Publiée une fois par année, la Revue électronique suisse de science de l'information (RESSI) a pour but principal le développement scientifique de cette discipline en Suisse.
Publié par Ressi
S'applique aux numéros publiés et contenus disponibles au public.
Conférence nationale Open Access
Ressi — 20 décembre 2018
Benoît Epron, Haute école de Gestion, Genève
Conférence nationale Open Access
Le 26 octobre 2018, swissuniversities organisait une conférence nationale Open Access à l'Université de Lausanne.
A l'occasion de la semaine internationale de l'Open Access, cette journée souhaitait proposer un point sur l'Open Access dans un contexte suisse marqué par la mise en place de la stratégie nationale suisse sur l'Open Access et par l'annonce du Plan S (initiative de soutien à l’Open Access porté par la commission européenne et Science Europe).
Au travers des différentes interventions cette journée, qui a rassemblé 300 personnes environ, a permis de dresser un état des lieux des problématiques liées à la dynamique Open Access en Suisse.
Ces problématiques se retrouvent principalement à trois niveaux, académique, économique, politiques, repris par plusieurs intervenants. Nous proposons ici un compte rendu personnel de cette journée, il reflète notre propre lecture des enjeux et informations marquantes et ne prétend pas retranscrire l'intégralité des interventions et des débats.
Le premier plan est un plan académique. Tout au long de la journée ont été abordées deux facettes académiques de l'activité de publication scientifique. La première concerne la problématique de la diffusion et des usages. Souvent oublié, cet aspect des modèles OA de l'édition scientifique a été illustré lors de cette journée par la présentation de Mme Nouria Hernandez, rectrice de l'Université de Lausanne. Ainsi, lors de son intervention elle a évoqué la situation de Serval, dépôt institutionnel de l'Université de Lausanne et dont la fréquentation a quasiment doublé en septembre 2018 pour atteindre 100 000 consultations, notamment à l'occasion de l'intégration de Serval dans Google Scholar. Cette variation illustre par l'exemple un paradoxe des dépôts institutionnels, utilisés d'une part par les institutions universitaires comme infrastructures support pour l'Open Access et l'évaluation des chercheurs et dont d'autre part l'utilisation par les chercheurs eux-mêmes passe largement par Google Scholar, les rendant de fait peu visibles.
Sur le plan académique, la question des indicateurs de la recherche a également été largement abordée avec deux problématiques différentes s'y rattachant.
D'une part la nécessité d'imaginer de nouveaux indicateurs de la production scientifique permettant d'échapper à la dépendance actuelle vis-à-vis des plateformes fournissant actuellement les principaux indicateurs bibliométriques. Cette dépendance est donc double, elle concerne d'une part les indicateurs eux-mêmes qui restent uniquement quantitatifs et placent les revues et les éditeurs au centre des processus d'évaluation et de recrutement. Elle porte également sur les producteurs de ces indicateurs, plateformes d'éditeurs commerciaux qui s'appuient sur la maîtrise d'une part quasi-exhaustive des publications d'un domaine pour produire ces indicateurs.
Cette situation restreint le champ des possibles pour le développement de modèles Open Access pour la publication scientifique en rendant incontournables certaines revues et plateformes.
Sur le plan économique, la dynamique suisse de l'Open Access est confrontée à une situation de transition. Cette transition des modèles de publication académique est déjà bien avancée en Suisse. Ainsi d'après la présentation de Mme Angelina Kalt, Directrice générale du Fonds national suisse de la recherche scientifique, ce sont aujourd'hui 28% des publications scientifiques suisses qui sont disponibles en Green Open Access (auto-archivage de la publication par l’auteur dans une archive ouverte, souvent après une période d’embargo) et 11% disponibles en Gold Open Access (publication directement accessible en Open Access, souvent avec un financement en amont). Cela laisse donc 61% des publications non disponibles en Open Access en Suisse et place la Suisse devant les Pays-Bas, le Royaume-Uni, l'Autriche, la France, l'Allemagne et l'Italie, qui atteignent un taux de publication indisponibles en Open Access compris entre 64% et 72%.
Ce développement fort de l'Open Access en Suisse laisse toutefois une réelle marge de progression pour laquelle le FNS souhaite se positionner comme un levier d'accompagnement des politiques OA, que ce soit pour les revues ou pour les monographies.
L'ambition suisse pour le développement de l'Open Access vise un passage de la totalité des publications en Open Access à l'horizon 2024, soit après l'échéance prévue au niveau de l’Union européenne en 2020.
Du point de vue financier, la présentation de M. Michael Hengartner, Président de swissuniversities et Recteur de l'Université de Zurich, s'appuyait en partie sur l'étude Financial Flows in Swiss Publishing produite en 2016 pour le FNS. Il en a présenté quelques données et notamment le coût total d'accès à l'information en Suisse, soit approximativement 109 millions de francs suisses. Ce montant se répartit de la façon suivante : 70 millions pour les abonnements à des revues, 31 millions pour l'achat de monographies, 6 millions pour les APC (Articles Processing Charges, financement amont par le chercheur ou son institution pour rendre son article disponible en Open Access sans embargo) et 2 millions pour les infrastructures.
Les enjeux financiers relevés dans cette étude rejoignent les interrogations de Mme Nouria Hernandez qui s'inquiète de la capacité des institutions comme la sienne de supporter le triple coût de la publication académique de ses chercheurs aujourd’hui pour lesquels elles doivent assurer à la fois le prix des abonnements, celui des APC et enfin le coût de développement et de maintenance des infrastructures nécessaires à la mise en place des dépôts institutionnels.
A ces coûts il convient enfin d'ajouter les efforts de pédagogie et d'acculturation portés par les institutions scientifiques à destination des chercheurs et qui apparaissent prioritaires dans l'étude annuelle sur l'Open Access réalisée par l'EUA (European University Association). En effet, les trois actions prioritaires d'après cette enquête sont, par ordre d'importance, la sensibilisation des chercheurs, la mise en place d'incitations supplémentaires à destination des chercheurs et enfin la mise en place de politiques nationales de soutien à l'Open Access.
Cette enquête européenne présentée par M. Jean-Pierre Finance, Président de l'Open Science Experts Group, au sein de European University Association, a permis d'apporter d'autres éléments financiers à la réflexion. En effet, l'enquête chiffre à plus de 421 millions d'euros les dépenses annuelles pour les périodiques, les bases de données et les livres numériques, dont plus de 383 millions d'euros pour les seuls périodiques.
Plusieurs intervenants ont enfin balayé plusieurs enjeux politiques relatifs à l'Open Access. Le premier de ces enjeux a été la nécessité d'une organisation cohérente et unifiée des différents acteurs. C'est dans cette logique que devrait se mettre en place d'ici le premier trimestre 2019 une Open Access Alliance pilotée par swissuniversities (programme P-5) et regroupant l'ensemble des parties prenantes : Académies, éditeurs suisses, CSS (Conseil suisse de la science), etc. mais également des membres de projets comme Sliner, le FNS ou la délégation recherche de swissuniversities.
La place des HES dans les modèles Open Access a également été soulignée avec notamment la nécessité de concevoir des solutions qui permettent de prendre en compte les partenaires économiques impliqués dans l'activité de recherche appliquée des HES et pour lesquels l'ouverture des résultats doit se construire de façon cohérente avec leurs enjeux économiques et commerciaux.
La journée s'est terminée sur une intervention rafraichissante de M. Jacques Dubochet, prix Nobel de Chimie en 2017, qui a replacé, à travers son expérience de chercheur, "la connaissance comme un bien commun pour le bénéfice de tous".
- Vous devez vous connecter pour poster des commentaires
Cinquante ans de numérique en bibliothèque
Ressi — 20 décembre 2018
Alexis Rivier, Conservateur Ressources numériques et périodiques, BGE
Cinquante ans de numérique en bibliothèque
Dans l’essai d’Yves Desrichard, conservateur des bibliothèques et ancien rédacteur en chef du Bulletin des bibliothèques de France, les professionnels actifs depuis une vingtaine d’années ou davantage reconnaîtront des personnes, des sigles, des événements politiques qui ont façonné le destin numérique des bibliothèques françaises.
En France, l’histoire est une discipline prestigieuse et valorisée. Nombre d’historiens ont occupé de hautes fonctions à la Bibliothèque nationale, comme Jean-Noël Jeanneney, président de la BnF de 2002 et 2007 et préfacier de l’ouvrage. Pour autant le parcours rétrospectif sur ce facteur fondamental de transformation des bibliothèques qu’a représenté l’arrivée de l’informatique a été plutôt négligé, ou cantonné à l’intérieur d’ouvrages au périmètre plus large .
Cinquante ans de numérique en bibliothèque s’articule en cinq « temps », couvrant chacun approximativement une décennie. Suivre les faits et les avancées dans ce continuum chronologique s’avère efficace et très parlant.
Le premier temps est celui des pionniers, qui mettent au point les premiers formats de catalogage. Peu après, les premières politiques d’ «automatisation» des bibliothèques voient le jour.
S’ensuit le temps des découvreurs qui consolident les acquis, développent les fonctionnalités et s’emparent de technologies qui semblaient prometteuses : Minitel, CD-Rom, vidéodisque.
Le temps des bâtisseurs concrétise les chantiers d’informatisation de la BnF, la rétroconversion des catalogues, les réseaux informatisés.
Le temps des expérimentateurs suggère une nouvelle étape de tâtonnements. La montée en puissance des ressources numériques entraîne des stratégies de rassemblement autour des consortiums, puis une mobilisation en faveur de l’open access. Des services d’Internet affichent une croissance surprenante, les bibliothèques s’y adaptent : Web 2.0, archivage du numérique, grands programmes de numérisation.
Le dernier temps appartient aux médiateurs : la mise en concurrence des bibliothèques les oblige à repenser leurs fondamentaux, principalement dans la mise en relation des usagers avec des sources et des contenus d’information. Un certain renversement de perspective s’opère : l’usager devient prioritaire et non plus la collection, dont le statut doit être revisité. On ne peut s’empêcher de voir dans ce titre un hommage au dernier opus d’un grand nom de la bibliothéconomie française, disparu prématurément : Les bibliothèques et la médiation des connaissances de Bertrand Calenge.
Chaque partie relate de façon très complète les initiatives, les structures institutionnelles et les personnages qui ont forgé cette histoire, générant une floraison de sigles dont peu ont subsisté jusqu’à nos jours. La concision du livre (132 pages) en fait une excellente synthèse. Non sans modestie, Yves Desrichard estime cependant qu’une histoire complète de l’informatisation des bibliothèques reste à écrire…
Une fois posé à gros traits les étapes, quels sont les principaux enseignements de cette rétrospective ? Nous en proposons quelques-uns.
-
A ses débuts, l’informatisation des bibliothèques apparaît presque simultanément dans les pays développés. Mais l’avance des Etats-Unis est réelle. C’est à la Bibliothèque du Congrès que le format Marc, pierre angulaire de l’informatique en bibliothèque, a été défini en 1966. Le prétendu retard français est cependant minime : cette même année, Henri-Jean Martin travaille à la Bibliothèque municipale de Lyon sur un format de catalogage pour le livre ancien et en 1968 Marc Chauveinc conçoit le format Monocle à Grenoble. C’est également dans ces années-là que l’aventure commence en Grande-Bretagne , mais aussi en Suisse avec les projets Sibil à Lausanne et Ethics à Zurich. Il y a là une remarquable convergence, tant il apparut très tôt que l’informatique était un outil essentiel pour les bibliothèques.
-
On s’en doute, l’informatisation n’est pas une route paisible. Les réussites y côtoient les échecs. Ce n’est pas le moindre mérite de ce livre d’y faire place. Certaines idées viennent trop tôt, d’autres fois la réalisation est laborieuse. Enfin certaines technologies n’ont pas été confirmées. Parfois les bibliothèques sont confrontées à des temporalités qui les dépassent, le volontarisme ne suffit pas toujours. "Ceux qui ont réussi ne savaient pas qu'ils allaient réussir; ceux qui ont échoué ne savaient pas qu'ils allaient échouer." (p. 11). Deux cas sont symptomatiques. Le système centralisé Libra, voulu et conçu par le Ministère de la culture entre 1982 et 1989 pour combler le retard des bibliothèques centrales de prêt n’a jamais fonctionné correctement, et les lois de décentralisation ont précipité son abandon. Le projet d’informatisation de la BnF, aussi ambitieux dans son genre que celui de la construction du nouveau bâtiment sur le site de Tolbiac, a été émaillé de difficultés qui ont beaucoup ému la profession. Le système n’a été véritablement opérationnel qu’en 2002, soit 4 ans après les prévisions. Plus récemment le projet Relire, complexe montage technico-juridique au bénéfice d’une noble idée : la remise à disposition du public d’œuvres protégées par le droit d’auteur mais plus commercialisées, n’a pas eu l’effet désiré. Le dispositif a été décrié par les auteurs et invalidé par l’Union européenne.
-
Se pencherait-on sur le passé parce que le présent et surtout le futur inquiètent ? Yves Desrichard se défend de se prêter au jeu de la prophétie, mais sait que l’on attend de lui qu’il dise ce que l’examen du passé lui inspire pour l’avenir des bibliothèques. Le numérique a pris partout une telle place qu’il n’est plus perçu comme aussi désirable qu’au temps des pionniers.
A ses débuts l’informatisation est un facteur de modernisation accueilli avec enthousiasme. C’est un moyen de gérer un « monde physique » qui ne remet aucunement en cause la position de la bibliothèque, ni même son fonctionnement, ses instruments. L’informatique aide d’abord à mettre sur pied des outils de travail comme les catalogues sur fiches ou des bibliographies. Dans les années 1970, le groupe Gibus (Groupe informatiste de bibliothèques universitaires et spécialisées) prône un accès direct par les usagers aux données informatisées, mais c’est bien plus tard que le catalogue sera mis à disposition en ligne via les Opac.
La véritable fracture, et nous suivons l’auteur sur ce point, survient avec le développement de l’information primaire – les contenus – sous forme numérique. Les bibliothèques ont gardé le monopole de l’information imprimée mais ne maîtrisent qu’une petite partie des ressources numériques, celle de la numérisation de leurs fonds. Les ressources sont pour l’essentiel commercialisées et difficiles à acquérir par les bibliothèques. En témoigne la délicate mise en place de la plate-forme Prêt numérique en bibliothèques (PNB) permettant de prêter des ebooks. Malgré tout, cela stimule aussi les capacités d’adaptation des institutions, à l’instar de la création des consortiums Couperin et Carel, respectivement pour les bibliothèques universitaires et pour les bibliothèques de lecture publique. « La profession a toujours été aux avant-postes de l'expérimentation et de l'appropriation des outils informatiques et numériques » (p. 12). Elle a investi Internet avec enthousiasme et continue de le faire, dans la bataille pour l’open access et des contenus gratuits de qualité. Mais le public est capté par d’autres acteurs, puissants et très performants sur le plan des technologies, qui mettent en suspicion l’utilité des bibliothèques, même au niveau politique. J.-N. Jeanneney souligne dans sa préface « l’inquiétude » des professionnels et n’hésite pas à qualifier cette mutation de leur métier comme « la plus violente, en somme, depuis l’invention de l’imprimerie » (p. 10). A cela s’ajoutent des tendances contradictoires qui rendent peu lisibles l’évolution numérique. Le cas le plus typique est celui du livre électronique, dont Desrichard rappelle que « plus de 15 ans après sa première apparition », en 2000, il « continue à provoquer questionnements, enthousiasmes, critiques et incertitudes » (p. 84). C’est donc sur un optimisme prudent qu’il clôt son ouvrage.
Au fil de ce parcours de Cinquante ans de numérique en bibliothèque, on prend la mesure des conditions spécifiques liées au développement informatique de ce secteur en France : influence déterminante de l’Etat central et des ministères concernés, poids de la Bibliothèque nationale, volontarisme technologique. Mais au final, en raison de la globalisation des technologies, la situation des bibliothèques françaises n’est pas si différente de celle d’autres pays. Yves Desrichard a tracé une voie prometteuse.
Bibliographie
Yves Desrichard. Cinquante ans de numérique en bibliothèque. Paris: Electre-Ed. du Cercle de la Librairie, 2017 (collection Bibliothèques)
- Vous devez vous connecter pour poster des commentaires
Les bibliothèques de la Communauté du savoir
Ressi — 20 décembre 2018
Agnès Dervaux-Duquenne, bibliothécaire-responsable, Haute Ecole Arc Ingénierie
Les bibliothèques de la Communauté du savoir

Des solutions simples pour des défis complexes
Un des derniers livres blancs partagés sur le site http://www.archimag.com/ [1] nous propose une étude intitulée « Les défis des bibliothèques universitaires au cœur de l’enseignement, de l’apprentissage et de la recherche » [2].
Notre métier change, c’est une évidence, notre profession évolue, et nous aussi, les professionnel-le-s. Les défis identifiés se posent donc autant au niveau des lieux, des institutions et des objectifs que des ressources, des outils et enfin des compétences des personnels.
C’est une chance dès lors de faire partie d’une des institutions membres de la Communauté du savoir et de bénéficier des encouragements et des infrastructures mises en place pour se rencontrer, partager sur nos pratiques, nos savoir-faire, nos questions et nos solutions et tenter de développer des projets à haute valeur ajoutée avec nos collègues régionaux transfrontaliers.
Mais qu’est-ce que cette Communauté du savoir ?
La Communauté du savoir : historique et composantes
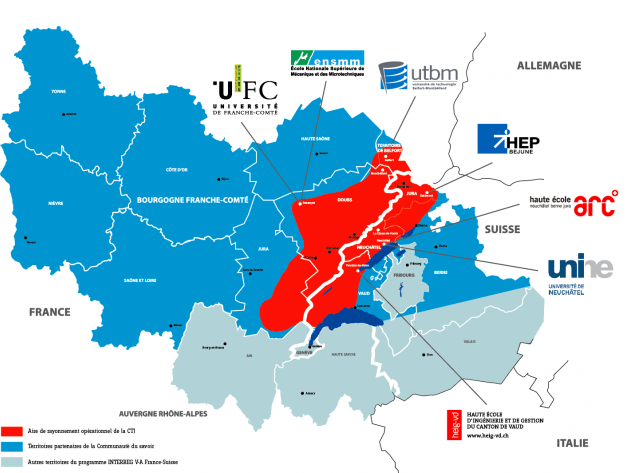
La Communauté du savoir (Cds) est un réseau visant à renforcer, valoriser et stimuler les collaborations franco-suisses dans l'Arc jurassien en matière d'enseignement supérieur, de recherche et d'innovation.
D'abord sous l'égide de la Conférence TransJurassienne, la Communauté du savoir a organisé tous les deux ans (2012, 2014, 2016) un colloque transfrontalier afin de permettre aux acteurs de la collaboration transfrontalière dans les domaines de l'enseignement supérieur, de la recherche et de l'innovation de se rencontrer et d'échanger sur les solutions à apporter aux problématiques inter-régionales générées par les frontières. Les colloques se sont tenus alternativement en France et en Suisse afin de permettre aux participant-e-s de visiter un établissement partenaire.
Le premier colloque de 2012 a été organisé à l'’École Nationale Supérieure de Mécanique et des Microtechniques (Besançon, France) et a réuni une centaine d'acteurs des échanges franco-suisses. Il a donné lieu à la signature d'une déclaration d'intention signée par 17 partenaires présents et a permis de créer les prémices d’une communauté du savoir, de la recherche et de l’innovation de l’Arc jurassien.
Le deuxième colloque de 2014 s’est tenu à la Haute Ecole Arc (Neuchâtel, Suisse) et a réuni environ 150 participant-e-s autour de la thématique : "La collaboration transfrontalière : aller au-delà des outils existants". C’est lors de ce colloque qu’ont été proposées de nouvelles pistes d'actions franco-suisses structurantes dans plusieurs domaines - dont les bibliothèques, et que le nom de cette communauté a été validé par les participant-e-s.
Le troisième colloque de 2016 a eu lieu à l'Atria de Belfort (France) sur le thème "Frontières : dynamique et enjeux d'un territoire transfrontalier", et a permis de mettre en lumière les avantages (également pour les acteurs publics et politiques) liés à la coopération au sein du réseau de la Communauté du savoir. La signature d’un accord-cadre entre sept membres académiques est venue consolider cette volonté de travailler ensemble et de soutenir activement le développement de leurs collaborations.
Les sept membres académiques sont les suivants :
- l’Ecole Nationale Supérieure de Mécanique et des Microtechniques (ENSMM) - Besançon
- la Haute Ecole Arc (HE-Arc) – Neuchâtel
- la Haute Ecole d’Ingénierie et de Gestion du canton de Vaud (HEIG-VD) - Yverdon
- la Haute Ecole Pédagogique des cantons de Berne, Jura et Neuchâtel (HEP-BEJUNE)
- l’Université de Franche-Comté (UFC)
- l’Université de Neuchâtel (UniNE)
- l’Université de Technologie de Belfort-Montbéliard (UTBM)
Inscrite dans un territoire de coopération qui couvre actuellement la Franche-Comté côté français et les cantons de Berne, Jura, Neuchâtel et Vaud côté suisse, la Cds est, par son existence et son développement, un facteur de dépassement de la frontière au profit d’une mise en commun de potentiels scientifiques, académiques, culturels et économiques de l’entier de l’Arc jurassien franco-suisse.
Depuis 2014, ce projet est soutenu par le programme européen de coopération transfrontalière Interreg V France-Suisse 2014-2020 et a bénéficié à ce titre d'un soutien financier du Fonds européen de développement régional (FEDER). Grâce à ces fonds, les premiers objectifs de la Cds ont pu être atteints, à savoir un soutien direct à la mobilité des personnes engagées, à l’organisation d’actions, de journées thématiques, de mises en réseau des structures d’innovation et de groupes comme celui des bibliothèques.
Actuellement, la dernière phase du projet Cds est en préparation et son objectif est de pérenniser les acquis et les actions de ce réseau dont l'autonomie de fonctionnement doit être atteinte au 1er janvier 2020.
Dans cette perspective, le projet se développera en 2019 autour de trois nouveaux objectifs qui rassemblent et prolongent ceux de la période 2015-2018 :
-
Un campus transfrontalier à même de poursuivre et d’impulser des projets de collaborations ;
-
Un incubateur de projets transfrontaliers destiné à accompagner au cas par cas la structuration et le montage de projets de collaborations ;
-
La pérennisation du réseau en vue de préparer le transfert des responsabilités et des financements aux établissements membres à l’horizon 2020.
Bilan Cds 2015-2018
Une évaluation globale réalisée en octobre 2018 a montré que, entre les projets et groupes de travail prospectifs, séminaires et journées thématiques, réunions de gouvernance et de coordination du réseau, webcasts et stages, 118 rencontres franco-suisses ont eu lieu entre 2015 et 2018 et 4263 personnes ont participé à ces échanges. Ces chiffres ont fini de convaincre les partenaires engagés de pérenniser leur soutien pour maintenir actifs les groupes engagés et tenter de poursuivre les démarches encore en réflexion.
Voici à quoi ressemble aujourd’hui le bilan de ces actions et préconisations.
Les groupes de travail dits de "proposition"
Cotutelles de thèse
A l'issue de ses séances de travail, la principale préconisation du groupe a été d’élaborer une procédure pilote entre les établissements partenaires de la Communauté du savoir en ciblant 3-4 diplômes de masters éligibles à l’inscription d’une formation doctorale donnée. L’idée est de démontrer la valeur ajoutée d'un réseau comme la Cds et notamment sa capacité à favoriser des synergies interdisciplinaires.
Formations continues
Le groupe de travail a livré les préconisations suivantes :
-
Proposer des partages d’expérience pédagogique entre les acteurs du réseau ;
-
Faciliter les échanges de pratiques en termes d’activités métier opérationnelles (intitulé des offres de formation, partenariats dans les formations continues, mise à disposition de ressources en ligne) ;
-
Constituer un annuaire des personnes-ressources dans chaque établissement.
Formations initiales
Sur la base d’une analyse des situations de formations bi ou tri-nationales existantes, de la typologie de ces situations sur la base de leur organisation (doubles diplômes, élaboration de titres commun, …), quelques recommandations ont été proposées :
-
combiner des formations existantes afin de déboucher sur des "doubles diplômes " ;
-
intégrer dans des programmes au sein de différents établissements des modules de cours/formations construits en communs ;
-
développer un « annuaire » d’enseignant-e-s (par discipline/compétence) qui pourrait faciliter l’émergence d’un tel ensemble de cours;
-
développer un référentiel d'aides à la mobilité des étudiant-e-s (identification de lieux de stages, ...).
Offensive Sciences
Ce groupe a orienté ses travaux sur trois niveaux :
-
Etudier le fonctionnement du programme de financement des travaux de recherche « Offensive Sciences » de la Région Métropolitaine Trinationale (RMT);
-
Explorer des pistes de réflexions autour de nouveaux outils de financement pour la recherche dans le réseau de la Communauté du savoir;
-
Exprimer des recommandations pour les futures programmations de la Communauté du savoir sur le sujet.
Toutefois, il était impossible pour ce groupe de produire des résultats directement exploitables, les enjeux évoqués étant plutôt de nature "politique". Les discussions devront donc se poursuivre au sein du comité de pilotage et des responsables d'établissements de la Cds, la mise en place éventuelle d'un fonds de ressources mutualisées relevant de ce niveau de décision.
En parallèle à ces différents groupes de travail, des études et actions ont été menées qui ont permis de proposer des guides de financements, un soutien à la mobilité des collaborateurs et collaboratrices des structures académiques de la Cds, la mise en place de stages et séminaires communs, l'identification d'expert-e-s pour la constitution de jurys et l'offre d'une solution de visioconférence flexible pour les membres de la Cds.
Un accent important a également été mis sur les actions de communication : site internet, cartographie en ligne des acteurs du territoire, Webcastings et captations d’événements organisés par les partenaires de la Cds, plateforme de partage de fichiers/documents (GED), nouveaux outils de communication (flyers, livrets) pour faciliter la diffusion des objectifs du réseau auprès des différents publics-cibles et pour favoriser l'appropriation des différents financements proposés par les enseignant-e-s et les étudiant-e-s.
Les groupes de travail dits "actifs"
Jurassic Labs
Les FabLabs mettent à disposition de nouveaux dispositifs de fabrication numérique et la connaissance de leur utilisation.
L'intérêt de ces ateliers est de faire sortir la créativité des bureaux d’études et des laboratoires universitaires en ouvrant à la population des lieux d'expérimentation accessibles.
L’autre force des FabLabs est de mettre en relation des types de personnes qui ne se rencontrent généralement pas, ou peu : étudiant-e-s et spécialistes de différents domaines ; universitaires et industriel-le-s, artistes et ingénieur-e-s, générations différentes.
Jurassic Labs propose d’étendre ces mises en réseaux, internes à chaque FabLab, à tous les FabLabs et structures de créativité (existants ou futurs) du territoire de la Communauté du savoir. Il propose également que ce réseau devienne le lien naturel de tous ces territoires pour ce qui est des questions de créativité et d’innovation. Les FabLabs offrent en outre l’avantage d’être neutres, entre industries et universités, entre économie publique, économie privée et économie collaborative, un territoire commun où tout le monde se sent à l’aise pour interagir.
L’objectif de Jurassic Labs est ainsi résumé : créer des ponts verticaux entre trois niveaux identifiés :
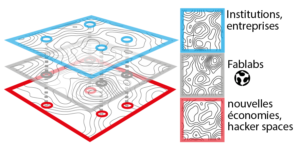
Sphère «maker» = espace citoyen ( Fablabs, HackerSpaces, MakerSpaces etc.).
Sphère «professionnelle» = espace de l’économie privée (réseau des centres créatifs [sens large], pépites, etc., connecté aux entreprises, start-ups, chambres de commerce, etc.).
Sphère «institutionnelle» = espace de l’économie publique (réseau des institutions [hautes écoles, universités], connecté au monde politique).
Deux actions principales ont pu être développées par ce groupe :
-
un FabLab mobile transfrontalier dans l'Arc jurassien, plus particulièrement à destination des publics scolaires, via des modules pédagogiques; une version expérimentale de ce FabLab mobile circulera côté France d’ici la fin 2018;
-
une forte implication au Crunch à Belfort en mai 2018, apportant ainsi un soutien « maker » aux 1'500 participant-e-s de ce hackathon universitaire et industriel.
ArcLab
Projet pilote et expérimental, l'action ArcLab a été mise en place à la rentrée 2018 avec pour objectifs l’identification et la définition de compétences pour des professions emblématiques du territoire, en lien avec les enjeux du 4.0 identifiés comme prioritaires par le Comité de pilotage.
Deux ateliers ont permis aux enseignant-e-s/chercheurs et chercheuses de la Cds d’identifier les professions sur lesquelles travailler et de poser les bases des compétences-clefs présentes et à venir, et profils-types qui les composent. A cette occasion, quatre professions emblématiques ont été identifiées (e-firmier-ère, community commerçant-e, digital transgénieur-e et digital transformateur-trice).
Cette expérimentation permettra la réalisation de vidéos thématisées sur chacune des quatre professions étudiées, à destination des établissements membres du réseau et des collectivités publiques.
Les bibliothèques de la Cds
Chacune des 7 institutions partenaires dispose d'une (ou d'un réseau de) bibliothèque(s) que l’on peut identifier sur cette carte :
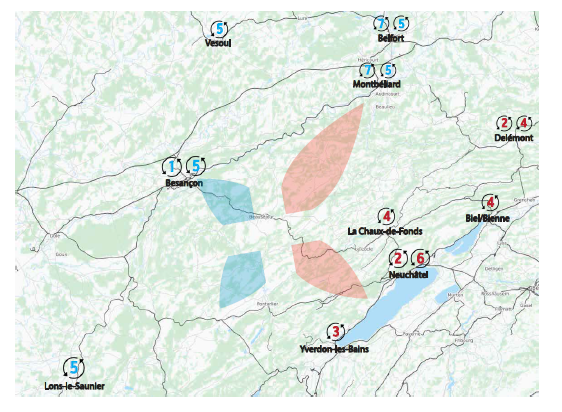

Ces bibliothèques partagent 20 lieux physiques et emploient 150 collaborateurs et collaboratrices environ. Certaines sont rassemblées en un seul lieu (pour des domaines différents), d'autres sont réparties sur un territoire géographique de type campus. Elles ont également en commun d'avoir comme principal public les étudiant-e-s et enseignant-e-s de leur établissement, ainsi que des chercheurs et chercheuses orientés "métier". Mais les personnes privées et professionnelles sont également bienvenues et présentes dans ces structures.
Toutes ensemble ces bibliothèques conservent et mettent à disposition de leurs publics environ 1.000.000 de documents papier et elles traitent environ 420.000 prêts par an. Organisées en consortiums dans leurs pays respectifs, elles proposent en outre un nombre imposant de ressources en ligne aux membres de leurs institutions.
Dès les balbutiements du réseau, ces mêmes bibliothèques se sont regroupées et ont immédiatement perçu l'intérêt qu'elles auraient à collaborer. Non seulement elles sont toutes pilotées au sein d'une institution d'enseignement supérieur mais en plus, les thématiques qu'elles couvrent sont parfois proches, voire très proches et donc complémentaires en terme de fonds documentaires (bibliothèques « jumelles » de part et d’autre de la frontière).
Très rapidement, elles ont mis en place des actions simples de collaborations basées sur une charte qui part du principe de base de réciprocité et qui favorise la mise en réseau de bibliothèques membres. Cette charte s’établit sur une base d’égalité et d’avantages mutuels.
Dès avant la signature de l'«accord-cadre» validé par les responsables des institutions partenaires en juillet 2017, les différentes actions prévues ont immédiatement été mises en œuvre ou en chantier. Il s'agit de :
1 : Accueil réciproque des étudiant-e-s des établissements membres de la Cds
Cela signifie que toute personne inscrite dans une de ces bibliothèques bénéficie gratuitement d’une carte de bibliothèque dans un autre établissement membre.
Ainsi les étudiant-e-s qui optent pour un parcours mixte (voir par exemple le partenariat mis en place entre la HE-Arc ingénierie et l'UTBM) ont accès aussi bien aux ressources de la bibliothèque de leur institution d'affiliation qu'aux ressources de la bibliothèque du lieu sur lequel ils poursuivent leur formation.
2 : Prêts entre bibliothèques
Les bibliothèques ont établi une procédure très simple qui permet, grâce à la mutualisation des liens vers les catalogues en ligne (voir plus loin), de demander en prêt entre bibliothèques un ouvrage détenu par une bibliothèque partenaire de l'autre côté de la frontière. La communication se fait par e-mail et une plateforme collaborative permet d'enregistrer les échanges ainsi convenus. Les prêts sont accordés gratuitement par les bibliothèques partenaires et les frais de livraison par poste sont centralisés et pris en charge par le budget Cds du groupe de travail. En effet, afin de favoriser les prêts transfrontaliers entre bibliothèques partenaires, les frais engagés pour la bonne marche de ces échanges de documents sont pris en charge par le réseau Cds.
3 : Mutualisation des catalogues
Par le biais d’une carte des bibliothèques partenaires publiée sur le site web de la Cds, les membres ont accès à tout moment aux catalogues des bibliothèques et à leurs coordonnées.
Un document interne partagé permet également de disposer des contacts-clés dans cette organisation pour que la communication se fasse directement avec la bonne personne (essentiellement les collaborateurs et collaboratrices qui gèrent le prêt entre bibliothèques).
Cet aspect de la collaboration entre bibliothèques est bien sûr évolutif : si la plupart des fonds documentaires des partenaires français sont accessibles en interrogeant un seul catalogue (le Sudoc donne accès aux collections des bibliothèques de l’enseignement supérieur et de la recherche et permet de visualiser la localisation des exemplaires et donc leur disponibilité dans les bibliothèques participantes), les partenaires suisses sont membres soit du réseau Nebis, soit du réseau RERO dont l’interrogation est un peu plus complexe pour les collègues français. On s’aperçoit que dans ce cadre, la solution Worldcat peut être plus intéressante mais on se réjouit surtout de voir les bibliothèques académiques suisses rassemblées prochainement dans un seul réseau SLSP à l’horizon 2021.
4 : Cartographie des thématiques
En cours de réalisation, cette carte permettra de visualiser rapidement les thématiques fortes de chaque bibliothèque partenaire. Cet outil est conçu pour assister aussi bien les personnels concernés que les publics intéressés et leur permettra d’identifier plus facilement les catalogues à interroger en priorité pour obtenir des réponses précises et immédiates à leurs recherches documentaires. Il permet également de visualiser rapidement quelles bibliothèques sont complémentaires en termes de fonds et d’orienter ainsi immédiatement le public vers la bibliothèque qui répondra le mieux à ses attentes selon le lieu où il se trouve.
Une chargée de mission a été engagée par la Communauté du savoir pour une période de 7 mois afin de réaliser ce projet qui demande une analyse plus précise des partenaires, de leurs fonds et de leurs services parallèlement à leur offre de formation.
Une version beta de cette carte est publiée sur le site web de la Cds. Elle pourra être mise à jour au fur à mesure de l'évolution des politiques documentaires des bibliothèques partenaires et sera relayée également sur les sites web de ces mêmes bibliothèques.
5 : Mutualisation de supports de communication
Un ensemble de supports ont été réalisés sur budget de la Cds pour permettre aux bibliothèques participantes d’informer
- d'une part les équipes en charge de la mise en pratique des échanges convenus,
- et d'autre part leurs publics selon un processus « réseau » clairement identifié.
Pour leurs équipes, les membres du groupe ont élaboré des affiches qui permettent d'identifier clairement le rôle du groupe du travail et le cadre dans lequel il évolue. Ces affiches ont pour thèmes :
- Les systèmes éducatifs en France et en Suisse ;
- Le réseau de bibliothèques et notamment : les lieux, les personnels, les environnements de travail, les publics, les catalogues et réseaux documentaires des uns et des autres ;
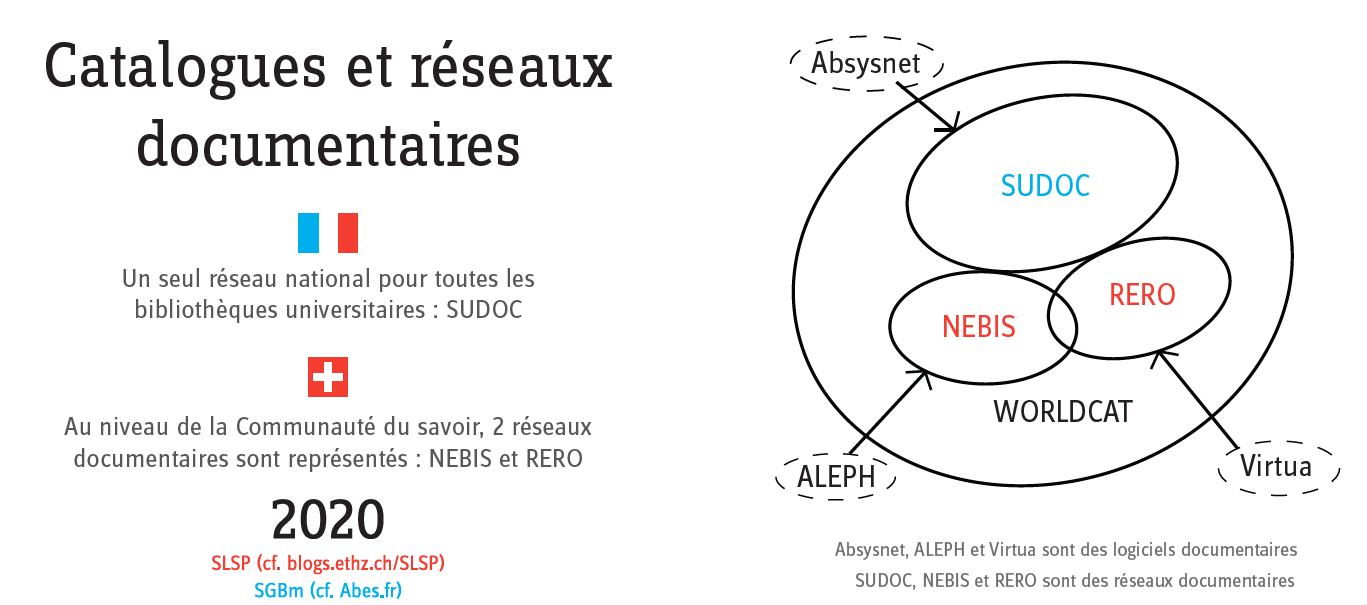
- Les collections et chiffres-clés des bibliothèques ;
- La carte des bibliothèques des établissements partenaires.
Ainsi les personnels des bibliothèques qui, sur le terrain, mettent en œuvre les échanges convenus entre les membres du groupe de travail ont une meilleure compréhension des situations des bibliothèques et de leurs réseaux dans leurs pays respectifs, et peuvent à leur tour promouvoir les services de la Communauté du savoir en exploitant les avantages de ces échanges au bénéfice de leurs lecteurs et lectrices.
Un élément important de cette communication interne est évidemment l'engagement des parties à respecter la législation nationale et les règlements intérieurs de chaque structure en matière de propriété intellectuelle et commerciale, y compris en matière de reproduction des œuvres. Elles s’engagent également à les faire respecter par leurs publics.
Pour communiquer cette fois avec ces mêmes publics, existants ou potentiels, et les informer des services que ce réseau peut leur offrir, le groupe de travail a également conçu des supports d'information mutualisés qui peuvent être partagés sur les sites web des bibliothèques et/ou institutions partenaires ainsi que sur les réseaux sociaux quand les bibliothèques disposent de tels supports de communication. Faire connaître les accès supplémentaires aux ressources documentaires que permet l’affiliation des bibliothèques à la Communauté du savoir est également un enjeu important de cette communication.
Enfin, dans l’idée de profiter de retours d'expériences entre elles, les bibliothèques ont également en projet le partage entre professionnel-le-s uniquement d'une newsletter par laquelle chaque membre peut informer les autres d'une initiative ou d'une animation particulière et de ses résultats. Cet échange de bonnes pratiques permet aux partenaires d'exploiter à leur façon des formats d'expériences nouvelles en les adaptant à leur propre structure.
6 : Projet de service questions-réponses
Selon l'évolution de la prise en charge du réseau par ses partenaires en 2019, le groupe bibliothèques a pour projet de mettre sur pied un service de questions-réponses à l'échelle transfrontalière. Il fait actuellement l'objet d'une étude de faisabilité et devrait bénéficier du soutien ponctuel d'une personne externe pour la mise en place et la réalisation concrète de cette action. Il pourrait dans un premier temps être intégré pour une phase test dans les bibliothèques de l’UFC à Besançon et, dans un deuxième temps, fédérer les unes après les autres toutes les bibliothèques affiliées à la Cds. Un tel service serait d’une grande richesse pour tous les publics de nos bibliothèques quelle que soit leur localisation géographique.
En conclusion, le groupe de travail «bibliothèques» de la Communauté du savoir est fier d’avoir pu mettre en place très rapidement des services documentaires transfrontaliers simples tout en poursuivant une réflexion de fond sur les projets qui pourraient profiter aux publics des bibliothèques participantes, qu’ils soient étudiant-e-s, enseignant-e-s, chercheurs, chercheuses ou membres à quelque titre que ce soit des institutions partenaires.
Et même si immédiatement, au sein de cette communauté, notre démarche collaborative nous a permis d’enrichir nos services par un prêt entre bibliothèques au niveau international, d’enrichir nos connaissances « métier » par le partage de nos bonnes pratiques et de réfléchir à la faisabilité d’un service transfrontalier de questions-réponses, nous abordons également ensemble toutes les questions que l'évolution de notre métier va nous amener à nous poser dans un proche avenir et notamment :
-
La définition de thématiques partagées puisque développer nos partenariats permet de mutualiser les ressources et de miser sur des points forts dans une optique de complémentarité (réduire les coûts, gagner en efficacité, exploiter les compétences expertes) et de se tourner vers une économie d’accès plutôt qu’une économie de stock ;
-
L’identification d’un service commun et uniformisé pour un public de plus en plus mobile qui pourra bénéficier du développement des synergies particulièrement encouragées dans un environnement géographique européen;
-
La promotion des résultats de la recherche et de la valorisation des données en partageant nos archives institutionnelles et nos ressources en open access ;
-
L’accès aux ressources documentaires et la prise en charge de nouvelles responsabilités dans le domaine des données de la recherche;
-
La communication via les réseaux sociaux qui permettent de faire connaître nos services et activités et participent au rayonnement des bibliothèques.
Si les défis à relever se nomment « recentrer les bibliothèques au cœur de l’apprentissage » pour qu’elles soient le relais des savoirs, « connecter les chercheurs et chercheuses avec leur bibliothèque » afin qu’ils bénéficient d’une expertise à leur service et qu’ils puissent utilement préciser leurs besoins, « rendre visibles les bibliothèques et en simplifier l’accès » grâce au développement de solutions réciproques, alors nous sommes au bon endroit avec les bonnes personnes pour les relever !
Pour le groupe de travail des bibliothèques de la Communauté du savoir :
Agnès Dervaux-Duquenne, bibliothécaire-responsable
Haute Ecole Arc Ingénierie
Notes
[1][Consulté le 20.06.2018]
[2] ©Ex Libris
Sources et liens utiles :
http://www.communautedusavoir.org/
http://www.conference-transjurassienne.org/
http://www.communautedusavoir.org/nos-actions/les-bibliotheques-arc-jurassien/
Groupe de travail des bibliothèques - documents internes
© des illustrations : Cds
- Vous devez vous connecter pour poster des commentaires
Rechercher l’information stratégique sur le web : sourcing, veille et analyse à l’heure de la révolution numérique
Ressi — 20 décembre 2018
Claire Wuillemin, Haute Ecole de Gestion, Genève
Rechercher l’information stratégique sur le web : sourcing, veille et analyse à l’heure de la révolution numérique
À la suite de la co-direction d’un cabinet spécialisé en veille technologique et de plusieurs années à l’Infothèque du pôle universitaire Léonard de Vinci, Véronique Mesguich est depuis 2012 consultante et formatrice freelance pour les domaines de la maitrise de l’information, de la veille stratégique et de l’intelligence économique. Ce dernier livre constitue une mise à jour bienvenue des différentes éditions de Net Recherche (rédigées alors en collaboration avec Armelle Thomas), le dernier datant de 2013. Elle propose ici théorie, méthodes, outils et études de cas sur la recherche d’information sur le web et la mise en place d’une veille efficace. Bien que ce sujet ait déjà fait l’objet de nombreux ouvrages de qualité, ce livre va plus loin en remettant la recherche d’information et la veille dans le contexte actuel du numérique –Big data, internet des objets, intelligence artificielle et nouveaux supports comme les smartphones – et actualise les outils, sources et compétences nécessaires pour sa mise en œuvre.
Publié en 2018, Rechercher l’information stratégique sur le web : sourcing, veille et analyse à l’heure de la révolution numérique s’inscrit dans la préoccupation très actuelle de développer les compétences informationnelles afin que tout un chacun puisse développer une véritable littératie numérique et évoluer en homo numericus. Comme l’indique son titre, ce livre s’attache à des questions de recherche d’information et de veille, et cherche en particulier à fournir des réponses aux questions suivantes :
-
Comment optimiser la recherche d’information afin de minimiser la redondance et la perte d’information ?
-
Comment et où collecter de l’information stratégique ?
-
Comment juger la qualité de l’information recueillie ?
À cette fin, le lecteur est accompagné à travers un cheminement logique sur les vastes thèmes de la recherche d’information et la veille à l’aide d’une structure solide de cinq chapitres qui s’enchainent avec cohérence. Son livre s’ouvre ainsi sur un chapitre qui pose de manière étendue le paysage du web en 2018 c’est-à-dire les enjeux qui se posent aujourd’hui pour les utilisateurs et les professionnels de l’information mais définit également tous les aspects techniques qui y sont liés ainsi que les principales tendances qui se profilent pour ses usages et ses évolutions.
Quelles sont donc ces forces qui agitent le web ? Pour commencer, on notera l’avènement du mobile first au sein de Google, qui dans un avenir proche privilégiera la version mobile des pages web pour son indexation. Ce tournant est le témoin d’une utilisation du web de plus en plus nomade. Les veilleurs et autres professionnels de l’information devront également prendre en compte les nouveaux usagers des réseaux sociaux. Apparus il y a une quinzaine d’années, ces derniers sont devenus incontournables dans la panoplie des sources d’informations. Les questions politiques et économiques s’introduisent également dans le paysage du web : neutralité du web, contenus ouverts, gratuits ou payants, le droit à l’oubli numérique et le fameux RGPD (règlement général européen sur la protection des données personnelles). L’auteure n’entre pas forcément dans le détail de ces diverses actualités, choisissant parfois de les développer dans des chapitres ultérieurs ou de laisser le soin au lecteur de trouver davantage de réponses par lui-même. La force de cette partie est indéniablement la pertinence et la quasi-exhaustivité des thématiques qui y sont abordées, qui permettent au lecteur d’entrer dans le sujet de l’ouvrage avec la connaissance des forces et des tendances qui s’y exercent. On saluera finalement la présence d’un lexique sur le jargon et les grands concepts du web, fort utile pour déchiffrer les nombreux acronymes courants.
Véronique Mesguich se lance ensuite dans le vif du sujet à travers un chapitre conséquent qui se propose d’explorer le vaste sujet qu’est la recherche d’information. À l’instar de la partie précédente, l’auteure commence par un point de théorie en présentant les typologies et le fonctionnement de la recherche d’information ainsi que les différents outils mobilisés par celle-ci, en particulier les moteurs de recherche. Il est appréciable que le fonctionnement et les attributs de ces derniers soient expliqués en détail, car si un grand nombre d’internautes suit la devise du « je Google donc je sais », une minorité est au courant des subtilités du page ranking et autres algorithmes et des biais que ceux-ci peuvent amener dans les résultats. Une liste d’alternatives à Google plus respectueuses de la vie privée est d’ailleurs proposée. La seconde grande section de ce chapitre décrit en détail les subtilités du choix des mots-clés de recherche et de la construction de requêtes, notamment à l’aide d’opérateurs et des fonctions de recherche avancée additionnés aux techniques d’optimisation de la recherche. Là encore, un certain nombre d’opérateurs et d’astuces sont proposés pour les recherches sur Google, mais également sur Qwant, Facebook, Twitter, Linkedin, ResearchGate et Academia. Un tableau récapitulatif permet d’obtenir en un coup d’œil les principaux opérateurs, étayés d’une définition ainsi qu’une liste des différents outils qui les utilisent. Le chapitre s’achève avec une brève typologie des sources d’information, des outils de bookmarking et d’une synthèse sur la méthodologie générale de la recherche d’information.
Suite à cette présentation des méthodes, sources et outils pour satisfaire un besoin d’information ponctuel, le lecteur est ensuite invité à se plonger dans la veille proprement dite. Tout d’abord, il est question de définir la veille, c’est-à-dire sa typologie et son fonctionnement. Puis, il est brièvement question du plan de veille, de son rôle et de son utilité. On regrette que cette section ne soit pas allée un peu plus loin pour présenter cet outil, ni n’en n’ait fourni un exemple, qui se serait avéré utile pour illustrer le propos et donner une idée au néophyte de la forme que peut avoir ce tableau de bord essentiel de la veille.
Cette partie se poursuit avec l’automatisation de la collecte d’information. Sont bien évidemment mentionnés les flux RSS, les agrégateurs et générateurs de flux, les alertes dans les bases de données (pour douze bases de données différentes) sans oublier les agents d’alerte et de surveillance. Un précieux tableau proposé en fin de chapitre résume l’ensemble de ces outils en listant leur intérêt pour la veille, leurs avantages et inconvénients et leur coût. Un focus est ensuite fait sur la veille des réseaux sociaux. En effet, ceux-ci sont des sources relativement nouvelles dans la panoplie des veilleurs et l’hétérogénéité de leurs fonctionnements appelle à des outils et approches spécifiques pour en tirer les pépites informationnelles qu’elles contiennent. Dans cette idée, l’auteure propose des conseils et des ressources pour surveiller Twitter, Facebook, Linkedin, Instagram, Pinterest et Youtube.
L’avènement des réseaux sociaux n’a néanmoins pas que des avantages, car les fake news rôdent. Comment s’assurer de la qualité et l’authenticité de l’information dans ces conditions ? La masse de l’information, appelée parfois infobésité ajoute une seconde difficulté à cet effort. L’analyse de l’information n’est pas toujours naturellement évoquée dans la veille, pourtant il s’agit d’une étape importante de ce processus. Véronique Mesguich passe en revue les ressources et les méthodes manuelles et automatiques à disposition pour évaluer l’information. Une fois l’information validée, le travail n’est pas encore terminé : il faut encore faire parler les données afin de rendre leur essence intelligible pour une audience sans pour autant y apporter de modifications. À cet effet, un rapide panorama de la data-visualisation est proposé et illustré à l’aide d’un tableau qui fait correspondre à des types de représentation les outils existants pour les créer.
L’ultime chapitre de cet ouvrage est un ensemble d’études de cas. À travers dix exemples communs de besoin d’information, l’auteure guide le lecteur à travers enjeux, ingrédients et étapes nécessaires pour y répondre. Ces besoins vont de l’étude documentaire pour une étude de marché, à la navigation anonyme, la surveillance de la concurrence en passant par la recherche de contenus académiques pour la rédaction d’une bibliographie. Évidemment, tous les besoins informationnels ne seront pas couverts par ces exemples, mais leur diversité devrait répondre aux attentes les plus courantes. Cela est par ailleurs une bonne façon de passer en revue et de mettre en pratique l’ensemble des approches, méthodes et outils vus dans les chapitres précédents.
En guise de conclusion, Véronique Mesguich catalogue une fois encore les tendances pour le web et la recherche d’information observables au premier trimestre 2018 et s’interroge sur la révolution numérique et les paradoxes que celle-ci a engendrés : l’explosion de la quantité d’informations disponibles versus sa qualité, la mémoire du web ou comment sauvegarder ses contenus dans ce contexte de big data et de revendication croissante du droit à l’oubli numérique ? L’auteure clôt son livre avec un plaidoyer pour la littératie numérique, soulignant l’importance pour tout un chacun de développer ses compétences, et espère que les nouvelles générations de digitial natives sauront prendre ce virage et montrer le chemin à suivre.
Critique
Le livre de Véronique Mesguich tient les promesses de son titre. On soulignera la richesse indéniable des thématiques abordées et le fait que le propos ne se limite pas à des méthodes et des outils, mais donne une place méritée au contexte et à ses tendances. On saluera aussi l’équilibre entre les différentes thématiques et la manière logique dont les propos s’enchaînent. Le lecteur n’est jamais laissé à lui-même, mais bien accompagné au long du cheminement du livre.
On peut se demander quel sont les publics cibles de cet ouvrage. En effet, si le paysage est vastement posé en termes d’hétérogénéité complémentaire des thématiques abordées, l’auteur ne rentre pas toujours suffisamment dans les détails pour permettre aux néophytes de comprendre les enjeux profonds de certains sujets. En ce sens, le livre semble s’adresser davantage à un public d’étudiant en sciences de l’information ou à des amateurs éclairés. De leur côté, les professionnels ne seront peut-être pas (toujours) surpris par les contenus abordés, car un certain nombre de connaissances leur seront déjà acquises, ou ils pourraient être laissés sur leur faim vis-à-vis de certaines thématiques pour lesquelles on aurait pu espérer une prise de position de l’auteur. Toutefois, l’intérêt du livre réside dans la réelle et consciencieuse mise à jour des savoirs, des connaissances et des outils, qui sera toujours utile pour les professionnels de la veille et de la recherche d’information, mais également dans le fait que celle-ci se fait de manière neutre, mais critique. De plus, la qualité synthétique des contenus, ses nombreuses astuces et ses tableaux récapitulatifs en fait un excellent support de cours dans le cadre d’une formation en sciences de l’information.
Le seul point noir de cet ouvrage est à imputer à l’éditeur : l’impression en noir et blanc des pages altère la qualité des captures d’écran et des illustrations contenues dans le livre et surtout en freine la compréhension par le lecteur.
Rechercher l’information stratégique sur le web : sourcing, veille et analyse à l’heure de la révolution numérique est un ouvrage à mettre entre les mains de toutes les personnes qui cherchent à parfaire leurs compétences de recherche d’information et/ou de veille, ou qui souhaitent mettre à jour leurs connaissances sur ces sujets. On en encouragera également la lecture par les étudiants, quel que soit leur domaine, afin de les sensibiliser aux écueils du net à l’heure de la toute-puissance des GAFAM et de leur donner les armes nécessaires pour les éviter.
Bibliographie
MESGUICH, Véronique, 2018. Rechercher l’information stratégique sur le web : sourcing, veille et analyse à l’heure de la révolution numérique. Louvain-la-Neuve : De Boeck Supérieur. Information & stratégie. ISBN 978-2-8073-1578-5.
- Vous devez vous connecter pour poster des commentaires
Consommer l’information : de la gestion à la médiation documentaire
Ressi — 20 décembre 2018
Siham Alaoui, M.S.I., Étudiante au doctorat en archivistique, Département des sciences historiques, Université Laval, Québec (QC), Canada
Consommer l’information : de la gestion à la médiation documentaire
Les développements technologiques ont changé les rapports entre les archivistes, les archives et le grand public. La fonction des archives se modifie dans la société, d’autant plus que l’archiviste, ce gardien de la mémoire, jouit désormais de nouveaux rôles socioculturels dans la médiation documentaire. Les usagers changent de positionnement : autrefois des simples récepteurs passifs de l’information documentaire, ils deviennent des sujets numériques qui participent activement à la chaîne archivistique. Une telle participation oriente l’archivistique vers une nouvelle posture épistémologique, celle de la collaboration et de l’ouverture. Elle dicte la révision des mécanismes de la diffusion des archives et les modalités de leur exploitation. Cet ouvrage est un recueil des réflexions d’un ensemble de spécialistes, issues des présentations faites sur la thématique abordée au 45ème congrès de l’Association des archivistes du Québec (AAQ), tenu le 13, 14 et 15 juin 2017 sous le thème : Consommer l’information, de la gestion à la médiation documentaire. Il est édité par Martine Cardin et Anne Klein, respectivement professeures titulaire et agrégée en archivistique au département des sciences historiques de l’Université Laval. L’ouvrage est structuré en deux grandes parties : la première, plus courte, aborde les postures épistémologiques et éthiques de l’archivistique collaborative, tandis que la deuxième traite de la médiation documentaire entre les institutions, les archivistes, les archives et les usagers.
Martine Cardin et Christian Desîlets, en exposant le cas des archives de la publicité, abordent une nouvelle perspective de l’archivistique à l’ère du numérique, soit celle de l’archivistique ouverte. Cette nouvelle approche retrouve ses bases dans les fondements du marketing ouvert. Elle est issue d’un besoin de valorisation des archives, intervention qui nécessite désormais l’implication de l’usager et qui induit une médiation documentaire multidirectionnelle entre les parties prenantes d’un système d’exploitation des archives. Didier Devriese s’attarde sur la valeur du document d’archive et considère qu’elle n’est pas jugée seulement par le producteur de celui-ci, mais aussi par son usager. Il rappelle que les métadonnées documentant le contexte de création des documents d’archives favorisent leur réexploitation et leur restitution par les usagers actuels et potentiels. Il conclut que l’archiviste n’est pas le seul acteur à intervenir dans la médiation documentaire, puisque c’est aussi à l’usager qu’incombent la responsabilité de l’évaluation des archives et l’interprétation de leur signification. Jean-Philippe Legois rejoint la même conception de médiation collaborative, mais se positionne plutôt dans la sphère des témoignages oraux. Il se sert de l’exemple de la Cité des mémoires pour illustrer les particularités de la mémoire collective estudiantine en France et les enjeux liés à sa préservation. Dans ce sens, il évoque l’expression de l’archivistique intégrale pour mettre en avant le rôle de l’archiviste dans la constitution et la préservation de la mémoire sociétale à travers la collecte d’archives privées en lien avec les activités des institutions publiques. Toutefois, l’archiviste n’y est pas un intervenant unique puisque la gestion et la sauvegarde de la mémoire collective orale fait également appel à d’autres intervenants, dont les producteurs et les usagers.
Guillaume Boutard examine la médiation documentaire sous la loupe de la conservation collaborative et distribuée des œuvres musicales numériques. L’auteur souligne le principal défi lié à la conservation des œuvres musicales numériques : d’être en mesure d’étudier et de réinterpréter une œuvre, et non seulement de conserver une performance unique à travers la captation d’un événement. L’auteur explique la tension entre l’œuvre artistique et le cycle de vie de sa conservation, et souligne l’importance d’une médiation documentaire adaptée à la nature de telles œuvres. Après l’exposé d’une étude de cas, il met l’accent sur la collaboration dans les pratiques de la conservation des œuvres musicales numériques, et ce, dans un contexte de médiations technologiques.
Sylvain Senécal aborde une autre facette de la médiation documentaire, celle de la tension entre la préservation et l’oubli. Il postule que la mémoire revêt des aspects sociaux qui soutiennent les processus de la réinvention des connaissances. Elle constitue aussi un fruit de la transaction entre l’individu et la société. Son intelligibilité et sa valeur sont déterminées non seulement par l’archiviste, mais aussi par les créateurs/producteurs des archives. Ainsi importe-t-il d’établir une chaîne de médiation documentaire continue entre ces divers acteurs.
À l’ère du numérique, la médiation documentaire collaborative fait naître de nouvelles responsabilités pour les institutions culturelles et les archivistes à l’égard des usagers. C’est dans ce contexte que Paul Servais s’interroge sur l’avenir de la profession de l’archiviste et la relation de celui-ci avec les usagers. Les réflexions de l’auteur mobilisent les constats tirés d’un projet nommé : Archives et archivistes dans 15 ans. Selon lui, l’archiviste n’est plus perçu comme un simple gardien du trésor des archives : ses missions vont au-delà du périmètre des institutions publiques pour englober patrimoine et mémoire au service de la société. Il endosse un rôle plus actif dans la médiation documentaire avec les usagers, et ce, dans la diversité de leurs profils.
Stéphan La Roche fait le portrait de l’expérience du Musée de la civilisation dans la médiation documentaire/culturelle à l’ère du numérique. Il s’attarde sur les enjeux du numérique dans le milieu de la culture et du patrimoine, et met l’emphase sur la réingénierie culturelle des rôles et fonctions associés à la conservation de la mémoire publique. Il postule que la mise en ligne des œuvres ne garantit pas leur intelligibilité : c’est le point sur lequel les musées sont appelés à redéfinir leurs rôles. Le numérique autorise une dimension supplémentaire : il ouvre les portes au grand public pour s’impliquer dans le processus de l’établissement des interactions entre les contenus et les contextes. L’auteur expose ensuite l’expérience du Musée de la civilisation et ses interventions dans le cadre de la transition vers le numérique et la redéfinition des responsabilités qu’il implique pour les archivistes et les conservateurs du patrimoine.
Laure Amélie Guitard, en présentant les résultats de sa recherche doctorale, définit la médiation culturelle dans un contexte différent, celui de l’entrevue de référence entre l’archiviste et l’usager. Inspirée de la conception muséologique, l’auteure voit la référence comme un acte de communication. Elle liste et décrit les étapes et l’entrevue de référence et les concrétise par des exemples pertinents. Elle démontre que, finalement, l’archiviste est à la fois un agent de médiation culturelle (i.e. transmission des archives) et sémantique (i.e. transmission du sens en décortiquant la portée du besoin informationnel de l’usager et en lui suggérant les sources d’archives qui répondent le mieux à ses attentes).
Annaëlle Winand discute de l’exploitation des archives audiovisuelles numériques par les artistes dans le cadre du cinéma de réemploi, et plus précisément dans l’optique de la production des films expérimentaux. Elle projette un regard archivistique sur le travail du cinéaste Bill Morrison. Elle analyse l’œuvre Decasia sous quatre facettes, soit la matérialité, le contexte, le dispositif et le rôle assigné au public. Sa réflexion débouche sur le constat selon lequel la dimension affective de l’archive intervient dans le processus de la médiation documentaire, et ce, dans la mesure où elle incite le spectateur à devenir une partie intégrante de l’œuvre artistique.
Anne Klein et Yvon Lemay s’intéressent à la question de la diffusion et de l’exploitation des archives. Ils mettent tout d’abord le point sur l’évolution de l’archivistique, de la conception classique à la vision postmoderne. Cette transition redéfinit les missions de l’archiviste dans un vecteur sociétal plutôt qu’institutionnel. Les auteurs présentent le projet Archives et création (de 2013 à 2016) visant à étudier l’exploitation des archives numériques comme un levier à la construction de l’espace de médiation à créer entre l’archiviste et l’usager. Afin de valoriser l’exploitation dans la chaîne archivistique, ils proposent une révision du modèle australien de la gestion documentaire, soit le Records Continuum, en ajoutant cette fonction (i.e. exploitation) aux quatre autres dimensions comme dimension dialectique.
Le sujet de l’ouvrage s’inscrit dans la continuité de la polémique sur le repositionnement de l’archiviste dans une perspective de transition entre les sphères institutionnelle et sociétale, de même que sur le numérique et l’essor des pratiques culturelles. Aussi, il devient de plus en plus crucial de se focaliser sur l’usager qui est désormais perçu comme un acteur numérique actif dans la médiation documentaire. La diversité des perspectives adoptées par les auteurs constitue la richesse de l’ouvrage: les contributeurs se positionnent tantôt dans la perspective des sciences historiques, tantôt dans celle des sciences de l’information, de la muséologie, voire même des sciences sociales connexes, telles que la communication, les études cinématographiques et la musique. Toutefois, tous se rejoignent dans la même idée : percevoir l’usager au centre de la médiation documentaire, valoriser le rôle de l’archiviste dans la société et encourager l’esprit de collaboration archivistique. La variété des approches épistémologiques justifie bien à quel point l’archivistique est une discipline souple qui s’insère dans l’interdisciplinarité avec les autres sciences humaines et sociales.
L’aspect novateur de cet ouvrage réside dans la nouvelle approche de l’archivistique, soit celle de l’archivistique ouverte. Elle résulte de l’interdisciplinarité entre l’archivistique et le marketing ouvert. Cette nouvelle conception axée sur la collaboration, témoigne de la nécessité de la concertation des interventions archivistiques d’un ensemble d’acteurs, et non seulement l’archiviste. Aussi, elle implique le sens multidirectionnel selon lequel la médiation documentaire se réalise, où le consensuel en devient la pierre angulaire. Cet ouvrage est ainsi une référence incontournable pour la communauté archivistique – scientifique et professionnelle – qui s’intéresse aux mutations archivistiques actuelles, notamment dans une perspective sociétale.
Bibliographie
Cardin, Martine et Anne Klein. 2018. Consommer l’information : de la gestion à la médiation documentaire. Québec : Presses de l’Université Laval, 181p. ISBN : 139782763739243
- Vous devez vous connecter pour poster des commentaires
La Perspective du Continuum des archives illustré par l’exemple d’un document personnel
Ressi — 20 décembre 2018
Viviane Frings-Hessami, Monash University, Australie
Résumé
La théorie du Continuum des archives développée en Australie peut apparaître complexe et difficile à appliquer à des exemples concrets. Certains parmi ses écrits de base sont denses et compliqués, et la littérature archivistique n’offre pas beaucoup d’exemples pratiques de son application. Dans les pays non anglophones, la situation est exacerbée par des problèmes de traduction et par le manque de textes écrits par des auteurs qui se placent dans la tradition du Continuum. Cet article écrit par un auteur francophone qui a étudié et enseigné le Continuum en Australie s’efforce de combler cette lacune dans la littérature archivistique francophone. Il présente une explication du Continuum des archives illustrée par un exemple simple, celui d’une photo de famille. Il discute différentes utilisations de cette photo par des utilisateurs divers à des moments et dans des endroits divers et pour des fins diverses afin de montrer comment une perspective de Continuum peut être appliquée à des documents personnels aussi bien qu’à des documents d’affaires et comment elle peut encourager un système de gestion des archives efficace, orienté vers l’avenir et qui permettra de remplir les besoins de tous les utilisateurs.
Abstract
The Continuum theory developed in Australia may appear complex and hard to apply to concrete cases. Some of its core writings are dense and complicated, and there are not many practical examples of its applications in the archival literature. In countries where the main language is not English, the situation is compounded by problems of translations and by the paucity of texts written by authors who position themselves in the Continuum tradition. This article, written by a Francophone author who has studied and taught the Continuum in Australia, aims to address this gap in the Francophone literature. It presents an explanation of the Records Continuum illustrated by a simple example, that of a family photograph. It discusses multiple uses of the photograph by multiple users in different times and places and with different aims in order to illustrate how a Continuum perspective can be applied to personal records as well as to business records and how it can foster a records management system that is effective and forward-looking and that will meet the needs of all the users.
La Perspective du Continuum des archives illustré par l’exemple d’un document personnel
Introduction
La théorie du Continuum des archives développée en Australie peut apparaît complexe. Certains parmi les écrits de base sont compliqués, denses et parfois difficiles à suivre (Piggot, 2010 ; p. 180), et la littérature n’offre pas beaucoup d’exemples pratiques de son application. Dans les pays non-anglophones, la situation est exacerbée par des problèmes de traduction qui entraînent des confusions et par le manque de textes écrits par des auteurs qui se placent dans la tradition du Continuum. Dans cet article, je m’efforce de combler cette lacune dans la littérature archivistique francophone. Je me base sur mon expérience personnelle de six années passées à étudier, enseigner et faire des recherches sur le Continuum des archives à l’Université Monash où le modèle fut développé. Je présente une explication du Continuum des archives illustrée par un exemple simple que tous les lecteurs peuvent facilement relier à leur expérience personnelle, celui d’une photo de famille. Je discute différentes utilisations de cette photo par des utilisateurs divers à des moments et dans des endroits divers et pour des fins diverses et je montre comment une perspective de Continuum peut être appliquée à des documents personnels aussi bien qu’à des documents d’affaires et comment elle peut encourager un système de gestion des archives efficace, orienté vers l’avenir et qui permettra de remplir les besoins de tous les utilisateurs.
Le modèle du Continuum des archives
Le modèle du Continuum des archives (Records Continuum) fut développé à l’Université Monash à Melbourne en Australie dans les années 1990 par Frank Upward et ses collègues Sue McKemmish, Livia Iacovivo et Barbara Reed afin d’expliquer les contextes complexes dans lesquels les documents sont créés et gérés à l’ère du numérique et de représenter les différentes perspectives selon lesquelles des documents peuvent être perçus (McKemmish 2017; Upward, 1996, 1997). Il s’appuie sur une tradition qui remonte à la notion d’un continuum entre les documents et les archives articulée pour la première fois dans les années 1950 par Ian Maclean, le directeur de la section des archives de la Bibliothèque nationale d’Australie (Maclean 1959, McKemmish, 2017). Le modèle met l’accent sur la continuité entre les documents et les archives et conteste la notion que les archives ne comprennent que les documents qui ont été sélectionnés pour être préservés à perpétuité. Dans la tradition du Continuum, les archives sont considérées comme archives dès le moment de leur création (McKemmish et al., 2010) et le concept de recordkeeping (écrit en un mot) englobe la création et la gestion des documents et des archives durant toute la durée de leur existence et quels que soient les usages qui en sont faits (McKemmish 2017; McKemmish et al., 2010).
Étant donné que le terme « archives » en français peut aussi être appliqué aux documents d’archives dès le moment de leur création[1], j’ai choisi de traduire Records Continuum par « Continuum des archives » et recordkeeping par « gestion des archives »[2]. Ces deux expressions représentent bien l’idée que les documents qui ont le potentiel de devenir un jour des archives permanentes doivent être traités avec soin dès le moment de leur création. Le recordkeeping, dans la tradition du Continuum, inclut aussi la gestion des systèmes d’archivage qui doivent être développés en tenant compte des besoins de l’organisme et des exigences législatives et mis en place avant que les archives ne soient créées de sorte que quand les archives sont créées, elles peuvent être immédiatement captées dans des systèmes qui préserveront leurs caractéristiques essentielles (McKemmish, 2017). La captation dans des systèmes archivistiques et l’attribution de métadonnées situent les archives dans un contexte précis à un moment précis et leur donnent un caractère fixe. Cependant, les archives sont perçues comme étant « toujours en devenir » (always in a process of becoming) (McKemmish, 1994 : p. 200), c’est-à-dire qu’elles sont toujours susceptibles d’être transformées par des nouveaux utilisateurs dans des contextes nouveaux.
Les caractéristiques fondamentales du Continuum des archives qui le distinguent d’autres modèles sont ses quatre dimensions. Les quatre dimensions ne sont pas des phases ou des étapes et elles ne se suivent pas dans un ordre déterminé, contrairement aux étapes du cycle de vie ou aux trois âges des archives. Elles coexistent parce que les archives sont impactées par les actions de différents acteurs et parce qu’elles peuvent être perçues de manières différentes par des utilisateurs différents.
Les quatre dimensions du Continuum des archives sont généralement représentées par quatre cercles concentriques (figure 1). Dans la première dimension, celle de la Création, des transactions prennent place et laissent des traces sous la forme de documents ou d’inscriptions[3]. Dans la deuxième dimension, celle de la Captation, les documents sont captés dans des systèmes d’archivage qui les situent dans un contexte précis et ajoutent les métadonnées nécessaires pour qu’ils puissent être utilisés comme preuves des transactions qui ont été performées. Les documents deviennent ainsi des records, des documents d’archives[4]. Dans la troisième dimension, celle de l’Organisation, les documents d’archives de différents services sont intégrés dans un système d’archivage au niveau d’un organisme de sorte qu’ils constituent des archives qui pourront être utilisées comme preuve des fonctions performées par l’organisme. Dans la quatrième dimension, celle de la Pluralisation, les archives sortent en dehors des confins de l’organisme qui les a créées et gérées de sorte qu’elles peuvent contribuer à la mémoire collective de la communauté générale et être réutilisées de façons multiples.
Figure 1 : Les quatre dimensions du Continuum des archives
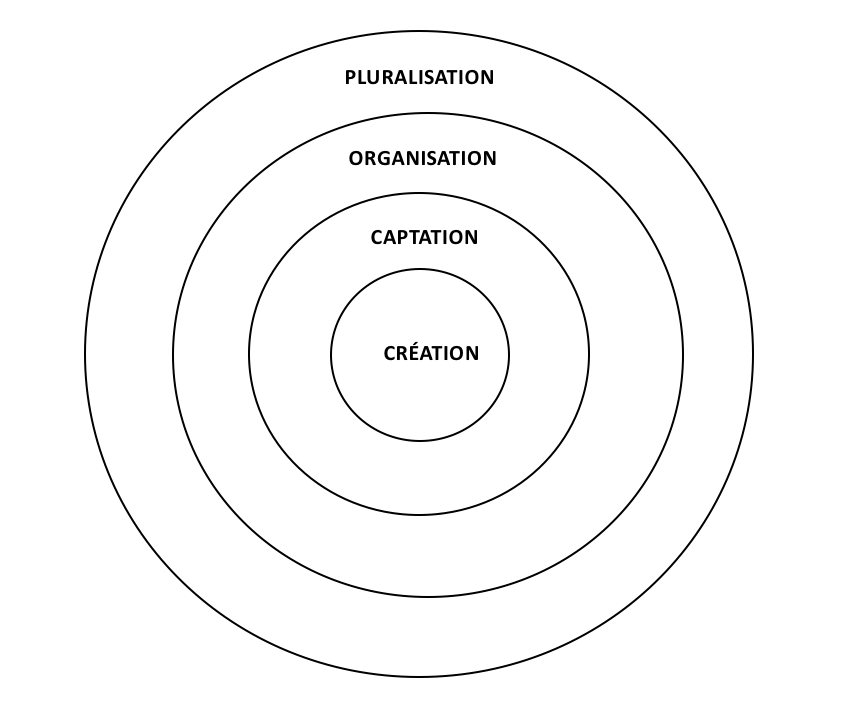
Étant donné que les dimensions coexistent dans le temps et l’espace, une représentation tridimensionnelle en forme de cône ou de sphère serait mieux appropriée pour représenter le Continuum des archives, mais elle serait plus difficile à dessiner et à utiliser comme un outil pédagogique. La représentation plate du Continuum des archives avec ses quatre cercles concentriques permet de représenter sur un diagramme différentes perspectives selon lesquelles un document peut être perçu et les voies diverses qu’il peut suivre comme Barbara Reed (2005b) l’a fait dans un des textes clés du Continuum des archives et comme je vais le faire dans la section suivante.
Une photo de famille
Tout document, que ce soit un document personnel ou un document politique de la plus haute importance, peut être interprété différemment par des personnes différentes. Le même document peut être utilisé de diverses façons ou peut être analysé selon des perspectives diverses. Je vais illustrer ceci par un simple exemple, celui d’une photo de mariage.
Figure 2 : Une photo de mariage

La photo présentée ci-dessus (figure 2) fut prise au mariage de Daniel et Sophie au mois de septembre 1996 par le photographe engagé pour prendre les photos du mariage avec un appareil photographique argentique. Plusieurs exemplaires furent imprimés pour le jeune couple qui choisit d’en garder un pour eux et de donner les autres à quelques-uns de leurs parents et amis. Chacune de ces photos est un document différent qui va suivre une trajectoire différente. Toutes ces trajectoires peuvent être représentées sur le diagramme du Continuum des archives. Prenons quelques exemples :
-
Les mariés : Daniel et Sophie insèrent la photo dans leur album de mariage avec les autres photos de leur mariage. Pour chaque photo, ils indiquent les noms des personnes présentes et parfois ajoutent quelques commentaires. Pendant les premiers mois après leur mariage, ils gardent l’album sur une petite table dans leur salon et le feuillettent souvent. Après quelques mois, l’album trouve sa place définitive sur une étagère à côté de leurs autres albums photos.
-
Les parents : Les parents de Sophie reçoivent une photo. Ils la mettent dans un de leurs albums photos avec d’autres photos du mariage et d’autres photos de Sophie. Ils indiquent la date du mariage, mais pas les noms des personnes présentes. Ils gardent cet album avec leurs autres albums qui contiennent des photos de famille.
-
Une cousine : Daniel envoie une photo par courrier à sa cousine qui habite en Australie. Elle la garde dans l’enveloppe avec laquelle elle est arrivée. Quoiqu’elle soit contente de la recevoir, elle ne prend pas le temps de la mettre dans un album photo et n’écrit pas la date, l’endroit ou les noms des personnes derrière la photo. Elle garde cette enveloppe dans une boîte avec les lettres envoyées par sa famille.
-
Une amie : Sophie donne une photo à une de ses amies qui l’insère dans un album de souvenirs qui contient des photos de ses amies d’école. Elle indique le lieu, la date et le nom des personnes qu’elle connaît et décore la page avec des petits dessins. Elle garde cet album sur une étagère dans sa chambre.
Représentons maintenant ces actions sur le diagramme du Continuum des archives. Chacune des trajectoires commence dans la première dimension, mais chacune suit un chemin séparé puisque les photos sont captées dans des systèmes différents. La photo en possession de Daniel et de Sophie est insérée dans leur album de mariage (ligne rouge sur la figure 3). La copie donnée aux parents de Sophie est incluse dans un album de photos de Sophie (ligne verte), la copie donnée à l’amie de Sophie dans un album de souvenirs (ligne orange) et la photo envoyée à la cousine de Daniel dans une enveloppe (ligne bleue).
Figure 3 : Quatre utilisations de la photo
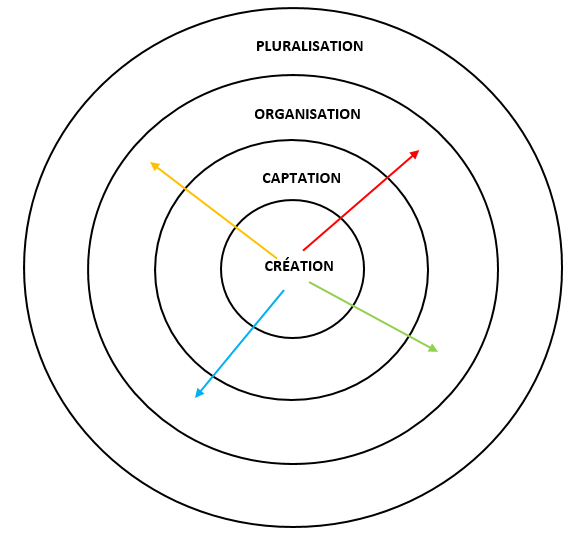
Aucune de ces photos n’est pluralisée. Aucune n’est rendue accessible en dehors du cercle de la famille et des amis proches du couple de jeunes mariés. Le mariage a eu lieu en 1996. Personne n’a utilisé un appareil photographique numérique.
Toutefois, en 2016, Sophie décide de numériser la photo, de la télécharger sur sa page Facebook et de la mettre en publication publique. Ceci constitue un nouvel usage de la photo qui, à son tour, rend d’autres usages possibles. L’acte de numériser la photo crée un nouveau document et implique un retour à la première dimension et le début d’une nouvelle trajectoire pour ce nouveau document qui est représentée en rouge sur la figure 4. La disponibilité de la photo sur Facebook, à son tour, rend d’autres usages de la photo possibles pour d’autres utilisateurs. Des amis de Sophie peuvent télécharger la photo et la partager sur un autre média social. Des personnes qui ne connaissent pas Sophie, mais s’intéressent à la mode des années 1990 ou qui collectionnent les photos de mariage, ou les photos de chapeaux, etc., peuvent copier la photo et l’inclure sur leur site. Deux exemples sont représentés en bleu et en vert sur la figure 4. Dès lors que la photo est rendue publique, particulièrement si elle est disponible sur Internet, il est difficile de mettre des limites à sa réutilisation pour des usages variés.
De nos jours, il est courant de prendre des photos et de les télécharger immédiatement sur des médias sociaux. Dans ces cas-là, les photos peuvent passer de la première à la quatrième dimension en une nanoseconde (Upward et al., 2018). Les quatre dimensions peuvent être passées d’une manière pratiquement simultanée, ou la deuxième et la troisième dimensions peuvent être sautées. Des photos peuvent être rendues publiques sans avoir été proprement captées dans un système, c’est-à-dire sans que des métadonnées leur aient été ajoutées (automatiquement ou manuellement) et sans qu’un système de classification leur ait été appliqué.
Figure 4 : Téléchargement de la photo sur des médias sociaux
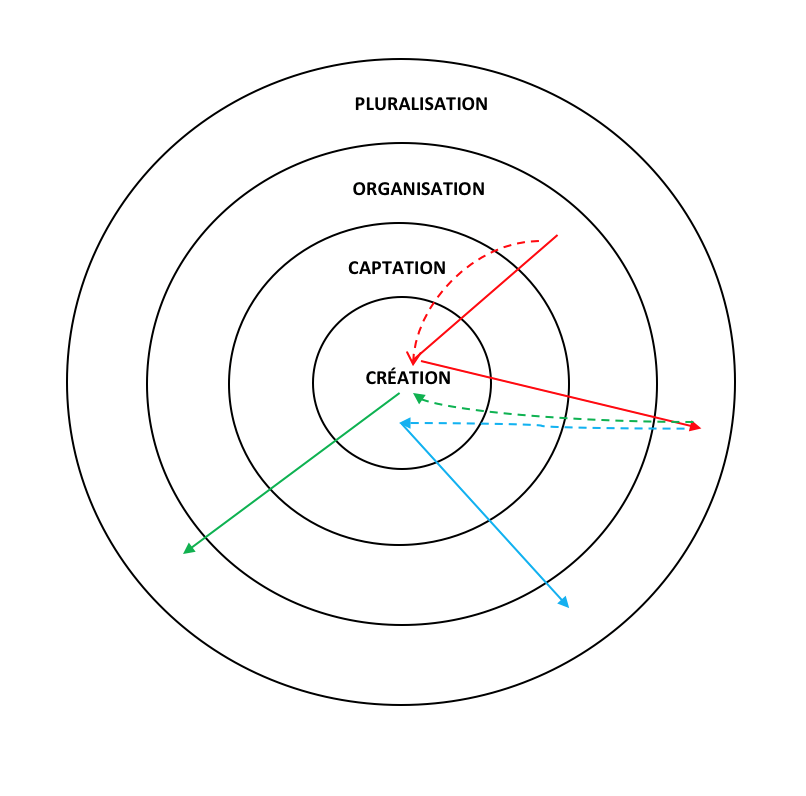
Tous les exemples dont nous avons parlés jusqu’ici regardent la photo comme un souvenir du mariage. Cependant, il est possible d’envisager qu’elle pourrait être utilisée comme preuve de quelque chose d’autre. Par exemple, supposons que la dame derrière les mariés sur la photo, cousine Anita, est accusée d’avoir tué son mari ce jour-là. Elle pourrait présenter la photo comme preuve qu’elle a assisté au mariage et par conséquent qu’elle n’aurait pas pu être à ce moment-là à l’endroit où son mari a été tué, à 200 kilomètres de là. Dans ce cas, la photo serait reçue comme preuve par les policiers en charge de l’enquête qui l’incluraient dans le dossier de l’enquête. La capture de la photo dans ce dossier serait accompagnée de l’ajout de métadonnées différentes de celles que l’on peut trouver dans des albums photos privés pour la relier à l’enquête judiciaire. En particulier, le moment exact où la photo fut prise serait un élément crucial pour son utilisation comme preuve et le sort d’Anita pourrait dépendre de la présence ou de l’absence de ces métadonnées. Le nom du photographe serait également important parce qu’il pourrait être appelé à témoigner. La photo serait captée dans le système de gestion des documents de la police judicaire et pourrait être présentée au tribunal si la police décide de lancer des poursuites judiciaires contre Anita. Elle serait aussi organisée dans les archives de la police et du tribunal et, après un certain temps pourrait être transférée aux archives nationales (ou cantonales, départementales, etc.) selon la procédure en place dans la juridiction concernée (figure 5). L’utilisation de la photo dans des reportages médiatiques sur l’enquête pourrait aussi l’amener dans la quatrième dimension du Continuum (ligne pointillée sur la figure 5).
Figure 5 : Utilisation de la photo comme preuve
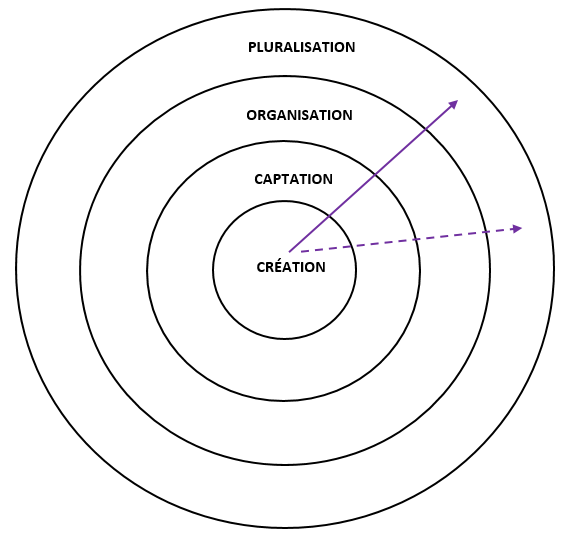
Les albums de photos de mariage, par contre, ne seront vraisemblablement jamais transférés dans un service d’archives. A moins que Sophie ou Daniel ne devienne un jour une célébrité et que quelqu’un ne décide de constituer des archives sur eux !
Il serait aussi intéressant de considérer ce qui adviendrait des photos en cas de divorce, celle en possession de Sophie et Daniel, et celles données à leurs parents et amis. Elles pourraient être détruites, ou déchirées en deux, ou enlevées des albums, ou les albums pourraient être mis au grenier. Elles pourraient donc commencer chacune une nouvelle trajectoire dans un nouveau contexte.
Une autre utilisation de la photo qui n’aurait pas pu être prévue au moment du mariage est celle que j’en fait dans cet article. J’ai pris la photo que Daniel m’avait envoyée en 1996 et je l’ai numérisée pour l’inclure dans cet article. Cette copie numérique de la photo est un nouveau document qui commence une nouvelle trajectoire dans la première dimension du Continuum des archives. Elle est utilisée pour un but totalement différent de celui pour lequel elle avait été créée puisque je l’utilise dans une fin pédagogique, pour expliquer le Continuum des archives. Je l’ai copiée et captée dans un document sur mon ordinateur et organisée avec les autres documents dont j’ai besoin pour écrire cet article. Son inclusion dans l’article, quand il est publié en accès libre, la porte dans la quatrième dimension puisqu’il la rend accessible à tout le monde. Dès lors, la réutilisation à fin pédagogique d’une photo qui n’était pas destinée à être vue en dehors du cercle de la famille et des amis du jeune couple en fait un exemple de réutilisation et de pluralisation d’une archive et la rend susceptible d’être réutilisée par les lecteurs de l’article pour la même fin ou pour d’autres fins.
Figure 6 : Utilisation de la photo dans cet article
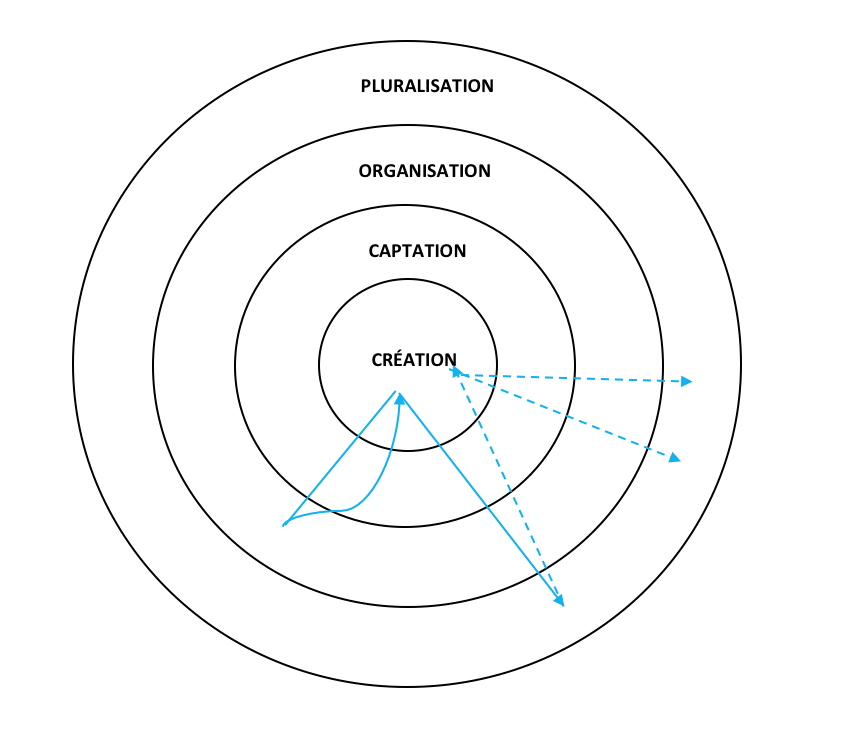
L’exemple de cette photo de mariage et de ses réutilisations illustre comment un document peut être perçu et utilisé différemment par différents utilisateurs à des moments différents et dans lieux différents. Toutes les utilisations de la photo peuvent être représentées séparément ou conjointement sur le diagramme du Continuum des archives. Chaque utilisation et réutilisation commence un nouveau parcours pour un nouveau document dans la première dimension du Continuum des archives, celle de la Création. La plupart de ces réutilisations de la photo passent par la deuxième et la troisième dimension, celles de la Captation et de l’Organisation, quand les archives sont captées dans un système (formel ou informel) et des métadonnées leurs sont ajoutées et quand elles sont organisées en fonction d’un système de classification (formel ou informel) qui permettra de les localiser. Mais seulement certaines d’entre elles atteignent la quatrième dimension, celle de la Pluralisation, parce que la décision de rendre les archives publiques est un choix que les utilisateurs peuvent faire dans chaque cas (tout en respectant les contraintes légales, réglementaires ou socio-culturelles qui peuvent s’appliquer).
Les dimensions du Continuum des archives
Les exemples d’utilisations de la photo de mariage détaillés ci-dessus ont présenté une explication linéaire de la trajectoire suivie par chacune des photos. Cependant, les quatre dimensions du Continuum des archives sont toujours présentes à tout moment et peuvent impacter sur les archives à tout moment (Reed, 2005a : p. 179). La création d’archives est influencée par des considérations qui proviennent de la troisième et de la quatrième dimensions. Pour que les archives soient gérées d’une manière efficace, il doit y avoir en place un système prêt à accueillir ces archives. Ce système doit avoir été développé de manière à ce que la création et la gestion d’archives puissent se conformer aux obligations légales, réglementaires, contractuelles et socioculturelles que les archives doivent respecter. Ces obligations proviennent soit de la quatrième dimension (les lois que l’organisme doit respecter et les attentes sociales et culturelles de la communauté), soit de la troisième dimension (les règles établies par l’organisme pour la création et la gestion de ses archives).
Les obligations que les organismes publics et les entreprises privées doivent respecter sont généralement évidentes et clairement articulées. Les organismes publics et privés doivent respecter les lois qui requièrent qu’ils produisent et conservent certains documents d’archives pour une période déterminée ou, dans certains cas, à perpétuité, comme preuves de leurs activités, et ils doivent respecter les lois sur l’accès à l’information et sur la protection des données à caractère personnel. Ces lois émanent de la quatrième dimension. D’autre part, les organismes qui produisent et gèrent de larges quantités de documents doivent avoir des règles en place au niveau de l’organisme pour régler la gestion de ces documents. Ces règles font partie de la troisième dimension. Ainsi des lois de la quatrième dimension et des règles de la troisième dimension déterminent quelles archives les organismes créent (dans la première dimension), comment ils les absorbent dans leurs systèmes (dans la deuxième dimension) et comment ils les gèrent (dans la deuxième et la troisième dimensions).
La façon dont des considérations de la troisième et de la quatrième dimensions impactent sur les documents personnels n’est pas aussi évidente, mais certaines de ces considérations exercent aussi une influence. Par exemple, les considérations de protection des données à caractère personnel (qui viennent de la quatrième dimension) peuvent aussi influencer la gestion des archives personnelles (dans les 3 autres dimensions) et la décision de les partager ou de ne pas les partager. En outre, la manière dont un individu ou une famille organisent leurs archives et les raisons pour lesquelles ils les gardent (qui sont des facteurs qui relèvent de la troisième dimension) peuvent aussi influencer leur décision de créer ou de ne pas créer des archives (dans la première dimension) et de les capter ou de ne pas les capter dans un système formel ou informel (dans la deuxième dimension). Inversement, la manière dont les archives ont été créés et captées (dans les deux premières dimensions) influence les utilisations futures de ces archives (dans la troisième et la quatrième dimensions).
Les axes du Continuum des archives
Les diagrammes présentés ci-dessus ont omis les axes et les 16 éléments que l’on trouve sur la représentation originelle du modèle du Continuum des archives. Cette omission est intentionnelle. L’inclusion des axes et des noms des éléments à l’intersection des axes et des dimensions compliquent le modèle et engendrent de nombreuses confusions à propos de la signification de ces éléments qui détractent l’attention des caractéristiques fondamentales du modèle. Néanmoins, dans cette section, je vais maintenant expliquer brièvement les quatre axes.
Figure 7 : Le Continuum des archives
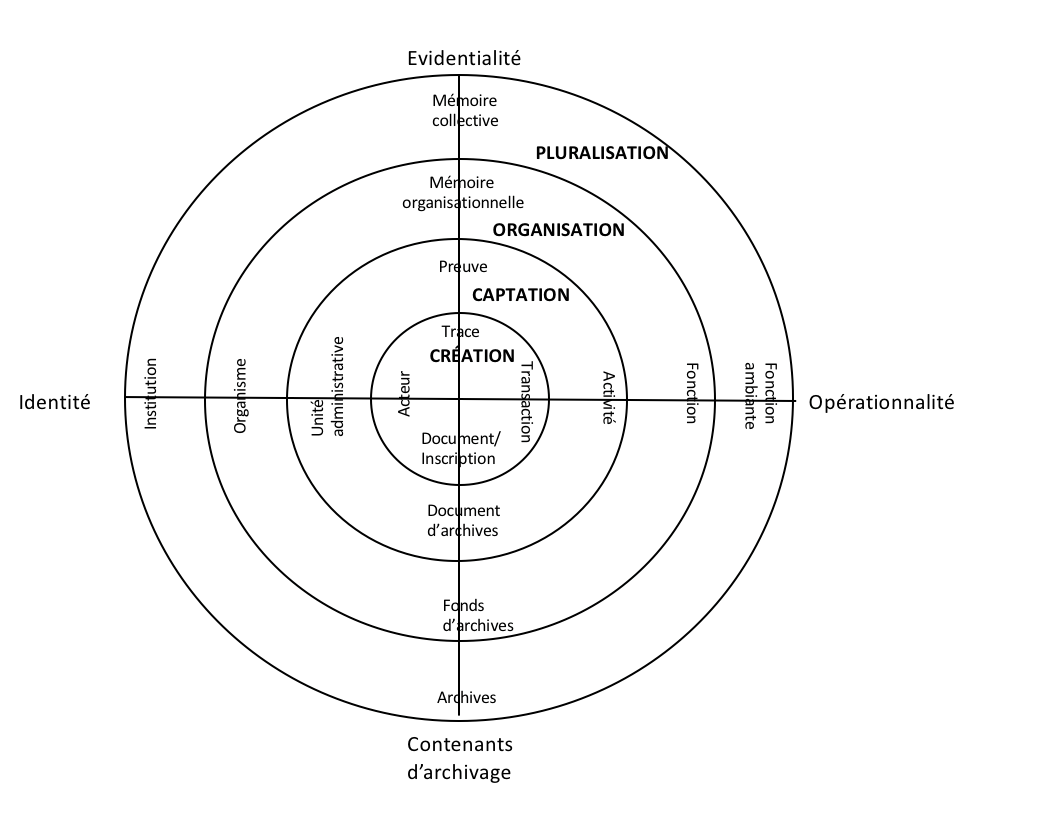
(adapté de Upward, 1996 et Upward et al., 2018)
L’axe de l’identité représente les acteurs et les organismes qui jouent un rôle dans la création et la gestion des archives : les acteurs dans la première dimension, les unités administratives dans la deuxième dimension, l’organisme dans la troisième dimension et l’institution qui accueille les archives quand elles sortent de l’organisme dans la quatrième dimension. L’axe de l’opérationnalité permet de représenter les actions et les processus qui sont appliqués aux archives et les interactions de toutes sortes entre les acteurs et les institutions : les transactions dans la première dimension, les activités auxquelles ces transactions se rapportent dans la deuxième, les fonctions que l’organisme effectue dans la troisième, et la fonction ambiante que les archives servent quand elles sont partagées dans la quatrième dimension. Sur l’axe des contenants d’archivage, sont représentés les documents et leurs agrégations: les documents ou inscriptions dans la première dimension, les documents d’archives (records) dans la deuxième dimension, les fonds d’archives dans la troisième dimension et les collections d’archives dans la quatrième dimension. Sur l’axe de l’évidentialité sont représentées les qualités probantes des archives : la trace qu’elles laissent qu’une transaction a eu lieu dans la première dimension, qui devient une preuve quand le document d’archives est capté dans un système d’archivage dans la deuxième dimension, puis contribue à la mémoire organisationnelle de l’organisme (ou à la mémoire personnelle d’un individu) dans la troisième dimension et enfin à la mémoire collective de la communauté dans la quatrième dimension.
Les noms des éléments inclus sur le diagramme ne sont pas importants. Ce qui est important, c’est de comprendre ce qu’ils représentent et où ils se situent dans les dimensions du Continuum. Il peut être difficile de les traduire et de trouver des équivalents dans des contextes archivistiques et culturels différents. Les quatre éléments sur l’axe des contenants d’archivage sont les plus difficiles à traduire en français parce que la tradition archivistique francophone est basée sur une conception différente de la tradition anglophone de ce que constitue des « archives » (Ketelaar, 2006) et parce qu’il n’y a pas d’équivalent exact en français pour le terme records. Cependant, quels que soient les termes qu’on utilise pour traduire les quatre termes document, record, archive et archives, ce qui importe c’est leur association avec les processus de création, de captation dans un système, d’organisation au niveau de l’organisme et d’incorporation dans un système plus large en dehors de l’organisme. Je les ai traduits ici par « document », « document d’archives », « fonds d’archives » et « collections d’archives ». En outre, il est aussi important de noter que ces termes font référence à des documents et à des agrégations de documents, et non pas à des lieux. La notion de lieu est une notion qui n’est pas considérée importante dans la théorie du Continuum. Les archives sont des archives quel que soit l’endroit où elles se trouvent (Cunningham, 2017; Upward, 1996).
La Perspective du Continuum des archives
La perspective du Continuum des archives peut être appliquée dans des domaines très divers, des documents personnels aux archives d’État, en passant par des documents d’affaires de toutes sortes, et dans des contextes culturels variés (Frings-Hessami, 2017, 2018a, 2018b). Elle est basée sur l’idée que nous devons penser, avant même que des archives ne soient créées, à toutes les personnes qui pourront avoir besoin de ces archives et à toutes les utilisations possibles dont elles pourront faire l’objet. Dès lors, les systèmes archivistiques qui seront développés pour gérer ces archives devront permettre la création des archives dont les utilisateurs pourront avoir besoin, la captation des métadonnées nécessaires pour les situer dans leur contexte et pour les trouver quand les utilisateurs en auront besoin, et la conservation des archives pour aussi longtemps qu’elles seront nécessaires. Les systèmes devront aussi protéger les droits que tous les acteurs pourront avoir sur ces archives, c’est-à-dire qu’ils devront protéger leurs droits sur les données à caractère personnel, leurs droits d’utiliser ces archives, mais aussi leurs droits de trouver dans ces archives les informations dont ils auront besoin, ce qui implique que des archives qui contiennent ces informations auront été créés et préservés de manière appropriée[5].
L’exemple d’une photo de mariage présenté dans cet article montre comment la perspective du Continuum des archives peut être appliquée à un document personnel et aux multiples utilisations et réutilisations dont il peut faire l’objet. Ce faisant, il illustre l’importance de prendre en considération toutes ces utilisations possibles quand un document est créé et, préférablement avant qu’il ne soit créé. L’importance d’avoir un système en place qui pourra absorber et gérer les archives est exacerbée dans le cas des archives numériques qui sont plus fragiles que les archives analogiques. Les archives numériques ne peuvent pas être négligées de la même manière que les documents papiers le pouvaient autrefois. Les copies analogiques de la photo dont nous avons parlé auraient pu être oubliées pendant des années dans les albums photos, mais, excepté en cas d’incendie ou d’une autre catastrophe, elles auraient toujours été disponibles quand la famille aurait voulu les regarder. Par contre, s’il s’agissait d’une photo numérique, il aurait été bien probable que vingt ans plus tard, ou même cinq ans plus tard, son propriétaire n’aurait plus eu accès à la technologie nécessaire pour la regarder. Quoi qu’il en soit, si personne n’avait pensé à engager un photographe pour le mariage ou si personne n’avait fait les efforts nécessaires pour conserver les photos, nous n’aurions pas de preuve photographique du mariage, pas de photos que la famille pourrait regarder comme des souvenirs, et plus sérieusement dans le cas d’Anita, pas de preuve qu’elle avait assisté au mariage. L’exemple de la photo de mariage illustre donc la nécessité de penser aux futurs usages et aux futurs utilisateurs d’un document dès le moment de sa création et de le capturer dans un système qui permettra de répondre aux besoins des utilisateurs futurs.
Bibliographie
CUNNINGHAM, Adrian, 2017. Archives as a place. In : MACNEIL, Heather et EASTWOOD, Terry. Currents of archival thinking. 2ème éd. Santa Barbara, Californie : Libraries Unlimited, 2017, pp. 53-79. ISBN: 9781440839092
FRINGS-HESSAMI, Viviane, 2017. Looking at Khmer Rouge Archives Through the Lens
of the Records Continuum Model: Towards an Appropriated Archive Continuum Model,
Information Research [en ligne]. décembre 2017. Vol. 22, no 4, [Consulté le 28.09.2018]. Disponible à l’adresse: http://www.informationr.net/ir/22-4/paper771.html.
FRINGS-HESSAMI, Viviane, 2018a, Care Leavers’ records: a case for a Repurposed Archive Continuum Model. Archives and Manuscripts. juillet 2018. Vol. 46, no 2, pp.158-173
FRINGS-HESSAMI, Viviane, 20178b. Indigenous Archives through time and space:
Towards a Continuum Model to explain the complex contexts of Indigenous Archives. Article présenté à la conférence Ngā Taonga Tuku Iho: A conference on Māori Archives and Records, Rotorua, Nouvelle Zélande, 22-24 août 2018.
GOLDING, Frank, 2016. The Care Leaver’s Perspective. Archives and Manuscripts. novembre 2016. Vol. 44, no 3, pp. 161-164.
KETELAAR, Eric, 2006. (Dé)construire l’archive. Matériaux pour l’histoire de notre temps. avril-juin 2006, no 82, pp. 65-70. [Consulté le 29 septembre 2018]. Disponible à l’adresse : https://www.cairn.info/revue-materiaux-pour-l-histoire-de-notre-temps-2006-2-page-65.htm
Loi n° 79-18 du 3 janvier 1979 sur les archives. Légifrance [en ligne]. 3 janvier 1979. Mise à jour le 28 février 1994. [Consulté le 28 septembre 2018]. Disponible à l’adresse : https://www.legifrance.gouv.fr/affichTexte.do;jsessionid=3DA3918B1389C13FBFAC47442565E30A.tpdjo16v_3?cidTexte=JORFTEXT000000322519&dateTexte=19940228.
MACLEAN, Ian, 1959. Australian experience in record and archives management. The American Archivist. octobre 1959, Vol. 22, no 4, pp. 387-418.
MCKEMMISH, Sue, 1994. Are records ever actual? In: MCKEMMISH, Sue et PIGGOTT, Michael. The Records Continuum: Ian Maclean and Australian Archives first fifty years. Clayton, Victoria, Australie : Ancora Press, 1994, pp. 187-203. ISBN: 086862019X
MCKEMMISH, Sue, 2017. Recordkeeping in the Continuum: an Australian tradition. In : GILLILAND, Anne J, MCKEMMISH, Sue et LAU, Andrew J. Research in the Archival Multiverse. Clayton, Victoria, Australie : Monash University Publishing, 2017, pp. 122-160. ISBN 9781925377699 [Consulté le 28 septembre 2018] Disponible à l’adresse : http://www.oapen.org/search?identifier=628143
MCKEMMISH, Sue, UPWARD, Frank H. et REED, Barbara, 2010. Records Continuum Model. In : BATES, Marcia J. et NILES-MAACK, Mary. Encyclopedia of Library and Information Sciences. 3ème éd. New York : Taylor & Francis, 2010, pp. 4447-4459. ISBN: 9780849397110
PIGGOTT, Michael, 2012. Archives and Societal Provenance: Australia Essays. Oxford: Chandos Publishing. ISBN: 9781843347125
REED, Barbara, 2005a. Beyond Perceived Boundaries: Imagining the Potential of Pluralised Recordkeeping. Archives and Manuscripts. mai 2005. Vol. 33, no1, pp. 176-198.
REED, Barbara, 2005b. Reading the Records Continuum: Interpretations and Explorations. Archives and Manuscripts. mai 2005. Vol. 33, no1, pp. 18-43.
SWAIN, Shurlee and MUSGROVE, Nell, 2012. We are the stories we tell about ourselves: Child welfare records and the construction of identity among Australians who, as children, experienced out-of-home ‘care’. Archives and Manuscripts. avril 2012. Vol. 40, no1, pp. 4-14.
UPWARD, Frank, 1996. Structuring the Records Continuum Part 1: Post custodial principles and properties. Archives and Manuscripts. novembre 1996. Vol. 24, n° 2, pp. 268-285.
UPWARD, Frank, 1997. Structuring the Records Continuum Part 2: Structuration theory and recordkeeping. Archives and Manuscripts. mai 1997. Vol. 25, n°1, pp. 10-35.
UPWARD, Frank, REED, Barbara, OLIVER, Gillian et EVANS Joanne, 2018. Recordkeeping Informatics. Clayton, Victoria, Australie: Monash University Press. ISBN 9781925495881
Notes
[1] Je me base ici sur la définition des archives dans la loi française du 3 janvier 1979 comme étant : « [l]’ensemble des documents, quelque soient leur date, leur forme at leur support matériel, produits ou reçus par toute personne physique ou morale, et par tout service ou organisme public ou privé, dans l’exercice de leur activité » (Loi n° 79-18 du 3 janvier 1979 sur les archives, Article 1).
[2] Recordkeeping est traduit par « archivage » dans la norme internationale ISO 15489 et dans la norme européenne MoReq2. Toutefois, j’ai choisi de ne pas utiliser cette traduction parce que dans la pratique française le terme est généralement utilisé spécifiquement pour désigner les opérations physiques de mise en archives et non pas la gestion des archives depuis le moment de leur création et au cours de tous les usages qui en sont faits.
[3] Les écrits récents de Frank Upward parlent d’« inscriptions » (Upward et al., 2018 : p. 193), plutôt que de documents, un terme plus englobant qui capture l’idée que l’action de création peut laisser une trace sur des supports divers.
[4] Dans cet article, je traduis généralement le terme records par « archives ». Cependant, quand je fais une référence spécifique à la deuxième dimension du modèle du Continuum des archives et que je veux rendre l’idée que des documents sont captés dans un système pour être préservés comme archives, je le traduis par « document d’archives ».
[5] De sérieux problèmes peuvent résulter du fait que les documents que des utilisateurs potentiels voudraient consulter n’ont jamais été créés parce que les organismes qui géraient les fonctions auxquels ces documents devraient se rapporter ne pensaient pas qu’il était utile de les créer. Telle est la situation du secteur de la protection de l’enfance en Australie au vingtième siècle (Golding, 2016 ; Swain & Musgrove, 2012).
- Vous devez vous connecter pour poster des commentaires
Service Science and the Information Professional
Ressi — 20 décembre 2018
Tullio Basaglia, Chef de section, Bibliothèque du CERN
Service Science and the Information Professional
Yvonne de Grandbois a été coordinatrice de la Bibliothèque des Library and Information Networks for Knowledge (LINK) de l’Organisation Mondiale de la Santé. Ensuite, elle a enseigné au sein des programmes de Bachelor et de Master de la filière Information documentaire de la Haute Ecole de Gestion de Genève et elle a été responsable du programme de Master en Sciences de l’Information, qui était alors commun à la HEG-Genève en Suisse et à l’Université de Montréal au Canada (EBSI).
Il est important de souligner, comme le fait l’auteure au début du livre, que la science des services ne traite pas seulement de la gestion des services d’Information.
La science des services est plutôt l’étude des services, des systèmes de services et des « propositions de valeur », c’est-à-dire des promesses de la valeur que vous allez délivrer à vos utilisateurs. La proposition de valeur représente la raison pour laquelle les utilisateurs devraient utiliser vos services. Ses origines sont récentes, car on peut en situer la naissance en 2006 ; IBM a contribué d’une manière décisive à la naissance cette discipline, IBM qui a vécu l’évolution généralisée vers l’informatisation des services dans les années 90.
Ce livre propose une synthèse de l’état des études dans la science des services appliquée au contexte des sciences de l’information, et il s’articule en cinq parties: la première vise à fournir une délimitation du concept de science des services, la deuxième dresse un historique succinct de cette discipline, qui a connu un développement important surtout à partir des années 70 du siècle passé, avec le passage d’un modèle économique dominé par l’industrie manufacturière à une société dominée par l’ « économie de la connaissance ».
La science des services est de par sa nature interdisciplinaire, car elle analyse les quatre éléments qui forment un système de services, les personnes, la technologie, les organisations et l’information, qui sont respectivement étudiés par les sciences sociales, l’informatique et l’ingénierie, la gestion des organisations et la science de l’information.
Le troisième chapitre examine les rapports entre la science des services et la science de l’information. Etant donné que le service est la raison d’être de chaque bibliothèque et service de documentation, les rapports entre les deux disciplines sont évidents et étroits. En tant que professionnel de l’information, nous appliquons déjà certains principes de la science des services. Toutefois celle-ci peut aider le professionnel de l’information à concevoir d’une manière plus efficace des systèmes pour l’évaluation des services, la mesure de l’impact et l’analyse des besoins. En un mot, elle peut stimuler l’innovation dans les services de documentation.
Evidemment, les parcours de formation des futurs professionnels de l’information et documentation doivent être adaptés aux besoins de la société de l’information.
Dans le quatrième chapitre, l’auteure souligne l’importance de la science des services dans le contexte d’une société et d’une planète qui est de plus en plus interconnectée, grâce à l’Internet des objets, au big data et à l’informatique «cloud». De nouvelles opportunités s’ouvrent pour montrer la valeur sociale du travail des spécialistes de l’information.
Le livre offre un aperçu succinct mais complet de la discipline, et il a le mérite de souligner l’importance de la science des services pour les professionnels de l’information, dont la plupart n’est même pas au courant de l’existence de ce domaine d’études. En plus, l’autrice met justement en évidence le fait que la science des services souvent n’est pas enseignée au sein des facultés universitaires des Sciences de l’Information.
Le livre est très focalisé sur les études et les expériences aux Etats Unis. Plus d’attention aurait pu être consacrée au contexte européen.
Le chapitre final est consacré aux réseaux professionnels, aux associations et aux écoles spécialisées dans l’enseignement de la science des services. Les références bibliographiques et la webographie de cette section sont très exhaustives.
Bibliographie
Yvonne de Grandbois. Service Science and the Information Professional. Cambridge, MA, United States : Elsevier, Chandos Publishing, 2016 ; 117 p., (Chandos Information Professional Series) ISBN 978-1-84334-649-4
- Vous devez vous connecter pour poster des commentaires
Conserver et valoriser les archives de la Société des Arts de Genève
Ressi — 20 décembre 2018
Sylvain Wenger, Directeur de projet : Valorisation du patrimoine et promotion de la recherche auprès de la Société des Arts
Résumé
À l’instar des innombrables sociétés d’émulation créées en Europe aux 18e et 19e siècles, la Société pour l’Avancement des Arts, de l’Agriculture et des Manufactures de Genève est fondée, en 1776, dans l’intention de soutenir l’économie locale en promouvant activement le développement de la nouveauté technique et commerciale. Cette institution, mieux connue sous son nom actuel de Société des Arts de Genève, a produit et acquis une masse considérable de documents et d’objets constituant aujourd’hui une richesse historique et culturelle unique pour nourrir l’histoire des beaux-arts, des techniques et des sciences à Genève. Ses responsables ont entrepris fin 2015 de dresser un inventaire détaillé de ses archives, conservées dans son Palais de l’Athénée, au cœur de la cité genevoise, et de mettre en place des actions de valorisation destinées à la communauté de la recherche et à un public plus large. Cet article se penche sur les enjeux et sur les étapes intermédiaires de cet ambitieux projet dont les résultats sont attendus pour 2019-2020.
Mots-Clés:
archives
inventaire
savoir
société d’émulation
valorisation Conserver et valoriser les archives de la Société des Arts de Genève
Enjeux et genèse du projet
La Société des Arts de Genève, créée en 1776 sous le nom de Société pour l’Avancement des Arts, de l’Agriculture et des Manufactures, a produit et acquis tout au long de son histoire une masse considérable de documents et d’objets constituant aujourd’hui une richesse patrimoniale unique pour nourrir l’histoire des beaux-arts, des techniques et des sciences à Genève.
Dès ses débuts, l’institution met en place une importante diversité d’opérations d’encouragement industriel et artistique incluant la distribution de récompenses, l’instauration d’enseignements gratuits et la publication d’informations techniques, commerciales et autres[1]. Originellement composée de groupes de travail appelés « comités »[2], l’association est réformée au début des années 1820 pour adopter une structure en trois « classes », toujours actives de nos jours, dédiées respectivement à l’agriculture, à l’industrie et au commerce, et aux beaux-arts. Une part importante des traces écrites et matérielles de leurs activités nous sont parvenues en très bon état. Des caves aux combles de son siège – le Palais de l’Athénée, situé au cœur de la cité genevoise – l’institution abrite des ressources historiques très recherchées, qui font actuellement l’objet d’une attention particulière en termes de catalogage et de pérennisation.
Fin 2015, les responsables de la Société des Arts ont entrepris de dresser un catalogue complet des archives de l’association, tout en menant des actions de valorisation destinées à la communauté de la recherche et au grand public. Les opérations, actuellement en cours, comprennent l’inventoriage numérique du fonds, l’optimisation des conditions de dépôt et de consultation ainsi que la mise en ligne d’un certain nombre de documents digitalisés sur une plateforme Internet dédiée.
Ce vaste projet patrimonial a vu le jour sous l’impulsion d’Etienne Lachat, secrétaire général de la Société des Arts depuis 2013. A l’automne 2015, il a formé une Commission des archives constituée de membres de l’association et d’autres personnes ayant un intérêt et des compétences dans le domaine des archives et, plus largement, du patrimoine genevois[3]. Dans un premier temps, ce groupe de travail a prodigué ses conseils et recommandations quant aux objectifs et aux orientations du projet, avant de jouer un rôle de conseil consultatif entre les instances dirigeantes de la Société et les acteurs du projet.
Figure 1 : Archives en cours de traitement / Image Collection Société des Arts - Greg Clément 2018

De l’inventaire sommaire à l’inventaire détaillé
Le projet d’inventaire a été conçu en deux phases principales. La première a consisté à procéder à une évaluation globale du volume et de la typologie des ressources historiques conservées au Palais de l’Athénée. Cette analyse de l’existant, réalisée en 2016 en collaboration avec l’entreprise Docuteam, a résulté sur un inventaire sommaire des archives. L’analyse s’est concentrée sur les ressources écrites, manuscrites et imprimées, tandis que le mobilier et les œuvres d'art n’ont pas été pris en compte car l’information à leur propos est déjà relativement bien maîtrisée. Des éléments importants ont été mis en évidence pour élaborer la stratégie de traitement du matériel, à commencer par la distinction entre les volumes d’archives et de collections d’ouvrages. Ainsi sait-on depuis lors que les archives de la Société des Arts et de ses sections représentent environ 141 mètres linéaires (ml), soit 42% du total des biens écrits conservés au Palais de l’Athénée[4], tandis que les collections d’imprimés extérieurs – des revues, essais et manuels théoriques et pratiques, pour l’essentiel – comptent pour 187 ml (55%), selon la distribution suivante : 95 ml pour la Classe d'Agriculture[5], 49 ml pour la Classe d’Industrie et Commerce, 43 ml pour la Classe des Beaux-Arts. L’analyse a aussi révélé que les collections d’imprimés comptent environ 6'800 volumes[6], et que les archives de tiers représentent environ 8 ml[7]. On a constaté, enfin, que le plus ancien document d'archives conservé à l’Athénée date de 1388, tandis que la publication la plus ancienne remonte à 1578.
Du point de vue typologique, l’analyse a montré que les archives comprennent principalement des procès-verbaux de séances, des dossiers personnels de présidents, de la correspondance, des documents comptables, des statuts et règlements, des listes de membres, ainsi que des documents de grand format tels que des plans et dessins architecturaux, des affiches, des programmes de concours ou des diplômes. Sur le plan thématique, le matériel porte sur l’ensemble des domaines d’intérêt de la Société des Arts, à savoir l’artisanat, l’industrie, l’agriculture et les beaux-arts, mais ne s’y limite pas[8]. Notons encore la présence de nombreux objets tels que des échantillons de plantes, de textiles ou de visserie, ainsi que des coins de médailles, des rubans et des bannières en tissu, des instruments de mesure anciens, des photographies et des diapositives. En synthèse, la phase d’évaluation a permis de quantifier l’importance matérielle de ces ressources historiques et de mettre en évidence leur contenu thématique, rappelant que la Société fût par le passé une incontournable plateforme d’acquisition, de production et de diffusion de savoir pour sa région.
En janvier 2017 a été lancée la seconde phase, consistant au traitement proprement dit des archives (nettoyage, conditionnement, description numérique). A cet effet, un manuel définissant les normes de traitement a été établi en étroite collaboration avec l’entreprise Docuteam et avec la participation active de la Commission des archives, tenant compte des différents types de pièces et cas particuliers rencontrés au fur et à mesure du dépouillement. Ce document d’une vingtaine de pages commence par exposer les principes généraux de traitement, dont le périmètre et le système de normes adopté[9], avant de détailler les choix relatifs à l’évaluation, au niveau de description, au reconditionnement, à la cotation et à la numérisation des archives. Pour définir ces éléments, la stratégie a consisté à traiter en priorité les rayons présentant la plus forte hétérogénéité et le plus faible degré de maîtrise de l’information, de sorte à faire émerger un maximum de cas problématiques : les liasses fermées, les boîtes diverses et les papiers entreposés pêle-mêle ont ainsi été traités avant les procès-verbaux et autres imprimés parfaitement reliés et rangés chronologiquement depuis des décennies.
Du point de vue du niveau de traitement, il a été décidé de traiter le dossier ou la série de dossiers. Cependant, même dans le cas d'une notice concernant un dossier, à moins que l'intitulé suffise à décrire clairement le contenu (dans le cas d'une publication, par exemple, ou d'un dossier très homogène sans pièces particulières), le contenu du dossier est décrit dans un champ spécifique, et les pièces importantes ou singulières sont indiquées. Cette formule, relativement flexible, permet d’enrichir l’inventaire de nombreux mots clefs indexés, sans toutefois astreindre l’ensemble du processus aux opérations par trop chronophages de la description à la pièce.
Une fois le manuel de traitement établi, à l’automne 2017, les opérations de traitement ont trouvé leur vitesse de croisière. Au mois de novembre 2018, près de 75 mètres linéaires avaient été traités, et près de 150 dossiers avaient fait l’objet de photographies indicatives ou de reproductions scannées en haute définition.
Figure 2 : Capture d’écran de la base de données de travail : divers documents et objets numérisés

Faciliter la consultation physique et virtuelle
L’amélioration des conditions de consultation physique et virtuelle des archives de la Société des Arts constitue un axe prioritaire du projet. Entre mars 2016 et novembre 2018, l’institution a traité près de 120 demandes de renseignements historiques provenant de la communauté de la recherche, de musées, de bibliothèques, de médias, ainsi que de privés[10]. Environ 30% des demandes ont débouché sur des consultations sur place, tandis que le reste a été traité à distance.
Il est prévu que dans le courant de l’année 2019, l’inventaire détaillé soit progressivement mis en ligne sur une nouvelle plateforme Internet, enrichi d’un certain nombre de documents scannés. L’outil de recherche par mots-clefs de la plateforme sera élémentaire, offrant des critères tels qu’un ou plusieurs termes à exclure, un filtre par types de pièces (manuscrit, tapuscrit, imprimés, objet), ainsi qu’une échelle temporelle. Le site permettra par ailleurs de refléter d’un coup d’œil la variété des types de pièces comprises dans les ressources historiques de la Société des Arts au moyen d’un damier de vignettes disposées de manière aléatoire sur la page d’accueil, donnant accès à des notices comportant un document digitalisé.
Figure 3 : Plateforme de consultation de l’inventaire des archives : projet de page d’accueil
Dans un premier temps, l’objectif est de mettre à disposition en ligne environ 5 à 10% des archives de la Société des Arts, en ciblant le matériel le plus fréquemment demandé. A cet effet, le projet tient compte des besoins régulièrement exprimés par les chercheurs. A terme, la prise en charge des requêtes nécessitera sans doute l’engagement de ressources spécialisées et l’aménagement de conditions appropriées, actuellement à l’étude.
L’importance d’un programme d’activités annexes
En marge de la production de l’inventaire détaillé, colonne vertébrale du projet, des activités scientifiques et culturelles ont été programmées et organisées au Palais de l’Athénée en 2016, 2017 et 2018. Outre leur rôle de réflexion et d’émulation, ces activités ont donné la visibilité nécessaire pour, d’une part, faciliter l’émergence et le développement de partenariats avec des institutions scientifiques et patrimoniales (universités suisses et étrangères, musées, etc.), et d’autre part, souligner l’importance des ressources patrimoniales de la Société des Arts.
Une première exposition organisée du 9 au 26 novembre 2016, intitulée Lumière ! Incursions dans les collections de la Société des Arts, proposait ainsi d’interroger le rôle de l’institution dans le développement économique, social et politique de la région genevoise et plus largement européen dans la longue durée, depuis la fin du 18e siècle[11]. A celle-ci a succédé, du 12 septembre au 11 novembre 2018, l’exposition intitulée L’héritage insoupçonné d’Alfred Dumont (1828-1894), accompagnée de la proposition Point d’ombre du plasticien Benoît Billotte. Cette exposition retraçant la trajectoire artistique et institutionnelle d’un peintre et collectionneur, membre important de la Société, quasiment absent de l’historiographie, mais fort reconnu de son temps, a été l’occasion de procéder à la mise à niveau de l’inventaire des quelques 3'000 dessins léguées à la Société des Arts et aujourd’hui conservés au Cabinet d’arts graphiques des Musées d’art et d’histoire de Genève.
Par ailleurs, trois rencontres scientifiques couvrant des champs d’intérêt particuliers de la Société des Arts ont été organisées : les journées d’étude Penser/Classer les collections des sociétés savantes les 24 et 25 novembre 2016, le colloque Produire du nouveau ? Arts – Techniques – Sciences en Europe (1400-1900) (23-25 novembre 2017), et enfin du colloque Regards croisés sur les arts à Genève (1846-1896). De la Révolution radicale à l’Exposition nationale, les 2 et 3 février 2018. Chacune de ces manifestations est assortie d’une publication des actes.
Conclusion
L'intérêt des archives de la Société des Arts pour l’histoire de l’économie et des arts de la région genevoise a été mis en lumière grâce aux résultats intermédiaires du projet d'inventaire lancé fin 2015. Une fois réorganisé, décrit, et rendu plus facilement accessible, dès 2019-2020, ce riche matériel offrira la possibilité d’interroger plus avant des champs historiques liés, par exemple, au développement de la formation professionnelle, des instruments d’encouragement artistique ou de multiples aspects de l’agriculture.
Si une histoire de la Société des Arts de Genève dans la longue durée reste à écrire, c'est avant tout en replaçant cette plateforme de savoir dans son paysage institutionnel historique et contemporain, qu’elle mérite de l’attention. C’est en ce sens qu’est profilé le projet de valorisation et de conservation actuellement en cours.
Notes
[1] Sur l’histoire de l’association voir notamment : Jean-Daniel Candaux, R. Sigrist, « Saussure et la Société des Arts », in R. Sigrist (éd.), H.-B. de Saussure (1740-1799), Genève, Georg, 2001, p. 431‑452 ; Danielle Buyssens, La question de l’art à Genève : du cosmopolitisme des Lumières au romantisme des nationalités, Genève, La Baconnière Arts, 2008, p. 181 ; Serge Paquier, « La Société des Arts, transition entre deux ères », in Marc J. Ratcliff, Laurence-Isaline Stahl-Gretsch (dir.), Mémoires d’instruments, Genève, S. Hurter, 2011, p. 114-123 ; Sylvain Wenger, « Innover, pratique ‘connectée’. Regards sur la Genève du début du xixe siècle », in Bernard Lescaze (dir.), Genève 1816, une idée, un canton, AEHR, Carouge, 2017, p. 119-147, et Sylvain Wenger, « Encourager la nouveauté ? Aux origines de la Société pour l’avancement des arts, de l’agriculture et des manufactures de Genève », xviii.ch, Annales de la Société suisse pour l'étude du XVIIIe siècle, vol. 9/2018, numéro thématique La Suisse manufacturière au 18e siècle, éd. par Rossella Baldi et Laurent Tissot. Pour d’autres références nourries directement ou indirectement par les archives de la Société des arts, voir la bibliographie proposée dans la brochure Lumière ! éditée à l’occasion de l’exposition du même nom : Vanessa Merminod, S. Wenger, Lumière ! Incursions dans les collections de la Société des arts, Genève, Société des arts de Genève, 2016.
[2] Les premiers comités institués furent les Comités des arts, et de l’agriculture, avant que n’apparaissent dès 1787 le Comité de dessin, le Comité de mécanique, le Comité de chimie et le Comité rédacteur.
[3] Les membres de la Commission des archives sont Jean-Daniel Candaux, Fabia Christen Koch, Olivier Fatio, Barbara Roth-Lochner, Dominique Zumkeller et Etienne Lachat.
[4] Le solde est composé, notamment, de dossiers administratifs courants.
[5] Cette section a été rebaptisée Classe d'Agriculture et Art de Vivre à partir de 1976.
[6] Les volumes sont répartis entre les collections de la Classe d’Agriculture (environ 3'630 volumes), celles de la Classe des Beaux-Arts (environ 1'650) et celles de la Classe d'Industrie et Commerce (environ 1'480).
[7] Il s’agit de la Société genevoise d'utilité publique (SGUP) et la Société des Amis des Beaux-Arts, par exemple.
[8] On trouve en effet par exemple des essais et autres types de pièces sur la musique, la littérature, ou la poésie.
[9] Le périmètre initial correspond aux archives produites par la Société des Arts, ses classes ou des tiers, depuis les plus anciennes jusqu'à 1990 – cette borne temporelle étant provisoire. Les autres ressources historiques, telles que les imprimés de tiers réunis par les classes, ne sont à ce stade pas pris en compte. Par ailleurs, les références employées pour la description archivistique et les notices d’autorité sont, respectivement, les suivantes : Conseil international des archives (ICA), « ISAD(G) : Norme générale et internationale de description archivistique - Deuxième édition » (Ottawa, 2000), http://www.ica.org/fr/node/15291, et Conseil international des archives (ICA), « ISAAR (CPF) : Norme internationale sur les notices d’autorité utilisées pour les Archives relatives aux collectivités, aux personnes ou aux familles - Deuxième édition », 2004, http://www.ica.org/fr/node/15298 (Consultation le 12 décembre 2018).
[10] Environ 70 % des demandes proviennent de Suisse, le reste d’Allemagne, d’Angleterre, d’Italie, du Japon, d’Espagne, et de France.
[11] L’exposition a donné lieu à l’édition d’une brochure du même nom, disponible auprès du secrétariat de la Société des Arts.
- Vous devez vous connecter pour poster des commentaires
Apprentissage et classification automatiques pour améliorer la pertinence d’un corpus d’articles
Ressi — 20 décembre 2018
Julien Gobeill, Haute École de Gestion, Genève, Institut Suisse de Bioinformatique (SIB), Genève, Suisse
Matthias van den Heuvel, École Polytechnique Fédérale de Lausanne (EPFL)
Laura Minu Nowzohour, Institut de Hautes Études Internationales et du Développement (IHEID)
Joëlle Noailly, Institut de Hautes Études Internationales et du Développement (IHEID)
Gaétan de Rassenfosse, École Polytechnique Fédérale de Lausanne (EPFL)
Patrick Ruch, Haute École de Gestion, Genève, Institut Suisse de Bioinformatique (SIB), Genève, Suisse
Résumé
Dans le cadre d’un projet étudiant le développement des politiques environnementales et climatiques sur les quatre dernières décennies, l’un des moyens envisagés par des chercheurs en sciences économiques est de construire puis exploiter un corpus d’articles de presse relatifs à cette thématique. La première année du projet s’est concentrée sur les seules archives du New York Times. Ce sont néanmoins 2,6 millions d’articles qui étaient à traiter – une masse trop importante pour l’homme. Des chercheurs en sciences de l’information et en fouille de texte ont donc été associés à cette tâche de recherche d’information. Dans un premier temps, les 2,6 millions d’articles ont été moissonnés depuis le Web, puis indexés dans un moteur de recherche. La conception d’une équation de recherche complexe a permis de sélectionner un corpus intermédiaire de 170 000 articles, dont la précision (taux d’articles pertinents) a été évaluée à 14%. Dans un deuxième temps, un algorithme d’apprentissage automatique a donc été entraîné et utilisé pour prédire la pertinence ou non d’un article. Pour nourrir l’algorithme, un échantillon de 700 articles a été manuellement étiqueté par les chercheurs en sciences économiques. L’application du classifieur à l’ensemble du corpus intermédiaire a produit un corpus final de 15 000 articles, dont la précision a été évaluée à 83%. Nos résultats montrent qu’une centaine d’articles étiquetés semble ici une quantité suffisante pour maximiser les performances du classifieur, et obtenir un corpus final de qualité proche de celle obtenue par des experts humains. La fouille de texte n’est plus une discipline émergente, ni extérieure aux sciences de l’information ; c’est une discipline mature qui peut dès à présent être utilisée pour assister le spécialiste de recherche documentaire dans une tâche de construction de corpus ou de classification de documents, tout spécialement avec des masses d’informations importantes.
Apprentissage et classification automatiques pour améliorer la pertinence d’un corpus d’articles
La construction d’un corpus de documents pertinents pour un besoin d’information donné, à l’aide d’un outil de recherche, est une tâche qui relève de la recherche d’information (RI). La RI peut être considérée selon deux points de vue en sciences de l’information : celui du spécialiste en recherche documentaire, et celui du spécialiste en sciences informatiques. Selon le point de vue adopté, les interactions entre l’outil de recherche et son utilisateur sont complémentaires. Le spécialiste de recherche documentaire s’attache à construire la meilleure équation de recherche possible pour un besoin d’information donné ; dans son travail, l’outil reste inchangé et la requête évolue afin d’obtenir un maximum de documents pertinents. L’informaticien spécialiste en fouille de texte (de l’anglais text mining) s’attache quant à lui à construire le meilleur outil de recherche possible ; dans son travail, la requête reste inchangée et l’outil évolue afin de prédire correctement et renvoyer un maximum de documents pertinents (Weiss, 2015). Les travaux que nous allons présenter ici combinent les deux approches.
Cette étude se déroule dans le cadre du Projet National de Recherche 73 sur l’économie durable, financé par le Fonds National Suisse de la Recherche Scientifique. Un groupe de chercheurs en sciences économiques, provenant de l’ Institut de Hautes Études Internationales et du Développement (IHEID) et de l’École Polytechnique Fédérale de Lausanne (EPFL), travaille sur l’investissement dans les technologies propres, et cherche à quantifier le développement des politiques environnementales et climatiques sur les quatre dernières décennies. L’un des moyens envisagés est l’exploitation d’articles de presse relatifs à cette thématique. A terme le but est de construire un indice mesurant le degré d’incertitude dans les politiques économiques liées au changement climatique. Cet indicateur devrait pouvoir refléter des pics et changements brusques dans les politiques climatiques, comme par exemple la sortie des Etats-Unis de l’accord de Paris sur le climat sous la présidence de Donald Trump.
Description générale de la tâche et de l’approche
Une tâche fondamentale du projet consiste donc à construire un corpus d’articles, issus d’une dizaine de revues généralistes de différents pays, relatifs aux politiques économiques liées au changement climatique. C’est pour cette tâche que l’expertise de chercheurs de la filière Information Documentaire de la Haute École de Gestion (HEG) a été mobilisée. Nous avons décomposé cette tâche en deux sous-tâches successives :
-
Sous-tâche 1, filtrage par équation de recherche : construire une équation de recherche large dans une base de données documentaire, pour ramener un corpus intermédiaire contenant le plus grand nombre d’articles pertinents possible ;
-
Sous-tâche 2, classification automatique : filtrer ce corpus intermédiaire grâce à un classifieur, utilisant des techniques de d’apprentissage et de classification automatiques de documents, afin d’obtenir le corpus final.
Enchaînement des deux sous-tâches de construction du corpus final
Le classifieur que nous avons développé pour la sous-tâche (2) a donc pour fonction de prédire automatiquement si un article est pertinent ou non pour un besoin d’information donné. Ce classifieur s’appuie sur l’apprentissage automatique. Dans les sciences informatiques, l’apprentissage automatique est un champ de l’intelligence artificielle dont le principe est d’entraîner un algorithme avec des exemples déjà étiquetés (pertinents ou non), pour lui donner la capacité d’étiqueter lui-même de nouveaux exemples. Contrairement à un système expert dans lequel le comportement de l’algorithme est régi par des règles explicites spécifiées par l’humain (comme la présence dans l’article de certains termes), un algorithme d’apprentissage artificiel généralise à partir de données d’entraînement pour adopter un comportement non explicitement programmé.
Études précédentes
L’étude (Baker et al., 2016) est fondatrice, car elle est la première de grande ampleur à essayer de mesurer l’incertitude de politique économique (EPU) avec des outils bibliométriques. Contrairement à notre projet NRP, l’étude de Baker et al. s’intéresse à tous les domaines économiques (pas seulement liés au réchauffement climatique) et remonte jusqu’au début du 19ème siècle, étudiant des faits comme la première guerre mondiale ou la crise de 1929. Une dizaine de revues américaines majeures sont considérées dans cette étude. Un premier corpus d’articles – appelé par les auteurs « computer-generated » – est construit grâce à une équation de recherche relativement simple : (“economic” OR “economy”) AND (“uncertain” OR “uncertainty”) AND (“congress” OR “deficit” OR “Federal Reserve” OR “legislation” OR “regulation” OR “White House”). Un second corpus d’articles (appelé human-generated) est construit après lecture et évaluation de 12 000 articles. La construction manuelle de ce second corpus a nécessité un effort conséquent : des équipes d’étudiants de l’université de Chicago ont lu et sélectionné des articles pendant dix-huit mois, s’appuyant sur un guide de 65 pages, et étant supervisés toutes les semaines par les auteurs de l’étude. Les deux corpus ainsi construits montrent une forte corrélation. Quant à l’indice d’incertitude de politique économique ainsi généré, il présente des corrélations avec plusieurs autres indicateurs économiques (comme la volatilité des marchés). De plus, l’indicateur généré présente des pics lors d’événements comme le 11 septembre, ou la faillite de Lehman Brothers.
Parmi les études inspirées par ces travaux, (Tobback et al., 2016) est tout à fait intéressante. Le point de départ est que l’équation de recherche utilisée par Baker et al. induit probablement des erreurs de type 1 et 2, qui doivent fausser l’indice. Les erreurs de type 1 sont des faux positifs : des articles qui satisfont l’équation de recherche mais ne sont pas pertinents. Les erreurs de type 2 sont des faux négatifs : des articles pertinents mais non ramenés car ils traitent du sujet en d’autres termes que ceux spécifiés dans l’équation de recherche. Les exemples suivants illustrent les deux types d’erreur.

Exemple de faux positif : retourné par la recherche mais non pertinent

Exemple de faux négatif : pertinent mais non retourné par la recherche
Dans leur publication, Tobback et al. proposent d’améliorer la qualité du corpus d’articles en le filtrant grâce à un outil de classification automatique. La collection initiale comprend 210 000 articles issus de cinq revues flamandes, collectées gratuitement sur le Web. Un échantillon de 400 articles est d’abord étiqueté (pertinent ou non-pertinent) manuellement, puis utilisé pour entraîner l’algorithme d’apprentissage. L’algorithme utilisé est une Machine à Support de Vecteurs, ou SVM (Joachims, 1998). Comparée à l’approche naïve de Baker et al., l’approche de Tobback et al. montre une précision (ou spécificité) comparable (97% contre 99%), mais un rappel (ou sensitivité) beaucoup plus élevé (68% contre 21%). En d’autres termes, l’équation de recherche ramène seulement 21% des articles pertinents, contre 68% pour le classifieur. Quant à l’indice d’incertitude de politique économique ainsi généré, les auteurs le présentent comme meilleur, et lui accordent même un pouvoir prédictif sur certains indicateurs économiques. Des fortes limites sont toutefois que l’étude de Tobback et al. se limite à l’économie belge, et ne remonte pas avant 2000.
Revues étudiées, Factiva, et New York Times
Comme nous devions accéder à des articles de revues de différents pays du monde, nous nous sommes naturellement tournés vers une base de données documentaires. Le consortium des bibliothèques universitaires suisses détient notamment des licences pour Factiva. Factiva est un outil de recherche d’information professionnel, détenu par Dow Jones & Company, et agrégeant plus de 32 000 sources différentes de 200 pays.
Les experts en économie de notre équipe ont donc construit méthodiquement une équation de recherche complexe dans l’interface de Factiva, ayant pour but de ramener le plus de documents possible traitant de politiques économiques liées au changement climatique. L’équation de recherche finale contient près de 6 000 caractères. Elle se compose de 297 opérateurs OR, 7 opérateurs AND, 150 opérateurs de proximité NEAR, 19 troncatures, et 215 paires de guillemets pour chercher des expressions exactes. C’est une équation de recherche largement plus complexe que celle utilisée par Baker et al., ce qui reflète aussi le fait que les politiques environnementales et climatiques couvrent des domaines plus variés que la politique monétaire économique. Le tableau suivant donne une indication des concepts considérés comme pertinents.
|
Environment |
Policy |
|
Renewable Energy Generation |
Regulation |
|
Energy Storage |
Standards & Certification |
|
Energy Infrastructure & Efficiency |
Feed-in tariffs & premiums |
|
Transportation |
Taxes & Subsidies |
|
Water & Wastewater |
Emissions trading schemes |
|
Air & Environment |
International agreements |
|
Recycling & Waste |
Loan guarantees |
|
Clean Manufacturing |
Green & Climate bonds |
Concepts considérés pour l’élaboration la requête
Dans la dizaine de revues étudiées, cette équation ramène dans Factiva environ un million d’articles. Malheureusement, il nous est vite apparu que si l’interface de Factiva permettait à un humain de consulter et télécharger autant d’articles qu’il le voulait, elle l’interdisait techniquement à une machine. En fait, la licence du consortium interdit explicitement le text mining, et plus généralement toute lecture des articles par une machine. Ce genre de clauses peut être vu comme abusif, voire illégal ; toutefois, dans le cadre d’un projet, il est difficile d’entrer en confrontation avec une telle source de données. Nous sommes donc entrés en négociation avec Dow Jones pour une licence nous permettant de télécharger ce million d’articles et de les traiter avec du text mining.
Parallèlement aux négociations, nous avons décidé pour la première année du projet de télécharger les archives du New York Times, en libre accès, pour faire une première étude sur la classification d’articles. En juin 2018, nous avons donc téléchargé 2,6 millions de pages Web pour récupérer les archives du New York Times. 5% des pages n’ont pas pu être téléchargées à cause de dysfonctionnements techniques du côté de la revue. Le texte des articles a ensuite été extrait de ces pages Web.
Première sous-tâche : Filtrage par équation de recherche
Pour construire notre corpus intermédiaire, nous avons déployé un moteur de recherche dans les 2,6 millions d’articles du New York Times, en utilisant la solution open source Elasticsearch Lucene. Nous avons ensuite appliqué l’équation de recherche construite dans l’interface de Factiva. Les langages de requêtes n’étant pas parfaitement identiques (notamment pour l’opérateur de proximité NEAR qui est plus puissant dans l’interface de Factiva), nous avons dû légèrement modifier l’équation de recherche initiale. Nous verrons que cela aura une forte incidence sur le ratio de documents pertinents dans le corpus intermédiaire. Nous avons finalement obtenu notre corpus intermédiaire de 174 000 articles potentiellement pertinents.
Pour préparer la deuxième étape (élaboration du corpus final par classification automatique), nous avons étiqueté – c’est-à-dire jugé chaque élément comme pertinent ou non – un échantillon représentatif d’articles. En effet, les méthodes d’apprentissage automatique requièrent des données d’entraînement. Trois membres de l’équipe experts en économie ont donc parcouru un échantillon représentatif de 700 articles présents dans notre corpus intermédiaire. Sur ces 700 articles, 94 étaient pertinents. Ce ratio de 14% est très inférieur au ratio de 50% observé empiriquement dans les résultats de Factiva. Cette différence s’explique par la puissance de l’opérateur de proximité NEAR dans Factiva, qui peut être utilisé entre des expressions complexes, là où il ne peut être utilisé qu’entre deux termes simples dans le langage Lucene Elastisearch.
Prétraitement des articles
Avant d’être utilisés par le classifieur, les articles doivent être prétraités par des méthodes de fouille de texte. En effet, les algorithmes de classification reposent sur des méthodes statistiques, et prennent généralement en entrée des exemples décrits par des attributs qui ont des valeurs numériques ou catégorielles. Ce type de données structurées peut typiquement se représenter dans un tableau, où les attributs sont des colonnes et les exemples sont des lignes. Par exemple, pour des données médicales d’un dossier patient, des attributs peuvent être la tension artérielle ou le poids (des nombres), ou bien le sexe ou la présence de codes maladies (des catégories). L’algorithme va alors apprendre à établir des seuils et des liens entre chaque attribut pour inférer ses décisions.
De leur côté, les articles de revues sont du texte : par nature, ils ne peuvent pas être représentés tels quels dans un tableau. Pour avoir une représentation compatible, la première chose à faire est d’obtenir l’ensemble des mots apparaissant dans le corpus d’articles. Cet ensemble de mots est appelé le dictionnaire, et chaque mot du dictionnaire va devenir un attribut. Dans les 700 articles que nous avons étiquetés, il y a ainsi 38 300 mots différents, donc potentiellement 38 300 colonnes dans un tableau représentant nos données. Pour remplir les lignes, la représentation la plus simple consiste à donner, pour chaque article et chaque mot, la valeur 1 si le mot apparaît dans l’article, ou la valeur 0 dans le cas contraire. Une représentation plus évoluée, que nous nommerons « count » dans les résultats présentés, consiste à donner le nombre de fois où le mot apparaît dans l’article ; l’hypothèse sous-jacente est qu’un mot répété plusieurs fois dans un article a plus de chances d’être représentatif de l’article. Enfin, une représentation pondérée et habituellement utilisée en fouille de texte est « term frequency inverse document frequency » (tfidf). Cette pondération prend en compte la fréquence d’un mot dans un article (tf), mais aussi l’inverse de la fréquence du mot dans tout le corpus (df). L’hypothèse sous-jacente est ici que plus un mot est présent dans tout le corpus, moins il est représentatif d’un article.
Dans cette étude, nous avons considéré les représentations count et tfidf.
Deuxième sous-tâche : classification automatique
L’algorithme de classification que nous avons choisi pour cette sous-tâche est une Machine à Vecteurs de Supports (SVM). L’approche par SVM est largement répandue dans la classification automatique de documents, et obtient généralement de très bons résultats (Sun et al., 2009). Une SVM cherche des régularités dans des articles déjà étiquetés, et sélectionne des combinaisons de mots qui ont les plus grands pouvoirs de discrimination. C’est l’algorithme utilisé par Tobback et al.
Nous avons entraîné et évalué le classifieur avec le jeu de 700 articles étiquetés : 94 positifs (pertinents) et 606 négatifs (non pertinents), soit un ratio de 14%, comme dans le corpus intermédiaire obtenu avec Elasticsearch. Mais nous avons aussi construit un deuxième jeu de données avec un ratio de 50%, pour étudier les performances du classifieur dans le futur corpus intermédiaire obtenu avec Factiva : les 94 positifs, et 94 négatifs. Le classifieur a donc été évalué avec deux jeux de données présentant des ratios différents. Pour chaque jeu de données, nous avons constitué quatre sous-jeux de taille croissante, pour étudier comment les performances du classifieur évoluaient avec la taille des données d’entraînement. L’évaluation s’est faite selon la méthode de « leave one out crossvalidation ». Pour chaque article étiqueté, un classifieur est entraîné avec tous les autres ; ensuite, le classifieur est évalué sur sa capacité à prédire correctement la classe (pertinent ou non) de l’article retiré des données d’entraînement. Le classifieur est ainsi entraîné sur un maximum de données ; d’autre part, il est évalué sur tous les articles du jeu de données, ce qui maximise la significativité de l’évaluation. Des valeurs de précision et de rappel peuvent ainsi être calculées pour tous les jeux de données.
La figure suivante indique les performances du classifieur pour deux ratios d’articles pertinents (50% et 14%), en utilisant deux représentations de documents (count ou tfidf). Les valeurs reportées sont les F-mesures du classifieur ; la F-mesure est calculée en effectuant la moyenne harmonique de la précision et du rappel.
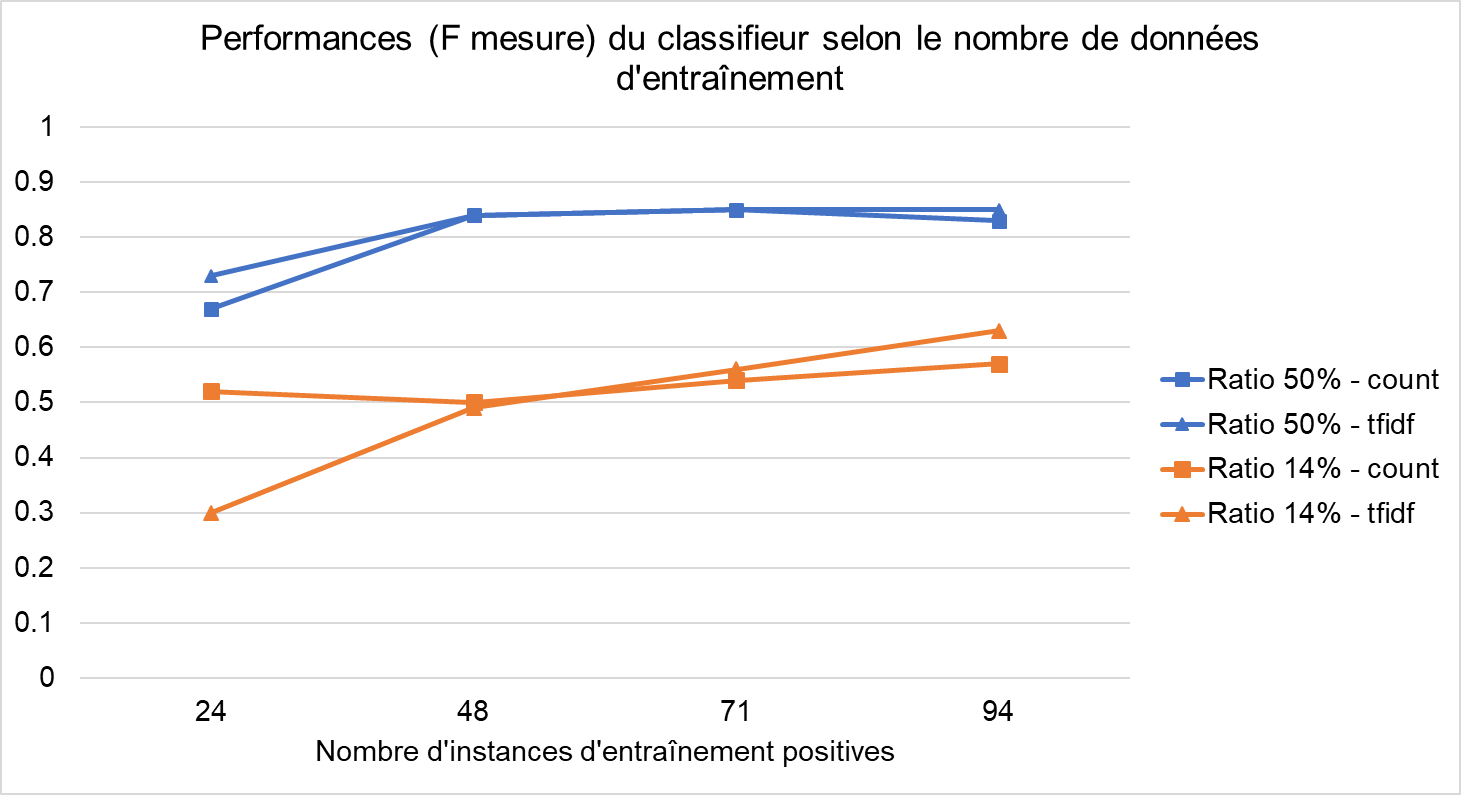
Concernant le jeu de données avec un ratio de 50% (courbes bleues), les courbes montrent un plafonnement rapide des performances. Une centaine d’articles étiquetés semble ici une quantité suffisante pour entraîner de manière optimale le classifieur. La différence entre les deux représentations (count et tfidf) apparaît comme minime. La meilleure F-mesure reportée est de 84%, ce qui est comparable à celle reportée par Tobback et al. (80%). Dans cette configuration, la précision du classifieur est de 80% et le rappel de 90%.
En revanche, concernant le jeu de données avec un ratio de 14% (courbes oranges), les courbes ne plafonnent pas encore. Ici, les articles positifs sont noyés dans le bruit, et obtenir une classification correcte est plus difficile, et demande plus de données d’entraînement. La différence entre les deux représentations est toujours minime, mais la représentation tfidf (marqueurs triangulaires) pourrait se montrer plus efficace avec plus de données. La meilleure F-mesure reportée est de 63%. Dans cette configuration, la précision du classifieur est de 83% mais le rappel seulement de 51%.
La figure suivante indique les mots les plus discriminants selon le classifieur, que ce soit pour prédire qu’un article est non-pertinent (en rouge) ou pertinent (en bleu). Les termes reportés sont majoritairement cohérents.
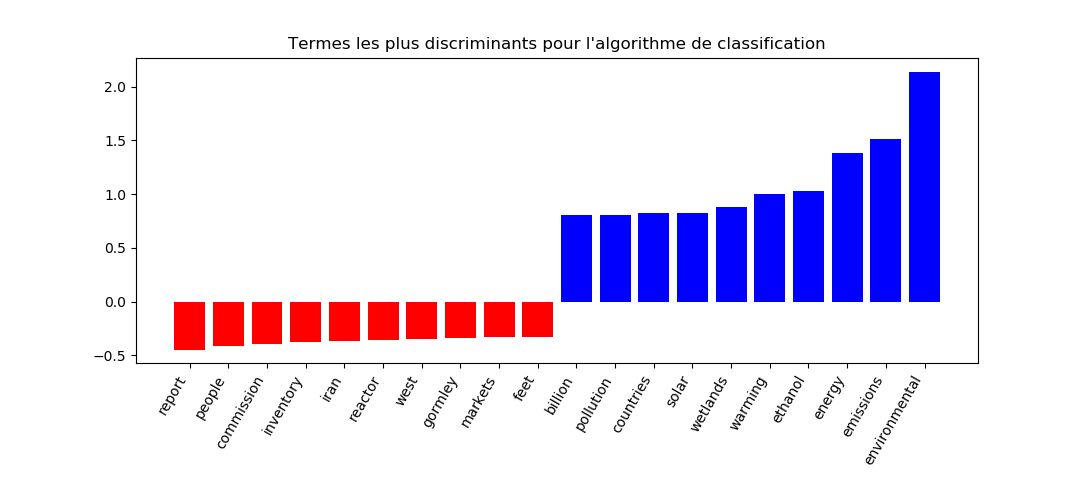
Enfin, pour interpréter les résultats, il est nécessaire de prendre en compte l’accord inter-annotateur. La pertinence d’un article est une notion subjective, qui dépend de l’expert jugeant l’article ; le même article peut ainsi être jugé comme pertinent ou non selon l’expert. Trois cents articles ont donc été jugés en parallèle par deux experts différents. Sur la totalité des 300 articles, les experts montrent un accord de 89%. Le calcul du kappa (mesure statistique pour mesurer l’accord inter-annotateur) donne une valeur de 0,63, ce qui est interprété comme un accord assez fort (Baeza-Yates et al., 2011). Ces valeurs sont à mettre en perspective avec les résultats du classifieur : si les experts s’accordent à 89% sur la pertinence d’un document, la performance du classifieur évalué sur leurs jugements ne peut théoriquement dépasser ce plafond. La F-mesure obtenue (84%) pour le jeu de données avec un ratio de 50% indique donc que le classifieur montre des performances assez proches de celles d’un expert humain, tout en étant bien sûr incomparablement plus rapide pour juger des milliers d’articles.
Corpus final
Nous avons entraîné un classifieur avec un échantillon de 700 articles, présentant un ratio de 14% d’articles positifs. Puis, nous l’avons appliqué sur un corpus intermédiaire de 174 000 articles potentiellement pertinents issus de la première sous-tâche (qui présente lui aussi un ratio de 14% d’articles pertinents). Nous avons ainsi généré le corpus final, qui ne contient plus que 15 000 articles. Ce corpus final affiche théoriquement une précision de 83%, mais un rappel de seulement 51% par rapport au corpus intermédiaire.
Le corpus final a été indexé dans un nouveau moteur de recherche Elasticsearch. Il est ainsi possible de faire des recherches dans le corpus final, comme le montre la figure suivante. Ici, une recherche est faite avec la requête « earth summit », qui ramène 195 articles. Les archives du site officiel du New York Times en comptent 438, mais on sait que le rappel de notre corpus final est d’environ 50%, et tous les articles du New York Times ne sont pas pertinents pour notre étude.
Il est aussi possible avec Elasticsearch de visualiser l’évolution du nombre d’articles mentionnant « earth summit », comme illustré dans la figure suivante. On observe ici un maximum pour 1992, année du sommet de la Terre à Rio, puis une diminution, hormis lors de pics en 1997 (année de signature du protocole de Kyoto déroulant de la conférence de Rio), 2002 (conférence de Johannesburg), 2012 (conférence de Rio+20) et 2015 (conférence de Paris).
Conclusion
Nous avons construit un corpus d’articles du New York Times relatifs aux politiques économiques liées au changement climatique, en enchaînant deux étapes : la construction d’une équation de recherche ramenant un maximum de documents potentiellement pertinents, et l’application d’un outil de classification automatique pour filtrer les résultats précédents. Pour un ratio de 50% d’articles pertinents issus de la première étape, une centaine d’articles étiquetés (en comparaison des 12 000 de Baker et al.) semble ici une quantité suffisante pour maximiser les performances du classifieur et obtenir un corpus final de qualité proche de celle obtenue par des experts humains. Dans la suite de l’étude, une fois obtenu de Factiva le million d’articles potentiellement pertinents issus d’une dizaine de revues, nous devrons ré-étiqueter de nouveaux articles pour entraîner et évaluer le classifieur avec les nouvelles revues.
Dans l’article de Baker et al., les auteurs écrivent qu’il est intéressant de noter que des archives de revues sont accessibles pour tous les pays du monde, et pour des dizaines d’années selon les pays. Ils clament que cette ubiquité, couplée avec les outils informatiques, offre des possibilités gigantesques d’approfondir notre compréhension des développements économiques, politiques et historiques, à travers des démarches scientifiques empiriques. Malheureusement, ces possibilités ne s’offrent que si les données sont accessibles aux chercheurs. Si cette accessibilité paraît encouragée par quelques revues, elle ne l’est clairement pas par les agrégateurs de contenu, qui différencient encore dans leurs licences d’utilisation l’utilisateur humain de l’utilisateur machine.
La fouille de texte n’est plus une discipline émergente, ni extérieure aux Sciences de l’Information ; c’est une discipline mature qui peut dès à présent être utilisée pour assister le spécialiste de recherche documentaire dans une tâche de construction de corpus ou de classification de documents, tout spécialement avec des masses d’informations importantes.
Bibliographie
Baeza-Yates, R., & Ribeiro, B. D. A. N. (2011). Evaluation in Information Retrieval. In Modern information retrieval. New York: ACM Press; Harlow, England: Addison-Wesley.
Baker, S. R., Bloom, N., & Davis, S. J. (2016). Measuring economic policy uncertainty. The Quarterly Journal of Economics, 131(4), 1593-1636.
Joachims, T. (1998). Text categorization with support vector machines: Learning with many relevant features. In European conference on machine learning (pp. 137-142). Springer, Berlin, Heidelberg.
Sun, A., Lim, E. P., & Liu, Y. (2009). On strategies for imbalanced text classification using SVM: A comparative study. Decision Support Systems, 48(1), 191-201.
Tobback, E., Naudts, H., Daelemans, W., de Fortuny, E. J., & Martens, D. (2016). Belgian economic policy uncertainty index: Improvement through text mining. International journal of forecasting.
Weiss, S. M., Indurkhya, N., & Zhang, T. (2015). Fundamentals of predictive text mining. Springer.
- Vous devez vous connecter pour poster des commentaires
Editorial
Ressi — 20 décembre 2017
Comité RESSI
Editorial n°18
Nous avons le plaisir de vous proposer le 18ème numéro de RESSI, revue électronique suisse en science de l’information qui paraît une fois par an.
Lecture numérique, valorisation innovante d’archives audiovisuelles, gestion des données de la recherche, utilisabilité, démocratisation des archives, protection des biens culturels : ce sont quelques-uns des thèmes abordés dans ce numéro, riche en retours d’expériences, dus autant à des jeunes chercheurs qu’à des praticiens, juniors et seniors.
Sous la rubrique « Compte rendu d’expérience », sept contributions.
La première, intitulée eLectures : la lecture numérique grand public à la BCUL, est signée par quatre collaborateurs du site de la Riponne de la Bibliothèque cantonale et universitaire de Lausanne, à savoir Laurent Albenque, directeur adjoint, Charlotte de Beffort, responsable du prêt, Christophe Bezençon, responsable des collections, et Françoise Simonet, responsable des renseignements et de l’accueil. Il s’agit d’un retour d’expérience approfondi sur l’exploitation de la plateforme eLecture à la BCUL depuis 2 ans. Il décrit l’origine du projet, la mise en œuvre, les solutions choisies, l’offre et sa communication, et propose un bilan de son utilisation ainsi que des développements possibles.
Toujours sur la lecture numérique, la deuxième contribution, Livres et presse numériques en bibliothèque de lecture publique : état des lieux de l’expérience menée par les bibliothèques de Carouge, sous la plume d’Yves Martina, directeur des bibliothèques de Carouge, décrit également le contexte et le bilan intermédiaire d’une offre en presse et livres numériques dans un contexte de bibliothèques municipales.
La troisième contribution émane conjointement d’Alain Dufaux, directeur des opérations et du développement au centre Metamedia, à l’EPFL et de Thierry Amsallem, président de la Fondation Claude Nobs. Intitulée Le Montreux Jazz Digital Project : la sauvegarde des archives audiovisuelles du Montreux Jazz Festival, un patrimoine pour l’innovation et la recherche, l’article décrit les différentes activités du projet de sauvegarde, à savoir la numérisation des archives, la gestion de l’archivage et surtout, l’identification et le suivi de -nombreux- projets de recherche et d’innovation associés aux archives du festival de jazz, puis donne quelques perspectives pour l’avenir.
La quatrième contribution est aussi signée par des collaborateurs de l’EPFL, mais de la bibliothèque, cette fois. Rédigée par Eliane Blumer, coordinatrice des données de recherche, bibliothécaire de liaison pour les sciences de la vie, et par Jan Krause, data librarian, l’article Le service de gestion des données de la recherche à la bibliothèque de l’EPFL : historique, services proposés, perspectives décrit l’origine du service, son fonctionnement, son mode d’organisation et donne des exemples précis de ses services de soutien et de formation.
La cinquième contribution, intitulée Archives démocratiques et signée Andreas Kellerhals, directeur des Archives fédérales suisses, est une réflexion originale sur les conditions d’une plus grande participation des citoyens à la constitution des archives (sélection, sauvegarde et description) et à leur accessibilité.
La sixième contribution est due à Nelly Cauliez, conservatrice responsable de l’Unité Régie de la Bibliothèque de Genève. Intitulée Un container mobile pour la sauvegarde des collections sinistrées : la BERCE PBC Ville de Genève, elle décrit le contexte d’acquisition, les caractéristiques et le fonctionnement de ce dispositif essentiel à la protection des biens culturels que constitue la BERCE.
La septième compte rendu d’expérience constitue la synthèse d’un travail de bachelor. Signé Julien Raemy, assistant HES à la HEG-Genève, intitulé Interopérabilité des images : de la nécessité des tests d’utilisabilité, l’article présente les initiatives existantes en termes d’interopérabilité des systèmes de diffusion d’images,-la communauté IIIF et le projet NIE-INE- et détaille les résultats de tests d’utilisabilité de deux systèmes de visionnement d’images, Universal Viewer et Mirador.
Pour la rubrique Compte rendu d’événement, on trouvera trois contributions.
La première, dans la lignée du dernier retour d’expérience, toujours signée par Julien Raemy, intitulée Retour sur la conférence IIIF (International Image Interoperability Framework), 7-9 juin 2017 au Vatican décrit le déroulement de la conférence IIIF, qui a été l’occasion d’échanges entre participants sur la visualisation, la comparaison, la manipulation et l'annotation d'images.
La deuxième est un compte rendu de la conférence Bibliosuisse qui s’est tenue à Bienne le 3 novembre 2017, et qui a réuni plus de 100 personnes membres des associations CLP et BIS, visant à réfléchir aux conditions d’une fusion des deux associations représentatives de la bibliothéconomie et de la documentation en Suisse. Si cette fusion aboutit à une seule association, en 2018, la nouvelle association ainsi créée, Bibliosuisse, deviendra un porte-parole majeur de la fonction documentaire en Suisse. Signée Halo Locher, secrétaire général BIS et CLP, et Katia Röthlin, secrétaire générale adjointe BIS et CLP, intitulée Les fondements de Bibliosuisse : état des discussions elle explicite les grands principes qui devraient gouverner la future association.
La troisième est un retour sur la 4ème école d’été internationale francophone en sciences de l’information et des bibliothèques qui s’est tenue à Montréal en juillet 2017. Intitulée Marketing et public, ou comment repenser l’approche bibliothèques sur l’accueil de leur public et signée par Elise Pelletier, assistante du Master IS (Sciences de l’information) de la HEG-Genève, l’article détaille, aussi bien sur le fond que sur la forme, les différentes interventions sur le nécessaire marketing en bibliothèque, qui ont eu lieu durant la première semaine de cours de l’école d’été.
Finalement, on trouvera le compte rendu de l’ouvrage de Jean-David Sandoz, intitulé Du bon usage des Lumières : le livre numérique libre, sous la plume d’Alain Jacquesson, ancien directeur de la Bibliothèque de Genève, qui résume cet ouvrage, lequel recense les différents outils et formats existants pour la publication de livres électroniques libres.
Nous vous souhaitons une très bonne lecture et remercions vivement les auteurs de cette édition, ainsi que les fidèles réviseurs et ceux et celles qui ont contribué à la mise en ligne de RESSI. Nous vous encourageons à nous soumettre des propositions d’article à tout moment, et à contribuer à faire connaître RESSI à toute personne intéressée.
Le Comité de rédaction
- Vous devez vous connecter pour poster des commentaires