verte" de l'Open Access - Jocelyne Jerdelet et Sandrine Reyes
Evénements :
- Un exemple de coopération et de solidarité: les 10 ans d’« Archivistes sans Frontières » - Alfred Garcia i Puig, adap. Didier Grange et Giovanni Gregoletto
- Intelligence économique et gestion des risques : mieux maîtriser l'incertitude [5ème Journée franco-suisse Intelligence économique et veille stratégique - Neuchâtel - 12 juin 2008] - Jacqueline Deschamps, François Courvoisier, Françoise Simonot
Concordance des classifications et étude comparative du recoupement des collections : les bibliothèques de la Faculté des Sciences de l'Université de Genève
Ressi — 30 avril 2008
Résumé
Cette étude évalue la collection de monographies de la Faculté des Sciences de l'Université de Genève. Sur cette base, une étude plus approfondie peut être menée dans le but de mettre en place une politique d'acquisition et une gestion des collections communes des sept bibliothèques de la faculté. Un tableau de concordance entre les sept classifications a été établi afin d'obtenir un référentiel commun et d'étudier les sujets couverts par plusieurs bibliothèques. Des scripts Python ont été développés pour obtenir des statistiques de recoupement des collections. L'algorithme UPGMA de GNU-R a été appliqué pour créer un dendrogramme, essai original de comparaison des collections. Les résultats mettent en évidence les recoupements et redondances entre les sept collections et un manque de consistance dans leur gestion.
En parallèle aux classifications en usage dans chaque bibliothèque, une classification commune basée sur le tableau de concordance faciliterait la mise en place d'une politique documentaire globale et cohérente. Affiner cette analyse requiert une étude des collections complètes, notamment en ce qui concerne les niveaux des documents et leurs usages.
Abstract
This analysis lends an initial assessment of the monograph collection of the Faculty of Science at the University of Geneva. These results can be used as a basis for a more detailed study aiming to help the establishment of a common management of the libraries' collections in the future. In order to allow the comparative study of the subjects covered by the libraries, a table of correspondence was constructed to provide insight and a common reference point for the classifications used in the seven locations. Statistical data concerning overlaps in the different collections were gathered using Python scripts, and a dendrogram was created using the GNU-R's UPGMA algorithm. The results showed some management inadequacies including cross-checking and redundancy across the seven collections. In parallel with the currently used classifications in each library, a common classification based on the correspondence table can be implemented to facilitate the set-up of a global and coherent collection development and management policy. To take this study further, we can consider the entire collections and take into account the documents' levels and their usage.
Mots-Clés:
Etude des collections, Classification, Politique documentaire, Bibliothèque scientifique universitaire
Dernière modification:
23/06/2009 1 Introduction
Cette étude a pour objet d’établir une concordance entre les classifications utilisées pour les monographies dans les bibliothèques de la Faculté des Sciences de l’Université de Genève, et d'étudier le recoupement documentaire d’une partie des collections de ces bibliothèques. De telles informations sont nécessaires pour débuter une étude détaillée des collections de ces bibliothèques, et finalement mettre en place une politique d’acquisition commune aux bibliothèques de la Faculté.
La Faculté des Sciences de l'Université de Genève comporte six bibliothèques, correspondant à des sections ou départements, soit les bibliothèques d’anthropologie, de mathématiques, de l’Observatoire, de physique, de Sciences II (biologie, chimie et sciences pharmaceutiques) et des Sciences de la Terre. Le Centre universitaire d’informatique (CUI) a été également intégré à cette étude car il est lié à plusieurs facultés dont celle des Sciences. Toutes ces bibliothèques sont situées à moins d’un quart d’heure de marche les unes des autres, sauf celle de l’Observatoire qui se trouve à 20 kilomètres.
En terme de collection (monographies et périodiques reliés), la bibliothèque de Sciences II est la plus importante avec 68'700 volumes, viennent ensuite les mathématiques avec 43'339 volumes, les Sciences de la Terre avec 43'000 volumes, la physique avec 34'360 volumes, l’anthropologie avec 20'600 volumes, l’Observatoire avec 20'095 volumes et le CUI avec 12'500 volumes.
Jusqu’à présent, ces sept bibliothèques fonctionnaient de manière relativement autonome. Elles sont sous la direction de leur section ou département respectif. Dans le but d’améliorer la qualité des services des différentes bibliothèques, plusieurs projets, tel un site Web commun, ont été lancés. De même, l’idée d’une politique d’acquisition commune à toutes les bibliothèques des Sciences est née.
Suite à l’arrivée d’une nouvelle Directrice de l’information scientifique à l’Université, un projet identique a été initié pour toute l’institution. Cette étude a débuté avant la création de ce poste, mais les résultats seront évidemment utiles dès le début du processus de création d’une politique d’acquisition, qu’elle soit facultaire ou institutionnelle.
2 Méthodologie
Cette étude a débuté par les visites des sept bibliothèques afin d’obtenir leurs classifications et de rencontrer leurs responsables pour avoir des renseignements supplémentaires concernant ces classifications (contexte, historique, évolution, etc.).
Un tableau de concordance a ensuite été établi entre la CDU (Classification décimale universelle) (UDC Consortium, 2004) et les classifications utilisées (voir tableau 1 pour un extrait de ce tableau). La CDU a été choisie comme référence car celle-ci est utilisée dans deux des bibliothèques concernées et possède une version récente datant de 2004 en français. Les concordances ont été définies manuellement par Aline Maurer et Cynthia Dufaux en comparant les diverses classifications à la CDU. Cela leur a été facilité par leurs connaissances en sciences, toutes deux étant de formation scientifique (respectivement biologie/botanique et sciences de la Terre).
Les classifications utilisées par les bibliothèques diffèrent dans leur degré de détails. Celle d’anthropologie est par exemple très générale, alors que celle du CUI, avec trois niveaux, est très détaillée. Le niveau hiérarchique de chaque indice CDU a été choisi au plus proche de celui de la classification locale, et est parfois plus élevé lorsque la CDU n’était pas assez détaillée. Pour la classification du CUI, tous les niveaux n’ont pas été pris en compte car ils étaient trop détaillés par rapport à la CDU.
Ce tableau a permis ensuite de déterminer les sujets communs à plusieurs bibliothèques. Seuls les indices CDU ayant un équivalent dans trois bibliothèques ou plus ont été retenus pour être étudiés, le nombre de documents concernés étant déjà conséquent.
A noter que dans le texte, le terme « domaine » est utilisé pour les thèmes représentés par deux chiffres dans la CDU, à l’exception de l’informatique (trois chiffres pour des raisons historiques). Les domaines sont par exemple les mathématiques, la physique, la biologie, etc. Le terme « sujet » désigne les subdivisions de ces domaines.
Afin de mieux comparer les sujets identiques dans plusieurs bibliothèques, une deuxième visite sur place a permis de déterminer de façon plus précise lesquels étaient traités par les documents présents dans les indices retenus.
Un programme informatique, comprenant deux scripts, a également été créé pour obtenir des statistiques concernant le nombre de documents se trouvant dans plusieurs bibliothèques, et donc les taux de recoupement entre les bibliothèques. Le premier script va chercher les notices bibliographiques dans le catalogue du Réseau des bibliothèques genevoises (Réseau des bibliothèques genevoises, 2007) pour un indice donné. La recherche est faite par classification, c’est-à-dire par un sigle décrivant la bibliothèque suivi de l’indice (ex : « ge-ussa O » pour l’indice O en anthropologie). Cette classification est saisie lors du catalogage d’un document en zone 980_2 du format MARC21. Le deuxième script compare le résultat du premier avec l’indice en question pour éliminer les notices ne correspondant pas à la recherche (erreurs et doublons). Ce script produit également un tableau avec un indice recherché par ligne, et en colonne les bibliothèques possédant les documents représentés par chaque indice.
Les résultats obtenus permettent d’analyser la cohérence de l’échantillon étudié des collections de la Faculté des Sciences, et de faire des suggestions pour la mise en place d’une future politique d’acquisition commune aux sept bibliothèques.
3 Résultats
3.1 Tableau de concordance des classifications
Le tableau 1 présente un extrait du tableau de concordance (celui-ci comportant environ 110 pages, il n’est pas inclus dans cet article mais est disponible sur demande).
Un indice CDU est attribué à chaque indice de chaque classification. Ainsi le tableau se compose, dans la colonne de gauche, des indices CDU retenus et des intitulés correspondants, puis à droite, sur deux colonnes par bibliothèque, des indices locaux et leur intitulé. Le degré de spécificité des indices CDU retenus est très variable, étant donné que les classifications étudiées ont des degrés de précision différents. Par contre, les indices généraux CDU qui n’avaient pas de correspondance, mais dans lesquels des sous-indices étaient utilisés dans le tableau, ont été rajoutés. Le tableau se compose ainsi de 1031 indices CDU, dont 151 ne correspondent pas à des indices appartenant aux autres classifications mais sont les indices généraux des indices spécifiques retenus.
Pour chaque indice CDU retenu, il est donc possible de savoir combien de bibliothèques possèdent des ouvrages y correspondant.
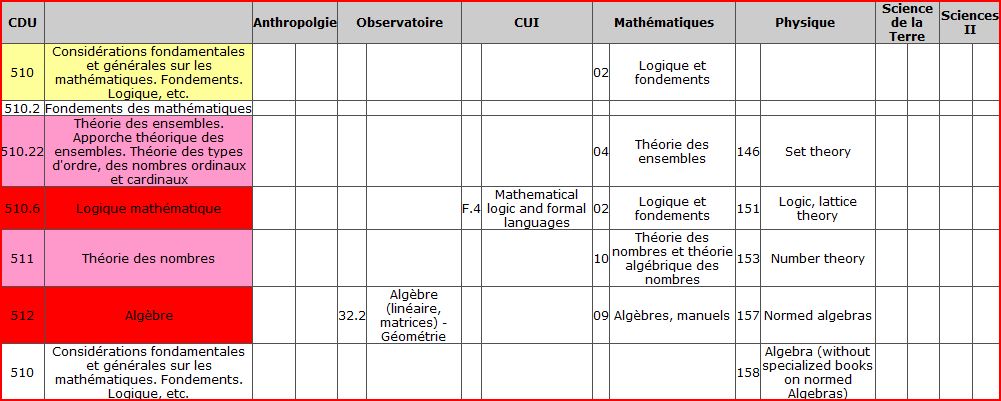
La figure 1 montre que 85% des indices se trouvent uniquement dans une bibliothèque. Le pourcentage d’indices présents dans deux bibliothèques ou plus peut donc paraître assez faible, pourtant le nombre de documents concernés est important étant donné l’étendue des collections, et concerne tout de même environ 150 indices et sous-indices.
Deux domaines et sujets seulement se trouvent dans six bibliothèques. Il s’agit de l’informatique et des probabilités et statistiques. Viennent ensuite les mathématiques présentes dans cinq bibliothèques.
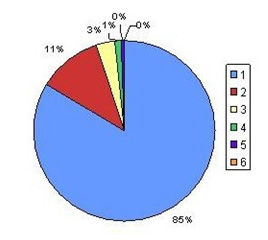
Fig. 1 : Pourcentage des indices présents dans 1, 2, 3, 4, 5 ou 6 bibliothèques
Les domaines et sujets présents dans quatre bibliothèques sont les suivants :
- Langages de programmation
- Histoire des sciences
- Mathématique numérique, analyse numérique, programmation (informatique), science des ordinateurs
- Astronomie, astrophysique, recherche spatiale, géodésie
- Physique
- Mécanique
- Mécanique des fluides, hydraulique
- Vibration, acoustique
- Optique
- Chaleur, thermodynamique
- Electricité, magnétisme, électromagnétisme
- Chimie, sciences minéralogiques, cristallographie
- Climatologie
- Biologie
Il s’agit de domaines généraux (biologie, chimie, physique), et de sujets (mathématique numérique, mécanique, etc.) appartenant principalement à la physique.
Les domaines et sujets apparaissant dans trois bibliothèques sont essentiellement sujets concernant l’informatique, les mathématiques, la physique, la chimie et les Sciences de la Terre :
- Langages de programmation
- Intelligence artificielle
- Traitement des images
- Bibliothéconomie, lecture
- Mathématiques. Sciences naturelles
- Généralités sur les sciences pures : Philosophie. Psychologie
- Sciences environnementales. Ressources naturelles. Conservation des ressources naturelles. Protection de l'environnement
- Logique mathématique
- Algèbre
- Géométrie
- Analyse mathématique
- Théorie de l'information: aspects mathématiques
- Théorie quantique
- Langages de programmation
- Intelligence artificielle
- Traitement des images
- Bibliothéconomie, lecture
- Mathématiques. Sciences naturelles
- Généralités sur les sciences pures : Philosophie. Psychologie
- Sciences environnementales. Ressources naturelles. Conservation des ressources naturelles. Protection de l'environnement
- Logique mathématique
- Algèbre
- Géométrie
- Analyse mathématique
- Théorie de l'information: aspects mathématiques
- Théorie quantique
En général, tous les indices présents dans trois bibliothèques ou plus représentent des sujets assez vastes et généraux ou des domaines. Les indices très spécifiques n’existent souvent que dans une seule bibliothèque.
Le graphique suivant (figure 2) a été élaboré en regroupant tous les indices spécifiques sous leur indice général (comportant au maximum trois chiffres) et indique donc combien de domaines ou sujets généraux sont présents dans plusieurs bibliothèques, même si à l’intérieur de ceux-ci, les sujets plus spécifiques traités ne sont pas les mêmes. Cela permet de déterminer si les bibliothèques contiennent des ouvrages concernant les mêmes types de domaines ou sujets généraux.
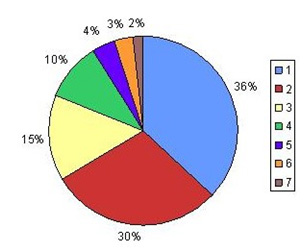
Fig. 2 : Pourcentages des indices spécifiques cumulés présents dans 1, 2, 3, 4, 5, 6 ou 7 bibliothèques
64% des domaines et sujets généraux représentés par trois chiffres dans la CDU sont donc traités dans plusieurs bibliothèques. Cela signifie que leurs collections ne sont pas limitées à leurs domaines respectifs.
Le troisième graphique (figure 3) permet de relativiser le précédent. En effet, celui-ci prend en compte uniquement les indices sans chiffre après la virgule. On remarque que ces indices généraux ne sont présents que dans un moindre pourcentage par rapport au graphique précédent. Seul 43% de ces domaines et sujets généraux existent dans deux à six bibliothèques. 11% ne sont présents dans aucune bibliothèque, ce sont des indices qui ont été rajoutés pour compléter des indices spécifiques existant dans le tableau.
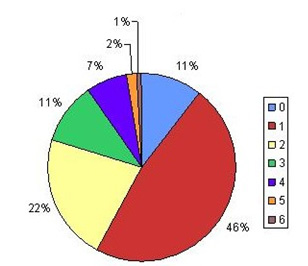
Finalement, ces taux de recoupement montrent que certains domaines et sujets sont redondants. Il est sûr que certaines applications d’un domaine peuvent en concerner un autre, ou qu’une science a besoin d’éléments d’une autre, ce qui implique que certains ouvrages soient classés dans une autre partie de la CDU que celle qui concerne en premier lieu la bibliothèque.
3.2 Données statistiques
Comme la recherche des données statistiques a été effectuée sur la base locale genevoise de RERO, les bibliothèques touchées sont celles de la Faculté des Sciences et toutes celles faisant parties du Réseau des bibliothèques genevoises. L'analyse porte principalement sur les sept bibliothèques étudiées, mais quelques remarques seront également faites en relations avec les autres localisations genevoises.
Le tableau obtenu à l'aide du deuxième script a été travaillé de différentes manières, notamment en additionnant les résultats de tous les indices d’une bibliothèque pour avoir une comparaison des totaux par bibliothèques, en nombre de notices et en pourcentage (tableau 2 et 3). Il a également été nécessaire de produire une matrice triangulaire contenant la moyenne des totaux par couple de bibliothèques. En effet, la comparaison d’une bibliothèque A avec une B, ou de B avec A, devrait théoriquement donner le même résultat. Mais principalement à cause de différences de cotations et du fait que notre étude ne concerne qu’une partie des collections, ce n’est pas le cas. La moyenne des deux résultats a été calculée afin de n'avoir qu'un seul chiffre par couple de bibliothèques. Il faut comprendre par différences de cotations le fait que, même si il a été décidé de faire correspondre deux indices, un même livre ne sera pas forcément coté dans la bibliothèque selon le tableau de concordance: la bibliothèque d’anthropologie mettra un livre de mathématiques dans l’indice correspondant aux mathématiques générales, alors que la bibliothèque de mathématiques mettra peut-être ce même livre dans un indice plus précis. Cela explique par exemple que le nombre de notices en commun obtenu en cherchant, dans les livres de la bibliothèque de mathématiques, ceux que possède la bibliothèque d’informatique, est égal à 145, alors que le contraire donne 62.
Seules les collections formées par les indices retenus grâce au tableau de concordance des classifications ont été étudiées et non les collections dans leur ensemble, il faut lire ces résultats en conséquence.
Dans les deux tableaux suivants, on trouve horizontalement un échantillon de notices d’une bibliothèque dans lequel on a cherché la présence des zones MARC 980_2 des bibliothèques représentées verticalement. Par exemple, 2101 documents ont été extraits pour la bibliothèque du CUI, et 62 de ces documents se trouvent également dans la bibliothèque de mathématiques (n'importe où dans la collection).
Il est important de remarquer que le nombre de notices prises en compte pour la bibliothèque des Sciences de la Terre est très faible car peu de documents possèdent une cote, ce qui rend les résultats peu comparables avec les autres bibliothèques.
Le tableau 1 présente un extrait du tableau de concordance (celui-ci comportant environ 110 pages, il n’est pas inclus dans cet article mais est disponible sur demande).
3.3 Analyse par bibliothèque
Le tableau 2 montre, pour chaque ligne, le nombre de notices de la bibliothèque en question retrouvées dans les bibliothèques en colonne. Le nombre total de notices pris en compte pour chacune des bibliothèques est en gris. Par exemple, dans les livres étudiés à la bibliothèque de mathématiques, 145 se trouvent aussi au CUI, mais ceux-ci ne sont pas forcément dans les indices étudiés au CUI.
Tableau 2 : Nombre de notices en commun entre les sept bibliothèques de la Faculté des Sciences

Sur ce tableau, les bibliothèques partageant le plus grand nombre de notices avec d’autres localisations sont les bibliothèques de physique et de mathématiques. Entre elles deux, elles possèdent plus de 200 documents en commun, et passablement avec les cinq autres (surtout la bibliothèque de l’Observatoire et du CUI). Viennent ensuite le CUI, la bibliothèque de l’Observatoire et de Sciences II. Les bibliothèques des Sciences de la Terre et d’anthropologie sont celles qui ne partagent que peu de notices : moins de 50. Sur le tableau 3, le nombre de notices est pondéré par le nombre de notices total trouvées par bibliothèque, pour donner un pourcentage de notices en commun.
Tableau 3 : Pourcentage de notices en commun entre les sept bibliothèques de la Faculté des Sciences

Ici, en lisant le tableau en colonne, on remarque que les bibliothèques de physique et de mathématiques sont celles qui possèdent le plus grand pourcentage de notices se trouvant dans les collections des indices retenus des autres bibliothèques.
Horizontalement, on voit par contre que la bibliothèque de mathématiques partage un pourcentage plutôt faible de sa collection avec les autres, physique à part. Par exemple, plus de 10% de la collection représentée par les indices retenus à l'Observatoire se trouve en mathématiques, alors que seulement 1.8% de la collection représentée par les indices retenus en mathématiques se retrouve dans la bibliothèque de l’Observatoire. Ceci est dû au nombre de livres, et au fait que ce sont essentiellement des indices généraux qui ont été retenus. D’une part, il y a relativement peu de livres qui concernent le domaine des mathématiques à l’Observatoire et ils sont classés dans des indices généraux (les indices détaillés concernent logiquement l’astronomie). En contrepartie, il y a évidemment un grand nombre de livres de mathématiques dans la bibliothèque de mathématiques et ils sont éparpillés dans des indices détaillés ne correspondant pas aux indices retenus.
Toujours horizontalement, c’est la bibliothèque de l’Observatoire qui partage le plus grand nombre de notices avec les autres bibliothèques, en particulier avec les bibliothèques de mathématiques et physique, un peu moins avec le CUI et Science II. Viennent ensuite les bibliothèques de physique, Sciences II et mathématiques avec plus de 5% de notices en commun avec une autre bibliothèque, puis les bibliothèques d’anthropologie et du CUI avec plus de 3%. La collection de la bibliothèque des Sciences de la Terre, comme mentionné ci-dessus est difficile à commenter puisque le nombre de documents étudiés est faible. On peut tout de même remarquer environ 3% de notices en commun avec les bibliothèques de l’Observatoire et de Sciences II.
3.4 Analyse par dendrogramme
A partir de la matrice triangulaire, un dendrogramme a été produit à l’aide du programme R (R-Project, 2007), suivant l’algorithme (UPGMA Christian de Duve Institute of cellular pathology, 1997 ; Wikipédia, l'encyclopédie libre, 2007).Cet algorithme produit un arbre phylogénétique (dendrogramme) à partir d’une matrice de distances. Ceci est normalement utilisé pour étudier des séquences génomiques ou l’évolution des espèces à partir de leur génome. Le résultat illustre les distances entre bibliothèques, avec les deux bibliothèques les plus proches à l’extrémité de l’arbre (la branche la plus lointaine de la racine), puis la bibliothèque la plus proche de ce couple, etc., jusqu’à la dernière bibliothèque. Ce dendrogramme est un essai d’une méthode originale de comparaison des collections et il n'est pas aisé d’en faire l’analyse.
Pour créer le dendrogramme de la figure 4, il a fallu prendre « 1-le pourcentage de notices en commun » (ramené à un nombre entre 0 et 1) du tableau 2, puis appliquer l’algorithme UPGMA. Il faut se souvenir que la matrice triangulaire à la base de ces données résulte d’un calcul de moyenne entre deux résultats. Ceci peut donc parfois tirer le pourcentage vers le haut ou vers le bas. Pour analyser ce dendrogramme, il faut prendre en compte la distance horizontale et verticale entre les bibliothèques. Les deux bibliothèques les plus proches en terme des collections étudiées sont celles de l’Observatoire et de physique (à l’extrémité du dendrogramme). Ensuite, la bibliothèque la plus proche de ce couple est celle de mathématiques, puis celle de Sciences II, etc. Il faut remarquer que chaque bibliothèque est comparée avec le groupe formé par celles qui la précèdent dans l’arbre. Du point de vue de la distance verticale, on voit que le groupe Observatoire-physique est relativement éloigné de la bibliothèque de mathématiques, qui est elle-même éloignée de celle de Sciences II. Par contre, Sciences II, le CUI, les bibliothèques des Sciences de la Terre et d’anthropologie sont relativement proches.
On peut donc distinguer trois parties dans le dendrogramme: le couple du bas (observatoire et physique), le groupe du haut (anthropologie, Sciences de la Terre, CUI et Sciences II), et la bibliothèque de mathématiques au milieu. Il faut toujours garder à l’esprit que les résultats concernant la bibliothèque des Sciences de la Terre ne sont pas représentatifs. On peut donc dire que les collections étudiées dans le premier couple sont relativement proches. La collections de la bibliothèque de mathématiques est la plus proche de ce couple, mais relativement éloignée vu la longueur de la barre verticale les séparant. La bibliothèque de Sciences II est la plus proche de ces trois mais avec une distance verticale également relativement grande. Les quatre dernières bibliothèques sont peu distantes verticalement.
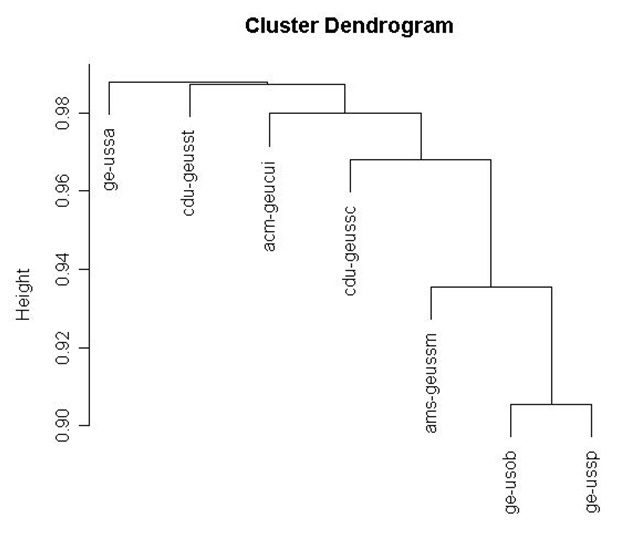
Fig. 4 : Dendrogramme obtenu par l’algorithme UPGMA
Légende: ge-ussa = anthropologie, cdu-geusst = Sciences de la Terre, amc-geucui = CUI, cdu-geussc = Sciences II, ams-geussm = mathématiques, ge-usob = Observatoire, ge-ussp = physique
3.5 Comparaison avec les autres bibliothèques genevoises
L'analyse des notices en commun entre les bibliothèques de la Faculté des Sciences et les autres bibliothèques genevoises montre que les bibliothèques des Sciences économiques et sociales (SES), et de la Faculté de psychologie et des sciences de l’éducation (FPSE) possèdent plus de 100 notices en communs avec la bibliothèque de mathématiques.
Entre la bibliothèque d’histoire des sciences et celle de physique, il y a plus de 50 notices en commun. Cela montre à quel point la bibliothèque de physique possède une grande collection de livres sur l’histoire des sciences et de la physique.
Plus de 50 notices en commun se trouvent également:
- entre les bibliothèques d’anthropologie, de l’Observatoire et de physique et celle de SES. Il est difficile de dire quels sont les sujets couverts par ces documents, mais on peut imaginer qu’avec les bibliothèques de l’Observatoire et de physique, ça peut être des livres de statistiques et de mathématiques. Avec l’anthropologie, cela doit être un mélange de différents sujets : la sociologie et la démographie, la géographie et les statistiques, les mathématiques et l’informatique.
- entre la bibliothèque de philosophie et celles de mathématiques et physique. D'une part ces deux bibliothèques de la Faculté des Sciences possèdent un bon nombre de livres concernant la philosophie des sciences, et d’autre part, les logiques philosophique et mathématique sont liées.
- entre la bibliothèque de la Faculté de médecine (BFM) et Sciences II. Ces deux bibliothèques partagent probablement des documents de biologie, pharmacie et médecine.
4 Discussion
Il est évidemment difficile de dire que tel pourcentage de notices en commun entre deux bibliothèques est trop élevé ou pas, cela dépend du domaine, du type de bibliothèque et des usages de la bibliothèque.
La redondance des documents a des «pour» et des «contre». Les «pour» sont :
- L’accessibilité: la redondance entre bibliothèques rend les documents plus proches des usagers, d’autant plus que la grande majorité des monographies étudiées ici ne sont pas accessible en ligne à la Faculté des Sciences.
- La conservation: la redondance permet d’augmenter les chances de préservation à long terme. Ce n’est pas la mission principale des bibliothèques de la Faculté, bien que les documents anciens soient importants pour certains domaines.
- Usages simultanés: Les étudiants des différents départements ou sections de la Faculté ont une majorité de cours en commun au début de leur cursus et ont donc besoin des mêmes ouvrages.
Les «contre» sont :
- Coût élevé de la surface à Genève: plusieurs bibliothèques se trouvent dans des locaux inadaptés et manquent de place.
- Budget d’acquisition: il est en diminution systématique dans toutes les bibliothèques.
- Budget de fonctionnement: plus la collection est importante plus les coûts sont élevés.
Par ailleurs, pour pouvoir faire une bonne critique de ces résultats, il faudrait faire l’étude complète des collections, et notamment connaître le niveau des documents et leurs usages.
Le niveau des documents est intéressant car, comme le mentionne l'étude de Missingham & Walls (2003), il est justifiable que les ouvrages de référence et ceux destinés aux étudiants de premier cycle soient redondants, étant donné la nécessité d'un accès immédiat et multiple à ces documents.
Les usages et en particulier le taux de prêt permettent de savoir si une section de la collection est utile dans la bibliothèque étudiée bien que hors de son domaine. Cela permet également de se rendre compte si les usagers sont prêts à se rendre dans la bibliothèque de référence pour satisfaire leurs besoins en information.
Il faut également tenir compte l’environnement qui influence le comportement de l’usager:
- la distance entre les bibliothèques, qui peut être un obstacle au déplacement des usagers, même lorsqu’elle est faible ;
- les conditions de prêt qui limitent la disponibilité des documents (dans le temps et l’espace) ;
- etc.
4.1 Discussion de l'analyse par bibliothèque
En analysant les pourcentages globaux de notices en commun pour chaque bibliothèque, il ressort nettement que les bibliothèques se recoupant le plus sont celles de physique, mathématiques et astronomie. Cette constatation est renforcée par le dendrogramme qui rassemble ces trois bibliothèques en un cluster. Cela paraît assez logique puisque l’astronomie est apparentée à la physique, et que ces deux domaines ont pour outils principaux les mathématiques.
Le peu de notices en commun entre les bibliothèques d’anthropologie et de Sciences II (contenant les collections de biologie) est en revanche plus étonnant. Les tableaux montrent peu de recoupement et les deux bibliothèques sont éloignées dans le dendrogramme. On aurait pu imaginer plus de similitudes car la bibliothèque d’anthropologie contient une collection importante de documents sur la biologie, la génétique et l’évolution, qui sont des sujets de recherche couverts par des chercheurs du département d'anthropologie.
4.2 Discussion des résultats indice par indice
Une analyse de tous les indices présents dans trois bibliothèques ou plus a été faite à partir du tableau obtenu avec la deuxième partie du programme. Les détails ne sont pas présentés ici, mais en voici les points principaux :
- Une bibliothèque se distingue des autres : la bibliothèque de physique. Elle a souvent un taux de recoupement élevé avec les autres bibliothèques, en particulier avec celles de l’Observatoire, de mathématiques et dans une moindre mesure Sciences II.
- La bibliothèque de mathématiques ressort également du lot. Mais dans ce cas, c’est souvent les autres bibliothèques qui possèdent des livres de mathématiques, et il est donc normal que les mathématiques possèdent les ouvrages que les autres bibliothèques ont acquis dans son domaine. De plus, cette bibliothèque a un grand nombre de documents classés dans des indices qui a priori ne sont pas des mathématiques, mais il s’agit en réalité souvent d’ouvrages de mathématiques appliquées à un autre domaine et donc classés sous cet autre domaine, pour les distinguer des mathématiques non appliquées.
- La bibliothèque de Sciences II a, de manière générale et au contraire de ces deux premières bibliothèques, un taux de recoupement très faible avec les autres. Ses documents sont donc plus ciblés sur les sujets qu’elle couvre.
- Les taux de recouvrement relativement élevés qu’on peut trouver avec la bibliothèque du CUI, ne concernent pratiquement que des indices de sujets informatiques. Comme pour les mathématiques, ces taux de recoupement sont donc à attribuer aux autres bibliothèques et non à celle du CUI qui reste bien limitée à son domaine.
- Les taux de recouvrement les plus élevés qu’on trouve avec la bibliothèque de l’Observatoire sont liés aux bibliothèques de mathématiques et physique, ce qui est logique vu la proximité de ces trois sciences.
- Pour la bibliothèque des Sciences de la Terre, il est difficile de tirer des conclusions pertinentes, car peu de documents de cette bibliothèque sont dotés d’une cote.
- Les résultats pour la bibliothèque d’anthropologie sont également difficiles à commenter car les indices utilisés couvrent plusieurs sujets différents. En général, les taux de recouvrement sont assez faibles. Cependant, les visites sur place ont montré qu’il existait un nombre relativement élevé de documents traitant d’autres sujets et domaines que ceux normalement couverts par cette bibliothèque. De plus, la majorité de ces documents « hors sujet » étaient pour la plupart très anciens (vieux de plusieurs dizaines d’années), ce qui diminue encore l’intérêt de leur présence dans cette bibliothèque.
4.3 Discussion de la précision des données (approximation d'erreur)
L’imprécision de la méthode de récolte des statistiques est due à trois sources d’erreurs :
- les documents étudiés ne représentant pas la totalité de la collection des bibliothèques
- les incohérences dans les méthodes de catalogage, notamment pour les documents en plusieurs volumes
- la concordance établie entre les classifications dans cette étude, potentiellement différente des pratiques de cotation dans les bibliothèques
Etant donné l’asymétrie du tableau 2, une estimation de l’erreur a été calculée pour déterminer si les résultats sont tout de même significatifs. Pour chaque couple de bibliothèques (i, j), la formule | ni,j – nj,i | / max(ni,j , nj,i) a été appliquée (tableaux 4 et 5).
Tableau 4: Approximation d'erreur pour toutes les bibliothèques: somme totale = 9.85, moyenne = 0.47

Tableau 5: Approximation d'erreur sans la bibliothèque des Sciences de la Terre: somme totale = 4.78, moyenne = 0.32

En comparant deux bibliothèques de deux façon différentes tel que dans le tableau 2, les résultats obtenus sont relativement proches car la variation entre les deux parties du tableau de cette figure est de 32% sans tenir compte de la bibliothèque des Sciences de la Terre En général, la corrélation est bonne, ce qui montre que la méthode est assez représentative. Une mauvaise corrélation, par contre, ressort nettement chaque fois que la bibliothèque des Sciences de la Terre est concernée. Ceci était prévisible car le nombre de documents cotés et donc étudiés dans cette bibliothèque est faible et non représentatif.
4.4 Synthèse de l'analyse
Des tendances se détachent clairement de l’étude de ces statistiques et donnent une bonne idée des relations entre les échantillons des collections des sept bibliothèques étudiées. Elle souligne notamment la redondance, nécessaire ou non, de certains sujets et documents dans les diverses bibliothèques.
Selon le nombre de notices communes entre les sept bibliothèques, celles de mathématiques et physique partagent le plus de documents avec les autres localisations. Viennent ensuite les bibliothèques du CUI, de l’Observatoire et de Sciences II. En ce qui concerne le dendrogramme, l’ordre est un peu différent : les bibliothèques de l’Observatoire et de physique sont les plus proches, suivies de celles de mathématiques. Les bibliothèques du CUI et de Sciences II se rapprochent plus, elles, de l’anthropologie et des Sciences de la Terre.
L’étude des statistiques et les visites sur place ont fait ressortir certains points :
- Pour la bibliothèque de physique, le nombre de documents concernant l’histoire et la philosophie des sciences est important. De plus, le nombre de notices en commun avec certaines bibliothèques hors de la Faculté des Sciences comme celles du Musée d’histoire des sciences, de la Faculté des sciences économiques et sociales et du Département de philosophie est élevé. Il serait nécessaire de mener une réflexion sur la politique à suivre pour la gestion de cette partie de la collection.
- Pour la bibliothèque de physique en particulier, mais également pour celles de mathématiques, d’anthropologie, et dans une moindre mesure en astronomie, Sciences de la Terre et à Sciences II, les collections d’informatique contiennent beaucoup d’ouvrages sur des sujets redondants, souvent obsolètes. Sachant que la bibliothèque du CUI ne conserve en général pas les ouvrages trop anciens, les autres bibliothèques devraient d’autant plus désherber leurs collections dans ce domaine.
- Il y a beaucoup de recoupement entre les collections des bibliothèques de physique et de l’Observatoire, mais vu la distance entre les deux localisations, la proximité des domaines de recherche et le prêt exclu à l’Observatoire, ceci est en partie justifié. Il serait intéressant d’étudier l’usage des documents de ces deux bibliothèques pour savoir si ce recoupement correspond réellement à un besoin.
- Pour la bibliothèque de l’Observatoire, outre les remarques ci-dessus, on trouve un recoupement important avec la bibliothèque de mathématiques, que la distance peut à nouveau expliquer.
- La bibliothèque de mathématiques a beaucoup de recoupement avec les autres bibliothèques, mais il s’agit surtout de documents de mathématiques possédés par les autres. Par ailleurs, cette bibliothèque possède plus de 250 livres de physique et 90 livres d’histoire/philosophie des sciences. Ici aussi, l’étude de l’usage de documents pourrait apporter d’avantage d’éléments pour décider de la nécessité ou non d’un tel recoupement.
- En ce qui concerne la bibliothèque de Sciences II, la plus grande des sept, il y a peu de recoupement avec les autres bibliothèques. La seule remarque à faire concerne le domaine de la physique qui est très représenté, d’autant plus que la bibliothèque de physique se trouve à environ 200 mètres.
- La collection de la bibliothèque du CUI est ciblée car le recoupement avec les autres localisations concerne principalement des livres d’informatique. Les mathématiques y sont bien représentées, mais elles constituent un outil essentiel de l’informatique.
- Le tableau 2 montre que très peu des livres étudiés dans la bibliothèque des Sciences de la Terre se retrouvent dans les autres collections. Il y a par contre plus de livres en commun si on étudie les collections des autres bibliothèques par rapport à celle des Sciences de la Terre. Cela veut dire qu’il s’agit dans ce cas de livres catalogués mais non cotés dans cette localisation. Si tous les livres étaient cotés, plus de recoupement aurait peut-être été mis en évidence.
- Pour la bibliothèque d’anthropologie, les observations sur place ont montré la présence de beaucoup de livres hors des sujets étudiés au département. Ceci est dû à l’historique, au manque de désherbage et à l’évolution des sujets couverts par la bibliothèque. Seuls 2% des livres étudiés se retrouvent à la bibliothèque de Sciences II (comprenant la section de biologie), ce qui est très peu sachant qu’un des sujets d’étude du département d’anthropologie est la génétique des populations et l’évolution. Cela tient peut-être au fait qu’il s’agit d’un sujet très précis de la génétique.
Ces résultats mériteraient d’être complétés par d’autres études concernant les usages et des indicateurs détaillés sur les ouvrages eux-mêmes. Cependant ils posent une base utile pour une future étude complète des collections à la Faculté des Science, étape nécessaire à la mise en place d’une politique d’acquisition commune, et à une gestion des collections concertée entre les bibliothèques.
4.5 Les politiques d’acquisition à la Faculté des Sciences et à l'Université de Genève
Il n’y a pas de politique d’acquisition commune aux bibliothèques de la Faculté des Sciences, et pas non plus de politique d’acquisition formelle par bibliothèque. Chaque bibliothécaire responsable des acquisitions a bien sûr sa politique, mais elle n’est pas formalisée.
La situation de l’ensemble de l’Université de Genève ressemble à une plus large échelle à celle de la Faculté des Sciences: il n’y a pas véritablement de politique documentaire commune à l’Université. Plus précisément, concernant la politique d’acquisition, aucune charte des collections n’existe. Ce manque est sur le point d’être comblé puisqu’une directrice de l’information scientifique (fonction qui n’existait pas auparavant) vient d’être engagée au niveau de l’Université. Celle-ci a mis en place plusieurs groupes de travail, dont un est chargé des collections. Ce groupe est actuellement en train d’établir une vision à long terme des collections (10 ans), et a commencé à faire une évaluation des collections pour réunir les indicateurs nécessaires à la mise en place d’un plan de développement des collections.
Etant donné qu’une politique d’acquisition au niveau de l’Université (1) va bientôt voir le jour, celle de la Faculté des Sciences devra s’y conformer. Mais il faudra détailler celle-ci davantage pour chaque bibliothèque afin établir des plans de développement des collections ainsi que des protocoles de sélection propres à chaque domaine, et rendre ainsi la politique d’acquisition de l’Université applicable à chaque bibliothèque de la Faculté des Sciences.
Voici quelques remarques dont il serait intéressant de tenir compte au moment où la politique d’acquisition sera mise en place dans les sept bibliothèques.
Dans les bibliothèques de la Faculté des Sciences, les publics sont assez bien définis, suite à un travail de diplôme de la HEG sur les pratiques documentaires de leurs usagers (Bui et al., 2006). Par contre, les collections sont assez mal connues, totalement indépendantes les unes des autres (il n’y a pas de concertation entre les bibliothèques à ce sujet) et parfois, à cause de leur historique, surprenantes dans leur contenu. Une étude globale des sept collections paraît fondamentale si l’on désire avoir un jour un ensemble de collections cohérent, et pouvoir considérer les acquisitions en réseau ou centralisées pour la Faculté.
Ce travail s’inscrit donc dans un premier pas vers cette étude des collections. Pour cela, le tableau de concordance des classifications peut servir comme repère pour la segmentation des collections en catégories comparables d’une bibliothèque à l’autre. Même s’il semble peu probable qu’une classification unique soit utilisée dans toutes les bibliothèques pour classer les monographies, ce tableau pourrait être utilisé pour gérer de manière centrale les acquisitions, et les répartir en fonction d’une classification unique. Les sujets couverts par les bibliothèques étant pointus, ce serait, dans certains cas, une perte de précision que de vouloir tout classer selon la CDU. Par contre, une cote CDU attribuée à chaque document pourrait être utilisée pour la gestion globale des collections, et une cote selon la classification locale permettrait de le ranger en rayon.
Les résultats montrent que les collections se recoupent, tant du point de vue des sujets que des documents eux-mêmes. Il est visible que chaque collection a été gérée comme une entité indépendante, et les vestiges de l’histoire de la bibliothèque n’ont pas été remis en cause. Par exemple, quatre bibliothèques possèdent une collection non négligeable de documents sur l’histoire et la philosophie des sciences, sujets tout à fait d’actualité dans un environnement universitaire et scientifique. Mais on peut imaginer qu’il n’est pas nécessaire d’en avoir autant, éparpillés dans quatre localisations. Une bibliothèque pourrait être désignée comme référence sur le sujet, et le reste des documents non conservés pourraient être donnés à la bibliothèque d’Histoire des Sciences.
Il en est de même pour l’informatique où toutes les bibliothèques regorgent de livres sur les logiciels et langages de programmation, dont certains tout à fait obsolètes. Pour ce qui est des statistiques et probabilités, toutes les sciences utilisent ces outils. Mais on pourrait ne laisser dans chaque bibliothèque que les documents présentant les mathématiques appliquées au domaine couvert par la bibliothèque, ainsi qu’un ou deux ouvrages généraux de qualité, et rassembler l’excédant à la bibliothèque de mathématiques.
En général, définir les responsabilités des bibliothèques en matière d’achat et de conservation des différents domaines en présence paraît être la solution pour rationaliser la gestion des collections.
5 Conclusion
La redondance des sujets mise en lumière par cette étude est en partie nécessaire car elle concerne les catégories suivantes : les sujets inhérent à l’environnement scientifique (comme l’histoire ou la philosophie des sciences), les outils de base en sciences (comme les mathématiques ou l’informatique).
Diverses études se sont penchées sur la redondance de collections, notamment celle de Missingham & Walls (2003). Contrairement à celles-ci, notre étude se base sur sept bibliothèques spécialisées par domaines. De plus, nous n'avons analysé que les documents correspondant aux indices présents dans trois bibliothèques ou plus. Ainsi, notre étude concerne un sous ensemble des collections des bibliothèques de la Faculté des Sciences, choisi pour obtenir une estimation maximale de la redondance. Il est donc inapproprié de comparer nos résultats à ceux des études mentionnées précédemment. La suite logique de ce travail serait d'étudier les collections dans leur ensemble à l'aide d'un tableau d’indicateurs détaillé. Cela permettrait d'obtenir entre autres des chiffres comparables à la littérature mentionnée ci-dessus. Pour pouvoir tirer des conclusions définitives, il serait également important de prendre en compte les statistiques d'usages des collections.
Sur la base du tableau de concordance, une classification unique destinée à la gestion des collections pourrait être attribuée à chaque document, tout en gardant les classifications propres à chaque localisation pour le rangement en rayon. Cela permettrait de développer une vue d'ensemble des collections de la Faculté des Sciences et de mettre en place une gestion globale cohérente.
Si la gestion centralisée des sept bibliothèques, telle qu’envisagée à une période, semble difficile en tenant compte des remarques des chercheurs, on pourrait en revanche tout à fait imaginer une « centralisation des documents par domaines ». Selon ce modèle, chaque bibliothèque s’occuperait de ses domaines, ce qui est en partie déjà le cas du point de vue des acquisitions, mais pas de la gestion de la collection en général (désherbage par exemple). Pour les bibliothèques ayant des domaines se chevauchant, mathématiques et physique par exemple, chaque bibliothèque pourrait être désignée comme référence pour un certain nombre de sujets. Ainsi la répartition des acquisitions serait clarifiée et il serait plus facile de prendre des décisions en matière de désherbage. Six des sept bibliothèques se trouvant dans le même quartier, la contrainte de déplacement est légère, et le sentiment de réseau en serait renforcé.
Remerciements
Nous remercions Anne-Christine Robert, coordinatrice des bibliothèques de la Faculté des Sciences de l’Université de Genève, qui a commandité cette étude, et Bertrand Calenge pour la direction de ce travail dans le cadre de la formation du CESID.
Notes
(1) Le poste de Direction est vacant depuis août et les projets subiront certainement quelques retards.
Bibliographie
AMERICAN INSTITUTE OF PHYSICS (2007). PACS, physics and astronomy classification scheme [en ligne]. [Consulté le 21.05.2007]. http://www.aip.org/pacs/
AMERICAN MATHEMATICAL SOCIETY (2007). MathSciNet: mathematical reviews on the Web [en ligne]. [Consulté le 21.05.2007]. http://ams.u-strasbg.fr/mathscinet/otherTools.html
ASSOCIATION FOR COMPUTING MACHINERY (2007). The guide to computing literature [en ligne]. [Consulté le 25.07.2007]. http://portal.acm.org/ccs.cfm?part=author&coll=GUIDE&dl=GUIDE&CFID=24852534&CFTOKEN=71835811
BAKER, Sharon L., LANCASTER, F. Wilfrid (1991). The measurement and evaluation of library services. Second ed. Alington, Information Resources Press
BUI, Céline, LEHNER Susanne, MORESI Nadia (2006). étude des pratiques documentaires des usagers : quels services pour la bibliothèque de demain ? 153 p. Mémoire de diplôme HES, Haute école de gestion de Genève
CALENGE, Bertrand (1994). Les politiques d’acquisition : constituer une collection dans une bibliothèque. Paris, Editions du Cercle de la Librairie. Collection Bibliothèques
CALENGE, Bertrand (1999). Conduire une politique. Paris, Editions du Cercle de la Librairie. Collection Bibliothèques
CALENGE, Bertrand (2006). Politique documentaire et gestion des collections : cours donnée au CESID, volée 2005-2007
CHRISTIAN DE DUVE INSTITUTE OF CELLULAR PATHOLOGY (1997). Construction of a distance tree using clustering with the Unweighted Pair Group Method with Arithmatic Mean (UPGMA) [en ligne]. [Consulté le 04.06.2007]. http://www.icp.ucl.ac.be/~opperd/private/upgma.html
MISSINGHAM, Roxanne, WALLS, Robert (2003). Australian university libraries: collections overlap study. The Australian Library Journal [en ligne], [Consulté le 14.11.2007]. http://www.alia.org.au/publishing/alj/52.3/full.text/missingham.walls.html
R-PROJECT (2007). The R Project for Statistical Computing [en ligne]. [Consulté le 06.06.2007]. http://www.r-project.org/
RESEAU DES BIBLIOTHEQUES GENEVOISES (2007). Catalogue [en ligne]. [Consulté le 06.06.2007]. http://opac.ge.ch/gateway?lng=fr-ch
TABAH, Albert N (1995). Evaluation des collections. In CALENGE, Bertrand … [et al.] Diriger une bibliothèque d’enseignement supérieur. Sainte-Foy, Presses universitaires du Québec. P. 285-296. Gestion de l’information. ISBN 2760508706
UDC CONSORTIUM, (2004). Classification décimale universelle. Edition moyenne internationale. Liège, Editions du CEFAL
WIKIPEDIA, L’ENCYCLOPEDIE LIBRE (2007). UPGMA [en ligne]. [Consulté le 04.06.2007]. http://fr.wikipedia.org/wiki/UPGMA
N°7 mai 2008
Ressi — 30 avril 2008
Sommaire - N°7, Mai 2008
Etudes et recherches :
- Concordance des classificiations et étude comparative du recoupement des collections : les bibliothèques de la Faculté des Sciences de l'Université de Genève - Cynthia Dufaux, Jan Krause, Aline Maurer
- Eléments d'architecture pour une mémoire d'entreprise orientée processus métier - Mahmoud Brahimi et Laid Bouzidi
- Le web comme outil de diffusion des archives - Lorraine Filippozzi
- Bibliothèque 1 1/2 : le passage vers la modernité : De l'importance et de la confrontation entre les bibliothèques et le Web 2.0 - Nicolas Bugnon, Simone König et René Schneider
Comptes-rendus d'expériences :
- WikiBiGe, un wiki qui bouge - Marie-Laure Berchel, Iris Buunk, Jean-Blaise Claivaz, Dimitri Donzé, Jan Krause, Aline Maurer, Pedro Nari, Anne-Christine Robert et Estelle Tinguely
Evénements :
Eléments d’architecture pour une mémoire d’entreprise orientée processus métier
Ressi — 30 avril 2008
Mahmoud Brahimi, Université Lyon 3, France
Laid Bouzidi, Université Lyon 3, France
Résumé
Les entreprises disposent d’un capital de connaissances (documents, données, référentiels, messages, …) souvent mal exploité notamment durant l’exécution des processus métiers. A cela, plusieurs raisons peuvent être invoquées : des workflows peu ou pas automatisés, une exploitation très réduite de ces connaissances car seules les données sont principalement utilisées, l’absence d’architecture qui pourraient fédérer ou intégrer tous ces connaissances en vue d’une utilisation efficace. En outre, on constate que ces connaissances sont très peu reliées aux processus métier. De nombreuses tentatives ont vu le jour pour tenter de juguler ce manque de gestion de ce capital, à travers des systèmes de gestion de connaissances, de portails (intranet), ou plus largement par des mémoires d’entreprises. Toutefois de nombreuses préoccupations restent encore en suspens. Quelles sont les connaissances liées à un processus métier ? Quel est l’apport d’une mémoire d’entreprise pour l’exécution des processus métiers ? Comment considérer les liens entre les connaissances ? Quelles architectures génériques est-il possible d’envisager pour la construction des mémoires d’entreprise ? Voilà les questions auxquelles cet article tente de répondre.
Abstract
Enterprises have got a huge amount of knowledge (documents, data, emails, …) which is often bad treated particularly when a business process is executed. Several reasons motivate this fact among them: few or no automated workflow, exploitation limited of this knowledge because only data are mainly used, the lack of framework capable to federate or integrate all kind of knowledge for an efficient use. . In addition we observe that knowledge is not really linked with business processes. Several temptations were made in order to reduce this insufficiency of capital management using knowledge management systems, intranet, or more generally corporate memories. However many problems still require new solutions. What is knowledge linked to business process? Which is the contribution of corporate memories in the processes execution? How to considerer the link between knowledge? What are the generic architectures that can be envisaged for corporate memory building? These are the questions that this paper attempts to answer.
Mots-Clés:
Mémoire d’entreprise, Processus métier, Connaissances, Architecture, Documentation
/ Keywords : Memory, Business Process, Knowledge, Architecture, Documentation
Dernière modification:
23/06/2009 Eléments d’architecture pour une mémoire d’entreprise orientée processus métier
I. Introduction :
« La gestion des connaissances désigne la gestion de l’ensemble des savoirs et savoir-faire en action mobilisés par les acteurs de l’entreprise pour lui permettre d’atteindre ses objectifs » (Charlet et al, 1999). Plusieurs étapes ont été identifiées dans un processus de gestion de connaissances : il s’agit de l’explicitation de connaissances tacites repérées comme cruciales pour l’entreprise, du partage du capital des connaissances rendu explicite sous forme de mémoire et de l’appropriation et de l’exploitation d’une partie de ces connaissances par les acteurs de l’entreprise (Nonaka et Takeuchi, 1995). L’architecture décisionnelle autour de laquelle sont bâtis les systèmes d’aide à la décision assure le processus de transformation des données en informations à usage décisionnelle (Lebraty, 2000). Ces informations à usage décisionnel contribuent à l’amélioration des performances des savoir-faire structurés sous forme de processus métiers, et la connaissance contenue dans les ressources utilisées apporte des moyens pour l’amélioration de la prise de décisions. Cette prise de décision est fortement dépendante des informations et des connaissances qui vont servir de support à cette décision et des outils et des méthodes entrant dans l’exécution des processus. En effet, une décision est le fruit de l’utilisation d’un ensemble d’informations et de connaissances interprétées dans un contexte bien précis. Aussi, certaines catégories de processus peuvent faire appel au même ensemble d’outils et de méthodes, dont la mise en œuvre comporte de nombreux paramètres. Elles nécessitent de prendre des décisions sur le choix des outils et des méthodes dont la qualité influera fortement sur celle du processus. L’amélioration du processus va alors reposer principalement sur l’amélioration des décisions dans l’application de ces outils et méthodes. Les acteurs s’appuient pour cela sur des connaissances acquises antérieurement par d’autres et matérialisées sous forme de mémoires d’entreprise.
Pour capitaliser et rendre explicite des connaissances dans une entreprise, des méthodes issues de l’ingénierie des connaissances (tel que MASK, REX, CommonKADS, KOD, etc.) et du travail assisté par ordinateur (tel que QOC, DIPA, etc.) (Dieng-Kuntz et al, 2001) ont été élaborées. Ces méthodes permettent de définir des mémoires d’entreprise. Une mémoire d’entreprise est définie comme la « représentation persistante, explicite, désincarnée, des connaissances et des informations dans une organisation, afin de faciliter leur accès, leur partage et leur réutilisation par les membres adéquats de l’organisation, dans le cadre de leurs tâches ». Particulièrement, une mémoire métier peut être définie comme l’explicitation des connaissances produites dans et pour un métier donné. Les méthodes de capitalisation des connaissances utilisent des techniques d’ingénierie de connaissances pour extraire les connaissances, que ce soit auprès des experts ou à partir des documents, afin de les formaliser avec des modèles conceptuels, où la connaissance (dans notre cas en rapport avec les processus métiers) qui guide la résolution de problèmes est rendue explicite. Par ailleurs, (Nagendra Prasad et Plaza, 1996) définissent la mémoire d’entreprise comme « l’ensemble des données collectives et des ressources de connaissances d’une entreprise ». La gestion des connaissances selon cette approche, peut être vue comme « la gestion d’un réservoir de taille plus au moins importante rassemblant les connaissances de l’entreprise. La taille la plus petite correspondant à une mémoire individuelle, celle d’un expert d’un domaine donné, la taille la plus grande correspondant à la mémoire de l’entreprise et rassemblant à ce titre l’ensemble des connaissances sur l’organisation, les activités, les produits, etc., de l’entreprise.» (Meingan, 2002).
Selon la typologie de la mémoire d’entreprise, celle-ci peut inclure des connaissances sur les produits, les procédés de production, les clients, les stratégies de ventes, les résultats financiers, les plans et buts stratégiques, etc. Elle peut également inclure des bases de données, des documents électroniques, des rapports, des spécifications de produits et de la logique de conception. En effet, il existe une variété de typologies de mémoire d’entreprises : mémoire de projet, mémoire métier, mémoire distribuée, mémoire documentaire, mémoire à base de cas, etc. Les caractéristiques de quelques unes de ces mémoires d’entreprise sont définies dans (Gandon, 2002).
Pour atteindre les objectifs définis par la stratégique globale de l’entreprise, les acteurs disposent d’un capital de connaissances souvent très important matérialisé à travers les documents et les données mais aussi les référentiels, les messages électroniques, etc. (figure 1) mais généralement mal exploité durant l’exécution des processus métiers. A cela, plusieurs raisons peuvent être invoquées : des workflows peu ou pas automatisés, une exploitation très réduite de ces connaissances car seules les données sont principalement utilisées, l’absence d’architecture qui pourraient fédérer ou intégrer toutes ces connaissances en vue d’une utilisation efficace.
Nous proposons dans ce papier de concevoir une architecture de mémoire d’entreprise orientée processus métier permettant de mettre à la disposition des acteurs les fonctionnalités nécessaires à l’intégration de nouvelles connaissances et tenant compte de l’obligation, pour les entreprises, de disposer d’un outil fédérateur capable de s’interfacer avec le système d’information de l’entreprise et d’interroger simultanément et « intelligemment » les ressources de connaissances via une interface d’accès centralisé.
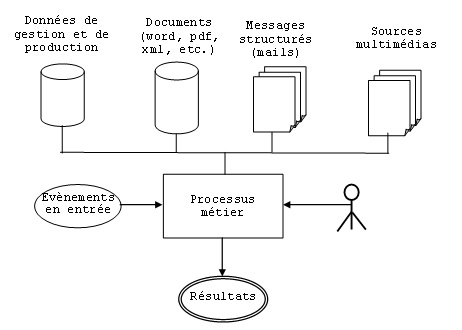
Figure 1. Synoptique général des ressources nécessaires à l’exécution d’un processus métier
II. Connaissances liées aux processus
La définition de référence des processus est aujourd’hui celle qui est donnée par la norme ISO9000 :2000. C’est « un ensemble d’activités corrélées ou interactives qui transforme des éléments d’entrée en éléments de sortie ». Cette définition est succincte, ce qui autorise une application très large. On peut donner la définition suivante dans le cadre d’un processus métier : « un processus métier est un ensemble d’activités, entreprises dans un objectif déterminé. La responsabilité d’exécution de tout ou partie des activités par un acteur correspond à un rôle. Le déroulement du processus utilise des ressources et peut être conditionné par des événements, d’origine interne ou externe. L’agencement des activités correspond à la structure du processus ».
Un processus métier organise le travail des acteurs pour répondre à des objectifs définis par la stratégie de l’organisation; l’objectif étant l’expression de la finalité du processus.
L’acteur est une personne physique, une entité organisationnelle ou une machine qui prend une part aux activités du processus. Ainsi, pour S.Alter (Information Systems : A Management perspective, 3eme éd., The Benjamin /Cummings Publishing Company, 1999), un processus est un ensemble coordonné d’activités, visant à produire un résultat pour des clients internes ou externes, et exécuté par des acteurs humains ou automates, utilisant des ressources.
L’activité est un ensemble de travaux correspondant à une unité d’évolution du système. Les activités décrivent comment l’objectif d’un processus pourra être atteint. Pour pouvoir maîtriser le déroulement d’un processus, on s’attache à faire apparaître différents états. On considère que les travaux de l’activité modifient l’état du système processus et permettent le passage d’un état stable à un autre.
L’acteur peut être interne ou externe à l’entreprise, et un processus peut ainsi être exécuté par plusieurs partenaires qui coopèrent. En général, les acteurs interviennent dans le cadre organisé du processus, c'est-à-dire que les activités ont été regroupées pour être confiées à un même acteur.
L’évaluation des processus entre généralement dans le cadre de l’évolution du système d’information de l’entreprise et permet de mesurer l’écart entre l’objectif du processus actuel, tel qu’il est perçu et vécu par les différents acteurs, et l’objectif tel qu’il découle de la stratégie de l’entreprise. L’évaluation peut être structurée en deux niveaux : dans un premier niveau, le processus existant est observé globalement par rapport à son apport au management et au fonctionnement de l’entreprise, ce qui permet entre autre d’estimer l’importance et la pérennité des connaissances mises en œuvre dans le processus existant et des savoir-faire acquis par les acteurs, et dans un deuxième niveau, le processus est analysé en détail et la mise en évidence de problèmes ou de carences prépare des améliorations, voire même des ruptures. C’est ainsi que les indicateurs de performance des processus doivent être améliorés en permanence et impliquent :
- la réduction du temps de traitement des instances de processus (efficacité) ;
- l’élimination des tâches ou activités non indispensables (contrôle, support, coordination,…) et la réduction du coût de celles que l’on conserve (efficience) ;
- l’augmentation de la satisfaction du client en améliorant la qualité des processus (l’élimination des tâches ou activités jugées non indispensables ou n’ajoutant aucune valeur ne doit en aucun cas diminuer la qualité de la relation avec le client) ;
- pouvoir répondre rapidement à des demandes de travaux inhabituelles en quantité ou en qualité et la possibilité de modifier facilement la structure et les activités du processus (flexibilité).
Cependant, les dispositions d’amélioration peuvent avoir des effets contradictoires. Ainsi, l’augmentation de la flexibilité est souvent coûteuse. Une plus grande efficacité entraîne parfois une rigidité accrue. Une focalisation sur les coûts et l’efficience peut se faire au détriment de la relation client, de l’efficacité et de la flexibilité. L’orientation du choix du vecteur d’amélioration et des actions conduisant à l’évolution du processus nécessite le ciblage sur une catégorie d’objectif considérée comme la plus importante pour l’organisation.
Le métier est l'ensemble des activités qui mobilisent des compétences et savoir-faire. Ces activités sont les unités élémentaires pour la décomposition des processus (les processus métier), et pour l’adaptation continue au changement.
II.1. Description des connaissances
La définition du processus métier telle qu’énoncée plus haut précise que l’exécution d’un processus par les acteurs de l’organisation nécessite le savoir-faire de ces derniers matérialisés sous forme de connaissances tacites ou explicites. Il nécessite aussi l’utilisation des ressources qui se résument en un ensemble de moyens, d’informations et d’outils nécessaires au déroulement des activités du processus. Ces ressources, matérialisées sous forme de documents, données du système d’information, e-mails, messages vidéo, messages audio, etc…, renferment des connaissances et des informations utiles et nécessaires pour l’exécution des processus et qu’il faudra capturer et intégrer dans des mémoires d’entreprise en utilisant les méthodes issues de l’ingénierie des connaissances. Une fois intégrées, ces informations et connaissances sont souvent diffuser via les intranets des entreprises et permettent ainsi d’être des sources importantes pour guider et orienter les acteurs de l’organisation tout au long de l’exécution du processus et améliorent, au fil du temps, les indicateurs de performance de ces derniers (figure 2).
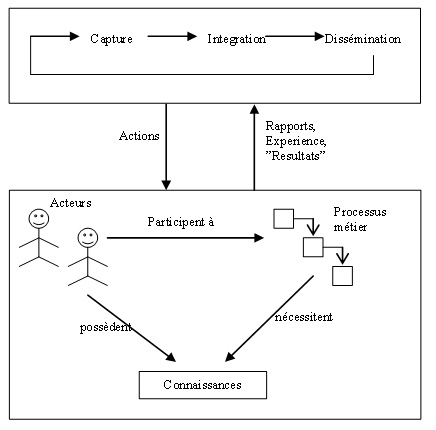
Figure 2. Processus d’acquisition de connaissances et principaux concepts associés
II.2 Réseaux de connaissances et représentation
La perception de ce qu’est ou devrait être une représentation de connaissances s’est nettement affinée au cours des dernières années, voir synthèse dans [Davis 93]. Parmi les formalismes généraux de représentation des connaissances proposés dans la littérature :
- le formalisme des réseaux sémantiques (Quilian ,1968),
- le formalisme des frames est attribué à Marvin Minksy (Minsky, 1975),
- les logiques de description, appelées aussi logiques terminologiques ou logiques de concepts, par exemple : KLONE (Brachman, 1977), logiques de description [Bläsius 89] ;
- les graphes conceptuels, introduits par J. F. Sowa (Sowa, 1984) et muni d’une définition formelle grâce à des travaux tels que ceux de M. Chein et M-L. Mugnier [Chein 92, Mugnier 96].
Plus récemment, d’autres langages, associés à une syntaxe XML, sont apparus avec l’émergence du web sémantique [Dieng 02] : RDF, RDFS, OWL, XTM…
Il existe des liens entre les différentes sources d’information. Ces liens sont le plus souvent d’ordre sémantique. Par exemple, entre un message électronique d’un client et un référentiel client, il existe un lien permettant de dire que le message a été envoyé par un client enregistré dans le système d’information de l’entreprise dans lequel il est possible de retrouver les coordonnées détaillées du client. Les liens entre les documents et les autres sources de données est un peu plus complexe. Selon le degré de précision souhaité, les liens entre les documents et les autres sources se fera par rapport à des unités de documents les plus fines possibles (il peut s’agir du paragraphe ou de la section dans le cas d’un document de type rapport par exemple). Les liens entre les sources multimédia et les autres sources de données sont des liens qui peuvent permettre de retrouver des composants multimédias à partir d’éléments ou fragments textuels se trouvant dans des sources d’information documentaire ou de données. Ces fragments constituent alors des éléments d’indexation et de recherche. Toute source d’information peut être représentée par un graphe. C’est ainsi que :
- les données du système d’information peuvent être représentées par des graphes de dépendances fonctionnelles et/ou d’inclusion,
- les documents ou messages peuvent être représentés par des graphes où les sommets représentent des unités documentaires et les nœuds terminaux des contenus. Les arcs désignent les liens sémantiques ou de structuration entre éléments documentaires,
- les sources multimédia seront représentées par des graphes dans lesquels les sommets sont des unités d’indexation et les arcs des liens entre ces unités.
L’intérêt d’une représentation en graphe est de pouvoir effectuer le même type de raisonnement sur les différentes sources de données (recherche de chemin, recherche d’éléments, vérification de propriétés, recherche de similarité, etc.) et de pouvoir exprimer les liens entre les sources de manière uniforme. Nous obtenons ainsi un réseau de graphe dans lequel les liens permettent le passage d’un graphe d’une source à un autre graphe d’une autre source. Formellement, soit G1={S1, T1} et G2={S2,T2}, 2 graphes pour 2 sources de données, alors on peut définir un réseau R={Sr, Tr} construit tel que P1(Sr) ? S1 et P2(Sr) ? S2, Pi est une partie de R. Tr est l’ensemble des liens Lr tel que une élément de Lr relie 2 sommets de G1 et G2.
Le réseau de connaissances ainsi construit est alors un support pour les processus métier en vue d’accéder aux informations nécessaires à son exécution. L’accès à un élément d’information appartenant à une source quelconque va entraîner la recherche d’autres informations appartenant à d’autres sources grâce à une navigation dans le réseau de connaissances. Parmi de nombreuses approches de modélisation des connaissances les ontologies sont apparues comme un outil incontestable de modélisation des connaissances du domaine. Rappelons qu'une ontologie est une description des concepts et des relations caractérisant un domaine. Plusieurs ontologies de domaine ont été développées dans différents secteurs d'activité. Ainsi, l'utilisation des ontologies pour la modélisation des connaissances du domaine s'est vue croître ces dernières années notamment dans les domaines suivants: médecine, biologie, environnement, tourisme et domaine juridique. D’un point de vue formel, une ontologie de ramène à une représentation et manipulation de graphes (ou de réseaux).
II.3. Représentation des processus métier
La description des processus métiers peut se faire sous forme de texte et/ou sous forme d’illustrations. Cependant, la communication, est un enjeu important dans les études sur les processus à tous les stades des travaux. Plusieurs acteurs ayant des cultures et des préoccupations différentes sont impliqués dans ces travaux. L’utilisation de formalismes partagés par une communauté d’acteurs facilite la communication, épargne l’effort d’explicitation des termes méthodologiques employés et guide le modélisateur dans la sélection d’éléments clés à faire figurer. Chaque méthode fournit une collection de modèles, de digrammes et une démarche plus ou moins adaptée aux besoins d’un projet particulier. L’application stricte des méthodes a laissé la place à une utilisation plus pragmatique des modèles et diagrammes en fonction des besoins rencontrés. Les acteurs chargés de décrire et d’améliorer un système, ont maintenant une « boite à outil » dans laquelle ils peuvent trouver le formalisme adapté à la réalisation de leur tâche.
Différentes techniques permettent de décrire les processus. Elles sont proposées à travers des ensembles méthodologiques plus larges. Certains ont fait l’objet d’une normalisation telle que IDEFO et UML, d’autres sont le résultat de projets publics et ont reçu un appui officiel telle que OSSAD et MERISE.
Les diagrammes d’activités de UML ou les modèles conceptuels de traitements de MERISE sont des techniques de représentation des processus souvent utilisés. Toutefois, les réseaux de Pétri (RdP) sur lequel ces techniques s’appuient fournissent une représentation plus formelle des processus. Le réseau de Pétri (RdP) est une spécification mathématique qui se base sur des outils graphiques permettant de modéliser et analyser les systèmes discrets, plus particulièrement les systèmes concurrents et parallèles [Petri62]. Le succès des RdP est dû à plusieurs facteurs. Grâce à son rôle d’outil graphique, il est possible de produire une compréhension facile du système modélisé. Il permet également de simuler les activités dynamiques et concurrentes. De plus, son rôle d’outil mathématique permet d’analyser le système modélisé grâce aux modèles de graphes et aux propriétés algébriques (borné, vivacité du réseau, absence de blocage, etc...). Un RdP est un graphe biparti comprenant deux sortes de nœuds : les places et les transitions. Les arcs de ce graphe relient les transitions aux places ou les places aux transitions. Les places contiennent des jetons qui vont de place en place en franchissant les transitions suivant des règles de franchissement [Reisig98].
L’avantage de tels réseaux est de pouvoir effectuer un certain nombre de vérifications qui pourraient mettre en avant des dysfonctionnements des processus tel que les inter-blocages par exemple. Par ailleurs, l’extension des RdP pour préciser les conditions de déclenchement des transitions est possible. En l’occurrence, pour un processus métier, le déclenchement d’une de ses transitions peut être soumis à un déclenchement manuel que réaliserait un acteur lorsqu’il aura pris connaissance des informations nécessaires à l’exécution de la transition. Des expressions logiques peuvent également être attachées aux transitions. Leur évaluation peut être élaborée à partir de l’agrégation d’information multi-sources.
II.4. Connexion processus – connaissances
L’exécution du processus nécessite des informations provenant de sources hétérogènes. Le déclenchement d’une activité est toujours conditionnel. Il nécessite l’arrivée d’évènements, représentée par la production de jetons dans les places, mais doit être validé par l’expert lorsqu’il prend connaissances des informations provenant des sources de données, de documents, de messages, etc. Cette validation est représentée par des liens (arcs du RdP) que l’on peut qualifié d’exogènes, par rapport aux arcs (natifs) du RdP que nous qualifierons d’endogènes. Dans la figure 3, on notera que le processus représenté par une activité (la transition du RdP) nécessite un jeton sur la place en entrée mais également la validation des informations provenant du réseau de connaissances constitué :
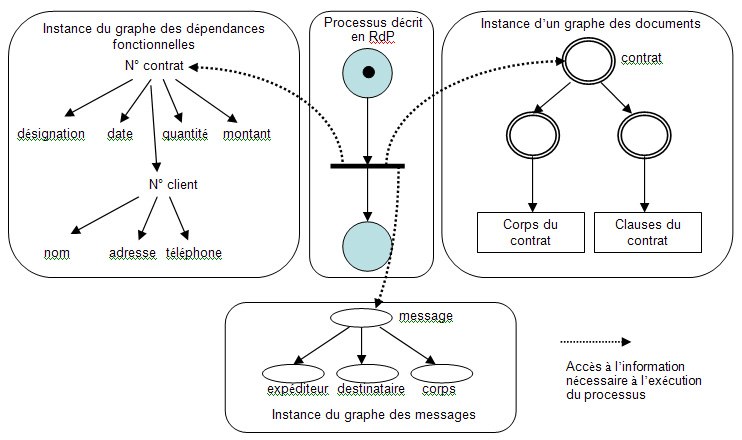
Figure 3. Connaissances nécessaires à l’exécution du processus représenté par un RdP. Le processus est décrit par un réseau de Pétri (à 2 places pour simplifier l’illustration). La transition correspond à l’exécution d’une activité. Les flèches en pointillés symbolisent le fait que l’activité a besoin d’information de type données, documentaires, mail, …
III. Proposition d’une architecture d’une mémoire d’entreprise
Cette section consacrée au cœur de notre proposition commence par présenter une étude de cas qui met en évidence la nécessité, pour les entreprises, de disposer d’un outil fédérateur capable d’interroger simultanément et « intelligemment » les sources de connaissances d’une entreprise à travers divers supports que sont les bases de données, les serveurs de messageries, les bases de documents, etc. La proposition d’architecture d’une mémoire d’entreprise orientée processus métier que nous faisons vise à prendre en charge les outils qui permettent d’offrir la « bonne information » aux acteurs des processus.
III.1. Etude de cas
Une société de négoce international en produits agricoles et alimentaires, qui assure deux métiers principaux : le négoce et le courtage Ces deux métiers, aux finalités très différentes, sont effectués par un même intervenant au sein de la société. En effet, dans une même journée, il peut être à la fois courtier et négociant. Cette situation peut aller jusqu'à "convertir" un contrat de courtage en contrat de négoce. La société est donc extrêmement souple au niveau de son activité. La finalité majeure est :
- Acheter des produits a des fournisseurs dans l'intention de les revendre,
- Gérer des stocks virtuels; ceux-ci sont présents sous la forme de lots réserves chez les fournisseurs, ou en cours de transfert vers les clients
- Financer les opérations d'achat et de vente,
- Assurer la marchandise et les transports,
Nous considérons ici le processus d’affrètement qui consiste à établir les contrats de transport (fixant le prix, la quantité, le point d'enlèvement, le point de destination, la date d'enlèvement, etc,).
Les messages
- appel client : Il s'agit d'une demande de produit en termes de qualité, quantité et date faite par le client, ou bien une proposition faite par le vendeur à un client dans les mêmes termes.
- proposition : C'est une proposition ferme faite à un client suite à une demande; le client approuve en effectuant une confirmation de contrat.
Les documents
- contrat (vente ou achat) : C'est le document qui engage les deux parties d'une manière contractuelle. Il ne concerne qu'un seul produit. On y consigne des informations telles que le produit, la quantité, la qualité, la marque, le prix, le mode de conditionnement, le mode de paiement, la date d'exécution, le lieu de livraison, les clauses particulières.
- avis de réception : Cet avis confirme le transfert de propriété; le produit livré correspond bien aux attentes du client et aux termes du contrat. Le client est désormais propriétaire de la marchandise livrée.
- contrat de transport : document contractuel qui engage la société et un transporteur. On y consigne des informations telles que le produit, la quantité, le mode de conditionnement, le prix, les dates d'enlèvement et de livraison, les points d'enlèvement et de livraison, les points de dédouanement. Plusieurs transporteurs pouvant intervenir pour une même livraison (terre, mer, air).
- ordre de transport : C'est la demande de confirmation de l'exécution d'un contrat de transport. Cet ordre est généralement accompagné de la demande d'identification transport afin de retransmettre cet identificateur au fournisseur et aux transitaires en douane.
- avis d'expédition : C'est un message avisant le fournisseur de l'enlèvement d'une certaine quantité de produit établie lors d'un contrat d'achat. Ce message indique la date d'enlèvement, l'identificateur du transporteur et le moyen de transport.
- bon d'enlèvement : C'est un document remis au fournisseur par le transporteur lorsqu'il se présente au point d'enlèvement. (idem pour les enlèvements intermédiaires)
- facture proforma : C'est une facture donnée à titre indicatif afin d'identifier une transaction qui s'est effectuée entre ALIX et un client; celle-ci est surtout utile aux transitaires afin de répertorier le passage en douane.
- documents douaniers: Ce sont les documents de dédouanement établis par les transitaires, indiquant la nature du passage en douane en termes de produits, quantité, valeur monétaire. Ces documents sont visés par le service des douanes et ils attestent du passage conformément au règlement des douanes.
- certificats vétérinaires : Ce sont des certificats visés par des organismes agréés attestant de la conformité du produit par rapport aux normes européennes et internationales en terme qualitatif et sanitaire.
- bon de livraison : C'est la confirmation vis-à-vis d'un client de la livraison d'une certaine quantité de produit à une certaine date. Cette livraison est en rapport avec un contrat de vente. Il est également mentionné l'identificateur du transport. Ce bon est en général apporté au client par le transporteur.
Les données Cette société s’appuie sur le modèle de données suivant (figure 4), illustré par son modèle logique, pour gérer les données de gestion et les données métiers.
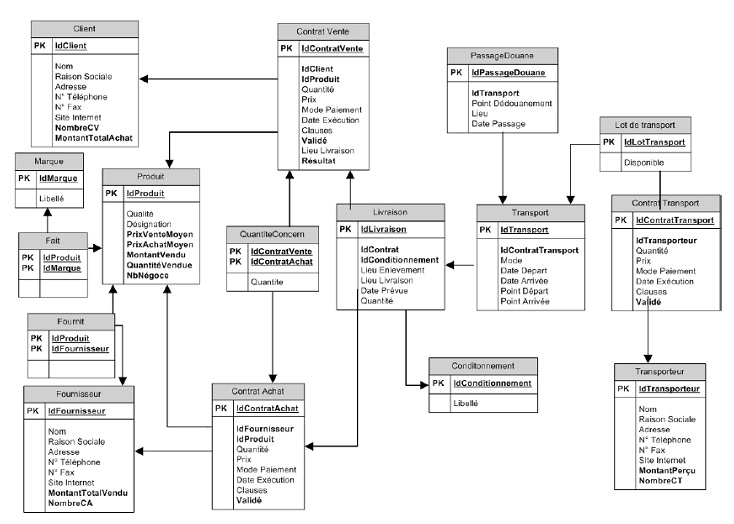
Figure 4. Modèle logique de données pour une entreprise de négoce internationale
Le processus de gestion de l’affrètement est illustré au travers un enchainement d’activités. On notera que ces activités nécessitent données et documents pour être exécutées le plus efficacement possible, ce qui implique une structuration robuste des informations nécessaires, une gestion rigoureuse et une répartition des responsabilités de mise à jour. A titre d’exemple, pour négocier des contrats de transports, outre l’intérêt de connaitre les données sur les transporteurs, les livraisons, les clients et fournisseurs, il est utile de connaître les règlements, les conventions et avoir accès aux informations juridiques nécessaires à une bonne négociation. Aussi, lors de l’exécution de l’activité « choix/appel transporteur/négociation » (figure 5) qui permet, entre autre, de choisir le transporteur pour la négociation, l’acteur de l’entreprise doit-il disposer des moyens lui permettant de consulter toutes les ressources d’information de son entreprise pour rechercher touts documents, informations ou autres types de données provenant de ces transporteurs les rendants indisponibles pour le transport. Ce contrôle peut augmenter la durée du cycle de vie du processus mais garantira la qualité du résultat de ce dernier et améliorera son efficacité. Nous nous appuyons sur l’hypothèse qu’il est préférable de ralentir un processus pour garantir la qualité des résultats produits. L’accès se fait, généralement, par le biais d’une multitude d’outils. L’absence d’un moteur de recherche permettant l’interrogation simultanée des sources d’informations (serveur GED, serveur mail, serveur multimédias, serveur de données, etc.) amène l’acteur de l’entreprise à interroger plusieurs outils (tous les serveurs de l’entreprise) séparément avant de réunir les informations répondant à la même requête, à savoir « y a-t-il eu des informations, non encore prises en compte par le système, qui peuvent modifier la liste-transport après son établissement par l’activité précédente? ». Du point de vue des acteurs de l’entreprise, pour des raisons de gain de temps et d’amélioration de l’efficacité des processus, il serait souhaitable de n’avoir qu’une seule interface permettant d’interroger plusieurs sources d’information et de disposer, ainsi, d’un outil fédérateur capable d’interroger simultanément toutes les sources de connaissances. Cet outil fédérateur met à la disposition de l’acteur de l’entreprise des documents et des données qui lui permettent de distinguer les documents et données utiles en fonction du contexte. Ce dernier pouvant être défini par rapport au client, fournisseur et transporteur. En effet, l’acteur peut mener des négociations différentes selon qu’il s’agit d’un transporteur aérien ou routier, d’un fournisseur de denrées biologiques ou de produits carnés, ou encore d’un client local et un client international. Les différences d’appréciations relèvent des contrats qui sont le plus souvent individualisés. La sous-section III-3 répond à ces questionnements en proposant une architecture de mémoire d’entreprise orientée processus métier et s’appuyant sur une approche hybride basée sur l’ingénierie des connaissances, l’ingénierie documentaire et la médiation sémantique et exploitant le référentiel processus comme ontologie de domaine.
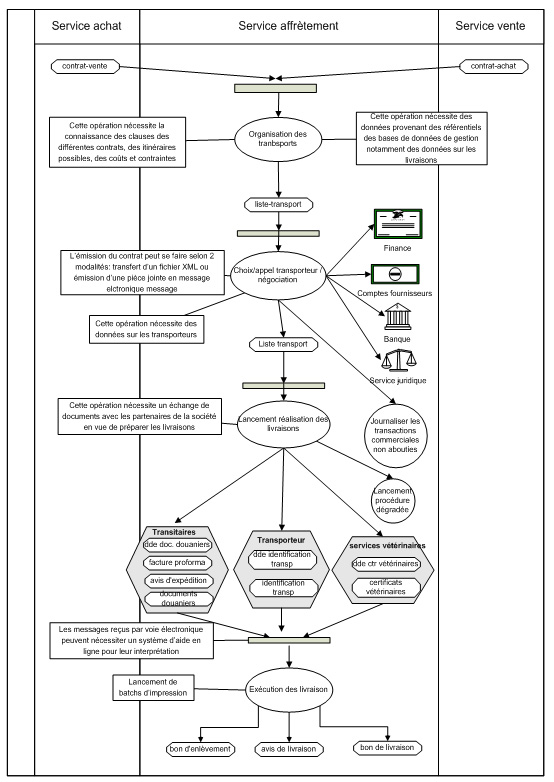
Figure 5. Processus illustrant de l’affrètement pour une société de négoce. Les activités sont symbolisées par des ovales
III-2. Architecture générale pour une mémoire d’entreprise orientée-métier
Causannel (Caussanel, 1999) distingue au travers des différents travaux qui ont été réalisés dans le domaine de la gestion des connaissances, l’approche orientée information de l’approche orientée connaissances. Selon l’auteur, l’approche orientée information pour la gestion des connaissances se concentre sur l’amélioration de la gestion et de l’échange d’informations en essayant d’éviter les frontières organisationnelles ou professionnelles. Elle se fonde sur l’élaboration d’outils informatiques facilitant le travail coopératif et la communication entre les différents collaborateurs de l’entreprise (ex : outils de groupware). Elle permet également l’échange de connaissances explicites au moyen d’outils de type workflow ou gestion documentaire. L’approche orientée connaissances, très liée aux recherches effectuées en Ingénierie des Connaissances, se base sur une étape de capitalisation qui consiste à recenser puis à modéliser les connaissances (Abecker, 1998). Les connaissances sont alors modélisées (i.e. représentées sous forme d’informations) tout en intégrant une sémantique et un contexte pour former une Base de Connaissances. L’élaboration d’un tel système correspond à une phase de capitalisation d’un sous-ensemble ou de l’ensemble des connaissances de l’organisation.
C’est dans la première approche que s’inscrit notre contribution. Pour tenter une définition de la mémoire d’entreprise sur le plan technique, nous dirons qu’une mémoire d’entreprise est l’ensemble des outils permettant de rechercher et d’exploiter l’ensemble des ressources de l’organisation ou de l’entreprise en vue de reproduire des savoir-faire, de rendre efficace des processus, et de capitaliser les connaissances. Pour concevoir une telle mémoire d’entreprise, il est important d’en définir une architecture. Celle que nous proposons ici vise à fournir l’infrastructure modulaire nécessaire à l’élaboration d’un système de gestion des connaissances qui s’interface avec le SIE tout en s’appuyant sur les techniques du Web sémantique et les standards des technologies de l’information et de la communication. Au sein de cette architecture (figure 6), trois niveaux sont distingués :
- le niveau exploration de la mémoire d’entreprise qui fournit des services directement destinés aux différentes catégories d’utilisateurs de la mémoire en s’appuyant sur l’infrastructure de gestion ;
- le niveau gestion de la mémoire d’entreprise qui est doté d’un ensemble de modules et de composants qui fournissent les fonctionnalités élémentaires de la gestion de la mémoire d’entreprise ;
- le niveau sources d’information de l’entreprise au sein duquel sont localisées les ressources de connaissances.
Cette architecture permet de mettre en œuvre un processus d’intégration (voir section IV) qui vise à aider un acteur d’une entreprise dans la recherche d’informations utiles à l’exécution des processus métier. Cette architecture nous permet donc d’envisager un mémoire d’entreprise orientée processus métier car elle peut être sollicitée à chaque exécution d’une activité qui nécessite des données complexes provenant de sources hétérogènes.
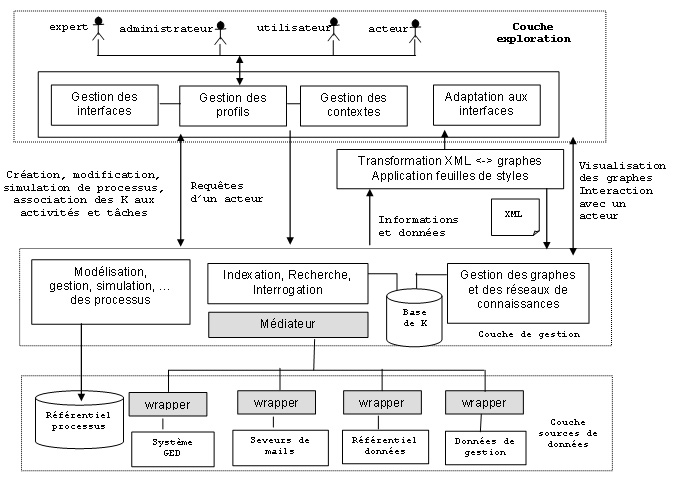
Figure 6. Architecture technique générale pour une mémoire d’entreprise orientée-métier A noter qu’un wrapper est un traducteur qui, dédié à une base de données en particulier, traduit les informations venant du médiateur en un langage compréhensible par les bases de données à laquelle il est attaché, et inversement. Un médiateur quant à lui est chargé d'interroger une ou plusieurs bases de données et est donc relié à un ou plusieurs wrappers
III.2.1. La couche exploration
L’exploration de la mémoire d’entreprise comprend un nombre de services permettant à des acteurs différents de l’entreprise d’accéder à des informations pour optimiser les processus qu’ils exécutent. Les services offerts par la couche exploration doivent donc être tournés vers les acteurs. Ils permettent la gestion des profiles, des contextes et des interfaces. On peut y trouver des fonctions d’adaptation des interfaces aux contenus selon qu’il s’agisse de pocket PC, de téléphone portable, etc. La gestion des profils permet de prendre en compte l’organisation des responsabilités des acteurs au sein de l’entreprise. En effet la mémoire d’entreprise doit s’adapter à l’acteur. Par exemple, un décideur a besoin de connaissances synthétiques, un acteur lambda a besoin de connaissances opérationnelles. La gestion du profil s’appuie sur la description, le plus souvent hiérarchique des acteurs. La mémoire d’entreprise doit également prendre en compte le contexte qui peut se déterminer par rapport à un ensemble de tâches effectuées par l’acteur. Le contexte se définit alors par la trace d’exploitation de la mémoire d’entreprise dans un intervalle de temps. La combinaison du profil des acteurs et des contextes d’utilisation permet d’affiner les attentes des acteurs et de rendre pertinent les processus de recherche de l’information. Faciliter la mise en contexte de l’information est également un objectif de la couche d’exploration car une information est d’autant plus vite assimilée qu’elle est présentée dans un contexte proche de celui que l’acteur connaît bien.
III.2.2. La couche gestion de la mémoire
La couche de gestion de connaissances réutilisables est chargée de mettre à la disposition des utilisateurs, en particulier les experts du domaine, des fonctionnalités nécessaires à l’intégration de nouvelles connaissances dans le système. Grâce à ces fonctionnalités l’expert doit pouvoir saisir les connaissances implicites selon le formalisme du référentiel des processus préalablement prédéfini et transformer ainsi les savoir-faire en une matière utilisable. Cela passe souvent par la mise en œuvre d’ontologies de processus métier. Une solution pratique est ensuite de générer les éléments de connaissances introduits par l’expert, en documents XML selon des structures prédéfinies par les DTDs ou de schéma XML par exemple. Les principales fonctionnalités des modules de modélisation, de gestion, et de simulation des processus concernent :
- l’intégration et la validation des connaissances sous forme de ressources documentaires générées en format XML ;
- l’association de métadonnées aux ressources documentaires;
- l’enregistrement et la pérennité des connaissances nouvellement intégrées dans le serveur ;
- la recherche des ressources documentaires selon des métadonnées.
L'indexation étant l'étape préparatoire pour la recherche dans la mémoire d’entreprise, le module d’indexation se connecte systématiquement à la base de connaissance via le module de traitement de requêtes. Le module de traitement des requêtes (médiateur) est responsable de fournir les résultats pertinents aux requêtes des utilisateurs de la mémoire d’entreprise. Il est chargé d’analyser et de traiter les requêtes exprimées par l’utilisateur afin de construire des requêtes précises. Ces traitements reposent sur la base de connaissances, où le module permet l’interrogation du schéma de l’ontologie à la fois pour l’explorer et pour s’assurer de sa cohérence. L’interrogation de l’ontologie se caractérise donc par deux aspects importants :
- la possibilité d’interroger ou explorer le schéma aussi bien que le contenu de l’ontologie, et ;
- le raisonnement sur les concepts et les instances de l’ontologie.
III.2.3. La couche source d’information
Le principe de l'architecture du système à mettre en place consiste à autoriser un accès centralisé et structuré à des sources d’information multiples et hétérogènes. Une des approches les plus usuelles est d’utiliser la notion de « médiateur ». Dans cette approche, les données restent stockées et réparties au niveau des sources d’information, ce qui est fort intéressant dans le cadre de la mise en place de mémoires d’entreprise autour d’un existant. Le médiateur joue alors le rôle d’interface entre l’utilisateur et les sources d’information en lui donnant l’impression qu’il interroge un système centralisé et homogène. Les programmes à écrire doivent pouvoir permettre :
- L’extraction des données et informations des bases sources (selon les requêtes prédéfinies) ;
- La comparaison de ces informations avec les requêtes des acteurs (matching) ;
- La conversion de ces information sous forme exploitable (documents xml ou html) ;
Lorsque l'on doit interroger différentes bases de données, plusieurs problèmes sont à prendre en compte dont les suivants :
- la disparité des types de données
- la différence entre les langages d’interrogation des divers systèmes
- l’hétérogénéité des schémas de données.
Lorsqu'un utilisateur émet une requête vers une interface centrale, cette interface doit déterminer vers quelle(s) source(s) envoyer la requête, et doit aussi être capable de modifier la requête si nécessaire avant de l'envoyer à une source. Cette requête doit arriver au système gérant la source de données dans un langage compréhensible par ce système. Pour réaliser l’interprétation aussi bien des requêtes que des résultats, il est nécessaire de disposer d’un système capable de réaliser ces deux fonctions. On parle alors de « médiateur ». Un médiateur peut donc "dialoguer" avec plusieurs wrappers (qui, de plus, peuvent aussi être interrogé par différents médiateurs). Un wrapper sera en revanche dédié à une seule source de données.
Le rôle du médiateur est donc "d'aiguiller" la requête vers la bonne base de données. Ensuite, un wrapper va être chargé de traduire la requête dans le langage compréhensible par le système gérant la base de données en question. Le wrapper récupère ensuite la réponse du système et la renvoie au médiateur après l'avoir traduite dans le langage compréhensible par le médiateur. Les wrappers ont également pour rôle de transformer les sources de données de « la couche source de données » en documents XML pour faciliter la fusion des résultats. On a ainsi les transformations suivantes :
- système GED -> document XML GED
- serveur mail -> document XML mail
- référentiel données -> document XML référentiel données
- données de gestion -> document XML données de gestion
III.3. Complémentarité entre l’Ingénierie documentaire et l’Ingénierie des connaissances
La conception et la réalisation d’une telle architecture se doit de combiner différentes approches et techniques. Les dimensions « document » et « connaissance » sont centrales dans une mémoire d’entreprise et nécessite donc aussi bien l’usage de techniques documentaires que de technique de gestion de connaissances. En effet :
- L’ingénierie documentaire désigne « le projet de recourir à des éléments de structuration du contenu des documents et à des métadonnées de description pour faciliter la gestion des documents à travers tout leur cycle de vie » (Parent et Boulet, 1998). S’agissant des ressources électroniques, ces métadonnées ont pour rôle d’offrir la possibilité d’accéder à des parties d’un document à travers sa structure et de pouvoir y naviguer intelligemment (Le Maitre et al, 2004).
- L’ingénierie des connaissances correspond, quand à elle, à l’étude des concepts, méthodes et techniques permettant de modéliser et/ou d’acquérir les connaissances. De fait, les méthodes et techniques utilisées dans ce domaine sont utiles notamment pour « construire une mémoire d’entreprise basée sur le recueil et la modélisation explicite des connaissances de certains experts ou spécialistes de l’entreprise. Elle peut aussi servir pour une représentation formelle des connaissances sous-jacentes à un document ». (Dieng et al, 2000). « L’ingénierie des connaissances modélise les connaissances d’un domaine pour les opérationnaliser dans un système destiné à assister une tâche ou le travail intellectuel dans ce domaine (résolution de problème, aide à la décision, consultation documentaire, etc.) » (Bachimont, 2004).
Les techniques de l’ingénierie documentaire qui s’appuient sur des langages de description SGML, XML, RDF, RDFS, etc. offrent un bon niveau dans l’indexation, le stockage et la recherche d’informations. Par exemple, RDF permet d’annoter des documents avec un formalisme permettant de faire référence à des connaissances terminologiques sous formes d’ontologies. De cette manière, une requête de recherche d’information peut faire l’objet de raisonnements élémentaires reposant sur les connaissances modélisées. XML étant amené à jouer le rôle de standard international pour les documents structurés, cela permet d’assurer la pérennité des documents et des informations à long terme, dans le cadre de la mémoire d’entreprise. Cela ménage la possibilité de migrer vers de nouveaux outils de gestion documentaire en conservant le patrimoine d’information.
C’est ainsi que pour atteindre l’objectif visé par cet article et décrit dans l’introduction, le recours à l’ingénierie documentaire nous parait évident et l’avantage de combiner différentes méthodes et techniques issues de l’ingénierie des connaissances et l’ingénierie documentaire est de bénéficier des solutions complémentaires que fournissent ces deux domaines pour la gestion des connaissances ainsi que l’usage des méthodes associées de représentation des connaissances qui incluent le raisonnement et l’inférence.
IV. Processus d’intégration
Dans notre architecture, les couches interagissent entre elles. Le principe repose sur la notion de services ; aussi la couche n s’appuie t-elle les services de la couche n+1. C’est ainsi que la couche exploration sollicite la couche de gestion pour pouvoir répondre aux acteurs sur des besoins de d’interrogation, de recherche, de modélisation, d’indexation, etc. La couche de gestion sollicite la couche de données pour des besoins de restitution de connaissances issues de différents serveurs (données, GED, serveur de mails, …), mais aussi des besoins de stockage et d’accès au données. Sur la figure 6, on note, en guise d’illustration, que la couche exploration peut solliciter la couche de gestion pour assurer toutes les tâches liées à la manipulation des processus (création, stockage dans le référentiel, etc.). La couche exploration peut solliciter la couche de gestion pour interroger la mémoire d’entreprise en termes de connaissances (sur la figure 6, le message correspondant à la requête d’un acteur illustre ce fait). On notera qu’une bonne partie des échanges entre les couches doit se faire à travers l’utilisation de XML pour assurer la pérennité nécessaire à ce type de mémoire. Le principe de fonctionnement et d’articulation des couches, illustré par la figure 7, se fait selon un certain nombre d’étapes qui organise en séquence des processus décrits en section IV.2.
IV.1. Liste des processus d’intégration des sources hétérogènes
Processus de formulation : ce processus est déclenché par un acteur externe. Dans ce processus :
- l’acteur se positionne comme utilisateur de la « couche exploration » ;
- l’acteur formule une requête de type : quelles sont les informations nécessaires pour exécuter ma requête et améliorer la performance de mon processus ?;
Processus de transformation : ce processus se charge de construire des requêtes suite aux exigences de l’acteur. Il se base notamment sur la transformation de demandes des acteurs sous une forme compréhensible par la « couche de gestion ». Il soumet la requête au médiateur.
Processus de médiation : ce processus se déroule selon les étapes suivantes :
- réception des requêtes par « la couche de gestion » ;
- le médiateur de « la couche de gestion » contient les schémas de tous les documents XML de « la couche source de données ». Il sollicite les « wrapper » en prenant le soin de transformer la requête qu’il reçoit en autant de services d’exécution des requêtes que de sources de données (service d’exécution des requêtes « mail », service d’exécution des requêtes « GED », service d’exécution des requêtes « référentiels données », service d’exécution des requêtes « données de gestion ») ;
Processus d’extraction : à travers les wrappers, les services d’exécution des requêtes (mails, GED, référentiels données, données de gestion) interrogent respectivement les documents XML correspondants dans la « couche source de données » ; les résultats des interrogations sont stockés respectivement dans :
- « document résultat XML mails » correspondant au résultat de l’interrogation des documents XML mail de « la couche source de données » ;
- « document résultat XML GED» correspondant au résultat de l’interrogation des documents XML GED de la « couche source de données » ;
- « document résultat XML données » correspondant au résultat de l’interrogation des documents XML données de « la couche source de données » ;
- « document résultat XML données de gestion » correspondant au résultat de l’interrogation des documents XML données de gestion de « la couche source de données ».
Processus de restitution : c’est le processus qui est exécuté en fin de séquence en ordonnant les étapes suivantes :
- fusion de ces résultats en un seul « document XML résultat » ;
- application de feuille de style XSL au « document XML résultat » et retour vers l’utilisateur;
- visualisation du « document XML résultat » par l’utilisateur.
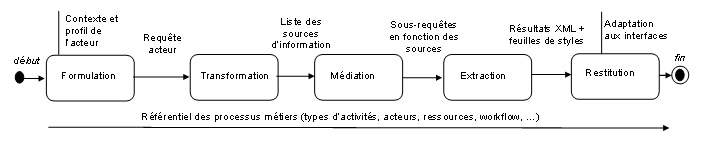
Figure 7. Processus d’intégration qui met en œuvre les grandes fonctions de la mémoire d’entreprise
Il est à noter qu’une tâche récurrente est exécutée par le système indépendamment des accès explicites des utilisateurs. Cette étape permet d’indexer toute nouvelle source d’information et alimenter la base de connaissances. L’indexation est une tâche cruciale qui nécessite des experts du domaine pour le choix des termes du corpus à indexer. Dans notre solution, le système d’indexation permet en outre d’établir des liens entre sources hétérogènes dans le cadre de processus métier clairement définis en termes d’activités, d’acteurs et de ressources.
IV.2. Illustration : aide à la négociation de contrats
Lors du processus d’affrètement d’une entreprise de négoce international présenté dans la section III.1, un acteur est amené, lors de la négociation de contrats avec des transporteurs, à solliciter des informations pouvant provenir des bases de données et des référentiels, des messageries et du système documentaire. La première source va permettre à l’acteur d’accéder à des informations factuelles des clients, des fournisseurs et des transporteurs telles que ses coordonnées mais aussi leurs chiffres d’affaire. La deuxième source permet à l’acteur d’accéder à une information qui lui fournit des connaissances sur les échanges qu’il a eus avec ces partenaires avant la négociation. La troisième source d’information lui permettra d’avoir une sorte de best-practise sur la gestion de contrats puisqu’il peut avoir accès soit aux derniers contrats qu’il a négociés avec ces partenaires mais aussi des guides de négociation de contrats similaires. Plus précisément, lors de son activité de « choix de transporteur », un acteur du département « Affrètement » déroule un scénario qui s’appuie sur un algorithme visant à choisir le « meilleur » transporteur, en termes de coût, pour assurer des livraisons d’un point à un autre tout en respectant les délais. Pour cela, il contacte chacun des transporteurs d’une liste préalable et négocie avec chacun d’eux. Il s’appuie pour cela sur les informations suivantes :
- Les clients à livrer : distributeur et grandes surfaces par exemple. Les clients sont décrits par leurs adresses, leur chiffre d’affaire, le domaine d’activité, leur organisation (sièges, magasins).
- Les fournisseurs des produits classés selon la nature des produits et décrits par des attributs similaires à ceux des clients.
- Le transporteur est décrit pas ses coordonnées mais également ses moyens de transport tel que aérien, maritime, routier, ferroviaire.
- Les messages qui ont été envoyés
- par le service commercial des clients, qui précisaient les points de livraisons, les produits et les quantités ainsi que les livraisons devant être réalisées au niveau des magasins.
- par le service commercial des fournisseurs pour indiquer les lieux d’enlèvement qui sont des entrepôts,
- Le guide du contrat de transport sous forme de document word.
- Les derniers contrats de transport déjà négociés.
Une fois le transporteur sélectionné comme étant celui qui répond le mieux aux critères et contraintes de coûts, de délais et de fiabilité, un contrat de transport est élaboré et signé. Les données sur les clients, fournisseurs et livraisons y sont consignés. Le guide de rédaction des contrats permet à l’acteur de négocier les différentes clauses du contrat.
Une mémoire d’entreprise doit fournir à cet acteur la possibilité d’accéder à tout instant à l’ensemble des informations nécessaires pour réaliser son activité. Notre architecture est conçue de sorte à ce que ce type d’information soit rendu disponible à travers des interfaces appropriées pour faciliter à l’acteur des navigations dans des structures d’information complexes. Les liens entre les informations sont exploités au niveau des interfaces pour permettre à l’acteur une navigation sémantique et passer d’un espace à un autre, par exemple passer d’un espace numérique (qui présentent des données factuelles ou statistiques) à un espace documentaire contenant des hyperliens de navigation dans des sommaires ou des contenus.
Dans un tel scénario, on peut imaginer que l’acteur formule la requête : « retrouvez toute l’information utile pour négocier un contrat de transport avec tels clients et tels fournisseurs». La mémoire d’entreprise doit permettre de restituer, sous forme lisible, les informations nécessaires. Pour cela, elle s’appuie sur le type d’activité que l’acteur est entrain d’exécuter, en explorant le référentiel des processus métier de la mémoire d’entreprise pour établir les liens entre informations.
La mise en œuvre du mécanisme de fonctionnement de l’architecture que nous proposons pour cet exemple est illustrée par le tableau Tab 1.
| Processus | Objectif / buts | Information / Connaissance |
|---|---|---|
| Formulation | L’acteur formule une requête pour l’obtention d’une information qui l’aiderait à mieux gérer le contrat avec le client. Il demande donc à la mémoire d’entreprise de mettre à sa disposition les informations en relation avec le client. | Retrouver mails, contrats et données sur le client. |
| Transformation | La couche exploration fournit à la couche de données la requête de l’acteur et s’attend à un document XML qui correspond aux résultats trouvés. La couche de gestion traduit cette requête dans le langage du médiateur. | Rechercher données clients (coordonnées, chiffres d’affaires) + messages dont l’expéditeur et/ou le destinataire correspondent au client + le guide contrat de vente + les contrats du client ; soit Q cette requête. |
| Médiation | La couche de gestion, à travers le médiateur, éclate la requête en autant de requêtes que de type de sources de données. | La requête Q est décomposée en Q1 (vers les référentiels et données), Q2 (vers la messagerie), Q3 (vers la GED). |
| Extraction | La couche de données de l’architecture est sollicitée par le biais des wrappers qui permettent d’extraire les informations demandées. | Chacune des requêtes Q1, Q2 et Q3 est traité par le wrapper approprié. W1 pour lancer des requêtes de types SQL à des SGBD relationnels, W2 à travers des protocoles de messageries SMTP permet de collecter les messages utiles et enfin W3 charger de récupérer des documents correspondants aux contrats ou guide de contrats. |
| Restitution | La couche de gestion, à travers le médiateur, reçoit les réponses de la couche de données. Celles-ci sont transformées, fusionnées et transmises à la couche exploration. | La couche exploration applique une feuille de style pour présenter les informations fournies sous forme XML par la couche de données. Elle permet de simplifier la complexité due à l’hétérogénéité des informations. |
V. Conclusion et discussions
L’enjeu de toute entreprise est d’atteindre ses objectifs planifiés dans sa stratégie globale. Nous avons montré que pour atteindre les objectifs de l’entreprise, les acteurs doivent prendre les bonnes décisions lors de l’exécution des processus métiers et l’amélioration, en continue, des performances de ces derniers, nécessite l’exploitation des mémoires d’entreprise dont il faudra définir l’architecture. Concernant l’architecture d’une mémoire d’entreprise, l’ingénierie documentaire peut fournir un levier pour la concrétisation de la mise en œuvre de la mémoire d’entreprise. Ainsi, l’indexation documentaire peut-elle se révéler particulièrement intéressante dans le contexte d’une mémoire d’entreprise. L’ingénierie documentaire peut également être exploitée, pour la formalisation des savoir-faire d’experts. Ceci consiste à transcrire les connaissances sous une forme exploitable et échangeable entre les individus mais aussi, entre des applications hétérogènes. L’utilisation d’XML comme support de formalisation et d’explicitation des savoir-faire offre l’avantage de structurer les connaissances selon des balises. Ces dernières sont fournies par les métadonnées et les concepts préalablement créés à partir de l’ontologie.
L’enjeu premier en gestion des connaissances réside non pas seulement dans l’implantation d’outils de gestion des connaissances, mais aussi dans l’implantation d’une habitude d’entrée des connaissances dans les outils par les membres de l’organisation et d’établir une arborescence de fonctions et de tâches à faire une fois que la connaissance a été acquise. Cependant, l’objectif d’une capitalisation des connaissances est bien le partage des connaissances dans le but de leur réutilisation par les membres adéquats de l’entreprise. Les technologies de l’information et de la communication peuvent constituer un support de diffusion intéressant pour favoriser le partage. Cependant, la diffusion doit être guidée si l’on veut fournir la bonne information au bon moment et éviter la surinformation. De plus, la diffusion d’une information ne suffit pas à garantir la réutilisation de la connaissance qu’elle est susceptible de transmettre. En effet, pour qu’une connaissance soit réutilisée, il est nécessaire qu’elle soit assimilée par l’acteur c'est-à-dire l’intégrer à sa base d’expérience et de connaissances propres et mobilisée à tout moment dans l’action (Tounkara et al, 2001). C’est dans ce sens qu’elle contribue à l’acquisition des compétences par les acteurs dans l’organisation.
Bibliographie
ABECKER A., BERNARDI A., HINKELMANN K., KUHN O., et SINTEK M. (1998). Toward a technology for organizational memories. IEEE Intelligent Systems, May/June. http://citeseer.nj.nec.com/abecker98toward.html
BACHIMONT B. Pourquoi n’y a-t-il pas d’experience en ingénierie des connaissances ? In Actes de la conférence (Ingénierie des connaissances IC2004), N. MATTA (ed), Lyon. Presses Universitaires de Grenoble.
BLASIUS K.H., HEDSTUCK U., ROLLINGER C-R. (1989). Sorts and Types in Artificial Intelligence, volume 418 of Lecture Notes in Artificial Intelligence. Springer Verlag, Berlin. 307 p.
BRACHMAN R. (1977). A Structural Paradigm for Representing Knwoledge. Thèese : Harvard University, USA,.
CAUSSANEL J., CHOURAQUI E. (1999). Information et Connaissances : quelles implications pour les projets de Capitalisation des Connaissances, in: Revue Document numérique - Gestion des documents et Gestion des connaissances, vol. 3-4, pp. 101-119.
CHARLET, J. (2002). L’ingénierie des connaissances : développement, résultats et perspectives pour la gestion des connaissances médicales. HDR. Paris : Université Pierre et Marie Curie, 142p
CHEIN Michel et MUGNIER Marie-Laure (1992). Conceptual Graphs : Fundamental Notions. Revue d’Intelligence Artificielle, vol 6, n°4, p. 365-406.
DAVIS, R., SHROBE, H., SZOLOVITS, P., (1993). What Is a Knowledge Representation ? AI Magazine, vol 14, n°1, p 17-33.
DIENG, R., CORBY O., GANDON F., GIBOIN A., GOLEBIOWSKA J., MATTA N., RIBIERE M. (2005). Knowledge Management: Méthodes et outils pour la gestion des connaissances. 3ème éd. Paris, Dunod. P 450. ISBN 2 10 049635 2
LEBRATY J.F, (2000). Les systèmes décisionnels, Encyclopédie des systèmes d'information, Vuibert.
Le MAITRE J., MURISASCO E., BRUNO E. (2004). Recherche d’informations sur les documents XML, In : Méthodes avancées pour les systèmes de recherche d’informations, Traité STI, Hermès, pp. 35-44, M.Ihadjadene.
MINSKY, M. (1975). A Framework for Representing Knowledge. The Psychology of Computer Vision. Edited by Winston P.H., p 245–262. McGraw-Hill, New York.
MORLEY C., HUGUES J., LEBLANC B., HUGIES O. (2005). Processus métiers et S.I: Evaluation, modélisation, mise en œuvre. Paris, Dunod. P 237. ISBN 2 10 007099 1
MUGNIER M-L, CHEIN M. (1996). Représenter des connaissances et raisonner avec des graphes. Revue d’intelligence artificielle, vol 10, n°1, p 7-56.
NONAKA I., TAKEUCHI H. (1995). The Knowledge-Creating Company: How Japanese Companies Create the Dynamics of Innovation. Oxford University Press, 304 p.
PARENT R., BOULET N. (1998). Rôle des professionnels et l’ingénierie documentaire. Rapport issu de la journée de réflexion portant sur les rôles professionnels et l’ingénierie documentaire. Quebec, (www.services.gouv.qc.ac/fr/publications/enligne/administration/ingenierie/role_prof.pdf).
QUILIAN M. (1968). Semantic Memory. Semantic Information Processing, pp 227–270. MIT Press, Cambridge,MA, US.
SOWA J.F. (1984). Conceptual Structures : Information Processing in Mind and Machine. The system programming series. Addison-Wesley. 481 p.
Logiciels de gestion de références bibliographiques : citons le libre !
Ressi — 30 avril 2008
Carole Zweifel
Résumé
Depuis 2005 la situation des logiciels libres pour les bibliothèques évolue rapidement. Dans la liste des logiciels à disposition, les logiciels de gestion de références bibliographiques semblent attirer aussi bien les bibliothécaires que les étudiants et les chercheurs. Afin de réaliser un état des lieux approfondi des solutions libres existant aujourd’hui, un test comparatif de sept outils a été réalisé en été 2007 et ce sont les résultats qui sont présentés dans cet article.
Mots-Clés:
Logiciels libres,
Gestion de références bibliographiques,
Base de données bibliographiques
Dernière modification:
23/06/2009 Logiciels de gestion de références bibliographiques : citons le libre !
1. Introduction
Ludivine Berrizi et moi avions publié un article dans le RESSI no 2 (juillet 2005) sur les logiciels libres en bibliothèque, avec un accent sur les logiciels de gestion de bibliothèque (SIGB). A cette époque, parler d’applications libres pour les bibliothèques en Suisse était assez novateur. Il existait en effet peu de choix et presque aucun utilisateur. Mais nous concluions notre article en relevant un potentiel très fort du libre en bibliothèque.
Force est de constater que depuis 2005, la situation des logiciels libres pour les bibliothèques a évolué dans le bon sens et rapidement. Une lecture du rapport annuel sur l’informatisation des bibliothèques en France, publiée chaque année dans Livre Hebdo (Maisonneuve, 2007) en mars, nous informe en effet que « un projet informatique sur quatre porte sur l’implantation d’un système de logiciel libre ». De plus, PMB (certainement le SIGB libre le plus performant actuellement avec Koha) représente plus d’un dixième des logiciels installés en 2007 dans des bibliothèques municipales françaises. Et l’on compte 302 nouveaux contrats avec PMB dans tous les types de bibliothèques en France en 2006.
Voilà des chiffres tout à fait encourageants chez nos voisins français ! Du côté suisse (romand essentiellement), il a été porté à ma connaissance depuis 2005 plus d’une dizaine d’installations de logiciels libres en bibliothèque et centres de documentation. Signalons par exemple l’installation prochaine de PMB au centre de documentation de l’antenne suisse de Médecins sans Frontières (Genève) ou l’utilisation de Koha à la bibliothèque du Gymnase Intercantonal de la Broye, à Payerne.
Mais le SIGB n’est pas le seul type de logiciel libre qui concerne les bibliothèques. Greenstone devient un incontournable quant à la création de bibliothèques numériques et l’UNESCO ne s’est pas trompé en soutenant ce projet. On peut également trouver plusieurs outils de transformations de données MARC, des logiciels de gestion de documents audio-visuels ou encore les logiciels de gestion de références bibliographiques.
Il y a maintenant plus d’un an, je me suis intéressée à cette dernière catégorie. Le logiciel de gestion de références bibliographiques (que j’abrégerai par LGRB dans cet article) est utilisé de manière assez mineure en bibliothèque mais le message de Madame Ariane Sujatha Henry sur Swiss-lib du 20 juin 2007 et les diverses réponses a montré qu’il y’avait un besoin dans ce domaine, que ce soit pour gérer une petite base de références internes ou pour soutenir les nombreux étudiants et chercheurs qui utilisent un LGRB.
En cherchant des références récentes sur le sujet, j’ai constaté que celui-ci était encore peu traité de manière approfondie. Deux billets de blog récents (Mahbub Murshed, 2007 / Fauskes, 2007) citent plusieurs logiciels libres et de nombreux commentaires de développeurs de LGRB y ont été ajouté avec des informations récentes. On trouve également une grille de comparaison des LGRB (dont 9 solutions libres) fort bien faite sur Wikipedia (2007b). Mais ces informations ont-elles été pêchées sur le site officiel du site ou proviennent-elles d’un réel test ? Dans le but d’établir un état des lieux approfondi des solutions libres existantes actuellement, j’ai donc réalisé un test complet puis un comparatif des applications existantes, entre elles et par rapport à deux logiciels propriétaires classiques (Endnote et Reference Manager).
Les résultats de cette étude, comprenant le test de 7 outils réalisé en juillet et août 2007, m’ont étonné de manière très positive. Il existe en effet plusieurs solutions, chacune unique et pour la plupart très performantes, voire meilleures que les solutions propriétaires, dont Endnote ou Reference Manager sont les plus utilisées. On découvrira également que, moyennant quelques adaptations, ce type de logiciel pourrait fort bien convenir comme base de référence pour des petits centres de documentation. Il y a donc de bonnes raisons de connaître ces solutions !
2. Quelques définitions essentielles
Définition du logiciel libre
Le concept du logiciel libre date du milieu des années 80, lorsque Richard Stallman, travaillant sur le système d’exploitation Unix, s’exaspère de la fermeture de plus en plus répandue du code source du logiciel au profit d’une licence d’utilisation (méthode popularisée par Microsoft). Richard Stallman crée alors la Free Software Foundation et développe la licence GPL pour définir le logiciel libre.
Celui-ci doit respecter les 4 libertés suivantes :
- La liberté d'exécuter le programme, pour tous les usages (liberté 0).
- La liberté d'étudier le fonctionnement du programme, et de l'adapter à ses besoins (liberté 1). Pour ceci, l'accès au code source est une condition requise.
- La liberté de redistribuer des copies, donc d'aider son voisin, (liberté 2).
- La liberté d'améliorer le programme et de publier ses améliorations, pour en faire profiter toute la communauté (liberté 3). Pour ceci l'accès au code source est une condition requise.
Les logiciels libres se caractérisent également par la gratuité de leur acquisition et par leur communauté, « assemblée démocratique » du logiciel composée de ses développeurs, traducteurs et utilisateurs, et remplaçant l’éditeur du logiciel.
On peut citer quelques logiciels libres très connus tel le système d’exploitation Linux, le navigateur web Firefox, le logiciel de messagerie Thunderbird, le serveur Apache ou encore la suite bureautique Open Office.
Le terme « Open source » est souvent utilisé pour qualifier ce type de logiciel. Les deux termes sont très proches mais pas tout à fait équivalents. Nous n’entrerons cependant pas dans une telle finesse de définition dans cet article.
Définition du LGRB
Le logiciel de gestion de références bibliographiques (LGRB) permet de gérer des références bibliographiques au sein d’une base de données : description de chaque référence (article, monographie, page web, thèse,…) à l’aide d’une grille de catalogage, importation des références depuis des bases bibliographiques en ligne (Medline, ArXiv, INSPEC, Citeseer…), recherches dans les références, regroupement selon plusieurs critères puis création automatique d’une liste bibliographique selon les exigences de présentation spécifiques aux diverses publications scientifiques.
Il existe plusieurs normes de rédaction de références bibliographiques dont les plus connues sont ISO 690, 690-2 (pour les documents électroniques), ISO 4 et ISO 832 (pour les normes d’abréviations). Les normes peuvent aussi être fixées par un éditeur, une université ou un périodique. Chacun demandera, comme le RESSI , de suivre une convention précise.
Le LGRB s’adresse avant tout à un public académique (professeurs, chercheurs ou étudiants avancés), rédigeant des documents faisant de nombreuses références aux articles ayant nourris leur travail. Une liste bibliographique normalisée étant indispensable en fin de travail, le LGRB permet de gagner un temps considérable à l’étape de création de cette liste.
Le LGRB n’est a priori pas prévu pour être utilisé en bibliothèque mais les bibliothécaires peuvent tout à fait être amenés à l’utiliser lorsqu’ils réalisent eux-mêmes des travaux de recherche ou pour gérer une petite base de données de références personnelles. Les bibliothèques universitaires étant souvent le refuge de chercheurs et universitaires, sont également des lieux de formation privilégiés de ces logiciels, en attestent plusieurs manuels d’utilisation sur des sites de bibliothèques universitaires.
Enfin, il n’est pas rare de croiser un LGRB dans un petit centre de documentation. Tout le monde ne fait pas, en effet, du prêt, des échanges de notices au format MARC, ni ne participe à un catalogue collectif demandant d’utiliser des formats spécifiques. Ces outils ont l’avantage de pouvoir gérer simplement une documentation selon des besoins simples…et évitent d’utiliser un tableau Excel ou la base Filemaker Pro dont plus personne ne se souvient du concepteur ! Deux projets d’installation d’un LGRB libre dans un centre de documentation ont d’ailleurs été menés, à la grande satisfaction des mandants, au travers des travaux de diplômes de la Haute école de gestion de Genève en 2006 (Argenzio-Fortuna, 2006 ; Chabloz, 2006).
Certains de ces outils sont assez flexibles et peuvent donc être adaptés aux particularités de la bibliothèque utilisatrice, par exemple en ajoutant des champs, en réorganisant les grilles de catalogage ou en développant une indexation contrôlée. Mais, entre SIGB et LGRB, les formats sont différents ainsi que la puissance du logiciel ou les fonctionnalités.
Le format des références
Le format le plus courant des notices est le BibTEX. Complément du format LaTeX, le BibTEX a été crée par Oren Patashnik et Leslie Lamport en 1985 et permet de décrire des documents à l’aide de 14 grilles différentes (adaptées au type de document) et 26 champs. BibTEX est devenu, après 20 ans d’existence, un format utilisé comme langage natif par de nombreux LGRB, gage de sa qualité. Mais les logiciels propriétaires les plus répandus utilisent en majorité leur propre format, permettant heureusement de plus en plus l’import et l’export de fichiers BibTEX.
Il existe des formats alternatifs plus récents et donc moins courants : Amsrefs, biblatex ou encore Pybtex. Signalons également que l‘usage de XML est de plus en plus courant.
Au passage, on ne saurait rappeler l’importance de l’usage d’un langage standard dans tout logiciel, dans le but de migrer les données en cas d’obsolescence du logiciel employé. Cette question est d’autant plus essentielle dans le milieu des bibliothèques où l’on se doit d’avoir une vision à long terme de la conservation des données informatiques.
Aspects techniques et architecture
Les langages de programmation varient pour les logiciels propriétaires. Au niveau du libre, on voit très couramment l’usage du langage libre MYSQL/PHP ou le langage Perl, couplés à l’usage d’un serveur Apache (ce qu’on appelle une architecture LAMP). On trouve également du Java.
Coté architecture, les LGRB sont typiquement des petits logiciels monopostes, à usage personnel. Le logiciel est installé sur le poste de l’utilisateur. Si son ordinateur est relié à un réseau, il est possible d’installer le logiciel sur un disque commun. Mais un usage simultané par plus d’une personne n’est pas possible. Endnote ou Reference Manager, ne sont, par exemple, pas adaptés à l’usage en réseau par plusieurs utilisateurs simultanés.
On trouve dans les logiciels libres testés deux autres architectures : base de donnée en full-web et architecture hybride (Bibus, Zotero).
La base de donnée en full-web fonctionne souvent avec les langages libres MySQL/PHP. Il est possible de créer une base de donnée sur Internet (ou sur un serveur local – Intranet par exemple) puis de la consulter avec un simple navigateur Internet. L’intérêt de cette architecture réside dans le fait que le logiciel n’est installé qu’une seule fois, sur un serveur, et qu’il est ensuite accessible par n’importe qui, du moment que l’utilisateur puisse se connecter à Internet ou au serveur local. Cette architecture est idéale pour un usage en réseau.
Bibus et Zotero proposent une architecture hybride. Le premier permet à l’utilisateur d’installer le logiciel soit en monoposte, soit avec une base de donnée en ligne. Zotero est un « add-on » du navigateur Internet libre Firefox. Il faut donc installer premièrement Firefox (ce qui est de toute façon une bonne idée…) puis télécharger Zotero qui s’installe automatiquement. Il suffit ensuite d’ouvrir Firefox (avec ou sans connexion à Internet) pour avoir accès à Zotero.
3. Méthodologie du test
Le test des LGRB libres s’est déroulé en plusieurs étapes : repérage des logiciels , deux étapes de sélection consécutives, installation, test identique pour tous les logiciels, bilan pour chaque logiciel puis comparaisons entre eux.
La sélection
Plusieurs sources ont été consultées pour repérer les LGRB libres à tester. Premièrement, une recherche sur le site Web Sourceforge (plateforme regroupant une grande quantité de projets libres) selon divers mots-clés, ainsi que plusieurs annuaires de logiciels libres, a permis de repérer une bonne trentaine de projets en cours. J’ai également consulté plusieurs articles sur la thématique, glanés sur Internet ou dans des revues spécialisées, et repéré les logiciels cités. Une première sélection d’environ 20 logiciels a ainsi été faite.
J’ai ensuite visité le site web des logiciels les plus cités pour évaluer leur degré de développement et de pertinence. Un mini-test, via installation du logiciel ou démonstration en ligne, a également été réalisé si cela était possible. Une deuxième sélection a été faite selon les critères suivants :
- logiciel stable (version 1.0 ou supérieure) ou version beta (< 1.0) ne présentant pas de bug fatal à l’utilisation
- logiciel proposant les fonctionnalités indispensables du genre.
- projets présentant des développements réguliers ou ne semblant pas assoupis depuis trop longtemps ou abandonnés.
Les logiciels ne fonctionnant que sur Linux ont été éliminés car trop peu d’utilisateurs utilisent exclusivement ce système d’exploitation.
A la fin de l’étape de sélection, les logiciels suivants ont été choisis pour un test approfondi:
- logiciels monopostes : Jabref et Bibdesk
- logiciels fullweb : WikiNDX, Aigaion et Refbase
- logiciels hybrides : Zotero et Bibus
Le test
Pour faciliter leur évaluation et comparaison, les logiciels libres sélectionnés ont été soumis à un test identique :
- Installation sur un ordinateur avec Widows XP et un portable avec MacOS X
- Création de 3 bases et ajout de notices de différents types de documents
- Importation d’une base Endnote ou Reference Manager et un lot de 120 notices BibTeX
- Import de notices via Medline (ou Pubmed)
- Export de la base en BibTeX ou autre format standard
- Création d’une liste bibliographique au format .rtf comprenant un choix de références
- Recherche d’un document ajouté selon 2 mots du titre ou sujet
- Changement du style de présentation des références selon les préceptes de RESSI
- Vérification de la rapidité de la communauté selon une question précise
Le même test a été réalisé, en vue d’une comparaison libre/propriétaire, sur deux logiciels propriétaires couramment utilises : Endnote et Reference Manager.
Une grille de comparaison a ensuite été établie puis remplie pour permettre de relever les avantages et désavantages des logiciels testés entre eux et par rapports aux deux logiciels propriétaires testés.
4. Présentation des logiciels testés
Voici ci-dessous un bref descriptif des logiciels testés avec leurs principales particularités:
Logiciels monopostes :
Jabref, de par son look, ses fonctionnalités et son adaptabilité, est le logiciel testé le plus similaire à Endnote et Reference Manager. Ses fonctionnalités sont d’excellente qualité: import et export de nombreux formats de notices ou depuis des bases de données en ligne, nombreuses grilles de catalogage avec possibilité de joindre le fichier, listes d’autorités et groupes intelligents. Ergonomique et facilement maniable, Jabref est également aisément adaptable (grilles de catalogage, styles bibliographiques). L’interaction avec Word ou Open Office est bonne. On regrettera seulement le peu d’intuitivité du moteur de recherche. Programme en Java, Jabref fonctionne sur tout système d’exploitation.
Bibdesk est un logiciel pour MacOS uniquement. Ce sera son seul point négatif car pour le reste, Bibdesk est un excellent logiciel monoposte. Les fonctions de catalogage permettent de décrire les documents via 21 grilles différentes, facilement adaptable. L’utilisateur peut ajouter plusieurs métadonnées, gérer plusieurs listes d’autorités de manière intelligente, joindre un fichier ou faire un lien sur une adresse web. La création de listes bibliographiques est aisée et souple. Bibdesk est le seul logiciel qui propose une importation de notices via Z39.50, ce qui pourrait se révéler fort pratique pour des bibliothécaires utilisateurs. Au rayon innovation, le logiciel propose également la génération de filets RSS. Pour ne rien gâcher a cette excellence, Bibdesk est très convivial et intuitif.
Logiciels full-web :
WikiNDX est une base de données en full-web, fonctionnant avec MySQL et PHP. Cette architecture lui permet de proposer plusieurs fonctionnalités de multi-utilisation, tel un espace personnel ou des outils de communication entre utilisateurs, et un réel OPAC accessible à tous, sans mot de passe. Les fonctionnalités sont de qualité, entre autre, les moteurs de recherches simples et avancés, les listes d’autorités, les nombreuses metadonnées disponibles ou encore la possibilité de joindre des fichiers aux notices. Il est également possible de créer une classification des références via des catégories. Les styles de présentation des références sont modifiables et le logiciel génère ensuite un fichier au format .rtf, qu’il faudra ensuite ouvrir dans son logiciel de traitement de texte.
On regrettera essentiellement le peu de formats disponibles pour l’importation et l’exportation des notices. Reste que WikiNDX est un outil agréable à l’utilisation et plusieurs professeurs de la HEG de Genève ont migré leurs bases de référence sur cet outil avec satisfaction. WikiNDX fonctionne sur tous les systèmes d’exploitation.
Refbase est également une base de données full-web programmée en MySQL/PHP. Moins abouti que WikiNDX, Refbase a présenté de nombreuses erreurs de programmation lors du test, parfois assez handicapantes. Mais ces bugs s’expliquent probablement par le fait que ce logiciel est encore en version beta et de nombreux utilisateurs ne semblent pas avoir eu autant d’ennui. Passé ces désagréments, Refbase se révèle être un logiciel correct mais sans plus : une seule grille de catalogage (comprenant quand même les champs essentiels pour tout type de document) et un moteur de recherche peu performant (pas de recherche par sujet). Par contre, les fonctions d’import et d’export de notices sont de bonne qualité. On trouve aussi la possibilité de générer des filets RSS et un OPAC.
Aigaion est un projet assez récent (2005). Base de données en full-web programmée en MySQL/PHP, Aigaion souffre peut-être de sa jeunesse, ce qui pourrait expliquer la trop grande simplicité de ses fonctionnalités. Si celles-ci sont très poussées au niveau du paramétrage des comptes des utilisateurs, et de bonne qualité pour le catalogage, les imports/exports de notices ou l’organisation des référence via une arborescence, les fonctions de recherche et de création de listes bibliographiques ne sont pas assez poussées. Le logiciel est également peu modulable. La base du projet est bonne, de bonne qualité et le logiciel suffisant pour des besoins simples mais il vaudrait mieux attendre que le projet soit plus mature avant d’envisager une utilisation avancée de ce logiciel. A surveiller !
Logiciels hybrides
Zotero semble l’outil idéal pour le chercheur qui récupère de nombreuses notices depuis des bases de données sur Internet. En effet, Zotero est un « complément » du navigateur Internet Firefox et s’utilise via le programme Firefox. Il suffit de se trouver sur une page comprenant les références d’un document, cliquer sur un bouton, et une grille de catalogage (parmi 33 types différents) est automatiquement remplie. Il suffit ensuite de réviser les informations, les compléter avec des mots-clés, des métadonnées ou joindre un document électronique et la référence est ajoutée dans la base de donnée du logiciel… Le logiciel permet d’organiser les références importées selon des catégories. Un bon moteur de recherche permet aussi de s’y retrouver. La création de listes bibliographiques est très simple et il est possible d’exporter les références dans de nombreux formats.
Zotero est un outil très simple d’utilisation et intuitif. On regrettera juste le peu de place accordé à la grille de catalogage et le fait que les grilles et les styles bibliographiques ne soient pas modifiables. On se demande également de quelle manière le logiciel stocke les références. Le développement de l’outil est très dynamique et de plus en plus de bases de données deviennent compatibles avec le logiciel, permettant de récupérer des références bibliographiques sur presque toutes les bases de référence, mais aussi sur des serveurs Z39.50. On peut prédire un grand succès à cet outil !
Bibus fonctionnant avec une base de données MySQL (installation en réseau) ou SQLite (installation monoposte) et le langage Python. Bibus devrait fonctionner sur n’importe quelle plateforme. Le logiciel est assez complet au niveau des fonctionnalités et soigné au niveau de la présentation. Il est en outre assez agréable et facile à l’utilisation. Il est possible de faire des recherches simples ou complexes. Des imports de notices peuvent être faites dans les formats standards mais uniquement sur Medline coté bases Internet. L’utilisateur peut paramétrer lui-même la présentation des références et ajouter 5 champs personnalisés dans les grilles de catalogage. Par contre, les liens Internet ne sont pas cliquables et il n’existe aucun moyen d’attacher un fichier. Bibus a particulierement développé sa compatibilité avec OpenOffice ou Word. Ce logiciel sera donc une bonne solution pour l’utilisateur qui génère de nombreuses listes et a besoin de modifier facilement les styles.
5. Des outils concurrentiels
A la lecture de la grille de comparaison des 7 logiciels testés, voilà ce que l’on peut conclure sur les solutions libres, de manière globale :
Architectures
Autant au niveau des applications monopostes que web, les LGRB testés sont tous construits avec des architectures récentes : langage JAVA, base de données MySQL ou « add-on » de Firefox. Les logiciels full-web ont particulièrement tiré parti des possibilités d’une base de données en ligne pour créer des fonctionnalités collaboratives, tels la création d’un compte pour chaque utilisateur et la gestion du workflow. On a donc enfin affaire à des logiciels facilement utilisables en réseau, ce qui est l’un des points noirs des produits phares propriétaires.
Ces logiciels sont relativement faciles d’installation. Aucun n’a demandé l’intervention d’un informaticien pour une installation sur mon poste personnel. La connaissance minimale des bases MySQL/PHP, dans le cas des logiciels full-web, rend la tâche plus aisée mais n’est pas indispensable, d’autant plus que l’installation de ces logiciels est bien documentée, et compréhensible pour un non-averti. Jabref, Bibus, Bibdesk et Zotero proposent même une installation automatisée.
Le test a révélé encore quelques erreurs de programmation dans une moitié des LGRB, mais heureusement pour la plupart parfaitement bénignes et non gênantes. Seul Refbase fut passablement bloqué lors du test par de nombreux bugs, que ce soit au niveau de l’affichage ou lors d’opérations. S’agissant encore d’une version béta (0.9), on espère que ces erreurs seront corrigées pour la première version stable.
Fonctionnalités
La grande question qui se pose lorsqu’on choisit un logiciel libre est de savoir s’il est réellement concurrentiel concernant ses fonctionnalités par rapport aux produits propriétaires reconnus. On souhaite évidemment obtenir un logiciel aussi performant que celui que l’on utilise depuis des années ! Les LGRB y arrivent-ils ? De manière générale, je fus surprise par la grande qualité et la richesse des fonctionnalités de ces applications. Aucun ne répondra à 100% aux exigences idéales mais le niveau de qualité est élevé, même pour des critères pointilleux de bibliothécaire et, surtout, chaque logiciel est différent et propose au moins un apport original, ce qui offre un choix plus varié.
Les LGRBL sont essentiellement faibles quant à l’importation de notices, que ce soit depuis des bases de données sur Internet ou via un fichier avec une extension particulière. Si tous importent sans problèmes des notices au format BibTeX et les formats hérités de Endnote (RIS, Endnote XML), il en va autrement des formats liées à des bases de données en ligne, tel CSA, INSPEC, ISI, JSTOR,…. L’importation de notices depuis Internet devient une évidence pour tout chercheur et il est donc très dommage que plusieurs logiciels testés ne proposent que le minimum. On relativisera ce constat en utilisant le logiciel libre « Bibutils », qui permet de transformer des notices de tous les formats classiques vers BibTeX (et vers ces mêmes formats). Ce petit applicatif est donc un logiciel de liaison par excellence, et moyennant quelques clics supplémentaires, permettra d’importer n’importe quelle notice dans votre logiciel libre. Et relevons quand même les excellentes performances de Jabref, Refbase et surtout Zotero, dont l’import depuis des bases on-line est le principal atout.
Principal point fort, les LGRB proposent beaucoup d’innovations fonctionnelles par rapport aux logiciels classiques. Premièrement, le choix d’une architecture « full-web » avec une base de données permet de créer plusieurs comptes d’utilisateurs, avec espace personnel et gestion, selon le type de rôle, du workflow des références. Tous les logiciels « full-web » testés proposent ce type de fonctionnalité à des degrés divers de sophistication.
Autre fonction provenant du web, le filet RSS est proposée par trois logiciels : Aigaion, Bibdesk et Refbase.
L’export des références dans un logiciel de bureautique n’est pas toujours direct (il faut parfois sauvegarder un fichier temporaire puis l’ouvrir avec un programme) mais certains logiciels (Jabref, Bibus) proposent des fonctions très avancées, comme la création d’une base de donnée relais sur Open Office. Plusieurs logiciels proposent également de rédiger directement son article via le logiciel, qui génère directement les citations et les renvois. Fonction peut-être peu pertinente dans le cas de la rédaction d’un long document mais pourquoi pas dans le cas de courts articles?
Les fonctions traditionnelles sont également présentes et souvent de manière très satisfaisante. On retrouve par exemple au minimum 13 grilles différentes de catalogage, selon le type de document (37 pour WikiNDX et 33 pour Zotero). Seul Refbase ne propose qu’une grille généraliste. Si les grilles ne sont pas adaptables par tous (Jabref, Bibdesk et Bibus le permettent), il est au moins possible d’ajouter des champs supplémentaires. Chaque logiciel permet donc de modifier les grilles, d’une manière ou d’une autre. Jabref, Bibdesk, WikiNDX et Aigaion proposent également des listes d’autorité et tous les logiciels proposent une indexation sujet. La plupart des logiciels possède également un ou plusieurs champs de métadonnées sur les référence : notes, remarques de lecture, cotation, lu ou non, etc.
La qualité du moteur de recherche et sa facilité d’utilisation est variable mais de manière générale, tous les logiciels ont répondu correctement aux mêmes recherches. S’ils proposent tous la recherche booléenne, ce n’est par contre pas le cas de l’usage de troncatures. Chaque logiciel permet de trier puis classer les références dans des dossiers. Enfin, relevons l’importation de notices via Z39.50 possible avec Bibdesk et Zotero.
Formats
L’usage ou la conversion vers le format BibTeX est généralisé. Tous les logiciels proposent un import et un export dans ce format, mais également dans le format RIS (format de Reference Manager et Endnote). Il est donc possible de migrer facilement les notices de tous les logiciels testés.
Langues
La traduction dans de nombreuses langues, parfois peu communes, est un aspect particulièrement innovant des logiciels libres et les LGRB ne font pas exception. à part Aigaion qui n’est disponibles qu’en anglais, les autres logiciels proposent au minimum l’anglais, l’allemand et le français, mais également le norvégien, l’italien ou le néerlandais (Jabref), le turc, le galicien, le portugais ou le polonais (WikiNDX). Bibus est même disponible en chinois !
Ergonomie et présentation
Tous les logiciels testés ont une présentation agréable (et souvent modifiable) ou tout du moins lisible. La présentation des références et les listes, à part sur Zotero qui fait le minimum, est claire.
L’intuitivité n’est pas parfaite pour tous les logiciels et Jabref, WikiNDX, Refbase et Aigaion pourraient faire des efforts pour simplifier leur interface, ou la rendre plus clair. A l’opposé, Bibdesk et Zotero sont remarquablement faciles à utiliser. Mais de manière générale, on constate que le look a été réfléchi et l’utilisation de chacun des logiciels testés fut, somme toute, assez agréable.
6. Conclusion
Un test plus approfondi et des retours d’expériences d’utilisations réelles permettraient de donner un avis plus complet sur les logiciels testés. Les résultats obtenus par cette étude sont néanmoins très réjouissants et permettent de relever les tendances suivantes :
De plus en plus de solutions sont en développement ou déjà opérationnels. Il existe donc un choix intéressant (quantitativement plus important que pour les SIGB libres), qui plus est de logiciels tous différents. En plus de respecter les standards du domaine, l’ensemble des produits testés était d’une qualité tout à fait acceptable dans le cadre d’une utilisation classique (avec un bémol pour Refbase). Surtout (ce qui n’est pas étonnant dans le domaine des logiciels libres), ces logiciels présentent beaucoup plus d’innovations fonctionnelles, souvent liées aux dernières tendances du web (web collaboratif, add-on firefox, filets RSS), que pour les solutions propriétaires standards.
Parmi toutes ces applications, les utilisateurs potentiels devraient sans peine trouver une solution correspondant de manière très satisfaisante à leurs besoins spécifiques (outil collaboratif, import de références du web, export de bibliographie,…).
Et si les besoins ne sont pas satisfaits par l’un d’entre eux, il est aussi possible de coupler l’usage de deux logiciels, comme le propose Hervé Ponsot (PONSOT, 2007)…et les possibilités deviennent infinies ! Par exemple, nous pouvons utiliser Zotero pour récupérer des notices sur des bases on-line puis les transférer au format BibTeX dans WikiNDX (si l’on souhaite une base multi-utilisateurs avec OPAC), Jabref (si l’on souhaite un logiciel monoposte performant dans la création de listes bibliographiques) ou Bibdesk (pour les utilisateurs de MacOS). Jabref, étant très performant dans l’import de nombreux formats, il peut aussi être utilisé comme passerelle pour une migration vers un autre logiciel utilisant le format BibTEX. Rappelons aussi l’existante de Bibutil, petite application libre permettant de changer le format des références depuis et vers presque tous les formats utilisés actuellement
En résumé, moyennant quelques manipulations, on peut obtenir une solution très souple et satisfaisante. Evidemment, le bricolage et l’utilisation de plusieurs logiciels en chaîne a ses limites et des usagers très exigeants, ou peu portés sur la technique, n’y trouveront peut-être pas leur bonheur complet. Mais, force est de constater que le libre devient un incontournable et propose de plus en plus, dans notre cas aussi, des applications sérieusement concurrentielles à des solutions propriétaires souvent onéreuses. On aurait donc tort de ne pas les tester avant toute acquisition de logiciel ou les proposer aux étudiants ou chercheurs !
Bibliographie
Documents consultés
(2007) Bibliographic Software and Standards Information - OpenOffice.org Wiki [en ligne]. OpenOffice.org wiki, [consulté le 20 octobre 2007]. http://wiki.services.openoffice.org/wiki/Bibliographic_Software_and_Standards_Information
(2007b) Comparison of reference management software [en ligne]. Wikipedia , the free encyclopedia, [consulté le 20 octobre 2007] http://en.wikipedia.org/wiki/Comparison_of_reference_management_software
(2007c) BibTeX [en ligne]. Wikipedia, the free encyclopedia, [consulté le 20 octobre 2007] http://en.wikipedia.org/wiki/BibTeX
ARGENZIO-FORTUNA, Carla, BEYLARD-OZEROFF, Rossana, MONTERO BARROS, Liliam C. (2006). Mise en place d’une cartothèque au muséum d’histoire naturelle de la Ville de Genève : propositions. 2 vol. Travail de diplôme présenté à la Filière Information documentaire, Haute école de gestion de Genève http://doc.rero.ch/search.py?recid=6532&ln=fr
CHABLOZ, Julie, NEPA, Claudia, TORRENT, Fanny (2006), La doc ça change LAVI : élaboration d'une structure documentaire pour le Centre de consultation LAVI. 2 vol. Travail de diplôme présenté à la Filière Information documentaire, Haute école de gestion de Genève http://doc.rero.ch/search.py?recid=6530&ln=fr
FAUSKE, Kjell Magne (2007). Finding the right reference/bibliographic tool [en ligne] fauskes.org, [consulté le 20 octobre 2007]. http://www.fauskes.net/nb/bibtools/
KESSLER, Jane Kessler et ULLEN, Mary K. van (2005). Citation generators : generating bibliographies for the next generation. The Journal of Academic Librarianship , vol. 31, no. 4, 15 juillet 2005, p. 310-316
MAHBUB MURSHED, Suman M. (2007). Comparison of Free Bibliographic Managers [en ligne]. Beyond my mind, [consulté le 20 octobre 2007]. http://mahbub.wordpress.com/2007/03/04/comparison-of-free-bibliographic-managers/
MAISONNEUVE, Marc (2007). Informatisation des bibliothèques : l'investissement reprend. Livres Hebdo, no. 679, 2 mars 2007, p. 94-102
PONSOT, Hervé (2007). Outils bibliographiques récents via Internet : pour presque tout le monde, possesseurs de Mac exceptés... [en ligne]. Paulissimo, [consulté le 20 octobre 2007] http://paulissimo.dominicains.com/spip.php?article171
SUJATHA HENRY, Ariane (2007). Logiciel Endnote. In Swiss-lib [liste de diffusion]. 20 juin 2007
Sites web[consultés le 20 octobre 2007]
Free software foundation et GPL : http://www.fsf.org
Sourceforge : http://sourceforge.net
Jabref : http://jabref.sourceforge.net
Bibdesk : http://bibdesk.sourceforge.net
WikiNDX: http://wikindx.sourceforge.net
Refbase: http://refbase.sourceforge.net
Aigaion: http://www.aigaion.nl
Zotero: http://www.zotero.org
Bibliothèque 1 ½ - Le passage vers la modernité : de l'importance et de la confrontation entre les bibliothèques et le Web 2.0
Ressi — 30 avril 2008
Nicolas Bugnon
Simone König
Rene Schneider
Dernière modification:
26/06/2009 Bibliothèque 1 ½ - Le passage vers la modernité : De l'importance et de la confrontation entre les bibliothèques et le Web 2.0
Un débat a lieu en ce moment concernant la transposition des principes du Web 2.0 dans le monde professionnel des bibliothèques. Ce qui ne se fait pas sans difficultés, car le concept du Web 2.0 est très hétérogène et les conditions de sa transposition pas encore tout à fait résolues. Cependant, ses principes ne sont pas du tout nouveaux, mais sont basés sur des techniques culturelles très anciennes. Dans leur nouvelle forme technologique, elles offrent également une série de points d'accès pour le monde des bibliothèques.
Classement
« Une société est considérée comme moderne, si elle est affirmative envers un pluralisme de sources d'inspiration, c'est-à-dire : un marché des confessions, servant de lieu de rencontre pour des gens qui s'enthousiasment et qui s'inspirent pour différents sujets ; une culture est considérée comme ‘moyenâgeuse‘, quand elle se définit par un monisme de l'inspiration; dans laquelle ‘celui qui fait le nécessaire‘ détient un monopole en tant que source de l'enthousiasme légitime.» (1) De ce point de vue le Moyen Age du WoldWideWeb est prétendument dépassé. Rétrospectivement, nous l'appelons le Web 1.0 et célébrons, en plus du triomphe de l'individu (appelé désormais user), également le triomphe de l'intelligence collective dans une modernité portant le nom de Web 2.0. Dans ce cadre, chacun peut être son propre journaliste dans des blogs, auxquels il est possible de s’abonner par leurs flux RSS; chacun son propre photographe, metteur en scène, promoteur, mettant à disposition ses œuvres sur des plateformes de photos et de vidéos pour des recensions. Finalement chacun est son propre créateur dans le jeu du Cyberspace. Un phénomène qui ne signifie rien d'autre que la réanimation de la parole présupposée morte, «chacun selon ses capacités, chacun selon ses besoins ! » (2) et, transposé dans le monde des bibliothèques, « chacun son propre bibliothécaire, chacun sa propre bibliothèque ».
Evolution et discontinuité
Ces éléments permettent la distinction entre deux générations de Web, mais le problème est l’abstraction de toute base à cette distinction. Au tout début du Web, le rôle de l'utilisateur était déjà décrit comme s'il était pensé pour le Web 2.0. : «Bien ces possibilités soit limitées, il est très utile de connaître qui a fait quoi, qui est qui, quels sont les documents existant, etc. On peut ainsi garder trace de l'utilisateur et ajouter quelques informations» (3). Cette correspondance fait la différenciation de deux types de Web, mais note tout de même une retenue (“possibilités limitées“). Il s’agit des limites techniques des premières années du Web qui ont été perfectionnées par une série d'évolution et de développement. Certains changements représentatifs sont à mentionner, comme le développement de nouveaux langages de programmation, par exemple AJAX (4) ou le nouveau langage de description XUL (5). Tous deux mettent l'accent sur l'importance accrue des dérivés d'XML. En découlent une augmentation de la bande passante d'information et une hausse de multimédialité du contenu, dont la manipulation devient de plus en plus facile et les interfaces de plus en plus fluides.
Curieusement, ces arguments ne sont mentionnés que très rarement dans les discussions sur la transition du Web 1.0 au Web 2.0. L'événement décisif marquant la distinction entre les versions du web est lié à l'éclatement de la bulle d'Internet et du crash boursier consécutif de l'année 2002. Par la suite la question s'est posé de savoir comment et pourquoi quelques entreprises ont pu surmonter si facilement ce crash. Ce phénomène s'explique par les faits suivants :
- le moteur de recherche le plus connu peut accompagner chaque requête d’une publicité correspondante, peu importe la taille du groupe d'intérêt;
- par des chaînes de requête du type « celui qui a lu ce livre, a également lu celui-là », une offre à la fois élargie et spécifique peut être faite;
- les ventes aux enchères sur Internet peuvent satisfaire chaque besoin d'achat en dépit d'une demande massive.
De manière générale, cela signifie un épanouissement des niches communément appelées « The Long Tail » (6) qui aboutie à une mise en exploitation de l'intelligence collective : « Le principe central ayant permit le succès des géants nés à l’âge du Web 1.0, étant ceux qui ont survis pour amener l’âge du Web 2.0, semble être le fait qu’ils ont compris le pouvoir du web d’exploiter l’intelligence collective» (7).
Cependant certaines communautés du Web créées par une intelligence collective existent depuis le début d'Internet. En fin de compte, ce qui a été décisif est le développement technique ayant amené de nouvelles bases plus conviviales pour les utilisateurs, et permettant non seulement un échange d'informations entre personnes mais aussi un échange collectif sur des artefacts humains.
Outils de l'intelligence collective
Cet échange est soumis à quelques principes du patrimoine culturel qui nous sont familiers depuis l'Antiquité. Depuis, ceux-ci ont trouvé, en partie indépendamment et en partie dans de nouvelles combinaisons, un chemin dans l'ère virtuelle. Il s'agit plus particulièrement de :
- la publication de messages personnels ou d’oeuvres artistiques, comme cela se passe dans les blogs, les plateformes de photos ou de vidéos, combinant souvent informations textuelles et visuelles;
- l'étiquetage ou le tagging, qui par leur assemblage forment une folksonomie, sont devenu un nouvel outil pour les moteurs de recherche et également une alternative à l'indexation contrôlée;
- La formulation de critiques, c'est-à-dire d’annotations ciblées, souvent polémiques, sont avec les tags, des composants essentiels de toute plateforme du Web 2.0;
- La pratique du palimpseste (8), c’est-à-dire l'effacement de textes et leur réécriture; une technique qui empêche, particulièrement dans les wikis, la pérennité de composants informationnels;
- La constitution de paquets ou fascicules composés de feuilles volantes ou l’assemblage de fragments ou d'éclats, pouvant être comparé à un patchwork ou une mosaïque, pratiqué dans la technologie des mash-ups, ainsi que dans les pages personnelles de sites communautaires.
Toutes ces activités demandent différentes compétences des utilisateurs et selon les niveaux de ces derniers et les bases technologiques du Web, une utilisation très différente en sera faite. Les possibilités d’applications résultantes semblent énormes, ce qui provient de la multitude des individus participant et des possibilités de combinaisons des différents points cités.
Le point fort de ces outils d'intelligence collective est qu’ils sont utilisables avec très peu de moyens, aussi bien pour la réalisation de petits projets que pour la gestion de grands projets complexes : ainsi, les participants d'un projet peuvent se connecter à un groupe à travers leurs pages personnelles, des informations intéressantes concernant le projet peuvent être réunies dans un Wiki ou dans des social bookmarks, la progression du projet peut être communiquée dans un blog et par conséquent diffusée par des flux RSS. Il est également possible de rassembler les résultats d’un projet de manière visuelle dans un Mash-up.
Bibliothèque 2.0
L’utilisation de ses outils devrait également retenir l’attention dans les domaines des bibliothèques, des archives et de la documentation. Pourtant, l’emploi interne des technologies du Web 2.0 dans les bibliothèques n’amènent pas automatiquement à celle dont on parle tant, la Bibliothèque 2.0.
« Etonnamment, la simple utilisation des techniques du Web 2.0 pour la gestion et la présentation d’information par les bibliothèques, comme dans des blogs ou des Wikis, est considérée comme étant une Bibliothèque 2.0. Cet amalgame n’existe que dans le monde des bibliothèques : en effet, il est difficile d’accepter que les marchands de pneus qualifient un blog sur leur commerce de commerce du pneu 2.0. (9)» L’organisation d’une bibliothèque 2.0 digne de ce nom, demande en conséquence, que la gestion bibliothéconomique soit conduit à l’aide du monde du Web 2.0, comme cela arrive déjà dans quelques excellentes applications et offres au public.
C’est le cas entre autres, lorsque les bibliothèques produisent leurs propres fils RSS, pour informer des nouvelles acquisitions et d’autres événements d’actualité les concernant. Selon la taille de la bibliothèque et l’hétérogénéité du public, ces fils RSS sont si divers, qu’il est possible de répondre aux besoins de tous les groupes d’utilisateurs de manière ciblée.
Cet exemple montre que la bibliothèque 2.0 signifie, dans un premier temps, atteindre les utilisateurs (non seulement les utilisateurs existants, mais aussi les potentiels), qui dans un deuxième temps s’intègreront à une communauté ou rendront accessible à la collectivité leur propre savoir à travers les technologies du Web 2.0. Dans ce contexte, on ne doit pas exclure une variante de la bibliothèque 2.0, proposant que les petites bibliothèques et centres de documentation, avant tout les institutions qui sont passées à côté du Web 1.0, puissent se considérer elles-mêmes comme des individus et mettre leurs ressources à disposition des utilisateurs à l’aide des outils du Web 2.0.
Le logiciel en ligne de gestion de bibliothèque Library Thing illustre bien ce propos (10): le concept est de transformer les privés en gestionnaires de leur propre bibliothèque, c’est-à-dire que chacun catalogue ses livres pour ainsi dire de manière professionnelle et se met en relation avec les personnes ayant les mêmes intérêts par l’intermédiaire de la plateforme. Cet outil représente une alternative intéressante pour les institutions qui ne sont pas encore «en ligne», et en particulier les petites bibliothèques. Celles-ci peuvent rattraper la mise en ligne de leur catalogue de cette manière et en même temps présenter leur offre aux utilisateurs intéressés.
Une autre application ayant purement trait aux bibliothèques serait que les utilisateurs ouvrent leurs comptes personnels, ou une partie de ceux-ci, à la vue de tous. Les critiques et les tags laissés par les uns au sujet de leurs emprunts et de leurs lectures sont pleins de sens pour les autres lecteurs. La réunion de ces données dans un moteur de recherche aboutirait à un service orienté utilisateurs, dont le capital-sens dépasserait de loin la prise en compte des citations.
Ce sont en fait les tags attribués de manière libre qui représentent un outil très pertinent non seulement pour l’établissement de signets communautaires, mais aussi pour l’indexation du contenu de livres et autres médias, ce qui enrichirait dans tous les cas le travail des bibliothèques. Avec les derniers développements dans le domaine des interfaces utilisateurs, différencier les descripteurs attribués par les bibliothécaires de ceux attribués par les utilisateurs est devenu un jeu d’enfant. Cela peut être concrétisé par exemple par la couleur ou par une différence de taille des mots affichés. Ces tags librement attribués forment finalement une folksonomie, particulièrement riche de sens, qui est ensuite amplement utilisable par des moteurs de recherche. En définitive, une attention particulière devrait être accordée à la folksonomie et aux fils RSS, car tous deux, vu leur fort potentiel et de leur large diffusion, vont survivre à la mode du Web 2.0.
Par contre, les possibilités que les mash-ups deviennent une nouvelle forme de service d’information des bibliothèques est encore difficile à évaluer. A ce propos, l’intégration d’autres sources de données aux informations scannées par les catalogues, mais aussi l’intégration du moteur de recherche du catalogue dans des pages web personnelles est facilement réalisable. La connexion à différents médias (les bibliothèques numériques et le reste du web) représente encore une autre possibilité. Comme les mash-ups demandent si bien une compétence qu’une habilité de recherche et de rassemblement de résultats, le bibliothécaire pourrait jouer le rôle de l’Information Broker afin de rendre accessible ce service.
Bibliothèque 1 ½
La présence en parallèle d’applications concrétisées et de théories sur la Bibliothèque 2.0 laissent penser qu’actuellement le terme de bibliothèque 1 ½ est plus approprié, d’autant plus qu’il reste encore à faire de profondes analyses du transfert vers le Web 2.0 dans le monde professionnel. D’autre part, il est également imprévisible de dire dans quelle direction se développent les technologies du web. Dans certains cercles, on parle déjà du Web 3.0, mais on n’y apprend finalement que rarement de quoi il s’agit exactement. Dans tous les cas, cela ne devrait pas mener à délaisser les développements technologiques, si ce n’est que pour ne pas encore une fois être dépassé par ceux-ci.
La plus grande gêne provient des prétendus intérêts économiques, qui sont liés au Web 2.0 et le fait que jusqu’à aujourd’hui, pratiquement aucun bénéfice n’a été dégagé avec les technologies concernées. Ce n’est pas la première fois que des rêves économiques devraient prétendument être réalisés. Au contraire, le bilan de l’achat du plus populaire fournisseur de téléphonie internet par la plus grande maison de vente aux enchères en ligne s’est récemment terminé avec une perte d’un milliard. Pour tous ceux qui se souviennent encore de la place de la bulle Internet 1.0, cela devrait être plus qu’un simple avertissement.
Un rapide coup d’œil sur les plateformes du Web 2.0 montre que les utilisateurs ont un grand intérêt aux produits qu’ils ont eux-mêmes engendrés et ceux qui y sont apparentés. Ainsi, les groupes qui enlèveraient le catalogage aux bibliothécaires ou qui voudraient y participer, excéderaient à peine la masse critique qui est nécessaire à une application du Web 2.0 aux catalogues, car peu d’utilisateurs seraient prêts à tagger les références qui ne les concernent pas directement. Il est également important de garder à l’esprit que l’introduction de grandes solutions « bibliothèque 2.0 » doit être accompagnée par des mesures internes de gestion du changement.
En outre, il est plausible que, dans quelques années et de manière analogue aux développements du domaine des multimédias, beaucoup d’éléments que nous qualifions aujourd’hui de web 2.0 trouvent leur place dans le web sans que quelqu’un ne fasse d’association entre eux et le qualificatif, alors qu’ils seront largement utilisés. Ceci représente un argument pour déterminer les bibliothèques et les centres d’information à s’approprier les technologies du Web 2.0 et à développer des alternatives aux services d’information traditionnels, mais ces institutions doivent s’y intéresser également pour éviter que leurs compétences ne soient encore plus absorbées par le web, comme cela s’est déjà passé avec les moteurs de recherche. Finalement, la décision du succès ou de l’échec des nouveaux services revient aux utilisateurs, indépendamment de quelle numéro de version est attribué au web.
Notes
(1) Peter Sloterdijk : « Der mystische Imperativ. Bemerkungen zum Formwandel des Religiösen in der Neuzeit. » in : ders. (Hrsg.) : Mystische Weltliteratur. Diederichs Gelbe Reihe. 2007, S. 9. « Als modern bezeichnen wir eine Gesellschaft, wenn sie einen Pluralismus an Inspirationsquellen zugesteht, sagen wir : einen Pluralismus an Inspirationsquellen zugesteht, sagen wir : einen Konfessionen-Markt; auf ihm können sich Menschen begegnen, die sich für verschiedenes begesistern und Verschiedenem inspiriert werden; "mittelalterlich" nennen wir eine Kultur, die sich durch einen Monismus der Inspiration definiert; in ihr besitzt das " Eine das nottut" ein Monopol darauf, als Quelle legitimer Enthusiasmen zu wirken. »
(2) Karl Marx : Kritik des Gothaer Programms, 1987, MEW 19, Seite 21. "Jeder nach seinen Fähigkeiten, jedem nach seinen Bedürnissen!"
(3) Tim Berners-Lee : « Information Management. A proposal. » März 1989, Mai 1990. http://www.w3.org/History/1989/proposal.html. vérifié le 05.10.2007. «Although limited, it is very useful for recording who did what, where they are, what documents exist, etc. Also, one can keep track of users, and can easily append any extra little bits of information »
(4) Asynchronous JavaScript and XML
(5) XML User Interface Language
(6) Chris Anderson : The Long Tail. Wired 12.10. Octobre 2004. http://www.wired.com/wired/archive/12.10/tail.html. vérifié le 05.10.2007.
(7) Tim O’Reilly : What is Web 2.0 ? Design Patterns and Business Models for the Next Generation of Software. September 2005. http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-20.html. vérifié le 05.10.2007. « The central principle behind the success of the giants born in the Web 1.0 era who have survived to lead the Web 2.0 era appears to be this, that they have embraced the power of the web to harness collective intelligence.»
(8) Dans le contexte de la programmation du Web 2.0, parfois aussi appelé version Beta perpétuelle
(9) Ulrich Herb : Ohne Web 2.0 keine Bibliothek 2.0. Telepolis. 13.09.2007.http://www.heise.de/tp/r4/artikel/26/26013/1.html, vérifié le 08.10.2007. «Ausserdem wird erstaunlicherweise unter Bibliothek 2.0 auch die reine Nutzung von Web 2.0-Techniken zur Verwaltung und Präsentation bibliothekarischer Information etwa in Blogs oder Wikis gehandelt. Das lässt auf bibliothekarisches Standesbewusstsein schliessen : Kaum anzunehmen, dass Reifenhändler ein Weblog über ihr Geschäft als Reifenhandel 2.0 bezeichnen würden.»
Editorial n°7
Ressi — 30 avril 2008
Editorial n°7
C’est un numéro 7 particulièrement riche que nous vous proposons. Dans sa première livraison de l’année 2008, le Comité de rédaction a toujours l’ambition que RESSI soit une chambre d’écho des recherches menées dans notre discipline en Suisse mais aussi à l’étranger.
Dans la rubrique Etudes et Recherches, Cynthia Dufaux, Jan Krause et Aline Maurer évaluent de manière originale la collection de monographies de la Faculté des sciences de l’Université de Genève. A partir de données recueillies dans plusieurs bibliothèques, les auteurs ont élaboré un dendogramme qui montre les distances entre les collections des bibliothèques et donc fournit un instrument pour une gestion centralisée des documents par domaines. Mahmoud Brahimi et Laid Bouzidi se sont penchés sur le capital de connaissances des entreprises, souvent mal exploité. Nos collègues lyonnais tentent alors de répondre à un certain nombre de questions sur les connaissances liées au processus métier. Lorraine Filippozzi a étudié la question de la fonction diffusion des archives et tout particulièrement de la présence des archives sur Internet et les conséquences pour les chercheurs. Carole Zweifel fait une étude comparative de quelques logiciels libres de gestion de références bibliographiques donnant ainsi un aperçu de leurs fonctionnalités. Cet article intéressera chercheurs et étudiants en quête d’outils informatisés. Nicolas Bugnon, Simone König et René Schneider abordent le thème de la transposition du Web 2.0 dans le monde des bibliothèques. Il s’agit là d’une préoccupation actuelle pour les professionnels des bibliothèques et, en plus de quelques points de repères, les auteurs entament une réflexion qui ne fait que commencer.
Dans les comptes-rendus d’expériences, Didier Grange nous fait partager une réflexion menée aux Archives de la Ville de Genève sur les risques et catastrophes pour les archives. Les nombreuses références présentées par l’auteur vont être indéniablement utiles aux institutions en réflexion sur ce thème. Un groupe de bibliothécaires de l’Université de Genève nous montre un bel exemple de collaboration entre professionnels en nous présentant la mise en œuvre d’un wiki comme outil de communication et de partage des connaissances.
Dans la rubrique Evénements Ariane Rezzonico, qui a suivi le Congrès Online à Londres en décembre 2007 nous fait part des dernières tendances en matière d’information où le Web 2.0 est encore au cœur des débats. Ce numéro se clôt avec le texte d’une conférence prononcée par Andreas Kellerhals sur la solidarité archivistique pour les Archives fédérales suisses. Qu’est-ce que la solidarité archivistique et où s’exerce- t-elle ?
Nous avons beaucoup de plaisir à vous proposer un numéro aussi riche et nous le devons aux auteurs qui y ont contribué aussi nous les en remercions vivement. Nos remerciements vont aussi aux membres du Comité de lecture.
RESSI ne peut vivre sans auteurs, c’est pourquoi nous vous invitons à nous proposer des articles pour nos prochains numéros et par avance nous vous en remercions.
Le Comité de rédaction
Risques et catastrophes : une approche en trois phases et trois plans
Ressi — 30 avril 2008
Didier Grange, Archiviste, Ville de Genève
Dernière modification:
23/06/2009 Risques et catastrophes : une approche en trois phases et trois plans
1. – Contexte
Ces dernières années, de nombreuses institutions préservant des archives ont été victimes de dégâts importants suite à des catastrophes naturelles ou à des catastrophes dues à l’action de l’homme (1).Quelques minutes peuvent suffire pour que des pans entiers de la mémoire locale, nationale ou internationale soient gravement endommagés, voire même disparaissent.
Certes, toutes les catastrophes n’ont pas la même ampleur et les mêmes conséquences. Les institutions sont le plus souvent confrontées à des incidents (2). Toutefois, les professionnels ont le devoir de tout mettre en œuvre pour diminuer les risques que court leur institution, intervenir en cas de catastrophes et prendre les mesures nécessaires pour sauver le patrimoine qui leur est confié.
Or, à l’échelle internationale, même si des progrès ont été accomplis lors des dernières décennies, les lacunes sont encore importantes. D’après une étude réalisée aux Etats-Unis en 2005, par exemple, un tiers seulement des institutions conservant des archives disposerait d’un plan d’urgence (3). Ce résultat est plutôt faible. Si une telle enquête était menée en Europe, le pourcentage serait certainement encore plus bas.
Il y a une dizaine d’années, les Archives de la Ville de Genève (AVG) ont créé un Plan d’urgence. Or, au fil du temps, la façon d’aborder les risques et les catastrophes dans notre service a fortement évolué. Nous estimons que nous ne pouvons plus nous reposer uniquement sur un Plan d’urgence. Après réflexion, nous avons décidé de changer notre approche et produire de nouveaux instruments.
Bien que les travaux entrepris ne soient pas encore achevés au moment de la rédaction de cette contribution, nous avons pensé qu’il serait intéressant de partager notre expérience. Elle est susceptible de nourrir la réflexion, susciter un débat ou encourager certaines institutions à chercher leur voie en matière de gestion des risques et des catastrophes.
2. – Renouveler notre approche
En 2006, nous avons entamé la révision de notre Plan d’urgence. Conçu à la fin des années nonante, il nous paraissait mélanger trop souvent les genres, les cibles, voire les publics. Mais, au-delà des critiques que nous pouvions formuler, et au-delà du contenu même de ce document, c’est surtout notre approche que nous avons souhaité changer. Nous nous étions focalisés jusqu’alors sur la réponse à donner en cas de catastrophe (Plan d’urgence). Or, il nous a paru nécessaire de prendre un peu de recul et élargir notre horizon pour prendre en considération tout le cycle des catastrophes (voir Figure 1).
Nous avons choisi de découper le cycle en trois phases : prévention / urgence / rétablissement (4). Nous avons considéré que pour chaque phase un plan particulier devait être créé. C’est pourquoi, en plus de la révision du Plan d’urgence dont nous disposions déjà, nous avons préparé deux autres plans : le Plan de prévention et le Plan de rétablissement.
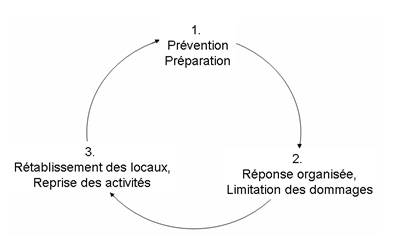
Figure 1 : Le cycle des catastrophes
En résumé, on peut dire que le Plan de prévention se concentre sur les risques et les mesures de précaution. Cette phase doit faire l’objet d’une attention particulière, car c’est en limitant les risques qu’on a le plus de chance de ne jamais devoir utiliser le second Plan, le Plan d’urgence.
Si, malgré les mesures préventives décidées, un problème -mineur ou majeur- survient, on recourt alors au Plan d’urgence. Celui-ci vise uniquement à couvrir la période de crise, que l’on peut évaluer, en général, à 48 heures (voire 72 heures) depuis le moment où l’alerte est donnée.
Ensuite de quoi, le Plan de rétablissement prend le relais. Ce dernier tente d’aborder les nombreux problèmes qui résultent d’une catastrophe, une fois l’urgence passée. Les travaux à accomplir peuvent alors s’échelonner sur de nombreux mois, voire parfois des années. Les institutions doivent être en mesure de suivre le processus sur une longue durée.
Figure 2 : Trois phases, trois plans
3. – Les trois Plans (1)
Le contenu des trois Plans doit être adapté à chaque phase. La répartition des informations entre ces trois documents est cruciale. Ceux-ci doivent s’articuler les uns avec les autres. Bien que distincts, ils sont complémentaires. Nous les aborderons ici tour à tour, sans entrer dans les détails. Toutefois, de manière à ce que lecteur puisse se faire une idée du contenu de chacun des plans, nous avons mis en exergue la table des matières des trois documents.
3.1 – Le Plan de prévention
3.1.1 - Prévenir plutôt que guérir
Nous n’insisterons jamais assez sur le fait qu’il faut faire de la prévention une priorité dans chaque institution. Les catastrophes naturelles sont une fatalité, mais bien des problèmes graves pourraient être évités -ou atténués- si des mesures adéquates étaient prises et appliquées méthodiquement.
De très nombreuses institutions font de la prévention. Mais les règles que doivent suivre les collaborateurs ne sont pas toujours clairement établies, et les consignes sont données trop souvent par oral. Très vite, la routine s’installe et la vigilance se relâche ; la probabilité que l’institution rencontre un problème augmente alors. C’est pourquoi nous recommandons que le Plan de prévention soit écrit, tenu à jour et partagé par l’ensemble des collaborateurs d’une institution.
On peut considérer que le Plan de prévention est directement lié à la conservation préventive (6). Il n’en constitue cependant qu’un élément, car il ne prend pas en compte tous les facteurs que couvre normalement cette activité. Il se focalise en particulier sur la notion de risque. Si l’on se réfère au Petit Larousse (1997), le risque est un danger ou un inconvénient plus ou moins probable auquel on est exposé (7). Les risques que peuvent encourir les bâtiments d’archives et les documents eux-mêmes sont nombreux. Des listes ont été publiées dans des ouvrages spécialisés ou mises à disposition sur des sites web (8). Chaque institution doit déterminer les mesures nécessaires afin de prévenir les risques auxquels elle est exposée ; elle doit ensuite les atténuer ou les éliminer – quand cela est possible. Dans le même temps, elle doit établir les responsabilités et déterminer qui fait quoi, à quel moment et avec quel(s) moyen(s).
3.1.2 - Le Plan de prévention
Notre Plan de prévention est assez simple et concis : il ne comprend que dix pages. Plus que l’élaboration du document ou le choix des points qui doivent être vérifiés, la mise en place et le suivi des mesures préconisées constituent le cœur même de l’exercice. Au quotidien, une certaine discipline est nécessaire, faute de quoi, on retombe dans les travers dénoncés plus haut.
Notre Plan de prévention comprend six parties (Figure 3). Les cinq premières ont trait à l’organisation du travail, la mise en application du Plan et sa tenue à jour. La dernière partie comprend la liste des actions ainsi que leur planification dans le temps.
| PLAN DE PREVENTION | |
|
Les actions correspondent à une série de contrôles qui doivent être effectués. Nous devons vérifier par exemple l’état des canalisations qui passent à proximité de nos locaux, le fonctionnement du système d’alarme effraction et incendie, l’étanchéité de la dalle se trouvant au-dessus de notre magasin et le remplacement régulier du filtre à particule de l’appareil qui ventile notre local de conservation. La liste établie comprend vingt points.
Les actions peuvent être quotidiennes, hebdomadaires, mensuelles, voire être planifiées de manière à être effectuées plusieurs fois dans l’année. Nous avons également défini quelle est la personne au sein de notre équipe responsable de chaque action, son remplaçant, la fréquence à laquelle la tâche doit être faite et, si possible, à quelle date.
| No | Quoi | Qui | Remplaçant |
|---|---|---|---|
| 1.1 | Vérifier en début de journée les relevés de température et d’hygrométrie | NM | DG |
| 1.2 | Vérifier en fin de matinée et de journée la fermeture de la porte d’entrée des AVG [Archives de la Ville de Genève] | JD | DG |
| 1.3 | Vérifier en fin de journée la fermeture de la porte du compactus [salle dans laquelle sont conservées les archives] | JD | DG |
| 1.4 | Vérifier en fin de journée que les appareils électriques sont éteints et débranchés | JD | DG |
| 1.5 | Vérifier en fin de journée que les armoires mobiles du compactus sont bien fermées | JD | DG |
| 1.6 | Vérifier que les clés sont à leur place | JD | DG |
| 1.7 | Vérifier la fermeture de la porte du local de Saint-Léger | DG | FB |
Parallèlement, nous avons créé un tableau de bord récapitulatif qui permet de suivre la totalité des actions. Dans ce document, une colonne permet de signaler si l’action a été réalisée et de faire d’éventuelles observations. L’Archiviste de la Ville suit l’ensemble des opérations et intervient si cela s’avère nécessaire.
3.2. - Le Plan d’urgence
3.2.1 – Quand la catastrophe survient
Malgré toutes les précautions prises, une institution peut être projetée dans une situation de crise plus ou moins grave. Le cas échéant, c’est le Plan d’urgence qui devient le document de référence. Celui-ci couvre les premières 48 heures (voire 72 heures) de la crise ; il ne va pas au-delà. Ce laps de temps correspond à la période qui va du déclenchement de l’alarme à la fin de l’intervention des spécialistes des catastrophes (pompiers en particulier). Une fois la situation maîtrisée, les spécialistes se retirent et laissent place aux personnes qui doivent prendre en charge les conséquences de la catastrophe. Parmi ces dernières, il y a les archivistes. Le sauvetage des documents touchés peut alors commencer.
3.2.2 - Nos sources d’information
Nous avons effectué des recherches dans la littérature professionnelle afin de trouver des points de comparaison et des documents qui puissent nous servir de sources d’inspiration (9). Quelques catastrophes récentes, comme l’ouragan Katrina, ont contribué à l’essor du nombre de publications liées à la gestion des catastrophes. Elles ont parfois aussi poussé des institutions à préparer des plans d’urgence. En Europe, des initiatives ont été prises ces dernières années, mais elles demeurent encore peu nombreuses à ce jour. Mentionnons le plan d’urgence mis en ligne par les Archives nationales hollandaises (10), les recommandations des Archives nationales anglaises (11), la base de données développée en Allemagne, baptisée NORA (Notfall-Register Archive) (12) ou le réseau mis en place par différentes institutions de Lausanne, baptisé COSADOCA (Consortium de Sauvetage du Patrimoine Documentaire en cas de Catastrophe) (13). Les réalisations ou les travaux en cours ne se limitent pas au continent européen. Des initiatives ont été prises dans différentes régions du monde (14). La prise de conscience de la nécessité de disposer d’un Plan d’urgence est particulièrement marquée aux Etats-Unis. En effet, avec le passage de Katrina, les Etats-Unis ont dû faire face à l’une des pires catastrophes que le pays ait vécues. Même si, sur le moment, la réponse apportée en particulier par le Gouvernement fédéral n’a pas toujours été à la hauteur des attentes des citoyens et des institutions, il faut reconnaître que, depuis lors, on assiste à une poussée très forte dans le domaine de la prévention et de la réponse aux catastrophes. Ce mouvement est également perceptible dans la sphère des archives. Nos collègues américains ont produit ces derniers mois beaucoup de matériel et d’exemples fort utiles pour toutes les institutions et personnes qui souhaitent se lancer dans la préparation et la rédaction d’un plan d’urgence (15).
3.2.3 – Le Plan d’urgence
Même si nous avons décidé de reprendre en bonne partie le cœur du Plan d’urgence de 1999, nous avons effectué quelques modifications et apporté des compléments. Nous avons revu par exemple l’ordre dans lequel se font les appels téléphoniques en cas d’alerte et mis en place une liste d’appels téléphoniques en cascade. Nous avons établi de manière plus claire les responsabilités entre les différents intervenants et défini la chaîne de commandement sur le champ des opérations. Nous avons également établi une liste de volontaires. Nous avons ajouté dans notre liste de contacts les coordonnées du responsable des Assurances de la Municipalité et celui de l’Information. Et, finalement, nous avons étoffé la partie consacrée aux premières mesures à prendre en cas d’urgence, en particulier par rapport à celles qui ont trait aux documents endommagés (16).
| PLAN D’URGENCE | |
|
Au final, il n’y a pas eu une véritable révolution par rapport à notre Plan d’urgence précédent. Nous avons effectué des aménagements et introduit des compléments qui mériteront d’être testés et revus si nécessaire. Notre but est de rendre ce document aussi opérationnel et fiable que possible.
3.2.4 – Les réseaux
Dans une catastrophe, on se sent bien démuni et seul. Il serait important que des réseaux se développent entre institutions, à l’image du réseau COSADOCA (17). Même si l’éventualité de la création d’un tel réseau a été abordée à maintes reprises à Genève, rien ne s’est fait jusqu’à présent. Nous aurions pourtant la taille critique et les compétences nécessaires dans notre milieu professionnel pour réaliser un tel projet. Comme différentes institutions genevoises se sont lancées dans la préparation d’un Plan d’urgence récemment, nous espérons que le débat sera relancé et qu’il aboutira à un résultat concret.
3.3. - Le Plan de rétablissement
3.3.1 - Après la catastrophe
Le dernier document que nous avons créé est intitulé « Plan de rétablissement ». Il est consacré aux mesures qui doivent être prises pour rétablir la situation après une catastrophe.
Lors d’une catastrophe, les premières actions entreprises visent bien sûr à sauver des vies humaines et ensuite à sauver un maximum de documents. Les documents, triés en fonction de leur état physique, doivent être emballés, transportés dans d’autres locaux et nettoyés. Mais une fois cette phase accomplie, les travaux menant du simple empaquetage à la restauration, voire à l’élimination des documents trop endommagés, peut durer plusieurs mois voire plusieurs années. Comme le précise Helen Forde, « Recovery is the slowest part of any plan » (18). Le travail à effectuer est complexe et demande l’intervention de différents corps de métiers spécialisés. Les ressources financières permettant d’entreprendre les travaux nécessaires ne sont pas toujours disponibles au moment de la catastrophe. On peut également rencontrer des problèmes d’intendance : manque de place, matériel inadéquat, logistique défaillante, spécialistes indisponibles, négociations difficiles avec les assurances, etc.
La littérature spécialisée consacrée aux mesures liées au rétablissement de la situation après une catastrophe est assez abondante. Aussi, notre idée de départ était de rédiger une synthèse en nous basant sur les informations collectées et de les compléter par nos propres observations. Après réflexion, nous avons cependant changé d’idée. Plutôt que de rédiger une synthèse, nous avons préparé un Plan de rétablissement divisé en deux parties. Dans la première, nous avons mis les photocopies de documents provenant de la littérature ou de sites web relatifs aux traitements qui peuvent être administrés aux différents supports de l’information ayant subi des dommages. Dans la seconde, nous avons constitué une liste récapitulative des points essentiels auxquels une institution doit penser lors d’une phase de rétablissement. Le Plan de rétablissement comprend dix chapitres (voir Figure 6).
| PLAN DE RETABLISSEMENT | |
Introduction
|
4. – Un bilan provisoire
La manière d’approcher les risques et les catastrophes peut être différente d’une institution à l’autre. De nombreux facteurs peuvent entrer en ligne de compte au moment de traiter cette question : contexte, risques, ressources, compétences, existence ou absence d’un réseau, etc.
En modifiant notre approche et en créant les trois plans que nous venons de décrire brièvement, nous sommes convaincus d’avoir passé un cap. Nous ne reviendrons plus en arrière en nous contentant seulement d’un Plan d’urgence, comme nous l’avons fait jusqu’à présent. Les documents que nous avons préparés remplissent des objectifs différents, mais complémentaires. Ils ont leur raison d’être.
Même si, a priori, nous sommes globalement satisfaits du résultat, nous sommes conscients que ces documents ne sont pas parfaits. Ils subiront certainement des aménagements voire des changements radicaux, si cela s’avère nécessaire.
Toutefois, à ce stade, nous devons tenter de ne plus nous concentrer uniquement sur la préparation de documents, mais d’appréhender la réalité en mettant en pratique ces plans. En résumé, nous devons tester les Plans que nous avons conçus. Qu’en est-il des méthodes, des techniques, du matériel, de la conduite des uns et des autres en cas de crise ? Seules des simulations nous permettraient de mesurer l’écart entre notre approche et les besoins. C’est pourquoi il serait souhaitable que dans un avenir proche nous organisions des exercices avec des partenaires et nos volontaires, sur le modèle de ce que fait COSADOCA dans le Canton de Vaud. Cette confrontation nous permettrait non seulement de retoucher nos différents plans mais aussi d’améliorer la réaction des personnes qui pourraient être impliquées dans de tels événements (19).
De plus, nous nous interrogeons sur un certain nombre de points :
- la répartition des informations entre les plans est-elle vraiment adéquate ? Par exemple, où mettre les recommandations relatives aux mesures d’urgence à prendre pour tenter de sauver les différents types de supports ? Doivent-elles être placées dans le Plan d’urgence ou dans le Plan de rétablissement ? Voire dans les deux ?
- que faudrait-il faire par rapport à la phase de préparation à l’intervention ? Doit-on rédiger un document particulier à ce sujet -en-dehors des trois plans- ou mettre un chapitre dans le Plan de prévention ?
- en ne voulant pas donner trop de détails, avons-nous omis une information importante ? Aurions-nous dû en dire plus sur certains points ?
Les questions sont encore nombreuses.
Finalement, le doute oblige à rester vigilant, à s’interroger, à peser les pour et les contre et à remettre l’ouvrage sur le métier. Cette approche en trois phases et trois plans ne peut se concevoir que d’une manière itérative. La pratique et l’expérience doivent nourrir sans cesse notre réflexion et nous amener à améliorer, dans la mesure du possible, non seulement nos plans mais aussi nos comportements.
5. – En guise de conclusion
Le découpage des phases et les instruments qui sont mis en place importent peu. Chaque institution doit trouver sa voie en tenant compte de ses propres caractéristiques. L’accumulation d’expériences, la collaboration avec d’autres corps de métiers et la possibilité de recourir à un réseau de professionnels sont autant de possibilités d’enrichir la façon d’aborder la problématique. Aussi, avec le temps, chaque institution peut arriver à un résultat satisfaisant.
De toute manière, nous ne pouvons pas échapper à notre responsabilité ; nous devons créer les instruments nécessaires afin de gérer -au mieux- les risques et les situations de crise. Cette responsabilité n’est pas uniquement valable pour les personnes qui assument des fonctions hiérarchiques, mais touche tous les employés. L’ensemble du personnel doit en effet consacrer le temps et l’énergie nécessaires pour accompagner, soigner -quand nécessaire, protéger et transmettre le patrimoine qui lui a été confié. Il s’agit là d’une véritable responsabilité collective.
Orientation bibliographique
Au fil des ans, la bibliographie consacrée à la gestion des risques et des catastrophes s’est considérablement allongée. Elle est encore en majorité anglo-saxonne, et nord-américaine en particulier (20). Plutôt que de préparer une bibliographie, j’ai préféré signaler dans les notes un certain nombre de références utiles.
De nos jours, pour suivre l’évolution des stratégies, méthodes, techniques et projets en matière de gestion des risques et des catastrophes, le plus simple est certainement de visiter régulièrement certains sites web, soit d’Archives et de Bibliothèques nationales, soit d’institutions spécialisées. La bibliographie va encore s’étoffer ces prochaines années au vu des nombreux projets en cours dans des institutions patrimoniales ou ceux entrepris par des gouvernements.
Notes
Tous les liens aux sites web mentionnés dans les notes ont été vérifiés le 29 août 2007.
(1) Au fil des ans, négligences, actes de malveillance, erreurs humaines et faits de guerre endommagent ou détruisent de nombreux documents dans les quatre coins du monde. Des événements récents sont là pour nous le rappeler. On peut signaler les destructions récentes perpétrées au Liban et en Irak par exemple. Plus largement, voir : CONSEIL INTERNATIONAL DES ARCHIVES, Memory of the World at Risk. Archives Destroyed, Archives Reconstituted, Munich : K.G. Saur, 1996 (Archivum XLII) dans lequel plusieurs cas de destructions dues aux guerres sont mentionnés. Voir également le rapport de Hans VAN DER HOEVEN ; Joan VAN ALBADA, Mémoire perdue. Bibliothèques et archives détruites au XXe siècle, Paris : UNESCO, 1996, http://unesdoc.unesco.org/images/0010/001055/105557fb.pdf.
(2) En terme de catastrophes, on définit différentes catégories. Selon Andrea Giovannini, on en trouve quatre : sinistre mineur, sinistre limité, sinistre majeur et catastrophe. Andrea GIOVANNINI, « La gestion des catastrophes : pour un plan de prévention et d’intervention en cas de catastrophe », Archi’V, n.23, octobre 2005, pp.43-44. Pour mémoire, mentionnons quelques catastrophes récentes : les inondations qui ont touché l’Allemagne ainsi que le centre et l’est de l’Europe (2002), le tsunami qui a ravagé certains pays du Sud-est asiatique (2004), l’ouragan Katrina qui a causé des dégâts considérables sur son passage à travers une bonne partie des Etats-Unis, du Mexique et de Cuba (2005), l’inondation qui a endommagé le bâtiment historique des National Archives and Records Administration (NARA), à Washington (2006). Cette liste n’est bien sûr pas exhaustive.
(3) HERITAGE PRESERVATION, A Public Trust at Risk : The Heritage Health Index Report on the State of America’s Collections, s.l., 2005, p.7. Pour consulter le rapport en ligne, voir : http://www.heritagepreservation.org/HHI/index.html. Pour le chapitre relatif à la préparation en cas de catastrophe, voir : http://www.heritagepreservation.org/HHI/HHIchp7.pdf.
(4) D’autres modèles répartissent le cycle en quatre phases : prévention, préparation, réponse et récupération (prevention, preparedness, response, recovery). Voir par exemple Maria Barbara BERTINI, La conservazione dei beni archivistici e librari. Prevenzione e piani di emergenza, Roma : Carocci Editore, 2005, p.155 ; voire en cinq phases : prevention, preparation, reaction, recovery, evaluation, Helen FORDE, Preserving archives, Londres : Facet Publishing, 2007, p.121.
(5) Cette partie est largement inspirée d’un texte à paraître dans la revue Lligal, intitulé « Les Archives de la Ville de Genève face aux risques et aux catastrophes : une nouvelle approche » et pour ce qui a trait au Plan de prévention (3.1), je me suis inspiré d’un texte présenté à La Habana, le 7 mai 2007, intitulé « Mas vale prevenir que lamentar : la importancia de un Plan de prevención » (Actes à paraître).
(6) On peut définir la conservation préventive comme étant « l’ensemble des actions destinées à ralentir le processus de vieillissement et de destruction des biens culturels en limitant la probabilité de dommages éventuels », ARCHIVES DEPARTEMENTALES DU VAUCLUSE, Blessures d’archives, Rêve d’éternité. De la conservation préventive à la restauration, Avignon : Archives départementales du Vaucluse, 2004, p.49. Voir également Maria Barbara BERTINI, Op.cit., pp.19-38.
(7) Toutefois, cette définition peut être nuancée en fonction des contextes et des interlocuteurs, comme le montre très bien le site web du Bouclier Bleu Français : http://www.bouclier-bleu.fr/risques/les-risques.htm.
(8)Voir par exemple l’ouvrage de l’Association des Archivistes Français, La sécurité dans les Services d’archives, Paris : Association des Archivistes Français, 2007 et Jonathan ASHLEY-SMITH, Risk Assessment for Object Conservation, Oxford : Butterworth-Heinemann, 1999, p.26. Le Bouclier Bleu Français met à disposition sur son site une liste : http://www.bouclier-bleu.fr/prevention/aide-memoire-2.htm. Il en est de même sur les sites de l’ICOM (International Council on Museums) : http://icom.museum/guide12A.html, de l’Institut Canadien de Conservation : http://www.cci-icc.gc.ca/tools/framework/index_f.aspx?content=framework et de The National Archives, intitulé « Protecting archives and manuscripts against disasters » : http://www.nationalarchives.gov.uk/documents/memo6.pdf, par exemple. On peut consulter une bibliographie établie pour un cours dédié aux risques dans le domaine du patrimoine, organisé à Ottawa en 2006 par l’Institut Canadien de la Conservation et l’ICCROM (International Centre for the Study of the Preservation and Restoration of Cultural Property), http://www.iccrom.org/eng/prog2006-07_en/02preven_en/archive_en/2006_10risks_biblio_en.pdf. Finalement, on peut consulter le module du Portail International d’Archivistique Francophone (PIAF) intitulé « Lutter contre les catastrophes » : http://www.piaf-archives.org/sections/formation/module_08/.
(9) En plus des informations mises à disposition sur les sites web de nombreuses institutions, nous avons utilisé différentes publications. Parmi celles-ci, nous recommandons : Johanna WELLHEISER ; Jude SCOTT, An Ounce of Prevention, Boston : The Scarecrow Press, 2002 (2e ed.), CONSEIL INTERNATIONAL DES ARCHIVES, Guidelines on Disaster Prevention and Control in Archives, Paris : CIA, 1997, Maria Barbara BERTINI, La conservazione dei beni archivistici e librari. Prevenzione e piani di emergenza, Roma : Carocci Editore, 2005, pp.145-189, Virginia A. JONES ; Kris E. KEYES, Emergency Management, for records and Information Management Programs, Prairie Village : ARMA International, 2001 (2nd ed.), Judith FORTSON, Disaster Planning and Recovery, New-York-Londres : Neal-Schuman Publishers, 1992, Miriam B. KAHN, Disaster response and Planning for Libraries, Chicago, Londres : American Library Association, 1998, Robert E. SCHNARE Jr ; Susan G. SWARTZBURG ; George M. CUNHA, Bibliography of Preservation Litterature, 1983-1996, London : The Scarecrow Press, Lanham, 2001, Helen FORDE, « Managing risks and avoiding disaster », Preserving archives, Londres : Facet Publishing, 2007, pp.113-139.
(10) http://www.en.nationaalarchief.nl/images/4_6107.doc. Le document mentionné est en anglais.
(11) The National Archives, Protecting Archives and Manuscripts against disasters (juin 2004), http://www.nationalarchives.gov.uk/documents/memo6.pdf - consulté le 3 octobre 2006, et The National Archives, Business Recovery Plan (novembre 2005), http://www.nationalarchives.gov.uk/documents/business_recovery_plan.pdf.
(12) Pour une brève introduction à ce programme, http://www.bundesarchiv.de/aktuelles/fachinformation/00044/index.html (en allemand). Voir aussi Das deutsche Notfallvorsorge-Informationssystem (ou deNIS), Système allemand de préparation en cas de catastrophe, http://www.denis.bund.de/ueber_denis/index.html (en allemand).
(13) Le site créé par des étudiants de la Haute Ecole de Gestion de Genève pour leur Travail de Diplôme comprend nombre d’informations utiles : http://www.cosadoca.ch.
(14) Mentionnons par exemple les travaux présentés par différents collègues latino-américains lors d’une conférence internationale qui s’est tenue à Cuba, entre les 7 et 9 mai 2007 intitulée « Taller sobre la Conservación del Patrimonio documental y la Prevención contra Catástrofes en Países de Clima Tropical » (Actes à paraître). Le Japon, pays où les tremblements de terre et les typhons sont fréquents, semble avoir développé des instruments intéressants. Malheureusement, faute de traductions, la littérature est difficile d’accès. Les collègues australiens ont aussi produit des recommandations, comme, par exemple, le Disaster Preparedeness Manual for Commonwealth Agencies (http://www.naa.gov.au/recordkeeping/preservation/disaster/contents.html).
(15) Les références sont très nombreuses. Mentionnons plus particulièrement : Conservation on Line (CooL), qui présente un grand nombre de liens sur des conseils et des exemples de Plans d’urgence ainsi qu’une rubrique spéciale consacrée à Katrina (http://palimpsest.stanford.edu/bytopic/disasters/) ; Northeast Document Conservation Center (NEDCC), qui met à disposition des petites brochures spécialisées, des ressources ainsi qu’un logiciel qui permet de créer son propre Plan d’urgence, baptisé « dPlan » (http://www.nedcc.org/home.php) ; National Archives and Records Administration (NARA), qui met à disposition différentes ressources en ligne (http://www.archives.gov/preservation/disaster-response/) ; American Institute for Conservation (AIC) (http://aic.stanford.edu/library/online/disaster/index.html) ; Heritage Emergency National Task Force (http://www.heritagepreservation.org/PROGRAMS/TASKFER.HTM ainsi que http://www.heritagepreservation.org/PROGRAMS/TFHurricaneRes.htm) ; Council of State Archivists (CoSA), dont la rubrique « Emergency Preparedness and Preservation » de son site renvoie à des liens (http://www.statearchivists.org/arc/index.htm). Cette organisation a également réalisé le « Pocket Response Plan (PReP), outil de travail fort utile (http://www.statearchivists.org/prepare/framework/prep.htm). Finalement, la Society of American Archivists a également été très active durant Katrina en mettant à disposition aussi bien des informations sur l’évolution de la situation qu’en prodiguant des conseils - http://www.archivists.org/index.asp.
(16) Des échanges avec nos collègues Pompiers nous ont convaincus que seuls des ajustements étaient nécessaires. Nous avons donc conservé les listes relatives aux personnes à prévenir, au matériel, aux fournisseurs de biens et services ainsi qu’aux sauvetages prioritaires par exemple. La description des installations physiques, quelque peu complétée, a également été reprise ainsi que les plans des installations (électricité, eau, etc). Quant aux procédures qui avaient été établies, une bonne partie d’entre elles ont été reconduites dans le nouveau document. En revanche, nous avons créé, comme signalé, un petit groupe de volontaires qui pourrait nous soutenir en cas de besoin.
(17) Ce Consortium regroupe trois institutions importantes, soit la Bibliothèque cantonale et universitaire de Lausanne, les Archives cantonales vaudoises et le SISB, c’est-à-dire le regroupement des bibliothèques scientifiques de l’Ecole Polytechnique Fédérale. Ces trois partenaires mettent en commun leurs connaissances, leur expérience, leur matériel et des locaux de repli en cas de crise. Ils réalisent également des exercices et mettent à disposition un site web. http://www.cosadoca.ch/.
(18) Op.cit, p.136.
(19) Nous pourrions aussi choisir d’introduire, sur le modèle de ce qui se fait maintenant aux Etats-Unis, une journée particulière dédiée à la préparation et à la réaction en cas de catastrophe. Les institutions américaines ont choisi la date du premier mai de chaque année pour célébrer. Cette journée a été baptisée « Mayday » ; « Archives, libraries, museums, and historic preservation organizations across America are setting aside May 1, 2007, to participate in MayDay, a national effort to protect collections from disasters. The Heritage Emergency National Task Force urges cultural institutions across the country to observe MayDay by taking at least one step to prepare to respond to a disaster », http://www.heritagepreservation.org/PROGRAMS/TASKFER.HTM. Voir également le site de la Society of American Archivists, http://www.archivists.org/mayday/index.asp.
(20) La consultation de différents sites bibliographiques nous confirme la chose : PIAF (Portail International d’Archivistique Francophone) http://www.piaf-archives.org/, CIDA (Centro de Información Documental de Archivos ), http://www.mcu.es/archivos/MC/CIDA/index.html (pour les mots « plan de emergencia » et « catastrofes »), Bibliographie se trouvant dans l’article intitulé « Preservation of Archives in Tropical Climate », Comma 2001, 3-4, pp.33-257.
Le web comme outil de diffusion des archives
Ressi — 30 avril 2008
Lorraine Filippozzi, Haute Ecole de Gestion, Genève
Résumé
Internet est aujourd’hui un outil de communication privilégié dans de nombreux domaines d’activité, dont les archives font partie. Dans cet article, je présenterai un état des lieux de la présence des archives sur Internet en commençant par une synthèse de la littérature sur le sujet suivie d’une analyse des sites internet d’archives actuels. Cet état des lieux permettra de contextualiser et d’appuyer la démarche de conception d’un site web d’archives que je présenterai en fin d’article. Ce guide méthodologique de diffusion constitue l’aboutissement d’un projet de recherche sur la diffusion des archives sur Internet mené dans la continuité d’un travail de diplôme sur le même sujet.
Dernière modification:
23/06/2009 Le web comme outil de diffusion des archives
La diffusion des archives : synthèse de la littérature
Les évolutions technologiques dans le domaine de la diffusion des archives méritent que l’on s’intéresse aux nouveaux enjeux qui en résultent. En effet, Internet est à présent le point de départ de la plupart des recherches, et un service d’archives, s’il souhaite être connu du public et mener à bien sa fonction de diffusion, se doit d’y être présent. Le web offre par ailleurs de nombreuses possibilités encore sous-exploitées.
La diffusion comme fonction archivistique
Selon la théorie de la discipline, la diffusion est à la fois une fonction archivistique et une mission pour les services d’Archives. Elle est une fonction archivistique car elle constitue l’aboutissement des activités de création et/ou d’acquisition, d’évaluation, de classification, de description et de préservation. Elle est aussi une mission car « la diffusion de l’information que contiennent les archives est parmi les finalités les plus importantes de l’archivistique » (Couture, [et al.], 2003 : p. 22). Ainsi, on la définit comme étant « l’action de faire connaître, de mettre en valeur, de transmettre et/ou de rendre accessible une ou des informations contenues dans des documents d’archives à des utilisateurs (personnes ou organismes) connus ou potentiels pour répondre à leurs besoins spécifiques » (ibid. : p. 22). Cette définition sous-tend les notions de communication et de promotion, ce qui démontre la tendance actuelle allant vers l’ouverture et la transparence des archives (Laurent, 2003 : p. 13). On observe véritablement une « mutation de la pratique vers des priorités axées sur la diffusion, sur la promotion de nos interventions et sur l’accroissement de l’accès à la connaissance et au savoir » (Aubin, 1999-2000 : p. 11).
Cet effort d’ouverture et de promotion est aussi dû au fait que « la diffusion assure aux centres d'archives une renommée grâce à laquelle ils peuvent justifier les ressources qui leur sont attribuées et prétendre au développement des archives dont ils ont la garde ainsi qu'au développement des services qu'ils offrent » (Couture, [et al.], 2003 : p. 386). Ainsi, le positionnement de la diffusion au sein du système de gestion d’un service d’archives est stratégique. En effet, la diffusion étant le meilleur moyen d'obtenir visibilité et notoriété, elle permet le maintien, voire l'augmentation des ressources pour l'ensemble du service. Il est par conséquent capital d'intégrer cette fonction à la planification générale des activités et, plus globalement, à la stratégie de l'institution. Occupant une position stratégique au sein du système de gestion des archives, la diffusion se doit d’être intégrée à l’appareil normatif et administratif du service d’Archives. Dans ce but, il est recommandé d’établir une politique de diffusion. Cette dernière permet de formaliser et de coordonner les différents aspects liés aux activités de diffusion d’un service d’Archives, ainsi que d’optimiser l’usage des différents moyens de diffusion possibles.
Les moyens de diffusion
Selon la littérature existante, on peut distinguer deux ordres de diffusion des archives : la diffusion par les archives et la diffusion par les archivistes (Couture, Rousseau, 1983 : p. 257). La diffusion par les archives inclut notamment la mise à disposition des archives, la mise à disposition d'instruments de recherche et d'informations générales, la publication (sur tous supports) et l’exposition de documents d’archives, d’instruments de recherche et d’informations générales. Tandis que la diffusion par les archivistes comprend la réglementation de l'accès, de la consultation, de la reproduction, la gestion des chercheurs (le service de référence, la consultation), la participation à des activités culturelles ou de formation et l'entretien des relations publiques.
La diffusion des archives est fondée sur différents moyens, chacun d’eux entraînant le choix et la mise en œuvre d’outils spécifiques. Ces moyens sont le service de référence, la règlementation, la consultation, la publication et la promotion. L'accès est une notion à appréhender tant au niveau intellectuel, physique, que légal. Le service de référence a pour but d’assurer la médiation entre le chercheur et le matériel mis à sa disposition. Il permet l'accès intellectuel aux documents d'archives, mais il doit tenir compte de la réglementation en vigueur. La règlementation peut être de trois types : « la restriction à la consultation, celle qui empêche la reproduction et celle qui interdit la diffusion » (Couture, [et al.], 2003 : p. 404). Ceux-ci influencent considérablement les possibilités de recherche offertes au chercheur, c’est pourquoi un service d'Archives doit faire preuve de transparence dans l’application des lois, règlements et politiques en vigueur. Il s'agit de ce fait d'instaurer « un équilibre entre les besoins des uns et les intérêts ou les ressources des autres » (ibid. : p. 408). La notion de consultation, quant à elle, inclut l'ensemble des éléments permettant l'accès physique aux documents. Elle dépend directement du service de référence qui la précède et l'accompagne. Autre moyen de diffusion, « la publication peut prendre plusieurs formes : publications de documents d'archives, publication d'instruments de recherche, publication d'informations générales » (Couture, Rousseau, 1983 : p. 257). La publication des documents d'archives, principalement sous forme de microfiches ou de documents numériques, permet d'élargir l'accès aux sources tout en les préservant. Mais avant les pièces elles-même, la publication des instruments de recherche permet au chercheur d'estimer l'utilité des fonds proposés sans avoir à se déplacer. De manière complémentaire, la publication d'informations générales, de la présentation du service à l’article historique complet, est aussi un excellent moyen de diffusion et de promotion. Les types et les supports de publication sont aujourd'hui nombreux : dépliant, guide de recherche, livre, périodique, audiovisuel, site web, etc. Ils permettent par ailleurs de contribuer à la promotion des archives.
Le contact entre les archives et leurs publics
Le contact entre les archivistes et les chercheurs peut être établi en face-à-face ou à distance, par téléphone, courrier ou Internet (Cohen, 1997 : p. 6). La diffusion par Internet, « assimilable à une publication, permet de pallier la pénurie des ressources qui limite les possibilités de publication d’instruments de recherche ou de guides du chercheur tout en favorisant un accès à distance et une mise à jour régulière à des coûts, à moyen terme tout au moins, plus faibles. Le contenu de ces sites est à la croisée du contenu du guide du chercheur, du dépliant et de l’état général des fonds. Il informe souvent sur les dernières acquisitions du centre d’Archives. Il peut aussi donner accès aux instruments de recherche spécifiques des fonds ou collections et même aux documents numérisés (unités de description complètes ou spécimens). Parfois, il rend aussi disponibles les normes, procédures et règles suivies par le centre d’Archives dans le cours de ses activités » (Couture, [et al.], 2003 : p. 397).
En informant le chercheur de manière inédite, un site Internet permet ainsi de rassembler en un lieu d’accès unique tous les moyens de diffusion précédemment exposés. Il offre une vitrine des Archives au public, il permet de fédérer tous les moyens de diffusion sur une même plateforme. En effet, un site web permet de proposer simultanément les informations sur l'institution, sur les fonds qu'elle conserve, sur les services offerts et sur la réglementation, ainsi qu'exposer des documents. Permettant à la fois d'anticiper une partie du travail de référence, de préparer le chercheur à la consultation, de disposer d'un espace de communication et d'exposition tout en participant à la promotion de l'institution à moindre coût, un site web se substitue parfaitement aux autres formes de publication (Abraham, 1996 : p. 2).
De plus en plus, l’internaute accède aux sites et aux inventaires d’archives grâce aux moteurs de recherche (Hamburger, 2004). Les services d’Archives se doivent donc d’y apparaître en bonne position. Pour cela il s’agit de suivre les recommandations concernant le bon référencement d’un site ainsi que de démarcher les moteurs de recherche afin que leurs robots recensent aussi les enregistrements contenus dans la base de données du service (Hill, 2004).
Loin de le rendre inutile, tous les moyens de diffusion mis à disposition du chercheur révèlent le rôle de médiateur de l’archiviste. La relation entre l’archiviste et le chercheur est un échange, et la « mission d’information n’est pas à négliger. C’est à l’archiviste qu’il incombe souvent de traduire la demande en termes d’archives » (Favier, 2000 : p. 192). En proposant un nouveau moyen d’accès à leurs utilisateurs, les services d’Archives doivent aussi se donner les moyens de répondre à la demande : salle de consultation adéquate, procédure de réquisition des documents, copies, indication des droits et devoirs de chacun, etc. (Couture, [et al.], 2003 : p. 400). « L’enjeu [de la diffusion] est de faire en sorte que la mémoire soit diffusée de façon à susciter l’intérêt et la curiosité et augmenter le nombre de personnes qui s’y intéressent : il faut adapter, modifier, créer, innover sans nécessairement vulgariser » (Aubin, 1999-2000 : p. 13).
Les activités liées à la diffusion abordent donc à la fois les notions de stratégie, de législation, de gestion des chercheurs et de communication des documents. Intégrée à un système de gestion des archives global et cohérent, la diffusion est un bon moyen d’obtenir visibilité et notoriété, et ainsi de justifier les ressources allouées au service auprès des décideurs.
La présence des Archives sur Internet : analyse des sites actuels
Internet a permis de faire évoluer la communication des services d’Archives et d’influencer leur mission de diffusion des fonds historiques. La littérature spécialisée donne un bon aperçu des attentes du public, des pratiques et des différents enjeux qui se présentent actuellement. Parallèlement, une analyse des sites web d’archives existant sur Internet permet de dresser schématiquement un modèle de site web et de souligner les spécificités techniques qui leur sont propres.
L’évolution des publics
Le monde des Archives l’a vite compris, Internet représente une opportunité à saisir. A la fois source de développement pour la diffusion des documents conservés et nouveau moyen de valorisation des fonds, l’outil web offre de multiples possibilités de présentation des fonds et des services d’Archives au public. Avant de les exposer, il s’agit cependant de mieux comprendre les attentes de ce public, qui change et se diversifie.
Le public classique des Archives, constitué d’historiens et de chercheurs universitaires, a de moins en moins de temps. A l’ère des moteurs de recherche généralisés, « les usagers sont habitués […] à une information rapide, aisément disponible, accessible quasiment à domicile » (Ermisse, 1994 : p. IX). Ils sont de plus en plus réticents à se déplacer sans savoir ce qu’ils trouveront. L’ordinateur est devenu l’outil de travail privilégié, et Internet leur permet de rassembler à distance les informations qui leur seront utiles lors de leur déplacement dans le service pour recherches approfondies. En marge de ces chercheurs avertis, d’autres types d’utilisateurs fréquentent les Archives. Il s’agit principalement des généalogistes, qui depuis une vigtaine d’années ne cessent d’augmenter. A leurs côté, étudiants, amateurs passionnés d’histoire et professionnels de divers domaines (architecture, sciences politiques, géographie, etc.) commencent à s’intéresser aux archives (ibid. : p. 3). Pour canaliser ces différents publics, les services d’archives peuvent leur donner les moyens d'estimer à distance la spécificité et la pertinence des fonds conservés.
L’enjeu pour les services d’Archives est de ne pas passer à côté de cette nouvelle génération familiarisée avec l’outil informatique et développant de nouvelles habitudes de recherche. Il s’agit donc de continuer à promouvoir l’utilisation des fonds et à favoriser la recherche historique en s’daptant à ces nouveaux besoins d’information. Rendu possible par le web, ce véritable rapprochement avec le public permet aux archives de dynamiser leurs activités et de donner d’elles-même une image plus attirante. Pour ces différentes raisons, que les services d’archives ont bien saisies, il est primordial d’être présent sur Internet.
Sites web d’archives : différents niveaux
Pour répondre aux besoin de ces différents publics lors de l’élaboration d’un site web d’Archives, il est possible de rendre disponibles simultatément plusieurs niveaux d'information (Uhde, 2001). Les quelques exemples proposés démontrent que la préoccupation de répondre aux attentes des publics distincts est constante.
Le premier niveau, le plus basique, contient les informations de présentation générale des services d’Archives. Il est composé des informations pratiques sommaires comme les coordonnées de contact, les heures d’ouverture, une description sommaire des fonds (type et volume), et éventuellement le guide du chercheur. A ce niveau déjà, différentes options existent pour présenter les fonds et les collections : listes alphabétiques, répertoires numériques ou thématiques, cadre de classement, regroupement des fonds par périodes historiques ou par sujet. Il est aussi possible de prévoir des chemins d'accès différents pour chaque type de chercheurs ou pour des centres d’intérêt spécifiques.
Le deuxième niveau offre la fonction de recherche dans les archives en mettant à disposition les inventaires des fonds selon les différents procédés possibles. Il est ainsi envisageable de scanner les inventaires et de les proposer en format image ou texte sur le site. Un autre procédé est la conversion des inventaires en format HTML (2). De manière plus élaborée que ces deux premières options plutôt « bricolées », la plupart des services d'Archives mettent à disposition des outils de recherche dynamiques. Il s’agit de moteurs de recherche directement liés aux bases de données des services. Il est en effet possible, selon le système utilisé pour la description, d'en proposer une interface de recherche en ligne (Rosenbusch, 2001 : p. 46), laquelle peut être guidée par différents index et listes d’autorités (géographiques, noms de personnes et de collectivités, etc.). On peut alors véritablement parler de salle des inventaires virtuelle.
Le troisième niveau offre à l’utilisateur la possibilité de consulter directement les pièces du fonds numérisées à l’écran. Les documents d’archives sont accessibles au format image ou même en texte, grâce aux logiciels de reconnaissance optique des caractères. On peut alors parler d’« archives virtuelles » (Valacchi, 2003 : p. 190 ; Lemay, 1998-1999 : p. 12), voire de « salle de lecture virtuelle ». Une des premières réalisation de ce niveau d'information est le site des Archives municipales de Rennes (Rennes, en ligne), qui, depuis 2003, donne progressivement accès en haute résolution aux registres paroissiaux, à une partie du cadastres et des recensements ainsi qu'à deux tiers de l'état civil. Cette option est également souvent utilisée pour mettre en valeur des fonds cartographiques et photographiques. « Depuis 2003, les statistiques de fréquentation des sites internet des services d’archives ayant mis en ligne ce type de documents montrent un afflux de visites dans ces salles de lectures virtuelles » (Minstère de la culture et de la comunication, 2007 : p. 5).
Complémentairement à ces différents niveaux d'information, plusieurs éléments accessoires sont utiles sur un site web d’Archives. Ainsi, avant même de lui donner accès aux sources, il est intéressant d'indiquer au chercheur l'usage qu’il pourra faire des archives. Dans cette optique, il est intéressant de relever l’offre de didacticiels et de foires aux questions (FAQ). Par ailleurs, la mise à disposition de formulaires de demande de recherche et de réservation de documents permet aux chercheurs d'émettre l’objet de leurs recherche et les documents requis et ainsi de préparer leur venue.
Le site web «modèle»
La majorité des services d'Archives a choisi de créer un site à plusieurs niveaux, chacun s'adressant à un public spécifique, du profane à l'averti. « Le contenu de ces sites est à la croisée du contenu du guide du chercheur, du dépliant et de l'état général des fonds » (Couture, [et al.], 2003 : p. 397). La combinaison d’éléments des différents niveaux permet de brosser le portrait d’un site web « modèle », qui contient au moins les rubriques suivantes : présentation du service, informations pratiques, présentation des fonds et des inventaires et, finalement, la proposition de sources complémentaires.
La présentation du service permet de décrire la mission et les activités de l’organisme, d’exposer sa structure interne et son personnel. En tant que « vitrine » du service, cette présentation doit être attractive afin de véhiculer une image positive du service.
Les informations pratiques regroupent tous les éléments ponctuels utiles aux chercheurs qui envisagent une visite du service : horaires d’ouverture, adresse et plan d’accès, conditions d’accès aux documents, présence d’un service de référence, procédures de demandes de recherche, règlement de consultation et de reproduction, etc. Ces informations doivent lui permettre de préparer sa venue dans les meilleures conditions. Dans cette rubrique peut aussi être offert un moyen de contact des archives : téléphone, email, formulaire de contact, etc.
La présentation des fonds et des inventaires constitue le cœur du site web d’un service d’archives. Elle peut contenir différents moyens d’accès aux fonds : liste des fonds, cadre de classement, inventaires statiques ou dynamiques avec ou sans lien aux fonds numérisés ainsi que diverses options de recherche. Cette rubrique centrale remplit une double fonction : d’information d’une part, en fournissant des informations aussi exhaustives que possible pour permettre au chercheur de juger de l’utilité d’une visite ; de promotion d’autre part, en mettant en valeur et en attirant son attention sur certains thèmes ou documents particulièrement intéressants.
Les sources complémentaires permettent de diriger le chercheur vers d’autres sites ou sources d’informations utiles : bibliothèques, services d’archives, portails thématiques, associations, etc.
L’ensemble de ces rubriques permet de remplir les différentes fonctions que l’on attend d’un site web d’archives. Chacune participe à guider et à canaliser le chercheur dans sa recherche d’information. Cependant celui-ci demande avant tout d’avoir accès aux instruments de recherche (Salzmann, 2004 : p. 46).
Les instruments de recherche en ligne
Les choix stratégiques de diffusion des instruments de recherche dépendent directement de la technologie utilisée dans le service d’archives. En effet, le logiciel employé et les possibilités qu’il offre au niveau de la recherche et des formats de résultats influenceront largement le niveau d’information offert au public sur Internet. Tous les systèmes de gestion de bases de données offrent actuellement des options de recherche et de rendu de rapports de recherche paramétrables.
Ainsi la plupart des systèmes de gestion de bases de données utilisent le format SQL, qui est le standard le plus répandu pour la structuration de bases de données. Or, en informatique, des données standardisées peuvent être utilisées par différents logiciels, contrairement aux données propriétaires. Il est donc possible d'exploiter directement ces données bien adaptées au web soit en élaborant soi-même - ou avec l'aide d'un informaticien qualifié - un module de connexion à cette base de données au web, soit en utilisant un autre logiciel permettant de mettre en ligne une base de donnée de format SQL (3).
Une autre option est le recours au standard XML (4). Le format XML est adopté par de plus en plus de professionnels, comme une méthode de description de données digitales, internationale, non propriétaire et indépendante. Ce format facilite l'échange de données électroniques, la manipulation des données et la recherche Internet (Higgins, 2003 : p. 199). XML est d'autant plus approprié à la description des archives qu'il a été spécialement adapté à la norme ISAD(G) par l'élaboration de EAD, une définition de type de document (DTD) spécialement conçue pour la recherche Internet de données hiérarchisées d'archives (ibid. : p. 204). En outre, XML est le format utilisé dans la plupart des projets exposés dans la littérature professionnelle (Higgins, 2003 ; Burgy, 2004). Le transfert des systèmes de gestion dans un environnement XML est une possibilité pour mettre en ligne les inventaires d’archives. Actuellement, les principaux logiciels documentaires utilisés dans les services d’archives offrent des fonctions d’export automatique des données en XML. Par ailleurs, un tel transfert permet d'être en phase avec les pratiques archivistiques actuelles, de conformer tous les inventaires qui ne le sont pas encore à la norme ISAD(G), de se détacher de la dépendance envers les sociétés propriétaire et de s'inspirer des projets de mise en ligne d'inventaires menés par différentes institutions.
Il est aujourd’hui capital d’appliquer les différentes recommandations de la profession concernant les normes techniques et l’usage de formats libres pour permettre une collaboration optimale entre les institutions. Cette collaboration est nécessaire à une plus grande ouverture des archives car, par un effort commun de partage de compétences et de moyens, elle rend possible un accès public étendu aux informations conservées dans les services d’archives.
Perspectives et enjeux actuels
Comme le démontrent les exemples exposés précédemment, les technologies offertes par le web rendent possible de nouveaux concepts, tels que celui de salle des inventaires, voire de salle de lecture virtuelle. Cette tendance a été accentuée par l’avènement du web 2.0, ou web de seconde génération, qui permet une plus grande interaction entre les archivistes et leurs publics. Ici encore, les Archives municipales de Rennes ont été pionnières en proposant à leurs internautes volontaires (surtout des généalogistes) un procédé d’indexation collaborative des registres d’état civil rennais (Rennes, en ligne). Bien cadrée par des procédures de contrôle de la qualité de l’indexation proposée, cette opération a rencontré un vif succès et a fait naître d’autres projets du même type, notamment avec l’Université de Rennes. Autre réalisation intéressante faisant participer le public aux tâches archivistiques, le projet « Your Archives » des Archives nationales du Royaume Uni, où les usagers contribuent aux descriptions, transcriptions et rédaction des notices biographiques (England, Wales and United Kingdom, en ligne). Les mécanismes de « navigation sociale » offerts par le web 2.0 permettent en outre aux internautes de commenter, de filtrer les requêtes en fonction des intérêts (filtre collaboratif), de marquer les pages ou encore de voir qui est en ligne (Yakel, Shaw, Reynolds, 2007).
En outre, l’élan d’ouverture des archives tend a se fédérer et à se structurer. Ainsi, Archives Canada propose son Réseau canadien d’information archivistique, métamoteur permettant d’effectuer une seule recherche dans l’ensemble des bases de données des services participants (Archives Canada, en ligne). Dans le même ordre d’idée, « Bora Archives privées » fédère les bases de données des archives privées françaises (Direction des Archives de France, en ligne). « Les passerelles sont également nombreuses entre patrimoine et archives dans le domaine de la recherche et de la mise en valeur documentaire » (Rambaud, 2005 : p. 96). En effet, les efforts de diffusion mis en œuvre par les Archives tendent de plus à rejoindre ceux des autres institutions patrimoniales telles que les bibliothèques et les musées. Les attentes des utilisateurs et la mise en place de standards facilitant la mise en place d’outils de recherche transversaux conduisent à un rapprochement entre institutions patrimoniales. Des portails en tels que « MICHAEL » [Multilingual inventory of cultural heritage in Europe] démontrent d’une volonté commune de partage et de transversalité entre insitutions patrimoniales et témoignent de la mise en œuvre d’une véritable « mémopolitique », ou politique patrimoniale coordonnée (MICHAEL, en ligne). Seule l’absence de standard commun et le relatif cloisonnement des pratiques professionnelles freinent ce rapprochement et créent une prolifération des outils de recherche qui nuit à leur utilisation.
Les enjeux actuels sont donc la normalisation des pratiques de descriptions archivistiques, l’adoption de standards favorisant l’interopérabilité entre institutions patrimoniales ainsi que l’homogénéisation des outils de recherche offerts. Ainsi le public, jusque là usager mais peu critique face à la prolifération d’outils de tout genre, pourra réellement bénéficier d’instruments cohérents et de données normalisées. L’impact des outils proposés sur le public est encore peu étudié, mais les services d’archives proposant de véritables salles de lecture virtuelles ont constaté une nette diminution des visites dans le service. Face à cette baisse de fréquentation et en l’absence de statistique d’utilisation des sites web et des outils de recherche qui y sont proposés, les services émettent certaines craintes légitimes. Comment, en effet, justifier les ressources allouées au service de référence en l’absence d’usagers ? Et, paradoxalement, comment faire revenir le public dans les archives après lui avoir donné les moyens de s’en distancer ?
Démarche de conception d’un site web d’archives
Afin de correspondre au mieux aux exigences archivistiques ainsi qu’aux besoins du public, la démarche de conception d’un site web d’archives peut être divisée en six grandes étapes, dont voici une brève présentation. La première étape est l’analyse de l’existant et des besoins. Elle permet de cibler les objectifs du service ainsi que les attentes de ses usagers en matière de diffusion. La seconde étape propose la mise en place d’une stratégie de diffusion, qui détermine la politique de diffusion du service ainsi que ses priorités en termes de diffusion. La troisième étape consiste en la modélisation du site sur la base d’un cahier des charges établi à partir des informations recueillies durant les étapes précédentes. Suit alors l’étape de la réalisation, qui nécessite des choix logistiques et techniques ainsi que la priorisation dans la création du contenu. Il est en effet inévitable, et c’est l’objet de cette avant-dernière étape), de procéder à des choix. Ceux-ci concernant notamment les modalités d’accès aux documents, qui posent des problèmes tant intellectuels que techniques : sous-traitance de la création du site, traitement des informations confidentielles, tarification des services, etc. La dernière étape permet d’inscrire le site dans la durée en assurant sa maintenance et sa promotion. L’ensemble de ces étapes est détaillé et enrichi dans un wiki relatant l’ensemble de la démarche et son contexte de recherche.
A propos du guide de diffusion des archives…
Toutes les réalisations existantes convergent vers une diffusion de plus en plus large des archives. Cependant tous les services n’ont pas encore entamé cette démarche, c’est pourquoi j’ai capitalisé dans un wiki les résultats de mes recherches sur la diffusion ainsi qu’un guide exposant la démarche de conception et de réalisation d’un site web d’archives. Cette plateforme se veut évolutive et je laisse le soin à qui le souhaite d’y intégrer ses considérations. Elle se trouve à l’adresse suivante : http://archiveswebsites.pbwiki.com.
Pour conclure…
La fonction « diffusion » bénéficie largement de l’esprit d’ouverture et de promotion qui s’est développé dans le domaine des archives. Intégrée à la stratégie des services, elle s’institutionnalise et se traduit par la mise en œuvre souvent combinée de différents moyens de diffusion. Dans cette fonction, les archivistes ont su tirer parti des avancées technologiques pour répondre aux besoins du public. Ils offrent ainsi aux chercheurs, très demandeurs de services à distance, un accès de plus en plus complet au monde des archives, allant de la présentation des services aux documents d’archives numérisés en ligne. Par des sites web offrant plusieurs niveaux d’information destinés aux différents publics, ils guident à distance les chercheurs vers les sources appropriées. La mise à disposition d’instruments de recherche est l’élément central à résoudre lors de la conception d’un site web d’archives. Différentes technologies et systèmes de description se côtoient, avec pour conséquence un manque d’homogénéité des sites existant. Cependant un effort de normalisation (notamment avec EAD) et une volonté de synergie entre institutions patrimoniales présupposent une harmonisation prochaine des pratiques. De plus, les apports d’outils de type « web 2.0 » aux sites web d’archives ont déjà été salués par les chercheurs, qui en apprécient les nouvelles possibilités d’interaction.
Notes
(1) BUGNON, Nicolas, ERARD, Reynald, FILIPPOZZI, Lorraine (2006). RAS on the web : élaboration d'une stratégie de diffusion et création du site web du Service Records et Archives de l'OMS. 136 p. Travail de diplôme, Haute Ecole de Gestion, Filière Information et documentation, Genève, [consulté le 05.12.2007]. http://doc.rero.ch/search.py?recid=6529&ln=fr
(2) HTML [Hypertext markup language] est un langage informatique de balisage conçu pour écrire des pages web [Wikipédia]
(3) SQL [Structured query language], ou langage structuré de requêtes, est un pseudo-langage informatique standard et normalisé destiné à interroger ou à manipuler une base de données relationnelle [Wikipédia]
(4) XML [Extensible markup language], ou langage de balisage extensible, est un langage de balisage générique destiné à faciliter l’échange automatisé de contenus entre systèmes d’information hétérogènes [Wikipédia]
(5) OFFICE FEDERAL DE LA CULTURE (SUISSE). « Mémopolitique » - la mémoire nationale. Berne, Office fédéral de la culture, 2006. 5 p. [consulté le 05.12.2007]. Publications, Administration Suisse
Bibliographie
ABRAHAM, Terry (1996). Net worth : adding value to the archival web site. University of Idaho [en ligne]. Moscow, University of Idaho, [consulté le 05.12.2007]. http://www.uidaho.edu/special-collections/papers/networth.htm
ARCHIVES CANADA. Réseau canadien d’information archivistique [en ligne]. Canada, Patrimoine canadien, [consulté le 05.12.2007]. http://www.archivescanada.ca/fr/index.html
AUBIN, Danielle (1999-2000). La mondialisation et la diffusion des archives : entre continuité et rupture. Archives (Québec). Vol. 31, no 3, p.7-19.
BURGY, François Marc (2004). ISAD(G) et XML/EAD pour les inventaires des Archives de la Ville de Genève. Arbido. No 5, p. 53-55.
COHEN, Laura B (1997). Reference services for archives and manuscripts. New York, The Haworth Press. 215 p. ISBN 0789000423
COUTURE, Carol, ROUSSEAU, Jean-Yves (1983). Les archives au XXème siècle. Montréal, Université de Montréal. 491 p. ISBN 2891190262
COUTURE, Carol, [et al.] (2003). Les fonctions de l’archivistique contemporaine. Sainte-Foy, Presses de l’Université du Québec, 559 p. ISBN 2760509419
DIRECTION DES ARCHIVES DE FRANCE. Base d’Orientation et de Recherche dans les Archives : BORA Archives privées [en ligne]. Direction des Archives de France, BORA, [consulté le 05.12.2007]. http://daf.archivesdefrance.culture.gouv.fr/sdx/ap/
ENGLAND, WALES AND UNITED KINGDOM. The National Archives [en ligne]. England, Wales and United Kingdom website, [consulté le 05.12.2007]. http://www.nationalarchives.gov.uk/
ERMISSE, Gérard (1994). Les services de communication des archives au public. Munich, K.G. Saur, X, 306 p. ISBN 3598202814
FAVIER, Jean (2000). Les archivistes et les chercheurs. Archivum. Vol. 45, p.191-197
HAMBURGER, Susan. How researchers search for manuscript and archival collections. Journal of archival organization. Vol. 2 (1/2), 2004, p. 79-102
HIGGINS, Sarah (2003). Implementing EAD : the experience of the NAHSTE project. Journal of the Society of archivists. Vol. 24, n° 2, p. 199-214
HILL, Amanda. Serving the invisible researcher : meeting the needs of online users. Journal of the Society of Archivists. Vol. 25, no 2, 2004, p. 139-148
LAURENT, Sébastien. Archives « secrètes », secrets d’archives ? : L’historien et l’archiviste face aux archives sensibles. Paris : CNRS Editions, 2003, 288 p.
LEMAY, Yvon (1998-1999). Les sites web des services d'Archives universitaires au Canada et la diffusion. Archives (Québec). Vol. 30, no 1, p. 3-24
MINISTERE DE LA CULTURE ET DE LA COMMUNICATION. Aperçu des usages d’Internet par les généalogisteshttp://www2.culture.gouv.fr/deps/pdf/dt/dt1272.pdf [en ligne]. Minstère de la Culture et de la Communication, [consulté le 05.12.07].
Multilingual inventory of cultural heritage in Europe (MICHAEL) [en ligne]. Site web de MICHAEL, [consulté le 05.12.2007]. http://www.michael-culture.org/fr/home
RAMBAUD, Isabelle (2005). Archives, patrimoine, musées : l’exemple de la Seine et Marne. La gazette des archives. N°200, vol. 4, p. 83-100
RENNES. Archives municipales [en ligne]. Rennes, Archives municipales, [consulté le 05.12.2007]. http://www.archives.rennes.fr/
ROSENBUSCH, Andrea (2001). Are our users being served?: a report on online archival databases. Archives and manuscripts. Vol. 29, no 1, p. 44-61
SALZMANN, Katharine A. « Contact us » : archivists and remote users in the digital age. The reference libararian. No 85, 2004, p. 43-50
UHDE, Karsten (2001). 2001-2010 : Gegenwart und Zukunft des Internet als gemeinsame Arbeitsplattform von Archivaren und Historikern. Arbido. Vol. 16, no 6, p. 9-14
VALACCHI, Federico (2003). Sites internet et recherche archivistique : typologie et possibilités de recherche. Comma. No 2-3, p.185-190
YAKEL, Elizabeth, SHAW, Seth, REYNOLDS, Polly. Creating the next generation of archival finding aids. D-Lib [en ligne]. Vol. 13, no 5/6, [consulté le 05.12.2007]. http://www.dlib.org/dlib/may07/yakel/05yakel.html