Publiée une fois par année, la Revue électronique suisse de science de l'information (RESSI) a pour but principal le développement scientifique de cette discipline en Suisse.
Publié par Ressi
S'applique aux numéros publiés et contenus disponibles au public.
Formation en gestion des données de recherche: propositions de dispositifs d’e-learning pour le projet DLCM
Ressi — 21 décembre 2020
Marielle Guirlet, Diplômée du Master en Sciences de l'Information HEG, HES-SO (2020) et assistante de recherche à la HEG-Genève
Manuela Bezzi, Diplômée du Master en Sciences de l'Information HEG, HES-SO (2020) et Bibliothécaire documentaliste archiviste spécialiste de disciplines à l’Université de Genève
Manon Bari, Diplômée du Master en Sciences de l'Information HEG, HES-SO (2020) et Archiviste chez Lombard Odier Group
Résumé
Le projet DLCM financé par Swissuniversities a pour objectif de fournir un soutien et des ressources adaptées à chaque étape du cycle de vie des données, et de permettre aux chercheu-r-se-s académiques suisses d’implémenter une gestion des données de la recherche (GDR). La seconde phase du projet (2019-2020) se concentre sur la définition des approches et la mise en place d’outils et de services pour la GDR les mieux adaptés aux besoins de l’environnement académique suisse. Cet article fournit des recommandations et des propositions d’options pour la conception d’un dispositif de formation e-learning en GDR qui rentre dans le cadre de cette seconde phase du projet DLCM. Il reprend certains résultats du mémoire d’un projet de recherche d’étudiantes du Master of Science HES-SO en Sciences de l’information.
Après une revue de la littérature sur les formations à la GDR, sur le projet DLCM et sur l’e-learning, les principales observations portant sur l’inventaire des formations et des ressources en GDR des partenaires DLCM sont présentées. Elargi à l’international, cet inventaire permet d’identifier les ressources éventuellement réutilisables pour la formation e-learning de DLCM. A partir de cet inventaire, un panorama global des activités dans ce domaine est dressé, et la typologie des ressources disponibles est identifiée. Puis, à partir d’études de cas (le suivi de cinq formations e-learning sur la GDR et d’autres sujets variés), des recommandations pour la formation e-learning de DLCM sont formulées. Elles concernent le contenu de la formation, le parcours de formation, l’accompagnement des apprenant-e-s et les possibilités d’interaction.
Une formation e-learning peut se décliner selon de multiples modalités. Certaines d’entre elles, particulièrement importantes pour le contexte DLCM, sont discutées. En s’appuyant sur ces différents éléments développés précédemment, en fonction de profils-types du public-cible pour la formation, trois dispositifs e-learning adaptés sont alors proposés: un SPOC (Small Private Online Course), un MOOC (Massive Open Online Course) et une formation libre. Les avantages spécifiques apportés par la formation libre au projet DLCM et à ses partenaires sont discutés plus en détail.
Abstract
The Swissuniversities-funded DLCM project aims at providing support and resources for every step of the data lifecycle and allowing Swiss academic researchers to implement Research Data Management (RDM) practices. The second phase of the project (2018-2020) focuses on specifying strategies and setting up tools and services in RDM most suited to the needs of the Swiss academic environment.
This paper makes recommendations and suggestions for the design of an e-learning training in RDM in the frame of the second phase of the DLCM project. It is based on a research project by students of the Master of Science HES-SO in Information Science, and as such, uses some results already presented in the research project report.
After the literature review on RDM training, on the DLCM project and on e-learning, we present our main observations on the inventory of RDM training activities and resources from the partner institutions of DLCM project. By bringing up this inventory to the international level, we identify some reusable and adaptable material for the DLCM e-learning training. We then use the inventory to draw a global landscape and to set up a typology of e-learning resources in RDM. From five case studies (e-learning trainings on RDM and other topics), we formulate recommendations for the DLCM e-learning training. These recommendations address the training content, the learning pathway, the coaching and the interaction between the trainer and the learners. E-learning trainings may be very diverse, depending on many components. Some of these components which are specifically important for DLCM environment are presented in detail. Basing on the previously discussed items and taking into consideration some personas typical from the target audience of DLCM training, three e-learning models are presented: a SPOC (Small Private Online Course), a MOOC (Massive Open Online Course) and a free training. The specific advantages of the free training model for DLCM and its partners are emphasized.
Mots-Clés:
DLCM,
partenaires DLCM,
données de (la) recherche,
gestion des données de (la) recherche,
research data management,
formation,
e-learning,
dispositif d’e-learning,
MOOC,
SPOC,
formation en présentiel,
DLCM partners,
research data,
research data management,
training,
e-learning,
face-to-face training
Nombre de mots:
15992 Formation en gestion des données de recherche: propositions de dispositifs d’e-learning pour le projet DLCM
Introduction et méthodologie de recherche
Depuis une dizaine d’années, la problématique de la gestion des données de recherche*(1);(notée GDR dans la suite) apparaît comme un enjeu principal dans le domaine de la recherche (Vela et Shin 2019). Le projet DLCM*, lancé en 2015 par huit institutions suisses, propose des services pour accélérer le développement de bonnes pratiques de GDR en Suisse et pour contribuer à une culture commune autour de la GDR, en renforçant la collaboration et la coordination entre les écoles supérieures de Suisse. L’e-learning*, outil récent boosté par les nouvelles technologies, apparaît comme le meilleur outil pour former à distance de larges communautés de chercheu-r-se-s dispersé-e-s sur le territoire.
Dans le cadre de notre Master of Science HES-SO en Sciences de l’information à la HEG de Genève, Haute Ecole de la HES-SO, nous avons effectué un projet de recherche portant sur la mise en place de dispositifs de formation* e-learning sur la GDR, et sur la formulation de recommandations pour le projet DLCM sur les meilleurs dispositifs à utiliser par celui-ci en tenant compte de son contexte et de ses missions. Ce projet de recherche était encadré par la Prof. Dr. B. Makhlouf-Shabou. Cet article est une compilation des principaux résultats de ce projet de recherche et à ce titre il contient un certain nombre de citations et d’éléments du mémoire correspondant (Bari, Bezzi et Guirlet 2020).
Une liste d’acronymes et un glossaire sont disponibles à la fin de l’article.
Plusieurs objectifs de recherche sous-jacents à notre réflexion ont jalonné notre travail.
L’exploration de l’existant en termes de dispositifs e-learning: à partir de la littérature sur l’e-learning et l’étude de formations* e-learning existantes, nous établissons la typologie de ces formations (MOOC* et autres dispositifs, en Suisse et ailleurs). A partir de l’inventaire des ressources en GDR fournies par les partenaires DLCM, nous établissons l’état des lieux de l’activité de ces partenaires dans le domaine de la formation en GDR. En élargissant cet inventaire à l’international, nous identifions des ressources potentiellement réutilisables pour une formation e-learning en GDR.
Sur la base de notre expérience d’utilisatrices d’une sélection de formations e-learning, nous émettons des recommandations pour la future formation e-learning en GDR de DLCM.
La caractérisation des parties prenantes: le public-cible pour la formation est identifié et ses besoins sont caractérisés à partir de la littérature et de l’inventaire des ressources en GDR fournies par les partenaires DLCM. Nous identifions les autres parties prenantes ainsi que leurs contributions possibles à la formation DLCM.
Le choix d’options de dispositif d’e-learning: en fonction de profils-types d’utilisat-eur-rice-s dans le contexte DLCM, nous présentons et comparons différentes options de dispositifs, et nous en recommandons une en particulier.
Le résultat attendu de cette recherche, à savoir des recommandations pour le projet DLCM concernant un dispositif d’e-learning en GDR à destination des chercheu-r-se-s en Suisse, se situe à l’intersection des trois thématiques : formation en GDR, projet DLCM, e-learning (Figure 1).
Figure 1: Schématisation des thématiques de recherche abordées, recoupement et principales questions de recherche associées (voir texte)
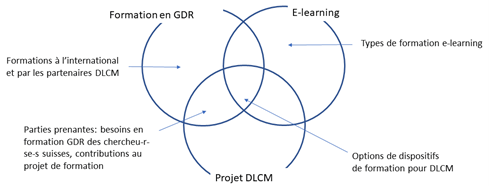
Les questions de recherche reliées à ces objectifs sont les suivantes :
- Qu’est-ce qu’une formation e-learning, quels sont ses différents types ?
- Quelles formations en GDR sont dispensées par les partenaires DLCM ? Quelles formations en GDR sont disponibles à l’international ? Quelles bonnes pratiques des formations e-learning sont intéressantes pour DLCM ?
- Quels sont les types de besoins de formation en GDR des chercheu-r-se-s suisses ? Quelles sont les parties prenantes et leurs contributions possibles au projet de formation ? (à l’intersection des thématiques formation en GDR et projet DLCM)
- Quels dispositifs de formation e-learning en GDR sont les plus adaptés à la communauté DLCM ? Quels dispositifs est-il judicieux que le DLCM propose ? (à l’intersection des trois thématiques)
Les résultats de notre revue de la littérature sur la GDR, les services d’accompagnement et les formations en GDR, l’e-learning et le projet DLCM sont présentés dans la suite. A partir de ces résultats, nous émettons des recommandations à propos de la conception de la formation DLCM. Sont ensuite discutés les principaux résultats de l’inventaire des ressources en soutien à la GDR par les partenaires DLCM et à l’international, et des études de cas de formation e-learning, dont nous tirons aussi des recommandations. Différentes modalités possibles pour la formation e-learning DLCM sont ensuite explorées et discutées, avant la présentation détaillée de nos propositions de dispositifs spécifiques adaptés au projet.
Le soutien à la gestion des données de recherche dans la littérature
Un contexte incitatif et le besoin de services
Le volume des données digitales (”data deluge”, “digital deluge” : Pryor 2012 ; Pinfield, Cox et Smith 2014 ; Blumer et Burgi 2015) a très fortement augmenté au cours de la dernière décennie, favorisée par la diffusion par Internet sans limite matérielle de reproductibilité. Ces données deviennent aussi de plus en plus hétérogènes et complexes. En réponse à ce phénomène, les concepts et les modèles dans le domaine de la GDR se sont développés et se sont formalisés (Vela et Shin 2019): cycle de vie des données (DCC Curation Lifecycle Model : Higgins 2008); data continuum (Data Curation Continuum : Treloar, Groenewegen et Harboe-Ree 2007).
L’émergence de l’Open Science et de l’ouverture des données de recherche* pour leur réutilisation possible a aussi contribué au développement du domaine de la GDR. Le partage des données de recherche s’appuie en effet sur une bonne gestion de ces données tout au long de leur cycle de vie (Kruse et Thestrup 2018, p.51). Cette dynamique Open Science se traduit de façon très concrète pour les chercheu-r-se-s par des directives des agences de financement de la recherche. Dans la recherche publique suisse, ces chercheu-r-se-s doivent en effet se soumettre aux exigences des deux principales agences de financement. La Commission Européenne, dans le cadre du programme-cadre H2020 (Horizon 2020) impose de rendre accessibles les données issues de projets qu’elle finance et associées à des publications (European Commission 2016, 2017). Le FNS lui aussi impose de rendre accessibles les données des projets qu’il subventionne (FNS 2017). Certains éditeurs scientifiques exigent également la publication des données associées aux articles qui paraissent dans leur revue (Nature 2016 ; Springer Nature [sans date] ; PLOS ONE 2019).
Outre la conformité à ces directives, les chercheu-r-se-s peuvent répondre à d’autres motivations pour partager leurs données de recherche, et implicitement, adopter de bonnes pratiques de GDR. Ces motivations peuvent relever d’un engagement personnel pour l’Open Science ou d’autres facteurs tels que l’opportunité de nouvelles collaborations et de nouvelles études, le soutien à une publication et la validation des travaux, la reconnaissance de la valeur des données partagées (Van den Eynden et Bishop 2014; Van den Eynden et al. 2016), le souhait de ne pas dupliquer l’effort consacré à collecter ou à produire les données (Wallis, Rolando et Borgman 2013), ou encore un taux de citation plus élevé pour les publications dont les données ont été rendues publiques (Piwowar, Day et Fridsma 2007). Des leviers s’ajoutent à ces facteurs de motivation, tels que la culture et les pratiques usuelles dans la communauté de recherche ainsi que l’existence d’infrastructures pour le partage des données et de services d’accompagnement pour la GDR.
Néanmoins, malgré ce contexte, on constate que les compétences des chercheu-r-se-s et les services qui leur sont apportés dans ce domaine ne se développent pas assez vite (Pryor, Jones et Whyte 2014, p.18; Whitmire, Boock et Sutton 2015) et ne répondent pas suffisamment aux besoins (Barone et al. 2017). En particulier, selon l’enquête de Dennie et Guidon (2017), les chercheu-r-se-s de l’Université de Concordia (Montréal) reconnaissent manquer de compétences et d’outils en GDR, avec pour conséquence un frein au partage de leurs données. Une aide pour préparer ses données (Van den Eynden et al. 2016, fig. 16), la maîtrise de compétences en GDR et un support institutionnel (Dennie et Guindon 2017, Sayogo et Pardo 2013) font partie des facteurs incitatifs importants.
Dans ce contexte, pour accompagner leurs chercheu-r-se-s, les institutions de recherche s’appuient sur trois composantes: une politique et un cadre de gouvernance, une infrastructure technique et des outils pertinents pour chaque étape du cycle de vie des données, et des services de soutien et d’accompagnement (Jones 2014, p.89 ; Schirrwagen et al. 2019).
Dans les grandes institutions, ces services sont souvent sous la responsabilité des bibliothèques académiques (Johnson, Butler et Johnston 2012; Akers et Doty 2013 et références données dans l’article ; Cox et Pinfield, 2014 ; Pinfield, Cox et Smith 2014 ; Morgan, Duffield et Walkley 2017). Celles-ci ont un rôle-clé à jouer dans leur développement (Lewis 2010), mais elles doivent aussi impliquer d’autres partenaires de l’institution : les services des technologies de l’information, l’administration de la recherche, les chercheu-r-se-s (Cox et Pinfield 2014 ; Guindon 2013 ; Cox et Verbaan 2018, chap.8), et le département juridique (Dennie et Guindon 2017 ; Vela et Shin 2019).
Ces services incluent des activités de communication et de formation pour le développement des compétences en GDR. Ils peuvent alors prendre la forme de pages institutionnelles sur la GDR (avec des outils de référence, des tutoriels, etc.), de consultations pour un accompagnement plus personnalisé (notamment pour la rédaction du DMP), d’ateliers (Jones, Pryor et Whyte 2013 ; Jones 2014, p.106) et de formations proprement dites.
Evaluer les besoins en formation
Une formation vient combler un écart entre un état initial de connaissances, de maîtrise d’outils, de techniques, de compétences et un niveau cible. Pour la concevoir efficacement, il faut donc évaluer cet état initial et définir le niveau à atteindre.
L’évaluation des besoins de formation en GDR auprès des chercheu-rse-s (2)est souvent réalisée à l’échelle institutionnelle (alors difficilement transposable à une autre institution, Vela et Shin 2019) et à l’aide d’enquêtes (Parham, Bodnar et Fuchs 2012; Dennie et Guindon 2017; Vela et Shin 2019), de focus groups (Perrier et Barnes 2018), d’entretiens (approche choisie pour le projet DLCM(3) : Blumer et Burgi 2015; Burgi, Blumer et Makhlouf-Shabou 2017; Burgi et Blumer 2018), d’ateliers (Pryor, Jones, White 2014, p.65) ou d’une combinaison de ces méthodes (Brown et White 2014, p. 138). Cette collecte d’informations porte sur les pratiques (le niveau de connaissance et de maîtrise des outils et des techniques) (Choudhury 2014, p.127 ; Brown and White 2014, p.138 ; Dennie et Guindon 2017 ; Yu, Deuble et Morgan 2017) et sur les besoins ressentis(4) en outils et services supplémentaires (Parham, Bodnar et Fuchs 2012 ; Parsons 2013 ; Dennie et Guindon 2017 ; Perrier et Barnes 2018 ; Vela et Shin 2019). L’échantillonnage peut être strictement disciplinaire (Vela et Shin 2019) ou multi-disciplinaire (Blumer et Burgi 2015; Van den Eynden et al. 2016 ; Burgi, Blumer et Makhlouf-Shabou 2017 ; Dennie et Guindon 2017 ; Burgi et Blumer 2018 ; Perrier et Barnes 2018); dans ce second cas, la discipline d’appartenance des chercheu-r-se-s approchées est identifiée et les résultats sont traités par discipline.
Pour déterminer les niveaux cibles que la formation doit permettre d’atteindre, il est nécessaire de tenir compte des différents facteurs qui peuvent impacter les pratiques existantes et les besoins : le cadre politique (à l’échelle nationale, européenne, etc.), l’environnement institutionnel (lignes directrices, exigences éventuelles, ressources à disposition, efforts de sensibilisation, etc.), mais aussi la discipline (voir à ce propos l’approche de Wittenberg, Sackmann et Jaffe 2018) et la communauté de recherche. Des normes et une culture spécifiques peuvent en effet induire de grandes différences de niveau en GDR et des pratiques contrastées d’une discipline à l’autre (voir à ce propos les résultats de Akers et Doty, 2013, ceux de Tenopir et al. 2011 et Tenopir et al. 2015 ; et ceux de Van den Eynden et al. 2016, p.54 pour les chercheuses du Wellcome Trust; ainsi que Blumer et Burgi 2015 ; Burgi, Blumer et Makhlouf 2017; Cox et Verbaan 2018, p.79) et parfois au sein même d’une discipline (Frugoli, Etgen and Kuhar 2010). Cela étant dit, certaines préoccupations sont récurrentes dans les disciplines échantillonnées, comme la sécurité des données (Perrier et Barnes 2018). On peut alors imaginer de fournir des ressources génériques sur ces aspects, plus des ressources spécifiques selon le domaine de recherche, la spécialité de recherche ou l’institution (Thielen et Hess 2017). C’est aussi l’approche déjà envisagée pour la formation DLCM, avec des modules de base sur les principes et les méthodes de la GDR et des modules avancés, adaptés aux besoins spécifiques des disciplines ou des institutions (Makhlouf-Shabou 2017).
De même que la discipline, l’”ancienneté” en recherche (étudiant-e-s chercheu-r-se-s vs. chercheu-r-se-s senior par exemple) peut avoir une influence sur les pratiques en GDR (Tenopir et al. 2015 ; Van den Eynden et al. 2016, p.53; Cox et Verbaan 2018, p.88). Il est parfois préconisé d’insérer la formation en GDR dans des programmes académiques de formation et d’intégration déjà existants (étudiant-e-s et étudiant-e-s-chercheu-r-se-s), pour éviter que cette formation ne reste optionnelle et pour qu’elle s’inscrive dans un processus durable. Cette démarche permet à la fois de sensibiliser et de responsabiliser les étudiant-e-s produisant déjà des données, et de faire prendre de bonnes habitudes aux futur-e-s chercheu-r-se-s dès le début de leur carrière (Carlson et Stowell-Bracke 2013 ; Jones 2014, p.107 ; voir aussi les pratiques déjà mises en place et relatées par Thielen et Hess 2017; par Yu, Deuble et Morgan 2017; et par Verhaar et al. 2017). Dans le cadre du projet Open Exeter, les étudiant-e-s-chercheu-r-se-s ont participé à la conception de leur propre programme de formation (Evans et al. 2013). Les cours de base pour étudiant-e-s-chercheu-r-se-s à l’Université de Northumbria (Jones 2014, pp. 107-108) et le programme de formation à l’Université de Monash (Beitz et al. 2014 p.173) ont aussi été développés en partie par les futur-e-s participant-e-s.
L’évaluation des besoins s’intéresse aussi au mode de diffusion que les futur-e-s participant-e-s souhaitent pour les services et la formation (Perrier et Barnes 2018, Vela et Shin 2019): en présentiel (consultations, formations individuelles, ateliers, ...), en ligne (guides, tutoriels, modules de formation, ateliers, ...) ou une combinaison de ces deux modes.
La formation e-learning du projet DLCM doit donc permettre aux chercheu-r-se-s, comme une autre formation en GDR, de développer ou d’acquérir des compétences en GDR et une connaissance des outils, et de favoriser le développement d’une culture de bonnes pratiques en GDR. Comme souligné plus haut, la maîtrise de ces compétences est un levier important pour les chercheu-r-se-s pour s’engager plus dans le partage des données et l’Open Science. Elle leur donne les moyens de faire face au phénomène actuel d’augmentation très importante du volume des données (Big Data), de leur complexité et leur hétérogénéité. Elle leur permet d’être en capacité de répondre aux exigences des organismes financeurs de la recherche et des éditeurs scientifiques (le partage public des données de recherche). Former les chercheu-r-se-s à de bonnes pratiques en GDR est aussi pour une institution de recherche un outil de mise en oeuvre de sa politique institutionnelle d’engagement pour l’Open Science.
Plus spécifiquement, les objectifs de la formation DLCM sont (Makhlouf-Shabou et Krug 2020):
- se familiariser avec la gouvernance des données et saisir les enjeux
- gérer ses données actives
- partager et préserver ses données et choisir les outils les plus appropriés
- maîtriser les aspects légaux et éthiques de la GDR
- rédiger un DMP
Concevoir et évaluer la formation
Il est conseillé de développer une formation d’abord sur une petite échelle (Christensen-Dalsgaard et al. 2012) en testant et en évaluant une version pilote, pour éventuellement en ajuster les méthodes et le contenu, avant de la déployer à plus grande échelle (Thielen et Hess 2017).
Chaque institution doit tenir compte de ses spécificités quand elle développe ses services en GDR, comme mentionné plus haut. Néanmoins, pour la conception d’une formation, elle peut utiliser des ressources génériques adaptables à des contextes particuliers, avec l’avantage de réduire les coûts de conception et de développement. On peut citer le matériel de formation réutilisable produit en 2011 pour des disciplines spécifiques par le projet RDMTrain du Jisc (DCC [sans date]b; JISC [sans date]), d’autres exemples donnés par Jones (2014, p. 107) ainsi que la liste de Jones, Pryor et Whyte (2013) de matériel de formation réutilisable (la majorité étant d’origine britannique).
La participation des chercheu-r-se-s à la conception de la formation, avec leur connaissance approfondie de leur discipline, des normes et pratiques, augmente les chances que la formation soit adaptée, et donc les chances qu’elle soit mieux perçue plus tard et mieux acceptée (voir à ce sujet l’exemple de l’Université de Southampton relatée par Brown et White (2014)).
L’évaluation et la revue régulière de la formation pour sa mise à jour peut être assurée par des pairs. C’est l’approche intéressante relatée par Soyka et al. (2017) pour des modules de formation en GDR. Cette démarche élargit la communauté impliquée qui apporte son expertise. La formation est davantage visible (dans l’expérience de Soyka et al. (2017) en particulier, le code du matériel et des modules est librement accessible sur Github). Enfin, comme la contribution est sur une base volontaire, l’avantage est aussi d’ordre économique.
L’efficacité de la formation peut être évaluée par enquête auprès des participant-e-s (Southall et Scutt 2017 ; Thielen et Hess 2017). Pour évaluer plus précisément son impact sur les pratiques en GDR, on peut tester le niveau de connaissance des participant-e-s à la formation avant et après qu’il-elle-s aient suivi celle-ci; pour les étudiant-e-s obligé-e-s de suivre cette formation, un test montrant leur progression serait un facteur de motivation supplémentaire (Cox et Verbaan 2018).
Le projet DLCM
Le projet DLCM fait partie du programme CUS-P2 2013-2016 de Swissuniversities: “Information scientifique: accès, traitement et sauvegarde” (Swissuniversities [sans date]). Ce programme a pour finalité de concrétiser et de mutualiser les efforts en matière de GDR à l’échelle nationale. DLCM doit fournir les ressources (modèle de politique, infrastructures, outils, services) adaptées à chaque étape du cycle de vie (Burgi 2015) et permettant aux chercheu-r-se-rs académiques suisses d’implémenter de bonnes pratiques de gestion des données de la recherche (Blumer et Burgi 2015 ; Burgi et Blumer 2018). Un portail doit mettre à disposition des informations, des politiques et des guides sur la GDR adaptés au contexte national, ainsi que des ressources externes, tels que des modules de formation (Blumer et Burgi 2015).
Co-dirigé par l’Université de Genève (P.Y. Burgi) et la HEG-Genève (B. Makhlouf-Shabou), le projet s’appuie sur ses autres partenaires : EPFL, ETHZ, SWITCH, Université de Bâle, Université de Lausanne et Université de Zurich, pour atteindre une envergure nationale en prenant en compte la diversité des cultures, et les spécificités des domaines et des disciplines de recherche du milieu académique suisse (Makhlouf-Shabou 2017).
La première phase du projet (09/2015-12/2018) comportait cinq volets d’activités : lignes directrices et politique ; données de recherche actives ; préservation à long terme des données ; consultation, formation et éducation ; dissémination des services au niveau national (Blumer et Burgi 2015 ; Burgi 2015 ; Burgi, Blumer et Makhlouf-Shabou, 2017) pour deux disciplines “pilotes” (humanités numériques et sciences de la vie ; Blumer et Burgi 2015).
La seconde phase du projet (depuis 01/2019 et jusqu’en 12/2020) se concentre sur la définition d’approches et la mise en place d’outils et de services pour la GDR au travers du volet préservation à long terme (avec la nouvelle solution d’archivage Yareta et son instance nationale OLOS respectivement disponibles depuis le 26.06.2019 (Université de Genève 2019) et le 22.10.2020 (DLCM 2019b)); et du volet consultation, formation et éducation.
Dans le cadre de ce second volet, le DLCM Coordination Desk à la HEG-Genève coordonne les ressources et les services disponibles, et répond aux demandes d’information ou les renvoie vers les expert-e-s des partenaires DLCM (Blumer et Burgi 2015, Makhlouf-Shabou 2017). Des modules de formations sont répertoriés et créés (voir à ce propos la liste des formations en présentiel déjà dispensées ou planifiées sur https://www.dlcm.ch/blog), et certains modules sont intégrés dans les cursus d’enseignement pour futur-e-s professionnel-le-s de la GDR (Burgi, Blumer et Makhlouf-Shabou 2017 ; Makhlouf-Shabou 2017 ; Burgi et Blumer 2018). Depuis septembre 2017, le Master of Science HES-SO en Sciences de l’information à la HEG-Genève propose une spécialisation en gouvernance des données qui inclut une partie sur les données de recherche (Makhlouf-Shabou 2017).
Le dispositif d’e-learning qui sera fourni par le DLCM s’inscrit donc dans un ensemble de services en données de recherche. Il est destiné au public-cible précisé dans la littérature DLCM pour répondre à leurs besoins communs: les chercheu-r-se-s et doctorant-e-s en Suisse (Blumer et Burgi 2015; Makhlouf-Shabou 2017).
En tenant compte de ce contexte du projet DLCM, nous identifions des avantages supplémentaires apportés par ce dispositif. Il devrait en effet contribuer à partager les ressources, l’expertise et les bonnes pratiques en GDR; à fédérer les chercheu-r-se-s suisses autour d’une culture nationale en GDR; et à mutualiser les efforts de façon à optimiser les ressources financières.
Recommandations de la littérature et application au contexte DLCM
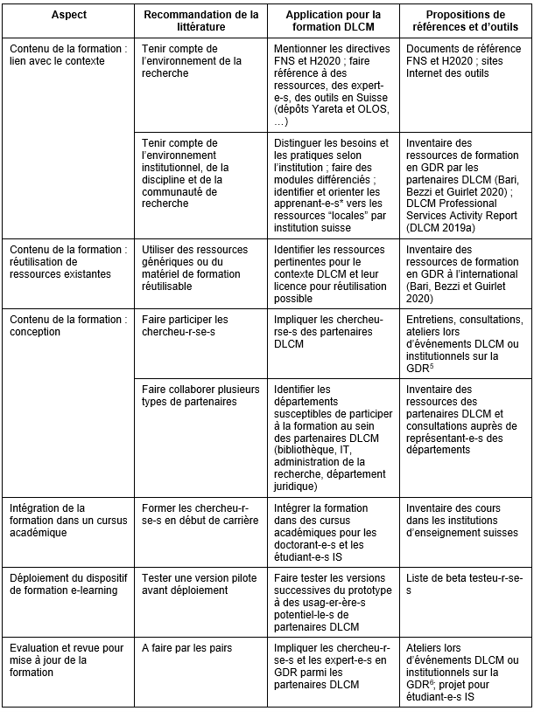
Au terme de cette revue de littérature sur la GDR, sur les formations en GDR et sur le projet DLCM, nous sommes en mesure de formuler des recommandations pertinentes pour la conception d’une formation en GDR par le projet DLCM (Tableau 1).
Tableau 1: Recommandations pour une formation en GDR relevées dans la revue de la littérature et mise en application pour le projet DLCM
E-learning : définition et dispositifs
La Commission Européenne définit l’e-learning comme (Commission Européenne 2001):
« l’utilisation des nouvelles technologies multimédias et de l’Internet, pour améliorer la qualité de l’apprentissage en facilitant l’accès à des ressources et des services, ainsi que les échanges et la collaboration à distance »
A partir de 1990, avec l’avènement d’Internet, les institutions qui possédaient déjà un cursus d’enseignement à distance transforment ce cursus en enseignement en ligne (Benraouane 2011, p. 10). En 2005, l’enseignement en ligne est transformé radicalement avec l’évolution d’Internet qui passe d’un contenu statique (web 1.0) à un contenu dynamique (web 2.0*), ceci permettant de créer, de collaborer et de partager du contenu (Benraouane 2011, p. 13). L’apparition des réseaux sociaux contribue à la création de communautés d’apprenant-e-s (Benraouane 2011, p. 13). L’utilisation de ces réseaux sociaux développe les compétences de collaboration des apprenant-e-s, encourage la communication entre format-eur-rice-s et apprenant-e-s, et cela même hors du cours, et permet à l’apprenant-e de personnaliser son apprentissage en l’incitant à choisir la solution qu’il-elle juge la plus adaptée (Benraouane 2011, p. 15).
L’e-learning a révolutionné le rapport entre format-eur-rice et apprenant-e. D’un contenu et d’un rythme de cours déterminés par le-la format-eur-rice, on est passé à une situation dans laquelle l’apprenant-e agit lui-même ou elle-même sur le contenu de sa formation et sur son rythme d’apprentissage (Prat 2015, pp. 17-18 ; Bourban 2010, p. 5).
L’e-learning doit maintenant s’adapter à différents supports et pratiques (Cristol 2017), selon les nouvelles tendances d’apprentissage en ligne, telles que le mobile learning* (accès à une formation possible depuis plusieurs types de supports en alternance; Prat 2015, pp. 46-51), ou le serious game* et l’adaptative learning*, avec lesquels l’itinéraire pédagogique dépend des actions de l’apprenant-e (Prat 2012, p. 36 ; Lhommeau 2014, p. 130).
On peut distinguer trois types de dispositifs e-learning (MOOC et e-learning, quelles différences ? 2014).
Le cours en ligne fermé* est distribué par une institution et est accessible uniquement aux membres de cette institution. Il est animé par une intervenant-e ou accompagnant-e*. Le parcours peut prévoir des moments synchrones* tels que des “classes virtuelles*”. Le cours en ligne ouvert* est aussi distribué par une institution et est ouvert (sur inscription) aux personnes hors institution, mais n’est pas certifié. Les apprenant-e-s communiquent entre eux-elles (mais pas avec l’apprenant-e) via les outils standards tels qu’un forum. Enfin, les ressources d’apprentissage en ligne comprennent tout type de ressources en ligne permettant aux apprenant-e-s de s’autoformer (tutoriels vidéo ou cours filmés, support de cours écrits, manuels d’apprentissage en ligne, etc.).
Le MOOC (Massive Open Online Course) est un dispositif de formation e-learning se définissant comme une (Pfeiffer 2015, p.52):
« formation accessible à tous, dispensée dans l’Internet par des établissements d’enseignement, des entreprises, des organismes ou des particuliers, qui offre à chacun la possibilité d’évaluer ses connaissances et peut déboucher sur une certification ».
Il se situe entre le cours en ligne ouvert et le cours en ligne fermé dont il reprend plusieurs caractéristiques. Il est gratuit et ouvert sans condition d’accès, et on peut y accéder et le quitter librement à tout moment. Mais il est aussi distribué sur un temps limité et généralement à dates fixes, dans le but de faire interagir entre elles les apprenant-e-s à des fins d’apprentissage (MOOC et e-learning, quelles différences ? 2014).
Le MOOC se décline lui-même en différents types. Avec le xMOOC*, le savoir se transmet de manière verticale de l’enseignant-e à l’apprenant-e (Lhommeau 2014, p.25 ; Daïd et Nguyen 2014, pp.26-28). Avec le cMOOC* (MOOC connectiviste), le savoir se transmet de manière horizontale. Le cours se construit au fil de son avancement grâce aux conversations entre apprenant-e-s et en fonction de leurs choix d’approfondissement (Lhommeau 2014, p.24 ; Daïd et Nguyen 2014, pp.26-28). Le SPOC* (Small Private Online Course), quant à lui, fonctionne sur le même modèle que le xMOOC mais est limité à une cinquantaine d’apprenant-e-s (Daïd et Nguyen 2014, p.177). Ouvert à dates fixes, il implique une interaction soutenue et un accompagnement individuel très poussé. Celui-ci s’appuie sur le suivi du parcours de l’apprenant-e et de ses évaluations. Il se manifeste par des relances en cas de ralentissement de la progression, et une réactivité très forte aux questions d’ordre pédagogique ou technique de l’apprenant-e. Une composante présentielle peut aussi intervenir. Le regroupement ponctuel des apprenant-e-s de la même session permet de travailler en groupe sous la direction de l’enseignant-e et de valider les connaissances (Lhommeau 2014, p.25). Le SPOC se rapproche alors du concept de classe inversée* (Lhommeau 2014, p. 216; Pomerol, Epelboin et Thoury 2014, p. 11, p. 100), avec lequel les apprenant-e-s suivent une formation de type MOOC à distance, puis complètent leur formation avec ces sessions en présentiel (Lhommeau 2014, p. 25).
Le cours hybride (ou blended learning*) utilise à la fois le mode présentiel et le mode à distance. Ce type de cours combine trois dimensions (espace/temps, modalités du dispositif, méthodes) à partir desquelles se décline tout un éventail de possibilités pour l’apprenant-e (Prat 2015, p.62).
Les principaux avantages de l’e-learning sont la flexibilité, l’accessibilité*, la maîtrise des coûts de formation, une réduction de la durée de formation et la souplesse d’apprentissage en termes de lieu et de temps (Benraouane 2011, p.5 ; Prat 2015, pp. 46-47). Toutefois, les coûts de conception et de déploiement d’un dispositif d’e-learning peuvent être conséquents, tout comme les contraintes techniques. Il est également nécessaire de tenir compte des paramètres intrinsèques de l’apprenant-e (ses compétences techniques, son degré d’autonomie, ses motivations et son mode d’organisation). Mais il faut surtout relever que le problème récurrent des formations e-learning, en particulier des MOOC, est leur fort taux d’abandon, aussi appelé taux d’attrition* (Lhommeau 2014, p. 55 ; Prat 2015, pp. 46-51, Cisel 2016), ce taux pouvant aller jusqu’à 80%-90% des inscrit-e-s (MOOCs@Edinburgh Group, 2013; Cisel 2013 ; Pomerol, Epelboin et Thoury 2014, p. 77).
Le challenge consiste donc à trouver un moyen de motiver suffisamment l’apprenant-e, afin qu’il-elle n’abandonne pas sa formation en cours. Ceci peut se faire par la mise en place d’un accompagnement optimal, par une inscription payante ou par un format de cours plus concis (Prat 2015, pp. 46-51 ; Lhommeau 2014, p. 55).
Le Tableau 2 ci-dessous reprend les avantages et inconvénients des dispositifs d’e-learning (Prat 2015, pp. 46-48).
Tableau 2 : Avantages et inconvénients des dispositifs d’e-learning
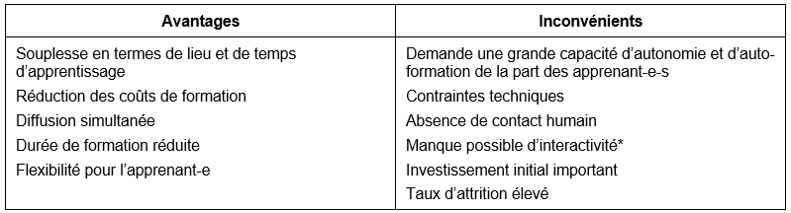
(d'après Prat 2015)
De même que l’apprentissage en présentiel, l’e-learning peut faire recours à différentes stratégies d’enseignement, chacune d’entre elles présentant des avantages et des inconvénients, dont certains sont spécifiques au mode de formation à distance. Ces avantages et inconvénients sont donnés dans le Tableau 3.
Tableau 3 : Avantages et inconvénients des stratégies d’enseignement dans un contexte de formation à distance
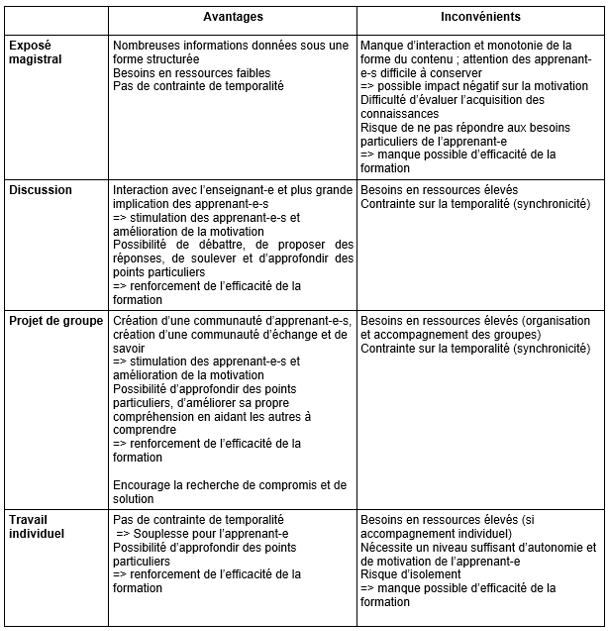
(d’après Comment choisir les stratégies d’enseignement ? [sans date] ; Daïd et Nguyen 2014; Prat 2015; Pomerol, Epelboin et Thoury 2014)
On peut aussi remarquer que, de l’exposé magistral au travail individuel, ces stratégies d’enseignement sont de moins en moins centrées sur l’action de l’enseignant-e et de plus en plus centrées sur l’activité des apprenant-e-s (Comment choisir les stratégies d’enseignement ? [sans date]).
Revue de l’existant des formations et ressources e-learning en GDR
A partir de la littérature et de recherches libres sur internet, nous avons dressé un inventaire des ressources disponibles pour les chercheu-r-se-s pour la GDR. Ces ressources inventoriées, existant sous la forme d’information, de formation ou de matériel de formation, ont été divisées en deux catégories: d’une part les ressources mises à disposition par les partenaires du projet DLCM, et d’autre part celles mises à disposition par d’autres institutions à l’international. Cet inventaire contribue à répondre à trois objectifs. En identifiant les ressources de formation en GDR fournies par les partenaires DLCM, en caractérisant leur nombre, leur type et en dégageant d’autres éléments éventuels, on peut établir un état des lieux de l’activité des différents partenaires dans ce domaine. On peut aussi en déduire un panorama global des activités et une typologie des ressources de formation en GDR. Enfin, en procédant à cet inventaire, on peut identifier précisément les ressources exploitables pour une formation e-learning en GDR pour le projet DLCM, qu’elles soient sous forme de matériel de référence ou de ressources réutilisables.
Le détail de l’inventaire est donné dans Bari, Bezzi et Guirlet (2020). Nous présentons ici nos principales observations à propos de cet inventaire.
Les partenaires DLCM qui fournissent des ressources en ligne sur la GDR sont l’EPFL, l’ETHZ, la HEG-Genève, l’Université de Bâle, l’Université de Genève, l’Université de Lausanne et l’Université de Zurich (seul SWITCH n’en fournit pas). Pour des raisons de faisabilité, l’exploration de la partie GDR des sites des institutions s’est limitée à deux niveaux de profondeur. Cette partie de l’inventaire nous permet de faire les observations suivantes:
- Toutes les institutions proposent des formations en GDR en présentiel, à l’exception de l’Université de Bâle.
- Chaque institution produit les ressources qu'elle fournit, sans mutualiser leur production avec d’autres institutions.
- La responsabilité des ressources de formation en GDR incombe essentiellement à la bibliothèque, ou peut être partagée entre la bibliothèque, le département de la recherche et le département informatique (cas de l’université de Bâle).
- Le projet DLCM, les services et les ressources qu’il fournit (“Coordination Desk”(9) et “Data Management Checklist”(10) par exemple) sont très peu mentionnés.
- l’EPFL et l’Université de Genève catégorisent leurs services par profil d’utilisat-eur-rice-s : étudiantes, chercheuses, enseignantes.
- Plusieurs institutions font référence à des expert-e-s et des personnes-clés pour la GDR: l’Université de Lausanne propose des points de contacts par faculté pour les données de la recherche et l’EPFL a instauré sa communauté de « Data Champions ».
Sur la base de ces observations, nous recommandons DLCM d’encourager ses partenaires à mentionner DLCM et ses services de façon plus visible sur leurs pages institutionnelles consacrées à la GDR, à utiliser davantage les ressources procurées par le projet, et à mentionner plus souvent les formations présentielles de DLCM.(9)
Les ressources des institutions ou organismes à l’international (Suisse comprise, mais hors partenaires DLCM) se présentent sous forme de pages web (informations textuelles données sur un site), de documents textuels téléchargeables, de formations en ligne et de supports de formation en présentiel ou en ligne, et de matériel générique spécifiquement conçu pour être réutilisé et adapté à d’autres contextes. Celui-ci est particulièrement intéressant pour une réutilisation possible pour la formation e-learning en GDR de DLCM. Dans un second temps, on pourra aussi réutiliser et adapter certaines ressources dont la licence le permet.
La Figure 2 synthétise le nombre de ressources par pays et leur répartition par catégorie. Dans le cas des formations en ligne, les institutions européennes proposant aussi des ressources, une sous-section « Europe » a été insérée.
Figure 2 : Nombre de ressources par pays et répartition par catégorie ; part des ressources modifiables et non-modifiables pour la Grande-Bretagne et les Etats-Unis
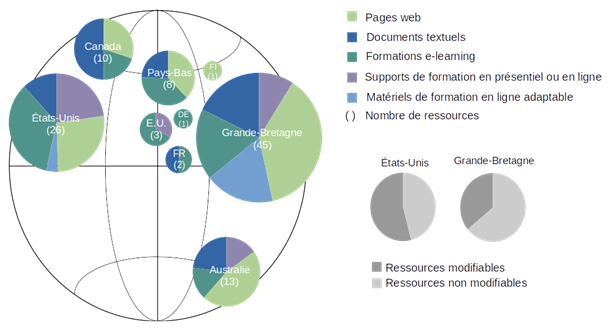
De façon peu surprenante, on observe le rôle très actif en soutien et en formation à la GDR des institutions et organismes de Grande-Bretagne, bénéficiant de la coordination de leurs activités dans ce domaine par le centre d’expertise DCC (Digital Curation Center, DCC [sans date]a) (voir également Fachinotti, Gozzelino et Lonati 2016, p.15). Ceci se traduit par le nombre important de ressources en ligne mises à disposition (quarante-cinq au total) qui se répartissent entre les ressources textuelles, les formations en ligne et les supports de formation. Il est intéressant de noter que ce rôle important de la Grande-Bretagne se reflète aussi dans le matériel de formation adaptable mis à disposition (huit ressources), tel que celui des projets disciplinaires du programme RDMTrain (DCC [sans date]b; JISC [sans date]) et d’autres ressources (Jones, Pryor et Whyte 2013, pp. 9-10) déjà évoquées dans la revue de la littérature.
Les Etats-Unis arrivent en deuxième position (vingt-six ressources au total). Si le nombre de supports de formation qu’ils fournissent est plus important que celui de la Grande-Bretagne (six au lieu de quatre), ils ne proposent qu’une seule ressource de matériel de formation en ligne adaptable (Data Carpentry [sans date]).
En troisième position, l’Australie, soutenue dans ce domaine par le centre d’expertise ANDS (Australian National Data Service [sans date] ; Australian National Data Service 2017 ; Dennie et Guindon 2017), met à disposition treize ressources au total. Parmi celles-ci on a très peu de formations en ligne et de matériel de formation en ligne, et aucun matériel de formation adaptable.
Pour la Grande-Bretagne et les Etats-Unis, on a distingué le nombre de ressources modifiables et le nombre de ressources non modifiables selon leur licence (voir Figure 2). Dans les deux cas, une partie significative des ressources (seize de Grande-Bretagne, quatorze des Etats-Unis) pourra être réutilisée et adaptée au contexte spécifique du projet DLCM.
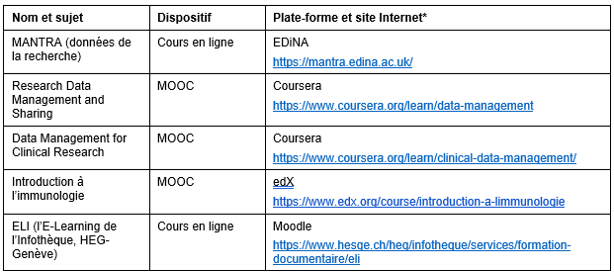
Le second volet de notre revue de l’existant a consisté en une analyse du point de vue d’apprenant-e-s de cinq formations en ligne hébergées par différentes plateformes (Tableau 4), dans l’objectif d’observer des bonnes pratiques et d’en déduire des recommandations pour la formation DLCM.
Chaque formation en ligne a été caractérisée suivant des critères portant sur la formation en général, sur son contenu et sa structure, sur les conditions d’accès, l’interaction (apprenant-e-s, format-eur-rice), l’évaluation de l’apprenant-e- et les aspects légaux. Les descriptions complètes suivant notre grille d’analyse sont données dans Bari, Bezzi et Guirlet (2020).
Tableau 4 : Formations sélectionnées pour les études de cas
Nos principales observations portent sur les points suivants :
Forme du contenu: l’absence de contenu animé (cas de “Data Management for Clinical Research“) rend le suivi plus difficile. On cerne ici l’importance d’avoir un bon équilibre des types de contenu : texte sur des diapositives, images, vidéos, activités interactives afin de maintenir l’attention et la stimulation des participant-e-s. Pour MANTRA et “Research Data Management and Sharing” sur Coursera, les interviews et témoignages de chercheu-r-se-s sur leurs pratiques permettent vraiment d’ancrer la formation dans le réel et de rendre le sujet plus vivant.
Lien du contenu avec le contexte local: pour MANTRA et “Research Data Management and Sharing”, une grande place est donnée au contexte de l’institution ou du pays (politiques, directives, guides, outils de l’Université d’Edimbourg ; financements de la recherche aux Etats-Unis). On voit l’importance d’ancrer une formation en GDR dans le contexte local ; il faut tenir compte des contraintes de l’environnement (politique, institutionnel), tout en rendant la formation pertinente et utile au plus grand nombre.
Liens entre formations et complémentarité: MANTRA renvoie vers le MOOC ”Research Data Management and Sharing” les apprenant-e-s qui veulent bénéficier d’une certification. ELI informe les apprenant-e-s qu’ils-elles peuvent bénéficier d’une formation personnalisée et en présentiel de la part de l’infothèque. Ce sont deux exemples de formations qui reconnaissent l’utilité et la complémentarité d’autres ressources, qu’elles soient en e-learning ou en présentiel.
Adaptabilité* du parcours (personnalisation): seule MANTRA redirige les participant-e-s vers des modules différents selon leur profil, professionnel-le de l’information, chercheu-r-se, doctorant-e, pour une personnalisation du parcours d’apprentissage. Le questionnaire proposé en préalable à ELI permet d’établir son profil documentaire et d’évaluer en fin de formation sa progression, mais celui-ci n’est pas utilisé pour individualiser le parcours d’apprentissage.
Appréciation de la formation par les apprenant-e-s: toutes les formations étudiées ici permettent aux participant-e-s d’envoyer leur appréciation sur le cours, et d’éventuellement lui attribuer une évaluation (sous forme de note ou sous forme d’un nombre d’étoiles pour les MOOC Coursera). Pour les MOOC Coursera, cette appréciation, présentée comme un moyen d’améliorer la formation, est aussi utilisée pour la promotion du cours faite sur la page d’accueil.
Avantages de l’environnement des plates-formes MOOC: les formations délivrées sur Coursera et edX bénéficient évidemment de tous les avantages procurés par l’environnement de la plate-forme. Le suivi individuel du parcours des apprenant-e-s permet à chacun-e de connaître le temps estimé pour finir la formation, de reprendre là où on s’est arrêté, de recevoir des e-mails de rappels. Coursera et edX proposent également, et c’est là une spécificité importante des MOOC, un environnement propice à l’interaction entre les apprenant-e-s : forum de discussion, hashtag Twitter sur le cours, notation des devoirs par les pairs. C’est une tentative de recréer une communauté, la communauté qui se forme naturellement lors d’une formation en présentiel. Coursera et edX permettent également du mobile learning, répondant ainsi aux nouvelles pratiques des utilisat-eur-rice-s.
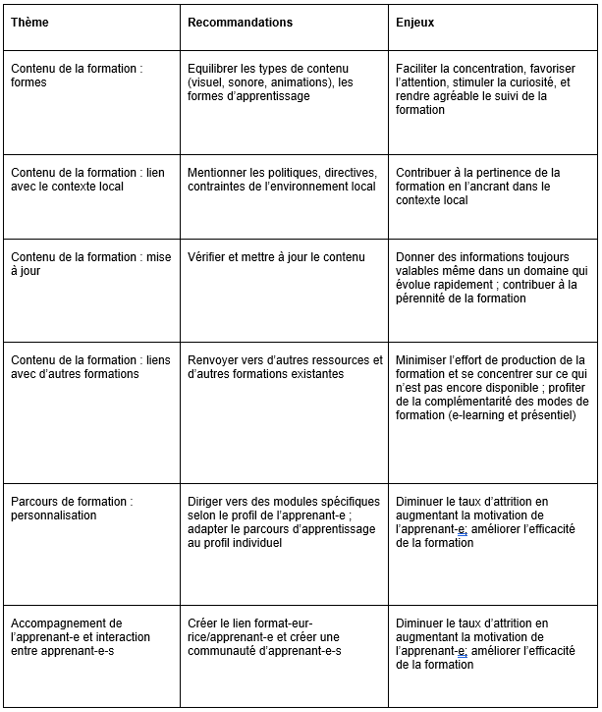
A partir de ces observations nous formulons à nouveau des recommandations pour la formation e-learning de DLCM (Tableau 5).
Tableau 5 : Recommandations déduites des études de cas pour la formation e-learning de DLCM
Conception de la formation DLCM
En ce qui concerne la conception elle-même de la formation e-learning, plusieurs auteur-e-s recommandent de suivre une démarche projet (Prat 2015, pp. 74-78 ; Pomerol, Epelboin et Thoury 2014, pp. 21-57). Nous discutons ici de quelques aspects-clés de cette démarche: les besoins du public-cible, l’implication des apprenant-e-s et des partenaires DLCM, les modalités des formations e-learning.
Besoins du public-cible
Pour rappel, le public-cible de la formation DLCM est constitué des chercheu-r-se-s et des doctorant-e-s d’une institution académique suisse, que cette institution soit partenaire ou non de DLCM. Plusieurs outils sont à disposition pour cibler précisément les besoins du public-cible de la formation et rendre celle-ci plus efficace. Les enquêtes sur l’évaluation des besoins pour le projet DLCM ont été déjà mentionnées dans la partie sur la revue de la littérature (Blumer et Burgi 2015; Burgi, Blumer et Makhlouf-Shabou 2017; Burgi et Blumer 2018), et une première typologie des besoins (profils des utilisat-eur-rice-s, zone linguistique, discipline, sujet) a été établie à partir de l’analyse des requêtes reçues par le Coordination Desk du DLCM (DLCM 2019a). Nous suggérons de poursuivre cette démarche pour enrichir cette typologie. Nous suggérons également de répertorier et d’analyser les interrogations récurrentes durant les formations en présentiel données par DLCM (DLCM 2019c). Par ailleurs, comme nous l’avons vu avec notre inventaire, les partenaires DLCM sont eux aussi déjà fortement engagés dans la formation à la GDR et leur expérience dans ce domaine peut certainement contribuer à cibler les besoins spécifiques des futures apprenant-e-s.
Implication des apprenant-e-s
Si les auteur-e-s ne s’accordent pas tous-tes à impliquer les apprenant-e-s dans le projet de conception de la formation (Benraouane 2011, p.41 ; Prat 2015, pp. 80-84 ; Pomerol, Epelboin et Thoury 2014, pp. 24-31), la réussite du projet nous semble indissociable de leur participation. C’est pourquoi nous recommandons de les intégrer au projet (futur-e-s, présent-e-s et ancien-ne-s apprenant-e-s), dès la phase d’analyse du projet, sur les aspects et avec les contributions détaillés dans le Tableau 6.
Tableau 6 : Contributions possibles par les apprenant-e-s à la conception et à la maintenance de la formation.
|
Gestion de projet |
Identifier les départements (bibliothèque, IT, administration de la recherche, département juridique) et les personnes-clés susceptibles d’être impliquées dans l’équipe projet |
|
Contenu de la formation |
Identifier les besoins des futures apprenant-e-s |
|
Contribuer à la création de contenu en fonction de ses compétences et en fonction des disciplines pour les modules avancés |
|
|
Contribuer à la traduction des cours et des ressources dans les différentes langues nationales |
|
|
Revoir et mettre à jour le contenu |
|
|
Communication – visibilité à l’externe |
Prendre part à la communication sur la formation |
|
Communication – valorisation à l’interne |
Mentionner la formation DLCM sur le catalogue de formations de l’institution |
|
Inciter les bibliothécaires de l’institution à informer sur la formation DLCM et à l’utiliser |
|
|
Inclure la formation DLCM dans un cursus académique de l’institution |
Les contributions et les suggestions des apprenant-e-s peuvent être récoltées à l’aide d’ateliers en groupe, d’entretiens individuels ou de questionnaires.
Implication des partenaires DLCM
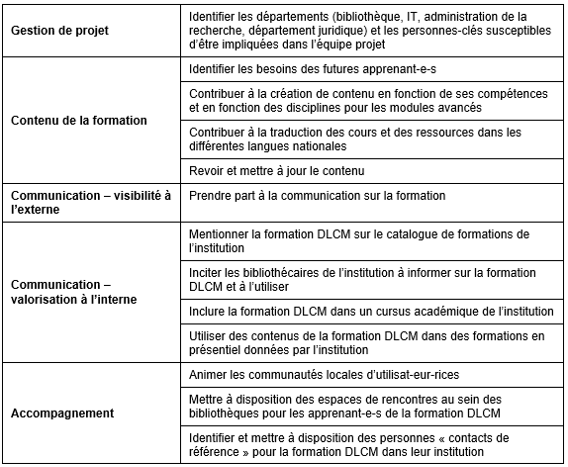
L’ambition du DLCM est de proposer une formation au niveau national. Pour ce faire, nous encourageons fortement à faire participer davantage ses partenaires à ce projet de formation. Le Tableau 7 décrit leurs possibles contributions qui pourraient favoriser la réussite et l’efficacité de la formation.
Tableau 7 : Contributions possibles par les partenaires DLCM
Modalités des formations e-learning
Une formation e-learning peut se décliner selon de multiples modalités: tout à distance ou hybride (blended learning), inscription payante ou pas, interactivité ou pas et types d’interaction, délivrance d’un certificat ou pas, etc. Pour chaque aspect, l’équipe projet doit faire un choix parmi ces modalités au moment de l’analyse des besoins, en fonction de critères liés au public-cible et aux besoins des utilisat-eur-rice-s, aux ressources du projet, etc.
L’éventail complet des modalités possibles pour les différents aspects caractérisant une formation e-learning est présenté sur la Figure 3 et discuté en détail par Bari, Bezzi et Guirlet (2020). Nous présentons ici une sélection des plus pertinentes d’entre elles pour le choix de dispositifs adaptés au contexte DLCM.
Figure 3 : Modalités de formations e-learning pour différents aspects
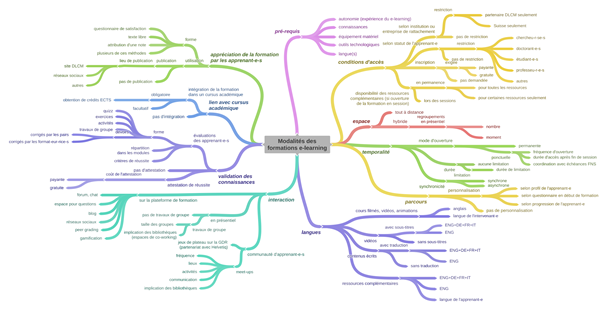
Conditions d’accès
En théorie, l’accès à la formation peut être ouvert ou restreint. Dans ce second cas, les restrictions peuvent s’appliquer en fonction de l’institution d’affiliation de l’apprenant-e (partenaire ou non de DLCM), et du statut de l’apprenant-e (chercheu-r-se ou doctorant-e, ou autre, e.g. étudiant-e ou professeur-e), et l’inscription peut être rendue obligatoire ou pas. De même, on peut mettre à disposition de manière permanente des ressources complémentaires fournies avec la formation ou uniquement une partie d’entre elles, ou au contraire décider qu’elles ne seront accessibles que durant les sessions de formation.
La composante nationale étant primordiale pour DLCM, il faudrait que cette formation soit accessible a minima à la communauté scientifique suisse, par le biais d’une authentification avec une adresse e-mail d’une institution suisse. Concernant l’accès aux ressources complémentaires, donner accès de manière permanente à certaines ressources inciterait les apprenant-e-s à utiliser le site de DLCM comme source première de formation en GDR et permettrait de fidéliser cette communauté d’apprenant-e-s. Cela simplifierait aussi le travail des institutions qui pourraient directement référencer les ressources de DLCM plutôt que de créer les leurs, avec l’avantage du point de vue de DLCM d’augmenter la visibilité de ces ressources. Ouvrir la formation à un public plus large (par exemple les étudiant-e-s et les professeur-e-s, ou encore les professionnel-le-s de l’information) permettrait aussi d’augmenter les chances de la formation d’être utilisée.
Temporalité
Deux aspects sont à considérer pour la temporalité : l’ouverture de la formation et sa durée. La formation est accessible soit en permanence soit à des périodes déterminées. La durée de la formation peut également être illimitée ou restreinte (à un certain nombre de semaines par exemple). Dans le cas d’une formation à dates et à durée fixes, la méthode synchrone (Prat 2015, p. 64) propose de surcroît une interaction directe : la formation est donnée en temps réel sous forme d’une classe virtuelle où sont “rassemblé-e-s” intervenant-e-s et apprenant-e-s.
Une ouverture permanente de la formation a l’avantage de ne pas contraindre le public à un calendrier imposé, mais peut toutefois rendre la formation moins attrayante. Sachant qu’il-elle pourra s’y inscrire à n’importe quel moment, l’apprenant-e pourrait être tenté-e de repousser le moment de concrétiser cette formation. Le plan de communication devra être pensé en conséquence. L’absence de contrainte sur la date de fin de formation entraîne aussi le risque pour l’apprenant-e de ne pas être assez incité-e à terminer la formation.
Interaction
Plusieurs formes d’interaction peuvent ponctuer la formation en ligne du DLCM : des outils tels que ceux des plates-formes classiques d’e-learning de type Coursera (forum ou chat entre étudiant-e-s ou d’étudiant-e à accompagnat-eur-rice, réseaux sociaux, etc.), le peer grading* ou la gamification*. Dans notre cas, vues la dimension nationale du projet et la proximité géographique entre apprenant-e-s et format-eur-rice-s sur le territoire suisse, il nous semble tout à fait envisageable qu’une partie de cet accompagnement se fasse en mode présentiel, au moyen de travaux de groupes et de rencontres plus informelles, propices à créer une communauté locale d’apprenant-e-s. Des meet-ups* (opportunément appelés “DLCM” pour “Data Literacy Coffee Meet-ups”) pourraient avoir lieu dans différentes régions et dans différentes langues en fonction des apprenant-e-s inscrit-e-s. Ces différentes activités seraient initiées par le DLCM qui se chargerait de communiquer sur ces évènements et de proposer des lieux de rencontre. Sur le modèle des Learning Hubs(10), les bibliothèques académiques pourraient fournir des espaces de co-working et de discussion autour de la formation.
Validation des connaissances, certificat de réussite
Des évaluations en cours de formation permettent de faire des retours à l’apprenant-e sur ses progrès et de ce fait, d’entretenir sa motivation. C’est aussi un moyen de solliciter sa participation avec des activités interactives, des quizz, des exercices, des devoirs (le peer grading renforce aussi l’interaction entre apprenant-e-s), parfois des jeux.
Dans le cas de l’adaptative learning, ces évaluations intermédiaires fournissent les informations pour adapter le parcours d’apprentissage au fur et à mesure. Dans tous les cas, elles seront aussi utilisées après les sessions pour s’assurer que la formation est efficace et pour éventuellement l’améliorer. Pour ces différentes raisons, il est important de les répartir régulièrement tout au long du parcours.
L’évaluation finale, seule ou combinée avec les évaluations intermédiaires, en cas de bons résultats selon les critères fixés par les format-eur-rice-s, peut conduire à une attestation ou un certificat de réussite de la formation. On peut choisir de faire payer ce certificat à l’apprenant-e, sur le modèle actuel des plates-formes de MOOC les plus importantes.
Présentation de trois options de dispositifs e-learning en GDR pour la formation DLCM
Afin de proposer des types de dispositifs pertinents, nous identifions trois profils-types parmi le public-cible et, en fonction de leurs besoins spécifiques, nous suggérons trois dispositifs pour la formation e-learning DLCM selon les scénarii présentés ci-dessous et sur la Figure 4.
Scénario 1 : un SPOC, une formation très encadrée et créditée pour les doctorant-e-s
Dans ce premier scénario, une université exige de ses doctorant-e-s qu’il-elle-s suivent une formation e-learning en GDR dans le cadre de leur cursus académique(11) et leur octroie des crédits en cas de réussite. L’objectif est à la fois de sensibiliser à la GDR, de responsabiliser et de faire prendre de bonnes habitudes aux doctorant-e-s dès le début de leur carrière (Carlson et Stowell-Bracke 2013 ; Jones 2014, p.107). L’intégration de la formation dans le cursus académique s’accompagne aussi d’une reconnaissance de sa qualité. Cette intégration rend la formation plus visible, évite qu’elle ne reste optionnelle et assure sa pérennité. Et pour l’université, elle est un outil utile pour la mise en pratique de sa politique de formation en GDR. Dans le contexte DLCM, ce dispositif pourrait être étendu aux étudiant-e-s de Bachelor et de Master qui produisent des données avec leurs travaux, et pour les former avant le début d’un doctorat éventuel.
Nous recommandons dans ce cas une formation sous forme de SPOC (Figure 4, cas de Malala Y.). Comme mentionné plus haut, ce dispositif est très exigeant en termes de ressources, du fait de la préparation, de l’accompagnement et de l’interaction plus poussés.
Scénario 2 : un MOOC en GDR pour chercheu-r-se-s
Prenons maintenant le cas d’un-e chercheu-r-se qui souhaite acquérir des compétences solides en GDR et intégrer de bonnes pratiques dans son quotidien professionnel. Cette personne sait qu’elle dispose de pré-requis techniques et de connaissances suffisants pour se former de façon autonome. Elle apprécie la souplesse de l’e-learning tout en bénéficiant d’un cadre temporel fixé et d’outils d’accompagnement en ligne pour aller au terme de sa formation.
Le MOOC, ouvert à tout public et sur inscription, et qui se déroule lors de sessions à durée fixe, est le dispositif le plus adapté (Figure 4, cas de Svetlana A.). L’apprenant-e y bénéficie d’un environnement propice à l’interaction avec l’accès possible à un forum, à un espace de chat et à des réseaux sociaux. Grâce au suivi par la plate-forme de son parcours d’apprentissage, cette personne est informée du temps nécessaire pour finir sa formation, et reçoit des e-mails de relance si elle ne se connecte pas régulièrement à la formation. En cas de réussite, elle peut recevoir un certificat payant. Le niveau de ressources engagées est ici plus faible que celui du SPOC, du fait d’un accompagnement moins poussé.
Scénario 3 : des ressources en libre accès pour des besoins ponctuels
Dans un contexte de changement très rapide du domaine de la GDR, il est tout à fait vraisemblable qu’un-e chercheu-r-se, ayant des connaissances préalables en GDR, ait ponctuellement besoin de mettre à jour ses connaissances, de vérifier une information ou de trouver un outil (document-type de DMP par exemple, dépôt de données le plus adapté, etc.) à différentes étapes d’un projet ou de sa carrière.
Nous préconisons dans ce cas d’utiliser une formation libre (Figure 4, cas de Françoise B.-S.), de type MANTRA (Rice 2014, MANTRA 2018), comme une base de ressources, ouverte à tout moment et à tout type de chercheu-r-se. L’apprenant-e n’y bénéficie d’aucun accompagnement ni d’aucune interaction avec les autres apprenant-e-s et ne reçoit pas de certification (son parcours individuel n’est pas suivi et les éventuelles activités ne sont pas utilisées pour une évaluation finale; elles servent seulement à stimuler sa motivation). Les ressources engagées sont moins importantes que pour les deux autres dispositifs. Elles sont essentiellement utilisées pour mettre en place la formation et la mettre à jour régulièrement.
Figure 4 : Proposition de dispositifs e-learning pour trois profils-types

Compte tenu du contexte du projet DLCM, nous identifions d’autres avantages spécifiques à ce dispositif de formation libre.
Dans le cadre du volet consultation, formation et éducation de sa deuxième phase, DLCM organise régulièrement des formations en présentiel (DLCM 2019c). Avec notre inventaire des formations et des ressources e-learning en GDR des partenaires DLCM, nous avons observé l’importance des activités de formation en présentiel par ces partenaires, sous la forme de consultations individuelles, et d’ateliers et de cours (Bari, Bezzi et Guirlet 2020).
Un accès sans condition aux ressources de la formation e-learning permettrait d’utiliser ou de rediriger les apprenant-e-s vers celle-ci à différents stades des formations en présentiel (Figure 5). Avant la formation en présentiel, ces ressources en accès libre servent pour la préparation des participant-e-s (on retrouve alors une approche de classe inversée) (Lhommeau 2014, p. 216; Pomerol, Epelboin et Thoury 2014, p. 11, p. 100). Pendant son déroulement, la projection de vidéos ou la réutilisation d’activités faisant partie de ces ressources e-learning viennent soutenir la formation en présentiel. Enfin, après la formation en présentiel, des modules ou des séquences spécifiques permettent un approfondissement de certains aspects par les participant-e-s. Ainsi utilisée, et vraisemblablement plus référencée dans les catalogues de formation des institutions, la formation e-learning DLCM deviendrait plus visible. Cette formation libre, ou base de ressources communes, dans un esprit d’ouverture et de partage, pourrait même inclure des ressources clés en main, adaptables au contexte de chaque institution, de façon similaire au matériel de formation réutilisable produit par le projet RDMTrain du Jisc (DCC [sans date]b ; JISC [sans date]). Ce fonctionnement aussi lui donnerait plus de visibilité et lui garantirait une meilleure pérennité (du fait de sa plus forte utilisation).
Inversement, on peut imaginer orienter les apprenant-e-s de cette formation e-learning libre, selon leurs intérêts et leur localisation, vers les formations en présentiel de DLCM ou de ses partenaires (Figure 5). Ce qui contribuerait là encore à recréer une communauté d’apprenant-e-s et à tirer bénéfice au maximum des deux types d’apprentissage, en présentiel et à distance.
Figure 5 : Proposition de fonctionnement couplé entre les formations en présentiel de DLCM et de ses partenaires et la formation e-learning de DLCM
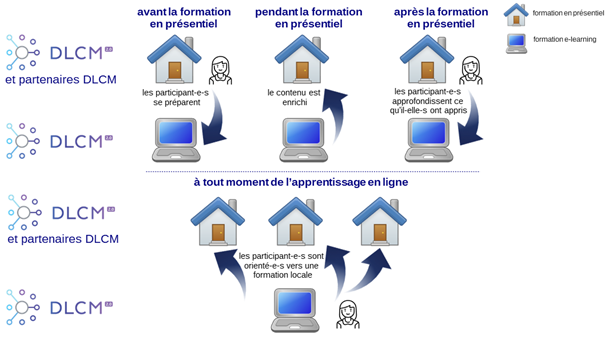
Les deux parties, DLCM et ses partenaires, ont toutes deux à gagner de ces échanges. Les partenaires profitent de ressources toutes faites, fiables car mises à jour régulièrement, et adaptées au contexte national. La formation e-learning peut faire partie de leurs outils de mise en œuvre de leur politique institutionnelle d’engagement vers l’Open Science. Participer au projet de formation e-learning de DLCM leur offre également l’opportunité de jouer un rôle actif dans la formation à la GDR à l’échelle nationale.
De son côté, la formation DLCM, en combinant formation e-learning et composante présentielle, tire avantage des bénéfices de ces deux types d’approches : la souplesse de l’e-learning et la stimulation apportée par les contacts humains. Cette complémentarité est efficace pour amoindrir le taux d’attrition couramment très élevé en e-learning. En s’appuyant sur les formations en présentiel déjà existantes au sein de DLCM et en impliquant ses partenaires, cette démarche aura en outre l’avantage de renforcer l’attractivité et le rayonnement de la formation e-learning. Et le lien entre DLCM et ses partenaires en sera d’autant plus renforcé.
Enfin, ce fonctionnement en synergie des deux parties contribuerait effectivement à remplir les trois objectifs de la formation identifiés plus haut: partager les ressources en formation à la GDR déjà existantes, fédérer autour d’une culture nationale en GDR et mutualiser les efforts pour optimiser les ressources financières.
Conclusion
Au terme de ce travail, les objectifs identifiés ont été atteints et des réponses aux questions de recherche ont été apportées. A partir de la revue de la littérature et de la revue de l’existant, nous avons établi la typologie des formations e-learning en GDR, dressé un panorama des ressources en GDR par les partenaires DLCM et à l’international, identifié des ressources réutilisables et émis des recommandations pour la formation future du DLCM. Nous avons discuté des aspects-clé pour la conception de la formation DLCM, en tenant compte des spécificités du contexte du projet. Nous avons suggéré des contributions possibles à la formation pour les partenaires DLCM. En tenant compte aussi des particularités des catégories de public-cible pour cette formation, nous avons proposé trois options de dispositifs adaptés : un SPOC, un MOOC et une formation libre. Nous avons discuté plus en détail les avantages spécifiques que la formation libre apporte au projet et à ses partenaires. Celle-ci favorise en effet le renforcement du lien entre partenaires DLCM, le partage de ressources et d’expertise en formation à la GDR, la construction d’une culture nationale en GDR, la mutualisation des efforts et l’efficacité de la formation en amoindrissant son risque d’attrition.
La seconde phase de DLCM devant se terminer d’ici peu (à la fin de l’année 2020), et compte tenu des évolutions rapides dans le domaine de la GDR, il nous semble important de réfléchir à plus long terme sur la pérennité de la formation. Au cours de ce travail, nous avons évoqué à plusieurs reprises des pistes pouvant contribuer à assurer cette pérennité : assurer des mises à jour et une maintenance régulières, encourager son utilisation, l’ouvrir à un large public, l’intégrer dans un cursus académique. Le domaine de l’e-learning se caractérisant par un fort dynamisme, nous encourageons également DLCM à se tourner le plus possible pour sa formation vers des outils innovants, de façon à être en mesure de répondre aux nouvelles attentes des apprenant-e-s en e-learning : mobile learning, microlearning*, adaptative learning, ou dispositif intelligent qui collecterait des informations mises à jour sur le web, ... Ceci permettrait de continuer à placer l’apprenant-e au centre de la démarche projet, quel que soit le dispositif, et de rendre la formation, toujours et encore, la plus efficace possible.
Notes
(1)Les termes définis dans le glossaire sont marqués d’un astérisque lors de leur première apparition dans le texte.
(2)Voir à ce propos la revue de la littérature donnée dans Dennie et Guindon (2017).
(3)La typologie des besoins est aussi évaluée à partir de l’analyse des requêtes reçues par le DLCM (profils des utilisat-eur-rice-s, zone linguistique, discipline, sujet) (voir DLCM 2019a pour le premier semestre de l’année 2019).
(4)Les pratiques et les besoins peuvent aussi être évalués en consultant les DMP produits par les chercheu-r-se-s de l’institution (voir par exemple Choudhury 2014, p.127 pour le Johns Hopkins University Data Management Services).
(5)Par exemple, lors d’un Swiss Research Data Day (DLCM 2019b) ou d’une Journée Open Science Day à l’EPFL (EPFL 2019)
(6)Par exemple, lors d’un Swiss Research Data Day (DLCM 2019b) ou d’une Journée Open Science Day à l’EPFL (EPFL 2019)
(7)https://www.dlcm.ch/services/dlcm-training
(8)https://www.dlcm.ch/resources/dlcm-training
(9)https://www.dlcm.ch/resources/dlcm-dmp
(10)« ces lieux de rencontre dédiés aux MOOC et localisés dans des bibliothèques, des consulats, ou autres lieux publics », lancés par la plate-forme Coursera (Cisel 2018).
(11)comme déjà appliqué par certaines universités, tel que présenté plus haut.
Glossaire
Accompagnant-e : voir accompagnement
Accessibilité : dans le cas des normes des modules pédagogiques et selon Prat (2011, p. 35), “capacité de repérer des composantes pédagogiques à partir d’un site distant, d’y accéder et de les distribuer à d’autres sites”.
Accompagnement (pédagogique, technique), fonctions (services) d’accompagnement (des formations e-learning) : selon Prat (2010, p. 290), “tâches, missions, compétences que les formateurs (tuteurs, coachs) mettent en oeuvre pour la conduite des formations à distance: contact direct, coordination, support technique, animation de forum, suivi pédagogique, évaluation …”. Ces tâches sont assurées par la ou les format-eur-rice-s e-learning et par la ou les tut-eur-rice-s (ou coachs). Nous ne faisons pas de distinction entre ces termes pour ce qui concerne ces tâches d’accompagnement et employons à la place le terme “accompagnant-e”. Pour plus de détails sur les rôles de l’accompagnant-e, on peut consulter Prat (2010, pp. 212-213) et Pomerol, Ebelpoin et Thoury (2014, p. 130).
Adaptabilité : dans le cas des normes des modules pédagogiques et selon Prat (2011, p. 35), “capacité à personnaliser l’enseignement en fonction des besoins définis pour les apprenants”.
Adaptative learning : le parcours d’apprentissage des apprenant-e-s est adapté en temps réel par des algorithmes à partir du suivi des actions de l’apprenant-e (Lhommeau 2014 p.130).
Apprenant-e : selon Prat (2010, p. 290), “personne engagée et active dans un processus d’acquisition ou de perfectionnement des connaissances et de leur mise en oeuvre (AFNOR)”.
Blended learning (ou cours hybride): terme anglais désignant un parcours alternant formation à distance et face à face pédagogique (présentiel) (Prat 2012, p.293)
Classe inversée : selon Lhommeau (2014, p. 216), “méthode pédagogique visant à donner des cours magistraux sur l’Internet et à réserver le présentiel pour de l’échange et de la mise en pratique”. On parle aussi de flipped pedagogy ou flipped classrooms: cours mis à disposition des élèves pour que ceux-ci puissent les préparer chez eux (Pomerol, Epelboin et Thoury 2014, p. 11) et temps avec l’enseignant-e consacré à un dialogue approfondi (Pomerol, Epelboin et Thoury 2014, p. 100).
Classe virtuelle : selon Prat (2010, p. 292), “désigne la simulation d’une classe réelle. Elle permet de réunir en temps réel sur Internet ou un réseau, des participants et un formateur qui peuvent notamment discuter, se voir, visionner des documents, des vidéos, réaliser des quizz, partager leur écran.”
Cours en ligne fermé : distribué par un organisme de formation ou un établissement d'enseignement, destiné à un groupe d'apprenant-e-s régulièrement inscrit-e-s et ayant donc acquitté des droits d'inscription, distribué sur une plate-forme (Learning Management System ou LMS), dispensé seul ou dans le cadre d'un parcours de formation, diplômant ou pas. Ce cours est généralement animé par une enseignant-e ou un-e tut-eur-rice qui assure la communication avec les participant-e-s et peut aussi animer des temps de formation en direct (appelés "synchrones"). Il comprend des ressources de contenus (i.e. la partie "cours"), des activités d'apprentissage (i.e. des exercices à faire, des épreuves d'évaluation...) et un espace d'interaction (généralement un forum) qui permet aux participant-e-s d'interagir entre elles et avec les animat-eur-rice-s du cours (MOOC et e-learning, quelles différences ? 2014).
Cours en ligne ouvert : distribué par un organisme de formation ou un établissement d'enseignement, destiné à toutes celles qui veulent s'autoformer sur un sujet qui les intéresse, généralement distribué sur une plate-forme, non diplômant. Ce cours n'est pas tutoré, l'apprenant-e doit suivre son parcours seul-e. A côté des ressources de "cours" proprement dites, on trouve dans ces cours quelques exercices à correction automatique tels que des quiz, qui permettent à l'apprenant-e d'évaluer sa compréhension. Ces cours ouverts ne comprennent généralement pas d'espace d'interaction, puisqu'ils ne sont pas suivis par des groupes constitués, mais par des personnes qui les suivent à titre individuel, quand bon leur semble. Ils ne comprennent pas non plus de temps de formation synchrones (MOOC et e-learning, quelles différences ? 2014).
Dispositif de formation : selon Prat (2010, p. 291), “ensemble des moyens techniques, logistiques et humains organisés dans le temps et dans l’espace pour répondre à la demande du commanditaire pour la formation d’une population précise.”
DLCM : DLCM est l’acronyme de l’expression Data Life-Cycle Management (qu’on pourrait traduire par “gestion des données tout au long de leur cycle de vie”) et désigne également le projet lancé en 2015 par huit institutions suisses1. Dans ce document, DLCM est utilisé exclusivement pour désigner ce projet.
Données de recherche : de nombreuses définitions sont disponibles dans la littérature ainsi que sur les pages Web des institutions sur la GDR (voir le document liste de ressources). Pour une définition intentionnellement inclusive, on peut consulter le guide ANDS : What is research data (Australian National Data Service 2017). On peut aussi se référer à la définition du Conseil de recherches en sciences humaines (CRSH, Canada) citée par Guindon (2013). Nous utilisons ici la définition de l’OCDE, qui nous paraît la plus pertinente pour le contexte de ce projet (OCDE 2007, p.18) :
« Enregistrements factuels (chiffres, textes, images et sons), qui sont utilisés comme sources principales pour la recherche scientifique et sont généralement reconnus par la communauté scientifique comme nécessaires pour valider des résultats de recherche ».
E-learning : la Commission Européenne (2001) définit l’e-learning comme « l’utilisation des nouvelles technologies multimédias et de l’Internet, pour améliorer la qualité de l’apprentissage en facilitant l’accès à des ressources et des services, ainsi que les échanges et la collaboration à distance ».
Formation : en reprenant la définition de training donnée dans Makhlouf-Shabou (2017), on peut définir une formation comme le processus d’apprentissage permettant à une personne d’acquérir les connaissances et les compétences nécessaires à l’exercice de son activité professionnelle. Ce processus peut aussi permettre l’approfondissement des connaissances et l’amélioration de la maîtrise de compétences.
Gamification : selon Lhommeau (2014, p. 57), “réutilisation de mécaniques de jeu dans un autre contexte afin de faciliter l’appropriation d’un sujet chez n’importe quel individu”.
Gestion des données de recherche (notée GDR) ou Research Data Management : nous sélectionnons deux types de définitions qui nous semblent complémentaires dans leur perspective:
● sous la perspective des activités, et en lien avec le cycle de vie, selon Cox et Verbaan (2018, p.4): [Research Data Management] “is about creating, finding, organising, storing, sharing and preserving data within any research process”; et selon Whyte and Tedds (2011): “Research data management concerns ‘the organisation of data, from its entry to the research cycle through to the dissemination and archiving of valuable results’’
● sous la perspective des finalités, selon le site Open research Data de l’Université de Lausanne (2019) : “cette gestion s'avère indispensable et cruciale à de multiples égards:
- elle assure la conformité avec le cadre légal et réglementaire tout comme les exigences des bailleurs de fonds et éditeurs scientifiques
- elle garantit l’authenticité, l’intégrité, la fiabilité et l’exploitabilité des données ;
- elle en facilite la reproductibilité, le partage et la réutilisation ;
- enfin elle rend davantage visibles les travaux et résultats de recherche et participe à la qualité de celle-ci“
Interactivité : selon Prat (2010, p. 292): “activité impliquant plusieurs personnes ou système dont le comportement s’ajuste suite à une action réalisée par l’un d’entre eux”.
Meet-up : selon Lhommeau (2014, p. 128), “se dit d’une soirée de réseautage social, centrée, pour les participants, sur un centre d’intérêts communs. La rencontre découle d’une mise en relation électronique en amont, initiée depuis une communauté virtuelle”. Les internautes se rassemblent physiquement dans leurs régions ou leurs villes respectives pour discuter et échanger autour de la formation (Pomerol, Epelboin et Thoury 2014, p. 76).
Microlearning : selon Wikipédia (Microlearning, 2018), "modalité de formation ou apprentissage en séquence courte de 30 secondes à 3 minutes, utilisant texte, images et sons."..." Comme technologie servant à l'instruction, le microlearning cible la création d'activités de micro-apprentissage à travers de très courtes étapes utilisant des environnements multimédias. Ces activités peuvent facilement être incluses dans la routine quotidienne de l'élève. À l'opposé des approches plus traditionnelles d'apprentissage, le microlearning utilise souvent la méthode du push (où l'élève déclenche par lui-même le processus au moment désiré)."
Mobile learning : selon Prat (2015, p. 356): “l’apprenant s’abonne à un contenu audio, il l’écoute ensuite quand et où il veut. Ce format de contenu peut être lu sur n’importe quel PC ou lecteur MP3.” Le contenu pédagogique s’adapte pour permettre à l’apprenant-e de suivre le MOOC tout le temps, où que cette personne soit, quel que soit le temps qu’elle ait à disposition (Lhommeau 2014, p. 131).
MOOC (Massive Open Online Course) : cours diffusé sur Internet, libre d’accès (aucun prérequis n’est nécessaire) et disponible à un nombre illimité d’apprenant-e-s (pas de limitation physique) (Université de Genève; Pomerol, Epelboin et Thoury 2014, p. 7). En français CLOM (Cours en Ligne Ouvert et Massif)
xMOOC (dit également “MOOC instructiviste” (Lhommeau 2014, p. 219)) : le savoir se transmet de manière verticale de l’enseignant-e à l’apprenant-e (Lhommeau 2014, p.25 ; Daïd et Nguyen 2014, pp. 26-28).
cMOOC (dit également “MOOC connectiviste” (Lhommeau 2014, p. 216)) : MOOC dont le savoir se transmet de manière horizontale. Le cours se construit au fil de son avancement grâce aux conversations entre apprenant-e-s et en fonction de leurs choix d’approfondissement (Lhommeau 2014, p.24 ; Daïd et Nguyen 2014, pp. 26-28; Pomerol, Epelboin et Thoury 2014, p. 15).
Peer grading ou peer assessment : correction par les pairs
Plate-forme (pour dispositif de formation e-learning, le plus souvent MOOC) : selon Pomerol, Epelboin et Thoury (2014, p. 124), elle se constitue de “l’ensemble du logiciel “éditeur” et du matériel “serveur” accompagné d’un logiciel de service (répondre aux questions, forum, gestion des inscriptions, des relations avec les maîtres statistiques, etc.).”
RDM (ou Research Data Management) : voir GDR
Serious game : selon Prat 2012 (p. 297), “jeu vidéo à visée pédagogique dans lequel le joueur, en accomplissant ses missions de jeu, vit une expérience unique qu’il transforme en une véritable expertise au fur et à mesure de ses victoires successives”.
SPOC (Small Private Online Course) : cours fonctionnant sur le même modèle que le xMOOC, mais est limité à une cinquantaine d’apprenant-e-s (Daïd et Nguyen 2014, p.177).
Synchrone (outils de communication) : selon Prat (2015, p. 357): “les questions et les réponses se font en direct, en temps réel, sans décalage temporel entre question et réponse. Une formation est dite synchrone lorsque les apprenants peuvent se connecter simultanément à un module et communiquer en temps réel” (voir aussi “classe virtuelle”).
Taux d’attrition : Pourcentage des inscrit-e-s à une formation en e-learning qui n’obtiennent pas de certificat (les non-certifié-e-s) ou qui abandonnent la formation en cours de cursus (Cisel 2017).
Web 2.0 : l’ensemble des technologies et des usages du Web permettant aux internautes d’être actif-ve-s sur le contenu et la structuration des pages Web (exemple: wikis, blogs, Web social…) (Prat 2012, p.298).
Bibliographie
AKERS, Katherine G. et DOTY, Jennifer, 2013. Disciplinary differences in faculty research data management practices and perspectives. In : International Journal of Digital Curation. 19.11.2013. Vol. 8, n° 2, p. 5-26. DOI : 10.2218/ijdc.v8i2.263
Australian National Data Service (ANDS), 2017. What is research data. ands.org.au [en ligne]. 11.01.2017. [Consulté le 03.11.2020]. Disponible à l’adresse : https://www.ands.org.au/guides/what-is-research-data
Australian National Data Service (ANDS), [sans date]. What we do. ands.org.au [en ligne]. [Consulté le 03.11.2020]. Disponible à l’adresse: https://www.ands.org.au/about-us/what-we-do
BARI, Manon, BEZZI, Manuela, GUIRLET, Marielle, 2020. Formation et éducation en gestion des données de recherche du point de vue du projet DLCM: dispositifs d’e-learning [en ligne]. 19.01.2020. [Consulté le 01.11.2020]. Disponible à l’adresse : http://doc.rero.ch/record/328462
BARONE, Lindsay, WILLIAMS, Jason et MICKLOS, David, 2017. Unmet needs for analyzing biological big data: A survey of 704 NSF principal investigators. In : OUELLETTE, Francis (éd.), PLOS Computational Biology. 19.10.2017. Vol. 13, n° 10, p. e1005755. DOI : 10.1371/journal.pcbi.1005755
BEITZ, Anthony, GROENEWEGEN, David, HARBOE-REE Cathrine, MACMILLAN Wilna, SEARLE, Sam, 2014. Case study 3: Monash University, a strategic approach. In: PRYOR, Graham, JONES, Sarah, WHYTE, Angus. Delivering Research Data Management Practices, fundamentals of good practice. facet publishing, pp. 163-189. ISBN 978-1-85604-933-7
BENRAOUANE, Sid Ahmed, 2011. Guide pratique du e-learning: Statégie, pédagogie et conception avec le logiciel Moodle [en ligne]. Paris : Dunod. [Consulté le 03.11.2020]. Fonctions de l’entreprise. Formation. ISBN 978-2-10-055786-8. Disponible à l’adresse : http://hesge.scholarvox.com/book/88800754 [accès par abonnement]
BLUMER, Eliane et BURGI, Pierre-Yves, 2015. Data Life-Cycle Management Project: SUC P2 2015-2018. Revue électronique suisse de science de l’information [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : http://www.ressi.ch/num16/article_110
BOURBAN, Alexandre, 2010. Elaboration d’une démarche d’évaluation de modules elearning de recherche à l’Organisation mondiale de la santé [en ligne]. Mémoire de bachelor : Haute école de gestion de Genève ; TDB 2112. [Consulté le 01.11.2020]. Disponible à l’adresse : http://doc.rero.ch/record/20932/files/TDB_2112.pdf
BROWN, Mark. L., WHITE, Wendy. 2014. Case study 2: University of Southampton – a partnership approach to research data management. In: PRYOR, Graham, JONES, Sarah, WHYTE, Angus. Delivering Research Data Management Practices, fundamentals of good practice. facet publishing, pp. 135-161. ISBN 978-1-85604-933-7
BURGI, Pierre-Yves, 2015. Data Life-Cycle Management: The Swiss Way. Bulletin / Académie suisse des sciences humaines et sociales. Vol. 4, pp. 48-50
BURGI, Pierre-Yves, BLUMER, Eliane et MAKHLOUF-SHABOU, Basma, 2017. Research data management in Switzerland: National efforts to guarantee the sustainability of research outputs. IFLA Journal. 01/2017. pp. 1-17
BURGI, Pierre-Yves et BLUMER, Eliane, 2018. Le projet DLCM : gestion du cycle de vie des données de recherche en Suisse. In : Alice Keller & Susanne Uhl. Bibliotheken der Schweiz: Innovation durch Kooperation. Festschrift für Susanna Bliggenstorfer anlässlich ihres Rücktrittes als Direktorin der Zentralbibliothek Zürich. Berlin : De Gruyter, pp. 235-249. ISBN 978-3-11-055379-6
CARLSON, Jake et STOWELL-BRACKE, Marianne, 2013. Data Management and Sharing from the Perspective of Graduate Students: An Examination of the Culture and Practice at the Water Quality Field Station. In : portal: Libraries and the Academy. 2013. Vol. 13, n° 4, pp. 343-361. DOI : 10.1353/pla.2013.0034
CHOUDHURY, G. Sayeed, 2014. Case study 1: Johns Hopkins University Data Management Services. In: PRYOR, Graham, JONES, Sarah, WHYTE, Angus. Delivering Research Data Management Practices, fundamentals of good practice. facet publishing, pp. 114-133. ISBN 978-1-85604-933-7
CHRISTENSEN-DALSGAARD, Birte, BERG, Marc, GRIM, Rob, HORTSMANN, Wolfram, JANSEN, Dafne, POLLARD, Tom et ROOS, Annikki, 2012. Ten Recommendations for Libraries to Get Started with Research Data Management: Final Report of the LIBER Working Group on E-Science / Research Data Management [en ligne]. S.l. Ligue des Bibliothèques Européennes de Recherche (LIBER). [Consulté le 01.11.2020]. Disponible à l’adresse : https://libereurope.eu/wp-content/uploads/The%20research%20data%20group%202012%20v7%20final.pdf
CISEL, Matthieu, 2013. La révolution MOOC [en ligne]. 01.06.2013. [Consulté le 01.11.2020]. Disponible à l’adresse: http://blog.educpros.fr/matthieu-cisel/2013/06/01/mooc-ce-que-les-taux-dabandon-signifient/
CISEL, Matthieu, 2016. Utilisations des MOOC : éléments de typologie [en ligne]. Paris: Université Paris-Saclay. Thèse de doctorat. [Consulté le 01.11.2020]. Disponible à l’adresse : https://tel.archives-ouvertes.fr/tel-01444125/document
CISEL, Matthieu, 2017. Une analyse de l’utilisation des vidéos pédagogiques des MOOC par les non-certifiés. Sticef [en ligne]. vol. 24, numéro 2. [Consulté le 04.11.2020]. Disponible à l’adresse : https://www.persee.fr/doc/stice_1764-7223_2017_num_24_2_1744
CISEL, Matthieu, 2018. Interactions entre utilisateurs de MOOC : quelques propositions. La révolution MOOC [en ligne]. 09.01.2018. [Consulté le 04.11.2020]. Disponible à l’adresse: http://blog.educpros.fr/matthieu-cisel/2018/01/09/interactions-entre-utilisateurs-de-mooc-quelques-propositions/#more-5852
COMMISSION EUROPEENNE, 2001. e-Learning – Penser l’éducation de demain [archive], Communication de la Commission au conseil et au parlement européen ; 28 mars 2001 Bruxelles, COM(2001)172 final, page 2. [Consulté le 01.11.2020]. Disponible à l’adresse : http://www.oidel.org/doc/Education/E-learning/E-Learning_penser%20l%27education.pdf
Comment choisir les stratégies d’enseignement ? [sans date]. profinnovant.com [en ligne]. [Consulté le 20.11.2020]. Disponible à l’adresse : https://www.profinnovant.com/choisir-strategies-denseignement/
COX, Andrew M. et PINFIELD, Stephen, 2014. Research data management and libraries: Current activities and future priorities. In: Journal of Librarianship and Information Science. décembre 2014. Vol. 46, n° 4, pp. 299-316. DOI: 10.1177/0961000613492542
COX, Andrew M. et VERBAAN, Eddy, 2018. Exploring research data management. London : Facet Publishing. ISBN 978-1-78330-279-6
CRISTOL, Dennis, 2017. Le mobile learning en pratique [en ligne]. 12.06.2017. [Consulté le 01.11.2020]. Disponible à l’adresse : https://cursus.edu/articles/37303/le-mobile-learning-en-pratique#.XXF5hHs6_IU
DAÏD, Gilles et NGUYEN, Pascal, 2014. Guide pratique des MOOC [en ligne]. éd. Eyrolles. [Consulté le 04.11.2020]. Disponible à l’adresse : https://hesge.scholarvox.com/catalog/search/searchterm/Guide%20pratique%20des%20MOOC?searchtype=title [accès par abonnement]
DATA CARPENTRY, [sans date]. Data Carpentry. Building communities teaching universal data literacy. datacarpentry.org. [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse: https://datacarpentry.org/
DCC, [sans date]a. About the DCC. dcc.ac.uk [en ligne]. [Consulté le 04.11.2020]. Disponible à l’adresse: http://www.dcc.ac.uk/about
DCC, [sans date]b. Disciplinary RDM Training. dcc.ac.uk [en ligne]. [Consulté le 02.11.2020]. Disponible à l’adresse : https://www.dcc.ac.uk/news/disciplinary-rdm-training-materials
DENNIE, Danielle et GUINDON, Alex, 2017. Résultats d’une enquête sur les pratiques et attitudes des chercheurs de l’Université Concordia en matière de gestion des données de recherche. In : Documentation et bibliothèques. 2017. Vol. 63, n° 4, p. 59. DOI : 10.7202/1042311ar
DLCM, 2019a. Professional Services Activity Report, Semester 1, 2019 (1.1.2019-30.6.2019). 2019. Document interne au projet DLCM
DLCM, 2019b. SWISS RESEARCH DATA DAY 2020. dlcm.ch [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : https://www.dlcm.ch/swiss-research-data-day-2020
DLCM, 2019c. Training & Consulting. dlcm.ch [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : https://www.dlcm.ch/services/dlcm-training
EPFL, 2019. Open Science Day. epfl.ch [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : https://www.epfl.ch/campus/events/celebration-en/open-science-day/
EUROPEAN COMMISSION, DIRECTORATE-GENERAL FOR RESEARCH & INNOVATION, 2016. H2020 Programme - Guidelines on FAIR Data Management in Horizon 2020 [en ligne]. [Consulté le 04.11.2020]. Disponible à l’adresse : https://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-data-mgt_en.pdf
EUROPEAN COMMISSION, 2017. H2020 programme: guidelines to the rules on open access to scientific publications and open access to research data in Horizon 2020. European Commission [en ligne]. 21.03.2017. [Consulté le 01.11.2020]. Disponible à l’adresse : http://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-pilot-guide_en.pdf
EVANS, Jill, LLOYD-JONES, Hannah, COLE, Gareth, 2013. Final report on the Open Exeter project to Jisc. 09.07.2013. [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : https://ore.exeter.ac.uk/repository/handle/10871/14845
FACHINOTTI, Elena, GOZZELINO, Eva et LONATI, Sara, 2016. Les bibliothèques scientifiques et les données de la recherche : défis et enjeux [en ligne]. Genève : Haute École de Gestion Genève. Mémoire de recherche. [Consulté le 01.11.2020]. Disponible à l’adresse : http://doc.rero.ch/record/258991
FNS, 2017. Open Research Data : les requêtes devront inclure un plan de gestion des données. FNS [en ligne]. 6 mars 2017. [Consulté le 01.11.2020]. Disponible à l’adresse : http://www.snf.ch/fr/pointrecherche/newsroom/Pages/news-170306-open-research-data-bientot-une-realite.aspx
FRUGOLI, Julia, ETGEN, Anne M. et KUHAR, Michael, 2010. Developing and Communicating Responsible Data Management Policies to Trainees and Colleagues. In : Science and Engineering Ethics. Décembre 2010. Vol. 16, n° 4, pp. 753-762. DOI : 10.1007/s11948-010-9219-1
GUINDON, Alex, 2013. La gestion des données de recherche en bibliothèque universitaire. In : Documentation et bibliothèques. 2013. Vol. 59, n° 4, p. 189. DOI : 10.7202/1019216ar
HIGGINS, Sarah, 2008. The DCC Curation Lifecycle Model. In : The International Journal of Digital Curation [en ligne]. juin 2008. [Consulté le 01.11.2020]. Disponible à l’adresse : http://www.ijdc.net/article/view/69
JISC, [sans date]. Research data management training materials (RDMTrain). The national archives. UK Government Web Archive. [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse: https://webarchive.nationalarchives.gov.uk/20140702195402/http://www.jisc.ac.uk/whatwedo/programmes/~/link.aspx?_id=677B9C0D0E8F4B12A7E2ACC86FD9D736&_z=z
JOHNSON, Layne M., BUTLER, John T. et JOHNSTON, Lisa R., 2012. Developing E-Science and Research Services and Support at the University of Minnesota Health Sciences Libraries. In: Journal of Library Administration. Novembre 2012. Vol. 52, n° 8, pp. 754-769. DOI : 10.1080/01930826.2012.751291
JONES, Sarah, PRYOR, Graham et WHYTE, Angus, 2013. How to Develop Research Data Management Services - a guide for HEIs. DCC How-to Guides [en ligne]. Edinburgh: Digital Curation Centre. [Consulté le 01.11.2020]. Disponible à l’adresse: http://www.dcc.ac.uk/resources/how-guides/how-develop-rdm-services
JONES, Sarah, 2014. The range and components of RDM infrastructure and services. In: PRYOR, Graham, JONES, Sarah, WHYTER, Angus (éd.). Delivering Research Data Management Practices, fundamentals of good practice. London: Facet Publishing, pp. 89-114. ISBN 978-1-85604-933-7
KRUSE, Filip et THESTRUP, Jesper Boserup (éd.), 2018. Research data management: a [an] European perspective. Berlin: De Gruyter Saur. Current topics in library and information practice. ISBN 978-3-11-036944-1
LEWIS, Martin, 2010. Libraries and the management of research data. In: MCKNIGHT, Sue (éd.). Envisioning Future Academic Library Services. London: Facet Publishing, pp. 145-168. ISBN 978-1-85604-691-6
LHOMMEAU, Clément, 2014. MOOC : l’apprentissage à l’épreuve du numérique. Éd. Fyp. ISBN 978-2-36405-112-6
MAKHLOUF-SHABOU, Basma, 2017. Training, consulting and teaching for sustainable approach for developing research data life-cycle management expertise in Switzerland. In: INFuture2017 Integrating ICT in Society, Zagreb, 8-10 Novembre 2017. Department of Information and Communication Sciences, Faculty of Humanities and Social Sciences, University of Zagreb, Croatia, pp. 79-86
MAKHLOUF-SHABOU, Basma et KRUG, Silas, 2020. DLCM’s MOOC : Bring your questions & pick up your answers. In : Swiss Research Data Day 2020, Geneva, HEG/HES-SO, 22.10.2020 [en ligne]. [Consulté le 20.11.2020]. Disponible à l’adresse : https://www.dlcm.ch/swiss-research-data-day-2020/presentations
MANTRA, 2018. About MANTRA. MANTRA Research Data Management Training [en ligne]. 05.2018. [Consulté le 01.11.2020]. Disponible à l’adresse : https://mantra.edina.ac.uk/about.html
MICROLEARNING. Wikipédia : l’encyclopédie libre [en ligne]. Dernière modification de la page le 23 novembre 2018 à 15:24. [Consulté le 04.11.2020]. Disponible à l’adresse : http://fr.wikipedia.org/w/index.php?title=Microlearning&oldid=154194722
MOOCs@Edinburgh Group, 2013. MOOCs @ Edinburgh 2013: Report #1. [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : https://era.ed.ac.uk/handle/1842/6683
MOOC et e-learning, quelles différences ? Thot Cursus : formation et culture numérique [en ligne]. Publié le 15.04.2014. Mis à jour le 09.05.2014 [Consulté le 01.11.2020]. Disponible à l’adresse: https://cursus.edu/articles/27809/mooc-et-e-learning-quelles-differences#.XWjsBXskzIV
MORGAN, Ann, DUFFIELD, Nel et WALKLEY HALL, Liz, 2017. Research Data Management Support: Sharing Our Experience. Journal of the Australian Library and Information Association, Vol. 66, Issue 3, pp. 299-305, DOI: 10.1080/24750158.2017.1371911
NATURE, 2016. Data availability statements and data citations policy: Guidance for authors. Nature [en ligne]. 09/2016. [Consulté le 01.11.2020]. Disponible à l’adresse: http://www.nature.com/authors/policies/data/data-availability-statements-data-citations.pdf
OCDE, 2007. Principes et lignes directrices de l’OCDE pour l’accès aux données de la recherche financée sur fonds publics. [en ligne]. [Consulté le 04.11.2020]. Disponible à l’adresse : http://www.oecd.org/fr/sti/inno/38500823.pdf
PARHAM, Susan Wells, BODNAR, Jon et FUCHS, Sara, 2012. Supporting tomorrow’s research: Assessing faculty data curation needs at Georgia Tech. In : College & Research Libraries News. 01.01.2012. Vol. 73, n° 1, pp. 10-13. DOI: 10.5860/crln.73.1.8686
PARSONS, Thomas, 2013. Creating a Research Data Management Service. International Journal of Digital Curation. 19.11.2013. Vol. 8, n° 2, pp. 146-156. DOI : 10.2218/ijdc.v8i2.279
PERRIER, Laure et BARNES, Leslie, 2018. Developing Research Data Management Services and Support for Researchers: A Mixed Methods Study. In : Partnership: The Canadian Journal of Library and Information Practice and Research [en ligne]. 08.05.2018. Vol. 13, n° 1. [Consulté le 01.11.2020]. DOI : 10.21083/partnership.v13i1.4115. Disponible à l’adresse : https://journal.lib.uoguelph.ca/index.php/perj/article/view/4115
PFEIFFER, Laetitia, 2015. MOOC, COOC : la formation professionnelle à l’ère du digital. Paris : Dunod. Fonctions de l’entreprise. ISBN : 978-2-10-072467-3
PINFIELD, Stephen, COX, Andrew M. et SMITH, Jen, 2014. Research Data Management and Libraries: Relationships, Activities, Drivers and Influences. In : LAUNOIS, Pascal (éd.), PLoS ONE. 08.12.2014. Vol. 9, n° 12, p. e114734. DOI: 10.1371/journal.pone.0114734.
PIWOWAR, Heather A., DAY, Roger S. et FRIDSMA, Douglas B., 2007. Sharing Detailed Research Data Is Associated with Increased Citation Rate. In : IOANNIDIS, John (éd.), PLoS ONE. 21.03.2007. Vol. 2, n° 3, p. e308. DOI : 10.1371/journal.pone.0000308
PLOS ONE, 2019. Data availability. PLOS [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : http://journals.plos.org/plosone/s/data-availability
POMEROL, Jean-Charles, EPELBOIN, Yves et THOURY, Claire. 2014. Les MOOC : conception, usages et modèles économiques. Dunod. ISBN : 978-210-071283-0
PRAT, Marie, 2010. E-learning : Réussir un projet : pédagogie, méthode et outils de conception, déploiement, évaluation ... (2ème édition). Edition ENI : St Herblain.Objectif Solutions. ISBN 978-2-7460-5949-8
PRAT, Marie, 2011. E-learning : utiliser les outils Web 2.0 pour développer un projet. Edition ENI : St Herblain. Objectif Solutions, ISBN 978-2-7460-6118-7
PRAT, Marie, 2012. Les meilleurs outils web 2.0 pour développer un projet e-learning, Edition ENI : St Herblain. Solutions Business, ISBN 978-2-7460-7612-9
PRAT, Marie, 2015. Réussir votre projet Digital Learning. Formation 2.0: les nouvelles modalités d’apprentissage. Edition ENI: St Herblain. Solutions Business, ISBN 978-2-7460-9393-5
PRYOR, Graham, 2012. Why manage research data? Managing Research Data. Londres: Facet Publishing, pp.1-16. ISBN 978-1-85604-756-2
PRYOR, Graham, JONES, Sarah et WHYTE, Angus (éd.), 2014. A patchwork of change. Delivering Research Data Management Services. London: Facet Publishing, 2014, pp.1-19. ISBN 978-1-85604-933-7
RICE, Robin, 2014. Research Data MANTRA: A Labour of Love. Journal of eScience Librarianship [en ligne]. 2014. Vol. 3, n° 1. [Consulté le 01.11.2020]. DOI: 10.7191/jeslib.2014.1056. Disponible à l’adresse : http://escholarship.umassmed.edu/jeslib/vol3/iss1/4/
SAYOGO, Djoko Sigit et PARDO, Theresa A., 2013. Exploring the determinants of scientific data sharing: Understanding the motivation to publish research data. In : Government Information Quarterly. Janvier 2013. Vol. 30, pp. S19-S31. DOI : 10.1016/j.giq.2012.06.011
SCHIRRWAGEN, Jochen, CIMIANO, Philipp, AYER, Vidya, PIETSCH, Christian, WILJES, Cord, VOMPRAS, Johanna et PIEPER, Dirk, 2019. Expanding the Research Data Management Service Portfolio at Bielefeld University According to the Three-pillar Principle Towards Data FAIRness. In: Data Science Journal. 15.01.2019. Vol. 18, p. 6. DOI : 10.5334/dsj-2019-006
SOUTHALL, John et SCUTT, Catherine, 2017. Training for Research Data Management at the Bodleian Libraries: National Contexts and Local Implementation for Researchers and Librarians. In : New Review of Academic Librarianship. 03.07.2017. Vol. 23, n° 2-3, pp. 303-322. DOI : 10.1080/13614533.2017.1318766
SOYKA, Heather, BUDDEN, Amber, HUTCHISON, Viv, BLOOM, David, DUCKLES, Jonah, HODGE, Amy, MAYERNIK, Matthew, POISOT, Timothée, RAUCH, Shannon, STEINHART, Gail, WASSER, Leah, WHITMIRE, Amanda et WRIGHT, Stephanie, 2017. Using Peer Review to Support Development of Community Resources for Research Data Management. In : Journal of eScience Librarianship. 08.09.2017. Vol. 6, n° 2, p. e1114. DOI : 10.7191/jeslib.2017.1114
SPRINGER NATURE, [sans date]. Research Data Policies FAQ. Springer Nature [en ligne]. [Consulté le 04.11.2020]. Disponible à l’adresse : https://www.springernature.com/gp/authors/research-data-policy/data-policy-faqs
SWISSUNIVERSITIES, [sans date]. Projets et programmes - P5-information scientifique: accès, traitement et sauvegarde. swissuniversities.ch [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : https://www.swissuniversities.ch/fr/organisation/projets-et-programmes/p-5/
TENOPIR, Carol, ALLARD, Suzie, DOUGLASS, Kimberly, AYDINOGLU, Arsev Umur, WU, Lei, READ, Eleanor, MANOFF, Maribeth et FRAME, Mike, 2011. Data Sharing by Scientists: Practices and Perceptions. In : NEYLON, Cameron (éd.), PLoS ONE. 29.06.2011. Vol. 6, n° 6, p. e21101. DOI : 10.1371/journal.pone.0021101
TENOPIR, Carol, DALTON, Elizabeth D., ALLARD, Suzie, FRAME, Mike, PJESIVAC, Ivanka, BIRCH, Ben, POLLOCK, Danielle et DORSETT, Kristina, 2015. Changes in Data Sharing and Data Reuse Practices and Perceptions among Scientists Worldwide. In : VAN DEN BESSELAAR, Peter (éd.), PLOS ONE. 26.08.2015. Vol. 10, n° 8, p. e0134826. DOI : 10.1371/journal.pone.0134826
THIELEN, Joanna et HESS, Amanda Nichols, 2017. Advancing Research Data Management in the Social Sciences: Implementing Instruction for Education Graduate Students Into a Doctoral Curriculum. In : Behavioral & Social Sciences Librarian. 02.01.2017. Vol. 36, n° 1, pp. 16-30. DOI : 10.1080/01639269.2017.1387739
TRELOAR, Andrew, GROENEWEGEN, David et HARBOE-REE, Cathrine, 2007.The Data Curation Continuum. Managing Data Objects in Institutional Repositories. D-Lib Magazine [en ligne]. Septembre/Octobre 2007. Vol. 13, Number 9/10 [Consulté le 01.11.2020]. Disponible à l’adresse : http://www.dlib.org/dlib/september07/treloar/09treloar.html
UNIVERSITE DE GENEVE, 2019. Données de recherche. Yareta : Une nouvelle solution numérique pour archiver et partager vos données de recherche. Université de Genève [en ligne]. 14.06.2019. [Consulté le 01.11.2020]. Disponible à l’adresse : https://www.unige.ch/researchdata/fr/actualites/yareta/
UNIVERSITE DE LAUSANNE, 2019. Open research Data. unil.ch [en ligne]. [Consulté le 06.09.2019]. Disponible à l’adresse : https://www.unil.ch/openscience/home/menuinst/open-research-data.html
VAN DEN EYNDEN, Verle et BISHOP, Libby, 2014. Incentives and motivations for sharing research data, a researcher’s perspective. [en ligne]. [Consulté le 01.11.2020]. Knowledge Exchange. Disponible à l’adresse : http://repository.jisc.ac.uk/5662/1/KE_report-incentives-for-sharing-researchdata.pdf
VAN DEN EYNDEN, Verle, KNIGHT, Gareth, VLAD, Anca, RADLER, Barry, TENOPIR, Carol, LEON, David, MANISTA, Franck, WHITWORTH, Jimmy et CORTI Louise, 2016. Survey of Wellcome researchers and their attitudes to open research [en ligne]. [Consulté le 01.11.2020]. DOI : 10.6084/m9.figshare.4055448.v1. Disponible à l’adresse: https://figshare.com/articles/Survey_of_Wellcome_researchers_and_their_attitudes_to_open_research/4055448/1
VELA, Kathryn et SHIN, Nancy, 2019. Establishing a Research Data Management Service on a Health Sciences Campus. Journal of eScience Librarianship. 21.03.2019. Vol. 8, n° 1, p. e1146. DOI : 10.7191/jeslib.2019.1146
VERHAAR, Peter, SCHOOTS, Fieke, SESINK, Laurents et FREDERIKS, Floor, 2017. Fostering Effective Data Management Practices at Leiden University. In : LIBER QUARTERLY. janvier 2017. Vol. 27, n° 1, pp. 1-22. DOI : 10.18352/lq.10185
WALLIS, Jillian C., ROLANDO, Elizabeth et BORGMAN, Christine L., 2013. If We Share Data, Will Anyone Use Them? Data Sharing and Reuse in the Long Tail of Science and Technology. PLoS ONE [en ligne]. 23.07.2013. Vol. 8, n° 7, p. e67332. DOI : 10.1371/journal.pone.0067332. [Consulté le 01.11.2020]. Disponible à l’adresse : https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0067332
WHITMIRE, Amanda L., BOOCK, Michael et SUTTON, Shan C., 2015. Variability in academic research data management practices: Implications for data services development from a faculty survey. In: ANDREW COX, Dr (éd.), electronic library and information systems. septembre 2015. Vol. 49, n° 4, pp. 382-407. DOI : 10.1108/PROG-02-2015-0017
WHYTE, Angus et TEDDS, Jonathan, 2011. Making the Case for Research Data Management. DCC Briefing Papers. Edinburgh : Digital Curation Centre. [en ligne]. [Consulté le 04.11.2019]. Disponible à l’adresse : http://www.dcc.ac.uk/resources/briefing-papers/making-case-rdm
WITTENBERG, Jamie, SACKMANN, Anna et JAFFE, Rick, 2018. Situating Expertise in Practice: Domain-Based Data Management Training for Liaison Librarians. In : The Journal of Academic Librarianship. mai 2018. Vol. 44, n° 3, pp. 323-329. DOI : 10.1016/j.acalib.2018.04.004
YU, Fei, DEUBLE, Rebecca et MORGAN, Helen, 2017. Designing Research Data Management Services Based on the Research Lifecycle – A Consultative Leadership Approach. In : Journal of the Australian Library and Information Association. 14.09.2017. pp. 287-298
- Vous devez vous connecter pour poster des commentaires
Ouverture des données de recherche dans le domaine académique suisse : outils pour le choix d’une stratégie institutionnelle en matière de dépôt de données
Ressi — 18 décembre 2020
Marielle Guirlet, Diplômée du Master en Sciences de l'Information HEG, HES-SO (2020) et assistante de recherche à la HEG-Genève
Résumé
Le contexte actuel de l’Open Science se traduit par des exigences d’ouverture des données de recherche. Le dépôt de données est un instrument crucial pour partager publiquement ces données. Néanmoins, l’offre actuelle pléthorique et très diverse rend la sélection du dépôt difficile pour les chercheurs et les chercheuses. Pour les aider, leurs institutions d’affiliation émettent des recommandations pour le choix du meilleur dépôt. Elles proposent parfois aussi leur propre dépôt de données ou envisagent de le créer.
Cette étude, basée sur un travail de Master en sciences de l’information, s’intéresse à la démarche que les institutions académiques suisses peuvent suivre pour définir leur stratégie de soutien aux chercheurs et aux chercheuses en termes de dépôt. Elle identifie aussi les informations qui vont aider ces institutions à choisir entre orienter ces chercheurs et ces chercheuses vers un dépôt existant (et lequel) et créer un nouveau dépôt, et aux spécifications que ce dépôt doit remplir.
Après avoir défini les concepts des données de recherche et des dépôts ouverts, les fonctionnalités, les outils et les services nécessaires à un dépôt pour mettre en œuvre le partage public de données sont discutés. A partir des critères utilisés par la certification CoreTrustSeal pour évaluer la qualité d’un dépôt, et en tenant compte de ces fonctionnalités, de ces outils et ces services, un modèle de description d’un dépôt de données de recherche ouvertes est élaboré. Ce modèle peut être utilisé pour l’évaluation d’un dépôt existant ou pour la conception d’un nouveau dépôt. Les stratégies de neuf institutions académiques suisses en matière de dépôt de données de recherche, dépôts utilisés et dépôts recommandés, sont analysées. Des recommandations sont formulées, sur la base des bonnes pratiques observées.
Des outils développés pour le choix de la meilleure stratégie en termes de dépôt de données de recherche ouvertes sont alors présentés. Un vade-mecum se présentant comme une liste de questions permet de collecter certaines informations utiles. Un guide décisionnel accompagne l’institution dans sa réflexion et lui permet de choisir sa stratégie de façon éclairée, avec les informations collectées précédemment. Une fois cette stratégie choisie, des informations complémentaires et des recommandations sont disponibles pour sa mise en pratique. Une version prototype de ces outils pour navigateur Internet est aussi présentée. Elle est adaptable à une évolution du contexte et transposable à d’autres pays.
Abstract
The current context of Open Science translates into requirements for the openness of research data. Data repositories are crucial instruments for publicly sharing those data. However, the current plethoric and very diverse offer makes difficult for researchers to select a specific repository. In order to support them, their affiliation institutions make recommendations to select the most fitted repository. They may also sometimes provide their own institutional repository or consider creating one of their own.
This study, based on a Master thesis in information science, looks at the approach that Swiss academic institutions can take to define their strategy for supporting researchers in terms of repositories. It also identifies the information that will help them choose between those options: direct the researchers to an already existing repository - and which one - or create a new repository - with which specifications.
After defining the concepts of open research data and repositories, we investigate the functionalities, the tools and the services needed by a repository for implementing public data sharing. Based on the quality criteria used by CoreTrustSeal certification to assess the quality of a repository, and taking into account those functionalities, tools and services, a model description of open data repositories is set up. This model may be used either for the evaluation of an existing repository or for the design of a new repository. The strategies in terms of data repositories - used repositories and recommended ones - by nine Swiss academic institutions are analyzed. Some strategy recommendations are also formulated based on observed good practices.
Tools developed for the selection of the best strategy in terms of open data repositories are then presented. A reference list of questions (vade-mecum) allows to collect some useful information. A decision-making guide details the process steps to be followed by the institution to fix its strategy. At each step, the selection of a specific path or option is supported by the information collected beforehand. Once the strategy has been chosen, additional information and recommendations to put it up into practice are made available in a companion document. A prototype version of these tools for Internet browsers is also presented. This version may be adapted to take into account some changes in the context as well as the specific cases of other countries.
Mots-Clés:
Open Science,
données de (la) recherche,
dépôt de données de (la) recherche
données de (la) recherche ouvertes,
ouverture des données,
accessibilité et réutilisabilité des données,
partage des données,
préservation des données,
archivage des données,
dépôt institutionnel,
dépôt disciplinaire,
gestion de données de (la) recherche,
research data management,
principes FAIR sur les données,
curation de données,
CoreTrustSeal,
institutions académiques suisses,
recherche suisse,
HEI,
Open Science,
research data,
(research) data repositories,
Open Research Data,
data openness,
data accessibility and reusability,
data sharing,
data preservation,
data archiving,
institutional repository,
disciplinary repository,
research data management,
FAIR principles,
FAIR data,
data curation,
CoreTrustSeal,
Swiss academic institutions,
Swiss research,
HEIs
Nombre de mots:
14200 Ouverture des données de recherche dans le domaine académique suisse : outils pour le choix d’une stratégie institutionnelle en matière de dépôt de données
Introduction
Depuis les années 1990, l’apparition d’Internet permet la mise à disposition en ligne de contenus numériques sans limite matérielle de reproductibilité. L’explosion du volume des données digitales (« data deluge », « digital deluge » ; Pryor 2012 ; Pinfield, Cox et Smith 2014 ; Blumer et Burgi 2015) associée à une augmentation de leur complexité et de leur hétérogénéité pose de nouveaux défis pour leur gestion et leur conservation.
Elle s’accompagne aussi de nouvelles opportunités. Dans le domaine spécifique de la recherche scientifique, le mouvement Open Science pose les bases d’un nouveau fonctionnement de la recherche, basé sur la collaboration. D’abord concentré sur la mise à disposition gratuite et publique des publications scientifiques (la composante Open Access de l’Open Science), il englobe maintenant les autres produits de la recherche, dont les données. Les motivations sous-jacentes de l’ouverture des données sont d’améliorer l’efficacité de la recherche et d’augmenter sa transparence, de faciliter les recherches transdisciplinaires et l’innovation. Elle doit aussi permettre à tout public d’accéder à ce qui a été financé par l’argent public (Foreign Commonwealth Office 2013, Amsterdam Call for Action on Open Science 2016, The Concordat Working Group 2016, Sorbonne declaration on research data rights 2020).
Les chercheurs et les chercheuses peuvent s’engager dans ce mouvement par conviction personnelle. Ils doivent aussi se conformer à des recommandations ou des exigences de la part de leur institution de rattachement, des agences de financement de la recherche ou éventuellement des éditeurs d’articles scientifiques leur demandant de publier leurs données.
Le dépôt de données de recherche (celles-ci sont aussi parfois notées DR dans la suite) est un instrument essentiel de cette démarche. Il permet aux producteurs et productrices de données de partager celles-ci et de les archiver. Il permet à de possibles futurs utilisateurs et utilisatrices de les découvrir et d’y accéder.
Depuis l’ouverture des premiers dépôts (par exemple ICPSR pour les données quantitatives en sciences sociales, ouvert en 1962 (ICPSR [sans date])), de multiples autres dépôts se sont créés. Ils se distinguent par leur finalité principale (donner accès aux données ou préserver les données), la communauté de chercheurs et chercheuses à laquelle ils s’adressent, le fait qu’ils soient rattachés à une institution ou à d’autre formes d’organisations, les technologies sur lesquelles ils s’appuient, ou encore les services qu’ils offrent.
Devant cette diversité, et compte tenu des particularités locales de chaque institution et de ses données de recherche (la discipline de recherche, l’échelle de l’institution, l’existence d’une infrastructure de stockage ou pas), il n’existe pas de dépôt « one size fits all » répondant de manière certaine et exhaustive aux besoins de l’institution. Les chercheurs et les chercheuses, pour répondre correctement aux exigences qui leur sont imposées, peuvent ressentir le besoin d’être conseillé-e-s pour sélectionner le dépôt le plus adapté à leur type de données, à la culture et aux pratiques de leur discipline de recherche. Les institutions, de leur côté, doivent décider d’une stratégie : vers quel(s) dépôt(s) orienter les chercheurs et les chercheuses ? Faut-il créer un nouveau dépôt au risque de multiplier encore les offres possibles ? Faut-il améliorer un dépôt existant ? Quelles fonctionnalités le dépôt doit-il avoir, quels services doit-il proposer ?
Cette problématique a été étudiée en détail dans le cadre d'un travail de Master of Science HES-SO en Sciences de l'information, à la HEG de Genève, Haute Ecole de la HES-SO. Ce travail a été encadré par le Prof. Dr. René Schneider et a été effectué entre mars et août 2020. Ce travail avait pour objectif d’élaborer des outils pour aider les institutions suisses de la recherche publique à définir leur stratégie de soutien aux chercheurs et aux chercheuses pour le partage public de leurs données sur un dépôt. Cet article reprend certains résultats de ce travail, et à ce titre, contient des éléments, des citations et des références du mémoire correspondant (Guirlet 2020).
Après la présentation de la méthodologie et de la démarche, sont ici abordés le contexte de l’Open Science et les exigences posées aux chercheurs et aux chercheuses du milieu académique suisse pour l’ouverture de leurs données de recherche. La partie suivante est consacrée à ce qu’est un dépôt de données de recherche ouvertes, et aux concepts et aux outils importants pour la mise en œuvre de l’ouverture des données sur un dépôt. En prenant aussi en compte des critères d’évaluation de la qualité, une grille de description complète des dépôts de données de recherche ouvertes est alors élaborée. Les principaux résultats de l’étude de la stratégie de neuf institutions académiques suisses, des dépôts qu’elles utilisent et qu’elles recommandent, sont ensuite discutés. Ceci permet de dresser un panorama de ses dépôts de données de recherche ouvertes et d’identifier des bonnes pratiques à partir desquelles sont formulées des recommandations. S’appuyant sur les résultats précédents, les outils proposés aux institutions pour le choix de leur stratégie sont présentés en détail : un vade-mecum permettant le recueil d’informations utiles pour entreprendre la démarche, un guide décisionnel, et des informations complémentaires et des recommandations.
Méthodologie de recherche
Dans un premier temps le travail s’est fait sous forme de recherche théorique, avec la revue de littérature à propos des concepts (données de recherche, dépôts) et des aspects-clés du sujet : le contexte d’ouverture des données de recherche et le rôle des dépôts dans le processus de la recherche. Dans le but de caractériser un dépôt de DR ouvertes et d’élaborer un modèle de description, cette revue de littérature a également couvert les fonctionnalités et les services usuels d’un dépôt, la mise en pratique des services FAIR et les approches d’évaluation de la qualité d’un dépôt.
Lui a succédé une phase de recherche exploratoire et descriptive, pour la revue de l’existant, afin d’identifier et d’analyser les cas à étudier (les institutions académiques et les dépôts utilisés et recommandés). Cette phase s’est appuyée sur la consultation des sites Internet des dépôts et des pages sur la GDR des sites institutionnels.
La troisième phase a englobé la réflexion pour l’analyse et la comparaison de cet existant, la synthèse des résultats et la production des outils décisionnels.
De l’étude théorique à la production des outils finaux, la progression du travail a été jalonnée de plusieurs sous-objectifs associés à des questions de recherche et donnant lieu à des résultats intermédiaires (Tableau 1).
Tableau 1 : Objectifs de recherche, questions de recherche et résultats obtenus
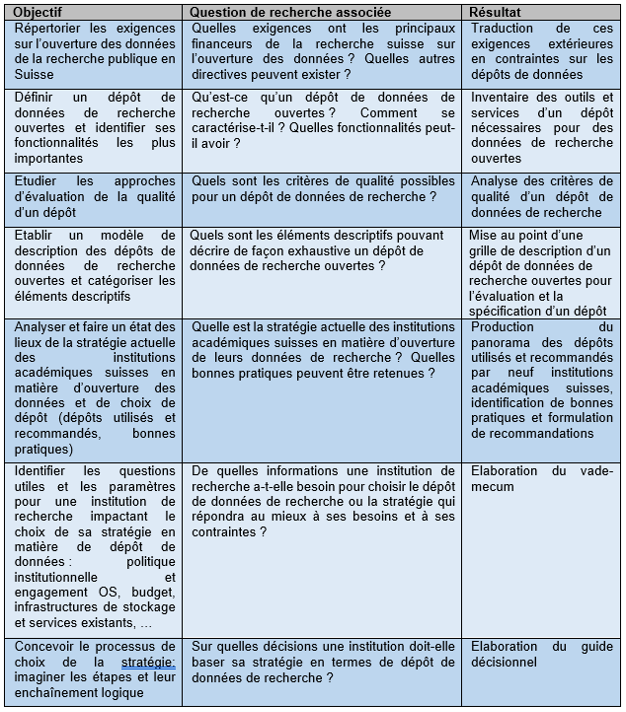
La démarche globale est schématisée sur la Figure 1.
Figure 1 : Schématisation de la démarche
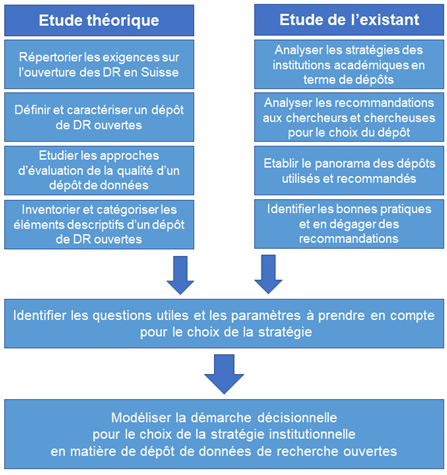
Contexte
Les deux principaux financeurs de la recherche académique suisse, la Commission Européenne et le FNS, imposent des conditions sur les données de recherche des projets qu’ils financent. Dans le cadre du projet pilote ORD Pilot (Open Research Data (ORD) – the uptake in Horizon 2020 2016), pour certaines thématiques de recherche pendant la période 2014-2016, les chercheurs et chercheuses postulant pour le financement de projets de recherche auprès de la Commission Européenne doivent fournir un plan de gestion des données de la recherche (Data Management Plan ou DMP). Ils doivent s’engager dans ce document à partager autant que possible les données issues du projet ou associées aux publications, et y spécifier les conditions de conservation, de documentation et de partage de ces données (European Commission, Directorate-General for Research & Innovation 2016, p.6). Ces obligations sont étendues en 2017 à tous les projets (European Commission, Directorate-General for Research & Innovation 2017, p.8). En pratique, les données de recherche doivent être versées sur un dépôt, de préférence certifié, et être conformes aux principes FAIR (Wilkinson 2016 ; European Commission, Directorate-General for Research & Innovation 2016, p.7).
Le FNS, quant à lui, demande à ce que les données de recherche des projets qu’il finance soient partagées, à moins de « clauses légales, éthiques, de copyright, de confidentialité ou autres », et qu’elles soient déposées avec des métadonnées dans des archives publiques, « dans des formats accessibles et réutilisables sans restriction » (FNS [sans date]a). Les données doivent aussi être rendues conformes aux principes FAIR. Le dépôt utilisé doit être non-commercial (FNS 2020). Comme pour H2020, les demandes de financement de projets auprès du FNS doivent s’accompagner d’un DMP détaillant en particulier les conditions de partage des données. Ce DMP a été rendu obligatoire par le FNS en octobre 2017 (FNS 2017).
Certains éditeurs scientifiques, de leur côté, exigent que les données sous-tendant les publications soient versées sur un dépôt, dans un but de transparence de la recherche publiée (voir par exemple Nature 2016, PLOS ONE [sans date]a, Springer Nature [sans date]a). Sur certains dépôts, ces données sont dans un premier temps partagées seulement avec les reviewer et les éditeurs pendant la phase de revue de la publication, puis elles sont rendues accessibles publiquement une fois que la publication est acceptée (PLOS ONE [sans date]a).
Dans ce contexte, les institutions de recherche accompagnent leurs chercheurs et chercheuses dans la gestion de leurs données pendant l’ensemble du processus de recherche, depuis la planification et l’écriture du DMP jusqu’au versement des données sur un dépôt. Elles encouragent ainsi l’usage de bonnes pratiques, favorisent la mise en pratique de leur politique institutionnelle pour la GDR et leur engagement en Open Science, et aident leurs chercheurs et chercheuses à se conformer aux exigences des financeurs de leur recherche et des éditeurs de leurs publications. En ce qui concerne les dépôts de données de recherche, elles émettent des recommandations sur le choix du dépôt le plus adapté sur lequel verser les données.
Données de recherche ouvertes et dépôts de DR ouvertes
Des données sont ouvertes si on peut y accéder librement et si elles peuvent être utilisées, modifiées et partagées librement, dans n’importe quel but et par n’importe qui, sous condition d’en attribuer l’origine à leurs auteur-e-s (The Concordat Working Group 2016 ; Hodson, Jones et al. 2018).
Selon le rapport Science as an Open Enterprise (The Royal Society 2012), les données de recherche ouvertes doivent être « assessable and intelligible » : on doit pouvoir évaluer leur qualité, leur pertinence et leur utilité pour envisager de les réutiliser. On doit pouvoir les interpréter et les comprendre pour les réutiliser correctement. Cette notion d’interprétation contextuelle est d’ailleurs présente dans la définition des données de recherche par The Consultative Committee for Space Data Systems (2012, p. 1–10) :
« A reinterpretable representation of information in a formalized manner suitable for communication, interpretation, or processing. »
Ces données ouvertes sont accessibles publiquement, généralement sur un dépôt de données, à partir duquel on peut les chercher, les extraire, et les télécharger (Johnston et al. 2017, p.3), sans restriction de copyright, de droits de brevets ou d’autres mécanismes de contrôle (Jong et al. 2020).
D’après l’Université de Genève ([sans date]) :
« un dépôt de données (data repository) est un terme général utilisé pour désigner un lieu pour le stockage des données ».
L’Université de Boston citant le Registry of Research Data Repositories (Re3data) donne la définition suivante du dépôt de données de recherche (Boston University Data Services [sans date]):
« a subtype of a sustainable information infrastructure which provides long-term storage and access to research data that is the basis for a scholarly publication »
mentionnant ainsi les deux objectifs de ce type d’infrastructure, le stockage et l’accessibilité des données de recherche sur le long terme.
Avec sa définition du dépôt, le Data Curation Network souligne aussi l’importance de la notion de services (Johnston et al. 2016) :
« A digital archive that provides services for the storage and retrieval of digital content »
Selon le modèle du Data Curation Continuum de Treloar, Groenewegen et Harboe-Ree (2007), le dépôt intervient à différents moments du processus de la recherche. Un dépôt est utilisé pour partager les données d’un projet de façon publique vers la fin de celui-ci. Il est aussi utilisé pour préserver les données à long terme après la fin du projet (Treloar, Groenewegen et Harboe-Ree 2007 ; Treloar 2012).
Les dépôts ayant pour mission principale le partage des données répondent à l’objectif de donner accès à celles-ci le plus vite possible (approche plus orientée Open Science). Les dépôts ayant pour mission principale la préservation des données répondent à l’objectif de préserver celles-ci le plus longtemps possible (approche plus orientée archivage), tout en assurant pour certains d’entre eux l’accessibilité des données. Dans la suite, on prendra en compte les deux types de dépôts, pour autant que les dépôts de type préservation garantissent aussi l’accès aux données. Certains dépôts mettent à disposition les données de façon ouverte par défaut, mais permettent aussi aux dépositaires de restreindre l’accès à leurs données (par exemple Zenodo (zenodo [sans date]a) et Harvard Dataverse (Dataverse project [sans date]). On prend également en compte ce type de dépôt. La Figure 2 illustre les dépôts de données utilisés au cours du processus de recherche et ceux auxquels on s’intéresse dans le cadre de cette étude.
Figure 2 : Types d’espaces de stockage et de dépôts de données, et niveau de partage selon la progression de la recherche
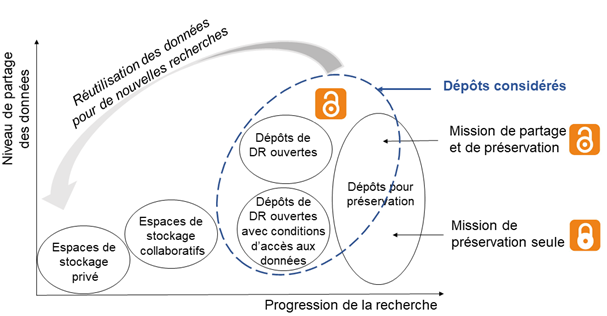
Les dépôts de données prennent diverses formes selon cette mission principale (accessibilité à court terme ou préservation sur le plus long terme), mais aussi selon la communauté à laquelle ils s’adressent (dépôt disciplinaire ou généraliste), leur entité de rattachement (dépôt institutionnel ou pas), leur business model (commercial ou à but non lucratif), le type de technologies qu’ils utilisent (open source ou propriétaires). Comme on va le voir dans la suite, les dépôts se distinguent aussi les uns des autres selon les fonctionnalités et les services qu’ils fournissent, et la façon dont ceux-ci sont déclinés. On peut évoquer par exemple le niveau de curation appliqué aux données déposées, le type d’identifiant pérenne attribué aux données, les standards utilisés pour les métadonnées, la possibilité de mettre les données sous embargo, et évidemment le niveau d’ouverture des données. Certains de ces services peuvent dépendre éventuellement de la catégorie de dépôt (disciplinaire ou généraliste).
Modèle de description d’un dépôt de DR ouvertes
Outils et services
Selon les définitions données plus haut, le dépôt de DR peut donc se définir comme une infrastructure informatique qui stocke des données et les rend accessibles sur le long terme. Ces deux finalités font partie des principes FAIR sur les données (Wilkinson et al. 2016), qui, on le rappelle, selon le FNS et H2020, doivent être appliqués par les dépôts utilisés pour partager ses données.
Les principes A (Accessibilité) et R (Réutilisation) de FAIR correspondent directement aux objectifs du dépôt de rendre et de maintenir les données accessibles et réutilisables. Pour appliquer le principe F (Findability ou Découvrabilité), le dépôt doit rendre les données recherchables et trouvables par des humains et par des machines. L’application du principe I (Interopérabilité) permet l’échange efficace de contenu (données, métadonnées) entre chercheurs et chercheuses, entre institutions, entre systèmes, et par des machines aussi bien que par des humains, pour une utilisation la plus large possible (Swiss National Science Foundation [sans date]).
Comme noté par Hodson, Jones et al. (2018), les principes FAIR et l’ouverture des données (aboutissant à des données librement utilisables, modifiables et partageables, selon les définitions vues plus haut) ont en commun l’objectif ultime de contribuer à la réutilisabilité des données. Néanmoins, des données accessibles selon le principe A de FAIR ne sont pas forcément ouvertes. Pour autant que cela n’aille pas à l’encontre de restrictions légitimes à leur ouverture (concernant en particulier les données personnelles et les données sensibles), les données hébergées par les dépôts, en plus d’être FAIR, doivent donc être rendues ouvertes.
Les quatre grands principes FAIR et l’ouverture des données sont mis en pratique par les dépôts à l’aide de services et d’outils spécifiques (FNS [sans date]b, Swiss National Science Foundation [sans date], Perini 2019).
Identifiants uniques pour les données : un identifiant unique permet de trouver, de citer et de tracer les données auxquelles il est assigné. On peut l’utiliser afin de citer les données utilisées pour obtenir les résultats présentés dans une publication, afin de se référer aux données d’origine lorsqu’on décrit des données secondaires, ou encore dans la liste de ses jeux de données ou sur son profil ORCID pour la description de ses activités de recherche. Les identifiants uniques pour les données doivent être pérennes (PID) et globaux (c’est-à-dire non internes au dépôt). Le DOI, délivré contre rétribution par Datacite (Datacite [sans date]) est couramment utilisé. Les principaux autres identifiants uniques sont les suivants : ARK (utilisé par le dépôt DaSCH ([sans date])), Handle ou hdl (utilisé par B2SHARE EUDAT; Re3data.org 2017), PURL, URN et RRID (Digital Preservation Coalition [sans date], Swiss National Science Foundation [sans date]).
Métadonnées : la description des données et de leur contexte, essentielle comme on l’a vu pour une possible réutilisation des données, est assurée en grande partie par les métadonnées. En plus du contexte et de la provenance des données, celles-ci détaillent la structuration et le contenu des jeux de données (EPFL Library, Research Data Library Team [sans date]). Elles aident ainsi à découvrir les données, à y accéder, à connaître leurs conditions de réutilisation (informations utiles pour les utilisateurs et utilisatrices), et à les gérer (pour le dépôt).
La structuration des métadonnées sous une forme interprétable par les machines permet l’automatisation de leur traitement (lecture, recherche, extraction) (Johnston et al. 2018). Les dépositaires doivent alors fournir ces métadonnées par le biais de formulaires conformes à des schémas standards. On utilise fréquemment les schémas Dublin Core (Dublin Core 2020, Dublin Core Metadata Initiative 2020) et DataCite Metadata (DataCite Metadata Working Group 2019, DataCite [sans date]) pour les métadonnées descriptives. Dans le cas de dépôts spécialisés, des métadonnées supplémentaires peuvent être fournies suivant le schéma couramment utilisé dans le domaine de recherche ou dans la discipline (schéma DDI pour les sciences sociales par exemple). Certains dépôts (ou solutions techniques) proposent d’utiliser son propre standard pour les métadonnées ou d’étendre celui proposé par défaut (Dryad, B2SHARE EUDAT, OLOS, Figshare ; Guirlet 2020, Annexes 4 et 5).
Formats des fichiers : l’utilisation de formats conformes à des standards ouverts, disponibles publiquement et non propriétaires pour les fichiers de données et de métadonnées permet une utilisabilité à la fois par un plus grand nombre de chercheurs et chercheuses mais aussi sur le plus long terme. Les dépôts publient souvent à l’intention des dépositaires des listes de formats recommandés et acceptables(1). Certains dépôts assurent la migration des formats lorsque celui des fichiers versés n’est pas pérenne. Dans le cas d’une préservation à long terme, une veille régulière du risque d’obsolescence des formats déclenche le cas échéant des actions préventives, dont cette migration des formats (Rosenthaler, Fornaro et Clivaz 2015 ; L’Hours, Kleemola et de Leeuw 2019). C’est le cas du dépôt suisse FORSbase (DARIS 2018, p.29). Sur les dépôts disciplinaires, la conformité des formats à des standards spécialisés permet aussi aux utilisateurs et utilisatrices de les manipuler et de les interpréter selon leurs pratiques usuelles.
Citation des données : la formule de citation des données est générée automatiquement à partir des métadonnées descriptives (avec Datacite par exemple, si elles sont conformes au schéma DataCite Metadata). Elle est fournie aux utilisateurs et utilisatrices en même temps que les données récupérées. Dans les conditions et les termes sur la réutilisation des données de certains dépôts, ces utilisateurs s’engagent à citer les données de la façon qui leur est suggérée (voir par exemple FORS [sans date]). Sur FORSbase, ceux-ci s’engagent en outre à informer le dépôt de toute publication basée sur la réutilisation des données, permettant ainsi le traçage de cette réutilisation (FORS [sans date]).
Conditions de réutilisation et restrictions d’accès : le dépôt doit préciser les conditions de réutilisation des données, au moyen d’une licence sur les données ou des termes du copyright. La définition des données ouvertes de CASRAI(2) est la suivante (CASRAI [sans date]b):
« Structured data that are accessible, machine-readable, usable, intelligible, and freely shared. Open data can be freely used, re-used, built on, and redistributed by anyone – subject only, at most, to the requirement to attribute and sharealike. »
Selon CASRAI, les contraintes pour la réutilisation des données sont donc au maximum d’attribuer l’origine des données à leurs auteur-e-s et de les partager à l’identique. Les licences Creative Commons correspondantes sont les licences CC0, CC BY, et CC BY-SA, la licence CC0 étant celle dont l’ouverture est la plus élevée (Creative Commons [sans date]). Dans la suite, on considérera que les dépôts proposant une ou plusieurs de ces trois licences, pour au moins une partie de leurs données, hébergent des données ouvertes(3).
Sur certains dépôts, les dépositaires ont la possibilité de restreindre l’accès à leurs données : accès sur demande, accès privé (groupe de personnes identifiées) ou mise sous embargo. Aucune de ces configurations ne convient pour des données ouvertes, mais des données à l’accès restreint peuvent facilement devenir des données ouvertes, à la fin de la période d’embargo ou si les dépositaires suppriment les restrictions à la fin du projet. Restreindre l’accès pour des données personnelles ou sensibles dans le but de respecter leur confidentialité n’est pas approprié (elles resteront toujours consultables par les gestionnaires du dépôt). Par contre, une fois anonymisées, les données personnelles et les données sensibles peuvent être publiées (EPFL Library [sans date], Université de Lausanne [sans date]a).
Curation des données et des métadonnées : selon le Data Curation Network, la curation des données facilite leur découvrabilité et leur récupération, et contribue à leur réutilisabilité dans le temps (Johnston et al. 2017). Une définition plus complète des objectifs de la curation, incluant aussi le maintien de la qualité et l’ajout de valeur, est donnée par Cragin et al. (2007):
« Data curation is the active and on-going management of data through its lifecycle of interest and usefulness to scholarship, science, and education; curation activities enable data discovery and retrieval, maintain quality, add value, and provide for re-use over time. »
En pratique, elle consiste d’abord à préparer les données qui ont été sélectionnées afin qu’elles remplissent les conditions d’accès imposées par le dépôt : nommage des fichiers et des dossiers, structuration du jeu de données, changement de format éventuel et autres. La curation a aussi pour rôle de rendre et de maintenir les données FAIR, et de vérifier et de contrôler leur qualité. Les activités correspondantes incluent la création de métadonnées, la préparation de documentation, la vérification, la validation et l’enrichissement des données et des métadonnées. Elle peut aussi vérifier la conformité des données ou les rendre conformes aux règles légales et aux normes éthiques. Pour un détail des activités de curation, on peut consulter Johnston et al. (2016, 2017, 2018) et Johnston (2017).
Certaines activités de curation sont plus appliquées à la préservation. Elles concernent le maintien de la qualité des données sur le plus long terme, le soutien à leur préservation et leur transformation si nécessaire avec notamment la migration des formats mentionnée ci-dessus (Data Curation Network [sans date]). Des efforts supplémentaires sont aussi à fournir pour surveiller l’évolution possible des pratiques et des besoins au sein de la communauté cible. Si besoin, la curation met en œuvre les mesures d’adaptation nécessaires, telles que l’utilisation de nouveaux formats et standards pour le dépôt, l’utilisation de métadonnées plus riches, ou la mise à jour de la documentation.
Sur certains dépôts, les tâches de curation sont assurées par des « data steward » (OLOS 2020a) ou par des « data curator » (Dryad [sans date]).
Services complémentaires : outre les grandes fonctions assurées par les dépôts de données (l’ingestion, le stockage et la gestion des métadonnées et des données, et leur mise à disposition), ceux-ci proposent fréquemment des services complémentaires facilitant la visibilité et la découvrabilité des données.
Le résultat du moissonnage automatique de métadonnées conformes au schéma Dublin Core est utilisé par des services d’agrégation, des portails et des moteurs de recherche (tels que Google Dataset Search et Elsevier DataSearch) et renforce ainsi la visibilité des données à l’externe. Le protocole OAI-PMH est l’un des protocoles standards et/ou ouverts permettant ce moissonnage. Le dépôt doit disposer de l’interface OAI et s’enregistrer comme fournisseur de métadonnées auprès du service OAI-Data Provider de l’Open Archives Initiative (OAI) (DINI 2011, p.14, p.35). Thomson Reuters’ Data Citation Index moissonne aussi le contenu des dépôts pour tracer les citations de données dans la littérature (Rice et Southall 2016, p.118).
Le web sémantique avec les Linked Open Data relie des entités décrites de façon structurée selon le cadre RDF, qui fournit un modèle pour la représentation, l’échange et l’interconnexion des métadonnées. Convertir les métadonnées en RDF et les exposer permet de les connecter à d’autres entités du web, et ce faisant, d’augmenter la découvrabilité des données auxquelles sont associées ces métadonnées (Arlitsch et al. 2016, Rice et Southall 2016).
Avec certains dépôts, on peut faire le lien entre ses données déposées et sa page personnelle ORCID (par exemple avec Figshare [sans date]) ou avec les pages de ses projets (par exemple depuis Zenodo vers la page du projet sur le portail OpenAIRE ; zenodo [sans date]f). On peut parfois relier les publications et les données les sous-tendant (ETHZ Research Collection, ETHZ – ETH Bibliothek [sans date]), ou les données et le code qui a servi à les produire (zenodo [sans date]f), alors que ces éléments sont hébergés sur des dépôts distincts (par exemple PLOS pour les publications, GitHub pour le code). Les dépôts permettant de faire ce type de liens reconnaissent les identifiants ORCID et GitHub. Ces fonctionnalités sont là encore un moyen de favoriser la visibilité des données.
Un outil de recherche avancée sur le site du dépôt est utile pour l’exploration et la découvrabilité des données. Des outils de visualisation donnent un premier aperçu du contenu des fichiers. L’information disponible sous forme de guide utilisateur et de rubrique FAQ renseigne sur le dépôt en général, sur les conditions d’hébergement ou sur les procédures de versement des données. Les réseaux sociaux, un forum ou un blog sont des moyens d’accéder à une communauté d’usagers et d’usagères du dépôt. Enfin, les métriques et les statistiques d’usage sur la fréquentation du dépôt rendent compte de son dynamisme et permettent d’évaluer si le dépôt est bien utilisé et reconnu par cette communauté. Quand ces métriques concernent les jeux de données eux-mêmes (nombre de vues et de téléchargements), elles donnent aux dépositaires une estimation de l’intérêt porté à leurs données.
Les outils et les services d’un dépôt de données de recherche hébergeant des données conformes aux principes FAIR et ouvertes sont schématisés sur la Figure 3.
Figure 3 : Les outils et services d’un dépôt de données de recherche ouvertes
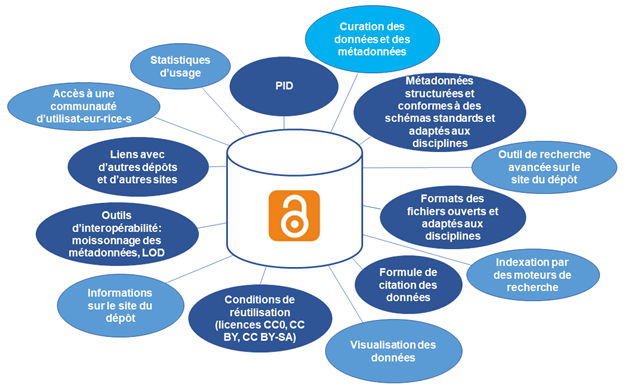
Critères de qualité
Les objectifs du dépôt de DR ouvertes sont donc de rendre et de maintenir les données accessibles et réutilisables à partir du moment du versement et dans le futur. Assurer que le dépôt est en capacité de remplir ces objectifs instaure la confiance des parties prenantes (présentées sur la Figure 4 avec leurs contributions et leurs attentes par rapport au dépôt de données). Cela leur garantit que les données sont en effet accessibles et réutilisables, mais aussi qu’elles sont conservées de façon sûre et qu’elles sont traçables (pour les agences de financement), qu’elles sont visibles et citables (pour les producteurs et productrices de données), et qu’elles sont fiables et de bonne qualité (pour les utilisateurs et utilisatrices).
Figure 4 : Parties prenantes du dépôt de DR ouvertes avec leurs contributions et leurs attentes
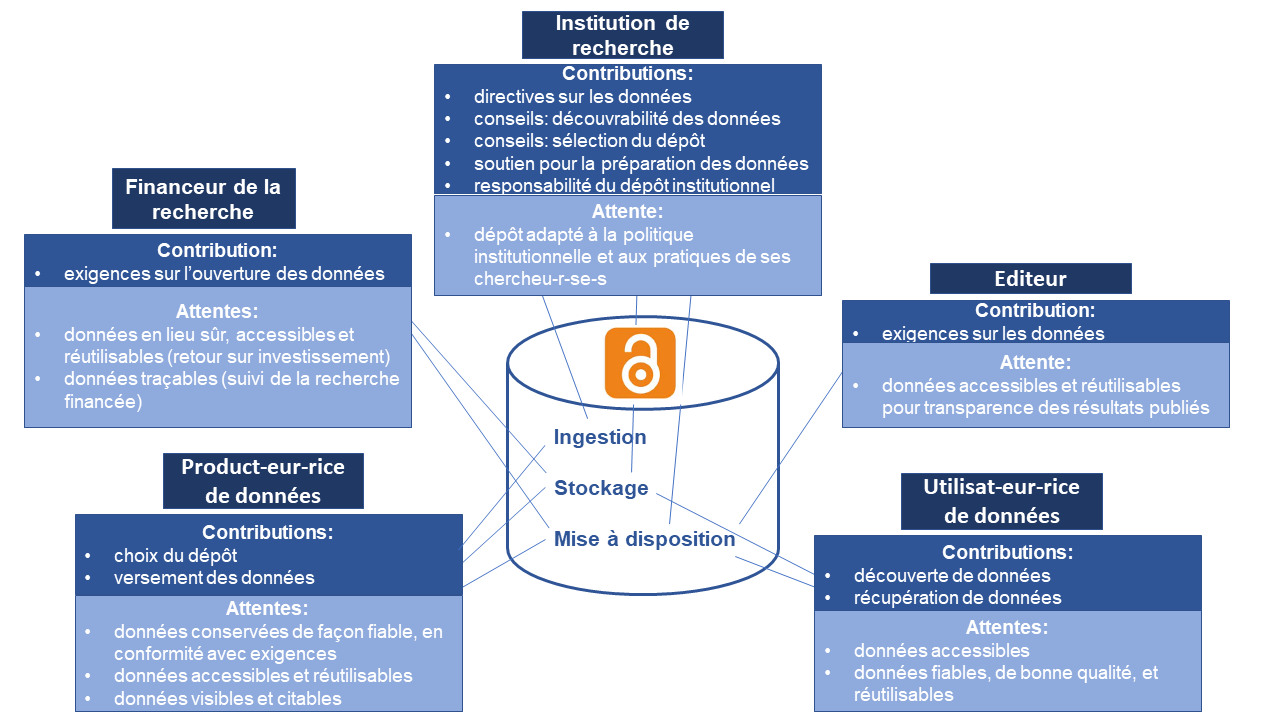
Depuis les années 1990, plusieurs démarches sur la base de normes et de standards ainsi que des certifications ont été élaborées pour évaluer de façon indépendante la qualité et la fiabilité d’un dépôt sur le long terme. Selon UK Data Archive, Standards of Trust (cité par l’Université d’Edimbourg, The University of Edinburgh 2019):
« The standards provide the basis of a framework by which different levels of trust of digital repositories can be demonstrated ».
Le cas échéant, le dépôt est reconnu « dépôt de confiance » (trusted digital repository, trustworthy digital repository).
L’approche d’évaluation de la qualité d’un dépôt la plus récente et la plus utilisée (Guirlet 2020, Tableau 14) est la Certification CoreTrustSeal mise au point en 2017 par un groupe de travail de la RDA, à partir de DSA et ICSU-WDS (Dillo et de Leeuw 2018 ; Corrado 2019 ; L’Hours, Kleemola et de Leeuw 2019). Les critères sont révisés tous les trois ans et la version la plus récente couvre maintenant la période 2020-2022 (CoreTrustSeal 2020a).
Plusieurs critères de CTS font référence aux standards du modèle OAIS (The Consultative Committee for Space Data Systems 2012) pour évaluer la fiabilité du dépôt à long terme (critères R9, R15 ; CoreTrustSeal 2020a). Le respect de cinq principes fondamentaux sur les données atteste que les données numériques sont archivées de façon durable. Selon ces principes, les données doivent être trouvables sur Internet, être accessibles en tenant compte de la législation en vigueur sur les informations personnelles et la propriété intellectuelle des données, être disponibles sous un format utilisable, être fiables et être référençables (Dillo et de Leeuw 2018). Enfin, un rôle important est donné à la qualité des métadonnées pour assurer la découvrabilité et l’accessibilité des données (ceci impliquant l’intervention de personnel qualifié ou la contribution d’expert-e-s externes), et à l’évaluation de la qualité de ces métadonnées. On pourrait d’ailleurs décrire de façon schématique la certification CTS comme une approche d’évaluation d’un dépôt englobant à la fois les exigences OAIS pour sa fiabilité à long terme, les principes FAIR sur les données pour leur accessibilité et leur réutilisabilité, et des critères sur la qualité des données et des métadonnées.
Les critères de certification CTS sont organisés en trois catégories, selon le Tableau 2.
Tableau 2 : Catégories de critères CTS
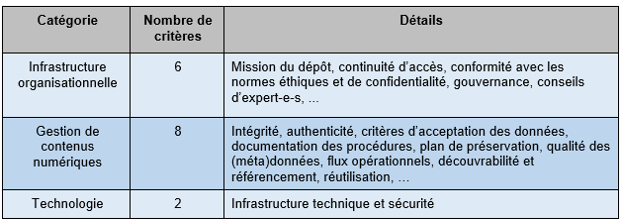
(d’après CoreTrustSeal 2020b; CoreTrustSeal Standards and Certification Board 2020; Corrado 2019)
Elaboration du modèle
L’ajout à ces trois catégories de critères d’une nouvelle catégorie englobant les outils et les services d’un dépôt décrits précédemment permet de faire l’analogie avec la représentation par couches du système d’information d’une entreprise selon Hewlett (2006) (voir la Figure 5 ci-dessous). Dans cette représentation, l’infrastructure organisationnelle forme la base de la pyramide. Viennent ensuite l’infrastructure technique et les technologies, puis la gestion des données. Les services aux usager-e-s du dépôt forment la couche du sommet de la pyramide.
Figure 5 : Représentation par couches d’un dépôt de DR par analogie avec l’architecture du système d’information d’une entreprise
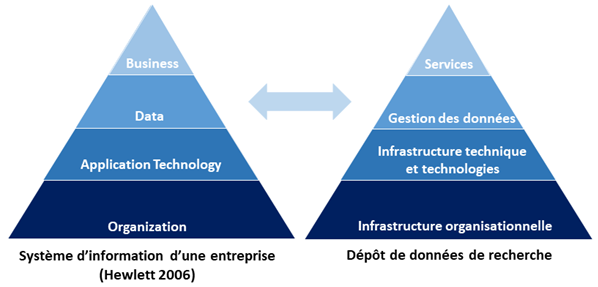
En pratique, dans le but de traduire cette conception du dépôt de DR ouvertes en une grille de description détaillée, plusieurs sources sont considérées pour identifier les éléments de cette grille :
- les critères d’évaluation de la qualité utilisés pour la certification CTS ;
- les outils et services d’un dépôt décrits plus haut et identifiés à partir de la revue de la littérature ; les éléments descriptifs correspondants ont été affinés grâce à une revue détaillée des dépôts généralistes, disciplinaires et institutionnels utilisés en Suisse (voir Guirlet 2020, Annexes 4 et 5).
On y ajoute des éléments supplémentaires permettant d’assurer la conformité aux exigences des financeurs de la recherche (e.g., dépôt non-commercial exigé par le FNS), au cadre légal, aux normes éthiques et disciplinaires en vigueur (gestion adéquate des données personnelles et sensibles), ainsi que des éléments relatifs à la qualité de l’expérience utilisateur ou utilisatrice (e.g., convivialité du site, facilité du versement, …). La grille complète ainsi produite est donnée dans Guirlet (2020).
Cette grille de description peut être utilisée soit pour évaluer un dépôt existant (et aussi dans le but éventuel de l’améliorer), soit pour spécifier un dépôt à créer. La mise en œuvre satisfaisante de tous les aspects décrits par les éléments du modèle, que le dépôt existe déjà ou qu’il soit à l’état de projet, assure que ce dépôt est de qualité (car conforme aux critères CTS), qu’il héberge des données accessibles et réutilisables, conformes aux principes FAIR et ouvertes, et qu’il répond aux exigences des principaux financeurs de la recherche, ainsi qu’au cadre légal et aux normes sur la gestion des données personnelles et sensibles.
Panorama des dépôts utilisés et recommandés en Suisse
Dans le but d’établir un état des lieux des dépôts utilisés par les chercheurs et les chercheuses et recommandés par les institutions académiques en Suisse, la stratégie des plus engagées d’entre elles en termes d’ouverture des données de recherche (soit neuf institutions) a été passée en revue. Pour chaque institution en particulier, on a identifié, s’ils existent, le dépôt institutionnel de données ou de publications, le dépôt de données en projet, les dépôts disciplinaires développés dans le cadre d’un partenariat entre institutions, ainsi que les dépôts de données recommandés. Le détail de cette revue et les références bibliographiques associées sont donnés dans Guirlet (2020, Annexe 5). Elaborée sur la base de celle-ci mais en prenant aussi en compte l’ouverture récente d’OLOS (OLOS 2020b), la Figure 6 mentionne ces différents dépôts.
Figure 6 : Dépôts institutionnels et dépôts de DR recommandés pour neuf institutions académiques suisses ((p) : dépôt pour publications seulement; (p+d) : dépôt pour publications archivant aussi des DR ; disc. : disciplinaire)
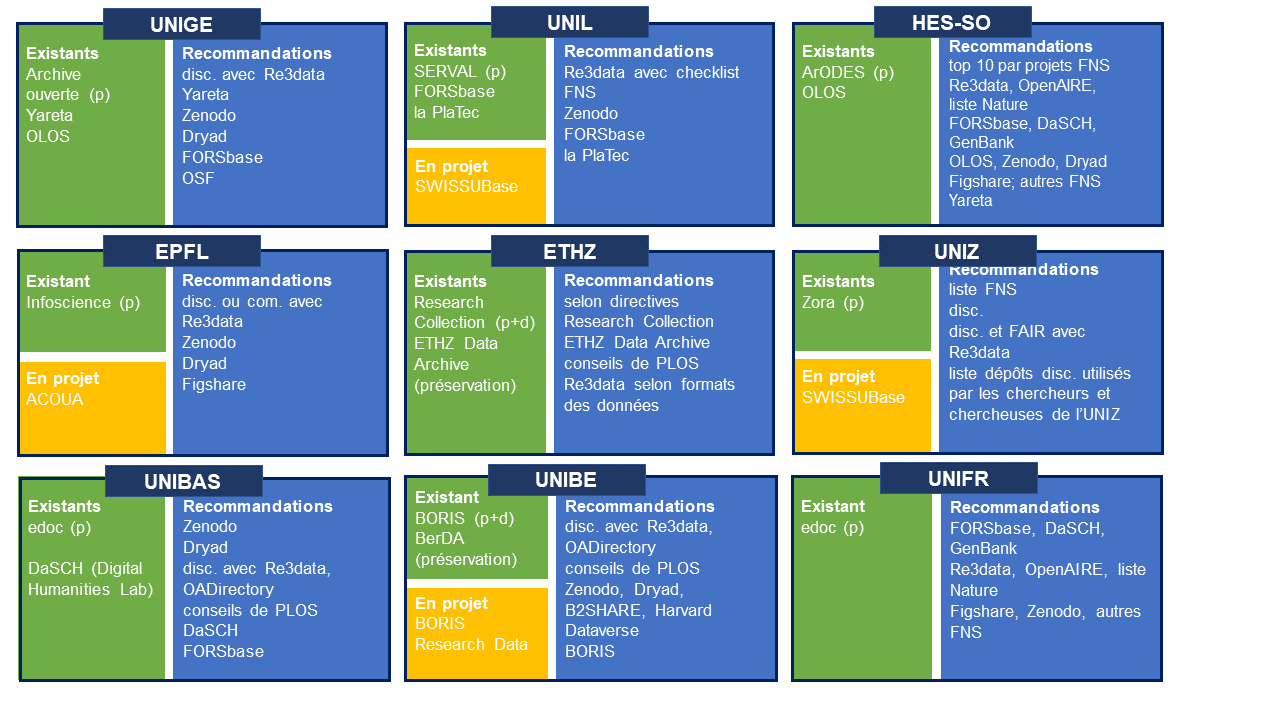
(d’après les sources données dans Guirlet 2020, Annexe 5)
Cette revue met en lumière les différents cas de figure suivants selon les institutions (avec des recoupements possibles).
- L’existence d’un dépôt de données institutionnel (Research Collection et Data Archive pour l’ETHZ ; BerDA pour l’Université de Berne) ;
- l’existence d’un dépôt à l’échelle cantonale (Yareta pour l’Université de Genève et pour la HES-SO), d’un dépôt à l’échelle nationale (OLOS, développé par l’Université de Genève et la HES-SO dans le cadre du projet DLCM) ou d’un dépôt disciplinaire auquel a contribué une entité de l’institution (DaSCH pour l’Université de Bâle ; FORSbase et la PlaTec pour l’Université de Lausanne) ;
- un projet de dépôt institutionnel (ACOUA pour l’EPFL) ou en partenariat avec d’autres institutions (SWISSUbase pour l’Université de Lausanne et l’Université de Zurich);
- un projet d’extension de l’archive institutionnelle de publications (BORIS Research Data pour l’Université de Berne) ;
- l’absence de dépôt institutionnel pour les données et pas de projet formulé pour en développer un (Université de Fribourg).
Ces institutions émettent toutes des recommandations pour le choix du dépôt de données de recherche (pour le détail, voir Guirlet 2020, Annexe 5). Celles-ci varient en fonction des disciplines de recherche au sein de l’institution, et de l’existence ou pas d’un dépôt institutionnel. Ces recommandations peuvent s’appuyer sur les exigences des agences de financement (FNS, H2020), et se référer aux conseils donnés par des éditeurs scientifiques (PLOS ONE [sans date]b, Springer Nature [sans date]b). Elles suivent aussi fréquemment les conseils du FNS, qui donne quatre exemples de dépôts généralistes répondant à ses exigences : Zenodo, Dryad, EUDAT et Harvard Dataverse (Swiss National Science Foundation 2017).
Du fait de la spécialisation et de l’expertise des dépôts disciplinaires, il est fréquent que les recommandations faites aux chercheurs et aux chercheuses orientent vers le dépôt disciplinaire adapté à leur spécialité avant un dépôt généraliste ou même avant le dépôt institutionnel. La position de l’Université de Berne sur ce point est bien marquée (Universität Bern, [sans date]a):
« Wherever possible, data should be deposited in disciplinary repositories. These are designed to meet the needs of the particular field, are aware of specific data formats and often also offer specific disciplinary metadata. »
L’utilisation de registres de dépôts tels que Re3data et ses filtres (Re3data.org [sans date]) pour la prise en compte d’autres critères est conseillée. Deux institutions renvoient aussi vers les pratiques d’une communauté : l’UNIZ fait référence aux dépôts utilisés par ses chercheurs et chercheuses (Universität Zürich, Hauptbibliothek 2019), et la HES-SO mentionne les pratiques des bénéficiaires de subsides FNS (HES-SO [sans date]).
Le Tableau 3 reprend les recommandations des neuf institutions pour le choix du dépôt.
Tableau 3 : Synthèse des recommandations des neuf institutions étudiées pour le choix du dépôt de données
Les recommandations d’une institution correspondent aux cellules marquées en bleu clair. Les recommandations des cellules marquées en bleu foncé sont celles d’une institution pour son propre dépôt institutionnel (marquage étendu à FORSbase et à la PlaTEC pour l’UNIL, à DaSCH pour UNIBAS et à Yareta et à OLOS pour UNIGE et la HES-SO).
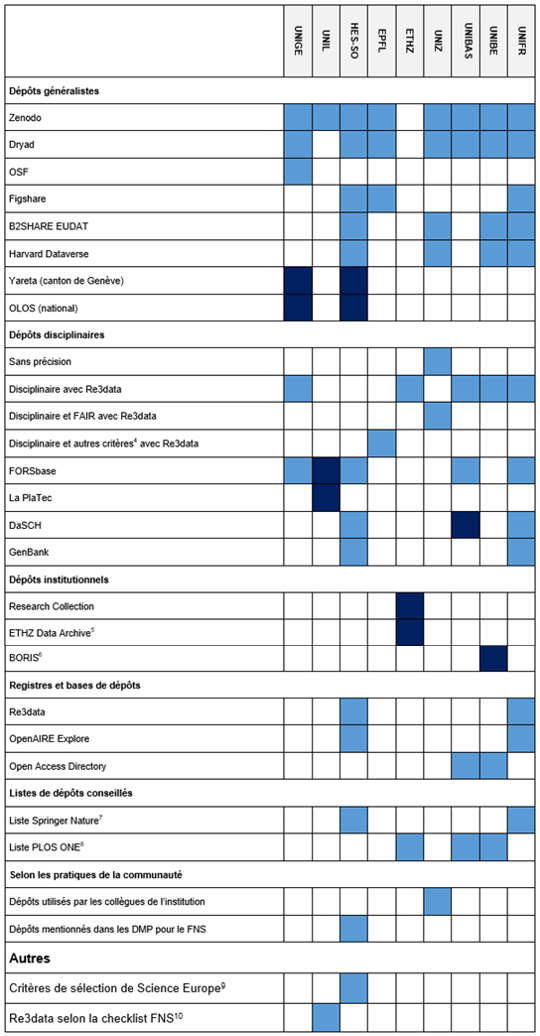
(4)(5)(6)(7)(8)(9)(10)
(d’après les sources données dans Guirlet 2020, Annexe 5)
Bonnes pratiques observées
A partir de l’étude de la stratégie de ces institutions, on peut également dégager des exemples de bonnes pratiques sur plusieurs aspects.
Découvrabilité des données : parmi les ressources en ligne fournies, seules l’Université de Zurich et l’Université de Bâle donnent des conseils ou mentionnent des outils (tels que des registres et des moteurs de recherche) pour la recherche et la découvrabilité de données sur des dépôts (Universität Basel [sans date] ; Universität Zürich, Hauptbibliothek 2020). Les autres institutions, sans doute plus concentrées sur la conformité aux exigences des financeurs de la recherche, conseillent surtout sur la sélection d’un dépôt de données adapté. Etendre les conseils à la découvrabilité des données et à leur réutilisation est néanmoins essentiel pour donner sa pleine place au dépôt comme instrument de partage et de réutilisation des données.
Suivi des pratiques : on a mentionné précédemment que l’Université de Zurich, parmi ses recommandations pour le choix du dépôt, fournit une liste des dépôts fréquemment utilisés par ses chercheurs et chercheuses (Universität Zürich, Hauptbibliothek 2019). Pour toute institution, un suivi précis des dépôts utilisés et du nombre de jeux de donnés versés par dépôt peut lui fournir un état des lieux des pratiques de ses chercheurs et chercheuses. Ces informations sur les pratiques sont normalement fournies dans le DMP du projet. Rendre ce DMP obligatoire en interne permet ainsi à l’institution de suivre les pratiques institutionnelles. De même, tenir compte des données partagées par les chercheurs et les chercheuses pour évaluer leur carrière académique (voir plus bas), outre le fait d’inciter à partager ces données, permet aussi à leur institution d’affiliation de tracer ces données et les modalités de leur partage.
L’analyse par Milzow et al. (2020, fig.5) des DMP des projets financés en 2017-2018 par le FNS a identifié les dépôts qui y sont mentionnés en prévision du versement des données de recherche à la fin des projets. Comme mentionné plus haut, la HES-SO s’appuie sur la liste des dépôts les plus cités dans ces DMP pour ses recommandations sur le choix du dépôt (HES-SO [sans date]). La rédaction du DMP ayant été rendue obligatoire par le FNS en octobre 2017 (FNS 2017), et les projets correspondants arrivant prochainement à terme, il serait intéressant, en se basant sur la version finale des DMP, de faire un suivi des versements effectués (nombre de jeux de données, dépôts utilisés), éventuellement par discipline(11) et par institution. Ce suivi pourrait être utilisé par chaque institution pour éventuellement modifier sa stratégie, en ajustant ses recommandations pour le choix du dépôt ou en intensifiant ses efforts de sensibilisation et de communication, ou encore pour adapter ses mesures d’incitation.
Evaluation des chercheurs et des chercheuses : certaines données de stockage et d’utilisation des contenus hébergés par BORIS (dépôt pour publications) sont exploitées dans le processus d’évaluation de la recherche de l’Université de Berne (Universität Bern [sans date]b). Toutes les institutions étudiées ici sont signataires de la Déclaration de San Francisco sur l’évaluation de la recherche (DORA ou San Francisco Declaration on Research Assessment 2012, 2020), s’engageant ainsi à prendre en compte la valeur et l’impact des produits de la recherche autres que les publications. Un des moyens possibles de mettre en pratique cet engagement consiste à considérer également les métriques sur les dépôts de données de recherche ouvertes (le nombre de jeux de données et de téléchargements, le suivi de la réutilisation) par chercheur ou chercheuse, par projet, par département, pour l’évaluation académique.
Mesures d’incitation et visibilité des pratiques par communauté : les mesures pour inciter à adopter de meilleures pratiques en gestion des données de recherche peuvent prendre diverses formes. La HES-SO a lancé un appel à projet pour l’obtention de fonds complémentaires soutenant le versement des données de recherche sur un dépôt FAIR (HES-SO 2020). L’EPFL, quant à elle, a mis en place une communauté de Data Champions, reconnus pour leur expertise et leurs bonnes pratiques en GDR, et offre visibilité et soutien à cette communauté (EPFL [sans date]). Sur ce modèle, toute institution pourrait aussi attribuer aux chercheurs et chercheuses qui partagent publiquement un grand nombre de données sur des dépôts des badges Open Science (Center for Open Science [sans date]), afin de reconnaître et de mettre en avant leurs bonnes pratiques. L’Université de Lausanne, de son côté, incite à ouvrir sur Zenodo des espaces communautaires par faculté (Université de Lausanne [sans date]b). Plusieurs autres institutions ou départements d’institutions y disposent déjà de leur espace communautaire(12). Sur des dépôts généralistes, cette organisation en communauté de pratiques et d’intérêt donne de la visibilité aux données de recherche par institution, et par faculté ou par département, et facilite le suivi des versements, selon la recommandation faite précédemment. Elle contribue aussi à l’identification et à la centralisation des données d’un domaine particulier, donnant ainsi une chance supplémentaire à ces données d’être découvertes et réutilisées.
Le Tableau 4 synthétise les recommandations que l’on peut formuler à l’adresse des institutions de recherche à partir de l’observation de ces bonnes pratiques.
Tableau 4 : Recommandations à l’adresse des institutions de recherche, basées sur les bonnes pratiques observées
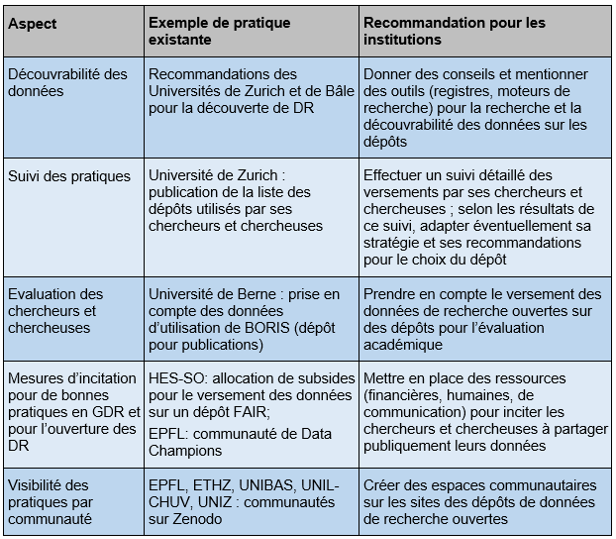
Outils pour le choix de la stratégie
Au terme de cette étude, on a abouti à la production d’un vade-mecum pour le recueil d’informations et d’un guide décisionnel. Ces outils sont destinés aux personnes mandatées par une institution pour décider de la démarche à adopter concernant le soutien aux chercheurs et chercheuses pour le partage public de leurs données sur un dépôt. Dans l’idéal, ces personnes sont des représentant-e-s de services déjà engagés dans des activités de GDR et contribuant au dépôt existant ou potentiellement au futur dépôt : la bibliothèque de recherche, le service IT, le département légal, l’administration de la recherche, ainsi que des représentant-e-s des instances décisionnelles de haut niveau de l’institution, du département financier et des ressources humaines.
Le vade-mecum regroupe les questions auxquelles l’institution est invitée à répondre avant de commencer la démarche. Les informations ainsi collectées seront utiles à différentes étapes de la démarche. Le guide décisionnel se présente sous forme d’un logigramme. Un troisième document fournit des recommandations et des ressources complémentaires pour la mise en pratique de la stratégie, une fois celle-ci fixée à l’aide du guide décisionnel (Figure 7).
Figure 7 : Démarche pour le choix de la stratégie institutionnelle et outils correspondants

Présentation de la démarche décisionnelle
En fonction des exigences des agences de financement de la recherche et de celles des éditeurs de journaux scientifiques, l’institution caractérise le dépôt qui permettra à ses chercheurs et chercheuses de partager publiquement leurs données dans le respect de ces exigences. Ce dépôt souhaité doit aussi prendre en compte les spécificités du contexte institutionnel : la politique institutionnelle, les pratiques, la culture en matière de GDR, les ressources financières et humaines. La confrontation du dépôt souhaité avec les dépôts existants offre alors trois voies possibles (voir la Figure 8). La première consiste à orienter les chercheurs et chercheuses vers un dépôt existant (un dépôt disciplinaire, son dépôt institutionnel ou un dépôt généraliste) qui est suffisamment similaire à ce qu’on souhaite. Il faut pour cela identifier les critères permettant de sélectionner le dépôt adéquat. Dans le cas où aucun dépôt existant ne se rapproche suffisamment de ce qu’on souhaite, la deuxième voie possible est l’élargissement aux données de recherche du dépôt institutionnel pour publications, s’il existe. Et dans le cas où le dépôt pour publications n’existe pas, la troisième voie est celle de la création d’un nouveau dépôt de données de recherche.
Pour deux raisons principales, la priorité est donnée à l’utilisation d’un dépôt déjà existant plutôt qu’à la création d’un nouveau dépôt. D’une part, les ressources nécessaires pour développer et faire fonctionner un dépôt sont bien plus élevées que l’utilisation d’un dépôt existant (gratuite pour une grande partie des dépôts, dans une certaine limite de taille ou de nombre de fichiers versés) (Guirlet 2020, p.35 et suivantes). D’autre part, l’analyse ci-dessus des dépôts utilisés et recommandés par les institutions académiques suisses a montré une fragmentation poussée du paysage des dépôts de données de recherche. Cette fragmentation correspond à celle observée à une plus grande échelle par l’étude de von der Heyde (2019) qui recommande de ne pas financer de nouveaux dépôts, pour éviter d’accentuer ce phénomène, mais plutôt de consolider les dépôts déjà existants. Le FNS prévoit d’ailleurs d’étendre sur son site ses recommandations sur les dépôts conformes aux principes FAIR, afin de donner plus de visibilité aux dépôts spécialisés déjà existants (Milzow et al. 2020). Dans le guide décisionnel, pour le choix d’un dépôt existant, on s’oriente d’abord vers un dépôt disciplinaire, mieux adapté aux standards, à la culture et aux pratiques disciplinaires (Universität Bern [sans date]a), puis vers le dépôt institutionnel de données de recherche s’il existe, puis vers un dépôt généraliste.
Figure 8 : Les voies possibles pour le choix de sa stratégie par une institution
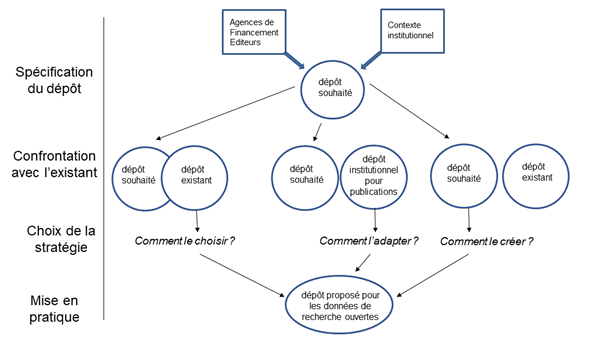
Cette démarche se traduit dans le vade-mecum et le guide décisionnel de la façon décrite ci-dessous.
Le vade-mecum
Le vade-mecum permettant de collecter les informations nécessaires pour la démarche est organisé par rubrique. Chaque rubrique comprend une question principale et une liste de pistes suggérées pour explorer la question de manière approfondie (Tableau 5). Les informations récoltées correspondent soit à des paramètres décisionnels, décisifs pour l’orientation de la démarche (repérés avec des chiffres en orange), soit à des spécifications et des informations non décisionnelles, mais qui enrichissent le processus et contribuent au résultat final (par exemple les caractéristiques du dépôt que l’on va utiliser, adapter ou développer) (repérés avec des lettres en vert). Le chiffre ou la lettre de chaque rubrique est reporté sur le guide décisionnel à l’étape correspondante.
On commence par identifier les exigences et les directives pertinentes sur l’ouverture des données de recherche (rubrique 1). On s’intéresse alors aux pratiques des chercheurs et chercheuses de l’institution dans ce domaine (rubrique 2). On caractérise ensuite les données de recherche produites ou manipulées au sein de l’institution : les disciplines, la présence de données sensibles ou non, les volumes en jeu, les formats, … (rubrique 3). On rassemble aussi les informations sur les ressources financières et humaines disponibles, qui seront notamment décisives pour le choix entre l’utilisation d’un dépôt existant (et lequel) et le développement d’un nouveau dépôt (rubriques 4 et 5), et pour les choix techniques associés (rubrique 6).
Les spécifications pour le choix d’un dépôt existant sont aussi précisées au moyen de ce vade-mecum (rubrique A), de même que les spécifications pour le nouveau dépôt éventuel (rubrique B). Elles incluent les éléments qui permettent de répondre aux exigences et aux directives dans la mesure des ressources internes, et d’autres souhaits possibles (la convivialité, l’adaptabilité, l’extensibilité, …). Une rubrique spécifique concerne le cahier des charges à remplir pour l’élargissement ou la création d’un nouveau dépôt (rubrique C).
Tableau 5 : Rubriques du vade-mecum accompagnant le guide décisionnel
Si l’institution choisit d’encadrer les chercheurs et les chercheuses pour le choix du dépôt, elle commence par évaluer leurs pratiques de partage public de leurs données (rubrique 2 du vade-mecum) en fonction des exigences sur les données de recherche (rubrique 1). Si ces pratiques ne sont pas satisfaisantes ou si l’institution décide de poursuivre quand même la démarche, elle est invitée à se tourner vers les dépôts déjà existants : des dépôts disciplinaires adaptés, le dépôt institutionnel de données de recherche s’il existe ou des dépôts généralistes. Pour les dépôts disciplinaires et les dépôts généralistes, on confronte les exigences, les caractéristiques des données de recherche (rubrique 3) et les ressources disponibles pour l’utilisation d’un dépôt existant (rubrique 4) aux spécifications du dépôt existant qui serait le plus adapté (rubrique A).
Si aucun dépôt existant ne répond aux spécifications définies et si un dépôt institutionnel pour publications existe, on envisage d’élargir celui-ci aux données de recherche. La décision est prise en fonction des ressources et des compétences disponibles en interne (rubrique 5).
Enfin, s’il n’existe pas de dépôt pour publications, on envisage de créer un nouveau dépôt. Le choix de la solution technique (out of the box/customized/from scratch, propriétaire/Open Source, cloud ou externe/locale) se fait avec un outil fourni dans le vade-mecum (et détaillé dans Guirlet 2020) en fonction des préférences concernant l’échelle de temps et le niveau d’adaptabilité et de contrôle sur la solution et les données hébergées (rubrique 6). En fonction des ressources disponibles (rubrique 5), on confirme ces choix, on choisit d’autres options techniques ou on sort de la démarche.
L’élargissement du dépôt de publications ou la création d’un nouveau dépôt se fait en se basant sur les spécifications du nouveau dépôt (rubrique B) et sur le cahier des charges du projet correspondant (rubrique C).
Figure 9 : Guide décisionnel pour le choix de la stratégie institutionnelle sur les dépôts de données de recherche (la légende est en haut à droite)
Recommandations et ressources complémentaires
Des recommandations et des ressources utiles pour la mise en pratique de la stratégie fixée à l’étape précédente ont été regroupées dans un troisième outil (Tableau 6). Une partie de ces recommandations peut aussi être utilisée pour améliorer les pratiques ou améliorer un dépôt existant.
Tableau 6 : Recommandations et ressources complémentaires pour la mise en pratique de la stratégie fixée à l’aide du guide décisionnel (les références et les détails sont donnés dans Guirlet 2020)
Version pour navigateur Internet
Dans l’objectif de rendre la démarche plus souple et l’utilisation de ces outils interactive et collaborative, ces outils pourraient être rendus disponibles en version Internet. A titre de démonstration, quelques pages d’un prototype appelé InSTOReD, pour Institutional Strategy Tool for Open Research Data, ont été développées (Figure 10). Avec cette version, l’accès aux outils décisionnels se fait à partir de l’un des quatre points d’entrée possibles (ou tâches) placés au même niveau sur la page d’accueil du site. Ces points d’entrée sont : l’évaluation de l’alignement des pratiques actuelles avec les exigences sur les DR, l’identification d’un dépôt existant correspondant aux besoins, l’adaptation d’un dépôt pour publications aux DR, et la spécification et la création d’un dépôt de DR institutionnel (Figure 10, haut). Cette version inclut aussi toutes les rubriques du vade-mecum (la Figure 10, milieu, présente les rubriques sur la spécification du dépôt institutionnel à créer et sur le cahier des charges).
Dans le cas de la première tâche (l’évaluation de l’alignement des pratiques avec les exigences), les exigences sur les dépôts par le FNS et par H2020 sont rappelées. En cas de changement de ces exigences, ou de l’apparition de nouvelles exigences, il serait facile de mettre à jour cette rubrique. Il est également possible de remplir les exigences qui s’appliquent à l’ouverture des données de recherche dans un autre pays (Figure 10, bas), élargissant ainsi l’utilité des outils à d’autres institutions que les institutions suisses.
Ce format permet aussi de prévoir un espace collaboratif, où les institutions ayant déjà effectué cette démarche décisionnelle seraient invitées à déposer leurs retours d’expérience pour en faire bénéficier d’autres.
Figure 10 : Pages extraites du prototype InSTOReD de version pour navigateur Internet des outils décisionnels : points d’entrée (ou tâches) proposés (haut); spécification du nouveau dépôt institutionnel pour données de recherche (milieu); transposabilité à d’autres pays de la comparaison des exigences et des pratiques (bas)
Conclusion
Au terme de cette étude, on a abouti aux principaux résultats suivants.
On a identifié les directives pour l’ouverture des données de recherche en Suisse, ainsi que les moyens de les mettre en pratique. On a défini ce qu’est un dépôt pour le partage public des données et pour leur réutilisation, quelles formes il peut prendre, quels outils et services il peut fournir. On a identifié des critères de qualité pour ce dépôt et élaboré un modèle de description pouvant être utilisé soit pour l’évaluation soit pour la conception d’un dépôt de DR ouvertes. On a dressé un panorama des dépôts de données généralistes, disciplinaires et institutionnels utilisés et recommandés par neuf institutions académiques. On a identifié les informations et les paramètres importants pour le choix d’un dépôt ou la création d’un nouveau.
A partir des résultats précédents, on a produit des outils qui formalisent la démarche de choix de la meilleure stratégie possible par une institution de recherche en matière de dépôt de données de recherche ouvertes. En suivant cette démarche, l’institution fait un choix éclairé qui lui permettra de répondre aux exigences en vigueur sur les données de recherche, tout en tenant compte des besoins et des pratiques des chercheurs et chercheuses et du contexte et des ressources à l’échelle locale.
Les institutions de recherche sont invitées à utiliser régulièrement ces outils. Le découpage modulaire de certaines étapes du guide décisionnel permet de les suivre indépendamment les unes des autres, en effectuant une partie de la démarche seulement. Avec les premières étapes de ce guide, on peut vérifier régulièrement la conformité entre les exigences et les pratiques, et adapter le cas échéant les conseils donnés aux chercheurs et chercheuses pour le choix du dépôt. Avec les étapes suivantes, on peut aussi réévaluer régulièrement, s’il existe, un ou des dépôts disciplinaires ou généralistes plus pertinents que ceux couramment utilisés par ses chercheurs et chercheuses, ou encore, adapter le dépôt institutionnel de données pour qu’il réponde aux besoins de façon plus satisfaisante.
Ces outils sont également adaptables en fonction des changements du paysage des dépôts et transposables à un autre contexte hors de Suisse. Avec la version prototype pour Internet développée au terme de cette étude, on facilite la mise à jour des outils, leur adaptabilité et leur transposabilité. Cette version offre en plus l’avantage d’inclure des aspects collaboratifs, pour le partage de retours d’expérience et l’échange de bonnes pratiques par des institutions ayant déjà effectué la démarche.
En aidant les institutions à proposer aux chercheurs et chercheuses le dépôt le plus adapté, ces outils les aident à mettre en pratique leur politique en matière d’ouverture des données de recherche, à répondre aux exigences en vigueur, et à fournir un instrument qui convient à leurs chercheurs et chercheuses et au contexte institutionnel. En proposant d’autres options que la création d’un nouveau dépôt, selon un argumentaire construit et adapté à chaque cas, dans un souci de rationalisation et de mutualisation des ressources, ces outils devraient contribuer aussi à limiter la fragmentation de l’offre et la multiplication inutile de dépôts de données de recherche en Suisse.
Notes
(1)On peut consulter la liste de Docuteam ([sans date]) des formats de fichiers reconnus comme adaptés à l’archivage des données. Cette liste est inspirée du catalogue des formats de données d’archivage du CECO ([sans date]).
(2)CASRAI est une organisation à but non lucratif travaillant sur la standardisation de formats pour la gestion et l’échange de l’information dans le domaine de la recherche (CASRAI [sans date]a).
(3)D’autres licences ouvertes telles que celles des Open Data Commons sont possibles (Open Data Commons [sans date] ; Ball 2011). Mais comme seules les licences CC ont été rencontrées dans le cadre de cette étude, on se limite à celles-ci.
(4)Ces autres critères sont : la facilité du versement, l’accessibilité, la découvrabilité, la curation, l’infrastructure de préservation, la pérennité de l’organisation, et le soutien pour les formats et les standards utilisés (EPFL Library, Research Data Library Team [sans date], p.31).
(5)(pour la préservation des données en accès restreint seulement)
(6)(pour les données liées à une publication aussi hébergée par BORIS)
(7)Springer Nature [sans date]b
(8)PLOS ONE [sans date]b
(9)Science Europe 2018
(10)FNS [sans date]b; voir aussi Perini 2019
(11)On peut déjà consulter la liste des dépôts par discipline établie par von der Heyde (2019, fig. 13 et fig. 18), à partir des réponses à ses questionnaires auprès des chercheurs et chercheuses de la communauté académique suisse en 2018.
(12)Voir les espaces communautaires de la FBM de l’Université de Lausanne et du CHUV (depuis 2016 ; zenodo [sans date]b), de l’Institute for Atmospheric and Climate Science ETH Zürich (depuis 2019 ; zenodo [sans date]c), l’espace Research Data University of Basel (depuis 2019 ; zenodo [sans date]d), et l’espace University of Zurich (depuis 2013 ; zenodo [sans date]e).
(13)Ou San Francisco Declaration on Research Assessment (2012)
Acronymes et abréviations
ACOUA ACademic OUtput Archive
ARK Archival Resource Key
ArODES Archive Ouverte des Domaines de la HES-SO
BerDA Bern Digital Archive
BORIS Bern Open Repository and Information System
CASRAI Consortia Advancing Standards in Research Administration Information
CC Creative Commons
CCSDS Consultative Committee for Space Data Systems
CECO Centre de coordination pour l’archivage à long terme de documents électroniques
CHUV Centre Hospitalier Universitaire Vaudois
CTS CoreTrustSeal
DaSCH Data and Service Center for the Humanities
DDI Data Documentation Initiative
DINI Deutsche Initiative für NetzwerkInformation
DLCM Data Life Cycle Management
DMP Data Management Plan
DOI Digital Object Identifier
DORA Declaration On Research Assessment
DR Données de la Recherche
DSA Data Seal of Approval
EUDAT EUropean Data Infrastructure
EPFL Ecole Polytechnique Fédérale de Lausanne
ETHZ Eidgenössische Technische Hochschule Zürich ou Ecole Polytechnique Fédérale de Zurich
FAIR Findable, Accessible, Interoperable, Reusable
FAQ Frequently Asked Questions, Foire Aux Questions
FBM Faculté de Biologie et de Médecine (UNIL-CHUV)
FNS Fonds National Suisse de la Recherche Scientifique
GDR Gestion des Données de la Recherche
H2020 Horizon 2020
HEG Haute Ecole de Gestion de Genève
HES-SO Haute Ecole Spécialisée de Suisse Occidentale
HEI Haute Ecole Institutionnelle
ICPSR Inter-university Consortium for Political and Social Research
ICSU-WDS International Council for Science’s World Data System
InSTOReD Institutional Strategy Tool for Open Research Data
OAI Open Archives Initiative
OAI-PMH Open Archives Initiative Protocol for Metadata Harvesting
OAIS Open Archival Information System
ORCID Open Researcher and Contributor ID
OS Open Science
OSF Open Science Framework
PID Persistent Identifier
PURL Persistent Uniform Resource Locator
RDA Research Data Alliance
RDF Resource Description Framework
Re3data Registry of Research Data Repositories
RRID Research Resource Identifier
Serval Serveur académique lausannois
UNIBAS Université de Bâle
UNIBE Université de Berne
UNIFR Université de Fribourg
UNIGE Université de Genève
UNIL Université de Lausanne
UNIZ Université de Zurich
URN Uniform Resource Name
ZORA Zürich Open Repository Archive
Bibliographie
Amsterdam Call for Action on Open Science, 2016. [en ligne]. 04.04.2016. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.government.nl/documents/reports/2016/04/04/amsterdam-call-for-action-on-open-science
ARLITSCH, Kenning, OBRIEN, Patrick, MIXTER, Jeffrey K., CLARK, Jason A. et STERMAN, Leila, 2016. Ensuring Discoverability of IR Content. In : CALLICOTT, Burton B., SCHERER, David et WESOLEK, Andrew. Making Institutional Repositories Work [en ligne]. Ed. Purdue University Press. [Consulté le 07.11.2020], pp. 31-50. ISBN 978-1-55753-902-1. Disponible à l’adresse : http://www.jstor.org/stable/10.2307/j.ctt1wf4drg
BALL, Alex, 2011. How to License Research Data. dcc.ac.uk [en ligne]. 09.02.2011. Version modifiée le 17.07.2014. [Consulté le 07.11.2020]. Disponible à l’adresse : https://dcc.ac.uk/guidance/how-guides/license-research-data
BLUMER, Eliane et BURGI, Pierre-Yves, 2015. Data Life-Cycle Management Project: SUC P2 2015-2018. Revue électronique suisse de science de l’information [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : http://www.ressi.ch/num16/article_110
BOSTON UNIVERSITY DATA SERVICES, [sans date]. Selecting a data repository. bu.edu [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.bu.edu/data/share/selecting-a-data-repository/#openbu
CASRAI [sans date]a. Welcome to CASRAI. casrai.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://casrai.org/
CASRAI [sans date]b. Research Data Management Glossary. casrai.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://casrai.org/rdm-glossary/
CECO, [sans date]. Catalogue des formats de données d'archivage. kost-ceco.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://kost-ceco.ch/cms/formats-de-donnees.html
CENTER FOR OPEN SCIENCE, [sans date]. Open Science badges enhance openness, a core value of scientific practice. cos.io [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.cos.io/initiatives/badges
CORETRUSTSEAL, 2020a. Core Certified Repositories. CoreTrustSeal [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.coretrustseal.org/why-certification/certified-repositories/
CORETRUSTSEAL, 2020b. CoreTrustSeal Trustworthy Data Repositories Requirements 2020-2022, version 02.00 [en ligne]. S.l. : s.n. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.coretrustseal.org/why-certification/requirements/
CORETRUSTSEAL STANDARDS AND CERTIFICATION BOARD, 2020. CoreTrustSeal Trustworthy Data Repositories Requirements: Extended Guidance 2020-2022, version 2.0 [en ligne]. S.l. : s.n. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.coretrustseal.org/why-certification/requirements/, https://zenodo.org/record/3632533
CORRADO, Edward M., 2019. Repositories, Trust, and the CoreTrustSeal. Technical Services Quarterly. 02.01.2019. Vol. 36, n 1, p. 61‑72. DOI 10.1080/07317131.2018.1532055
CRAGIN, Melissa H., HEIDORN, P. Bryan, PALMER, Carole L. et SMITH, Linda C., 2007. An Educational Program on Data Curation [en ligne]. 25.06.2007. [Consulté le 07.11.2020]. Disponible à l’adresse : http://hdl.handle.net/2142/3493
CREATIVE COMMONS [sans date]. About CC licenses. creativecommons.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://creativecommons.org/about/cclicenses/
DARIS, 2018. Implementation of the CoreTrustSeal. coretrustseal.org [en ligne]. 20.03.2018. [Consulté le 02.12.2020]. Disponible à l’adresse: https://www.coretrustseal.org/wp-content/uploads/2018/03/DARIS.pdf
DASCH, [sans date]. Services. dasch.swiss [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://dasch.swiss/services/#appendix
DATA CURATION NETWORK, [sans date]. Mission. datacurationnetwork.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://datacurationnetwork.org/about/our-mission/
DATACITE, [sans date]. Welcome to DataCite. datacite.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://datacite.org/
DATACITE METADATA WORKING GROUP, 2019. DataCite Metadata Schema Documentation for the Publication and Citation of Research Data v4.3. 2019. pp. 73 pages. Disponible à l’adresse: https://doi.org/10.14454/7xq3-zf69
DATAVERSE PROJECT, [sans date]. User Guide. dataverse.org. [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : http://guides.dataverse.org/en/4.20/user/
DIGITAL PRESERVATION COALITION, [sans date]. Digital Preservation Handbook. dpconline.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.dpconline.org/handbook/technical-solutions-and-tools/persistent-identifiers
DILLO, Ingrid et de LEEUW, Lisa, 2018. CoreTrustSeal. In : Mitteilungen der Vereinigung Österreichischer Bibliothekarinnen und Bibliothekare. 19.07.2018. Vol. 71, n° 1, p. 162‑170. DOI 10.31263/voebm.v71i1.1981
DINI 2011. DINI-Zertifikat Dokumenten- und Publikationsservice 2010. Version 3.1. [en ligne]. 03.2011. [Consulté le 07.11.2020]. Disponible à l’adresse : https://edoc.hu-berlin.de/handle/18452/2145
DOCUTEAM, [sans date]. Standard de versement. docuteam.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.docuteam.ch/fr/prestations/archivage-electronique-docuteam-cosmos/standard-de-versement/#_ftn1
DRYAD, [sans date]. Submission process. dryad.org [en ligne]. [Consulté le 03.12.2020]. Disponible à l’adresse : https://datadryad.org/stash/submission_process#upload-methods
Dublin Core. 2020. Wikipédia : l’encyclopédie libre [en ligne]. Dernière modification de la page le 05.10.2020 à 8:14. [Consulté le 07.11.2020]. Disponible à l’adresse : https://fr.wikipedia.org/wiki/Dublin_Core#Autres_r%C3%A9f%C3%A9rentiels_de_m%C3%A9tadonn%C3%A9es
DUBLIN CORE METADATA INITIATIVE, 2020. dublincore.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.dublincore.org/
EPFL, [sans date]. EPFL Data Champions. epfl.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.epfl.ch/campus/library/services/services-researchers/rdm-contacts-communities/epfl-data-champions/#more
EPFL LIBRARY, [sans date]. Research Data Management Fast Guides. epfl.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.epfl.ch/campus/library/services/services-researchers/rdm-guides-templates/
EPFL LIBRARY, RESEARCH DATA LIBRARY TEAM, [sans date]. RDM Walkthrough Guide. epfl.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.epfl.ch/campus/library/services/services-researchers/rdm-guides-templates/
ETHZ - ETH-BIBLIOTHEK, [sans date]. FAQs de. ethz.ch [en ligne]. [Consulté le 08.11.2020]. Disponible à l’adresse: https://documentation.library.ethz.ch/display/RC/FAQs+de
EUROPEAN COMMISSION, DIRECTORATE-GENERAL FOR RESEARCH & INNOVATION, 2016. H2020 Programme - Guidelines on FAIR Data Management in Horizon 2020 [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-data-mgt_en.pdf
EUROPEAN COMMISSION, DIRECTORATE-GENERAL FOR RESEARCH & INNOVATION, 2017. H2020 Programme - Guidelines to the Rules on Open Access to Scientific Publications and Open Access to Research Data in Horizon 2020 [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-pilot-guide_en.pdf
FIGSHARE, [sans date]. How to upload and publish your data. figshare.com [en ligne]. [Consulté le 08.11.2020]. Disponible à l’adresse : https://help.figshare.com/article/how-to-upload-and-publish-your-data
FNS, [sans date]a. Open Research Data. snf.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : http://www.snf.ch/fr/leFNS/points-de-vue-politique-de-recherche/open_research_data/Pages/default.aspx#D%E9claration%20de%20principe%20du%20FNS%20sur%20le%20libre%20acc%E8s%20aux%20donn%E9es%20de%20la%20recherche%20%28Open%20Research%20Data%29
FNS, [sans date]b. Data Management Plan (DMP) - Directives pour les chercheuses et chercheurs. snf.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : http://www.snf.ch/fr/leFNS/points-de-vue-politique-de-recherche/open_research_data/Pages/data-management-plan-dmp-directives-pour-les-chercheuses-et-chercheurs.aspx
FNS, 2017. Open Research Data : les requêtes devront inclure un plan de gestion des données. FNS. snf.ch [en ligne]. 06.03.2017. [Consulté le 07.11.2020]. Disponible à l’adresse : http://www.snf.ch/fr/pointrecherche/newsroom/Pages/news-170306-open-research-data-bientot-une-realite.aspx
FNS, 2020. Règlement d’exécution général relatif au règlement des subsides. snf.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: http://www.snf.ch/SiteCollectionDocuments/fns-reglement_execution_general_relatif_au_reglement_subsides_f.pdf#page=15
FOREIGN COMMONWEALTH OFFICE, 2013. G8 Science Ministers Statement. gov.uk [en ligne]. 12.06.2013. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.gov.uk/government/news/g8-science-ministers-statement
FORS, [sans date]. Contrat utilisateur. unil.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://forsbase.unil.ch/media/general_documentation/fr/User_contract_F.pdf
GUIRLET, Marielle, 2020. Guide décisionnel et vade-mecum pour la mise à disposition d’un dépôt de données de recherche ouvertes en Suisse. [en ligne]. Genève : Haute école de gestion de Genève. Travail de Master. Version révisée. 18.12.2020. DOI: 10.5281/zenodo.4357134. [Consulté le 18.12.2020]. Disponible à l'adresse: https://zenodo.org/record/4357134
HES-SO, [sans date]. Archiver ses données de recherche. hes-so.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://openscience.hes-so.ch/fr/archiver-donnees-recherche-14819.html
HES-SO, 2020. Appel à projets Open Data HES-SO. hes-so.ch [en ligne]. 02.06.2020. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.hes-so.ch/fr/appel-projets-open-data-hes-so-16822.html
HEWLETT, Niles E, 2006. The USDA Enterprise Architecture Program. [en ligne]. 25.01.2006. [Consulté le 07.11.2020]. Disponible à l’adresse : https://web.archive.org/web/20070508175931/http://www.ocio.usda.gov/p_mgnt/doc/PM_Class_EA_NEH_012506_Final.ppt
HODSON, Simon, JONES, Sarah et al., 2018. Turning FAIR data into reality. Interim report of the European Commission Expert Group on FAIR data [en ligne]. S.l. [Consulté le 07.11.2020]. Disponible à l’adresse : https://zenodo.org/record/1285272ICPSR, [sans date]. History. icpsr.umich.edu [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.icpsr.umich.edu/web/pages/about/history/
JOHNSTON, Lisa R, CARLSON, Jake, HUDSON-VITALE, Cynthia, IMKER, Heidi, KOZLOWSKI, Wendy, OLENDORF, Robert et STEWART, Claire, 2016. Data Curation Terms and Activities [en ligne]. 23.10.2016. [Consulté le 07.11.2020]. Disponible à l’adresse : https://conservancy.umn.edu/bitstream/handle/11299/188638/DefinitionsofDataCurationActivities%20%281%29.pdf?sequence=1&isAllowed=y
JOHNSTON, Lisa R., 2017. Data Curation Handbook Steps. In: JOHNSTON, Lisa R., 2017. Curating Research Data Volume Two: A Handbook of Current Practice. Ed: American Library Association, 2017. [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://conservancy.umn.edu/bitstream/handle/11299/183502/Data%20Curation%20Handbook%20Steps_v2.pdf?sequence=1&isAllowed=y
JOHNSTON, Lisa, CARLSON, Jake, HUDSON-VITALE, Cynthia, IMKER, Heidi, KOZLOWSKI, Wendy, OLENDORF, Robert et STEWART, Claire, 2017. Data Curation Network: A Cross-Institutional Staffing Model for Curating Research Data [en ligne]. S.l. [Consulté le 07.11.2020]. Disponible à l’adresse : http://hdl.handle.net/11299/188654
JOHNSTON, Lisa R, CARLSON, Jacob, HUDSON-VITALE, Cynthia, IMKER, Heidi, KOZLOWSKI, Wendy, OLENDORF, Robert et STEWART, Claire, 2018. How Important is Data Curation? Gaps and Opportunities for Academic Libraries. Journal of Librarianship and Scholarly Communication. 26.04.2018. Vol. 6, n° 1, pp. 2198. DOI 10.7710/2162-3309.2198
JONG (de), Michiel, ZUIDERWIJK, Anneke, WILL, Nicole et JANSSEN, Marijn, 2020. Open Science: Sharing Your Research with the World [online course]. TU Delft. edx.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.edx.org/course/open-science-sharing-your-research-with-the-world
L’HOURS, Hervé, KLEEMOLA, Mari et de LEEUW, Lisa, 2019. CoreTrustSeal: From academic collaboration to sustainable services. In : IASSIST Quarterly. 10.05.2019. Vol. 43, n°1, p. 1‑17. DOI 10.29173/iq936
MILZOW, Katrin, VON ARX, Martin, SOMMER, Cornélia, CAHENZLI, Julia et PERINI, Lionel, 2020. Open Research Data: SNSF monitoring report 2017-2018 [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://zenodo.org/record/3618123
NATURE, 2016. Data availability statements and data citations policy: Guidance for authors. Nature [en ligne]. 09.2016. [Consulté le 07.11.2020]. Disponible à l’adresse: http://www.nature.com/authors/policies/data/data-availability-statements-data-citations.pdf
OLOS, 2020a. OLOS Specifications [fichier texte Office Open]. Version 1. Dernière mise à jour le 19.05.2020. Document interne au projet.
OLOS, 2020b. Integrated data management solution for researchers and institutions. olos.swiss. [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse. https://olos.swiss/
OPEN DATA COMMONS, [sans date]. Open Data Commons, Legal tools for Open Data [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://opendatacommons.org/licenses/odbl/
Open Research Data (ORD) – the uptake in Horizon 2020, 2016. EU Open Data Portal, europa.eu [en ligne]. 10.05.2016. 19.04.2018. [Consulté le 03.12.2020]. Disponible à l’adresse : https://data.europa.eu/euodp/en/data/dataset/open-research-data-the-uptake-of-the-pilot-in-the-first-calls-of-horizon-2020
PERINI, Lionel, 2019. SNSF Open Research Data Policy. Journée Open Science [en ligne]. HES-SO, 18 March 2019. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.hes-so.ch/data/documents/4-L.Perini-FNS-PolitiqueFNS-OpenData-10357.pdf
PINFIELD, Stephen, COX, Andrew M. et SMITH, Jen, 2014. Research Data Management and Libraries: Relationships, Activities, Drivers and Influences. In : LAUNOIS, Pascal (éd.), PLoS ONE. 08.12.2014. Vol. 9, n° 12, p. e114734. DOI: 10.1371/journal.pone.0114734 Pryor 2012
PLOS ONE, [sans date]a. Data availability. plos.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: http://journals.plos.org/plosone/s/data-availability
PLOS ONE, [sans date]b. How to Store and Manage Your Data. plos.org [en ligne]. [Consulté le 06.12.2020]. Disponible à l’adresse : https://plos.org/resource/how-to-store-and-manage-your-data/#choosing-repository
PRYOR, Graham, 2012. Why manage research data? Managing Research Data. Londres: Facet Publishing, pp.1-16. ISBN 978-1-85604-756-2
RE3DATA.ORG, [sans date]. re3data.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.re3data.org/
RE3DATA.ORG, 2017. B2SHARE. re3data.org [en ligne]. 22.11.2017 [Consulté le 08.11.2020]. Disponible à l’adresse : https://www.re3data.org/repository/r3d100011394
RICE, Robin et SOUTHALL, John, 2016. The data librarian’s handbook. London : Facet Publishing. ISBN 978-1-78330-047-1.
ROSENTHALER, Lukas, FORNARO, Peter et CLIVAZ, Claire, 2015. DaSCH: Data and Service Center for the Humanities. In : Digital Scholarship in the Humanities. 2015. Vol. 30, p. i43‑i49. [en ligne]. [Consulté le 08.11.2020]. Disponible à l’adresse : https://academic.oup.com/dsh/article/30/suppl_1/i43/365238
San Francisco Declaration on Research Assessment, 2012. DORA [en ligne]. 16.11.2012. [Consulté le 07.11.2020]. Disponible à l’adresse : https://sfdora.org/read/
San Francisco Declaration on Research Assessment. 2020. DORA Signers. [en ligne]. [Consulté le 08.11.2020]. Disponible à l’adresse: https://sfdora.org/signers/
Science Europe, 2018. Practical Guide to the International Alignment of Research Data Management. scienceeurope.org [en ligne]. 11.2018. [Consulté le 08.11.2020]. Disponible à l’adresse: https://www.scienceeurope.org/media/jezkhnoo/se_rdm_practical_guide_final.pdf
Sorbonne declaration on research data rights, 2020. [en ligne]. [Consulté le 07.12.2020]. Disponible à l’adresse: https://sorbonnedatadeclaration.eu/
SPRINGER NATURE, [sans date]a. Research Data Policies FAQ. Springer Nature [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.springernature.com/gp/authors/research-data-policy/data-policy-faqs
SPRINGER NATURE, [sans date]b. Research Data Policies. Recommended Repositories. Springer Nature [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.springernature.com/gp/authors/research-data-policy/recommended-repositories
SWISS NATIONAL SCIENCE FOUNDATION, [sans date]. Explanation of the FAIR data principles [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : http://www.snf.ch/SiteCollectionDocuments/FAIR_principles_translation_SNSF_logo.pdf
SWISS NATIONAL SCIENCE FOUNDATION, 2017. Examples of data repositories [en ligne]. 27.04.2017. [Consulté le 07.11.2020]. Disponible à l’adresse : http://www.snf.ch/SiteCollectionDocuments/FAIR_data_repositories_examples.pdf
THE CONCORDAT WORKING GROUP, 2016. Concordat on Open Research Data [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.bolton.ac.uk/assets/ConcordatonOpenResearchData.pdf
THE CONSULTATIVE COMMITTEE FOR SPACE DATA SYSTEMS, 2012. Reference Model for an Open Archival Information System (OAIS) - Recommended Practice CCSDS 650.0-M-2 [en ligne]. Washington, DC, USA. CCSDS. [Consulté le 07.11.2020]. Recommendation for Space Data System Practices. Disponible à l’adresse : https://public.ccsds.org/Pubs/650x0m2.pdf
THE ROYAL SOCIETY, 2012. Science as an Open Enterprise [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://royalsociety.org/topics-policy/projects/science-public-enterprise/report/
THE UNIVERSITY OF EDINBURGH, 2019. Trustworthy Digital Repository. ed.ac.uk [en ligne]. 20.06.2019. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.ed.ac.uk/information-services/research-support/research-data-service/after/data-repository/trustworthy-digital-repository
TRELOAR, Andrew, GROENEWEGEN, David et HARBOE-REE, Cathrine, 2007. The Data Curation Continuum: Managing Data Objects in Institutional Repositories. D-Lib Magazine [en ligne]. Septembre 2007. Vol. 13, n° 9/10. [Consulté le 07.11.2020]. DOI 10.1045/september2007-treloar. Disponible à l’adresse : http://www.dlib.org/dlib/september07/treloar/09treloar.html
TRELOAR, Andrew, 2012. Private Research, Shared Research, Publication, and the Boundary Transitions. Version 1.4.3 [en ligne]. 19.03.2012. [Consulté le 07.11.2020]. Disponible à l’adresse : https://andrew.treloar.net/research/diagrams/
UNIVERSITAT BASEL, [sans date]. Sharing data. unibas.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://researchdata.unibas.ch/en/publish-and-share/
UNIVERSITAT BERN, [sans date]a. Universitätsbibliothek. Forschungsdatenmanagement. unibe.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.unibe.ch/universitaet/dienstleistungen/universitaetsbibliothek/service/open_science/forschungsdatenmanagement/index_ger.html
UNIVERSITAT BERN, [sans date]b. Universitätsbibliothek. BORIS Repository. unibe.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.unibe.ch/universitaet/dienstleistungen/universitaetsbibliothek/service/elektronisch_publizieren/boris_repository/index_ger.html
UNIVERSITAT ZURICH, HAUPTBIBLIOTHEK, 2019. Empfohlene Repositories. uzh.ch [en ligne]. 05.12.2019. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.hbz.uzh.ch/de/open-access-und-open-science/daten-repositories/empfohlene-repositories.html
UNIVERSITAT ZURICH, HAUPTBIBLIOTHEK, 2020. Nutzen von Daten in Repositories. uzh.ch [en ligne]. 06.02.2020. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.hbz.uzh.ch/en/open-access-und-open-science/daten-repositories/auffinden-von-daten-in-repositories.html
UNIVERSITE DE GENEVE, [sans date]. Données de recherche. Définitions. unige.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.unige.ch/researchdata/fr/footer/definitions/
UNIVERSITE DE LAUSANNE, [sans date]a. L’Open Science à l’UNIL. Données personnelles & sensibles. unil.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.unil.ch/openscience/home/menuinst/open-research-data/conformite--exigences/donnees-personnelles--sensibles.html
UNIVERSITE DE LAUSANNE, [sans date]b. L’Open Science à l’UNIL. Archivage & partage. unil.ch [en ligne]. [Consulté le 08.11.2020]. Disponible à l’adresse : https://www.unil.ch/openscience/home/menuinst/open-research-data/gerer-ses-donnees-de-recherche/archivage--partage.html
VON DER HEYDE, Markus, 2019. Open Research Data: Landscape and cost analysis of data repositories currently used by the Swiss research community, and requirements for the future [Report to the SNSF] [en ligne]. 22.05.2019 [Consulté le 07.11.2020]. Disponible à l’adresse : https://zenodo.org/record/2643460
WILKINSON, Mark D., DUMONTIER, Michel, AALBERSBERG, IJsbrand Jan, APPLETON, Gabrielle, AXTON, Myles, BAAK, Arie, BLOMBERG, Niklas, BOITEN, Jan-Willem, DA SILVA SANTOS, Luiz Bonino, BOURNE, Philip E., BOUWMAN, Jildau, BROOKES, Anthony J., CLARK, Tim, CROSAS, Mercè, DILLO, Ingrid, DUMON, Olivier, EDMUNDS, Scott, EVELO, Chris T., FINKERS, Richard, GONZALEZ-BELTRAN, Alejandra, GRAY, Alasdair J.G., GROTH, Paul, GOBLE, Carole, GRETHE, Jeffrey S., HERINGA, Jaap, ’T HOEN, Peter A.C, HOOFT, Rob, KUHN, Tobias, KOK, Ruben, KOK, Joost, LUSHER, Scott J., MARTONE, Maryann E., MONS, Albert, PACKER, Abel L., PERSSON, Bengt, ROCCA-SERRA, Philippe, ROOS, Marco, VAN SCHAIK, Rene, SANSONE, Susanna-Assunta, SCHULTES, Erik, SENGSTAG, Thierry, SLATER, Ted, STRAWN, George, SWERTZ, Morris A., THOMPSON, Mark, VAN DER LEI, Johan, VAN MULLIGEN, Erik, VELTEROP, Jan, WAAGMEESTER, Andra, WITTENBURG, Peter, WOLSTENCROFT, Katherine, ZHAO, Jun et MONS, Barend, 2016. The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data. décembre 2016. Vol. 3, n° 1, pp. 160018. DOI 10.1038/sdata.2016.18
ZENODO, [sans date]a. About Zenodo. zenodo.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://about.zenodo.org/
ZENODO, [sans date]b. Faculty of Biology and Medicine at University of Lausanne & Lausanne University Hospital. zenodo.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://zenodo.org/communities/fbm_chuv/?page=1&size=20
ZENODO, [sans date]c. Atmospheric physics group, Institute for Atmospheric and Climate Science, ETH Zurich. zenodo.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://zenodo.org/communities/eth_zurich_iac_atmospheric_physics/?page=1&size=20
ZENODO, [sans date]d. Research Data University of Basel. zenodo.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://zenodo.org/communities/rdm_unibas/?page=1&size=20
ZENODO, [sans date]e. University of Zurich. zenodo.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://zenodo.org/communities/uzh/?page=1&size=20
ZENODO, [sans date]f. Frequently Asked Questions. zenodo.org [en ligne]. [Consulté le 08.11.2020]. Disponible à l’adresse : https://help.zenodo.org/
- Vous devez vous connecter pour poster des commentaires
The Knowledge & Learning Commons – a library’s evolution driving cultural change at the United Nations in Geneva
Ressi — 17 décembre 2020
Viviane Brunne, Programme Manager, bibliothèque des Nations Unies à Genève
Sigrun Habermann, Manager de la bibliothèque des Nations Unies à Genève
Résumé
L’évolution des bibliothèques au cours des trois dernières décennies a souvent pris la forme de "Commons" (Biens communs). La présente étude de cas présente l’adaptation unique de ce modèle au sein de la Bibliothèque & Archives de l’ONU Genève, où le Commons est devenu le véhicule d’une plus grande ambition, conduisant le changement culturel à l’intérieur des Nations Unies à Genève.
Cet article retrace le développement de l’Espace commun "savoirs et formation" des Nations Unies Genève "Commons" depuis ses premières étapes expérimentales vers un programme plus structuré il démontre comment les approches de conception centrées sur l’être humain ont été appliquées pour le développer davantage, en co-création avec ses utilisateurs.
À la lumière des expériences plus récentes au cours du confinement provoqué par la COVID-19 depuis mars 2020, la conclusion fournit une réflexion sur les défis et les opportunités actuels, en anticipant certains développements dans un avenir proche.
Abstract
The evolution of libraries over the past three decades has often taken the form of a “commons”. The present case study showcases the unique adaptation of this model at the UN Library&Archives Geneva, where it has become an approach for a larger ambition, that of driving cultural change at the United Nations in Geneva towards more openness for innovation. This article retraces the development of the UN Geneva Commons from its early experimental stage into a more structured programme and explains how human-centred design approaches were applied to develop it further, in co-creation with its users. In light of the more recent experiences during the lockdown caused by Covid-19 from March 2020 onwards, the conclusion provides a reflection on current challenges and opportunities, anticipating some developments for the near future.
Zusammenfassung
In den letzten drei Jahrzehnten haben sich Bibliotheken oft in Form von "Commons" weiterentwickelt. Die folgende Fallstudie zeigt, wie die Bibliothek & Archive der Vereinten Nationen in Genf sich dieses Modell zu eigen gemacht haben und wie sie es als Vehikel nutzen, um ein noch ambitiöseres Projekt voranzutreiben, nämlich die Veränderung der Organisationskultur der Vereinten Nationen Genf hin zu einer grösseren Offenheit für Innovation. Der Artikel zeichnet die Entwicklung des "Commons" der Vereinten Nationen in Genf nach - von seinem experimentellen Anfangsstadium hin zu einem strukturierten Programm. Der Beitrag erklärt, wie human-centred design, ein auf die Bedürfnisse des Menschen ausgerichtetes Designkonzept, das den Nutzer in den Schaffensprozess mit einbezieht, zur Weiterentwicklung des Programms beitrug. In Anbetracht der jüngsten Erfahrungen mit den Arbeitsbeschränkungen durch COVID-19 seit März 2020, reflektiert die Schlussfolgerung einige Gedanken zu den derzeitigen Herausforderungen und den neuen Möglichkeiten und prognostiziert damit einige wahrscheinliche Entwicklungen der nahen Zukunft.
Mots-Clés:
bibliothèques,
archives,
formation,
partage de connaissances,
innovation,
développement de communautés,
libraries,
archives,
learning,
knowledge sharing,
innovation,
community-building,
Commons,
Bibliotheken,
Archive,
Lernen,
Wissensaustausch,
Innovation,
Gemeinschaftsbildung The Knowledge & Learning Commons – a library’s evolution driving cultural change at the United Nations in Geneva
1. Introduction
A “commons” is a mechanism to pool and jointly use resources. In economic and political theory, the concept is famously linked to a metaphor by Garrett Hardin, with herdsmen sharing a common pasture. In Hardin’s example, what sounds like a reasonable approach goes terribly wrong, because – in the absence of any regulation or governance mechanism, the herdsmen put in as many cattle as possible to graze to maximize their own benefit. In the end, overgrazing meant ruin for all (cf. Hess/Ostrom 2006: 10-11).
Libraries, in a way, have adopted the approach of pooling resources – books, journals, newspapers – and make them available as a common good. Often funded publicly and available to users for free or against a small fee, they provide just the type of management structure that helps to maximize the use of the pooled resources for as many people as possible and over longer periods of time.
In the context of libraries, it appears that the benefits of information, knowledge and learning resources can actually be multiplied when shared, rather than depleted as in the example of the pasture (Bollier 2006: 28, 34). It may come as no surprise that libraries have evolved naturally around the concept of the commons, taking it further to encompass new areas of activity. This article will explore the evolution of libraries as commons and illustrate it with the case study of the UN Library&Archives Geneva (L&A).
To better understand the context, we will first outline the particularities of this specialized Library which is embedded in the institutional context of the United Nations and bears the heritage of the League of Nations, in many ways its predecessor. This will help to flag the differences to the libraries in university campuses and public libraries that have experimented with various types of commons over the past three decades. Taking their examples as a point of departure, we will show the unique particularities of the Knowledge & Learning Commons at the UN in Geneva (1) which is not only a vehicle for the L&A to evolve but one to drive innovation and cultural change across the organization at large. We will follow the path of the UN Geneva Commons from its early experimental stages into a more structured programme and explain how human-centred design approaches were applied to develop it, in co-creation with its users. We will show how constant assessment has been the driver of the programme which was put to a sudden test by the new situation caused by Covid-19 from March 2020 onwards. Following its own innovation principles, the UN Geneva Commons adjusted through experimentation and is ready to move to the next level in 2021. We will conclude with a reflection on the current challenges and opportunities and anticipate some developments of the near future.
2. A brief look at who we are - The United Nations Library & Archives Geneva
The beginnings of the UN L&A Geneva were with the League of Nations, the first global intergovernmental organization for peace. With its founding in 1919, the League started a library service. A major milestone for the Library was the donation of a dedicated building by John D. Rockefeller Jr. Finished in 1936, it represents an entire wing of the Palais des Nations. The Library was then one of the most modern in Europe: with 9 public halls, 10 floors of stacks, and ample office space it was ready to serve as a centre of international research and an instrument of international understanding (Sevensma 1927).
World War II and the demise of the League put a temporary hold on further developments, and when the League’s assets were transferred to the United Nations in 1946, the Library collections and the historical Archives became part of the European Office of the organization, later named the United Nations Office at Geneva (UNOG). UNOG today is a diplomatic centre with near universal representation of UN Member States, bringing them together with individuals and organizations working on peace, rights and well-being for all. About 12’000 meetings are held every year and the Library’s resources and services reflect the multitude of their topics, including key collections in the areas of international law, human rights, diplomacy and international relations, disarmament, sustainable development, humanitarian affairs, and the environment. The Library today is uniquely placed to inform and enable work on multilateralism.


Over time, UNOG conferred further responsibilities to the Library, including managing the United Nations and League of Nations Archives and managing UNOG records. It is the curator of the League of Nations Museum and of more than 2'000 art works at the Palais des Nations, and it manages UNOG’s rich cultural activities programme. These significant functional additions allowed the Library to reinforce its role, both as research centre and as an instrument of international understanding.
With its broadening scope of activity, the L&A staff have acquired skills and experience in cultural diplomacy, event management and outreach. These competencies are put to use, for example by coordinating the activities around the celebrations of “100 Years of Multilateralism in Geneva” in 2019/2020, and supporting global agendas, such as the 2030 Agenda for Sustainable Development. They also enabled L&A staff to reply to a call to action on innovation launched by UN Secretary-General António Guterres, to cater for the rapidly changing nature of the UN systems. In response to this call and based on research in library trends and the future of working and learning, the UN L&A proposed a novel cross-service initiative – “the Knowledge and Learning Commons”.
3. The development of the concept of commons in other libraries
The idea of creating new organizational forms and label them as “commons” as an evolution of libraries first appeared with the emergence of the internet in the mid-1990s, often on university campuses, responding to changing user needs by making library services and technological resources available in one place. McMullen (2007: 2) summarizes the approach: “Whether they call themselves an Information Commons, Learning Commons, Knowledge Commons or simply Library, they are envisioning new spaces and new partnerships to create environments that can support the integrated service needs of the digital generation. ‘As a new model of service delivery, it is not about technology per se, but how an organization reshapes itself around people using technology in pursuit of learning’ (Beagle 2006: p. xv)”.
Information commons have often been described as the first stage in this new development. Pursuing a new model of information service delivery, they contribute to information literacy, building the competence of users to access information effectively and to be able to judge its value. While providing computer workstations and collaborative learning spaces, overall, information commons remain library-centric (Bailey/Gunter Tierney 2008: 1-3; cf. also Wolfe/Naylor/Drueke 2010: 109).
As Heitsch/Holley (2011) explain, “The Learning Commons is an evolution of the Information Commons in which the basic tenets of the information are enhanced and expanded upon in order to create an environment more centreed around the creation of knowledge and self-directed learning.” The core activity of a learning commons is no longer merely the mastery of information, “but the collaborative learning by which students turn information into knowledge and sometimes into wisdom” (Wolfe/Naylor/Drueke 2010: 109).
Learning commons are normally more strategically aligned with an institution-wide vision and mission. They become an active partner in implementing the broader educational and research agendas of institutions, often collaborating with the learning centres but also bringing in other partners such as administrators, faculty and students (Sullivan 2010: 132; Bailey/Gunter Tierney 2008: 1-3, 7-8). Learning commons move away from a library-centric approach to more human-centred design. They involve the users to develop the learning environments they need, and they use a multitude of creative formats - cultural events, exhibits, concerts, discussion forums etc. - to promote the social inclusion of a learning community (Sullivan 2010: 139-143). As “a place for experimenting, playing, making, doing, thinking, collaborating, and growing”, the learning commons is a place the users treasure as “their space” (Loertscher/Koechlin 2014: E3-E4).
Inspired by the literature about library commons elsewhere, the L&A commissioned an external researcher to study the feasibility of the model at UNOG. Analyzing scientific literature, the outcomes of user and staff surveys at UNOG and of interviews with the commons staff at Harvard University, the University of Nebraska, (both US), and the London School of Economics (UK), she concluded that the concept supported the Organization’s mission and vision of promoting multilateralism, sustainable development and intercultural dialogue through education, information, and communication. The study suggested that especially if created as a partnership between the L&A and UNOG’s Centre for Learning and Multilingualism (CLM)(2) part of UNOG’s Human Resources Management Service, the Commons would enhance a “culture of shared knowledge, community learning and innovation" while also enhancing the role of the individual entities’ core activities.
4. What is the concept of the Commons at UNOG?
Encouraged by the conclusions of the study, L&A engaged with the Centre for Learning and Multilingualism in a cooperative approach to developing the Commons. To achieve a unified knowledge on learning environment for the common client base - UN staff and diplomats - the Library’s events hall and specialized reading rooms were identified as ideal spaces for both, quiet and collaborative activities. Added value would be achieved through the pooling of competencies and technological resources, and through a more diversified approach to building and sharing knowledge.
New natural partners became available through “#NewWork”, an innovation initiative to promote a collaborative environment, favouring innovation and risk-taking as well as flexible working. The initiative had emerged, partly in response to the Secretary-General’s call for innovation, partly as a reaction to demands from staff for changes in the workplace culture. When the Commons was presented to UNOG’s senior management, the group recognized that it was a matter of “common sense” for the organization. The Commons provided the space where this new vision could be shared and where collaboration across services could happen in practice.
Outside UNOG’s internal setting, the UNOG operates within a dynamic ecosystem, with more than 40 international organizations, more than 400 NGOs and academic institutions specializing in international relations. This means that there is a constant supply of resource persons with the potential for peer learning. Research suggests that informal learning is likely to amount to 90% of staff learning, with only 10% of knowledge creation happening through formal training (3). Complementing the approach of informal learning in the immediate work environment, the Commons also lends itself as a space to bring the wealth of knowledge available in the larger international community in Geneva to a wider audience.
In addition, the Commons is well-placed to provide a space where the traditional silos that form around technical organizations could be broken down. As Niestroy/Meulemann (2016) point out, building transversal awareness has become a new requirement at a time when the UN system, along with its Member States, have commited to implement the ambitious 2030 Agenda for Sustainable Development. With this new all-encompassing and transformational policy framework, a new need to “focus on facilitating dialogue, interaction and learning” came to the fore (Niestroy/Meuleman 2016). The idea of the Commons was to facilitate the creation of knowledge and learning communities around topics of common interest across organizations and user groups.
From its early days, the Commons was meant:
- to create synergies between L&A and CLM to build knowledge communities among UN staff, Permanent Missions and interns in Geneva
- serve as a space for informal learning, knowledge exchange and collaboration
- provide a space to experiment and innovate, thereby promoting a cultural change within the organization.



5. From the experimental phase to a structured programme
To drive and accompany the development of the Commons, an Engine Group was established consisting of a cross-section of staff from both, the UN L&A and CLM. In addition, management structures at the Commons were consciously kept lean to promote innovation and set an example in light of the hierarchical organizational culture. Senior management played a minimal role in setting general directions or pointing to some key opportunities. Anyone, including a diversity of partners and our own interns, was invited to bring in ideas for events and decisions about best topics were taken collectively at the Commons team level.
To get started, planned L&A and CLM events in the pipeline were reviewed as to their Commons compatibility and some were redesigned using formats that favoured innovation and interactivity. In April 2018, the first Knowledge and Learning Commons event took place called: “Face Value – how to overcome stereotypes in our professional and personal lives”. Other events followed, on libraries and knowledge networks, digital diplomacy and design thinking. Overall, some 20 activities took place during the first year of the Commons’ operation.
To give the programme a clearer profile, a management decision was taken to carry out a Knowledge and Learning needs assessment. Based on the evidence of this assessment about the real needs of the target group, the focus of the Commons’ activities should be further refined. The assessment also served to gain potential partners who might be willing to become co-creators of the Commons’ programme. At the same time, senior management were involved, enquiring about their vision for the organization as an indicator of new capabilities for the staff.
The assessment was implemented between October 2018 and January 2019, in time to drive the development of the catalogue of activities for the pilot year 2019. This assessment combined qualitative and quantitative methods and included 134 participants in interviews and focus group discussions, of which 22 were diplomats (including several Permanent Representatives and Deputy-Permanent Representatives) and 7 interns. Several internal debriefs and discussions about lessons learnt at the Commons also fed into the overall analysis for this assessment.
Based on the information collected, five priority streams were identified for 2019 and the purple hand (purple being the colour of the Commons, a mix of the red of the Library and the blue of CLM) became the visual identifier for the Commons. The streams were to focus the activities and to facilitate the evolution of knowledge communities around themes of common interest. Given the prominence of gender among potential users, it was included as a cross-cutting theme, symbolically marked in the palm of the hand.
To remain open to emerging issues and unexpected opportunities, a conscious decision was taken to keep 20% of the capacity for good ideas.
While offering learning events seemed an obvious first step, in the medium-term it was also envisaged to provide other products and services. Conceptualizing the Commons as a “space” was also a defining element. The spacious and newly renovated Library Events Room lent itself to creative use as it could be set up flexibly (unlike many of the typical conference rooms around the Palais des Nations). By using the spaces of the Library creatively, we hoped to contribute to building the brand and inspire users to think out of the box, simply by venturing outside their usual environments.

6. The Pilot year: 2019
The pilot year was launched with a housewarming party inviting our three target groups to experience the 2019 programme with short taster sessions. Some 250 participants participated in the event which resulted in a boost in subscriptions to our newsletter. By the end of the year we had held 47 events with a cumulative total of 2.870 participants. Among the highlights was a session with the trainers of previous TEDx events held at the Palais des Nations who coached volunteers of all ranks in effective public speaking, much as they would the speakers for a real TEDx event. In a Dragon’s Den, UN staff was asked to submit their innovative ideas to improve the UN’s operations. Five selected teams were invited to promote their projects and two finalists, one selected by the audience and one by the “dragons” (senior staff and an external innovation champion), subsequently received mentoring and innovation time off to work to advance their projects. One of the winners, Conecta, a skills data base connecting staff to opportunities, was recently launched. Ready to scale, the project pitched again at a global Dragon’s Den organized by the UN at headquarters and was once more selected as one of the winners. The #MondayMotivation series inspired participants concerning IT applications, software or other tools that facilitate remote working or collaboration, for example with MS Teams. To promote an innovative culture, creative event formats or proposed activities were encouraged that directly promote creativity, for example related to creative writing or collaborative music playing.
As Sullivan (2010: 143) points out, human-centred design approaches, as used for the UN Geneva Knowledge & Learning Commons, require ongoing assessment. Launching into the implementation of the pilot year, it was obvious that evidence was required on how the initial planning decisions were developed. Therefore a comprehensive monitoring and evaluation strategy was developed, combining OECD evaluation criteria with the Kirkpatrick model commonly used to evaluate learning activities (4). Within a small working group, a number of high-level analytical questions were developed, which were then further broken down into questions pertaining to three levels: the project level, the priorities for the year and the organization of individual events. Six information sources were identified as relevant to respond to our guiding questions:
- Quantitative indicators
- A short user feedback survey (online)
- In-depth client interviews (in-person, at events)
- A survey among non-users (online and in-person)
- Interviews with senior management (in-person)
- An internal debrief among the core team (in-person).
Firstly, with regard to the project-level, the surveys showed that users attached high value to informal learning and knowledge exchange. Users and non-users alike supported the goals of the Commons – to provide a space to innovate and experiment, thereby promoting a cultural change towards more innovation. With the main goals so strongly confirmed, by the end of 2019 it was accepted that there was a proof of concept.
Figure 1 : The non-users' perspective on the goals of the Commons
Secondly, looking at our priority streams, the programme’s focus on innovation was reflected in the high number of events in the “Innovation & Technology” stream - almost a third of the 2019 programme. The feedback gathered during the year from both, users and non-users, confirmed an overwhelming interest in Innovation & Technology and Communication. Both streams were therefore maintained for the following year. Events labelled as “Other”, representing our “20% for good ideas”, accounted for another third of events, with about half of them covering issues related to wellbeing. Given the interest in the topic and the availability of excellent partners, it was decided to include Well@work as a new separate stream into our 2020 catalogue, thereby broadening the former Conflict resolution & mediation stream of 2019.
In response to a growing interest in efforts to “green” the Palais des Nations and to promote more sustainable behaviours at the individual and organizational level, the emphasis on the Sustainable Development Goals (SDGs) evolved into a Sustainability stream in 2020. This was a conscious decision for a niche that was outside the mainstream SDG events where the Commons had no comparative advantage.
Only two events had taken place under the Languages & Multilingualism stream, however, multilingualism - at least for the UN Secretariat languages English and French - was mainstreamed across many events. Conscious that multilingualism was best promoted by actually creating a multilingual environment, rather than by simply organizing events promoting it, this stream was discontinued in 2020.
Figure 2 : Events by steam in 2019
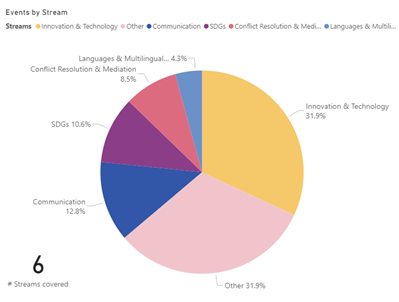
The Partnerships topic had already been relatively prominent during the initial needs assessment. In the 2019 non-user survey, it ranked third. It was decided to include a corresponding stream into the 2020 catalogue, given its potential to bring new audiences.
Figure 3 : Priority topics for non-users
Organizing events that were of interest for Permanent Missions was already a priority in 2019. Communication efforts to make the Commons better known among diplomats had yielded some results – about a fourth of new subscriptions to the newsletter came from Permanent Mission staff. In 2020 it was decided to go one step further and introduce a separate Diplomacy stream that could provide a space uniquely dedicated to diplomats and their needs.
In terms of gender balance, the Commons had a good record in 2019: 55% of participants in 2019 were female and 48 of the speakers were female and 53 were male. To keep this issue in focus and also become more conscious of promoting other aspects such as accessibility, we introduced the broader headline of inclusion and diversity as a cross-cutting principle.
Thirdly, through the different feedback mechanisms, critical insight was received which helped to improve the way events were organized. For example, participants were asked if they had acquired knowledge or information from the events which they could apply in their work or elsewhere, to which 69% of survey participants responded in the affirmative. In the internal debrief difficulties were openly discussed including issues faced when working on learning events with partners who were not professional trainers. For 2020 a more standardized template was developrd for the preliminary discussions with partners that would obligate the articulation of learning objectives for every event. These objectives would then also be communicated with all event announcements, as a constant reminder to all contributors.
Figure 4 : Learning outcomes and applicability
Since an important aspiration of the Commons was to offer innovative and interactive sessions, event participants were also asked about these factors. Users generally appreciated the use of the software Slido or other software to facilitate the discussion. Based on the overall feedback, however, it was decided that these were areas that required more investment. In 2019, it was noted with surprise that many of the partners who came to the Commons as a space to experiment with innovation, had insisted on using standard formats such as panel discussions. Knowing that they would not be the most effective formats for adult learning, it was decided to ban the use of panel discussions in 2020, and to commit to continuously explore innovative and interactive formats that we would be suggested to our partners. To facilitate longer-lasting interactions among participants, it was also planned to make a more concerted effort to cultivate “communities of practice” around certain core issues of the Commons where participants could exchange about their experiences in applying some of their new learning insights in practice.
Figure 5 : Innovation and interativity in event formats
Overall, by using a scientifically sound and highly analytical approach to monitoring and evaluating the pilot year at the Commons, the programme set a new precedent, inspiring evidence-based service development also in other parts of the L&A.


7. The COVID-year: 2020
With the launch of new approaches, by 2020, it would be one year since the housewarming in early February. At that point partners were contacted and the new priority streams were presented, brainstorming with them about activities for the year.
By the end of 2019 the initiative became a victim of its own success. Four events per month seemed like a healthy maximum of what could be managed, however, by early 2020 there were as many as eight pre-bookings per month.
Confronted with lockdown from mid-March, all events in the pipeline had to be put on hold. The upside: it freed up time to bring a project to the fore that had been pursued on the sidelines - the Conference Primers platform (5). The idea went back to feedback received from Permanent Missions, especially the smaller ones, who were struggling to follow all relevant conferences to be able to brief their capitals about main outcomes. The Conference Primers would be a service to them, as much as to all our target groups, curating the best summary information about key conferences of interest in international Geneva. The platform covers all key areas of work in Geneva, including human rights, innovation and technology, economics and trade, the sustainable development goals, etc. It contains official conference pages alongside summaries prepared by NGOs, think tanks or news media. The approach to the Conference Primers was, once more, very much related to that of a “Commons”, as experts were engaged to assist in identifying and vetting the best resource pages on specific topics. While Commons staff regularly invest time into updating the platform, the idea is that the Primers may evolve into a “Wikipedia”-type of page, with users continuously adding their best resources. As Bollier points out (2006: 36), the evolution of “participatory media” is just another expression of the commons paradigm.
In the meantime, the event production team got ready to offer the first events online. In response to an obvious need, a series of talks with the staff counselors were organized, under our Well@work stream. Topics included “Keeping a healthy mind” and “Coping with fear and anxiety during COVID-19” or “Preparing emotionally for the return to the workplace”. In addition, regular mindfulness sessions in English and French were scheduled.
As the team became more used to managing the available online events platforms, other topics were gradually brought back in. In September a new series called HiSTORIES was launched, with a first session on “The League of Nations Essentials: Shedding New Light on the 1st Global Multilateral Organization”. This initiative responded to feedback suggesting the Commons should capitalize more on the strengths and resources available at the L&A. Another series, produced by the Commons under the headline #UNGenevaReads, went back to an initiative by staff of the L&A. As in a traditional book club, colleagues gathered to jointly read a book about climate change, pointing to concrete corrective actions any individual could take.
An online event was the organized, broadcast from the Palais des Nations, discussing the book with the authors and responding to questions from the global readership. A small group of colleagues is currently selecting the books for future discussions.
Figure 7 : The #UNGenavaReads announcement

By end of October, the Commons had hosted 52 events with 3685 participants – more than in the whole of 2019. From mid-March onward, they were all held online. The team has built a unique experience in organizing virtual events, making the Commons a go-to place for such formats. Remote working had been a topic at the Commons before. The crisis provided the necessary impetus to make remote participation in events part of the “new normal”, thereby responding to the needs expressed by our users already in our initial assessment.
8. Conclusion and what’s next?
Two years into its existence, the Knowledge & Learning Commons of the UN Geneva has proven its worth. Many close observers have judged the pilot year to be a “resounding success”. An important factor was support from senior managers and strong allies within and outside the organization. Over time, partnerships have evolved and become more complex, suggesting that a more strategic approach to partnerships management might soon become necessary. In the near future, working with UNOG’s IT service might become even more important. Even before Covid-19, it was recognized that the learning commons required “a fundamentally new degree of collaboration between librarians and information technologists, who bring different professional training and cultures together in newly designed spaces that support [...] learning” (Bennet 2007). The #MondayMotivation series testified to that. Evolving with the technological advances will now more than ever be a key factor to maintain the Commons as a vibrant innovation space.
While fully embracing the technological advances, they have also made community-building - at the core of the initial Commons idea – all the more difficult. Virtual events meant a greater difficulty to create a sense of community among users being virtually connected. #UNGenevaReads is one attempt to build back community. Increased interactivity in virtual sessions is another, but the challenge remains.
As the monitoring and evaluation results confirm, Commons activities are contributing to a cultural change towards more innovation within the organization in many practical ways. The ongoing challenge remains - to strike a good balance between letting partners and users own the Commons while also guiding them to the adoption of more innovative formats. The hope is that with the increase of the Commons community, “Learning for Us” becomes an enabling tool, letting innovation come to full circle.
What is crucial is the willingness and capacity of the Commons team to continually learn, not only in the IT area, but also in terms of innovation in substance and form of delivery. As Sullivan (2010: 144) highlights: “the single unifying element of the many manifestations of the learning commons is change”. Commons staff members have to remain agile and always be a few steps ahead of the users. Delivering constant innovation becomes a crucial staff skill in itself. It is the ability to identify emerging trends and quickly explore their potential. As McMullen (2007: 20) confirms for other learning commons: “Individual staff members […] are constantly in a learning mode and continually evolving to meet user demands. […] Staff continually update their job skills, enjoy learning and don’t feel threatened by the changeable nature of their jobs”. In this manner, the Commons innately realizes the cultural change the UN is looking for.
While the growing demand of the Commons translates into an increasing need for human and financial resources, pressures to reduce budgets greatly affect L&A and CLM. Programme sustainability can only be achieved when these needs are addressed, and alternative ways of funding have to be explored.
It’s clear that the Knowledge & Learning Commons at the UN in Geneva has established itself as a vehicle that has allowed the UN Library & Archives to profit from its multifaceted activities – ranging from library, records and archives services, to outreach, artworks management and cultural programming – and to evolve into an institution that can face the information and communication challenges of the 21st century. Within the bureaucracy of the United Nations, the programme reaches sustainability through agility and innovation, interaction and inclusion, thereby turning staff and users into drivers for cultural change. Looking back at the humble beginnings of the Commons, the staff are proud to be able to contribute to the renewal of the Organization through this innovative approach, providing concrete results for knowledge sharing.
Notes
(1)https://libraryresources.unog.ch/conferenceprimers
(2)CLM provides learning opportunities, mostly to UN staff, in some cases also to Permanent Mission staff, in particular in the six official UN languages, in management and communication. CLM also promotes an increasing number of online learning offerings, produced at headquarters in New York or accessible through online learning platforms such as LinkedIn learning.
(3)What is the 70:20:10 Model?, https://www.growthengineering.co.uk/70-20-10-model/ (last accessed 6 November 2020).
(4)For the OECD evaluation criteria, cf. www.oecd.org/dac/evaluation/daccriteriaforevaluatingdevelopmentassistance.htm; for the Kirkpatrick model, cf. for example here: https://www.mindtools.com/pages/article/kirkpatrick.htm; some of the pitfalls of the model mentioned in the article are alleviated by the complementary use of the broader approach of the DAC criteria.
Bibliography
Bailey, D. Russel/Gunter Tierney, Barbara (2008), Transforming Library Services Through Information Commons, Chicago.: American Library Association.
Bennett, Scott (2008), The Information or the Learning Commons: Which Will We Have?, in: The Journal of Academic Librarianship, vol. 34, no. 3, pp. 183-185, https://libraryspaceplanning.com/wp-content/uploads/2015/09/The-Learning-or-Information-Commons-Which-Will-We-have.pdf (last accessed 25 October 2020).
Blake, Sheila (2015), The Challenges of Creating a Learning Commons, University of Central Missouri, Warrensburg, Missouri, http://docplayer.net/163627834-The-challenges-of-creating-a-learning-commons-sheila-l-blake.html, (last accessed 25 October 2020).
Bollier, David (2006), “The Growth of the Commons Paradigm”, in: Understanding Knowledge as Commons: From Theory to Practice, Hess, Charlotte/Ostrom, Elinor (editors) Cambridge, MA: MIT Press, pp. 27-40.
Brooks Kirkland, Anita/Koechlin, Carol (2015), Leading Learning: Standards of Practice for School Library Learning Commons in Canada, https://llsop.canadianschoollibraries.ca/, (last accessed 25 October 2020).
Canadian Library Association (2014), Standards of Practice for School Library Learning Commons in Canada, http://apsds.org/wp-content/uploads/Standards-of-Practice-for-SchoolLibrary-Learning-Commons-in-Canada-2014.pdf (last accessed 25 October 2020).
Clement House rotunda project: An Evaluation of Clement House Informal Learning Spaces (2016/2017) London School of Economics, http://eprints.lse.ac.uk/82259/1/Roger_The%20Clement%20House%20rotunda%20projectn_author_2017.pdf (last accessed 25 October 2020).
Fuller, Kate (2009), Learning Commons @ UConn Assessment Report: Use and Satisfaction of the Learning Commons, http://learningcommons.uconn.edu/about/UConn_Learning_Commons_Report.pdf (last accessed 25 October 2020).
Heitsch, Elizabeth K./Holley, Robert P. (2011), “The information and learning commons: Some reflections”, in: Review of Academic Librarianship, Vol 17 No. 1, pp. 64-77.
Hess, Charlotte/Ostrom, Elinor (2006), “Introduction: An Overview of the Knowledge Commons”, in: Understanding Knowledge as Commons: From Theory to Practice, Charlotte Hess and Elinor Ostrom (editors), MIT Press.
Holland, Beth (2015), 21st-Century Libraries: The Learning Commons; in: Edutopia, https://www.edutopia.org/blog/21st-century-libraries-learning-commons-beth-holland (last accessed 25 October 2020).
Lippincott, Joan K. Chapter (2006), Linking the Information Commons to Learning. In: Learning Spaces, Diana G. Oblinger, ed., Educause, https://www.educause.edu/research-and-publications/books/learning-spaces/chapter-7-linking-information-commons-learning (last accessed 25 October 2020).
Loertscher, David/Koechlin, Carol (2014), Climbing to Excellence: defining characteristics of successful learning commons, https://www.davidloertscherlibrary.org/wp-content/uploads/2020/07/2014-Climbing-to-Excellence-Defining-Characteristics-of-Successful-Learning-Commons-1.pdf (last accessed 25 October 2020).
McKay, Richard (2015), Building a Learning Commons: Necessary Conditions for Success. Community & Junior College Libraries, volume 20, 2014 – issue 3-4, Taylor & Francis online
http://www.tandfonline.com/doi/abs/10.1080/02763915.2015.1056705?journalCode=wjcl20 (last accessed 25 October 2020).
McMullen, Susan (2007),The Learning Commons Model: Determining Best Practices for Design, Implementation, and Service, Sabbatical Study, Roger Williams University
Available at: http://faculty.rwu.edu/smcmullen/index.html (last accessed 25 October 2020).
Niestroy, Ingeborg/Meuleman, Louis (2016), Teaching Silos to Dance: A Condition to Implement the SDGs, http://sdg.iisd.org/commentary/guest-articles/teaching-silos-to-dance-a-condition-to-implement-the-sdgs/ (last accessed 22 October 2020).
Letter from A. Sevensma, Director of the League of Nations Library to R. Fosdick, Rockefeller Foundation, New York, NY. (1927), LON archives 16/29433/3749
Sullivan, Rebecca M. (2010), Common Knowledge: Learning Spaces in Academic Libraries, in: Academic Libraries, College & Undergraduate Libraries, Volume 17, pp. 130-148.
Thibou, Shevell (2016), The Learning Commons. Western Washington University Libraries
http://cedar.wwu.edu/cgi/viewcontent.cgi?article=1005&context=research_process (last accessed 25 October 2020).
The University of Iowa Libraries – Learning Commons
Available at: https://www.lib.uiowa.edu/commons/ (last accessed 25 October 2020).
University of Nebraska Adele Hall Learning Commons, https://libraries.unl.edu/learning-commons and https://news.unl.edu/newsrooms/today/article/learning-commons-named-for-alumna-adele-coryell-hall/ (last accessed 25 October 2020).
Vasisht, Prateek, The Public Library of 2027, Snipette
https://medium.com/snipette/the-public-library-of-2027-50eabd05b8c2 (last accessed 25 October 2020).
Wolfe, Judith A./Naylor, Ted/Drueke, Jeanetta (2010), “The Role of Academic Reference Librarian in the Learning Commons”, in: Reference and User Services Quarterly, Volume 50, Issue 2, pp. 108-113.
- Vous devez vous connecter pour poster des commentaires
The No-nonsense guide to research support and scholarly communication (2020)
Ressi — 17 décembre 2020
Thomas Pasche, Haute Ecole de Gestion, Genève
The No-nonsense guide to research support and scholarly communication (2020)
L’auteure de cet ouvrage paru en 2020, Claire Sewell, travaille au bureau de la communication scientifique de la bibliothèque de Cambridge en qualité de coordinatrice des compétences en matière de soutien à la recherche. Elle est également coordinatrice de conférence pour le conseil d’administration de la Special Librairies Association (SLA) et contributrice pour de nombreuses revues professionnelles.
L’explosion d’internet et la multiplication des plateformes de recherche auraient dû rendre le travail des chercheurs plus simple : plus d’information publiées et plus de points d’accès pour les trouver et les consulter. La réalité est tout autre : la multiplicité des sources d’informations et la prolifération des fake news et autres sources de désinformations rendent le travail des chercheurs de plus en plus compliqué, s’ajoutent à cela les coûts, souvent prohibitifs d’accès aux ressources de qualité ainsi qu’un système de publication de plus en plus restreint, tant économiquement que géographiquement. C’est dans ce contexte que le rôle du bibliothécaire chargé de la communication académique est mis en question. Quelles qualifications doit-il posséder, quelles expertises et quelle place a-t-il dans ce milieu à l’évolution rapide et souvent chaotique.
Le premier chapitre de cet ouvrage pose un cadre à cette question. Il explique le rôle que chacun se doit de jouer, explique les bases de la recherche académique tant du point de vue des chercheurs que du point de vue des bibliothécaires, brouillant parfois l’identité de ces deux rôles, le premier se retrouvant parfois à occuper le poste du second sans pour autant avoir une formation bibliothéconomique. Le rôle du bibliothécaire est par ailleurs changeant en fonction de son répondant, celui-ci ayant un besoin plus ou moins important de guidance et de soutien. Ce chapitre conclut sur le cycle de vie que toute recherche, aussi basique soit-elle, doit suivre afin d’avoir un impact et une portée maximale.
Le second chapitre fait un focus tout particulier sur les données et leur prise en charge. Tout d’abord d’un point de vue linguistique : peut-on encore parler de données lorsque son répondant travaille dans ls domaine des sciences humaines, domaine dans lequel les données vont plutôt être nommées informations. Ainsi, le bibliothécaire devra faire preuve d’adaptabilité en fonction de son répondant afin que son message soit bel et bien compris. Il aura par ailleurs la charge de faire comprendre au chercheur combien il est important d’avoir un plan de gestion des données, tant au niveau du nommage qu’en ce qui concerne leur classement, qu’il soit physique ou numérique. Les données devront ainsi être trouvables, accessibles, interopérables et réutilisables et devront être parfois maniées avec précaution, surtout si ces dernières sont des données sensibles (personnelles, médicales ou juridiques).
L’Open access est au cœur du chapitre suivant, en le définissant comme la possibilité de rendre accessibles librement les résultats de la recherche, en partie grâce à l’essor des nouvelles technologies, notamment celles du web et en s’opposant aux moyens traditionnels de publication. Ce chapitre revient également sur l’historique de l’open access, depuis l’apparition du terme au début des années 2000 et son développement dans les années qui suivirent, notamment par les trois actes fondateurs que sont : l'Initiative de Budapest en faveur de l'accès libre, la Déclaration de Bethesda sur l'édition en libre accès et la Déclaration de Berlin sur le libre accès à la connaissance dans le domaine des sciences. L’auteure aborde également les problèmes afférant à cette méthode de diffusion, en évoquant le cas de certains scientifiques qui craignent que l’open access nuise à la crédibilité de leurs travaux. Il est également question des avantages apportés par l’open access pour les chercheurs ainsi que pour le grand public. Le rôle des bibliothécaires peut être d’apporter des solutions techniques aux chercheurs, une compréhension de ce qu’est l’open access et peut également être utile dans le cadre de leurs propres recherches en leur donnant accès à un vaste volume d’informations utiles.
L’auteure évoque ensuite les méthodes de dissémination des résultats de la recherche. Il est question des différentes questions que les chercheurs doivent se poser quant au partage du résultat de leurs recherches, notamment quant au format ou aux supports servant à partager les données de la recherche : dépôt institutionnel, réseaux sociaux, plateformes dédiées, etc. Le texte met également en garde contre les « éditeurs prédateurs », des organisations qui exploitent l’open access pour un gain financier, en promettant de fournir des services spécialisés en matière de dissémination des données de la recherche, mais qui, finalement, se contentent de publier ce qui leur a été transmis sans travail supplémentaire.
Dans le cinquième chapitre, Claire Sewell évoque les critères servant à mesurer l’impact (en anglais : metrics) et la qualité de la recherche. Les bibliothécaires académiques ont ici un rôle important à jouer, dans la mesure où ils connaissent bien, en général, ces méthodes de mesures d’impact et peuvent aider les chercheurs en les soulageant de ce calcul. Dans cette partie du livre, l’auteure décrit ces différents outils de mesures et dans quelles situations les utiliser.
Le chapitre suivant se différencie des autres parties de ce livre dans la mesure où l’auteure s’adresse directement à des personnes souhaitant entamer une carrière dans le domaine de la communication académique et de l’aide à la recherche. Pour ce faire, Claire Sewell clarifie le vocabulaire propre aux offres d’emploi dans ce domaine et détaille les compétences nécessaires pour travailler dans ce domaine. Le chapitre offre également des études de cas, sous la forme de postes mis au concours dans des bibliothèques académiques et comment les décrypter.
A travers le dernier chapitre, l’auteure encourage les bibliothécaires à publier leurs propres travaux, qu’ils soient dignes de journaux revus par les pairs ou plus modestes. Il est normal pour un bibliothécaire de chercher régulièrement des solutions aux problèmes auquel il va quotidiennement être confronté et les solutions trouvées sont dignes d’être partagées avec les pairs, afin de leur permettre de résoudre des problèmes similaires. Par ailleurs, un spécialiste de l’information entreprenant ses propres recherches, quelle que soit l’ampleur de cette dernière, aura une expérience concrète lui permettant d’aider au mieux les chercheurs car il les aura également vécues. Cette expérience peut aussi ouvrir des possibilités professionnelles car elle permet d’acquérir des compétences managériales, de gestion du temps, de communication, de capacité de recul et de capacités analytiques. Cela permet aussi au chercheur en herbe de se familiariser avec les difficultés habituelles que rencontrent les chercheurs : le temps, les finances, la politique, le perfectionnisme, le manque de confiance et la motivation, pour ne citer qu’eux. Enfin, l’auteure souligne les différents moyens de diffuser le résultat de ces recherches bibliothéconomiques : conférence, poster, publication, newsletter et réseaux sociaux.
Claire Sewell conclut en mettant en avant les thèmes communs aux différents chapitres. La connaissance du domaine du support à la recherche et de ses particularités est acquise via l’expérience, et le domaine est encore pour l’instant une spécialité émergente. Aussi, à défaut de critère de recrutement précis, on préférera des qualités telles que l’adaptabilité, la capacité de communication avec divers types d’interlocuteur et enfin, la capacité de s’adapter au changement, point essentiel pour se maintenir à jour avec les dernières techniques et informations du domaine. Enfin, l’aide à la recherche ne concerne pas uniquement le domaine universitaire mais peut également être abordé plus tôt, y compris en école obligatoire : cela permet en effet de pré-former les enfants à la gestion des informations, leur utilisation et à leur sauvegarde.
En conclusion, l'ouvrage de Claire Sewell, en abordant différentes thématiques, donne un tour d'horizon clair et synthétique du domaine de l'aide à la recherche académique et montre bien comment les bibliothécaires peuvent s’impliquer utilement dans ces processus de soutien aux chercheurs. L'ouvrage comporte de nombreux exemples pratiques et concrets, permettant aux personnes déjà actives dans ce domaine, tout comme au nouveau venu de mieux cerner les enjeux de la communication académique. De plus, le livre propose une documentation fournie permettant à ceux qui le souhaitent d'explorer plus avant les différentes thématiques abordées, faisant de cet ouvrage une référence dans le domaine.
Bibliograhie
SEWELL, Claire, 2020. The No-nonsense Guide to Research Support and Scholarly Communication. London : Facet Publishing. ISBN : 9781783303939
- Vous devez vous connecter pour poster des commentaires
Conférence annuelle LIBER 2020 online : compte rendu d’évènement
Ressi — 16 décembre 2020
Piergiuseppe Esposito, Chargé de mission BCU Lausanne
Nombre de mots:
1000 Conférence annuelle LIBER 2020 online : compte rendu d’évènement
La première conférence virtuelle de LIBER s’est tenue du 22 au 26 juin 2020, sous le thème Building Trust with Research Libraries. Initialement prévue à Belgrade, la 49e conférence annuelle LIBER a été hébergée en ligne sur la plateforme AnyMeeting. Organisée en un temps record en raison de l’évolution de la situation sanitaire au printemps, la conférence a rencontré un vif succès auprès des membres de la communauté des bibliothèques européennes de recherche, avec 5’544 inscriptions de plus de 1’700 personnes, dont le personnel de 276 institutions membres de LIBER. En une semaine, plus de 50 orateurs ont animé et présenté : 1 keynote address, 2 panel sessions, 6 workshops, 10 parallel sessions et 11 posters, dont l’enregistrement et les diapositives sont disponibles sur YouTube et Zenodo via le site web de la conférence LIBER (https://liberconference.eu/liber-2020-presentations-posters/). Les grands thèmes de la conférence – Information & Research Integrity, Preservation of Collections, Leadership, Impact of Libraries, Securing Trust in Libraries, Open Knowledge – ont été abordés aussi bien sous un angle théorique que pratique, c’est-à-dire à partir de l’analyse de retours d’expérience. Une place importante a été consacrée aux sessions de questions-réponses permettant des échanges de vues et d’informations avec les spécialistes connectés, autour de divers sujets d’actualité.
«Challenging times»
Cette édition de la conférence annuelle LIBER a bien évidemment été marquée par la crise du coronavirus, qui a eu un effet disruptif sur la vie et les habitudes de travail dans le monde entier. Dans un contexte en constante mutation et face aux incertitudes liées à la crise sanitaire, les défis sont de taille pour les bibliothèques de recherche. «À quoi ressemblera l’ère post-COVID-19 ?». Dans son mot de bienvenue, la présidente de LIBER, Jeannette Frey, directrice de la BCU Lausanne, a souligné la nécessité d’ajuster et de réinventer les services selon les besoins pour refléter les restrictions liées au COVID-19. À ce propos, une enquête adressée aux institutions membres de LIBER permettra d’ici la fin de l’année 2020 de mapper la situation des bibliothèques européennes de recherche. Cette enquête ne vise pas qu’à montrer l’impact de la crise du COVID-19, mais la situation à laquelle les bibliothèques de recherche vont être confrontées dans l’année à venir (deuxième vague, post-COVID-19). Dans leurs discours d’ouverture, les trois chefs de secteurs stratégiques de LIBER – Dr Bertil F. Dorch, Dr Birgit Schmidt et Dr Giannis Tsakonas – ont réfléchi quant à eux à l’impact du COVID-19 sur la science ouverte. L’ouverture des connaissances et le partage des données primaires de la recherche sont non seulement essentiels pour comprendre et atténuer la pandémie, mais aussi un moyen d’accroître la transparence, la reproductibilité, la responsabilité et la confiance dans la recherche. De ce point de vue, les bibliothèques de recherche ont un rôle crucial à jouer dans la construction de cette confiance.
Pour aller plus loin : https://www.youtube.com/watch?v=jHc8-4lH_4U&feature=emb_logo
Retours d’expérience
À l’heure actuelle, renforcer la confiance entre les bibliothèques universitaires et la communauté scientifique est un enjeu de taille. Exemple parmi d’autres d’une collaboration fructueuse, on remarquera la présentation dans le cadre de la session Libraries as Open Innovators and Leaders de la réalisation d’un projet pilote d’édition et de publications scientifiques dénommé «Editori», basé sur le logiciel Open Journal Systems (OJS). Ce projet a été réalisé à la bibliothèque universitaire d’Helsinki en collaboration étroite avec des membres de la communauté universitaire (enseignants, doctorants) dans le cadre d’un séminaire organisé au sein d’un programme doctoral en sciences humaines et sociales. Les participants y ont été accompagnés dans toutes les étapes du processus éditorial d’une revue fictive dénommée FTY journal. Cette étude de cas illustre le rôle que peuvent jouer les bibliothèques de recherche dans le développement de compétences en matière d’édition et de publication au sein de la communauté académique. En particulier, le personnel de la bibliothèque universitaire a formé les enseignants impliqués à l’utilisation de la plateforme et a servi de support technique tout au long du séminaire. Cette expérience a permis de tirer plusieurs leçons au regard de la collaboration entre enseignants et bibliothécaires. Il en résulte trois facteurs essentiels de la réussite d’un tel projet pilote : la communication, l’implication de la bibliothèque déjà dans la phase de planification du séminaire et la collecte systématique de feedback pour l’implémentation du service.
Pour aller plus loin : https://libraryguides.helsinki.fi/editorieng
Citizen Science & SDGs
Un autre thème intéressant abordé dans le cadre de la conférence est l’émergence d’une nouvelle plateforme pour la science citoyenne. La Citizen Science a gagné en importance de façon spectaculaire ces dernières années : des milliers de projets qui intègrent le public à la recherche sont disponibles en ligne et les organismes de financement soutiennent le domaine. Du côté de LIBER, le groupe de travail Citizen Science, créé en juin 2019, s’est engagé à fournir d’ici l’année prochaine un modèle (ou une série de modèles) et à plaider en faveur d’un point de contact unique pour la science citoyenne qui pourrait être mis en place dans les bibliothèques de recherche. À travers la participation active à des projets de science citoyenne, les bibliothèques sont encouragées à œuvrer dans l’établissement d’un «BESPOC» virtuel – acronyme de Broad Engagement in Society, Point of Contact(1)– avec la collaboration de citoyens et d’autres institutions. Comme souligné dans le cadre de la session Citizen Science Supporting Sustainable Development Goals: The Possible Role of Libraries, la science citoyenne dans les bibliothèques peut en outre être considérée dans la perspective de la réalisation de l’Agenda 2030 pour le développement durable de l’ONU. À l’exemple de la bibliothèque de l’université du sud du Danemark (SDU Library) qui s’est engagée dès 2019 à améliorer son action de sensibilisation à l’échelle locale dans le cadre des 17 objectifs du développement durable (SDGs) au sein d’un Citizen Science Network.
Pour aller plus loin : https://www.sdu.dk/en/forskning/forskningsformidling/citizenscience
Notes
(1)Tiberius Ignat et Paul Ayris, “Built to last! Embedding open science principles and practice into European universities”, Insights, 33 (9), 2020, pp. 1-19 (ici p. 15).
- Vous devez vous connecter pour poster des commentaires
Le Projet de Loi 12146 : Infrastructures et services numériques pour la recherche
Ressi — 27 janvier 2020
Pierre-Yves Burgi, Directeur adjoint des systèmes d'information, Université de Genève
Résumé
Le projet de loi (PL) 12146 du canton de Genève, en vigueur depuis janvier 2018, porte sur les infrastructures et services numériques pour la recherche. Une thématique d’actualité, sa rédaction en 2011 a nécessité une approche visionnaire, favorisée par le contexte du moment, aussi bien au niveau de l’Université de Genève (UNIGE) qu’au niveau suisse avec les prémisses en 2011 du prochain programme fédéral « CUS P2 2013-2016 : Information scientifique : accès, traitement et sauvegarde ». L’UNIGE a joué dès le début du programme fédéral un rôle déterminant avec le lancement du projet « Data Life-Cycle Management » (DLCM) en 2015, un des plus importants en nombre d’institutions partenaires (9 au total). Ce projet est entré dans sa deuxième phase en 2018. Le PL et le projet DLCM progressent par conséquent en synergie : la technologie de préservation long terme développée dans le projet DLCM a servi d’accélérateur pour la mise en production de Yareta, le système d’archivage long terme des données de recherche pour les institutions universitaires du canton de Genève. L’expérience acquise dans l’exploitation de Yareta va à son tour bénéficier à la mise en place de l’instance nationale, dénommée « OLOS », prévue début 2020.
Abstract
The bill 12146 of the Canton of Geneva, in force since January 2018, concerns digital infrastructure and services for research. A hot topic, its drafting in 2011 required a visionary approach, favored by the current context, both at the University of Geneva (UNIGE) and at the Swiss level, with the premises being laid in 2011 for the next federal programme "CUS P2 2013-2016: Scientific information: access, processing and preserving". Indeed, since the beginning of federal programme, UNIGE has played a decisive role with the launch of the "Data Life-Cycle Management" (DLCM) project in 2015, one of the largest in number of partner institutions (9 in total). This project entered its second phase in 2018. The bill 12146 and DLCM project are therefore progressing in synergy: the long-term preservation technology developed in the DLCM project served as an accelerator for the production of Yareta, the long-term archiving system for research data for academic institutions of the canton of Geneva. The experience acquired in the operation of Yareta will in turn benefit the establishment of the national version, called "OLOS", scheduled for early 2020.
Mots-Clés:
PL12146,
HPC,
Préservation long terme,
OAIS,
Données de Recherche,
Programme CUS P2 et swissuniversities P5,
Projet DLCM,
Humanités numériques,
Yareta Le Projet de Loi 12146 : Infrastructures et services numériques pour la recherche
Introduction
La révolution numérique impacte et transforme la recherche scientifique dans tous les domaines, aussi bien dans les sciences dites dures que dans les sciences sociales et humaines. Les découvertes et avancées scientifiques majeures ne sont aujourd’hui plus possibles sans disposer de services et d’infrastructures informatiques à haute performance permettant la simulation numérique de phénomènes complexes ainsi que la recherche axée sur une exploitation intensive des données numériques (Hey et al., 2009). Afin de répondre à ces nouveaux défis et rester compétitive et attractive, il est impératif que l’Université de Genève (UNIGE) ainsi que les autres HE(1) du canton de Genève puissent mutualiser et développer les services et infrastructures numériques à disposition de tous leurs chercheurs, tout en gagnant en efficience. Cela nécessite des efforts coordonnés et des financements adéquats pour mettre en œuvre des solutions concrètes qui s’intègrent harmonieusement aux environnements des chercheurs et répondent aux exigences des bailleurs de fonds de la recherche scientifique.
Ces développements s’inscrivent dans la vision de l’UNIGE à l’horizon 2025 et contribuent pleinement au projet stratégique transversal de l’Université numérique (https://www.unige.ch/plan-strategique). Il est cependant utile de rappeler l’historique du Projet de Loi 12146, antérieur à cette vision numérique, comme expliqué dans la section suivante.
Historique
Les prémisses du projet de loi remontent à l’été 2011. Avec mon collègue Jean-François Rossignol, alors responsable des infrastructures informatiques de l’UNIGE, nous avions rédigé une première version du projet de loi (PL) sur les thèmes du calcul haute performance (HPC) et du Research Data Management (RDM). Ces deux thèmes avaient déjà été jugés importants, tant l’analyse et la conservation des données scientifiques nous semblaient complémentaires. Sur la base de cette version préliminaire, nous avions organisé le 13 octobre 2011 une présentation à la Commission informatique (COINF) de l’UNIGE des concepts et idées contenus dans ce nouveau projet.
La COINF est la commission consultative du Rectorat en matière de politique institutionnelle des systèmes d’information (SI) et des services numériques qui lui sont associés. Elle oriente l’évolution des SI au sein de l’institution en tenant compte des besoins de l'enseignement et de la recherche ainsi que de l'administration universitaire, tout en veillant à l’optimisation des ressources. Elle favorise une large participation facultaire de par sa composition et son articulation avec les Commissions Informatiques Facultaires (CIF). Aussi, suite à cette présentation, il était naturel de présenter le projet plus largement dans les CIF des différentes facultés. Cette consultation plus large des chercheurs au sein de leur faculté a duré plusieurs mois et a permis de dresser une image qualitative plus précise des besoins en HPC et RDM. Il est cependant intéressant de relever qu’à cette période la question de la gestion des données de recherche n’était pas nécessairement une priorité et que l’information récoltée sur ce sujet n’a pas amené des éléments majeurs dans la rédaction du PL. Tout au plus, cette information n’a pas infirmé ce que nous avions déjà rédigé.
Quant au HPC, les informations récoltées sont venues renforcer une enquête quantitative réalisée précédemment au printemps 2011 qui était axée sur les besoins en calculs scientifiques (simulations, analyse de données, etc.). En effet, durant les 15 années précédentes, le nombre de chercheurs utilisant l’informatique pour la modélisation et l’analyse de données n’a cessé de croître. Plusieurs dizaines de serveurs de calculs ont été acquis et se sont retrouvés dispersés dans plusieurs salles machines de l’Université, voire dans des bureaux et laboratoires. Cette dispersion entraînait de nombreux problèmes et désagréments, notamment de fortes difficultés à assurer une administration système efficace. En vue de regrouper les machines servant au calcul, une enquête des besoins en termes de consommation électrique et d’espace nécessaire pour la période 2012 à 2015 a donc été réalisée. La tâche s’est avérée complexe, car les différentes structures de l’Université sont habilitées à acquérir des machines de calcul de manière décentralisée (achats souvent effectués au niveau des groupes de recherche ou des départements). Par ailleurs, les besoins futurs sont extrêmement difficiles à estimer à priori, vu le caractère hétérogène des applications et des équipements. L’enquête a néanmoins révélé un fort besoin des utilisateurs pour un serveur de calcul centralisé. Les réponses ont indiqué un besoin de plus de 30 millions d’heures de calcul annuel, qui correspond à une ferme de calcul d’environ 4’000 cœurs(2).
L’évolution technologique a été intégrée dans les prévisions des besoins en appliquant la loi de Moore qui prévoit que le nombre de transistors pouvant être placés sur une puce à un prix acceptable est multiplié par 2 tous les 2 ans (Moore, 1965). Le corollaire de cette augmentation de la densité des composants électroniques est que la consommation électrique et la place occupée par processeur sont divisées en principe par 2 tous les 2 ans (mais voir Waldrop, 2006 pour l’évolution de cette loi de Moore qui se modifie dans le contexte technologique actuel). Au vu de ces estimations, on a pu estimer les caractéristiques nécessaires d’une salle machines regroupant tous les serveurs de calcul de l’Université, avec une projection de 35 racks pour une puissance totale de 520 KW en 2015. À noter qu’à ce jour (2019), et grâce aux progrès technologiques, la ferme (serveurs) de calcul de l’UNIGE (dénommée « Baobab ») possède de l’ordre de 4’400 cœurs, occupe 6 racks et consomme environ 60 kWh. L’étape suivante (d’ici à 2020) vise à acquérir 3’000 cœurs de nouvelle génération, plus puissants et donc nécessitant moins de cœurs comparé à la génération précédente, dans 3 racks pour une consommation d’environ 37 kWh.
Ce travail d’étude des besoins, mené sous l’égide de la COINF et en étroite collaboration avec les facultés, a conduit à préaviser positivement en mai 2012 la nécessité d’une part de réaliser ces investissements majeurs en infrastructure pour répondre aux nouveaux besoins de la recherche et d’autre part de consolider à terme des postes d’ingénieur possédant des compétences pointues en HPC, indispensables pour les chercheurs pour mener à bien leurs calculs.
Dans sa séance du 18 juin 2012, le Rectorat a quittancé ce travail et décidé d’aller de l’avant avec le dépôt auprès de l’Etat de Genève du PL pour l’ouverture d’une subvention d’investissement de l’ordre de 15 millions sur 5 ans, couvrant l’achat d’équipements informatiques de calcul et de stockage, ainsi que l’engagement du personnel requis pour le développement et la mise en œuvre des nouveaux services. La procédure de dépôt a été ajustée avec la Présidence du Département de l’Instruction Publique (DIP) en réunion DIP-UNIGE-HESGE(3). La version définitive du « Projet de Loi HPC & DM » a été transmise le 29 novembre 2012 à la division des finances de l’UNIGE pour dépôt auprès de la direction des finances du DIP le 21 mai 2013.
Ce dossier a néanmoins été bloqué jusqu’en juillet 2016, date à laquelle le vice-recteur Denis Hochstrasser, en charge du système d’information de l’UNIGE, a transmis un argumentaire au DIP afin d’appuyer le PL dans le cadre du plan d’investissement de l’Etat. Le dépôt du PL par le Conseil d’Etat est devenu effectif au 21 juin 2017 avec une re-planification du projet sur la période 2018-2022. Le 22 septembre 2017 le Grand Conseil a envoyé la proposition de loi à sa commission des travaux pour être mis à l’ordre du jour du Grand Conseil du 23-24 novembre(4). Elle a finalement été acceptée sans débat le 24 novembre 2017, pour un début officiel qui a été fixé au 1er janvier 2018.
Périmètre
Le périmètre du PL a été conçu afin de répondre au 4ème paradigme de la recherche que représente l’utilisation intensive des données pour progresser dans les découvertes scientifiques et qui vient compléter les méthodes classiques que sont l’expérimentation, la théorie et la simulation (Hey et al., 2009). Cette nouvelle manière de faire ne concerne pas uniquement les sciences dites « dures » (physique, astronomie, génomique, informatique, neurosciences, sciences de l’environnement, etc.), mais également les sciences sociales et humaines. En effet, par le biais de ce que l’on nomme les « digital humanities » (humanités numériques), la puissance de calcul des ordinateurs rend possible l'examen de larges corpus (textes ou autres types de média), y compris de millions de livres numérisés. Bien qu’émergente, cette approche transdisciplinaire, qui bénéficie de l’initiative du libre accès, et plus généralement de « l’Open Science », conduit déjà à de nouvelles connaissances en linguistique, en histoire, en archéologie, dans l’interprétation d’anciens textes, etc. (see e.g., Borgman, 2010).
Ce 4ème paradigme représente donc un élément déterminant pour l’exploration et le progrès de la connaissance en général, ainsi que pour promouvoir une recherche interdisciplinaire à fort potentiel pour résoudre des problèmes scientifiques et sociétaux complexes. Pour faciliter le passage à ce nouveau paradigme, l’évolution des infrastructures et services associés de calcul à haute performance et de stockage long terme afin d’optimiser et faciliter l’utilisation des données issues de la recherche dans les hautes écoles universitaires genevoises constitue l’essence du PL 12146. Aussi, ce PL se décline en quatre objectifs prioritaires :
- Mettre en place une infrastructure pouvant répondre de manière optimisée aux besoins en matière de calcul scientifique et de gestion du cycle de vie des données de la recherche (qui comprend également la gestion des données dites « actives ») ;
- Mettre en place une architecture de stockage sécurisée construite sur les standards internationaux permettant la conservation à moyen et long terme des données scientifiques ;
- Développer des interfaces logicielles qui répondent aux besoins des chercheurs et facilitent l’utilisation de ces infrastructures aussi bien pour le calcul que pour le dépôt, la gestion, et l’accès aux données ;
- Concevoir des environnements informatiques favorisant la collaboration entre chercheurs, facilitant l’exploration, la visualisation et le partage des données, ainsi que leur utilisation dans l’enseignement.
Le principe général est de mettre à disposition des membres de la communauté scientifique, au travers d’un « cloud académique », des infrastructures et services mutualisés et sécurisés. En effet, plutôt que de continuer de financer des infrastructures dédiées exclusivement à des domaines scientifiques particuliers, qui s’avèrent souvent insuffisantes, la voie prise par le « cloud académique » est de mutualiser autant que possible les différentes couches de services, à savoir IaaS (Infrastructure as a Service), PaaS (Platform as a Service), et SaaS (Software as a Service), afin d’accroître et d’optimiser l’offre de services.
D’autre part, afin de permettre un usage adéquat de ces nouvelles infrastructures et des logiciels associés, des services d’accompagnement et d’expertise doivent être mis en place pour aider les chercheurs : conseils en HPC, interfaces utilisateurs, environnements informatiques favorisant la collaboration, l’échange de données et leur utilisation en conformité avec les nouvelles exigences des bailleurs de fonds et des éditeurs, etc.
Selon la volonté du DIP, ces infrastructures et services mutualisés, gérés par l’UNIGE, sont ouverts aux partenaires académiques genevois (HES-SO Genève et IHEID). Ils sont également conçus pour s’intégrer dans l’écosystème national, mais aussi au-delà, du fait qu’ils sont basés sur des standards internationaux. À noter que pour des raisons de pérennité des solutions informatiques, les logiciels sous-jacents à ces infrastructures sont pour la majorité des logiciels libres(5) soutenus par des communautés internationales. Il serait en effet illusoire de compter sur des solutions propriétaires, sujettes aux aléas des marchés économiques.
Plus concrètement, ces quatre objectifs prioritaires se déclinent par :
– Le renouvellement, l’extension et l’amélioration de la ferme de calcul Baobab, à savoir augmenter la puissance de calcul et la capacité de stockage pour les données actives, diversifier le matériel avec l’ajout de GPU(6), et bénéficier des nouvelles technologies de serveurs moins énergivores ;
– Du « cloud computing » permettant aux chercheurs d’utiliser les ressources d’une manière flexible, selon leurs besoins, à la demande ;
– Du conseil et de l’expertise en HPC afin de garantir aux chercheurs une meilleure adéquation entre leurs algorithmes et l’architecture des machines disponibles ;
– L’archivage des données selon des standards internationaux en vigueur dans le domaine archivistique (tels que l’OAIS Reference Model – ISO 14721:2012), permettant la conservation à moyen terme (moins de 10 ans) et long terme (au-delà de 10 ans) des données scientifiques, répliquées sur plusieurs sites dans différentes technologies ;
– L’accompagnement des chercheurs dans leurs projets d’exploitation de leurs données selon de nouveaux algorithmes, particulièrement dans les sciences sociales et humaines (digital humanities), domaine qui est amené à se développer et dont le potentiel, largement sous-exploité à ce jour, intéresse de plus en plus les chercheurs de l’UNIGE (par exemple, en facultés des lettres, de théologie, de traduction et d’interprétation, et des sciences économiques et sociales) ;
– Le développement d’interfaces permettant aux étudiants et plus largement aux citoyens d’accéder et de visualiser des données issues de la recherche et rendues spécifiquement compréhensibles pour cette population d’utilisateurs.
La feuille de route (roadmap) de la réalisation de ces objectifs est présentée dans la Figure 1 pour la période 2018 à mi-2020 (le PL doit se terminer en décembre 2022).
Figure 1 : Feuille de route intermédiaire
Réalisations
Le PL se concentre sur deux axes principaux : pour commencer, un axe « Infrastructures », dans lequel l’acquisition de matériel est effectuée sur la base d’appels d’offres publics. Cela concerne l’évolution des serveurs de calcul de Baobab avec un objectif de 4'000 cœurs, l’extension du stockage « Network Attached Storage » (NAS) à 3.5 PB(7) (répliqué sur un deuxième site), et destiné au traitement des données actives (Active Data Management), de l’acquisition d’un robot pour le stockage sur bande de grands volumes de données (plusieurs dizaines de PB), ainsi que du stockage de type « S3 »(8) destiné à la préservation long terme.
Le deuxième axe du PL concerne le développement des environnements et interfaces logiciels permettant aux chercheurs de bénéficier des nouvelles infrastructures.
Après deux ans d’activité du PL, nous pouvons citer deux réalisations principales : Yareta, le système d’archivage long terme des données de recherche et la plateforme « DH » (Digital Humanities).
Yareta
Yareta (https://yareta.unige.ch) est le nouveau dépôt de données FAIR(9) (Findable, Accessible, Interoperate, Reusable – Wilkinson et al., 2016) disponible depuis juin 2019 pour la communauté de chercheurs genevoise, permettant de promouvoir le partage des données et la reproductibilité scientifique. « Powered by the DLCM technology » (https://www.dlcm.ch), Yareta se compose d'une architecture OAIS (norme ISO 14721:2012) ouverte et modulaire pour la conservation à long terme (voir Figure 2), qui est centrée sur l'utilisateur afin de faciliter le dépôt des données de recherche. De plus, il a été conçu pour s'intégrer facilement aux systèmes de gestion de l'information des laboratoires et/ou s’interfacer avec des environnements de gestion active des données (« ADM »), puisque basé sur la technologie « Web services » (ou API(10)) (voir Figure 3).
L’architecture est composée de 3 parties : la soumission, l’archivage, et la dissémination, qui correspondent respectivement aux composants « Submission Information Package » (SIP), « Archival Information Package » (AIP), et « Dissemination Information Package » (DIP) de la norme OAIS. Chaque sous-module (Pre-Ingest, Ingest, Archival Storage, Data Management, Access) est indépendant et peut s’exécuter dans le cloud sur des serveurs distincts. Le DOI (Digital Object Identifier) d’un dataset peut être réservé lors du « pre-ingest », ou assigné lors de l’« ingest ». Les métadonnées au format Datacite (https://schema.datacite.org/), complétées par les données administratives PREMIS (https://www.loc.gov/standards/premis/), sont indexées et moissonnables au travers du protocole OAI-PMH. Lorsque les données sont soumises, le processus inclut entre autres le calcul d’un checksum assurant l’intégrité des informations, le contrôle par un antivirus, et l’identification et la qualification du format. Le module « data management » définit les modalités de stockage physique (nombre de réplications, technologie, durée, etc.).
En résumé, Yareta est une solution d’archivage long terme des données de recherche :
- non-commerciale, sur sol suisse et qui répond aux exigences FAIR du Fonds National Suisse (FNS) ;
- conforme aux normes internationales pour l’interopérabilité des données (OAIS, DOI, OAI-PMH, PREMISE, Datacite, etc.) ;
- compatible avec tous les formats en vigueur dans les différentes disciplines scientifiques et qui constitue donc un dépôt générique des données de recherche ;
- conçue « the swiss way », à savoir décentralisée tout en assurant une indexation à l’échelle nationale ;
- flexible quant au nombre de copies et leur stockage physique dans différentes technologies pour assurer la pérennité des données ;
- basée sur une technologie moderne qui s’interconnecte aux environnements des chercheurs (Web services).
Dans les objectifs futurs de développement de Yareta, on peut citer :
- l’amélioration de l’ergonomie des interfaces utilisateur ;
- l’extension des fonctionnalités offertes afin de faciliter l'accès aux données de recherche, par exemple le développement de "plug-in" permettant de visualiser les données scientifiques via le module « International Image Interoperability Framework » (IIIF) pour les humanités numériques, un module 3D pour la visualisation de molécules, etc. ;
- le développement d’un module pour implémenter la politique de préservation permettant de compléter le cycle de vie des données (migration, fin de vie, etc.) et une plus grande souplesse dans le choix du nombre de réplications et des supports physiques ;
- l’ajout de mécanismes de "data privacy" permettant de gérer les données sensibles.
Figure 2 : Architecture de Yareta
Figure 3 : De l’active data management (ADM) à l’archivage long terme (LTP)

La plateforme DH
La plateforme DH (Figure 4) a été conçue pour que les chercheurs en humanités numériques puissent gérer leurs données en format RDF(11) (Resource Description Framework). Ce format apporte beaucoup plus de possibilités que la forme plus traditionnelle, qui consiste à organiser les données dans des bases de données relationnelles. Développé par le W3C(12), RDF est le langage de base du Web sémantique représenté sous la forme de graphes composés d’associations « sujet, prédicat, objet », dénommées « triplets ». L’avantage d’une telle représentation est de pouvoir faire des requêtes dans un langage de plus haut niveau sémantique que celles des bases de données relationnelles (Structured Query Langage – SQL).
Dans la plateforme DH, deux approches sont proposées pour passer des bases de données relationnelles à la représentation RDF :
(1) une conversion automatique qui génère des relations sémantiques entre les objets, ces relations correspondant aux liens relationnels existants entre les différents champs de la base de données ; cette manière de faire ne bénéficie pas de tout le potentiel de la représentation sémantique, mais permet de minimiser le travail du chercheur lorsque les bases de données sont préexistantes ;
(2) la conception d’un modèle de données par les chercheurs avec l’aide d’experts du domaine RDF. Ce modèle est ensuite traduit en RDF.
Le format RDF permet de faire du « Linked data » (« Web des données » en français) qui consiste à publier sur le Web les données structurées non pas sous la forme de silos de données isolés les uns des autres, mais en reliant les données entre elles pour constituer un réseau global d'informations. L’usage d’ontologies prédéfinies disponibles sur le Web permet d’avoir des interprétations communes de ces informations. Cela permet par exemple de décrire des personnes (VIAF) et les relations qu’elles entretiennent entre elles (FOAF), ou des lieux géographiques (GeoNames), ainsi que des réseaux de connaissances (e.g., DBpedia).
Figure 4 : Architecture de la plateforme DH
Les données RDF sont gérées par le logiciel « Fedora Commons », le système avec lequel est construite l’Archive Ouverte de l’UNIGE (https://archive-ouverte.unige.ch/). La mise à jour des données RDF se fait via le logiciel Concrete 5, qui est le Content Management System (CMS) de l’UNIGE et avec lequel les pages Web de l’UNIGE sont gérées. L’avantage d’utiliser des outils institutionnels préexistants est double : parcimonie dans l’exploitation des outils et prise en main plus aisée par les utilisateurs qui les utilisent déjà dans d’autres contextes. Finalement, la préservation sur le long terme de ces données RDF est possible au travers d’un connecteur vers Yareta.
À ce jour (novembre 2019), deux projets pilotes bénéficient de cette plateforme DH : « Turrettini », la correspondance de Jean-Alphonse Turrettini, et « Tronchin », la publication des archives du collectionneur genevois François Tronchin.
Gouvernance
La gouvernance du PL se mène de manière transversale et agile dans laquelle la priorisation des tâches, contenues dans un « backlog », est essentielle (Al-Baik & Miller, 2015). Cette gouvernance, représentée dans la Figure 5, est par ailleurs construite sur la base de trois communautés de chercheurs (HPC, ADM, LTP) qui ont pour vocation d'impulser une dynamique ascendante et interdisciplinaire. Elle nécessite conjointement l'implication de nombreux partenaires et équipes d'expertises diverses (services « recherche », « information scientifique », « système d’information », etc.) travaillant en étroite collaboration afin d’assurer une adéquation avec les besoins des chercheurs des différentes facultés, ainsi que des institutions bénéficiant du PL. Pour ces raisons, une gouvernance impliquant des représentants de ces différentes entités a été mise en place sous la forme d’un comité de pilotage. Ce comité, qui se réunit environ 4 fois par année, est composé d’un représentant de chaque faculté et institution.
Modèle de coûts
Les services couverts par le PL12146 et pour lesquels un financement s’avérera nécessaire afin d’assurer leur exploitation et leur renouvellement à son terme sont les suivants :
- Le calcul haute performance (HPC) ;
- Les solutions de type IAAS qui permettent aux chercheurs de bénéficier de « machines virtuelles » sans nécessiter d’acquérir et gérer des serveurs dédiés, souvent sous-exploités ;
- Le stockage puis l’archivage des données de la recherche ;
- La maintenance évolutive du portefeuille de solutions logicielles qui seront créées pour la gestion des données actives (e.g. la plateforme « Digital Humanities ») ;
- Le conseil aux chercheurs sur les infrastructures et services numériques ainsi que l’animation des communautés de pratiques.
Après consultations auprès du Rectorat et du service des finances de l’UNIGE, les tarifs des services numériques issus du PL qui utilisent des ressources de manière exclusive ont récemment été fixés et communiqués à la communauté universitaire du canton. Il s'agit en particulier des services de stockage et d'archivage des données de la recherche, dont les tarifs annuels sont les suivants :
- stockage disque (backupé) : 75 CHF / TB
- stockage bande (backupé) : 25 CHF / TB
- préservation long terme : 100 CHF / TB (copies sur deux technologies différentes)
Afin de limiter le travail administratif et de se conformer aux pratiques du marché, 50 GB sont mis à disposition gratuitement. Ces tarifs seront révisés annuellement afin de rester compétitifs avec les tarifs du marché.
Figure 5 : Gouvernance du PL
Appel à projets
Afin de faire participer les communautés de chercheurs à la mise en place de nouvelles solutions numériques pour la gestion des données, un appel à projets a été lancé en novembre 2019. Celui-ci s’adresse à toutes les disciplines scientifiques.
À cette fin, les chercheurs sont appelés à soumettre des propositions de projets informatiques en vue de faciliter la collecte, le traitement, la gestion, le partage ou la diffusion des données de recherche, activités communément désignées sous le terme de gestion des données actives (« ADM », voir ci-dessus).
Les projets proposés doivent s’inscrire dans ce thème et mener à une solution numérique :
- mutualisable – qui soit utile à plusieurs groupes de recherche, éventuellement de disciplines différentes, et soit suffisamment générique pour être utilisée par le plus grand nombre de chercheurs,
- institutionnalisable – qui aspire à devenir un service numérique institutionnel complétant l’offre disponible à l’UNIGE et autres HE, ou à étendre un service existant,
- novatrice – qui se distingue par son originalité, n’existe pas au sein de la communauté de recherche genevoise ou soit développée selon une approche innovante.
Le large périmètre tant technique (développement, intégration, solutions open source, etc.) que thématique de l’appel à projets a pour volonté de favoriser l’innovation et l’expression de besoins au sein des nombreux domaines de recherche constituant la communauté scientifique genevoise.
Synergie avec les projets nationaux
Il est intéressant de relever que l’élaboration du PL en été 2011 coïncide avec la mise en place du programme suisse « accès à l’information scientifique », de la Conférence Universitaire Suisse (CUS) – qui est devenue par la suite swissuniversities (SWU) à partir du 1er janvier 2015 – dont les prémisses des idées et concepts remontent à fin 2010. À cette époque, l’explosion de la numérisation était relevée comme un élément disruptif qui contribuait à placer les universités et la communauté scientifique devant de nouveaux défis en matière d’information scientifique dont il n’était pas encore possible de définir le périmètre de manière définitive. Des mesures urgentes étaient donc jugées nécessaires pour que la communauté scientifique suisse puisse avoir durablement accès aux informations scientifiques dont elle avait besoin tout en limitant les coûts pour l’ensemble du système.
En conséquence, durant le premier semestre 2011, l’élaboration du programme fédéral 2013-2016 a sollicité l’apport de propositions de la communauté universitaire. Dans ce contexte d’appel à contributions, j’ai eu l’opportunité de me positionner sur le sujet du cycle de vie des données dans lequel je précisais qu’il devenait primordial de sensibiliser l’ensemble des chercheurs à la problématique de l’explosion de la quantité de données numériques produites quotidiennement. Il convenait dès la création des données de recherche de mettre à leur disposition des services de « data life cycle management » (DLCM), basés sur les meilleures pratiques professionnelles et adaptés aux différents contextes scientifiques. Il était également relevé que l’accessibilité des données devenait une condition posée par certaines agences gouvernementales de financement de la recherche ainsi que par certains éditeurs.
Dans cette perspective, j’avais introduit le concept de « Scientific Object Repositories » (SOR) visant à une gestion plus efficiente des données numériques avec des mécanismes de stockage, de partage (data sharing), d’accès sécurisé, de catalogage, d’annotation, ainsi que d’archivage à long terme, selon des pratiques qui correspondent à des standards internationaux établis. Le concept de SOR devait reposer sur une architecture distribuée permettant de mutualiser et de capitaliser les efforts et les connaissances. Ce concept devait également permettre une valorisation des données au-delà de celle initialement pensée par les chercheurs, au travers d’outils de data mining, data visualization, mashup, etc. dont les bénéficiaires seront d’autres communautés exerçant leurs activités dans la recherche et l’enseignement et plus largement la société civile. Même si aujourd’hui le terme SOR n’a pas survécu, le concept a été en bonne partie repris dans le projet DLCM (https://www.dlcm.ch).
Concernant le HPC, il était aussi relevé que pour répondre de manière maîtrisée et sécurisée aux besoins émergents de la science vis-à-vis de la croissance exponentielle des données la mise en place d’un « cloud académique » au niveau national s’avérait nécessaire. Afin de faciliter les collaborations à l’échelle nationale et internationale, tout en optimisant les investissements consentis à différents niveaux, ce cloud devait être conçu selon le principe du fédéralisme en mettant à disposition des communautés scientifiques, en modes IaaS et SaaS, les services requis pour soutenir l’évolution de la recherche.
Aussi, après une période de gestation qui a duré jusqu’en 2012, le programme CUS P-2 a pris sa forme finale et son titre : « Information scientifique : accès, traitement et sauvegarde », pour démarrer en 2013. C’est à ce moment que j’ai concrétisé le projet DLCM (Burgi et al., 2017) en prenant contact en novembre 2013 avec des experts du domaine DLCM dans les universités et écoles polytechniques suisses dans le but de former un partenariat avec l’objectif de déposer une proposition de projet CUS P-2 en 2014. Au terme de cette démarche, un partenariat entre les deux écoles polytechniques fédérales (ETH-Z et EPF-L), les universités de Zurich, Bâle, Lausanne, et Genève, la Haute Ecole de Gestion (HEG) de la Haute Ecole Spécialisée de Suisse occidentale (HES-SO), et SWITCH s’est finalement établi, avec à la clé une proposition aboutie et soumise en février 2015. Suite à l’acceptation de cette proposition en juillet 2015, le démarrage officiel du projet a eu lieu le 1er septembre 2015. Cette première phase du projet s’est terminée en juillet 2018, pour être prolongée dans une deuxième phase qui doit se terminer en décembre 2020, et qui implique un nouveau partenaire, la Zürcher Hochschule für Angewandte Wissenschaften (ZHAW).
La naissance du projet de loi dans ce contexte d’effervescence d’idées au niveau national n’est par conséquent pas un hasard, et a fortement bénéficié de cette synergie. Pourtant, comme mentionné dans la section 2, l’agenda politique fédéral et celui du canton de Genève ont chacun suivi leur feuille de route, et il aura fallu attendre janvier 2018 pour initier le projet de loi. Quant au programme CUS P-2, il est entre-temps devenu SWU P5 couvrant la période 2017-2020. Cette resynchronisation des deux projets a néanmoins permis au canton de Genève de dynamiser le développement de la technologie DLCM qui conduira dès juin 2019 à mettre en production le système d’archivage long terme Yareta, mis à disposition des HE du canton, soit avant l’instance nationale (dénommée « OLOS »), qui devrait voir le jour durant le premier trimestre 2020.
Conclusions
Au-delà de fournir des infrastructures modernes et efficientes aux chercheurs, leur permettant ainsi de pleinement exercer leurs travaux de recherche selon le 4ème paradigme, le projet de loi a potentiellement plusieurs autres impacts. D’une part, la mise en place des trois thématiques, HPC, ADM, et LTP, a permis d’activer des communautés de chercheurs, contribuant ainsi à une mutualisation des pratiques et des outils. D’autre part, du fait que le projet de loi concerne toutes les HE du canton de Genève, des synergies entre des institutions travaillant sur des thématiques similaires sont facilitées. Par exemple, la Haute école de santé avec la Faculté de médecine ; la Haute école de gestion avec la Faculté en sciences économiques ; ou la Haute École du paysage, d'ingénierie et d'architecture avec la Faculté des sciences, etc.
Un autre aspect durable concerne la gestion des données de recherche qui, avec la mise en opération de Yareta, permet de franchir une première étape vers l’Open Science dans laquelle l’accès et le partage des données devrait amener à une plus grande transparence de la recherche, et selon des études, une plus grande citabilité des publications, et la promotion des résultats à une plus grande audience (Popkin, 2019). Ce pas vers l’Open Science est cohérent avec le prochain programme de swissuniversities qui va couvrir la période 2021-2028. Le PL « Infrastructures et services numériques pour la recherche » représente par conséquent une excellente opportunité de préparer les HE genevoises à cette nouvelle orientation que prend la recherche suisse.
Remerciements
Je tiens à remercier Alain Jacot-Descombes, directeur de la division des Systèmes d'Information et de Communication (DiSTIC) de l’UNIGE pour ses commentaires constructifs sur une version préliminaire du texte, ainsi que l’équipe du PL12146 et du pôle eResearch de la DiSTIC pour leurs apports (figures, informations, etc.) qui ont contribué à enrichir cet article.
Notes
(1) Hautes écoles (universitaires et spécialisées)
(2) Un cœur (physique) est un ensemble de circuits capables d’exécuter des programmes de façon autonome.
(3) Charles Beer, conseiller d’Etat genevois de 2003 à 2013, en charge du DIP, avait demandé d’inclure dans le périmètre du PL les Hautes Ecoles Spécialisées (HES) du canton de Genève afin de couvrir également leurs besoins en calcul et gestion des données.
(4) Le rapport de la commission, http://ge.ch/grandconseil/data/texte/PL12146A.pdf est passé devant la parlement le 24 novembre 2017, cf. http://ge.ch/grandconseil/sessions/seances-odj/67/?session=48.
(5) Ce point est important du fait qu’un projet de loi concerne uniquement des investissements, et que des coûts de licences (locations) ne peuvent pas être pris en charge dans ce contexte.
(6) Les GPU (Graphics Processing Unit) permettent d’effectuer des calculs plus rapidement dans les domaines impliquant des algorithmes fortement parallélisables.
(7) Un Peta Byte (PB) correspond à 1'000 Tera Bytes (TB).
(8) Le protocole S3 (Simple Storage Service) a été développé par Amazon. Il consiste à stocker l’information sous la forme d’objets, et non plus selon une organisation en fichiers.
(9) Les principes FAIR ont été rédigés en 2015 lors d'un atelier du Centre Lorentz à Leyde, aux Pays-Bas.
(10) API (Application Programming Interface) est un ensemble normalisé de fonctions, méthodes, etc. qui sert de façade par laquelle un logiciel offre des services à d'autres logiciels.
(11) RDF, développé par le W3C, est le langage de base du Web sémantique destiné à décrire de façon formelle les ressources Web et leurs métadonnées, permettant le traitement automatique de telles descriptions.
(12) Le World Wide Web Consortium, abrégé par le sigle W3C, est un organisme de standardisation à but non lucratif, fondé en octobre 1994 chargé de promouvoir la compatibilité des technologies du World Wide Web.
Bibliographie
Al-Baik, O. & Miller, J. (2015) The kanban approach, between agility and leanness: a systematic review, Empirical Software Engineering, 20(6), 1861-1897.
doi :10.1007/s10664-014-9340-x
Borgman, C.L. (2009). The digital future is now: A call to action for the humanities. Digital Humanities Quarterly, 3(4). Retrieved from http://digitalhumanities.org/dhq/vol/3/4/000077/000077.html
Burgi, P.-Y., Blumer, E., Makhlouf-Shabou, B. (2017). Research Data Management in Switzerland: National Efforts to Guarantee the Sustainability of Research Outputs. IFLA Journal [online], 43(1), 5–21. doi:10.1177/0340035216678238
Hey, T., Tansley, S., & Tolle, K. (Eds.) (2010). The Fourth Paradigm: Data-Intensive Scientific Discovery, Microsoft Research
Moore, G.E. (1965). Cramming more components onto integrated circuits. Electronics, 38(8), 114–117.
Popkin, G. (2019) Data sharing and how it can benefit your scientific career, Nature 569, 445-447. doi: 10.1038/d41586-019-01506-x
Waldrop, M.M. (2016) The chips are down for Moore’s law, Nature 530, 144-147.
Wilkinson, M.D. et al. (2016) The FAIR Guiding Principles for scientific data management and stewardship, Scientific Data volume 3, Article number: 160018
- Vous devez vous connecter pour poster des commentaires
N°20 décembre 2019
Ressi — 31 décembre 2019
Sommaire - N° 20, Décembre 2019
Études et recherche :
-
Faciliter et soutenir le travail des chercheurs : état des lieux, perspectives et réflexions sur l’exemple de la Haute école de travail social de Genève - Claire Wuillemin
Comptes-rendus d'expériences :
- Interroge : le service de référence en ligne des bibliothèques de la Ville de Genève - Susana Cameàn, Florent Dufaux et Jürgen Haepers
- Enquête 2018 sur les besoins non documentaires du public du site Riponne de la BCUL : méthodologie et principales conclusions - Christophe Bezençon et Françoise Simonet
- Alignement et enrichissement des données de l’inventaire d’un fonds d’archives en Linked Open Data: le cas du Montreux Jazz Digital Project - Alain Chardonnens
- Le Projet de Loi 12146 : Infrastructures et services numériques pour la recherche - Pierre-Yves Burgi
- Un plan de gestion de sinistres au sein des Archives de Montreux : de la conception à la mise à jour - Ludovic Ramalho
Comptes-rendus d'événements :
- Retours sur le congrès IFLA 2019 - Florence Bugy, Matthieu Cevey, Benoît Epron, Michel Gorin et Anouk Santos
- Première journée Open Science de la HES-SO - Cynthia A. Germond
- Forum annuel des bibliothèques HES-SO, 22 août 2019 : les données de la recherche « un marché à occuper » - Elise Pelletier
- De la veille classique au social listening : compte rendu de la 16ème journée franco-suisse sur la veille stratégique et l’intelligence économique, 20 juin 2019, Genève - Hélène Madinier
Recensions :
- Ce que le numérique fait aux livres - Benoît Epron
- La médiation : un concept pour les sciences de l’information et de la communication – Jacqueline Deschamps, 2018 - Elise Pelletier
- New Top Technologies Every Librarian needs to know (2019) - Claire Wuillemin
- Anleitungen und Vorschläge für Makerspaces in Bibliotheken: Sammelrezension, Teil II (2017-2019) - Karsten Schuldt
- Vous devez vous connecter pour poster des commentaires
Anleitungen und Vorschläge für Makerspaces in Bibliotheken: Sammelrezension, Teil II (2017-2019)
Ressi — 31 décembre 2019
Karsten Schuldt, Schweizerisches Institut für Informationswissenschaft, FHS Graubünden
Résumé
Si on compare avec les années précédentes, la littérature sur le thème Fablab en bibliothèque semble avoir perdu massivement de sa pertinence, et ce sur tous les plans : aussi bien dans les monographies, les sujets de recherche, les objets d’enquêtes que les travaux d’étudiants.
Il y a très peu de connaissances nouvelles sur le sujet ; à l’exception du fait que lorsque les fablabs existent dans une bibliothèque, ils s’élargissent à des espaces qui laissent tomber l’aspect technologique, aspect qui était, avant 2017, un des sous-thèmes prégnants de la littérature bibliothéconomique.
En outre il apparait que lorsque le fablab s’inscrit dans la technique, c’est avant tout une technique relativement simple qui s’est imposée.Seuls quelques rares projets, dans la littérature bibliothéconomique ne paraissent pas avoir réduit de manière significative, mais se déroulent à un niveau comparable à celui de 2014-2016.
Si on pouvait escompter, il y a quelques années, un développement des fablabs en bibliothèque, il apparait maintenant une certaine désillusion. Il y a certes des fablabs, il y en a de nouveaux, et il y a toujours des collègues enthousiasmés par les fablabs. On peut citer le projet de la fondation Bibliomedia Suisse, qui –d’abord pour la Suisse alémanique- met à disposition des boîtes à outils (toolkits) de fablabs en prêt pour les bibliothèques communales de toute taille. [Ce projet est du reste évalué par l’auteur de cette recension].
A contrario il y a aussi des exemples de fablabs, également dans l’espace germanophone, qui étaient mentionnés dans la littérature professionnelle en 2014-2016, et qui ont l’air de ne plus exister. La phase de développement, phase de promesses et d’essais, parait bien terminée pour les fablabs en bibliothèque. Ce serait vraiment bien s’il y avait maintenant une phase d’évaluation, lors de laquelle on pourrait étudier de manière réaliste ce que ces fablabs apportent réellement, quels sont leurs impacts et les raisons pour lesquelles certains perdurent et pas les autres. Comme l’écrit Barnikis (2017), cette recherche empirique n’a pas encore réellement été menée.
Übersicht
Dieser Text schliesst direkt an die Sammelrezension des gleichen Autors an, in welcher Ende 2016 die wichtigsten, bis dahin erschienen Bücher und Texte zu Makerspaces und Fablabs in Bibliotheken besprochen wurden (Schuldt 2016). Hier sollen nur die zwischen 2017 und 2019 zum Thema publizierten vorgestellt werden.
Grundsätzlich kann festgehalten werden, dass das Thema Makerspaces (hier, wie in der bibliothekarischen Literatur allgemein, auch als Synonym für Fablabs u.ä. verwendet) weiterhin in der bibliothekarischen Literatur immer wieder aufgegriffen wird, aber in einem viel kleineren Rahmen als in den Jahren zuvor. Der Grossteil der Texte sind kurze Projektberichte und Ideenskizzen (z.B. Geißler & Schumann 2017, Jaouan 2017, Ravoux & Ripert 2017, Vallauri 2017, Jaouan 2018, Wetendorf 2018). Ein im Januar 2017 erschienenes Themenheft der BuB: Forum Bibliothek und Information (69 (2017) 1) – auch vor allem aus Projektberichten zusammengesetzt und trotz dem Titel „Makerspace – lass dich inspirieren‟ mit Projekten zu anderen Themenbereichen (Gaming, Repaircafé, „Bibliothek der Dinge‟) angereichert – scheint die intensivste Auseinandersetzung zum Thema in der deutsch- und französischsprachigen Bibliotheksliteratur im Berichtszeitraum 2017-2019 gewesen zu sein.
Auch im englischsprachigen Raum erschienen – im Vergleich zur letzten Sammelrezension – kaum noch spezifische Werke zu Makerspaces in Bibliotheken. Einige wurden wieder aufgelegt (Burke & Kroski 2018, siehe weiter unten), aber neu wurden nur zwei relevante Werke (Kroski 2017, Willingham et al. 2018, siehe weiter unten) publiziert. Hinzu kommen Reihen von kurzen Büchern – die allerdings nicht auf Bibliotheken ausgerichtet sind –, welche sehr kurz Vorschläge für einzelne Projekte in Makerspaces machen. Diese sind eher auf Schulen ausgerichtet, können aber ebenso von anderen Einirchtungen, und damit auch Bibliotheken, genutzt werden.
Gleichzeitig sind Forschungsbeiträge zu Makerspaces selten geworden. Während in früheren Jahren einige Umfragen zu Makerspaces in Bibliotheken durchgeführt wurden, scheint das grosse Forschungsinteresse erloschen zu sein. Wenn, dann werden vor allem einzelne Einrichtungen untersucht oder gar Vorprojekte für Makerspaces dargestellt. Auch aus anderen Bereichen als dem Bibliothekswesen liegen wenige Abschlussarbeiten oder Studien vor (Gappmaier 2018). Als neues Thema wurde in einigen, weniger Texten die Frage aufgegriffen, wie Makerspaces evaluiert werden können. (Cun, Abramovich & Smith 2017; Gahagan & Calvert 2019; Calov 2017; Gahagan 2016)
Als eigenes Genre verschwunden sind Bücher, die missionierend die Idee von Makerspaces oder der Maker-Kultur verbreiten wollen. Während sich teilweise noch übertriebene Schilderungen der angeblichen Potentiale von Makerspaces in einigen Vorworten der oben genannten Bücher finden, scheint das Thema an sich so verbreitet zu sein, dass weitere Werbung für die Grundidee nicht mehr notwendig erscheint.
Im Fazit der Sammelrezension von 2016 wurde festgehalten, dass sich das Thema Makerspaces in Bibliotheken etabliert hätte, eigentlich genügend Literatur zum Thema vorläge und es jetzt die Aufgabe der Bibliotheken wäre, diese in ihrem lokalen Rahmen zu übersetzen. Es scheint heute, drei Jahre später, nicht so, als hätte das flächendeckend stattgefunden. Eher vermitteln die Beiträge und (wenigen) Publikationen den Eindruck, als sei die Zeit der enormen Hoffnungen auf die Potentiale von Makerspaces vorbei. Einzelne Bibliotheken scheinen weiter daran interessiert, vereinzelt wurden Makerspaces eingerichtet. Aber die Zeit der Expansion von Makerspaces in Bibliotheken scheint schon wieder vorbei zu sein.
Ein Schwachpunkt der Literatur zum Thema ist, dass nur wenige Bibliotheken berichten, was sie tun und wie ihre Erfahrungen sind. Auffällig ist, dass die publizierten Berichte praktisch nur von positiven Erfahrungen berichten, nicht von Schwierigkeiten oder auch nicht erfüllten Erwartungen. Ebenso wäre mehr konkrete Forschung zum Funktionieren der jetzt schon einige Jahre eingerichteten Makerspaces zu erwarten, die allerdings bislang offenbar kaum betrieben wird(1).
Zu erwähnen ist zudem, dass der bis dahin führende Verlag in diesem Feld, „Maker Media‟, welcher auch die englischsprachige Ausgabe der Zeitschrift Make: herausgab und den Markenname „Maker Faire‟ hielt, Mitte 2019 Konkurs anmeldete. Das kommerzielles Geschäftsmodell schien nicht tragend gewesen zu sein. (Andere Ausgaben der Zeitschrift existieren weiter, u.a. die deutschsprachige Ausgabe, die von einem anderen Verlag publiziert wird. Ebenso wurden einige Aufgaben des Verlages in eine „Community‟ übertragen.)
(1) Beim Verfolgen der thematischen Mailinglisten oder Social Media-Accounts (u.a. Facebook-Gruppen) stellt sich auch schnell der Eindruck ein, dass die dynamische Zeit der Makerspaces in Bibliotheken schon wieder vorbei ist. Es scheinen immer weniger Fragen gestellt, Berichte geteilt und Diskussionen geführt zu werden. Dies ist aber schwierig zu verifizieren, schliesslich kann es immer weitere Mailinglisten oder Social Media-Accounts geben, die nur nicht bekannt sind, dafür aber eine dynamische Diskussion widerspiegeln. Das scheint aber unwahrscheinlich.
Anleitungen und Vorschläge für Makerspaces in Bibliotheken: Sammelrezension, Teil II (2017-2019)
Monographien
Handbücher (Kroski 2017, Willingham et al. 2018)
Zwei Bücher, die 2017 und 2018 erschienen sind, treten mit dem Anspruch an, jeweils komplette Anleitung zum Einrichten und Betreiben eines Makerspaces in Bibliotheken zu geben. Das heisst, sie behandeln alle Themen von der Gründung eines Makerspaces (Warum überhaupt Makerspaces?, Etat, Räume, Policies usw.), nennen eine Anzahl von Technologien und Veranstaltungen, führen eine Anzahl von Makerspaces als Beispiel an und versuchen, einen Blick in die weitere Entwicklung zu geben. Will eine Bibliothek also einen Makerspace einrichten, hat sie jetzt zwei Anleitungen vorliegen, denen sie folgen kann. Für diesen Zweck sind beide Werke gleich gut nutzbar, die Unterschiede sind gering.
Das von Ellyssa Kroski (2017) herausgegebene „the makerspace librarianʹs sourcebook‟ ist etwas umfangreicher, die meisten Beiträge halten sich mit zu grossen Versprechungen zurück. Wie alle diese Bücher ist klar, dass die Entscheidung, in Beiträgen spezifische Technologien zu erwähnen, es der Gefahr aussetzt, schnell zu veralten. Allerdings zeigen die Technologien, die besprochen werden, auch, dass sich auf diesem Gebiet seit der letzten Sammelrezension wenig getan hat. Einzig Drohnen scheinen eine neue Technologie zu sein, alle anderen wurden auch schon 2014-2016 erwähnt.
Kroski und ihre Mitautorinnen und Mitautoren rufen dazu auf, eine „Diverse Maker Culture‟ zu entwickeln, was hier heisst, darauf zu achten, durch Einbeziehen der Nutzerinnen und Nutzer bei der Entwicklung von Angeboten und dadurch, dass man darauf achtet, für wen man spezifische Angebote macht, den Zugang inklusiv zu gestalten. Als Trend nennt sie mobile Makerspaces.
Das vorrangig von Theresa Willingham verfasste Buch (Willingham et al. 2018) schliesst an das von ihr und Jeroen de Boer publizierte – und in der letzten Sammelrezension besprochene – Makerspace in libraries (Willingham & de Boer 2015) an. Hatte ihr Buch von 2015 noch vor allem Beispiele vorgestellt und für die Idee Makerspace geworben, ist das jetzige Buch sowohl inhaltlich als auch von der Seitenzahl her weit umfangreicher. Willingham hat in der Zwischenzeit als Beraterin Bibliotheken (in den USA) dabei unterstützt, Makerspaces einzurichten. Dies ist dem Buch anzumerken: Immer wieder verfällt sie in die spezifische „Beratungs-Terminologie‟, die eher verdeckt als erklärt, gleichzeitig kann sie offensichtlich auf viele Erfahrungen aus tatsächlich eingerichteten Makerspaces zurückgreifen.
Sie argumentiert, dass die Nutzerinnen und Nutzer heute wüssten, was Making wäre, wie 3D-Drucker funktionieren etc. Dies müsse nicht mehr erläutert werden. Wichtiger wäre, dass in Bibliotheken Personal vorhanden sein müsse, welches sich auf Makerspaces und die dortige Arbeitskultur (Ständiges Lernen und Ausprobieren neuer Techniken, Projekte, Scheitern als normales Ergebnis) einstellen könnte. Willingham et al. schlagen kurz ein spezifisches Entwicklungsprogramm für das Bibliothekspersonal vor. Auf der Basis ihrer Erfahrungen aus der Beratung gehen sie davon aus, dass nicht neues Personal notwendig ist, sondern nur anders ausgebildetes. Ebenso offenbar aus der Erfahrungspraxis heraus bestehen sie darauf, dass Bibliotheken sich vor dem Aufbau eines Makerspaces Gedanken dazu machen, wozu dieser genutzt werden soll. Nur ein Makerspace, der auf den Interessen der lokalen Community aufbauen würde, wäre sinnvoll.
Gemeinsam ist beiden Büchern, dass sie am Ende die wichtigen Entscheidungen an die Bibliotheken selber zurückgeben. Sie beschreiben, auf welche Punkte geachtet werden muss und wie Probleme gelöst werden können, aber da es keine eindeutigen Lösungen und keine immer gleichen Makerspaces gibt, verweisen sie immer darauf, dass die Bibliotheken eigene Lösungen suchen und eigene Makerspaces einrichten müssen.
Projektbücher (Seymour 2018, Burke & Kroski 2018)
In der Sammelrezension von 2016 wurde auf eine ganze Reihe von Monographien hingewiesen, die vor allem Sammlungen von Projekten darstellten, welche in Makerspaces in Bibliotheken umgesetzt werden können. Teilweise waren diese Projekte sehr detailliert beschrieben, teilweise etwas unkonkreter. Aber immer ging es darum, dass Bibliotheken aus diesen Sammlungen fertige Projekte übernehmen können sollten.
Für die spezifische Institution Bibliothek scheint auch dieses Genre fast schon wieder eingegangen zu sein. In den letzten zwei Jahren erschienen offenbar nur zwei relevante Titel dieser Art. Dabei ist das erste von Burke & Kroski (2018) eine überarbeitete, zweite Auflage. Was hier als „Praxishandbuch‟ angepriesen wird, ist vor allem eine Sammlung von Beispielen und Listen. Das Buch zeichnet sich durch einen sehr übersichtlichen Aufbau aus. Jedes Kapitel endet mit einer kurzen Zusammenfassung, welche die wichtigsten Aussagen des jeweiligen Kapitels in Listen zusammenfasst. Ellyssa Kroski, welche für die Überarbeitung zuständig war, führte zudem eine Umfrage zu Makerspaces in Bibliotheken in verschiedenen (englischsprachigen) Mailinglisten durch. Die Idee war, eine Anzahl von Beispielen aktiver Makerspaces zu sammeln und im Buch darzustellen. Allerdings drängt sich der Eindruck auf, dass diese Umfrage wenig erfolgreich war und kaum zu Rückmeldungen führte. Genannt sind im Buch eher wenige Beispiele. (Dies deckt sich mit den Ergebnissen der Forschungsbeiträge, siehe weiter unten.)
Das zweite Buch dieses Genre (Seymour 2018) erhebt gleich den Anspruch, die Makerspaces in Bibliotheken wieder zu verändern. Der Meinung der Autorin nach seien diese viel zu sehr auf die MINT-Förderung ausgerichtet. Dies wäre aber nur eine Möglichkeit und zudem eine, die auch schon in Schulen genutzt würde. Vielmehr schlägt sie vor, Makerspaces als Ort für die Lösung sozialer Aufgaben einzusetzen. Das scheint etwas sehr hoch gegriffen, hat aber im englischsprachigen Raum unter dem Begriff „Service Learning‟ eine Tradition. (Ähnliches wird auch unter anderen Namen in vielen Schulen im DACH-Raum praktiziert.) Vor allen Kinder und Jugendliche sollen ein Problem beziehungsweisen eine Frage aus der nahen Umgebung vorgestellt bekommen – z.B. unsichere Verkehrsregelungen vor Schulen und Kindergärten, lokale Lebensbedingungen von Obdachlosen – und diese möglichst lokal lösen – z.B. bei den betreffenden Behörden auf andere Verkehrsregeln zu insistieren, die Lebensbedingungen von Obdachlosen etwas verbessern, z.B. indem Zugang zu öffentlichen Räumen eingefordert wird – und auf diesem Weg etwas über die Gesellschaft und die Möglichkeiten, die Gesellschaft zu verändern, zu lernen. Seymour schlägt nun vor, dies auch in Makerspaces in Bibliotheken zu tun, da hier die Lernräume dafür vorhanden seien und an eine soziale Rolle von Bibliotheken angeschlossen werden könne. Sie liefert dafür auch zahlreiche Beispielprojekte, die allerdings oft sehr spezifisch auf die US-amerikanische Realität zugeschnitten sind.
Ansonsten aber scheint das Interesse an solchen Beispielsammlungen gesunken zu sein – oder aber der Wille der betreffenden Verlage, solche Publikationen herauszubringen. Eventuell haben sich einfach die Vorgänger nicht so massiv verkauft, wie erhofft.
How-To-Serien
Während das spezifische Genre von „How-To‟-Übersichten für Makerspaces in Bibliotheken kaum noch bedient wird, hat sich das gleiche Genre für Makerspaces im Allgemeinen etabliert. Wurden sie vor einigen Jahren noch als Orte beschrieben, in welchen vor allem mit Technik gearbeitet wurde und erschienen Bücher und Broschüren mit Projektbeispielen vor allem bei einem Verlag (Maker Media), scheint sich der Begriff und das Konzept zumindest in englischsprachigen Raum soweit durchgesetzt zu haben, dass er (a) nicht mehr weiter erklärt, sondern vielmehr als werbewirksamer Begriff genutzt wird und (b) ausgedehnt wird auf alle möglichen Materialien und Themen. Eine ganze Reihe von Verlagen hat Reihen von Büchern aufgelegt oder für sich allein stehende Monographien veröffentlicht, die vor allem von Kindern und Jugendlichen selber genutzt werden sollen, um Projekte auszuwählen und nachzubauen bzw. nachzugestalten. Die Zahl dieser Reihe und Einzelpublikationen – von denen eine ganze Reihe auch ausserhalb des Buchhandels erscheint – ist nicht mehr zu überschauen.
Alle diese Werke gehen davon aus, dass es zahlreiche Makerspaces gibt, solche in verschiedenen Einrichtungen und solche, die für sich alleine stehen. Bibliotheken werden immer wieder, neben Schulen, Community-Centres und anderen, als eine dieser Einrichtungen aufgezählt, aber nicht gesondert hervorgehoben. Zumindest diesen Medien nach, ist der Makerspace auch im englischsprachigen Raum kein Alleinstellungsmerkmal von Bibliotheken, gleichzeitig aber scheint es allgemein akzeptiert zu sein, dass sie solche betreiben. Die Publikationen reagieren aber auf das Problem, dass all diese Makerspaces auch mit Programm gefüllt werden müssen(2).
Sehr einfache, für Kinder gedachte, Projekte beschreibt die Reihe „Be a Maker!‟, immer mit dem Untertitel „Maker Projects for kids who love...‟, gefolgt vom jeweiligen Thema wie Robotics, Electronics, Games, Printmaking u.a. (Crabtree Publishing, bislang rund 20 Titel). Jeder Band (je 32 Seiten) enthält, gut bebildert, einige wenige Projekte, beginnt mit einer kurzen Einführung in Makerspaces an sich und das jeweilige Thema. Nicht immer ist ganz klar, was an den jeweiligen Projekten das spezifische „Making‟ ist, oftmals scheinen normale Bastelprojekte als „Making‟ gebrandet worden zu sein.
Jeweils zehn Projekte, auch gut bebildert, aber mit mehr Text, enthält die Reihe „Using Makerspaces for School Projects: 10 Great Makerspace Projects using...‟, gefolgt vom jeweiligen Thema wie Social Studies, Science, Art (Rosen Publishing, bislang fünf Titel). An diesen Themen ist schon sichtbar, dass der Begriff „Making‟ sehr weit gedehnt wird. Hier wird das weiter oben geschilderte „Service Learning‟ genauso integriert wie Kunstprojekte oder Mathematik. Auch diese Reihe ist eher dafür gedacht, dass sie direkt von Jugendlichen verwendet wird, deshalb enthält sie ebenso Aufforderungen zum sorgsamen Umgang mit Materialien und mit anderen Personen.
„Cool Makerspace Gadgets & Gizmos‟, gefolgt vom einem Thema, beendet mit „It!‟ („Code It!‟, „Robotify It!‟ (ABDO, bislang 6 Titel) ist eine weitere Reihe, diesmal explizit auf Kinder ausgerichtet. Aufgebaut wie die anderen Reihen, nur mit explizit viel Bildern, endet jeder Band mit einer Aufforderung, den genutzten Arbeitsplatz auch wieder aufzuräumen.
Positiv zu vermerken ist, dass bei allen diese Serien offensichtlich darauf geachtet wird, Diversität vorzuleben. Niemals sind die abgebildeten Kinder, Jugendliche und Erwachsenen nur weiss und blond, niemals werden in den Informationsboxen nur „grosse Männer‟ vorgestellt, niemals wird ein Thema nur Mädchen oder nur Jungen zugeschrieben.
Alle diese – und weitere, hier ungenannte, aber gleich aufgebaute – Reihen sind dafür gedacht, dass die einzelnen Hefte Kindern und Jugendlich Anweisungen für eigene Projekte geben. Selbstverständlich lassen sie sich aber auch nutzen, um sie für die Planung und Organisation von Veranstaltungen in Makerspaces zu nutzen. Jedes der vorgestellten Projekte in jeder dieser Reihen stellt klar, welche Materialien benötigt werden und welche Ziele erreicht werden sollen. Durch die engen Vorgeben ist manchmal nicht ganz klar, wie bei diesen Projekten ein Lerneffekt eintreten oder gar „soziales Lernen‟ stattfinden soll. Die dafür notwendige Offenheit muss wohl anders hergestellt werden, als durch das sture Folgen der Anweisungen. Problematisch ist auch, dass in vielen Fällen explizit jeweils ein Produkt einer spezifischen Firma verwendet wird, obwohl viele Projekte wohl auch mit alternativen Produkten anderer Firmen durchgeführt werden könnten.
Neben diesen Reihen erscheinen weiterhin einzelne Werke, die mit ähnlichem Anspruch auftreten. Diese sind eher textlastig, aber grundsätzlich ähnlich. Als Beispiele seien hier das „Science Maker Book‟ (Beattie 2018) und „Makerspace Sound and Music Projects for All Ages‟ (Glendening & Glendening 2018) genannt. „School Library Makerspaces‟ (Moorefield-Lang 2018) stellt eine Sammlung von Beispielen aus US-amerikanischen Schulen vor, in deren Bibliotheken Makerspace aufgebaut wurden. Diese Beispiele sind alle sehr spezifisch amerikanisch, liefern trotzdem viele Anregungen für konkrete Veranstaltungen. Gleichzeitig gehen sie gerade beim Nachdenken, wie bestimmte Zielgruppen angesprochen werden oder mehr Diversität erreicht werden kann, etwas tiefer.
Viele dieser Publikationen erheben zusätzlich den Anspruch, an unterschiedlichen nationalen Lernplänen für Schulen ausgerichtet zu sein (USA, Kanada). Was bislang nicht passiert zu sein scheint, ist, dass diese Welle in den deutsch- oder französischsprachigen Ländern angekommen wäre. Publikationen in diesen Sprachen beziehen sich eher auf ausserschulische Bildungsaktivitäten. Sichtbar ist aber, dass das Konzept „Makerspace‟ durch diese Publikationen sehr auf Lernaktivitäten und auf Kinder und Jugendliche fokussiert wird. Makerspaces (in und ausserhalb von Bibliotheken) in Hochschulen, insbesondere technischen Hochschulen, die existieren, kommen hier nicht vor, ebenso wenig wie Projekte für andere Altersgruppen.
Literatur aus pädagogischen Zusammenhängen (making + coding 2018, Boy & Sieben 2017, Brejcha 2018)
Ausserhalb von Bibliotheken wurden in den letzten Jahren vor allem im pädagogischen Rahmen (sowohl in Schulen und Kindergärten als auch ausserhalb dieser) Projekte zu Making und Makerspace durchgeführt. Viele davon ohne grössere Dokumentation. Z.B. finden sich heute in vielen Pädagogischen Hochschulen Makerspaces, vor allem für die Ausbildung von Lehrpersonen, ohne das deren Arbeit breiter dokumentiert würde. Eine Anzahl der Projekte publizierte aber immer wieder ähnliche Broschüren, die vor allem Projekte für Makerspaces enthalten. Diese sind ähnlich aufgebaut, wie die schon beschriebenen „How-To‟-Serien. Der Unterschied ist, dass die vorgestellten Projekte oft in deutschen Schulen, Jugendclubs etc. ausprobiert wurden. Als Beispiel sei die Broschüre „Making + Coding‟ (2018) genannt.
Etwas umfangreicher ist die Broschüre des jfc-Medienzentrum Köln (Boy & Sieben 2017), welches im Rahmen des Projektes „Fablab Mobil‟ entstand. Hier wird Making in den Rahmen von Jugendarbeit gestellt. Die Broschüre ist ein Hybrid aus Forschungsbericht und Beschreibung von Projekten. Im Forschungsprojekt wurde getestet, ob ein mobiler Makerspace als Form der Jugendarbeit funktioniert und wie Veranstaltungen in diesen gestaltet sein müssten, damit die Kinder und Jugendlichen, die teilnehmen, möglichst viel lernen. Ergebnis war, dass es für den Lerneffekt egal war, ob (a) relativ frei nur die Aufgabe gestellt wurde, Produkte zu gestalten, welche die Teilnehmerinnen und Teilnehmer aus Vorschlägen aussuchen konnten, ob (b) spezifische Produkte als Ziel festgesetzt wurden oder aber (c) zu den Produkten noch konkrete Arbeitsschritte vorgegeben waren. Solange die Aufgabe machbar erschien und solange die Kinder und Jugendlichen zwar unterstützt wurden, wenn sie Hilfe benötigten, aber ihnen dabei nicht das Denken und Machen abgenommen wurde, lernten sie ungefähr das Gleiche. Was nicht funktionierte, so die Broschüre, war, einfach Technologien zur Verfügung zu stellen und zu hoffen, dass die Kinder und Jugendlichen mit diesen selbstständig Projekte generieren würden. Die Broschüre eignet sich für Bibliotheken vor allem dafür, darüber nachzudenken, wie eng (z.B. nur angeleitete Veranstaltungen) oder weit (z.B. ganz offen) sie ihren Makerspace gestalten wollen.
Eine Anleitung, wie Makerspaces in (US-amerikanischen) Schulen aufgebaut und betrieben werden können, will die Monographien von Lacy Brejcha (2018) geben. Basis ist der Makerspace, den sie selber in einer US-amerikanischen Schule betreibt. Aufgebaut ist das Buch wie ein Curriculum für ein Schuljahr, in dem in jedem Monat etwas gelernt wird und auch am Ende jeden Monats reflektiert wird, indem den Lesenden Aufgaben gegeben werden. Inhaltlich ist an diesem Buch wenig überraschend, es gibt auch wenige konkret nachzumachende Beispiele. Dafür sind diese immer nur sehr knapp dargestellt. Vielmehr konzentriert sich die Autorin auf die Planungs- und Organisationsaufgaben von Lehrpersonen und der Einbindung des Makerspaces in den Kontext der Schule.
Abschlussarbeiten
Angesichts dessen, dass das Thema Makerspace in der bibliothekarischen Literatur immer wieder als vorgebliches Zukunftsthema auftaucht, scheinen erstaunlich wenige Abschlussarbeiten bibliothekarischer Studiengänge zum Thema geschrieben worden zu sein. Zumindest unter den öffentlichen zugänglichen Abschlussarbeiten im DACH-Raum finden sie sich kaum.
In der Reihe „b.i.t.Online innovativ‟ erschien die Bachelorarbeit von Sabrina Lorenz (2018) unter dem irreführenden Titel „Makerspaces in Öffentlichen Bibliotheken‟. Das ist nicht das Thema der Arbeit, z.B. ist die Literaturübersicht viel zu wenig umfangreich für eine solche übergreifende Benennung. Vielmehr geht es darum, eine Makerspace-Veranstaltung in einer spezifischen Schulbibliothek zu konzipieren und durchzuführen. Diese Veranstaltung wird explizit als pädagogische definiert – inklusive didaktischer Planung – und auch als solche evaluiert (z.b. durch ein Interview mit einer Lehrperson). Was die Arbeit zeigt, ist, dass solche Veranstaltungen möglich sind und es auch mit wenig Aufwand für Bibliotheken möglich ist, Maker-Veranstaltungen so zu planen, dass sie von Lehrpersonen als pädagogisch sinnvoll angesehen werden.
Umfangreicher ist die in den Churer Schriften zur Informationswissenschaft publizierte Arbeit von Marcel Hanselmann (2018) mit dem gleichen Titel. Auch diese zielt letztlich darauf, zu erheben, ob eine spezifische Veranstaltungsform – hier: Makerspace-Veranstaltungen mit littleBits – umgesetzt werden können. Dazu wurde ein Workshop mit Bibliothekarinnen und Bibliothekaren durchgeführt. Relevanter sind aber die in der Arbeit dargestellten Vorarbeiten zu diesem Workshop, u.a. eine Umfrage unter Bibliotheken mit Makerspaces und der Versuch, die Pädagogik hinter Makerspaces zu definieren. Auch wenn der Autor selber die Ergebnisse positiver darstellt, zeigt sich hier doch, dass sowohl der pädagogische Hintergrund von Makerspaces wenig geklärt ist als auch, dass viele Bibliotheken keine klare Definition davon haben, was sie mit den Makerspaces eigentlich erreichen wollen.
In einer Abschlussarbeit aus der Informatik untersuchte Lena Gappmaier eine konkrete Veranstaltung, „Maker Days‟, die schon 2015 in Bad Reichenhall über einen Zeitraum von vier Tagen durchgeführt wurden. Während dieser wurden die meisten Angebote, die sich auch in Makerspaces in Bibliotheken, Schulen, Jugendzentren etc. finden, als Workshops für Jugendliche angeboten. Die Autorin untersuchte die Beteiligung und den Kompetenzerwerb der Teilnehmenden. Sie stellt fest, dass – obwohl explizit versucht wurde, dem entgegenzuwirken – die „Maker Days‟ Mädchen viel weniger ansprachen als Jungen und das der Kompetenzerwerb – wenig überraschend – in einem engen Zusammenhang mit der Länge der Teilnahme an den Veranstaltungen stand: Jugendliche, die länger und öfter teilnahmen, erwarben auch mehr Kompetenzen. Ansonsten fast die Arbeit im ersten Teil noch einmal alle Versprechen und Überlegungen zu Makerspaces gut zusammen.
Forschungsbeiträge
Auch die konkrete Forschung zu Makerspaces in Bibliotheken scheint in den letzten Jahren zurückgegangen zu sein. Weiterhin erscheinen Forschungsartikel zum Thema, aber nur wenige und kaum solche, die sich mit übergreifenden Fragen beschäftigen. Systematische Forschungsprogramme scheinen nicht entwickelt worden zu sein.
Eine Ausnahme ist die Arbeit von Shannon Crawford Barniskis (2017) zum Zusammenhang von bibliothekarischen Vorstellungen davon, was die Bibliothek sein soll und welche Wirkungen sie in der Welt haben soll („library faith‟) und dem Diskurs um Makerspaces in Bibliotheken. Der Text bezieht sich auf die Diskurse in den USA, die Ergebnisse lassen sich aber übertragen: In der bibliothekarischen Literatur hätte sich die Idee „Makerspace‟ durchgesetzt, so wie sich zuvor auch andere Ideen als „modern‟ durchgesetzt hätten, gleichzeitig gäbe es für die meisten Versprechen (also, was mit Makerspaces in Bibliotheken erreicht werden soll) keine empirische Basis, sondern wenn überhaupt, dann eher indirekte Evidenzen. Von den unterschiedlichen Versprechungen, wie Demokratisierung, Spass, Community-Bildung (vgl. für eine Aufzählung solcher Versprechen die Abschlussarbeit von Calvo (2017)), werden im Zusammenhang mit Makerspaces vor allem ökonomische Versprechen gemacht: Nutzerinnen und Nutzer würden besser lernen und dadurch mehr Kompetenzen für die Arbeitsmarkt haben, teilweise gibt es auch das Versprechen, dass ein Makerspace die lokale Wirtschaft voranbringen würde. Ob, wie in vielen Texten versprochen, Makerspaces in Bibliotheken dafür genutzt werden, dass Nutzerinnen und Nutzer partizipativ mehr an Entscheidungen beteiligt werden, zumindest im Makerspace, sei nicht ersichtlich. (Ähnliches stellte Braybrooke (2018) für Makerspaces in Museen, zumindest in London, fest. Auch hier ist der Anspruch, das Museum mit Makerspaces zu verändern, grösser, als die Realität.)
Die Ergebnisse einer Umfrage zu Makerspace in Bibliotheken an Hochschulen in New England, die allerdings schon 2015 durchgeführt wurde, präsentiert Davis (2018). Solche Umfragen wurden vor 2017 eher durchgeführt als näher, diese wurde einfach sehr spät publiziert. Sie haben alle den – undiskutierten – Bias, dass die Umfragen so durchgeführt werden, dass eigentlich nur die Bibliotheken antworten, welche ein Interesse an Makerspaces haben. Dadurch entsteht schnell der Eindruck einer weitreichenden Bewegung, da z.B. die antwortenden Bibliotheken berichten, in den letzten Jahren Makerspaces gegründet zu haben oder solche zu planen. (Die Gegenprobe, ob diese Pläne dann auch umgesetzt wurden, ob Makerspaces auch geschlossen wurden oder ob sie in anderen Bibliotheken nie angedacht wurden, wird in diesen Studien nicht gemacht.) Ansonsten werden bei Davis (2018) einfach Grundwerte zu den Makerspaces abgefragt und dann im Artikel deskriptiv dargestellt. Sichtbar wird in ihnen vor allem, dass die Bibliotheken zumindest 2015 eher auf die Suche danach waren, was ein Makerspace erreichen soll, wie er finanziert werden soll etc. und dabei zu sehr unterschiedlichen Antworten kamen.
Einen weiteren Überblick zur Verbreitung von Makerspaces, diesmal in Wissenschaftlichen Bibliotheken in Deutschland, bieten Späth, Seidl & Heinzel (2019), die einmal nicht auf einer Umfrage setzten, sondern systematisch die Homepages der 84 deutschen Universitäten (nicht der Fachhochschulen und auch nicht die privater Einrichtungen) durchsuchten. Vermerkt wird im Artikel, dass Makerspaces in Bibliotheken schon eine Weile existieren und deshalb erwartet werden könnte, dass diese sich auch in Deutschland verbreitet hätten. Die Ergebnisse zeigen das nur zum Teil. Von den 84 Universitäten haben 18 einen oder mehrere Makerspaces. Oft sind es die grossen Universitäten und die Technischen Universitäten, welche diese anbieten. Nur einer dieser Makerspaces untersteht direkt einer Bibliothek. Der Text informiert zudem über die Angebote und Ausstattung dieser Makerspaces. Die Autorinnen und der Autor interpretieren die Ergebnisse dahingehend, dass es sich bei Makerspaces um einen neuen Trend handeln würde, bei dem in Zukunft ein starkes Wachstum möglich sei. Allerdings lassen sich die Ergebnisse auch genau gegenteilig lesen als Hinweis darauf, dass dieser Trend sich nicht über einzelne, grosse Einrichtungen hinaus verbreitet hat.
Dass sich diese Ziele von Makerspaces weit von den geäusserten Versprechen entfernen können – und sich dann irgendwann die Frage stellt, ob das Makerspaces sind oder ob es etwas anderes bedeutet, dass solche Räume eingerichtet werden – zeigt die Darstellung von Megan Lotts (2017) zum von ihr betriebenen Makerspace in der Art Library der Rutgers University, New Jersey. In dieser wird vor allem mit Materialien aus der Kunstpraxis (Papier, Stifte, Farben etc.) gearbeitet, dass Hauptziel ist nicht mehr Lernen oder Innovation, sondern Stressabbau der Studierenden.
Eine weitere Umfrage von Bossaller und Haggerty (2018) fügt sich in dieses Bild ein. Thema ist eigentlich, wie Bibliothekarinnen und Bibliothekare Fragen des Copyrights in Bezug auf 3D-Druck sehen – die Antwort darauf steht im Titel: „We Are Not Police‟ –, interessanter ist, dass nur recht wenig Bibliotheken (81 von 900 angeschrieben) etwas zum Thema Makerspace sagen wollten, dass sich diese Bibliotheken über die verschiedenen Grössen von Bibliotheken (von kleinsten zu grössten) verteilten und das vor allem „low-tech‟, also einfache Technologien, in diesen Bibliotheken eingesetzt wird, wenn sie einen Makerspace haben.
Wenig überraschende Ergebnisse lieferte eine Interview-Studie mit sechs Bibliotheken (vier Schulbibliotheken, zwei Öffentliche Bibliotheken) in den USA, die schon länger einen Makerspace betreiben und zum Zeitpunkt des Interviews planten, diesen neu zu konzipieren. (Moorefield-Lang 2018b) Was hatten diese aus dem schon betriebenen Makerspace gelernt? Die Interviewten betonten, dass beim ersten Makerspace praktisch alles Mögliche ausprobiert wurde, während der neue genauer geplant würde. Es würden Ziele bestimmt und dann – auf der Basis der gesammelten Erfahrung – entschieden, wie der neue Makerspace aussehen sollte. Sie betonten gelernt zu haben, dass das Vorhandensein einer Community wichtig sei und dass sie deshalb einen Fokus darauf legen würden, diese zu pflegen. Grundsätzlich wären die Makerspaces insoweit erfolgreich, dass sie ständig besucht würden. Schwierig sei aber zu bestimmen, was genau in ihnen gelernt wird.
Auffällig ist, dass zur Evaluation der bestehenden Makerspaces in Bibliotheken bislang wenig publiziert wurde. Makerspaces scheinen weiterhin ohne grössere Überprüfung ihrer Wirksamkeit betrieben zu werden. Dies deckt sich z.B. mit der Beobachtung von Hanselmann (2017), dass die meisten dieser Einrichtungen ohne genauer Zieldefinition eröffnet wurden. In einer Abschlussarbeit (von 2016, aber bei der letzten Sammelrezension noch nicht vorliegend) zu der Frage, wie solche Evaluationen aussehen oder aussehen könnten, kommt Gahagan (2016) ebenso zum Ergebnis, dass solche kaum vorgenommen werden. Cun, Abramovich und Smith (2019) legt als ersten Teil eines Forschungsprojektes eine Matrix vor, um solche Evaluationen vorzunehmen. Diese scheint noch sehr komplex. Im Rahmen ihres Projektes soll sie überprüft und für den Alltag handhabbar gemacht werden. Bislang zeigt sie vor allem, dass viele Ansprüche an Makerspaces in Bibliotheken bestehen. Gahagan und Calvert (2019) besuchten 2016 und dann noch einmal 2019 den 2013 eingerichteten Makerspace der Central City Library in Auckland (Neuseeland) mit dem Ziel zu klären, wie in diesem der Erfolg des Makerspaces evaluiert wird. Zu ihrer Überraschung hatte sich in den letzten drei Jahren wenig geändert. Der Makerspace wurde von neuem Personal betrieben. Eingesetzt wurden zur Evaluation – neben der Zählung der Benutzerinnen und Benutzer – vor allem Meinungserhebungen am Ende von Veranstaltungen, Ad-hoc erhobenes Feedback von Nutzerinnen und Nutzern sowie Beobachtungen des Personals. Das alles wenig systematisch. Was Gahagan und Calvert feststellten war, dass das heutige Personal wenig davon zu wissen scheint, warum der Makerspace einst, auf der Basis einer Bibliotheksstrategie der Stadt, eingerichtet wurde. Vielmehr scheinen sie eigene Begründungen für ihn gefunden zu haben und ihn nicht mehr an den Zielen zu messen, die 2013 aufgestellt wurden.
Zwei Studien, die ausserhalb des Bibliothekswesens über Fablabs bzw. Makerspaces entstanden, verdienen eine Erwähnung. Davies (2017) untersuchte mit ethnographischem Blick die Realität von einem Dutzend Makerspaces in der USA: Wie funktionieren die sozialen Prozesse in ihnen? Wer benutzt sie und wer nicht? Wie sind die ungeschriebenen Regeln, die man einhalten muss, um Zugang zu erhalten? Sie zeigt, dass die Community um Makerspaces nicht einfach so entsteht, sondern das dafür immer von Personen im Makerspace Arbeit dafür geleistet werden muss. Gleichzeitig zeigt sie, dass die Offenheit für alle Personen, welche im Zusammenhang mit Makerspaces immer wieder genannt wird, nicht gelebt wird. Makerspaces schliessen nicht absichtlich Personen aus, aber sie haben gewisse Prozesse (Orientierung an Projektarbeit, individuelles Arbeiten, eine bestimmte Terminologie und Prozesse der Aushandlung von Regeln und Konflikten), die dazu führen, dass die meisten Makerspaces vor allem von gut situierten, mittelalten, weissen Männern benutzt werden. Calabresse Barton und Tan (2018) versuchen in einem Action Research Projekt genau gegen diese Einseitigkeit zu arbeiten: Wie können Jugendliche aus einer sozial benachteiligten Gegend in den USA sinnvoll einen Makerspace nutzen – und wofür? Sie arbeiteten zwei Jahren mit den Jugendlichen, die in einem Community Centre einen für sie passenden Makerspace einrichteten und diesen auch nutzten. Er sah anders aus, als andere Makerspaces: Kindgerechter, mehr auf gemeinsame Interaktion hinausgelegt, integriert in das Community Centre. Ausserdem waren die Projekte, welche die Jugendlichen interessierten, immer darauf ausgelegt, Probleme in ihrer Community zu lösen, nicht die individuellen Interessen der Jugendlichen selber. Die Arbeit im Makerspace funktionierte auch, weil die Autorinnen die Jugendlichen mit einer Struktur (also festen Terminen) unterstützten, diese aber gleichzeitig mit Bezug auf die sozialen Umstände der Jugendlichen flexibel hielt, also z.B. ein längeres Fehlen (weil Jugendliche kein Geld für den Bus zum Community Center hatten) nicht als Ausschlussgrund galt. Makerspaces mit diversen Nutzerinnen und Nutzern sind also möglich, wenn explizit darauf geachtet wird.
Fazit
Im Vergleich zu den Jahren zuvor scheint das Thema Makerspaces in Bibliotheken in der Literatur 2017-2019 massiv an Relevanz verloren zu haben, und zwar auf allen Ebenen: Bei Überblickswerken, als Forschungsthema, als Thema von Umfragen und als Thema studentischer Abschlussarbeiten. Es gibt kaum einen neuen Erkenntnisgewinn, ausser, dass sich Makerspaces in Bibliotheken, wenn sie existieren, thematisch massiv erweitern hin zu Räumen, die z.T. den ganzen technologischen Aspekt, welcher vor 2017 ein die Makerspaces definierendes Thema in der bibliothekarischen Literatur war, wieder fallen lassen. Zudem scheint, dass sich, wenn Technik eingesetzt wird, in den Makerspaces vor allem einfache Technik durchgesetzt hat.
Einzig die einzelnen Projektberichte in der bibliothekarischen Literatur scheinen nicht sonderlich weniger oder inhaltlich geringer geworden zu sein, sondern bewegen sich auf einem ähnlichen Niveau wie 2014-2016.
Konnte man vor einigen Jahren noch von einer Entwicklung hin zu Makerspaces in Bibliotheken ausgehen, scheint jetzt schon wieder eine gewisse Ernüchterung eingetreten zu sein. Es gibt Makerspaces, auch immer wieder neue und damit auch immer wieder Kolleginnen und Kollegen, die sich dafür begeistern. Zu erwähnen ist auch ein Projekt der Stiftung Bibliomedia Schweiz, welche – vorerst für die Deutschschweiz – Makerspace-Toolkits zur Ausleihe für Gemeindebibliotheken aller Grössen zur Verfügung stellt. [Diese Projekt wird vom Autor dieser Besprechung evaluiert.] (Es gibt aber auch Beispiele von Makerspaces, auch im DACH-Raum, von denen in der Literatur 2014-2016 berichtet wurde, die aber jetzt schon nicht mehr zu existieren scheinen.) Die Aufbauphase, also die Phase, in der viel versprochen und ausprobiert wird, scheint für Makerspaces in Bibliotheken aber schon wieder vorbei zu sein. Gut wäre es wohl, wenn jetzt eine Phase eintritt, in der realistisch geschaut wird, was diese Makerspaces jetzt wirklich bringen, welche Effekte sie tatsächlich haben und aus welchen Gründen einige erfolgreich nachhaltig weitergeführt werden und andere nicht. Allerdings ist Barniskis (2017) zuzustimmen, dass gerade diese empirische Forschung kaum betrieben wird.
(Stand: Oktober 2019)
Fussnote
(2)Auffällig im Vergleich zur Literatur bis 2016 ist, dass eigentlich kaum noch von Communities gesprochen oder geschrieben wird, die sich um Makerspaces herum selbstorganisiert bilden würden, sondern vor allem davon, welche Projekte und Veranstaltungen in den Makerspaces umgesetzt werden sollen.
Literatur
Barniskis, Shannon Crawford (2017). To what ends, by which means? In: Information Research 22 (2017) 1: 1-18, http://www.informationr.net/ir/22-1/colis/colis1646.html
Beattie, Rob (2018). Science Maker Book. London: Quarto Publishing, 2018
Bossaller, Jenny ; Haggerty, Kenneth (2018). We Are Not Police: Public Librariansʹ Attitudes about Making and Intellectual Property. In: Public Library Quarterly 37 (2018) 1: 36-52, https://doi.org/10.1080/01616846.2017.1422173
Boy, Henrike ; Sieben, Gerda (Hrsg.) (2017). Kunst & Kabel: Konstruieren. Programmieren. Selbermachen. München: kopaed, 2017
Braybrooke, Kat (2018). Hacking the museum? Practices and power geometries at collections makerspaces in London. In: The Journal of Peer Production (2018) 12: 40-59, http://peerproduction.net/issues/issue-12-makerspaces-and-institutions/peer-reviewed-papers/hacking-the-museum/
Brejcha, Lacy (2018). Makerspaces in School: A Month-by-Month Schoolwide Model for Building Meaningful Makerspaces. Waco, Texas: Prufrock Press, 2018
Burke, John J. ; Kroski, Ellyssa (2018). Makerspaces : A practical guide for librarians. (Practical guides for librarians, 38) (2. Edition) Lanham: Rowman & Littlefield, 2018
Calabresse Barton, Angela ; Tan, Edna (2018). STEM-Rich Maker Learning: Designing for Equity with Youth of Color. New York: Teachers College Press, 2018
Calov, Pablo (2017). Library Makerspaces: Evaluating the Value of Digital Making in a UK Public Library Setting. (Submitted in partial fulfilment of the requirements for the degree of Msc in Library Science) London: City University London, 2017, http://dx.doi.org/10.17613/M6SR30
Cun, Aijuan ; Abramovich, Samuel ; Smith, Jordan M. (2019). An assessment matrix for library makerspaces. In: Library and Information Science Research 41 (2019) 1, 39-47, https://doi.org/10.1016/j.lisr.2019.02.008
Davis, Ann Marie L. (2018). Current Trends and Goals in the Development of Makerspaces at New England College and Reserach Libraries. In: Information Technology and Libraries 37 (2018) 2, https://doi.org/10.6017/ital.v37i2.9825
Davis, Sarah R. (2017). Hackerspaces: Making the Maker Movement. Cambridge; Malden: Polity Press, 2017
Eck, Virginie (2017). Un fablab à la BML. In: Bibliothèque(s) (2017) 88-89: 97
Gahagan, Pia Margaret ; Calvert, Philip James (2019). Evaluating a Public Library Makerspace. In: Public Library Quarterly, 38 (2019), https://doi.org/10.1080/01616846.2019.1662756
Gahagan, Pia Margaret (2016). Evaluating Makerspaces: exploring methods used to assess the outcomes of public library makerspaces. (Submitted to the School of Information Management, Victroia University of Wellington). Wellington: Victoria University of Wellington, 2016, http://dx.doi.org/10063/5193
Gappmaier, Lena (2018). Maker Days for Kids: Analyse und Konzepterstellung. (Internet-Tenchologie und Gesellschaft, 8) Norderstedt: Books on Demand, 2018
Geißler, Jens A. ; Schumann, Tim (2017). Makerspace, Mundraub-Tour und Foodsharing. In: Bibliotheksdienst 51 (2017) 2: 181-196, https://doi.org/10.1515/bd-2017-0018
Glendening, Mary L. ; Glendening, Isaac W. (2018). Makerspace Sound and Music Projects for All Ages. New York u.a.: McGraw-Hill Education, 2018
Hanselmann, Marcel (2017). Makerspaces in öffentlichen Bibliotheken: Eine Untersuchung der didaktischen ziele und eine Evaluation der Technologie littleBits. (Churer Schriften zur Informationswissenschaft, 88) Chur: HTW Chur, 2017, https://www.htwchur.ch/fileadmin/htw_chur/angewandte_zukunftstechnologien/SII/churer_schriften/CSI88-Makerspaces_in_oeffentlichen_Bibliotheken.pdf
Jaouan, Cyrille (2017). Le Bibliofab : ou comment faire entrer le fablab en bibliothèque ?. In: Bibliothèque(s) (2017) 90-91: 82-83
Jaouan, Cyrille ; Gueidan, Audric ; Domas, Guillaume (2018). De la bibliothèque au fablab : entretien avec Audric Gueidan et Guillaume Domas. In: Bibliothèque(s) (2018) 92-93: 82-85
Kroski, Ellyssa (edit.) (2017). the makerspace librarianʹs sourcebook. Chicago: ala editions, 2017
Lorenz, Sabrian (2018). Makerspaces in Öffentlichen Bibliotheken – Konzeption und Durchführung eines Making-Angebots für die Schul- und Stadtteilbücherei Weibelfeldschule in Dreieich. (b.i.t.Online innovativ, 70) Wiesbaden: b.i.t. Verlag, 2018
Lotts, Megan (2017). Low-Cost High-Impact Makerspaces at the Rutgers University Art Library. In: Art Documentation: Journal of the Art Libraries Society of North America 36 (2017) 2: 345-362, https://doi.org/10.1086/694249
Making + Coding: 14 kreative Medienideen für die Schule. Ludwigshafen: medien + bildung, 2017, https://medienundbildung.com/uploads/tx_ttproducts/datasheet/Making-Coding_2.Aufl_web96.pdf
Moorefield-Lang, Heather (edit.) (2018a). School Library Makerspaces in Action. Santa Barbara; Denver: Libraries Unlimited, 2018
Moorefield-Lang, Heather (2018b). Lessons learned: intentional implementation of second makerspaces. In: Reference Services Review 47 (2018) 1: 37-47, https://doi.org/10.1108/RSR-07-2018-0058
Ravoux, Élisabeth ; Ripert, Isabelle (2017). Le projet cré@lab de la médiathèque de Saint-Raphaël. In: Bibliothèque(s) (2017) 88-89: 96
Schuldt, Karsten (2016). Anleitungen und Vorschläge für Makerspaces in Bibliotheken: Sammelrezension. In: RESSI (2016) 17, http://www.ressi.ch/num17/article_133
Seymour, Gina (2018). Makers with a cause: Creative Service Projects for Library Youth. Santa Barbara ; Denver: Libraries Unlimited, 2018
Späth, Katharina ; Seidl, Tobias ; Heinzel, Viktoria (2019). Verbreitung und Ausgestaltung von Makerspaces an Universitäten in Deutschland. In: o-bib 6 (2019) 3, https://doi.org/10.5282/o-bib/2019H3S40-55
Vallauri, Benoît (2017). Culture numérique en valises (clandestines). In: Bibliothèque(s) (2017) 88-89: 94-95
Willingham, Theresa ; Stephens, Chuck ; Willingham, Steve ; de Boer, Jeroen (2018). Library Makerspaces : The Complete Guide. Lanham ; Boulder ; New York ; London : Rowland & Littlefield, 2018
Willingham, Theresa ; de Boer, Jeroen (2015). Makerspaces in libraries. (Library technologies essentials, 4). Lanham ; Boulder ; New York ; London : Rowland & Littlefield, 2015
Wetendorf, Lisa (2018). „Mobiler Makerspace Schleswig-Holstein‟: Bibliotheken schaffen Wissen. In: BuB 70 (2018) 4: 165
- Vous devez vous connecter pour poster des commentaires
New Top Technologies Every Librarian needs to know (2019)
Ressi — 31 décembre 2019
Claire Wuillemin, Haute Ecole de Gestion, Genève
Résumé
Comme dit le proverbe, « un peu plus tard, un peu plus vite, nous venons tous au même gîte », ce qui s’applique parfaitement à la place et à l’influence des nouvelles technologies sur les sciences de l’information et la vitesse avec laquelle celles-ci les accueillent et les intègrent. En effet, certains dénoncent l’apparente inertie de la profession face aux changements et en particulier vis-à-vis de l’adoption de nouvelles technologies et supports –on pensera à l’éternelle et enflammée rivalité entre le livre papier et le livre numérique dont un exemple a été présenté sous la forme d’une autre recension dans le numéro 16 de cette revue (http://www.ressi.ch/num16/article_119). Pourtant, l’ouvrage New Top Technologies Every Librarian needs to know démontre que les professionnels s’interrogent sur comment les technologies déjà implantées dans la vie de tous les jours ou dans d’autres domaines peuvent venir enrichir les services et les prestations des centres d’information documentaire, et en particulier les bibliothèques.
Publié durant la première moitié de l’année 2019 par les éditions de la Library and Information Technology Association (LITA) – division de la renommée American Library Association (ALA) – cet ouvrage succède à The Top Technologies Every Librarian Needs to Know sorti pour sa part en 2014, qui synthétisait déjà les interrogations et réflexions des professionnels sur les technologies phares de l’époque. Cette année, c’est 24 contributeurs et contributrices employés dans diverses universités américaines qui exposent tour à tour des technologies triées sur le volet et rattachées à 4 grandes thématiques : les données, les services, les dépôts et l’accessibilité et l’interopérabilité. Ils proposent donc une réflexion sur les applications possibles de celles-ci au sein des bibliothèques, services d’archives et tout autre service d’information documentaire et plus généralement exposent les influences qui peuvent être attendue(s) sur l’avenir des métiers en sciences de l’information.
New Top Technologies Every Librarian needs to know (2019)
La première partie de New Top Technologies Every Librarian needs to know traite des technologies liées aux données et à leur gestion. Quatre professionnels de l’information proposent tour à tour une réflexion sur différentes technologies liées à cette thématique et dont un impact est attendu sur les SID. Tout d’abord, il est question des fameuses Linked Open Data visant à abattre les silos formés par les bases de données propriétaires pour faciliter l’accessibilité aux données et ainsi la recherche d’information dans sa globalité. Cet aspect d’interconnexion des entités se poursuit dans le chapitre suivant qui traite de l’internet des objets et des objets connectés. Ces derniers sont principalement connus pour leurs usages domestiques, mais en bibliothèque ils pourraient notamment être utiles pour suivre les mouvements et l’inventaire des collections physiques grâce à la technologie RFID par exemple. En effet, un lecteur RFID monté sur un scanner mobile attaché au rayon permettrait de balayer un rack et d’obtenir des informations sur la présence ou l’absence de documents. On pourrait ainsi limiter considérablement la perte des livres et ne plus être tributaire d’un rangement séquentiel. L’internet des objets pose néanmoins encore de grandes questions sur la protection des données privées des utilisateurs. Les professionnels ont un devoir de tirer parti des objets connectés sans mettre en péril la vie privée de leurs usagers. Le thème suivant est celui des link and reference rot (littéralement liens et référence pourrie) et des résolveurs de liens. Tout un chacun a déjà expérimenté la désagréable surprise de se retrouver face à un lien mort et l’impossibilité de retrouver un contenu. Le link rot décrit donc ce processus par lequel un lien ne pointe plus vers un contenu accessible ou que le contenu original a été modifié ou mis à jour. C’est le problème inhérent au dynamisme des pages et contenus web. Il existe par ailleurs le content drift (littéralement dérive du contenu) qui qualifie un lien qui fonctionne toujours, mais dirige vers un contenu qui ne se trouve plus dans son contexte original. L’addition du link rot et du content drift amène au reference rot ; la référence telle que disponible dans un article n’a plus sa valeur de preuve originale. Le domaine des sciences de l’information n’a eu de cesse de préserver les productions scientifiques, mais il faut désormais qu’il s’attaque à la préservation des liens internes aux publications et autres documents diffusés. Dans une veine voisine, il est ensuite question de la participation des bibliothèques à l’archivage du web. Le web est le reflet de la société contemporaine et des grands évènements qui la traversent. À ce titre, son contenu doit être sauvegardé par devoir de mémoire. Selon l’auteur, cette entreprise devrait être effectuée par les professionnels de l’information malgré les contraintes techniques qui leur donneront sans doute du fil à retordre.
La deuxième partie du livre est consacrée aux services. Le premier chapitre vient compléter le précédent en présentant les technologies et les outils existants pour préserver la vie privée, et le rôle que peuvent jouer les bibliothèques dans leur diffusion et la formation des usagers. Le chapitre propose une revue des outils disponibles, met en lumière les efforts actuellement déployés pour les bibliothèques et suggère des développements futurs pour qu’elles prennent une place prépondérante dans l’encadrement des publics dans ce domaine.
Dans le futur des services, il est aussi question de la data discovery ou exploration de données, tout particulièrement à travers les interfaces de recherche interactive, qui pourraient incorporer des graphiques et autres visualisations de l’information comme des nuages ou des clusters de mots. Il est suggéré que ce genre d’interface pourrait être mis en place pour permettre une autre exploration des ressources des bibliothèques. Le chapitre suivant vient compléter ces réflexions avec la représentation de l’information en proposant un point sur les enjeux de la mise en visualisation et son utilité pour les bibliothèques. Il donne divers outils propriétaires et gratuits, des conseils pour la réalisation de ces figures ainsi que des tutoriels. La partie se clôt avec une réflexion sur la réalité virtuelle (Virtual Reality ou VR). Elle serait un nouveau médium potentiel pour partager du contenu de formation, réaliser des réunions dans des salles de conférence virtuelles, mettre à disposition des espaces pour de la modélisation 3D de maquettes, etc.
L’avant-dernière partie du livre s’intéresse aux canaux et aux méthodes novatrices à travers lesquels les bibliothèques soutiennent les académiques, en s’attachant tout particulièrement à la place du numérique dans l’accès, la diffusion et l’archivage du savoir. Elle débute avec les bibliothèques et les humanités numériques en proposant un retour d’expérience des bibliothèques de Hesburgh de l’Université de Notre Dame en Indiana qui ont testé la mise en place d’une plateforme regroupant collections numériques ainsi qu'humanités numériques. Vient ensuite la question des digital repositories ou dépôt numériques, traitée en profondeur à travers des définitions, l’identification des tendances, la présentation des systèmes existants (Fedora, DSpace, Eprints, etc.), et les enjeux futurs de cette thématique. Le chapitre suivant s’intéresse également aux digital repositories, mais avec l’angle d’approche de la double-utilité traditionnelle de ces dépôts, à savoir : assurer un accès à des objets numériques ou préserver ceux produits au sein d’une institution. Il est question des bonnes pratiques pour ces deux usages ainsi que des directions futures à prendre en considération. La partie se termine avec la valorisation des collections et des livres rares grâce à la numérisation et la publication numérique. En effet, les sésames des collections jusqu’à récemment n’étaient accessibles que sur place. Avec l’arrivée du numérique, il est désormais possible de rendre accessibles ces objets à des chercheurs d’autres pays voire d’autres continents et ainsi en faciliter la dissémination. Ce chapitre propose pour ce faire un tour d’horizon des technologies impliquées ainsi qu’un retour de cas dans deux bibliothèques de l’université du Minnesota.
Poursuivant sur les enjeux des collections numériques, il est ensuite discuté de l’interopérabilité entre les plateformes numériques des différentes institutions, en particulier vis-à-vis de l’efficience des recherches d’images. En effet, la plupart des plateformes sont des silos cantonnés à chaque institution. Or pour l’intérêt des chercheurs, il serait intéressant que les plateformes puissent être interopérables. L’auteur propose un retour d’expérience sur l’implémentation de l’International Image Interoperability Framework (IIIF) dans les bibliothèques de l’Université de Toronto en présentant tout d’abord ce framework et son fonctionnement. Les outils d’enseignement sont aussi touchés par les enjeux d’interopérabilité notamment avec les plateformes de cours (Learning Management System ou LMS) comme Moodle par exemple. On parle alors de Learning tools interoperability (LTI). Dans le domaine des bibliothèques, il peut s’agir d’intégrer directement un outil de navigation sur le catalogue des collections sur Moodle. Plusieurs exemples d’applications sont ensuite exposés respectivement dans les Universités des États de la Louisiane et de l’Utah aux États-Unis et celle de Nouvelle-Galles du Sud en Australie. Un grand sujet actuel de société et qui touche déjà les bibliothèques est les robots (bots). Qu’il s’agisse de chatbot ou de programme informatique permettant d’automatiser des processus, les robots prennent une place de plus en plus importante (et pour certains inquiétante) dans le milieu du travail. Pourtant l’auteure de ce chapitre souligne la diversité des robots et des utilisations potentielles que les bibliothèques peuvent en faire pour améliorer les services qu’elles proposent actuellement et agrémente son propos de ressources pour créer soi-même des bots. Cette thématique est complétée par le chapitre suivant qui s’intéresse à l’intelligence artificielle et au Machine learning. Il est proposé des cas d’application concrets qui pourraient être utiles pour les bibliothèques. Le livre se clôt avec une contribution sur la technologie mobile. En effet, depuis quelques années, l’accès à l’information devient de plus en plus nomade et cela a eu des retombées sur l’industrie informatique en premier lieu, et par répercussion sur le reste des acteurs utilisant les technologies de l’information et de la communication. Les interfaces doivent ainsi être pensées au-delà des accès à l’aide de PC, et intégrer l’accès par téléphone mobile, tablettes, etc. qu’il s’agisse d’interfaces responsives ou de mise en place d’apps.
Critique
La plupart des thèmes abordés font partie du paysage de l’information documentaire depuis un certain temps déjà ; ils ne surprendront probablement personne. Toutefois, ils sont ancrés dans l’air du temps et pertinents dans les métamorphoses profondes qui s’opèrent sur le domaine. Pleines de potentiel, ces technologies sont néanmoins source de tourments pour des professionnels qui ne savent pas comment les aborder ou savoir comment ils pourraient avoir autant de cordes à leur arc. La majorité des chapitres propose toujours en début de parcours une définition des enjeux et des concepts en présence, permettant aux néophytes comme aux confirmés de suivre l’auteur le long de son exposé et d’en comprendre la subtilité des enjeux et l’ingéniosité (ou non) des arguments avancés.
En revanche, puisqu’il s’agit d’un recueil d’articles rédigés par des contributeurs américains, il accuse plusieurs faiblesses liées à son origine : d’une part il est écrit en anglais, ce qui pourra le rendre inaccessible à des professionnels non-locuteurs puisqu’il n’existe pas de version française disponible à ce jour. D’autre part, les observations et les études de cas sont enracinées dans leurs contextes national, réglementaire, culturel et académique. C’est un élément à garder en tête lors de tentatives de transpositions des suggestions à notre contexte helvétique. Des ajustements devront être considérés et une certaine tolérance de mise.
On concédera tout de même que la qualité et l’intérêt des chapitres restent fortement dépendants des auteurs : certains proposent des retours d’expérience et de tentatives menés directement sur le terrain alors que d’autres proposent uniquement des essais ou des spéculations – par conséquent qui n’ont pas été éprouvées. Or, l’expérience a maintes fois démontré que les souhaits des professionnels (ou de leurs publics d’ailleurs) ne sont pas toujours réalisés ni même réalisables ; voire que les projections qui en sont faites sont erronées – comme avec la fameuse annonce de la mort du livre papier annoncée par l’arrivée des e-books ; apocalypse qui se fait toujours attendre.
Il faut néanmoins reconnaître que les contributeurs ne jouent pas les Nostradamus : leurs propositions sont pour la vaste majorité réalistes et, même si elles n’ont pas toutes été éprouvées, restent de bonnes inspirations pour alimenter les réflexions dans le cadre de la mise en place de stratégies futures. On retiendra que les technologies qui s’offrent aux professionnels sont multiples tout comme leurs applications potentielles. Somme toute, c’est un livre à conserver sur une étagère ou dans sa liseuse et à re-consulter chaque année pour voir si les prévisions se réalisent...ou non.
Bibliographie
VARNUM, Kenneth J. (éd), 2019. New top technologies every librarian needs to know. Chicago: ALA Neal-Schuman. A Lita guide. ISBN 9780838917824
- Vous devez vous connecter pour poster des commentaires
La médiation : un concept pour les sciences de l’information et de la communication – Jacqueline Deschamps, 2018
Ressi — 31 décembre 2019
Elise Pelletier, Haute Ecole de Gestion, Genève
La médiation : un concept pour les sciences de l’information et de la communication – Jacqueline Deschamps, 2018
Avec cet ouvrage, Jacqueline Deschamps inaugure la série « Des concepts pour penser la société » aux éditions ISTE. Dirigée par Valérie Larroche de l’ENSSIB, cette série a pour objectif de donner un cadre théorique à des concepts régulièrement utilisés en Sciences de l’information et de la communication (SIC) en montrant leur transversalité avec d’autres disciplines. À « la médiation » se sont désormais ajoutés « le pouvoir » d’Olivier Dupont, « le dispositif » de Valérie Larroche et « le discours » de Jean-Paul Metzger. En tout, douze ouvrages devraient constituer cette série.
Enseignante à la Haute école de gestion de Genève jusqu’en 2009, Jacqueline Deschamps s’est notamment intéressée aux questions d’identité professionnelle des spécialistes de l’information. Dans cette lignée, il est assez cohérent que la thématique de la médiation vienne accroître ses publications. En effet, le rôle de médiateur des bibliothécaires et/ou archivistes est traditionnellement vu comme une évidence, de par leur rôle d’intermédiaire entre les collections et les usagers. Néanmoins, la réalité de ce concept disparaît parfois derrière une image floue qui englobe aussi bien l’animation que la communication. De plus, ce rôle d’intermédiaire est plus difficile à circonscrire dans un environnement numérique où les questions de médiations peuvent sembler assez désuètes. Ce livre re-pose donc de manière très utile les bases de la médiation en SIC.
Deux parties composent cet ouvrage. La première est consacrée aux « fondements épistémologiques » en s’appuyant sur les apports d’autres disciplines. La seconde partie replace la médiation et ses implications au sein des SIC.
L’auteure souligne dans l’introduction de la première partie, que le concept de « médiation » dépasse largement le cadre des SIC et est utilisé dans d’autres disciplines. Il a également envahi notre société et s’affiche dans l’espace public « comme une sorte de remède miracle pour régler des conflits de toute nature et à tous niveaux. » (Deschamps 2018, p.7). En réalité, la médiation a une « définition rigoureuse » basée sur une structure ternaire précise autour de ces éléments : « un tiers », « une relation » et « des sujets ». Ces trois éléments sont indispensables et c’est l’équilibre entre eux qui va garantir l’acte de médiation. L’auteure vient ensuite définir précisément ces éléments constitutifs. Elle explique, par exemple, que le positionnement neutre du tiers est central. S’il vient imposer aux sujets un choix moral, juridique ou autre…, alors on se trouve plutôt dans un cadre de conciliation, d’arbitrage ou même d’enseignement. Le tiers n’a aucun pouvoir de décision et n’est pas forcément une personne physique. Il peut prendre différentes formes: humaine, institutionnelle, symbolique. Le langage, par exemple, est une forme de tiers dans la médiation « c’est lui qui organise les relations entre les hommes et leur permet de représenter symboliquement le réel qu’ils perçoivent » (ibid., p. 23). La « relation », deuxième élément de la médiation, est à appréhender comme un processus. Dans cette perspective, la médiation peut intervenir à tout moment de la création à la rupture de la relation (ibid. p.25). Le troisième élément constitutif « les sujets » est beaucoup plus complexe à définir. Jacqueline Deschamps s’appuie dans cette partie sur plusieurs approches en philosophie, mais aussi bien évidemment en psychanalyse. Comme elle le souligne elle-même, l’exercice reste compliqué tant les approches sont complexes et parfois controversées. Contrairement, à l’élément tiers, « le sujet est celui qui n’est pas objet, qui ne peut se saisir comme un objet » (ibid. p.31).
Après avoir redéfini les trois éléments constitutifs de la médiation, l’auteure évoque ses caractéristiques du point de vue de son organisation et de sa temporalité. Elle insiste sur l’importance du cadre spatio-temporel, car la médiation, par essence, ne peut pas s’inscrire dans l’immédiateté. C’est sur cette importante question du « temps de la médiation » que se termine la première partie du livre. L’approche proposée dans cette première partie est volontairement conceptuelle et emprunte à plusieurs disciplines pour pouvoir, dans un second temps, repositionner la médiation dans le cadre plus restreint des SIC.
La deuxième partie intitulée « Mobilisation du concept de médiation en SIC » s’organise autour de cinq types : les médiations communicationnelles, informationnelles, culturelles, organisationnelles et sociétales. Même si le concept de médiation n’est pas réservé uniquement au SIC, il y a rapidement pris une place prépondérante. Pour preuve, Jacqueline Deschamps s’amuse à égrainer les nombreux laboratoires de recherche qui ont intégré le terme « médiation » dans leur nom (ibid. p.53).
Les médiations communicationnelles qui inaugurent cette partie rappellent que l’approche française de la discipline réunit les sciences de l’information et celles de la communication (SIC). Jacqueline Deschamps note que la communication permet un « transport dans l’espace » ce qui la rapproche de la notion de « transmission » qui permet un « transport dans le temps » (ibid.). Le parallèle avec les institutions emblématiques des SIC que sont les bibliothèques et les services d’archives est assez évident, car ce sont traditionnellement des lieux de transmission. Ils intègrent par conséquent cette médiation communicationnelle asynchrone. C’est également dans cette partie que l’auteure aborde les médiations numériques qui interrogent la notion d’accessibilité de l’information. Elle met en exergue l’importance actuelle de « l’individualisation des usages » (c’est-à-dire des interfaces d’accessibilité construites sur l’analyse des besoins des individus) qui déstabilise une approche de l’information documentaire qui s’est traditionnellement orientée vers une « visée collective » (ibid. p.53). La médiation informationnelle couvre un plus large spectre de professionnels de l’information et englobe aussi bien le documentaliste(1) que le chargé de veille. L’auteure précise notamment que l’intelligence économique est un « processus de médiation d’information spécialisée » (ibid, p.74). La partie sur les médiations culturelles permet de revenir sur deux conceptions antagonistes de la médiation. L’une « verticale » est traditionnellement présente dans les institutions culturelles dans lesquelles le médiateur est présent pour offrir la culture « qu’il détient » au plus grand nombre. L’autre « circulaire » déconstruit cet accès parfois élitiste et le rôle du médiateur est plutôt de « promouvoir d’autres types de relation à la culture » (ibid., p.77). On peut citer pour illustration le développement des réflexions sur les bibliothèques participatives. Pour les deux derniers types, Jacqueline Deschamps rappelle que la médiation est « au centre de la construction du social ». Elle s’interroge donc sur la place des médiations organisationnelles et sur celles des médiations sociétales qui abordent les questions politiques, écologiques, etc. La médiation est ici perçue sous l’aspect de l’établissement de la relation entre l’individu et le collectif au sens sociétal.
En conclusion, l’auteure rappelle que « la médiation remplit une fonction fondamentale de rétablissement de la communication » (ibid., p.101). Effectivement, dans le contexte des bibliothèques et des services d’archives, cette relation entre les usagers et les collections est parfois restreinte, voire inexistante. Le rôle du professionnel de l’information est de créer et maintenir cette relation sans l’influencer par un jugement moral ou autre. Paradoxalement, avec le développement des données numériques, la relation préexiste avant l’intervention du professionnel. L’acte de médiation intervient alors plus tard dans le processus de relation et le rôle du professionnel se concentre sur l’amélioration de cette relation.
Le grand intérêt de cet ouvrage est de proposer une approche conceptuelle complète. Comme plusieurs fois souligné, l’acte de médiation est souvent abordé de manière approximative dans la littérature professionnelle ce qui met en péril sa crédibilité au sein des SIC. D’ailleurs, un des bémols du livre, que l’auteure relève elle-même, est le manque de références scientifiques récentes dans la bibliographie. Cela fait écho à un autre problème soulevé : l’aspect polymorphe de la médiation qui rend sa conceptualisation assez complexe. Il n’est effectivement pas aisé de circonscrire l’ensemble des concepts et notions abordées dans cet ouvrage. Néanmoins, sa construction permet des entrées par éléments constitutifs et/ou par types de médiation, ce qui lui confère un statut d’ouvrage de référence sur le sujet.
Notes
(1)Au sens français du terme, c’est-à-dire le bibliothécaire en milieu académique.
Bibliographie
DESCHAMPS, Jacqueline, 2018. La médiation: Un concept pour les sciences de l’information et de la communication (Vol. 1). ISTE Group. ISBN : 9781784054830
- Vous devez vous connecter pour poster des commentaires