Publiée une fois par année, la Revue électronique suisse de science de l'information (RESSI) a pour but principal le développement scientifique de cette discipline en Suisse.
Services Web
La homepage dans la communication des hôpitaux suisses francophones
Ressi — 19 novembre 2010
Pablo Medina Aguerrebere, Université de Navarre, Faculté de Communication
Résumé
La création d’une homepage performante constitue l’un des enjeux stratégiques les plus importants pour les institutions hospitalières. Les homepage caractérisées par la précision informative, la simplicité d’accès et la qualité des informations aident, d’une part, les patients à devenir plus actifs dans l’éducation thérapeutique de santé; et d’une autre part, l’organisation hospitalière à simplifier les processus de recrutement des nouveaux professionnels de la santé. La conclusion de cet article est que la homepage représente une opportunité stratégique fondamentale qui peut aider l’hôpital à établir des relations stables avec le patient grâce à la diffusion d’informations corporatives et à l’éducation thérapeutique du patient dans les sujets de santé.
Abstract
The creation of a powerful homepage is one of the most important strategic issues for the hospital institutions. Homepage with informational accuracy, ease of access, and quality information help, on the one hand, patients to become more active in therapeutic education; and, on the other hand, hospital organization to simplify the process of recruitment of new health professionals. The conclusion of this article is that homepage is a fundamental strategic opportunity that can help hospital to establish stable relations with the patient through the dissemination of corporate information and the patient therapeutic education in health topics.
Mots-Clés:
santé, hôpital, communication institutionnelle, internet, homepage La homepage dans la communication des hôpitaux suisses francophones
Introduction
Aujourd’hui, l’internet est l’un des outils de communication les plus importants dans le milieu hospitalier. La page d’accueil (homepage) constitue la partie la plus visible du site internet, et se base sur le concept de la précision informative, laquelle permet de satisfaire, d’une part, les patients, lesquels ont accès aux informations d’une manière plus simple, ce qui les mène à s’intéresser aux sujets de la santé; et, d’une autre part, l’organisation hospitalière, laquelle peut utiliser la homepage pour garder le contact direct avec les patients à travers les blogs ou l’email ainsi que pour simplifier les processus de recrutement des professionnels de la santé. Afin de comprendre l’enjeu stratégique de la homepage des institutions hospitalières, cet article analyse, tout d’abord, l’impact de la structure de la homepage sur l’hôpital, le médecin et le patient; ensuite, le contexte sanitaire en Suisse; et, finalement, avant de conclure le document, la structure de la homepage de neuf hôpitaux suisses francophones.
L’impact de la homepage dans la communication hospitalière
Même si les applications de Google permettent de trouver des informations sans passer par la homepage des sites internet, le patient est toujours influencé par ses expériences médicales préalables dans son centre hospitalier, ce qui permet de souligner le fait que le patient priorise le site internet de son hôpital quand il a besoin d’informations sanitaires. Cette réalité justifie l’importance des homepages des hôpitaux. Les sites internet de santé considérés comme effectifs transmettent une image de qualité fiable, de confiance, d’intelligence, et, finalement, de simplicité en ce qui concerne leur utilisation (Fisher et al., 2008 : p. 477). Cette simplicité détermine l’accessibilité aux informations, laquelle, selon Jones (2003 : p. 337), exige, avant tout, la diffusion d’informations précises permettant aux patients de ne pas « être submergés » par des informations inutiles. La précision dans l’information médicale mène les institutions hospitalières à faire très attention au langage utilisé sur leur site internet. Afin de minimiser le problème de la complexité du langage médical, il est intéressant de mettre sur les sites internet de santé les définitions de certains mots (Lorence & Spink, 2004). Soit, le développement d’un dictionnaire médical online peut apporter des bénéfices aux patients; mais, malgré tout, il faut que les professionnels de la santé sachent aussi adapter leur discours et leur langage aux besoins du patient. Dans le cadre d’une consultation online, si l’usager d’internet utilise un langage technique au moment de poser une question aux professionnels de la santé, ces derniers préfèrent continuer d’utiliser le langage technique; par contre, si l’usager utilise un langage plus familier, les professionnels de la santé savent adapter leur discours à ce langage moins précis (Bromme et al., 2005). En plus de l’attention faite au langage, les hôpitaux développent des outils visuels permettant de rendre leur homepage plus effective. Les organisations utilisant sur leurs sites internet des photographies et « des images abstraites » provoquent chez leurs utilisateurs une réaction positive (Vilnai-Yavetz & Tifferet, 2009 : p. 161). Ces réactions positives sont stratégiques puisque, selon Robins et al. (2010 : p. 27), les sites internet de santé qui suscitent des « préférences positives » grâce à leur design visuel génèrent aussi des jugements positifs concernant leur crédibilité.
Les sites internet transmettant des informations sanitaires doivent évoluer de la diffusion d’informations générales à la satisfaction des besoins informatifs précis des usagers (Huntington et al., 2003). Les institutions hospitalières essayent de satisfaire les besoins communicatifs de leurs groupes d’intérêt (employés, patients, journalistes, etc.) et, pour cela, il est convenable de créer sur le site internet des profils d’usager. La création de ces profils rend plus effective la diffusion d’informations médicales, ce qui est très important puisque, d’une part, selon Wasson et al. (2007), les patients utilisent l’internet pour faire part de leurs perceptions sur leurs expériences de santé négatives; et, d’une autre part, parce que l’usage d’internet comme source d’information sanitaire renforce la capacité des gens à mettre en doute les professionnels de la santé, et mène la population à avoir besoin de rester en contact avec ces professionnels afin de bien utiliser l’information trouvée sur internet (Lee, 2008 : p. 461). La création de profils d’usager aide les hôpitaux à mieux satisfaire les patients d’un point de vue de la communication, et ainsi à éviter la diffusion de rumeurs négatives et à garantir l’autorité professionnelle du personnel médical de l’institution.
L’internet a fait changer la manière dont les patients parlent avec les médecins sur les sujets de santé (Bylund et al., 2007). Néanmoins, « l’un des effets les plus spectaculaires d’internet et du world wide web est sa capacité à engager les patients et les consommateurs d’une manière active dans les sujets de santé » (Nguyen et al., 2004 : p. 95). D’ailleurs, l’utilisation de wikis et de blogs dans le milieu de la santé aide à impliquer les usagers d’une manière active dans leur propre construction de connaissances (Boulos et al., 2006). Donc, la diffusion d’informations médicales pousse les patients à devenir plus actifs et à mieux connaître le milieu de la santé. En plus, l’information e-Health qui est interactive, interoperable, personnelle, adaptée au contexte et qui peut être diffusée aux audiences massives peut vraiment aider à améliorer la qualité des soins de santé et les efforts de promotion de la santé (Kreps & Neuhauser, 2010 : p. 334). Par ailleurs, l’usage d’internet et de l’email influence les résultats de santé du patient à travers plusieurs moyens, comme par exemple, l’amélioration de la diffusion d’informations, ce qui peut apporter «des bénéfices intangibles comme rendre les patients plus confortables ou confiants sur leur état de santé» (Baker et al., 2003 : p. 2405). L’impact sanitaire de la diffusion d’informations médicales à travers le site internet des hôpitaux justifie le besoin de bien réfléchir à la structure de la homepage. Dans ce cadre de l’éducation thérapeutique du patient dans les sujets de la santé, la creátion d’un site internet consacré à la bibliothèque existante dans l’hôpital constitue un «outil extrêmement important» (Kammerer, 2009 : p. 40), puisque le patient peut aussi s’instruire grâce aux livres dont dispose l’hôpital.
Quant aux professionnels de la santé, eux aussi, ils peuvent profiter d’internet pour mieux connaître le milieu sanitaire. Afin de promouvoir d’une manière efficace l’éducation thérapeutique constante dans le milieu sanitaire, il est important que les éducateurs comprennent l’impact éducatif de l’internet comme support (media) pouvant être utilisé par les professionnels de la santé (Copley Cobb, 2004). Dans ce cadre, il est intéressant d’organiser des cours de formation online, lesquels, selon Carroll et al. (2009), permettent d’améliorer l’expérience d’autoapprentissage des professionnels de la santé. Par ailleurs, internet s’avère comme un moyen très utile dans le recrutement des professionnels de la santé. L’usage d’internet comme moyen de recrutement « semble aller au-delà de la seule opération de recrutement pour s’étendre à la prospection plus générale du marché, et ceci vaut aussi bien pour le positionnement des entreprises que pour celui des candidats” (Bessy & Marchal, 2006 : p. 38). Dans le but d’optimiser le pouvoir d’internet comme source de recrutement, d’une part, selon, Williamson et al. (2003), le site internet doit avoir un haut niveau de contenus utiles afin de devenir attractif auprès des employés potentiels; et, d’une autre part, selon Van Hoye & Lievens (2007 : p. 380), il doit être à la base du word-of-mouse (l’application online du bouche-à-oreille), lequel « peut être une source de recrutement crédible et influente ».
La homepage, ainsi que le site internet de l’hôpital dans son ensemble, doit assurer la qualité des informations transmises. Les fournisseurs d’information « doivent développer des systèmes permettant de garantir sa qualité, et ainsi de protéger les usagers de la désinformation » (Ayantunde et al., 2007 : p. 461). L’usage du web pour se procurer des informations médicales est influencé par les perceptions du consommateur sur les sources traditionnelles d’information (Rains, 2007), d’où l’intérêt que les sites internet développent, à l’instar de ces sources d’information traditionnelles, des systèmes permettant d’accréditer la qualité des informations diffusées. L’accréditation de la qualité est importante puisque, selon Wang et al. (2008), il existe un rapport direct entre l’évaluation de la qualité du message online de santé et la décision d’agir. Soit, les messages crédibles qui transmettent une image de qualité mènent les usagers à agir. Une évaluation complète des sites d’internet diffusant des informations sanitaires comporte des études des usagers, des méthodes d’inspection pour mieux évaluer l’usability et les indicateurs de qualité, des enquêtes sur le contexte pour comprendre l’importance et l’utilité du site pour les groupes d’usagers actuels et potentiels, ainsi qu’une analyse des archives log permettant d’examiner l’utilisation du site (Williams et al., 2002 : p. 106-107). Dans ce cadre, plusieurs institutions sanitaires essayent d’obtenir la certification de la Health On the Net Foundation, une organisation qui octroie un label de qualité (Honcode) une fois qu’elle a vérifié que l’institution diffusant des informations sanitaires sur internet respecte les huit principes fondamentaux établis par ce label: a) indiquer la qualification des rédacteurs, b) compléter la relation patient-médecin, c) préserver la confidentialité des informations personnelles, d) citer les sources des informations, e) justifier les affirmations sur les traitements ou sur les produits, f) rendre l’information la plus accessible possible, g) présenter les sources de financement et h) séparer la politique publicitaire de la politique éditoriale(1).
Contexte sanitaire suisse
Le système sanitaire suisse a l’une des densités médicales les plus importantes au niveau international puisque, en 2007, cette densité était de 3,9 médecins par 1.000 habitants (Organisation pour la Coopération et le Développement Economique, 2010). En 2007, en Suisse on comptait 29.052 médecins, ce qui représente une augmentation de 0,8% par rapport à 2006 (Fédération des Médecins Suisses, 2008). En 2007, la dépense sanitaire totale en Suisse représentait le 10,8% du PIB de la même année (Organisation pour la Coopération et le Développement Economique, 2010). Quant au nombre de lits d’hospitalisation pour soins aigus, en 2007 la Suisse avait 3,5 lits par milliers d’habitants (OCDE, 2010). En 2007, le système sanitaire suisse comptait 321 hôpitaux – dont 130 hôpitaux privés-, lesquels employaient 130.990 personnes – dont 96.604 dans les hôpitaux de soins généraux- (Office Fédérale de la Santé Publique, 2010a : p. 21-22). En 2007, le 86,8% des personnes âgées de 15 ans et plus se sentait en bonne ou très bonne santé; ce qui peut être expliqué par le fait que seulement le 19,6% des hommes et le 9% des femmes consommaient quotidiennement de l’alcool, et que le pourcentage de fumeurs était de 32,3% chez les hommes et de 23% chez les femmes (Office Fédérale de la Statistique, 2010b).
La structure de la homepage dans les hôpitaux suisses francophones
Le choix des hôpitaux suisses francophones analysés dans cette recherche se base sur le « Ranking Web d’Hôpitaux du Monde », élaboré par le Département de Cybermétrie du Conseil National de Recherches Scientifiques d’Espagne(2). Selon le classement de ce ranking au mois de janvier 2010, les neuf premiers hôpitaux suisses ayant leur site internet en français étaient dans cet ordre: 1) Centre Hospitalier Universitare Vaudois Lausanne, 2) Hôpitaux Universitaires de Genève, 3) Hôpital de la Chaux de Fonds, 4) Kurzentrum Rheinfelden, 5) Clinique Générale Beaulieu, 6) Hôpital du Valais, 7) Uniklinik Balgrist Spital und Chirurgie, 8) Hôpital Riviera et 9) Clinique Pyramide(3).
L’objectif de cette recherche est de comprendre comment ces institutions hospitalières organisent la structure de leur homepage(4). Afin d’étudier cette structure, dans cette recherche on utilise neuf indicateurs différents: 1) l’image a-t-elle plus d’espace que le texte?; 2) les images du patient ont-elles plus d’espace que les images des professionnels de la santé?; 3) le langage scientifique est-il plus présent que le langage familier?: 4) y a-t-il un lien vers les services de santé (départements médicaux) de l’hôpital?; 5) peut-on observer des traitements médicaux mis en avant dans un autre format que celui du communiqué de presse?; 6) y a-t-il un lien vers une rubrique consacrée à l’éducation thérapeutique du patient dans les sujets concernant la santé ?; 7) y a-t-il des logos des organisation externes qui accréditent l’hôpital?; 8) existe-t-il un accès personnalisé pour les patients et pour les professionnels de la santé?; et 9) y a-t-il un lien vers la rubrique consacrée aux activités de recrutement de l’hôpital ? Ces neufs indicateurs essayent d’évaluer le niveau de navigabilité des sites internet en tenant compte du contexte hospitalier et des besoins du patient (recherche de traitements médicaux, langage familier, éducation thérapeutique du patient dans les sujets concernant la santé…). Mais, malgré tout, il s’agit de critères limités qui pourraient être complétés par d’autres indicateurs.
Par rapport à l’image et au texte, sept hôpitaux sur neuf accordent plus d’importance au texte qu’à l’image (Hôpitaux Universitaires de Genève, Hôpital de la Chaux de Fonds, Kurzentrum Rheinfelden, Clinique Générale Beaulieu, Hôpital du Valais, Uniklinik Balgrist Spital und Chirurgie et Clinique Pyramide), ce qui représente le 77,80% des hôpitaux analysés. En ce qui concerne les images du patient et du professionnel de la santé, deux hôpitaux sur neuf (Hôpitaux Universitaires de Genève et Kurzentrum Rheinfelden) priorisent les images du patient sur celles du professionnel de la santé, ce qui représente le 22,22% des hôpitaux étudiés. Quant au langage scientifique et au langage familier, tous les hôpitaux utilisent un langage familier permettant de diffuser d’une manière claire les informations concernant l’institution hospitalière. Par rapport à la présence de liens vers les services de santé proposés (départements médicaux), tous les hôpitaux analysés disposent de ces liens. En ce qui concerne la mise en avant de certains traitements médicaux sans utiliser un format de communiqué de presse, on dénombre quatre organisations (Hôpitaux Universitaires de Genève, Uniklinik Balgrist Spital und Chirurgie, Hôpital Riviera et Clinique Pyramide) qui utilisent cette technique informative, ce qui représente le 44,44% des hôpitaux analysés.
Quant à l’existence de liens vers une rubrique sur l’éducation thérapeutique du patient, il y a deux organisations (Hôpitaux Universitaires de Genève et Hôpital Riviera) qui ont sur leur homepage un lien direct vers la page consacrée à l’éducation thérapeutique du patient. Par rapport à l’existence de logos des organisations externes accréditant l’hôpital, il y a trois institutions disposant de ces informations (Hôpitaux Universitaires de Genève, Clinique Générale Beaulieu et Clinique Pyramide), ce qui représente le 33,33% des hôpitaux étudiés - la première institution citée utilise le logo du Hon Code; et la deuxième et la troisième, celui du groupe hospitalier The Swiss Leading Hospitals-. En ce qui concerne la division de l’information selon le profil patient ou professionnel de la santé, il y a trois hôpitaux (Hôpital du Valais, Uniklinik Balgrist Spital und Chirurgie et Hôpital Riviera) qui appliquent d’une manière claire cette division. Finalement, quant à l’existence d’un lien vers la rubrique de recrutement, six hôpitaux sur neuf disposent de ce lien (Centre Hospitalier Universitare Vaudois Lausanne, Hôpitaux Universitaires de Genève, Clinique Générale Beaulieu, Hôpital du Valais, Hôpital Riviera et Clinique Pyramide), ce qui représente le 66,70% des hôpitaux analysés.
Afin de mieux comprendre la réalité des hôpitaux suisses, on a mené la même recherche auprès des hôpitaux français. Selon le classement du « Ranking Web d’Hôpitaux du Monde » au mois de janvier 2010, les quinze premiers hôpitaux français étaient dans cet ordre: 1) Centre Hospitalier Universitaire (CHU) de Lyon, 2) CHU de Rouen, 3) Assistance Publique Hôpitaux de Marseille, 4) Assistance Publique Hôpitaux de Paris, 5) Institut Curie, 6) CHU de Toulouse, 7) CHU de Saint-Étienne, 8) CHU de Clermont-Ferrand, 9) CHU de Nantes, 10) Centre Hospitalier Régional Universitaire (CHRU) de Montpellier, 11) CHU de Nice, 12) CHU de Besançon, 13) CHU de Poitiers, 14) CHU de Brest et 15) CHU de Grenoble(5). Dans le but de faire une comparaison entre la situation des hôpitaux suisses et celle des hôpitaux français, on présente un tableau permettant d’apprécier les différences existantes :
Tableau 1. Indicateurs hôpitaux Suisse et hôpitaux France.
|
Indicateurs |
Hôpitaux Suisse |
Hôpitaux France |
|
1. Le texte a plus d’espace que l’image. |
77,80% |
80% |
|
2. L’image du patient a plus d’espace que celle du médecin. |
22,22% |
6,70% |
|
3. Le langage familier est plus présent que le langage scientifique. |
100% |
93,3% |
|
4. Existence d’un lien vers les services de santé de l’hôpital. |
100% |
86,70% |
|
5. Présence de traitements médicaux mis en avant sans avoir le format du communiqué de presse. |
44,44% |
26,70% |
|
6. Existence d’un lien vers la rubrique d’éducation thérapeutique du patient dans les sujets concernant la santé. |
22,22% |
26,70% |
|
7. Présence de logos des organisations externes qui accréditent l’hôpital. |
33,33% |
26,70% |
|
8. Existence d’un accès personnalisé patient et professionnel de la santé. |
33,33% |
80% |
|
9. Présence d’un lien vers les activités de recrutement de l’hôpital. |
66,70% |
80% |
Discussion
Les hôpitaux suisses ayant leur site en français ont bien compris l’importance d’avoir une homepage performante, ce qui représente aujourd’hui un outil de communication très important. La priorité du texte sur l’image (77,80% des hôpitaux suisses analysés), l’utilisation d’un langage familier (100%) et l’existence d’un lien vers les services de santé proposés par l’hôpital (100%) mettent en évidence le souci des hôpitaux de vouloir informer le patient d’une manière précise et de l’aider ainsi dans ses démarches online. Pourtant, ces hôpitaux peuvent encore s’améliorer à travers plusieurs initiatives, comme par exemple, la création d’un profil d’usager pour les patients et d’un autre profil d’usager pour les professionnels de la santé, ce qui, aujourd’hui, existe dans le 33,30% des hôpitaux suisses analysés et dans le 80% des hôpitaux français étudiés. La principale différence existant entre les hôpitaux suisses et les hôpitaux français analysés réside dans le fait que les hôpitaux suisses consacrent plus d’importance au rôle du patient qu’a celui de l’institution hospitalière: l’image du patient a plus d’espace que celle du médecin (22,22% en Suisse ; 6,70% en France), mise en avant de certains traitements médicaux sans utiliser le format du communiqué de presse (44,44% en Suisse ; 26,70% en France) et présence d’un lien vers les activités de recrutement - ce qui n’intéresse pas le patient- (66,70% en Suisse ; 80% en France).
La création d’une homepage performante représente un enjeu stratégique important parce que, souvent, cette homepage constitue le contact principal entre le patient et l’institution hospitalière. Il est difficile d’établir des consignes générales permettant les hôpitaux de créer des homepage performantes puisque le contexte de chaque hôpital, de chaque pays et de chaque système de santé détermine les choix stratégiques à suivre. Pourtant, on peut signaler trois idées qui peuvent s’appliquer à tous les hôpitaux. En premier lieu, l’hôpital doit disposer d’un département de communication capable de comprendre la logique communicative du milieu sanitaire et de satisfaire aux besoins organisationnels de l’hôpital. En deuxième lieu, l’approche utilisée dans le design de la homepage doit être basée, tout d’abord, sur les besoins communicatifs et médicaux du patient et, ensuite, sur les besoins communicatifs de l’organisation hospitalière. En troisième lieu, la homepage constitue un point de contact entre le patient et l’hôpital, mais ce contact ne peut pas se limiter à un rapport online, d’où l’importance que les hôpitaux conçoivent la homepage comme un outil qui peut rendre plus simple la consultation du patient quand il se rend à l’hôpital. Le développement de la télémédecine rend de plus en plus intéressantes les applications du web 2.0 dans le milieu sanitaire. Pourtant, l’internet suppose une vraie menace de perte de confiance du patient dans la relation thérapeutique établie avec le médecin (Fostier, 2005). Les hôpitaux doivent concevoir des homepages performantes, mais ils ne doivent pas négliger que la communication, qu’elle soit online ou pas, est toujours au service du médecin, lequel est le vrai responsable de l’amélioration de l’état de santé du patient.
Conclusion
Les institutions hospitalières sont de plus en plus présentes dans la vie du patient, d’où la nécessité de voir dans la structure de la homepage, non pas uniquement une opportunité de présenter d’une manière formelle l’hôpital, mais plutôt la possibilité de créer et de mettre à jour une carte de présentation online dont le but est d’établir des relations stables et satisfaisantes avec le patient à travers la diffusion d’informations institutionnelles et l’éducation thérapeutique du patient sur les sujets de santé. Par rapport aux hôpitaux suisses francophones analysés, on peut affirmer qu’ils tiennent compte de cette réalité, puisqu’ils priorisent le texte sur l’image (donc, la diffusion d’informations) ainsi que le langage familier sur le langage scientifique; mais, ils doivent donner une importance plus grande à la rubrique consacrée à l’éducation thérapeutique du patient, ce qui se traduit par la création dans la homepage d’un lien visible et direct menant l’usager à une rubrique performante et interactive sur ce sujet.
Notes
(1) Site internet officiel consulté le 10 mai 2010: <http://www.hon.ch/HONcode/Guidelines/guidelines.html>.
(2) Cet organisme (Consejo Superior de Investigaciones Científicas) est l’une des organisations de recherche les plus importantes d’Europe, et dépend du Ministère de Science et de Technologie du Gouvernement Espagnol. L’élaboration du ranking des hôpitaux se base sur des indicateurs web qui mesurent l’activité professionnelle et de recherche de l’institution hospitalière. Le ranking tient compte uniquement des hôpitaux ayant un domaine web indépendant. Afin de mesurer le « facteur d’impact web », on utilise quatre indicateurs différents: taille du site web, visibilité, fichiers riches et caractère académique. Site internet officiel consulté le 12 mai 2010: <http://hospitals.webometrics.info/about_rank.html>.
(3) Le ranking complet peut être consulté sur le site officiel du Conseil National de Recherches Scientifiques d’Espagne: http://hospitals.webometrics.info/top100_europe.asp?country=ch&submit=go.
(4) L’analyse des pages web a été réalisé entre le 3 mai et le 20 mai 2010. Dans le cas de l’Hôpital de la Chaux de Fonds et du Kurzentrum Rheinfelden, la homepage analysée est celle des groupes hospitaliers auxquels appartiennent ces hôpitaux.
(5) Le ranking complet peut être consulté sur le site officiel du Conseil National de Recherches Scientifiques d’Espagne: http://hospitals.webometrics.info/top100_europe.asp?country=fr&submit=go.
L’analyse des pages web a été réalisé entre le 25 et le 30 juin 2010.
Bibliographie
AYANTUNDE, A.; WELCH, N. & PARSONS, S. (2007). A survey of patient satisfaction and use of the internet for health information. International Journal of Clinical Practice, vol. 61, nº 3, p. 458-462
BAKER, Laurence; WAGNER, Todd; SINGER, Sara & BUNDORF, Kate (2003). Use of the internet and e-mail for health care information. Results from a national survey. Journal of the American Medical Association, vol. 289, nº 18, p. 2400-2406
BESSY, Christian & MARCHAL, Emmanuelle (2006). La mobilisation d’internet pour recruter: aux limites de la sélection à distance. Revue de l'Ires, vol. 52, nº 3, p. 11-39
BOULOS, Maged Kamel; MARAMBA, Inocencio & WHEELER, Steve (2006). Wikis, blogs and podcasts: a new generation of web-based tools for virtual collaborative clinical practice and education. BMC Medical Education, vol. 6:41
BROMME, Rainer; JUCKS, Regina & WAGNER, Thomas (2005). How to refer to ‘diabetes’? Language in online health advice. Applied Cognitive Psychology, vol. 19, nº 5, p. 569-586
BYLUND, Carma; GUEGUEN, Jennifer; SABEE, Christina; IMES, Rebecca; LI, Yuelin & SANDFORD, Amy (2007). Provider–patient dialogue about internet health information: an exploration of strategies to improve the provider–patient relationship. Patient Education and Counseling, vol. 66, nº 3, p. 346–352
CARROLL, Christopher; BOOTH, Andrew; PAPAIOANNOU, Diana; SUTTON, Anthea & WONG, Ruth (2009). UK health-care professionals’ experience of on-line learning techniques: a systematic review of qualitative data. Journal of Continuing Education in the Health Professions, vol. 29, nº 4, p. 235-241
COPLEY COBB, Susan (2004). Internet continuing education for health care professionals: an integrative review. The Journal of Continuing Education in the Health Professions, vol. 24, nº 3, p. 171-180
FÉDÉRATION DES MÉDECINS SUISSES (2008). [Consulté le 23 avril 2010]. http://www.fmh.ch/files/pdf4/stt011.pdf.
FISHER, Julie; BURSTEIN, Frada; LYNCH, Kathy & LAZARENKO, Kate (2008). “Usability + usefulness = trust”: an exploratory study of Australian health web sites. Internet Research, vol. 18, nº 5, p. 477-498
FOSTIER, Pierrik. (2005). La communication professionnelle en santé. Québec, Éditions du Renouveau Pédagogique Inc. Chap. 27, L’influence de l’internet sur la communication médecin-patient, p. 693-714.
HUNTINGTON, Paul; NICHOLAS, David & WILLIAMS, Peter (2003). Characterising and profiling health web user and site types: going beyond “hits”. Aslib Proceedings, vol. 55, nº 5/6, p. 277-289
JONES, Ray (2003). Making health information accessible to patients. Aslib Proceedings, vol. 55, nº 5/6, p. 334-338
KAMMERER, Judith (2009). Migrating a hospital library web site to sharepoint and expanding its usefulness. Journal of Hospital Librarianship, vol. 9, nº 4, p. 408-418
KREPS, Gary & NEUHAUSER, Linda (2010). New directions in eHealth communication: opportunities and challenges. Patient Education and Counseling, vol. 78, nº 3, p. 329-336
LEE, Chul-Joo (2008). Does the internet displace health professionals? Journal of Health Communication, vol. 13, nº 5, p. 450-464
LORENCE, Daniel & SPINK, Amanda (2004). Semantics and the medical web: a review of barriers and breakthroughs in effective healthcare query. Health Information and Libraries Journal, vol. 21, nº 2, p. 109-116
NGUYEN, Huong; CARRIERI-KOHLMAN, Virginia; RANKIN, Sally; SLAUGHTER, Robert & STULBARG, Michael (2004). Internet-based patient education and support interventions: a review of evaluation studies and directions for future research. Computers in Biology and Medicine, vol. 34, nº 2, p. 95-112
ORGANISATION POUR LA COOPERATION ET LE DEVELOPPEMENT ECONOMIQUE (2010). Eco-santé OCDE 2009. Statistiques et indicateurs pour 30 pays. Paris, Organisation pour la Coopération et le Développement Economique. ISBN 97892-64-06050-0
OFFICE FÉDÉRALE DE LA SANTÉ PUBLIQUE (2010a). Chiffres-clés des hôpitaux suisses 2007. Berne, Office Fédérale de la Santé Publique. ISBN 3-905235-68-4
OFFICE FÉDÉRALE DE LA STATISTIQUE (2010b). [Consulté le 23 avril 2010]. http://www.bfs.admin.ch/bfs/portal/fr/index/themen/14/01/new.html.
RAINS, Stephen (2007). Perceptions of traditional information sources and use of the world wide web to seek health information: findings from the health information national trends survey. Journal of Health Communication, vol. 12, nº 7, p. 667-680
ROBINS, David; HOLMES, Jason & STANSBURY, Mary (2010). Consumer health information on the web: the relationship of visual design and perceptions of credibility. Journal of the American Society for Information Science and Technology, vol. 61, nº 1, p. 13-29
VAN HOYE, Greet & LIEVENS, Filip (2007). Investigating web-based recruitment sources: employee testimonials Vs. word-of-mouse. International Journal of Selection and Assessment, vol. 15, nº 4, p. 372-382
VILNAI-YAVETZ, Iris & TIFFERET, Sigal (2009). Images in academic web pages as marketing tools: meeting the challenge of service intangibility. Journal of Relationship Marketing, vol. 8, nº 2, p. 148-164
WANG, Zuoming; WALTHER, Joseph; PINGREE, Suzanne & HAWKINS, Robert (2008). Health information, credibility, homophily, and influence via the internet: web sites versus discussion groups. Health Communication, vol. 23, nº 4, p. 358-368
WASSON, John; MACKENZIE, Todd & HALL, Michael (2007). Patients use an internet technology to report when things go wrong. Quality and Safety in Health Care, vol. 16, nº 3, p. 213-215
WILLIAMS, Peter; NICHOLAS, David; HUNTINGTON, Paul & MCLEAN, Fiona (2002). Surfing for health: user evaluation of a health information website. Part one: background and literature review. Health Information and Libraries Journal, vol. 19, nº 2, p. 98-108
WILLIAMSON, Ian; LEPAK, David & KING, James (2003). The effect of company recruitment web site orientation on individuals’ perceptions of organizational attractiveness. Journal of Vocational Behavior, vol. 63, nº 2, p. 242-263
- Vous devez vous connecter pour poster des commentaires
Les catalogues des bibliothèques : du web invisible au web social (I)
Ressi — 29 mars 2007
Isabelle de Kaenel, CHUV, Lausanne
Pablo Iriarte, CHUV, Lausanne
Résumé
Les catalogues des bibliothèques sont rentrés dans une phase critique. Les dernières évolutions du web, avec l’entrée en jeu enfin de XML, des nouveaux usages et nouveaux outils, ainsi que le déplacement du centre de gravité qui s’est fortement rapproché des utilisateurs, ouvrent de nouvelles voies et de nouveaux champs d’application pour les catalogues en ligne. Le catalogue n’est plus un outil isolé du monde : dans un mouvement à double sens, il doit s’ouvrir à Internet autant pour tirer parti des services web externes, de plus en plus importants, que pour l’alimenter en contenu et fournir des informations structurées et validées tout en permettant aux utilisateurs d’apporter du contenu et du sens, ainsi que de s’approprier les données du catalogue en lui offrant des nouvelles possibilités de réutilisation à travers les réseaux. Cet article fait un inventaire de ces nouveaux champs d’application possibles et analyse les conditions de base qu’un catalogue devrait remplir pour pouvoir quitter le web invisible et investir pleinement les possibilités actuelles du web social pour devenir enfin un « OpenCatalog ».
Dernière modification:
26/06/2009 Les catalogues des bibliothèques : du web invisible au web social (I)
Introduction
Les catalogues des bibliothèques sont tombés en disgrâce (Markey, 2007). Délaissés, ignorés, critiqués (1) et, dans le pire des cas, ridiculisés(2) , ils nous lancent un dernier cri d’alarme avant de tomber dans le tiroir des outils oubliés. Or, les dernières évolutions du web(3) , avec l’entrée en jeu enfin de XML(4) , des nouveaux usages et nouveaux outils, ainsi que le déplacement du centre de gravité qui s’est fortement rapproché des utilisateurs, ouvrent de nouvelles voies et de nouveaux champs d’application pour les catalogues en ligne. Le temps est donc venu d’aider ces outils de recherche à sortir de cette image négative liée à une complexité, certes inévitable mais jamais compensée par un aspect créatif. Peu armés pour affronter la rapidité des changements de l’ère Internet au cours de ces dix dernières années, les bibliothécaires se sont plus ou moins contentés d’un fonctionnement qui semblait avoir fait ses preuves, avec de promesses d’améliorations, sans vouloir se rendre compte que, tout autour, le monde de l’information numérique expérimentait plusieurs révolutions. Il est bien connu que celui qui n’avance pas…
La tendance est pourtant depuis quelque temps vers la flexibilité et l'ouverture : « Open Source(5) » (ouverture du code source des logiciels), « Open Access(6) » (accès ouvert aux publications et données issues de la recherche scientifique et technique) et « Open Archives Initiative(7) » (ouverture et interopérabilité entre serveurs institutionnels dépositaires de cette production), « OpenURL(8) » (liens ouverts grâce aux métadonnées encodées dans l'URL(9) ), « OpenSearch(10) » (syntaxe des requêtes et format des résultats ouverts), sont des exemples concrets des réalisations qui ont modifié le monde de la documentation numérique. Le but de cet article est donc de faire un petit inventaire de ces nouveaux champs d’application possibles et d’analyser les conditions de base qu’un catalogue devrait remplir (sans devoir tout remettre en question et sans renoncer aux acquis qui font sa spécificité et sa richesse), afin d’investir pleinement les possibilités actuelles et devenir enfin un « OpenCatalog(11) ».
Plusieurs raisons peuvent expliquer ce retard en dépit d’une communauté de bibliothèques bien structurée et dynamique. Les contraintes physiques et matérielles importantes imposées aux catalogues (catalogues papier reliés en volumes, format des cartes pour les cardex ou limitations de mémoire pour les premiers systèmes informatisés) ont probablement joué un rôle majeur (Calhoun, 2006, p. 36). Ainsi, le catalogue a pris l’option d’être un système autoréférentiel, autarcique, dans le sens où il s’autosuffisait, ne citant pratiquement pas de ressources externes en dehors de son propre univers informationnel. Par conséquent, la bibliothèque de type universitaire ou encyclopédique, utilisant ce modèle de catalogue, qui a parfaitement fonctionné et perduré pendant des siècles, complété par d’imposantes bibliographies, des répertoires des périodiques, des services de commandes et de prêt entre bibliothèques, pouvait alors prétendre à une très large exhaustivité.
La combinaison de ces deux aspects a engendré des méthodes de travail : le catalogage, et un produit : le catalogue, qui ont peu évolué en comparaison avec le reste des outils informatiques dans le domaine de l’édition commerciale qui, eux, ont dû faire face et s’adapter plus rapidement aux changements radicaux survenus depuis l’arrivée du web et des NTICs(12). Les bibliothèques ne se sont pas mobilisées pour faire évoluer leurs catalogues face à ces bouleversements. Les évolutions restent très lentes, avec beaucoup d'expérimentations et des réalisations partielles(13).
Si nous remontons dans le temps, nous pouvons constater que les bibliothèques ont été très actives dans la période d’informatisation des catalogues au cours des années 70-80, dont l’un des meilleurs exemples est le système de catalogage et de gestion SIBIL(14) développé à la BCU(15) de Lausanne (Gavin, 1997). Cette étape a apporté le format MARC(16) utilisé actuellement dans la plupart des bibliothèques, malgré une remise en question récurrente. Les bibliothèques ont aussi participé activement au projet du WWW. Par exemple, il est significatif que le premier site web en dehors du CERN(17) fût créé par Louise Addis, bibliothécaire du Stanford Linear Accelerator Center (SLAC)(18), qui devenait ainsi la première bibliothécaire–webmaster de l’histoire(19). Aussi, dès les premiers temps du web, les catalogues des bibliothèques sont devenus accessibles sur la Toile de manière libre et gratuite pour la plus grande satisfaction des utilisateurs du monde entier. Ces OPACs (« Online Public Access Catalog ») ont été aussi l'une des premières réalisations à grande échelle du principe de la séparation entre contenu et mise en page, principe popularisé plus tard pour les systèmes de gestion de contenu (CMS)(20). L’aspect collaboratif du travail de catalogage partagé (chaque notice du catalogue peut en principe être corrigée ou améliorée par n’importe quel autre catalogueur du réseau) était aussi en avant par rapport à son temps. Cependant, ce sont les wikis(21) qui, en donnant cette possibilité d’édition des données à tout un chacun, ont poussé le concept de travail collaboratif à l’extrême et l’ont popularisé dans l’univers du web. De la même façon, le protocole de communication Z39.50(22) , développé et maintenu depuis plus de 20 ans par la Library of Congress(23) , fut l’un des précurseurs d’Internet et, malgré un déclin important dû à son « incompatibilité » avec les technologies web(24) , il est toujours utilisé par un bon nombre de logiciels (bibliographiques ou de pompage des notices) et de plateformes de métarecherche comme le KVK(25).
Lorsque les catalogues informatisés (souvent gérés, comme dans le cas de SIBIL, avec des outils développés localement) ont atteint une taille trop importante, ils ont dû migrer sur des outils devenus propriétaires et développés par des entreprises commerciales internationales. Cette évolution a peut-être tué une bonne partie de l’initiative des bibliothèques qui se sont peu à peu tournées vers d’autres fronts (Open Access et serveurs institutionnels pour lutter contre la crise des prix des périodiques et gérer les publications institutionnelles par exemple) et vers d’autres outils destinés au web et venant compléter le catalogue (portails, CMS, blogs(26) et wikis, podcasts(27) , outils de gestion de liens(28) et de recherche fédérée…), laissant un peu pour compte son outil principal de travail dont on annonce régulièrement plus ou moins la fin ou la désintégration.
Ainsi, la publication web des catalogues reflète encore passablement cet ancien esprit autarcique, et les OPACs restent souvent « déconnectés » du reste des ressources en ligne(29) et sont, encore aujourd’hui, conditionnés par d’anciennes limitations qui n’ont plus de sens dans l’environnement culturel et technologique actuel.
Le catalogue n’est plus un outil isolé du monde. Dans un mouvement à double sens, il doit s’ouvrir au web autant pour tirer parti des services web externes, de plus en plus importants, que pour alimenter le web en contenu et fournir des informations structurées et validées. L’enjeu est de taille : comment rester fidèle à son sens premier (répertorier de manière cohérente les ressources mises à disposition du public et aider à la recherche, découverte, localisation, et gestion des collections) tout en permettant aux utilisateurs d’apporter du contenu et du sens, ainsi que de s’approprier les données du catalogue en lui offrant des nouvelles possibilités de réutilisation à travers le web. Sans se pervertir, le catalogue doit évoluer rapidement pour pouvoir rester dans la course où il a déjà pris un retard considérable.
La conclusion d’un rapport commandé par la Library of Congress en 2006 ne laisse pas de doutes sur le chemin qui reste à parcourir : “The future will require the kind of catalog that is one link in a chain of services enabling users to find, [pick], and obtain the information objects they want. One requirement of this future catalog is thus to ingest and disperse data from and to many systems inside and outside the library. It would be helpful to reconsider what needs to be part of catalog data —and where catalog data needs to be present— to facilitate the user’s process of discovering, requesting, and getting the information they need.” (Calhoun, 2006, p. 38).
Dans les pages suivantes, nous essayerons d’explorer les possibilités de mise en place de ces deux ouvertures souhaitables du catalogue : l'ouverture à l'intégration des nouveaux contenus (internes ou externes) et, d'autre part, l'ouverture à de nouvelles formes d'utilisation de ses propres données par des tiers.
1ère partie : ouverture du catalogue à l'intégration des nouveaux contenus
1. Intégration de l’hypertexte : deux modèles à suivre
Grâce aux logiciels libres et surtout au couple PHP/MySQL(30), l’architecture de la Toile a changé et repose désormais sur un vaste ensemble de bases de données. Le Web est devenu une véritable plateforme de travail, autonome, indépendante des contraintes spatiales ou matérielles liées à des systèmes d’exploitation, des versions des logiciels, etc. De la même façon que la messagerie peut être utilisée depuis n’importe quel ordinateur relié à Internet à l’aide d’un simple navigateur, il sera bientôt possible de travailler avec un minimum de logiciels et clients lourds installés sur les postes, car la plupart des outils seront disponibles en version 100% web(31).
A l’image des développements réalisés pour les autres outils de gestion et de diffusion de l’information, la logique et les mécanismes de fonctionnement du catalogue sont de plus en plus orientés vers le web, au détriment des autres formes de consultation ou de publication (clients professionnels en mode OPAC installés sur les postes de consultation, bulletins de nouvelles acquisitions, bibliographies nationales…). Si cette tendance suit un certain effet de mode, elle correspond aussi à un changement dans le mode de fonctionnement de la société occidentale, de plus en plus relié à Internet à haut débit, et qui dédie de plus en plus de temps à la « consommation » de médias numériques, qui dépassent déjà chacun des autres médias traditionnels (TV, radio, journaux et revues papier, cinéma, etc.)(32) . Cette évolution qui semble pour l’instant irréversible, nous pousse à repenser le catalogue comme un outil fait par et pour le web, intégrant ainsi de manière véritable ce média dont la caractéristique et l’avantage principal réside dans l’immédiateté et dans la navigation à travers les liens hypertexte. Les deux outils principaux de publication web actuels, les blogs et les wikis, sont des bons exemples de la façon dont cette dimension hypertextuelle peut être ajoutée à l’information de manière simple et rapide.
Les blogs
Tout comme la messagerie web, le blog, né directement dans l’univers de l’Internet, a adopté le HTML comme langage principal. Il utilise toutefois un intermédiaire pour aider les non initiés à la saisie : le code HTML est généré et caché automatiquement par un outil d’édition de type WYSIWYG(33) . Pour les courriels, le code HTML est encapsulé dans le corps du message. Dans les blogs, il est enregistré dans la base de données et re-proposé à nouveau tel quel sur le web(34) :
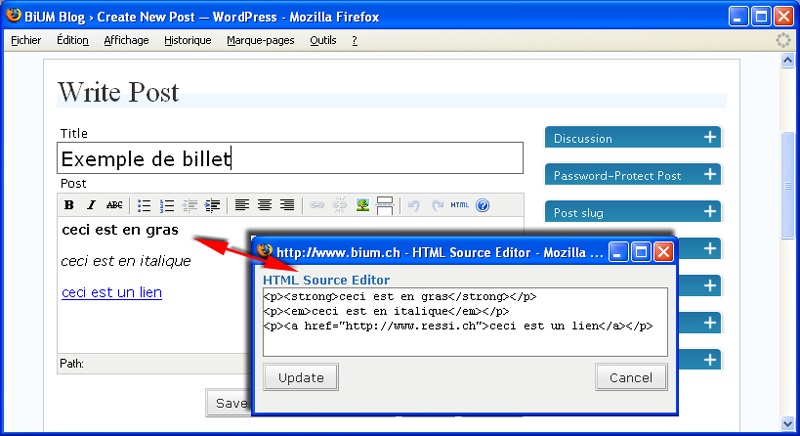
Les wikis
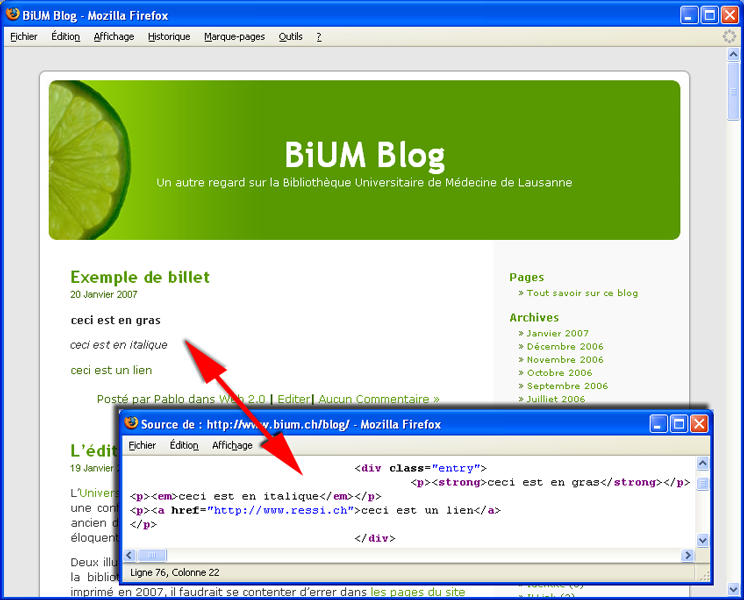
Dans les wikis, le code HTML est simplement produit à la volée(35) au moment de l’affichage de la page. Les balises HTML sont créées dynamiquement en fonction de la syntaxe propre au wiki. On assiste alors à la transformation d’une syntaxe arbitraire et plus ou moins proche du HTML vers la syntaxe HTML. Par exemple :
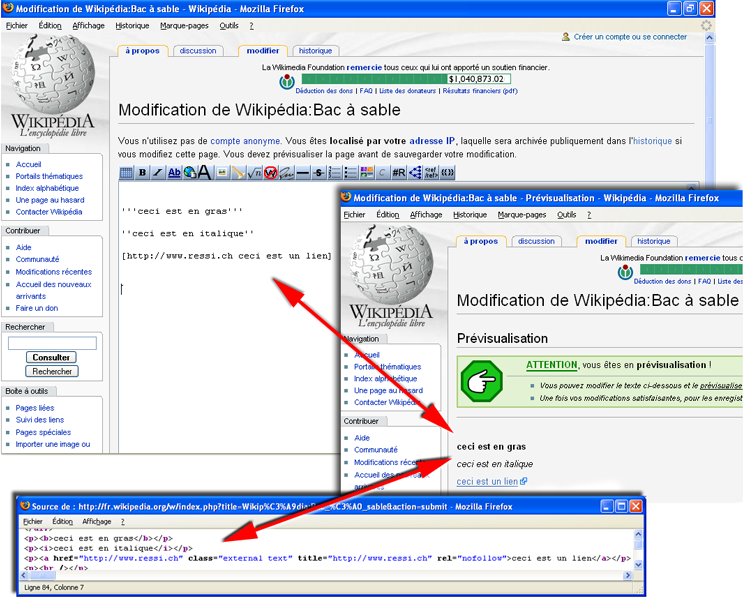
La syntaxe wiki étant plus facile à retenir que les balises HTML, les textes peuvent être alors écrits rapidement et on peut utiliser l’aide des boutons de l’éditeur qui effectuent les mêmes fonctions que les éditeurs WYSIWYG, mais sans cacher le code et sans faire la transformation en HTML. Seul le texte avec la syntaxe propre au wiki est alors enregistré dans la base de données et non pas du code HTML.
Cette intégration du code au message, en HTML ou selon une syntaxe propre, permet d’apporter les améliorations suivantes avec peu d’efforts :
- Disposer du véritable hypertexte, avec des liens internes ou externes intégrés au message sans devoir à chaque fois afficher l’URL en clair.
- Ajouter une mise en page simple à l’intérieur du texte (courriel, corps d’un billet sur un blog, page entière d’un wiki) : gras, italique, souligné, listes numérotées ou à puces, tableaux, ajout d’images.
Extraire certaines parties (titres) dans le cas du wiki, pour créer des tables des matières à la volée.
Ces applications peuvent être utiles aussi aux catalogues dans les zones destinées aux notes, commentaires, résumés ou tables des matières, qui souffrent aujourd’hui du manque de mise en page et d’hypertexte :
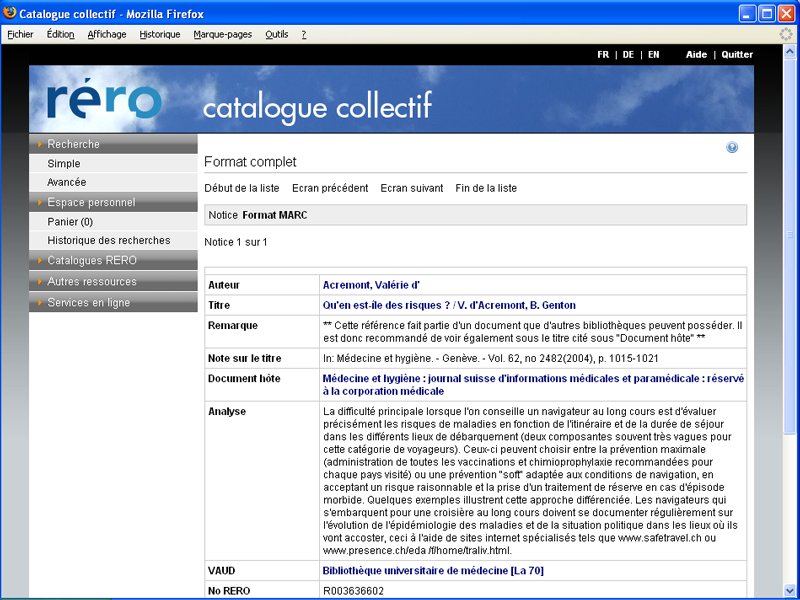 Source : http://opac.rero.ch/get_bib_record.cgi?rero_id=R003636602
Source : http://opac.rero.ch/get_bib_record.cgi?rero_id=R003636602 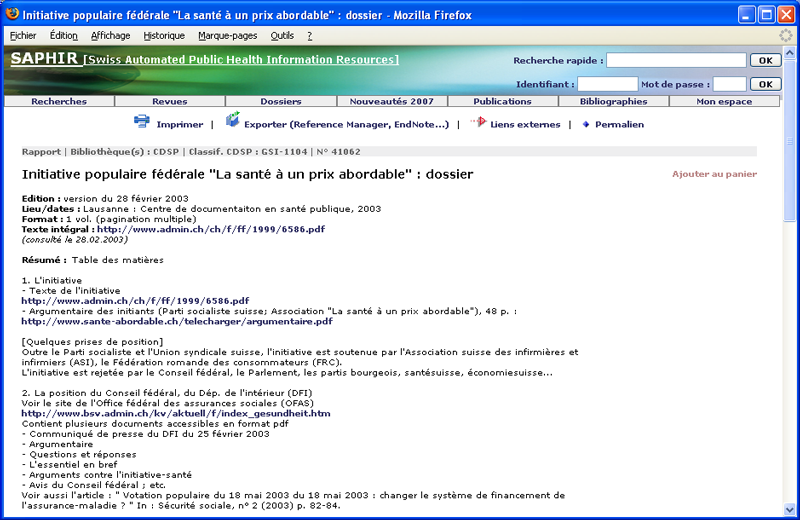 Source : http://www.saphirdoc.ch/permalien.htm?saphirid=41062
Source : http://www.saphirdoc.ch/permalien.htm?saphirid=41062
Cependant, avant d’appliquer l’un ou l’autre modèle au catalogue, il faut évaluer en profondeur les utilisations pour lesquelles cette introduction des balises ou des syntaxes pourrait être nuisible (impression des catalogues sur papier, maintenance à long terme des tables de conversion entre la syntaxe ou les balises et la mise en page…).
Malgré l’absence encore du véritable hypertexte dans les catalogues, il faut noter que le format MARC prévoit la zone 856(36) pour les URLs en admettant un sous-champ pour ajouter un commentaire qui permet de le qualifier ou de lui donner un contexte sommaire. Ces URLs sont alors transformés à la volée en hyperliens par le système au moment de l’affichage qui, trop souvent encore, se fait uniquement au niveau de la notice complète(37).
La présence des URLs dans la notice (champ 856 mais aussi dans le champ du titre, des notes, du résumé…) est un pas important, mais il n’est pas tout. Pour être vraiment utiles à l’internaute, ces URLs doivent impérativement être transformés en lien hypertexte dans la page HTML de l’OPAC, faute de quoi ils seront affichés comme du simple texte qui ne peut pas « être cliqué », et l’utilisateur doit faire recours au copier/coller pour placer cet URL dans l’adresse du navigateur. Pour éviter cela, les logiciels de gestion tentent systématiquement d’effectuer cette transformation URL -> hyperlien en scrutant chaque champ au moment de l’affichage, à la recherche d’un URL. Certains le font mieux que d’autres, car si en principe il est simple pour une machine de trouver le début et la fin d’un URL bien formé au milieu d’une chaîne de caractères (commence par « http:// » et fini par un espace), il est plus complexe de tester toutes les autres variantes possibles (l’URL ne commence pas par « http:// » mais directement par « www. » ; ou ne finit pas par un espace mais par un point, une virgule ou la fin d’une parenthèse…). Ce problème, récurrent aussi dans le cas des courriels qui portent des URLs dans le corps du message, est de difficile solution sans l’utilisation d’un codage à priori comme ceux utilisés par les blogs et les wikis.
Dans le cas du catalogue de RERO(38), le système convertit automatiquement à la volée chaque champ contenant « http:// » (856 mais aussi les champs de titre et des notes) en lien hypertexte, au moment de l’affichage sur l’OPAC. Cependant cette conversion se limite au premier URL trouvé dans le champ(39), et elle ne se fait pas pour les URLs qui ne commencent pas par « http:// » mais par exemple « www.»(40) , ce qui limite l’utilisation des liens dans un même champ. Dans le réseau SAPHIR(41), étant donné que le nombre des URLs est plus important à l’intérieur d’un seul champ comme le résumé, la transformation a été étendue à tout URL contenu dans ce champ, et aussi pour ceux qui commencent par « www. ».
Si cette génération à la volée des hyperliens est possible grâce aux caractéristiques reconnaissables des URLs, pour les autres points utiles du codage à priori (mise en page, gras, italique, listes…) il n’y a pas de solution automatique à posteriori. Par conséquent, pour améliorer la mise en page et faciliter la lecture pour les longs résumés correspondant à certains dossiers thématiques, le catalogue SAPHIR a adopté le modèle du wiki de façon encore informelle comme nous le montre la copie d’écran ci-dessous.
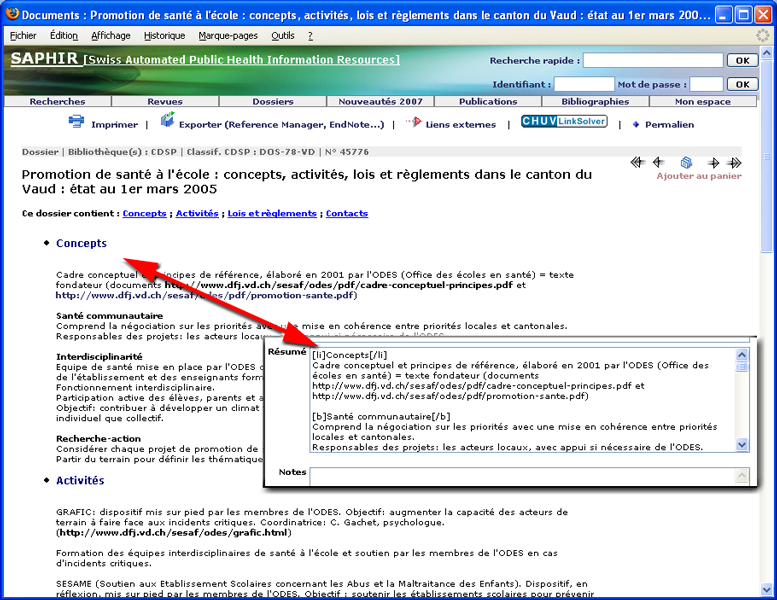 Source : http://www.saphirdoc.ch/permalien.htm?saphirid=45776
Source : http://www.saphirdoc.ch/permalien.htm?saphirid=45776
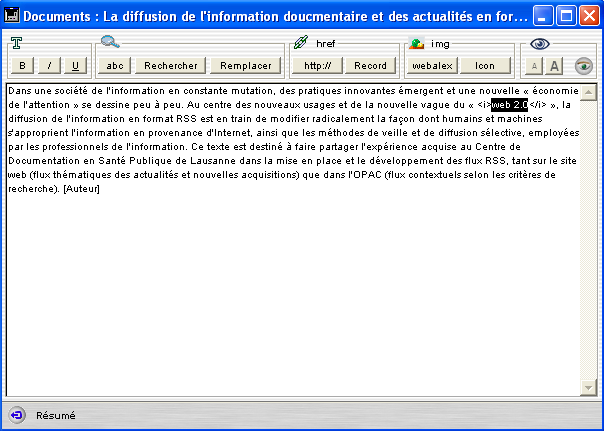
De son coté, le logiciel Alexandrie(42), SIGB utilisé par ce réseau, a aussi introduit une possibilité de mise en page dans les résumés des documents, en suivant le modèle du blog : trois boutons permettent d’ajouter les balises HTML pour appliquer au texte les styles gras, italique et souligné. Deux autres boutons permettent d’ajouter des liens hypertexte sur des pages externes ou des documents internes à la base, et encore deux pour ajouter des images du serveur :
Dans le champ de logiciels de gestion bibliographiques, le système RefWorks(43), qui fonctionne entièrement sur le web, a aussi introduit un éditeur WYSIWYG pour ajouter certains styles (gras, italique, souligné, exposant ou indice) aux champs titre, notes et commentaire :
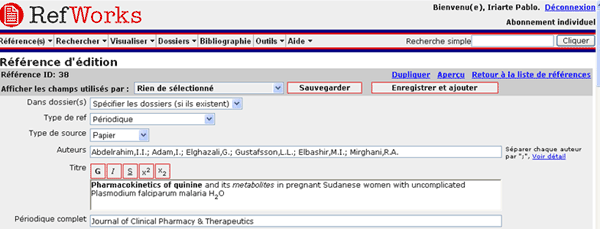
Le code HTML introduit dans la base est correctement supprimé dans tout format d’export sauf pour les bibliographies de type HTML ou RTF, dans lesquelles l’enrichissement graphique est utile et peut être conservé.
2. L'enrichissement des catalogues
Les systèmes automatisés mis au point pour la recherche d'informations textuelles sur le web, moteurs de recherche, annuaires, méta moteurs, rivalisent en performance et en innovations et montrent le chemin en matière de fonctionnalités et d'enrichissements possibles pour les catalogues. Plusieurs niveaux sont concernés : le graphisme, l'ergonomie de l'affichage, l’intégration d’informations complémentaires (résumés, commentaires, tables des matières), l'aide à la recherche, les possibilités de tri des résultats, etc.
Images de couverture, résumés et tables des matières des livres
Les catalogues de bibliothèques sont des mines d'information librement disponibles. Mais les données sont très dépouillées et certaines informations importantes manquent encore terriblement à l'appel, comme les tables des matières et les résumés.
Depuis plusieurs années, les moteurs de recherche et les sites commerciaux comme Amazon(44) ont montré une très grande inventivité en enrichissant de plus en plus leur contenu qui, en devenant plus étendu, attire de plus en plus d'utilisateurs qui à leur tour le complètent, dans un phénomène de cercle vertueux qui s’auto-génère une fois dépassée une certaine masse critique. Des fournisseurs de services sont alors apparus permettant aux bibliothèques de s'offrir ce que d’autres avaient réussi à intégrer : tables des matières, résumés et images de couverture sont maintenant vendus ou loués par des sociétés comme Electre(45) ou Syndetics(46). Il est ainsi possible de les ajouter au catalogue à la demande (au moment de la visualisation de la notice complète par exemple) à partir de l'ISBN(47) du document.
Avec une autre logique commerciale visant plutôt à étendre son rayon d’influence et à promouvoir son site grâce aux liens hypertexte, les services web mis en place par Amazon(48) , permettent depuis l’année 2002 d'utiliser gratuitement le contenu en provenance de sa propre base (images des couvertures, revues des lecteurs, prix, etc.) sur n'importe quel autre site Internet qui respecte les conditions légales d’utilisation. Ainsi plusieurs catalogues utilisent déjà les services web d’Amazon pour enrichir les pages du catalogue : Dreiländerkatalog(49) , Lamson Library(50), etc.
Le catalogue SAPHIR, qui a toujours repris dans ses notices des résumés et éléments de tables des matières, utilise maintenant aussi ces services web pour afficher l’image de couverture sur la page de la notice complète des livres. En utilisant de façon contextuelle l’ISBN et le code de la langue du document introduits au catalogage, la technique AJAX(51) permet d’appeler les services web d’Amazon.fr, Amazon.de ou Amazon.com du côté client (c’est le navigateur qui fait le travail) sans aucune charge supplémentaire du coté serveur(52) :
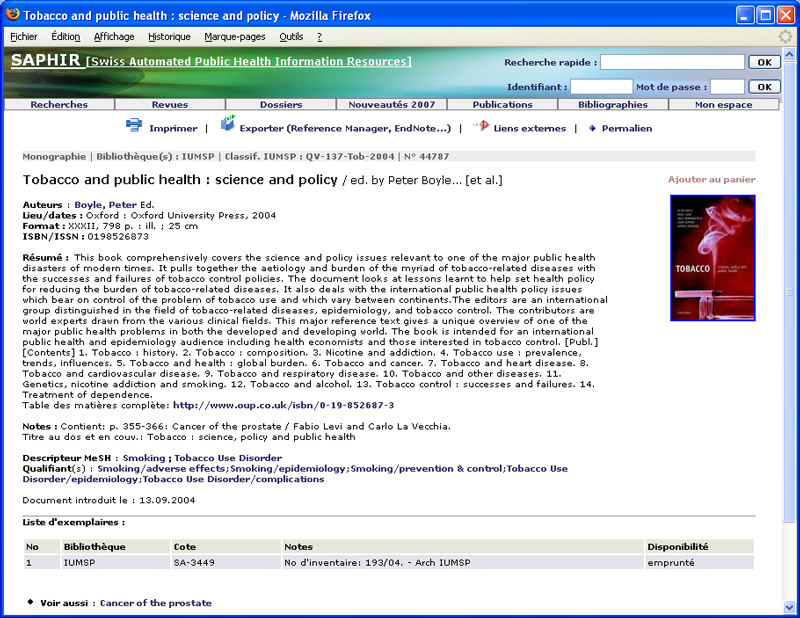 Source : http://www.saphirdoc.ch/permalien.htm?saphirid=44787
Source : http://www.saphirdoc.ch/permalien.htm?saphirid=44787
Si l’affichage à la demande dans l'OPAC de contenus externes est intéressant et relativement facile à mettre en place, il a le désavantage de ne pas enrichir le contenu de la base de données. Si les tables des matières et les résumés ne sont pas indexés comme les autres champs, il ne sont pas recherchables en même temps que les données du catalogue. D'autres services permettent de remédier à cet inconvénient en permettant d'importer dans la base de données des résumés et tables des matières qui sont alors vendus, et non plus simplement accessibles sous licence comme dans le cas précédent.
Echanges des notices entre catalogues
Avec l’utilisation des AACR2(53) comme règles communes de catalogage et, grâce à des outils simples de pompage(54), intégrés au système de gestion et qui utilisent le protocole Z39.50 mais aussi des techniques d’extraction à partir de pages web, les bibliothèques ont commencé plus que jamais à réutiliser des notices en provenance d’autres catalogues.
En dépit de la réticence de certains catalogueurs qui voient là un risque de perte de créativité (Gavin, 2006), cet usage est devenu très courant et soutenu(55) par la plupart des bibliothèques des réseaux suisses (RERO, IDS(56), etc.).
Importation et syndication des notices d’articles
L’explosion de la production scientifique a poussé depuis quelques années les producteurs de bases de données bibliographiques à développer des partenariats forts avec les éditeurs. Par exemple, la NLM(57), qui produit une base de la taille et de l’importance de PubMed(58), a cessé en 2006 d’introduire manuellement les métadonnées dans sa base, grâce au développement à grande échelle de l’importation des notices d’articles en format XML fournis par les éditeurs(59). Cette technique d’importation des flux XML permet à PubMed de diffuser très rapidement l’information reçue, car les contrôles et les améliorations successives des notices (corrections, indexation…) se font progressivement sans entraver la diffusion des références, qui gardent le même identificateur quel que soit le stade du traitement dans le système. Lorsque les éditeurs ne sont pas à même de fournir les notices dans ce format XML, un système de numérisation puis d’OCR(60) est utilisé pour importer les références avec les résumés dans la base.
Ces partenariats ont toujours fait défaut dans le domaine des bibliothèques, où la relation avec les éditeurs n’est pas de toute évidence, car l’un des rôles subversifs de la bibliothèque provient du fait qu’elle donne accès, à moindre coût, à des contenus soumis au droit d’auteur (Le Moal, 2004) et surtout aux lois du commerce. Du moment où l’hypertexte entre en jeu, les bibliothèques ont un argument pour la négociation, car elles peuvent rendre service aux éditeurs en ajoutant des liens vers leurs plateformes de commerce électronique (ou via des librairies en ligne), ce qui pourrait permettre de développer des collaborations plus importantes.
Une autre possibilité à explorer pour les bases qui ont des ressources plus modestes est d’utiliser les flux RSS(61) offerts par les éditeurs comme source pour l’importation des données dans le catalogue. Le projet TOCRRoS(62) va dans ce sens, en permettant d’ajouter automatiquement et périodiquement les articles publiés par les revues pour lesquelles la bibliothèque dispose d’un abonnement en cours. Le logiciel de gestion Alexandrie permet depuis la version 6 d’importer automatiquement des contenus en provenance des flux RSS externes.
Sans arriver à l’intégration de ces informations dans le catalogue lui-même, une dernière possibilité consiste à afficher le contenu du dernier numéro d’un périodique proposant un flux RSS, au moment de l’affichage de la notice complète dans l’OPAC (Iriarte, 2006). Cette possibilité nécessite l’enregistrement préalable de l’adresse du flux RSS dans le catalogue, pour ensuite pouvoir utiliser de façon contextuelle des services de conversion RSS -> Javascript offerts par différents sites(63).
Importation des notices en provenance des archives ouvertes : utilisation du protocole OAI-PMH(64)
De la même façon qu’aujourd’hui nous pouvons importer dans le catalogue des informations en provenance des flux XML (en format ONIX(65), RSS ou autre) proposés par les éditeurs, il serait possible d’utiliser le protocole OAI-PMH pour ajouter des références en provenance des archives ouvertes ou des dépôts institutionnels comme e-prints(66), arXiv(67), HAL(68), RERO DOC(69), Infoscience(70), etc.
Cette possibilité de moissonner des serveurs de documents à partir du catalogue ne semble pas, à notre connaissance, avoir été exploitée dans les bibliothèques. C’est plutôt dans le sens inverse, c’est-à-dire l’intégration des notices du catalogue dans une base externe, que nous pouvons trouver des réalisations, comme dans les cas des notices de l’OPAC intégrées au serveur institutionnel du CERN (CERN Document Server(71)) ou dans la plateforme Infoscience de l’EPFL (72).
Cette intégration des références provenant de sources hétérogènes dans une couche supplémentaire, permet une plus grande souplesse : il n’y a pas le risque de toucher aux notices qui servent en même temps à la gestion, et éviter d’appliquer aux données importées les mêmes critères de qualité et de sécurité que pour les notices du catalogue. La base de données située dans cette couche (par exemple WorldCat(73), Dreiländerkatalog, TEL(74), etc.) peut alors proposer de nouveaux services et peut être ouverte aux contenus générés par les utilisateurs, dans la ligne des outils sociaux ou web 2.0(75). Dans ce sens il y a un nouveau marché qui se développe, avec des nouveaux outils orientés web 2.0 qui sont proposés aux bibliothèques comme RLG(76), Primo(77), etc.
Texte intégral
L’année 2006 a vu le développement de la campagne de numérisation de livres à grande échelle, « Google Books(78) » , entreprise par la société Google en 2004 en collaboration avec deux groupes de partenaires : d’un côté certains éditeurs et de l’autre un groupe restreint de bibliothèques(79) . D’abord appelé « Google Print », le nom du programme est devenu « Google Books » en 2006, pour palier entre autres aux tensions entre Google et certains éditeurs.
Sans complexe, Google Books affiche l’ambition « de travailler avec des éditeurs et des bibliothèques pour créer un catalogue virtuel complet de tous les livres et dans toutes les langues, dans lequel les internautes pourront effectuer des recherches. »
Si ce projet reste encore très controversé (Salaün, 2005), il a eu le mérite de réveiller la communauté des bibliothèques qui, avec le Président de la Bibliothèque Nationale de France M. Jeanneney à la tête, a réagi de façon active en donnant une impulsion plus forte au projet de la bibliothèque numérique européenne(80) . D’autres bibliothèques ont aussi annoncé des projets de numérisation à large échelle. La British Library(81) a conclu un partenariat avec la société Microsoft(82). De leur côté Yahoo! et la fondation Internet Archive(83) ont aussi annoncé le début de sa propre campagne « Open Content Alliance(84) » . La Library of Congress est, quant à elle, en discussion avec l’UNESCO pour amorcer le lancement d’une Bibliothèque numérique mondiale(85).
Le projet de Google a aussi commencé à porter ses fruits et une grande quantité d’information contenue dans ces bibliothèques est devenue accessible, même si la qualité de numérisation peut être jugée décevante(86). A l’heure actuelle, 10'000 éditeurs et 13 bibliothèques font partie du projet dans son ensemble et, selon les chiffres donnés par Google, le nombre des livres dans son index avoisine le million(87).
Selon le contrat que les bibliothèques participant au volet « Google Books for Libraries » ont signé avec la société Google(88), les fichiers issus de la numérisation ne pourront pas être diffusés par la bibliothèque sans l’accord de Google, ce qui limite leur utilisation dans le catalogue. Malgré cette entrave commerciale, la bibliothèque de l’Université de Michigan(89) propose de visualiser le document numérisé(90)en format image, texte ou pdf dans sa propre plateforme digitale(91) par le biais d’un lien figurant dans la notice complète du catalogue, parallèlement au lien sur le même document dans la plateforme de Google :
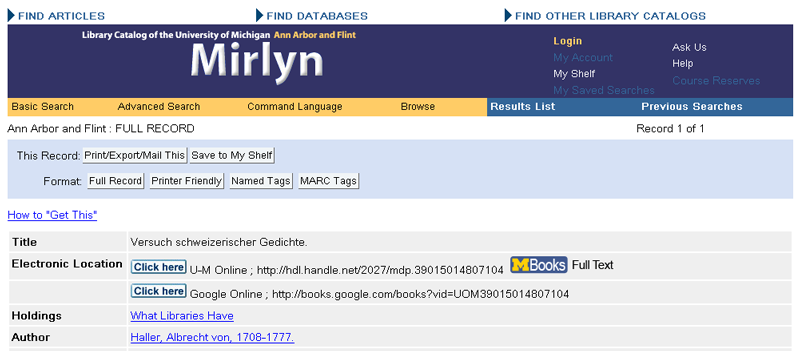 Source : http://mirlyn.lib.umich.edu/F?func=find-b&find_code=MDN&local_base=MIU01_PUB&request=39015014807104
Source : http://mirlyn.lib.umich.edu/F?func=find-b&find_code=MDN&local_base=MIU01_PUB&request=39015014807104
Selon ce même principe, les bibliothèques établissent aujourd’hui de plus en plus des liens vers le texte intégral des documents situés sur des serveurs externes au catalogue : articles de périodiques électroniques (en open access ou payants), documents disponibles en libre accès dans les bibliothèques numériques nationales ou internationales (Gallica(92), Projet Gütenberg(93), Biblioteca Virtual Cervantes(94) …), e-prints et thèses des archives ouvertes, etc. Cependant, dans la plupart des cas, ce lien est créé uniquement manuellement (avec les risques que cela comporte, comme la faible pérennité des liens quand on sort du cadre du DOI(95)) et facultativement au moment de la création d’une nouvelle notice et non pas de façon rétrospective. Vu le rythme des campagnes de numérisation en cours, cela signifie que de plus en plus de notices dans nos catalogues resteront sans lien hypertexte avec la version électronique disponible pourtant quelque part sur Internet. Seul un outil performant de gestion des liens peut servir de solution à ce problème, comme nous l’évoquerons dans la deuxième partie, seulement. Après les difficultés rencontrées au moment vouloir intégrer les revues en format électronique au catalogue, nous risquons de nouveau de voir s’agrandir le fossé entre catalogue et ressources en texte intégral en ligne.
Concernant la recherche sur le texte intégral, étant donné que le stockage des documents numériques se situe généralement sur des serveurs déconnectés du catalogue, la recherche simultanée dans les métadonnées et dans le texte intégral des documents ne peut pas être proposée dans l’OPAC, sauf si c’est le catalogue lui-même qui rejoint cette plateforme des documents numériques, comme nous l’avons vu plus haut dans l’exemple du CERN et de l’EPFL.
Dans le cas de l’Université de Michigan, de même que dans le service « Search Inside » d’Amazon(96), la recherche dans le texte intégral ne peut se réaliser que sur un seul document à la fois. Il faut alors passer par Google Books pour pouvoir effectuer une recherche sur l’ensemble du texte intégral de la collection en même temps que sur les métadonnées fournies par la bibliothèque.
Liens profonds : le rôle des identificateurs
Comme nous venons de constater plus haut, les catalogues de bibliothèques introduisent de plus en plus de liens profonds pointant sur le texte intégral du document répertorié ou sur la notice bibliographique résidant sur une base de données externe comme PubMed, dans le but de donner à l’utilisateur le plus grand nombre d’informations disponibles et de source sure, concernant le document catalogué : résumé et liens offerts par PubMed, texte intégral ou résumé offert par l’éditeur de la revue ou sur une plateforme Open Access, nombre de fois que l’article est cité, offerts par une base de données comme Google Scholar, etc.
L’utilisation de ces liens profonds pose de nouveaux problèmes et de nouveaux défis aux catalogues, qui devraient en plus les maintenir à jour à l’aide des méthodes plus ou moins automatisés. Dans cette recherche de stabilité, seulement les liens profonds basés sur des identificateurs pérennes comme le DOI(97) , le PMID(98) ou un identificateur OAI-PMH(99) , ont de garanties de perdurer dans le temps. Il est donc évident qu’il faut utiliser ces identificateurs de façon préférentielle pour établir des liens dans le catalogue, et que nous devons les prendre en charge avec le même soin que nous appliquons à l’ISBN : dans un champ à part bien identifié et avec une syntaxe cohérente et normalisée de type URN(100) . Par exemple il serait préférable d’enregistrer le DOI ou le PMID dans un champ ad hoc et de générer l’URL à la demande, au lieu d’enregistrer cette adresse directement dans le champ dédié aux liens Internet :
- doi:10.1000/182 -> http://dx.doi.org/10.1000/182
- pmid:1234 -> http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?cmd=retrieve&db=pubmed&list_uids=1234
La raison de cette préférence réside dans le fait qu’il est possible d’utiliser cet identificateur à d’autres fins que celui de construire un URL, comme par exemple l’utiliser dans un OpenURL destiné à trouver d’autres services associés au document ou bien dans un format d’export destiné à des logiciels bibliographiques. Bien qu’il soit toujours possible d’extraire automatiquement l’identificateur à partir de l’URL, c’est bien le cas contraire qui est plus aisé et canonique, d’autant plus que les URLs utilisés par CrossRef(101) et par PubMed, bien que garantis pour un bon nombre d’années, ne sont pas des liens pérennes et peuvent varier dans le futur (on peut imaginer par exemple un nouveau protocole qui remplacerait le http, etc.).
Dans la même optique, le catalogage des notices d’articles (aussi appelées notices analytiques) devraient incorporer autant que possible ces identificateurs pérennes ainsi que l’ISSN(102), seul élément d’identification fiable de la revue à laquelle ils appartiennent. Si ces informations, ainsi que la date de publication, le numéro du périodique, du volume, la page de début et celle de fin de l’article étaient codées de façon structurée dans ce type de notices, ce qui est loin d’être le cas aujourd’hui dans la plupart de catalogues de bibliothèques(103), l’utilisation d’un outil de gestion de liens serait beaucoup plus efficace et permettrait une plus grande précision à l’heure d’identifier l’existence du texte intégral ou de proposer des services associés via un OpenURL en provenance de l’OPAC.
Contenu généré par les utilisateurs
Suivant l’exemple des sites commerciaux comme Amazon et des outils sociaux de plus en plus nombreux (Wikio(104), del.icio.us(105), Flickr(106), Connotea(107) …), il est grand temps que les lecteurs puissent déposer des annotations, des tags ou des commentaires par rapport aux livres disponibles dans les catalogues des bibliothèques et, pourquoi pas, les laisser intervenir sur l'indexation des documents avec des tags, sans utiliser les ressources du SIGB, mais en offrant des applications s’appuyant sur des services web comme le fait par exemple HubMed(108).
Cette possibilité de commenter ou tagger l’information est déjà implémentée dans certains catalogues ou archives ouvertes : WorldCat, Lamson Library(109), Dreiländerkatalog, CERN Document Server… Cependant, elle est absent de la plupart des OPACs classiques gérés par un SIGB.
Utilisation des données de gestion
En s’inspirant d’Amazon, les catalogues ont commencé à exploiter les données générées par l’activité des utilisateurs pour effectuer des suggestions de lecture :
- à partir des données anonymisées en provenance des emprunts, comme le fait la Ann Arbor District Library (AADL)(110) : « Les utilisateurs qui ont emprunté ce document ont aussi emprunté…»
- à partir des données en provenance de la consultation web, comme le fait RERO DOC : « Les utilisateurs qui ont vu cette page ont aussi vu… »
La possibilité d’exploiter de façon dynamique et pondérée les données du document en cours de visualisation, peut aussi conduire à des suggestions de type « Related articles » de PubMed ou « Related Books » de WorldCat.
Autres services web bibliographiques
En dehors des services web d’Amazon, il y a malheureusement un choix très restreint pour le moment :
- XISBN(111) (OCLC) : ISBNs en relation avec l’ISBN envoyé (utilisé par le Dreiländerkatalog)
- CrossRef(112) : Métadonnées à partir d’un DOI et vice-versa
- PubMed(113) : une des applications les plus avancées dans ce domaine, il met à disposition de la communauté plusieurs services web : métadonnées à partir d’un ou plusieurs PMIDs ou vice-versa, ainsi que les articles liés ou les informations des bases de données connexes (génétique, moléculaire, etc.) à partir de l’identificateur d’une ou de plusieurs références. Il offre aussi par service web la correction orthographique des termes de recherche.
D’autres services web généralistes pourraient être aussi exploités, comme par exemple l’affichage des localisations géographiques des bibliothèques d’un réseau qui possèdent un document en particulier, en utilisant l’API de Google Maps(114). Un service web de ce type pourrait aussi être utilisé pour afficher l’emplacement précis dans lequel une image ou un film du catalogue a été prise. Ceci nécessiterait l’ajout des métadonnées géographiques (ou « geotagging »(115) ) au catalogage des images fixes ou animées, comme cela se fait déjà sur des plateformes de partage des photos comme Flickr(116).
Conclusion
Après cette énumération de services, d’outils et d’informations externes au catalogue dignes d’être incorporés dans cet outil, la question de la surcharge informationnelle pourrait être posée. Toutes ces options ne risquent-elles pas d’engendrer confusion et désorientation ? La force du catalogue résiderait-elle alors dans son dépouillement ? Nous pouvons en douter. Les catalogues offrent actuellement peu de possibilités pour que les utilisateurs, y compris les professionnels de l’information eux-mêmes, s’approprient cet outil, ce qui est indispensable pour qu’il puisse trouver une place importante dans l’ensemble du paysage informationnel du web, devenu aujourd’hui notre plateforme de travail.
Certes, le risque est grand de se retrouver noyé sous une masse impressionnante d'applications et d'informations. Mais en offrant des données riches, bien structurées et ouvertes à l’extérieur, ainsi qu’une interface ergonomique, simple d’utilisation et d’appropriation par les usagers, le catalogue peut prouver à nouveau son utilité et redevenir ainsi un élément fort dans l’univers d’Internet. Pour y arriver, nous avons parcouru quelques pistes qui vont dans le sens d’une maîtrise des technologies du web par les bibliothèques et dans l’intégration d’éléments externes au catalogue. L’autre aspect clé de la question, la face opposée de la même monnaie, réside dans l’ouverture du catalogue à de nouvelles formes d'utilisation de ses propres données par des tiers, dans un changement de mentalité qui considérerait « le web » comme un utilisateur à part entière.
Dans la deuxième partie de cet article, nous traiterons donc les aspects suivants liés à cette ouverture du catalogue vers la réutilisation de ses données :
- Citabilité et Permaliens
- OpenURL et COINS
- RSS
- Sitemaps
- Indexation par des moteurs de recherche
- Export XML pour Google Scholar
- Open search et SRU/SRW
- Services web et APIs
Notes
(1) Quelques exemples sortis de la « biblioblogsphère » : Burn the catalog http://www.swarthmore.edu/SocSci/tburke1/perma12004.html ; Disintegration, disenchantment, distrust, and development http://www.polarislibrary.com/forums/blogs/techtidbits/archive/2006/12/0...
(2) If amazon sucked like our old opac http://library2.csusm.edu/amazon/index.htm
(3) Caractérisés par le phénomène connu sous le nom du « web 2.0 »
(4) eXtensible Markup Language http://www.w3.org/XML/
(5) http://www.opensource.org
(6) http://openaccess.inist.fr
(7) http://www.openarchives.org
(8) http://openurl.info/registry
(9) Uniform Resource Locator http://www.w3.org/Addressing/URL/Overview.html
(11) http://www.opensearch.org
(12) Si ce terme est complètement nouveau, le concept ne l’est pas. Voir par exemple le projet « eXtensible Catalog (XC) » de l’Université de Rochester à New-York http://www.extensiblecatalog.info/ et http://www.rochester.edu/news/show.php?id=2518 Nouvelles Technologies de l’Information et la Communication
(13) Pour suivre l’évolution et les nouveaux OPACs innovateurs, vous pouvez utiliser la liste de diffusion « NGC4Lib - Next Generation Catalogs for Libraries » et ses archives : http://dewey.library.nd.edu/mailing-lists/ngc4lib/
(14) SIBIL était à l’origine l’acronyme de « Système intégré pour les bibliothèques universitaires de Lausanne » (Gavin, 1997)
(15) http://www.unil.ch/bcu
(16) MAchine-Readable Cataloging http://www.loc.gov/marc/
(17) Conseil Européen pour la Recherche Nucléaire. Aujourd'hui le nom CERN désigne l'Organisation européenne pour la Recherche nucléaire http://www.cern.ch
(18) http://www.slac.stanford.edu
(19) http://news-service.stanford.edu/news/2001/april11/addis-411.html
(20) Content Management System
(21) Outil de publication web instantanée et ouvert aux modifications des utilisateurs. Il est utilisé par exemple pour le projet Wikipédia http://fr.wikipedia.org/wiki/Wiki
(22) Devenue norme ISO 23950 en 1998, ce protocole s’appelait dans sa version d’origine « Information Retrieval (Z39.50); Application Service Definition and Protocol Specification, ANSI/NISO Z39.50-1995 ». Il s’agit d’un protocole antérieur au web et qui spécifie des structures de données et les règles d’échange qui permettent à une machine client (nommé « origin ») de chercher des données dans un serveur (nommé « target ») et de d’obtenir les entrées résultant de cette recherche http://www.loc.gov/z3950/agency/resources/
(23) http://www.loc.gov
(24) La norme Z39.50, malheureusement très peu utilisée en dehors du domaine des bibliothèques, n’est pas exploitable à travers le protocole HTTP et il faut donc un logiciel spécifique pour l’utiliser. L’apparition de XML et les services web associés qui se développent un peu partout, sont en train de précipiter son déclin.
(25) Karlsruher Virtuelle Katalog http://www.ubka.uni-karlsruhe.de/kvk.html
(26) Outil de publication web personnelle appelé aussi weblog, carnet web, joueb… Pour plus d'information voir l’article de Wikipédia : http://fr.wikipedia.org/wiki/Blog
(27) Contraction de « iPod » et de « broadcasting ». Forme de flux RSS auquel on ajoute des fichiers sonores qui sont alors disponibles directement à partir du lecteur RSS ou téléchargeables automatiquement dans un baladeur numérique. Voir aussi la définition de Wikipédia : http://fr.wikipedia.org/wiki/Podcasting
(28) Aussi appelés « Link resolvers », ces outils permettent de générer dynamiquement une liste de liens cibles à partir des métadonnées de la source : lien vers le texte intégral ou vers le formulaire de commande, recherches par ISSN, auteur, titre ou descripteur dans les catalogues, etc. En Suisse l’outil le plus utilisé reste SFX http://www.exlibrisgroup.com/sfx.htm commercialisé par la société Ex.libris qui possède aussi le SIGB Aleph utilisé par le réseau suisse alémanique IDS.
(29) Les catalogues donnent pour le moment très peu des liens externes. Par exemple pour le catalogue collectif du réseau romand (RERO) seulement le 1% de notices portent un URL (environ 30.000 sur 3 millions)
(30) PHP est l'acronyme récursif de « PHP Hypertext Preprocessor ». PHP est un langage de script qui est très utilisé pour créer des sites web dynamiques. Site officiel : http://www.php.net. MySQL est un logiciel libre de gestion de bases de données de type SQL (Structured Query Language). Site officiel : http://www.mysql.com
(31) « Google Docs & Spreadsheets » http://docs.google.com et « Think free » http://www.thinkfree.com sont déjà des bons exemples de cette évolution. Les SIGB open source disponibles sur le marché (PMB http://www.sigb.net, Koha http://www.koha.org, OpenBiblio http://openbiblio.sourceforge.net…) sont pour la plupart déjà des systèmes « full-web » car, autant la gestion, le paramétrage, le catalogage que la consultation se font à travers le navigateur sans utiliser des clients lourds comme dans les systèmes propriétaires actuels, où seules la consultation et certaines options liées à la gestion des prêts et des lecteurs (inscriptions, réservations, prolongations, PEB, etc.) passent à travers le web
(32) Voir les statistiques publiées par l’OFS « Utilisation d'Internet dans les ménages en Suisse : Résultats de l'enquête 2004 et indicateurs » et qui montrent l’augmentation très forte de l’utilisation d’internet au sein de la population suisse ces dernières années : http://www.bfs.admin.ch/bfs/portal/fr/index/themen/kultur__medien__zeitv.... Ces chiffres suivent la tendance générale annoncée par l’UIT dans son rapport « digital.life » http://www.itu.int/digitalife et qui donnent, pour une personne entre 18 et 54 ans, une consommation moyenne hebdomadaire de médias numériques de 16 heures, tandis que de 13 heures pour la TV, 8 pour la radio, 4 pour les journaux et quotidiens papier et 1 pour le cinéma
(33) WYSIWYG est l’acronyme de la locution anglaise « What You See Is What You Get ». Les interfaces de ce type sont utilisées dans les logiciels de mise en page et surtout dans les plateformes de blogging comme outil pour pouvoir écrire facilement pour le web sans connaître le langage HTML
(34) Le fait de copier/coller du contenu en provenance d'une page web dans le corps d'un billet d'un blog peut poser des problèmes d'affichage car l'éditeur WYSIWYG cache le code HTML. Ce dernier peut pourtant contenir des balises pouvant interférer avec le code de la page du blog
(35) Généré automatiquement au moment de l’affichage
(36) http://www.rero.ch/page.php?section=zone&pageid=856
(37) C’est encore le cas des catalogues du réseau IDS et ce fut aussi le cas pendant longtemps pour les catalogues du réseau romand. Cependant, RERO a changé son approche et dans la nouvelle version de son OPAC http://opac.rero.ch, introduite depuis le 8 janvier 2007, les liens de la zone 856 sont désormais affichés déjà au niveau de la liste de résultats
(38) RERO est l’acronyme de « REseau Romand », et désigne le réseau des bibliothèques de Suisse occidentale majoritairement de langue française http://www.rero.ch
(39) Par exemple http://opac.rero.ch/get_bib_record.cgi?rero_id=R277678560
(40) Par exemple http://opac.rero.ch/get_bib_record.cgi?rero_id=R003636602
(41) SAPHIR (Swiss Automated Public Health Information Ressources) http://www.saphirdoc.ch. Base documentaire suisse spécialisé en santé publique et dont le CDSP est le responsable.
(42) http://www.gbconcept.com/pro_alexandrie.html
(43) http://www.refworks.com
(44) http://www.amazon.com
(45) http://www.electre.com
(46) http://www.syndetics.com
(47) « International Standard Book Number ». l’ISBN est un identificateur international, défini par la norme ISO 2108, et qui sert à identifier sans ambiguïté chaque livre. Existant depuis 1972, les ISBN son attribués et gérés par un réseau d’agences reparties dans 166 pays, avec une centrale à Londres. En suisse romande, c’était l'agence francophone pour la numérotation internationale du livre (AFNIL) qui gérait les numéros ISBN jusqu’à 1994. Depuis cette date, la gestion est assuré par la « Schweizer Buchhändler- und Verleger-Verband SBVV » ttp://www.swissbooks.ch/prestations/isbn/uebersicht.shtm. D’abord constitué par 10 chiffres significatives, il a passé à 13 depuis janvier 2007 devenant ainsi compatible avec les codes-barre de la norme EAN 13 http://isbn-international.org
(48) http://www.amazon.com/AWS-home-page-Money/b/ref=sc_iw_l_0/103-1555994-97...
(49) http://suchen.hbz-nrw.de/dreilaender/
(50) Projet expérimental d’OPAC http://www.plymouth.edu/library/opac/ basé sur la plateforme de blogging WordPress http://wordpress.org
(51) Asynchronous JavaScript And XML. C’est un ensemble de techniques qui permet à une page web d’échanger des informations externes sans devoir être actualisée. Voir l’article fondateur de Jesse James Garrett « Ajax: A New Approach to Web Applications » http://www.adaptivepath.com/publications/essays/archives/000385.php
(52) La technique est expliquée en détail sur le blog de la BiUM http://www.bium.ch/blog/?p=106
(53) Anglo-American Cataloguing Rules, 2nd Edition http://www.aacr2.org
(54) Comme par exemple « EZPump (EZP) » http://www.ngscan.com/easypump/index.htm, logiciel de pompage des notices bibliographiques avec client Z39.50, développé par un bibliothécaire de la Médiathèque Valais et utilisé par les bibliothèques de RERO
(55) Voir La Lettre de RERO, 2006-4 http://www.rero.ch/pdfview.php?section=lalettre&filename=LaLettre2006_04...
(56) IDS est l’acronyme de « Informationsverbund Deutschschweiz » et désigne le réseau des bibliothèques de Suisse orientale, majoritairement de langue allemande http://www.informationsverbund.ch
(57) http://www.nlm.nih.gov
(58) http://www.pubmed.org
(59) http://www.nlm.nih.gov/bsd/bsd_key.html
(60) Optical Character Recognition
(61) RSS est utilisé comme acronyme de « Really Simple Syndication », « Rich Site Summary », « RDF Site Summary » ou une autre variante de ces termes. Pour plus de détails, voir la page explicative faite par l'ADBS : http://www.adbs.fr/site/repertoires/outils/rss.php
(62) TOCRoSS http://www.jisc.ac.uk/whatwedo/programmes/programme_pals2/project_tocros...
(63) Par exemple http://itde.vccs.edu/rss2js/build.php ou http://www.rss-to-javascript.com
(64) « Open Archive Initiative and Protocol for Metadata Harvesting » http://www.openarchives.org/pmh/
(65) http://www.editeur.org/onix.html
(66) http://www.eprints.org
(67) http://arxiv.org
(68) http://hal.archives-ouvertes.fr
(69) http://doc.rero.ch
(70) http://infoscience.epfl.ch
(71) http://cdsweb.cern.ch
(72) http://www.epfl.ch
(73) http://www.worldcat.org
(74) The European Library : http://www.theeuropeanlibrary.org
(75) Voir par exemple l’article de wikipedia http://en.wikipedia.org/wiki/Web_2 et l’article fondateur de Tim O’Reilly « What Is Web 2.0 : Design Patterns and Business Models for the Next Generation of Software » http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-.... Version française : http://web2rules.blogspot.com/2006/01/what-is-web-20-par-tim-oreilly-ver...
(76) http://www.rlg.org
(77) Primo http://www.exlibrisgroup.com/webinar_1144862525.htm
(78) http://books.google.com et depuis quelque temps seulement aussi consultable sur http://books.google.ch
(79) D’abord limité à 5, maintenant ce sont 13 bibliothèques qui fournissent les documents en échange des données obtenues par la numérisation : la bibliothèque de l'Université de Virginie, de Californie, de Harvard, de Stanford, du Michigan, du Wisconsin-Madison, de Texas, de Princeton, de Madrid, d’Oxford ainsi que la bibliothèque publique de New York et les bibliothèque de Catalogne et de Bavière. La bibliothèque du Congrès américain (Library of Congress) fait l'objet d'un autre projet à part : http://www.washingtonpost.com/wp-dyn/content/article/2005/11/21/AR200511...
(80) Voir le communiqué de presse de la commission européenne : http://europa.eu/rapid/pressReleasesAction.do?reference=IP/06/253&format... et la page du programme de l’UE « i2010: Digital Libraries Initiative » : http://ec.europa.eu/information_society/activities/digital_libraries/ind...
(81) http://www.bl.uk
(82) http://www.microsoft.com
(83) http://www.archive.org
(84) http://www.opencontentalliance.org. Voir aussi l’article de CNET News.com : « Yahoo to digitize public domain books » http://news.com.com/Yahoo+to+digitize+public+domain+books/2100-1038_3-58...
(85) Voir l’annonce fait par l’UNESCO : http://portal.unesco.org/fr/ev.php-URL_ID=35949&URL_DO=DO_TOPIC&URL_SECT...
(86) Voir par exemple l’article et le billet de Lorcan Dempsey « Fingering volumes » http://orweblog.oclc.org/archives/001122.html, « Le travail bâclé de Google Print » http://www.dsi-info.ca/moteurs-de-recherche/2005/11/le-travail-bcl-de-go... ou « Digitized by Google » http://e-benedictins.blogspot.com/2006/09/digitalized-by-google.html
(87) http://librariancentral.blogspot.com/2007/03/checking-in-with-google-boo...
(88) Voir l’article de LibraryJournal.com « Release of Google Contract with UC Sparks Criticism » http://www.libraryjournal.com/article/CA6367340.html
(89) http://lib.umich.edu/
(90) Par exemple, la page 7 du document « Versuch schweizerischer Gedichte » : http://mdp.lib.umich.edu/cgi/m/mdp/pt?seq=7&size=100&id=39015014807104&v.... Voir aussi à ce sujet l’article de The Chronicle of Higher Education : « U. of Michigan Adds Books Digitized by Google to Online Catalog, but Limits Use of Some » http://chronicle.com/free/2006/08/2006083101t.htm
(91) « Mbooks » : http://www.lib.umich.edu/mdp/
(92) http://gallica.bnf.fr
(93) http://www.gutenberg.org
(94) http://www.cervantesvirtual.com
(95) Document Object Identifier : http://www.doi.org
(96) http://www.amazon.com/Search-Inside-Book-Books/b?ie=UTF8&node=10197021
(97) http://www.doi.org
(98) http://en.wikipedia.org/wiki/PMID ou http://pmid.us/
(99) http://www.openarchives.org/OAI/openarchivesprotocol.html#UniqueIdentifier
(100) http://fr.wikipedia.org/wiki/Uniform_Resource_Name
(101) Organisation chargée de gérer les DOI http://www.crossref.org
(102) L'ISSN (International Standard Serial Number) est un numéro à huit chiffres non significatives de la forme 1234-5678 et qui identifie les périodiques, y compris en format électronique. La gestion des ISSN, qui compte plus d'un million aujourd’hui, est effectuée par un réseau mondial de 80 centres nationaux (dont la Bibliothèque Nationale Suisse) coordonnés par un centre international à Paris http://www.issn.org/fr En effet dans la majorité de notices analytiques présentes dans les catalogues des bibliothèques universitaires, l’ISSN de la revue est absent.
(103) Les autres éléments clés pour identifier un article, tels le volume, et les pages de début et de fin, sont répertoriés dans une zone « In » peu normalisée et difficilement exploitables sans un traitement informatique
(104) http://www.wikio.com
(105) http://del.icio.us
(106) http://flickr.com
(107) http://www.connotea.org
(108) Interface alternative à PubMed utilisant les services web de cette dernière en ajoutant des nouvelles fonctionnalités comme le « tagging » ou la catégorisation par facettes : http://www.hubmed.org
(109) http://www.plymouth.edu/library/opac/
(110) http://www.aadl.org/catalog
(111) http://www.oclc.org/research/projects/xisbn/
(112) http://www.google.com/apis/maps/
(115) Voir l’article de Wikipedia http://en.wikipedia.org/wiki/GeoTagging
(116) http://www.flickr.com/groups/geotagging/
Bibliographie
BBF (2005). Dossier : Mort et transfiguration des catalogues. BBF : Bulletin des Bibliothèques de France [en ligne], [consulté le 15 janvier 2007], T. 50, n° 4. http://bbf.enssib.fr/sdx/BBF/frontoffice/2005/04/sommaire.xsp
BEARMAN, David (décembre 2006). Jean-Noël Jeanneney's Critique of Google: Private Sector Book Digitization and Digital Library Policy. D-Lib Magazine [en ligne], [consulté le 15 janvier 2007], vol. 12, n°12. http://www.dlib.org/dlib/december06/bearman/12bearman.html
BIBLIOGRAPHIC SERVICES TASK FORCE (décembre 2005). Rethinking How We Provide Bibliographic Services for the University of California [en ligne]. The University of California Libraries [consulté le 15 janvier 2007]. http://libraries.universityofcalifornia.edu/sopag/BSTF/Final.pdf
BROUDOUX, Evelyne, GRESILLAUD, Sylvie, LE CROSNIER, Hervé, LUX-POGODALLA, Véronika (18 septembre 2005). Construction de l’auteur autour de ses modes d’écriture et de publication. H2PTM'05 [en ligne], [consulté le 15 janvier 2007]. http://archivesic.ccsd.cnrs.fr/sic_00001552
CALHOUN, Karen, (2006). The Changing Nature of the Catalog and its Integration with Other Discovery Tools [en ligne]. Final report prepared for the Library of Congress, March 17, [consulté le 15 janvier 2007]. http://www.loc.gov/catdir/calhoun-report-final.pdf
ÇELIKBAS, Zeki (novembre 2004). What is RSS and how it can serve libraries. E-prints in Library and Information Science [en ligne], [consulté le 15 janvier 2007]. http://eprints.rclis.org/archive/00002531/
CHUDNOV, Daniel, CAMERON, Richard, FRUMKIN, Jeremy, SINGER, Ross,YEE, Raymond (avril 2005). Opening up OpenURLs with Autodiscovery. Ariadne [en ligne], issue 43, [consulté le 15 janvier 2007]. http://www.ariadne.ac.uk/issue43/chudnov/
DEMPSEY, Lorcan (2006). The Library Catalogue in the New Discovery Environment: Some Thoughts. Ariadne [en ligne], issue 48, [consulté le 15 janvier 2007]. http://www.ariadne.ac.uk/issue48/dempsey/
DEMPSEY, Lorcan (22 fevrier 2005). The integrated library system that isn't. Lorcan Dempsey's weblog On libraries, services and networks [en ligne], [consulté le 15 janvier 2007]. http://www.ariadne.ac.uk/issue48/dempsey/
DUCHEMIN, Pierre-Yves (2005). L’enrichissement des catalogues ? Et après ? BBF [en ligne], n° 4, p. 21-27 [consulté le 15 janvier 2007]. http://bbf.enssib.fr
GARREAU, Angélina (19 septembre 2005). Les blogs entre outil de publication et espace de communication : un nouvel outil pour les professionnels de la documentation [en ligne]. Maîtrise des sciences de l'information et de la documentation, CAOA, Université, [consulté le 15 janvier 2007]. http://memsic.ccsd.cnrs.fr/mem_00000273.html
GAVIN, Pierre (1997). SIBIL : un bilan pour le passé, et quelques jalons pour le futur [en ligne]. Lausanne : Nouvelle Association REBUS (Réseau des bibliothèques utilisant SIBIL), [consulté le 15 janvier 2007]. http://www.pierregavin.ch/documents/Sibil-bilan-jalon.pdf
GAVIN, Pierre (2006). Les AACR2 : menace ou chance ?. Hors texte, n° 80, p. 16-18
HAMMOND, Tony, HANNAY, Timo, LUND, Ben (décembre 2004). The Role of RSS in Science Publishing : Syndication and Annotation on the Web. D-Lib Magazine [en ligne], vol. 10, n°12, [consulté le 15 janvier 2007]. http://www.dlib.org/dlib/december04/hammond/12hammond.html
IRIARTE, Pablo (2006). La diffusion de l'information documentaire et des actualités en format RSS. In CHARTRON, Ghislaine [dir.], BROUDOUX, Evelyne [dir.]. Document numérique et société : actes de la conférence organisée dans le cadre de la semaine du document numérique à Fribourg (Suisse) les 20 et 21 septembre 2006 [imprimé]. Paris : ADBS, [consulté le 15 janvier 2007]. P. 123-148. http://archivesic.ccsd.cnrs.fr/sic_00079211
LEBOEUF, Patrick (2004). Le jour d’après : où serez-vous ?… [en ligne]. Journée d’étude Médiadix (Jeudi 21 Octobre 2004) : La fin du catalogage ?! [consulté le 15 janvier 2007]. http://netx.u-paris10.fr/mediadix/archivesje/leboeufweb.pdf
LE MOAL, Jean-Claude [coord.], HIDOINE, Bernard [coord.], CALDERAN, Lisette [coord.] (2004). Publier sur Internet : séminaire INRIA, 27 septembre - 1er octobre 2004, Aix-les-Bains [imprimé]. Paris : ADBS. ISBN 2843650720
MARKEY, Karen (janvier 2007). The Online Library Catalog : Paradise Lost and Paradise Regained?. D-Lib Magazine [en ligne], [consulté le 15 janvier 2007], vol. 13, n°1/2. http://www.dlib.org/dlib/january07/markey/01markey.html
MOFFAT, M (Mars 2006). “Marketing” with Metadata : How Metadata Can Increase Exposure and Visibility of Online Content [en ligne], version 1.0, 8 [consulté le 15 janvier 2007] http://www.icbl.hw.ac.uk/perx/advocacy/exposingmetadata.htm
SALAÜN, Jean-Michel (décembre 2005). Bibliothèques numériques et Google-Print. Version non révisée par l'éditeur de l’article pour la revue Regard sur l'actualité [en ligne], [consulté le 15 janvier 2007], n° 316. http://archivesic.ccsd.cnrs.fr/sic_00001576
SCHNEIDER, Karen G (20 Mai 2006). How OPACs Suck, Part 3: The Big Picture. ALA TechSource [en ligne], [consulté le 15 janvier 2007]. http://www.techsource.ala.org/blog/2006/05/how-opacs-suck-part-3-the-big...
STEPHENS, Michael (2006). Web 2.0 & Libraries : Best Practices for Social Software. Library Technology Reports, vol. 42, no. 4. ISSN 0024-2586
TENAILLEAU, Willy (14 mars 2006). Les services à distance d'une médiathèque - synthèse 3 : Les notices bibliographiques. LaConjuration/notes [en ligne], [consulté le 15 janvier 2007]. http://www.laconjuration.net/notes/?2006/03/14/33-les-services-a-distanc...