Publiée une fois par année, la Revue électronique suisse de science de l'information (RESSI) a pour but principal le développement scientifique de cette discipline en Suisse.
Open Access
Archives institutionnelles et archives centralisatrices: pratiques existantes et bonnes pratiques
Ressi — 31 décembre 2009
Lorraine Filippozzi, Haute Ecole de Gestion, Genève
Résumé
Cette étude a pour but de fournir une base documentaire solide au projet Info-Net Economy, futur portail thématique qui constituera le volet « Économie » de la bibliothèque électronique suisse E-Lib. Après avoir mis en évidence l’intérêt de proposer des portails centralisateurs et surtout l’opportunité que cela représente pour les professionnels de l’information, cette étude analyse les aspects organisationnels, techniques et marketing de projets similaires afin de mettre en évidence les bonnes pratiques à retenir.
Mots-Clés:
Archives ouvertes, Open acces, Portail, Bibliothèque électronique, Norme OAI-PMH
Dernière modification:
10/02/2010 Archives institutionnelles et archives centralisatrices: pratiques existantes et bonnes pratiques
Cette étude s’inscrit dans la première phase du projet Info-Net Economy (1), futur portail thématique qui constituera le volet « Économie » de la bibliothèque électronique suisse E-Lib (2). Ce portail sera notamment composé d’un accès aux publications électroniques issues des dépôts institutionnels d’un réseau de partenaires publics et académiques. Cette étude a pour objectif de retenir les bonnes pratiques en matière de dépôt institutionnel et de portails centralisateurs de ressources thématiques. Pour cela, une revue de la littérature concernant les portails centralisateurs de dépôts institutionnels et les archives ouvertes a été menée. Ces éléments de nature théorique ont été complétés par l’étude de projets similaires. Les bonnes pratiques retenues concernent principalement trois aspects : l’organisation, la technologie et la communication liées au projet. Mais avant des les aborder plus en détail, une description plus détaillée du contexte et une définition de la notion d’Open Access s’imposent.
1. Contexte de l’étude : Info-Net Economy
Info-Net Economy, qui fait partie du projet E-Lib, vise à offrir un point d’accès unique aux publications électroniques économiques suisses et à valoriser les ressources économiques provenant d’instituts suisses. Il doit favoriser les échanges entre institutions productrices d’informations économiques. Le portail contiendra les éléments suivants : un répertoire des différents acteurs économiques produisant des études/informations économiques (Hautes écoles, instituts spécialisés, offices spécialisés, etc.) ; un répertoire des publications électroniques de certains de ces organismes intéressés à être partenaires (11 en octobre 2009); un accès plus général à l’ensemble des sources d’information économiques utiles (accroissement de l’annuaire de sources ARESO (3)) ; un espace dédié aux échanges entre professionnels de l’information actifs dans le domaine, destiné à partager les produits documentaires réalisés ainsi que les bonnes pratiques.
La centralisation de ces informations sur un portail permettra de remédier au problème qui se pose actuellement en matière de recherche d’informations économiques validées : les ressources sont dispersées sur les sites des différentes institutions, ce qui nécessite de connaître ces différents acteurs. Même si certains sites proposent un regroupement de ressources, ils sont généralement limités à la sphère universitaire, les ressources d’autres types d’institutions restant méconnues. En outre, les avantages escomptés pour les partenaires sont les suivants : la valorisation de leurs publications ; la connaissance de nouvelles sources d’information et de nouveaux outils, du fait des échanges entre partenaires du réseau ; la garantie d’une meilleure visibilité pour leur service d’information documentaire mais aussi pour leur propre institution. Le réseau de partenaires créé pour Info-Net Economy regroupe des offices publics spécialisés, des instituts universitaires, des hautes écoles et des organisations faîtières qui publient dans le domaine de l’économie en Suisse et qui emploient des professionnels de l’information. En effet, le principal enjeu de ce projet est l’opportunité que représentent la centralisation et la diffusion des publications pour les professionnels de l’information, au niveau de leur institution, mais aussi au niveau plus global. Cette opportunité pourrait même constituer l’une des voies d’avenir de la profession.
En vue de la conception de ce portail spécialisé dans le domaine économique, et parallèlement à la phase de recensement des publications et des acteurs prévue durant la première partie du projet, une étude sur les répertoires institutionnels de recherche s’avère indispensable. De quoi faut-il tenir compte lors de la création d’un tel portail ?
La construction du portail d’accès aux publications spécialisées en économie provenant de notre réseau de partenaires se base sur les dépôts mis en place par ces derniers. Un dépôt institutionnel (institutional repository) est la collection numérique de la production intellectuelle d’une université ou d’un institut qui centralise, préserve et rend accessibles les connaissances générées par l’institution (4). Ces dépôts ont vu le jour grâce au principe d’archives ouvertes. Tel qu’entendu dans les universités et les hautes écoles suisses, il s’agit du dépôt des publications scientifiques sur un serveur institutionnel ou de la publication dans une revue fonctionnant selon le modèle Open Access (OA) (5). Les usagers ont ainsi un accès en ligne immédiat et gratuit aux articles de recherche : ils peuvent lire, décharger, copier et créer des liens vers le texte intégral sans réserve mais avec obligation de citation. Ce principe offre de nombreux avantages tant pour le chercheur que pour l’utilisateur : rapidité de publication, conservation des droits d’auteurs, accès gratuit et universel, etc. (6)
Ce principe défini, voici les différents projets similaires étudiés qui serviront de modèles pour mettre en valeur les bonnes pratiques retenues. Il s’agit d’un choix de dépôts institutionnels (ou archives institutionnelles), de dépôts centralisateurs (archives centralisatrices) (7) et de portails thématiques qui ont été sélectionnées en fonction de leur proximité géographique, de leur exemplarité et de leur originalité.
| Dépôts Institutionnels | Infoscience (8) Conçue comme une véritable archive institutionnelle, Infoscience centralise et conserve la production scientifique de l’EPFL. Infoscience est une référence en matière de dépôt institutionnel selon le classement Ranking of world repositories (9), où il est classé en septième position. |
Forschungsplattform Alexandria (10) Plateforme servant de vitrine à la recherche menée à l’Université de Saint-Gall, Alexandria a non seulement pour but de rendre publics les résultats de la recherche mené au sein de l’institution, mais aussi de mettre en valeur les instituts de recherche, leurs chercheurs (profils personnels) et les projets en cours. Alexandria n’est pas une archive institutionnelle au sens strict car il n’y a pas de vision d’archivage. Cette plateforme est néanmoins classée en huitième position dans le classement cité ci-contre. |
|---|---|---|
| Dépôts centralisateurs |
RERO DOC (11) |
Driver (12) Portail multidisciplinaire pour la recherche européenne en libre accès, Driver fédère les répertoires d’archives ouvertes européens. Il compte sur treize partenaires en Europe pour constituer le portail paneuropéen d’accès libre aux publications de recherche et regroupe à ce jour plus de 200 dépôts institutionnels ou thématiques, dont la plate-forme d’archives ouvertes française HAL (Hyper-article en ligne). Pour le moment, Driver couvre essentiellement des sujets tels que la biologie, l’anthropologie et l’informatique, avec un accès aux ressources par région géographique. |
| Portails thématiques | Econbiz(13) Conçue comme un portail thématique, la bibliothèque virtuelle des sciences économiques est un projet de collaboration entre la Deutsche Zentralbibliothek für Wirtschaftswissenschaften (ZBW) et l’Universitäts und Stadtbibliothek Köln (USB Köln). Elle contient un répertoire de signets électroniques, un métamoteur de recherche dans les catalogues des bibliothèques générales, des liens vers des bases de données en texte intégral, un agenda des manifestations scientifiques internationales et des services d’information. |
Economists online (14) NEREUS - Networked Economics Resources for European Scholars - représente un consortium de bibliothèques universitaires européennes, disposant de collections majeures en économie et se proposant de fournir collectivement de nouveaux contenus et de développer des services d'information innovateurs pour l'économiste. Le but est de créer un réseau européen de bibliothèques de recherche et de relier ainsi les ressources issues de la recherche universitaire en Europe. À travers le portail thématique Economists Online, l'accès en ligne à la production des principaux économistes universitaires constitue le service-clé de NEREUS. Ce projet consiste à numériser, organiser, archiver et diffuser la production complète des économistes, visant ainsi à rendre disponibles autant de textes intégraux que possible. |
Chacune de ces sources a été étudiée selon la même grille d’analyse, qui contenait les points suivants : contexte de création, objectifs, mode de fonctionnement, structure technique générale, contenu (types de publications), fonctionnalités (y compris web 2.0), interface, ergonomie, outil de recherche, types de recherche proposés, gestion du multilinguisme, format, récupération et qualité des métadonnées, promotion, et finalement les bonnes idées à retenir. Les conclusions de l’analyse de ces différents points ont été regroupées en trois parties : contexte et organisation, technologies et contenus offerts, et finalement promotion.
2. Contexte et organisation
Autant dans les projets de dépôts institutionnels que lors de la création de portails centralisateurs de ressources, le mode de fonctionnement est un facteur de réussite ou d’échec déterminant. Il est important de souligner les différents aspects à prendre en considération pour faire les choix les plus adaptés en fonction du contexte : mode de fonctionnement, type de partenaires, niveau de collaboration et rôle des professionnels en information documentaire dans de tels projets.
Mode de fonctionnement
Le mode de fonctionnement en réseau est très généralement adopté dans les projets de fédération de dépôts institutionnels (Econbiz, Driver, Economists online). Constitué autour d’un noyau dur de départ, le partenariat entre 2 à 10 institutions donne l’impulsion et assure le suivi du projet. Devenant un véritable centre de compétence, le réseau d’experts mis en place devient parfois même fournisseur de service pour les gestionnaires de dépôts. Les archives institutionnelles se sont structurées en réseaux nationaux, voire internationaux, avec pour objectif de partager les compétences, mais aussi de créer des outils et des services communs (15).
Type d’archives ouvertes
Il existe différents types d’archives ouvertes : elles peuvent être institutionnelles (liées à un organisme producteur, par exemple une université) ou centralisatrices (liées à plusieurs organismes producteurs, par exemple RERO-DOC qui sert de dépôt à plusieurs universités et hautes écoles), multidisciplinaires (elles couvrent plusieurs domaines de la connaissance) ou thématiques (focalisées sur un domaine de la connaissance, par exemple l’économie avec Repec (Research Paper in Economics) (16), ou les sciences de l’information et la bibliothéconomie avec E-lis (17)). L’impulsion de ces archives ouvertes institutionnelles, centralisatrices ou thématiques, provient le plus ouvent du milieu universitaire. Mais on trouve également des intituts de recherche tels que le Centre national de la recherche scientifique (CNRS) français, qui a créé le dépôt multidisciplinaire HAL (Hyper Articles on Line) (18), ont aussi intérêt à rendre publics les publications de leurs chercheurs. La multiplication des projets démontre l’intérêt des différentes communautés scientifiques à créer des archives ouvertes ainsi qu’à être présentes sur des portails centralisateurs dans un effort collaboratif de valorisation de la publication scientifique.
Niveau de collaboration
Toutefois, comment entretenir cette collaboration sur le long terme ? Comment créer un vrai centre de compétences ? En observant les projets similaires, on constate qu’il est nécessaire que les partenaires du réseau soient soutenus par leur instance dirigeante, qui doit être sensibilisée au principe des archives ouvertes. Les professionnels de l’information ont ici un rôle primordial à jouer. Pour convaincre les autorités de tutelle, ils peuvent s’appuyer sur les chiffres concernant l’Open Access et les dépôts institutionnels. Aux États-Unis, plus de 90% des universités ont institué un système de dépôt institutionnel ou sont en cours de réflexion pour y parvenir (19). Ce soutien au mouvement des archives ouvertes peut même être élevé au niveau national, comme c’est le cas pour HAL (20), qui est soutenu par le CNRS et auquel participent universités et centres de recherche publics (21). Dans la même optique, Repec (22) est né d’un effort collectif de volontaires provenant de plus de 60 pays dans le but d’améliorer la diffusion de la recherche en économie. Si, à l’heure actuelle, très peu de pays se sont dotés d’une politique gouvernementale de soutien à l’Open Access, celui-ci est très courant un niveau des universités (23). En Suisse, l’étude menée en 2009 par la Hochschule für Technik und Wirtschaft (HTW) de Coire a identifié 9 dépôts de hautes écoles universitaires et 8 dépôts en projet qui verront le jour d’ici un à deux ans (24). Le projet E-lib verra par ailleurs la création de la bibliothèque électronique suisse, portail scientifique national (25).
Rôle des professionnels en information documentaire
La démocratisation du principe d’archives ouvertes au sein des institutions de recherche académique représente une opportunité pour les bibliothèques scientifiques. En effet, en s’impliquant dans les projets mis en œuvre, elles obtiennent un nouveau rôle au niveau de l’acquisition, de l’évaluation et de la diffusion de la recherche (26). Elles peuvent se positionner en intermédiaire entre les chercheurs et les éditeurs, mais aussi entre les chercheurs et le public. Ce nouveau rôle renforce la proximité entre les bibliothèques et les chercheurs et s’inscrit dans l’évolution globale, voire la mutation de leur mission (27). L’information scientifique représente un enjeu de taille pour les bibliothèques académiques et de recherche car elle soulève des défis importants non seulement quant à sa diffusion et à sa conservation, mais aussi quant à sa maîtrise par les usagers. La formation des usagers revient au cœur de leur mission dans des projets de learning centers, ou centres d’apprentissage (28), qui offrent notamment des formations à la maîtrise de l’information et des technologies de l’information et de la communication. Les professionnels de l’information ont donc un rôle stratégique à jouer dans ce climat de changement de comportement des usagers et des modes de publication. Il est même possible, voire souhaitable, qu’ils obtiennent le leadership de projets liés aux archives ouvertes (29).
Cependant, les bibliothèques doivent parfois faire face à des difficultés d’intégration entre le pôle informatique qui réalise les dépôts institutionnels et les instituts de recherche qui les rempliront. Il devient alors nécessaire pour elles de faire valoir leurs compétences en matière d’information numérique et de prendre une place centrale dans sa conservation et sa diffusion. Elles sont en effet, par leur position d’intermédiaire, les plus à même de relayer les besoins et les demandes de leurs usagers (30). Cette collaboration avec les développeurs, qui ont une vision d’ensemble des différents systèmes en place et assurent la bonne intégration du dépôt au système d’information en place, est un des facteurs de succès de tels projets (31).
Si le soutien politique est nécessaire à la vie des centres de compétences mis en place, il est aussi central dans la diffusion du principe des archives ouvertes. Tous les projets étudiés ont pour base une politique interne régissant le dépôt des publications et la création d’archives institutionnelles. Ces politiques se basent sur la Déclaration de Berlin sur le libre accès à la connaissance (2003), où les signataires s’engagent, entre autres, à inciter les chercheurs à éditer leur travail selon les principes du libre accès et à encourager les établissements culturels à soutenir l'accès aux ressources sur Internet. Depuis, un nombre croissant d’institutions académiques ont mis en place leur propre dépôt et instauré l’obligation pour leurs chercheurs d’y déposer leurs publications. Il est difficile de recenser le nombre total de dépôts dans le monde, mais il existe un répertoire où les entrepôts d’archivage libre peuvent se déclarer (32).
Pourtant, malgré le soutien hiérarchique des organes de direction de la recherche, il reste un gros travail à accomplir pour sensibiliser et inciter les chercheurs à publier selon ce modèle. On observe en effet dans certains domaines une méfiance et une certaine résistance au changement. Elles sont peut-être dues à la méconnaissance du principe de l’OA et à la crainte d’une perte de qualité et de renommée. Les bibliothèques doivent contribuer à l’information de leurs utilisateurs dans le but de renforcer leur confiance et s’assurer qu’ils adhèrent aux projets de dépôts institutionnels. Elles doivent aussi offrir un support technique aux instituts pour éviter que chacun fasse comme il pense/peut et faciliter l’harmonisation des pratiques. Pour cela, elles peuvent s’appuyer sur les travaux effectués par des leaders des archives institutionnelles tels que SHERPA (33), consortium qui promeut la création d’archives dans tous les établissements de recherche et d’enseignement supérieur au Royaume-Uni. Un service particulièrement utile est Sherpa-RoMEO (Rights MEtadata for Open archiving) : il fournit une liste des licences de publications des éditeurs concernant l’archivage de leurs publications par les auteurs qui permet de savoir si l’éditeur permet ou non le dépôt de la publication dans une archive institutionnelle (34), et, si oui, quelles en sont les conditions (par exemple s’il y a une période d’embargo suivant la publication). Actuellement, selon les statistiques du site SHERPA-RoMEO, 95 % des périodiques donnent le droit aux auteurs d’auto-archiver, et il a été prouvé que l’autoarchivage augmente la visibilité et donc le lectorat (35). Communiquer et informer sur les enjeux liés aux dépôts institutionnels est donc la première bonne pratique à retenir lors de projets liés à l’Open Access.
3. Technique, contenu et fonctionnalités
Une fois le projet mis sur pied, il s’agit d’étudier les différents projets similaires afin de procéder à certains choix techniques concernant notamment la structure, les contenus et les fonctionnalités souhaités, ainsi que les outils existants et les normes à respecter.
Structure technique
La structure technique des différents portails similaires au futur portail Info-Net Economy repose sur le principe de la confédération de dépôts institutionnels hébergés localement. Ces dépôts, comme Infoscience (36) ou Alexandria (37), sont constitués non seulement des objets eux-mêmes, mais aussi de métadonnées descriptives. Dans une structure de fédération de dépôts, comme Driver (38), les publications des institutions partenaires restent dans leur dépôt local et le portail ne fait que signaler ces sources par les métadonnées qu’il y a récoltées et pointer vers elles par des liens. Il est ainsi possible de fédérer la recherche dans les métadonnées des différentes institutions productrices tout en leur en laissant la responsabilité de la gestion et la complète propriété.
Contenus et fonctionnalités
Ces portails offrent divers contenus et fonctionnalités. Au niveau du contenu, on trouve différents types de publications académiques : articles scientifiques en majorité, livres et chapitres de livres, travaux d’étudiants (mémoire de master et thèses de doctorat, parfois aussi mémoires de bachelor), mais aussi travaux de professeurs-chercheurs publiés ou non (pré-publications, working papers, papiers et actes de conférences, etc.) ainsi que, comme dans le cas de l’Archive Ouverte de l’Université de Genève (39), matériel de cours (supports, enregistrements, etc.). Ces contenus de type académique sont souvent complétés par des publications plus vulgarisées telles que des articles de journaux et des communiqués de presse. Dans certains cas il n’y a pas de limitation à la typologie des documents ; il est ainsi de moins en moins rare de voir des données brutes de recherche ou des contenus multimédia. Le contenu des dépôts est généralement détaillé dans leur politique, outil essentiel permettant de définir de manière précise la portée du dépôt. En plus des publications elles-mêmes, presque tous les sites observés proposent une rubrique « Actualités » qui recense aussi bien les nouveaux projets de recherche que la parution d’ouvrages. Ces différents contenus sont généralement mêlés et ce sont les fonctionnalités de recherche qui permettent de cibler l’un ou l’autre des contenus selon ses besoins. Le défi à relever est celui de l’ergonomie. En effet, comment structurer les différents contenus de manière simple pour rendre la recherche la plus intuitive possible ? Pour répondre aux différents besoins, les fonctions de recherche doivent être complètes. De la barre de recherche simple aux champs de recherche combinés de la recherche avancée, en passant par la navigation dans la classification thématique, les types de documents et les acteurs concernés, sans oublier les options de filtrage des résultats, il s’agit d’offrir une large palette de services. Deux exemples sont à signaler pour la simplicité de la recherche et la bonne exploitation des filtres de recherche : il s’agit d’Infoscience (EPFL) (40) et d’Alexandria (Université de Saint-Gall) (41). L’ergonomie de la fonction de dépôt des publications par les chercheurs est généralement bien soignée, et les marches à suivre sont claires et simples.
Les fonctionnalités de type web 2.0 sont encore peu présentes dans les portails de recherche académiques. Dans les projets observés pour cette étude, l’usage de flux RSS est courant pour signaler les nouveautés (Alexandria) ou les nouvelles publications sur une recherche effectuée (Infoscience). Cependant peu de possibilités d’interactions sont offertes aux usagers des portails, chercheurs ou grand public. Aucun des portails observés, de type académique, ne permet aux usagers de « tagger » eux-mêmes les notices ou de poster des commentaires au sujet des ressources. Les possibilités de recherche sémantique sont donc amoindries. Pourtant le projet Inspire (42), portail de nouvelle génération dans le domaine de la physique, prévoit de faire contribuer les usagers au « taggage » et au commentaire des ressources (43). Cet exemple permettra de démontrer la pertinence d’une telle approche. Il est intéressant de relever qu’Infoscience permet à l’utilisateur, une fois enregistré, de s’approprier les données en créant sa collection personnelle en ligne ou en paramétrant le moteur de recherche selon ses besoins. Par ailleurs, si tous les portails observés offrent des FAQ (Frequently asked questions ou Foire aux questions) en ligne, seul Econbiz (44) propose un véritable service de renseignement et de référence en ligne.
Le choix de proposer un site multilingue soulève la question de la gestion du multilinguisme. C’est un aspect particulièrement important dans un projet suisse tel qu’Info-Net Economy. Il s’agit en effet de proposer une interface, un outil de recherche et un affichage des résultats en plusieurs langues sans alourdir la présentation générale du site. La solution la plus couramment adoptée est celle de proposer une interface en plusieurs langues et des métadonnées dans la langue de la publication déposée. Dans ces cas, pour améliorer la recherche, les mots-clés peuvent éventuellement être traduits en plusieurs langues.
Outils et normes
Au niveau technique toujours, il est important de connaître et de bien comprendre les différents outils servant au dépôt de publications d’une part et à la recherche fédérée dans différents dépôts d’autre part.
Concernant les outils de dépôts, selon le Registry of Open Access Repositories (45), les deux outils logiciels les plus utilisés dans le monde sont Dspace (46) (plus de 400 utilisateurs) et Eprints (47) (plus de 300 utilisateurs, dont l’Université de Zürich). CDS-Ware/Invenio (48), le système développé par le CERN, arrive quant à lui en septième position et compte parmi ses utilisateurs l’EPFL et RERO-DOC. Il s’agit de systèmes d’entrepôts de données.
Cependant, pour que cette fédération des ressources soit possible, il faut appliquer les mêmes normes. En effet, l’aspect déterminant de ces portails est la recherche, qui passe forcément par les métadonnées, et à ce sujet le mot d’ordre est « standardisation ». On parle de dépôts compatibles OAI. Mais qu’est-ce qu’OAI ? Mouvement de promotion des archives ouvertes, l’Open Archive Initiative développe un ensemble de protocole et de standards d’interopérabilité facilitant la diffusion des contenus des documents. Le protocole central est OAI-PMH, Open Archive Initiative Protocol for Metadata Harvesting, ou « Protocole de collecte de métadonnées de l’Initiative Archives Ouvertes ». Il définit un standard pour transférer des collections de métadonnées. Il a été établi dans le cadre de l’Initiative Archives Ouvertes pour implanter des bases interopérables de pré-publications scientifiques soumises par leurs auteurs. L’objectif de l’Initiative Archives Ouvertes est donc très spécifique aux communautés de chercheurs. Pourtant le protocole se révèle aussi intéressant pour des applications plus patrimoniales.
Pour les métadonnées, le protocole OAI-PMH repose sur une norme de description bibliographique, le Dublin Core non qualifié : schéma de métadonnées numériques qui permet de décrire des ressources numériques et d’établir des relations avec d’autres ressources. Il comprend 15 éléments de description formelle (titre, créateur, éditeur), intellectuels (sujet, description, langue) et relatifs à la propriété intellectuelle. On peut convertir les notices primaires en format Dublin Core. De plus, le Dublin Core est facilement encodable en XML.
Un dépôt institutionnel qui applique la norme OAI-PMH possède une base de métadonnées qu’il « expose » aux moissonneurs (49). Ces métadonnées y sont disponibles dans différentes formats pour répondre à différents besoins. Si le format Dublin Core est l’exigence minimale imposée par la Norme OAI-PMH, le format MARCXML permet d’obtenir des métadonnées plus riches à partir de catalogues de bibliothèque par exemple. Ainsi le protocole permet de centraliser les métadonnées référençant diverses ressources tout en laissant ces ressources à leur emplacement initial. Il est alors possible d’accéder à ces ressources en architecture distribuée, en rassemblant les métadonnées et en les exploitant pour les besoins spécifiques d’un service. Dans le cadre de projets de portails tels qu’Info-Net Economy, les ressources sont gérées dans différents établissements. Pour fournir un accès commun à ces ressources, un système permet d’en rassembler les métadonnées dans une base commune. En bref, ce protocole d’échange permet de créer, d’alimenter et de tenir à jour, par des procédures automatisées, des serveurs de métadonnées qui signalent, décrivent et rendent accessibles des documents, sans les dupliquer ni modifier leur localisation d’origine (50). Il permet aussi l’agrégation de ressources hétérogènes d’origines diverses. Ce procédé de recherche et d’agrégation des ressources est nommé moissonnage, ou harvesting (voir Figure 1).
Moissonnage OAI-PMH
Le moissonnage OAI-PMH nécessite deux types d’acteurs : d’une part les entrepôts déclarés (fournisseurs de données) ; et d’autre part les moissonneurs (fournisseurs de services). Les fournisseurs de données exposent leurs métadonnées en implémentant le protocole OAI et en donnant accès à leur catalogue au moyen d’un entrepôt OAI, outil chargé de répondre aux requêtes formulées par les fournisseurs de service ; tandis que les moissonneurs parcourent les dépôts et recueillent les métadonnées à l’aide du protocole OAI. Les réponses sont données au format XML et contiennent, selon la requête formulée, des informations sur l’entrepôt, des identifiants, des métadonnées. Par « moissonner » on entend ici le fait de récupérer une copie des métadonnées en local puis de la rendre cherchable comme valeur ajoutée. Un même dépôt peut parfaitement être interrogé par plusieurs moissonneurs. Les moissonneurs permettent d’agréger les ressources provenant de différents dépôts OAI. Ils nourrissent une base XML, qui peut aussi être alimentée par d’autres moyens, y compris en ressources locales et par intervention humaine. Dans ce cas, il faut établir en amont le processus de recherche et de sélection des URL des bases à moissonner (automatique ou manuel, parfois les deux), avec la fréquence de visites et de mises à jour pour chaque base et déterminer, en aval, le stockage, l’indexation, l’exploitation et l’affichage des données (transformation XSLT). En l’absence de dépôt institutionnel moissonnable répondant à la norme OAI-PMH, il est donc possible d’alimenter une base de métadonnées au moyen de flux RSS adaptés pour signaler des publications disponibles sur un site web ou au moyen d’une application web 2.0 basée sur des requêtes URL pré-paramétrées, comme le prévoit le projet RODIN (51), outil pour l’agrégation et le couplage de sources d’information. Il est par ailleurs aussi possible de récupérer les données de certains dépôts non OAI au moyen de ce même type de requêtes.
Figure 1(52)
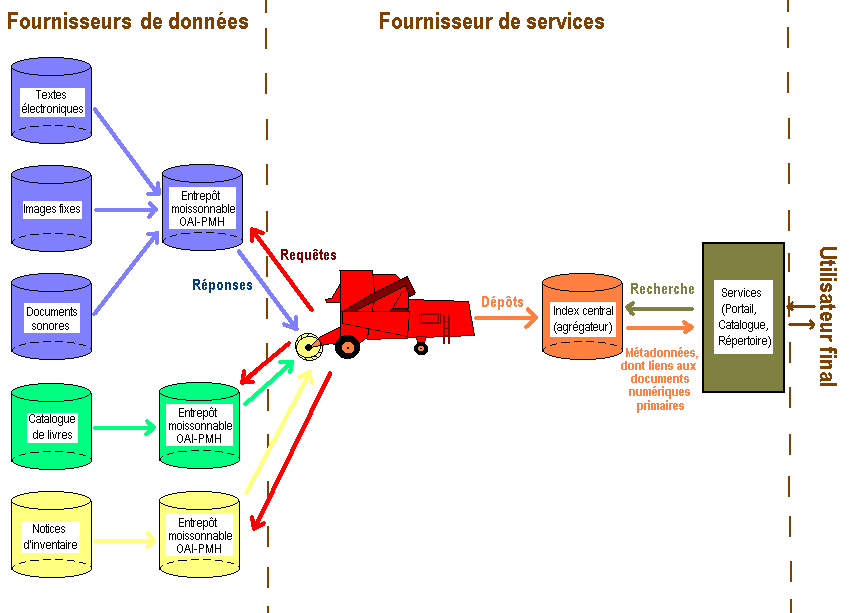
Le schéma ci-dessus (Figure 1) expose le principe du moissonnage, avec :
- à gauche les différents dépôts institutionnels fournisseurs de données, avec chacun leur entrepôt de métadonnées ;
- au milieu le moteur de moissonnage qui comprend un moteur de moissonnage et un agrégateur de métadonnées (fournisseur de services)
- et à droite l’interface de recherche fédérée proposée à l’utilisateur final.
Il existe des moteurs de moissonnage open source, parmi lesquels les plus utilisés sont OAIster (53), CiteBase Search (54), OAIHarvester2 (55), PKP Harvester (57), Framework SDX (57) ou encore Google Scholar (58). On peut aussi développer sa propre fonction de recherche dans les métadonnées de plusieurs archives sélectionnées (59), toujours au moyen de requêtes URL dédiées.
Ainsi, les données exposées OAI sont référencées par les moteurs de recherche de documentation scientifique au niveau mondial (comme Google Scholar, Bielefeld academic search engine), mais aussi par les moteurs de recherche simple (Google, Yahoo, MSN, etc.). Les dépôts créés peuvent donc être moissonnés à leur tour et ainsi gagner en visibilité. On constate ainsi que les différents types de dépôts sont complémentaires.
Si le jeu de métadonnées et la manière de les exposer aux moissonneurs est dictée par la norme OAI-PMH, l’indexation thématique de chaque document reste libre. Chaque institution décide donc de sa manière d’indexer, de suivre un thésaurus de vocabulaire contrôlé ou de laisser ce champ libre aux auteurs qui déposent leurs publications. Cela pose problème au moment de la centralisation des métadonnées de plusieurs institutions, car il faut établir des listes de concordances pour faciliter la recherche fédérée par sujet. Driver, portail centralisateur de plus de 200 dépôts, a pris l’option de laisser le champ sujet libre et ne propose donc pas de recherche par sujet ou de navigation dans la classification.
La standardisation des métadonnées concerne non seulement leur moissonnage et leur exposition, mais aussi leur conservation. Si le jeu de métadonnées requis par Dublin Core convient bien à la manipulation des données, il est limité en termes de gestion et de conservation. Des formats internes de gestion et de conservation existent, plus complets et recouvrant les champs requis par Dublin Core : actuellement le plus courant est MARC (60), plus précisément MARCXML, qui est facilement transformable en différents formats (HTML pour l’affichage direct, Dublin Core ou MODS pour supporter les protocoles de harvesting) (61).
Il est par ailleurs intéressant de relever l’autre projet de l’Open Archive Intitiative, conjoint à OAI-PHM : OAI-ORE (Open Archives Initiative Object Reuse and Exchange) (62). Ce protocole définit un standard pour la description et l’échange de ressources web complexes (exemple : une thèse est un tout composé d’un ensemble de chapitres, elle peut avoir différentes versions, être suivie d’articles, etc.). Tandis qu’OAI-PMH est centré sur les métadonnées, OAI-ORE prend en compte les ressources (les objets de la description). Il s’agit d’une nouvelle manière d'enrichir et d'utiliser les métadonnées décrivant les documents conservés dans des entrepôts OAI en vue de leur réutilisation. Les logiciels de dépôt d’archives Dspace et Eprints (63) supportent ce nouveau protocole.
En définitive, malgré les standards qui permettent l’agrégation des données, celle-ci ne se fait pas sans adaptations ni ajustements. En effet, il reste souvent un travail d’homogénéisation des données à effectuer, car la norme laisse une certaine marge de manœuvre au niveau des métadonnées descriptives. En particulier, le Dublin Core n’est pas interprété partout de la même manière. En effet, la « non-qualification » du Dublin Core, si elle laisse une certaine souplesse et une marge de manœuvre dans son utilisation, entraîne de légères disparités dans les métadonnées. Il en résulte un travail d’uniformisation qui peut être important en cas de nombreux dépôts à centraliser. Dans ces cas aussi, il faut veiller à la fusion des termes d’indexation et de la classification des différents dépôts en un thésaurus et un classement communs. Pour pallier à ce genre d’obstacles, Driver propose un guide très précis aux dépôts souhaitant être présents sur le portail. Ces instructions doivent obligatoirement être suivies pour que leur participation soit validée et leur données recherchables sur le portail. En contrepartie, Driver leur offre soutien et retours d’expériences sous forme de mentorat (64).
4. Communication
La communication est un aspect crucial lors de la création d’un dépôt d’archives ouvertes ou d’un portail centralisateur de ressources. Dès le départ, la communication entre partenaires de projets est déterminante du bon déroulement du projet. Ensuite, une fois le dépôt créé, il s’agit non seulement de convaincre les chercheurs de déposer leurs publications, mais aussi de sensibiliser les instances dirigeantes à l’importance de l’auto-archivage et à l’intérêt de figurer dans un portail centralisateur. La visibilité est un enjeu à mettre en avant et à développer.
Avec les partenaires
Le travail de communication commence donc au sein de l’équipe de projet. Autour d’un noyau dur de professionnels, il s’agit de mettre en place une véritable dynamique de collaboration et de partenariat autour d’objectifs communs. Le partage du savoir-faire est évidemment bénéfique à chacun, et une bonne répartition des tâches en fonction des compétences permet à chacun de s’impliquer activement. Pour les dépôts institutionnels, il est important d’obtenir une masse critique de contenu pour donner l’impulsion aux autres dépositaires potentiels. Pour les portails centralisateurs, une fois l’outil fonctionnel, le noyau dur de départ peut être étendu à d’autres partenaires.
Avec la hiérarchie
Tout au long du projet, la communication avec les instances de tutelles des institutions est nécessaire, car ce sont elles qui peuvent inciter, voire éventuellement imposer le dépôt obligatoire des publications. Ce soutien « politique » est nécessaire au bon fonctionnement des dépôts. Quant aux portails centralisateurs, il est important de souligner aux instances dirigeantes des partenaires de projets que leur participation constitue un gain en termes de visibilité et de promotion de la recherche.
Avec les usagers
La communication entre partenaires et avec les instances décisionnelles est certes importante, mais elle l’est aussi vis-à-vis du public. Il s’agit de promouvoir l’outil mis en place auprès des chercheurs et des usagers. Les chercheurs doivent être formés à l’utilisation du dépôt, et une aide à la saisie ainsi qu’une interface simple et conviviale sont nécessaires à leur appropriation de l’outil. Les arguments de promotion sont la visibilité offerte aux chercheurs et la valeur ajoutée par la centralisation des ressources et la recherche fédérée pour le public. Dans l’environnement actuel, les chercheurs attendent une recherche aisée et efficace, et nous nous devons de leur permettre d’être autonomes en leur offrant des interfaces simples où ils peuvent être autonomes dans leur dépôt d’une part, et obtenir des contenus directement utilisables d’autre part. Il s’agit de mettre à leur disposition non seulement un support technique, organisationnel et institutionnel, mais aussi de leur prodiguer information et formation ainsi que différents services associés à valeur ajoutée : saisie facilitée des références, réutilisation aisée des données, création automatique de listes bibliographiques, interopérabilité avec d’autres systèmes et analyse de l’impact. Infoscience (65) ou l’Archive ouverte de l’Université de Genève (66) proposent ainsi à leurs chercheurs une rubrique d’information sur l’Open Access, une aide au dépôt ainsi que des services à valeur ajoutée tels que l’extraction de listes bibliographiques re-exploitables, des flux RSS personnalisés, etc. L’étude menée par Driver (67) relève l’importance de ces services à valeur ajoutée dans le succès des dépôts observés.
L’effort de « marketing » est aussi important vis-à-vis du large public d’Internet. Il y a donc un vrai travail de référencement et de communication dans différents médias pour toucher le maximum de public. Exposer soi-même ses métadonnées pour se rendre moissonnable à un plus haut niveau est une suite logique au moissonnage des dépôts institutionnels. Il est important que les dépôts moissonnés par de plus grands portails reçoivent un feedback quant à leur interopérabilité et à la qualité des métadonnées qu’ils exposent. Collaborer dans des projets d’ampleur internationale leur permet aussi de gagner en visibilité. Des projets pionniers tels que Driver se veulent multidisciplinaires et collaborent volontiers notamment en partageant leur savoir-faire (68).
5. CONCLUSION
Inscrite dans le cadre du projet de portail Info-Net Economy, dont le cœur sera constitué d’un dépôt de métadonnées OAI-PMH, la présente étude met en évidence les bonnes pratiques à observer lors de la création de portails centralisateurs de ressources. De tels portails sont aujourd’hui nécessaires à la recherche, car les sources sont dispersées et peu valorisées. Le contenu de ces portails étant notamment puisé dans des dépôts institutionnels d’archives ouvertes, nous nous devions d’en explorer les tenants et les aboutissants.
Premièrement, on observe que le mouvement d’Open Access a enclenché une véritable révolution dans le monde de la publication scientifique qui permet un meilleur échange des savoirs dans les milieux académiques. Le succès des dépôts institutionnels, des dépôts centralisateurs de ressources et des portails thématiques repose en partie sur le mode de fonctionnement adopté et l’équipe de professionnels en charge du projet. Il reste cependant encore un gros travail d’information à effectuer auprès des universités pour sensibiliser les directions et les chercheurs. Communiquer et informer sur les enjeux liés aux dépôts institutionnels est donc la première bonne pratique à retenir. Ce rôle peut parfaitement être endossé par les bibliothèques ; cela représente même une véritable opportunité dans l’environnement évolutif de l’information scientifique. Aider les instituts et leurs chercheurs à valoriser leur travail sur le web est une nouvelle mission des bibliothèques académiques. Pour cela elles peuvent s’organiser en partenariats pour échanger les compétences et constituer des réseaux collaboratifs. Au niveau des universités, les bibliothécaires peuvent mettre à profit leurs compétences documentaires dans la création de dépôts institutionnels (comme dans le cas d’Infoscience à l’EPFL) ou proposer aux chercheurs de déposer leurs publications dans un dépôt centralisateur (tel que RERO-DOC en Suisse romande). Une fois le système de dépôt mis en place, la participation à des portails thématiques tels que Driver est souhaitable car elle augmente la visibilité potentielle des institutions productrices.
Puis, en termes de contenu, la bonne pratique à observer est l’établissement d’une politique claire qui définit ce qui entre dans le cadre du dépôt ou du portail. Techniquement, la centralisation des ressources provenant de différents dépôts est rendue possible par la norme OAI-PMH, elle-même basée sur la norme de description Dublin Core. Le moissonnage des métadonnées permet d’offrir ensuite une recherche fédérée sur tous les dépôts exposés. Ce procédé permet de rendre plus visible des dépôts peu connus, par exemple sur un portail thématique tel qu’Info-Net Economy, qui regroupera les ressources de différents acteurs suisses qui publient de l’information scientifique dans le domaine de l’économie. Appliquer les normes et les outils permettant l’harmonisation et l’échange des métadonnées est la troisième bonne pratique à observer.
Enfin, pour faire l’unanimité, les dépôts et les portails qui les moissonnent se doivent de mettre tous les atouts de leur côté en offrant des interfaces ergonomiques et riches en fonctionnalités à valeur ajoutée. Offrir un cadre de recherche convivial et des services à valeur ajoutée en profitant d’outils novateurs est la quatrième bonne pratique mise en évidence.
En conclusion, on peut souligner l’importance des protocoles et normes d’échanges des données, mais aussi relever que l’organisation et la communication liées aux projets sont tout aussi cruciales pour leur réussite. Réussite que l’on peine encore à mesurer, par manque d’indicateurs éprouvés (69). Si la démocratisation de l’Open Access et le nombre croissant de projets qui voient le jour est un succès en soi, ils doivent être poursuivis et enrichis selon des critères de qualité reconnus dans le milieu de l’information documentaire et de la recherche académique.
6. Notes
(1) Info-Net Economy [en ligne]. http://www.e-lib.ch/net_economy_f.html
(2) La bibliothèque électronique suisse, portail pour la communauté scientifique nationale qui proposera un accès centralisé à une vaste offre d'informations scientifiques et de services de bibliothèques dans un point d'accès unique.
E-lib [en ligne]. http://www.e-lib.ch/index_f.html
(3) ARESO : annuaire de ressources économiques de Suisse occidentale créé par la filière Information documentaire de la Haute Ecole de Gestion de Genève en 2008.
ARESO [en ligne]. http://campus.hesge.ch/areso/
(4) Définition de l’association des bibliothèques canadiennes de recherche, ABCR
(5) Voir à ce sujet le dossier proposé par l’Université de Genève : http://www.unige.ch/biblio/chercher/openaccess/brochure.pdf
(6) Pour plus d’informations et une bibliographie complète sur le sujet des publications en Open Access, voir le site de Charles W. Bailey Jr : http://www.digital-scholarship.org/
(7) Bosc, Hélène. Archives ouvertes : 15 ans d’histoire. Les archives ouvertes : enjeux et pratiques. Paris, ADBS, 2005. pp. 27-54.
(8) Infoscience [en ligne]. http://infoscience.epfl.ch/
(9) Ce classement a pour but de soutenir les projets d’archives ouvertes en les évaluant selon leur visibilité et leur impact. Ranking web of world repositories [en ligne]. http://repositories.webometrics.info/
(10) Forschungsplattform Alexandria [en ligne]. http://www.alexandria.unisg.ch/
(11) RERO-DOC[en ligne]. http://doc.rero.ch/?ln=fr
(12) Driver [en ligne]. http://www.driver-repository.eu/
(13) Econbiz [en ligne]. http://www.econbiz.de/
(14) Economists online [en ligne]. http://www.nereus4economics.info/
(15) Muriel Foulonneau, Réseaux d’archives institutionnelles en Europe : logiques de développement et convergences, Archive Ouverte en Sciences de l'Information et de la Communication [en ligne], 2007, http://archivesic.ccsd.cnrs.fr/sic_00205049/en/
(16) Repec [en ligne]. http://repec.org/
(17) E-LIS [en ligne]. http://eprints.rclis.org/
(18) HAL [en ligne]. http://hal.archives-ouvertes.fr/
(19) Lynch, Clifford A., Lippincott, Joan K., Institutional Repository Deployment in the United States as of Early 2005. D-Lib Magazine [en ligne], vol. 11, no 9, 2005. http://www.dlib.org/dlib/september05/lynch/09lynch.html
(20) Op. cit.
(21) Andre, Francis, Charnay, Daniel, Support of Open Archives at National Level : the HAL experience, Institutional archives for research : experiences and programs in open access [en ligne], Rome 30 November – 1 December 2006, http://archivesic.ccsd.cnrs.fr/docs/00/18/72/60/PDF/Rome_ISS_FANDRE.pdf
(22) Ibid.
(23) Chen, Kuang-hua, The unique approach to institutional repository. The electronic library [en ligne], vol. 27, no 2, 2009, pp. 204-221,
http://www.emeraldinsight.com/Insight/viewPDF.jsp?contentType=Article&Filename=html/Output/Published/EmeraldFullTextArticle/Pdf/2630270201.pdf
(24) Pfister, Joachim, Weinhold, Thomas, Zimmermann, Hans-Dieter. Open Access in der Schweiz : status quo und geplanter Aktivitäten im Bereich von Institutional Repositories bei Hochschul- und Foschungs-einrichtungen in der Schweiz. In Information : Droge, Ware oder Commons ? : Wertschöpfungs – und Transformationsprocesse auf den Informationsmärkten [en ligne]. Boizenburg : Werner Hülsbusch, 2009. Pp. 259-270
(25) Op. cit.
(26) Vezina, Kumiko. Dépôts institutionnels : principaux enjeux [en ligne]. 38ème congrès annuel – perspectives d’avenir : fonctions, réseaux et relations, Corporation des bibliothécaires professionnels du Québec, mai 2007
http://www.cbpq.qc.ca/congres/congres2007/Actes/Vezina.pdf
(27) Blin, Frédéric, Les bibliothèques académiques européennes : Brève synthèse prospective, BBF [en ligne], t. 53, no 1, 2008, pp. 12-18, http://bbf.enssib.fr/consulter/bbf-2008-01-0012-002
(28) Ibid.
(29) Jones, Catherine. Institutional repositories: content and culture in an Open Access environment. Oxford : Chandos Publishing, 2007.
(30) The research library’s role in digital repository services [en ligne], Association of research libraries, 2009, http://www.arl.org/bm~doc/repository-services-report.pdf
(31) Salo, Dorothea. Innkeeper at the roach motel. Library Trends [en ligne], vol. 57. No 2, 2008. http://minds.wisconsin.edu/handle/1793/22088
(32) University of Nottingham (UK). OpenDOAR : the Directory of Open Access Repositories [en ligne].
http://www.opendoar.org/
(33) SHERPA [en ligne]. http://www.sherpa.ac.uk/index.html
(34) SHERPA-RoMEO [en ligne]. http://www.sherpa.ac.uk/romeo/
(35) Harnad, Steven, Brody, Tim. Comparing the Impact of Open Access (OA) vs. Non-OA Articles in the Same Journals. D-Lib Magazine [en ligne], vol. 10, no 6, 2004. http://www.dlib.org/dlib/june04/harnad/06harnad.html
(36) Op. cit.
(37) Op. cit.
(38) Op. cit.
(39) Archives Ouvertes UNIGE [en ligne]. http://www.unige.ch/biblio/chercher/archiveouverte.html
(40) Op. cit.
(41) Op. cit.
(42) INSPIRE [en ligne]. http://www.projecthepinspire.net/
(43) Brooks, Travis. Giving researchers what they want: SPIRES, high energy physics and subject repositories. Genève, OAI6, juin 2009.
http://indico.cern.ch/getFile.py/access?contribId=20&sessionId=6&resId=1&materialId=slides&confId=48321
(44) Op. cit.
(45) Registry of Open Access Repositories (ROAR) [en ligne]. http://roar.eprints.org/index.php
(46) Dspace [en ligne]. http://www.dspace.org/
(47) Eprints [en ligne]. http://www.eprints.org/
(48) CDS-Ware/Invenio [en ligne]. http://cdsware.cern.ch/invenio/index.html
(49) Jones, Catherine. Institutional repositories: content and culture in an Open Access environment. Oxford : Chandos Publishing, 2007.
(50) François Nawrocki, Le protocole OAI et ses usages en bibliothèque [en ligne], Paris, Ministère de la culture et de la communication, 2005. http://www.culture.gouv.fr/culture/dll/OAI-PMH.htm
(51) RODIN [en ligne]. http://www.e-lib.ch/rodin_f.html
(52) François Nawrocki, op. cit.
(53) OAIster [en ligne]. http://www.oaister.org/
(54) Citebase search [en ligne]. http://www.citebase.org/
(55) OAI Harvester 2 [en ligne]. http://www.oclc.org/research/Software/oai/harvester2.htm
(56) Open archive harvester [en ligne]. http://pkp.sfu.ca/?q=harvester
(57) Sévigny, Martin, Pichot, Malo. SDX et la moisson OAI [en ligne]. Paris, Ministère de la culture et de la communication, 2005. http://www.nongnu.org/sdx/docs/html/doc-sdx2/fr/oai/moissonneur.html
(58) Google scholar [en ligne]. http://scholar.google.com/intl/fr/scholar/about.html
(59) Boutros, Nader. Moissonnage des données : exposée général sur les principes. Carrefour des acteurs de l’édition en archéologie, 1er décembre 2005.
(60) MARC Standards [en ligne]. http://www.loc.gov/marc/
(61) Jones, Catherine. Institutional repositories: content and culture in an Open Access environment. Oxford : Chandos Publishing, 2007.
(62) OAI-ORE [en ligne]. http://www.openarchives.org/ore/
(63) Op. cit.
(64) Feijen, Martin, et al. DRIVER : building the network for accessing digital repositories across Europe [en ligne]. Ariadne. Issue 53, October 2007. http://www.ariadne.ac.uk/issue53/feijen-et-al/
(65) Op. cit.
(66) Op. cit.
(67) A DRIVER's Guide to European Repositories : Five studies of important Digital Repository related issues and good Practices [en ligne], 2007, University of Amsterdam, http://dare.uva.nl/aup/nl/record/260224
(68) Driver support website [en ligne]. http://www.driver-support.eu/index.html
(69) Bosc, Hélène, Archives Ouvertes : quinze ans d’histoire, In Les Archives Ouvertes : enjeux et pratiques. Guide à l’usage des professionnels de l’information [en ligne], C. Aubry, J. Janik (eds.), Paris : ADBS, 2005. pp 27-54 http://cogprints.org/4408/2/Ouvragearchive.htm
Institutionelle und zentrale Archive: existierende Praktiken und Best Practices
Ressi — 31 décembre 2009
Lorraine Filippozzi, Haute Ecole de Gestion, Genève
Zusammenfassung
Das Projekt Info-Net Economy, zukünftiges Themenportal für den Bereich Wirtschaftswissenschaften der Elektronischen Bibliothek Schweiz E-lib, soll durch diese Studie eine solide Dokumentationsgrundlage erhalten. Nach einem Bedarfsnachweis zentraler Portale und einer Diskussion der damit verbundenen Möglichkeiten für Informationsfachleute werden die organisatorischen, technischen und marketingbezogenen Aspekte vergleichbarer Projekte untersucht und Best Practices aufgezeigt, die für eine Umsetzung zu berücksichtigen sind.
Mots-Clés:
Offene Archive, Open Access, Portal, Elektronische Bibliothek, Norm OAI-PMH
Dernière modification:
10/02/2010 Institutionelle und zentrale Archive: existierende Praktiken und Best Practices
Diese Studie ist Teil der ersten Phase des Projekts Info-Net Economy (1), zukünftiges Themenportal für den Bereich Wirtschaftswissenschaften der Elektronischen Bibliothek Schweiz E-lib (2). Das Portal wird einen Zugang zu elektronischen Publikationen bieten, die aus den institutionellen Beständen eines Netzwerks öffentlicher und akademischer Partner stammen. Die Studie gibt eine Übersicht über die Best Practices als institutionelles Archiv und zentrales Ressourcenportal zu einem bestimmten Thema. Die Literatur zu zentralen Portalen und institutionellen Archiven wurde eingehend analysiert und mit einer Untersuchung ähnlicher Projekte ergänzt. Die resultierenden Best Practices betreffen insbesondere drei Aspekte: Projekt-Organisation, -Technologie und -Kommunikation. Bevor jedoch detaillierter darauf eingegangen wird, muss zunächst der Kontext genauer beschrieben und eine Definition des Begriffs Open Access geliefert werden.
1. Kontext der Studie: Info-Net Economy
Info-Net Economy bietet als Teil des Projekts E-lib einen Zugang im Sinn eines „Single Point of Access“ zu digitalen wirtschaftswissenschaftlichen Veröffentlichungen der gesamten Schweiz und wertet die wirtschaftlichen Ressourcen der Schweizer Institutionen damit auf. Der Austausch zwischen Institutionen, die wirtschaftswissenschaftliche Informationen veröffentlichen, wird gefördert. Das Portal wird die folgenden Elemente umfassen: ein Verzeichnis der verschiedenen Akteure, die wirtschaftswissenschaftliche Studien/Informationen hervorbringen (Hochschulen, spezialisierte Institute, spezialisierte Ämter usw.); ein Verzeichnis elektronischer Publikationen einiger interessierten Partnerorganisationen (11 Partner bis Oktober 2009); ein allgemeinerer Zugang zur Gesamtheit der nützlichen wirtschaftswissenschaftlichen Informationen (Erweiterung der Liste durch Quellen aus ARESO (3)); eine Plattform, über welche die im Bereich aktiven Informationsfachleute Dokumentationsprodukte und Best Practices austauschen können.
Die Zentralisierung dieser Informationen auf einem Portal soll ein Problem beheben, das sich gegenwärtig bei der Suche nach validierten wirtschaftswissenschaftlichen Informationen stellt: Die Ressourcen befinden sich verteilt auf den Websites der verschiedenen Institutionen; um auf sie zuzugreifen, muss man die verschiedenen Akteure kennen. Auch wenn manche Websites die Ressourcen eigens auflisten, beschränkt sich dies üblicherweise auf den universitären Bereich, und Ressourcen aus anderen Institutionen bleiben aussen vor. Zudem können die Partner mit grossen Vorteilen rechnen: Ihre Publikationen werden aufgewertet, durch den Austausch mit den Partnern im Netzwerk lernen sie neue Informationsquellen und Werkzeuge kennen und der Dokumentationsdienst sowie die gesamte Institution erhalten eine grössere öffentliche Sichtbarkeit. Das Partnernetzwerk von Info-Net Economy vereint spezialisierte Ämter, Universitätsinstitute, Fachhochschulen und Dachverbände, die im Bereich der Wirtschaftswissenschaften in der Schweiz publizieren und Informationsfachleute beschäftigen. Hauptaufgabe des Projekts ist in der Tat die Zentralisierung und Verbreitung von Publikationen für Informationsfachleute innerhalb ihrer Institution, aber auch auf einer umfassenderen Ebene. Diese Möglichkeiten könnten sogar ein zukunftsträchtiger Weg für den Berufszweig sein.
Im Hinblick auf die Gestaltung dieses auf den Bereich Wirtschaftswissenschaften spezialisierten Portals und parallel zur Erfassungsphase der Publikationen sowie der Akteure, welche während der ersten Projektphase vorgesehen ist, erscheint eine Analyse einiger institutioneller Forschungsrepositorien unerlässlich. Was muss bei der Schaffung eines solchen Portals berücksichtigt werden?
Der Aufbau eines Portals für den Zugang zu wirtschaftswissenschaftlichen Publikationen aus unserem Partnernetzwerk stützt sich auf die Archive der Partner. Ein institutionelles Archiv (oder Repositorium, institutional repository) ist eine digitale Sammlung der geistigen Produktion einer Universität oder einer Institution, in der das von der Institution generierte Wissen zentralisiert, erhalten und verfügbar gemacht wird (4). Diese Repositorien sind durch das Prinzip der offenen Archive entstanden. Nach Auffassung der Schweizer Universitäten und Fachhochschulen sollen dabei wissenschaftliche Informationen auf einem institutionellen Server oder in einer nach dem Modell Open Access (OA)(5) funktionierenden Zeitschrift bereitgestellt werden. Die Nutzer haben so einen direkten und kostenlosen Online-Zugriff auf die Forschungsartikel: Sie können sie unbeschränkt lesen, herunterladen, kopieren und verlinken, müssen jedoch stets die Quelle angeben. Dieses Prinzip hat sowohl für die Wissenschaftler als auch für die Nutzer zahlreiche Vorteile: schnelle Veröffentlichung, Wahrung des Urheberrechts, kostenloser und grenzenloser Zugang usw. (6)
Im Folgenden werden verschiedene ähnliche Projekte aufgelistet, die als Modell dienen. Dabei geht es um eine Auswahl von institutionellen Archiven, zentralen Archiven (7) und Themenportalen, die wegen ihrer geografischen Nähe, Beispielhaftigkeit und Originalität ausgewählt wurden.
| Institutionelle Archive | Infoscience (8) Angelegt als institutionelles Archiv im eigentlichen Sinne, zentralisiert und erhält Infoscience die wissenschaftliche Produktion der ETHL. Infoscience gilt gemäss dem Ranking of world repositories (9) weltweit als Referenz für institutionelle Archive und steht an siebter Stelle. |
Forschungsplattform Alexandria (10) Die Plattform Alexandria dient als Schaufenster für die Forschung der Universität St. Gallen und soll nicht nur die Ergebnisse der an der Institution tätigen Forschung publik machen, sondern auch die einzelnen Forschungsinstitute, Forschenden (persönliche Profile) und laufenden Projekte vorstellen. Alexandria ist kein institutionelles Archiv im engeren Sinn, da die Archivierungsperspektive fehlt. Dennoch wird die Plattform im erwähnten Ranking an achter Stelle geführt. |
|---|---|---|
| Zentrale Archive | RERO DOC(11) RERO-DOC ist die digitale Bibliothek des Westschweizer Bibliothekenverbundes RERO (Réseau des bibliothèques de Suisse occidentale). Sie wurde im Rahmen der Einführung offener Archive geschaffen und bietet den Forschenden der Universitäten und anderen teilnehmenden Institutionen eine Plattform zur Archivierung ihrer wissenschaftlichen Literatur. Es handelt sich also um ein zentrales Archiv für die Publikationen zahlreicher Schweizer Institutionen, die über kein eigenes institutionelles Archiv verfügen. |
Driver (12) Driver umfasst als frei zugängliches multidisziplinäres Portal für die europäische Forschung die Verzeichnisse von offenen Archiven in Europa. 13 Partner aus ganz Europa sind an diesem paneuropäischen Portal für einen freien Zugang zu wissenschaftlichen Publikationen beteiligt, in dem bis heute mehr als 200 institutionelle und thematische Archive verzeichnet sind, so z.B. die französische Plattform offener Archive HAL (Hyper-articles en ligne). Gegenwärtig sind in Driver hauptsächlich Fachgebiete wie Biologie, Anthropologie und Informatik vertreten, wobei der Zugang zu den Ressourcen nach geografischer Region aufgeteilt ist. |
| Themenportale | Econbiz (13) Die Virtuelle Fachbibliothek Wirtschaftswissen-schaften wurde als Themenportal angelegt und ist eine Zusammenarbeit zwischen der Deutschen Zentralbibliothek für Wirtschaftswissenschaften (ZBW) und der Universitäts- und Stadtbibliothek Köln (USB Köln). Sie umfasst Internetquellen, eine Metasuchmaschine für allgemeine Bibliotheks-kataloge, ein Linkverzeichnis zu Volltextdaten-banken, einen internationalen wissenschaftlichen Veranstaltungskalender und Informationsdienst-leistungen. |
Economists online (14) Die Networked Economics Resources for European Scholars (NEREUS) sind ein Konsortium europäischer Universitätsbibliotheken, die über grössere Bestände in Wirtschaftswissenschaften verfügen. Gemeinsam bieten sie neue Inhalte und entwickeln neuartige Informationsdienste für Wirtschaftswissenschaftler. Ziel ist Schaffung und Ausbau eines europäischen Netzwerks von Forschungsbibliotheken, das die Ressourcen, welche aus der universitären Forschung in Europa stammen, miteinander verbindet. Der wichtigste Dienst von NEREUS ist Economists Online, ein Onlinezugang zu den Veröffentlichungen der bedeutendsten universitären Wirtschafts-wissenschaftler. Die gesamte Produktion der Wirtschaftler wird digitalisiert, strukturiert, archiviert und zugänglich gemacht, so dass möglichst viele Dokumente im Volltext einsehbar sind. |
Jede dieser Quellen wurde nach demselben Raster analysiert: Kontext der Entstehung, Ziele, Organisationsstruktur, allgemeine technische Struktur, Inhalt (Arten von Publikationen), Funktionen (einschliesslich Web 2.0), Schnittstelle, Benutzerfreundlichkeit, Suchmaschine, mögliche Sucharten, Mehrsprachigkeit, Design, Erfassung und Qualität der Metadaten, öffentliche Kommunikation und sonstige gute Eigenschaften. Die Schlussfolgerungen wurden in drei Teile aufgeteilt: Kontext und Organisation, Technologien und Inhalte sowie Kommunikation.
2. Kontext und Organisation
Sowohl bei institutionellen Archiven als auch bei zentralen Ressourcenportalen ist die Organisationsstruktur ein wichtiger Faktor, der über Erfolg oder Misserfolg entscheiden kann. Es ist wichtig, die folgenden Aspekte näher zu beleuchten, um je nach Kontext eine geeignete Wahl zu treffen: Organisationsstruktur, Art der Partnerschaften, Niveau der Zusammenarbeit und Rolle der Fachleute aus dem Bereich Information und Dokumentation in derartigen Projekten.
Organisationsstruktur
Beim Zusammenschluss institutioneller Archive wird allgemein die Organisationsstruktur eines Netzwerks gewählt (Econbiz, Driver, Economists online). Um einen anfänglichen Kern werden 2-10 Partnerschaften eingegangen, welche die Fortdauer des Projekts gewährleisten. Wenn das Netzwerk sogar zu einem Kompetenzzentrum wird, können die versammelten Experten den Archivverwaltern manchmal auch Dienste anbieten. Die institutionellen Archive sind als nationale oder internationale Netzwerke strukturiert und sollen Kompetenzen verfügbar machen, aber auch Werkzeuge und gemeinsame Dienste bereitstellen (15).
Typen offener Archive
Es wird zwischen verschiedenen Typen offener Archive unterschieden: Entweder sie sind institutionell (an eine wissenschaftlich tätige Institution, z.B. eine Universität gebunden), zentral (an mehrere produzierenden Institutionen gebunden, wie z.B. RERO-DOC, das mehreren Universitäten und Hochschulen als Archiv dient), multidisziplinär (sie decken mehrere Wissensgebiete ab) oder thematisch (auf ein Fachgebiet konzentriert, wie etwa auf die Wirtschaftswissenschaften bei Repec (Research Papers in Economics) (16) oder auf die Informations- und Bibliothekswissenschaften bei E-LIS (17). Der Impuls zur Schaffung solcher offener institutioneller, zentraler oder thematischer Archive kommt meist aus dem universitären Bereich. Aber es finden sich auch Forschungsinstitute wie das französische Centre national de la recherche scientifique (CNRS), welches das multidisziplinäre Archiv HAL (Hyper Articles on Line) (18) ins Leben rief und ebenfalls Interesse hat, die Arbeiten seiner Forschenden publik zu machen. Die Vielzahl solcher Projekte zeigt, wie sehr die verschiedenen Wissenschaftsgemeinden daran interessiert sind, offene Archive zu schaffen und auf zentralen Portalen präsent zu sein, damit sie gemeinsam die wissenschaftliche Literatur aufwerten können.
Niveau der Zusammenarbeit
Wie kann eine solche Zusammenarbeit jedoch auf lange Frist gesichert werden? Wir baut man ein echtes Kompetenzzentrum auf? Bei der Betrachtung ähnlicher Projekte stellt man fest, dass es nötig ist, dass die Partner im Netzwerk von ihrer Führungsebene unterstützt werden: Die jeweilige Institutionsleitung muss für das Prinzip der offenen Archive gewonnen werden. Dabei fällt den Informationsfachleuten eine wichtige Rolle zu. Um die Vorgesetzten zu überzeugen, können sie sich auf einige Zahlen zum Open Access und den institutionellen Archiven stützen. In den Vereinigten Staaten haben über 90% der Universitäten ein System mit einem institutionellen Archiv bereits eingerichtet oder befinden sich in der Evaluierungsphase (19). Eine Unterstützung für die Bewegung der offenen Archive kann sogar auf nationaler Ebene festgestellt werden, wie etwa im Fall des Archivs HAL (20), das vom CNRS unterstützt wird und an dem sowohl Universitäten als auch öffentlichen Forschungszentren teilnehmen (21). Desgleichen ist Repec (22) durch die gemeinsame Anstrengung in mehr als 60 Ländern entstanden, mit dem Ziel, die Verbreitung wirtschaftswissenschaftlicher Literatur zu fördern. Heute verfügen zwar erst sehr wenige Länder über eine politische Unterstützung für Open Access, aber auf Universitätsebene ist diese gang und gäbe (23). In der Schweiz erfasste die 2009 durchgeführte Studie der Hochschule für Technik und Wirtschaft Chur (HTW) 9 Archive an universitären Hochschulen und 8 weitere Projekte, die bis in zwei Jahren angeschlossen sein werden (24). Das Projekt E-lib wird übrigens mit der Elektronischen Bibliothek Schweiz ein umfassendes nationales Wissenschaftsportal einrichten (25).
Rolle der Fachleute aus dem Bereich Information und Dokumentation
Die Demokratisierung des Prinzips der offenen Archive innerhalb der akademischen Forschungsinstitute stellt für die wissenschaftlichen Bibliotheken eine Chance dar. Indem sie sich an besagten Projekten beteiligen, übernehmen sie eine neue Rolle bei der Aufnahme, Evaluierung und Verbreitung der Forschung (26). Sie können sich zwischen den Forschenden und den Verlagen positionieren, aber auch zwischen der Forschergemeinschaft und dem allgemeinen Publikum. Diese neue Rolle fördert die Nähe zwischen Bibliotheken und Forschenden und ist Teil einer globalen Entwicklung, wodurch ihr Auftrag eine Änderung erfährt (27). Wissenschaftliche Informationen sind ein wichtiges Gut für Universitäts- und Forschungsbibliotheken, da sie nicht nur hinsichtlich ihrer Verbreitung und Erhaltung erhebliche Anforderungen stellen, sondern auch hinsichtlich ihrer Beherrschung durch die Nutzer. Die Schulung der Nutzer wird zu ihrer Hauptaufgabe und in Learning Centers (28) werden Kurse zur Informationskompetenz und zur Beherrschung der Informations- und Kommunikationstechnologien angeboten. Informationsfachleute spielen somit eine strategisch wichtige Rolle bei der Änderung des Benutzerverhaltens und der Veröffentlichungsmodalitäten. Es ist sogar möglich, wenn nicht gar wünschenswert, dass sie in Projekten mit offenen Archiven eine Führungsrolle einnehmen (29).
Dennoch bekunden die Bibliotheken manchmal Schwierigkeiten, die Informatikseite, welche die institutionellen Archive betreibt, und die Forschungsinstitute, die diese mit Inhalten beliefern, aufeinander abzustimmen. Dann müssen die Bibliotheken ihre Kompetenzen bei der Verwaltung digitaler Informationen geltend machen und bei der Erhaltung und Verbreitung einen zentralen Platz einnehmen. Durch ihre Zwischenposition sind sie in der Tat am ehesten in der Lage, Bedarf und Anfragen der Nutzer weiterzuleiten (30). Diese Zusammenarbeit mit den Entwicklern, die einen Überblick über die verschiedenen Systeme vor Ort haben und die Einbindung des Archivs in das aktuelle Informatiksystem gewährleisten, ist einer der Erfolgsfaktoren solcher Projekte (31).
Die politische Unterstützung ist nicht nur wichtig für den Betrieb der Kompetenzzentren, sondern auch für die Verbreitung des Prinzips der offenen Archive. Alle hier untersuchten Projekte können sich auf eine interne Politik stützen, der die Literatursammlung und die Schaffung institutioneller Archive untersteht. Diese Politik bezieht sich meist auf die Berliner Erklärung über den offenen Zugang zu wissenschaftlichem Wissen (2003), in der sich die Unterzeichner unter anderem verpflichten, die Forschenden dazu anzuhalten, ihre Arbeiten nach dem Prinzip des offenen Zugangs zu veröffentlichen, und kulturelle Einrichtungen zu ermutigen, den Zugang zu den Ressourcen über das Internet zu ermöglichen. Seither hat eine wachsende Anzahl akademischer Institutionen ihr eigenes Online-Archiv eingerichtet und die Forschenden dazu verpflichtet, ihre Veröffentlichungen darin frei zugänglich zu machen. Es ist schwierig, die Gesamtheit der offenen Archive weltweit zu erfassen, aber es gibt ein Verzeichnis, in das sich die frei zugänglichen Online-Archive eintragen können (32).
Trotz der Unterstützung der Leitungsorgane im Bereich Forschung bleibt viel zu tun, um die Forscher dafür zu gewinnen und dazu anzuhalten, nach diesem Modell zu veröffentlichen. In einigen Bereichen besteht grosses Misstrauen und Widerstand gegen Änderungen. Dies ist vielleicht auf die Unkenntnis des Prinzips des Open Access sowie auf die Furcht vor einem Qualitäts- und Ansehensverlust zurückzuführen. Die Bibliotheken müssen ihre Nutzer dahingehend informieren, dass ihr Vertrauen gestärkt und auch sichergestellt wird, dass sie sich an den Projekten institutioneller Archive beteiligen. Sie müssen den Forschungsinstituten auch eine technische Unterstützung bieten, damit nicht jeder handelt, wie er allein es für richtig hält, sondern damit die Praxis vereinheitlicht wird. Hierfür können sich die Bibliotheken auf die Arbeiten der Vorreiter institutioneller Archive wie SHERPA (33) stützen, ein Konsortium, das die Schaffung von Archiven in allen Forschungseinrichtungen und höheren Lehranstalten des Vereinigten Königreichs unterstützt. Ein besonders nützlicher Dienst ist Sherpa-RoMEO (Rights MEtadata for Open archiving): Er liefert eine Liste von Veröffentlichungsrechten der Verlage zur Archivierung der Veröffentlichungen durch die Autoren, aus der ersichtlich ist, ob der Verlag die Archivierung der Publikation in einem öffentlichen Archiv gestattet oder nicht (34) und falls ja, welches seine Bedingungen sind (ob z.B. nach der Veröffentlichung eine Embargo-Zeit eingehalten werden muss). Gegenwärtig geben laut Statistiken der Website SHERPA-RoMEO 95 % der Periodika dem Autor das Recht, selber archivieren zu lassen, und es wurde erwiesen, dass diese sogenannte Auto-Archivierung die Sichtbarkeit erhöht und damit die Leserschaft vergrössert(35). Die umfassende Kommunikation und Information über die Vorteile institutioneller Archive sind somit erste Best Practices, die für Projekte mit Open Access zu berücksichtigen sind.
3. Technologie, Inhalte und Funktionen
Sobald der Entscheid für das Projekt gefallen ist, müssen ähnliche Projekte sowie bestehende Werkzeuge und Normen, die einzuhalten sind, untersucht werden, um gewisse technische Entscheide zu fällen insbesondere hinsichtlich Struktur, Inhalte und gewünschter Funktionen.
Technische Struktur
Die technische Struktur von Portalen, die dem geplanten Portal Info-Net Economy ähnlich sind, beruht auf dem Prinzip der Zusammenführung lokal verwalteter institutioneller Archive. Diese Archive, wie Infoscience (36) oder Alexandria (37), bestehen nicht nur aus den Objekten selbst, sondern zusätzlich aus beschreibenden Metadaten. In einer Struktur einer Zusammenlegung von Archiven wie Driver (38) bleiben die Veröffentlichungen der Partnerinstitutionen in ihrem lokalen Depot und das Portal zeigt diese Quellen nur durch Metadaten an, die es gesammelt hat und die durch Verbindungen auf die Veröffentlichungen verweisen. So wird es möglich, die Suche innerhalb der Metadaten der produzierenden Institutionen zu vereinen und ihnen gleichzeitig die Verwaltungsverantwortung sowie das volle Eigentumsrecht zu gewähren.
Inhalte und Funktionen
Diese Portale bieten unterschiedliche Inhalte und Funktionen an. Inhaltlich findet man verschiedene Typen akademischer Veröffentlichungen: in der Mehrheit wissenschaftliche Artikel, Bücher und Kapitel aus Büchern, Studienarbeiten (Master- und Doktorarbeiten, manchmal auch Bachelorarbeiten), aber auch veröffentlichte oder nicht veröffentlichte Arbeiten von Professoren und Forschenden (Vorveröffentlichungen, Working Papers, Konferenz-Papers und -Proceedings usw.) sowie, wie etwa im Fall des Offenen Archivs der Universität Genf (39), Unterrichtsmaterialien (Skripte, Videoaufzeichnungen usw.). Diese akademischen Inhalte werden oft ergänzt durch allgemeinere Veröffentlichungen wie Zeitungsartikel und Medienmitteilungen. In einigen Fällen gibt es keine Begrenzung für den Dokumententyp; so finden sich immer häufiger auch rohe Forschungsdaten und Multimedia-Inhalte. Der Inhalt der Archive wird allgemein in der Absichtserklärung festgelegt; diese ist ein wichtiges Werkzeug, um den Umfang des Archivs zu definieren. Neben den Veröffentlichungen selbst bieten fast alle der untersuchten Websites eine Rubrik „Aktuelles“, die sowohl neue Forschungsprojekte aufführt, als auch auf Neuerscheinungen hinweist. Diese verschiedenen Inhalte werden oft unsortiert präsentiert und erst über die Suchfunktionen können einzelne Inhalte gezielt abgefragt werden. Die Hauptherausforderung liegt hier bei der Ergonomie. Wie können die verschiedenen Inhalte einfach strukturiert werden, damit möglichst intuitiv danach gesucht werden kann? Da unterschiedlichste Bedürfnisse befriedigt sein wollen, müssen die Suchfunktionen sehr umfassend sein. Es muss eine breite Palette von Diensten angeboten werden: vom einfachen Suchfeld bis zu den kombinierten Suchfeldern der erweiterten Suche und hin zur Navigation nach Themen, Dokumententyp und Akteuren, nicht zu vergessen die Optionen zur Einschränkung der Suchergebnisse. Zwei Beispiele stechen durch die Einfachheit der Suche und die gute Nutzung der Suchfilter heraus: Infoscience (ETHL) (40) und Alexandria (Universität St. Gallen) (41). Die Ergonomie der Funktion der Archivierung von Publikationen durch die Forschenden ist allgemein gut, und die Anweisungen sind einfach und klar.
Funktionen vom Typ Web 2.0 sind in den akademischen Forschungsportalen noch wenig vorhanden. In den in dieser Studie untersuchten Projekten ist die Verwendung von RSS-Feeds üblich zur Bekanntmachung von Neuerscheinungen (Alexandria) oder von neuen Publikationen zu einer durchgeführten Suche (Infoscience). Dennoch werden den Nutzern der Portale, Forschende oder allgemeines Publikum, wenige Interaktionsmöglichkeiten geboten. Keines der untersuchten Portale vom akademischen Typ erlaubt den Nutzern, selber Meldungen zu „taggen“ oder Kommentare zu den Ressourcen zu posten. Die semantischen Suchmöglichkeiten sind also beschränkt. Trotzdem plant das Projekt Inspire (42), ein Portal der neuen Generation im Bereich Physik, den Nutzern die Möglichkeit zu bieten, sich am „Tagging“ und den Kommentaren zu den Ressourcen zu beteiligen (43). Anhand dieses Beispiels wird klar, wie gut ein solcher Ansatz funktionieren kann. Interessant ist, dass der Nutzer bei Infoscience nach der Registrierung eine persönliche Datensammlung anlegen oder die Suchmasschine nach seinem besonderen Bedarf anpassen kann. Überdies werden zwar auf allen untersuchten Portalen Online-FAQ (Frequently asked questions) aufgelistet, aber nur Econbiz (44) bietet eine echte Beratung und Kurzauskünfte online an.
Der Entscheid, eine mehrsprachige Seite anzubieten, wirft die Frage nach der Behandlung der Mehrsprachigkeit auf. Dies ist bei einem Schweizer Projekt wie Info-Net Economy besonders wichtig. Es geht darum, eine Schnittstelle, eine Suchmaske und eine Ergebnisanzeige in mehreren Sprachen anzubieten, ohne dass die allgemeine Präsentation der Seite darunter leidet. Die am häufigsten verwendete Lösung besteht darin, die Schnittstelle in mehreren Sprachen und die Metadaten in der Sprache der archivierten Veröffentlichung zu fassen. Zur Verbesserung der Suche können die Schlagwörter gegebenenfalls in mehrere Sprachen übersetzt werden.
Werkzeuge und Normen
Immer noch auf der technischen Ebene ist es ebenfalls wichtig, die verschiedenen Werkzeuge für die Archivierung der Publikationen einerseits und die gemeinsame Suche in verschiedenen Archiven andererseits zu kennen und zu verstehen.
Bei den Archivierungswerkzeugen gehören gemäss dem Registry of Open Access Repositories (45) zu den zwei weltweit am meisten genutzten Programmen Dspace (46) (mehr als 400 Portale) und Eprints (47) (mehr als 300 Portale, darunter die Universität Zürich). CDS-Ware/Invenio (48), das vom CERN entwickelte System, steht auf dem siebten Platz und zählt als Anwender die ETHL und RERO-DOC. Dies sind alles Systeme zur Datenablage.
Damit diese gemeinsame Nutzung von Ressourcen möglich wird, müssen dieselben Normen eingehalten werden. Der bestimmende Faktor für diese Portale ist die Suche, die natürlich auf die Metadaten zugreift, und hier heisst das Motto „Standardisierung“. Man spricht allgemein von OAI-kompatiblen Archiven. Die Open Archive Initiative (OAI) ist eine Bewegung zur Förderung offener Archive und hat eine Reihe von Protokollen und Standards zur Interoperabilität entwickelt, welche die Verbreitung von Dokumenteninhalten erleichtern. Das zentrale Protokoll heisst Open Archive Initiative Protocol for Metadata Harvesting (OAI-PMH), auf Deutsch: Protokoll der Initiative für offene Archive zur Sammlung von Metadaten. In ihm wird ein Standard zur Übertragung gesammelter Metadaten festgelegt. Das OAI-PMH wurde im Rahmen der Open Archives Initiative entwickelt, um die von den Autoren eingereichten Vorveröffentlichungen mit einer interoperablen Basis zu erweitern. Die Open Archives Initiative ist also spezifisch auf die Wissenschaftsgemeinschaft ausgerichtet. Dennoch erweist sich das Protokoll auch für allgemeinere Anwendungen interessant.
Das Protokoll OAI-PMH stützt sich in den Metadaten auf eine Norm zur bibliografischen Beschreibung, den sogenannten nicht qualifizierten Dublin Core: Dies ist ein Schema digitaler Metadaten, mit dem die digitalen Ressourcen beschrieben und Beziehungen mit anderen Ressourcen angezeigt werden können. Es umfasst 15 Elemente formaler (Titel, Urheber, Verlag), intellektueller (Thema, Beschreibung, Sprache) und urheberrechtlicher Natur. Primäre bibliografische Informationen können ins Format Dublin Core umgewandelt werden. Zudem kann Dublin Core leicht als XML kodiert werden.
Ein institutionelles Archiv auf der Grundlage von OAI-PMH verfügt über eine Metadatenbasis, welche das Depot den Sammlern „anbietet“ (49). Diese Metadaten sind in verschiedenen Formaten verfügbar, je nach Bedarf. Die Minimalanforderung der Norm OAI-PMH ist zwar das Format Dublin Core, aber mit dem Format MARCXML verfügt man über umfangreichere Metadaten, beispielsweise aus den Bibliothekskatalogen. So können die Metadaten mit dem Protokoll zentralisiert werden, indem auf verschiedene Ressourcen verwiesen wird, ohne dass diese von ihrem Standort bewegt werden müssen. Es ist also möglich, in einer verteilten Architektur auf Ressourcen zuzugreifen, indem Metadaten zusammengeführt und für die spezifischen Bedürfnisse eines Dienstes ausgewertet werden. Im Rahmen von Portalprojekten wie Info-Net Economy werden die Ressourcen in verschiedenen Einrichtungen verwaltet. Für einen gemiensamen Zugang zu diesen Ressourcen sammelt ein System die Metadaten in einer gemeinsamen Basis. Mit diesem Austauschprotokoll können also über automatisierte Prozeduren Metadatenserver eingerichtet, gefüttert und aktualisiert werden, so dass diese die Dokumente signalisieren, beschreiben und zugänglich machen, ohne dass sie dupliziert oder ihr ursprünglicher Standort verändert werden müsste (50). Damit können auch heterogene Ressourcen aus unterschiedlichsten Quellen zusammengefasst werden. Dieses Verfahren zur Suche und Zusammenfassung von Ressourcen wird Sammeln oder Harvesting genannt (siehe Abbildung 1).
Harvesten mit OAI-PMH
Für das Harvesten mit OAI-PMH sind zweierlei Akteure nötig: einerseits die eingetragenen Archive (Datenanbieter) und andererseits die Sammler (Dienstleister). Die Datenanbieter bieten ihre Metadaten an, indem sie das OAI-Protokoll anwenden und mittels eines OAI-Archivs, das die Anfragen der Dienstleister bearbeitet, den Zugang zu ihrem Katalog ermöglichen; die Harvester suchen derweil die Archive ab und sammeln die Metadaten gemäss OAI-Protokoll. Die Antworten werden im Format XML gegeben und enthalten je nach Anfrage Informationen über das Archiv, Kennzeichen und Metadaten. Mit „Sammeln“ wird hier die Tätigkeit bezeichnet, die lokal eine Kopie der Metadaten erstellt und sie dann als zusätzlichen Wert suchbar macht. Ein einziges Archiv kann gleichzeitig von mehreren Sammlern abgefragt werden. Mithilfe der Sammler können die Ressourcen aus verschiedenen OAI-Archiven zusammengefasst werden. Sie füttern eine XML-Basis, die auch auf anderem Weg befüllt werden kann, einschliesslich durch lokale Ressourcen oder menschlichen Eingriff. In diesem Fall muss der Prozess der URL-Suche und -Auswahl der zu sammelnden Basen im Voraus erstellt werden (automatisch oder manuell, manchmal auch beides), inklusive der Häufigkeit der Besuche und der Aktualisierungen für jede Basis; danach werden Speicherung, Indexierung, Nutzung und Anzeige der Daten bestimmt (XSLT-Transformation). Wenn kein institutionelles Archiv zur Verfügung steht, von dem gemäss der Norm OAI-PMH gesammelt werden kann, kann die Metadatenbasis auch mit einem entsprechend aufgebauten RSS-Feed auf einer Website verfügbare Publikationen anzeigen oder mit einer Web-2.0-Anwendung gefüttert werden, die sich auf vorparametrisierte URL-Anfragen stützt, wie etwa beim Projekt RODIN (51), einem Werkzeug zur Aggregation und Koppelung von Informationsquellen. Es ist übrigens auch möglich, mit solchen Anfragen auf die Daten aus einigen Nicht-OAI-Archiven zuzugreifen.
Abbildung 1(52)
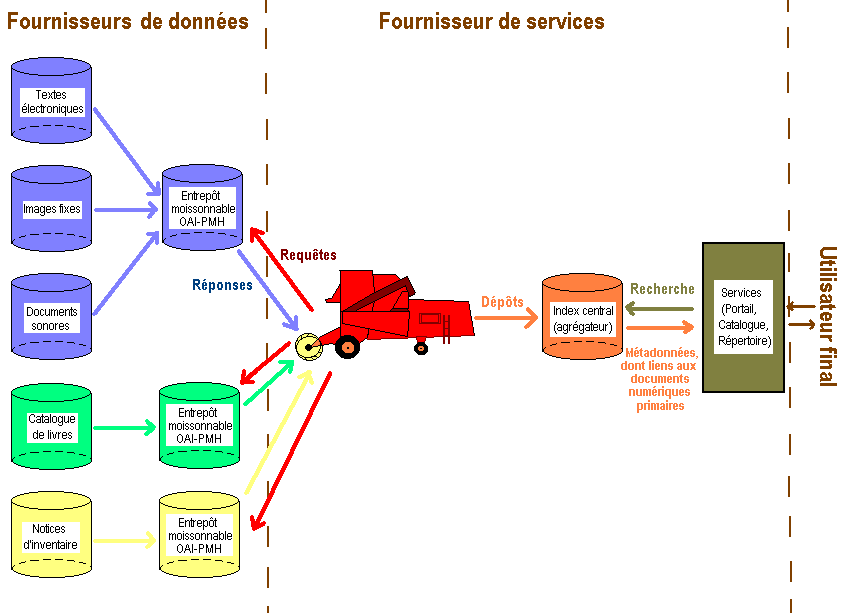
Das obenstehende Schema (Abbildung 1) zeigt das Prinzip des Sammelns von Metadaten, wobei:
- links die verschiedenen institutionellen Archive stehen, die als Datenlieferanten fungieren, wobei jedes über ein eigenes Metadatenarchiv verfügt;
- in der Mitte die Sammelmaschine steht, die eine Sammeleinheit und einen Metadatenaggregator enthält (Dienstleister);
- und rechts die gemeinsame Suchschnittstelle für den Endnutzer ist.
Es gibt Open Source-Sammelmaschinen (Harvester), von denen am häufigsten OAIster (53), CiteBase Search (54), OAIHarvester2 (55), PKP Harvester (56), Framework SDX (57) und Google Scholar (58) eingesetzt werden. Man kann auch eine eigene Funktion zur Suche nach Metadaten in verschiedenen ausgewählten Archiven entwickeln (59), wobei stets gezielte URL-Anfragen nötig sind.
Die angebotenen OAI-Daten werden also weltweit von den wissenschaftlichen Suchmaschinen (wie etwa Google Scholar, Bielefeld academic search engine), aber auch von den einfachen Suchmaschinen (Google, Yahoo, MSN usw.) referenziert. Von den geschaffenen Archiven können also Metadaten gesammelt werden, was ihre Sichtbarkeit erhöht. Letztlich stellt man fest, dass die verschiedenen Archivtypen einander ergänzen.
Die Zusammensetzung der Metadaten und die Art, wie sie den Sammlern angeboten werden, wird zwar durch die Norm OAI-PMH bestimmt, doch die thematische Indexierung jedes Dokuments bleibt frei. Jede Institution entscheidet selbst darüber, wie indexiert wird, ob ein Thesaurus mit kontrolliertem Vokabular verwendet wird oder ob dieses Feld den Autoren überlassen wird, die ihre Publikationen ablegen. Kritisch wird es dann, wenn die Metadaten verschiedener Institutionen zentralisiert werden, da Konkordanzlisten erstellt werden müssen, um die gemeinsame Suche nach Themen zu erleichtern. Das Portal Driver, das mehr als 200 Archive vereint, hat sich dafür entschieden, das Feld „Thema“ frei zu lassen und bietet deshalb keine Suche nach Themen und keine Navigation in der Klassifizierung an.
Die Standardisierung der Metadaten betrifft aber nicht nur das Harvesting und Anbieten, sondern auch ihre Aufbewahrung. Obzwar der von Dublin Core verlangte Metadatensatz sich gut zur Datenänderung eignet, bleibt er hinsichtlich Verwaltung und Aufbewahrung beschränkt. Es gibt interne Verwaltungs- und Aufbewahrungsformate, die umfassender sind und zugleich die von Dublin Core verlangten Felder abdecken: Das derzeit gängigste ist MARC (60), genauer MARCXML, das sich leicht in andere Formate umwandeln lässt (HTML für die direkte Anzeige, Dublin Core oder MODS zur Unterstützung von Sammelprotokollen) (61).
Interessant ist übrigens, neben dem OAI-PMH auch ein anderes Projekt der Open Archive Initiative genauer zu betrachten: OAI-ORE (Open Archives Initiative Object Reuse and Exchange) (62). Dieses Protokoll definiert einen Standard zur Beschreibung und zum Austausch komplexer Webressourcen (eine Doktorarbeit besteht beispielsweise aus einer Vielzahl von Kapiteln, sie kann in verschiedenen Versionen existieren, von Artikeln gefolgt sein usw.). Während sich OAI-PMH auf die Metadaten beschränkt, geht OAI-ORE genauer auf die Ressourcen (die Objekte der Beschreibung) ein. Es handelt sich um eine neue Art, Metadaten anzureichern und zu nutzen, indem die in den OAI-Archiven aufbewahrten Dokumente für eine allfällige Wiederverwendung beschrieben werden. Die Archivierungsprogramme Dspace und Eprints (63) unterstützen dieses neue Protokoll.
Trotz der Standards, die eine Aggregation der Daten erlauben, müssen diese immer noch angepasst werden. Oft müssen die Daten homogenisiert werden, da die Norm einigen Spielraum bei den beschreibenden Metadaten lässt. Insbesondere Dublin Core wird nicht überall gleich interpretiert. Die „Nicht-Qualifizierung“ von Dublin Core macht, dass die Nutzung bis zu einem gewissen Grad flexibel ist, was zu leichten Ungleichheiten in den Metadaten führt. Daraus ergibt sich ein Vereinheitlichungsaufwand, der im Fall zahlreicher einzubindender Archive nicht unerheblich sein kann. Um dem entgegenzuwirken, bietet Driver eine Anleitung für Archive, die ins Portal eingebunden werden wollen. Diese muss genau eingehalten werden, damit die Teilnahme möglich wird und die Daten über das Portal abgefragt werden können. Im Gegenzug bietet Driver Beratung und Erfahrungsaustausch in Mentoring-Form (64).
4. Kommunikation
Die Kommunikation ist bei der Schaffung offener Archive oder eines zentralen Ressourcenportals äusserst wichtig. Von Beginn an ist die Kommunikation zwischen den Projektpartnern entscheidend für einen erfolgreichen Ablauf des Projekts. Sobald das Archiv eingerichtet ist, müssen nicht nur die Forschenden dazu angeregt werden, ihre Publikationen abzulegen, sondern auch die leitenden Instanzen von der Bedeutung der Auto-Archivierung und der Präsenz in einem zentralen Portal überzeugt werden. Die Sichtbarkeit ist ein wichtiges Argument, welches es hervorzuheben und zu vertiefen gilt.
Mit den Partnern
Die Kommunikation beginnt innerhalb der Projektgruppe. Es geht darum, um einen Kern von Fachleuten herum ein Klima der Zusammenarbeit und Partnerschaft mit gemeinsamen Zielen zu schaffen. Die Weitervermittlung von Know-how nützt natürlich allen, und eine vernünftige Aufgabenteilung je nach Kompetenzen erlaubt jedem, sich aktiv einzubringen. Bei den institutionellen Archiven ist es wichtig, dass eine kritische Masse an Inhalten erreicht wird, damit sich andere Archive angesprochen fühlen, sich zu beteiligen. Bei zentralen Portalen kann der anfängliche Kern der Fachleute, sobald der Betrieb aufgenommen ist, auch auf andere Partner ausgeweitet werden.
Innerhalb der Hierarchie
Während des gesamten Projektverlaufs ist die Kommunikation mit den Führungsorganen der Institutionen wichtig, denn diese können die Autoren zur Ablage der Publikationen anregen oder sogar dazu verpflichten. Diese „politische“ Unterstützung ist notwendig für ein gutes Funktionieren der Archive. Bei zentralen Portalen kommt es darauf an, den Führungsorganen der Projektpartner klarzumachen, dass ihre Teilnahme ein Gewinn für die Sichtbarkeit und Förderung der Forschung im Allgemeinen ist.
Mit den Nutzern
Die Kommunikation unter den Partnern und mit den Entscheidungsinstanzen ist gewiss von entscheidender Bedeutung, aber auch die Öffentlichkeit muss entsprechend berücksichtigt werden. Es geht darum, das geschaffene Werkzeug bei den Forschenden und Nutzern geeignet zu bewerben. Die Forschenden müssen in der Nutzung des Archivs geschult werden; damit sie das Werkzeug akzeptieren, braucht es eine gute Hilfestellung bei der Erfassung sowie eine einfache und benutzerfreundliche Schnittstelle. Die Argumente, die eingebracht werden können, sind die erhöhte Sichtbarkeit für die Forschenden, der Mehrwert durch die Zentralisierung der Ressourcen und die umfassenderen Suchöglichkeiten für die Öffentlichkeit. Im gegenwärtigen Umfeld sind die Forschenden auf eine einfache und effektive Suche angewiesen und es ist die Aufgabe der Informationsfachleute, ihnen zu ermöglichen, selbständig zu arbeiten, indem sie ihnen einfache Schnittstellen bieten, die es ihnen erlauben, sowohl im eigenen Archiv als auch in fremden Inhalten rasch ihre Fragen selber zu beantworten. Es geht nicht nur darum, ihnen ein technisches, organisatorisches und institutionelles Hilfsmittel an die Hand zu geben, sondern ihnen auch Informationen und Schulungen sowie verschiedene wertvolle Dienstleistungen anzubieten: vereinfachte Quellenerfassung, einfache Wiederverwendung von Daten, automatische Erstellung bibliografischer Listen, Interoperabilität mit anderen Systemen und Analyse des Impact Factors. Infoscience (65) und das offene Archiv der Universität Genf (66) bieten ihren Forschenden etwa eine Rubrik mit Informationen über Open Access, eine Hilfe bei der Ablage sowie wertvolle Dienste wie die Entnahme bibliografischer Listen zur Wiederverwendung, persönliche RSS-Feeds usw. Die von Driver (67) durchgeführte Studie zeigt, wie wichtig diese wertsteigernden Dienste für den Erfolg der untersuchten Archive sind.
Schliesslich ist Marketing auch im Hinblick auf die Internetgemeinde wichtig. Die Referenzierung und Kommunikation in verschiedenen Medien, um möglichst viele Menschen zu erreichen, ist keine kleine Arbeit. Wer seine Metadaten zur Sammlung in institutionellen Archiven anbietet, möchte diese bald auch auf der allgemeinsten Ebene sichtbar machen. Es ist unerlässlich, dass die Archive, deren Metadaten von den grössten Portalen gesammelt werden, ein Feedback hinsichtlich Interoperabilität und Qualität der angebotenen Metadaten erhalten. Die Zusammenarbeit in Projekten mit internationaler Reichweite erlaubt ihnen, ihre Sichtbarkeit zu erhöhen. Pionierprojekte in diesem Bereich wie Driver verstehen sich als multidisziplinäre Projekte, die gerne mit anderen zusammenarbeiten und ihr Know-how frei weitergeben (68).
5. Schlussfolgerung
Die vorliegende Studie untersucht im Rahmen des Projekts Info-Net Economy, dessen Kern aus einem Metadaten-Archiv nach OAI-PMH bestehen wird, die Best Practices, die bei der Gestaltung eines zentralen Ressourcenportals zu berücksichtigen sind. Solche Portale sind heutzutage notwendig für die Forschung, da die Quellen oft verteilt und nicht entsprechend sichtbar sind. Da sich der Inhalt dieser Portale im Wesentlichen aus offenen institutionellen Archiven zusammensetzt, haben wir einige von diesen genauer analysiert.
Erstens stellt man fest, dass die Open-Access-Bewegung in der Welt der wissenschaftlichen Publikationen eine wahre Revolution ausgelöst hat, was den Wissensaustausch in der akademischen Gemeinschaft stark erleichtert. Der Erfolg von institutionellen Archiven, zentralen Ressourcenablagen und Themenportalen beruht auf ihrer einzigartigen Organisationsstruktur sowie auf dem Team der um das Projekt gescharten Fachleute. Dennoch bleibt hinsichtlich der Bekanntmachung bei den Universitäten noch viel zu tun, da die Führungsorgane und die Forschenden von diesem Ansatz überzeugt werden müssen. Kommunikation und Information über die Bedingungen und Erfolge institutioneller Archive sind deshalb die erste Best Practice, die zu berücksichtigen ist. Diese Rolle kann sehr gut von den Bibliotheken übernommen werden; dies ist sogar eine echte Chance innerhalb des sich verändernden Umfelds wissenschaftlicher Informationen. Eine neue Aufgabe der wissenschaftlichen Bibliotheken wird darin bestehen, den Instituten und Forschenden bei der Aufwertung ihrer Arbeiten durch das Web behilflich zu sein. Hierfür ist der Zusammenschluss in Partnerschaften und Netzwerken zum Austausch von Know-how und Inhalten ein wichtiger Schritt. Gegenüber den Universitäten können die Bibliotheksfachleute ihre Kompetenzen im Bereich Dokumentation bei der Schaffung institutioneller Archive einbringen (wie im Fall von Infoscience an der ETHL) und die Forschenden dazu anregen, ihre Publikationen auf einem zentralen Archiv abzulegen (wie etwa RERO-DOC in der Westschweiz). Sobald das Archiv seinen Betrieb aufgenommen hat, ist dessen Teilnahme in ein Themenportal wie Driver wünschenswert, da dies die Sichtbarkeit der hervorbringenden Institution erhöht.
Eine weitere zu berücksichtigende Best Practice besteht darin, eine klare Strategie zu entwickeln, die festlegt, welche Arten von Inhalten das Archiv oder Portal beherbergen soll. Technisch machbar ist die Zentralisierung von Ressourcen aus verschiedenen Archiven dank der Norm OAI-PMH, die sich ihrerseits auf die Beschreibungsnorm Dublin Core stützt. Mit den gesammelten Metadaten kann eine gemeinsame Suche in allen angebotenen Archiven erfolgen. So erhalten auch wenig bekannte Archive eine grössere Sichtbarkeit, etwa auf dem Portal Info-Net Economy, das die Ressourcen verschiedener Schweizer Akteure versammelt, die wissenschaftliche Informationen im Bereich Wirtschaftswissenschaften publizieren. Die Anwendung von Normen und Werkzeugen, welche die Vereinheitlichung und damit den Austausch von Metadaten erleichtern, ist die dritte Best Practice, die zu beachten ist.
Schlussendlich haben auch die Archive und Portale, welche die Daten sammeln, die Verantwortung, benutzerfreundliche Oberflächen mit wertsteigernden Funktionen und Diensten anzubieten. Das Angebot eines benutzerfreundlichen Rahmens für die Forschenden mit wertsteigernden Diensten und Werkzeugen auf dem neusten Stand ist damit die vierte Best Practice, die sich aus dieser Untersuchung ergibt.
Als Fazit soll noch einmal die Bedeutung der Normen und Protokolle für den Datenaustausch hervorgehoben werden, wobei nicht vergessen werden darf, dass auch die Organisationsstruktur und Projektkommunikation entscheidend sind. Ein Erfolg ist jedoch noch schwer zu messen, da es an bewährten Indikatoren mangelt (69). Obschon die Verbreitung von Open Access und die wachsenden Zahl der darauf beruhenden Projekte bereits als Erfolg gewertet werden können, so müssen diese doch weiterverfolgt und sorgfältig gemäss Qualitätskriterien ausgebaut werden, die in den Bereichen der Informationswissenschaft sowie der akademischen Recherche anerkannt sind.
6. Notes
(1) Info-Net Economy [online]. http://www.e-lib.ch/net_economy_f.html
(2) Die Elektronische Bibliothek Schweiz, das Portal für die nationale Wissenschaftsgemeinde, das über eine gemeinsame Benutzeroberfläche einen zentralen Zugang zu einem breiten Angebot wissenschaftlicher Informationen sowie Bibliotheksdienste anbieten wird.
E-lib [online]. http://www.e-lib.ch/index_f.html
(3) ARESO : annuaire de ressources économiques de Suisse occidentale, Verzeichnis der wirtschaftswissenschaftlichen Ressourcen der Westschweiz, seit 2008 betrieben vom Studiengang Information und Dokumentation der Hochschule für Wirtschaft, Genf.
ARESO [online]. http://campus.hesge.ch/areso/
(4) Definition des Kanadischen Verbands der Forschungsbibliotheken, ABCR.
(5) Siehe das Dossier der Universität Genf: http://www.unige.ch/biblio/chercher/openaccess/brochure.pdf
(6) Für weitere Informationen und eine komplette Bibliographie zum Thema der Publikationen unter Open Access, siehe die Website von Charles W. Bailey Jr.:http://www.digital-scholarship.org/
(7) Bosc, Hélène. Archives ouvertes : 15 ans d’histoire. Les archives ouvertes : enjeux et pratiques. Paris, ADBS, 2005. pp. 27-54.
(8) Infoscience [online]. http://infoscience.epfl.ch/
(9) Dieses Ranking hat zum Ziel, die Projekte mit offenen Archiven zu unterstützen, indem es sie nach Sichtbarkeit und Wirkung bewertet. Ranking web of world repositories [online]. http://repositories.webometrics.info/
(10) Forschungsplattform Alexandria [online]. http://www.alexandria.unisg.ch/
(11) RERO-DOC[online]. http://doc.rero.ch/?ln=fr
(12) Driver [online]. http://www.driver-repository.eu/
(13) Econbiz [online]. http://www.econbiz.de/
(14) Economists online [online]. http://www.nereus4economics.info/
(15) Muriel Foulonneau, Réseaux d’archives institutionnelles en Europe : logiques de développement et convergences, Archive Ouverte en Sciences de l'Information et de la Communication [online], 2007, http://archivesic.ccsd.cnrs.fr/sic_00205049/en/
(16) Repec [online]. http://repec.org/
(17) E-LIS [online]. http://eprints.rclis.org/
(18) HAL [online]. http://hal.archives-ouvertes.fr/
(19) Lynch, Clifford A., Lippincott, Joan K., Institutional Repository Deployment in the United States as of Early 2005. D-Lib Magazine [online], vol. 11, no 9, 2005. http://www.dlib.org/dlib/september05/lynch/09lynch.html
(20) Op. cit.
(21) Andre, Francis, Charnay, Daniel, Support of Open Archives at National Level : the HAL experience, Institutional archives for research : experiences and programs in open access [online], Rome 30 November – 1 December 2006, http://archivesic.ccsd.cnrs.fr/docs/00/18/72/60/PDF/Rome_ISS_FANDRE.pdf
(22) Ibid.
(23) Chen, Kuang-hua, The unique approach to institutional repository. The electronic library [online], vol. 27, no 2, 2009, pp. 204-221,
http://www.emeraldinsight.com/Insight/viewPDF.jsp?contentType=Article&Filename=html/Output/Published/EmeraldFullTextArticle/Pdf/2630270201.pdf
(24) Pfister, Joachim, Weinhold, Thomas, Zimmermann, Hans-Dieter. Open Access in der Schweiz : status quo und geplanter Aktivitäten im Bereich von Institutional Repositories bei Hochschul- und Foschungs-einrichtungen in der Schweiz. In Information : Droge, Ware oder Commons ? : Wertschöpfungs – und Transformationsprocesse auf den Informationsmärkten [online]. Boizenburg : Werner Hülsbusch, 2009. Pp. 259-270
(25) Op. cit.
(26) Vezina, Kumiko. Dépôts institutionnels : principaux enjeux [online]. 38ème congrès annuel – perspectives d’avenir : fonctions, réseaux et relations, Corporation des bibliothécaires professionnels du Québec, mai 2007
http://www.cbpq.qc.ca/congres/congres2007/Actes/Vezina.pdf
(27) Blin, Frédéric, Les bibliothèques académiques européennes : Brève synthèse prospective, BBF [online], t. 53, no 1, 2008, pp. 12-18, http://bbf.enssib.fr/consulter/bbf-2008-01-0012-002
(28) Ibid.
(29) Jones, Catherine. Institutional repositories: content and culture in an Open Access environment. Oxford : Chandos Publishing, 2007.
(30) The research library’s role in digital repository services [online], Association of research libraries, 2009, http://www.arl.org/bm~doc/repository-services-report.pdf
(31) Salo, Dorothea. Innkeeper at the roach motel. Library Trends [online], vol. 57. No 2, 2008. http://minds.wisconsin.edu/handle/1793/22088
(32) University of Nottingham (UK). OpenDOAR : the Directory of Open Access Repositories [online].
http://www.opendoar.org/
(33)SHERPA [online]. http://www.sherpa.ac.uk/index.html
(34) SHERPA-RoMEO [online]. http://www.sherpa.ac.uk/romeo/
(35) Harnad, Steven, Brody, Tim. Comparing the Impact of Open Access (OA) vs. Non-OA Articles in the Same Journals. D-Lib Magazine [online], vol. 10, no 6, 2004. http://www.dlib.org/dlib/june04/harnad/06harnad.html
(36) Op. cit.
(37) Op. cit.
(38) Op. cit.
(39) Archives Ouvertes UNIGE [online]. http://www.unige.ch/biblio/chercher/archiveouverte.html
(40) Op. cit.
(41) Op. cit.
(42) INSPIRE [online]. http://www.projecthepinspire.net/
(43) Brooks, Travis. Giving researchers what they want: SPIRES, high energy physics and subject repositories. Genève, OAI6, juin 2009.
http://indico.cern.ch/getFile.py/access?contribId=20&sessionId=6&resId=1&materialId=slides&confId=48321
(44) Op. cit.
(45) Registry of Open Access Repositories (ROAR) [online]. http://roar.eprints.org/index.php
(46) Dspace [online]. http://www.dspace.org/
(47) Eprints [online]. http://www.eprints.org/
(48) CDS-Ware/Invenio [online]. http://cdsware.cern.ch/invenio/index.html
(49) Jones, Catherine. Institutional repositories: content and culture in an Open Access environment. Oxford : Chandos Publishing, 2007.
(50) François Nawrocki, Le protocole OAI et ses usages en bibliothèque [online], Paris, Ministère de la culture et de la communication, 2005. http://www.culture.gouv.fr/culture/dll/OAI-PMH.htm
(51) RODIN [online]. http://www.e-lib.ch/rodin_f.html
(52) François Nawrocki, op. cit.
(53) OAIster [online]. http://www.oaister.org/
(54) Citebase search [online]. http://www.citebase.org/
(55) OAI Harvester 2 [online]. http://www.oclc.org/research/Software/oai/harvester2.htm
(56) Open archive harvester [online]. http://pkp.sfu.ca/?q=harvester
(57) Sévigny, Martin, Pichot, Malo. SDX et la moisson OAI [online]. Paris, Ministère de la culture et de la communication, 2005. http://www.nongnu.org/sdx/docs/html/doc-sdx2/fr/oai/moissonneur.html
(58) Google scholar [online]. http://scholar.google.com/intl/fr/scholar/about.html
(59) Boutros, Nader. Moissonnage des données : exposée général sur les principes. Carrefour des acteurs de l’édition en archéologie, 1er décembre 2005.
(60) MARC Standards [online]. http://www.loc.gov/marc/
(61) Jones, Catherine. Institutional repositories: content and culture in an Open Access environment. Oxford : Chandos Publishing, 2007.
(62) OAI-ORE [online]. http://www.openarchives.org/ore/
(63) Op. cit.
(64) Feijen, Martin, et al. DRIVER : building the network for accessing digital repositories across Europe [online]. Ariadne. Issue 53, October 2007. http://www.ariadne.ac.uk/issue53/feijen-et-al/
(65) Op. cit.
(66) Op. cit.
(67) A DRIVER's Guide to European Repositories : Five studies of important Digital Repository related issues and good Practices [online], 2007, University of Amsterdam, http://dare.uva.nl/aup/nl/record/260224
(68) Driver support website [online]. http://www.driver-support.eu/index.html
(69) Bosc, Hélène, Archives Ouvertes : quinze ans d’histoire, In Les Archives Ouvertes : enjeux et pratiques. Guide à l’usage des professionnels de l’information [online], C. Aubry, J. Janik (eds.), Paris : ADBS, 2005. pp 27-54 http://cogprints.org/4408/2/Ouvragearchive.htm
Les catalogues des bibliothèques : du web invisible au web social (I)
Ressi — 29 mars 2007
Isabelle de Kaenel, CHUV, Lausanne
Pablo Iriarte, CHUV, Lausanne
Résumé
Les catalogues des bibliothèques sont rentrés dans une phase critique. Les dernières évolutions du web, avec l’entrée en jeu enfin de XML, des nouveaux usages et nouveaux outils, ainsi que le déplacement du centre de gravité qui s’est fortement rapproché des utilisateurs, ouvrent de nouvelles voies et de nouveaux champs d’application pour les catalogues en ligne. Le catalogue n’est plus un outil isolé du monde : dans un mouvement à double sens, il doit s’ouvrir à Internet autant pour tirer parti des services web externes, de plus en plus importants, que pour l’alimenter en contenu et fournir des informations structurées et validées tout en permettant aux utilisateurs d’apporter du contenu et du sens, ainsi que de s’approprier les données du catalogue en lui offrant des nouvelles possibilités de réutilisation à travers les réseaux. Cet article fait un inventaire de ces nouveaux champs d’application possibles et analyse les conditions de base qu’un catalogue devrait remplir pour pouvoir quitter le web invisible et investir pleinement les possibilités actuelles du web social pour devenir enfin un « OpenCatalog ».
Dernière modification:
26/06/2009 Les catalogues des bibliothèques : du web invisible au web social (I)
Introduction
Les catalogues des bibliothèques sont tombés en disgrâce (Markey, 2007). Délaissés, ignorés, critiqués (1) et, dans le pire des cas, ridiculisés(2) , ils nous lancent un dernier cri d’alarme avant de tomber dans le tiroir des outils oubliés. Or, les dernières évolutions du web(3) , avec l’entrée en jeu enfin de XML(4) , des nouveaux usages et nouveaux outils, ainsi que le déplacement du centre de gravité qui s’est fortement rapproché des utilisateurs, ouvrent de nouvelles voies et de nouveaux champs d’application pour les catalogues en ligne. Le temps est donc venu d’aider ces outils de recherche à sortir de cette image négative liée à une complexité, certes inévitable mais jamais compensée par un aspect créatif. Peu armés pour affronter la rapidité des changements de l’ère Internet au cours de ces dix dernières années, les bibliothécaires se sont plus ou moins contentés d’un fonctionnement qui semblait avoir fait ses preuves, avec de promesses d’améliorations, sans vouloir se rendre compte que, tout autour, le monde de l’information numérique expérimentait plusieurs révolutions. Il est bien connu que celui qui n’avance pas…
La tendance est pourtant depuis quelque temps vers la flexibilité et l'ouverture : « Open Source(5) » (ouverture du code source des logiciels), « Open Access(6) » (accès ouvert aux publications et données issues de la recherche scientifique et technique) et « Open Archives Initiative(7) » (ouverture et interopérabilité entre serveurs institutionnels dépositaires de cette production), « OpenURL(8) » (liens ouverts grâce aux métadonnées encodées dans l'URL(9) ), « OpenSearch(10) » (syntaxe des requêtes et format des résultats ouverts), sont des exemples concrets des réalisations qui ont modifié le monde de la documentation numérique. Le but de cet article est donc de faire un petit inventaire de ces nouveaux champs d’application possibles et d’analyser les conditions de base qu’un catalogue devrait remplir (sans devoir tout remettre en question et sans renoncer aux acquis qui font sa spécificité et sa richesse), afin d’investir pleinement les possibilités actuelles et devenir enfin un « OpenCatalog(11) ».
Plusieurs raisons peuvent expliquer ce retard en dépit d’une communauté de bibliothèques bien structurée et dynamique. Les contraintes physiques et matérielles importantes imposées aux catalogues (catalogues papier reliés en volumes, format des cartes pour les cardex ou limitations de mémoire pour les premiers systèmes informatisés) ont probablement joué un rôle majeur (Calhoun, 2006, p. 36). Ainsi, le catalogue a pris l’option d’être un système autoréférentiel, autarcique, dans le sens où il s’autosuffisait, ne citant pratiquement pas de ressources externes en dehors de son propre univers informationnel. Par conséquent, la bibliothèque de type universitaire ou encyclopédique, utilisant ce modèle de catalogue, qui a parfaitement fonctionné et perduré pendant des siècles, complété par d’imposantes bibliographies, des répertoires des périodiques, des services de commandes et de prêt entre bibliothèques, pouvait alors prétendre à une très large exhaustivité.
La combinaison de ces deux aspects a engendré des méthodes de travail : le catalogage, et un produit : le catalogue, qui ont peu évolué en comparaison avec le reste des outils informatiques dans le domaine de l’édition commerciale qui, eux, ont dû faire face et s’adapter plus rapidement aux changements radicaux survenus depuis l’arrivée du web et des NTICs(12). Les bibliothèques ne se sont pas mobilisées pour faire évoluer leurs catalogues face à ces bouleversements. Les évolutions restent très lentes, avec beaucoup d'expérimentations et des réalisations partielles(13).
Si nous remontons dans le temps, nous pouvons constater que les bibliothèques ont été très actives dans la période d’informatisation des catalogues au cours des années 70-80, dont l’un des meilleurs exemples est le système de catalogage et de gestion SIBIL(14) développé à la BCU(15) de Lausanne (Gavin, 1997). Cette étape a apporté le format MARC(16) utilisé actuellement dans la plupart des bibliothèques, malgré une remise en question récurrente. Les bibliothèques ont aussi participé activement au projet du WWW. Par exemple, il est significatif que le premier site web en dehors du CERN(17) fût créé par Louise Addis, bibliothécaire du Stanford Linear Accelerator Center (SLAC)(18), qui devenait ainsi la première bibliothécaire–webmaster de l’histoire(19). Aussi, dès les premiers temps du web, les catalogues des bibliothèques sont devenus accessibles sur la Toile de manière libre et gratuite pour la plus grande satisfaction des utilisateurs du monde entier. Ces OPACs (« Online Public Access Catalog ») ont été aussi l'une des premières réalisations à grande échelle du principe de la séparation entre contenu et mise en page, principe popularisé plus tard pour les systèmes de gestion de contenu (CMS)(20). L’aspect collaboratif du travail de catalogage partagé (chaque notice du catalogue peut en principe être corrigée ou améliorée par n’importe quel autre catalogueur du réseau) était aussi en avant par rapport à son temps. Cependant, ce sont les wikis(21) qui, en donnant cette possibilité d’édition des données à tout un chacun, ont poussé le concept de travail collaboratif à l’extrême et l’ont popularisé dans l’univers du web. De la même façon, le protocole de communication Z39.50(22) , développé et maintenu depuis plus de 20 ans par la Library of Congress(23) , fut l’un des précurseurs d’Internet et, malgré un déclin important dû à son « incompatibilité » avec les technologies web(24) , il est toujours utilisé par un bon nombre de logiciels (bibliographiques ou de pompage des notices) et de plateformes de métarecherche comme le KVK(25).
Lorsque les catalogues informatisés (souvent gérés, comme dans le cas de SIBIL, avec des outils développés localement) ont atteint une taille trop importante, ils ont dû migrer sur des outils devenus propriétaires et développés par des entreprises commerciales internationales. Cette évolution a peut-être tué une bonne partie de l’initiative des bibliothèques qui se sont peu à peu tournées vers d’autres fronts (Open Access et serveurs institutionnels pour lutter contre la crise des prix des périodiques et gérer les publications institutionnelles par exemple) et vers d’autres outils destinés au web et venant compléter le catalogue (portails, CMS, blogs(26) et wikis, podcasts(27) , outils de gestion de liens(28) et de recherche fédérée…), laissant un peu pour compte son outil principal de travail dont on annonce régulièrement plus ou moins la fin ou la désintégration.
Ainsi, la publication web des catalogues reflète encore passablement cet ancien esprit autarcique, et les OPACs restent souvent « déconnectés » du reste des ressources en ligne(29) et sont, encore aujourd’hui, conditionnés par d’anciennes limitations qui n’ont plus de sens dans l’environnement culturel et technologique actuel.
Le catalogue n’est plus un outil isolé du monde. Dans un mouvement à double sens, il doit s’ouvrir au web autant pour tirer parti des services web externes, de plus en plus importants, que pour alimenter le web en contenu et fournir des informations structurées et validées. L’enjeu est de taille : comment rester fidèle à son sens premier (répertorier de manière cohérente les ressources mises à disposition du public et aider à la recherche, découverte, localisation, et gestion des collections) tout en permettant aux utilisateurs d’apporter du contenu et du sens, ainsi que de s’approprier les données du catalogue en lui offrant des nouvelles possibilités de réutilisation à travers le web. Sans se pervertir, le catalogue doit évoluer rapidement pour pouvoir rester dans la course où il a déjà pris un retard considérable.
La conclusion d’un rapport commandé par la Library of Congress en 2006 ne laisse pas de doutes sur le chemin qui reste à parcourir : “The future will require the kind of catalog that is one link in a chain of services enabling users to find, [pick], and obtain the information objects they want. One requirement of this future catalog is thus to ingest and disperse data from and to many systems inside and outside the library. It would be helpful to reconsider what needs to be part of catalog data —and where catalog data needs to be present— to facilitate the user’s process of discovering, requesting, and getting the information they need.” (Calhoun, 2006, p. 38).
Dans les pages suivantes, nous essayerons d’explorer les possibilités de mise en place de ces deux ouvertures souhaitables du catalogue : l'ouverture à l'intégration des nouveaux contenus (internes ou externes) et, d'autre part, l'ouverture à de nouvelles formes d'utilisation de ses propres données par des tiers.
1ère partie : ouverture du catalogue à l'intégration des nouveaux contenus
1. Intégration de l’hypertexte : deux modèles à suivre
Grâce aux logiciels libres et surtout au couple PHP/MySQL(30), l’architecture de la Toile a changé et repose désormais sur un vaste ensemble de bases de données. Le Web est devenu une véritable plateforme de travail, autonome, indépendante des contraintes spatiales ou matérielles liées à des systèmes d’exploitation, des versions des logiciels, etc. De la même façon que la messagerie peut être utilisée depuis n’importe quel ordinateur relié à Internet à l’aide d’un simple navigateur, il sera bientôt possible de travailler avec un minimum de logiciels et clients lourds installés sur les postes, car la plupart des outils seront disponibles en version 100% web(31).
A l’image des développements réalisés pour les autres outils de gestion et de diffusion de l’information, la logique et les mécanismes de fonctionnement du catalogue sont de plus en plus orientés vers le web, au détriment des autres formes de consultation ou de publication (clients professionnels en mode OPAC installés sur les postes de consultation, bulletins de nouvelles acquisitions, bibliographies nationales…). Si cette tendance suit un certain effet de mode, elle correspond aussi à un changement dans le mode de fonctionnement de la société occidentale, de plus en plus relié à Internet à haut débit, et qui dédie de plus en plus de temps à la « consommation » de médias numériques, qui dépassent déjà chacun des autres médias traditionnels (TV, radio, journaux et revues papier, cinéma, etc.)(32) . Cette évolution qui semble pour l’instant irréversible, nous pousse à repenser le catalogue comme un outil fait par et pour le web, intégrant ainsi de manière véritable ce média dont la caractéristique et l’avantage principal réside dans l’immédiateté et dans la navigation à travers les liens hypertexte. Les deux outils principaux de publication web actuels, les blogs et les wikis, sont des bons exemples de la façon dont cette dimension hypertextuelle peut être ajoutée à l’information de manière simple et rapide.
Les blogs
Tout comme la messagerie web, le blog, né directement dans l’univers de l’Internet, a adopté le HTML comme langage principal. Il utilise toutefois un intermédiaire pour aider les non initiés à la saisie : le code HTML est généré et caché automatiquement par un outil d’édition de type WYSIWYG(33) . Pour les courriels, le code HTML est encapsulé dans le corps du message. Dans les blogs, il est enregistré dans la base de données et re-proposé à nouveau tel quel sur le web(34) :
Les wikis
Dans les wikis, le code HTML est simplement produit à la volée(35) au moment de l’affichage de la page. Les balises HTML sont créées dynamiquement en fonction de la syntaxe propre au wiki. On assiste alors à la transformation d’une syntaxe arbitraire et plus ou moins proche du HTML vers la syntaxe HTML. Par exemple :
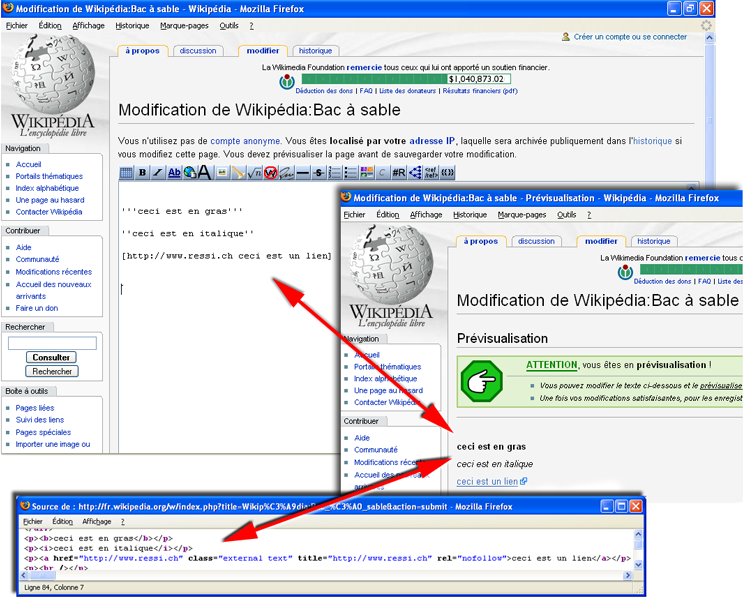
La syntaxe wiki étant plus facile à retenir que les balises HTML, les textes peuvent être alors écrits rapidement et on peut utiliser l’aide des boutons de l’éditeur qui effectuent les mêmes fonctions que les éditeurs WYSIWYG, mais sans cacher le code et sans faire la transformation en HTML. Seul le texte avec la syntaxe propre au wiki est alors enregistré dans la base de données et non pas du code HTML.
Cette intégration du code au message, en HTML ou selon une syntaxe propre, permet d’apporter les améliorations suivantes avec peu d’efforts :
- Disposer du véritable hypertexte, avec des liens internes ou externes intégrés au message sans devoir à chaque fois afficher l’URL en clair.
- Ajouter une mise en page simple à l’intérieur du texte (courriel, corps d’un billet sur un blog, page entière d’un wiki) : gras, italique, souligné, listes numérotées ou à puces, tableaux, ajout d’images.
Extraire certaines parties (titres) dans le cas du wiki, pour créer des tables des matières à la volée.
Ces applications peuvent être utiles aussi aux catalogues dans les zones destinées aux notes, commentaires, résumés ou tables des matières, qui souffrent aujourd’hui du manque de mise en page et d’hypertexte :
 Source : http://opac.rero.ch/get_bib_record.cgi?rero_id=R003636602
Source : http://opac.rero.ch/get_bib_record.cgi?rero_id=R003636602  Source : http://www.saphirdoc.ch/permalien.htm?saphirid=41062
Source : http://www.saphirdoc.ch/permalien.htm?saphirid=41062
Cependant, avant d’appliquer l’un ou l’autre modèle au catalogue, il faut évaluer en profondeur les utilisations pour lesquelles cette introduction des balises ou des syntaxes pourrait être nuisible (impression des catalogues sur papier, maintenance à long terme des tables de conversion entre la syntaxe ou les balises et la mise en page…).
Malgré l’absence encore du véritable hypertexte dans les catalogues, il faut noter que le format MARC prévoit la zone 856(36) pour les URLs en admettant un sous-champ pour ajouter un commentaire qui permet de le qualifier ou de lui donner un contexte sommaire. Ces URLs sont alors transformés à la volée en hyperliens par le système au moment de l’affichage qui, trop souvent encore, se fait uniquement au niveau de la notice complète(37).
La présence des URLs dans la notice (champ 856 mais aussi dans le champ du titre, des notes, du résumé…) est un pas important, mais il n’est pas tout. Pour être vraiment utiles à l’internaute, ces URLs doivent impérativement être transformés en lien hypertexte dans la page HTML de l’OPAC, faute de quoi ils seront affichés comme du simple texte qui ne peut pas « être cliqué », et l’utilisateur doit faire recours au copier/coller pour placer cet URL dans l’adresse du navigateur. Pour éviter cela, les logiciels de gestion tentent systématiquement d’effectuer cette transformation URL -> hyperlien en scrutant chaque champ au moment de l’affichage, à la recherche d’un URL. Certains le font mieux que d’autres, car si en principe il est simple pour une machine de trouver le début et la fin d’un URL bien formé au milieu d’une chaîne de caractères (commence par « http:// » et fini par un espace), il est plus complexe de tester toutes les autres variantes possibles (l’URL ne commence pas par « http:// » mais directement par « www. » ; ou ne finit pas par un espace mais par un point, une virgule ou la fin d’une parenthèse…). Ce problème, récurrent aussi dans le cas des courriels qui portent des URLs dans le corps du message, est de difficile solution sans l’utilisation d’un codage à priori comme ceux utilisés par les blogs et les wikis.
Dans le cas du catalogue de RERO(38), le système convertit automatiquement à la volée chaque champ contenant « http:// » (856 mais aussi les champs de titre et des notes) en lien hypertexte, au moment de l’affichage sur l’OPAC. Cependant cette conversion se limite au premier URL trouvé dans le champ(39), et elle ne se fait pas pour les URLs qui ne commencent pas par « http:// » mais par exemple « www.»(40) , ce qui limite l’utilisation des liens dans un même champ. Dans le réseau SAPHIR(41), étant donné que le nombre des URLs est plus important à l’intérieur d’un seul champ comme le résumé, la transformation a été étendue à tout URL contenu dans ce champ, et aussi pour ceux qui commencent par « www. ».
Si cette génération à la volée des hyperliens est possible grâce aux caractéristiques reconnaissables des URLs, pour les autres points utiles du codage à priori (mise en page, gras, italique, listes…) il n’y a pas de solution automatique à posteriori. Par conséquent, pour améliorer la mise en page et faciliter la lecture pour les longs résumés correspondant à certains dossiers thématiques, le catalogue SAPHIR a adopté le modèle du wiki de façon encore informelle comme nous le montre la copie d’écran ci-dessous.
 Source : http://www.saphirdoc.ch/permalien.htm?saphirid=45776
Source : http://www.saphirdoc.ch/permalien.htm?saphirid=45776
De son coté, le logiciel Alexandrie(42), SIGB utilisé par ce réseau, a aussi introduit une possibilité de mise en page dans les résumés des documents, en suivant le modèle du blog : trois boutons permettent d’ajouter les balises HTML pour appliquer au texte les styles gras, italique et souligné. Deux autres boutons permettent d’ajouter des liens hypertexte sur des pages externes ou des documents internes à la base, et encore deux pour ajouter des images du serveur :
Dans le champ de logiciels de gestion bibliographiques, le système RefWorks(43), qui fonctionne entièrement sur le web, a aussi introduit un éditeur WYSIWYG pour ajouter certains styles (gras, italique, souligné, exposant ou indice) aux champs titre, notes et commentaire :
Le code HTML introduit dans la base est correctement supprimé dans tout format d’export sauf pour les bibliographies de type HTML ou RTF, dans lesquelles l’enrichissement graphique est utile et peut être conservé.
2. L'enrichissement des catalogues
Les systèmes automatisés mis au point pour la recherche d'informations textuelles sur le web, moteurs de recherche, annuaires, méta moteurs, rivalisent en performance et en innovations et montrent le chemin en matière de fonctionnalités et d'enrichissements possibles pour les catalogues. Plusieurs niveaux sont concernés : le graphisme, l'ergonomie de l'affichage, l’intégration d’informations complémentaires (résumés, commentaires, tables des matières), l'aide à la recherche, les possibilités de tri des résultats, etc.
Images de couverture, résumés et tables des matières des livres
Les catalogues de bibliothèques sont des mines d'information librement disponibles. Mais les données sont très dépouillées et certaines informations importantes manquent encore terriblement à l'appel, comme les tables des matières et les résumés.
Depuis plusieurs années, les moteurs de recherche et les sites commerciaux comme Amazon(44) ont montré une très grande inventivité en enrichissant de plus en plus leur contenu qui, en devenant plus étendu, attire de plus en plus d'utilisateurs qui à leur tour le complètent, dans un phénomène de cercle vertueux qui s’auto-génère une fois dépassée une certaine masse critique. Des fournisseurs de services sont alors apparus permettant aux bibliothèques de s'offrir ce que d’autres avaient réussi à intégrer : tables des matières, résumés et images de couverture sont maintenant vendus ou loués par des sociétés comme Electre(45) ou Syndetics(46). Il est ainsi possible de les ajouter au catalogue à la demande (au moment de la visualisation de la notice complète par exemple) à partir de l'ISBN(47) du document.
Avec une autre logique commerciale visant plutôt à étendre son rayon d’influence et à promouvoir son site grâce aux liens hypertexte, les services web mis en place par Amazon(48) , permettent depuis l’année 2002 d'utiliser gratuitement le contenu en provenance de sa propre base (images des couvertures, revues des lecteurs, prix, etc.) sur n'importe quel autre site Internet qui respecte les conditions légales d’utilisation. Ainsi plusieurs catalogues utilisent déjà les services web d’Amazon pour enrichir les pages du catalogue : Dreiländerkatalog(49) , Lamson Library(50), etc.
Le catalogue SAPHIR, qui a toujours repris dans ses notices des résumés et éléments de tables des matières, utilise maintenant aussi ces services web pour afficher l’image de couverture sur la page de la notice complète des livres. En utilisant de façon contextuelle l’ISBN et le code de la langue du document introduits au catalogage, la technique AJAX(51) permet d’appeler les services web d’Amazon.fr, Amazon.de ou Amazon.com du côté client (c’est le navigateur qui fait le travail) sans aucune charge supplémentaire du coté serveur(52) :
 Source : http://www.saphirdoc.ch/permalien.htm?saphirid=44787
Source : http://www.saphirdoc.ch/permalien.htm?saphirid=44787
Si l’affichage à la demande dans l'OPAC de contenus externes est intéressant et relativement facile à mettre en place, il a le désavantage de ne pas enrichir le contenu de la base de données. Si les tables des matières et les résumés ne sont pas indexés comme les autres champs, il ne sont pas recherchables en même temps que les données du catalogue. D'autres services permettent de remédier à cet inconvénient en permettant d'importer dans la base de données des résumés et tables des matières qui sont alors vendus, et non plus simplement accessibles sous licence comme dans le cas précédent.
Echanges des notices entre catalogues
Avec l’utilisation des AACR2(53) comme règles communes de catalogage et, grâce à des outils simples de pompage(54), intégrés au système de gestion et qui utilisent le protocole Z39.50 mais aussi des techniques d’extraction à partir de pages web, les bibliothèques ont commencé plus que jamais à réutiliser des notices en provenance d’autres catalogues.
En dépit de la réticence de certains catalogueurs qui voient là un risque de perte de créativité (Gavin, 2006), cet usage est devenu très courant et soutenu(55) par la plupart des bibliothèques des réseaux suisses (RERO, IDS(56), etc.).
Importation et syndication des notices d’articles
L’explosion de la production scientifique a poussé depuis quelques années les producteurs de bases de données bibliographiques à développer des partenariats forts avec les éditeurs. Par exemple, la NLM(57), qui produit une base de la taille et de l’importance de PubMed(58), a cessé en 2006 d’introduire manuellement les métadonnées dans sa base, grâce au développement à grande échelle de l’importation des notices d’articles en format XML fournis par les éditeurs(59). Cette technique d’importation des flux XML permet à PubMed de diffuser très rapidement l’information reçue, car les contrôles et les améliorations successives des notices (corrections, indexation…) se font progressivement sans entraver la diffusion des références, qui gardent le même identificateur quel que soit le stade du traitement dans le système. Lorsque les éditeurs ne sont pas à même de fournir les notices dans ce format XML, un système de numérisation puis d’OCR(60) est utilisé pour importer les références avec les résumés dans la base.
Ces partenariats ont toujours fait défaut dans le domaine des bibliothèques, où la relation avec les éditeurs n’est pas de toute évidence, car l’un des rôles subversifs de la bibliothèque provient du fait qu’elle donne accès, à moindre coût, à des contenus soumis au droit d’auteur (Le Moal, 2004) et surtout aux lois du commerce. Du moment où l’hypertexte entre en jeu, les bibliothèques ont un argument pour la négociation, car elles peuvent rendre service aux éditeurs en ajoutant des liens vers leurs plateformes de commerce électronique (ou via des librairies en ligne), ce qui pourrait permettre de développer des collaborations plus importantes.
Une autre possibilité à explorer pour les bases qui ont des ressources plus modestes est d’utiliser les flux RSS(61) offerts par les éditeurs comme source pour l’importation des données dans le catalogue. Le projet TOCRRoS(62) va dans ce sens, en permettant d’ajouter automatiquement et périodiquement les articles publiés par les revues pour lesquelles la bibliothèque dispose d’un abonnement en cours. Le logiciel de gestion Alexandrie permet depuis la version 6 d’importer automatiquement des contenus en provenance des flux RSS externes.
Sans arriver à l’intégration de ces informations dans le catalogue lui-même, une dernière possibilité consiste à afficher le contenu du dernier numéro d’un périodique proposant un flux RSS, au moment de l’affichage de la notice complète dans l’OPAC (Iriarte, 2006). Cette possibilité nécessite l’enregistrement préalable de l’adresse du flux RSS dans le catalogue, pour ensuite pouvoir utiliser de façon contextuelle des services de conversion RSS -> Javascript offerts par différents sites(63).
Importation des notices en provenance des archives ouvertes : utilisation du protocole OAI-PMH(64)
De la même façon qu’aujourd’hui nous pouvons importer dans le catalogue des informations en provenance des flux XML (en format ONIX(65), RSS ou autre) proposés par les éditeurs, il serait possible d’utiliser le protocole OAI-PMH pour ajouter des références en provenance des archives ouvertes ou des dépôts institutionnels comme e-prints(66), arXiv(67), HAL(68), RERO DOC(69), Infoscience(70), etc.
Cette possibilité de moissonner des serveurs de documents à partir du catalogue ne semble pas, à notre connaissance, avoir été exploitée dans les bibliothèques. C’est plutôt dans le sens inverse, c’est-à-dire l’intégration des notices du catalogue dans une base externe, que nous pouvons trouver des réalisations, comme dans les cas des notices de l’OPAC intégrées au serveur institutionnel du CERN (CERN Document Server(71)) ou dans la plateforme Infoscience de l’EPFL (72).
Cette intégration des références provenant de sources hétérogènes dans une couche supplémentaire, permet une plus grande souplesse : il n’y a pas le risque de toucher aux notices qui servent en même temps à la gestion, et éviter d’appliquer aux données importées les mêmes critères de qualité et de sécurité que pour les notices du catalogue. La base de données située dans cette couche (par exemple WorldCat(73), Dreiländerkatalog, TEL(74), etc.) peut alors proposer de nouveaux services et peut être ouverte aux contenus générés par les utilisateurs, dans la ligne des outils sociaux ou web 2.0(75). Dans ce sens il y a un nouveau marché qui se développe, avec des nouveaux outils orientés web 2.0 qui sont proposés aux bibliothèques comme RLG(76), Primo(77), etc.
Texte intégral
L’année 2006 a vu le développement de la campagne de numérisation de livres à grande échelle, « Google Books(78) » , entreprise par la société Google en 2004 en collaboration avec deux groupes de partenaires : d’un côté certains éditeurs et de l’autre un groupe restreint de bibliothèques(79) . D’abord appelé « Google Print », le nom du programme est devenu « Google Books » en 2006, pour palier entre autres aux tensions entre Google et certains éditeurs.
Sans complexe, Google Books affiche l’ambition « de travailler avec des éditeurs et des bibliothèques pour créer un catalogue virtuel complet de tous les livres et dans toutes les langues, dans lequel les internautes pourront effectuer des recherches. »
Si ce projet reste encore très controversé (Salaün, 2005), il a eu le mérite de réveiller la communauté des bibliothèques qui, avec le Président de la Bibliothèque Nationale de France M. Jeanneney à la tête, a réagi de façon active en donnant une impulsion plus forte au projet de la bibliothèque numérique européenne(80) . D’autres bibliothèques ont aussi annoncé des projets de numérisation à large échelle. La British Library(81) a conclu un partenariat avec la société Microsoft(82). De leur côté Yahoo! et la fondation Internet Archive(83) ont aussi annoncé le début de sa propre campagne « Open Content Alliance(84) » . La Library of Congress est, quant à elle, en discussion avec l’UNESCO pour amorcer le lancement d’une Bibliothèque numérique mondiale(85).
Le projet de Google a aussi commencé à porter ses fruits et une grande quantité d’information contenue dans ces bibliothèques est devenue accessible, même si la qualité de numérisation peut être jugée décevante(86). A l’heure actuelle, 10'000 éditeurs et 13 bibliothèques font partie du projet dans son ensemble et, selon les chiffres donnés par Google, le nombre des livres dans son index avoisine le million(87).
Selon le contrat que les bibliothèques participant au volet « Google Books for Libraries » ont signé avec la société Google(88), les fichiers issus de la numérisation ne pourront pas être diffusés par la bibliothèque sans l’accord de Google, ce qui limite leur utilisation dans le catalogue. Malgré cette entrave commerciale, la bibliothèque de l’Université de Michigan(89) propose de visualiser le document numérisé(90)en format image, texte ou pdf dans sa propre plateforme digitale(91) par le biais d’un lien figurant dans la notice complète du catalogue, parallèlement au lien sur le même document dans la plateforme de Google :
 Source : http://mirlyn.lib.umich.edu/F?func=find-b&find_code=MDN&local_base=MIU01_PUB&request=39015014807104
Source : http://mirlyn.lib.umich.edu/F?func=find-b&find_code=MDN&local_base=MIU01_PUB&request=39015014807104
Selon ce même principe, les bibliothèques établissent aujourd’hui de plus en plus des liens vers le texte intégral des documents situés sur des serveurs externes au catalogue : articles de périodiques électroniques (en open access ou payants), documents disponibles en libre accès dans les bibliothèques numériques nationales ou internationales (Gallica(92), Projet Gütenberg(93), Biblioteca Virtual Cervantes(94) …), e-prints et thèses des archives ouvertes, etc. Cependant, dans la plupart des cas, ce lien est créé uniquement manuellement (avec les risques que cela comporte, comme la faible pérennité des liens quand on sort du cadre du DOI(95)) et facultativement au moment de la création d’une nouvelle notice et non pas de façon rétrospective. Vu le rythme des campagnes de numérisation en cours, cela signifie que de plus en plus de notices dans nos catalogues resteront sans lien hypertexte avec la version électronique disponible pourtant quelque part sur Internet. Seul un outil performant de gestion des liens peut servir de solution à ce problème, comme nous l’évoquerons dans la deuxième partie, seulement. Après les difficultés rencontrées au moment vouloir intégrer les revues en format électronique au catalogue, nous risquons de nouveau de voir s’agrandir le fossé entre catalogue et ressources en texte intégral en ligne.
Concernant la recherche sur le texte intégral, étant donné que le stockage des documents numériques se situe généralement sur des serveurs déconnectés du catalogue, la recherche simultanée dans les métadonnées et dans le texte intégral des documents ne peut pas être proposée dans l’OPAC, sauf si c’est le catalogue lui-même qui rejoint cette plateforme des documents numériques, comme nous l’avons vu plus haut dans l’exemple du CERN et de l’EPFL.
Dans le cas de l’Université de Michigan, de même que dans le service « Search Inside » d’Amazon(96), la recherche dans le texte intégral ne peut se réaliser que sur un seul document à la fois. Il faut alors passer par Google Books pour pouvoir effectuer une recherche sur l’ensemble du texte intégral de la collection en même temps que sur les métadonnées fournies par la bibliothèque.
Liens profonds : le rôle des identificateurs
Comme nous venons de constater plus haut, les catalogues de bibliothèques introduisent de plus en plus de liens profonds pointant sur le texte intégral du document répertorié ou sur la notice bibliographique résidant sur une base de données externe comme PubMed, dans le but de donner à l’utilisateur le plus grand nombre d’informations disponibles et de source sure, concernant le document catalogué : résumé et liens offerts par PubMed, texte intégral ou résumé offert par l’éditeur de la revue ou sur une plateforme Open Access, nombre de fois que l’article est cité, offerts par une base de données comme Google Scholar, etc.
L’utilisation de ces liens profonds pose de nouveaux problèmes et de nouveaux défis aux catalogues, qui devraient en plus les maintenir à jour à l’aide des méthodes plus ou moins automatisés. Dans cette recherche de stabilité, seulement les liens profonds basés sur des identificateurs pérennes comme le DOI(97) , le PMID(98) ou un identificateur OAI-PMH(99) , ont de garanties de perdurer dans le temps. Il est donc évident qu’il faut utiliser ces identificateurs de façon préférentielle pour établir des liens dans le catalogue, et que nous devons les prendre en charge avec le même soin que nous appliquons à l’ISBN : dans un champ à part bien identifié et avec une syntaxe cohérente et normalisée de type URN(100) . Par exemple il serait préférable d’enregistrer le DOI ou le PMID dans un champ ad hoc et de générer l’URL à la demande, au lieu d’enregistrer cette adresse directement dans le champ dédié aux liens Internet :
- doi:10.1000/182 -> http://dx.doi.org/10.1000/182
- pmid:1234 -> http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?cmd=retrieve&db=pubmed&list_uids=1234
La raison de cette préférence réside dans le fait qu’il est possible d’utiliser cet identificateur à d’autres fins que celui de construire un URL, comme par exemple l’utiliser dans un OpenURL destiné à trouver d’autres services associés au document ou bien dans un format d’export destiné à des logiciels bibliographiques. Bien qu’il soit toujours possible d’extraire automatiquement l’identificateur à partir de l’URL, c’est bien le cas contraire qui est plus aisé et canonique, d’autant plus que les URLs utilisés par CrossRef(101) et par PubMed, bien que garantis pour un bon nombre d’années, ne sont pas des liens pérennes et peuvent varier dans le futur (on peut imaginer par exemple un nouveau protocole qui remplacerait le http, etc.).
Dans la même optique, le catalogage des notices d’articles (aussi appelées notices analytiques) devraient incorporer autant que possible ces identificateurs pérennes ainsi que l’ISSN(102), seul élément d’identification fiable de la revue à laquelle ils appartiennent. Si ces informations, ainsi que la date de publication, le numéro du périodique, du volume, la page de début et celle de fin de l’article étaient codées de façon structurée dans ce type de notices, ce qui est loin d’être le cas aujourd’hui dans la plupart de catalogues de bibliothèques(103), l’utilisation d’un outil de gestion de liens serait beaucoup plus efficace et permettrait une plus grande précision à l’heure d’identifier l’existence du texte intégral ou de proposer des services associés via un OpenURL en provenance de l’OPAC.
Contenu généré par les utilisateurs
Suivant l’exemple des sites commerciaux comme Amazon et des outils sociaux de plus en plus nombreux (Wikio(104), del.icio.us(105), Flickr(106), Connotea(107) …), il est grand temps que les lecteurs puissent déposer des annotations, des tags ou des commentaires par rapport aux livres disponibles dans les catalogues des bibliothèques et, pourquoi pas, les laisser intervenir sur l'indexation des documents avec des tags, sans utiliser les ressources du SIGB, mais en offrant des applications s’appuyant sur des services web comme le fait par exemple HubMed(108).
Cette possibilité de commenter ou tagger l’information est déjà implémentée dans certains catalogues ou archives ouvertes : WorldCat, Lamson Library(109), Dreiländerkatalog, CERN Document Server… Cependant, elle est absent de la plupart des OPACs classiques gérés par un SIGB.
Utilisation des données de gestion
En s’inspirant d’Amazon, les catalogues ont commencé à exploiter les données générées par l’activité des utilisateurs pour effectuer des suggestions de lecture :
- à partir des données anonymisées en provenance des emprunts, comme le fait la Ann Arbor District Library (AADL)(110) : « Les utilisateurs qui ont emprunté ce document ont aussi emprunté…»
- à partir des données en provenance de la consultation web, comme le fait RERO DOC : « Les utilisateurs qui ont vu cette page ont aussi vu… »
La possibilité d’exploiter de façon dynamique et pondérée les données du document en cours de visualisation, peut aussi conduire à des suggestions de type « Related articles » de PubMed ou « Related Books » de WorldCat.
Autres services web bibliographiques
En dehors des services web d’Amazon, il y a malheureusement un choix très restreint pour le moment :
- XISBN(111) (OCLC) : ISBNs en relation avec l’ISBN envoyé (utilisé par le Dreiländerkatalog)
- CrossRef(112) : Métadonnées à partir d’un DOI et vice-versa
- PubMed(113) : une des applications les plus avancées dans ce domaine, il met à disposition de la communauté plusieurs services web : métadonnées à partir d’un ou plusieurs PMIDs ou vice-versa, ainsi que les articles liés ou les informations des bases de données connexes (génétique, moléculaire, etc.) à partir de l’identificateur d’une ou de plusieurs références. Il offre aussi par service web la correction orthographique des termes de recherche.
D’autres services web généralistes pourraient être aussi exploités, comme par exemple l’affichage des localisations géographiques des bibliothèques d’un réseau qui possèdent un document en particulier, en utilisant l’API de Google Maps(114). Un service web de ce type pourrait aussi être utilisé pour afficher l’emplacement précis dans lequel une image ou un film du catalogue a été prise. Ceci nécessiterait l’ajout des métadonnées géographiques (ou « geotagging »(115) ) au catalogage des images fixes ou animées, comme cela se fait déjà sur des plateformes de partage des photos comme Flickr(116).
Conclusion
Après cette énumération de services, d’outils et d’informations externes au catalogue dignes d’être incorporés dans cet outil, la question de la surcharge informationnelle pourrait être posée. Toutes ces options ne risquent-elles pas d’engendrer confusion et désorientation ? La force du catalogue résiderait-elle alors dans son dépouillement ? Nous pouvons en douter. Les catalogues offrent actuellement peu de possibilités pour que les utilisateurs, y compris les professionnels de l’information eux-mêmes, s’approprient cet outil, ce qui est indispensable pour qu’il puisse trouver une place importante dans l’ensemble du paysage informationnel du web, devenu aujourd’hui notre plateforme de travail.
Certes, le risque est grand de se retrouver noyé sous une masse impressionnante d'applications et d'informations. Mais en offrant des données riches, bien structurées et ouvertes à l’extérieur, ainsi qu’une interface ergonomique, simple d’utilisation et d’appropriation par les usagers, le catalogue peut prouver à nouveau son utilité et redevenir ainsi un élément fort dans l’univers d’Internet. Pour y arriver, nous avons parcouru quelques pistes qui vont dans le sens d’une maîtrise des technologies du web par les bibliothèques et dans l’intégration d’éléments externes au catalogue. L’autre aspect clé de la question, la face opposée de la même monnaie, réside dans l’ouverture du catalogue à de nouvelles formes d'utilisation de ses propres données par des tiers, dans un changement de mentalité qui considérerait « le web » comme un utilisateur à part entière.
Dans la deuxième partie de cet article, nous traiterons donc les aspects suivants liés à cette ouverture du catalogue vers la réutilisation de ses données :
- Citabilité et Permaliens
- OpenURL et COINS
- RSS
- Sitemaps
- Indexation par des moteurs de recherche
- Export XML pour Google Scholar
- Open search et SRU/SRW
- Services web et APIs
Notes
(1) Quelques exemples sortis de la « biblioblogsphère » : Burn the catalog http://www.swarthmore.edu/SocSci/tburke1/perma12004.html ; Disintegration, disenchantment, distrust, and development http://www.polarislibrary.com/forums/blogs/techtidbits/archive/2006/12/0...
(2) If amazon sucked like our old opac http://library2.csusm.edu/amazon/index.htm
(3) Caractérisés par le phénomène connu sous le nom du « web 2.0 »
(4) eXtensible Markup Language http://www.w3.org/XML/
(5) http://www.opensource.org
(6) http://openaccess.inist.fr
(7) http://www.openarchives.org
(8) http://openurl.info/registry
(9) Uniform Resource Locator http://www.w3.org/Addressing/URL/Overview.html
(11) http://www.opensearch.org
(12) Si ce terme est complètement nouveau, le concept ne l’est pas. Voir par exemple le projet « eXtensible Catalog (XC) » de l’Université de Rochester à New-York http://www.extensiblecatalog.info/ et http://www.rochester.edu/news/show.php?id=2518 Nouvelles Technologies de l’Information et la Communication
(13) Pour suivre l’évolution et les nouveaux OPACs innovateurs, vous pouvez utiliser la liste de diffusion « NGC4Lib - Next Generation Catalogs for Libraries » et ses archives : http://dewey.library.nd.edu/mailing-lists/ngc4lib/
(14) SIBIL était à l’origine l’acronyme de « Système intégré pour les bibliothèques universitaires de Lausanne » (Gavin, 1997)
(15) http://www.unil.ch/bcu
(16) MAchine-Readable Cataloging http://www.loc.gov/marc/
(17) Conseil Européen pour la Recherche Nucléaire. Aujourd'hui le nom CERN désigne l'Organisation européenne pour la Recherche nucléaire http://www.cern.ch
(18) http://www.slac.stanford.edu
(19) http://news-service.stanford.edu/news/2001/april11/addis-411.html
(20) Content Management System
(21) Outil de publication web instantanée et ouvert aux modifications des utilisateurs. Il est utilisé par exemple pour le projet Wikipédia http://fr.wikipedia.org/wiki/Wiki
(22) Devenue norme ISO 23950 en 1998, ce protocole s’appelait dans sa version d’origine « Information Retrieval (Z39.50); Application Service Definition and Protocol Specification, ANSI/NISO Z39.50-1995 ». Il s’agit d’un protocole antérieur au web et qui spécifie des structures de données et les règles d’échange qui permettent à une machine client (nommé « origin ») de chercher des données dans un serveur (nommé « target ») et de d’obtenir les entrées résultant de cette recherche http://www.loc.gov/z3950/agency/resources/
(23) http://www.loc.gov
(24) La norme Z39.50, malheureusement très peu utilisée en dehors du domaine des bibliothèques, n’est pas exploitable à travers le protocole HTTP et il faut donc un logiciel spécifique pour l’utiliser. L’apparition de XML et les services web associés qui se développent un peu partout, sont en train de précipiter son déclin.
(25) Karlsruher Virtuelle Katalog http://www.ubka.uni-karlsruhe.de/kvk.html
(26) Outil de publication web personnelle appelé aussi weblog, carnet web, joueb… Pour plus d'information voir l’article de Wikipédia : http://fr.wikipedia.org/wiki/Blog
(27) Contraction de « iPod » et de « broadcasting ». Forme de flux RSS auquel on ajoute des fichiers sonores qui sont alors disponibles directement à partir du lecteur RSS ou téléchargeables automatiquement dans un baladeur numérique. Voir aussi la définition de Wikipédia : http://fr.wikipedia.org/wiki/Podcasting
(28) Aussi appelés « Link resolvers », ces outils permettent de générer dynamiquement une liste de liens cibles à partir des métadonnées de la source : lien vers le texte intégral ou vers le formulaire de commande, recherches par ISSN, auteur, titre ou descripteur dans les catalogues, etc. En Suisse l’outil le plus utilisé reste SFX http://www.exlibrisgroup.com/sfx.htm commercialisé par la société Ex.libris qui possède aussi le SIGB Aleph utilisé par le réseau suisse alémanique IDS.
(29) Les catalogues donnent pour le moment très peu des liens externes. Par exemple pour le catalogue collectif du réseau romand (RERO) seulement le 1% de notices portent un URL (environ 30.000 sur 3 millions)
(30) PHP est l'acronyme récursif de « PHP Hypertext Preprocessor ». PHP est un langage de script qui est très utilisé pour créer des sites web dynamiques. Site officiel : http://www.php.net. MySQL est un logiciel libre de gestion de bases de données de type SQL (Structured Query Language). Site officiel : http://www.mysql.com
(31) « Google Docs & Spreadsheets » http://docs.google.com et « Think free » http://www.thinkfree.com sont déjà des bons exemples de cette évolution. Les SIGB open source disponibles sur le marché (PMB http://www.sigb.net, Koha http://www.koha.org, OpenBiblio http://openbiblio.sourceforge.net…) sont pour la plupart déjà des systèmes « full-web » car, autant la gestion, le paramétrage, le catalogage que la consultation se font à travers le navigateur sans utiliser des clients lourds comme dans les systèmes propriétaires actuels, où seules la consultation et certaines options liées à la gestion des prêts et des lecteurs (inscriptions, réservations, prolongations, PEB, etc.) passent à travers le web
(32) Voir les statistiques publiées par l’OFS « Utilisation d'Internet dans les ménages en Suisse : Résultats de l'enquête 2004 et indicateurs » et qui montrent l’augmentation très forte de l’utilisation d’internet au sein de la population suisse ces dernières années : http://www.bfs.admin.ch/bfs/portal/fr/index/themen/kultur__medien__zeitv.... Ces chiffres suivent la tendance générale annoncée par l’UIT dans son rapport « digital.life » http://www.itu.int/digitalife et qui donnent, pour une personne entre 18 et 54 ans, une consommation moyenne hebdomadaire de médias numériques de 16 heures, tandis que de 13 heures pour la TV, 8 pour la radio, 4 pour les journaux et quotidiens papier et 1 pour le cinéma
(33) WYSIWYG est l’acronyme de la locution anglaise « What You See Is What You Get ». Les interfaces de ce type sont utilisées dans les logiciels de mise en page et surtout dans les plateformes de blogging comme outil pour pouvoir écrire facilement pour le web sans connaître le langage HTML
(34) Le fait de copier/coller du contenu en provenance d'une page web dans le corps d'un billet d'un blog peut poser des problèmes d'affichage car l'éditeur WYSIWYG cache le code HTML. Ce dernier peut pourtant contenir des balises pouvant interférer avec le code de la page du blog
(35) Généré automatiquement au moment de l’affichage
(36) http://www.rero.ch/page.php?section=zone&pageid=856
(37) C’est encore le cas des catalogues du réseau IDS et ce fut aussi le cas pendant longtemps pour les catalogues du réseau romand. Cependant, RERO a changé son approche et dans la nouvelle version de son OPAC http://opac.rero.ch, introduite depuis le 8 janvier 2007, les liens de la zone 856 sont désormais affichés déjà au niveau de la liste de résultats
(38) RERO est l’acronyme de « REseau Romand », et désigne le réseau des bibliothèques de Suisse occidentale majoritairement de langue française http://www.rero.ch
(39) Par exemple http://opac.rero.ch/get_bib_record.cgi?rero_id=R277678560
(40) Par exemple http://opac.rero.ch/get_bib_record.cgi?rero_id=R003636602
(41) SAPHIR (Swiss Automated Public Health Information Ressources) http://www.saphirdoc.ch. Base documentaire suisse spécialisé en santé publique et dont le CDSP est le responsable.
(42) http://www.gbconcept.com/pro_alexandrie.html
(43) http://www.refworks.com
(44) http://www.amazon.com
(45) http://www.electre.com
(46) http://www.syndetics.com
(47) « International Standard Book Number ». l’ISBN est un identificateur international, défini par la norme ISO 2108, et qui sert à identifier sans ambiguïté chaque livre. Existant depuis 1972, les ISBN son attribués et gérés par un réseau d’agences reparties dans 166 pays, avec une centrale à Londres. En suisse romande, c’était l'agence francophone pour la numérotation internationale du livre (AFNIL) qui gérait les numéros ISBN jusqu’à 1994. Depuis cette date, la gestion est assuré par la « Schweizer Buchhändler- und Verleger-Verband SBVV » ttp://www.swissbooks.ch/prestations/isbn/uebersicht.shtm. D’abord constitué par 10 chiffres significatives, il a passé à 13 depuis janvier 2007 devenant ainsi compatible avec les codes-barre de la norme EAN 13 http://isbn-international.org
(48) http://www.amazon.com/AWS-home-page-Money/b/ref=sc_iw_l_0/103-1555994-97...
(49) http://suchen.hbz-nrw.de/dreilaender/
(50) Projet expérimental d’OPAC http://www.plymouth.edu/library/opac/ basé sur la plateforme de blogging WordPress http://wordpress.org
(51) Asynchronous JavaScript And XML. C’est un ensemble de techniques qui permet à une page web d’échanger des informations externes sans devoir être actualisée. Voir l’article fondateur de Jesse James Garrett « Ajax: A New Approach to Web Applications » http://www.adaptivepath.com/publications/essays/archives/000385.php
(52) La technique est expliquée en détail sur le blog de la BiUM http://www.bium.ch/blog/?p=106
(53) Anglo-American Cataloguing Rules, 2nd Edition http://www.aacr2.org
(54) Comme par exemple « EZPump (EZP) » http://www.ngscan.com/easypump/index.htm, logiciel de pompage des notices bibliographiques avec client Z39.50, développé par un bibliothécaire de la Médiathèque Valais et utilisé par les bibliothèques de RERO
(55) Voir La Lettre de RERO, 2006-4 http://www.rero.ch/pdfview.php?section=lalettre&filename=LaLettre2006_04...
(56) IDS est l’acronyme de « Informationsverbund Deutschschweiz » et désigne le réseau des bibliothèques de Suisse orientale, majoritairement de langue allemande http://www.informationsverbund.ch
(57) http://www.nlm.nih.gov
(58) http://www.pubmed.org
(59) http://www.nlm.nih.gov/bsd/bsd_key.html
(60) Optical Character Recognition
(61) RSS est utilisé comme acronyme de « Really Simple Syndication », « Rich Site Summary », « RDF Site Summary » ou une autre variante de ces termes. Pour plus de détails, voir la page explicative faite par l'ADBS : http://www.adbs.fr/site/repertoires/outils/rss.php
(62) TOCRoSS http://www.jisc.ac.uk/whatwedo/programmes/programme_pals2/project_tocros...
(63) Par exemple http://itde.vccs.edu/rss2js/build.php ou http://www.rss-to-javascript.com
(64) « Open Archive Initiative and Protocol for Metadata Harvesting » http://www.openarchives.org/pmh/
(65) http://www.editeur.org/onix.html
(66) http://www.eprints.org
(67) http://arxiv.org
(68) http://hal.archives-ouvertes.fr
(69) http://doc.rero.ch
(70) http://infoscience.epfl.ch
(71) http://cdsweb.cern.ch
(72) http://www.epfl.ch
(73) http://www.worldcat.org
(74) The European Library : http://www.theeuropeanlibrary.org
(75) Voir par exemple l’article de wikipedia http://en.wikipedia.org/wiki/Web_2 et l’article fondateur de Tim O’Reilly « What Is Web 2.0 : Design Patterns and Business Models for the Next Generation of Software » http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-.... Version française : http://web2rules.blogspot.com/2006/01/what-is-web-20-par-tim-oreilly-ver...
(76) http://www.rlg.org
(77) Primo http://www.exlibrisgroup.com/webinar_1144862525.htm
(78) http://books.google.com et depuis quelque temps seulement aussi consultable sur http://books.google.ch
(79) D’abord limité à 5, maintenant ce sont 13 bibliothèques qui fournissent les documents en échange des données obtenues par la numérisation : la bibliothèque de l'Université de Virginie, de Californie, de Harvard, de Stanford, du Michigan, du Wisconsin-Madison, de Texas, de Princeton, de Madrid, d’Oxford ainsi que la bibliothèque publique de New York et les bibliothèque de Catalogne et de Bavière. La bibliothèque du Congrès américain (Library of Congress) fait l'objet d'un autre projet à part : http://www.washingtonpost.com/wp-dyn/content/article/2005/11/21/AR200511...
(80) Voir le communiqué de presse de la commission européenne : http://europa.eu/rapid/pressReleasesAction.do?reference=IP/06/253&format... et la page du programme de l’UE « i2010: Digital Libraries Initiative » : http://ec.europa.eu/information_society/activities/digital_libraries/ind...
(81) http://www.bl.uk
(82) http://www.microsoft.com
(83) http://www.archive.org
(84) http://www.opencontentalliance.org. Voir aussi l’article de CNET News.com : « Yahoo to digitize public domain books » http://news.com.com/Yahoo+to+digitize+public+domain+books/2100-1038_3-58...
(85) Voir l’annonce fait par l’UNESCO : http://portal.unesco.org/fr/ev.php-URL_ID=35949&URL_DO=DO_TOPIC&URL_SECT...
(86) Voir par exemple l’article et le billet de Lorcan Dempsey « Fingering volumes » http://orweblog.oclc.org/archives/001122.html, « Le travail bâclé de Google Print » http://www.dsi-info.ca/moteurs-de-recherche/2005/11/le-travail-bcl-de-go... ou « Digitized by Google » http://e-benedictins.blogspot.com/2006/09/digitalized-by-google.html
(87) http://librariancentral.blogspot.com/2007/03/checking-in-with-google-boo...
(88) Voir l’article de LibraryJournal.com « Release of Google Contract with UC Sparks Criticism » http://www.libraryjournal.com/article/CA6367340.html
(89) http://lib.umich.edu/
(90) Par exemple, la page 7 du document « Versuch schweizerischer Gedichte » : http://mdp.lib.umich.edu/cgi/m/mdp/pt?seq=7&size=100&id=39015014807104&v.... Voir aussi à ce sujet l’article de The Chronicle of Higher Education : « U. of Michigan Adds Books Digitized by Google to Online Catalog, but Limits Use of Some » http://chronicle.com/free/2006/08/2006083101t.htm
(91) « Mbooks » : http://www.lib.umich.edu/mdp/
(92) http://gallica.bnf.fr
(93) http://www.gutenberg.org
(94) http://www.cervantesvirtual.com
(95) Document Object Identifier : http://www.doi.org
(96) http://www.amazon.com/Search-Inside-Book-Books/b?ie=UTF8&node=10197021
(97) http://www.doi.org
(98) http://en.wikipedia.org/wiki/PMID ou http://pmid.us/
(99) http://www.openarchives.org/OAI/openarchivesprotocol.html#UniqueIdentifier
(100) http://fr.wikipedia.org/wiki/Uniform_Resource_Name
(101) Organisation chargée de gérer les DOI http://www.crossref.org
(102) L'ISSN (International Standard Serial Number) est un numéro à huit chiffres non significatives de la forme 1234-5678 et qui identifie les périodiques, y compris en format électronique. La gestion des ISSN, qui compte plus d'un million aujourd’hui, est effectuée par un réseau mondial de 80 centres nationaux (dont la Bibliothèque Nationale Suisse) coordonnés par un centre international à Paris http://www.issn.org/fr En effet dans la majorité de notices analytiques présentes dans les catalogues des bibliothèques universitaires, l’ISSN de la revue est absent.
(103) Les autres éléments clés pour identifier un article, tels le volume, et les pages de début et de fin, sont répertoriés dans une zone « In » peu normalisée et difficilement exploitables sans un traitement informatique
(104) http://www.wikio.com
(105) http://del.icio.us
(106) http://flickr.com
(107) http://www.connotea.org
(108) Interface alternative à PubMed utilisant les services web de cette dernière en ajoutant des nouvelles fonctionnalités comme le « tagging » ou la catégorisation par facettes : http://www.hubmed.org
(109) http://www.plymouth.edu/library/opac/
(110) http://www.aadl.org/catalog
(111) http://www.oclc.org/research/projects/xisbn/
(112) http://www.google.com/apis/maps/
(115) Voir l’article de Wikipedia http://en.wikipedia.org/wiki/GeoTagging
(116) http://www.flickr.com/groups/geotagging/
Bibliographie
BBF (2005). Dossier : Mort et transfiguration des catalogues. BBF : Bulletin des Bibliothèques de France [en ligne], [consulté le 15 janvier 2007], T. 50, n° 4. http://bbf.enssib.fr/sdx/BBF/frontoffice/2005/04/sommaire.xsp
BEARMAN, David (décembre 2006). Jean-Noël Jeanneney's Critique of Google: Private Sector Book Digitization and Digital Library Policy. D-Lib Magazine [en ligne], [consulté le 15 janvier 2007], vol. 12, n°12. http://www.dlib.org/dlib/december06/bearman/12bearman.html
BIBLIOGRAPHIC SERVICES TASK FORCE (décembre 2005). Rethinking How We Provide Bibliographic Services for the University of California [en ligne]. The University of California Libraries [consulté le 15 janvier 2007]. http://libraries.universityofcalifornia.edu/sopag/BSTF/Final.pdf
BROUDOUX, Evelyne, GRESILLAUD, Sylvie, LE CROSNIER, Hervé, LUX-POGODALLA, Véronika (18 septembre 2005). Construction de l’auteur autour de ses modes d’écriture et de publication. H2PTM'05 [en ligne], [consulté le 15 janvier 2007]. http://archivesic.ccsd.cnrs.fr/sic_00001552
CALHOUN, Karen, (2006). The Changing Nature of the Catalog and its Integration with Other Discovery Tools [en ligne]. Final report prepared for the Library of Congress, March 17, [consulté le 15 janvier 2007]. http://www.loc.gov/catdir/calhoun-report-final.pdf
ÇELIKBAS, Zeki (novembre 2004). What is RSS and how it can serve libraries. E-prints in Library and Information Science [en ligne], [consulté le 15 janvier 2007]. http://eprints.rclis.org/archive/00002531/
CHUDNOV, Daniel, CAMERON, Richard, FRUMKIN, Jeremy, SINGER, Ross,YEE, Raymond (avril 2005). Opening up OpenURLs with Autodiscovery. Ariadne [en ligne], issue 43, [consulté le 15 janvier 2007]. http://www.ariadne.ac.uk/issue43/chudnov/
DEMPSEY, Lorcan (2006). The Library Catalogue in the New Discovery Environment: Some Thoughts. Ariadne [en ligne], issue 48, [consulté le 15 janvier 2007]. http://www.ariadne.ac.uk/issue48/dempsey/
DEMPSEY, Lorcan (22 fevrier 2005). The integrated library system that isn't. Lorcan Dempsey's weblog On libraries, services and networks [en ligne], [consulté le 15 janvier 2007]. http://www.ariadne.ac.uk/issue48/dempsey/
DUCHEMIN, Pierre-Yves (2005). L’enrichissement des catalogues ? Et après ? BBF [en ligne], n° 4, p. 21-27 [consulté le 15 janvier 2007]. http://bbf.enssib.fr
GARREAU, Angélina (19 septembre 2005). Les blogs entre outil de publication et espace de communication : un nouvel outil pour les professionnels de la documentation [en ligne]. Maîtrise des sciences de l'information et de la documentation, CAOA, Université, [consulté le 15 janvier 2007]. http://memsic.ccsd.cnrs.fr/mem_00000273.html
GAVIN, Pierre (1997). SIBIL : un bilan pour le passé, et quelques jalons pour le futur [en ligne]. Lausanne : Nouvelle Association REBUS (Réseau des bibliothèques utilisant SIBIL), [consulté le 15 janvier 2007]. http://www.pierregavin.ch/documents/Sibil-bilan-jalon.pdf
GAVIN, Pierre (2006). Les AACR2 : menace ou chance ?. Hors texte, n° 80, p. 16-18
HAMMOND, Tony, HANNAY, Timo, LUND, Ben (décembre 2004). The Role of RSS in Science Publishing : Syndication and Annotation on the Web. D-Lib Magazine [en ligne], vol. 10, n°12, [consulté le 15 janvier 2007]. http://www.dlib.org/dlib/december04/hammond/12hammond.html
IRIARTE, Pablo (2006). La diffusion de l'information documentaire et des actualités en format RSS. In CHARTRON, Ghislaine [dir.], BROUDOUX, Evelyne [dir.]. Document numérique et société : actes de la conférence organisée dans le cadre de la semaine du document numérique à Fribourg (Suisse) les 20 et 21 septembre 2006 [imprimé]. Paris : ADBS, [consulté le 15 janvier 2007]. P. 123-148. http://archivesic.ccsd.cnrs.fr/sic_00079211
LEBOEUF, Patrick (2004). Le jour d’après : où serez-vous ?… [en ligne]. Journée d’étude Médiadix (Jeudi 21 Octobre 2004) : La fin du catalogage ?! [consulté le 15 janvier 2007]. http://netx.u-paris10.fr/mediadix/archivesje/leboeufweb.pdf
LE MOAL, Jean-Claude [coord.], HIDOINE, Bernard [coord.], CALDERAN, Lisette [coord.] (2004). Publier sur Internet : séminaire INRIA, 27 septembre - 1er octobre 2004, Aix-les-Bains [imprimé]. Paris : ADBS. ISBN 2843650720
MARKEY, Karen (janvier 2007). The Online Library Catalog : Paradise Lost and Paradise Regained?. D-Lib Magazine [en ligne], [consulté le 15 janvier 2007], vol. 13, n°1/2. http://www.dlib.org/dlib/january07/markey/01markey.html
MOFFAT, M (Mars 2006). “Marketing” with Metadata : How Metadata Can Increase Exposure and Visibility of Online Content [en ligne], version 1.0, 8 [consulté le 15 janvier 2007] http://www.icbl.hw.ac.uk/perx/advocacy/exposingmetadata.htm
SALAÜN, Jean-Michel (décembre 2005). Bibliothèques numériques et Google-Print. Version non révisée par l'éditeur de l’article pour la revue Regard sur l'actualité [en ligne], [consulté le 15 janvier 2007], n° 316. http://archivesic.ccsd.cnrs.fr/sic_00001576
SCHNEIDER, Karen G (20 Mai 2006). How OPACs Suck, Part 3: The Big Picture. ALA TechSource [en ligne], [consulté le 15 janvier 2007]. http://www.techsource.ala.org/blog/2006/05/how-opacs-suck-part-3-the-big...
STEPHENS, Michael (2006). Web 2.0 & Libraries : Best Practices for Social Software. Library Technology Reports, vol. 42, no. 4. ISSN 0024-2586
TENAILLEAU, Willy (14 mars 2006). Les services à distance d'une médiathèque - synthèse 3 : Les notices bibliographiques. LaConjuration/notes [en ligne], [consulté le 15 janvier 2007]. http://www.laconjuration.net/notes/?2006/03/14/33-les-services-a-distanc...