N°21 décembre 2020
Sommaire - N° 21, Décembre 2020
Visions d'ailleurs :
-
Apprendre « en commun » : L’expérience des ateliers de contribution à Wikipédia dans les bibliothèques publiques de Montréal - Marie D. Martel
Études et recherche :
- Formation en gestion des données de recherche: propositions de dispositifs d’e-learning pour le projet DLCM - Marielle Guirlet, Manuela Bezzi, Manon Bari
- The Knowledge & Learning Commons – a library’s evolution driving cultural change at the United Nations in Geneva - Viviane Brunne, Sigrun Habermann
- La place des ressources documentaires des bibliothèques académiques dans la lutte contre les Fake News. Le cas du COVID-19 - Benoît Epron, Séverine Gaudard
- Les bibliothèques face à la vague - Florence Burgy, Benoît Epron
Comptes-rendus d'événements :
- A review of the Swiss Research Data Day 2020 (SRDD2020): 48 experts shared their experiences on emergent approaches in Open Science - Pierre-Yves Burgi, Lydie Echernier
- Conférence annuelle LIBER 2020 online : compte rendu d’évènement - Piergiuseppe Esposito
Recensions :
Editorial n° 21
Editorial n°21
C’est un vingt-et-unième numéro riche en contributions de recherche que nous avons le plaisir de vous présenter.
Ce numéro comporte une innovation de taille : la rubrique Visions d’ailleurs.
Cette rubrique consiste à donner un aperçu des préoccupations, des pratiques et des sujets de recherche de spécialistes en sciences de l’information en dehors des frontières de la Suisse, et constitue ainsi un témoignage sur une expérience, une recherche ou encore un point de vue spécifique depuis l’étranger.
Le comité de rédaction a en effet pensé que cela pouvait constituer un apport instructif et complémentaire pour les lecteurs de RESSI et susciter des idées et échanges fructueux.
Cette rubrique est inaugurée par Marie Martel, professeure adjointe à l’EBSI de Montréal. Son article intitulé « Apprendre en commun : l’expérience des ateliers de contribution à Wikipedia dans les bibliothèques publiques de Montréal » relate une expérience très intéressante du rôle possible des bibliothèques au service de l’inclusion numérique, en l‘occurrence dans la réalisation et conduite des ateliers de contribution à Wikipedia, et en démontre les limites et les impacts.
Dans la rubrique Etudes et Recherches, vous trouverez un premier article intitulé Données médicales et dossiers patients comme actifs informationnels : la gouvernance de l’information dans les hôpitaux universitaires suisses. Ecrit par Anna Hug Buffo, archiviste principale aux Hôpitaux Universitaires de Genève (HUG), l’article fait un état des lieux des composantes de la gouvernance de l’information dans les hôpitaux universitaires suisses et propose un schéma général des flux des données médicales et de leurs diverses réutilisations.
Une deuxième contribution, signée par Marielle Guirlet, Manuela Bezzi et Manon Bari, diplômées du Master en Sciences de l'Information HEG, HES-SO (2020) intitulée Formation en gestion des données de recherche: propositions de dispositifs d’e-learning pour le projet DLCM, donne des recommandations et des propositions d’options pour la conception d’un dispositif de formation d’e-learning en gestion des données de recherche.
Une troisième contribution, signée également par Marielle Guirlet, co-auteure du précédent article, est intitulée Ouverture des données de recherche dans le domaine académique suisse : outils pour le choix d’une stratégie institutionnelle en matière de dépôt de données. L’article donne les informations nécessaires pour aider les institutions universitaires suisses à choisir leur stratégie de dépôt des données de recherche : soit orienter ses chercheurs et chercheuses vers un dépôt existant (et lequel) soit créer un nouveau dépôt, et il donne les spécifications que ce dépôt doit remplir.
Un quatrième et dernier article de recherche, signée Florence Burgy, assistante HES dans la filière Information documentaire de la HEG-Genève est intitulée L’océrisation d’imprimés anciens : les sciences de l’information au service des Humanités. Il relate le projet de recherche mené en collaboration avec le Bodmer Lab, qui a consisté à océriser des imprimés latins de la Renaissance, afin d’en obtenir une transcription et la rendre explorable par la recherche plein texte. Il donne les conclusions des tests d’océrisation faits avec plusieurs logiciels, dont Tesseract, qui a fourni les meilleurs résultats.
Dans la rubrique « Compte rendus d’expérience », nous vous proposons une contribution en anglais, signée Viviane Brunne et Sigrun Habermann, respectivement, Programme Manager à la bibliothèque des Nations Unies à Genève (UNOG) et manager de la même bibliothèque, intitulée The Knowledge & Learning Commons – a library’s evolution driving cultural change at the United Nations in Geneva. Cet article retrace le développement de l’Espace commun «Savoirs et formation des Nations Unies Genève, Commons» depuis ses premières étapes expérimentales vers un programme plus structuré, conçu en co-création avec ses utilisateurs. Il analyse également les expériences plus récentes tirées du semi-confinement dû au Covid-19, et propose des pistes de développement.
RESSI se devait aussi, en cette année de crise sanitaire et de fermeture temporaire des bibliothèques en Suisse de faire un bilan de l’utilisation des bibliothèques pendant cette période. On trouvera donc un premier article de Benoît Epron, professeur HES associé dans la filière Information documentaire de la HEG-Genève et de Séverine Gaudard, co-responsable de la PME Clio-Archives. Intitulé La place des ressources documentaires des bibliothèques académiques dans la lutte contre les Fake News : le cas du COVID-19, il relate les enseignements d’un projet sur 6 mois et donne des pistes pour accroître le rôle des bibliothèques universitaires dans la lutte contre les fake news. Et un deuxième, également de Benoît Epron et de Florence Burgy, assistante HES à la HEG-Genève, intitulé Les bibliothèques face à la vague, synthétise les pratiques d’utilisation de la bibliothèque - y compris d’e-books- lors du semi-confinement du printemps 2020, en prenant l’exemple de plusieurs bibliothèques romandes (bibliothèque municipale de Vevey la Médiathèque Valais, la BCUL-site Riponne) et de Bibliomedia,
Pour la rubrique Compte rendu d’événement, on trouvera deux contributions.
La première émane de Piergiuseppe Esposito, chargé de missions à la BCU Lausanne. Intitulée Conférence annuelle LIBER 2020 online, elle résume les sujets et débats évoqués à la conférence annuelle LIBER, (Ligue des Bibliothèques Européennes de Recherche) qui s’est tenue à distance, en juin 2020, sur le thème Building Trust with Research Libraries.
La seconde, rédigée en anglais et intitulée A review of the Swiss Research Data Day 2020 (SRDD2020): 48 experts shared their experiences on emergent approaches in Open Science a été écrite par Lydie Echernier et Pierre-Yves Burgi, et revient sur le symposium Swiss Research Data Day 2020, qui s’est tenu à Genève, à distance, en octobre 2020. Les auteurs sont respectivement coordinatrice du projet DLCM, Division Systèmes et technologies de l'information et de la communication (STIC) à l’Université de Genève, et directeur du projet DLCM, directeur SI adjoint, Division Systèmes et technologies de l'information et de la communication (STIC) à l’Université de Genève.
Pour la rubrique des recensions, on trouvera le compte rendu de l’ouvrage d’Alain Jacquesson, ancien directeur de la BGE et membre du comité de rédaction de RESSI, et Gabrielle von Roten, ancienne cheffe du service de coordination des bibliothèques universitaires de Genève, Histoire d’une (r)évolution : l’informatisation des bibliothèques genevoises, 1963-2018 sous la plume d’Alex Boder, maître d’enseignement dans la filière Information documentaire de la HEG-Genève.
Finalement, on trouvera la recension de l’ouvrage intitulé The non-sense guide to research support and Scholarly Communication de Claire Sewell, recension signée Thomas Pasche, assistant HES dans la filière Information documentaire de la HEG-Genève. L’ouvrage détaille les rôles possibles des bibliothécaires dans le domaine de l’aide à la recherche académique.
Nous vous souhaitons une très bonne lecture et nous remercions vivement les auteurs de cette édition, ainsi que les fidèles - et les nouveaux ! - réviseurs, et ceux qui ont contribué à la mise en ligne de RESSI.
Nous sommes prêts à recevoir vos propositions d’article à tout moment, et nous vous encourageons à faire part de vos commentaires sur l’évolution de RESSI et à contribuer à faire connaître RESSI autour de vous.
Le Comité de rédaction
Apprendre « en commun » : L’expérience des ateliers de contribution à Wikipédia dans les bibliothèques publiques de Montréal
Marie D. Martel, professeure adjointe, EBSI (Université de Montréal)
Apprendre « en commun » : L’expérience des ateliers de contribution à Wikipédia dans les bibliothèques publiques de Montréal
1. Contexte
Wikipédia célèbre ses 20 ans cette année. Née en 2001, la rencontre inévitable entre cette dernière et le monde des bibliothèques n’a guère tardé. Du rejet à la suspicion puis à la collaboration, des initiatives conjointes se mettent en place à partir de 2012, tant dans les bibliothèques universitaires que publiques, sous la forme de journées contributives, ou édit-a-thons, qui constituent encore aujourd’hui un des principaux scénarios de médiation wikipédienne. Dans cette mouvance, des ateliers de contribution ont été déployés et intégrés dans le calendrier régulier de certaines institutions québécoises comme à la Grande bibliothèque et dans le réseau des Bibliothèques de Montréal. Les retombées de ces activités sont à géométrie variable, oscillant entre l’enthousiasme et la déception, mais d’une façon générale, il est reconnu que ce n’est pas la performance (soit le nombre de participant.e.s ou le nombre de contributions) qui constitue un bon indicateur pour mesurer la valeur de ces activités. L’impact est ailleurs et nous y reviendrons par le biais de ce récit ethnologique qui est porté par les questions : Comment pourrait-on créer une communauté créatrice de savoirs communs numériques en bibliothèque ? Comment pourrait-on évaluer et accroître l’impact des ateliers contributifs impliquant les bibliothèques et Wikipédia - ou plus généralement, les projets soutenus par la fondation Wikimédia ?
Nos analyses et nos conclusions, ancrées dans une pratique réflexive(1), sont principalement influencées par les situations observées directement sur le terrain au cours de ces dernières années à organiser, animer, expérimenter des ateliers de contribution en bibliothèque(2). Après une brève chronologie des initiatives québécoises, nous explorerons momentanément un cadre de référence visant à inscrire ces actions dans un contexte qui les justifie en regard des finalités et des missions des bibliothèques aujourd’hui. Cette « réflexion sur l’action » nous permettra de partager un certain nombre de constats instructifs en s’attachant particulièrement aux leçons que l’on peut tirer pour faciliter l’aménagement social de ce projet wikipédien en bibliothèque et valoriser encore l’apport de ces ateliers contributifs au sein des communautés.
2. Les bibliothèques québécoises et Wikipédia : Un bref historique
Le premier motif de l’intérêt des bibliothèques à l’endroit de l’encyclopédie a été d’abord été critique. À partir de 2005, plusieurs études en sciences de l’information analysent ce projet d’encyclopédie libre et questionnent la qualité du contenu de Wikipédia (son étendue, son actualité, sa fiabilité) et son statut d’ouvrage de référence au sens traditionnel du terme(3).
À partir de 2010, la British Library entreprend une collaboration avec la Wikimedia Foundation et une première expérience de wikipédienne en résidence dans cette même institution révèle les nombreuses opportunités issues du croisement entre Wikipédia et les institutions de mémoire(4). Les avantages en termes de valorisation du patrimoine et des collections numériques qui sont extraites dans le cadre des projets GLAMs (pour Galleries, LIbraries, Archives, Museums) aident peu à peu à dissiper la méfiance, et en même temps les réserves sur la qualité du contenu tendent à s’estomper.
Au Québec, plutôt que de passer par les institutions de mémoire, c’est d’abord par le biais de journées contributives à l’échelle locale que seront scellées les premières relations entre Wikipédia et le monde des bibliothèques. Un atelier consacré à Jean Talon(5), premier intendant de la Nouvelle-France, se déroule à la bibliothèque de l’Université Laval le 18 février 2012(6). Une année plus tard, le 6 avril 2013, à la Bibliothèque Mile End (aujourd’hui Mordecai-Richler) se tient la première activité de type édit-a-thon en bibliothèque publique au Québec. L’activité porte sur le Projet Mile End, lancé au mois de février, initié par l’organisme d’histoire locale, Mémoire du Mile End, et le chapitre Wikimédia Canada. La bibliothèque met son espace et la documentation sur le quartier à la disposition des participant.e.s et une bibliothécaire du réseau des bibliothèques de Montréal est du nombre des contributeurs(7).
Plus tard, la même année, le samedi 19 octobre 2013, lors d’une journée organisée par l’Association canadienne française pour l’avancement des sciences (ACFAS) et Wikimédia Canada dans le cadre du Mois international de la contribution francophone, se tient un atelier de contribution qui inaugure un partenariat soutenu entre Bibliothèque et archives nationales du Québec (BAnQ), et Wikimédia Canada(8). Ce premier événement à la bibliothèque nationale se prolonge dans le programme des Mardi, c’est Wiki, des ateliers qui se tiennent tous les premiers mardis du mois depuis 2014 en proposant une formation, plus qu’un atelier à proprement parler, réunissant conjointement des formateurs wikipédiens et des bibliothécaires. BAnQ est progressivement devenue un des partenaires canadiens les plus actifs du mouvement des GLAMs en s’investissant dans une diversité de projets tant de médiation que d’extraction de ses collections dont des fonds d’archives photographiques(9).
Du côté des bibliothèques de Montréal, les activités reprendront sur une base régulière entre 2016 et 2018, avec plus d’une vingtaine d’ateliers contributifs(10). Ces initiatives ont été menées, dans la très grande majorité des cas, en collaboration avec le Café des savoirs libres (CSL), un collectif rassemblant des bibliothécaires et des libristes engagés dans la création des communs du savoir. Suite à une invitation lancée au réseau des bibliothèques, ces ateliers mensuels accueillent entre 6 et 10 participant.e.s par événement. Les rencontres comptent principalement des membres du CSL qui reviennent à toutes les activités, quelques usagers et généralement un membre du personnel de la bibliothèque dont la participation est, selon le cas, plus ou moins instrumentale. Certains usagers participants viennent de l’extérieur de Montréal, mais leur provenance est surtout locale. Les événements se déroulent les soirs de la semaine entre 17h et 20h. Après une programmation nomade se déplaçant dans une bibliothèque différente à chaque séance, une stratégie alternative est progressivement privilégiée avec une série de rencontres récurrentes dans une même bibliothèque dans le but d’explorer la possibilité de démarrer une communauté locale d’adeptes qui deviendrait autonome dans la durée.
En plus des ateliers locaux, quelques édit-a-thons thématiques ont été organisés en lien avec le Festival international de la bande dessinée de Montréal, la Journée internationale des femmes, le Mois de l’art et des rites funéraires, le centenaire de la bibliothèque centrale de Montréal, etc. Après 2018, les rendez-vous des ateliers contributifs dans les Bibliothèques de Montréal sont devenus plus irréguliers, CSL ayant choisi de poursuivre son engagement à la bibliothèque de la Cinémathèque québécoise où la structure s’était engagée de façon intentionnelle dans l’organisation de ces activités avec un projet sur les « Savoirs communs du cinéma »(11). Avant ce déménagement, la période d’activités qui s’étendait de 2016 à 2018 a été l’occasion de recueillir une série d’observations, d’expérimenter différents scénarios d’usage, d’interroger aussi le sens et la portée de ces ateliers en bibliothèque: c’est cet épisode que nous allons considérer.
3. Un cadre de référence pour mieux comprendre les bibliothèques wikipédiennes
Pourquoi organiser ce type d’activités, à savoir des ateliers contributifs wikipédiens, plutôt que d’autres actions en bibliothèque ? Les raisons qui expliquent et justifient la collaboration entre les milieux documentaires et la Fondation Wikimedia sont nombreuses et relativement bien documentées depuis quelques années. On peut en rappeler quelques-unes : la convergence des missions autour de l’accès libre aux savoirs; un intérêt soutenu pour la connaissance appuyée par des sources fiables. En particulier à cette époque où l’on discute âprement de post-vérité et de fausses nouvelles, les édit-a-thons offrent l’occasion de créer des contenus en ligne en pressant les éditeurs de recourir à des sources d’information fiables - incidemment susceptibles d’être trouvées en bibliothèque, ce qui permet du même coup de valoriser les collections. Ces activités deviennent aussi un excellent tremplin pour améliorer les compétences en littératie de l’information non seulement en initiant une réflexion critique sur les sources, mais aussi sur le caractère construit de l’information et sur les licences régissant l’accès et l’usage des savoirs(12). Pour plusieurs participants, l’atelier wikipédien devient un atelier de littératie numérique qui permet de combler tour à tour des lacunes tant en matière d’alphabétisation technologique, de pratiques numériques ou de valeurs associés à la culture et la citoyenneté numérique.
Au plan international, l’IFLA (International Federation of Libraries Association) a produit en 2016 une étude d’opportunité sur les bénéfices d’une collaboration avec Wikipédia, dans laquelle cette association invite les bibliothécaires à s’engager davantage pour faire de leur bibliothèque, une bibliothèque wikipédienne(13). Cet argumentaire appuie la reconnaissance de Wikipédia comme source d’information et défend son rôle comme plate-forme pour la culture et les connaissances locales qui sont soutenues par les bibliothèques publiques. Au moment où l’IFLA met à disposition cette étude, elle lance une seconde campagne de contribution mondiale auprès de la communauté des bibliothécaires. Cette campagne, menée entre le 15 janvier et le 3 février 2017, encourage les bibliothécaires à ajouter une source (au moins) dans l’encyclopédie libre. Imaginez un monde où chaque bibliothécaire ajouterait une référence de plus à Wikipédia... dit l’accroche de cette campagne qui se déroule désormais chaque année depuis 2017(14)
Les activités wikipédiennes bénéficient d’un discours sur les bibliothèques dirigées par la communauté (« community-led ») et d’une vision de la bibliothèque qui supportent les capacités créatives des publics. Dans cette veine, R. D. Lankes, auteur influent en bibliothéconomie, soutient que la finalité des bibliothèques consiste à « faciliter la création de connaissances dans les communautés en vue d’améliorer la société.»(15)
On assiste, par conséquent, à l’émergence de dispositifs qui sont de plus en plus structurés dans le milieu des bibliothèques à travers les associations internationales, la formation, la théorie et la pratique. Pour les bibliothécaires, en particulier, membres de CSL, cette initiative est aussi, de façon prioritaire, en phase avec un discours sur les bibliothèques comme « maisons des communs », c’est-à-dire comme espace de création, de valorisation et de défense des savoirs libres.(16)
Du point de vue du contexte interne, notamment celui de la Direction des Bibliothèques de Montréal, les ateliers de contribution dans le réseau s’inscrivent dans le Plan d’action Montréal Ville intelligente et numérique en contribuant au développement des compétences numériques. Ces activités ont été identifiées comme des indicateurs de la réalisation du Chantier sur la littératie numérique constituant une des actions de ce plan pour les bibliothèques de Montréal. Cet intérêt venu de services extérieurs à celui des bibliothèques ont contribué à légitimer cet engagement. Les ateliers étaient aussi alignés sur le Plan stratégique des Bibliothèques de Montréal 2016-2019 qui visait à « Consolider et développer des services, des programmes et des activités de littératie numérique et technologique.»(17) .
4. Carnet de terrain : Des constats et des enjeux
Chaque atelier s’avère une occasion inédite de s’interroger sur le format, les ressources nécessaires, les finalités et les retombées du projet, afin d’en tirer des leçons et de bonifier la proposition.
a. L’espace 1 : le territoire et l’équipement. Le modèle est au départ inspiré des ateliers mobiles des voyageurs du code avec l’intention de se déplacer à chaque séance dans une nouvelle bibliothèque(18). L’hypothèse est qu’une rencontre animée par l’équipe de CSL suffira à poser les bases d’une communauté wikipédienne locale qui poursuivra ensuite de manière autonome les ateliers à la façon d’un club de lecture. Un des premiers obstacles très basiques est l’équipement dont la quantité et la qualité sont variables d'un établissement à l’autre. Les bibliothèques n’avaient pas toujours l’équipement informatique requis pour recevoir une dizaine de participants, et les usagers, même avertis d’apporter leurs propres outils (suivant la formule BYOD) ne sont pas toujours dotés d’autre chose que d’un téléphone portable. En outre, l’intention de conduire des ateliers, mais surtout de créer une dynamique d’apprentissage actif et collaboratif, amènent progressivement les organisateurs à délaisser le cadre rigide du laboratoire informatique et le format de la « classe ». Cette orientation appelle un ajustement en termes d’équipements mobiles adaptés à une configuration spatiale flexible. La solution proposée par la Direction des bibliothèques de Montréal consiste à mettre sur pied une flotte d’ordinateurs portables rangés dans des valises que transportent les bibliothécaires membres de CSL. Un projecteur portatif complète l'équipement et les bibliothèques fournissent généralement l’écran, sinon le mur blanc pour la présentation et la démonstration.
Il est apparu assez évident, toutefois, qu’une seule séance pour établir une communauté numérique était pour le moins utopique. Le modèle sédentaire et la voie de l’accompagnement sur un même site, avec un ancrage communautaire dans la durée, associé à un programme thématique basée sur une série de rencontres typiquement sur le modèle des « clubs » offrent des conditions plus favorables et productives.
b. Le temps : le programme et les heures d’ouverture. Le point précédent pose déjà un repère en matière de temporalité en privilégiant une périodicité que nous avons identifiée comme mensuelle en se fondant sur les disponibilités des participants. Par ailleurs, en considérant que ce sont des activités bénévoles qui se déroulent généralement le soir, l’enjeu des heures d’ouverture en soirée s’est posé puisque les horaires des bibliothèques à Montréal ne sont pas toujours compatibles avec cette contrainte. Pour y surseoir, les bibliothèques sont retenues en tenant compte de leur accessibilité ou, le cas échéant, en proposant une activité en dehors de leurs horaires habituels.
c. La collaboration : 1+1+1. Ces ateliers sont d’abord portés par l’engagement du collectif CSL qui constitue un premier levier de collaboration - avec son noyau de participants réguliers. L’originalité des ateliers montréalais consiste à accueillir conjointement des formateurs liés à Wikimédia et aussi à Openstreetmap (OSM), parfois eux-mêmes membres de CSL, qui diversifient la proposition en présentant aussi la cartographie libre; ce qui permet également d’accroître les publics intéressés. De plus, dans les arrondissements où l’on retrouve une société d’histoire active, les ateliers de contribution suscitent un intérêt particulier avec un désir de s’impliquer; ces organisations locales représentent un second levier de collaboration. La démarche tend à confirmer que les communautés ne se créent pas ex-nihilo mais plutôt en s’attachant aux projets des communautés d’intérêts déjà existantes sur le territoire(19). Encore faut-il que la bibliothèque, troisième levier de la collaboration, entretienne déjà des relations significatives avec des organismes culturels, éducatifs ou des groupes ayant des affinités ou des expertises spécifiques(20).
d. Le personnel : mobilisation et coapprentissage. Malgré la bonne volonté et l’intérêt manifeste d’accueillir ces ateliers par les gestionnaires des bibliothèques, la participation du personnel sur le terrain, pour différentes raisons, s’est avérée un autre enjeu notable. La première année, en dépit des invitations explicites adressées aux bibliothécaires dans les bibliothèques visitées, aucun d’entre eux n’a participé aux ateliers à l’exception de deux - et dont l’un avait été fortement incité, sinon contraint, de le faire par sa hiérarchie. Ces expériences nous ont amenés à créer une typologie en trois temps comprenant « le bibliothécaire qui ouvre la porte » (et qui se sauve); « le bibliothécaire qui dit un mot pour légitimer l’activité » (et qui se sauve - mais qui revient de temps à autres pour vérifier que tout est encore légitime); et, enfin, le bibliothécaire qui s’assoit, ce qui est un signe d’attention plus marqué, mais pour dix minutes - parce qu’il n’ose pas se sauver considérant qu’il reconnaît des collègues qui font partie du collectif.
Toutefois, les organisateurs des ateliers avaient dès le départ pour objectif d’initier au moins un membre de la bibliothèque aux rudiments de la contribution, y voyant un élément stratégique pour la pérennité des apprentissages et la mise en place d’une communauté durable. La deuxième année, cette demande est devenue une condition pour accepter de conduire un atelier dans une bibliothèque qui proposait sa candidature. Cette nouvelle condition a permis de former une dizaine de bibliothécaires dans le réseau et, en même temps, de créer les pages des bibliothèques hôtes sur lesquelles ceux-ci s’exerçaient. On peut suggérer d’expliquer cette attitude relativement peu volontariste a priori par l’état de sous-dotation affectant les bibliothèques montréalaises, autant que québécoises. Selon nous, l’enjeu était également d’ordre culturel, en termes professionnels, et découlait d’une conception de l’offre qui est abordée dans la perspective d’une prestation de services, où la bibliothèque définit son engagement communautaire, non pas sur le mode d’une approche de « planification en collaboration avec la communauté »(21), mais à partir d’un rôle instrumental ⎼ fort utile au demeurant pour ce type de programmes venus de l’extérieur mais plus limité en termes d’investissements relationnels ⎼ de « prêteuse de salle ». Les ateliers contributifs n’étaient pas assimilables, selon CSL, à un atelier comme un autre, il comportait une invitation à expérimenter une forme de médiation professionnelle négociée en commun. L’enjeu de l’engagement du personnel n’a jamais été tout à fait résolu et les activités ont été interprétées, au final, comme des situations avec une portée interculturelle où les bibliothécaires-hôtes sont appelés à expérimenter, comme les autres, le passage d’une culture de la prestation de services à une culture de la relation communautaire (community-led) et de la culture numérique, conçu en termes de participation active, de collaboration, d’échanges horizontaux, de bricolage de matériaux et de contenus pour créer des communs numériques qui émergent avec de nouveaux savoirs professionnels.
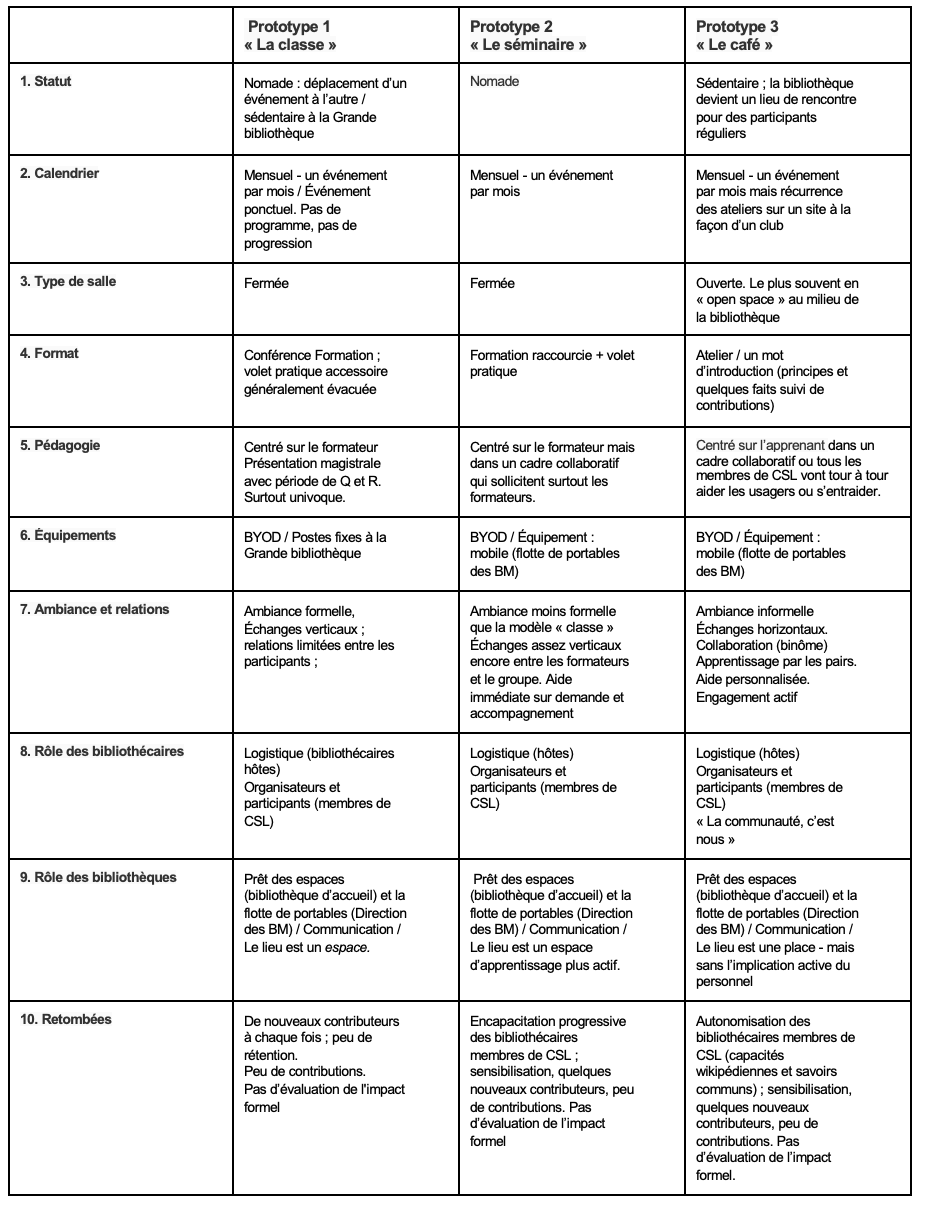
e. L’espace 2 : L’aménagement social. Cette intention relationnelle avec un parti pris pour la culture numérique était portée par un questionnement touchant le design des ateliers. Les observations et les notes de terrain indiquent trois approches, trois prototypes avec des pratiques socio-spatiales distinctes qui ont été expérimentées et qui se sont succédé dans le but d’aménager les rencontres et l’apprentissage « en commun ». Un tableau comparatif présente les caractéristiques de ces prototypes en annexe(22).
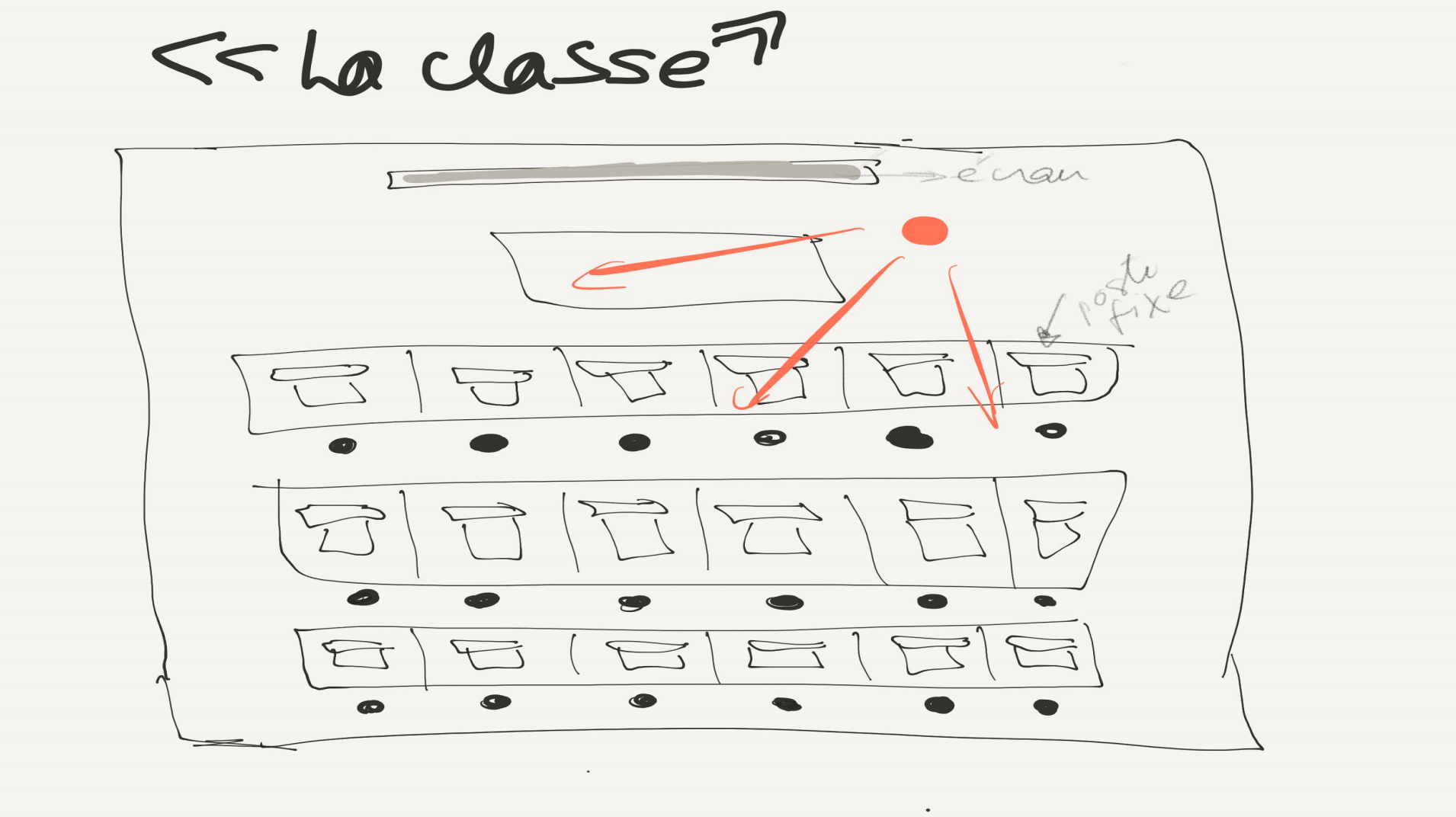
Prototype 1 : « La classe » ou le plan en rangée (voir schéma 1). Le premier dispositif adopté est celui de la salle fermée avec une organisation des participants en rangée sur le modèle de la classe. Les séances sont des formations de type magistral où les contenus sont abordés de manière aussi détaillée que possible en trois heures à peu près. Même si l’intention est de mettre en pratique les acquis, la durée de la présentation est telle que le volet atelier est généralement évacué. Les échanges, les collaborations, les contributions sont quasi absents. La conférence est donnée par les experts de Wikipédia et d’Openstreetmap. De nouvelles personnes se joignent à chaque séance bien qu’il était envisageable que des participant.e.s reviennent et suivent les déplacements des activités à travers le réseau des bibliothèques. Le modèle de la classe est aussi celui qui est privilégié à la Grande bibliothèque au même moment, et si les rencontres ne sont pas nomades, la rétention des participant.e.s est aussi faible.
Figure 1 : La classe
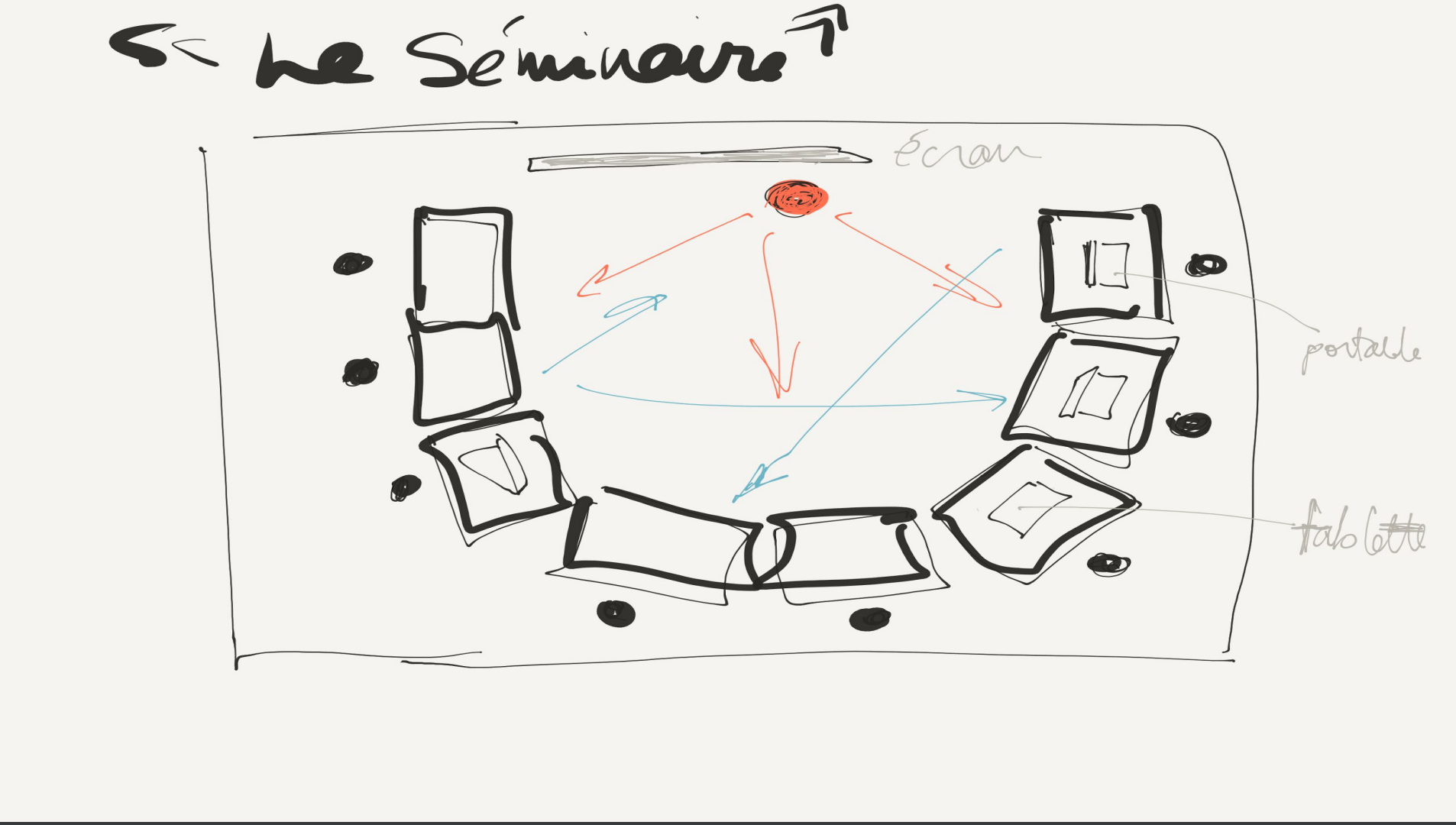
Prototype 2 : Le séminaire ou le plan en « U » (voir schéma 2). Le second scénario est un modèle de transition qui reflète l’intention de rompre avec le cours magistral pour se rapprocher d’un format de rencontre informel, moins centré sur le formateur, plus actif et, en ce sens, plus près de ce qui est annoncé et visé, c’est-à-dire, un atelier avec un volet “hands on”. La salle est organisée de manière à placer les tables en forme de U avec un écran et un projecteur au sommet du U pour la présentation. Les participant.e.s se côtoient, ils peuvent se voir. La rencontre prévoit deux parties d’une durée égale, soit une présentation donnée par les représentants de Wikimania Canada et de OpenStreetMap Montréal, suivie d’un atelier d’initiation. Peu à peu, une version alternative de ce modèle se met en place, ce qui représente un changement notable : ce sont les bibliothécaires membres de CSL qui commencent à prendre en charge la partie consacrée à la formation sur Wikipédia.
Figure 2 : La classe
Sans avoir procédé à une évaluation de l’impact en bonne et due forme, le critère associé au volet contributif apparaît plus conséquent, certains participants ouvrent un compte, apprivoisent les plate-formes (Wiki ou OSM), contribuent au sujet de leur choix ou à ceux qui sont proposés en lien avec des articles touchant le quartier ou la bibliothèque. Un accompagnement est pratiqué et des conversations surviennent, non seulement, par le biais des Q et R aux présentateurs, mais aussi entre les membres du CSL et les participants. Du point de vue du nombre de participants, de la rétention ou du nombre de contributions, les résultats sont à peine plus éloquents. En revanche, les apprentissages acquièrent une qualité expérientielle et suscitent un intérêt; les échanges deviennent le mode de communication qui occupent une part significative de la rencontre.
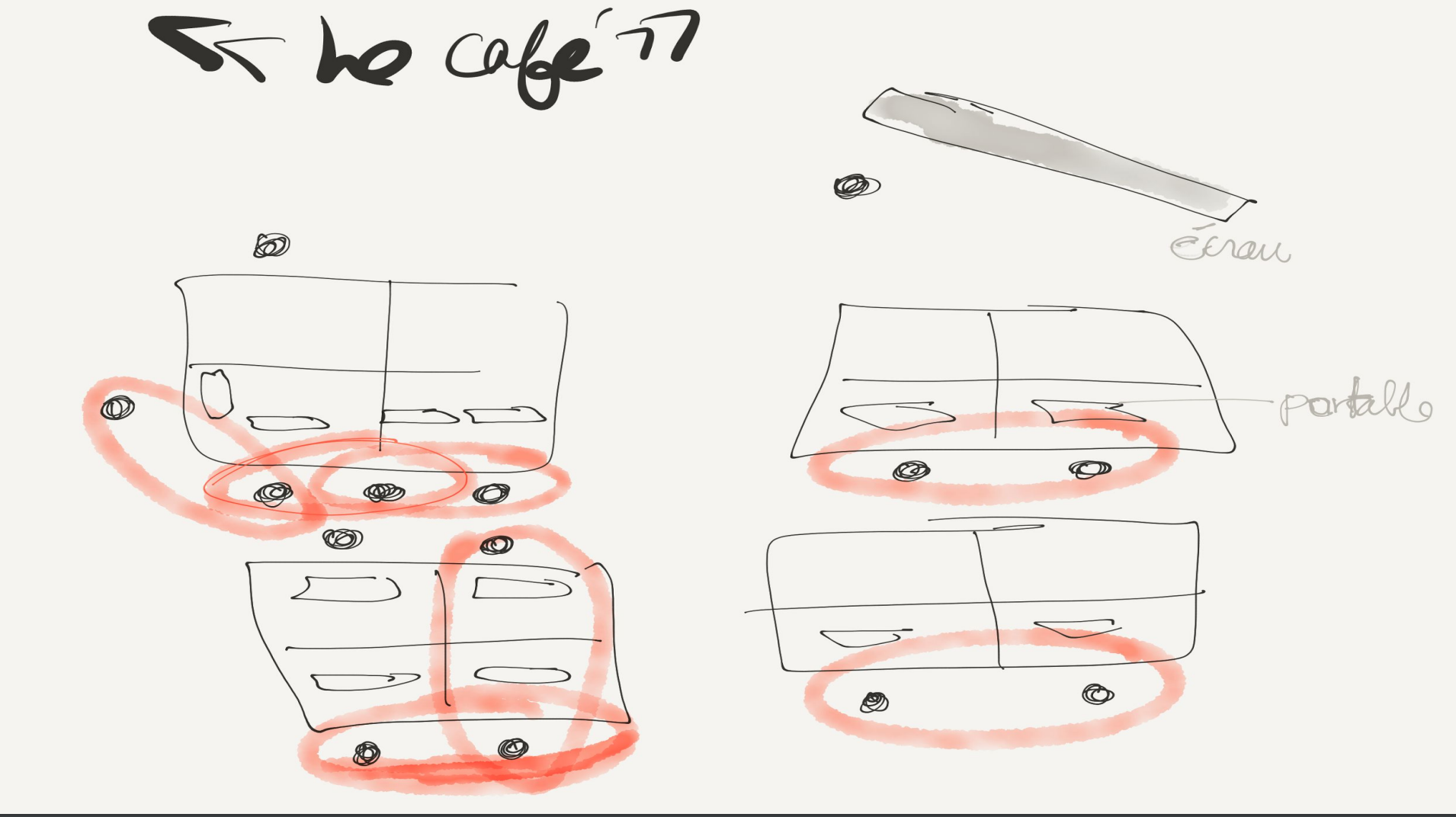
Prototype 3 : Le café ou le plan en îlot (voir schéma 3). Est-ce que l’on pourrait faire mieux « en commun » ? En faisant un retour sur les activités, en interrogeant les partenaires de Wikimédia Canada, OSM, des organismes locaux et des sociétés d’histoire, l’effort de conception suivant a porté sur les moyens d’accroître la sensibilisation aux savoirs communs, de rehausser les compétences, des participants comme celles des membres de CSL en matière d’édition. et de contribuer davantage aux données communautaires. En saisissant l’opportunité de l’invitation de la bibliothèque Mordecai-Richler de devenir des presque « wikipédien en résidence » dans le cadre de la programmation saisonnière, CSL a conçu un nouveau prototype d’atelier : le café. Cette nouvelle approche visait moins à créer et former une communauté, finalement extérieure aux formateurs-commoners que de reconnaître simplement que CSL faisait partie de la communauté en s’y identifiant ⎼ avec l’espoir que la bibliothèque ferait peut-être le même cheminement.
Figure 3 : Le café
Ce modèle met l’accent sur l’engagement de CSL lui-même dans les projets locaux tout en partageant les pratiques de commoners avec les personnes qui voudraient éventuellement se joindre : « La communauté numérique, c’est nous ». La salle est organisée en îlots de travail rapprochés qui favorise les échanges personnalisés, souvent en binôme. Il n’y a plus de cours, de formation, de conférence, seulement un mot de bienvenue avec un rappel des principes, de quelques faits, de la philosophie des savoirs libres, et la séance est consacrée à la contribution et à l’entraide qu’elle requiert presque inévitablement. C’est le design d’atelier dont les attributs s’apparentent le plus au tiers-lieu ou aux learning commons avec une approche basée sur la convivialité et les conversations qui soutiennent des apprentissages informels.
Après quelques séances dans une salle fermée, les participants réguliers de CSL ont jugé que les ateliers gagneraient à se dérouler dans un espace ouvert dans la bibliothèque, notamment parce que cette configuration pouvait favoriser différents degrés de participation. Les usagers de la bibliothèque qui y travaillaient étaient naturellement prévenus de la tenue d’un atelier dans les heures précédant celui-ci par l’entremise d’une signalisation appropriée, et ils avaient le loisir d’écouter (ou de se retrancher dans une zone plus silencieuse), éventuellement de se rapprocher, puis de se joindre aux activités. Ce qui s’est effectivement produit dans certains cas. Il n’y a pas eu plus d’usagers participants, mais pas moins. Dans un tel contexte, les participants du CSL n’étaient plus seulement présents pour donner une formation, mais pour contribuer aux pages et aux projets qui étaient à l’ordre du jour et de ce point de vue, les rencontres s’avéraient non seulement plus productives mais aussi plus satisfaisantes en termes de réalisation et d’apprentissage.

5. Discussion : La question des retombées et de l'évaluation de l'impact
Un modèle d’atelier et l’évaluation de l’impact. Les questions de départ étaient les suivantes: Comment pourrait-on créer une communauté créatrice de savoirs communs numériques en bibliothèque ? Comment évaluer et accroître l’impact des ateliers contributifs impliquant les bibliothèques et Wikipédia - ou plus généralement, les projets soutenus par la fondation Wikimédia ? La première question a guidé l’ensemble de cette démarche expérientielle, faites d’observations et d’analyse, et a conduit à la proposition d’une série de conditions pratiques décrivant un modèle d’atelier notamment en termes socio-spatiaux : un espace ouvert, des îlots de travail pour des petits groupes, un temps consacré à la théorie réduit au minimum versus un temps dédié à la pratique étendu au maximum; un programme thématique situé avec une résonance locale; une approche orientée sur les apprenants dans un cadre informel, où tout le monde peut servir de référent et d’aide et pas seulement les formateurs en titre. Notons que CSL a introduit une contrainte supplémentaire à ce sujet en proposant une rotation chez les formateurs : la responsabilité de la présentation est attribuée à un membre différent de CSL à chaque séance, ce qui concourt non seulement à stabiliser les connaissances, mais aussi à développer des compétences d’éditeur et de médiateur numérique, ainsi qu’une confiance, en tant que wikipédien. Les membres, bibliothécaires et libristes, si l’on veut pointer des comportements, ont adopté une pratique plus régulière en matière d’édition tout en consolidant, en tant que groupe, des habitudes de travail et en rehaussant, par itération, leur capacité de communauté éditrice dont profiteront d’autres projets par la suite.
Ces retombées au final n’ont pas été celles qui au départ avaient été anticipées par le collectif. Les objectifs qui visaient à rehausser les capacités en termes de production de savoirs communs ont été réalisés principalement du côté des bibliothécaires membres de CSL, mais sans équivalent du côté des personnels des bibliothèques ou des usagers rencontrés et à peu près sans effet sur la rétention et le nombre de contributions. On ne peut pas, pour autant, nier la sensibilisation aux savoirs communs numériques et à la contribution wikipédienne effectuée à travers ces dizaines de rencontres menées auprès des bibliothécaires-hôtes et des usagers ⎼ bien que l’on ne puisse pas rapporter des effets véritablement durables. Néanmoins, les bibliothèques de l’arrondissement du Plateau (dont la Bibliothèques Mordecai-Richler fait partie) ont initié de leur propre chef quelques ateliers wikipédiens à la suite de ce programme. On peut également penser que ces interventions auront concouru à promouvoir la bibliothèque comme actrice dans l’éducation au numérique et à changer la perception de celle-ci non plus seulement comme lieu de diffusion mais comme place de création, en adoptant un rôle en amont de la chaîne de la production des connaissances ⎼ alors qu’on la situe traditionnellement plutôt à la fin(23).
Ces retombées évoquées qui témoignent d’un succès mitigé donnent à penser que les bibliothèques publiques disposent d’un réel potentiel pour se poser comme actrices de la transition numérique et médiatrice des savoirs communs, mais que de nombreux obstacles gênent encore l’adoption d’un rôle plus significatif sur ce plan. Le problème ici résiderait dans la transition entre une culture de la prestation de services en bibliothèque qui peine à s’opérer en faveur d’une approche orientée «community-led» ou «critical librarianship», les deux étant souvent interconnectées, basées sur la triade «équité-diversité-inclusion» et structurées par le développement de capacités et la participation comme leviers d’une infrastructure de justice sociale. D’autres obstacles sont identifiés tels que des mécanismes préférentiels, ancrés dans le capitalisme, favorisant des savoirs ou des produits culturels issus du monde marchand, une compréhension stratégique approximative des enjeux numériques actuels, une maîtrise inégale des outils technologiques, le manque de personnel, etc.
À partir d’ici, cette réflexion sur l’impact se poursuivra en recourant aux catégories du modèle d’évaluation de l’impact issu de Project Outcome de Public Libraries Association (PLA) qui s’intéresse à la mesure de ce qui se fait par le biais des actions de bibliothèque, plutôt qu’à la mesure de la quantité ou de la performance (soit le nombre de participants, de contributions, etc.) reliées à celles-ci(24). Les critères d’évaluation dans le cadre de Project Outcome prennent en compte i. les apprentissages, les connaissances, ii. la confiance, iii. les transformations comportementales et iv. la perception du rôle de la bibliothèque et sa promotion. L’impact des ateliers contributifs impliquant les bibliothèques et Wikipédia ⎼ et en vue de compléter la réponse à la seconde question ⎼ pourrait être accru en tirant parti du modèle d’atelier présenté ainsi qu’en mesurant les retombées à l’aide d’évaluations inspirées de l’approche de PLA. La réflexion sur la démarche décrite a été guidée par cette approche de l’évaluation de l’impact a posteriori, mais de nouvelles initiatives gagneraient à procéder à une évaluation plus formelle en situation par le biais d’un moment réservé à la fin des ateliers, permettant aux participants de répondre aux questionnaires qui sont fournis à cet effet via la méthode de PLA.
La littératie numérique et l’évaluation de l’impact. Cette approche converge avec les constats et les suggestions que l’on trouve dans la littérature, à savoir que ce n’est pas une mesure de la performance qui importe, mais plutôt les bénéfices notamment sur le plan des apprentissages liés à l’amélioration des compétences informationnelles et numériques :
In my view, the most successful edit-a-thons are not just about producing the greatest number of citations, new articles, backlinks, and image uploads. The fact is, a significant impact on the encyclopedia itself will take time and dedication from repeat contributors, not just sporadic interjections by newbies. As wonderful and fulfilling as those first edits might be in terms of meeting educational or information literacy goals, they might only gain you a handful of quality paragraphs on Wikipedia.org. And while the Wikimedia community might be tempted to try and measure success by the number of new recruits that are converted into committed contributors and editors, I’m not sure this is the only measure of success either. Edit-a-thons can be about an unquantifiable opening of minds, and learning about where Wikipedia— and, crucially, the verifiable, factual sources it cites— fit into the modern information ecosystem. Edits happen, certainly, but the best events could just as reasonably be called “learn-a-thons.”(25)
Il faut noter que l’outil d’évaluation de l’impact dans Project Outcome comporte spécifiquement un questionnaire pour évaluer les activités de médiation numérique à court terme, à moyen terme et à long terme.
Soulignons par ailleurs, en revenant sur le sujet des politiques publiques encadrant des initiatives de cette nature, que celles-ci tendent à devenir toujours plus explicites et rendre plus prégnantes leurs raisons d’être. Depuis la tenue de ces activités, la publication d’un référentiel sur la compétence numérique(26) ainsi qu’une volonté de soutenir « l’éducation au numérique »(27) dans une perspective nationale ainsi que, incidemment, la promotion des ressources éducatives libres, offrent de nouveaux appuis qui interpellent directement les bibliothèques publiques.
L’agenda 2030 et l’évaluation de l’impact. Selon Lankes, comme nous avons vu ci-dessus, la mission de la bibliothèque consiste à faciliter la création de savoirs dans les communautés - un énoncé fortement aligné sur un projet de création de savoirs communs numériques - avec cette finalité qui l'accompagne et visant à «améliorer la société». Or, cette finalité gagne aujourd’hui à être mise en rapport et explicitée en se fondant sur le programme de l’agenda 2030 des Nations-Unis et les 17 objectifs de développement durable (ODDs) qui le composent.(28)
Déjà promoteur de la médiation wikipédienne, l’IFLA est aussi activement impliquée dans la réalisation des objectifs de cet agenda(29). Selon les initiatives, les ateliers wikipédiens sont susceptibles de figurer parmi les actions visant l’atteinte de ces ODD comme par exemple, l’objectif 2 pour une « éducation de qualité », et visant la réduction des barrières à l’accès ou l’objectif 16 touchant « la paix, la justice et les institutions efficaces » en lien avec la lutte contre les fausses nouvelles, ou encore l’objectif 17 en favorisant « les partenariats pour la réalisation des objectifs » et en soulignant les liens créées entre les communautés, et pour les communautés, par l’entremise de ces projets.
Les objectifs de développement durable de l’agenda 2030 comportent un ensemble de cibles auxquelles sont rattachés des indicateurs élaborés pour l’évaluation de l’impact et qui peuvent être mis à contribution à cette fin comme au service de la seconde question (accroissement de l'impact des bibliothèques).(30)
6. Conclusion : D’autres expériences et pistes d’action pour les savoirs communs
Nous avons exploré un modèle d’atelier numérique avec ses avantages, en termes de mise en capacité de création de savoirs communs par la contribution wikipédienne, et ses limites, quant à l’adhésion du personnel des bibliothèques-hôtes ou même de leurs usagers. Ses obstacles, avons-nous suggéré, pourraient être atténués en privilégiant certains aménagements socio-spatiaux, mais surtout un engagement communautaire intentionnellement participatif.
À la lumière de cette démarche expérientielle, d’autres pistes, dans cette mouvance, peuvent encore être pointées. D’abord, par l’entremise des associations et des écoles en sciences de l’information et des bibliothèques, il importe de continuer à discuter des opportunités de ces collaborations entre les bibliothèques et Wikipédia tout en encourageant les activités d’apprentissage et les ateliers contributifs avec des wikipédiens; de promouvoir activement les projets locaux visant à documenter et valoriser et relier les données culturelles, sociales, communautaires, historiques, territoriales; de conduire ce plaidoyer en l’insérant dans le cadre de l’agenda 2030 et d’une responsabilité socio-environnementale assumée de la part des bibliothèques. Un projet wikipédien peut, à ce titre, être abordé à la façon d’un projet-pilote permettant d’expérimenter les approches de type «community-led», où la relation et la participation avec les groupes locaux sont abordées comme des leviers critiques pour la planification, la programmation et aussi la transformation.
Dans cette perspective, et pour concrétiser cette proposition, que ce soit, par exemple, dans le cadre de la Journée du livre et du droit d’auteur ou d’autres événements, la création et l’enrichissement des contenus des pages des créateurs et créatrices, de leurs œuvres, des listes afférentes liées à la culture locale, montréalaise et québécoise offrent des avenues de collaboration qui sont étroitement en phase avec la mission séculaire des bibliothèques(31). Cette contribution aux communs de la connaissance doit s’étendre à Wikidata. Cette base de connaissances ouverte, qui centralise en données structurées, ouvertes et liées, les données créées à travers une diversité de langues et de cultures, permet, non seulement de maintenir l’information à jour à travers l’ensemble des versions linguistiques de Wikipédia, mais aussi d’assurer la présence des cultures et des savoirs locaux, voire leur existence et leur coexistence, au sein de l’environnement numérique. Et sans revenir à des questions de performance, ou de nombre de contributions ou de contributeurs, l’engagement collaboratif et la responsabilité partagée des bibliothèques publiques en réseau, de même que l’accompagnement à cette littératie des données auprès des créateurs et de leurs publics, pourraient faire une différence dans la découvrabilité de la culture locale et nationale en étendant l’accès de ces mondes à découvrir parmi les mondes connectés.
Un autre exemple de projet pourrait consister à créer une collaboration 1+1+1 en bibliothèque impliquant des wikipédiens et des groupes locaux ou des scientifiques qui sont actifs sur le plan de l’engagement écologique. Cette alliance visant à consolider la littératie à la fois numérique et environnementale, pourrait porter cette fois sur la création des articles ou l’enrichissement des contenus liés aux savoirs rattachés à ces enjeux et discutés par les climato-sceptiques. En tablant non pas sur les nuisances des innovations technologiques, mais sur le potentiel participatif de la culture numérique dans la production des contenus, leur mise en réseau et leur valorisation à grande échelle, de telles initiatives pourraient avoir des retombées politiques significatives à l’heure de la crise climatique(32). Dans cette convergence des transitions, si l’on retient ces discours, qui se jouent sur les savoirs communs, la capacité numérique des bibliothèques publiques dans une perspective autant locale, que nationale et internationale, pourrait avoir un impact non négligeable sur l’atterrissage des humains et des non-humains dans un monde durablement habitable(33).
Annexe 1
Tableau comparatif des caractéristiques des trois prototypes
Notes
(1)Dans la perspective des travaux de Donald Schön sur l’épistémologie professionnelle : The Reflective Practitioner: How professionals think in action. London: Temple Smith, 1983.
(2)Au moment de cette démarche expérientielle, j’étais bibliothécaire dans les bibliothèques de Montréal et membre du collectif du Café des savoirs libres (CSL), c’est à partir de ce double point de vue et sur la base des compte-rendus des ateliers wikipédiens de CSL que la narration est construite. Je remercie François Charbonnier, bibliothécaire et membre du CSL, avec qui le travail de synthèse relié à cette démarche expérientielle a été mené et dont certains résultats ont été présentés à l’occasion de la conférence Wikimania 2017 à Montréal :https://upload.wikimedia.org/wikipedia/commons/7/76/Pr%C3%A9sentation_wikimania_CSL_11092017fin.pdf. Je voudrais aussi remercier Pascale F. Chartier, Pierre Choffet, Marina Gallet, Danielle Noiseux, Josée Plamondon, membres réguliers du CSL, et Benoit Rochon, de Wikimédia Canada, qui ont participé et signficativement contribué à ce projet.
(3)Les premiers articles sur Wikipédia dans la littérature savante remonteraient à 2004.“The sum of all human knowledge”: A systematic review of scholarly research on the content of Wikipedia http://onlinelibrary.wiley.com/doi/10.1002/asi.23172/full /
(4)https://en.wikipedia.org/wiki/Wikipedia:GLAM/About
(5)https://fr.wikipedia.org/wiki/Jean_Talon
(6)https://commons.wikimedia.org/wiki/Category:Journ%C3%A9e_contributive_%C3%A0_l%27Universit%C3%A9_Laval,_Qu%C3%A9bec
(7)http://mile-end.qc.ca/2013/03/journee-contributive-le-mile-end-dans-wikipedia/ et https://fr.wikipedia.org/wiki/Projet:Quartier_Mile_End
(8)https://fr.wikipedia.org/wiki/Wikip%C3%A9dia:Mois_de_la_contribution/2013/Montr%C3%A9al et https://commons.wikimedia.org/wiki/Category:Journ%C3%A9e_contributive_Acfas_-_BAnQ
(9)http://www.banq.qc.ca/activites/wiki/wiki-mardi.html et https://fr.wikipedia.org/wiki/Wikip%C3%A9dia:BAnQ/Mardi,_c%27est_Wiki_!
(10)https://fr.wikipedia.org/wiki/Wikip%C3%A9dia:Caf%C3%A9_des_savoirs_libres. Toutes les activités ne sont pas documentées sur la page projet du CSL.
(11)Le projet Savoirs communs du cinéma de la Cinémathèque québécoise : https://scc.hypotheses.org/1351
(12)Une étude rapporte que 96% des instructeurs dans les milieux universitaires estiment que Wikipédia est plus utile pour enseigner la littératie de l’information que les exercices traditionnels. https://blog.wikimedia.org/2017/06/19/wikipedia-information-literacy-study/
(13) https://www.ifla.org/files/assets/hq/topics/info-society/iflawikipediaandpubliclibraries.pdf et https://www.ifla.org/node/11131
(14)Les événements #1lib1ref se déroulent même depuis quelques années à raison de deux fois par an.
(15)Lankes, R.D. (2016) Expect More.
(16)Dujol, Lionel (ed.). 2017. Communs du savoir et bibliothèques. Paris : Éditions du cercle de la librairie.
(17) http://bibliomontreal.com/abonnez-vous/wp-content/uploads/2018/03/plan_strategique_bibliotheques_mtl_20162019.pdf
(18)Les Voyageurs du code offrent des ateliers mobiles qui se constituent comme des communautés numériques. http://voyageursducode.fr/
(19)Leveraging Wikipedia : Connecting Communities of Knowledge, edited by Merrilee Proffitt, American Library Association, 2018, p.37
(20)Autrement, on peut le voir comme une occasion de créer ces liens dans l’esprit des bibliothèques dirigées par la communauté mais cette capacité communautaire est inégalement répartie dans l’approche et la culture des bibliothèques du réseau, ce qui est un enjeu.
(21)Selon l’approche de planification en collaboration avec la communauté que l’on retrouve dans la trousse d’outils également connue sous le nom de « Working Together » qui sert de référentiel pour la bibliothéconomie canadienne : https://www.vpl.ca/working-together-community-led-libraries-toolkit.
(22)Cette réflexion sur les prototypes a été amorcée dans le cadre d’une présentation réalisé avec François Charbonnier, bibliothécaire et membre du CSL, dans le cadre de la conférence Wikimania à Montréal en 2017 : https://upload.wikimedia.org/wikipedia/commons/7/76/Pr%C3%A9sentation_wikimania_CSL_11092017fin.pdf
(23)Voir à ce sujet : Berthiaume, G. (2020). “If You Want to Go Far, Go Together: The Collaboration among the GLAM Community in Canada (2016–2019).” Research Library Issues, no. 300 : 10. https://doi.org/10.29242/rli.300.2.
(24)Project Outcome : http://www.ala.org/pla/initiatives/performancemeasurement
(25)Merrilee Proffitt, ed. (2018). Leveraging Wikipedia : Connecting Communities of Knowledge, American Library Association.
(26)MEES. Cadre de référence sur la compétence numérique : http://www.education.gouv.qc.ca/references/tx-solrtyperecherchepublicationtx-solrpublicationnouveaute/resultats-de-la-recherche/detail/article/cadre-de-reference-de-la-competence-numerique/
(27)https://www.cse.gouv.qc.ca/wp-content/uploads/2020/11/50-0534-SO-eduquer-au-numerique.pdf
(28)Programme des Nations-Unies pour le développement. https://www.undp.org/content/undp/fr/home/sustainable-development-goals.html
(29)IFLA. Libraries, Development and the United Nations 2030 Agenda : https://www.ifla.org/libraries-development.
(30)Cadre mondial d’indicateurs relatifs aux objectifs et aux cibles du Programme de développement durable à l’horizon 2030. https://unstats.un.org/sdgs/indicators/Global%20Indicator%20Framework_A.RES.71.313%20Annex.French.pdf ou https://sdg.humanrights.dk/fr/goals-and-targets
(31)https://fr.wikipedia.org/wiki/Mile_End_(Montr%C3%A9al)#Livres et https://fr.wikipedia.org/wiki/Outremont#Fictions_dont_l.27action_se_situe_.C3.A0_Outremont_.28ou_qui_r.C3.A9f.C3.A8rent_.C3.A0_Outremont.29
(32)Monnoyer-Smith, L. (2017). Transition numerique et transition ecologique. Annales des Mines - Responsabilité et environnement, 87(3), 5-7. https://doi.org/10.3917/re1.087.0005
(33)Pour reprendre l’esprit du titre et le propos de Bruno Latour dans Où atterrir ? Comment s'orienter en politique. Éditions La Découverte.
Données médicales et dossiers patients comme actifs informationnels : la gouvernance de l’information dans les hôpitaux universitaires suisses
Anna Hug, Archiviste principale chez HUG
Données médicales et dossiers patients comme actifs informationnels : la gouvernance de l’information dans les hôpitaux universitaires suisses
1. Introduction
Dans cet article, nous examinons la thématique du dossier patient et des données médicales du point de vue de la gouvernance de l’information (GI), c’est-à-dire des règles qui sont mises en place pour assurer une gestion conforme des données, et ceci dans le contexte des hôpitaux universitaires suisses (HUS). Le choix du sujet découle de la réalité professionnelle de l’auteure, qui est l’archiviste principale des Hôpitaux universitaires de Genève.
Cet article est la version raccourcie d’un travail de master en sciences de l’information à la Haute école de gestion de Genève (Hug Buffo 2020). Nous invitons les personnes intéressées par le sujet à s’y référer, car les différentes thématiques y sont détaillées davantage. On y trouve notamment de nombreuses annexes (fiches descriptives des HUS, comparaison des lois cantonales, fil conducteur des entretiens, bibliographie complète, etc.).
Deux précisions terminologiques :
- Nous avons opté pour le terme « dossier patient », plutôt que « dossier médical » ou « dossier médico-soignant », pour souligner qu’il s’agit d’un outil partagé et que le patient est au centre, et non un groupe professionnel en particulier.
- Afin d’équilibrer la représentation des deux genres dans ce texte, nous utiliserons de préférence des tournures neutres et des termes épicènes. Dans les cas où cela s’avère impossible, nous alternerons entre le féminin et le masculin génériques.
Contexte de la recherche
La Suisse compte cinq hôpitaux universitaires (à Bâle, Berne, Genève, Lausanne et Zurich), qui, tout en entretenant des multiples collaborations entre eux, fonctionnent chacun selon un cadre juridique spécifique. Ils fournissent des soins de qualité à la fois dans des domaines de médecine de pointe, pour le grand public et dans le cadre de missions d’intérêt général. Ils mènent également des activités de formation, d’enseignement et de recherche. Toutes ces activités génèrent de grands volumes de données, le plus souvent sous forme numérique, qui constituent les dossiers patients.
Les multiples rôles du dossier patient
Le dossier patient est un outil indispensable dans nos institutions hospitalières. Il englobe des informations de divers corps de métiers (soignantes, médecins, professions médico-techniques…), sur différents supports (papier, microformes, radiographies, numérique…). Il permet de connaître les antécédents d’une patiente. Les informations qui s’y trouvent sont nécessaires pour la facturation des prestations et pour l’évaluation de la qualité. Pour l’individu, son dossier patient retrace une partie de sa vie – aujourd’hui, tout un chacun peut être acteur de sa santé grâce à la prise de connaissance, voire l’alimentation de son propre dossier. La science peut trouver des enseignements précieux dans les données de santé qui constituent le dossier, qu’il s’agisse de la médecine de précision (dite « personnalisée ») ou, ultérieurement, de recherches en sociologie ou en histoire de médecine.
Longtemps, le dossier patient était évidemment physique, sous forme de classeur, de fourre à rabats ou encore suspendu, et contenait des papiers divers ; certains types de documents particuliers, comme les radiographies, étaient classés à part. Puis, vers les années 1970, en raison du manque de place dans les grandes institutions hospitalières, le support a changé : le microfilmage a permis de comprimer considérablement le volume nécessaire au stockage de ces informations. Parallèlement, l’informatique se développait de plus en plus, d’abord pour les données administratives, puis progressivement pour la partie médico-soignante. Au tournant du siècle, la numérisation a pris la place du microfilmage, et de plus en plus de documents et données ont été générés directement sous forme digitale. Aujourd’hui, le dossier patient est le plus souvent « né-numérique ».
La gouvernance de l’information, pourquoi ?
La GI est une approche pour optimiser la gestion de l’information, la protéger et en tirer de la valeur, tout en minimisant les risques qui y sont associés. Cette démarche, qui doit se situer au niveau stratégique d’une institution, définit des politiques et processus transversaux, des rôles et des responsabilités. Elle pose un cadre de référence en tenant compte des obligations légales et réglementaires.
Plan de l’article
Après l’introduction (chapitre 1), nous détaillerons d’abord les objectifs et la méthodologie (2) de notre recherche, puis nous expliquerons les concepts utilisés et en donnerons les définitions (3), avant de décrire la GI avec ses tenants et aboutissants (4). Nous parlerons ensuite du contexte hospitalier suisse et des cinq institutions qui sont la cible de notre recherche (5). Nous nous intéresserons aux formes du dossier patient (6) et à son histoire (7). Nous évoquerons les diverses utilisations des données médicales (8) avant d’éclaircir quelques aspects du droit de la santé (9). Puis, nous relaterons et discuterons les résultats des entretiens menés avec des représentants des hôpitaux universitaires (10, 11). Nous démontrerons que les données médicales sont bel et bien des actifs informationnels (12), et nous proposerons une modélisation de la GI appliquée aux données médicales telle que nous l’avons perçue à travers notre recherche, et une ouverture vers des pistes de recherches futures (11). Nous conclurons par un résumé des points principaux (12).
2. Objectifs et méthodologie
Le travail de master visait à :
- décrire la typologie des données médicales dans les HUS, leur genèse et leur utilisation ;
- retracer l’évolution et les formes du dossier patient ;
- dresser le portrait des pratiques informationnelles (consignées ou implicites) en matière de gestion des données à travers leur cycle de vie ;
- décrire le contexte et les principaux enjeux de la GI, en regard des institutions examinées ;
- modéliser la GI appliquée aux données médicales, avec les compétences et fonctions nécessaires.
Pour ce faire, nous avons adopté une démarche exploratoire descriptive qualitative : nous cherchions à savoir ce qui est préconisé en matière de GI dans le domaine médical – et ce qui se fait réellement dans les HUS. Dans ce but, nous avons combiné plusieurs méthodes :
- étude de la littérature sur les sujets de la gouvernance informationnelle, de l’histoire du dossier patient et des différents enjeux liés aux données médicales ;
- étude de la documentation disponible sur les HUS et des cadres réglementaires (plus particulièrement les lois cantonales) ;
- enquête auprès des cinq HUS concernant leurs pratiques informationnelles à l’aide d’entretiens semi-dirigés.
Périmètre de l’étude et éléments de validité
Nous nous sommes concentrées sur les données médicales et n’avons pas traité les autres types de données (administratives) qui peuvent se trouver dans un hôpital : dossiers des ressources humaines, données financières, rapports de projets, brochures d’information…
Les détails opérationnels de la gestion de l’information, tels que les durées de conservation précises pour un certain type de documents, n’ont pas été étudiés. Par ailleurs, il ne s’agissait pas de comparer les HUS entre eux ni d’évaluer leur maturité en matière de GI, mais de dresser un portrait global des pratiques existantes.
Nous avons procédé à une triangulation des données récoltées, d’une part en confrontant les données récoltées lors des entretiens avec les enseignements tirés de la revue de littérature, d’autre part en comparant les réponses des HUS entre elles afin de cerner les points saillants.
Tout au long de la recherche, nous nous sommes efforcées de documenter notre méthodologie, afin de l’expliciter et de permettre une reproductibilité ultérieure.
3. Considérations terminologiques
Les données sont les plus petites unités, porteuses de sens, de l’information (InterPARES [s.d.]a). Elles sont « ce qui est connu et admis, et qui sert de base à un raisonnement, à un examen ou à une recherche » (Centre national de ressources textuelles et lexicales [s.d.]).
Lorsqu’elles sont assemblées, contextualisées, analysées, dans le but d’être communiquées, les données deviennent information (InterPARES [s.d.]b; Bennett 2017). Pour qu’elle soit de qualité, l’information doit être intègre, authentique, complète, à jour, exacte, fiable et crédible (Maurel 2013).
Un document est un ensemble constitué d'un support et de l'information qu'il porte (Direction des archives de France 2002). Il peut s’agir d’un texte imprimé sur du papier, de sons enregistrés sur CD… De nos jours, le « support » est souvent virtuel : les fichiers informatiques sont des enregistrements électroniques qui ne peuvent être lus que par l’intermédiaire d’une machine.
Un dossier est l’ensemble des documents (physiques ou numériques) réunis pour la conduite ou le traitement d'une affaire par une personne physique ou morale dans l'exercice de ses activités (Portail international archivistique francophone 2015). Le dossier patient quant à lui est « (…) une mémoire écrite de toutes les informations d’un malade, à la fois individuelle et collective constamment mise à jour » (Roger France 1982, cité dans Servais 1996) ; il doit servir à la fois aux soins, à la recherche, à la gestion de l’hôpital et à l’évaluation de la qualité des soins (Servais 1996). Les différentes législations sanitaires cantonales proposent également des définitions du dossier patient.
Terminologie hospitalière
Un hôpital est défini comme « élément d'une organisation de caractère médical et social dont la fonction consiste à assurer à la population des soins médicaux complets, curatifs et préventifs (...) c'est aussi un centre d'enseignement de la médecine et de recherche bio-sociale » (Organisation mondiale de la santé 1957).
Le système d’information clinique (SIC), aussi appelé système d’information hospitalière ou dossier patient informatisé, constitue le cœur du système d’information d’un hôpital. Il peut s’agir d’une solution globale intégrée ou d’un ensemble de systèmes indépendants. Par la dématérialisation du dossier patient, il permet une vision centrée sur les processus de soins. Les documents et données peuvent être mis à jour, consultés, interrogés et transférés instantanément, à l’interne ou à l’externe de l’institution ; les droits d’accès des utilisateurs peuvent être finement gérés afin de garantir la confidentialité des données. Le SIC peut améliorer la prise de décision clinique, p.ex. en produisant une alerte en cas d’interaction médicamenteuse dangereuse, et l’efficacité du fonctionnement de l’hôpital en centralisant les informations sur les rendez-vous ou les ordonnances (privatim 2015; Hôpital du Jura, Hôpital neuchâtelois, Hôpital du Jura bernois SA 2011; Batigne, Pozzebon, Rodriguez 2010).
4. La gouvernance de l’information
La GI cherche à optimiser la gestion de l’information, tout en respectant les obligations légales et réglementaires (compliance) et en minimisant les risques. Elle définit un cadre de référence, des politiques et processus transversaux, des rôles et des responsabilités.
Les spécialistes s’accordent à dire que la GI doit se situer au niveau stratégique d’une institution et être portée par un haut dirigeant (Smallwood 2019; Bennett 2017). La « gouvernance », ce n’est en effet pas la même chose que la « gestion » de l’information. Cette dernière s’occupe d’un aspect spécifique, opérationnel, quotidien, tandis que la GI a un caractère multidimensionnel, touchant l’ensemble du cycle de vie, en impliquant différents domaines d’activité. Anderfuhren et Romagnoli (2018) insistent sur les trois dimensions qui composent la GI : l’information vue comme ressource – l’optimisation globale et stratégique – la mitigation des risques.
Ce n’est pas la gouvernance des données, ni celle des systèmes d’information
Il y a parfois une confusion terminologique avec la gouvernance des données ou data governance. Cette dernière comporte des procédures et outils pour assurer la qualité des données (donc des éléments factuels, les unités de base de l’information) et est située à un niveau opérationnel. Il s’agit p.ex. d’assurer l’unicité d’une donnée (dédoublonnage), de gérer les données de référence (master data management) et les métadonnées. La gouvernance des données est une des parties d’une démarche GI (Butler 2017; Smallwood 2014; Perrein 2011).
La gouvernance des systèmes et technologies d’information (SI) ou IT governance, quant à elle, vise une utilisation efficace et efficiente des SI dans le but de permettre à l’institution d’atteindre ses objectifs (Gartner [s.d.]a). Il s’agit de la mise à disposition de moyens techniques en fonction de besoins exprimés par les autres métiers.
Les actifs informationnels
Les actifs informationnels ou information assets englobent tous les éléments d’information ayant de la valeur pour une institution, de manière très large et indépendamment du support : le savoir des parties prenantes (écrit ou tacite), les données structurées dans des bases, les documents non structurés numériques ou physiques, l’information publiée sur Internet ou achetée à des tiers, les systèmes d’information, etc. (Gartner [s.d.]b; Maurel 2013). Dans la démarche de GI, ils sont inventoriés et référencés pour en tirer de la valeur et les sécuriser (Smallwood 2014; Perrein 2011).
Cette valeur n’est que rarement chiffrée et ne figure pas dans le bilan d’une société (les brevets sont l'exception qui confirme la règle). Souvent, elle est créée par une utilisation novatrice des données, telles que les applications de big data. Mais l’on se rend surtout compte de cette valeur lorsqu’il y a un problème, que ce soit par un acte d’inadvertance ou criminel : la fuite d’informations confidentielles, la perte d’un document de preuve, le départ d’une personne très expérimentée. Dans le domaine médical, où les informations sont sensibles par nature, un tel problème peut être particulièrement délicat.
Un exemple récent : en septembre 2019 l’entreprise allemande Greenbone, spécialisée dans la sécurité des réseaux informatiques, a révélé que des millions de jeux de données médicales, dont de l’imagerie, étaient librement accessibles via Internet. Les serveurs de stockage et les systèmes de visualisation n’étaient en effet pas suffisamment protégés contre un accès en ligne. 52 pays étaient concernés, dont la Suisse. Greenbone estime que l’ensemble de ces données médicales a une valeur de 1,2 milliards de dollars (Greenbone Networks GmbH 2019; Meibert 2019; Chavanne, Jaun 2019).
Une approche interdisciplinaire
La GI englobe toute une série d’activités effectuées par différents acteurs (Smallwood 2019). Les spécialisations nécessaires pour mener un programme de GI vont du droit à la gouvernance des données, en passant par les systèmes d’information, le records management ou la cybersécurité.
Différentes associations professionnelles ont publié ces dernières années des standards et bonnes pratiques dans le contexte de la GI, par exemple des cadres de référence ou des modèles de maturité. Un exemple sont les Generally Accepted Recordkeeping Principles® (GARP), publiés en 2009 et mis à jour en 2017 (ARMA International [s.d.]a), complétés par le Information Governance Implementation Model qui liste les différentes briques nécessaires à une bonne GI (ARMA International [s.d.]b). L’American Health Information Management Association (AHIMA) a décliné ces standards en fonction des besoins spécifiques des institutions de santé sous les titres de Information Governance Principles for Healthcare (IGPHC) (AHIMA 2014) et Information Governance Adoption Model (Smallwood 2019).
5. Le monde hospitalier suisse et les hôpitaux universitaires
La typologie des établissements de soins en Suisse, élaboré par l’Office fédéral de la statistique, est basée à la fois sur le nombre de disciplines ou types de traitements proposés, sur les possibilités de formation médicale offertes dans l’institution et sur le nombre de cas d’hospitalisation. Elle tient donc compte non seulement de la taille de l’établissement, mais aussi de son infrastructure et du rôle qu’il joue dans une région, dans une optique de politique sanitaire (Office fédéral de la statistique 2006).
Sur les presque 300 hôpitaux qui existent actuellement en Suisse, cinq sont qualifiés d’ « universitaires » :
- Bâle : Universitätsspital Basel (USB)
- Berne : Hôpital de l’Île (Insel)
- Genève : Hôpitaux universitaires de Genève (HUG)
- Lausanne : Centre hospitalier universitaire vaudois (CHUV)
- Zurich : Universitätsspital Zürich (USZ)
Les cinq hôpitaux universitaires suisses (HUS) comptent entre 7229 et 11’945 employés et traitent annuellement entre 38'750 et 64'134 cas hospitaliers (chiffres 2019). Ils reçoivent une contribution financière de leur canton siège, notamment pour les missions d’intérêt général (dont l’enseignement), et génèrent également des revenus par leurs activités.
Certains HUS englobent la totalité des spécialités médicales ; dans d’autres cantons la pédiatrie, la psychiatrie ou encore la gériatrie relèvent d’institutions indépendantes. La gouvernance hospitalière comporte généralement un Conseil d’administration (nommé par le Conseil d’État du canton respectif) et un Conseil de direction, composé d’un directeur général et des responsables des directions transversales.
Toutes les institutions ont des systèmes d’information cliniques, achetés ou développés en interne, qui permettent de gérer les données médicales. Le dossier numérique est aujourd’hui la règle dans les cinq HUS. En analysant leurs publications, nous n’avons pas trouvé de document dédié à la GI en tant que telle, mais des éléments d’information se trouvent dans les rapports d’activité et de gestion : projets liés à l’informatique médicale, démarches d’urbanisation des systèmes d’information, mise en place du dossier électronique du patient (DEP), etc. Les sites web des institutions, à l’intention du public, ont généralement des rubriques dédiées au consentement à la recherche ou à la démarche nécessaire pour demander des copies de son propre dossier.
6. La notion de dossier patient
Comme nous l’avons déjà mentionné dans l’introduction, les raisons d’être du dossier patient sont multiples. Dans le cadre de la prise en charge, il sert à assurer la continuité de traitement et permet la transmission d’informations au sein d’une équipe pluri-professionnelle. La qualité des soins dépend directement de la qualité de l’information à disposition. La facturation des actes effectués n’est possible que si ces actes ont été documentés. Le dossier est également la base de référence pour une réserve ou un refus de prestations de la part d’une assurance, ou pour des mesures tutélaires ou de droit pénal. De même, des informations fiables et trouvables au moment opportun sont indispensables pour les autres utilisations qui en sont faites : audits, études épidémiologiques, recherches en tout genre, analyses statistiques et économiques, benchmarking entre institutions, veille sanitaire etc. (Donaldson, Walker 2004; PFPDT 2002; Servais 1996).
Pour toutes ces raisons, la documentation clinique fait donc naturellement partie du quotidien des professionnelles médico-soignantes. De nos jours l’écriture des actes peut être automatisée : des machines transmettent des données, des signaux, des images directement dans les systèmes d’information cliniques. Un cas particulier de contenus audio sont les enregistrements sur dictaphone, transcrits ultérieurement pour générer par exemple une lettre de sortie.
Comme de nombreux corps de métier interviennent à différents moments de la trajectoire du patient, et en fonction de la documentation des activités, le dossier est constitué de plusieurs parties : médicale – de soins – sociale – administrative. En cas de dossier physique, les parties peuvent être séparées par des intercalaires ou même se trouver dans différentes fourres, pour des raisons pratiques de gestion. Elles sont toutefois liées par un identifiant (p.ex. numéro de patient et numéro d’épisode de soins / de séjour hospitalier / de traitement ambulatoire). Un dossier informatique, s’il regroupe virtuellement les données en provenance de différentes sources, permet généralement d’afficher des vues par métier ; d’une part pour cibler l’information sur les besoins immédiats de la personne qui consulte, d’autre part pour respecter la protection des données.
La métaphysique du dossier
Les changements de support impliquent des changements dans la manipulation, l’organisation ou encore la perception de l’information qui y est consignée. Ces questions n’ont, à notre connaissance, pas encore été étudiées de manière approfondie, mais il paraît probable qu’il y ait une influence de la forme du dossier sur la façon de « penser » celui-ci. En effet, dans un premier temps la version numérique reproduisait simplement la structure du dossier papier. De nos jours, où les données ont pris le dessus sur les documents, il s’agit du résultat de la mise en réseau des différents modules du système d’information clinique, assemblé et affiché selon diverses manières, en fonction de l’interrogation du moment ; le numérique crée de nouveaux narratifs de « l’histoire patient ».
7. Histoire du dossier patient – exemple des HUG
L’évolution du dossier patient jusqu’au 20ème siècle est assez bien étudiée, du « Corpus Hippocraticum » de la Grèce antique jusqu’aux registres d’entrées et de sorties dans les premières cliniques modernes, en passant par les échanges épistolaires entre médecins médiévaux. En revanche, à notre connaissance, il n’existe que très peu de publications qui relatent (partiellement) l’histoire récente du dossier patient en lien avec l’évolution technologique des dernières décennies. Par conséquent et à titre d’exemple, nous expliquons ici brièvement ces mutations telles qu’elles se sont passées aux Hôpitaux universitaires de Genève (HUG).
Les microformes
Un premier changement de support intervint à partir des années 1970 : les activités de l’hôpital ayant augmenté exponentiellement, on manquait d’espace pour le stockage des dossiers. Certains services médicaux décidèrent alors de remplacer les dossiers papier par des microformes (microfilms ou microfiches). Cette technologie, qui existe depuis les années 1850 déjà, permet de reproduire les pages du dossier, en version réduite, sur un support en pellicule photographique. Plusieurs dizaines de pages A4 tiennent ainsi sur une microfiche de taille A6. Des appareils de lecture permettent de visionner les documents, voire de les réimprimer. Aux HUG, la centrale de microfilmage était active de 1975 à 2005 et traita jusqu’à 1,7 millions de pages par année.
Les premières applications d’informatique médicale
Dès 1972 l’application DIOGENE, développée en interne, était utilisée pour diverses tâches administratives aux HUG, telles que la gestion du personnel ou la facturation. À partir de 1978 elle gérait également les admissions et les identités, permettant ainsi de maîtriser la trajectoire du patient du point de vue administratif. Progressivement, d’autres applications étaient développées pour former un véritable écosystème d’informatique médicale : gestion des examens de laboratoire (dès 1988), production de documents à partir des données DIOGENE (dès 1993), etc. En 2000, les différents volets médicaux et infirmiers furent intégrés dans un seul dossier : c’était la naissance du DPI (cet acronyme signifiant « dossier patient intégré », pas « informatique » comme on pourrait le croire). En 2004, DPA, le « dossier patient administratif », fut déployé, intégrant DIOGENE avec les applications administratives utilisées en gériatrie et en psychiatrie.
Par la suite, le DPI fut constamment élargi par des modules supplémentaires, des nouvelles vues furent développés en fonction des besoins métiers, ainsi que des applications annexes telles que la prescription informatisée, la gestion des blocs opératoires, etc. Ces centaines de réalisations mineures ou majeures permirent de forger le DPI d’aujourd’hui, devenu indispensable aux professionnelles de santé des HUG.
La numérisation et les dossiers nés-numériques
Dès 2000, une obsolescence à moyen terme de la filière microfilm était reconnue. On proposa alors la mise en place d’un système de gestion électronique des dossiers patients, en remplaçant le microfilmage des pages par la numérisation. L’avantage était notamment un accès facilité aux informations, sans nécessité de transporter un dossier physique. En 2006 la centrale de numérisation (CN) entra en service.
Parallèlement à l’activité de la CN pour la numérisation rétrospective, le DPI connut des évolutions supplémentaires, et de plus en plus de formulaires papier y étaient reconstitués sous forme dématérialisée. Ainsi, le dossier patient devint hybride : la plupart des documents sur papier provenaient en fait d’une impression depuis le DPI, et les données existaient à double.
On chercha à supprimer ces redondances et arriver au « tout numérique », en considérant le dossier patient électronique comme étant l’original et en ne scannant plus que les documents entrants. Ce changement de paradigme a été entériné par la validation en Comité de direction de la nouvelle « Directive sur la gestion des dossiers patients numérisés », le 21 février 2013. Aujourd’hui, plus de 90% des services médicaux des HUG travaillent avec le dossier né-numérique.
8. Autres utilisations des données médicales
Le dossier électronique du patient
Le concept de cybersanté (ou eHealth) est défini comme « l'utilisation intégrée des technologies de l’information et de la communication pour l’organisation, le soutien et la mise en réseau de tous les processus et acteurs du système de santé » (eHealth Suisse 2019). Le dossier électronique du patient (DEP) en est une application. Ses objectifs sont notamment de faciliter l’échange d’informations entre prestataires de soins (PS) concernant un patient commun et de favoriser l’empowerment de ce dernier.
La Loi fédérale sur le dossier électronique du patient (LDEP) est entrée en vigueur le 19 juin 2015 et oblige les établissements de soins stationnaires à disposer d’une telle solution. Depuis plusieurs années, acteurs publics et privés travaillent donc de concert pour réaliser ce nouveau service. Fédéralisme suisse oblige, il y aura différentes solutions, selon les régions. Concrètement, le DEP, considéré comme un « système secondaire », permettra l’affichage simultané de documents et de données en provenance des différents « systèmes primaires » des hôpitaux ou autres PS impliqués dans le traitement d’une patiente. En revanche, il n’y aura pas de stockage centralisé de données médicales.
La patiente peut visionner l’ensemble de ses documents et accorder l’accès aux PS avec lesquels elle est en relation, avec une gestion très fine des droits (pour une certaine catégorie de documents, pour une durée limitée…). Par la suite, ces PS pourront consulter les documents en provenance d’un autre prestataire et même les copier dans leur propre système primaire. La patiente peut aussi ajouter elle-même des documents, p.ex. un suivi de glycémies ou des directives anticipées.
Les applications big data
Les big data désignent de volumes massifs de données de grande variété, qui sont traitées et analysées dans de courts délais, et qui sont impossibles à gérer avec des outils classiques de gestion de l'information. Les progrès technologiques de ces dernières années et l’augmentation de puissance de calcul des ordinateurs en permettent désormais l’utilisation, y compris dans le domaine de la santé.
La « data driven medecine » ou médecine de précision permet de personnaliser l’approche de médecine pour chaque individu et optimiser sa prise en charge en tenant compte de ses caractéristiques individuelles, notamment la variabilité des gènes, les biomarqueurs moléculaires, l'environnement et le mode de vie. Pour ce faire, elle exploite le potentiel de différents ensembles de données liées à la santé humaine : des données génomiques par exemple, mais aussi des données cliniques provenant des institutions médicales, des données des biobanques ou des données de santé relevées par les personnes elles-mêmes (Swiss Personalized Health Network [s.d.]).
Les données de recherche
Les données de santé deviennent régulièrement données de recherche, que ce soit en lien avec des méthodes big data ou lors d’études cliniques ou épidémiologiques plus classiques. Dans le monde académique, ces dernières années, on assiste à un mouvement du Open Data : les données sont mises à disposition sur le web, de manière structurée, pour des réutilisations diverses. Il est clair que les données de recherche issues de données médicales, sensibles par nature, ne pourront jamais être totalement ouvertes. Il est en fait impossible de les anonymiser totalement : en croisant, dans les jeux de données, différentes informations individuelles, elles peuvent être reconnectées pour former un profil de personne. La recherche doit être encadrée par des règles d’éthique, et les données (primaires ou secondaires) devront toujours être protégées par les institutions qui les produisent. Mais elles seront partageables, grâce à l’interopérabilité sémantique, dans des contextes et partenariats bien définis, pour faire avancer la science (Lovis 2019; 2018).
9. Aspects juridiques – le droit de la santé
Dans le système politique suisse, la plupart des compétences en matière de santé se trouve au niveau des cantons, p.ex. l’attribution des ressources pour l’infrastructure hospitalière. La Confédération, et plus spécifiquement l’Office fédéral de la santé publique, gèrent certains domaines, notamment l’assurance maladie et accidents.
Quatre des cinq hôpitaux universitaires suisses sont des établissements de droit public, seul celui de Berne est une organisation de droit privé. Toutefois il possède un contrat de prestations avec le Canton de Berne concernant ses activités hospitalières. C’est pourquoi, pour tous les HUS, les législations cantonales respectives s’appliquent.
Nous nous sommes intéressées à quelques aspects essentiels du droit de la santé qui sont en lien avec la gouvernance de l’information. Plus spécifiquement, nous avons examiné certaines lois des cantons de Bâle-Ville (BS), Berne (BE), Genève (GE), Vaud (VD) et Zurich (ZH), qui sont les sièges des HUS. À noter qu’il existe évidemment beaucoup d’autres textes législatifs dont il faut tenir compte dans le cadre de la GI en milieu médical, p.ex. au sujet de la recherche sur l’être humain. En plus des lois, d’autres cadres réglementaires doivent aussi être pris en considération, dont le code de déontologie de l’association professionnelle des médecins (Foederatio Medicorum Helveticorum, FMH) ou les directives médico-éthiques de l’Académie suisse des sciences médicales.
Obligation de tenir un dossier patient et de l’archiver
Les prestataires de soins ont l’obligation de consigner, par ordre chronologique, les aspects importants de toute relation thérapeutique : anamnèse, diagnostic, thérapies suivies, documents transmis par des tiers, résultats de laboratoire, images radiographiques, etc. (Gächter, Rütsche 2018). Il est également très important de garder une trace des informations données à la patiente et du consentement de celle-ci. La documentation doit par ailleurs être véridique, complète et tenue en temps et heure (Wiegand 1994). Cette obligation figure dans les cinq lois sur la santé examinées. BE, GE et ZH indiquent que le dossier peut être tenu sous forme électronique.
Quant à la durée de conservation des dossiers après le dernier passage du patient, BE, GE et VD parlent de « au moins 10 ans », BS « [exactement] 10 ans », ZH « 10 ans » avec une option de prolongation jusqu’à 50 ans dans l’intérêt du patient ou dans une perspective de recherche.
GE spécifie que le dossier doit être détruit au plus tard après 20 ans si « aucun intérêt prépondérant pour la santé du patient ou pour la santé publique ne s’y oppose », formulation qui laisse une marge d’interprétation relativement grande. Par ailleurs, les dispositions de la Loi genevoise sur les archives publiques, imposant un délai plus long, sont réservées. L’obligation de proposer le versement aux archives cantonales, sans figurer dans la Loi sur la santé, existe aussi pour les hôpitaux universitaires de BS, VD et ZH, qui sont soumis à leurs Lois sur l’archivage respectives.
Consultation de dossiers patients en tant qu’archives historiques
Quant à la consultation des archives historiques, de manière générale, les dossiers contenant des données personnelles sont soumis à des délais de protection plus longs que les autres : selon les cantons, ces délais sont 3 à 10 ans après le décès, ou 100 à 110 ans après la naissance de la personne, ou 80 à 110 ans après l’ouverture ou la clôture du dossier. ZH est le seul canton qui mentionne spécifiquement les dossiers patients, en indiquant qu’ils deviennent accessibles 120 ans après leur clôture. À noter que le secret professionnel ne s’éteint en principe jamais, et que la consultation de dossiers patients archivés devrait par conséquent toujours nécessiter la levée de ce secret par l’autorité compétente – c’est en tout cas la pratique à GE. Mais l’interprétation juridique de cette question semble varier d’un canton à l’autre : les Archives d’État de BS, notamment, sont compétentes pour décider de la communication des dossiers patients qui leur ont été versés « s’il est apparent, en tenant compte de l’âge et du contenu des documents, qu’aucun intérêt protégé par le secret médical ne sera plus lésé ».
Droit de consulter son propre dossier
Dans l’ensemble des cantons examinés, la patiente a le droit de consulter son propre dossier et de se faire expliquer son contenu. BE et GE indiquent qu’une notice informative doit être remise aux patientes, les informant de leurs droits (dont celui de consultation de leur propre dossier) et devoirs. Selon les cas, il est possible d’exiger la remise du dossier original (BE, GE) ou seulement de copies, le dossier lui-même restant propriété du prestataire (BS, ZH). VD laisse le choix entre ces deux options. Les notes personnelles du médecin et les documents contenant des informations sur des tiers sont exclus du droit de consultation.
Protection des données
Les cinq cantons examinés possèdent une Loi sur la protection des données. Dans le cas de BS, GE et ZH celle-ci englobe également l’aspect de la transparence des actes administratifs (« information du public »). Les cinq lois définissent de manière très similaire les « données personnelles » comme des informations relatives à une personne identifiée ou identifiable. Parmi les données particulièrement dignes de protection figurent notamment les informations relatives à l’état de santé physique ou psychique. BS et ZH mentionnent spécifiquement les données génétiques, ZH également les biométriques.
Les principes de base à appliquer au traitement de ces données sont partout les mêmes : proportionnalité, information de la personne dont les données sont collectées, utilisation uniquement dans le but déclaré, droit de consultation par la personne concernée.
Secret professionnel
Un devoir de secret pour les professions de la santé, lié à l’éthique du médecin, est déjà mentionné dans le Serment d’Hippocrate, rédigé vers le 4e siècle avant notre ère. En Suisse, la prescription figure dans l’article 321 du Code pénal. Elle interdit aux professionnels de toute une série de métiers, notamment de santé, de révéler les informations dont ils auraient eu connaissance dans l’exercice de leur profession, sauf si la personne concernée ou l’autorité compétente les y autorise.
GE et VD disposent dans leurs Lois sur la santé respectives d’un article intitulé « Secret professionnel », qui indique les personnes concernées (toute personne qui pratique une profession de la santé, ainsi que ses auxiliaires) et le but du secret (protection de la sphère privée du patient), ainsi que la possibilité de se transmettre des informations entre professionnelles, dans l’intérêt du patient et avec son consentement.
BE parle d’un « devoir de discrétion » : « Les professionnels de la santé sont tenus de garder secrets tous les faits (…) ». ZH, sans utiliser le terme « secret », indique que des informations concernant des patientes peuvent uniquement être communiquées à des tiers avec l’accord de la personne concernée ; mais dans le cas des proches immédiats et du médecin traitant on part du principe que cet accord est tacitement donné, s’il n’y a pas eu de mention contraire expresse. Quant à BS, nous n’avons pas trouvé de mention des termes Patientengeheimnis ou Arztgeheimnis dans le recueil systématique de la législation cantonale.
10. Résultats des entretiens
Afin de compléter la partie « revue de la littérature » de notre recherche, cinq entretiens ont été menés avec un à deux représentants des HUS, dans le but de comprendre leurs pratiques informationnelles. Le choix des personnes de contact a été laissé aux institutions, ce qui a résulté en une grande variété de fonctions représentées : médecins avec spécialisation en télémédecine, juristes, qualiticiennes, archivistes, spécialistes de la cybersécurité ou de l’éthique de la recherche, gestionnaires des risques, etc. Les entretiens, d’une durée d’une heure environ, ont été menés soit en présentiel, soit par visio-conférence. Par la suite, ils ont été transcrits pour permettre leur relecture par les personnes interrogées, puis synthétisés en deux étapes (d’abord par HUS, puis globalement) afin de pouvoir restituer les résultats tout en conservant l’anonymat des personnes comme des institutions.
La terminologie de la GI
Les termes « gouvernance » ou « governance » sont utilisés dans les HUS, mais dans un contexte de « IT governance » ou « corporate governance », jamais en tant que locution « gouvernance de l’information ». Cette expression est effectivement très peu connue de nos interlocuteurs, qui n’ont qu’une vague idée de sa signification. « Actif informationnel » ou « information asset » sont totalement inconnus (quoique bien compris avec la définition livrée au moment de l’entretien).
Les personnes interrogées connaissent pour la plupart la notion de « cycle de vie » des données et documents, mais le définissent différemment : soit du besoin de création d'un document à sa destruction ; soit en distinguant les affaires courantes, les affaires terminées, et les documents dans l’archive ; soit ils font allusion à la trajectoire du patient dans l’hôpital, avec admission, traitement, sortie.
La valeur de l’information et son cadre réglementaire
Nos interlocuteurs sont unanimes sur le fait que la valeur de l'information est reconnue au plus haut niveau dans leurs institutions respectives. Cela transparaît dans les consignes institutionnelles, mais aussi dans l’allocation de ressources pour les services qui gèrent cette information. La protection des données est partout un sujet très présent. Les métiers médico-soignants connaissent bien la notion du « secret », qui fait partie de leur identité professionnelle.
Comme cadre réglementaire, les personnes interrogées évoquent les législations cantonale et fédérale ; les directives et procédures internes, les bonnes pratiques et guides ; la politique documentaire, le règlement d'utilisation des moyens informatiques, les règles de droits d'accès aux applications. Partout, il y a des formations internes obligatoires au sujet de la protection des données notamment, les nouveaux collaborateurs sont sensibilisés à la question dès leur journée d’accueil. Il y a des processus avec des rôles et responsabilités définis. Les HUS ont aussi mis en place des commissions transversales en la matière et différentes instances de décision. En revanche, il n’y a pas de politique globale de GI.
Données versus dossiers
Toutes les informations et données concernant la prise en charge d'un patient font partie du dossier, même quand elles se trouvent dans des systèmes séparés. Dès qu'un signal ou des données sont reçues, cela est rattaché à un patient et appartient donc au dossier. Les différentes lois cantonales définissent le contenu de celui-ci. Il peut s’agir d’un dossier hybride (papier/numérique), qui forme néanmoins une entité.
Lors des entretiens, nous avons évoqué oralement l’exemple d’une vidéo d’une intervention chirurgicale de 8 heures. Ce type de fichier, très volumineux, soulève la question de la nécessité de conservation de l’ensemble, ou seulement de séquences sélectionnées. D’après nos interlocuteurs, la vidéo entière fait indéniablement partie du dossier, même si tout n’est pas conservé in fine. Il faut déterminer la finalité de cet enregistrement – contrôle qualité, documentation de l'opération, extraits utiles dans le cadre de l’enseignement – et définir des délais de conservation en conséquence.
Création et capture des données médicales
Les données sont soit saisies dans le SIC par les collaborateurs, soit envoyées par des machines ou systèmes interfacés (imagerie, laboratoires…), et les métadonnées y sont associées automatiquement. Les documents papier nouvellement créés sont très rares aujourd'hui ; tout papier entrant est scanné et ajouté au SIC dans le but d’avoir toutes les données au même endroit, retrouvables et protégées par les mesures de sécurité du système informatique.
Utilisation et gestion des données médicales
Le dossier électronique est structuré et standardisé, parfois avec une granularité très fine pour la typologie des documents. Des données « assimilées à des données médicales » se trouvent aussi dans la base de données administratives, à la facturation, etc. En effet, une information du type « Mme A. a rendez-vous à la clinique B telle date », sans être médicale, est déjà considérée comme une information liée à la santé et donc confidentielle. La bonne gestion du dossier patient est de la responsabilité de la direction médicale, qui émet des directives et forme les utilisateurs.
Le DEP est partout en cours d'élaboration ; il existe déjà des canaux ciblés pour partager des informations médicales entre professionnels, p.ex. un portail pour les médecins de ville. Le patient doit évidemment donner son consentement pour la communication de données le concernant, mais selon les HUS, celui-ci est considéré comme implicite dans le cadre de la continuité des soins, s’il n’y a pas un refus clair.
Consultation du dossier
L’hôpital universitaire de Bâle a un service centralisé pour le contrôle et la communication du dossier numérique. Dans les autres HUS, la patiente doit adresser la demande de son dossier soit à la direction médicale, soit à la clinique concernée, qui va donner suite et communiquer les documents souhaités (copies papier, ou sur CD-Rom ou clé USB, ou consultation sur place). Les cas litigieux ou les demandes par des tiers passent par le service juridique.
Les accès internes dans le SIC sont bien réglementés. Les collaboratrices du service qui traite le patient peuvent visualiser son dossier sans autre ; les personnes rattachées à un autre service doivent procéder à un « bris de glace », c’est-à-dire qu’il faut justifier le besoin d’accès. Toutes ces activités sont consignées dans des logfiles.
Archivage et destruction
Il existe depuis longtemps des règles de gestion archivistique pour les supports physiques. Les dossiers sont conservés sur place pendant 20 ou 30 ans après le dernier passage de la patiente, dans certains cas spécifiques même jusqu'à 100 ans. Puis, les institutions qui sont soumises à une Loi cantonale sur les archives versent un échantillon aux archives cantonales. Les autres documents physiques sont détruits de manière confidentielle.
En ce qui concerne les données numériques, certains HUS ont un système d'archivage qui fonctionne en parallèle avec le SIC, et chaque document clinique y est copié dès sa création. Après un délai défini suivant la clôture du dossier, les documents peuvent donc être « purgés » du SIC actif. Le système d’archivage est intégré avec celui-ci pour permettre la visualisation des anciennes données, mais pas leur modification.
En revanche, il n’y a pas de destruction prévue après un certain délai, toutes les données restent pour l’instant dans le SIC (ou dans le système auxiliaire d’archivage) ad vitam aeternam. Cette question n’a pas été traitée pour l’instant. Selon les législations cantonales, le patient pourrait en effet exiger l’effacement des données le concernant, mais une telle demande serait en opposition avec le devoir de documentation de l’institution et/ou avec la législation sur les archives publiques.
Réutilisation pour la recherche
Un consentement général concernant cette réutilisation est systématiquement demandé aux patients lors de l'admission et la décision (accord ou refus) consignée dans la partie administrative du dossier patient.
Lors d’un projet de recherche, il faut préalablement obtenir l’autorisation de la commission cantonale d'éthique de la recherche sur l'être humain. Les demandes sont parfois centralisées à la direction recherche et enseignement pour avoir une vue globale et garantir le respect des règles. Les données sont ensuite extraites soit directement du SIC, soit d’un data lake constitué en amont en tant que source consolidée. Le grand défi est l'anonymisation ou désidentification des données, surtout si celles-ci ne sont pas structurées. Avec les SIC modernes on tend à avoir le plus possible de données sous forme structurée, plus exploitables.
Quant à l’archivage des données de recherche, de plus en plus demandé par les bailleurs de fonds ou par les revues scientifiques, aucun HUS n'a mis en place un dépôt spécifique. Il y a néanmoins des collaborations plus ou moins étroites avec les universités ; on commence à réfléchir à ce sujet.
Autres composantes de la GI
La cybersécurité relève de la compétence des services informatiques. Les HUS allouent plus ou moins de ressources humaines à ce domaine, mais font tous preuve d’un effort constant pour sensibiliser les collaborateurs avec des campagnes sur Intranet ou de la simulation de mails de phishing. Nos interlocuteurs estiment que tout le monde doit être attentif à son niveau, l'humain étant le point faible de beaucoup de systèmes techniques.
Tous les HUS effectuent régulièrement un recensement des risques, d’abord au niveau des services, puis consolidé au niveau institutionnel. Des risques qu’on peut qualifier « d’informationnels », comme les cyberattaques, fuites de données, usurpations d'identité, figurent dans la cartographie et sont qualifiés de haute priorité.
Dans aucun des HUS il n'y a de démarche institutionnelle de knowledge management (KM). Au niveau des services on peut trouver des wiki documentaires avec des expériences faites lors de projets ou des modes d'emploi pour une manipulation particulière. Il existe parfois des listes de collaboratrices avec des connaissances linguistiques spécifiques, notamment en langue des signes. La volonté de nos interlocuteurs est aussi de consigner, le plus possible, les règles établies oralement.
Des référentiels ou master data existent pour les données administratives des patients, les données des collaborateurs, et aussi pour l'organigramme structurel. On tend vers une source unique pour toutes ces données, avec intégration des applications. Il y a des démarches pour créer une nomenclature clinique unifiée.
La pertinence d’une démarche de GI
Tous nos interlocuteurs soulignent l’importance d’une bonne GI pour la sécurité du patient, afin d’assurer la prise en charge correcte et d’éviter des incidents médicaux. Une méconnaissance des rôles et responsabilités peut être à l’origine de malentendus potentiellement graves. En cas de litige juridique, l’institution doit pouvoir produire des preuves : si l’information donnée au patient n’est par exemple pas documentée, c’est comme si elle n’avait pas eu lieu.
Nos interlocuteurs mentionnent également le risque de perte de données ; ou les données existent, mais ne peuvent être retrouvées au moment opportun… Une mauvaise qualité des données (doublons, erreurs) aurait comme conséquence une mauvaise qualité des statistiques, ou de toute autre utilisation. Sans une documentation correcte des actes effectués, ceux-ci ne peuvent être facturés, et il y a donc un manque à gagner pour l’institution. Des données de qualité sont également nécessaires à l’intégrité de la recherche.
Selon nos interlocuteurs, la GI est aussi un moyen pour maintenir la confiance de la population et ne pas nuire à la réputation de l'institution. Même si dans 99,99% des cas tout se passe selon les règles, la moindre fuite des données aurait un impact sévère sur son image.
Leçons apprises, mesures prises, bonnes expériences
Nos interlocuteurs ne voulaient pas forcément faire part des incidents liés à une mauvaise gestion de la GI arrivés dans leurs institutions, réaction légitime malgré l’assurance d’anonymat que nous leur avions donnée. Quelques exemples ont quand même été mentionnés, avec les mesures prises pour y remédier :
- Des données médicales ont été envoyées par des canaux non sécurisés à développement d'un messenger interne pour remplacer WhatsApp.
- La réponse décentralisée aux demandes externes n'était pas assurée et trop lente à création d'un service spécialisé disposant de toutes les informations nécessaires.
- Retour des utilisateurs que les informations étaient difficiles à trouver dans le dossier électronique à adaptation de l’application, granularité plus fine pour la typologie des documents.
Plusieurs cas ont été cités où une bonne GI a permis de disposer des informations pertinentes au bon moment :
- Un patient inconscient arrive aux urgences à l’information concernant une allergie médicamenteuse se trouve dans son dossier et le traitement peut être adapté en conséquence.
- Une IRM est prévue pour une patiente porteuse d’un implant à on peut connaître le matériau utilisé pour assurer la sécurité au moment de l’examen.
- Les traitements complexes définis dans la classification suisse des interventions doivent être documentés précisément pour justifier la facturation à chaque étape de la prise en charge figure dans le dossier avec le professionnel responsable.
Défis actuels et à venir
Nos interlocuteurs reconnaissent une opposition entre protection des données d’une part et besoins pour la prise en charge et/ou la recherche d’autre part. Les deux sont en effet dans l'intérêt du patient, et il faut pouvoir gérer ces contradictions. Un exemple : si un médecin peu expérimenté envoie pendant son service de nuit l’image d'une blessure au spécialiste par WhatsApp, sans divulguer l'identité du patient – cela n’est pas vraiment conforme aux règles, mais permet une prise en charge ciblée. Comme une personne interrogée l’exprime : « Les règles, c'est bien, mais le bon sens est important aussi ».
Globalement, il s’agit d’opérationnaliser les dispositions légales et assurer la confidentialité, intégrité, disponibilité et traçabilité des données lors de leur traitement. La grande hétérogénéité dans le fonctionnement des services est un défi, malgré les standards définis au niveau institutionnel.
Les projets en lien avec la GI sont multiples : lancement du DEP, gestion documentaire, intégration des systèmes encore séparés, extension du data lake, projets liés à l'imagerie. Les directives et procédures doivent être tenues à jour ; il s’agit aussi de former et sensibiliser en continu l’ensemble des collaborateurs. Comme la stratégie globale de chacun des HUS tend vers le numérique et mise toujours plus sur les outils informatiques, les processus doivent être adaptés en pensant les principes d’une bonne GI dès leur conception.
11. Points communs des entretiens
Nous retrouvons dans les propos de nos interlocuteurs de nombreux éléments relevés lors de la revue de littérature :
- la valeur qui peut être tirée de l’information si elle est bien gérée et accessible au moment opportun,
- la nécessité d’une sensibilisation constante à tous les niveaux,
- la conjugaison du comportement humain et des outils technologiques,
- la complexité créée par les grandes masses de données informatiques,
- l’importance de la gestion des risques.
En effet, les cinq HUS interrogés ont un nombre conséquent de démarches qui font partie de la gouvernance de l’information, même si ce n’est pas sous ce qualificatif. Il n’existe ni de service, ni de personne en charge de la GI, ni de politique institutionnelle de GI, le terme n’est pas utilisé en tant que tel. Mais les HUS sont bien conscients de la valeur des données médicales, à la fois pour la prise en charge de leurs patients au quotidien et pour les différents usages ultérieurs.
La réglementation (fédérale, cantonale ou interne) est bien connue des personnes que nous avons interrogées. Ces lois ou directives sont effectivement un outil très important pour donner un cadre clair à l’ensemble des opérations effectuées sur les données médicales.
L’éthique est également un sujet récurrent, même si ce terme précis n’était pas forcément utilisé par nos interlocuteurs. Mais ils parlaient fréquemment de « l’intérêt du patient », de sa « sphère privée » qui doit être respectée, de la recherche « qui fait avancer la médecine pour le bien de tous ». La Loi relative à la recherche sur l’être humain était citée en long et en large, dont l’éthique est un pan important, notamment par l’instauration des commissions cantonales d’éthique dans la recherche, qui sont en contact étroit avec les HUS.
Il existe partout des services ou personnes en charge de la cybersécurité, et de la gestion des risques (dont les risques informationnels). La gestion documentaire en lien avec les données médicales est globalement bien prise en compte, même s’il n’y a pas de service dédié, et que les termes « records management » ou « archivage » ne sont pas vraiment utilisés ; la responsabilité en incombe à la direction médicale et à la direction des services d’information.
12. Des données qui correspondent à la définition de « actif informationnel »
Nous avons défini les actifs informationnels comme tout type d’information ayant de la valeur pour une institution, indépendamment du support.
Les données médicales sont des informations dans le sens qu’il s’agit de données contextualisées (liées à un patient et à un traitement / examen en particulier). Elles peuvent prendre des formes variées (chiffres, texte, signaux... électroniques ou fixées sur un support physique… structurées ou non, etc.).
De nombreux points relevés dans notre recherche, que ce soit via les lectures ou lors des entretiens, et constituant les chapitres précédents de ce travail, confirment que les données médicales ont une valeur pour l’institution :
- leur utilisation au quotidien dans le cadre de la prise en charge des patientes ;
- la nécessité d’une documentation correcte pour assurer la facturation ;
- la réutilisation des données pour la médecine personnalisée ou pour des projets de recherche ;
- l’importance d’une protection accrue de ce type de données en raison de leur caractère sensible ;
- les cas de vols ou fuites de données.
Par conséquent, oui, les dossiers patients et les données médicales sont des actifs informationnels.
Afin de maîtriser ces actifs et optimiser leur utilisation, il convient alors de mettre en place une GI, à savoir un ensemble de rôles, règles et opérations qui permettent de maîtriser les documents et données d’une institution pour en tirer de la valeur, en fonction de sa stratégie et dans le respect du cadre réglementaire.
13. Schéma des flux et dimensions de la GI dans le contexte médical et des compétences nécessaires à sa mise en œuvre
Nous avons souhaité modéliser la GI appliquée aux données médicales dans la figure 1 ci-dessous. Ce modèle ne représente pas le fonctionnement dans une institution précise, mais plutôt une variante qui nous semble « idéale », sur la base des différents enseignements tirés de notre recherche.
La grande zone à gauche montre les flux des données, à travers le cycle de vie (la réutilisation constante des données étant symbolisée par les flèches en cercle) :
- les données sont générées ou captées (input) :
- saisies dans le SIC par les professionnelles médico-soignantes, p.ex. notes d’observation,
- transmises par des dispositifs médicaux reliés, p.ex. valeurs vitales,
- transmises depuis d’autres systèmes tiers, notamment pour la gestion administrative des patients,
- documents papier, qui peuvent être numérisées rétrospectivement ou pas ;
- leur utilisation première (et réitérée) a lieu dans le cadre de la prise en charge du patient ;
- puis il y a l’output de données sous forme d’un data lake, contenant des données brutes, structurées ou non, sur des supports variés ;
- ces données peuvent ensuite être réutilisées de diverses manières, moyennant une mise en forme ou préparation spécifique selon les cas, et ré-alimentant le data lake à leur tour :
- réutilisation à des fins cliniques (partage au sein du réseau de soins ou via le dossier électronique du patient)
- séjours et actes codés pour la facturation,
- génération de statistiques,
- documentation à but légal, grâce à la valeur probante des données,
- recherches diverses,
- documentation à but historique,
- etc.
En bas, les dimensions transversales, les principes qui doivent guider toutes les décisions en lien avec ces données, les enjeux dont il faut impérativement tenir compte :
- juridique ;
- sécuritaire ;
- éthique ;
- économique ;
- technique ;
- technologique ;
- politique ;
- stratégique.
Le traitement de ces enjeux est en partie conditionné par le cadre légal et réglementaire qui entoure notre schéma. Dans le contexte des données médicales des HUS, il s’agit surtout des lois cantonales sur la santé publique et sur la protection des données, mais aussi de lois fédérales spécifiques, p.ex. celle relative à la recherche sur l’être humain. Il y a par ailleurs des éléments du droit international tel que le Règlement général européen sur la protection des données (RGPD), ainsi que des codes déontologiques et éthiques.
Les ressources à disposition de l’institution et la faisabilité technique jouent également un rôle, de même que la stratégie des organes de gouvernance ou des autorités cantonales en matière de santé publique. À droite, les compétences et fonctions à déployer dans le cadre de la GI, les acteurs à identifier et impliquer, et les rôles à définir. Selon l’organisation de l’institution, il peut s’agir d’une fonction liée à une personne dans un service spécifique ou d’une activité exercée en collaboration entre différents services. Il s’agit a minima des compétences suivantes :
- cybersécurité ;
- gestion des connaissances ;
- gestion des processus ;
- gestion de la qualité ;
- gestion des risques ;
- master data management (référentiels de données) ;
- protection des données personnelles ;
- records management et archivage ;
- systèmes d’information.
La démarche doit être coordonnée et pilotée par un organe transversal, qui a la vision globale et peut définir la politique de GI, et qui est soutenu par un sponsor au niveau du management. La formation et la sensibilisation constantes de l’ensemble des collaborateurs de l’institution sont par ailleurs primordiales.
Les compétences des personnes impliquées dans les axes fonctionnels devront couvrir les enjeux des dimensions transversales, on associera donc p.ex. une technicienne spécialiste du SIC et une juriste à l’organe de coordination.
Figure 1: Vue d’ensemble de la GI appliquée aux données médicales
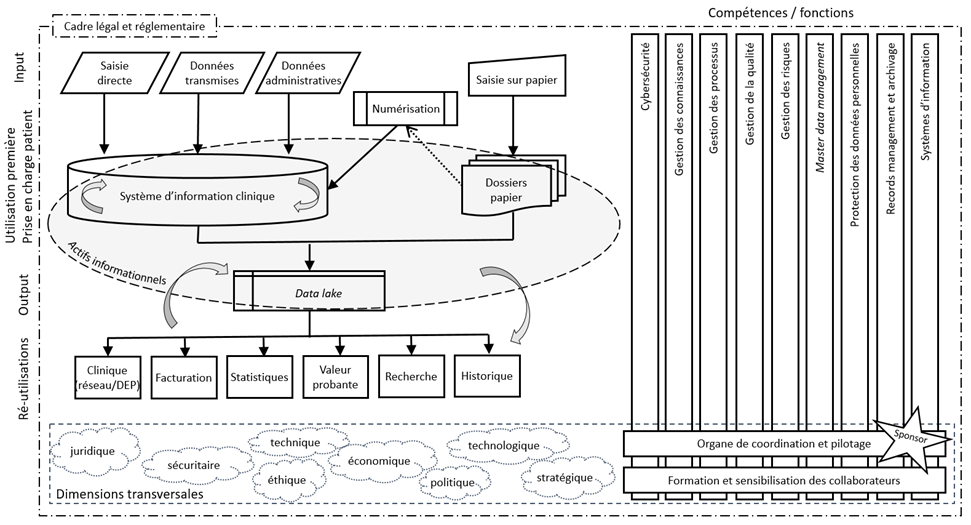
Pour aller plus loin – pistes de futures recherches
Le schéma que nous proposons vise à modéliser les points importants dont il faut tenir compte pour l’implémentation d’une démarche GI dans un hôpital universitaire, mais il ne constitue pas une feuille de route précise. Ce modèle abstrait devra être attaché à un contexte donné, puis testé. Seul un projet pilote concret pourra valider véritablement sa pertinence.
Il serait intéressant, après cette première exploration qualitative de la thématique de la GI des données médicales, de la compléter par une approche plus quantitative. Une observation in situ pourrait aussi éclaircir certains points quand les réponses lors des entretiens n’étaient pas très détaillées.
L’étude des pratiques informationnelles autour des données médicales dans un contexte différent, p.ex. dans des cabinets médicaux privés, apporterait un angle de vue complémentaire.
Nous n’avons pas pu analyser les textes réglementaires internes des HUS par manque d’accessibilité. Peut-être dans un autre contexte de recherche les institutions seront plus inclines à partager ces documents.
L’histoire et l’évolution du dossier patient depuis l’introduction de l’informatique mérite très clairement une étude approfondie et transversale à travers différentes institutions de santé. Comment le changement de support et les différentes vues par métier influencent-ils la façon de représenter la patiente et sa maladie ? Et l’essor de la médecine personnalisée et les futures évolutions technologiques, comment feront-ils évoluer la forme du dossier patient ?
14. Conclusion
Dans notre recherche, nous avons examiné la thématique de la gouvernance de l’information (GI), appliquée aux données médicales et aux dossiers patients, dans le contexte des hôpitaux universitaires suisses (HUS).
Méthodologie
Nous avons procédé à une revue de la littérature sur les définitions de la GI, sur ses composantes et les concepts associés, notamment les actifs informationnels, afin de faire un bilan des principaux enjeux de la GI en regard des institutions examinées.
Nous nous sommes intéressées à l’histoire et à l’évolution technologique du dossier patient, et à la façon dont les données médicales le constituent. Nous avons retracé plus particulièrement cette évolution aux Hôpitaux universitaires de Genève, allant des dossiers papier, en passant par le microfilmage, puis la numérisation, jusqu’aux dossiers nés-numériques d’aujourd’hui. Grâce à ces informations, nous avons pu cerner les différentes formes que les données médicales peuvent prendre, selon leurs utilisations diverses (prise en charge, statistiques, facturation, recherche, partage, etc.).
Afin de bien comprendre le contexte et le fonctionnement des institutions qui constituent notre échantillon, nous avons examiné les sites web des cinq HUS et les documents qu’ils mettent à disposition publiquement, en particulier leurs rapports annuels.
Nous avons également étudié, dans la législation des cinq cantons sièges d’un HUS, les textes en lien avec la protection des données, l’obligation de tenir et d’archiver les dossiers patients ou encore le secret professionnel.
À l’aide d’entretiens semi-dirigés menés avec une à deux personnes de chaque HUS nous avons récolté des données sur leur compréhension de la GI et sur les composantes en place. Ce portrait des pratiques informationnelles des cinq institutions a complété les éléments théoriques de la revue de littérature.
Résultats
Grâce aux enseignements tirés de notre recherche nous avons pu affirmer que les données médicales ont une valeur pour l’institution et répondent donc à la définition de « actif informationnel ». Nous avons également pu constater que les HUS couvrent, par des services ou fonctions spécifiques, un nombre conséquent des aspects de la GI – allant de la cybersécurité à l’archivage –, et que le cadre réglementaire est bien connu. Mais le terme « gouvernance de l’information » n’est pas utilisé, et il n’y a pas de politique institutionnelle de la GI ou une autre démarche coordonnée.
Le modèle de la GI
Nous avons par la suite élaboré une proposition de modèle pour la GI appliquée aux données médicales, avec leurs flux (input – prise en charge du patient – output vers le data lake) et leurs diverses (ré-)utilisations. Celles-ci englobent par exemple le partage avec des partenaires du réseau de soins, l’alimentation du dossier électronique du patient, la documentation des actes à des fins de facturation, l’élaboration de statistiques, des projets de recherche clinique ou épidémiologique, l’utilisation en tant que preuve en cas de litige ou encore la documentation des activités de l’institution dans un but historique.
Le schéma montre également les dimensions transversales (éthique, juridique, politique, etc.) et les compétences et fonctions nécessaires en la matière, dont notamment un organe de coordination et pilotage, soutenu par un sponsor au niveau du management. Il met en évidence l’importance cruciale de la sensibilisation et de la formation de l’ensemble des collaborateurs aux questions de la GI.
Notre modèle théorique tient compte de l’ensemble des connaissances dégagées durant le processus de recherche. Néanmoins, pour le concrétiser, il faudra encore développer des dispositifs concrets d’application.
La gouvernance de l’information, une stratégie gagnante
Le concept de la GI est encore peu connu des décideurs en dehors du monde des spécialistes de l’information ; les institutions de santé ne font pas exception. Celles-ci remplissent déjà bien les exigences de compliance en matière des différentes composantes de la GI, notamment de la protection de données. Mais le fonctionnement actuel, plutôt cloisonné par direction ou service, ne favorise pas une vision d’ensemble des différents processus.
Ainsi, les HUS auraient tout à gagner en instaurant une véritable politique de GI, afin d’intégrer cette approche au niveau stratégique et de valoriser et sécuriser leurs données médicales, ces précieux actifs informationnels.
Bibliographie
AHIMA, 2014. Information Governance Principles for Healthcare (IGPHC) [en ligne]. [Consulté le 14 août 2020]. Disponible à l’adresse :
https://www.colleaga.org/sites/default/files/attachments/IG_Principles.pdf
ANDERFUHREN, Sandrine et ROMAGNOLI, Patrizia, 2018. La maturité de la gouvernance de l’information dans les administrations publiques européennes: la perception de la gouvernance de l’information dans l’administration publique genevoise [en ligne]. Carouge : Haute école de gestion de Genève. Travail de recherche. [Consulté le 14 août 2020]. Disponible à l’adresse : http://doc.rero.ch/record/323127?ln=fr
ARMA INTERNATIONAL, [s.d.]a. The Principles®. ARMA [en ligne]. [Consulté le 14 août 2020]. Disponible à l’adresse : https://www.arma.org/page/principles
ARMA INTERNATIONAL, [s.d.]b. ARMA Information Governance Implementation Model (IGIM). ARMA [en ligne]. [Consulté le 14 août 2020]. Disponible à l’adresse :
https://www.arma.org/page/igim
BATIGNE, Stéphane, POZZEBON, Marlei et RODRIGUEZ, Charo, 2010. Le système d’information clinique OACIS au CHUM : histoire d’une implantation [en ligne]. Montréal : Les Éditions Rogers. 27 p. [Consulté le 14 août 2020]. L’actualité médicale, Groupe Santé. Disponible à l’adresse : https://marleipozzebon.files.wordpress.com/2011/06/oacis_2010.pdf
BENNETT, Susan, 2017. What is information governance and how does it differ from data governance? Governance Directions [en ligne]. Septembre 2017. Vol. 69, n° 8, pp. 462‑467. [Consulté le 14 août 2020]. Disponible à l’adresse : https://www.sibenco.com/wp-content/uploads/2017/09/Information_governance_data_governance_September_2017.pdf
BUTLER, Mary, 2017. Three Practical IG Projects You Should Implement Today. Journal of AHIMA [en ligne]. Février 2017. Vol. 88, n° 2, pp. 16‑19. [Consulté le 14 août 2020]. Disponible à l’adresse : http://library.ahima.org/doc?oid=302031
CENTRE NATIONAL DE RESSOURCES TEXTUELLES ET LEXICALES, [s.d.]. Donnée (définition). CNRTL [en ligne]. [Consulté le 14 août 2020]. Disponible à l’adresse :
https://www.cnrtl.fr/definition/donn%C3%A9e
CHAVANNE, Yannick et JAUN, René, 2019. Mehr als 200’000 Bilder von Schweizer Patienten stehen ungesichert im Netz. Netzwoche [en ligne]. 19 septembre 2019. [Consulté le 14 août 2020]. Disponible à l’adresse : https://www.netzwoche.ch/news/2019-09-19/mehr-als-200000-bilder-von-schweizer-patienten-stehen-ungesichert-im-netz
DIRECTION DES ARCHIVES DE FRANCE, 2002. Dictionnaire de terminologie archivistique [en ligne]. [Consulté le 14 août 2020]. Disponible à l’adresse :
DONALDSON, Alistair et WALKER, Phil, 2004. Information governance - a view from the NHS. International Journal of Medical Informatics [en ligne]. 31 mars 2004. Vol. 73, n° 3, pp. 281‑284. DOI 10.1016/j.ijmedinf.2003.11.009. [Consulté le 14 août 2020]. Disponible à l’adresse : http://www.sciencedirect.com/science/article/pii/S1386505603001953 [accès par abonnement]
EHEALTH SUISSE, 2019. eHealth. Glossaire eHealth Suisse [en ligne]. 26 septembre 2019. [Consulté le 14 août 2020]. Disponible à l’adresse :
https://www.e-health-suisse.ch/fr/header/glossaire.html#__854
GÄCHTER, Thomas et RÜTSCHE, Bernhard, 2018. Gesundheitsrecht : ein Grundriss für Studium und Praxis. 4., vollst. überarb. Aufl.. Basel : Helbing Lichtenhahn. ISBN 978-3-7190-3632-4
GARTNER, [s.d.]a. IT Governance (ITG). Gartner Glossary [en ligne]. [Consulté le 14 août 2020]. Disponible à l’adresse :
https://www.gartner.com/en/information-technology/glossary/it-governance
GARTNER, [s.d.]b. Information (knowledge) Assets. Gartner Glossary [en ligne]. [Consulté le 14 août 2020]. Disponible à l’adresse :
https://www.gartner.com/en/information-technology/glossary/information-knowledge-assets
GREENBONE NETWORKS GMBH, 2019. Sicherheitsbericht : Ungeschützte Patientendaten im Internet [en ligne]. Osnabrück : Greenbone Networks. [Consulté le 14 août 2020]. Disponible à l’adresse : https://www.greenbone.net/wp-content/uploads/Ungeschuetzte-Patientendaten-im-Internet_20190918.pdf
HOPITAL DU JURA, HOPITAL NEUCHATELOIS et HOPITAL DU JURA BERNOIS SA, 2011. Système d`information clinique : trois hôpitaux, un projet. studylibfr.com [en ligne]. 14 juin 2011. [Consulté le 25 juillet 2020]. Disponible à l’adresse :
https://studylibfr.com/doc/4814430/système-d-information-clinique
HUG BUFFO, Anna, 2020. La gouvernance de l’information dans les hôpitaux universitaires suisses : données médicales et dossiers patients comme actifs informationnels. Exploration, analyse et modélisation [en ligne]. Carouge : Haute école de gestion de Genève. Travail de master. [Consulté le 2 décembre 2020]. Disponible à l’adresse :
http://doc.rero.ch/record/329699?ln=fr
INTERPARES, [s.d.]a. Data. InterPARES Trust Terminology [en ligne]. [Consulté le 14 août 2020]. Disponible à l’adresse : https://interparestrust.org/terminology/term/data
INTERPARES, [s.d.]b. Information. InterPARES Trust Terminology [en ligne]. [Consulté le 14 août 2020]. Disponible à l’adresse :
https://interparestrust.org/terminology/term/information/en
LOVIS, Christian, 2018. Des données partageables plutôt qu’ouvertes. Campus / Université de Genève [en ligne]. Mars 2018. N° 132, pp. 30‑31. [Consulté le 14 août 2020]. Disponible à l’adresse : https://www.unige.ch/campus/132/dossier3/
LOVIS, Christian, 2019. Quand les données transforment l’hôpital. Campus / Université de Genève [en ligne]. Septembre 2019. N° 138, pp. 30‑33. [Consulté le 14 août 2020]. Disponible à l’adresse : https://www.unige.ch/campus/138/dossier4/
MAUREL, Dominique, 2013. Gouvernance informationnelle et perspective stratégique. In : L’information professionnelle. Paris : Lavoisier, pp. 175‑198. Systèmes d’information et organisations documentaires. ISBN 978-2-7462-4541-9.
MEIBERT, Patricia, 2019. Ungeschützte Patientendaten im Internet – ein massives globales Datenleck. Greenbone Networks [en ligne]. 16 septembre 2019. [Consulté le 14 août 2020]. Disponible à l’adresse : https://www.greenbone.net/ungeschuetzte-patientendaten-im-internet-ein-massives-globales-datenleck/
OFFICE FÉDÉRAL DE LA STATISTIQUE, 2006. Statistique des établissements de santé (soins intra-muros) : typologie des hôpitaux [en ligne]. Version 5.2. Berne : OFS. [Consulté le 14 août 2020]. Disponible à l’adresse :
https://www.bfs.admin.ch/bfsstatic/dam/assets/227888/master
ORGANISATION MONDIALE DE LA SANTÉ, 1957. Le rôle de l’hôpital dans les programmes de protection de la santé : premier rapport du Comité d’experts des soins médicaux [réuni à Genève du 18 au 23 juin 1956] [en ligne]. Genève : OMS. [Consulté le 14 août 2020]. Série de rapports techniques, 122. ISBN 978-92-4-220122-2. Disponible à l’adresse : https://apps.who.int/iris/handle/10665/36960
PERREIN, Jean-Pascal, 2011. Définition de la gouvernance de l’information. 3org - Points de vue sur le flux Information [en ligne]. 11 janvier 2011. [Consulté le 14 août 2020]. Disponible à l’adresse : https://www.3org.com/news/gouvernance_de_linformation/definition-de-la-gouvern ance-de-linformation/
PFPDT, 2002. Guide relatif au traitement des données personnelles dans le domaine médical : Traitement des données personnelles par des personnes privées et des organes fédéraux [en ligne]. Juillet 2002. [Consulté le 14 août 2020]. Disponible à l’adresse :
PORTAIL INTERNATIONAL ARCHIVISTIQUE FRANCOPHONE, 2015. Glossaire [en ligne]. [Consulté le 14 août 2020]. Disponible à l’adresse :
http://www.piaf-archives.org/sites/default/files/bulk_media/glossaire/glossaire_papier.pdf
PRIVATIM, LES PRÉPOSÉ(E)S SUISSES À LA PROTECTION DES DONNÉES, 2015. Systèmes d’information clinique (SIC) : exigences liées à la protection des données [en ligne]. Décembre 2015. [Consulté le 14 août 2020]. Disponible à l’adresse : https://www.fr.ch/sites/ default/files/contens/atprd/_www/files/pdf85/systemes-dinformation-clinique.pdf
ROGER FRANCE, Francis H., 1982. Le résumé du dossier médical : indicateur informatisé de performance et de qualité de soins. Bruxelles : Université catholique de Louvain. 333 p.
SERVAIS, Paul, 1996. L’information médicale clinique : archivage, utilisation et gestion du dossier médical. Liège : Louvain-la-Neuve : Ed. du CLPCF ; Academia. Rencontres de bibliothéconomie, 7. ISBN 978-2-87209-432-5
SMALLWOOD, Robert F, 2014. Defining the Differences Between Information Governance, IT Governance, & Data Governance. aiim community [en ligne]. 8 août 2014. [Consulté le 14 août 2020]. Disponible à l’adresse : https://community.aiim.org/blogs/robert-smallwood/2014/08/18/defining-the-differences-between-information-governance-it-governance--data-governance
SMALLWOOD, Robert F, 2019. Information governance for healthcare professionals : a practical approach. Boca Raton : CRC Press Taylor & Francis Group. 135 p. ISBN 978-1-138-56806-8
SWISS PERSONALIZED HEALTH NETWORK, [s.d.]. Qu’est-ce que la santé personnalisée ? SPHN [en ligne]. [Consulté le 14 août 2020]. Disponible à l’adresse : https://sphn.ch/fr/organization/about-personalized-health/
WIEGAND, Wolfgang, 1994. Die Aufklärungspflicht und die Folgen ihrer Verletzung. In : Handbuch des Arztrechts [en ligne]. Zürich : Schulthess. pp. 119‑213. [Consulté le 14 août 2020]. ISBN 978-3-7255-3211-7. Disponible à l’adresse : http://wolfgangwiegand.ch/ publikationen/_47_Die%20Aufklarungspflicht%20und%20die%20Folgen%20ihrer%20Verletzung_Handbuch%20des%20Arztrechts%201994/119_insgesamt.pdf
Formation en gestion des données de recherche: propositions de dispositifs d’e-learning pour le projet DLCM
Marielle Guirlet, Diplômée du Master en Sciences de l'Information HEG, HES-SO (2020) et assistante de recherche à la HEG-Genève
Manuela Bezzi, Diplômée du Master en Sciences de l'Information HEG, HES-SO (2020) et Bibliothécaire documentaliste archiviste spécialiste de disciplines à l’Université de Genève
Manon Bari, Diplômée du Master en Sciences de l'Information HEG, HES-SO (2020) et Archiviste chez Lombard Odier Group
Formation en gestion des données de recherche: propositions de dispositifs d’e-learning pour le projet DLCM
Introduction et méthodologie de recherche
Depuis une dizaine d’années, la problématique de la gestion des données de recherche*(1);(notée GDR dans la suite) apparaît comme un enjeu principal dans le domaine de la recherche (Vela et Shin 2019). Le projet DLCM*, lancé en 2015 par huit institutions suisses, propose des services pour accélérer le développement de bonnes pratiques de GDR en Suisse et pour contribuer à une culture commune autour de la GDR, en renforçant la collaboration et la coordination entre les écoles supérieures de Suisse. L’e-learning*, outil récent boosté par les nouvelles technologies, apparaît comme le meilleur outil pour former à distance de larges communautés de chercheu-r-se-s dispersé-e-s sur le territoire.
Dans le cadre de notre Master of Science HES-SO en Sciences de l’information à la HEG de Genève, Haute Ecole de la HES-SO, nous avons effectué un projet de recherche portant sur la mise en place de dispositifs de formation* e-learning sur la GDR, et sur la formulation de recommandations pour le projet DLCM sur les meilleurs dispositifs à utiliser par celui-ci en tenant compte de son contexte et de ses missions. Ce projet de recherche était encadré par la Prof. Dr. B. Makhlouf-Shabou. Cet article est une compilation des principaux résultats de ce projet de recherche et à ce titre il contient un certain nombre de citations et d’éléments du mémoire correspondant (Bari, Bezzi et Guirlet 2020).
Une liste d’acronymes et un glossaire sont disponibles à la fin de l’article.
Plusieurs objectifs de recherche sous-jacents à notre réflexion ont jalonné notre travail.
L’exploration de l’existant en termes de dispositifs e-learning: à partir de la littérature sur l’e-learning et l’étude de formations* e-learning existantes, nous établissons la typologie de ces formations (MOOC* et autres dispositifs, en Suisse et ailleurs). A partir de l’inventaire des ressources en GDR fournies par les partenaires DLCM, nous établissons l’état des lieux de l’activité de ces partenaires dans le domaine de la formation en GDR. En élargissant cet inventaire à l’international, nous identifions des ressources potentiellement réutilisables pour une formation e-learning en GDR.
Sur la base de notre expérience d’utilisatrices d’une sélection de formations e-learning, nous émettons des recommandations pour la future formation e-learning en GDR de DLCM.
La caractérisation des parties prenantes: le public-cible pour la formation est identifié et ses besoins sont caractérisés à partir de la littérature et de l’inventaire des ressources en GDR fournies par les partenaires DLCM. Nous identifions les autres parties prenantes ainsi que leurs contributions possibles à la formation DLCM.
Le choix d’options de dispositif d’e-learning: en fonction de profils-types d’utilisat-eur-rice-s dans le contexte DLCM, nous présentons et comparons différentes options de dispositifs, et nous en recommandons une en particulier.
Le résultat attendu de cette recherche, à savoir des recommandations pour le projet DLCM concernant un dispositif d’e-learning en GDR à destination des chercheu-r-se-s en Suisse, se situe à l’intersection des trois thématiques : formation en GDR, projet DLCM, e-learning (Figure 1).
Figure 1: Schématisation des thématiques de recherche abordées, recoupement et principales questions de recherche associées (voir texte)
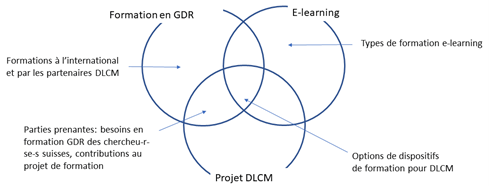
Les questions de recherche reliées à ces objectifs sont les suivantes :
- Qu’est-ce qu’une formation e-learning, quels sont ses différents types ?
- Quelles formations en GDR sont dispensées par les partenaires DLCM ? Quelles formations en GDR sont disponibles à l’international ? Quelles bonnes pratiques des formations e-learning sont intéressantes pour DLCM ?
- Quels sont les types de besoins de formation en GDR des chercheu-r-se-s suisses ? Quelles sont les parties prenantes et leurs contributions possibles au projet de formation ? (à l’intersection des thématiques formation en GDR et projet DLCM)
- Quels dispositifs de formation e-learning en GDR sont les plus adaptés à la communauté DLCM ? Quels dispositifs est-il judicieux que le DLCM propose ? (à l’intersection des trois thématiques)
Les résultats de notre revue de la littérature sur la GDR, les services d’accompagnement et les formations en GDR, l’e-learning et le projet DLCM sont présentés dans la suite. A partir de ces résultats, nous émettons des recommandations à propos de la conception de la formation DLCM. Sont ensuite discutés les principaux résultats de l’inventaire des ressources en soutien à la GDR par les partenaires DLCM et à l’international, et des études de cas de formation e-learning, dont nous tirons aussi des recommandations. Différentes modalités possibles pour la formation e-learning DLCM sont ensuite explorées et discutées, avant la présentation détaillée de nos propositions de dispositifs spécifiques adaptés au projet.
Le soutien à la gestion des données de recherche dans la littérature
Un contexte incitatif et le besoin de services
Le volume des données digitales (”data deluge”, “digital deluge” : Pryor 2012 ; Pinfield, Cox et Smith 2014 ; Blumer et Burgi 2015) a très fortement augmenté au cours de la dernière décennie, favorisée par la diffusion par Internet sans limite matérielle de reproductibilité. Ces données deviennent aussi de plus en plus hétérogènes et complexes. En réponse à ce phénomène, les concepts et les modèles dans le domaine de la GDR se sont développés et se sont formalisés (Vela et Shin 2019): cycle de vie des données (DCC Curation Lifecycle Model : Higgins 2008); data continuum (Data Curation Continuum : Treloar, Groenewegen et Harboe-Ree 2007).
L’émergence de l’Open Science et de l’ouverture des données de recherche* pour leur réutilisation possible a aussi contribué au développement du domaine de la GDR. Le partage des données de recherche s’appuie en effet sur une bonne gestion de ces données tout au long de leur cycle de vie (Kruse et Thestrup 2018, p.51). Cette dynamique Open Science se traduit de façon très concrète pour les chercheu-r-se-s par des directives des agences de financement de la recherche. Dans la recherche publique suisse, ces chercheu-r-se-s doivent en effet se soumettre aux exigences des deux principales agences de financement. La Commission Européenne, dans le cadre du programme-cadre H2020 (Horizon 2020) impose de rendre accessibles les données issues de projets qu’elle finance et associées à des publications (European Commission 2016, 2017). Le FNS lui aussi impose de rendre accessibles les données des projets qu’il subventionne (FNS 2017). Certains éditeurs scientifiques exigent également la publication des données associées aux articles qui paraissent dans leur revue (Nature 2016 ; Springer Nature [sans date] ; PLOS ONE 2019).
Outre la conformité à ces directives, les chercheu-r-se-s peuvent répondre à d’autres motivations pour partager leurs données de recherche, et implicitement, adopter de bonnes pratiques de GDR. Ces motivations peuvent relever d’un engagement personnel pour l’Open Science ou d’autres facteurs tels que l’opportunité de nouvelles collaborations et de nouvelles études, le soutien à une publication et la validation des travaux, la reconnaissance de la valeur des données partagées (Van den Eynden et Bishop 2014; Van den Eynden et al. 2016), le souhait de ne pas dupliquer l’effort consacré à collecter ou à produire les données (Wallis, Rolando et Borgman 2013), ou encore un taux de citation plus élevé pour les publications dont les données ont été rendues publiques (Piwowar, Day et Fridsma 2007). Des leviers s’ajoutent à ces facteurs de motivation, tels que la culture et les pratiques usuelles dans la communauté de recherche ainsi que l’existence d’infrastructures pour le partage des données et de services d’accompagnement pour la GDR.
Néanmoins, malgré ce contexte, on constate que les compétences des chercheu-r-se-s et les services qui leur sont apportés dans ce domaine ne se développent pas assez vite (Pryor, Jones et Whyte 2014, p.18; Whitmire, Boock et Sutton 2015) et ne répondent pas suffisamment aux besoins (Barone et al. 2017). En particulier, selon l’enquête de Dennie et Guidon (2017), les chercheu-r-se-s de l’Université de Concordia (Montréal) reconnaissent manquer de compétences et d’outils en GDR, avec pour conséquence un frein au partage de leurs données. Une aide pour préparer ses données (Van den Eynden et al. 2016, fig. 16), la maîtrise de compétences en GDR et un support institutionnel (Dennie et Guindon 2017, Sayogo et Pardo 2013) font partie des facteurs incitatifs importants.
Dans ce contexte, pour accompagner leurs chercheu-r-se-s, les institutions de recherche s’appuient sur trois composantes: une politique et un cadre de gouvernance, une infrastructure technique et des outils pertinents pour chaque étape du cycle de vie des données, et des services de soutien et d’accompagnement (Jones 2014, p.89 ; Schirrwagen et al. 2019).
Dans les grandes institutions, ces services sont souvent sous la responsabilité des bibliothèques académiques (Johnson, Butler et Johnston 2012; Akers et Doty 2013 et références données dans l’article ; Cox et Pinfield, 2014 ; Pinfield, Cox et Smith 2014 ; Morgan, Duffield et Walkley 2017). Celles-ci ont un rôle-clé à jouer dans leur développement (Lewis 2010), mais elles doivent aussi impliquer d’autres partenaires de l’institution : les services des technologies de l’information, l’administration de la recherche, les chercheu-r-se-s (Cox et Pinfield 2014 ; Guindon 2013 ; Cox et Verbaan 2018, chap.8), et le département juridique (Dennie et Guindon 2017 ; Vela et Shin 2019).
Ces services incluent des activités de communication et de formation pour le développement des compétences en GDR. Ils peuvent alors prendre la forme de pages institutionnelles sur la GDR (avec des outils de référence, des tutoriels, etc.), de consultations pour un accompagnement plus personnalisé (notamment pour la rédaction du DMP), d’ateliers (Jones, Pryor et Whyte 2013 ; Jones 2014, p.106) et de formations proprement dites.
Evaluer les besoins en formation
Une formation vient combler un écart entre un état initial de connaissances, de maîtrise d’outils, de techniques, de compétences et un niveau cible. Pour la concevoir efficacement, il faut donc évaluer cet état initial et définir le niveau à atteindre.
L’évaluation des besoins de formation en GDR auprès des chercheu-rse-s (2)est souvent réalisée à l’échelle institutionnelle (alors difficilement transposable à une autre institution, Vela et Shin 2019) et à l’aide d’enquêtes (Parham, Bodnar et Fuchs 2012; Dennie et Guindon 2017; Vela et Shin 2019), de focus groups (Perrier et Barnes 2018), d’entretiens (approche choisie pour le projet DLCM(3) : Blumer et Burgi 2015; Burgi, Blumer et Makhlouf-Shabou 2017; Burgi et Blumer 2018), d’ateliers (Pryor, Jones, White 2014, p.65) ou d’une combinaison de ces méthodes (Brown et White 2014, p. 138). Cette collecte d’informations porte sur les pratiques (le niveau de connaissance et de maîtrise des outils et des techniques) (Choudhury 2014, p.127 ; Brown and White 2014, p.138 ; Dennie et Guindon 2017 ; Yu, Deuble et Morgan 2017) et sur les besoins ressentis(4) en outils et services supplémentaires (Parham, Bodnar et Fuchs 2012 ; Parsons 2013 ; Dennie et Guindon 2017 ; Perrier et Barnes 2018 ; Vela et Shin 2019). L’échantillonnage peut être strictement disciplinaire (Vela et Shin 2019) ou multi-disciplinaire (Blumer et Burgi 2015; Van den Eynden et al. 2016 ; Burgi, Blumer et Makhlouf-Shabou 2017 ; Dennie et Guindon 2017 ; Burgi et Blumer 2018 ; Perrier et Barnes 2018); dans ce second cas, la discipline d’appartenance des chercheu-r-se-s approchées est identifiée et les résultats sont traités par discipline.
Pour déterminer les niveaux cibles que la formation doit permettre d’atteindre, il est nécessaire de tenir compte des différents facteurs qui peuvent impacter les pratiques existantes et les besoins : le cadre politique (à l’échelle nationale, européenne, etc.), l’environnement institutionnel (lignes directrices, exigences éventuelles, ressources à disposition, efforts de sensibilisation, etc.), mais aussi la discipline (voir à ce propos l’approche de Wittenberg, Sackmann et Jaffe 2018) et la communauté de recherche. Des normes et une culture spécifiques peuvent en effet induire de grandes différences de niveau en GDR et des pratiques contrastées d’une discipline à l’autre (voir à ce propos les résultats de Akers et Doty, 2013, ceux de Tenopir et al. 2011 et Tenopir et al. 2015 ; et ceux de Van den Eynden et al. 2016, p.54 pour les chercheuses du Wellcome Trust; ainsi que Blumer et Burgi 2015 ; Burgi, Blumer et Makhlouf 2017; Cox et Verbaan 2018, p.79) et parfois au sein même d’une discipline (Frugoli, Etgen and Kuhar 2010). Cela étant dit, certaines préoccupations sont récurrentes dans les disciplines échantillonnées, comme la sécurité des données (Perrier et Barnes 2018). On peut alors imaginer de fournir des ressources génériques sur ces aspects, plus des ressources spécifiques selon le domaine de recherche, la spécialité de recherche ou l’institution (Thielen et Hess 2017). C’est aussi l’approche déjà envisagée pour la formation DLCM, avec des modules de base sur les principes et les méthodes de la GDR et des modules avancés, adaptés aux besoins spécifiques des disciplines ou des institutions (Makhlouf-Shabou 2017).
De même que la discipline, l’”ancienneté” en recherche (étudiant-e-s chercheu-r-se-s vs. chercheu-r-se-s senior par exemple) peut avoir une influence sur les pratiques en GDR (Tenopir et al. 2015 ; Van den Eynden et al. 2016, p.53; Cox et Verbaan 2018, p.88). Il est parfois préconisé d’insérer la formation en GDR dans des programmes académiques de formation et d’intégration déjà existants (étudiant-e-s et étudiant-e-s-chercheu-r-se-s), pour éviter que cette formation ne reste optionnelle et pour qu’elle s’inscrive dans un processus durable. Cette démarche permet à la fois de sensibiliser et de responsabiliser les étudiant-e-s produisant déjà des données, et de faire prendre de bonnes habitudes aux futur-e-s chercheu-r-se-s dès le début de leur carrière (Carlson et Stowell-Bracke 2013 ; Jones 2014, p.107 ; voir aussi les pratiques déjà mises en place et relatées par Thielen et Hess 2017; par Yu, Deuble et Morgan 2017; et par Verhaar et al. 2017). Dans le cadre du projet Open Exeter, les étudiant-e-s-chercheu-r-se-s ont participé à la conception de leur propre programme de formation (Evans et al. 2013). Les cours de base pour étudiant-e-s-chercheu-r-se-s à l’Université de Northumbria (Jones 2014, pp. 107-108) et le programme de formation à l’Université de Monash (Beitz et al. 2014 p.173) ont aussi été développés en partie par les futur-e-s participant-e-s.
L’évaluation des besoins s’intéresse aussi au mode de diffusion que les futur-e-s participant-e-s souhaitent pour les services et la formation (Perrier et Barnes 2018, Vela et Shin 2019): en présentiel (consultations, formations individuelles, ateliers, ...), en ligne (guides, tutoriels, modules de formation, ateliers, ...) ou une combinaison de ces deux modes.
La formation e-learning du projet DLCM doit donc permettre aux chercheu-r-se-s, comme une autre formation en GDR, de développer ou d’acquérir des compétences en GDR et une connaissance des outils, et de favoriser le développement d’une culture de bonnes pratiques en GDR. Comme souligné plus haut, la maîtrise de ces compétences est un levier important pour les chercheu-r-se-s pour s’engager plus dans le partage des données et l’Open Science. Elle leur donne les moyens de faire face au phénomène actuel d’augmentation très importante du volume des données (Big Data), de leur complexité et leur hétérogénéité. Elle leur permet d’être en capacité de répondre aux exigences des organismes financeurs de la recherche et des éditeurs scientifiques (le partage public des données de recherche). Former les chercheu-r-se-s à de bonnes pratiques en GDR est aussi pour une institution de recherche un outil de mise en oeuvre de sa politique institutionnelle d’engagement pour l’Open Science.
Plus spécifiquement, les objectifs de la formation DLCM sont (Makhlouf-Shabou et Krug 2020):
- se familiariser avec la gouvernance des données et saisir les enjeux
- gérer ses données actives
- partager et préserver ses données et choisir les outils les plus appropriés
- maîtriser les aspects légaux et éthiques de la GDR
- rédiger un DMP
Concevoir et évaluer la formation
Il est conseillé de développer une formation d’abord sur une petite échelle (Christensen-Dalsgaard et al. 2012) en testant et en évaluant une version pilote, pour éventuellement en ajuster les méthodes et le contenu, avant de la déployer à plus grande échelle (Thielen et Hess 2017).
Chaque institution doit tenir compte de ses spécificités quand elle développe ses services en GDR, comme mentionné plus haut. Néanmoins, pour la conception d’une formation, elle peut utiliser des ressources génériques adaptables à des contextes particuliers, avec l’avantage de réduire les coûts de conception et de développement. On peut citer le matériel de formation réutilisable produit en 2011 pour des disciplines spécifiques par le projet RDMTrain du Jisc (DCC [sans date]b; JISC [sans date]), d’autres exemples donnés par Jones (2014, p. 107) ainsi que la liste de Jones, Pryor et Whyte (2013) de matériel de formation réutilisable (la majorité étant d’origine britannique).
La participation des chercheu-r-se-s à la conception de la formation, avec leur connaissance approfondie de leur discipline, des normes et pratiques, augmente les chances que la formation soit adaptée, et donc les chances qu’elle soit mieux perçue plus tard et mieux acceptée (voir à ce sujet l’exemple de l’Université de Southampton relatée par Brown et White (2014)).
L’évaluation et la revue régulière de la formation pour sa mise à jour peut être assurée par des pairs. C’est l’approche intéressante relatée par Soyka et al. (2017) pour des modules de formation en GDR. Cette démarche élargit la communauté impliquée qui apporte son expertise. La formation est davantage visible (dans l’expérience de Soyka et al. (2017) en particulier, le code du matériel et des modules est librement accessible sur Github). Enfin, comme la contribution est sur une base volontaire, l’avantage est aussi d’ordre économique.
L’efficacité de la formation peut être évaluée par enquête auprès des participant-e-s (Southall et Scutt 2017 ; Thielen et Hess 2017). Pour évaluer plus précisément son impact sur les pratiques en GDR, on peut tester le niveau de connaissance des participant-e-s à la formation avant et après qu’il-elle-s aient suivi celle-ci; pour les étudiant-e-s obligé-e-s de suivre cette formation, un test montrant leur progression serait un facteur de motivation supplémentaire (Cox et Verbaan 2018).
Le projet DLCM
Le projet DLCM fait partie du programme CUS-P2 2013-2016 de Swissuniversities: “Information scientifique: accès, traitement et sauvegarde” (Swissuniversities [sans date]). Ce programme a pour finalité de concrétiser et de mutualiser les efforts en matière de GDR à l’échelle nationale. DLCM doit fournir les ressources (modèle de politique, infrastructures, outils, services) adaptées à chaque étape du cycle de vie (Burgi 2015) et permettant aux chercheu-r-se-rs académiques suisses d’implémenter de bonnes pratiques de gestion des données de la recherche (Blumer et Burgi 2015 ; Burgi et Blumer 2018). Un portail doit mettre à disposition des informations, des politiques et des guides sur la GDR adaptés au contexte national, ainsi que des ressources externes, tels que des modules de formation (Blumer et Burgi 2015).
Co-dirigé par l’Université de Genève (P.Y. Burgi) et la HEG-Genève (B. Makhlouf-Shabou), le projet s’appuie sur ses autres partenaires : EPFL, ETHZ, SWITCH, Université de Bâle, Université de Lausanne et Université de Zurich, pour atteindre une envergure nationale en prenant en compte la diversité des cultures, et les spécificités des domaines et des disciplines de recherche du milieu académique suisse (Makhlouf-Shabou 2017).
La première phase du projet (09/2015-12/2018) comportait cinq volets d’activités : lignes directrices et politique ; données de recherche actives ; préservation à long terme des données ; consultation, formation et éducation ; dissémination des services au niveau national (Blumer et Burgi 2015 ; Burgi 2015 ; Burgi, Blumer et Makhlouf-Shabou, 2017) pour deux disciplines “pilotes” (humanités numériques et sciences de la vie ; Blumer et Burgi 2015).
La seconde phase du projet (depuis 01/2019 et jusqu’en 12/2020) se concentre sur la définition d’approches et la mise en place d’outils et de services pour la GDR au travers du volet préservation à long terme (avec la nouvelle solution d’archivage Yareta et son instance nationale OLOS respectivement disponibles depuis le 26.06.2019 (Université de Genève 2019) et le 22.10.2020 (DLCM 2019b)); et du volet consultation, formation et éducation.
Dans le cadre de ce second volet, le DLCM Coordination Desk à la HEG-Genève coordonne les ressources et les services disponibles, et répond aux demandes d’information ou les renvoie vers les expert-e-s des partenaires DLCM (Blumer et Burgi 2015, Makhlouf-Shabou 2017). Des modules de formations sont répertoriés et créés (voir à ce propos la liste des formations en présentiel déjà dispensées ou planifiées sur https://www.dlcm.ch/blog), et certains modules sont intégrés dans les cursus d’enseignement pour futur-e-s professionnel-le-s de la GDR (Burgi, Blumer et Makhlouf-Shabou 2017 ; Makhlouf-Shabou 2017 ; Burgi et Blumer 2018). Depuis septembre 2017, le Master of Science HES-SO en Sciences de l’information à la HEG-Genève propose une spécialisation en gouvernance des données qui inclut une partie sur les données de recherche (Makhlouf-Shabou 2017).
Le dispositif d’e-learning qui sera fourni par le DLCM s’inscrit donc dans un ensemble de services en données de recherche. Il est destiné au public-cible précisé dans la littérature DLCM pour répondre à leurs besoins communs: les chercheu-r-se-s et doctorant-e-s en Suisse (Blumer et Burgi 2015; Makhlouf-Shabou 2017).
En tenant compte de ce contexte du projet DLCM, nous identifions des avantages supplémentaires apportés par ce dispositif. Il devrait en effet contribuer à partager les ressources, l’expertise et les bonnes pratiques en GDR; à fédérer les chercheu-r-se-s suisses autour d’une culture nationale en GDR; et à mutualiser les efforts de façon à optimiser les ressources financières.
Recommandations de la littérature et application au contexte DLCM
Au terme de cette revue de littérature sur la GDR, sur les formations en GDR et sur le projet DLCM, nous sommes en mesure de formuler des recommandations pertinentes pour la conception d’une formation en GDR par le projet DLCM (Tableau 1).
Tableau 1: Recommandations pour une formation en GDR relevées dans la revue de la littérature et mise en application pour le projet DLCM
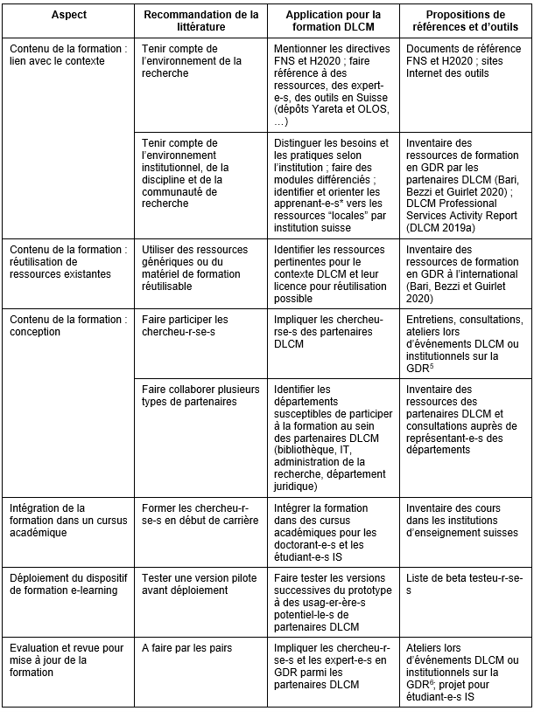
E-learning : définition et dispositifs
La Commission Européenne définit l’e-learning comme (Commission Européenne 2001):
« l’utilisation des nouvelles technologies multimédias et de l’Internet, pour améliorer la qualité de l’apprentissage en facilitant l’accès à des ressources et des services, ainsi que les échanges et la collaboration à distance »
A partir de 1990, avec l’avènement d’Internet, les institutions qui possédaient déjà un cursus d’enseignement à distance transforment ce cursus en enseignement en ligne (Benraouane 2011, p. 10). En 2005, l’enseignement en ligne est transformé radicalement avec l’évolution d’Internet qui passe d’un contenu statique (web 1.0) à un contenu dynamique (web 2.0*), ceci permettant de créer, de collaborer et de partager du contenu (Benraouane 2011, p. 13). L’apparition des réseaux sociaux contribue à la création de communautés d’apprenant-e-s (Benraouane 2011, p. 13). L’utilisation de ces réseaux sociaux développe les compétences de collaboration des apprenant-e-s, encourage la communication entre format-eur-rice-s et apprenant-e-s, et cela même hors du cours, et permet à l’apprenant-e de personnaliser son apprentissage en l’incitant à choisir la solution qu’il-elle juge la plus adaptée (Benraouane 2011, p. 15).
L’e-learning a révolutionné le rapport entre format-eur-rice et apprenant-e. D’un contenu et d’un rythme de cours déterminés par le-la format-eur-rice, on est passé à une situation dans laquelle l’apprenant-e agit lui-même ou elle-même sur le contenu de sa formation et sur son rythme d’apprentissage (Prat 2015, pp. 17-18 ; Bourban 2010, p. 5).
L’e-learning doit maintenant s’adapter à différents supports et pratiques (Cristol 2017), selon les nouvelles tendances d’apprentissage en ligne, telles que le mobile learning* (accès à une formation possible depuis plusieurs types de supports en alternance; Prat 2015, pp. 46-51), ou le serious game* et l’adaptative learning*, avec lesquels l’itinéraire pédagogique dépend des actions de l’apprenant-e (Prat 2012, p. 36 ; Lhommeau 2014, p. 130).
On peut distinguer trois types de dispositifs e-learning (MOOC et e-learning, quelles différences ? 2014).
Le cours en ligne fermé* est distribué par une institution et est accessible uniquement aux membres de cette institution. Il est animé par une intervenant-e ou accompagnant-e*. Le parcours peut prévoir des moments synchrones* tels que des “classes virtuelles*”. Le cours en ligne ouvert* est aussi distribué par une institution et est ouvert (sur inscription) aux personnes hors institution, mais n’est pas certifié. Les apprenant-e-s communiquent entre eux-elles (mais pas avec l’apprenant-e) via les outils standards tels qu’un forum. Enfin, les ressources d’apprentissage en ligne comprennent tout type de ressources en ligne permettant aux apprenant-e-s de s’autoformer (tutoriels vidéo ou cours filmés, support de cours écrits, manuels d’apprentissage en ligne, etc.).
Le MOOC (Massive Open Online Course) est un dispositif de formation e-learning se définissant comme une (Pfeiffer 2015, p.52):
« formation accessible à tous, dispensée dans l’Internet par des établissements d’enseignement, des entreprises, des organismes ou des particuliers, qui offre à chacun la possibilité d’évaluer ses connaissances et peut déboucher sur une certification ».
Il se situe entre le cours en ligne ouvert et le cours en ligne fermé dont il reprend plusieurs caractéristiques. Il est gratuit et ouvert sans condition d’accès, et on peut y accéder et le quitter librement à tout moment. Mais il est aussi distribué sur un temps limité et généralement à dates fixes, dans le but de faire interagir entre elles les apprenant-e-s à des fins d’apprentissage (MOOC et e-learning, quelles différences ? 2014).
Le MOOC se décline lui-même en différents types. Avec le xMOOC*, le savoir se transmet de manière verticale de l’enseignant-e à l’apprenant-e (Lhommeau 2014, p.25 ; Daïd et Nguyen 2014, pp.26-28). Avec le cMOOC* (MOOC connectiviste), le savoir se transmet de manière horizontale. Le cours se construit au fil de son avancement grâce aux conversations entre apprenant-e-s et en fonction de leurs choix d’approfondissement (Lhommeau 2014, p.24 ; Daïd et Nguyen 2014, pp.26-28). Le SPOC* (Small Private Online Course), quant à lui, fonctionne sur le même modèle que le xMOOC mais est limité à une cinquantaine d’apprenant-e-s (Daïd et Nguyen 2014, p.177). Ouvert à dates fixes, il implique une interaction soutenue et un accompagnement individuel très poussé. Celui-ci s’appuie sur le suivi du parcours de l’apprenant-e et de ses évaluations. Il se manifeste par des relances en cas de ralentissement de la progression, et une réactivité très forte aux questions d’ordre pédagogique ou technique de l’apprenant-e. Une composante présentielle peut aussi intervenir. Le regroupement ponctuel des apprenant-e-s de la même session permet de travailler en groupe sous la direction de l’enseignant-e et de valider les connaissances (Lhommeau 2014, p.25). Le SPOC se rapproche alors du concept de classe inversée* (Lhommeau 2014, p. 216; Pomerol, Epelboin et Thoury 2014, p. 11, p. 100), avec lequel les apprenant-e-s suivent une formation de type MOOC à distance, puis complètent leur formation avec ces sessions en présentiel (Lhommeau 2014, p. 25).
Le cours hybride (ou blended learning*) utilise à la fois le mode présentiel et le mode à distance. Ce type de cours combine trois dimensions (espace/temps, modalités du dispositif, méthodes) à partir desquelles se décline tout un éventail de possibilités pour l’apprenant-e (Prat 2015, p.62).
Les principaux avantages de l’e-learning sont la flexibilité, l’accessibilité*, la maîtrise des coûts de formation, une réduction de la durée de formation et la souplesse d’apprentissage en termes de lieu et de temps (Benraouane 2011, p.5 ; Prat 2015, pp. 46-47). Toutefois, les coûts de conception et de déploiement d’un dispositif d’e-learning peuvent être conséquents, tout comme les contraintes techniques. Il est également nécessaire de tenir compte des paramètres intrinsèques de l’apprenant-e (ses compétences techniques, son degré d’autonomie, ses motivations et son mode d’organisation). Mais il faut surtout relever que le problème récurrent des formations e-learning, en particulier des MOOC, est leur fort taux d’abandon, aussi appelé taux d’attrition* (Lhommeau 2014, p. 55 ; Prat 2015, pp. 46-51, Cisel 2016), ce taux pouvant aller jusqu’à 80%-90% des inscrit-e-s (MOOCs@Edinburgh Group, 2013; Cisel 2013 ; Pomerol, Epelboin et Thoury 2014, p. 77).
Le challenge consiste donc à trouver un moyen de motiver suffisamment l’apprenant-e, afin qu’il-elle n’abandonne pas sa formation en cours. Ceci peut se faire par la mise en place d’un accompagnement optimal, par une inscription payante ou par un format de cours plus concis (Prat 2015, pp. 46-51 ; Lhommeau 2014, p. 55).
Le Tableau 2 ci-dessous reprend les avantages et inconvénients des dispositifs d’e-learning (Prat 2015, pp. 46-48).
Tableau 2 : Avantages et inconvénients des dispositifs d’e-learning
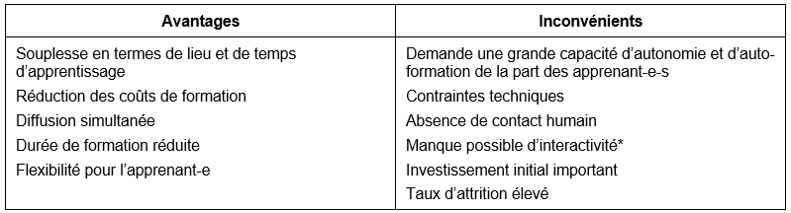
(d'après Prat 2015)
De même que l’apprentissage en présentiel, l’e-learning peut faire recours à différentes stratégies d’enseignement, chacune d’entre elles présentant des avantages et des inconvénients, dont certains sont spécifiques au mode de formation à distance. Ces avantages et inconvénients sont donnés dans le Tableau 3.
Tableau 3 : Avantages et inconvénients des stratégies d’enseignement dans un contexte de formation à distance
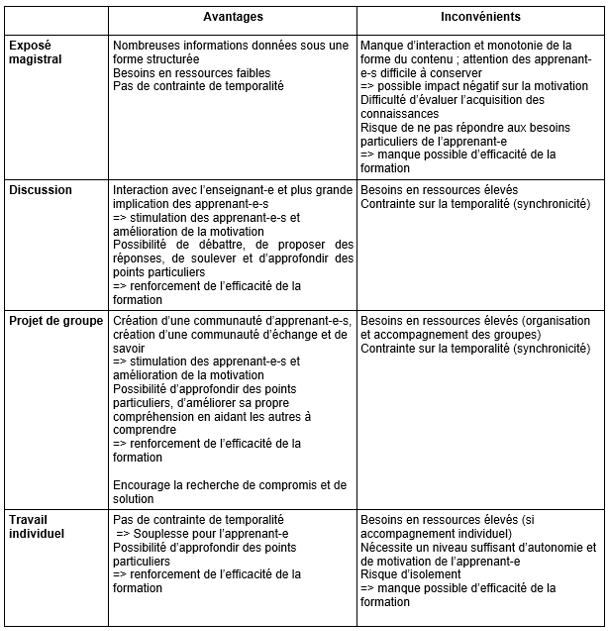
(d’après Comment choisir les stratégies d’enseignement ? [sans date] ; Daïd et Nguyen 2014; Prat 2015; Pomerol, Epelboin et Thoury 2014)
On peut aussi remarquer que, de l’exposé magistral au travail individuel, ces stratégies d’enseignement sont de moins en moins centrées sur l’action de l’enseignant-e et de plus en plus centrées sur l’activité des apprenant-e-s (Comment choisir les stratégies d’enseignement ? [sans date]).
Revue de l’existant des formations et ressources e-learning en GDR
A partir de la littérature et de recherches libres sur internet, nous avons dressé un inventaire des ressources disponibles pour les chercheu-r-se-s pour la GDR. Ces ressources inventoriées, existant sous la forme d’information, de formation ou de matériel de formation, ont été divisées en deux catégories: d’une part les ressources mises à disposition par les partenaires du projet DLCM, et d’autre part celles mises à disposition par d’autres institutions à l’international. Cet inventaire contribue à répondre à trois objectifs. En identifiant les ressources de formation en GDR fournies par les partenaires DLCM, en caractérisant leur nombre, leur type et en dégageant d’autres éléments éventuels, on peut établir un état des lieux de l’activité des différents partenaires dans ce domaine. On peut aussi en déduire un panorama global des activités et une typologie des ressources de formation en GDR. Enfin, en procédant à cet inventaire, on peut identifier précisément les ressources exploitables pour une formation e-learning en GDR pour le projet DLCM, qu’elles soient sous forme de matériel de référence ou de ressources réutilisables.
Le détail de l’inventaire est donné dans Bari, Bezzi et Guirlet (2020). Nous présentons ici nos principales observations à propos de cet inventaire.
Les partenaires DLCM qui fournissent des ressources en ligne sur la GDR sont l’EPFL, l’ETHZ, la HEG-Genève, l’Université de Bâle, l’Université de Genève, l’Université de Lausanne et l’Université de Zurich (seul SWITCH n’en fournit pas). Pour des raisons de faisabilité, l’exploration de la partie GDR des sites des institutions s’est limitée à deux niveaux de profondeur. Cette partie de l’inventaire nous permet de faire les observations suivantes:
- Toutes les institutions proposent des formations en GDR en présentiel, à l’exception de l’Université de Bâle.
- Chaque institution produit les ressources qu'elle fournit, sans mutualiser leur production avec d’autres institutions.
- La responsabilité des ressources de formation en GDR incombe essentiellement à la bibliothèque, ou peut être partagée entre la bibliothèque, le département de la recherche et le département informatique (cas de l’université de Bâle).
- Le projet DLCM, les services et les ressources qu’il fournit (“Coordination Desk”(9) et “Data Management Checklist”(10) par exemple) sont très peu mentionnés.
- l’EPFL et l’Université de Genève catégorisent leurs services par profil d’utilisat-eur-rice-s : étudiantes, chercheuses, enseignantes.
- Plusieurs institutions font référence à des expert-e-s et des personnes-clés pour la GDR: l’Université de Lausanne propose des points de contacts par faculté pour les données de la recherche et l’EPFL a instauré sa communauté de « Data Champions ».
Sur la base de ces observations, nous recommandons DLCM d’encourager ses partenaires à mentionner DLCM et ses services de façon plus visible sur leurs pages institutionnelles consacrées à la GDR, à utiliser davantage les ressources procurées par le projet, et à mentionner plus souvent les formations présentielles de DLCM.(9)
Les ressources des institutions ou organismes à l’international (Suisse comprise, mais hors partenaires DLCM) se présentent sous forme de pages web (informations textuelles données sur un site), de documents textuels téléchargeables, de formations en ligne et de supports de formation en présentiel ou en ligne, et de matériel générique spécifiquement conçu pour être réutilisé et adapté à d’autres contextes. Celui-ci est particulièrement intéressant pour une réutilisation possible pour la formation e-learning en GDR de DLCM. Dans un second temps, on pourra aussi réutiliser et adapter certaines ressources dont la licence le permet.
La Figure 2 synthétise le nombre de ressources par pays et leur répartition par catégorie. Dans le cas des formations en ligne, les institutions européennes proposant aussi des ressources, une sous-section « Europe » a été insérée.
Figure 2 : Nombre de ressources par pays et répartition par catégorie ; part des ressources modifiables et non-modifiables pour la Grande-Bretagne et les Etats-Unis
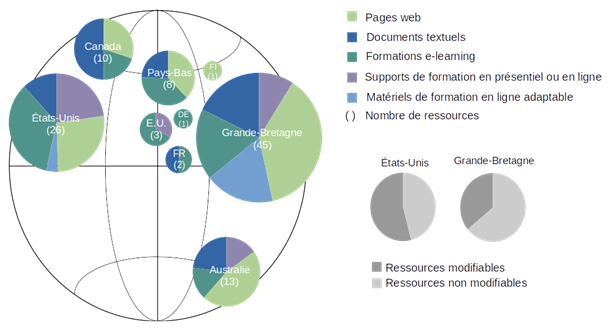
De façon peu surprenante, on observe le rôle très actif en soutien et en formation à la GDR des institutions et organismes de Grande-Bretagne, bénéficiant de la coordination de leurs activités dans ce domaine par le centre d’expertise DCC (Digital Curation Center, DCC [sans date]a) (voir également Fachinotti, Gozzelino et Lonati 2016, p.15). Ceci se traduit par le nombre important de ressources en ligne mises à disposition (quarante-cinq au total) qui se répartissent entre les ressources textuelles, les formations en ligne et les supports de formation. Il est intéressant de noter que ce rôle important de la Grande-Bretagne se reflète aussi dans le matériel de formation adaptable mis à disposition (huit ressources), tel que celui des projets disciplinaires du programme RDMTrain (DCC [sans date]b; JISC [sans date]) et d’autres ressources (Jones, Pryor et Whyte 2013, pp. 9-10) déjà évoquées dans la revue de la littérature.
Les Etats-Unis arrivent en deuxième position (vingt-six ressources au total). Si le nombre de supports de formation qu’ils fournissent est plus important que celui de la Grande-Bretagne (six au lieu de quatre), ils ne proposent qu’une seule ressource de matériel de formation en ligne adaptable (Data Carpentry [sans date]).
En troisième position, l’Australie, soutenue dans ce domaine par le centre d’expertise ANDS (Australian National Data Service [sans date] ; Australian National Data Service 2017 ; Dennie et Guindon 2017), met à disposition treize ressources au total. Parmi celles-ci on a très peu de formations en ligne et de matériel de formation en ligne, et aucun matériel de formation adaptable.
Pour la Grande-Bretagne et les Etats-Unis, on a distingué le nombre de ressources modifiables et le nombre de ressources non modifiables selon leur licence (voir Figure 2). Dans les deux cas, une partie significative des ressources (seize de Grande-Bretagne, quatorze des Etats-Unis) pourra être réutilisée et adaptée au contexte spécifique du projet DLCM.
Le second volet de notre revue de l’existant a consisté en une analyse du point de vue d’apprenant-e-s de cinq formations en ligne hébergées par différentes plateformes (Tableau 4), dans l’objectif d’observer des bonnes pratiques et d’en déduire des recommandations pour la formation DLCM.
Chaque formation en ligne a été caractérisée suivant des critères portant sur la formation en général, sur son contenu et sa structure, sur les conditions d’accès, l’interaction (apprenant-e-s, format-eur-rice), l’évaluation de l’apprenant-e- et les aspects légaux. Les descriptions complètes suivant notre grille d’analyse sont données dans Bari, Bezzi et Guirlet (2020).
Tableau 4 : Formations sélectionnées pour les études de cas
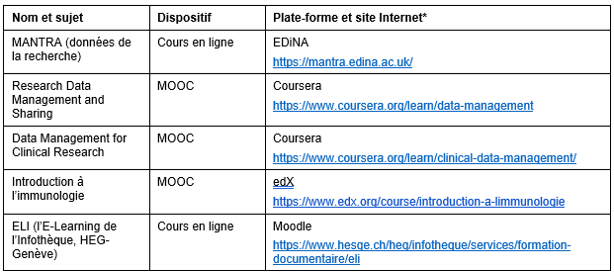
Nos principales observations portent sur les points suivants :
Forme du contenu: l’absence de contenu animé (cas de “Data Management for Clinical Research“) rend le suivi plus difficile. On cerne ici l’importance d’avoir un bon équilibre des types de contenu : texte sur des diapositives, images, vidéos, activités interactives afin de maintenir l’attention et la stimulation des participant-e-s. Pour MANTRA et “Research Data Management and Sharing” sur Coursera, les interviews et témoignages de chercheu-r-se-s sur leurs pratiques permettent vraiment d’ancrer la formation dans le réel et de rendre le sujet plus vivant.
Lien du contenu avec le contexte local: pour MANTRA et “Research Data Management and Sharing”, une grande place est donnée au contexte de l’institution ou du pays (politiques, directives, guides, outils de l’Université d’Edimbourg ; financements de la recherche aux Etats-Unis). On voit l’importance d’ancrer une formation en GDR dans le contexte local ; il faut tenir compte des contraintes de l’environnement (politique, institutionnel), tout en rendant la formation pertinente et utile au plus grand nombre.
Liens entre formations et complémentarité: MANTRA renvoie vers le MOOC ”Research Data Management and Sharing” les apprenant-e-s qui veulent bénéficier d’une certification. ELI informe les apprenant-e-s qu’ils-elles peuvent bénéficier d’une formation personnalisée et en présentiel de la part de l’infothèque. Ce sont deux exemples de formations qui reconnaissent l’utilité et la complémentarité d’autres ressources, qu’elles soient en e-learning ou en présentiel.
Adaptabilité* du parcours (personnalisation): seule MANTRA redirige les participant-e-s vers des modules différents selon leur profil, professionnel-le de l’information, chercheu-r-se, doctorant-e, pour une personnalisation du parcours d’apprentissage. Le questionnaire proposé en préalable à ELI permet d’établir son profil documentaire et d’évaluer en fin de formation sa progression, mais celui-ci n’est pas utilisé pour individualiser le parcours d’apprentissage.
Appréciation de la formation par les apprenant-e-s: toutes les formations étudiées ici permettent aux participant-e-s d’envoyer leur appréciation sur le cours, et d’éventuellement lui attribuer une évaluation (sous forme de note ou sous forme d’un nombre d’étoiles pour les MOOC Coursera). Pour les MOOC Coursera, cette appréciation, présentée comme un moyen d’améliorer la formation, est aussi utilisée pour la promotion du cours faite sur la page d’accueil.
Avantages de l’environnement des plates-formes MOOC: les formations délivrées sur Coursera et edX bénéficient évidemment de tous les avantages procurés par l’environnement de la plate-forme. Le suivi individuel du parcours des apprenant-e-s permet à chacun-e de connaître le temps estimé pour finir la formation, de reprendre là où on s’est arrêté, de recevoir des e-mails de rappels. Coursera et edX proposent également, et c’est là une spécificité importante des MOOC, un environnement propice à l’interaction entre les apprenant-e-s : forum de discussion, hashtag Twitter sur le cours, notation des devoirs par les pairs. C’est une tentative de recréer une communauté, la communauté qui se forme naturellement lors d’une formation en présentiel. Coursera et edX permettent également du mobile learning, répondant ainsi aux nouvelles pratiques des utilisat-eur-rice-s.
A partir de ces observations nous formulons à nouveau des recommandations pour la formation e-learning de DLCM (Tableau 5).
Tableau 5 : Recommandations déduites des études de cas pour la formation e-learning de DLCM
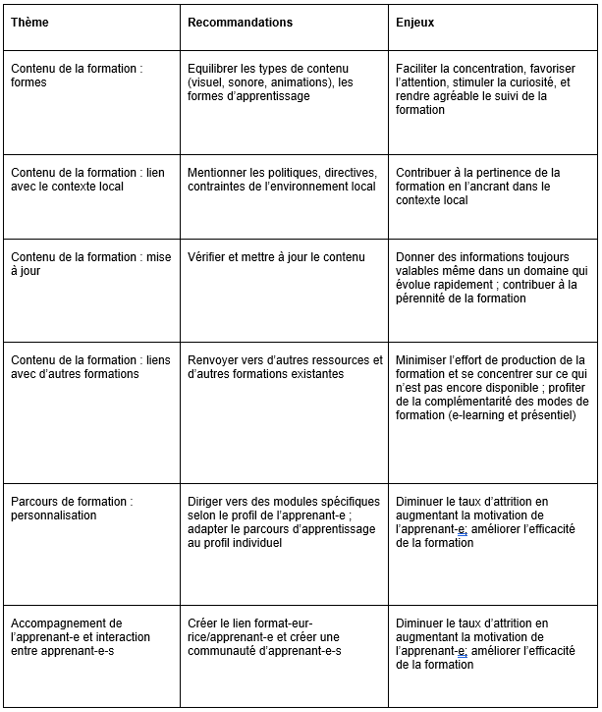
Conception de la formation DLCM
En ce qui concerne la conception elle-même de la formation e-learning, plusieurs auteur-e-s recommandent de suivre une démarche projet (Prat 2015, pp. 74-78 ; Pomerol, Epelboin et Thoury 2014, pp. 21-57). Nous discutons ici de quelques aspects-clés de cette démarche: les besoins du public-cible, l’implication des apprenant-e-s et des partenaires DLCM, les modalités des formations e-learning.
Besoins du public-cible
Pour rappel, le public-cible de la formation DLCM est constitué des chercheu-r-se-s et des doctorant-e-s d’une institution académique suisse, que cette institution soit partenaire ou non de DLCM. Plusieurs outils sont à disposition pour cibler précisément les besoins du public-cible de la formation et rendre celle-ci plus efficace. Les enquêtes sur l’évaluation des besoins pour le projet DLCM ont été déjà mentionnées dans la partie sur la revue de la littérature (Blumer et Burgi 2015; Burgi, Blumer et Makhlouf-Shabou 2017; Burgi et Blumer 2018), et une première typologie des besoins (profils des utilisat-eur-rice-s, zone linguistique, discipline, sujet) a été établie à partir de l’analyse des requêtes reçues par le Coordination Desk du DLCM (DLCM 2019a). Nous suggérons de poursuivre cette démarche pour enrichir cette typologie. Nous suggérons également de répertorier et d’analyser les interrogations récurrentes durant les formations en présentiel données par DLCM (DLCM 2019c). Par ailleurs, comme nous l’avons vu avec notre inventaire, les partenaires DLCM sont eux aussi déjà fortement engagés dans la formation à la GDR et leur expérience dans ce domaine peut certainement contribuer à cibler les besoins spécifiques des futures apprenant-e-s.
Implication des apprenant-e-s
Si les auteur-e-s ne s’accordent pas tous-tes à impliquer les apprenant-e-s dans le projet de conception de la formation (Benraouane 2011, p.41 ; Prat 2015, pp. 80-84 ; Pomerol, Epelboin et Thoury 2014, pp. 24-31), la réussite du projet nous semble indissociable de leur participation. C’est pourquoi nous recommandons de les intégrer au projet (futur-e-s, présent-e-s et ancien-ne-s apprenant-e-s), dès la phase d’analyse du projet, sur les aspects et avec les contributions détaillés dans le Tableau 6.
Tableau 6 : Contributions possibles par les apprenant-e-s à la conception et à la maintenance de la formation.
|
Gestion de projet |
Identifier les départements (bibliothèque, IT, administration de la recherche, département juridique) et les personnes-clés susceptibles d’être impliquées dans l’équipe projet |
|
Contenu de la formation |
Identifier les besoins des futures apprenant-e-s |
|
Contribuer à la création de contenu en fonction de ses compétences et en fonction des disciplines pour les modules avancés |
|
|
Contribuer à la traduction des cours et des ressources dans les différentes langues nationales |
|
|
Revoir et mettre à jour le contenu |
|
|
Communication – visibilité à l’externe |
Prendre part à la communication sur la formation |
|
Communication – valorisation à l’interne |
Mentionner la formation DLCM sur le catalogue de formations de l’institution |
|
Inciter les bibliothécaires de l’institution à informer sur la formation DLCM et à l’utiliser |
|
|
Inclure la formation DLCM dans un cursus académique de l’institution |
Les contributions et les suggestions des apprenant-e-s peuvent être récoltées à l’aide d’ateliers en groupe, d’entretiens individuels ou de questionnaires.
Implication des partenaires DLCM
L’ambition du DLCM est de proposer une formation au niveau national. Pour ce faire, nous encourageons fortement à faire participer davantage ses partenaires à ce projet de formation. Le Tableau 7 décrit leurs possibles contributions qui pourraient favoriser la réussite et l’efficacité de la formation.
Tableau 7 : Contributions possibles par les partenaires DLCM
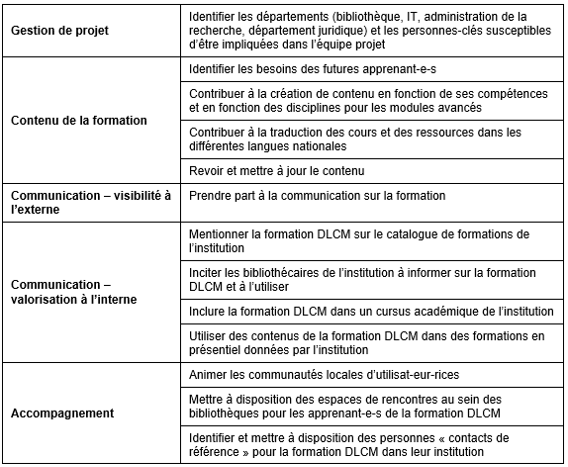
Modalités des formations e-learning
Une formation e-learning peut se décliner selon de multiples modalités: tout à distance ou hybride (blended learning), inscription payante ou pas, interactivité ou pas et types d’interaction, délivrance d’un certificat ou pas, etc. Pour chaque aspect, l’équipe projet doit faire un choix parmi ces modalités au moment de l’analyse des besoins, en fonction de critères liés au public-cible et aux besoins des utilisat-eur-rice-s, aux ressources du projet, etc.
L’éventail complet des modalités possibles pour les différents aspects caractérisant une formation e-learning est présenté sur la Figure 3 et discuté en détail par Bari, Bezzi et Guirlet (2020). Nous présentons ici une sélection des plus pertinentes d’entre elles pour le choix de dispositifs adaptés au contexte DLCM.
Figure 3 : Modalités de formations e-learning pour différents aspects
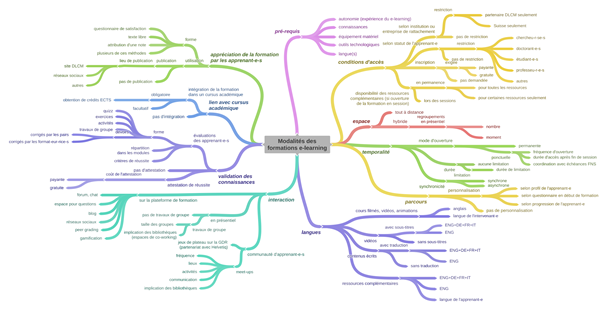
Conditions d’accès
En théorie, l’accès à la formation peut être ouvert ou restreint. Dans ce second cas, les restrictions peuvent s’appliquer en fonction de l’institution d’affiliation de l’apprenant-e (partenaire ou non de DLCM), et du statut de l’apprenant-e (chercheu-r-se ou doctorant-e, ou autre, e.g. étudiant-e ou professeur-e), et l’inscription peut être rendue obligatoire ou pas. De même, on peut mettre à disposition de manière permanente des ressources complémentaires fournies avec la formation ou uniquement une partie d’entre elles, ou au contraire décider qu’elles ne seront accessibles que durant les sessions de formation.
La composante nationale étant primordiale pour DLCM, il faudrait que cette formation soit accessible a minima à la communauté scientifique suisse, par le biais d’une authentification avec une adresse e-mail d’une institution suisse. Concernant l’accès aux ressources complémentaires, donner accès de manière permanente à certaines ressources inciterait les apprenant-e-s à utiliser le site de DLCM comme source première de formation en GDR et permettrait de fidéliser cette communauté d’apprenant-e-s. Cela simplifierait aussi le travail des institutions qui pourraient directement référencer les ressources de DLCM plutôt que de créer les leurs, avec l’avantage du point de vue de DLCM d’augmenter la visibilité de ces ressources. Ouvrir la formation à un public plus large (par exemple les étudiant-e-s et les professeur-e-s, ou encore les professionnel-le-s de l’information) permettrait aussi d’augmenter les chances de la formation d’être utilisée.
Temporalité
Deux aspects sont à considérer pour la temporalité : l’ouverture de la formation et sa durée. La formation est accessible soit en permanence soit à des périodes déterminées. La durée de la formation peut également être illimitée ou restreinte (à un certain nombre de semaines par exemple). Dans le cas d’une formation à dates et à durée fixes, la méthode synchrone (Prat 2015, p. 64) propose de surcroît une interaction directe : la formation est donnée en temps réel sous forme d’une classe virtuelle où sont “rassemblé-e-s” intervenant-e-s et apprenant-e-s.
Une ouverture permanente de la formation a l’avantage de ne pas contraindre le public à un calendrier imposé, mais peut toutefois rendre la formation moins attrayante. Sachant qu’il-elle pourra s’y inscrire à n’importe quel moment, l’apprenant-e pourrait être tenté-e de repousser le moment de concrétiser cette formation. Le plan de communication devra être pensé en conséquence. L’absence de contrainte sur la date de fin de formation entraîne aussi le risque pour l’apprenant-e de ne pas être assez incité-e à terminer la formation.
Interaction
Plusieurs formes d’interaction peuvent ponctuer la formation en ligne du DLCM : des outils tels que ceux des plates-formes classiques d’e-learning de type Coursera (forum ou chat entre étudiant-e-s ou d’étudiant-e à accompagnat-eur-rice, réseaux sociaux, etc.), le peer grading* ou la gamification*. Dans notre cas, vues la dimension nationale du projet et la proximité géographique entre apprenant-e-s et format-eur-rice-s sur le territoire suisse, il nous semble tout à fait envisageable qu’une partie de cet accompagnement se fasse en mode présentiel, au moyen de travaux de groupes et de rencontres plus informelles, propices à créer une communauté locale d’apprenant-e-s. Des meet-ups* (opportunément appelés “DLCM” pour “Data Literacy Coffee Meet-ups”) pourraient avoir lieu dans différentes régions et dans différentes langues en fonction des apprenant-e-s inscrit-e-s. Ces différentes activités seraient initiées par le DLCM qui se chargerait de communiquer sur ces évènements et de proposer des lieux de rencontre. Sur le modèle des Learning Hubs(10), les bibliothèques académiques pourraient fournir des espaces de co-working et de discussion autour de la formation.
Validation des connaissances, certificat de réussite
Des évaluations en cours de formation permettent de faire des retours à l’apprenant-e sur ses progrès et de ce fait, d’entretenir sa motivation. C’est aussi un moyen de solliciter sa participation avec des activités interactives, des quizz, des exercices, des devoirs (le peer grading renforce aussi l’interaction entre apprenant-e-s), parfois des jeux.
Dans le cas de l’adaptative learning, ces évaluations intermédiaires fournissent les informations pour adapter le parcours d’apprentissage au fur et à mesure. Dans tous les cas, elles seront aussi utilisées après les sessions pour s’assurer que la formation est efficace et pour éventuellement l’améliorer. Pour ces différentes raisons, il est important de les répartir régulièrement tout au long du parcours.
L’évaluation finale, seule ou combinée avec les évaluations intermédiaires, en cas de bons résultats selon les critères fixés par les format-eur-rice-s, peut conduire à une attestation ou un certificat de réussite de la formation. On peut choisir de faire payer ce certificat à l’apprenant-e, sur le modèle actuel des plates-formes de MOOC les plus importantes.
Présentation de trois options de dispositifs e-learning en GDR pour la formation DLCM
Afin de proposer des types de dispositifs pertinents, nous identifions trois profils-types parmi le public-cible et, en fonction de leurs besoins spécifiques, nous suggérons trois dispositifs pour la formation e-learning DLCM selon les scénarii présentés ci-dessous et sur la Figure 4.
Scénario 1 : un SPOC, une formation très encadrée et créditée pour les doctorant-e-s
Dans ce premier scénario, une université exige de ses doctorant-e-s qu’il-elle-s suivent une formation e-learning en GDR dans le cadre de leur cursus académique(11) et leur octroie des crédits en cas de réussite. L’objectif est à la fois de sensibiliser à la GDR, de responsabiliser et de faire prendre de bonnes habitudes aux doctorant-e-s dès le début de leur carrière (Carlson et Stowell-Bracke 2013 ; Jones 2014, p.107). L’intégration de la formation dans le cursus académique s’accompagne aussi d’une reconnaissance de sa qualité. Cette intégration rend la formation plus visible, évite qu’elle ne reste optionnelle et assure sa pérennité. Et pour l’université, elle est un outil utile pour la mise en pratique de sa politique de formation en GDR. Dans le contexte DLCM, ce dispositif pourrait être étendu aux étudiant-e-s de Bachelor et de Master qui produisent des données avec leurs travaux, et pour les former avant le début d’un doctorat éventuel.
Nous recommandons dans ce cas une formation sous forme de SPOC (Figure 4, cas de Malala Y.). Comme mentionné plus haut, ce dispositif est très exigeant en termes de ressources, du fait de la préparation, de l’accompagnement et de l’interaction plus poussés.
Scénario 2 : un MOOC en GDR pour chercheu-r-se-s
Prenons maintenant le cas d’un-e chercheu-r-se qui souhaite acquérir des compétences solides en GDR et intégrer de bonnes pratiques dans son quotidien professionnel. Cette personne sait qu’elle dispose de pré-requis techniques et de connaissances suffisants pour se former de façon autonome. Elle apprécie la souplesse de l’e-learning tout en bénéficiant d’un cadre temporel fixé et d’outils d’accompagnement en ligne pour aller au terme de sa formation.
Le MOOC, ouvert à tout public et sur inscription, et qui se déroule lors de sessions à durée fixe, est le dispositif le plus adapté (Figure 4, cas de Svetlana A.). L’apprenant-e y bénéficie d’un environnement propice à l’interaction avec l’accès possible à un forum, à un espace de chat et à des réseaux sociaux. Grâce au suivi par la plate-forme de son parcours d’apprentissage, cette personne est informée du temps nécessaire pour finir sa formation, et reçoit des e-mails de relance si elle ne se connecte pas régulièrement à la formation. En cas de réussite, elle peut recevoir un certificat payant. Le niveau de ressources engagées est ici plus faible que celui du SPOC, du fait d’un accompagnement moins poussé.
Scénario 3 : des ressources en libre accès pour des besoins ponctuels
Dans un contexte de changement très rapide du domaine de la GDR, il est tout à fait vraisemblable qu’un-e chercheu-r-se, ayant des connaissances préalables en GDR, ait ponctuellement besoin de mettre à jour ses connaissances, de vérifier une information ou de trouver un outil (document-type de DMP par exemple, dépôt de données le plus adapté, etc.) à différentes étapes d’un projet ou de sa carrière.
Nous préconisons dans ce cas d’utiliser une formation libre (Figure 4, cas de Françoise B.-S.), de type MANTRA (Rice 2014, MANTRA 2018), comme une base de ressources, ouverte à tout moment et à tout type de chercheu-r-se. L’apprenant-e n’y bénéficie d’aucun accompagnement ni d’aucune interaction avec les autres apprenant-e-s et ne reçoit pas de certification (son parcours individuel n’est pas suivi et les éventuelles activités ne sont pas utilisées pour une évaluation finale; elles servent seulement à stimuler sa motivation). Les ressources engagées sont moins importantes que pour les deux autres dispositifs. Elles sont essentiellement utilisées pour mettre en place la formation et la mettre à jour régulièrement.
Figure 4 : Proposition de dispositifs e-learning pour trois profils-types

Compte tenu du contexte du projet DLCM, nous identifions d’autres avantages spécifiques à ce dispositif de formation libre.
Dans le cadre du volet consultation, formation et éducation de sa deuxième phase, DLCM organise régulièrement des formations en présentiel (DLCM 2019c). Avec notre inventaire des formations et des ressources e-learning en GDR des partenaires DLCM, nous avons observé l’importance des activités de formation en présentiel par ces partenaires, sous la forme de consultations individuelles, et d’ateliers et de cours (Bari, Bezzi et Guirlet 2020).
Un accès sans condition aux ressources de la formation e-learning permettrait d’utiliser ou de rediriger les apprenant-e-s vers celle-ci à différents stades des formations en présentiel (Figure 5). Avant la formation en présentiel, ces ressources en accès libre servent pour la préparation des participant-e-s (on retrouve alors une approche de classe inversée) (Lhommeau 2014, p. 216; Pomerol, Epelboin et Thoury 2014, p. 11, p. 100). Pendant son déroulement, la projection de vidéos ou la réutilisation d’activités faisant partie de ces ressources e-learning viennent soutenir la formation en présentiel. Enfin, après la formation en présentiel, des modules ou des séquences spécifiques permettent un approfondissement de certains aspects par les participant-e-s. Ainsi utilisée, et vraisemblablement plus référencée dans les catalogues de formation des institutions, la formation e-learning DLCM deviendrait plus visible. Cette formation libre, ou base de ressources communes, dans un esprit d’ouverture et de partage, pourrait même inclure des ressources clés en main, adaptables au contexte de chaque institution, de façon similaire au matériel de formation réutilisable produit par le projet RDMTrain du Jisc (DCC [sans date]b ; JISC [sans date]). Ce fonctionnement aussi lui donnerait plus de visibilité et lui garantirait une meilleure pérennité (du fait de sa plus forte utilisation).
Inversement, on peut imaginer orienter les apprenant-e-s de cette formation e-learning libre, selon leurs intérêts et leur localisation, vers les formations en présentiel de DLCM ou de ses partenaires (Figure 5). Ce qui contribuerait là encore à recréer une communauté d’apprenant-e-s et à tirer bénéfice au maximum des deux types d’apprentissage, en présentiel et à distance.
Figure 5 : Proposition de fonctionnement couplé entre les formations en présentiel de DLCM et de ses partenaires et la formation e-learning de DLCM
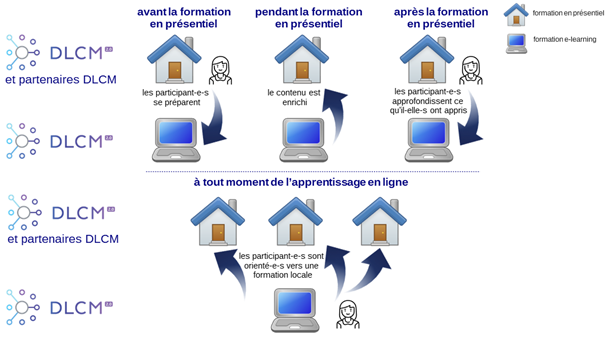
Les deux parties, DLCM et ses partenaires, ont toutes deux à gagner de ces échanges. Les partenaires profitent de ressources toutes faites, fiables car mises à jour régulièrement, et adaptées au contexte national. La formation e-learning peut faire partie de leurs outils de mise en œuvre de leur politique institutionnelle d’engagement vers l’Open Science. Participer au projet de formation e-learning de DLCM leur offre également l’opportunité de jouer un rôle actif dans la formation à la GDR à l’échelle nationale.
De son côté, la formation DLCM, en combinant formation e-learning et composante présentielle, tire avantage des bénéfices de ces deux types d’approches : la souplesse de l’e-learning et la stimulation apportée par les contacts humains. Cette complémentarité est efficace pour amoindrir le taux d’attrition couramment très élevé en e-learning. En s’appuyant sur les formations en présentiel déjà existantes au sein de DLCM et en impliquant ses partenaires, cette démarche aura en outre l’avantage de renforcer l’attractivité et le rayonnement de la formation e-learning. Et le lien entre DLCM et ses partenaires en sera d’autant plus renforcé.
Enfin, ce fonctionnement en synergie des deux parties contribuerait effectivement à remplir les trois objectifs de la formation identifiés plus haut: partager les ressources en formation à la GDR déjà existantes, fédérer autour d’une culture nationale en GDR et mutualiser les efforts pour optimiser les ressources financières.
Conclusion
Au terme de ce travail, les objectifs identifiés ont été atteints et des réponses aux questions de recherche ont été apportées. A partir de la revue de la littérature et de la revue de l’existant, nous avons établi la typologie des formations e-learning en GDR, dressé un panorama des ressources en GDR par les partenaires DLCM et à l’international, identifié des ressources réutilisables et émis des recommandations pour la formation future du DLCM. Nous avons discuté des aspects-clé pour la conception de la formation DLCM, en tenant compte des spécificités du contexte du projet. Nous avons suggéré des contributions possibles à la formation pour les partenaires DLCM. En tenant compte aussi des particularités des catégories de public-cible pour cette formation, nous avons proposé trois options de dispositifs adaptés : un SPOC, un MOOC et une formation libre. Nous avons discuté plus en détail les avantages spécifiques que la formation libre apporte au projet et à ses partenaires. Celle-ci favorise en effet le renforcement du lien entre partenaires DLCM, le partage de ressources et d’expertise en formation à la GDR, la construction d’une culture nationale en GDR, la mutualisation des efforts et l’efficacité de la formation en amoindrissant son risque d’attrition.
La seconde phase de DLCM devant se terminer d’ici peu (à la fin de l’année 2020), et compte tenu des évolutions rapides dans le domaine de la GDR, il nous semble important de réfléchir à plus long terme sur la pérennité de la formation. Au cours de ce travail, nous avons évoqué à plusieurs reprises des pistes pouvant contribuer à assurer cette pérennité : assurer des mises à jour et une maintenance régulières, encourager son utilisation, l’ouvrir à un large public, l’intégrer dans un cursus académique. Le domaine de l’e-learning se caractérisant par un fort dynamisme, nous encourageons également DLCM à se tourner le plus possible pour sa formation vers des outils innovants, de façon à être en mesure de répondre aux nouvelles attentes des apprenant-e-s en e-learning : mobile learning, microlearning*, adaptative learning, ou dispositif intelligent qui collecterait des informations mises à jour sur le web, ... Ceci permettrait de continuer à placer l’apprenant-e au centre de la démarche projet, quel que soit le dispositif, et de rendre la formation, toujours et encore, la plus efficace possible.
Notes
(1)Les termes définis dans le glossaire sont marqués d’un astérisque lors de leur première apparition dans le texte.
(2)Voir à ce propos la revue de la littérature donnée dans Dennie et Guindon (2017).
(3)La typologie des besoins est aussi évaluée à partir de l’analyse des requêtes reçues par le DLCM (profils des utilisat-eur-rice-s, zone linguistique, discipline, sujet) (voir DLCM 2019a pour le premier semestre de l’année 2019).
(4)Les pratiques et les besoins peuvent aussi être évalués en consultant les DMP produits par les chercheu-r-se-s de l’institution (voir par exemple Choudhury 2014, p.127 pour le Johns Hopkins University Data Management Services).
(5)Par exemple, lors d’un Swiss Research Data Day (DLCM 2019b) ou d’une Journée Open Science Day à l’EPFL (EPFL 2019)
(6)Par exemple, lors d’un Swiss Research Data Day (DLCM 2019b) ou d’une Journée Open Science Day à l’EPFL (EPFL 2019)
(7)https://www.dlcm.ch/services/dlcm-training
(8)https://www.dlcm.ch/resources/dlcm-training
(9)https://www.dlcm.ch/resources/dlcm-dmp
(10)« ces lieux de rencontre dédiés aux MOOC et localisés dans des bibliothèques, des consulats, ou autres lieux publics », lancés par la plate-forme Coursera (Cisel 2018).
(11)comme déjà appliqué par certaines universités, tel que présenté plus haut.
Glossaire
Accompagnant-e : voir accompagnement
Accessibilité : dans le cas des normes des modules pédagogiques et selon Prat (2011, p. 35), “capacité de repérer des composantes pédagogiques à partir d’un site distant, d’y accéder et de les distribuer à d’autres sites”.
Accompagnement (pédagogique, technique), fonctions (services) d’accompagnement (des formations e-learning) : selon Prat (2010, p. 290), “tâches, missions, compétences que les formateurs (tuteurs, coachs) mettent en oeuvre pour la conduite des formations à distance: contact direct, coordination, support technique, animation de forum, suivi pédagogique, évaluation …”. Ces tâches sont assurées par la ou les format-eur-rice-s e-learning et par la ou les tut-eur-rice-s (ou coachs). Nous ne faisons pas de distinction entre ces termes pour ce qui concerne ces tâches d’accompagnement et employons à la place le terme “accompagnant-e”. Pour plus de détails sur les rôles de l’accompagnant-e, on peut consulter Prat (2010, pp. 212-213) et Pomerol, Ebelpoin et Thoury (2014, p. 130).
Adaptabilité : dans le cas des normes des modules pédagogiques et selon Prat (2011, p. 35), “capacité à personnaliser l’enseignement en fonction des besoins définis pour les apprenants”.
Adaptative learning : le parcours d’apprentissage des apprenant-e-s est adapté en temps réel par des algorithmes à partir du suivi des actions de l’apprenant-e (Lhommeau 2014 p.130).
Apprenant-e : selon Prat (2010, p. 290), “personne engagée et active dans un processus d’acquisition ou de perfectionnement des connaissances et de leur mise en oeuvre (AFNOR)”.
Blended learning (ou cours hybride): terme anglais désignant un parcours alternant formation à distance et face à face pédagogique (présentiel) (Prat 2012, p.293)
Classe inversée : selon Lhommeau (2014, p. 216), “méthode pédagogique visant à donner des cours magistraux sur l’Internet et à réserver le présentiel pour de l’échange et de la mise en pratique”. On parle aussi de flipped pedagogy ou flipped classrooms: cours mis à disposition des élèves pour que ceux-ci puissent les préparer chez eux (Pomerol, Epelboin et Thoury 2014, p. 11) et temps avec l’enseignant-e consacré à un dialogue approfondi (Pomerol, Epelboin et Thoury 2014, p. 100).
Classe virtuelle : selon Prat (2010, p. 292), “désigne la simulation d’une classe réelle. Elle permet de réunir en temps réel sur Internet ou un réseau, des participants et un formateur qui peuvent notamment discuter, se voir, visionner des documents, des vidéos, réaliser des quizz, partager leur écran.”
Cours en ligne fermé : distribué par un organisme de formation ou un établissement d'enseignement, destiné à un groupe d'apprenant-e-s régulièrement inscrit-e-s et ayant donc acquitté des droits d'inscription, distribué sur une plate-forme (Learning Management System ou LMS), dispensé seul ou dans le cadre d'un parcours de formation, diplômant ou pas. Ce cours est généralement animé par une enseignant-e ou un-e tut-eur-rice qui assure la communication avec les participant-e-s et peut aussi animer des temps de formation en direct (appelés "synchrones"). Il comprend des ressources de contenus (i.e. la partie "cours"), des activités d'apprentissage (i.e. des exercices à faire, des épreuves d'évaluation...) et un espace d'interaction (généralement un forum) qui permet aux participant-e-s d'interagir entre elles et avec les animat-eur-rice-s du cours (MOOC et e-learning, quelles différences ? 2014).
Cours en ligne ouvert : distribué par un organisme de formation ou un établissement d'enseignement, destiné à toutes celles qui veulent s'autoformer sur un sujet qui les intéresse, généralement distribué sur une plate-forme, non diplômant. Ce cours n'est pas tutoré, l'apprenant-e doit suivre son parcours seul-e. A côté des ressources de "cours" proprement dites, on trouve dans ces cours quelques exercices à correction automatique tels que des quiz, qui permettent à l'apprenant-e d'évaluer sa compréhension. Ces cours ouverts ne comprennent généralement pas d'espace d'interaction, puisqu'ils ne sont pas suivis par des groupes constitués, mais par des personnes qui les suivent à titre individuel, quand bon leur semble. Ils ne comprennent pas non plus de temps de formation synchrones (MOOC et e-learning, quelles différences ? 2014).
Dispositif de formation : selon Prat (2010, p. 291), “ensemble des moyens techniques, logistiques et humains organisés dans le temps et dans l’espace pour répondre à la demande du commanditaire pour la formation d’une population précise.”
DLCM : DLCM est l’acronyme de l’expression Data Life-Cycle Management (qu’on pourrait traduire par “gestion des données tout au long de leur cycle de vie”) et désigne également le projet lancé en 2015 par huit institutions suisses1. Dans ce document, DLCM est utilisé exclusivement pour désigner ce projet.
Données de recherche : de nombreuses définitions sont disponibles dans la littérature ainsi que sur les pages Web des institutions sur la GDR (voir le document liste de ressources). Pour une définition intentionnellement inclusive, on peut consulter le guide ANDS : What is research data (Australian National Data Service 2017). On peut aussi se référer à la définition du Conseil de recherches en sciences humaines (CRSH, Canada) citée par Guindon (2013). Nous utilisons ici la définition de l’OCDE, qui nous paraît la plus pertinente pour le contexte de ce projet (OCDE 2007, p.18) :
« Enregistrements factuels (chiffres, textes, images et sons), qui sont utilisés comme sources principales pour la recherche scientifique et sont généralement reconnus par la communauté scientifique comme nécessaires pour valider des résultats de recherche ».
E-learning : la Commission Européenne (2001) définit l’e-learning comme « l’utilisation des nouvelles technologies multimédias et de l’Internet, pour améliorer la qualité de l’apprentissage en facilitant l’accès à des ressources et des services, ainsi que les échanges et la collaboration à distance ».
Formation : en reprenant la définition de training donnée dans Makhlouf-Shabou (2017), on peut définir une formation comme le processus d’apprentissage permettant à une personne d’acquérir les connaissances et les compétences nécessaires à l’exercice de son activité professionnelle. Ce processus peut aussi permettre l’approfondissement des connaissances et l’amélioration de la maîtrise de compétences.
Gamification : selon Lhommeau (2014, p. 57), “réutilisation de mécaniques de jeu dans un autre contexte afin de faciliter l’appropriation d’un sujet chez n’importe quel individu”.
Gestion des données de recherche (notée GDR) ou Research Data Management : nous sélectionnons deux types de définitions qui nous semblent complémentaires dans leur perspective:
● sous la perspective des activités, et en lien avec le cycle de vie, selon Cox et Verbaan (2018, p.4): [Research Data Management] “is about creating, finding, organising, storing, sharing and preserving data within any research process”; et selon Whyte and Tedds (2011): “Research data management concerns ‘the organisation of data, from its entry to the research cycle through to the dissemination and archiving of valuable results’’
● sous la perspective des finalités, selon le site Open research Data de l’Université de Lausanne (2019) : “cette gestion s'avère indispensable et cruciale à de multiples égards:
- elle assure la conformité avec le cadre légal et réglementaire tout comme les exigences des bailleurs de fonds et éditeurs scientifiques
- elle garantit l’authenticité, l’intégrité, la fiabilité et l’exploitabilité des données ;
- elle en facilite la reproductibilité, le partage et la réutilisation ;
- enfin elle rend davantage visibles les travaux et résultats de recherche et participe à la qualité de celle-ci“
Interactivité : selon Prat (2010, p. 292): “activité impliquant plusieurs personnes ou système dont le comportement s’ajuste suite à une action réalisée par l’un d’entre eux”.
Meet-up : selon Lhommeau (2014, p. 128), “se dit d’une soirée de réseautage social, centrée, pour les participants, sur un centre d’intérêts communs. La rencontre découle d’une mise en relation électronique en amont, initiée depuis une communauté virtuelle”. Les internautes se rassemblent physiquement dans leurs régions ou leurs villes respectives pour discuter et échanger autour de la formation (Pomerol, Epelboin et Thoury 2014, p. 76).
Microlearning : selon Wikipédia (Microlearning, 2018), "modalité de formation ou apprentissage en séquence courte de 30 secondes à 3 minutes, utilisant texte, images et sons."..." Comme technologie servant à l'instruction, le microlearning cible la création d'activités de micro-apprentissage à travers de très courtes étapes utilisant des environnements multimédias. Ces activités peuvent facilement être incluses dans la routine quotidienne de l'élève. À l'opposé des approches plus traditionnelles d'apprentissage, le microlearning utilise souvent la méthode du push (où l'élève déclenche par lui-même le processus au moment désiré)."
Mobile learning : selon Prat (2015, p. 356): “l’apprenant s’abonne à un contenu audio, il l’écoute ensuite quand et où il veut. Ce format de contenu peut être lu sur n’importe quel PC ou lecteur MP3.” Le contenu pédagogique s’adapte pour permettre à l’apprenant-e de suivre le MOOC tout le temps, où que cette personne soit, quel que soit le temps qu’elle ait à disposition (Lhommeau 2014, p. 131).
MOOC (Massive Open Online Course) : cours diffusé sur Internet, libre d’accès (aucun prérequis n’est nécessaire) et disponible à un nombre illimité d’apprenant-e-s (pas de limitation physique) (Université de Genève; Pomerol, Epelboin et Thoury 2014, p. 7). En français CLOM (Cours en Ligne Ouvert et Massif)
xMOOC (dit également “MOOC instructiviste” (Lhommeau 2014, p. 219)) : le savoir se transmet de manière verticale de l’enseignant-e à l’apprenant-e (Lhommeau 2014, p.25 ; Daïd et Nguyen 2014, pp. 26-28).
cMOOC (dit également “MOOC connectiviste” (Lhommeau 2014, p. 216)) : MOOC dont le savoir se transmet de manière horizontale. Le cours se construit au fil de son avancement grâce aux conversations entre apprenant-e-s et en fonction de leurs choix d’approfondissement (Lhommeau 2014, p.24 ; Daïd et Nguyen 2014, pp. 26-28; Pomerol, Epelboin et Thoury 2014, p. 15).
Peer grading ou peer assessment : correction par les pairs
Plate-forme (pour dispositif de formation e-learning, le plus souvent MOOC) : selon Pomerol, Epelboin et Thoury (2014, p. 124), elle se constitue de “l’ensemble du logiciel “éditeur” et du matériel “serveur” accompagné d’un logiciel de service (répondre aux questions, forum, gestion des inscriptions, des relations avec les maîtres statistiques, etc.).”
RDM (ou Research Data Management) : voir GDR
Serious game : selon Prat 2012 (p. 297), “jeu vidéo à visée pédagogique dans lequel le joueur, en accomplissant ses missions de jeu, vit une expérience unique qu’il transforme en une véritable expertise au fur et à mesure de ses victoires successives”.
SPOC (Small Private Online Course) : cours fonctionnant sur le même modèle que le xMOOC, mais est limité à une cinquantaine d’apprenant-e-s (Daïd et Nguyen 2014, p.177).
Synchrone (outils de communication) : selon Prat (2015, p. 357): “les questions et les réponses se font en direct, en temps réel, sans décalage temporel entre question et réponse. Une formation est dite synchrone lorsque les apprenants peuvent se connecter simultanément à un module et communiquer en temps réel” (voir aussi “classe virtuelle”).
Taux d’attrition : Pourcentage des inscrit-e-s à une formation en e-learning qui n’obtiennent pas de certificat (les non-certifié-e-s) ou qui abandonnent la formation en cours de cursus (Cisel 2017).
Web 2.0 : l’ensemble des technologies et des usages du Web permettant aux internautes d’être actif-ve-s sur le contenu et la structuration des pages Web (exemple: wikis, blogs, Web social…) (Prat 2012, p.298).
Bibliographie
AKERS, Katherine G. et DOTY, Jennifer, 2013. Disciplinary differences in faculty research data management practices and perspectives. In : International Journal of Digital Curation. 19.11.2013. Vol. 8, n° 2, p. 5-26. DOI : 10.2218/ijdc.v8i2.263
Australian National Data Service (ANDS), 2017. What is research data. ands.org.au [en ligne]. 11.01.2017. [Consulté le 03.11.2020]. Disponible à l’adresse : https://www.ands.org.au/guides/what-is-research-data
Australian National Data Service (ANDS), [sans date]. What we do. ands.org.au [en ligne]. [Consulté le 03.11.2020]. Disponible à l’adresse: https://www.ands.org.au/about-us/what-we-do
BARI, Manon, BEZZI, Manuela, GUIRLET, Marielle, 2020. Formation et éducation en gestion des données de recherche du point de vue du projet DLCM: dispositifs d’e-learning [en ligne]. 19.01.2020. [Consulté le 01.11.2020]. Disponible à l’adresse : http://doc.rero.ch/record/328462
BARONE, Lindsay, WILLIAMS, Jason et MICKLOS, David, 2017. Unmet needs for analyzing biological big data: A survey of 704 NSF principal investigators. In : OUELLETTE, Francis (éd.), PLOS Computational Biology. 19.10.2017. Vol. 13, n° 10, p. e1005755. DOI : 10.1371/journal.pcbi.1005755
BEITZ, Anthony, GROENEWEGEN, David, HARBOE-REE Cathrine, MACMILLAN Wilna, SEARLE, Sam, 2014. Case study 3: Monash University, a strategic approach. In: PRYOR, Graham, JONES, Sarah, WHYTE, Angus. Delivering Research Data Management Practices, fundamentals of good practice. facet publishing, pp. 163-189. ISBN 978-1-85604-933-7
BENRAOUANE, Sid Ahmed, 2011. Guide pratique du e-learning: Statégie, pédagogie et conception avec le logiciel Moodle [en ligne]. Paris : Dunod. [Consulté le 03.11.2020]. Fonctions de l’entreprise. Formation. ISBN 978-2-10-055786-8. Disponible à l’adresse : http://hesge.scholarvox.com/book/88800754 [accès par abonnement]
BLUMER, Eliane et BURGI, Pierre-Yves, 2015. Data Life-Cycle Management Project: SUC P2 2015-2018. Revue électronique suisse de science de l’information [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : http://www.ressi.ch/num16/article_110
BOURBAN, Alexandre, 2010. Elaboration d’une démarche d’évaluation de modules elearning de recherche à l’Organisation mondiale de la santé [en ligne]. Mémoire de bachelor : Haute école de gestion de Genève ; TDB 2112. [Consulté le 01.11.2020]. Disponible à l’adresse : http://doc.rero.ch/record/20932/files/TDB_2112.pdf
BROWN, Mark. L., WHITE, Wendy. 2014. Case study 2: University of Southampton – a partnership approach to research data management. In: PRYOR, Graham, JONES, Sarah, WHYTE, Angus. Delivering Research Data Management Practices, fundamentals of good practice. facet publishing, pp. 135-161. ISBN 978-1-85604-933-7
BURGI, Pierre-Yves, 2015. Data Life-Cycle Management: The Swiss Way. Bulletin / Académie suisse des sciences humaines et sociales. Vol. 4, pp. 48-50
BURGI, Pierre-Yves, BLUMER, Eliane et MAKHLOUF-SHABOU, Basma, 2017. Research data management in Switzerland: National efforts to guarantee the sustainability of research outputs. IFLA Journal. 01/2017. pp. 1-17
BURGI, Pierre-Yves et BLUMER, Eliane, 2018. Le projet DLCM : gestion du cycle de vie des données de recherche en Suisse. In : Alice Keller & Susanne Uhl. Bibliotheken der Schweiz: Innovation durch Kooperation. Festschrift für Susanna Bliggenstorfer anlässlich ihres Rücktrittes als Direktorin der Zentralbibliothek Zürich. Berlin : De Gruyter, pp. 235-249. ISBN 978-3-11-055379-6
CARLSON, Jake et STOWELL-BRACKE, Marianne, 2013. Data Management and Sharing from the Perspective of Graduate Students: An Examination of the Culture and Practice at the Water Quality Field Station. In : portal: Libraries and the Academy. 2013. Vol. 13, n° 4, pp. 343-361. DOI : 10.1353/pla.2013.0034
CHOUDHURY, G. Sayeed, 2014. Case study 1: Johns Hopkins University Data Management Services. In: PRYOR, Graham, JONES, Sarah, WHYTE, Angus. Delivering Research Data Management Practices, fundamentals of good practice. facet publishing, pp. 114-133. ISBN 978-1-85604-933-7
CHRISTENSEN-DALSGAARD, Birte, BERG, Marc, GRIM, Rob, HORTSMANN, Wolfram, JANSEN, Dafne, POLLARD, Tom et ROOS, Annikki, 2012. Ten Recommendations for Libraries to Get Started with Research Data Management: Final Report of the LIBER Working Group on E-Science / Research Data Management [en ligne]. S.l. Ligue des Bibliothèques Européennes de Recherche (LIBER). [Consulté le 01.11.2020]. Disponible à l’adresse : https://libereurope.eu/wp-content/uploads/The%20research%20data%20group%202012%20v7%20final.pdf
CISEL, Matthieu, 2013. La révolution MOOC [en ligne]. 01.06.2013. [Consulté le 01.11.2020]. Disponible à l’adresse: http://blog.educpros.fr/matthieu-cisel/2013/06/01/mooc-ce-que-les-taux-dabandon-signifient/
CISEL, Matthieu, 2016. Utilisations des MOOC : éléments de typologie [en ligne]. Paris: Université Paris-Saclay. Thèse de doctorat. [Consulté le 01.11.2020]. Disponible à l’adresse : https://tel.archives-ouvertes.fr/tel-01444125/document
CISEL, Matthieu, 2017. Une analyse de l’utilisation des vidéos pédagogiques des MOOC par les non-certifiés. Sticef [en ligne]. vol. 24, numéro 2. [Consulté le 04.11.2020]. Disponible à l’adresse : https://www.persee.fr/doc/stice_1764-7223_2017_num_24_2_1744
CISEL, Matthieu, 2018. Interactions entre utilisateurs de MOOC : quelques propositions. La révolution MOOC [en ligne]. 09.01.2018. [Consulté le 04.11.2020]. Disponible à l’adresse: http://blog.educpros.fr/matthieu-cisel/2018/01/09/interactions-entre-utilisateurs-de-mooc-quelques-propositions/#more-5852
COMMISSION EUROPEENNE, 2001. e-Learning – Penser l’éducation de demain [archive], Communication de la Commission au conseil et au parlement européen ; 28 mars 2001 Bruxelles, COM(2001)172 final, page 2. [Consulté le 01.11.2020]. Disponible à l’adresse : http://www.oidel.org/doc/Education/E-learning/E-Learning_penser%20l%27education.pdf
Comment choisir les stratégies d’enseignement ? [sans date]. profinnovant.com [en ligne]. [Consulté le 20.11.2020]. Disponible à l’adresse : https://www.profinnovant.com/choisir-strategies-denseignement/
COX, Andrew M. et PINFIELD, Stephen, 2014. Research data management and libraries: Current activities and future priorities. In: Journal of Librarianship and Information Science. décembre 2014. Vol. 46, n° 4, pp. 299-316. DOI: 10.1177/0961000613492542
COX, Andrew M. et VERBAAN, Eddy, 2018. Exploring research data management. London : Facet Publishing. ISBN 978-1-78330-279-6
CRISTOL, Dennis, 2017. Le mobile learning en pratique [en ligne]. 12.06.2017. [Consulté le 01.11.2020]. Disponible à l’adresse : https://cursus.edu/articles/37303/le-mobile-learning-en-pratique#.XXF5hHs6_IU
DAÏD, Gilles et NGUYEN, Pascal, 2014. Guide pratique des MOOC [en ligne]. éd. Eyrolles. [Consulté le 04.11.2020]. Disponible à l’adresse : https://hesge.scholarvox.com/catalog/search/searchterm/Guide%20pratique%20des%20MOOC?searchtype=title [accès par abonnement]
DATA CARPENTRY, [sans date]. Data Carpentry. Building communities teaching universal data literacy. datacarpentry.org. [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse: https://datacarpentry.org/
DCC, [sans date]a. About the DCC. dcc.ac.uk [en ligne]. [Consulté le 04.11.2020]. Disponible à l’adresse: http://www.dcc.ac.uk/about
DCC, [sans date]b. Disciplinary RDM Training. dcc.ac.uk [en ligne]. [Consulté le 02.11.2020]. Disponible à l’adresse : https://www.dcc.ac.uk/news/disciplinary-rdm-training-materials
DENNIE, Danielle et GUINDON, Alex, 2017. Résultats d’une enquête sur les pratiques et attitudes des chercheurs de l’Université Concordia en matière de gestion des données de recherche. In : Documentation et bibliothèques. 2017. Vol. 63, n° 4, p. 59. DOI : 10.7202/1042311ar
DLCM, 2019a. Professional Services Activity Report, Semester 1, 2019 (1.1.2019-30.6.2019). 2019. Document interne au projet DLCM
DLCM, 2019b. SWISS RESEARCH DATA DAY 2020. dlcm.ch [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : https://www.dlcm.ch/swiss-research-data-day-2020
DLCM, 2019c. Training & Consulting. dlcm.ch [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : https://www.dlcm.ch/services/dlcm-training
EPFL, 2019. Open Science Day. epfl.ch [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : https://www.epfl.ch/campus/events/celebration-en/open-science-day/
EUROPEAN COMMISSION, DIRECTORATE-GENERAL FOR RESEARCH & INNOVATION, 2016. H2020 Programme - Guidelines on FAIR Data Management in Horizon 2020 [en ligne]. [Consulté le 04.11.2020]. Disponible à l’adresse : https://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-data-mgt_en.pdf
EUROPEAN COMMISSION, 2017. H2020 programme: guidelines to the rules on open access to scientific publications and open access to research data in Horizon 2020. European Commission [en ligne]. 21.03.2017. [Consulté le 01.11.2020]. Disponible à l’adresse : http://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-pilot-guide_en.pdf
EVANS, Jill, LLOYD-JONES, Hannah, COLE, Gareth, 2013. Final report on the Open Exeter project to Jisc. 09.07.2013. [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : https://ore.exeter.ac.uk/repository/handle/10871/14845
FACHINOTTI, Elena, GOZZELINO, Eva et LONATI, Sara, 2016. Les bibliothèques scientifiques et les données de la recherche : défis et enjeux [en ligne]. Genève : Haute École de Gestion Genève. Mémoire de recherche. [Consulté le 01.11.2020]. Disponible à l’adresse : http://doc.rero.ch/record/258991
FNS, 2017. Open Research Data : les requêtes devront inclure un plan de gestion des données. FNS [en ligne]. 6 mars 2017. [Consulté le 01.11.2020]. Disponible à l’adresse : http://www.snf.ch/fr/pointrecherche/newsroom/Pages/news-170306-open-research-data-bientot-une-realite.aspx
FRUGOLI, Julia, ETGEN, Anne M. et KUHAR, Michael, 2010. Developing and Communicating Responsible Data Management Policies to Trainees and Colleagues. In : Science and Engineering Ethics. Décembre 2010. Vol. 16, n° 4, pp. 753-762. DOI : 10.1007/s11948-010-9219-1
GUINDON, Alex, 2013. La gestion des données de recherche en bibliothèque universitaire. In : Documentation et bibliothèques. 2013. Vol. 59, n° 4, p. 189. DOI : 10.7202/1019216ar
HIGGINS, Sarah, 2008. The DCC Curation Lifecycle Model. In : The International Journal of Digital Curation [en ligne]. juin 2008. [Consulté le 01.11.2020]. Disponible à l’adresse : http://www.ijdc.net/article/view/69
JISC, [sans date]. Research data management training materials (RDMTrain). The national archives. UK Government Web Archive. [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse: https://webarchive.nationalarchives.gov.uk/20140702195402/http://www.jisc.ac.uk/whatwedo/programmes/~/link.aspx?_id=677B9C0D0E8F4B12A7E2ACC86FD9D736&_z=z
JOHNSON, Layne M., BUTLER, John T. et JOHNSTON, Lisa R., 2012. Developing E-Science and Research Services and Support at the University of Minnesota Health Sciences Libraries. In: Journal of Library Administration. Novembre 2012. Vol. 52, n° 8, pp. 754-769. DOI : 10.1080/01930826.2012.751291
JONES, Sarah, PRYOR, Graham et WHYTE, Angus, 2013. How to Develop Research Data Management Services - a guide for HEIs. DCC How-to Guides [en ligne]. Edinburgh: Digital Curation Centre. [Consulté le 01.11.2020]. Disponible à l’adresse: http://www.dcc.ac.uk/resources/how-guides/how-develop-rdm-services
JONES, Sarah, 2014. The range and components of RDM infrastructure and services. In: PRYOR, Graham, JONES, Sarah, WHYTER, Angus (éd.). Delivering Research Data Management Practices, fundamentals of good practice. London: Facet Publishing, pp. 89-114. ISBN 978-1-85604-933-7
KRUSE, Filip et THESTRUP, Jesper Boserup (éd.), 2018. Research data management: a [an] European perspective. Berlin: De Gruyter Saur. Current topics in library and information practice. ISBN 978-3-11-036944-1
LEWIS, Martin, 2010. Libraries and the management of research data. In: MCKNIGHT, Sue (éd.). Envisioning Future Academic Library Services. London: Facet Publishing, pp. 145-168. ISBN 978-1-85604-691-6
LHOMMEAU, Clément, 2014. MOOC : l’apprentissage à l’épreuve du numérique. Éd. Fyp. ISBN 978-2-36405-112-6
MAKHLOUF-SHABOU, Basma, 2017. Training, consulting and teaching for sustainable approach for developing research data life-cycle management expertise in Switzerland. In: INFuture2017 Integrating ICT in Society, Zagreb, 8-10 Novembre 2017. Department of Information and Communication Sciences, Faculty of Humanities and Social Sciences, University of Zagreb, Croatia, pp. 79-86
MAKHLOUF-SHABOU, Basma et KRUG, Silas, 2020. DLCM’s MOOC : Bring your questions & pick up your answers. In : Swiss Research Data Day 2020, Geneva, HEG/HES-SO, 22.10.2020 [en ligne]. [Consulté le 20.11.2020]. Disponible à l’adresse : https://www.dlcm.ch/swiss-research-data-day-2020/presentations
MANTRA, 2018. About MANTRA. MANTRA Research Data Management Training [en ligne]. 05.2018. [Consulté le 01.11.2020]. Disponible à l’adresse : https://mantra.edina.ac.uk/about.html
MICROLEARNING. Wikipédia : l’encyclopédie libre [en ligne]. Dernière modification de la page le 23 novembre 2018 à 15:24. [Consulté le 04.11.2020]. Disponible à l’adresse : http://fr.wikipedia.org/w/index.php?title=Microlearning&oldid=154194722
MOOCs@Edinburgh Group, 2013. MOOCs @ Edinburgh 2013: Report #1. [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : https://era.ed.ac.uk/handle/1842/6683
MOOC et e-learning, quelles différences ? Thot Cursus : formation et culture numérique [en ligne]. Publié le 15.04.2014. Mis à jour le 09.05.2014 [Consulté le 01.11.2020]. Disponible à l’adresse: https://cursus.edu/articles/27809/mooc-et-e-learning-quelles-differences#.XWjsBXskzIV
MORGAN, Ann, DUFFIELD, Nel et WALKLEY HALL, Liz, 2017. Research Data Management Support: Sharing Our Experience. Journal of the Australian Library and Information Association, Vol. 66, Issue 3, pp. 299-305, DOI: 10.1080/24750158.2017.1371911
NATURE, 2016. Data availability statements and data citations policy: Guidance for authors. Nature [en ligne]. 09/2016. [Consulté le 01.11.2020]. Disponible à l’adresse: http://www.nature.com/authors/policies/data/data-availability-statements-data-citations.pdf
OCDE, 2007. Principes et lignes directrices de l’OCDE pour l’accès aux données de la recherche financée sur fonds publics. [en ligne]. [Consulté le 04.11.2020]. Disponible à l’adresse : http://www.oecd.org/fr/sti/inno/38500823.pdf
PARHAM, Susan Wells, BODNAR, Jon et FUCHS, Sara, 2012. Supporting tomorrow’s research: Assessing faculty data curation needs at Georgia Tech. In : College & Research Libraries News. 01.01.2012. Vol. 73, n° 1, pp. 10-13. DOI: 10.5860/crln.73.1.8686
PARSONS, Thomas, 2013. Creating a Research Data Management Service. International Journal of Digital Curation. 19.11.2013. Vol. 8, n° 2, pp. 146-156. DOI : 10.2218/ijdc.v8i2.279
PERRIER, Laure et BARNES, Leslie, 2018. Developing Research Data Management Services and Support for Researchers: A Mixed Methods Study. In : Partnership: The Canadian Journal of Library and Information Practice and Research [en ligne]. 08.05.2018. Vol. 13, n° 1. [Consulté le 01.11.2020]. DOI : 10.21083/partnership.v13i1.4115. Disponible à l’adresse : https://journal.lib.uoguelph.ca/index.php/perj/article/view/4115
PFEIFFER, Laetitia, 2015. MOOC, COOC : la formation professionnelle à l’ère du digital. Paris : Dunod. Fonctions de l’entreprise. ISBN : 978-2-10-072467-3
PINFIELD, Stephen, COX, Andrew M. et SMITH, Jen, 2014. Research Data Management and Libraries: Relationships, Activities, Drivers and Influences. In : LAUNOIS, Pascal (éd.), PLoS ONE. 08.12.2014. Vol. 9, n° 12, p. e114734. DOI: 10.1371/journal.pone.0114734.
PIWOWAR, Heather A., DAY, Roger S. et FRIDSMA, Douglas B., 2007. Sharing Detailed Research Data Is Associated with Increased Citation Rate. In : IOANNIDIS, John (éd.), PLoS ONE. 21.03.2007. Vol. 2, n° 3, p. e308. DOI : 10.1371/journal.pone.0000308
PLOS ONE, 2019. Data availability. PLOS [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : http://journals.plos.org/plosone/s/data-availability
POMEROL, Jean-Charles, EPELBOIN, Yves et THOURY, Claire. 2014. Les MOOC : conception, usages et modèles économiques. Dunod. ISBN : 978-210-071283-0
PRAT, Marie, 2010. E-learning : Réussir un projet : pédagogie, méthode et outils de conception, déploiement, évaluation ... (2ème édition). Edition ENI : St Herblain.Objectif Solutions. ISBN 978-2-7460-5949-8
PRAT, Marie, 2011. E-learning : utiliser les outils Web 2.0 pour développer un projet. Edition ENI : St Herblain. Objectif Solutions, ISBN 978-2-7460-6118-7
PRAT, Marie, 2012. Les meilleurs outils web 2.0 pour développer un projet e-learning, Edition ENI : St Herblain. Solutions Business, ISBN 978-2-7460-7612-9
PRAT, Marie, 2015. Réussir votre projet Digital Learning. Formation 2.0: les nouvelles modalités d’apprentissage. Edition ENI: St Herblain. Solutions Business, ISBN 978-2-7460-9393-5
PRYOR, Graham, 2012. Why manage research data? Managing Research Data. Londres: Facet Publishing, pp.1-16. ISBN 978-1-85604-756-2
PRYOR, Graham, JONES, Sarah et WHYTE, Angus (éd.), 2014. A patchwork of change. Delivering Research Data Management Services. London: Facet Publishing, 2014, pp.1-19. ISBN 978-1-85604-933-7
RICE, Robin, 2014. Research Data MANTRA: A Labour of Love. Journal of eScience Librarianship [en ligne]. 2014. Vol. 3, n° 1. [Consulté le 01.11.2020]. DOI: 10.7191/jeslib.2014.1056. Disponible à l’adresse : http://escholarship.umassmed.edu/jeslib/vol3/iss1/4/
SAYOGO, Djoko Sigit et PARDO, Theresa A., 2013. Exploring the determinants of scientific data sharing: Understanding the motivation to publish research data. In : Government Information Quarterly. Janvier 2013. Vol. 30, pp. S19-S31. DOI : 10.1016/j.giq.2012.06.011
SCHIRRWAGEN, Jochen, CIMIANO, Philipp, AYER, Vidya, PIETSCH, Christian, WILJES, Cord, VOMPRAS, Johanna et PIEPER, Dirk, 2019. Expanding the Research Data Management Service Portfolio at Bielefeld University According to the Three-pillar Principle Towards Data FAIRness. In: Data Science Journal. 15.01.2019. Vol. 18, p. 6. DOI : 10.5334/dsj-2019-006
SOUTHALL, John et SCUTT, Catherine, 2017. Training for Research Data Management at the Bodleian Libraries: National Contexts and Local Implementation for Researchers and Librarians. In : New Review of Academic Librarianship. 03.07.2017. Vol. 23, n° 2-3, pp. 303-322. DOI : 10.1080/13614533.2017.1318766
SOYKA, Heather, BUDDEN, Amber, HUTCHISON, Viv, BLOOM, David, DUCKLES, Jonah, HODGE, Amy, MAYERNIK, Matthew, POISOT, Timothée, RAUCH, Shannon, STEINHART, Gail, WASSER, Leah, WHITMIRE, Amanda et WRIGHT, Stephanie, 2017. Using Peer Review to Support Development of Community Resources for Research Data Management. In : Journal of eScience Librarianship. 08.09.2017. Vol. 6, n° 2, p. e1114. DOI : 10.7191/jeslib.2017.1114
SPRINGER NATURE, [sans date]. Research Data Policies FAQ. Springer Nature [en ligne]. [Consulté le 04.11.2020]. Disponible à l’adresse : https://www.springernature.com/gp/authors/research-data-policy/data-policy-faqs
SWISSUNIVERSITIES, [sans date]. Projets et programmes - P5-information scientifique: accès, traitement et sauvegarde. swissuniversities.ch [en ligne]. [Consulté le 01.11.2020]. Disponible à l’adresse : https://www.swissuniversities.ch/fr/organisation/projets-et-programmes/p-5/
TENOPIR, Carol, ALLARD, Suzie, DOUGLASS, Kimberly, AYDINOGLU, Arsev Umur, WU, Lei, READ, Eleanor, MANOFF, Maribeth et FRAME, Mike, 2011. Data Sharing by Scientists: Practices and Perceptions. In : NEYLON, Cameron (éd.), PLoS ONE. 29.06.2011. Vol. 6, n° 6, p. e21101. DOI : 10.1371/journal.pone.0021101
TENOPIR, Carol, DALTON, Elizabeth D., ALLARD, Suzie, FRAME, Mike, PJESIVAC, Ivanka, BIRCH, Ben, POLLOCK, Danielle et DORSETT, Kristina, 2015. Changes in Data Sharing and Data Reuse Practices and Perceptions among Scientists Worldwide. In : VAN DEN BESSELAAR, Peter (éd.), PLOS ONE. 26.08.2015. Vol. 10, n° 8, p. e0134826. DOI : 10.1371/journal.pone.0134826
THIELEN, Joanna et HESS, Amanda Nichols, 2017. Advancing Research Data Management in the Social Sciences: Implementing Instruction for Education Graduate Students Into a Doctoral Curriculum. In : Behavioral & Social Sciences Librarian. 02.01.2017. Vol. 36, n° 1, pp. 16-30. DOI : 10.1080/01639269.2017.1387739
TRELOAR, Andrew, GROENEWEGEN, David et HARBOE-REE, Cathrine, 2007.The Data Curation Continuum. Managing Data Objects in Institutional Repositories. D-Lib Magazine [en ligne]. Septembre/Octobre 2007. Vol. 13, Number 9/10 [Consulté le 01.11.2020]. Disponible à l’adresse : http://www.dlib.org/dlib/september07/treloar/09treloar.html
UNIVERSITE DE GENEVE, 2019. Données de recherche. Yareta : Une nouvelle solution numérique pour archiver et partager vos données de recherche. Université de Genève [en ligne]. 14.06.2019. [Consulté le 01.11.2020]. Disponible à l’adresse : https://www.unige.ch/researchdata/fr/actualites/yareta/
UNIVERSITE DE LAUSANNE, 2019. Open research Data. unil.ch [en ligne]. [Consulté le 06.09.2019]. Disponible à l’adresse : https://www.unil.ch/openscience/home/menuinst/open-research-data.html
VAN DEN EYNDEN, Verle et BISHOP, Libby, 2014. Incentives and motivations for sharing research data, a researcher’s perspective. [en ligne]. [Consulté le 01.11.2020]. Knowledge Exchange. Disponible à l’adresse : http://repository.jisc.ac.uk/5662/1/KE_report-incentives-for-sharing-researchdata.pdf
VAN DEN EYNDEN, Verle, KNIGHT, Gareth, VLAD, Anca, RADLER, Barry, TENOPIR, Carol, LEON, David, MANISTA, Franck, WHITWORTH, Jimmy et CORTI Louise, 2016. Survey of Wellcome researchers and their attitudes to open research [en ligne]. [Consulté le 01.11.2020]. DOI : 10.6084/m9.figshare.4055448.v1. Disponible à l’adresse: https://figshare.com/articles/Survey_of_Wellcome_researchers_and_their_attitudes_to_open_research/4055448/1
VELA, Kathryn et SHIN, Nancy, 2019. Establishing a Research Data Management Service on a Health Sciences Campus. Journal of eScience Librarianship. 21.03.2019. Vol. 8, n° 1, p. e1146. DOI : 10.7191/jeslib.2019.1146
VERHAAR, Peter, SCHOOTS, Fieke, SESINK, Laurents et FREDERIKS, Floor, 2017. Fostering Effective Data Management Practices at Leiden University. In : LIBER QUARTERLY. janvier 2017. Vol. 27, n° 1, pp. 1-22. DOI : 10.18352/lq.10185
WALLIS, Jillian C., ROLANDO, Elizabeth et BORGMAN, Christine L., 2013. If We Share Data, Will Anyone Use Them? Data Sharing and Reuse in the Long Tail of Science and Technology. PLoS ONE [en ligne]. 23.07.2013. Vol. 8, n° 7, p. e67332. DOI : 10.1371/journal.pone.0067332. [Consulté le 01.11.2020]. Disponible à l’adresse : https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0067332
WHITMIRE, Amanda L., BOOCK, Michael et SUTTON, Shan C., 2015. Variability in academic research data management practices: Implications for data services development from a faculty survey. In: ANDREW COX, Dr (éd.), electronic library and information systems. septembre 2015. Vol. 49, n° 4, pp. 382-407. DOI : 10.1108/PROG-02-2015-0017
WHYTE, Angus et TEDDS, Jonathan, 2011. Making the Case for Research Data Management. DCC Briefing Papers. Edinburgh : Digital Curation Centre. [en ligne]. [Consulté le 04.11.2019]. Disponible à l’adresse : http://www.dcc.ac.uk/resources/briefing-papers/making-case-rdm
WITTENBERG, Jamie, SACKMANN, Anna et JAFFE, Rick, 2018. Situating Expertise in Practice: Domain-Based Data Management Training for Liaison Librarians. In : The Journal of Academic Librarianship. mai 2018. Vol. 44, n° 3, pp. 323-329. DOI : 10.1016/j.acalib.2018.04.004
YU, Fei, DEUBLE, Rebecca et MORGAN, Helen, 2017. Designing Research Data Management Services Based on the Research Lifecycle – A Consultative Leadership Approach. In : Journal of the Australian Library and Information Association. 14.09.2017. pp. 287-298
Ouverture des données de recherche dans le domaine académique suisse : outils pour le choix d’une stratégie institutionnelle en matière de dépôt de données
Marielle Guirlet, Diplômée du Master en Sciences de l'Information HEG, HES-SO (2020) et assistante de recherche à la HEG-Genève
Ouverture des données de recherche dans le domaine académique suisse : outils pour le choix d’une stratégie institutionnelle en matière de dépôt de données
Introduction
Depuis les années 1990, l’apparition d’Internet permet la mise à disposition en ligne de contenus numériques sans limite matérielle de reproductibilité. L’explosion du volume des données digitales (« data deluge », « digital deluge » ; Pryor 2012 ; Pinfield, Cox et Smith 2014 ; Blumer et Burgi 2015) associée à une augmentation de leur complexité et de leur hétérogénéité pose de nouveaux défis pour leur gestion et leur conservation.
Elle s’accompagne aussi de nouvelles opportunités. Dans le domaine spécifique de la recherche scientifique, le mouvement Open Science pose les bases d’un nouveau fonctionnement de la recherche, basé sur la collaboration. D’abord concentré sur la mise à disposition gratuite et publique des publications scientifiques (la composante Open Access de l’Open Science), il englobe maintenant les autres produits de la recherche, dont les données. Les motivations sous-jacentes de l’ouverture des données sont d’améliorer l’efficacité de la recherche et d’augmenter sa transparence, de faciliter les recherches transdisciplinaires et l’innovation. Elle doit aussi permettre à tout public d’accéder à ce qui a été financé par l’argent public (Foreign Commonwealth Office 2013, Amsterdam Call for Action on Open Science 2016, The Concordat Working Group 2016, Sorbonne declaration on research data rights 2020).
Les chercheurs et les chercheuses peuvent s’engager dans ce mouvement par conviction personnelle. Ils doivent aussi se conformer à des recommandations ou des exigences de la part de leur institution de rattachement, des agences de financement de la recherche ou éventuellement des éditeurs d’articles scientifiques leur demandant de publier leurs données.
Le dépôt de données de recherche (celles-ci sont aussi parfois notées DR dans la suite) est un instrument essentiel de cette démarche. Il permet aux producteurs et productrices de données de partager celles-ci et de les archiver. Il permet à de possibles futurs utilisateurs et utilisatrices de les découvrir et d’y accéder.
Depuis l’ouverture des premiers dépôts (par exemple ICPSR pour les données quantitatives en sciences sociales, ouvert en 1962 (ICPSR [sans date])), de multiples autres dépôts se sont créés. Ils se distinguent par leur finalité principale (donner accès aux données ou préserver les données), la communauté de chercheurs et chercheuses à laquelle ils s’adressent, le fait qu’ils soient rattachés à une institution ou à d’autre formes d’organisations, les technologies sur lesquelles ils s’appuient, ou encore les services qu’ils offrent.
Devant cette diversité, et compte tenu des particularités locales de chaque institution et de ses données de recherche (la discipline de recherche, l’échelle de l’institution, l’existence d’une infrastructure de stockage ou pas), il n’existe pas de dépôt « one size fits all » répondant de manière certaine et exhaustive aux besoins de l’institution. Les chercheurs et les chercheuses, pour répondre correctement aux exigences qui leur sont imposées, peuvent ressentir le besoin d’être conseillé-e-s pour sélectionner le dépôt le plus adapté à leur type de données, à la culture et aux pratiques de leur discipline de recherche. Les institutions, de leur côté, doivent décider d’une stratégie : vers quel(s) dépôt(s) orienter les chercheurs et les chercheuses ? Faut-il créer un nouveau dépôt au risque de multiplier encore les offres possibles ? Faut-il améliorer un dépôt existant ? Quelles fonctionnalités le dépôt doit-il avoir, quels services doit-il proposer ?
Cette problématique a été étudiée en détail dans le cadre d'un travail de Master of Science HES-SO en Sciences de l'information, à la HEG de Genève, Haute Ecole de la HES-SO. Ce travail a été encadré par le Prof. Dr. René Schneider et a été effectué entre mars et août 2020. Ce travail avait pour objectif d’élaborer des outils pour aider les institutions suisses de la recherche publique à définir leur stratégie de soutien aux chercheurs et aux chercheuses pour le partage public de leurs données sur un dépôt. Cet article reprend certains résultats de ce travail, et à ce titre, contient des éléments, des citations et des références du mémoire correspondant (Guirlet 2020).
Après la présentation de la méthodologie et de la démarche, sont ici abordés le contexte de l’Open Science et les exigences posées aux chercheurs et aux chercheuses du milieu académique suisse pour l’ouverture de leurs données de recherche. La partie suivante est consacrée à ce qu’est un dépôt de données de recherche ouvertes, et aux concepts et aux outils importants pour la mise en œuvre de l’ouverture des données sur un dépôt. En prenant aussi en compte des critères d’évaluation de la qualité, une grille de description complète des dépôts de données de recherche ouvertes est alors élaborée. Les principaux résultats de l’étude de la stratégie de neuf institutions académiques suisses, des dépôts qu’elles utilisent et qu’elles recommandent, sont ensuite discutés. Ceci permet de dresser un panorama de ses dépôts de données de recherche ouvertes et d’identifier des bonnes pratiques à partir desquelles sont formulées des recommandations. S’appuyant sur les résultats précédents, les outils proposés aux institutions pour le choix de leur stratégie sont présentés en détail : un vade-mecum permettant le recueil d’informations utiles pour entreprendre la démarche, un guide décisionnel, et des informations complémentaires et des recommandations.
Méthodologie de recherche
Dans un premier temps le travail s’est fait sous forme de recherche théorique, avec la revue de littérature à propos des concepts (données de recherche, dépôts) et des aspects-clés du sujet : le contexte d’ouverture des données de recherche et le rôle des dépôts dans le processus de la recherche. Dans le but de caractériser un dépôt de DR ouvertes et d’élaborer un modèle de description, cette revue de littérature a également couvert les fonctionnalités et les services usuels d’un dépôt, la mise en pratique des services FAIR et les approches d’évaluation de la qualité d’un dépôt.
Lui a succédé une phase de recherche exploratoire et descriptive, pour la revue de l’existant, afin d’identifier et d’analyser les cas à étudier (les institutions académiques et les dépôts utilisés et recommandés). Cette phase s’est appuyée sur la consultation des sites Internet des dépôts et des pages sur la GDR des sites institutionnels.
La troisième phase a englobé la réflexion pour l’analyse et la comparaison de cet existant, la synthèse des résultats et la production des outils décisionnels.
De l’étude théorique à la production des outils finaux, la progression du travail a été jalonnée de plusieurs sous-objectifs associés à des questions de recherche et donnant lieu à des résultats intermédiaires (Tableau 1).
Tableau 1 : Objectifs de recherche, questions de recherche et résultats obtenus
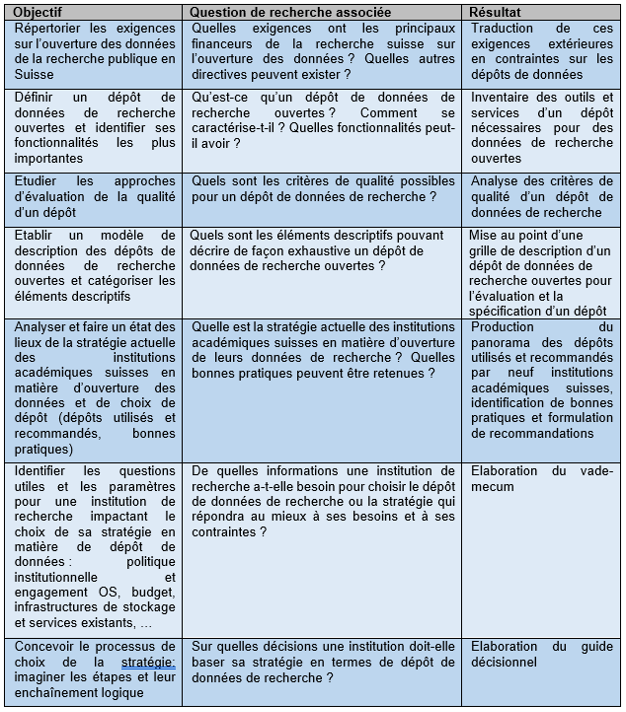
La démarche globale est schématisée sur la Figure 1.
Figure 1 : Schématisation de la démarche
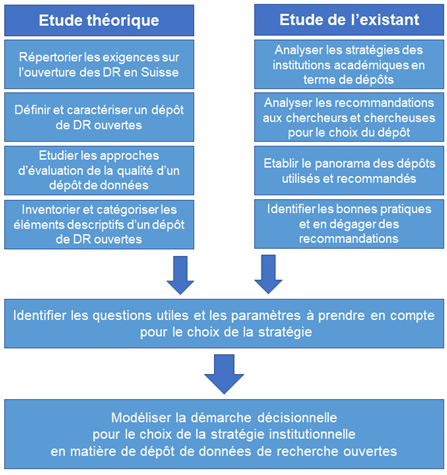
Contexte
Les deux principaux financeurs de la recherche académique suisse, la Commission Européenne et le FNS, imposent des conditions sur les données de recherche des projets qu’ils financent. Dans le cadre du projet pilote ORD Pilot (Open Research Data (ORD) – the uptake in Horizon 2020 2016), pour certaines thématiques de recherche pendant la période 2014-2016, les chercheurs et chercheuses postulant pour le financement de projets de recherche auprès de la Commission Européenne doivent fournir un plan de gestion des données de la recherche (Data Management Plan ou DMP). Ils doivent s’engager dans ce document à partager autant que possible les données issues du projet ou associées aux publications, et y spécifier les conditions de conservation, de documentation et de partage de ces données (European Commission, Directorate-General for Research & Innovation 2016, p.6). Ces obligations sont étendues en 2017 à tous les projets (European Commission, Directorate-General for Research & Innovation 2017, p.8). En pratique, les données de recherche doivent être versées sur un dépôt, de préférence certifié, et être conformes aux principes FAIR (Wilkinson 2016 ; European Commission, Directorate-General for Research & Innovation 2016, p.7).
Le FNS, quant à lui, demande à ce que les données de recherche des projets qu’il finance soient partagées, à moins de « clauses légales, éthiques, de copyright, de confidentialité ou autres », et qu’elles soient déposées avec des métadonnées dans des archives publiques, « dans des formats accessibles et réutilisables sans restriction » (FNS [sans date]a). Les données doivent aussi être rendues conformes aux principes FAIR. Le dépôt utilisé doit être non-commercial (FNS 2020). Comme pour H2020, les demandes de financement de projets auprès du FNS doivent s’accompagner d’un DMP détaillant en particulier les conditions de partage des données. Ce DMP a été rendu obligatoire par le FNS en octobre 2017 (FNS 2017).
Certains éditeurs scientifiques, de leur côté, exigent que les données sous-tendant les publications soient versées sur un dépôt, dans un but de transparence de la recherche publiée (voir par exemple Nature 2016, PLOS ONE [sans date]a, Springer Nature [sans date]a). Sur certains dépôts, ces données sont dans un premier temps partagées seulement avec les reviewer et les éditeurs pendant la phase de revue de la publication, puis elles sont rendues accessibles publiquement une fois que la publication est acceptée (PLOS ONE [sans date]a).
Dans ce contexte, les institutions de recherche accompagnent leurs chercheurs et chercheuses dans la gestion de leurs données pendant l’ensemble du processus de recherche, depuis la planification et l’écriture du DMP jusqu’au versement des données sur un dépôt. Elles encouragent ainsi l’usage de bonnes pratiques, favorisent la mise en pratique de leur politique institutionnelle pour la GDR et leur engagement en Open Science, et aident leurs chercheurs et chercheuses à se conformer aux exigences des financeurs de leur recherche et des éditeurs de leurs publications. En ce qui concerne les dépôts de données de recherche, elles émettent des recommandations sur le choix du dépôt le plus adapté sur lequel verser les données.
Données de recherche ouvertes et dépôts de DR ouvertes
Des données sont ouvertes si on peut y accéder librement et si elles peuvent être utilisées, modifiées et partagées librement, dans n’importe quel but et par n’importe qui, sous condition d’en attribuer l’origine à leurs auteur-e-s (The Concordat Working Group 2016 ; Hodson, Jones et al. 2018).
Selon le rapport Science as an Open Enterprise (The Royal Society 2012), les données de recherche ouvertes doivent être « assessable and intelligible » : on doit pouvoir évaluer leur qualité, leur pertinence et leur utilité pour envisager de les réutiliser. On doit pouvoir les interpréter et les comprendre pour les réutiliser correctement. Cette notion d’interprétation contextuelle est d’ailleurs présente dans la définition des données de recherche par The Consultative Committee for Space Data Systems (2012, p. 1–10) :
« A reinterpretable representation of information in a formalized manner suitable for communication, interpretation, or processing. »
Ces données ouvertes sont accessibles publiquement, généralement sur un dépôt de données, à partir duquel on peut les chercher, les extraire, et les télécharger (Johnston et al. 2017, p.3), sans restriction de copyright, de droits de brevets ou d’autres mécanismes de contrôle (Jong et al. 2020).
D’après l’Université de Genève ([sans date]) :
« un dépôt de données (data repository) est un terme général utilisé pour désigner un lieu pour le stockage des données ».
L’Université de Boston citant le Registry of Research Data Repositories (Re3data) donne la définition suivante du dépôt de données de recherche (Boston University Data Services [sans date]):
« a subtype of a sustainable information infrastructure which provides long-term storage and access to research data that is the basis for a scholarly publication »
mentionnant ainsi les deux objectifs de ce type d’infrastructure, le stockage et l’accessibilité des données de recherche sur le long terme.
Avec sa définition du dépôt, le Data Curation Network souligne aussi l’importance de la notion de services (Johnston et al. 2016) :
« A digital archive that provides services for the storage and retrieval of digital content »
Selon le modèle du Data Curation Continuum de Treloar, Groenewegen et Harboe-Ree (2007), le dépôt intervient à différents moments du processus de la recherche. Un dépôt est utilisé pour partager les données d’un projet de façon publique vers la fin de celui-ci. Il est aussi utilisé pour préserver les données à long terme après la fin du projet (Treloar, Groenewegen et Harboe-Ree 2007 ; Treloar 2012).
Les dépôts ayant pour mission principale le partage des données répondent à l’objectif de donner accès à celles-ci le plus vite possible (approche plus orientée Open Science). Les dépôts ayant pour mission principale la préservation des données répondent à l’objectif de préserver celles-ci le plus longtemps possible (approche plus orientée archivage), tout en assurant pour certains d’entre eux l’accessibilité des données. Dans la suite, on prendra en compte les deux types de dépôts, pour autant que les dépôts de type préservation garantissent aussi l’accès aux données. Certains dépôts mettent à disposition les données de façon ouverte par défaut, mais permettent aussi aux dépositaires de restreindre l’accès à leurs données (par exemple Zenodo (zenodo [sans date]a) et Harvard Dataverse (Dataverse project [sans date]). On prend également en compte ce type de dépôt. La Figure 2 illustre les dépôts de données utilisés au cours du processus de recherche et ceux auxquels on s’intéresse dans le cadre de cette étude.
Figure 2 : Types d’espaces de stockage et de dépôts de données, et niveau de partage selon la progression de la recherche
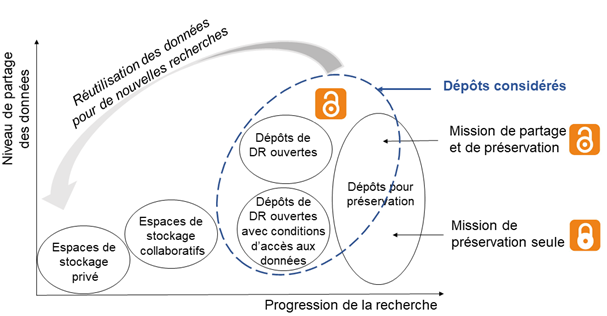
Les dépôts de données prennent diverses formes selon cette mission principale (accessibilité à court terme ou préservation sur le plus long terme), mais aussi selon la communauté à laquelle ils s’adressent (dépôt disciplinaire ou généraliste), leur entité de rattachement (dépôt institutionnel ou pas), leur business model (commercial ou à but non lucratif), le type de technologies qu’ils utilisent (open source ou propriétaires). Comme on va le voir dans la suite, les dépôts se distinguent aussi les uns des autres selon les fonctionnalités et les services qu’ils fournissent, et la façon dont ceux-ci sont déclinés. On peut évoquer par exemple le niveau de curation appliqué aux données déposées, le type d’identifiant pérenne attribué aux données, les standards utilisés pour les métadonnées, la possibilité de mettre les données sous embargo, et évidemment le niveau d’ouverture des données. Certains de ces services peuvent dépendre éventuellement de la catégorie de dépôt (disciplinaire ou généraliste).
Modèle de description d’un dépôt de DR ouvertes
Outils et services
Selon les définitions données plus haut, le dépôt de DR peut donc se définir comme une infrastructure informatique qui stocke des données et les rend accessibles sur le long terme. Ces deux finalités font partie des principes FAIR sur les données (Wilkinson et al. 2016), qui, on le rappelle, selon le FNS et H2020, doivent être appliqués par les dépôts utilisés pour partager ses données.
Les principes A (Accessibilité) et R (Réutilisation) de FAIR correspondent directement aux objectifs du dépôt de rendre et de maintenir les données accessibles et réutilisables. Pour appliquer le principe F (Findability ou Découvrabilité), le dépôt doit rendre les données recherchables et trouvables par des humains et par des machines. L’application du principe I (Interopérabilité) permet l’échange efficace de contenu (données, métadonnées) entre chercheurs et chercheuses, entre institutions, entre systèmes, et par des machines aussi bien que par des humains, pour une utilisation la plus large possible (Swiss National Science Foundation [sans date]).
Comme noté par Hodson, Jones et al. (2018), les principes FAIR et l’ouverture des données (aboutissant à des données librement utilisables, modifiables et partageables, selon les définitions vues plus haut) ont en commun l’objectif ultime de contribuer à la réutilisabilité des données. Néanmoins, des données accessibles selon le principe A de FAIR ne sont pas forcément ouvertes. Pour autant que cela n’aille pas à l’encontre de restrictions légitimes à leur ouverture (concernant en particulier les données personnelles et les données sensibles), les données hébergées par les dépôts, en plus d’être FAIR, doivent donc être rendues ouvertes.
Les quatre grands principes FAIR et l’ouverture des données sont mis en pratique par les dépôts à l’aide de services et d’outils spécifiques (FNS [sans date]b, Swiss National Science Foundation [sans date], Perini 2019).
Identifiants uniques pour les données : un identifiant unique permet de trouver, de citer et de tracer les données auxquelles il est assigné. On peut l’utiliser afin de citer les données utilisées pour obtenir les résultats présentés dans une publication, afin de se référer aux données d’origine lorsqu’on décrit des données secondaires, ou encore dans la liste de ses jeux de données ou sur son profil ORCID pour la description de ses activités de recherche. Les identifiants uniques pour les données doivent être pérennes (PID) et globaux (c’est-à-dire non internes au dépôt). Le DOI, délivré contre rétribution par Datacite (Datacite [sans date]) est couramment utilisé. Les principaux autres identifiants uniques sont les suivants : ARK (utilisé par le dépôt DaSCH ([sans date])), Handle ou hdl (utilisé par B2SHARE EUDAT; Re3data.org 2017), PURL, URN et RRID (Digital Preservation Coalition [sans date], Swiss National Science Foundation [sans date]).
Métadonnées : la description des données et de leur contexte, essentielle comme on l’a vu pour une possible réutilisation des données, est assurée en grande partie par les métadonnées. En plus du contexte et de la provenance des données, celles-ci détaillent la structuration et le contenu des jeux de données (EPFL Library, Research Data Library Team [sans date]). Elles aident ainsi à découvrir les données, à y accéder, à connaître leurs conditions de réutilisation (informations utiles pour les utilisateurs et utilisatrices), et à les gérer (pour le dépôt).
La structuration des métadonnées sous une forme interprétable par les machines permet l’automatisation de leur traitement (lecture, recherche, extraction) (Johnston et al. 2018). Les dépositaires doivent alors fournir ces métadonnées par le biais de formulaires conformes à des schémas standards. On utilise fréquemment les schémas Dublin Core (Dublin Core 2020, Dublin Core Metadata Initiative 2020) et DataCite Metadata (DataCite Metadata Working Group 2019, DataCite [sans date]) pour les métadonnées descriptives. Dans le cas de dépôts spécialisés, des métadonnées supplémentaires peuvent être fournies suivant le schéma couramment utilisé dans le domaine de recherche ou dans la discipline (schéma DDI pour les sciences sociales par exemple). Certains dépôts (ou solutions techniques) proposent d’utiliser son propre standard pour les métadonnées ou d’étendre celui proposé par défaut (Dryad, B2SHARE EUDAT, OLOS, Figshare ; Guirlet 2020, Annexes 4 et 5).
Formats des fichiers : l’utilisation de formats conformes à des standards ouverts, disponibles publiquement et non propriétaires pour les fichiers de données et de métadonnées permet une utilisabilité à la fois par un plus grand nombre de chercheurs et chercheuses mais aussi sur le plus long terme. Les dépôts publient souvent à l’intention des dépositaires des listes de formats recommandés et acceptables(1). Certains dépôts assurent la migration des formats lorsque celui des fichiers versés n’est pas pérenne. Dans le cas d’une préservation à long terme, une veille régulière du risque d’obsolescence des formats déclenche le cas échéant des actions préventives, dont cette migration des formats (Rosenthaler, Fornaro et Clivaz 2015 ; L’Hours, Kleemola et de Leeuw 2019). C’est le cas du dépôt suisse FORSbase (DARIS 2018, p.29). Sur les dépôts disciplinaires, la conformité des formats à des standards spécialisés permet aussi aux utilisateurs et utilisatrices de les manipuler et de les interpréter selon leurs pratiques usuelles.
Citation des données : la formule de citation des données est générée automatiquement à partir des métadonnées descriptives (avec Datacite par exemple, si elles sont conformes au schéma DataCite Metadata). Elle est fournie aux utilisateurs et utilisatrices en même temps que les données récupérées. Dans les conditions et les termes sur la réutilisation des données de certains dépôts, ces utilisateurs s’engagent à citer les données de la façon qui leur est suggérée (voir par exemple FORS [sans date]). Sur FORSbase, ceux-ci s’engagent en outre à informer le dépôt de toute publication basée sur la réutilisation des données, permettant ainsi le traçage de cette réutilisation (FORS [sans date]).
Conditions de réutilisation et restrictions d’accès : le dépôt doit préciser les conditions de réutilisation des données, au moyen d’une licence sur les données ou des termes du copyright. La définition des données ouvertes de CASRAI(2) est la suivante (CASRAI [sans date]b):
« Structured data that are accessible, machine-readable, usable, intelligible, and freely shared. Open data can be freely used, re-used, built on, and redistributed by anyone – subject only, at most, to the requirement to attribute and sharealike. »
Selon CASRAI, les contraintes pour la réutilisation des données sont donc au maximum d’attribuer l’origine des données à leurs auteur-e-s et de les partager à l’identique. Les licences Creative Commons correspondantes sont les licences CC0, CC BY, et CC BY-SA, la licence CC0 étant celle dont l’ouverture est la plus élevée (Creative Commons [sans date]). Dans la suite, on considérera que les dépôts proposant une ou plusieurs de ces trois licences, pour au moins une partie de leurs données, hébergent des données ouvertes(3).
Sur certains dépôts, les dépositaires ont la possibilité de restreindre l’accès à leurs données : accès sur demande, accès privé (groupe de personnes identifiées) ou mise sous embargo. Aucune de ces configurations ne convient pour des données ouvertes, mais des données à l’accès restreint peuvent facilement devenir des données ouvertes, à la fin de la période d’embargo ou si les dépositaires suppriment les restrictions à la fin du projet. Restreindre l’accès pour des données personnelles ou sensibles dans le but de respecter leur confidentialité n’est pas approprié (elles resteront toujours consultables par les gestionnaires du dépôt). Par contre, une fois anonymisées, les données personnelles et les données sensibles peuvent être publiées (EPFL Library [sans date], Université de Lausanne [sans date]a).
Curation des données et des métadonnées : selon le Data Curation Network, la curation des données facilite leur découvrabilité et leur récupération, et contribue à leur réutilisabilité dans le temps (Johnston et al. 2017). Une définition plus complète des objectifs de la curation, incluant aussi le maintien de la qualité et l’ajout de valeur, est donnée par Cragin et al. (2007):
« Data curation is the active and on-going management of data through its lifecycle of interest and usefulness to scholarship, science, and education; curation activities enable data discovery and retrieval, maintain quality, add value, and provide for re-use over time. »
En pratique, elle consiste d’abord à préparer les données qui ont été sélectionnées afin qu’elles remplissent les conditions d’accès imposées par le dépôt : nommage des fichiers et des dossiers, structuration du jeu de données, changement de format éventuel et autres. La curation a aussi pour rôle de rendre et de maintenir les données FAIR, et de vérifier et de contrôler leur qualité. Les activités correspondantes incluent la création de métadonnées, la préparation de documentation, la vérification, la validation et l’enrichissement des données et des métadonnées. Elle peut aussi vérifier la conformité des données ou les rendre conformes aux règles légales et aux normes éthiques. Pour un détail des activités de curation, on peut consulter Johnston et al. (2016, 2017, 2018) et Johnston (2017).
Certaines activités de curation sont plus appliquées à la préservation. Elles concernent le maintien de la qualité des données sur le plus long terme, le soutien à leur préservation et leur transformation si nécessaire avec notamment la migration des formats mentionnée ci-dessus (Data Curation Network [sans date]). Des efforts supplémentaires sont aussi à fournir pour surveiller l’évolution possible des pratiques et des besoins au sein de la communauté cible. Si besoin, la curation met en œuvre les mesures d’adaptation nécessaires, telles que l’utilisation de nouveaux formats et standards pour le dépôt, l’utilisation de métadonnées plus riches, ou la mise à jour de la documentation.
Sur certains dépôts, les tâches de curation sont assurées par des « data steward » (OLOS 2020a) ou par des « data curator » (Dryad [sans date]).
Services complémentaires : outre les grandes fonctions assurées par les dépôts de données (l’ingestion, le stockage et la gestion des métadonnées et des données, et leur mise à disposition), ceux-ci proposent fréquemment des services complémentaires facilitant la visibilité et la découvrabilité des données.
Le résultat du moissonnage automatique de métadonnées conformes au schéma Dublin Core est utilisé par des services d’agrégation, des portails et des moteurs de recherche (tels que Google Dataset Search et Elsevier DataSearch) et renforce ainsi la visibilité des données à l’externe. Le protocole OAI-PMH est l’un des protocoles standards et/ou ouverts permettant ce moissonnage. Le dépôt doit disposer de l’interface OAI et s’enregistrer comme fournisseur de métadonnées auprès du service OAI-Data Provider de l’Open Archives Initiative (OAI) (DINI 2011, p.14, p.35). Thomson Reuters’ Data Citation Index moissonne aussi le contenu des dépôts pour tracer les citations de données dans la littérature (Rice et Southall 2016, p.118).
Le web sémantique avec les Linked Open Data relie des entités décrites de façon structurée selon le cadre RDF, qui fournit un modèle pour la représentation, l’échange et l’interconnexion des métadonnées. Convertir les métadonnées en RDF et les exposer permet de les connecter à d’autres entités du web, et ce faisant, d’augmenter la découvrabilité des données auxquelles sont associées ces métadonnées (Arlitsch et al. 2016, Rice et Southall 2016).
Avec certains dépôts, on peut faire le lien entre ses données déposées et sa page personnelle ORCID (par exemple avec Figshare [sans date]) ou avec les pages de ses projets (par exemple depuis Zenodo vers la page du projet sur le portail OpenAIRE ; zenodo [sans date]f). On peut parfois relier les publications et les données les sous-tendant (ETHZ Research Collection, ETHZ – ETH Bibliothek [sans date]), ou les données et le code qui a servi à les produire (zenodo [sans date]f), alors que ces éléments sont hébergés sur des dépôts distincts (par exemple PLOS pour les publications, GitHub pour le code). Les dépôts permettant de faire ce type de liens reconnaissent les identifiants ORCID et GitHub. Ces fonctionnalités sont là encore un moyen de favoriser la visibilité des données.
Un outil de recherche avancée sur le site du dépôt est utile pour l’exploration et la découvrabilité des données. Des outils de visualisation donnent un premier aperçu du contenu des fichiers. L’information disponible sous forme de guide utilisateur et de rubrique FAQ renseigne sur le dépôt en général, sur les conditions d’hébergement ou sur les procédures de versement des données. Les réseaux sociaux, un forum ou un blog sont des moyens d’accéder à une communauté d’usagers et d’usagères du dépôt. Enfin, les métriques et les statistiques d’usage sur la fréquentation du dépôt rendent compte de son dynamisme et permettent d’évaluer si le dépôt est bien utilisé et reconnu par cette communauté. Quand ces métriques concernent les jeux de données eux-mêmes (nombre de vues et de téléchargements), elles donnent aux dépositaires une estimation de l’intérêt porté à leurs données.
Les outils et les services d’un dépôt de données de recherche hébergeant des données conformes aux principes FAIR et ouvertes sont schématisés sur la Figure 3.
Figure 3 : Les outils et services d’un dépôt de données de recherche ouvertes
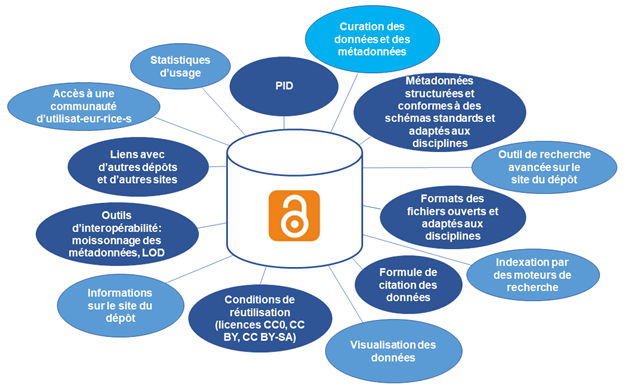
Critères de qualité
Les objectifs du dépôt de DR ouvertes sont donc de rendre et de maintenir les données accessibles et réutilisables à partir du moment du versement et dans le futur. Assurer que le dépôt est en capacité de remplir ces objectifs instaure la confiance des parties prenantes (présentées sur la Figure 4 avec leurs contributions et leurs attentes par rapport au dépôt de données). Cela leur garantit que les données sont en effet accessibles et réutilisables, mais aussi qu’elles sont conservées de façon sûre et qu’elles sont traçables (pour les agences de financement), qu’elles sont visibles et citables (pour les producteurs et productrices de données), et qu’elles sont fiables et de bonne qualité (pour les utilisateurs et utilisatrices).
Figure 4 : Parties prenantes du dépôt de DR ouvertes avec leurs contributions et leurs attentes
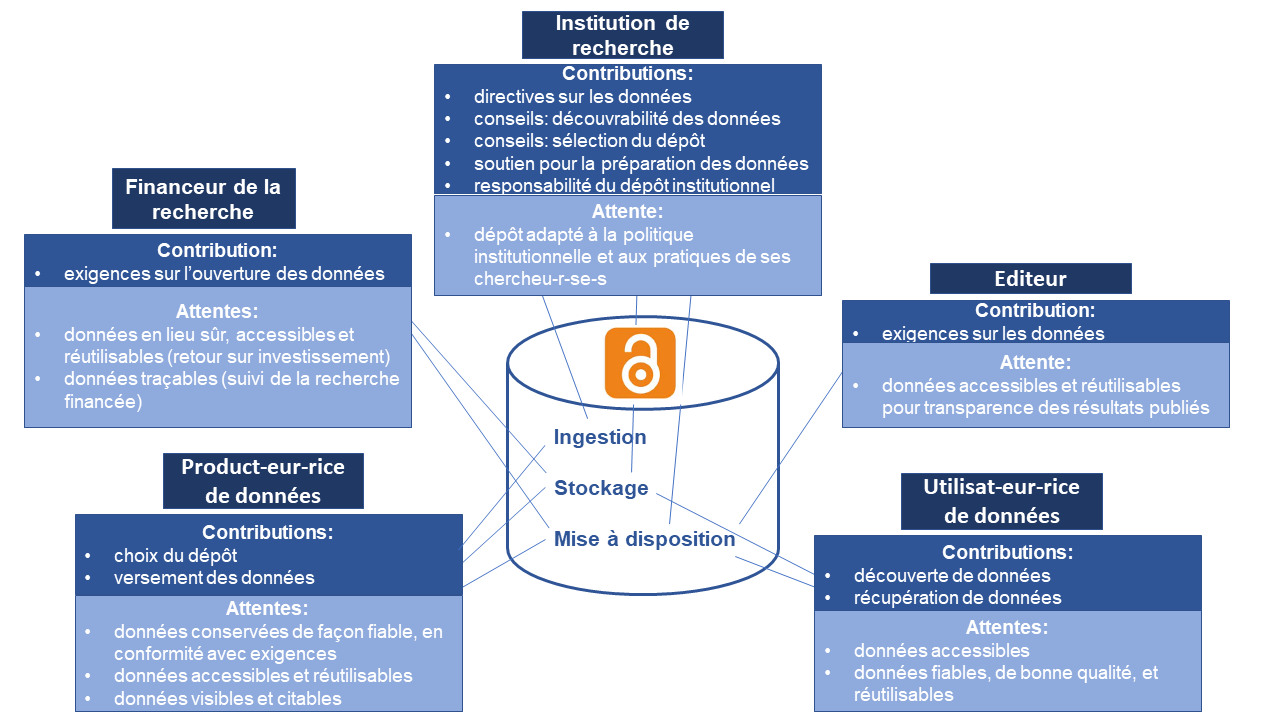
Depuis les années 1990, plusieurs démarches sur la base de normes et de standards ainsi que des certifications ont été élaborées pour évaluer de façon indépendante la qualité et la fiabilité d’un dépôt sur le long terme. Selon UK Data Archive, Standards of Trust (cité par l’Université d’Edimbourg, The University of Edinburgh 2019):
« The standards provide the basis of a framework by which different levels of trust of digital repositories can be demonstrated ».
Le cas échéant, le dépôt est reconnu « dépôt de confiance » (trusted digital repository, trustworthy digital repository).
L’approche d’évaluation de la qualité d’un dépôt la plus récente et la plus utilisée (Guirlet 2020, Tableau 14) est la Certification CoreTrustSeal mise au point en 2017 par un groupe de travail de la RDA, à partir de DSA et ICSU-WDS (Dillo et de Leeuw 2018 ; Corrado 2019 ; L’Hours, Kleemola et de Leeuw 2019). Les critères sont révisés tous les trois ans et la version la plus récente couvre maintenant la période 2020-2022 (CoreTrustSeal 2020a).
Plusieurs critères de CTS font référence aux standards du modèle OAIS (The Consultative Committee for Space Data Systems 2012) pour évaluer la fiabilité du dépôt à long terme (critères R9, R15 ; CoreTrustSeal 2020a). Le respect de cinq principes fondamentaux sur les données atteste que les données numériques sont archivées de façon durable. Selon ces principes, les données doivent être trouvables sur Internet, être accessibles en tenant compte de la législation en vigueur sur les informations personnelles et la propriété intellectuelle des données, être disponibles sous un format utilisable, être fiables et être référençables (Dillo et de Leeuw 2018). Enfin, un rôle important est donné à la qualité des métadonnées pour assurer la découvrabilité et l’accessibilité des données (ceci impliquant l’intervention de personnel qualifié ou la contribution d’expert-e-s externes), et à l’évaluation de la qualité de ces métadonnées. On pourrait d’ailleurs décrire de façon schématique la certification CTS comme une approche d’évaluation d’un dépôt englobant à la fois les exigences OAIS pour sa fiabilité à long terme, les principes FAIR sur les données pour leur accessibilité et leur réutilisabilité, et des critères sur la qualité des données et des métadonnées.
Les critères de certification CTS sont organisés en trois catégories, selon le Tableau 2.
Tableau 2 : Catégories de critères CTS
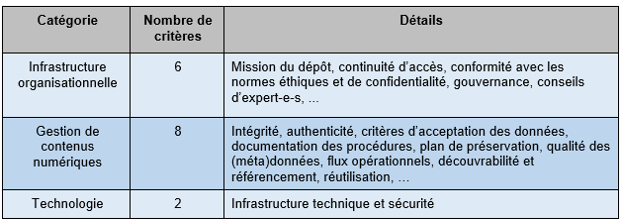
(d’après CoreTrustSeal 2020b; CoreTrustSeal Standards and Certification Board 2020; Corrado 2019)
Elaboration du modèle
L’ajout à ces trois catégories de critères d’une nouvelle catégorie englobant les outils et les services d’un dépôt décrits précédemment permet de faire l’analogie avec la représentation par couches du système d’information d’une entreprise selon Hewlett (2006) (voir la Figure 5 ci-dessous). Dans cette représentation, l’infrastructure organisationnelle forme la base de la pyramide. Viennent ensuite l’infrastructure technique et les technologies, puis la gestion des données. Les services aux usager-e-s du dépôt forment la couche du sommet de la pyramide.
Figure 5 : Représentation par couches d’un dépôt de DR par analogie avec l’architecture du système d’information d’une entreprise
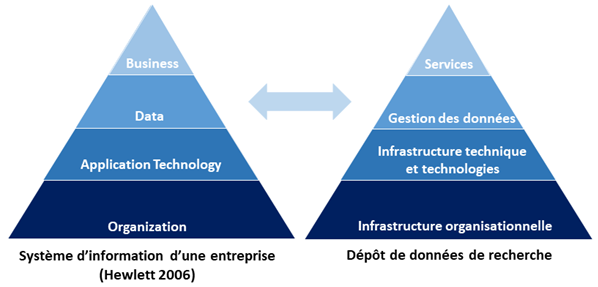
En pratique, dans le but de traduire cette conception du dépôt de DR ouvertes en une grille de description détaillée, plusieurs sources sont considérées pour identifier les éléments de cette grille :
- les critères d’évaluation de la qualité utilisés pour la certification CTS ;
- les outils et services d’un dépôt décrits plus haut et identifiés à partir de la revue de la littérature ; les éléments descriptifs correspondants ont été affinés grâce à une revue détaillée des dépôts généralistes, disciplinaires et institutionnels utilisés en Suisse (voir Guirlet 2020, Annexes 4 et 5).
On y ajoute des éléments supplémentaires permettant d’assurer la conformité aux exigences des financeurs de la recherche (e.g., dépôt non-commercial exigé par le FNS), au cadre légal, aux normes éthiques et disciplinaires en vigueur (gestion adéquate des données personnelles et sensibles), ainsi que des éléments relatifs à la qualité de l’expérience utilisateur ou utilisatrice (e.g., convivialité du site, facilité du versement, …). La grille complète ainsi produite est donnée dans Guirlet (2020).
Cette grille de description peut être utilisée soit pour évaluer un dépôt existant (et aussi dans le but éventuel de l’améliorer), soit pour spécifier un dépôt à créer. La mise en œuvre satisfaisante de tous les aspects décrits par les éléments du modèle, que le dépôt existe déjà ou qu’il soit à l’état de projet, assure que ce dépôt est de qualité (car conforme aux critères CTS), qu’il héberge des données accessibles et réutilisables, conformes aux principes FAIR et ouvertes, et qu’il répond aux exigences des principaux financeurs de la recherche, ainsi qu’au cadre légal et aux normes sur la gestion des données personnelles et sensibles.
Panorama des dépôts utilisés et recommandés en Suisse
Dans le but d’établir un état des lieux des dépôts utilisés par les chercheurs et les chercheuses et recommandés par les institutions académiques en Suisse, la stratégie des plus engagées d’entre elles en termes d’ouverture des données de recherche (soit neuf institutions) a été passée en revue. Pour chaque institution en particulier, on a identifié, s’ils existent, le dépôt institutionnel de données ou de publications, le dépôt de données en projet, les dépôts disciplinaires développés dans le cadre d’un partenariat entre institutions, ainsi que les dépôts de données recommandés. Le détail de cette revue et les références bibliographiques associées sont donnés dans Guirlet (2020, Annexe 5). Elaborée sur la base de celle-ci mais en prenant aussi en compte l’ouverture récente d’OLOS (OLOS 2020b), la Figure 6 mentionne ces différents dépôts.
Figure 6 : Dépôts institutionnels et dépôts de DR recommandés pour neuf institutions académiques suisses ((p) : dépôt pour publications seulement; (p+d) : dépôt pour publications archivant aussi des DR ; disc. : disciplinaire)
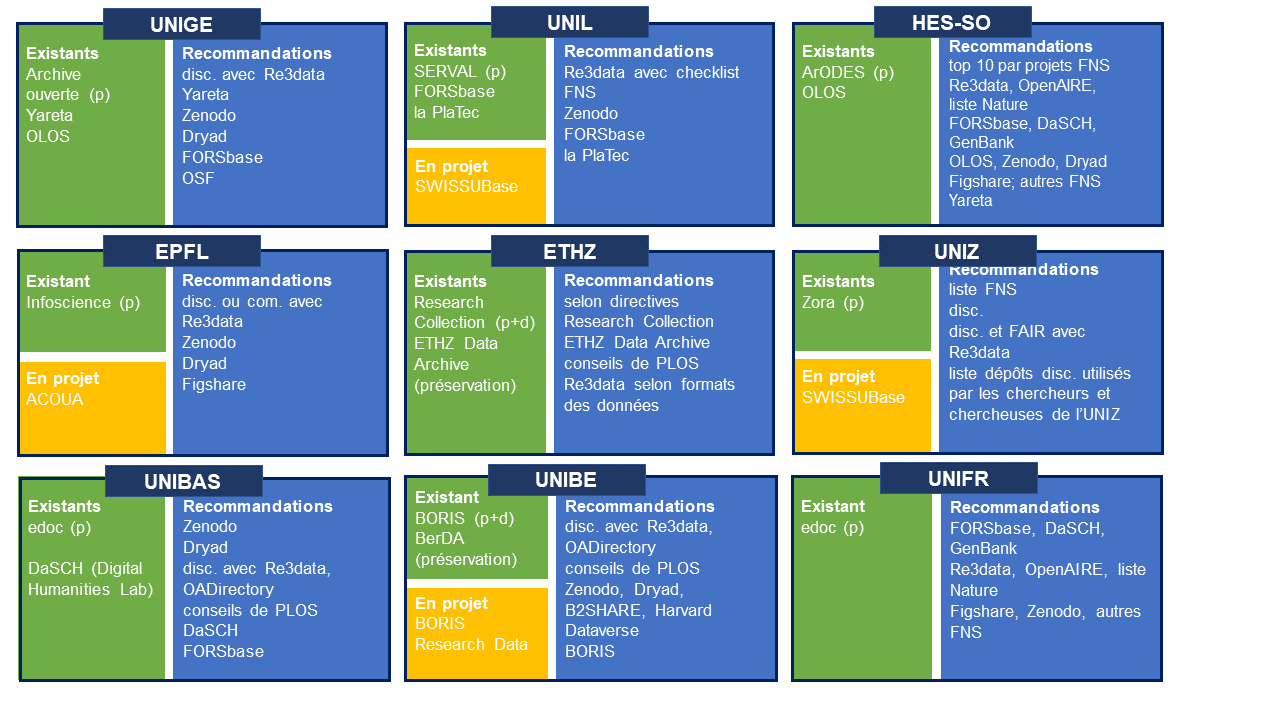
(d’après les sources données dans Guirlet 2020, Annexe 5)
Cette revue met en lumière les différents cas de figure suivants selon les institutions (avec des recoupements possibles).
- L’existence d’un dépôt de données institutionnel (Research Collection et Data Archive pour l’ETHZ ; BerDA pour l’Université de Berne) ;
- l’existence d’un dépôt à l’échelle cantonale (Yareta pour l’Université de Genève et pour la HES-SO), d’un dépôt à l’échelle nationale (OLOS, développé par l’Université de Genève et la HES-SO dans le cadre du projet DLCM) ou d’un dépôt disciplinaire auquel a contribué une entité de l’institution (DaSCH pour l’Université de Bâle ; FORSbase et la PlaTec pour l’Université de Lausanne) ;
- un projet de dépôt institutionnel (ACOUA pour l’EPFL) ou en partenariat avec d’autres institutions (SWISSUbase pour l’Université de Lausanne et l’Université de Zurich);
- un projet d’extension de l’archive institutionnelle de publications (BORIS Research Data pour l’Université de Berne) ;
- l’absence de dépôt institutionnel pour les données et pas de projet formulé pour en développer un (Université de Fribourg).
Ces institutions émettent toutes des recommandations pour le choix du dépôt de données de recherche (pour le détail, voir Guirlet 2020, Annexe 5). Celles-ci varient en fonction des disciplines de recherche au sein de l’institution, et de l’existence ou pas d’un dépôt institutionnel. Ces recommandations peuvent s’appuyer sur les exigences des agences de financement (FNS, H2020), et se référer aux conseils donnés par des éditeurs scientifiques (PLOS ONE [sans date]b, Springer Nature [sans date]b). Elles suivent aussi fréquemment les conseils du FNS, qui donne quatre exemples de dépôts généralistes répondant à ses exigences : Zenodo, Dryad, EUDAT et Harvard Dataverse (Swiss National Science Foundation 2017).
Du fait de la spécialisation et de l’expertise des dépôts disciplinaires, il est fréquent que les recommandations faites aux chercheurs et aux chercheuses orientent vers le dépôt disciplinaire adapté à leur spécialité avant un dépôt généraliste ou même avant le dépôt institutionnel. La position de l’Université de Berne sur ce point est bien marquée (Universität Bern, [sans date]a):
« Wherever possible, data should be deposited in disciplinary repositories. These are designed to meet the needs of the particular field, are aware of specific data formats and often also offer specific disciplinary metadata. »
L’utilisation de registres de dépôts tels que Re3data et ses filtres (Re3data.org [sans date]) pour la prise en compte d’autres critères est conseillée. Deux institutions renvoient aussi vers les pratiques d’une communauté : l’UNIZ fait référence aux dépôts utilisés par ses chercheurs et chercheuses (Universität Zürich, Hauptbibliothek 2019), et la HES-SO mentionne les pratiques des bénéficiaires de subsides FNS (HES-SO [sans date]).
Le Tableau 3 reprend les recommandations des neuf institutions pour le choix du dépôt.
Tableau 3 : Synthèse des recommandations des neuf institutions étudiées pour le choix du dépôt de données
Les recommandations d’une institution correspondent aux cellules marquées en bleu clair. Les recommandations des cellules marquées en bleu foncé sont celles d’une institution pour son propre dépôt institutionnel (marquage étendu à FORSbase et à la PlaTEC pour l’UNIL, à DaSCH pour UNIBAS et à Yareta et à OLOS pour UNIGE et la HES-SO).
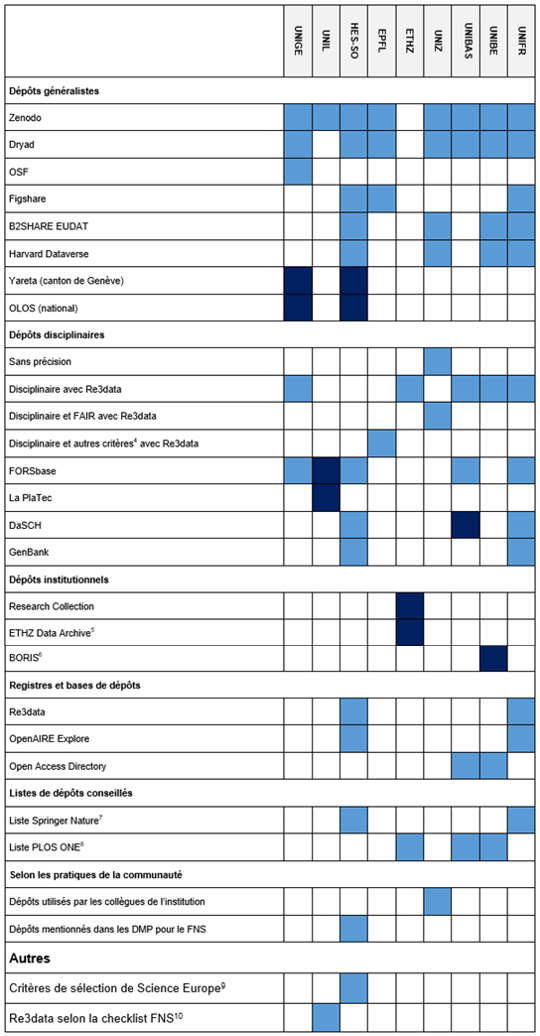
(4)(5)(6)(7)(8)(9)(10)
(d’après les sources données dans Guirlet 2020, Annexe 5)
Bonnes pratiques observées
A partir de l’étude de la stratégie de ces institutions, on peut également dégager des exemples de bonnes pratiques sur plusieurs aspects.
Découvrabilité des données : parmi les ressources en ligne fournies, seules l’Université de Zurich et l’Université de Bâle donnent des conseils ou mentionnent des outils (tels que des registres et des moteurs de recherche) pour la recherche et la découvrabilité de données sur des dépôts (Universität Basel [sans date] ; Universität Zürich, Hauptbibliothek 2020). Les autres institutions, sans doute plus concentrées sur la conformité aux exigences des financeurs de la recherche, conseillent surtout sur la sélection d’un dépôt de données adapté. Etendre les conseils à la découvrabilité des données et à leur réutilisation est néanmoins essentiel pour donner sa pleine place au dépôt comme instrument de partage et de réutilisation des données.
Suivi des pratiques : on a mentionné précédemment que l’Université de Zurich, parmi ses recommandations pour le choix du dépôt, fournit une liste des dépôts fréquemment utilisés par ses chercheurs et chercheuses (Universität Zürich, Hauptbibliothek 2019). Pour toute institution, un suivi précis des dépôts utilisés et du nombre de jeux de donnés versés par dépôt peut lui fournir un état des lieux des pratiques de ses chercheurs et chercheuses. Ces informations sur les pratiques sont normalement fournies dans le DMP du projet. Rendre ce DMP obligatoire en interne permet ainsi à l’institution de suivre les pratiques institutionnelles. De même, tenir compte des données partagées par les chercheurs et les chercheuses pour évaluer leur carrière académique (voir plus bas), outre le fait d’inciter à partager ces données, permet aussi à leur institution d’affiliation de tracer ces données et les modalités de leur partage.
L’analyse par Milzow et al. (2020, fig.5) des DMP des projets financés en 2017-2018 par le FNS a identifié les dépôts qui y sont mentionnés en prévision du versement des données de recherche à la fin des projets. Comme mentionné plus haut, la HES-SO s’appuie sur la liste des dépôts les plus cités dans ces DMP pour ses recommandations sur le choix du dépôt (HES-SO [sans date]). La rédaction du DMP ayant été rendue obligatoire par le FNS en octobre 2017 (FNS 2017), et les projets correspondants arrivant prochainement à terme, il serait intéressant, en se basant sur la version finale des DMP, de faire un suivi des versements effectués (nombre de jeux de données, dépôts utilisés), éventuellement par discipline(11) et par institution. Ce suivi pourrait être utilisé par chaque institution pour éventuellement modifier sa stratégie, en ajustant ses recommandations pour le choix du dépôt ou en intensifiant ses efforts de sensibilisation et de communication, ou encore pour adapter ses mesures d’incitation.
Evaluation des chercheurs et des chercheuses : certaines données de stockage et d’utilisation des contenus hébergés par BORIS (dépôt pour publications) sont exploitées dans le processus d’évaluation de la recherche de l’Université de Berne (Universität Bern [sans date]b). Toutes les institutions étudiées ici sont signataires de la Déclaration de San Francisco sur l’évaluation de la recherche (DORA ou San Francisco Declaration on Research Assessment 2012, 2020), s’engageant ainsi à prendre en compte la valeur et l’impact des produits de la recherche autres que les publications. Un des moyens possibles de mettre en pratique cet engagement consiste à considérer également les métriques sur les dépôts de données de recherche ouvertes (le nombre de jeux de données et de téléchargements, le suivi de la réutilisation) par chercheur ou chercheuse, par projet, par département, pour l’évaluation académique.
Mesures d’incitation et visibilité des pratiques par communauté : les mesures pour inciter à adopter de meilleures pratiques en gestion des données de recherche peuvent prendre diverses formes. La HES-SO a lancé un appel à projet pour l’obtention de fonds complémentaires soutenant le versement des données de recherche sur un dépôt FAIR (HES-SO 2020). L’EPFL, quant à elle, a mis en place une communauté de Data Champions, reconnus pour leur expertise et leurs bonnes pratiques en GDR, et offre visibilité et soutien à cette communauté (EPFL [sans date]). Sur ce modèle, toute institution pourrait aussi attribuer aux chercheurs et chercheuses qui partagent publiquement un grand nombre de données sur des dépôts des badges Open Science (Center for Open Science [sans date]), afin de reconnaître et de mettre en avant leurs bonnes pratiques. L’Université de Lausanne, de son côté, incite à ouvrir sur Zenodo des espaces communautaires par faculté (Université de Lausanne [sans date]b). Plusieurs autres institutions ou départements d’institutions y disposent déjà de leur espace communautaire(12). Sur des dépôts généralistes, cette organisation en communauté de pratiques et d’intérêt donne de la visibilité aux données de recherche par institution, et par faculté ou par département, et facilite le suivi des versements, selon la recommandation faite précédemment. Elle contribue aussi à l’identification et à la centralisation des données d’un domaine particulier, donnant ainsi une chance supplémentaire à ces données d’être découvertes et réutilisées.
Le Tableau 4 synthétise les recommandations que l’on peut formuler à l’adresse des institutions de recherche à partir de l’observation de ces bonnes pratiques.
Tableau 4 : Recommandations à l’adresse des institutions de recherche, basées sur les bonnes pratiques observées
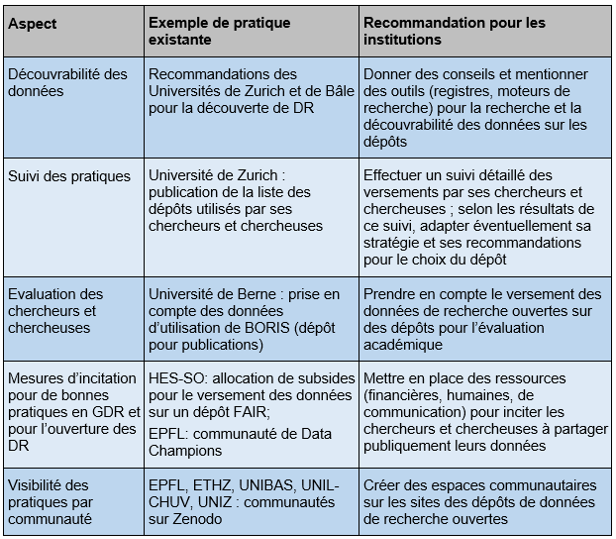
Outils pour le choix de la stratégie
Au terme de cette étude, on a abouti à la production d’un vade-mecum pour le recueil d’informations et d’un guide décisionnel. Ces outils sont destinés aux personnes mandatées par une institution pour décider de la démarche à adopter concernant le soutien aux chercheurs et chercheuses pour le partage public de leurs données sur un dépôt. Dans l’idéal, ces personnes sont des représentant-e-s de services déjà engagés dans des activités de GDR et contribuant au dépôt existant ou potentiellement au futur dépôt : la bibliothèque de recherche, le service IT, le département légal, l’administration de la recherche, ainsi que des représentant-e-s des instances décisionnelles de haut niveau de l’institution, du département financier et des ressources humaines.
Le vade-mecum regroupe les questions auxquelles l’institution est invitée à répondre avant de commencer la démarche. Les informations ainsi collectées seront utiles à différentes étapes de la démarche. Le guide décisionnel se présente sous forme d’un logigramme. Un troisième document fournit des recommandations et des ressources complémentaires pour la mise en pratique de la stratégie, une fois celle-ci fixée à l’aide du guide décisionnel (Figure 7).
Figure 7 : Démarche pour le choix de la stratégie institutionnelle et outils correspondants

Présentation de la démarche décisionnelle
En fonction des exigences des agences de financement de la recherche et de celles des éditeurs de journaux scientifiques, l’institution caractérise le dépôt qui permettra à ses chercheurs et chercheuses de partager publiquement leurs données dans le respect de ces exigences. Ce dépôt souhaité doit aussi prendre en compte les spécificités du contexte institutionnel : la politique institutionnelle, les pratiques, la culture en matière de GDR, les ressources financières et humaines. La confrontation du dépôt souhaité avec les dépôts existants offre alors trois voies possibles (voir la Figure 8). La première consiste à orienter les chercheurs et chercheuses vers un dépôt existant (un dépôt disciplinaire, son dépôt institutionnel ou un dépôt généraliste) qui est suffisamment similaire à ce qu’on souhaite. Il faut pour cela identifier les critères permettant de sélectionner le dépôt adéquat. Dans le cas où aucun dépôt existant ne se rapproche suffisamment de ce qu’on souhaite, la deuxième voie possible est l’élargissement aux données de recherche du dépôt institutionnel pour publications, s’il existe. Et dans le cas où le dépôt pour publications n’existe pas, la troisième voie est celle de la création d’un nouveau dépôt de données de recherche.
Pour deux raisons principales, la priorité est donnée à l’utilisation d’un dépôt déjà existant plutôt qu’à la création d’un nouveau dépôt. D’une part, les ressources nécessaires pour développer et faire fonctionner un dépôt sont bien plus élevées que l’utilisation d’un dépôt existant (gratuite pour une grande partie des dépôts, dans une certaine limite de taille ou de nombre de fichiers versés) (Guirlet 2020, p.35 et suivantes). D’autre part, l’analyse ci-dessus des dépôts utilisés et recommandés par les institutions académiques suisses a montré une fragmentation poussée du paysage des dépôts de données de recherche. Cette fragmentation correspond à celle observée à une plus grande échelle par l’étude de von der Heyde (2019) qui recommande de ne pas financer de nouveaux dépôts, pour éviter d’accentuer ce phénomène, mais plutôt de consolider les dépôts déjà existants. Le FNS prévoit d’ailleurs d’étendre sur son site ses recommandations sur les dépôts conformes aux principes FAIR, afin de donner plus de visibilité aux dépôts spécialisés déjà existants (Milzow et al. 2020). Dans le guide décisionnel, pour le choix d’un dépôt existant, on s’oriente d’abord vers un dépôt disciplinaire, mieux adapté aux standards, à la culture et aux pratiques disciplinaires (Universität Bern [sans date]a), puis vers le dépôt institutionnel de données de recherche s’il existe, puis vers un dépôt généraliste.
Figure 8 : Les voies possibles pour le choix de sa stratégie par une institution
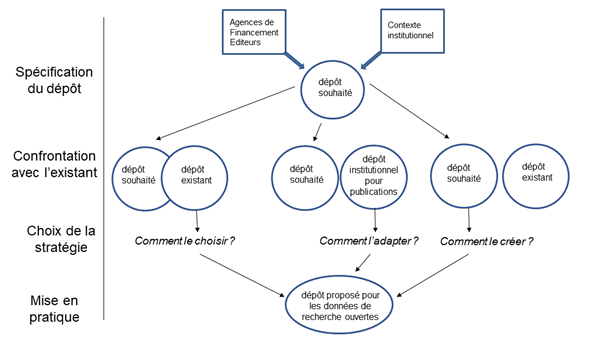
Cette démarche se traduit dans le vade-mecum et le guide décisionnel de la façon décrite ci-dessous.
Le vade-mecum
Le vade-mecum permettant de collecter les informations nécessaires pour la démarche est organisé par rubrique. Chaque rubrique comprend une question principale et une liste de pistes suggérées pour explorer la question de manière approfondie (Tableau 5). Les informations récoltées correspondent soit à des paramètres décisionnels, décisifs pour l’orientation de la démarche (repérés avec des chiffres en orange), soit à des spécifications et des informations non décisionnelles, mais qui enrichissent le processus et contribuent au résultat final (par exemple les caractéristiques du dépôt que l’on va utiliser, adapter ou développer) (repérés avec des lettres en vert). Le chiffre ou la lettre de chaque rubrique est reporté sur le guide décisionnel à l’étape correspondante.
On commence par identifier les exigences et les directives pertinentes sur l’ouverture des données de recherche (rubrique 1). On s’intéresse alors aux pratiques des chercheurs et chercheuses de l’institution dans ce domaine (rubrique 2). On caractérise ensuite les données de recherche produites ou manipulées au sein de l’institution : les disciplines, la présence de données sensibles ou non, les volumes en jeu, les formats, … (rubrique 3). On rassemble aussi les informations sur les ressources financières et humaines disponibles, qui seront notamment décisives pour le choix entre l’utilisation d’un dépôt existant (et lequel) et le développement d’un nouveau dépôt (rubriques 4 et 5), et pour les choix techniques associés (rubrique 6).
Les spécifications pour le choix d’un dépôt existant sont aussi précisées au moyen de ce vade-mecum (rubrique A), de même que les spécifications pour le nouveau dépôt éventuel (rubrique B). Elles incluent les éléments qui permettent de répondre aux exigences et aux directives dans la mesure des ressources internes, et d’autres souhaits possibles (la convivialité, l’adaptabilité, l’extensibilité, …). Une rubrique spécifique concerne le cahier des charges à remplir pour l’élargissement ou la création d’un nouveau dépôt (rubrique C).
Tableau 5 : Rubriques du vade-mecum accompagnant le guide décisionnel
Si l’institution choisit d’encadrer les chercheurs et les chercheuses pour le choix du dépôt, elle commence par évaluer leurs pratiques de partage public de leurs données (rubrique 2 du vade-mecum) en fonction des exigences sur les données de recherche (rubrique 1). Si ces pratiques ne sont pas satisfaisantes ou si l’institution décide de poursuivre quand même la démarche, elle est invitée à se tourner vers les dépôts déjà existants : des dépôts disciplinaires adaptés, le dépôt institutionnel de données de recherche s’il existe ou des dépôts généralistes. Pour les dépôts disciplinaires et les dépôts généralistes, on confronte les exigences, les caractéristiques des données de recherche (rubrique 3) et les ressources disponibles pour l’utilisation d’un dépôt existant (rubrique 4) aux spécifications du dépôt existant qui serait le plus adapté (rubrique A).
Si aucun dépôt existant ne répond aux spécifications définies et si un dépôt institutionnel pour publications existe, on envisage d’élargir celui-ci aux données de recherche. La décision est prise en fonction des ressources et des compétences disponibles en interne (rubrique 5).
Enfin, s’il n’existe pas de dépôt pour publications, on envisage de créer un nouveau dépôt. Le choix de la solution technique (out of the box/customized/from scratch, propriétaire/Open Source, cloud ou externe/locale) se fait avec un outil fourni dans le vade-mecum (et détaillé dans Guirlet 2020) en fonction des préférences concernant l’échelle de temps et le niveau d’adaptabilité et de contrôle sur la solution et les données hébergées (rubrique 6). En fonction des ressources disponibles (rubrique 5), on confirme ces choix, on choisit d’autres options techniques ou on sort de la démarche.
L’élargissement du dépôt de publications ou la création d’un nouveau dépôt se fait en se basant sur les spécifications du nouveau dépôt (rubrique B) et sur le cahier des charges du projet correspondant (rubrique C).
Figure 9 : Guide décisionnel pour le choix de la stratégie institutionnelle sur les dépôts de données de recherche (la légende est en haut à droite)
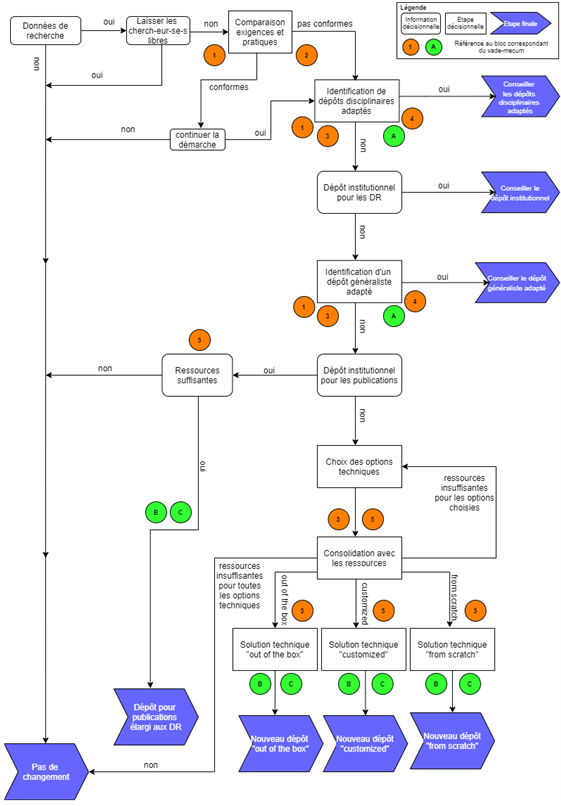
Recommandations et ressources complémentaires
Des recommandations et des ressources utiles pour la mise en pratique de la stratégie fixée à l’étape précédente ont été regroupées dans un troisième outil (Tableau 6). Une partie de ces recommandations peut aussi être utilisée pour améliorer les pratiques ou améliorer un dépôt existant.
Tableau 6 : Recommandations et ressources complémentaires pour la mise en pratique de la stratégie fixée à l’aide du guide décisionnel (les références et les détails sont donnés dans Guirlet 2020)
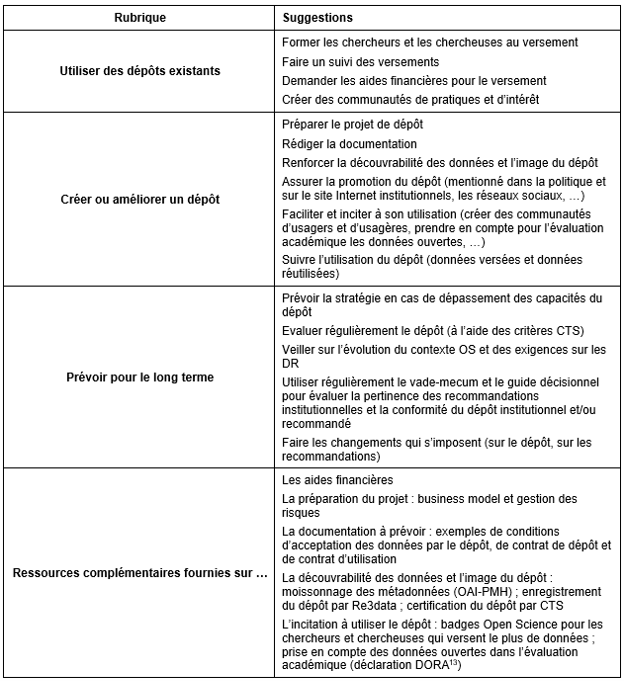
Version pour navigateur Internet
Dans l’objectif de rendre la démarche plus souple et l’utilisation de ces outils interactive et collaborative, ces outils pourraient être rendus disponibles en version Internet. A titre de démonstration, quelques pages d’un prototype appelé InSTOReD, pour Institutional Strategy Tool for Open Research Data, ont été développées (Figure 10). Avec cette version, l’accès aux outils décisionnels se fait à partir de l’un des quatre points d’entrée possibles (ou tâches) placés au même niveau sur la page d’accueil du site. Ces points d’entrée sont : l’évaluation de l’alignement des pratiques actuelles avec les exigences sur les DR, l’identification d’un dépôt existant correspondant aux besoins, l’adaptation d’un dépôt pour publications aux DR, et la spécification et la création d’un dépôt de DR institutionnel (Figure 10, haut). Cette version inclut aussi toutes les rubriques du vade-mecum (la Figure 10, milieu, présente les rubriques sur la spécification du dépôt institutionnel à créer et sur le cahier des charges).
Dans le cas de la première tâche (l’évaluation de l’alignement des pratiques avec les exigences), les exigences sur les dépôts par le FNS et par H2020 sont rappelées. En cas de changement de ces exigences, ou de l’apparition de nouvelles exigences, il serait facile de mettre à jour cette rubrique. Il est également possible de remplir les exigences qui s’appliquent à l’ouverture des données de recherche dans un autre pays (Figure 10, bas), élargissant ainsi l’utilité des outils à d’autres institutions que les institutions suisses.
Ce format permet aussi de prévoir un espace collaboratif, où les institutions ayant déjà effectué cette démarche décisionnelle seraient invitées à déposer leurs retours d’expérience pour en faire bénéficier d’autres.
Figure 10 : Pages extraites du prototype InSTOReD de version pour navigateur Internet des outils décisionnels : points d’entrée (ou tâches) proposés (haut); spécification du nouveau dépôt institutionnel pour données de recherche (milieu); transposabilité à d’autres pays de la comparaison des exigences et des pratiques (bas)
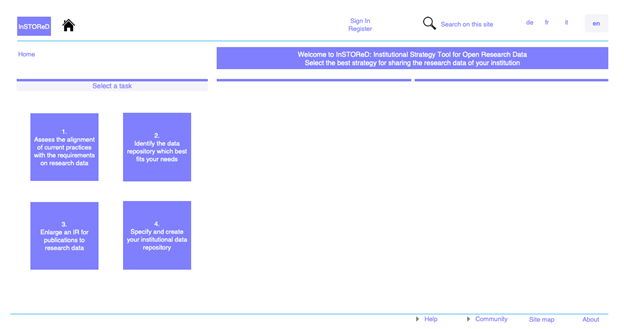
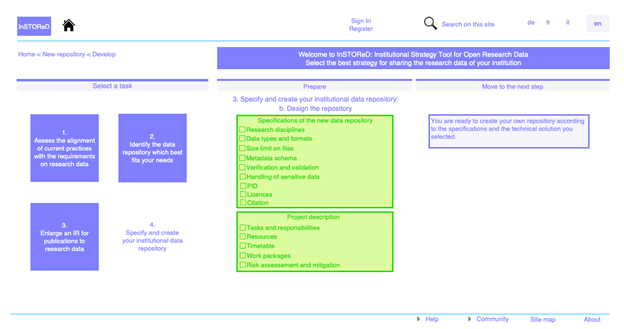
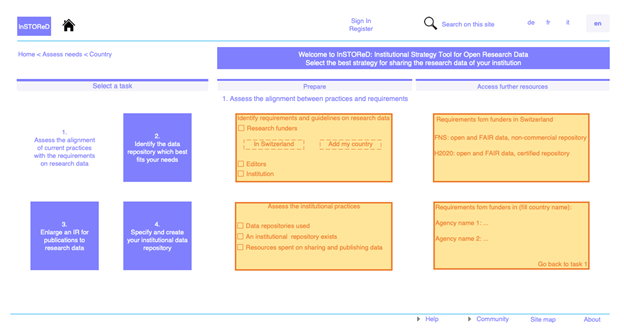
Conclusion
Au terme de cette étude, on a abouti aux principaux résultats suivants.
On a identifié les directives pour l’ouverture des données de recherche en Suisse, ainsi que les moyens de les mettre en pratique. On a défini ce qu’est un dépôt pour le partage public des données et pour leur réutilisation, quelles formes il peut prendre, quels outils et services il peut fournir. On a identifié des critères de qualité pour ce dépôt et élaboré un modèle de description pouvant être utilisé soit pour l’évaluation soit pour la conception d’un dépôt de DR ouvertes. On a dressé un panorama des dépôts de données généralistes, disciplinaires et institutionnels utilisés et recommandés par neuf institutions académiques. On a identifié les informations et les paramètres importants pour le choix d’un dépôt ou la création d’un nouveau.
A partir des résultats précédents, on a produit des outils qui formalisent la démarche de choix de la meilleure stratégie possible par une institution de recherche en matière de dépôt de données de recherche ouvertes. En suivant cette démarche, l’institution fait un choix éclairé qui lui permettra de répondre aux exigences en vigueur sur les données de recherche, tout en tenant compte des besoins et des pratiques des chercheurs et chercheuses et du contexte et des ressources à l’échelle locale.
Les institutions de recherche sont invitées à utiliser régulièrement ces outils. Le découpage modulaire de certaines étapes du guide décisionnel permet de les suivre indépendamment les unes des autres, en effectuant une partie de la démarche seulement. Avec les premières étapes de ce guide, on peut vérifier régulièrement la conformité entre les exigences et les pratiques, et adapter le cas échéant les conseils donnés aux chercheurs et chercheuses pour le choix du dépôt. Avec les étapes suivantes, on peut aussi réévaluer régulièrement, s’il existe, un ou des dépôts disciplinaires ou généralistes plus pertinents que ceux couramment utilisés par ses chercheurs et chercheuses, ou encore, adapter le dépôt institutionnel de données pour qu’il réponde aux besoins de façon plus satisfaisante.
Ces outils sont également adaptables en fonction des changements du paysage des dépôts et transposables à un autre contexte hors de Suisse. Avec la version prototype pour Internet développée au terme de cette étude, on facilite la mise à jour des outils, leur adaptabilité et leur transposabilité. Cette version offre en plus l’avantage d’inclure des aspects collaboratifs, pour le partage de retours d’expérience et l’échange de bonnes pratiques par des institutions ayant déjà effectué la démarche.
En aidant les institutions à proposer aux chercheurs et chercheuses le dépôt le plus adapté, ces outils les aident à mettre en pratique leur politique en matière d’ouverture des données de recherche, à répondre aux exigences en vigueur, et à fournir un instrument qui convient à leurs chercheurs et chercheuses et au contexte institutionnel. En proposant d’autres options que la création d’un nouveau dépôt, selon un argumentaire construit et adapté à chaque cas, dans un souci de rationalisation et de mutualisation des ressources, ces outils devraient contribuer aussi à limiter la fragmentation de l’offre et la multiplication inutile de dépôts de données de recherche en Suisse.
Notes
(1)On peut consulter la liste de Docuteam ([sans date]) des formats de fichiers reconnus comme adaptés à l’archivage des données. Cette liste est inspirée du catalogue des formats de données d’archivage du CECO ([sans date]).
(2)CASRAI est une organisation à but non lucratif travaillant sur la standardisation de formats pour la gestion et l’échange de l’information dans le domaine de la recherche (CASRAI [sans date]a).
(3)D’autres licences ouvertes telles que celles des Open Data Commons sont possibles (Open Data Commons [sans date] ; Ball 2011). Mais comme seules les licences CC ont été rencontrées dans le cadre de cette étude, on se limite à celles-ci.
(4)Ces autres critères sont : la facilité du versement, l’accessibilité, la découvrabilité, la curation, l’infrastructure de préservation, la pérennité de l’organisation, et le soutien pour les formats et les standards utilisés (EPFL Library, Research Data Library Team [sans date], p.31).
(5)(pour la préservation des données en accès restreint seulement)
(6)(pour les données liées à une publication aussi hébergée par BORIS)
(7)Springer Nature [sans date]b
(8)PLOS ONE [sans date]b
(9)Science Europe 2018
(10)FNS [sans date]b; voir aussi Perini 2019
(11)On peut déjà consulter la liste des dépôts par discipline établie par von der Heyde (2019, fig. 13 et fig. 18), à partir des réponses à ses questionnaires auprès des chercheurs et chercheuses de la communauté académique suisse en 2018.
(12)Voir les espaces communautaires de la FBM de l’Université de Lausanne et du CHUV (depuis 2016 ; zenodo [sans date]b), de l’Institute for Atmospheric and Climate Science ETH Zürich (depuis 2019 ; zenodo [sans date]c), l’espace Research Data University of Basel (depuis 2019 ; zenodo [sans date]d), et l’espace University of Zurich (depuis 2013 ; zenodo [sans date]e).
(13)Ou San Francisco Declaration on Research Assessment (2012)
Acronymes et abréviations
ACOUA ACademic OUtput Archive
ARK Archival Resource Key
ArODES Archive Ouverte des Domaines de la HES-SO
BerDA Bern Digital Archive
BORIS Bern Open Repository and Information System
CASRAI Consortia Advancing Standards in Research Administration Information
CC Creative Commons
CCSDS Consultative Committee for Space Data Systems
CECO Centre de coordination pour l’archivage à long terme de documents électroniques
CHUV Centre Hospitalier Universitaire Vaudois
CTS CoreTrustSeal
DaSCH Data and Service Center for the Humanities
DDI Data Documentation Initiative
DINI Deutsche Initiative für NetzwerkInformation
DLCM Data Life Cycle Management
DMP Data Management Plan
DOI Digital Object Identifier
DORA Declaration On Research Assessment
DR Données de la Recherche
DSA Data Seal of Approval
EUDAT EUropean Data Infrastructure
EPFL Ecole Polytechnique Fédérale de Lausanne
ETHZ Eidgenössische Technische Hochschule Zürich ou Ecole Polytechnique Fédérale de Zurich
FAIR Findable, Accessible, Interoperable, Reusable
FAQ Frequently Asked Questions, Foire Aux Questions
FBM Faculté de Biologie et de Médecine (UNIL-CHUV)
FNS Fonds National Suisse de la Recherche Scientifique
GDR Gestion des Données de la Recherche
H2020 Horizon 2020
HEG Haute Ecole de Gestion de Genève
HES-SO Haute Ecole Spécialisée de Suisse Occidentale
HEI Haute Ecole Institutionnelle
ICPSR Inter-university Consortium for Political and Social Research
ICSU-WDS International Council for Science’s World Data System
InSTOReD Institutional Strategy Tool for Open Research Data
OAI Open Archives Initiative
OAI-PMH Open Archives Initiative Protocol for Metadata Harvesting
OAIS Open Archival Information System
ORCID Open Researcher and Contributor ID
OS Open Science
OSF Open Science Framework
PID Persistent Identifier
PURL Persistent Uniform Resource Locator
RDA Research Data Alliance
RDF Resource Description Framework
Re3data Registry of Research Data Repositories
RRID Research Resource Identifier
Serval Serveur académique lausannois
UNIBAS Université de Bâle
UNIBE Université de Berne
UNIFR Université de Fribourg
UNIGE Université de Genève
UNIL Université de Lausanne
UNIZ Université de Zurich
URN Uniform Resource Name
ZORA Zürich Open Repository Archive
Bibliographie
Amsterdam Call for Action on Open Science, 2016. [en ligne]. 04.04.2016. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.government.nl/documents/reports/2016/04/04/amsterdam-call-for-action-on-open-science
ARLITSCH, Kenning, OBRIEN, Patrick, MIXTER, Jeffrey K., CLARK, Jason A. et STERMAN, Leila, 2016. Ensuring Discoverability of IR Content. In : CALLICOTT, Burton B., SCHERER, David et WESOLEK, Andrew. Making Institutional Repositories Work [en ligne]. Ed. Purdue University Press. [Consulté le 07.11.2020], pp. 31-50. ISBN 978-1-55753-902-1. Disponible à l’adresse : http://www.jstor.org/stable/10.2307/j.ctt1wf4drg
BALL, Alex, 2011. How to License Research Data. dcc.ac.uk [en ligne]. 09.02.2011. Version modifiée le 17.07.2014. [Consulté le 07.11.2020]. Disponible à l’adresse : https://dcc.ac.uk/guidance/how-guides/license-research-data
BLUMER, Eliane et BURGI, Pierre-Yves, 2015. Data Life-Cycle Management Project: SUC P2 2015-2018. Revue électronique suisse de science de l’information [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : http://www.ressi.ch/num16/article_110
BOSTON UNIVERSITY DATA SERVICES, [sans date]. Selecting a data repository. bu.edu [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.bu.edu/data/share/selecting-a-data-repository/#openbu
CASRAI [sans date]a. Welcome to CASRAI. casrai.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://casrai.org/
CASRAI [sans date]b. Research Data Management Glossary. casrai.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://casrai.org/rdm-glossary/
CECO, [sans date]. Catalogue des formats de données d'archivage. kost-ceco.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://kost-ceco.ch/cms/formats-de-donnees.html
CENTER FOR OPEN SCIENCE, [sans date]. Open Science badges enhance openness, a core value of scientific practice. cos.io [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.cos.io/initiatives/badges
CORETRUSTSEAL, 2020a. Core Certified Repositories. CoreTrustSeal [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.coretrustseal.org/why-certification/certified-repositories/
CORETRUSTSEAL, 2020b. CoreTrustSeal Trustworthy Data Repositories Requirements 2020-2022, version 02.00 [en ligne]. S.l. : s.n. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.coretrustseal.org/why-certification/requirements/
CORETRUSTSEAL STANDARDS AND CERTIFICATION BOARD, 2020. CoreTrustSeal Trustworthy Data Repositories Requirements: Extended Guidance 2020-2022, version 2.0 [en ligne]. S.l. : s.n. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.coretrustseal.org/why-certification/requirements/, https://zenodo.org/record/3632533
CORRADO, Edward M., 2019. Repositories, Trust, and the CoreTrustSeal. Technical Services Quarterly. 02.01.2019. Vol. 36, n 1, p. 61‑72. DOI 10.1080/07317131.2018.1532055
CRAGIN, Melissa H., HEIDORN, P. Bryan, PALMER, Carole L. et SMITH, Linda C., 2007. An Educational Program on Data Curation [en ligne]. 25.06.2007. [Consulté le 07.11.2020]. Disponible à l’adresse : http://hdl.handle.net/2142/3493
CREATIVE COMMONS [sans date]. About CC licenses. creativecommons.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://creativecommons.org/about/cclicenses/
DARIS, 2018. Implementation of the CoreTrustSeal. coretrustseal.org [en ligne]. 20.03.2018. [Consulté le 02.12.2020]. Disponible à l’adresse: https://www.coretrustseal.org/wp-content/uploads/2018/03/DARIS.pdf
DASCH, [sans date]. Services. dasch.swiss [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://dasch.swiss/services/#appendix
DATA CURATION NETWORK, [sans date]. Mission. datacurationnetwork.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://datacurationnetwork.org/about/our-mission/
DATACITE, [sans date]. Welcome to DataCite. datacite.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://datacite.org/
DATACITE METADATA WORKING GROUP, 2019. DataCite Metadata Schema Documentation for the Publication and Citation of Research Data v4.3. 2019. pp. 73 pages. Disponible à l’adresse: https://doi.org/10.14454/7xq3-zf69
DATAVERSE PROJECT, [sans date]. User Guide. dataverse.org. [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : http://guides.dataverse.org/en/4.20/user/
DIGITAL PRESERVATION COALITION, [sans date]. Digital Preservation Handbook. dpconline.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.dpconline.org/handbook/technical-solutions-and-tools/persistent-identifiers
DILLO, Ingrid et de LEEUW, Lisa, 2018. CoreTrustSeal. In : Mitteilungen der Vereinigung Österreichischer Bibliothekarinnen und Bibliothekare. 19.07.2018. Vol. 71, n° 1, p. 162‑170. DOI 10.31263/voebm.v71i1.1981
DINI 2011. DINI-Zertifikat Dokumenten- und Publikationsservice 2010. Version 3.1. [en ligne]. 03.2011. [Consulté le 07.11.2020]. Disponible à l’adresse : https://edoc.hu-berlin.de/handle/18452/2145
DOCUTEAM, [sans date]. Standard de versement. docuteam.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.docuteam.ch/fr/prestations/archivage-electronique-docuteam-cosmos/standard-de-versement/#_ftn1
DRYAD, [sans date]. Submission process. dryad.org [en ligne]. [Consulté le 03.12.2020]. Disponible à l’adresse : https://datadryad.org/stash/submission_process#upload-methods
Dublin Core. 2020. Wikipédia : l’encyclopédie libre [en ligne]. Dernière modification de la page le 05.10.2020 à 8:14. [Consulté le 07.11.2020]. Disponible à l’adresse : https://fr.wikipedia.org/wiki/Dublin_Core#Autres_r%C3%A9f%C3%A9rentiels_de_m%C3%A9tadonn%C3%A9es
DUBLIN CORE METADATA INITIATIVE, 2020. dublincore.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.dublincore.org/
EPFL, [sans date]. EPFL Data Champions. epfl.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.epfl.ch/campus/library/services/services-researchers/rdm-contacts-communities/epfl-data-champions/#more
EPFL LIBRARY, [sans date]. Research Data Management Fast Guides. epfl.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.epfl.ch/campus/library/services/services-researchers/rdm-guides-templates/
EPFL LIBRARY, RESEARCH DATA LIBRARY TEAM, [sans date]. RDM Walkthrough Guide. epfl.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.epfl.ch/campus/library/services/services-researchers/rdm-guides-templates/
ETHZ - ETH-BIBLIOTHEK, [sans date]. FAQs de. ethz.ch [en ligne]. [Consulté le 08.11.2020]. Disponible à l’adresse: https://documentation.library.ethz.ch/display/RC/FAQs+de
EUROPEAN COMMISSION, DIRECTORATE-GENERAL FOR RESEARCH & INNOVATION, 2016. H2020 Programme - Guidelines on FAIR Data Management in Horizon 2020 [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-data-mgt_en.pdf
EUROPEAN COMMISSION, DIRECTORATE-GENERAL FOR RESEARCH & INNOVATION, 2017. H2020 Programme - Guidelines to the Rules on Open Access to Scientific Publications and Open Access to Research Data in Horizon 2020 [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-pilot-guide_en.pdf
FIGSHARE, [sans date]. How to upload and publish your data. figshare.com [en ligne]. [Consulté le 08.11.2020]. Disponible à l’adresse : https://help.figshare.com/article/how-to-upload-and-publish-your-data
FNS, [sans date]a. Open Research Data. snf.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : http://www.snf.ch/fr/leFNS/points-de-vue-politique-de-recherche/open_research_data/Pages/default.aspx#D%E9claration%20de%20principe%20du%20FNS%20sur%20le%20libre%20acc%E8s%20aux%20donn%E9es%20de%20la%20recherche%20%28Open%20Research%20Data%29
FNS, [sans date]b. Data Management Plan (DMP) - Directives pour les chercheuses et chercheurs. snf.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : http://www.snf.ch/fr/leFNS/points-de-vue-politique-de-recherche/open_research_data/Pages/data-management-plan-dmp-directives-pour-les-chercheuses-et-chercheurs.aspx
FNS, 2017. Open Research Data : les requêtes devront inclure un plan de gestion des données. FNS. snf.ch [en ligne]. 06.03.2017. [Consulté le 07.11.2020]. Disponible à l’adresse : http://www.snf.ch/fr/pointrecherche/newsroom/Pages/news-170306-open-research-data-bientot-une-realite.aspx
FNS, 2020. Règlement d’exécution général relatif au règlement des subsides. snf.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: http://www.snf.ch/SiteCollectionDocuments/fns-reglement_execution_general_relatif_au_reglement_subsides_f.pdf#page=15
FOREIGN COMMONWEALTH OFFICE, 2013. G8 Science Ministers Statement. gov.uk [en ligne]. 12.06.2013. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.gov.uk/government/news/g8-science-ministers-statement
FORS, [sans date]. Contrat utilisateur. unil.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://forsbase.unil.ch/media/general_documentation/fr/User_contract_F.pdf
GUIRLET, Marielle, 2020. Guide décisionnel et vade-mecum pour la mise à disposition d’un dépôt de données de recherche ouvertes en Suisse. [en ligne]. Genève : Haute école de gestion de Genève. Travail de Master. Version révisée. 18.12.2020. DOI: 10.5281/zenodo.4357134. [Consulté le 18.12.2020]. Disponible à l'adresse: https://zenodo.org/record/4357134
HES-SO, [sans date]. Archiver ses données de recherche. hes-so.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://openscience.hes-so.ch/fr/archiver-donnees-recherche-14819.html
HES-SO, 2020. Appel à projets Open Data HES-SO. hes-so.ch [en ligne]. 02.06.2020. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.hes-so.ch/fr/appel-projets-open-data-hes-so-16822.html
HEWLETT, Niles E, 2006. The USDA Enterprise Architecture Program. [en ligne]. 25.01.2006. [Consulté le 07.11.2020]. Disponible à l’adresse : https://web.archive.org/web/20070508175931/http://www.ocio.usda.gov/p_mgnt/doc/PM_Class_EA_NEH_012506_Final.ppt
HODSON, Simon, JONES, Sarah et al., 2018. Turning FAIR data into reality. Interim report of the European Commission Expert Group on FAIR data [en ligne]. S.l. [Consulté le 07.11.2020]. Disponible à l’adresse : https://zenodo.org/record/1285272ICPSR, [sans date]. History. icpsr.umich.edu [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.icpsr.umich.edu/web/pages/about/history/
JOHNSTON, Lisa R, CARLSON, Jake, HUDSON-VITALE, Cynthia, IMKER, Heidi, KOZLOWSKI, Wendy, OLENDORF, Robert et STEWART, Claire, 2016. Data Curation Terms and Activities [en ligne]. 23.10.2016. [Consulté le 07.11.2020]. Disponible à l’adresse : https://conservancy.umn.edu/bitstream/handle/11299/188638/DefinitionsofDataCurationActivities%20%281%29.pdf?sequence=1&isAllowed=y
JOHNSTON, Lisa R., 2017. Data Curation Handbook Steps. In: JOHNSTON, Lisa R., 2017. Curating Research Data Volume Two: A Handbook of Current Practice. Ed: American Library Association, 2017. [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://conservancy.umn.edu/bitstream/handle/11299/183502/Data%20Curation%20Handbook%20Steps_v2.pdf?sequence=1&isAllowed=y
JOHNSTON, Lisa, CARLSON, Jake, HUDSON-VITALE, Cynthia, IMKER, Heidi, KOZLOWSKI, Wendy, OLENDORF, Robert et STEWART, Claire, 2017. Data Curation Network: A Cross-Institutional Staffing Model for Curating Research Data [en ligne]. S.l. [Consulté le 07.11.2020]. Disponible à l’adresse : http://hdl.handle.net/11299/188654
JOHNSTON, Lisa R, CARLSON, Jacob, HUDSON-VITALE, Cynthia, IMKER, Heidi, KOZLOWSKI, Wendy, OLENDORF, Robert et STEWART, Claire, 2018. How Important is Data Curation? Gaps and Opportunities for Academic Libraries. Journal of Librarianship and Scholarly Communication. 26.04.2018. Vol. 6, n° 1, pp. 2198. DOI 10.7710/2162-3309.2198
JONG (de), Michiel, ZUIDERWIJK, Anneke, WILL, Nicole et JANSSEN, Marijn, 2020. Open Science: Sharing Your Research with the World [online course]. TU Delft. edx.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.edx.org/course/open-science-sharing-your-research-with-the-world
L’HOURS, Hervé, KLEEMOLA, Mari et de LEEUW, Lisa, 2019. CoreTrustSeal: From academic collaboration to sustainable services. In : IASSIST Quarterly. 10.05.2019. Vol. 43, n°1, p. 1‑17. DOI 10.29173/iq936
MILZOW, Katrin, VON ARX, Martin, SOMMER, Cornélia, CAHENZLI, Julia et PERINI, Lionel, 2020. Open Research Data: SNSF monitoring report 2017-2018 [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://zenodo.org/record/3618123
NATURE, 2016. Data availability statements and data citations policy: Guidance for authors. Nature [en ligne]. 09.2016. [Consulté le 07.11.2020]. Disponible à l’adresse: http://www.nature.com/authors/policies/data/data-availability-statements-data-citations.pdf
OLOS, 2020a. OLOS Specifications [fichier texte Office Open]. Version 1. Dernière mise à jour le 19.05.2020. Document interne au projet.
OLOS, 2020b. Integrated data management solution for researchers and institutions. olos.swiss. [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse. https://olos.swiss/
OPEN DATA COMMONS, [sans date]. Open Data Commons, Legal tools for Open Data [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://opendatacommons.org/licenses/odbl/
Open Research Data (ORD) – the uptake in Horizon 2020, 2016. EU Open Data Portal, europa.eu [en ligne]. 10.05.2016. 19.04.2018. [Consulté le 03.12.2020]. Disponible à l’adresse : https://data.europa.eu/euodp/en/data/dataset/open-research-data-the-uptake-of-the-pilot-in-the-first-calls-of-horizon-2020
PERINI, Lionel, 2019. SNSF Open Research Data Policy. Journée Open Science [en ligne]. HES-SO, 18 March 2019. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.hes-so.ch/data/documents/4-L.Perini-FNS-PolitiqueFNS-OpenData-10357.pdf
PINFIELD, Stephen, COX, Andrew M. et SMITH, Jen, 2014. Research Data Management and Libraries: Relationships, Activities, Drivers and Influences. In : LAUNOIS, Pascal (éd.), PLoS ONE. 08.12.2014. Vol. 9, n° 12, p. e114734. DOI: 10.1371/journal.pone.0114734 Pryor 2012
PLOS ONE, [sans date]a. Data availability. plos.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: http://journals.plos.org/plosone/s/data-availability
PLOS ONE, [sans date]b. How to Store and Manage Your Data. plos.org [en ligne]. [Consulté le 06.12.2020]. Disponible à l’adresse : https://plos.org/resource/how-to-store-and-manage-your-data/#choosing-repository
PRYOR, Graham, 2012. Why manage research data? Managing Research Data. Londres: Facet Publishing, pp.1-16. ISBN 978-1-85604-756-2
RE3DATA.ORG, [sans date]. re3data.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.re3data.org/
RE3DATA.ORG, 2017. B2SHARE. re3data.org [en ligne]. 22.11.2017 [Consulté le 08.11.2020]. Disponible à l’adresse : https://www.re3data.org/repository/r3d100011394
RICE, Robin et SOUTHALL, John, 2016. The data librarian’s handbook. London : Facet Publishing. ISBN 978-1-78330-047-1.
ROSENTHALER, Lukas, FORNARO, Peter et CLIVAZ, Claire, 2015. DaSCH: Data and Service Center for the Humanities. In : Digital Scholarship in the Humanities. 2015. Vol. 30, p. i43‑i49. [en ligne]. [Consulté le 08.11.2020]. Disponible à l’adresse : https://academic.oup.com/dsh/article/30/suppl_1/i43/365238
San Francisco Declaration on Research Assessment, 2012. DORA [en ligne]. 16.11.2012. [Consulté le 07.11.2020]. Disponible à l’adresse : https://sfdora.org/read/
San Francisco Declaration on Research Assessment. 2020. DORA Signers. [en ligne]. [Consulté le 08.11.2020]. Disponible à l’adresse: https://sfdora.org/signers/
Science Europe, 2018. Practical Guide to the International Alignment of Research Data Management. scienceeurope.org [en ligne]. 11.2018. [Consulté le 08.11.2020]. Disponible à l’adresse: https://www.scienceeurope.org/media/jezkhnoo/se_rdm_practical_guide_final.pdf
Sorbonne declaration on research data rights, 2020. [en ligne]. [Consulté le 07.12.2020]. Disponible à l’adresse: https://sorbonnedatadeclaration.eu/
SPRINGER NATURE, [sans date]a. Research Data Policies FAQ. Springer Nature [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.springernature.com/gp/authors/research-data-policy/data-policy-faqs
SPRINGER NATURE, [sans date]b. Research Data Policies. Recommended Repositories. Springer Nature [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.springernature.com/gp/authors/research-data-policy/recommended-repositories
SWISS NATIONAL SCIENCE FOUNDATION, [sans date]. Explanation of the FAIR data principles [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : http://www.snf.ch/SiteCollectionDocuments/FAIR_principles_translation_SNSF_logo.pdf
SWISS NATIONAL SCIENCE FOUNDATION, 2017. Examples of data repositories [en ligne]. 27.04.2017. [Consulté le 07.11.2020]. Disponible à l’adresse : http://www.snf.ch/SiteCollectionDocuments/FAIR_data_repositories_examples.pdf
THE CONCORDAT WORKING GROUP, 2016. Concordat on Open Research Data [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.bolton.ac.uk/assets/ConcordatonOpenResearchData.pdf
THE CONSULTATIVE COMMITTEE FOR SPACE DATA SYSTEMS, 2012. Reference Model for an Open Archival Information System (OAIS) - Recommended Practice CCSDS 650.0-M-2 [en ligne]. Washington, DC, USA. CCSDS. [Consulté le 07.11.2020]. Recommendation for Space Data System Practices. Disponible à l’adresse : https://public.ccsds.org/Pubs/650x0m2.pdf
THE ROYAL SOCIETY, 2012. Science as an Open Enterprise [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://royalsociety.org/topics-policy/projects/science-public-enterprise/report/
THE UNIVERSITY OF EDINBURGH, 2019. Trustworthy Digital Repository. ed.ac.uk [en ligne]. 20.06.2019. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.ed.ac.uk/information-services/research-support/research-data-service/after/data-repository/trustworthy-digital-repository
TRELOAR, Andrew, GROENEWEGEN, David et HARBOE-REE, Cathrine, 2007. The Data Curation Continuum: Managing Data Objects in Institutional Repositories. D-Lib Magazine [en ligne]. Septembre 2007. Vol. 13, n° 9/10. [Consulté le 07.11.2020]. DOI 10.1045/september2007-treloar. Disponible à l’adresse : http://www.dlib.org/dlib/september07/treloar/09treloar.html
TRELOAR, Andrew, 2012. Private Research, Shared Research, Publication, and the Boundary Transitions. Version 1.4.3 [en ligne]. 19.03.2012. [Consulté le 07.11.2020]. Disponible à l’adresse : https://andrew.treloar.net/research/diagrams/
UNIVERSITAT BASEL, [sans date]. Sharing data. unibas.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://researchdata.unibas.ch/en/publish-and-share/
UNIVERSITAT BERN, [sans date]a. Universitätsbibliothek. Forschungsdatenmanagement. unibe.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.unibe.ch/universitaet/dienstleistungen/universitaetsbibliothek/service/open_science/forschungsdatenmanagement/index_ger.html
UNIVERSITAT BERN, [sans date]b. Universitätsbibliothek. BORIS Repository. unibe.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.unibe.ch/universitaet/dienstleistungen/universitaetsbibliothek/service/elektronisch_publizieren/boris_repository/index_ger.html
UNIVERSITAT ZURICH, HAUPTBIBLIOTHEK, 2019. Empfohlene Repositories. uzh.ch [en ligne]. 05.12.2019. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.hbz.uzh.ch/de/open-access-und-open-science/daten-repositories/empfohlene-repositories.html
UNIVERSITAT ZURICH, HAUPTBIBLIOTHEK, 2020. Nutzen von Daten in Repositories. uzh.ch [en ligne]. 06.02.2020. [Consulté le 07.11.2020]. Disponible à l’adresse: https://www.hbz.uzh.ch/en/open-access-und-open-science/daten-repositories/auffinden-von-daten-in-repositories.html
UNIVERSITE DE GENEVE, [sans date]. Données de recherche. Définitions. unige.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.unige.ch/researchdata/fr/footer/definitions/
UNIVERSITE DE LAUSANNE, [sans date]a. L’Open Science à l’UNIL. Données personnelles & sensibles. unil.ch [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://www.unil.ch/openscience/home/menuinst/open-research-data/conformite--exigences/donnees-personnelles--sensibles.html
UNIVERSITE DE LAUSANNE, [sans date]b. L’Open Science à l’UNIL. Archivage & partage. unil.ch [en ligne]. [Consulté le 08.11.2020]. Disponible à l’adresse : https://www.unil.ch/openscience/home/menuinst/open-research-data/gerer-ses-donnees-de-recherche/archivage--partage.html
VON DER HEYDE, Markus, 2019. Open Research Data: Landscape and cost analysis of data repositories currently used by the Swiss research community, and requirements for the future [Report to the SNSF] [en ligne]. 22.05.2019 [Consulté le 07.11.2020]. Disponible à l’adresse : https://zenodo.org/record/2643460
WILKINSON, Mark D., DUMONTIER, Michel, AALBERSBERG, IJsbrand Jan, APPLETON, Gabrielle, AXTON, Myles, BAAK, Arie, BLOMBERG, Niklas, BOITEN, Jan-Willem, DA SILVA SANTOS, Luiz Bonino, BOURNE, Philip E., BOUWMAN, Jildau, BROOKES, Anthony J., CLARK, Tim, CROSAS, Mercè, DILLO, Ingrid, DUMON, Olivier, EDMUNDS, Scott, EVELO, Chris T., FINKERS, Richard, GONZALEZ-BELTRAN, Alejandra, GRAY, Alasdair J.G., GROTH, Paul, GOBLE, Carole, GRETHE, Jeffrey S., HERINGA, Jaap, ’T HOEN, Peter A.C, HOOFT, Rob, KUHN, Tobias, KOK, Ruben, KOK, Joost, LUSHER, Scott J., MARTONE, Maryann E., MONS, Albert, PACKER, Abel L., PERSSON, Bengt, ROCCA-SERRA, Philippe, ROOS, Marco, VAN SCHAIK, Rene, SANSONE, Susanna-Assunta, SCHULTES, Erik, SENGSTAG, Thierry, SLATER, Ted, STRAWN, George, SWERTZ, Morris A., THOMPSON, Mark, VAN DER LEI, Johan, VAN MULLIGEN, Erik, VELTEROP, Jan, WAAGMEESTER, Andra, WITTENBURG, Peter, WOLSTENCROFT, Katherine, ZHAO, Jun et MONS, Barend, 2016. The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data. décembre 2016. Vol. 3, n° 1, pp. 160018. DOI 10.1038/sdata.2016.18
ZENODO, [sans date]a. About Zenodo. zenodo.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse : https://about.zenodo.org/
ZENODO, [sans date]b. Faculty of Biology and Medicine at University of Lausanne & Lausanne University Hospital. zenodo.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://zenodo.org/communities/fbm_chuv/?page=1&size=20
ZENODO, [sans date]c. Atmospheric physics group, Institute for Atmospheric and Climate Science, ETH Zurich. zenodo.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://zenodo.org/communities/eth_zurich_iac_atmospheric_physics/?page=1&size=20
ZENODO, [sans date]d. Research Data University of Basel. zenodo.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://zenodo.org/communities/rdm_unibas/?page=1&size=20
ZENODO, [sans date]e. University of Zurich. zenodo.org [en ligne]. [Consulté le 07.11.2020]. Disponible à l’adresse: https://zenodo.org/communities/uzh/?page=1&size=20
ZENODO, [sans date]f. Frequently Asked Questions. zenodo.org [en ligne]. [Consulté le 08.11.2020]. Disponible à l’adresse : https://help.zenodo.org/
L’océrisation d’imprimés anciens : les sciences de l’information au service des Humanités
Florence Burgy, Haute Ecole de Gestion, Genève
L’océrisation d’imprimés anciens : les sciences de l’information au service des Humanités
1. L’imprimeur et la machine
1.1. Les Humanités numériques
« Allier les humanités à l’informatique ou aux technologies numériques. » : comme l’explique Pierre Mounier dans son ouvrage daté de 2018, il ne s’agit pas là d’une idée neuve. On pourrait en effet en observer des applications dans les années 1960-1970 déjà, voire dès la fin de la seconde guerre mondiale (Mounier 2018), mais c’est avec la démocratisation de l’informatique et le développement des sciences de l’information que cette idée et sa mise en application ont commencé à s’imposer globalement. Ces pratiques sont très variées, couvrant toutes les étapes de la recherche, de la création, du traitement et de la gestion de données à la valorisation de résultats et de documents sources. L’expression « Humanités numériques », « Digital Humanities » en anglais, née tardivement, au début des années 2000 (Mounier 2018), apparaît donc comme un « big tent », un vaste terme englobant un très grand nombre d’usages et de techniques (Terras 2016).
En Suisse romande, cette évolution a notamment été marquée par l’ouverture du DHLAB de l’EPFL par Frédéric Kaplan en 2012 (EPFL 2020), auquel sont liés des cursus de formation Bachelor, Master et PhD, ainsi que par la création d’une chaire en Humanités numériques à l’Université de Genève en 2019 (Université de Genève 2020). En parallèle, et depuis 2014, un autre projet fait beaucoup parler de lui : le Bodmer Lab.
1.2. Le Bodmer Lab et la collection de Bry
Le Bodmer Lab se définit comme “un projet de recherche et de numérisation issu d'un partenariat entre l'Université de Genève et la Fondation Martin Bodmer” (Bodmer Lab 2019), dont l’objectif est de rendre accessible à un large public des documents provenant de la Bibliotheca Bodmeriana. Cette collection, que Martin Bodmer voulait “bibliothèque de la littérature mondiale” (Bodmer Lab 2019) au sens où l’entendait Goethe, regroupe en effet de nombreux ouvrages anciens, rares et fragiles, dont la valeur historique est unique. La numérisation de ces documents permet de les faire connaître et de les rendre exploitables par des chercheurs comme par le grand public. Un important travail de mise en valeur et de médiation complète ce processus.
Au sein de la Bibliotheca Bodmeriana, certains ensembles de documents présentent une structure suffisamment cohérente pour pouvoir être considérés comme des sortes de sous-collections. Ce fait a mené le Bodmer Lab à traiter ces ensembles, ou “constellations”, de manière indépendante et à en confier l’étude à des spécialistes des domaines concernés (Bodmer Lab 2019).
L’une de ces “constellations” est la collection de Bry, qui rassemble des récits de voyage de l’époque des Grandes découvertes. Cette collection exceptionnelle de vingt-neuf volumes illustrés par des gravures et datant des XVIe et XVIIe siècles est divisée en deux parties : les « Grands Voyages », ou India occidentalis, qui retracent l’exploration des Amériques, et les « Petits Voyages », ou India orientalis, qui concernent essentiellement les voyages en Afrique et en Asie. Ces ouvrages sont l’œuvre de l’éditeur-imprimeur liégeois Théodore de Bry (1528-1598) et de ses descendants. Ces volumes rares sortent de leur atelier de Francfort entre 1590 et 1634 et sont édités en plusieurs langues (Bodmer Lab 2019).
La première édition latine de cette collection, que la Fondation Bodmer possède dans son intégralité, est déjà numérisée et accessible en ligne sur le site du Bodmer Lab (Bodmer Lab 2019), mais il est impossible pour le moment d’y effectuer une recherche plein texte.
1.3. L’océrisation : un enjeu des Humanités numériques
Cette problématique est directement liée à un enjeu majeur des Humanités numériques : l’océrisation. De l’acronyme OCR, pour Optical Character Recognition, reconnaissance optique de caractères en français, il s’agit d’une technologie qui permet d’identifier des caractères dans un document numérisé au format image et de les extraire dans un format texte lisible par un humain comme par une machine, de manière totalement automatisée.
Si certains logiciels permettent aisément cette conversion avec des documents récents, cette tâche est rendue bien plus ardue avec des documents anciens. En effet, l’état du papier et de l’encre, la grande variété des polices de caractères et des mises en page et la méthode de numérisation sont parmi les éléments qui influent sur les performances d’un logiciel.
La collection de Bry est un exemple intéressant de document pour lequel un simple logiciel OCR ne suffit pas. Après un état de l’art de la technologie OCR, le présent article présente les méthodes et résultats d’un projet de recherche visant à tester différents logiciels d’océrisation afin de sélectionner le mieux adapté à ladite collection, Tesseract, puis à l’entraîner et à en optimiser les paramètres dans le but d’obtenir une transcription automatique au plus proche de l’original, avec un objectif de 95% de caractères et mots corrects.
2. OCR : un état de l’art
Le présent état de l’art s’articulera selon deux axes. Le premier présentera la technologie OCR dans son état actuel, en retraçant brièvement son histoire, en expliquant son fonctionnement et en présentant des méthodes d’évaluation des logiciels OCR. Le second axe présentera les développements récents dans le domaine de l’océrisation, et se focalisera plus précisément sur la problématique des documents anciens et des langues anciennes.
2.1. OCR – une technologie mature
2.1.1. Origines et développement de l’OCR
La technologie connue sous le nom d’OCR a vu le jour dans la première moitié du XXème siècle. Malgré de premiers développements intéressants, l’idée de créer des machines capables de lire les caractères et les chiffres est restée un rêve jusque dans les années 1950 (Mori, Suen, Yamamoto 1992). C’est à cette époque que l’OCR trouve son marché et se développe non seulement comme technologie mais comme produit commercial, sous l’impulsion, entre autres, de David Shepard, fondateur de Intelligent Machines Research Corporation (Nagy 2016).
Les progrès dans ce domaine sont rapides, et il serait impossible de citer les nombreuses recherches entreprises au cours des soixante dernières années. Mentionnons cependant la machine de Jacob Rabinow, développée dans les années 1960 et permettant de lire et trier les adresses postales américaines, et celle de Kurzweil, dans les années 1970, permettant la reconnaissance et la lecture de textes aux aveugles (Nagy 2016). Un historique plus complet des développements dans ce domaine à cette époque se trouve dans l’ouvrage de Herbert F. Schantz, The history of OCR, optical character recognition (Schantz 1982). Notons en outre que, dans un article proposant un panorama de l’évolution des technologies de l’information dans les années 1990, le développement des OCR est mentionné parmi les progrès importants (Bowers 2018).
Plus proche de nous, le projet de numérisation Google Books, entamé en 2004, a permis une grande reconnaissance de la technologie OCR et des possibilités qu’elle offre (Nagy 2016). En 2005, la mise à disposition du premier logiciel OCR libre, Tesseract (Smith 2007), ouvre la voie à une large diffusion de cette technologie (Blanke, Bryant, Hedges 2012).
Depuis, de nombreux projets de recherche dans ce domaine ont vu le jour, mais il est important de mentionner le plus influent au niveau européen, IMPACT. Ce projet à financement européen lancé en 2008 vise à proposer des outils et des méthodes de travail permettant l’océrisation de documents historiques numérisés avec un très haut niveau de précision (Balk, Ploeger 2009). L’aboutissement principal de ce projet est la création du centre de compétences IMPACT (IMPACT 2013) qui propose des outils, des lexiques et des numérisations pouvant servir de données d’entraînement.
2.1.2. Fonctionnement et perfectionnement
Avant l’océrisation, une numérisation de qualité est indispensable. Il est habituellement recommandé de choisir un format TIFF non compressé et de préparer les numérisations, en rognant les parties sans texte des images, par exemple (Zhou 2010), ceci afin de simplifier le travail de l’OCR. En outre, il existe des méthodes d’évaluation automatique des numérisations, permettant d’assurer une précision optimale des OCR (Brener, Iyengar et Pianykh 2005).
L’océrisation à proprement parler se déroule en quatre phases : le prétraitement, ou preprocessing, la segmentation, ou layout analysis, la reconnaissance, ou recognition, et le post-traitement, ou post-processing (Blanke, Bryant, Hedges 2012). La première phase consiste essentiellement à supprimer le bruit puis binariser pour distinguer les caractères (valeur des pixels 1) du fond (valeur des pixels 0). La seconde permet de repérer les lignes de textes et de délimiter les caractères. La troisième implique une extraction et une classification des features pour reconnaître lesdits caractères (Anugrah, Bintoro 2017), et la dernière phase consiste à corriger l’output pour diminuer le taux d’erreurs (Blanke, Bryant, Hedges 2012).
Pour cette dernière phase, plusieurs méthodes sont utilisées. Le machine learning, ou apprentissage supervisé, est rapidement apparu comme une solution efficace. Un article de 1992 précise déjà que l’usage du machine learning a permis aux auteurs de corriger 46% des erreurs d’océrisation avec un taux de précision de 91% sans intervention humaine (Sun et al. 1992).
De nos jours, le machine learning demeure l’une des solutions les plus recommandées pour la correction, souvent couplée avec l’utilisation de modèles de langue et de dictionnaires (Kissos, Dershowitz 2016). Ces deux procédés nécessitent néanmoins la présence de données d’entraînement fiables, c’est-à-dire des textes numérisés du même type et océrisés parfaitement, les ground truth. Certains chercheurs ont cependant tenté de proposer des méthodes de correction en l’absence de ground truth, basées notamment sur le traitement de l’information contextuelle, avec des résultats plutôt satisfaisants (Ghosh et al. 2016).
Des méthodes plus récentes proposent l’usage d’apprentissage statistique (Mei et al. 2018) ou encore de la distance de Levenshtein, qui permet de mesurer la différence entre des chaînes des caractères (Hládek et al. 2017). Un outil open source développé dans le cadre du projet IMPACT, PoCoTo, permet d’accélérer le repérage et la correction d’erreurs sur la base de modèles de langues correspondants (Vobl et al. 2014).
Des démarches moins techniques, mais non moins demandeuses en matière de ressources humaines, sont également en usage, tel le crowdsourcing, qui permet d’impliquer des volontaires pour corriger les erreurs de l’OCR (Clematide, Furrer, Volk 2016). Ce crowdsourcing peut prendre des formes diverses, à l’image des jeux créés par la Biodiversity Heritage Library et testés avec succès (Seidman et al. 2016) En Suisse, la plateforme e-newspaperarchives.ch propose une fonctionnalité de correction d’OCR.
2.1.3. Évaluation des performances
Dans un projet d’océrisation, il est essentiel d’évaluer les performances des logiciels OCR afin de sélectionner le mieux adapté et/ou d’optimiser celui sélectionné. Dans les années 1990 déjà, une équipe de l’Information Science Research Institute publiait annuellement les résultats de tests de précision des logiciels OCR disponibles sur le marché à l’époque. Leur méthode consistait à océriser un échantillon aléatoire de documents de différentes natures (journaux, textes de lois etc.) et en différentes langues afin d’estimer lequel présentait le moins d’erreurs.
La métrique principale utilisée dans leurs recherches est la précision des caractères, selon le calcul suivant : , où n représente le nombre de caractères de l’output (Rice, Jenkins, Nartker 1996).
Cette métrique est encore utilisée de nos jours et enrichie. Un article de 2018 (Karpinski, Lohani, Belaïd 2018) propose en effet les calculs suivants :
Erreurs = caractères ajoutés + caractères omis + caractères substitués.
Caractères corrects = caractères de l’output – erreurs.
Précision = caractères corrects / caractères dans l’output (Hypothesis zone). Il s’agit de fait de la métrique utilisée par l’Information Science Research Institute présentée ci-dessus
Rappel = caractères corrects / caractères dans l’input (Reference zone).
Ces mêmes calculs peuvent être étendus aux mots entiers afin de déterminer si la segmentation a été effectuée correctement (Saber et al. 2016).
Pour permettre de faire la balance entre précision et rappel, la moyenne harmonique de ces métriques, nommée « F-mesure », ou F1, a également été utilisée. Elle se calcule ainsi :
où est la précision et le rappel (Sasaki 2007).
Ceci permet en effet de prendre ces deux métriques en compte au sein d’un seul calcul (Bao, Zhu 2014). Un outil open source, ocrevaluation, a été développé pour permettre d’automatiser ces calculs sur la base des ground truth et des outputs proposés par l’OCR sélectionné (Carrasco 2014).
2.2 OCR - un champ de recherche en mouvement
2.2.1. Réseaux neuronaux artificiels
Parmi les avancées récentes dans le domaine de l’océrisation, l’utilisation de réseaux neuronaux artificiels est en pleine expansion. Le machine learning, au sens d’apprentissage supervisé, est déjà une pratique bien établie dans le domaine, mais l’usage d’apprentissage non-supervisé permet de nouveaux progrès.
En 2014 déjà, un article propose un état de l’art de l’usage des réseaux de neurones pour le prétraitement des documents avant océrisation (Rehman, Saba 2014). Cette technologie permet en effet de faciliter le repérage des lignes de textes, la segmentation et l’extraction de features, mais à l’époque de cet article, de nombreux problèmes se posent encore quant à ses limites, et au temps et à la masse de données d’entraînement nécessaires à son bon fonctionnement.
Un article de 2016 propose l’utilisation de la back propagation avec descente du gradient, qui permet de limiter la répercussion des erreurs. Dans cet article, les réseaux neuronaux sont essentiellement utilisés pour la classification et la reconnaissance des caractères à partir des pixels, et les résultats sont très positifs avec les caractères alphanumériques anglais. Les auteurs soulignent cependant que, dans le cas d’autres écritures, et entre autres celles présentant des ligatures entre les lettres, les résultats sont peu satisfaisants (Afroge, Ahmed, Mahmud 2016).
Dans un article de 2017 cité plus haut, des réseaux neuronaux sont également utilisés pour l’extraction de features et la classification, et les auteurs recommandent de procéder à une réduction du bruit au préalable pour réduire le temps d’entraînement du réseau neuronal et améliorer ses performances (Anugrah, Bintoro 2017).
Enfin, un article de 2019 présente un exemple d’ICR, pour intelligent character recognition – un OCR spécialement entraîné pour reconnaître les textes manuscrits – qui utilise un CNN, ou convolutional neural network, un type de réseau neuronal utilisé surtout pour la reconnaissance d’images non-textuelles. Cette technologie permet en effet de reconnaître une plus grande variété de caractères et de signes de ponctuation, d’après les auteurs (Ptucha et al. 2019).
Bien que les technologies présentées ici n’ont pas pu être utilisée dans le cadre du projet présenté ci-après, elles demeurent un champ de recherche que de futurs projets devront prendre en compte autant que possible.
2.2.2. Multilinguisme et systèmes d’écriture divers
L’un des domaines dans lesquels l’océrisation avance considérablement est la grande variété de langues et de formes d’écritures pour lesquelles un OCR peut proposer des résultats satisfaisants. Certaines langues non-européennes, comme le japonais ou le mandarin, ont très vite trouvé leur place au sein de la recherche dans ce domaine, du fait du vaste marché possible. D’autres, moins répandues ou moins connues des chercheurs, ne reçoivent de l’attention que depuis peu.
C’est le cas, par exemple, des langues d’Inde, comme l’odia (Dash, Puhan, Panda 2017), le bangla, le devanagari, le tamoul etc. (Kumar et al. 2018). D’autres, comme l’arabe et le farsi, sont des objets de recherche depuis longtemps, mais nécessite encore du travail du fait de la complexité de leur système alphabétique et numérique (Amin Shayegan, Aghabozorgi 2014 ; Alghamdi, Teahan 2017). Il en est de même pour le finnois, dont la richesse des inflexions rend les résultats des OCR encore parfois hasardeux (Järvelin et al. 2016).
Ces langues ont cependant l’avantage d’être dotées d’une production écrite riche, offrant une abondance de données d’entraînement. D’autres, comme le yiddish et l’occitan, présentent une faible quantité de données disponibles. Dans ce type de cas, la création de lexiques et l’établissement de traits spécifiques des langues et des caractères en amont est conseillé, afin d’améliorer les résultats de l’apprentissage supervisé (Urieli, Vergez-Couret 2013).
2.2.3. Documents historiques et langues anciennes
Imprimés anciens
L’océrisation de documents historiques est l’un des champs de recherche phares dans le domaine. En effet, les imprimés anciens présentent de grandes variations quant aux typographies utilisées, et l’usage ou non de ligature ainsi que l’état général du document sont des éléments pouvant limiter les performances des OCR.
Dans un article de 2015, la Bibliothèque Nationale d’Autriche présentait ses projets « Austrian Books Online », « Austrian Newspapers Online » et « Europeana Online », des projets de numérisations et d’océrisation permettant la recherche plein-texte dans des documents historiques. Parmi les problèmes rencontrés, les auteurs notent l’utilisation contrainte de lexiques et modèles de langue modernes, mal adaptés à ce type de documents n’ayant pas de modèles de langues anciennes à disposition. Ils notent cependant que le projet IMPACT, mentionné plus haut, a entre autres permis de reconnaître l’importance de l’implémentation de lexiques et de modèles de langues anciennes adaptés. L’OCR seul ne peut pas tout faire (Kann, Hintersonnleitner 2015).
S’assurer que l’OCR est entraîné avec des données adéquates est donc indispensable, qu’il s’agisse de données linguistiques, au point de faire intervenir la technicité de la linguistique de corpus (Tumbe 2019), ou de signes d’écriture. En effet, certaines langues ont subi une évolution rapide de leur système d’écriture au cours de leur histoire. Un article de 2016 présente le cas d’imprimés roumains produits entre le XVIIIème et le XXème siècle, dont l’écriture a beaucoup évolué, passant du cyrillique à différentes versions simplifiées de cet alphabet, puis enfin à l’écriture latine.
Là aussi, l’entraînement de l’OCR s’est fait à l’aide de données spécifiques – des lettres cyrilliques et latines roumaines des différentes époques concernées. Sans ces données, les performances du logiciel étaient fort limitées (Cojocaru et al. 2016).
Très récemment, un projet de l’Université de Würzburg en Allemagne a abouti à la création d’un logiciel libre, OCR4all, spécialement conçu pour traiter des imprimés anciens (Jost 2019). Cet outil a fait partie de ceux testés dans le cadre du projet présenté ici.
Manuscrits
La problématique des écritures se posent d’autant plus dans le cas de textes manuscrits, qui présentent de nombreuses difficultés pour les chercheurs dans le domaine de l’océrisation, et pour les humanités numériques en général.
Dominique Stutzmann, chargée de recherche à l’Institut de recherche et d’histoire des textes (IRHT), écrivait en 2017 que « [l]es années qui s'ouvrent sont certainement celles d'une interaction intense, aux bénéfices réciproques, entre l'homme et la machine en paléographie » (Stutzmann 2017), la paléographie étant l’étude et la transcription de manuscrits anciens.
En effet, beaucoup de chercheurs se penchent actuellement sur la question, et une compétition a même été organisée pour stimuler la recherche dans le domaine de la paléographie numérique. Un article de 2017 en retrace le déroulement, les méthodes développées dans ce cadre et les résultats, plutôt positifs (Kestermont, Christlein, Stutzmann 2017).
Un article plus récent encore se penche sur Transkribus, une plateforme libre de HTR, ou handwritten text recognition, et en démontre l’efficacité, dans le cas du corpus testé du moins (Muehlberger et al. 2019). La paléographie numérique a de beaux jours devant elle.
Langues anciennes : le cas du latin
Ne pouvant aborder le cas de toutes les langues anciennes, nous nous focaliserons sur le latin, et plus spécifiquement le latin de l’époque moderne, ou Early Modern Latin, car il s’agit de la langue qui concerne le projet de recherche présenté dans cet article.
Du fait de son corpus extrêmement riche, le latin est une langue ancienne qui a depuis longtemps intéressé les chercheurs dans le domaine de l’océrisation. En 2006 par exemple, un article signale que les OCR de l’époque ne sont pas adaptés au traitement de cette langue, et propose l’implémentation de modèles de langue spécifiques, une solution déjà mentionnée plus haut (Reddy, Crane 2006).
Une problématique propre au latin, qui concerne également notre projet, est celle des abréviations. En effet, il est très fréquent de rencontrer des abréviations dans les textes latins, manuscrits comme imprimés. Par exemple, « dns » peut remplacer dominus, le seigneur, ou encore un tilde sur une voyelle signale généralement qu’elle est suivie d’un « m » ou d’un « n ». Un logiciel OCR ne peut pas a priori traiter ce type de cas. Pourtant, un article de 2003 propose déjà une solution, via un algorithme permettant de déterminer les résolutions possibles d’une abréviation et de sélectionner la meilleure en fonction du contexte (Rydberg-Cox 2003).
Actuellement, certains outils tentent de répondre à ces problèmes en se spécialisant dans le traitement de textes anciens, comme OCR4all mentionné plus haut, voire dans les textes latins, comme Latinocr.org, qui propose des jeux de données d’entraînement.
3. Tests de logiciels OCR
La première partie du projet consistait à tester différents logiciels d’océrisation open source afin de déterminer lequel offrait les meilleurs résultats sans post-correction. Ce chapitre présente cette phase du projet.
3.1 OCR sélectionnés
Pour des raisons de faisabilité, il n’était pas possible de tester tous les logiciels OCR gratuits et open source disponibles, et le choix s’est donc porté sur quatre d’entre eux. Tesseract et OCR4all ont été sélectionnés car ce sont ceux que la littérature récente mentionne le plus, et Kraken et Calamari, car ce sont les forks les plus à jour d’OCRopy, anciennement OCRopus, un projet également très présent dans la littérature.
3.1.1. Tesseract
Tesseract est un logiciel d’océrisation développé initialement par Hewlett Packard entre 1984 et 1994, puis rendu open source en 2005 (Smith 2007). Il a ensuite été repris en 2006 par Google, qui en assure depuis la maintenance et l’a mis à disposition sous la licence Apache-2.0 sur github.com/tesseract-ocr. Il a pour avantage de proposer des modèles pré-entraînés dans de nombreuses langues, avec la possibilité de combiner les modèles entre eux. Il autorise en outre la création de modèles sur la base de numérisations.
3.1.2. Kraken
Kraken est un fork du projet OCRopy, lancé en 2007 par Thomas Breuel, du Deutsches Forschungszentrum für Künstliche Intelligenz, avec le soutien de Google (Breuel 2007). Kraken est supposé rectifier certains problèmes que posent OCRopus, mais présente des fonctionnalités similaires. Comme Tesseract, il propose quelques modèles pré-entraînés et offre la possibilité d’en entraîner soi-même. Il est développé en Python, conçu pour être utilisé sur Linux, et a son site dédié : kraken.re.
3.1.3. Calamari
Le logiciel d’océrisation Calamari, lancé en 2018, est basé sur les projets OCRopy et Kraken. Il est également implémenté en Python et utilise des réseaux neuronaux artificiels pour optimiser ses résultats (Wick, Reul, Puppe 2018). Il est disponible en ligne sur github.com/Calamari-OCR.
3.1.4. OCR4all
OCR4all est un projet de l’Université de Würzburg en Allemagne lancé en 2019. Il a été conçu pour traiter les documents historiques et est doté d’une interface qui facilite son utilisation, sans que des connaissances en informatiques préalables soient nécessaires (Jost 2019). Le projet, qui intègre déjà différents logiciels, tels que Calamari et Kraken, est en cours d’intégration de Tesseract pour la reconnaissance de caractères. Il est à disposition du public sur github.com/OCR4all.
3.2. Méthodologie
3.2.1. Données d’entraînement
Le jeu de données étant composé de 29 livres numérisés contenant plus d’une centaine de pages chacun, 29 images ont été sélectionnées comme données d’entraînement, chacune extraite de l’un des 29 livres. Cette sélection, faite au hasard à l’aide d’un script Python a permis d’obtenir un échantillon de chacun des livres, ceux-ci pouvant présenter des variantes au niveau de la typographie.
Ces numérisations ont ensuite été transcrites manuellement dans des fichiers textes afin d’obtenir le ground truth, la « transcription-témoin », c’est-à-dire l’objectif à atteindre pour l’OCR. Ceci permet de mesurer les performances des différents logiciels à tester.
Ces transcriptions ont en outre été réalisées de deux manières différentes : une première transcription dite « diplomatique », au plus proche du document, et donc au plus proche des résultats qu’un logiciel OCR devrait pouvoir obtenir, et une seconde transcription dite « normalisée », qui servira de base à la post-correction.
Dans cette dernière les abréviations ont été résolues et des choix ont été faits pour simplifier la recherche et la lecture du texte. Le caractère æ a été remplacé par ae, les i et les j ont tous été remplacés par des i et les u et les v ont tous été remplacés par des u, sauf lorsqu’il s’agissait de chiffres romains. Ces choix ont été faits sur la base d’habitudes de recherches en latin et de règles d’orthographe usuelle de cette langue.
3.2.2. Logiciels et paramétrage
Pour chacun des logiciels d’océrisation choisis, les tests ont été effectués en trois phases.
La première phase consistait à tester les différents logiciels avec leur modèle standard, leurs paramètres par défaut et sans aucune modification de notre part. Ceci a permis, sur un premier test, de voir quel logiciel était le plus performant, avec ses réglages de base. Les résultats sortis étaient alors totalement bruts.
Lors de la seconde phase, d’autres modèles que ceux standards ont été testés avec différents réglages proposés par chaque logiciel. Ceci a ainsi permis de comparer les performances de chaque logiciel avec différents paramètres. Les résultats sortis ont été comparés à ceux de la phase précédente, afin de pouvoir déterminer quels paramètres avaient une influence positive sur les premiers résultats.
Lors de la troisième et dernière phase de l’évaluation des différents logiciels, un pré-traitement a été effectué sur les images de notre jeu de test, afin de les retravailler et de voir si cela permettait d’optimiser les résultats.
Toute cette phase d’évaluation a permis de comparer les modèles d’apprentissage et la qualité des outputs de chacun des logiciels, afin de sélectionner le plus performant. Ces océrisations et calculs de résultats pouvant être longs, un script de threading permettant de lancer l’océrisation de plusieurs images en parallèle a été créé, afin de gagner du temps.
3.2.3. Métriques
Pour mesurer la performance des logiciels testés, des métriques usuelles dans le domaine des Sciences de l’Information ont été utilisées, à savoir la précision et le rappel (Burgy, Gerson, Schüpbach 2020b). La moyenne harmonique, ou F1, a également été utilisée afin de faire la balance entre les deux.
Comme il s’agit de texte, ces métriques ont été utilisées à la fois à l’échelle des caractères et à l’échelle des mots (Burgy, Gerson, Schüpbach 2020b), ceci afin de pouvoir mieux décider quelles stratégies choisir pour l’entraînement des modèles et la post-correction, en vue d’optimiser les résultats. De manière générale, il est fréquent que les résultats au niveau des mots soient moins bons qu’au niveau des caractères, car il suffit qu’un caractère soit incorrect pour que le mot entier soit considéré comme faux.
La distance de Levenshtein, qui permet de comparer deux chaînes de caractères et de repérer le nombre de caractères ajoutés, supprimés ou substitués, a également été utilisée. L’algorithme qui effectue cette opération donne en sortie une somme des erreurs (arvindpdmn, 2019), ce qui a été utile dans le calcul des métriques précédentes.
Pour obtenir un retour visuel, la librairie « difflib » qui affiche les caractères ajoutés, supprimés et substitués, a été utilisée. Cela permet de vérifier quelles parties des outputs présentent des erreurs.
Figure 1 : comparaison d’une transcription (gauche) avec un output de Tesseract (droite) grâce à la librairie "difflib"

3.3. Sélection finale
Par suite de la première phase de tests, les résultats obtenus avec Kraken et Calamari n’étaient pas satisfaisants. Avec OCR4all, les résultats étaient très bons, mais l’outil présentait un défaut problématique, à savoir qu’il tournait en boucle infinie lorsqu’il était confronté à une page blanche. Ce problème pouvant être un obstacle de taille et ralentir considérablement le travail, surtout au moment de l’océrisation de l’ensemble de la collection de Bry, le choix s’est finalement porté sur Tesseract. La totalité des tests des trois autres outils et leurs résultats sont disponibles dans le mémoire de recherche (Burgy, Gerson, Schüpbach 2020a).
4. Test en trois phases de Tesseract
4.1. Tesseract – phase 1
Dans la première phase de test avec Tesseract, le logiciel a été utilisé avec son modèle standard anglais et ses paramètres par défaut. Les premiers résultats sont déjà encourageants au niveau des caractères avec une F1 de 76%.
Les résultats au niveau des mots sont en revanche bien plus faibles. La F1 est de 31,4%, pour des raisons mentionnées plus haut.
Figure 2 : Tesseract – phase 1 – modèle anglais
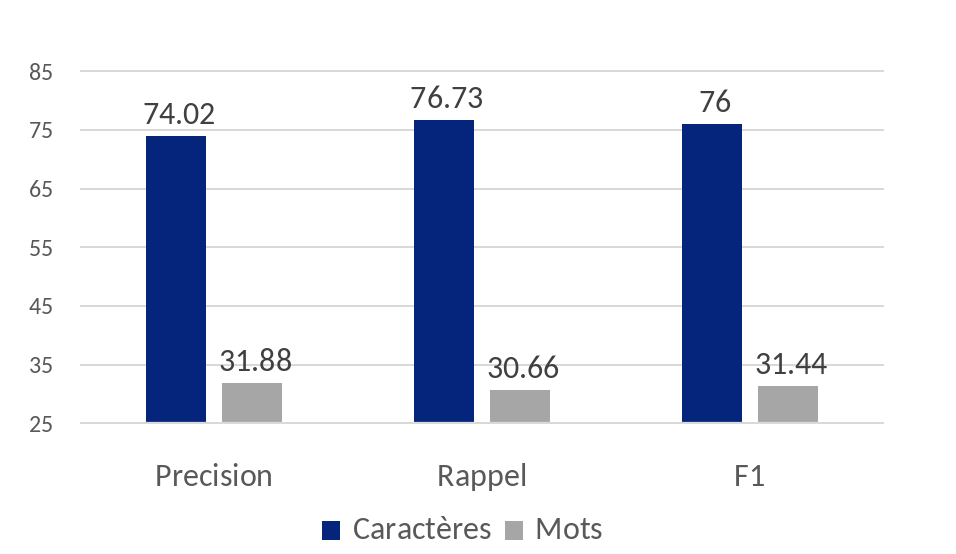
Quelques problèmes ont cependant été repérés. Dans le cas de pages vides, par exemple, le script Python de calcul automatique des métriques ne parvient pas à comparer les deux fichiers – la transcription et l’output – et produit des résultats incohérents. Afin de calculer les différentes métriques, il faut en effet connaître le nombre de caractères corrects ainsi que le nombre de caractères du ground truth (la transcription).
Dans le cas d’une transcription ne comportant pas de texte, le nombre de caractères corrects et le nombre de caractères de la transcription seront toujours égaux à 0 et fourniront toujours un résultat de 0 (ou une erreur de division par 0). Il a donc été décidé de définir automatiquement les valeurs de la précision, du rappel et de la F1 dans ce cas précis.
Figure 3 : numérisation d'une page blanche de la collection de Bry et output de Tesseract

Dans le cas ci-dessus, la transcription contient 0 caractères. L’OCR, lui, a trouvé 10 caractères (espaces compris), tous faux. Les calculs des différentes métriques seront alors les suivants :
P = 0/10 = 0
R = 0/0 → Division par 0 !
Dans tous les cas, les résultats des métriques donneront 0 ou une division par 0. Donc en définissant les résultats à 0, on peut limiter les risques de résultats incalculables sans fausser ces derniers.
Dans le cas de numérisations comportant des typographies différentes ou des gravures, les résultats tendent à chuter, car le logiciel peine à les traiter et cherche des caractères là où il n’y en a pas. Dans l’exemple ci-dessous, on peut voir que Tesseract a « trouvé » des caractères dans la gravure.
Figure 4 : numérisation d'une page de la collection de Bry comportant une image ; transcription et output de Tesseract
Enfin, dans la plupart des numérisations, une partie du texte de la page adjacente est visible. Tesseract tend à océriser ces caractères également, ce qui influe sur la précision. La figure ci-dessous illustre bien cette problématique, car on voit de nombreux caractères ajoutés – surlignés en vert – au début de la plupart des lignes de l’output.
Figure 5 : numérisation d'une page de la collection de Bry dont la page adjacente est visible ; transcription et output de Tesseract.

Ces observations ont été très utiles pour les phases suivantes.
4.2. Tesseract – phase 2
Dans la seconde phase, différents modèles proposés par Tesseract ont été testés, en sélectionnant des langues relativement proches du latin, à savoir les modèles allemand (deu), anglais (eng), espagnol (spa), français (fra), italien (ita), et latin (lat) bien entendu. Plusieurs de ces modèles ont été également combinés entre eux. Les résultats au niveau des caractères montrent que le modèle anglais testé dans la phase 1 se fait légèrement dépasser par la combinaison des modèles espagnol et anglais avec une F1 de 76.32%.
Figure 6 : Tesseract – phase 2 – modèles de langues – caractères
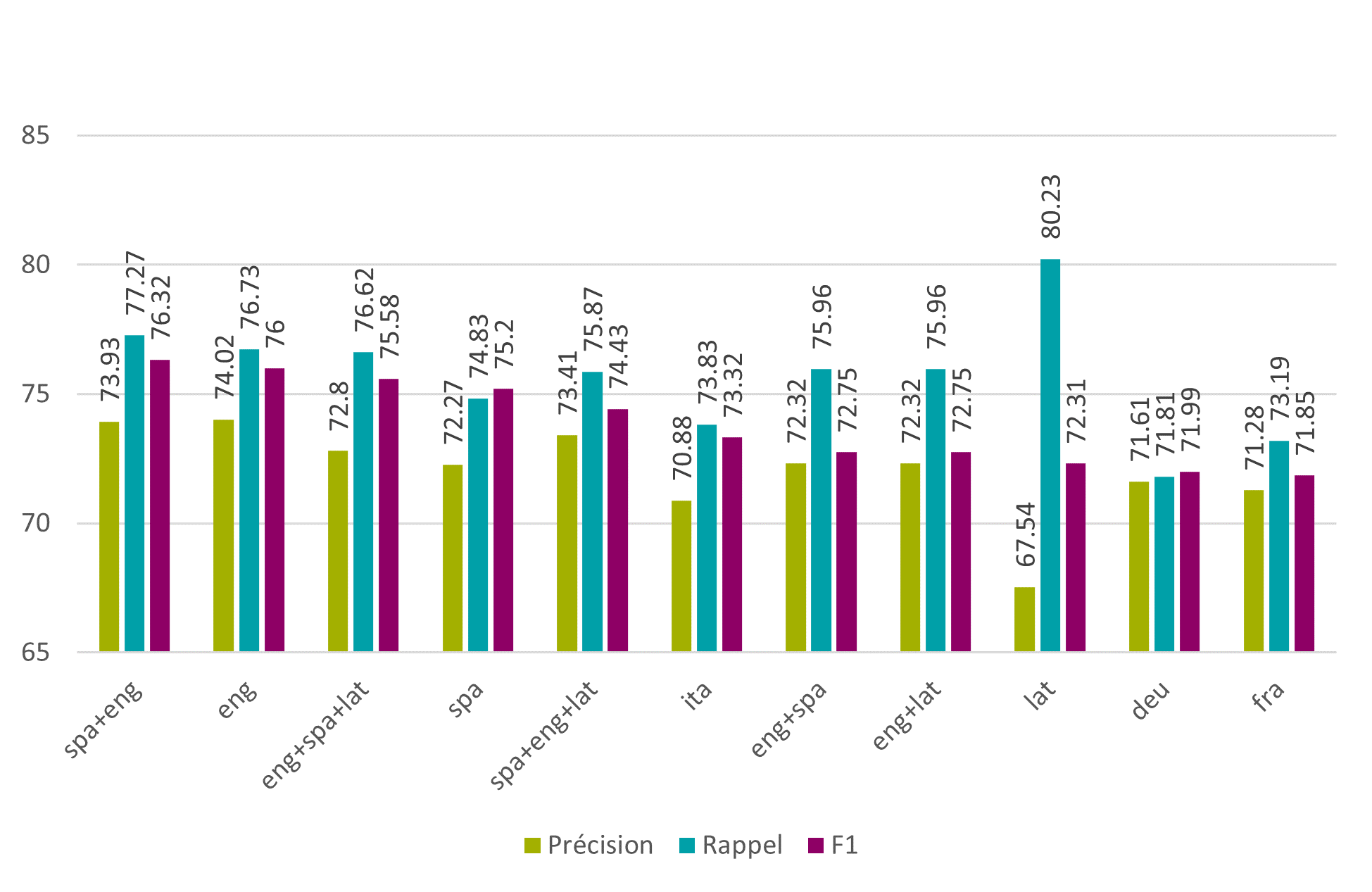
Au niveau des mots, le meilleur modèle est le modèle latin avec une F1 de 35.75%, suivi par la combinaison des modèles espagnol et anglais avec une F1 de 31.51%.
Figure 7 : Tesseract – phase 2 – modèles de langues – mots
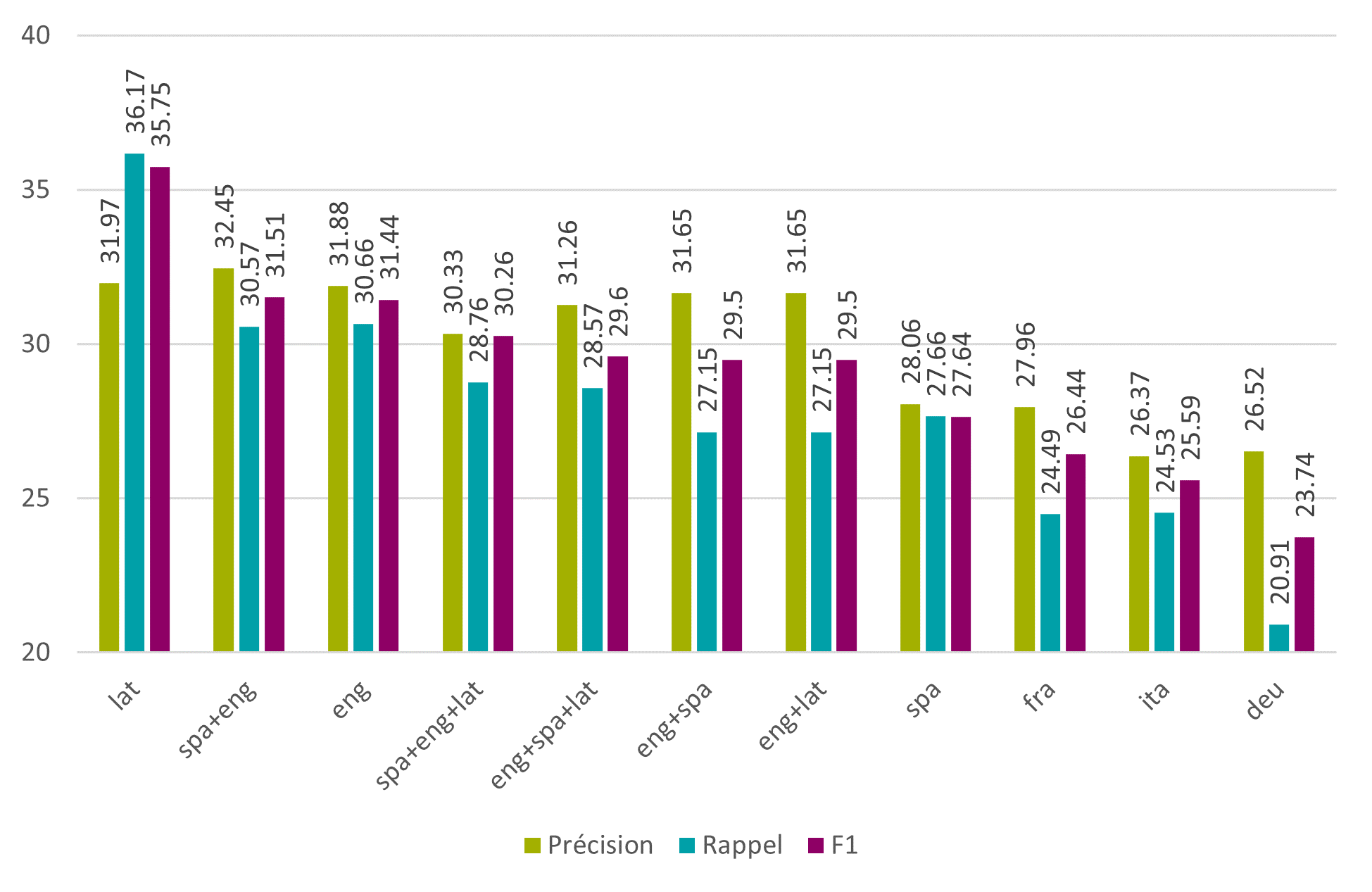
Le choix de l’ordre des modèles dans une combinaison est crucial. En effet, la combinaison espagnol/anglais offre de bien meilleurs résultats que la combinaison anglais/espagnol.
Il est également intéressant de noter que, bien que la F1 de la combinaison espagnol/anglais soit la plus élevée, ce n’est pas forcément le cas pour la précision et le rappel. On peut voir ici que le modèle avec la précision la plus élevée est le modèle anglais tandis que le modèle avec le rappel le plus élevé est le latin.
De fait, il est frappant de voir que le modèle latin, pourtant la langue de cette édition de la collection de Bry, a un taux de rappel si élevé, alors que sa précision est la plus mauvaise de tous les modèles testés. En effet, le modèle latin gère bien moins bien les espaces blancs et les marges ainsi que les images, et ajoute beaucoup de caractères incorrects.
En outre, le modèle latin donne des résultats moins bons lorsqu’il est confronté à des typographies différentes. Cela peut s’expliquer par la manière dont ces différents modèles sont entraînés. En effet, certaines langues vivantes, comme l’anglais, permettent de créer de vastes jeux de données d’entraînement présentant des typographies variées, alors que, pour le latin, la quantité de données à disposition est moindre, et les résultats s’en ressentent (theraysmith, 2017).
Ces deux problématiques sont visibles dans l’exemple ci-dessous.
Figure 8 : comparaison d'une transcription avec un output modèle latin (centre) et modèle anglais (droite)
Dans cette phase, différents paramètres de segmentation de pages (ou psm) qu’implémente Tesseract ont également été testés :
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
11 = Sparse text. Find as much text as possible in no particular order.
12 = Sparse text with OSD.
13 = Raw line. Treat the image as a single text line
Le graphique ci-dessous présente les résultats obtenus au niveau des caractères avec les six paramètres de segmentation les plus performants et le modèle anglais. On voit bien que la meilleure segmentation pour notre problème est la numéro 4 avec une F1 de 77,84%. La 1 et la 3 viennent ensuite, avec toutes les deux une F1 de 76,32%.
Figure 9 : Tesseract – phase 2 – psm – caractères
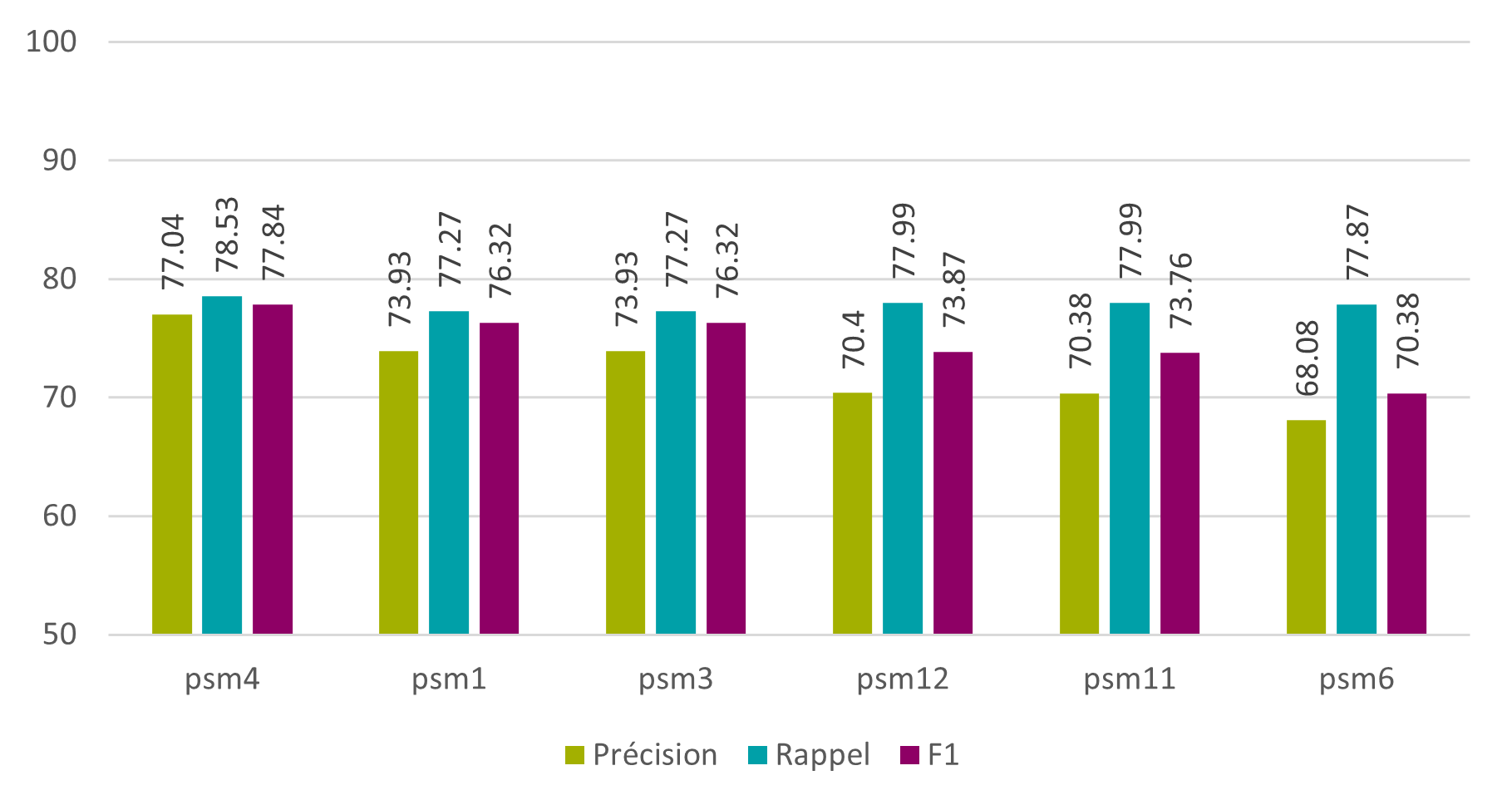
Au niveau des mots, les meilleures segmentations sont la 1 et la 3, avec une F1 de 31,51%.
Figure 10 : Tesseract – phase 2 – psm – mots
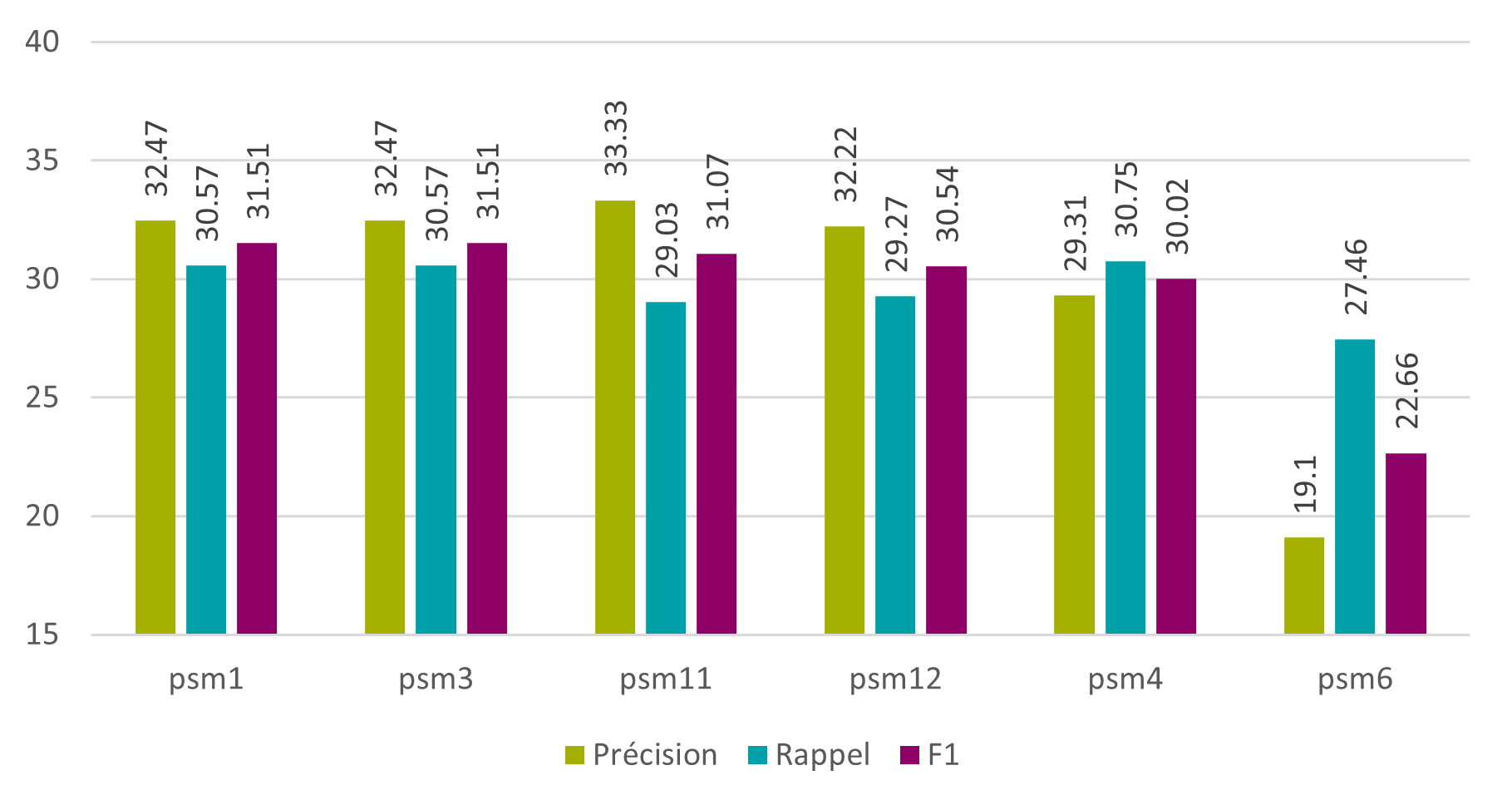
Ces résultats ont permis d’aiguiller les décisions de la dernière phase.
4.3. Tesseract – phase 3
Pour la dernière phase, les meilleurs paramètres identifiés précédemment (modèle espagnol/anglais et segmentation 1 ou 4) ont été utilisés afin de vérifier si un pré-traitement sur les images permet d’améliorer les résultats.
Trois types de pré-traitements différents ont été testés :
- Modification de l’image en nuance de gris (threshold)
- Modification de la taille de l’image (resample)
- Modification de la taille et modification en nuance de gris (full)
La méthode threshold consiste à modifier tous les pixels dépassant un certain seuil de couleur. Tout pixel plus clair que le seuil donné, 20% dans le cas présent, sera automatiquement transformé en pixel blanc. Tout autre pixel sera modifié en pixel noir.
La méthode resample consiste à rogner l’image en fonction de sa position dans le livre. Si la page est un recto (page de droite dans un livre), 400 pixels sont rognés de la gauche de l’image et 200 de la droite, et inversement si la page est un verso. Cela permet de supprimer assez facilement les pages adjacentes visibles. Néanmoins, comme les valeurs sont fixes, il est possible que le script rogne trop et qu’une partie du texte soit perdu.
La méthode full utilise les deux méthodes ci-dessus. Pour chacune de ces trois méthodes, une bordure blanche a en outre été ajoutée sur l’image, comme la documentation de Tesseract le conseille (Cimon 2019). Toutes les modifications ont été faites à l’aide de la librairie « ImageMagick », disponible sur imagemagick.org.
Les résultats obtenus montrent que ces méthodes peuvent améliorer la qualité des outputs. En effet la précision au niveau des caractères augmente de 0.9%, le rappel de 0.79% et la F1 de 0.78%.
Figure 11 : Tesseract – phase 3 – modèle « spa+eng » – pré-traitement des images – caractères
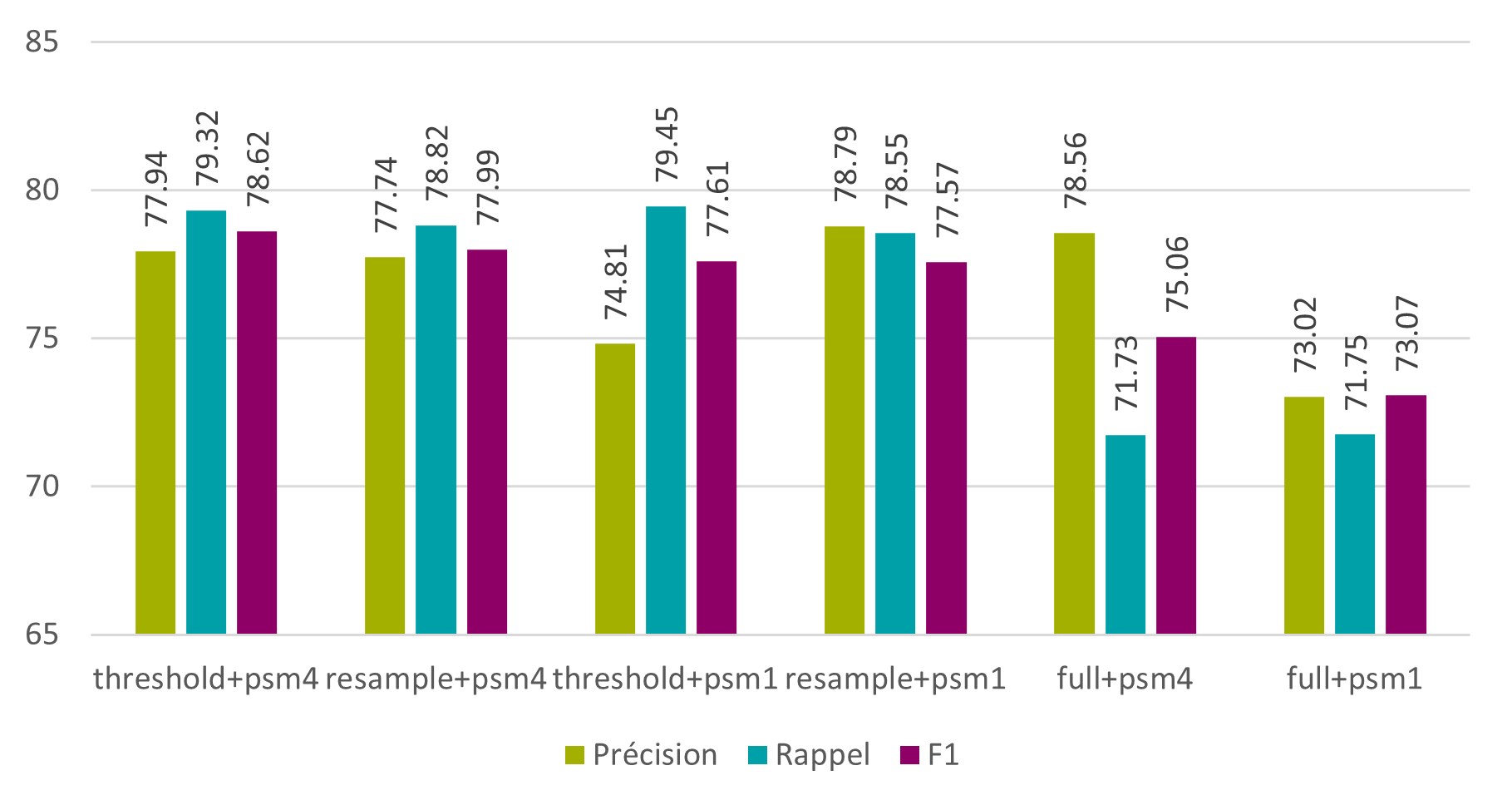
Au niveau des mots, une légère amélioration des résultats est aussi visible. On observe une augmentation de 0.28% en précision, une perte de 1.16% en rappel et une augmentation de 0.27% en F1.
Figure 12 : Tesseract – phase 3 – modèle « spa+eng » – pré-traitement des images – mots
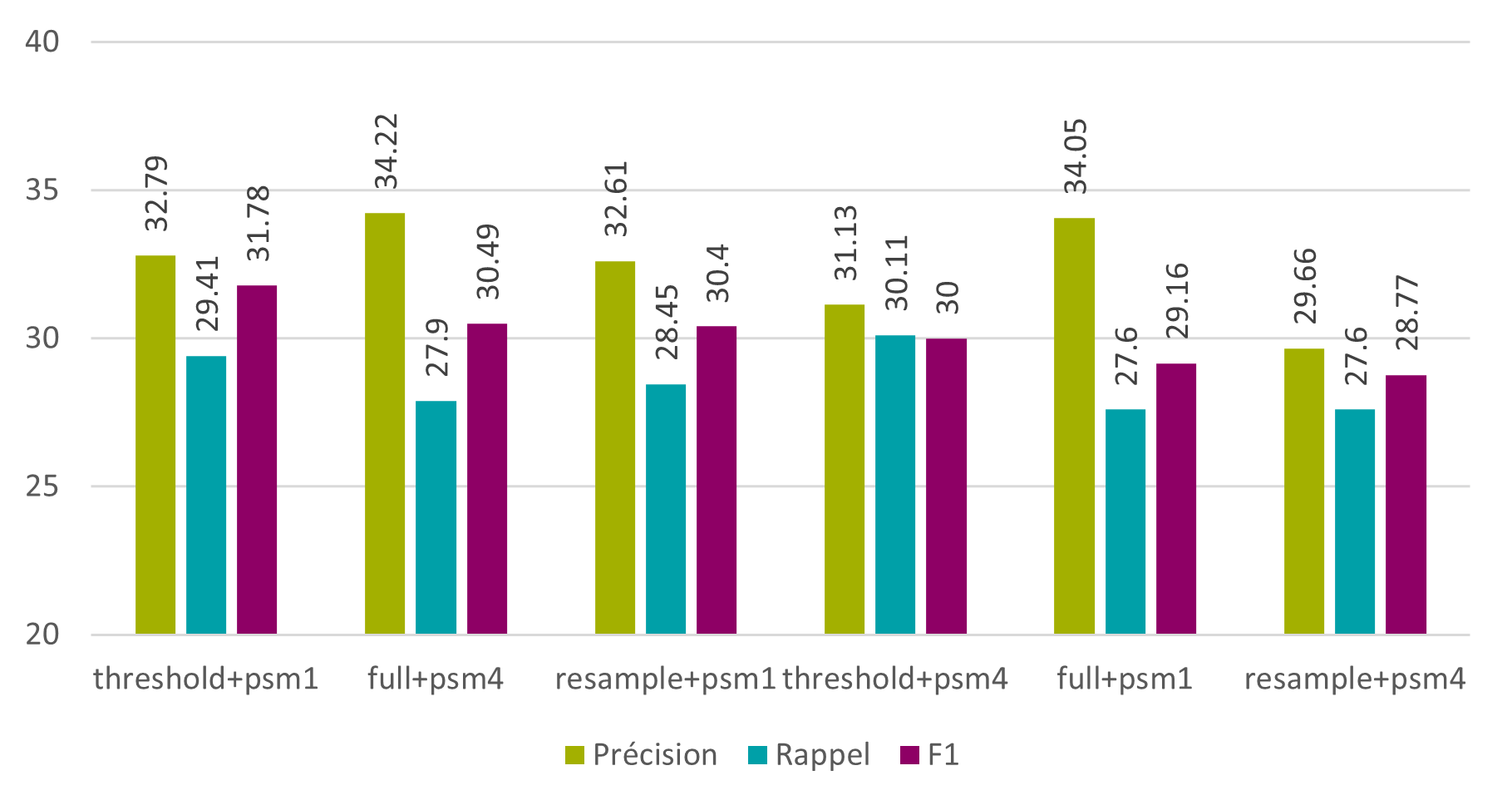
Ces trois méthodes de pré-traitement sont encore naïves et méritent d’être améliorées, mais il est d’ores et déjà possible d’affirmer que le pré-traitement des images augmente effectivement les résultats.
En définitive, la combinaison des modèles espagnol et anglais avec une segmentation de type 1 ou 4 semble être la méthode la plus adaptée au problème. Un pré-traitement sur les images augmente également légèrement les résultats. À ce stade, une F1 de 78.62% au niveau des caractères et de 31.78% au niveau des mots peut être obtenue. Il faut également noter que Tesseract est un logiciel stable, robuste et facile à utiliser qui n’a posé aucun problème de prise en main, ce qui est un avantage non négligeable.
5. Optimisation de l’océrisation
La suite de ce projet consistait à tester différentes méthodes pour améliorer les résultats de l’OCR sélectionné, Tesseract, en utilisant des techniques de pré-traitement des inputs, de post-correction des outputs, ou en utilisant des fonctionnalités du logiciel lui-même.
5.1. Méthodes
Plusieurs méthodes ont été testées :
- Pré-traitement intelligent des images
- Correction brute des outputs
- Transformation systématique des caractères
- Suppression de caractères indésirables
- Suppression des caractères non alphanumériques
- Utilisation d’un corpus latin pour la création d’un dictionnaire
- Remplacement des mots selon une distance de modification définie
- Utilisation de l’outil de post-correction PoCoTo
- Création d’un modèle Tesseract personnalisé
5.2. Pré-traitement intelligent des images
Comme vu dans Tesseract – phase 3, un pré-traitement intelligent des images peut améliorer les résultats des océrisations.
Pour ce faire, un algorithme de recherche permettant de savoir si la page actuellement traitée est un recto ou un verso a été créé dans le cadre du projet. En fonction de cela, un autre algorithme, développé dans ce même cadre, va trouver la position idéale pour rogner l’image et l’effectuer à l’aide de « ImageMagick », mentionné dans Tesseract – phase 3.
L’algorithme de sélection de l’orientation de la page calcule la somme des niveaux de gris de chaque pixel de la colonne de pixels la plus à droite et la plus à gauche de l’image. La somme la plus petite permet d’indiquer si l’image est un recto ou un verso.
A priori, cet algorithme fonctionne uniquement avec le jeu de données du projet, car le Bodmer Lab a pour habitude de cadrer ses numérisations en gardant une partie de la page adjacente ainsi qu'un fond noir sur le bord opposé. Ainsi, en déterminant quel côté est “le plus foncé”, il est possible de savoir si la page est un recto ou un verso.
Sur l’image suivante, la partie droite (en rouge) comporte uniquement des pixels noirs. Un pixel noir ayant une valeur d’environ 0 (dépendant de la luminosité de la pièce au moment de la numérisation), la somme sera petite. Inversement, la partie de gauche (en vert), aura une somme bien plus élevée. On peut donc dire que cette image est un recto car la somme la plus faible est celle de droite.
Figure 13 : détection des zones à rogner selon notre algorithme dans une numérisation extraite de la collection de Bry

Lorsque l’on sait si l’image est un recto ou un verso, il faut déterminer quel pourcentage de l’image doit être rogné pour enlever le surplus de la page adjacente. Pour ce faire, un algorithme dont c’est l’objectif a été créé. Si la page est recto, l’algorithme va calculer la somme des couleurs de chaque colonne entre la gauche et le centre de l’image. Ces sommes sont stockées dans un tableau. Par la suite, l’algorithme va récupérer l’indice de la valeur la plus faible dans ce tableau. Cet indice signale l’endroit où l’image doit être rognée.
Le processus est presque le même si l’on travaille sur un verso. La seule différence réside dans le calcul des sommes des colonnes de pixels. L’algorithme ne partira pas de la gauche vers le centre mais de la droite vers le centre.
Figure 14 : image non rognée et image rognée avec bordure blanche


Ces deux algorithmes ont également été utilisés avec différents paramètres pour en créer plusieurs versions. En effet, dans certains cas, le rognage était trop important et une partie du texte était alors perdue. Pour éviter cela, il a fallu faire des tests en divisant la valeur du rognage (crop) par son quart, son tiers et sa moitié.
Le script permettant l’appel à ImageMagick est le suivant :
Dans le cas d’une image recto :
convert imagePath -gravity West -chop chopx0 -trim -trim -resample -bordercolor white -border 20x20 savePath
Dans le cas d’une image verso :
convert imagePath -gravity East -chop chopx0 -trim -trim -resample -bordercolor white -border 20x20 savePath
Il suffit de remplacer les valeurs italiques soulignées par les valeurs récupérées dans l’algorithme.
Grâce à ces trois algorithmes, il est possible de supprimer la page adjacente sur l’image actuellement traitée. Avec la meilleure version de l’algorithme, la F1 passe de 78.62% à 79.23% au niveau des caractères et de 31.78% à 32.14% au niveau des mots.
Figure 16 : Tesseract – pré-traitement intelligent – caractères
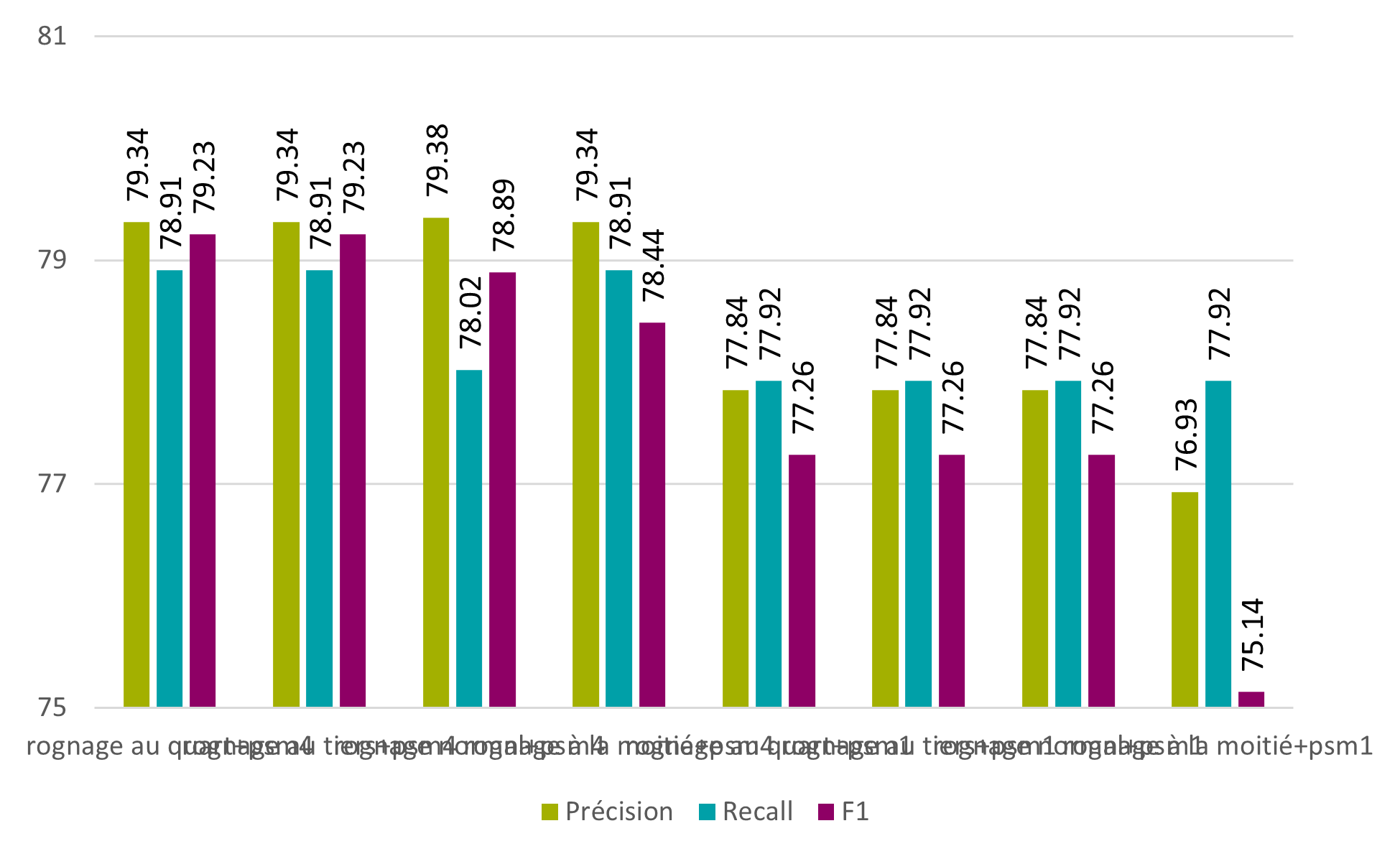
Figure 17 : Tesseract – pré-traitement intelligent – mots
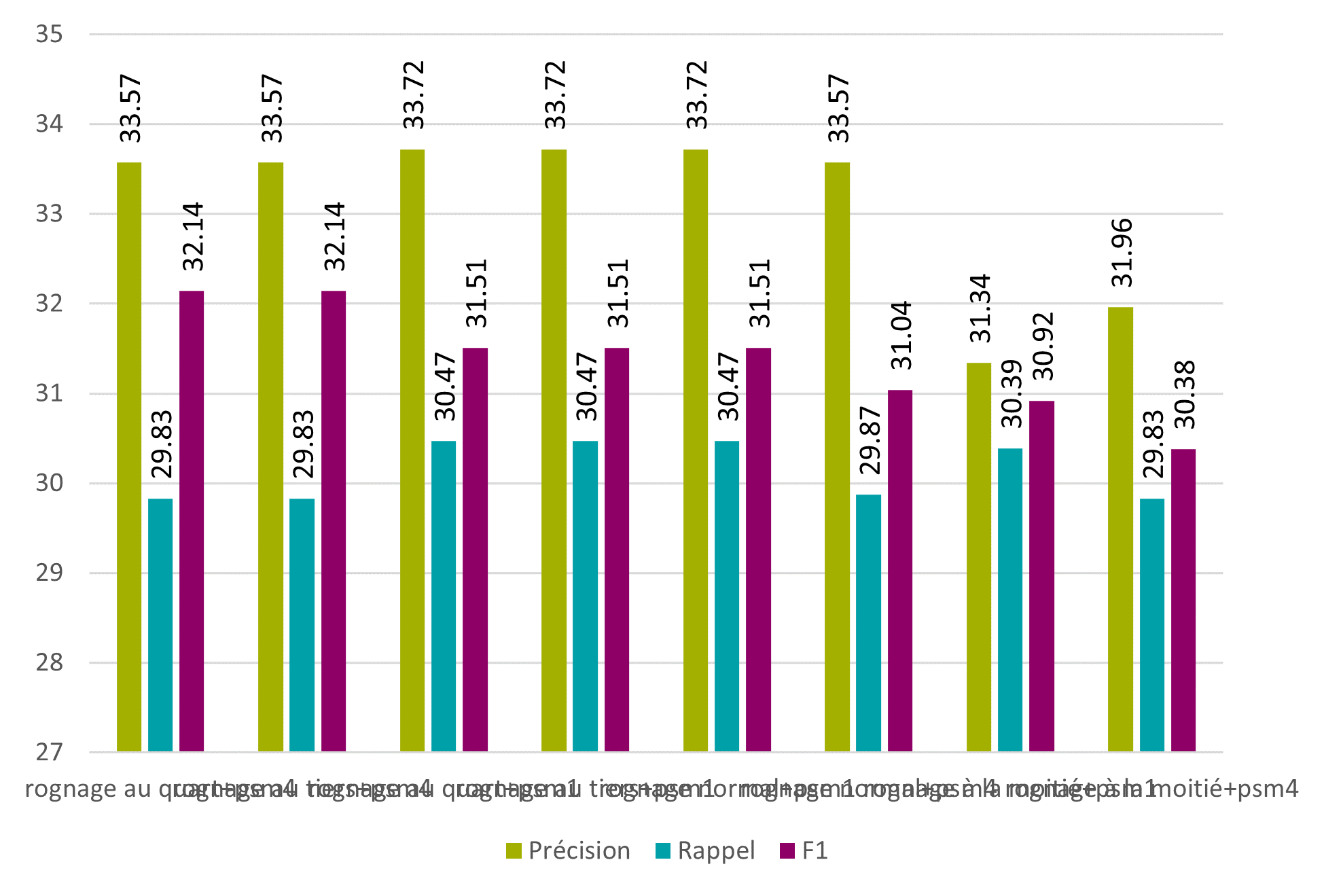
5.3. Correction brute des outputs
Après avoir appliqué les algorithmes de pré-traitement et océrisé l’ensemble des images rognées dans Tesseract, il est possible d’améliorer encore les résultats en effectuant une post-correction sur les outputs.
Pour ce faire, plusieurs algorithmes ont été testés :
- Suppression de tous les caractères différents d’un caractère d'espacement (vertical ou horizontal), d’une lettre (minuscule ou majuscule) ou d’un chiffre
- Par la suite, remplacement de tous les v par des u et les j par des i, du fait de l’équivalence de ces lettres en latin
- Uniquement de tous les v par des u et les j par des i
- Suppression de tous les caractères différents d’une lettre (minuscule ou majuscule), d’un chiffre, d’un point, d’une virgule, d’un espace ou d’un retour à la ligne
- Par la suite, remplacement de tous les v par des u et les j par des i
- Suppression de tous les caractères différents d’une lettre (minuscule ou majuscule), d’un chiffre, d’un double point, d’un tiret, d’un espace ou d’un retour à la ligne
- Par la suite, remplacement de tous les v par des u et les j par des i
- Suppression de tous les caractères différents d’une lettre (minuscule ou majuscule), d’un double point, d’un tiret, d’un espace ou d’un retour à la ligne
- Par la suite, remplacement de tous les v par des u et les j par des i
Les résultats montrent qu’un simple remplacement des lettres v et j améliore les résultats. En effet, la F1 passe de 79.23% à de 80.06% au niveau des caractères, et de 32.14% à 34.58% au niveau des mots.
Figure 18 : Tesseract – correction brute – caractères
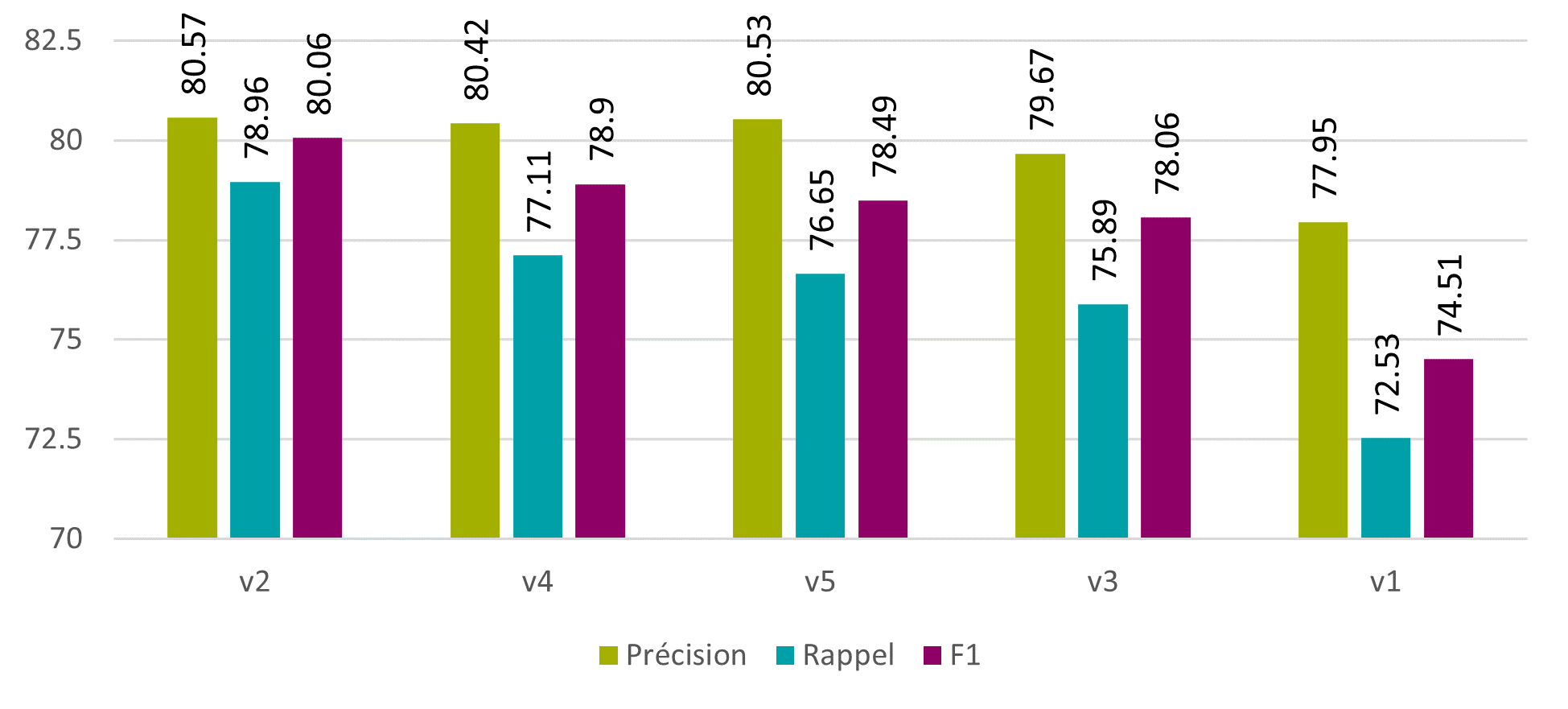
Figure 19 : Tesseract – correction brute – mots
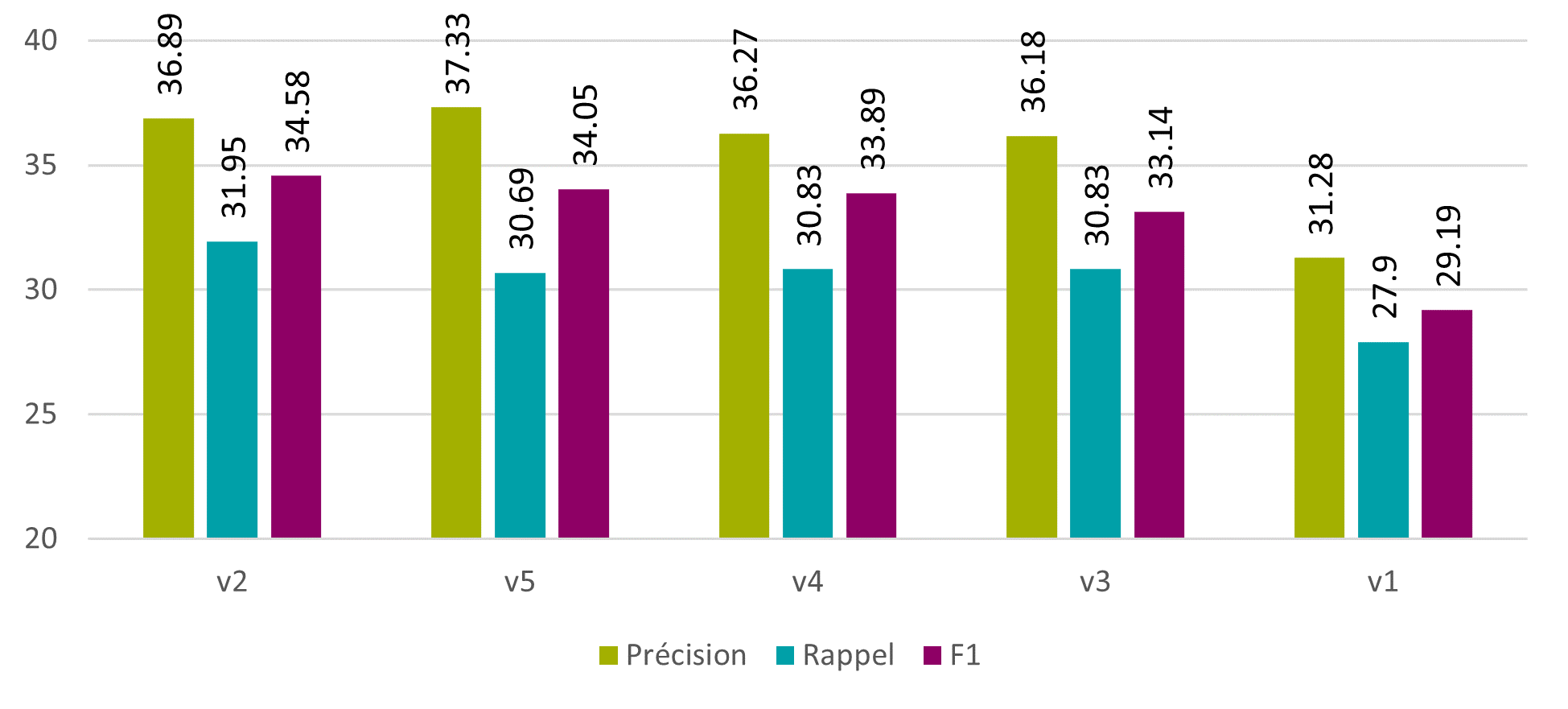
5.4. Utilisation d’un corpus latin pour la création d’un dictionnaire
Une autre méthode de post-correction envisageable était la modification directe des mots sur la base d’un corpus de textes latins. La librairie « symspellpy », disponible sur pypi.org/project/symspellpy, a été utilisée afin de créer le dictionnaire et de calculer la distance d’édition des mots. Pour le corpus, celui de Latinocr.org, mentionné dans l’état de l’art et qui se trouve sur ryanfb.github.io/latinocr/resources.html, a été utilisé.
L’algorithme suivant a ensuite été créé :

Cet algorithme utilise la librairie « symspellpy » pour comparer chaque mot avec ceux du dictionnaire. Pour ce faire, il est nécessaire de définir une distance de recherche maximale (2, dans notre cas). Cette distance limite les résultats aux mots qui ont une distance d’édition de maximum deux caractères.
Tesseract trouve parfois des espaces au milieu des mots. Afin de pouvoir les corriger automatiquement avec l’algorithme, il a fallu comparer chaque mot et celui qui le suit avec le dictionnaire. De cette manière, si un mot a été coupé en deux, il est possible de le traiter.
Plusieurs versions de cet algorithme ont été testées :
- Distance de suggestion du mot < distance de suggestion du mot et de celui qui le suit
- Distance de suggestion du mot <= distance de suggestion du mot et de celui qui le suit
- Distance de suggestion du mot et de celui qui le suit < distance de suggestion du mot
- Distance de suggestion du mot et de celui qui le suit <= distance de suggestion du mot
Aucune de ces versions n’a pu améliorer les résultats. Au contraire, ils baissent d’environ 5%. Cela est dû au fait que chaque mot va essayer d’être corrigé par rapport à un mot du corpus – même s’il est correct, pour autant que la distance d’édition soit inférieure ou égale à 2. De ce fait, la précision, le rappel et la F1, que ce soit au niveau des caractères ou des mots, baissent.
Figure 20 : Tesseract – corrections par dictionnaire – caractères
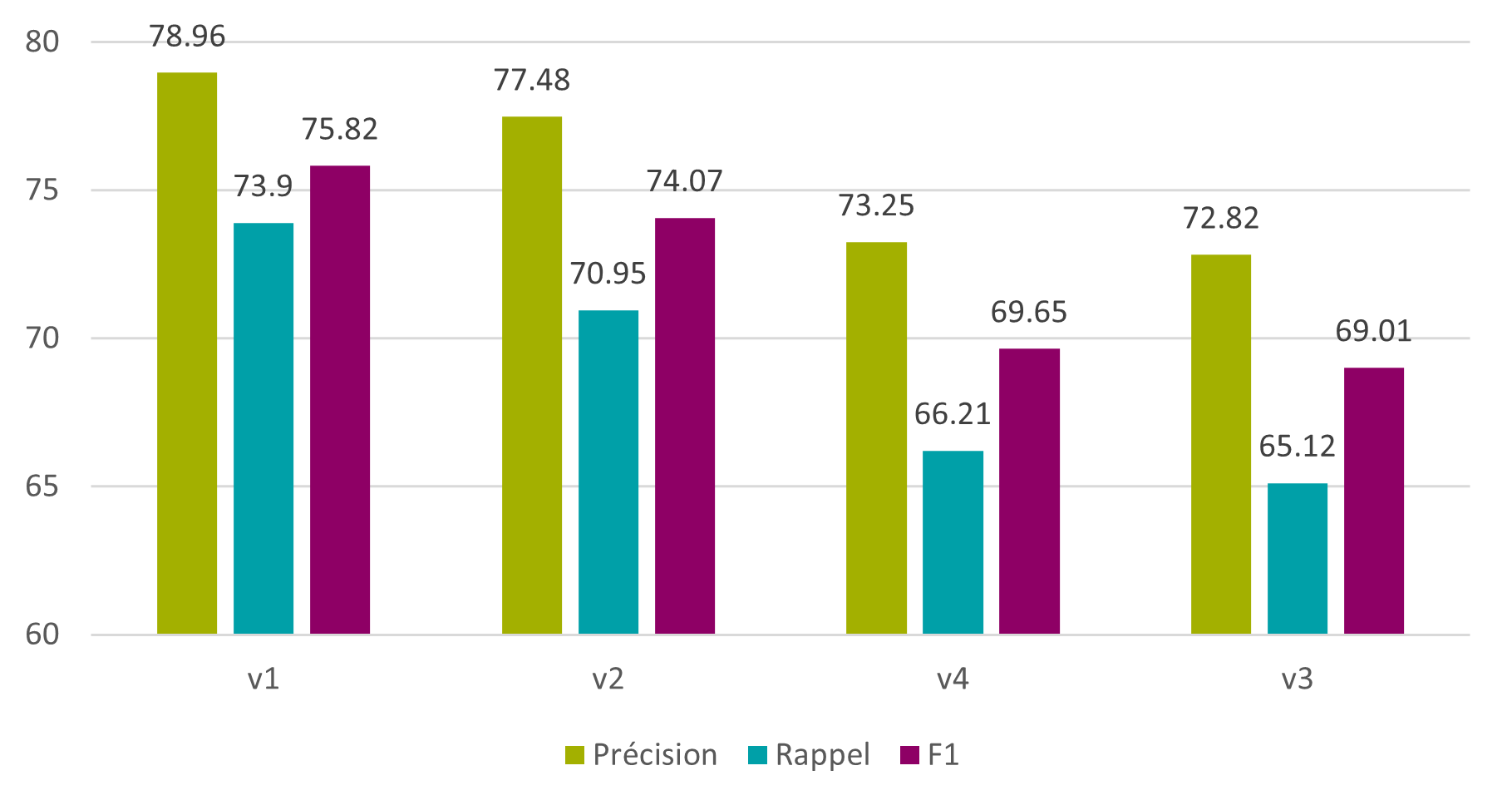
Figure 21 : Tesseract – corrections par dictionnaire – mots
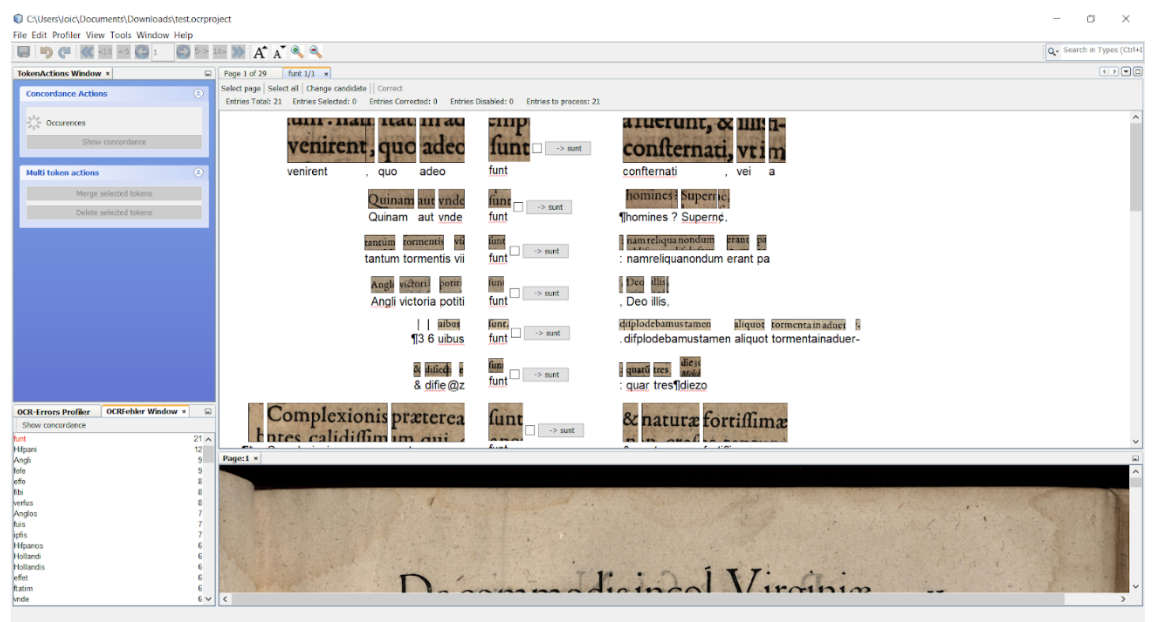
Ce problème peut s’expliquer entre autres par la complexité du latin, qui est une langue à cas. Dans la plupart des dictionnaires latins, un nom va être présenté sous la forme consul, -is, m., ce qui veut dire que c’est un mot masculin de la 3ème déclinaison, qui prend donc -is comme terminaison au génitif. Ce mot pourrait cependant apparaître sous des formes comme consules ou consulibus, mais le dictionnaire ne contient pas ces formes, évidentes pour un latiniste, mais non pour un ordinateur.
Il aurait cependant été intéressant de pousser plus loin l’expérience des dictionnaires, méthode de post-correction reconnue dans le domaine de l’océrisation, mais, pour des raisons de faisabilité, il a fallu s’en tenir là.
5.5. Utilisation de l’outil de post-correction PoCoTo
Une autre méthode de post-correction testée consistait à utiliser le logiciel PoCoTo. Il s’agit d’un logiciel de post-correction développé dans le cadre du projet IMPACT et permettant de corriger les erreurs des logiciels OCR (Vobl et al. 2014). Les avantages et limites de ce logiciel ont rapidement pu être repérées.
PoCoTo prend en input les images a océriser ainsi que leur océrisation au format HOCR. Ce format enregistre l’océrisation de chaque caractère (comme avec le format texte) mais également la position de la portion d’image qui lui a fait découvrir ce caractère. Il est donc possible par la suite, grâce à PoCoTo, de vérifier manuellement si l’output correspond au ground truth et de la corriger au besoin. Ceci est cependant long, car l’on corrige chaque mot un à un.
Figure 22 : capture d'écran du logiciel PoCoTo en cours d'utilisation
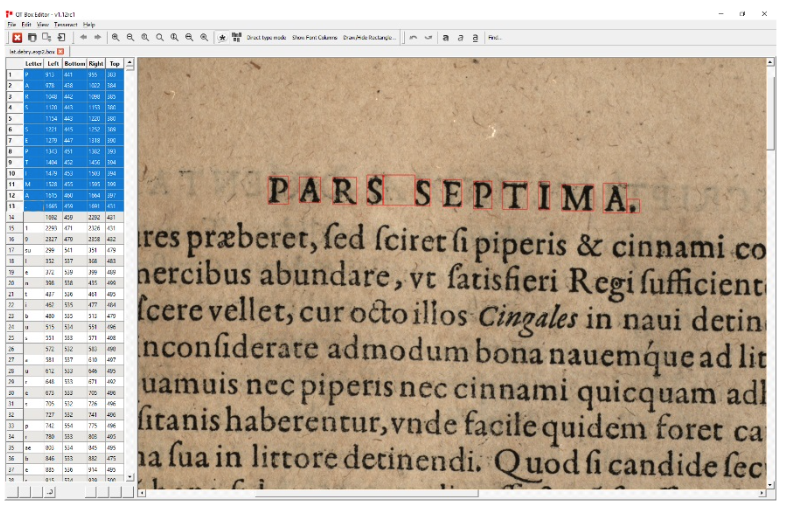
Une seconde option de PoCoTo permet de télécharger des profilers. Actuellement, il est possible de télécharger des profilers en latin, en grec ou en allemand pré-entraînés. Il est également possible de créer son propre profiler.
Ces derniers stockent les erreurs courantes des OCR pour un langage en particulier, afin d’effectuer une correction « semi-automatique » des outputs. Le profiler va détecter si un mot souvent reconnu incorrectement par les OCR se trouve dans l’un des outputs et propose une correction. Néanmoins, tout se fait depuis une interface graphique et une intervention humaine est alors obligatoire.
Figure 23 : capture d'écran du logiciel PoCoTo en cours d'utilisation avec le système de profiler latin
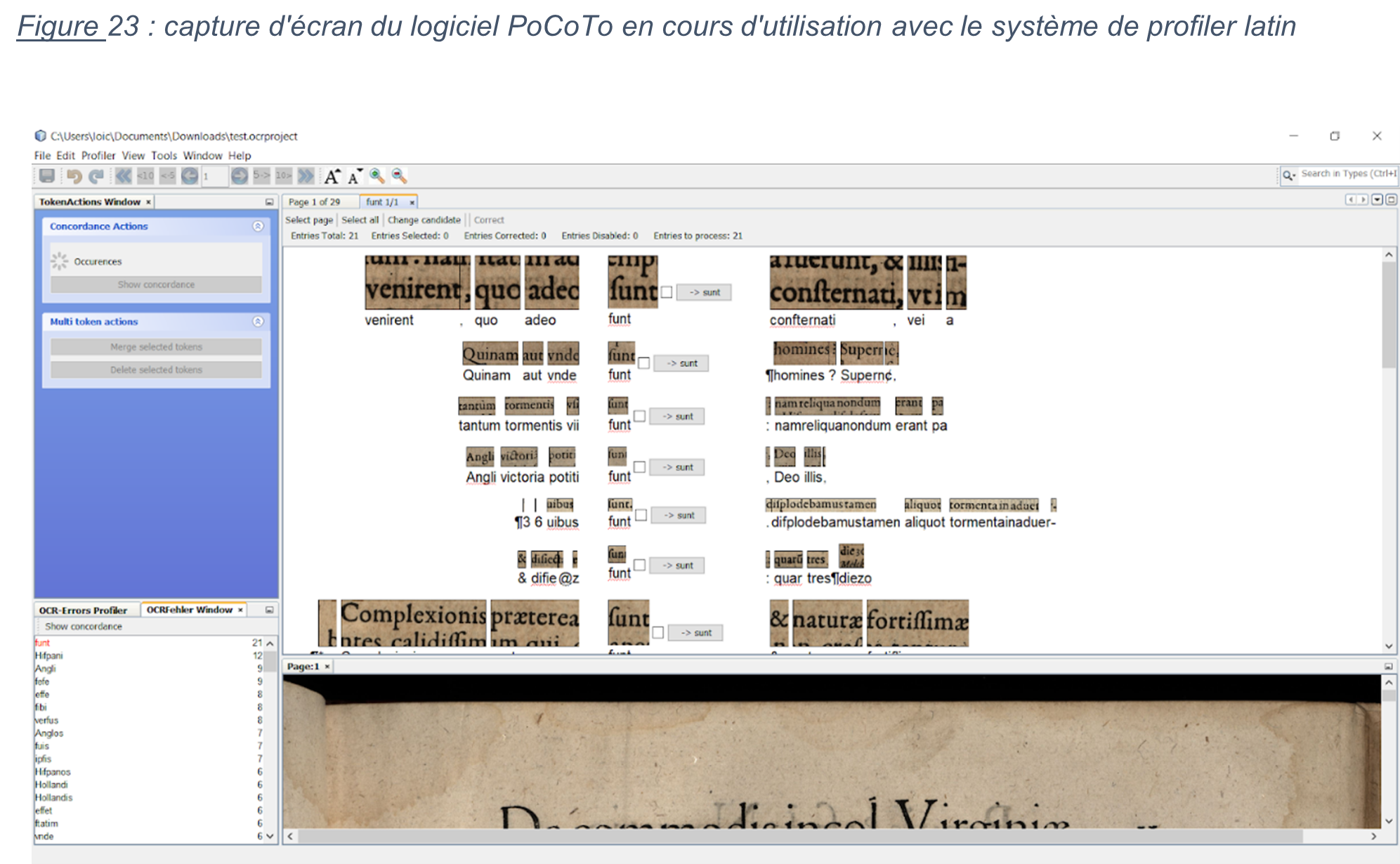
Cette obligation d’avoir une intervention humaine est chronophage et, au vu du temps disponible pour ce projet, il n’a pas été possible d’intégrer cet outil dans la post-correction.
5.6. Création d’un modèle Tesseract personnalisé
La dernière méthode d’optimisation des résultats testée est la création d’un modèle Tesseract personnalisé. Cette fonctionnalité est rendue possible par l’outil open source multi-plateforme, QT Box Editor, disponible sur github.com/zdenop/qt-box-editor. Cet outil offre la possibilité de corriger manuellement la segmentation des caractères sur la numérisation ainsi que chaque caractère identifié, afin de pouvoir créer un modèle basé sur les typographies de la collection de Bry.
Cette méthode a été testée en dernier car la création d’un modèle personnalisé prend un temps considérable mais n’assure pas pour autant d’améliorer les résultats. En outre, il y a de fortes chances que ce modèle ne soit pas réutilisable pour d’autres collections, étant donné que le logiciel s’entraîne à reconnaitre les typographies spécifiques de cette collection.
Tesseract préconise d’avoir au minimum trois fois chaque caractère dans un jeu d'entraînement, et trois images contenant la plupart des caractères ont alors été sélectionnées pour créer notre jeu de données. Une de ces images comporte une gravure afin que Tesseract apprenne également à ne pas y reconnaître de texte. Finalement, le travail fourni sur ces trois numérisations correspond à une vérification et correction manuelle d’environ 6'200 caractères.
Figure 24 : capture d’écran de QT Box Editor pendant la vérification et correction des caractères
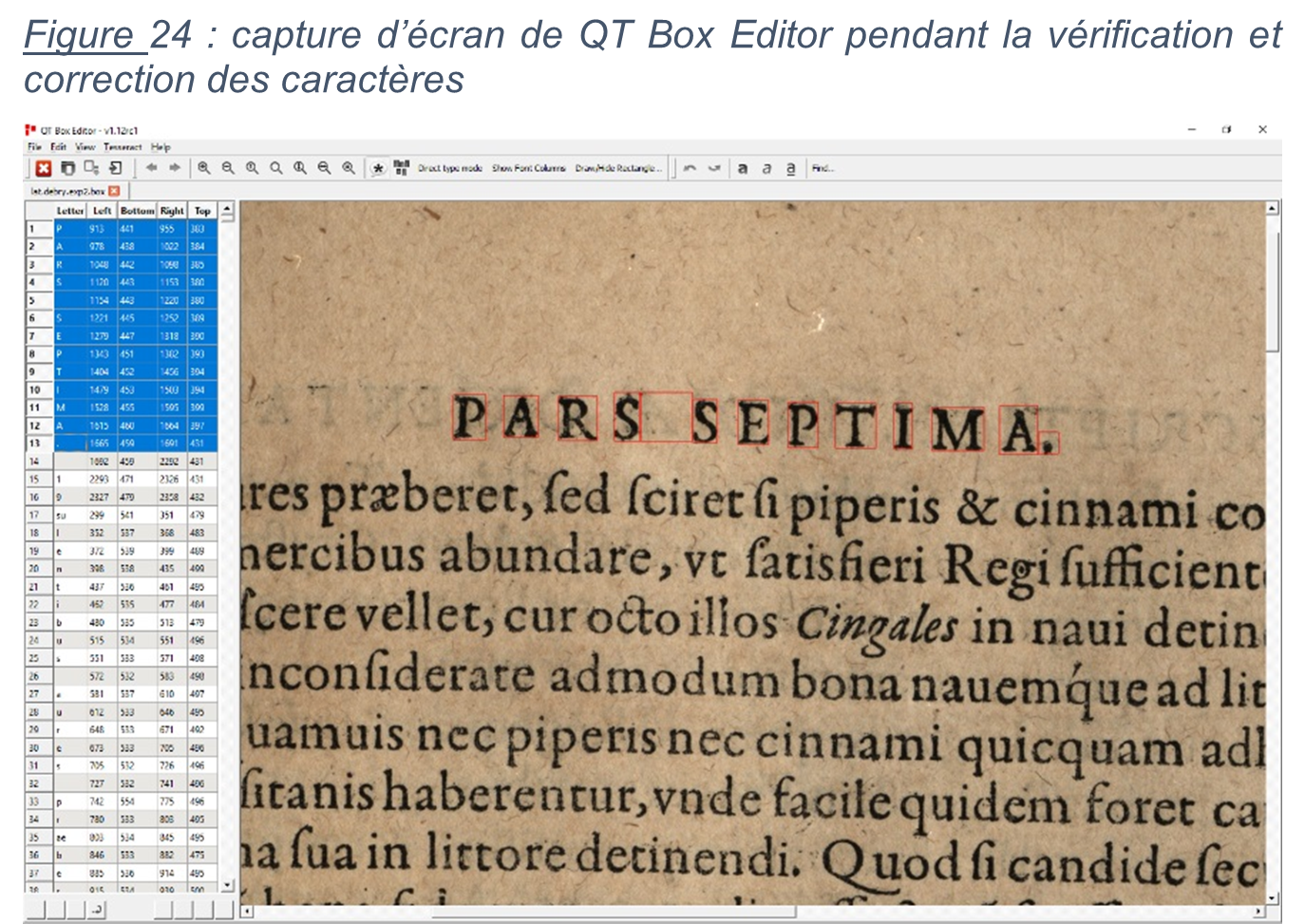
Cette ébauche de modèle a permis d’obtenir des résultats relativement positifs, au vu du peu de données ayant servi à sa création, mais c’est bien sûr insuffisant par rapport aux autres tests. L’idée reste cependant intéressante, et, si le temps permet de traiter quelques images de plus, les résultats pourraient peut-être dépasser ceux des modèles testés auparavant.
Figure 25 : Tesseract – modèle personnalisé – caractères
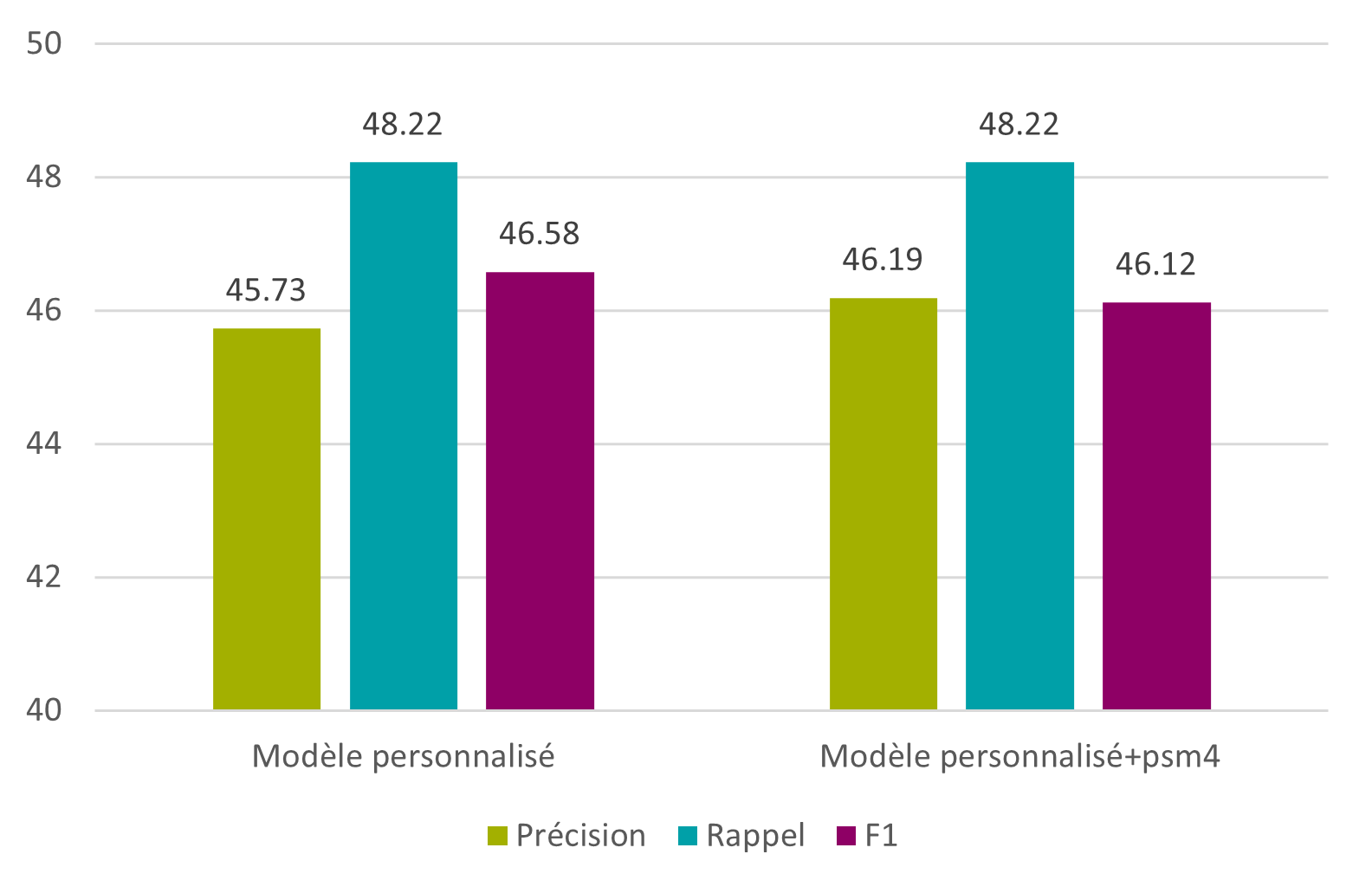
Figure 26 : Tesseract – modèle personnalisé – mots
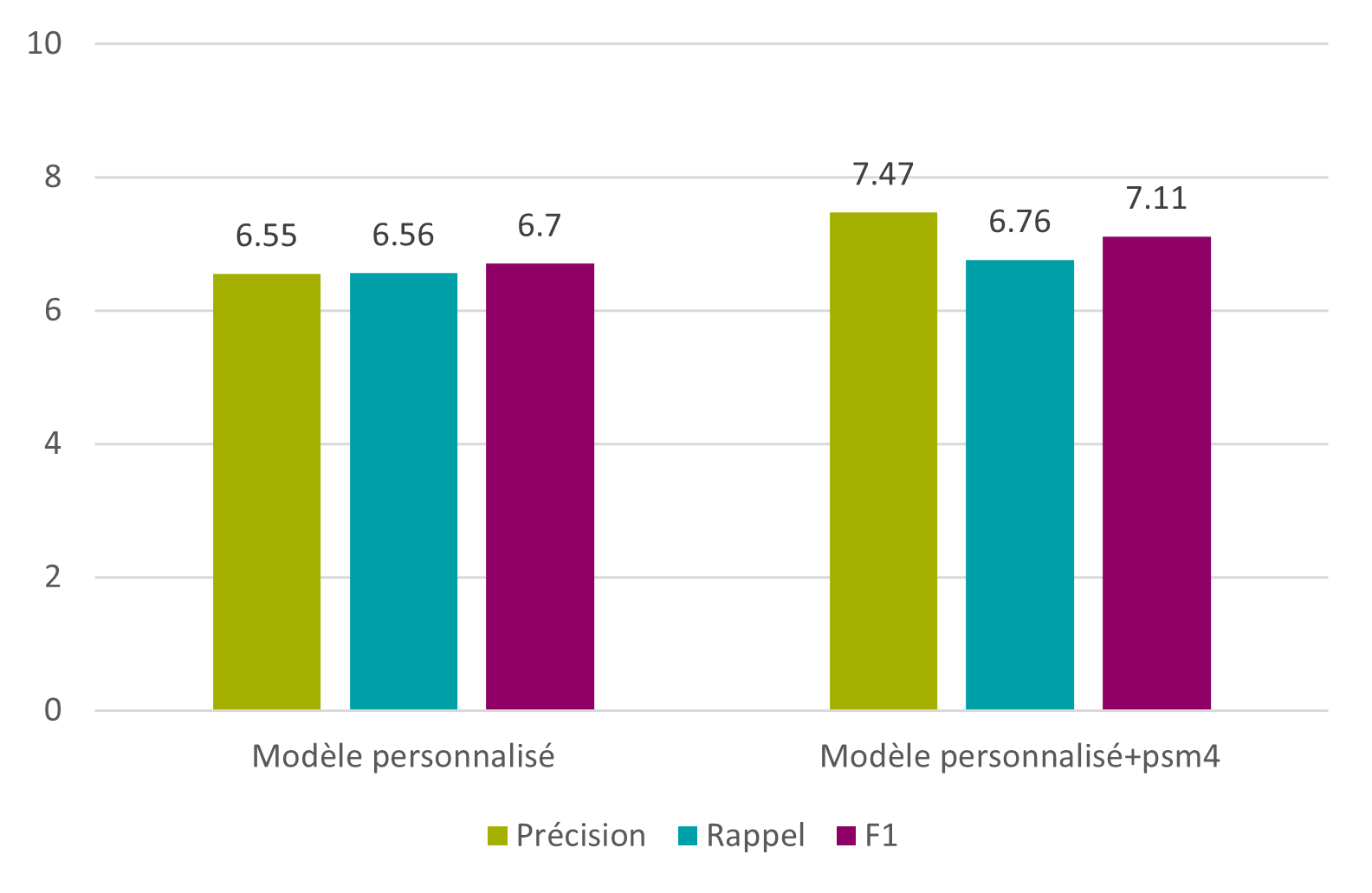
5.7. Résultats finaux
À la suite de tous ces tests, la F1 maximale obtenue est de 80.06% au niveau des caractères, et de 34.58% au niveau des mots. L’objectif de 95% au niveau des caractères et des mots n’est pas atteint, mais il a tout de même été possible de s’en rapprocher.
6.Conclusion et perspectives futures
Après avoir testé quatre logiciels d’océrisation, dont deux ont très vite posé des problèmes techniques (Kraken et Calamari), deux logiciels présentent de bonnes performances. Tesseract, lors du meilleur test, atteint une F1 de 78.62% au niveau des caractères et de 31.78% au niveau des mots (voir Tesseract – phase 3). OCR4all est également performant, mais présente un problème technique qui le met malheureusement hors course. Il est cependant recommandé de suivre l’évolution du problème technique posé par OCR4all car, s’il est réglé, ce logiciel pourraient alors devenir un excellent choix.
En utilisant différentes méthodes de pré-traitement et de post-correction, il a été possible de faire monter les résultats de Tesseract à une F1 de 80.06% au niveau des caractères et de 34.58% au niveau des mots (voir Résultats finaux). Le chemin est encore long jusqu’au 95%, mais la voie est à présent ouverte pour de futurs essais.
Ce projet était limité dans le temps, et il a été frappant de découvrir la durée nécessaire à ce type de travail, chaque paramètre modifié nécessitant une nouvelle itération et un nouveau temps de calcul. Il est de ce fait compréhensible qu’une technologie aussi ancienne que l’océrisation soit toujours en développement, du fait de sa complexité et de l’immense variété des données qu’elle traite.
Ce projet d’océrisation est un exemple parmi tant d’autres, mais il permet de donner un aperçu des logiciels OCR, des technologies et méthodes de travail qui leur sont liées, du traitement des imprimés anciens, de la complexité de la langue latine etc., et ainsi de mieux comprendre en quoi l’océrisation est un enjeu des Humanités numériques… et des sciences de l’information. Un tel projet nécessite en effet des connaissances et compétences à la fois en sciences humaines et en informatique, et c’est au cœur des Humanités numériques ainsi que des sciences de l’information que l’on peut trouver des profils de chercheurs correspondant aux besoins du domaine.
Bibliographie
AFROGE, Shyla, AHMED, Boshir et MAHMUD, Firoz, 2016. Optical character recognition using back propagation neural network. In : 2nd International Conference on Electrical, Computer Telecommunication Engineering (ICECTE), Rajshahi, 8-10 décembre 2016 [en ligne]. Décembre 2016. pp. 1–4. [Consulté le 28 août 2019]. Disponible à l’adresse : https://ieeexplore.ieee.org/document/7879615
ALGHAMDI, Mansoor et TEAHAN, William, 2017. Experimental evaluation of Arabic OCR systems. PSU Research Review [en ligne]. 28 novembre 2017. Vol. 1, no. 3, pp. 229–241. [Consulté le 28 août 2019]. Disponible à l’adresse : http://www.emeraldinsight.com/doi/10.1108/PRR-05-2017-0026
AMIN SHAYEGAN, Mohammad et AGHABOZORGI, Saeed, 2014. A new method for Arabic/Farsi numeral data set size reduction via modified frequency diagram matching. Kybernetes [en ligne]. 29 avril 2014. Vol. 43, n°5, pp. 817–834. [Consulté le 28 août 2019]. Disponible à l’adresse : http://www.emeraldinsight.com/doi/10.1108/K-10-2013-0226
ANUGRAH, Rio et BINTORO, Ketut Bayu Yogha, 2017. Latin letters recognition using optical character recognition to convert printed media into digital format. Jurnal Elektronika Dan Telekomunikasi [en ligne]. Décembre 2017. Vol. 17, n°2, pp. 56–62. [Consulté le 28 août 2019]. Disponible à l’adresse : https://www.jurnalet.com/jet/article/view/163
ARVINDPDMN [pseudonyme], 2019. Levenshtein distance. Developedia [en ligne]. 3 septembre 2019. Mis à jour le 4 septembre 2019. [Consulté le 11 novembre 2019]. Disponible à l’adresse : https://devopedia.org/levenshtein-distance
BALK, Hildelies et PLOEGER, Lieke, 2009. IMPACT : working together to address the challenges involving mass digitization of historical printed text. OCLC Systems & Services: International digital library perspectives [en ligne]. 30 octobre 2009. Vol. 25, n°4, pp. 233–248. [Consulté le 28 août 2019]. Disponible à l’adresse : https://www.emeraldinsight.com/doi/full/10.1108/10650750911001824
BAO, Ping et ZHU, Suoling, 2014. System design for location name recognition in ancient local chronicles. Library Hi Tech [en ligne]. 10 juin 2014. Vol. 32, n°2, pp. 276–284. [Consulté le 28 août 2019]. Disponible à l’adresse : http://www.emeraldinsight.com/doi/10.1108/LHT-07-2013-0101
BEINERT, Wolfgang 2018. Antiqua. Typolexicon [en ligne]. 1er avril 2018. [Consulté le 6 janvier 2020]. Disponible à l’adresse : https://www.typolexikon.de/antiqua/
BEINERT, Wolfgang 2019. Fraktur. Typolexicon [en ligne]. 1er août 2019. [Consulté le 6 janvier 2020]. Disponible à l’adresse : https://www.typolexikon.de/fraktur-schrift/
BLANKE, Tobias, BRYANT, Michael et HEDGES, Mark, 2012. Open source optical character recognition for historical research. Journal of Documentation [en ligne]. Août 2012. Vol. 68, n°5, pp. 659–683. [Consulté le 28 août 2019]. Disponible à l’adresse : https://www.emeraldinsight.com/doi/full/10.1108/00220411211256021
BODMER LAB, 2019. Bodmer Lab [en ligne]. 2019. Mis à jour le 9 janvier 2020. [Consulté le 9 janvier 2020]. Disponible à l’adresse : https://bodmerlab.unige.ch/fr
BOWERS, Steven K., 2018. Information Technology and Libraries at 50 : The 1990s in Review. Information Technology & Libraries [en ligne]. Décembre 2018. Vol. 37, n°4, pp. 9–14. [Consulté le 28 août 2019]. Disponible à l’adresse : http://search.ebscohost.com/login.aspx?direct=true&db=lih&AN=133718523&site=ehost-live
BRENER, Nathan E., IYENGAR, S. S. et PIANYKH, O. S., 2005. A conclusive methodology for rating OCR performance. Journal of the American Society for Information Science & Technology [en ligne]. Juillet 2005. Vol. 56, n°12, pp. 1274–1287. [Consulté le 28 août 2019]. Disponible à l’adresse : http://search.ebscohost.com/login.aspx?direct=true&db=lih&AN=18172083&site=ehost-live
BREUEL, Thomas M., 2007. Announcing the OCRopus Open Source OCR system. Google developpers [en ligne]. 9 avril 2007. [Consulté le 9 janvier 2020]. Disponible à l’adresse : https://developers.googleblog.com/2007/04/announcing-ocropus-open-source-ocr.html
BURGY, Florence, GERSON, Steeve, SCHÜPBACH, Loïc, 2020a. Ex imagine ad litteras : Projet d’océrisation de la collection de Bry [en ligne]. Genève : Haute école de gestion de Genève. Mémoire de recherche. [Consulté le 25 novembre 2020]. Disponible à l’adresse : https://doc.rero.ch/record/328465?ln=fr
BURGY, Florence, GERSON, Steeve, SCHÜPBACH, Loïc, 2020b. Ex imagine ad litteras : résultats actuels et espoirs futurs. Recherche d’IdéeS [en ligne]. 3 mars 2020. [Consulté le 30 mars 2020]. Disponible à l’adresse : https://campus.hesge.ch/blog-master-is/ex-imagine-ad-litteras-resultats-actuels-et-espoirs-futurs/
CARRASCO, Rafael C., 2014. An Open-source OCR Evaluation Tool. In : Proceedings of the First International Conference on Digital Access to Textual Cultural Heritage, Madrid, 19-20 mai 2014 [en ligne]. New York : ACM. 2014. pp. 179–184. [Consulté le 28 août 2019]. Disponible à l’adresse :
https://dl.acm.org/citation.cfm?doid=2595188.2595221
CIMON, Lucas, 2019. ImproveQuality. Tesseract Wiki [en ligne]. 25 novembre 2019. [Consulté le 9 janvier 2020]. Disponible à l’adresse : https://github.com/tesseract-ocr/tesseract/wiki/ImproveQuality
CLEMATIDE, Simon, FURRER, Lenz et VOLK, Martin, 2016. Crowdsourcing an OCR Gold Standard for a German and French Heritage Corpus. In : Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož, 23-28 mai 2016 [en ligne]. 2016. pp. 975-982. [Consulté le 28 août 2019]. Disponible à l’adresse : https://www.zora.uzh.ch/id/eprint/124786
COJOCARU, Svetlana et al., 2016. Optical Character Recognition Applied to Romanian Printed Texts of the 18th–20th Century. Computer Science Journal of Moldova [en ligne]. 2016. Vol. 24, n°1 (70), pp. 106-117. [Consulté le 28 août 2019]. Disponible à l’adresse : http://www.math.md/files/csjm/v24-n1/v24-n1-(pp106-117).pdf
DASH, Kalyan S., PUHAN, N. B. et PANDA, G., 2017. Odia character recognition : a directional review. The Artificial Intelligence Review [en ligne]. 2017. Vol. 48, n°4, pp. 473–497. [Consulté le 28 août 2019]. Disponible à l’adresse : https://search.proquest.com/lisa/docview/1961506152/abstract/35B11DA70B14444EPQ/2
EPFL, 2020. DHLAB. EPFL.ch [en ligne]. 3 décembre 2020. [Consulté le 3 décembre 2020]. Disponible à l’adresse : https://www.epfl.ch/labs/dhlab/
GHOSH, Kripabandhu et al., 2016. Improving Information Retrieval Performance on OCRed Text in the Absence of Clean Text Ground Truth. Information Processing & Management [en ligne]. 1 septembre 2016. Vol. 52, n°5, pp. 873–884. [Consulté le 28 août 2019]. Disponible à l’adresse : http://www.sciencedirect.com/science/article/pii/S030645731630036X
HLÁDEK, Daniel et al., 2017. Learning string distance with smoothing for OCR spelling correction. Multimedia Tools and Applications [en ligne]. Novembre 2017. Vol. 76, n°22, pp. 24549–24567. [Consulté le 28 août 2019]. Disponible à l’adresse : http://link.springer.com/10.1007/s11042-016-4185-5
IMPACT, 2013. IMPACT Centre of Competence [en ligne]. 2013. Mis à jour le 9 janvier 2020. [Consulté le 9 janvier 2020]. Disponible à l’adresse : https://www.digitisation.eu/
JÄRVELIN, Anni et al., 2016. Information retrieval from historical newspaper collections in highly inflectional languages: a query expansion approach. Journal of the Association for Information Science & Technology [en ligne]. Décembre 2016. Vol. 67, n° 12, pp. 2928–2946. [Consulté le 28 août 2019]. Disponible à l’adresse : http://search.ebscohost.com/login.aspx?direct=true&db=lih&AN=119478036&site=ehost-live
JOST, Clémence, 2019. Lancement d’OCR4all, un outil open source et gratuit de reconnaissance de caractères anciens pour les chercheurs en histoire et les archivistes. Archimag [en ligne]. 24 avril 2019. [Consulté le 5 septembre 2019]. Disponible à l’adresse : https://www.archimag.com/archives-patrimoine/2019/04/24/ocr4all-open-source-gratuit-reconnaissance-caracteres-anciens
KANN, Bettina et HINTERSONNLEITNER, Michael, 2015. Volltextsuche in historischen Texten. Bibliothek Forschung und Praxis [en ligne]. Avril 2015. Vol. 39, n° 1, pp. 73–79. [Consulté le 28 août 2019]. Disponible à l’adresse : https://www.degruyter.com/downloadpdf/j/bfup.2015.39.issue-1/bfp-2015-0004/bfp-2015-0004.pdf
KARPINSKI, R., LOHANI, D. et BELAÏD, A., 2018. Metrics for Complete Evaluation of OCR Performance. In : IPCV'18 - The 22nd Int'l Conf on Image Processing, Computer Vision, & Pattern Recognition, Las Vegas, juillet 2018 [en ligne]. 2018. pp. 23-29. [Consulté le 28 août 2019]. Disponible à l’adresse : https://csce.ucmss.com/cr/books/2018/LFS/CSREA2018/IPC3481.pdf
KESTEMONT, Mike, CHRISTLEIN, Vincent et STUTZMANN, Dominique, 2017. Artificial Paleography: Computational Approaches to Identifying Script Types in Medieval Manuscripts. Speculum [en ligne]. 2 octobre 2017. Vol. 92, S1, pp. S86–S109. [Consulté le 28 août 2019]. Disponible à l’adresse : https://www.journals.uchicago.edu/doi/10.1086/694112
KISSOS, Ido et DERSHOWITZ, Nachum, 2016. OCR Error Correction Using Character Correction and Feature-Based Word Classification. In : 12th IAPR Workshop on Document Analysis Systems (DAS), Santorini, 11-14 avril 2016 [en ligne]. Avril 2016. pp. 198–203. [Consulté le 28 août 2019]. Disponible à l’adresse : http://ieeexplore.ieee.org/document/7490117/
KUMAR, Munish et al., 2018. Character and numeral recognition for non-Indic and Indic scripts : a survey. The Artificial Intelligence Review [en ligne]. 2018. pp. 1–27. [Consulté le 28 août 2019]. Disponible à l’adresse : https://search.proquest.com/lisa/docview/1984338483/abstract/35B11DA70B14444EPQ/1
MEI, Jie et al., 2018. Statistical learning for OCR error correction. Information Processing & Management [en ligne]. 1 novembre 2018. Vol. 54, n° 6, pp. 874–887. [Consulté le 28 août 2019]. Disponible à l’adresse : http://www.sciencedirect.com/science/article/pii/S0306457317307823
MORI, Shunji, SUEN, Ching Y. et YAMAMOTO, Kazuhiko, 1992. Historical review of OCR research and development. Proceedings of the IEEE [en ligne]. Juillet 1992. Vol. 80, n° 7, pp. 1029-1058. [Consulté le 18 décembre 2019]. Disponible à l’adresse : http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=156468&isnumber=4050
MOUNIER, Pierre, 2018. Les humanités numériques : une histoire critique [en ligne]. Paris : Éditions de la Maison des sciences de l’homme. Interventions. [Consulte le 3 décembre 2020]. Disponible à l’adresse : https://books.openedition.org/editionsmsh/12006
MUEHLBERGER, Guenter et al., 2019. Transforming scholarship in the archives through handwritten text recognition: Transkribus as a case study. Journal of Documentation [en ligne]. 24 juillet 2019. [Consulté le 28 août 2019]. Disponible à l’adresse : https://www.emeraldinsight.com/doi/10.1108/JD-07-2018-0114
NAGY, George, 2016. Disruptive developments in document recognition. Pattern Recognition Letters [en ligne]. 1 août 2016. Vol. 79, pp. 106–112. [Consulté le 28 août 2019]. Disponible à l’adresse : http://www.sciencedirect.com/science/article/pii/S0167865515004109
PTUCHA, Raymond, et al., 2019. Intelligent character recognition using fully convolutional neural networks. Pattern Recognition [en ligne]. Avril 2019. Vol. 88, pp. 604–613. [Consulté le 28 août 2019]. Disponible à l’adresse : http://www.sciencedirect.com/science/article/pii/S0031320318304370
REDDY, Sravana et CRANE, Gregory, 2006. A Document Recognition System for Early Modern Latin. In: Chicago Colloquium on Digital Humanities and Computer Science: What Do You Do With A Million Books [en ligne]. 2006. Vol. 23, pp. 1-4. [Consulté le 28 août 2019]. Disponible à l’adresse : https://dl.tufts.edu/concern/pdfs/kd17d4036
REHMAN, Amjad et SABA, Tanzila, 2014. Neural networks for document image preprocessing: state of the art. The Artificial Intelligence Review [en ligne]. 2014. Vol. 42, n° 2, pp. 253–273. [Consulté le 28 août 2019]. Disponible à l’adresse : https://search.proquest.com/lisa/docview/1542796407/abstract/EC9B8EB6A5EF463APQ/41
RICE, Stephen V., JENKINS, Frank R. et NARTKER, Thomas A., 1996. The Fifth Annual Test of OCR Accuracy. Information Science Research Institute [en ligne]. 1996. pp. 1-46. [Consulté le 28 août 2019]. Disponible à l’adresse : http://stephenvrice.com/images/AT-1996.pdf
REUL, Christian, 2020. @chreul. thx for the hint and sorry […]. line segmentation hangs on empty pages · Issue #45 [en ligne]. 13 janvier 2020. [Consulté le 14 janvier 2020]. Disponible à l’adresse : https://github.com/OCR4all/OCR4all/issues/45
RYDBERG-COX, Jeffrey A., 2003. Automatic Disambiguation of Latin Abbreviations in Early Modern Texts for Humanities Digital Libraries. In : Proceedings of the 3rd ACM/IEEE-CS Joint Conference on Digital Libraries, Houston, 27-31 mai 2003 [en ligne]. Washington DC: IEEE Computer Society. 2003. pp. 372–373. [Consulté le 28 août 2019]. Disponible à l’adresse : http://dl.acm.org/citation.cfm?id=827140.827207
SABER, Shimaa et al., 2016. Performance Evaluation of Arabic Optical Character Recognition Engines for Noisy Inputs. In : Gaber T., Hassanien A., El-Bendary N. et Dey N. The 1st International Conference on Advanced Intelligent System and Informatics (AISI2015), Beni Suef, 28-30 novembre 2015. Cham : Springer, pp. 449-459. [Consulté le 28 août 2019]. Advances in Intelligent Systems and Computing, 407. Disponible à l’adresse : https://link.springer.com/chapter/10.1007/978-3-319-26690-9_40
SASAKI, Yutaka, 2007. The truth oft he F-measure. Teach Tutor mater [en ligne]. 26 Octobre 2007. Vol. 1, n° 5, pp. 1-5. [Consulté le 8 décembre 2019]. Disponible à l’adresse : https://www.researchgate.net/publication/268185911_The_truth_of_the_F-measure
SCHANTZ, Herbert F., 1982. The history of OCR, optical character recognition [en ligne]. Manchester Center, Vt. : Recognition Technologies Users Association. [Consulté le 18 décembre 2019]. Disponible à l’adresse : https://archive.org/details/historyofocropti0000scha
SEIDMAN, Max J., et al., 2016. Are games a viable solution to crowdsourcing improvements to faulty OCR ? - The Purposeful Gaming and BHL experience. Code4Lib Journal [en ligne]. Juillet 2016. Vol. 33, p. 1. [Consulté le 28 août 2019]. Disponible à l’adresse :
http://search.ebscohost.com/login.aspx?direct=true&db=lih&AN=116963678&site=ehost-live
SMITH, Ray, 2007. An overview of the Tesseract OCR engine. In : Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Paraná, Brésil, 23-26 septembre 2007 [en ligne]. Septembre 2007. Vol. 2, pp. 629-633. [Consulté le 26 octobre 2019]. Disponible à l’adresse : https://ieeexplore.ieee.org/document/4376991?arnumber=4376991
STUTZMANN, Dominique, 2017. Paléographie : la révolution numérique. L'Histoire [en ligne]. Septembre 2017. Vol. 439, p. 30. [Consulté le 28 août 2019]. Disponible à l’adresse : https://www.lhistoire.fr/irht-dans-le-secret-des-manuscrits/paléographie-la-révolution-numérique
SUN, Wei et al., 1992. Intelligent OCR Processing. Journal of the American Society for Information Science [en ligne]. Juillet 1992. Vol. 43, n°6, pp. 422–431. [Consulté le 28 août 2019]. Disponible à l’adresse : http://search.ebscohost.com/login.aspx?direct=true&db=lih&AN=16918942&site=ehost-live
TERRAS, Melissa, 2016. A Decade in Digital Humanities. Journal of Siberian Federal University [en ligne]. 2016. Vol. 9, pp.1637-1650. [Consulté le 3 décembre 2020]. Disponible à l’adresse: https://www.researchgate.net/publication/309217683_A_Decade_in_Digital_Humanities
THERAYSMITH [pseudonyme], 2017. The text corpus is from *all* the www, […]. Q&A : Indic - length of the compressed codes · Issue #654 [en ligne]. 23 janvier 2017. [Consulté le 22 décembre 2019]. Disponible à l’adresse : https://github.com/tesseract-ocr/tesseract/issues/654#issuecomment-274574951
TUMBE, Chinmay, 2019. Corpus linguistics, newspaper archives and historical research methods. Journal of Management History [en ligne]. 30 mai 2019. [Consulté le 28 août 2019]. Disponible à l’adresse : https://www.emeraldinsight.com/doi/10.1108/JMH-01-2018-0009
UNIVERSITÉ DE GENÈVE, 2020. Les missions de la chaire – Humanités numériques. Unige.ch [en ligne]. 3 décembre 2020. [Consulté le 3 décembre 2020]. Disponible à l’adresse : https://www.unige.ch/lettres/humanites-numeriques/fr/la-chaire/les-missions-de-la-chaire/
URIELI, Assaf et VERGEZ-COURET, Marianne, 2013. Jochre, océrisation par apprentissage automatique : étude comparée sur le yiddish et l’occitan. In : TALARE 2013 : Traitement automatique des langues régionales de France et d’Europe, Les Sables d’Olonne, juin 2013 [en ligne]. 21 juin 2013. pp. 221-234. [Consulté le 28 août 2019]. Disponible à l’adresse : https://hal-univ-tlse2.archives-ouvertes.fr/hal-00979665
VOBL, Thorsten et al., 2014. PoCoTo - an Open Source System for Efficient Interactive Postcorrection of OCRed Historical Texts. In: Proceedings of the First International Conference on Digital Access to Textual Cultural Heritage, Madrid, 19-20 mai 2014 [en ligne]. New York : ACM. 2014. pp. 57–61. [Consulté le 28 août 2019]. Disponible à l’adresse : https://dl.acm.org/citation.cfm?id=2595197
WICK, Christoph, REUL, Christian et PUPPE, Frank, 2018. Calamari - A High-Performance Tensorflow-based Deep Learning Package for Optical Character Recognition. [En ligne]. Preprint. 6 août 2018. [Consulté le 09 janvier 2020]. Disponible à l’adresse : https://arxiv.org/abs/1807.02004
ZHOU, Yongli, 2010. Are Your Digital Documents Web Friendly? : Making Scanned Documents Web Accessible. Information Technology & Libraries [en ligne]. Septembre 2010. Vol. 29, n°3, pp. 151–160. [Consulté le 28 août 2019]. Disponible à l’adresse : http://search.ebscohost.com/login.aspx?direct=true&db=lih&AN=52871764&site=ehost-live
The Knowledge & Learning Commons – a library’s evolution driving cultural change at the United Nations in Geneva
Viviane Brunne, Programme Manager, bibliothèque des Nations Unies à Genève
Sigrun Habermann, Manager de la bibliothèque des Nations Unies à Genève
The Knowledge & Learning Commons – a library’s evolution driving cultural change at the United Nations in Geneva
1. Introduction
A “commons” is a mechanism to pool and jointly use resources. In economic and political theory, the concept is famously linked to a metaphor by Garrett Hardin, with herdsmen sharing a common pasture. In Hardin’s example, what sounds like a reasonable approach goes terribly wrong, because – in the absence of any regulation or governance mechanism, the herdsmen put in as many cattle as possible to graze to maximize their own benefit. In the end, overgrazing meant ruin for all (cf. Hess/Ostrom 2006: 10-11).
Libraries, in a way, have adopted the approach of pooling resources – books, journals, newspapers – and make them available as a common good. Often funded publicly and available to users for free or against a small fee, they provide just the type of management structure that helps to maximize the use of the pooled resources for as many people as possible and over longer periods of time.
In the context of libraries, it appears that the benefits of information, knowledge and learning resources can actually be multiplied when shared, rather than depleted as in the example of the pasture (Bollier 2006: 28, 34). It may come as no surprise that libraries have evolved naturally around the concept of the commons, taking it further to encompass new areas of activity. This article will explore the evolution of libraries as commons and illustrate it with the case study of the UN Library&Archives Geneva (L&A).
To better understand the context, we will first outline the particularities of this specialized Library which is embedded in the institutional context of the United Nations and bears the heritage of the League of Nations, in many ways its predecessor. This will help to flag the differences to the libraries in university campuses and public libraries that have experimented with various types of commons over the past three decades. Taking their examples as a point of departure, we will show the unique particularities of the Knowledge & Learning Commons at the UN in Geneva (1) which is not only a vehicle for the L&A to evolve but one to drive innovation and cultural change across the organization at large. We will follow the path of the UN Geneva Commons from its early experimental stages into a more structured programme and explain how human-centred design approaches were applied to develop it, in co-creation with its users. We will show how constant assessment has been the driver of the programme which was put to a sudden test by the new situation caused by Covid-19 from March 2020 onwards. Following its own innovation principles, the UN Geneva Commons adjusted through experimentation and is ready to move to the next level in 2021. We will conclude with a reflection on the current challenges and opportunities and anticipate some developments of the near future.
2. A brief look at who we are - The United Nations Library & Archives Geneva
The beginnings of the UN L&A Geneva were with the League of Nations, the first global intergovernmental organization for peace. With its founding in 1919, the League started a library service. A major milestone for the Library was the donation of a dedicated building by John D. Rockefeller Jr. Finished in 1936, it represents an entire wing of the Palais des Nations. The Library was then one of the most modern in Europe: with 9 public halls, 10 floors of stacks, and ample office space it was ready to serve as a centre of international research and an instrument of international understanding (Sevensma 1927).
World War II and the demise of the League put a temporary hold on further developments, and when the League’s assets were transferred to the United Nations in 1946, the Library collections and the historical Archives became part of the European Office of the organization, later named the United Nations Office at Geneva (UNOG). UNOG today is a diplomatic centre with near universal representation of UN Member States, bringing them together with individuals and organizations working on peace, rights and well-being for all. About 12’000 meetings are held every year and the Library’s resources and services reflect the multitude of their topics, including key collections in the areas of international law, human rights, diplomacy and international relations, disarmament, sustainable development, humanitarian affairs, and the environment. The Library today is uniquely placed to inform and enable work on multilateralism.


Over time, UNOG conferred further responsibilities to the Library, including managing the United Nations and League of Nations Archives and managing UNOG records. It is the curator of the League of Nations Museum and of more than 2'000 art works at the Palais des Nations, and it manages UNOG’s rich cultural activities programme. These significant functional additions allowed the Library to reinforce its role, both as research centre and as an instrument of international understanding.
With its broadening scope of activity, the L&A staff have acquired skills and experience in cultural diplomacy, event management and outreach. These competencies are put to use, for example by coordinating the activities around the celebrations of “100 Years of Multilateralism in Geneva” in 2019/2020, and supporting global agendas, such as the 2030 Agenda for Sustainable Development. They also enabled L&A staff to reply to a call to action on innovation launched by UN Secretary-General António Guterres, to cater for the rapidly changing nature of the UN systems. In response to this call and based on research in library trends and the future of working and learning, the UN L&A proposed a novel cross-service initiative – “the Knowledge and Learning Commons”.
3. The development of the concept of commons in other libraries
The idea of creating new organizational forms and label them as “commons” as an evolution of libraries first appeared with the emergence of the internet in the mid-1990s, often on university campuses, responding to changing user needs by making library services and technological resources available in one place. McMullen (2007: 2) summarizes the approach: “Whether they call themselves an Information Commons, Learning Commons, Knowledge Commons or simply Library, they are envisioning new spaces and new partnerships to create environments that can support the integrated service needs of the digital generation. ‘As a new model of service delivery, it is not about technology per se, but how an organization reshapes itself around people using technology in pursuit of learning’ (Beagle 2006: p. xv)”.
Information commons have often been described as the first stage in this new development. Pursuing a new model of information service delivery, they contribute to information literacy, building the competence of users to access information effectively and to be able to judge its value. While providing computer workstations and collaborative learning spaces, overall, information commons remain library-centric (Bailey/Gunter Tierney 2008: 1-3; cf. also Wolfe/Naylor/Drueke 2010: 109).
As Heitsch/Holley (2011) explain, “The Learning Commons is an evolution of the Information Commons in which the basic tenets of the information are enhanced and expanded upon in order to create an environment more centreed around the creation of knowledge and self-directed learning.” The core activity of a learning commons is no longer merely the mastery of information, “but the collaborative learning by which students turn information into knowledge and sometimes into wisdom” (Wolfe/Naylor/Drueke 2010: 109).
Learning commons are normally more strategically aligned with an institution-wide vision and mission. They become an active partner in implementing the broader educational and research agendas of institutions, often collaborating with the learning centres but also bringing in other partners such as administrators, faculty and students (Sullivan 2010: 132; Bailey/Gunter Tierney 2008: 1-3, 7-8). Learning commons move away from a library-centric approach to more human-centred design. They involve the users to develop the learning environments they need, and they use a multitude of creative formats - cultural events, exhibits, concerts, discussion forums etc. - to promote the social inclusion of a learning community (Sullivan 2010: 139-143). As “a place for experimenting, playing, making, doing, thinking, collaborating, and growing”, the learning commons is a place the users treasure as “their space” (Loertscher/Koechlin 2014: E3-E4).
Inspired by the literature about library commons elsewhere, the L&A commissioned an external researcher to study the feasibility of the model at UNOG. Analyzing scientific literature, the outcomes of user and staff surveys at UNOG and of interviews with the commons staff at Harvard University, the University of Nebraska, (both US), and the London School of Economics (UK), she concluded that the concept supported the Organization’s mission and vision of promoting multilateralism, sustainable development and intercultural dialogue through education, information, and communication. The study suggested that especially if created as a partnership between the L&A and UNOG’s Centre for Learning and Multilingualism (CLM)(2) part of UNOG’s Human Resources Management Service, the Commons would enhance a “culture of shared knowledge, community learning and innovation" while also enhancing the role of the individual entities’ core activities.
4. What is the concept of the Commons at UNOG?
Encouraged by the conclusions of the study, L&A engaged with the Centre for Learning and Multilingualism in a cooperative approach to developing the Commons. To achieve a unified knowledge on learning environment for the common client base - UN staff and diplomats - the Library’s events hall and specialized reading rooms were identified as ideal spaces for both, quiet and collaborative activities. Added value would be achieved through the pooling of competencies and technological resources, and through a more diversified approach to building and sharing knowledge.
New natural partners became available through “#NewWork”, an innovation initiative to promote a collaborative environment, favouring innovation and risk-taking as well as flexible working. The initiative had emerged, partly in response to the Secretary-General’s call for innovation, partly as a reaction to demands from staff for changes in the workplace culture. When the Commons was presented to UNOG’s senior management, the group recognized that it was a matter of “common sense” for the organization. The Commons provided the space where this new vision could be shared and where collaboration across services could happen in practice.
Outside UNOG’s internal setting, the UNOG operates within a dynamic ecosystem, with more than 40 international organizations, more than 400 NGOs and academic institutions specializing in international relations. This means that there is a constant supply of resource persons with the potential for peer learning. Research suggests that informal learning is likely to amount to 90% of staff learning, with only 10% of knowledge creation happening through formal training (3). Complementing the approach of informal learning in the immediate work environment, the Commons also lends itself as a space to bring the wealth of knowledge available in the larger international community in Geneva to a wider audience.
In addition, the Commons is well-placed to provide a space where the traditional silos that form around technical organizations could be broken down. As Niestroy/Meulemann (2016) point out, building transversal awareness has become a new requirement at a time when the UN system, along with its Member States, have commited to implement the ambitious 2030 Agenda for Sustainable Development. With this new all-encompassing and transformational policy framework, a new need to “focus on facilitating dialogue, interaction and learning” came to the fore (Niestroy/Meuleman 2016). The idea of the Commons was to facilitate the creation of knowledge and learning communities around topics of common interest across organizations and user groups.
From its early days, the Commons was meant:
- to create synergies between L&A and CLM to build knowledge communities among UN staff, Permanent Missions and interns in Geneva
- serve as a space for informal learning, knowledge exchange and collaboration
- provide a space to experiment and innovate, thereby promoting a cultural change within the organization.



5. From the experimental phase to a structured programme
To drive and accompany the development of the Commons, an Engine Group was established consisting of a cross-section of staff from both, the UN L&A and CLM. In addition, management structures at the Commons were consciously kept lean to promote innovation and set an example in light of the hierarchical organizational culture. Senior management played a minimal role in setting general directions or pointing to some key opportunities. Anyone, including a diversity of partners and our own interns, was invited to bring in ideas for events and decisions about best topics were taken collectively at the Commons team level.
To get started, planned L&A and CLM events in the pipeline were reviewed as to their Commons compatibility and some were redesigned using formats that favoured innovation and interactivity. In April 2018, the first Knowledge and Learning Commons event took place called: “Face Value – how to overcome stereotypes in our professional and personal lives”. Other events followed, on libraries and knowledge networks, digital diplomacy and design thinking. Overall, some 20 activities took place during the first year of the Commons’ operation.
To give the programme a clearer profile, a management decision was taken to carry out a Knowledge and Learning needs assessment. Based on the evidence of this assessment about the real needs of the target group, the focus of the Commons’ activities should be further refined. The assessment also served to gain potential partners who might be willing to become co-creators of the Commons’ programme. At the same time, senior management were involved, enquiring about their vision for the organization as an indicator of new capabilities for the staff.
The assessment was implemented between October 2018 and January 2019, in time to drive the development of the catalogue of activities for the pilot year 2019. This assessment combined qualitative and quantitative methods and included 134 participants in interviews and focus group discussions, of which 22 were diplomats (including several Permanent Representatives and Deputy-Permanent Representatives) and 7 interns. Several internal debriefs and discussions about lessons learnt at the Commons also fed into the overall analysis for this assessment.
Based on the information collected, five priority streams were identified for 2019 and the purple hand (purple being the colour of the Commons, a mix of the red of the Library and the blue of CLM) became the visual identifier for the Commons. The streams were to focus the activities and to facilitate the evolution of knowledge communities around themes of common interest. Given the prominence of gender among potential users, it was included as a cross-cutting theme, symbolically marked in the palm of the hand.
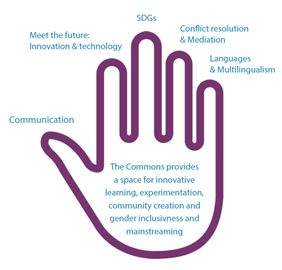
To remain open to emerging issues and unexpected opportunities, a conscious decision was taken to keep 20% of the capacity for good ideas.
While offering learning events seemed an obvious first step, in the medium-term it was also envisaged to provide other products and services. Conceptualizing the Commons as a “space” was also a defining element. The spacious and newly renovated Library Events Room lent itself to creative use as it could be set up flexibly (unlike many of the typical conference rooms around the Palais des Nations). By using the spaces of the Library creatively, we hoped to contribute to building the brand and inspire users to think out of the box, simply by venturing outside their usual environments.

6. The Pilot year: 2019
The pilot year was launched with a housewarming party inviting our three target groups to experience the 2019 programme with short taster sessions. Some 250 participants participated in the event which resulted in a boost in subscriptions to our newsletter. By the end of the year we had held 47 events with a cumulative total of 2.870 participants. Among the highlights was a session with the trainers of previous TEDx events held at the Palais des Nations who coached volunteers of all ranks in effective public speaking, much as they would the speakers for a real TEDx event. In a Dragon’s Den, UN staff was asked to submit their innovative ideas to improve the UN’s operations. Five selected teams were invited to promote their projects and two finalists, one selected by the audience and one by the “dragons” (senior staff and an external innovation champion), subsequently received mentoring and innovation time off to work to advance their projects. One of the winners, Conecta, a skills data base connecting staff to opportunities, was recently launched. Ready to scale, the project pitched again at a global Dragon’s Den organized by the UN at headquarters and was once more selected as one of the winners. The #MondayMotivation series inspired participants concerning IT applications, software or other tools that facilitate remote working or collaboration, for example with MS Teams. To promote an innovative culture, creative event formats or proposed activities were encouraged that directly promote creativity, for example related to creative writing or collaborative music playing.
As Sullivan (2010: 143) points out, human-centred design approaches, as used for the UN Geneva Knowledge & Learning Commons, require ongoing assessment. Launching into the implementation of the pilot year, it was obvious that evidence was required on how the initial planning decisions were developed. Therefore a comprehensive monitoring and evaluation strategy was developed, combining OECD evaluation criteria with the Kirkpatrick model commonly used to evaluate learning activities (4). Within a small working group, a number of high-level analytical questions were developed, which were then further broken down into questions pertaining to three levels: the project level, the priorities for the year and the organization of individual events. Six information sources were identified as relevant to respond to our guiding questions:
- Quantitative indicators
- A short user feedback survey (online)
- In-depth client interviews (in-person, at events)
- A survey among non-users (online and in-person)
- Interviews with senior management (in-person)
- An internal debrief among the core team (in-person).
Firstly, with regard to the project-level, the surveys showed that users attached high value to informal learning and knowledge exchange. Users and non-users alike supported the goals of the Commons – to provide a space to innovate and experiment, thereby promoting a cultural change towards more innovation. With the main goals so strongly confirmed, by the end of 2019 it was accepted that there was a proof of concept.
Figure 1 : The non-users' perspective on the goals of the Commons
Secondly, looking at our priority streams, the programme’s focus on innovation was reflected in the high number of events in the “Innovation & Technology” stream - almost a third of the 2019 programme. The feedback gathered during the year from both, users and non-users, confirmed an overwhelming interest in Innovation & Technology and Communication. Both streams were therefore maintained for the following year. Events labelled as “Other”, representing our “20% for good ideas”, accounted for another third of events, with about half of them covering issues related to wellbeing. Given the interest in the topic and the availability of excellent partners, it was decided to include Well@work as a new separate stream into our 2020 catalogue, thereby broadening the former Conflict resolution & mediation stream of 2019.
In response to a growing interest in efforts to “green” the Palais des Nations and to promote more sustainable behaviours at the individual and organizational level, the emphasis on the Sustainable Development Goals (SDGs) evolved into a Sustainability stream in 2020. This was a conscious decision for a niche that was outside the mainstream SDG events where the Commons had no comparative advantage.
Only two events had taken place under the Languages & Multilingualism stream, however, multilingualism - at least for the UN Secretariat languages English and French - was mainstreamed across many events. Conscious that multilingualism was best promoted by actually creating a multilingual environment, rather than by simply organizing events promoting it, this stream was discontinued in 2020.
Figure 2 : Events by steam in 2019
The Partnerships topic had already been relatively prominent during the initial needs assessment. In the 2019 non-user survey, it ranked third. It was decided to include a corresponding stream into the 2020 catalogue, given its potential to bring new audiences.
Figure 3 : Priority topics for non-users
Organizing events that were of interest for Permanent Missions was already a priority in 2019. Communication efforts to make the Commons better known among diplomats had yielded some results – about a fourth of new subscriptions to the newsletter came from Permanent Mission staff. In 2020 it was decided to go one step further and introduce a separate Diplomacy stream that could provide a space uniquely dedicated to diplomats and their needs.
In terms of gender balance, the Commons had a good record in 2019: 55% of participants in 2019 were female and 48 of the speakers were female and 53 were male. To keep this issue in focus and also become more conscious of promoting other aspects such as accessibility, we introduced the broader headline of inclusion and diversity as a cross-cutting principle.
Thirdly, through the different feedback mechanisms, critical insight was received which helped to improve the way events were organized. For example, participants were asked if they had acquired knowledge or information from the events which they could apply in their work or elsewhere, to which 69% of survey participants responded in the affirmative. In the internal debrief difficulties were openly discussed including issues faced when working on learning events with partners who were not professional trainers. For 2020 a more standardized template was developrd for the preliminary discussions with partners that would obligate the articulation of learning objectives for every event. These objectives would then also be communicated with all event announcements, as a constant reminder to all contributors.
Figure 4 : Learning outcomes and applicability
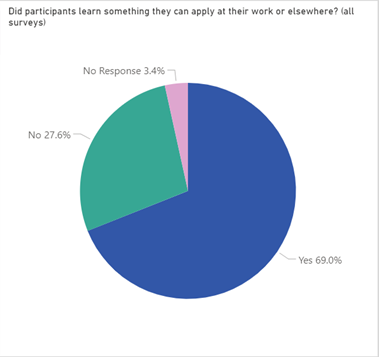
Since an important aspiration of the Commons was to offer innovative and interactive sessions, event participants were also asked about these factors. Users generally appreciated the use of the software Slido or other software to facilitate the discussion. Based on the overall feedback, however, it was decided that these were areas that required more investment. In 2019, it was noted with surprise that many of the partners who came to the Commons as a space to experiment with innovation, had insisted on using standard formats such as panel discussions. Knowing that they would not be the most effective formats for adult learning, it was decided to ban the use of panel discussions in 2020, and to commit to continuously explore innovative and interactive formats that we would be suggested to our partners. To facilitate longer-lasting interactions among participants, it was also planned to make a more concerted effort to cultivate “communities of practice” around certain core issues of the Commons where participants could exchange about their experiences in applying some of their new learning insights in practice.
Figure 5 : Innovation and interativity in event formats
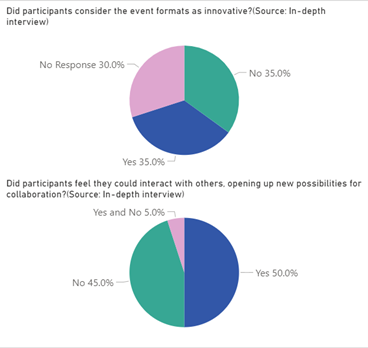
Overall, by using a scientifically sound and highly analytical approach to monitoring and evaluating the pilot year at the Commons, the programme set a new precedent, inspiring evidence-based service development also in other parts of the L&A.


7. The COVID-year: 2020
With the launch of new approaches, by 2020, it would be one year since the housewarming in early February. At that point partners were contacted and the new priority streams were presented, brainstorming with them about activities for the year.
By the end of 2019 the initiative became a victim of its own success. Four events per month seemed like a healthy maximum of what could be managed, however, by early 2020 there were as many as eight pre-bookings per month.
Confronted with lockdown from mid-March, all events in the pipeline had to be put on hold. The upside: it freed up time to bring a project to the fore that had been pursued on the sidelines - the Conference Primers platform (5). The idea went back to feedback received from Permanent Missions, especially the smaller ones, who were struggling to follow all relevant conferences to be able to brief their capitals about main outcomes. The Conference Primers would be a service to them, as much as to all our target groups, curating the best summary information about key conferences of interest in international Geneva. The platform covers all key areas of work in Geneva, including human rights, innovation and technology, economics and trade, the sustainable development goals, etc. It contains official conference pages alongside summaries prepared by NGOs, think tanks or news media. The approach to the Conference Primers was, once more, very much related to that of a “Commons”, as experts were engaged to assist in identifying and vetting the best resource pages on specific topics. While Commons staff regularly invest time into updating the platform, the idea is that the Primers may evolve into a “Wikipedia”-type of page, with users continuously adding their best resources. As Bollier points out (2006: 36), the evolution of “participatory media” is just another expression of the commons paradigm.
In the meantime, the event production team got ready to offer the first events online. In response to an obvious need, a series of talks with the staff counselors were organized, under our Well@work stream. Topics included “Keeping a healthy mind” and “Coping with fear and anxiety during COVID-19” or “Preparing emotionally for the return to the workplace”. In addition, regular mindfulness sessions in English and French were scheduled.
As the team became more used to managing the available online events platforms, other topics were gradually brought back in. In September a new series called HiSTORIES was launched, with a first session on “The League of Nations Essentials: Shedding New Light on the 1st Global Multilateral Organization”. This initiative responded to feedback suggesting the Commons should capitalize more on the strengths and resources available at the L&A. Another series, produced by the Commons under the headline #UNGenevaReads, went back to an initiative by staff of the L&A. As in a traditional book club, colleagues gathered to jointly read a book about climate change, pointing to concrete corrective actions any individual could take.
An online event was the organized, broadcast from the Palais des Nations, discussing the book with the authors and responding to questions from the global readership. A small group of colleagues is currently selecting the books for future discussions.
Figure 7 : The #UNGenavaReads announcement

By end of October, the Commons had hosted 52 events with 3685 participants – more than in the whole of 2019. From mid-March onward, they were all held online. The team has built a unique experience in organizing virtual events, making the Commons a go-to place for such formats. Remote working had been a topic at the Commons before. The crisis provided the necessary impetus to make remote participation in events part of the “new normal”, thereby responding to the needs expressed by our users already in our initial assessment.
8. Conclusion and what’s next?
Two years into its existence, the Knowledge & Learning Commons of the UN Geneva has proven its worth. Many close observers have judged the pilot year to be a “resounding success”. An important factor was support from senior managers and strong allies within and outside the organization. Over time, partnerships have evolved and become more complex, suggesting that a more strategic approach to partnerships management might soon become necessary. In the near future, working with UNOG’s IT service might become even more important. Even before Covid-19, it was recognized that the learning commons required “a fundamentally new degree of collaboration between librarians and information technologists, who bring different professional training and cultures together in newly designed spaces that support [...] learning” (Bennet 2007). The #MondayMotivation series testified to that. Evolving with the technological advances will now more than ever be a key factor to maintain the Commons as a vibrant innovation space.
While fully embracing the technological advances, they have also made community-building - at the core of the initial Commons idea – all the more difficult. Virtual events meant a greater difficulty to create a sense of community among users being virtually connected. #UNGenevaReads is one attempt to build back community. Increased interactivity in virtual sessions is another, but the challenge remains.
As the monitoring and evaluation results confirm, Commons activities are contributing to a cultural change towards more innovation within the organization in many practical ways. The ongoing challenge remains - to strike a good balance between letting partners and users own the Commons while also guiding them to the adoption of more innovative formats. The hope is that with the increase of the Commons community, “Learning for Us” becomes an enabling tool, letting innovation come to full circle.
What is crucial is the willingness and capacity of the Commons team to continually learn, not only in the IT area, but also in terms of innovation in substance and form of delivery. As Sullivan (2010: 144) highlights: “the single unifying element of the many manifestations of the learning commons is change”. Commons staff members have to remain agile and always be a few steps ahead of the users. Delivering constant innovation becomes a crucial staff skill in itself. It is the ability to identify emerging trends and quickly explore their potential. As McMullen (2007: 20) confirms for other learning commons: “Individual staff members […] are constantly in a learning mode and continually evolving to meet user demands. […] Staff continually update their job skills, enjoy learning and don’t feel threatened by the changeable nature of their jobs”. In this manner, the Commons innately realizes the cultural change the UN is looking for.
While the growing demand of the Commons translates into an increasing need for human and financial resources, pressures to reduce budgets greatly affect L&A and CLM. Programme sustainability can only be achieved when these needs are addressed, and alternative ways of funding have to be explored.
It’s clear that the Knowledge & Learning Commons at the UN in Geneva has established itself as a vehicle that has allowed the UN Library & Archives to profit from its multifaceted activities – ranging from library, records and archives services, to outreach, artworks management and cultural programming – and to evolve into an institution that can face the information and communication challenges of the 21st century. Within the bureaucracy of the United Nations, the programme reaches sustainability through agility and innovation, interaction and inclusion, thereby turning staff and users into drivers for cultural change. Looking back at the humble beginnings of the Commons, the staff are proud to be able to contribute to the renewal of the Organization through this innovative approach, providing concrete results for knowledge sharing.
Notes
(1)https://libraryresources.unog.ch/conferenceprimers
(2)CLM provides learning opportunities, mostly to UN staff, in some cases also to Permanent Mission staff, in particular in the six official UN languages, in management and communication. CLM also promotes an increasing number of online learning offerings, produced at headquarters in New York or accessible through online learning platforms such as LinkedIn learning.
(3)What is the 70:20:10 Model?, https://www.growthengineering.co.uk/70-20-10-model/ (last accessed 6 November 2020).
(4)For the OECD evaluation criteria, cf. www.oecd.org/dac/evaluation/daccriteriaforevaluatingdevelopmentassistance.htm; for the Kirkpatrick model, cf. for example here: https://www.mindtools.com/pages/article/kirkpatrick.htm; some of the pitfalls of the model mentioned in the article are alleviated by the complementary use of the broader approach of the DAC criteria.
Bibliography
Bailey, D. Russel/Gunter Tierney, Barbara (2008), Transforming Library Services Through Information Commons, Chicago.: American Library Association.
Bennett, Scott (2008), The Information or the Learning Commons: Which Will We Have?, in: The Journal of Academic Librarianship, vol. 34, no. 3, pp. 183-185, https://libraryspaceplanning.com/wp-content/uploads/2015/09/The-Learning-or-Information-Commons-Which-Will-We-have.pdf (last accessed 25 October 2020).
Blake, Sheila (2015), The Challenges of Creating a Learning Commons, University of Central Missouri, Warrensburg, Missouri, http://docplayer.net/163627834-The-challenges-of-creating-a-learning-commons-sheila-l-blake.html, (last accessed 25 October 2020).
Bollier, David (2006), “The Growth of the Commons Paradigm”, in: Understanding Knowledge as Commons: From Theory to Practice, Hess, Charlotte/Ostrom, Elinor (editors) Cambridge, MA: MIT Press, pp. 27-40.
Brooks Kirkland, Anita/Koechlin, Carol (2015), Leading Learning: Standards of Practice for School Library Learning Commons in Canada, https://llsop.canadianschoollibraries.ca/, (last accessed 25 October 2020).
Canadian Library Association (2014), Standards of Practice for School Library Learning Commons in Canada, http://apsds.org/wp-content/uploads/Standards-of-Practice-for-SchoolLibrary-Learning-Commons-in-Canada-2014.pdf (last accessed 25 October 2020).
Clement House rotunda project: An Evaluation of Clement House Informal Learning Spaces (2016/2017) London School of Economics, http://eprints.lse.ac.uk/82259/1/Roger_The%20Clement%20House%20rotunda%20projectn_author_2017.pdf (last accessed 25 October 2020).
Fuller, Kate (2009), Learning Commons @ UConn Assessment Report: Use and Satisfaction of the Learning Commons, http://learningcommons.uconn.edu/about/UConn_Learning_Commons_Report.pdf (last accessed 25 October 2020).
Heitsch, Elizabeth K./Holley, Robert P. (2011), “The information and learning commons: Some reflections”, in: Review of Academic Librarianship, Vol 17 No. 1, pp. 64-77.
Hess, Charlotte/Ostrom, Elinor (2006), “Introduction: An Overview of the Knowledge Commons”, in: Understanding Knowledge as Commons: From Theory to Practice, Charlotte Hess and Elinor Ostrom (editors), MIT Press.
Holland, Beth (2015), 21st-Century Libraries: The Learning Commons; in: Edutopia, https://www.edutopia.org/blog/21st-century-libraries-learning-commons-beth-holland (last accessed 25 October 2020).
Lippincott, Joan K. Chapter (2006), Linking the Information Commons to Learning. In: Learning Spaces, Diana G. Oblinger, ed., Educause, https://www.educause.edu/research-and-publications/books/learning-spaces/chapter-7-linking-information-commons-learning (last accessed 25 October 2020).
Loertscher, David/Koechlin, Carol (2014), Climbing to Excellence: defining characteristics of successful learning commons, https://www.davidloertscherlibrary.org/wp-content/uploads/2020/07/2014-Climbing-to-Excellence-Defining-Characteristics-of-Successful-Learning-Commons-1.pdf (last accessed 25 October 2020).
McKay, Richard (2015), Building a Learning Commons: Necessary Conditions for Success. Community & Junior College Libraries, volume 20, 2014 – issue 3-4, Taylor & Francis online
http://www.tandfonline.com/doi/abs/10.1080/02763915.2015.1056705?journalCode=wjcl20 (last accessed 25 October 2020).
McMullen, Susan (2007),The Learning Commons Model: Determining Best Practices for Design, Implementation, and Service, Sabbatical Study, Roger Williams University
Available at: http://faculty.rwu.edu/smcmullen/index.html (last accessed 25 October 2020).
Niestroy, Ingeborg/Meuleman, Louis (2016), Teaching Silos to Dance: A Condition to Implement the SDGs, http://sdg.iisd.org/commentary/guest-articles/teaching-silos-to-dance-a-condition-to-implement-the-sdgs/ (last accessed 22 October 2020).
Letter from A. Sevensma, Director of the League of Nations Library to R. Fosdick, Rockefeller Foundation, New York, NY. (1927), LON archives 16/29433/3749
Sullivan, Rebecca M. (2010), Common Knowledge: Learning Spaces in Academic Libraries, in: Academic Libraries, College & Undergraduate Libraries, Volume 17, pp. 130-148.
Thibou, Shevell (2016), The Learning Commons. Western Washington University Libraries
http://cedar.wwu.edu/cgi/viewcontent.cgi?article=1005&context=research_process (last accessed 25 October 2020).
The University of Iowa Libraries – Learning Commons
Available at: https://www.lib.uiowa.edu/commons/ (last accessed 25 October 2020).
University of Nebraska Adele Hall Learning Commons, https://libraries.unl.edu/learning-commons and https://news.unl.edu/newsrooms/today/article/learning-commons-named-for-alumna-adele-coryell-hall/ (last accessed 25 October 2020).
Vasisht, Prateek, The Public Library of 2027, Snipette
https://medium.com/snipette/the-public-library-of-2027-50eabd05b8c2 (last accessed 25 October 2020).
Wolfe, Judith A./Naylor, Ted/Drueke, Jeanetta (2010), “The Role of Academic Reference Librarian in the Learning Commons”, in: Reference and User Services Quarterly, Volume 50, Issue 2, pp. 108-113.
La place des ressources documentaires des bibliothèques académiques dans la lutte contre les Fake News. Le cas du COVID-19
Benoît Epron, professeur associé à la HEG-Genève
Séverine Gaudard, collaboratrice scientifique pour le projet, HEG-Genève
La place des ressources documentaires des bibliothèques académiques dans la lutte contre les Fake News. Le cas du COVID-19
1. Introduction
Comme toutes les crises, la crise du Covid-19 est une période propice à la diffusion de fausses informations, de contre-vérités ou de théories du complot. En effet, le besoin d’informations pour comprendre, anticiper ou se rassurer est exacerbé et les citoyens sont naturellement à la recherche de réponses ou de renseignements. Face à cette demande, les médias d’informations (journaux, TV, radio) sont évidemment en première ligne. Ces mécanismes de diffusion d’information sont aujourd’hui largement intégrés aux réseaux sociaux qui favorisent de fait la diffusion et la propagation d’informations sensationnelles, sans tenir compte de leur véracité. La diffusion de ces fausses informations complexifie la réponse à la crise sanitaire qui nécessite l’adhésion de la population aux mesures mises en place par les autorités. L’Organisation mondiale de la Santé effectue d’ailleurs un parallèle entre la circulation du virus et celle des fausses informations et sensibilise à la lutte pour « immuniser le public contre la désinformation ». Le paradoxe de cette situation réside en grande partie dans le fait que les informations n’ont jamais été aussi nombreuses et accessibles. En effet, dans cet « écosystème » informationnel, deux logiques se conjuguent, d’une part la circulation accélérée de l’information par les plateformes d’échanges et d’autre part l’ouverture de plus en plus large de la documentation scientifique.
La question à laquelle ce projet propose d’apporter des réponses est la place et le rôle que peuvent jouer les bibliothèques académiques dans cette lutte contre la mésinformation. En effet, en gérant et en traitant au quotidien des ressources scientifiques, les bibliothèques académiques disposent des ressources, de compétences et d’une légitimité importantes. La problématique de ce projet est donc d’identifier à la fois les stratégies mises en œuvre par les bibliothèques académiques dans ce domaine mais aussi l’usage qui est fait par les médias des ressources scientifiques disponibles.
Dans le cadre de l’appel à projet COVID-19 du domaine Economie et Services de la HES-SO nous avons bénéficié d’un soutien (assistant HES à 10%) pour un projet de 6 mois réalisé au cours du deuxième semestre 2020. Les éléments présentés ci-dessous s’appuient en grande partie sur les résultats de ce projet.
2. Méthodologie
Un premier axe de ce projet a consisté à constituer un corpus d’articles publiés par les médias d’information en Suisse romande traitant du Covid-19 et de deux thématiques : la 5G et l’hydroxychloroquine. La 5G est une technologie largement débattue, de plus, de nombreuses fausses informations en lien avec le Covid-19 et la 5G circulent. Quant à l’hydroxychloroquine, les débats et résultats de nombreuses recherches autour de ce médicament ont régulièrement été relayés dans la presse pendant la période de semi-confinement en Suisse, entre le 16 mars et le 19 juin 2020. L’urgence de trouver un remède au Covid-19 a démultiplié les recherches menées sur cette molécule présentée comme un remède miracle ou considérée comme inutile voire dangereuse. Les articles correspondant à ces deux thématiques publiés pendant la période extraordinaire(1) dans les 10 principaux journaux et sources d’informations quotidiens de Suisse romande ont été répertoriés. Ils ont été classés en 3 niveaux selon que les références citées permettent au public de remonter jusqu’à la source de l’information : 1) aucune référence citée ; 2) les informations citées sont suffisantes pour retrouver la source en faisant une simple recherche ; 3) un lien direct mène à la source citée.
Le second axe a pour but de repérer les stratégies de valorisation mises en place par les bibliothèques de Suisse romande au moyen d’observations et d’une enquête. Les observations ont porté sur 4 universités, une école polytechnique fédérale et 25 hautes écoles spécialisées de Suisse romande, soit un total de 30 institutions. Les éléments observés sont les informations en lien avec le Covid-19 mises à disposition du public sur le site ou la page web de la bibliothèque pendant la période de semi-confinement. Les données récoltées ont été classées en 4 niveaux selon les informations mises à disposition du public : 1) aucune information sur des ressources académiques en lien avec le Covid-19 ; 2) informations sur les publications scientifiques exceptionnellement ouvertes par les éditeurs (en lien avec le Covid-19 ou non) ; 3) liens vers des publications externes en lien avec le Covid-19 ; 4) liens vers des ressources internes en lien avec le Covid-19. Ces informations ont été complétées par une veille sur les actions de communication et de valorisation mises en place par des bibliothèques hors de Suisse romande.
Afin de compléter ces deux axes, une troisième approche se focalisant sur les publications scientifiques des chercheur-euse-s de Suisse romande nous a paru essentielle. Dans une logique de science ouverte, nous nous sommes concentrés sur les publications en lien avec le Covid-19 présentes dans les archives ouvertes des universités et autres hautes écoles de Suisse romande. Les publications associées au mot-clé « Covid-19 » des archives ouvertes suivantes ont été répertoriées: Archives ouvertes UNIGE, SERVAL, et RERO doc. Nous avons ensuite utilisé l’outil Altmetric Bookmarklet pour déterminer si elles avaient fait l’objet de citations dans les médias de Suisse romande.
3. Résultats
3.1 Bibliothèques
Les bibliothèques qui ont le plus valorisé leurs ressources en lien avec le Covid-19 sont les bibliothèques de médecine et de santé. Selon les observations menées sur les sites et pages web des bibliothèques de 30 bibliothèques académiques de Suisse romande, 2 bibliothèques ont obtenu le niveau 4 (Figure 1).
Figure 1 : Actions mises en place par les bibliothèques
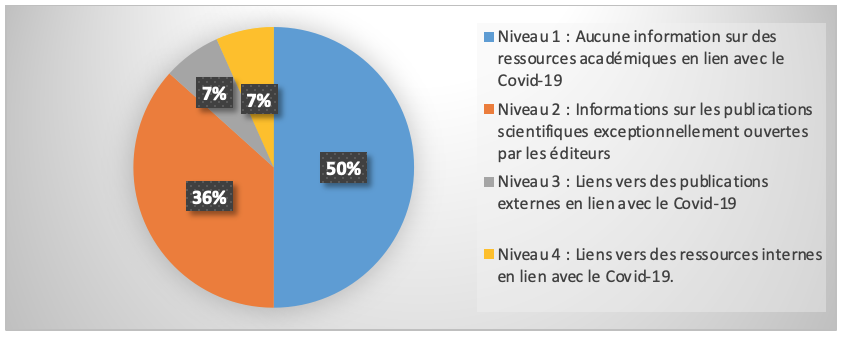
L’importance des actions de valorisation et de communication mises en place par les bibliothèques des domaines de la médecine et la santé s’explique de plusieurs manières ; ces bibliothèques disposent de ressources pertinentes dans leur catalogue à mettre en avant, elles sont habituées à collaborer avec du personnel de santé et disposent d’un statut hybride, en étant rattachées à la fois aux universités et institutions médicales.
Les ressources ouvertes de manière exceptionnelle par les éditeurs scientifiques ont été largement relayées. Selon les observations, 50% des bibliothèques académiques les ont mises en avant pendant le semi-confinement. Après les informations pratiques (fermeture, horaires d’ouvertures ou modalités de prêts), qui ont fait l’objet de communications de la part de toutes les bibliothèques ayant répondu à l’enquête, il s’agit de l’information qui a été la plus relayée auprès du public des bibliothèques académiques. Il serait également intéressant pour les bibliothèques d’observer statistiquement les variations dans les accès aux ressources proposées. Cela permettrait de déterminer si au-delà de l’effet d’annonce, cette ouverture a eu des conséquences tangibles sur les pratiques documentaires des chercheurs.
Les publications scientifiques en lien avec le Covid-19 disponibles dans les archives ouvertes des universités et autres hautes écoles de Suisse romande ne sont pas mises en valeur. 76 publications scientifiques sur la thématique du Covid-19 ont été identifiées à la fin de la période extraordinaire dans les différentes archives ouvertes institutionnelles (53 sur SERVAL, 20 sur l’archive ouverte UNIGE, et 3 sur RERO Doc). D’après l’analyse de ces 76 publications avec Altmetric Bookmarklet, aucune de ces publications n’a été citée d’une manière satisfaisante pour être reconnue par l’outil utilisé qui se base sur le DOI. Nous observons ainsi une occasion manquée de mettre en avant les résultats de la recherche scientifique effectuée dans les institutions de Suisse romande. Le fait que ces articles soient centralisés et ouverts au public perd de son intérêt si les archives ouvertes ne sont utilisées que comme un dépôt et ne font pas partie de la stratégie de valorisation de l’information scientifique des universités et autres hautes écoles.
Les réponses à l’enquête confirment les résultats des observations en ligne : aucun service de fact-checking sur le Covid-19 n’a été créé par une bibliothèque académique romande. Des services de Questions-réponses comme InterroGE ont évidemment vu arriver des questions relatives au Covid. Les réponses proposées sont principalement construites à partir de documents issus de l’administration et de grandes organisations (comme l’OMS) ou d’articles de presse. Les quelques articles scientifiques pointés dans les réponses sont issus de plateformes comme PLOS et de chercheurs hors Suisse. Les bibliothèques disposent pourtant de toutes les ressources nécessaires à la mise en place d’un tel service : l’accès à l’information scientifique via le catalogue de la bibliothèque ainsi que des professionnels avec des compétences en matière de recherche d’information. Accompagner le public dans sa recherche d’information fait partie des missions des bibliothèques, qu’il s’agisse de répondre directement à des questions posées par le public ou de vérifier les faits entourant des fausses informations largement relayées. Cette action de médiation aurait pu être à destination du grand public, mais elle pourrait aussi être relayée auprès des journalistes. Il s’agit également d’un moyen de mettre en avant les ressources de la bibliothèque ainsi que l’utilité d’une telle institution dans une période de crise.
Près de la moitié des répondant-e-s estiment que leur bibliothèque ne dispose pas de ressources en lien avec le Covid-19. 12 répondant-e-s à l’enquête sur 26, soit 46 %, répondent négativement à la question « Votre bibliothèque possède-t-elle des ressources en lien avec le Covid-19 ? ». Et seuls 27 % prévoient d’acquérir par la suite des ressources en lien avec le Covid-19. La crise a des impacts dans tous les domaines, ainsi, même les bibliothèques qui ne sont pas spécialisées dans la santé sont susceptibles d’acquérir des ressources sur le sujet. Cela renvoie à un fonctionnement des politiques d’acquisition qui suivent plutôt des logiques disciplinaires ou politiques. Les bibliothèques académiques pourraient se positionner davantage comme des acteurs de la circulation de l’information et des connaissances vers un public élargi, dépassant les limites du monde universitaire. Ces résultats interrogent également sur la maîtrise et la connaissance des fonds constitués de flux et de bouquets de revues, non contrôlés par les bibliothécaires.
3.2 Presse
Dans 89.5% des productions journalistiques étudiées, les informations ne sont pas suffisantes pour retrouver la source des références citées. Les résultats de ces observations soulignent le fait que seuls 4 articles sur l’échantillon (composé de 38 articles de presse et vidéos, 26 articles sur le Covid-19 et la chloroquine ou l’hydroxychloroquine et 12 articles sur le Covid-19 et la 5G) fournissent des informations suffisantes afin de permettre aux lecteurs et lectrices de remonter jusqu’à la source de l’information présentée. Seul un article de presse contient un lien direct vers l’article scientifique qui fait l’objet de l’article, 3 autres contiennent des informations suffisantes (les résultats de la recherche, le titre de la publication ainsi que le nom d’un ou plusieurs des auteurs). Aucun article ne fait de lien vers une ressource académique disponible directement dans une institution suisse romande comme le catalogue d’une bibliothèque ou les archives ouvertes d’une université ou haute école.
Un des éléments qui est apparu lors de l’analyse de l’échantillon de productions journalistiques est l’importance qui est donnée à des expert-e-s pour analyser les résultats des études ainsi que la situation sanitaire. La parole d’expertes ou experts est ainsi considérée comme une source fiable, citée parfois au détriment de références à des sources d’informations scientifiques. Si les professionnels de la santé ont évidemment un important rôle de médiateurs à jouer, les sources académiques devraient être plus fréquemment mises en avant. Si le format d’article contenant des réactions de spécialistes est privilégié, c’est certainement parce que celui-ci est apprécié des lecteurs et lectrices. En privilégiant ce format, tout en mettant à disposition dans les mêmes articles des références pertinentes et faciles d’accès, les journalistes peuvent sensibiliser un nouveau public et l’inviter à vérifier les sources mises à disposition.
4. Exemples d’actions de valorisation hors de Suisse romande
Afin de mettre en commun les ressources des différentes bibliothèques, de travailler en réseau et d’éviter les redondances, il est également utile de centraliser les actions effectuées. Dans un système décentralisé comme la Suisse, cela paraît compliqué à mettre en place. En France, c’est sur le site du Ministère de l’Enseignement Supérieur, de la Recherche et de l’Innovation que l’on retrouve une liste des initiatives des acteurs du supérieur en lien avec le Covid-19, comprenant l’accompagnement documentaire et les bibliothèques.
Certaines bibliothèques ont créé des services de fact-checking spécifiques sur le Covid-19, c’est le cas notamment de la bibliothèque de l’Université de Toronto qui répond chaque semaine à une question sur le Covid-19 en citant ses sources avec les informations scientifiques disponibles au moment de la réponse. Un exemple qui prouve que les bibliothèques ont les moyens nécessaires à la mise en place d’un tel service. D’autres bibliothèques, comme celle d’Old Dominion University en Virginie, ont mis en place des formations sous forme de workshop en ligne pour « Apprendre des stratégies pour combattre la désinformation sur la santé » en lien avec le Covid-19. En éduquant le public aux techniques pour repérer les fausses informations, les bibliothécaires permettent de responsabiliser le public et participent à l’éducation aux médias.
La crise du Covid-19 a favorisé les échanges entre professionnels de l’information sur la question des fake news. L’IFLA a notamment organisé une série de 4 webinaires intitulés « Fake News : Impact on Society » qui permet de présenter plusieurs projets de bibliothèques et associations des bibliothèques en lien avec les fake news. Le séminaire « Les bibliothèques en temps de crise » de l’ENSSIB donné par Raphaëlle Bats qui a réuni des bibliothécaires francophones en ligne a également consacré une session le 13 novembre 2020 aux fake news à l’heure du Covid-19 en bibliothèque.
5. Recommandations
Les bibliothèques académiques gagneraient à mettre en place une meilleure coordination entre bibliothèques d’universités et hautes écoles. Si l’on prend l’exemple des pages pour mettre en avant les publications des éditeurs scientifiques, ces pages auraient pu être réalisées en collaboration entre plusieurs bibliothèques puis diffusées. Nous constatons que la crise du Covid-19 n’a pas eu pour effet une remise en question des pratiques en bibliothèque. Nous observons que les actions de communication mises en place sont très variables d’une bibliothèque à l’autre ; certaines bibliothèques ne disposant pas des mêmes ressources ou compétences en raison des domaines spécifiques auxquels elles sont rattachées ou de leur taille bénéficieraient d’un tel travail en réseau.
Nous avons observé que les bibliothèques académiques ne sont pas un canal privilégié par les journalistes. En mettant en place une fonction dédiée à la relation médias dans les services communication des bibliothèques, elles amélioreraient leur visibilité et élargiraient leur public en incluant les journalistes. Des formations spécifiques des bibliothèques à destination des journalistes qui porteraient sur les recherches d’information au sein des catalogues, des archives ouvertes ainsi que sur la citation des sources dans les publications journalistiques pourraient également être envisagées. Ces actions auraient pour résultat de faciliter l’accès à l’information scientifique au public au travers des médias, ce qui permettrait d’aller vers une science citoyenne. C’est également l’occasion de valoriser le travail des universités et des bibliothèques et d’ainsi valoriser leur image auprès du grand public. Pour ce faire, une meilleure collaboration au sein des institutions est également nécessaire. Nous observons un certain cloisonnement entre les différents acteurs de la recherche scientifique : les chercheur-euse-s, les bibliothèques et la communication. En ayant accès aux publications scientifiques, les bibliothécaires ont les moyens d’être au courant des recherches en cours et des résultats publiés. Elles ont intérêt à valoriser ces informations, d’autant plus qu’elles sont amenées à devoir continuellement légitimer leur existence.
6. Conclusion
La période particulière que nous connaissons depuis le mois de février 2020 touche évidemment l’ensemble de la société et donc les bibliothèques universitaires. Cette crise sanitaire intervient dans un double contexte informationnel : d’une part une circulation accélérée de l’information, et parfois de fausses informations, via les réseaux sociaux notamment et d’autre part un accès à la documentation scientifique qui n’a jamais été aussi facilité.
Pourtant, ces deux sphères informationnelles semblent peu poreuses, il manque un acteur pouvant jouer un rôle de passeur, d’intermédiaire entre le monde académique et le grand public. Les bibliothèques ont sur ce point un rôle essentiel à jouer. En étant habituées à gérer des informations scientifiques au quotidien et en étant au contact du public, les bibliothèques sont les mieux placées pour occuper cet espace laissé vacant.
Ce rôle a évidemment une grande importance pour les bibliothèques académiques qui voient ainsi une opportunité de se positionner auprès du grand public comme référentes en matière de lutte contre les fake news. Cela leur permet également de renforcer leur visibilité et d’être par la suite mieux intégrées aux politiques publiques. Pour les autorités qui ont besoin, en période de crise sanitaire, de faire passer des messages, notamment concernant les mesures sanitaires, pouvoir s’appuyer sur un acteur comme la bibliothèque permet également de pouvoir compter sur un intermédiaire fiable qui est déjà en possession des compétences et ressources nécessaires pour éduquer le public.
Cette crise aura ainsi permis de mettre en évidence ce besoin et la place que les bibliothèques universitaires peuvent y occuper. Les périodes de fermeture et l’obligation ou la forte recommandation de télétravail auront également bouleversé les habitudes des bibliothécaires. La crise aura ainsi renforcé le besoin de trouver de nouveaux lieux – physiques ou virtuels - d’échanges entre les professionnels de l’information, de celles et ceux qui la produisent à celles et ceux qui la diffusent ainsi qu’entre les professionnels des bibliothèques académiques. Si ce travail en réseau est déjà une réalité sur le terrain, il reste à le rendre plus visible en ligne, notamment au travers de services partagés entre plusieurs bibliothèques universitaires.
Notes
(1)Les termes « situation extraordinaire » et « semi-confinement » désignent la période du 16 mars au 19 juin 2020.
Les bibliothèques face à la vague
Benoît Epron, Professeur HES, Haute Ecole de Gestion, Genève
Florence Burgy, Assistante HES, Haute Ecole de Gestion, Genève
Les bibliothèques face à la vague
1. Introduction : bouleversements et adaptations
Au printemps dernier, en Suisse romande comme ailleurs, le quotidien de toutes et tous se voyait bouleversé par une crise sans précédent. Gestes barrières, (semi-)confinement, fermetures des commerces non-essentiels et des lieux de culture, on aurait pu croire que laterre s’était arrêtée de tourner. La stupeur des premiers instants a cependant rapidement laissé place à une reprise de l'activité dans tous les secteurs ou presque, demandant à chacune et chacun de faire preuve de souplesse, de créativité, voire d’être prêt à se réinventer.
Les bibliothèques romandes n’ont pas été en reste. Pour elles, la nouvelle tombe le 13 mars 2020 : fermeture des bibliothèques, avec effet immédiat. Confusion, stupeur, et annulations en série. Nul ne sait combien de temps cela durera, nul ne sait que prévoir. Le samedi des bibliothèques tombe immédiatement à l’eau, et d’autres événements suivront. On ferme. Certaines institutions, comme la BCUL, voyant la vague arriver, avaient prévu un plan de crise, et notamment une marche à suivre en cas de fermeture complète. Toutes les bibliothèques n’ont malheureusement pas pu aussi bien se préparer, à l’instar de bien des institutions et entreprises en Romandie et ailleurs.
Mais rapidement, on se réorganise, on s’adapte, on cherche des solutions, et c’est tant mieux, car cette première phase de confinement n’est qu’un début. Elle sera suivie de plusieurs autres étapes avec des modalités variées (semi-confinement, fermeture des salles de lecture mais accès au prêt-retour…).
A l’heure actuelle, des restrictions d’accès sont encore régulièrement mises en place pour les bibliothèques académiques comme pour la lecture publique. Ces changements se font depuis un an au rythme de l’évolution des indicateurs épidémiologiques et conduisent aujourd’hui à une forme de “routine” de l’adaptation permanente du fonctionnement des bibliothèques. Cette adaptabilité permanente a entraîné, pour les professionnels des bibliothèques, la mise en place de plans ou de protocoles activables rapidement.
Dans cet article, nous traiterons de quelques aspects de ces adaptations, pour les personnels et les publics habituels des bibliothèques mais aussi pour toute une population de nouveaux utilisateurs qui émerge à l’occasion de cette crise. Nous présenterons ainsi la façon dont certaines de ces bibliothèques ont fait face à cette situation exceptionnelle, sur la base d’un travail de recherche documentaire ainsi que d’entretiens avec plusieurs professionnels des bibliothèques, à savoir Mme Mylène Badoux (Bibliothèque de Vevey), Mme Valérie Bressoud-Guérin (Médiathèque Valais), M. Laurent Albenque (BCUL - Site Riponne) et M. Laurent Voisard (Bibliomedia), qui ont bien voulu répondre à nos questions.
2. Fermées… aux collaborateurs
2.1. Tous en télétravail ?
Le facteur principal de bouleversement de l’activité des bibliothèques au cours de l’année 2020 est l’impossibilité d’accéder physiquement à certains espaces des bâtiments. Cette limitation concerne notamment l’accès aux espaces de travail pour le personnel des bibliothèques. Le passage rapide, massif et brutal au télétravail, qui concerne de nombreuses institutions et entreprises, et pas seulement les bibliothèques, bien entendu, revient dans nos entretiens avec des éclairages particuliers.
Dans certains cas, comme pour la Médiathèque Valais, les locaux permettent une distanciation physique suffisante pour maintenir la majorité des équipes sur place, et la fermeture permet en définitive de dégager du temps pour accélérer le traitement des documents et s’occuper de projets “laissés en rade”. À Lausanne aussi, dans les locaux de Bibliomedia, certains employés choisissent de venir sur place, lorsque l’agencement des espaces de travail le permet.
La BCUL est, quant à elle, passée plus massivement au télétravail en mettant en place un tournus d’employés volontaires pour assurer le suivi des tâches ne pouvant être effectuées à distance, et notamment maintenir une activité de prêts/retours des documents imprimés. Ce tournus sera maintenu à la sortie de la première vague, car il est indispensable pour permettre l’ouverture des sites.
Le point qui est revenu régulièrement dans nos entretiens est la problématique de la mise en place de nouveaux outils de travail en ligne pour assurer la coordination et le pilotage de l’activité (médiation des ressources et services en ligne, communication sur des aspects pratiques…). Sur ce point, des aspects très concrets (équipement à domicile, connexion suffisante…) ont rencontré des considérations plus complexes (formalisation d’échanges habituellement informels, disponibilité d’un support technique, enjeux d’une éventuelle confidentialité des échanges en fonction des outils utilisés…).
2.2. Rôles « non-essentiels » ?
Au-delà de ces questionnements opérationnels, des sujets plus délicats à appréhender ont également émergé. Ainsi, les notions d’équipe et de service public sont évoquées, lors de nos entretiens mais également plus largement dans la communauté professionnelle. Cette notion de “faire équipe” apparaît ainsi lors de la deuxième séance du séminaire BiblioCovid initié et animé par Raphaëlle Bats (http://raphaellebats.blogspot.com/2020/04/bibliocovid19-synthese2.html ). Dans la synthèse de cette séance on retrouve la préoccupation des bibliothécaires à accompagner les équipes dans un contexte où le rôle et les services de la bibliothèque sont qualifiés de “non-essentiels”, un terme dur à entendre pour des employés d’institutions culturelles qui ressentent au quotidien l’importance de leur travail pour leurs publics, quels qu’ils soient.
Ainsi, ce n’est pas seulement des questions de management et d’animation mais aussi des enjeux de légitimité et de sens du service public de la bibliothèque qui émergent au cours de cette période.
3. Fermées… aux publics
La fermeture des locaux physiques des bibliothèques implique bien entendu non pas uniquement le personnel des bibliothèques, mais aussi leurs publics. Il ressort de nos analyses que cette “disparition” de la bibliothèque comme espace a remis au centre des réflexions des questionnements plus anciens sur la place de la bibliothèque comme “espace public”.
3.1. Animations et médiation
Pour les bibliothèques de lecture publique, l’année 2020 aura été largement consacrée à l’adaptation de leurs activités de médiation culturelle. En effet, face à l’impossibilité d’accueillir les publics dans leurs espaces, les bibliothèques ont tenté de transformer leurs évènements et animations prévues dans des formats en ligne.
La Médiathèque Valais a ainsi dû annuler ses manifestations à l’occasion du samedi des bibliothèques. Idem pour Bibliomedia, avec la nécessaire adaptation de ses formations, des annulations ou des transformations pour pouvoir être maintenues dans une version en ligne, avec donc des publics et des modalités de médiation réinventées. Pour la bibliothèque de Vevey, même nécessité d’adapter un riche programme d’animations (café littéraire, conférences…).
Dans tous les cas, l’objectif est bien de continuer à proposer aux publics des moments d’échanges, des “points de contact” avec les usagers pour continuer à “faire vivre” la bibliothèque et répondre également aux besoins des personnes, confinées également, et à la recherche d’espaces d’échanges et de rencontres. On retrouve ainsi une autre modalité de proposition d’un espace virtuel dans lequel le rôle de médiateur de la bibliothèque se maintient et se transforme.
Cette adaptation des évènements des bibliothèques ne s’est évidemment pas faite sans difficultés. Le premier aspect est l’adaptation à ces nouvelles modalités. Pour Bibliomedia par exemple, c’est l’adaptation de son Printemps de la Poésie en une version mieux adaptée aux circonstances, “De ma fenêtre”. Pour Vevey c’est la production de vidéos à mettre en ligne ou encore pour la Médiathèque Valais cela passe par le fait de filmer des conteuses pour diffuser plus largement cette animation via les réseaux sociaux.
Les contraintes techniques constituent déjà un premier obstacle. Organiser, à distance, ces nouveaux évènements, maîtriser les outils de captation ou de diffusion, autant de points sur lesquels les bibliothécaires ont dû progresser très rapidement.
Avec cette “virtualisation” des évènements en bibliothèque émergent naturellement de nouveaux questionnements, notamment sur les publics concernés par ces offres. Les retours vont également dans le même sens, à savoir un double mouvement d’ouverture et d’élargissement des publics au-delà des zones géographiques habituelles et à l’inverse, l’impossibilité pour certains publics de participer ou de bénéficier de ces offres en raison d’équipements ou de compétences insuffisants vis-à-vis des outils numériques nécessaires.
Dans ce mouvement c’est une redéfinition des publics qui s’opère, dépassant la seule contrainte physique de mobilité pour en voir émerger d’autres liées à la littératie numérique ou aux moyens de connexion. En ce sens, cette transformation questionne le projet fondamental des bibliothèques de servir tous les publics, sans contraintes ou discriminations.
3.2. Collections et pratiques de lecture
À la BCUL comme ailleurs, la limitation des places de travail, voire leur suppression, a induit naturellement une baisse des visites des usagers. Ce phénomène a été paradoxalement accompagné d’une hausse des emprunts de documents imprimés. Ce croisement des courbes implique que le recours au catalogue, devenu le seul point d’accès aux collections, a progressé.
Le soir de l’annonce officielle, la BCUL, qui suit son plan de crise, maintient ses guichets ouverts jusqu’à 22h afin de permettre à ses lecteurs de “faire le plein”. Cette initiative rencontre un franc succès, avec une affluence jamais vue dans cette tranche horaire.
Cette sollicitation forte des collections de la bibliothèque n’est cependant pas propre à la BCUL et, au-delà de l’anecdote, les autres bibliothèques ont également observé une croissance importante de certains pans de leur activité.
Pendant les périodes de fermeture, la Médiathèque Valais a largement développé un service qu'elle proposait de façon très limitée auparavant, le prêt postal. La BCUL a proposé un service de distribution individuelle des ouvrages pour les enseignants et les chercheurs, lorsque le campus était de nouveau accessible. De plusieurs façons les bibliothèques ont imaginé et mis en place des services pour maintenir un accès à leurs collections d’imprimés.
Dans le même temps, elles ont naturellement renforcé et communiqué sur leurs offres de ressources numériques. Ainsi, l’offre de livres numériques eLectures de la BCUL a vu son nombre d’inscrits augmenter de 523% par rapport à la même période en 2019 et le nombre de livres numériques empruntés a crû de 57%.
Bibliomedia et sa plateforme e-bibliomedia ont naturellement été un point d’observation central pour l’évolution des pratiques. Ainsi, à cette occasion, la plateforme e-bibliomedia a vu 14 nouvelles bibliothèques la rejoindre. Ce sont ainsi 10’000 lecteurs en plus inscrits sur la plateforme et un nombre moyen de prêts mensuels qui est passé de 6000 à 8400, avec un pic à 13500 prêts en avril. Cet engouement pour le livre numérique a entraîné un net dépassement des budgets initialement prévus, de l’ordre de CHF 25’000.-.
La forte croissance de l’utilisation des livres numériques en bibliothèques n’est pas spécifique au contexte suisse. Plusieurs études ou articles font aussi état d’une évolution similaire dans d’autres pays.
4. Un usage des ressources numériques en croissance globale
Dans le reste du monde, on observe en effet des tendances similaires. Ainsi, aux Etats-Unis la crise du COVID a entraîné des évolutions importantes dans ce domaine. Overdrive, principal acteur du prêt de livres numériques dans les bibliothèques américaines a observé une augmentation de 50% des emprunts pour la période courant jusqu’à l’été 2020. Dans les écoles primaires, l’adhésion à la plateforme Sora qui propose des livres numériques et des livres audios a augmenté de 80% (ce sont 38’000 écoles de 71 pays qui utilisent le système aujourd’hui) et le nombre d’ouvrages empruntés a triplé (https://goodereader.com/blog/digital-library-news/289-million-ebooks-were-borrowed-from-the-public-library-in-2020 ).
En France, le système PNB (Prêt Numérique en Bibliothèque) a également largement bénéficié des périodes de confinement. Pour la période de janvier à mai 2020 le nombre de prêts a augmenté de 106% par rapport à la même période en 2019 (http://pretnumeriqueenbibliotheque.fr/acces-simplifie-au-livre-numerique-un-pari-presque-gagne/). Rien que pour le mois d’avril, le nombre de prêts a été multiplié par 3.5.
Dans ces différents contextes, la croissance forte du prêt de livres numériques s’est accompagnée d’un nécessaire effort de facilitation des accès et des procédures. Cela a pris la forme de formulaires en ligne, d’actions d’autonomisation des usagers comme à la Médiathèque Valais, ou encore cela a coïncidé avec le lancement de l’application Baobab pour PNB et le déploiement de licences LCP pour les livres numériques.
L’environnement des bibliothèques et des usagers a également beaucoup évolué au cours de cette crise. Internet Archive a ainsi ouvert très largement sa bibliothèque de livres numériques en proposant une “bibliothèque d’urgence nationale”, sans limitation d’accès aux plus de 2 millions d’ouvrages empruntables pour une durée de 14 jours (dont 60’000 environ en français). Face aux réactions très vives des associations américaines d’éditeurs et d'auteurs, ce fonctionnement a été supprimé au mois de juin.
Dans les différents pays observés se pose la même question : est-ce que le pic mesuré au cours de l’année 2020 est l’amorce d’une modification durable et pérenne des usages ou s’agit-il uniquement d’un effet conjoncturel de la crise ?
Pour les situations suisses et françaises, le déploiement de la solution Baobab, qui simplifie grandement le parcours de l’utilisateur pour le prêt de livres numériques en bibliothèques pourrait constituer un élément de soutien au maintien de ces pratiques.
Ce qui est en tout cas largement anticipé par les bibliothèques américaines c’est une crise du financement des bibliothèques par les collectivités locales dont les budgets risquent d’être largement touchés par les conséquences économiques de la crise du Covid-19, et qui pourraient donc trouver dans les budgets des bibliothèques une source d’économies.
Ce glissement des pratiques vers des supports numériques est lié à plusieurs éléments (confinement, fermeture des librairies, limitation des déplacements…). L’évolution est également observable pour certains types de publics comme les étudiants. Le passage à l’enseignement à distance a considérablement modifié les usages des étudiants par rapport aux manuels avec par exemple une croissance de 23% des dépenses en manuels numériques pour les étudiants américains, (https://publishingperspectives.com/2020/11/aap-course-materials-spending-report-23-percent-up-e-textbooks-usa-covid19/) au détriment de tous les autres formats.
5. Conclusion : fluctuations ou mutations durables ?
Les limitations d’accès aux espaces des bibliothèques au cours de l’année 2020 ont évidemment placé la fourniture de ressources numériques comme un service essentiel en bibliothèque. Pour plusieurs bibliothèques, une offre de ressources de ce type était déjà disponible mais celle-ci a été développée et mise en valeur. Ainsi, la Médiathèque Valais a accéléré l’intégration d’une plateforme de films en ligne, tout en cherchant à valoriser les podcasts de ses précédentes animations. La BCUL a fait la promotion de ressources au-delà des livres numériques, comme Assimil et Vodeclic. Ces efforts de valorisation des ressources numériques ont porté leurs fruits avec des niveaux d’utilisation en croissance.
Globalement, les différentes bibliothèques interrogées ont pu observer des courbes d’évolution des usages similaires pour l’ensemble des ressources en ligne. Un pic d’utilisation très net se produit dans les premiers temps du confinement, une réaction réflexe face au risque de ne plus pouvoir accéder à des contenus sur le long terme. Ce pic est suivi d’un repli progressif des usages pour se stabiliser à un niveau supérieur d’environ 25% au niveau pré-covid. Cette période aura donc entraîné avant tout une valorisation renforcée des offres de ressources numériques déjà proposées par les bibliothèques mais parfois peu mises en avant ou à l’accès trop complexe pour les usagers.
Pour l’animation culturelle et les espaces des bibliothèques, l’année 2020 aura également entraîné des réflexions en profondeur sur la façon d’appréhender le rôle de la bibliothèque. Cette crise intervient en effet à une période où beaucoup de bibliothèques ont entamé et développé des projets et des réflexions sur la valeur ajoutée de leurs espaces et sur les attentes du public. Ainsi, en transposant tant bien que mal leurs animations culturelles en ligne, les bibliothèques ont initié deux trajectoires a priori opposées. Elles ont touché des publics à distance qui dépassent leurs sphères d’influence habituelles, à la fois géographiques et sociologiques. Dans le même temps, une partie de leurs lecteurs ont été exclus, pour des raisons techniques, de compétences informationnelles ou de pratiques, de cette offre culturelle. Ce double processus, de même que leur statut d’acteurs publics “non-essentiels”, initiera probablement des débats professionnels passionnants pour les années à venir.
À un niveau plus général, la crise sanitaire de l’année 2020 a été un accélérateur très efficace de mutations déjà amorcées ou pendantes depuis plusieurs années. C’est le cas pour les offres de ressources numériques mais également pour le télétravail, la formation à distance ou l’optimisation des parcours usagers dans les démarches en ligne, et il est probable que cela obère un simple retour au “monde d’avant”.
A review of the Swiss Research Data Day 2020 (SRDD2020): 48 experts shared their experiences on emergent approaches in Open Science
Pierre-Yves Burgi, Directeur du projet DLCM et Directeur SI adjoint, Division Systèmes et technologies de l'information et de la communication (STIC), Université de Genève
Lydie Echernier, Coordinatrice du projet DLCM, Division Systèmes et technologies de l'information et de la communication (STIC), Université de Genève
A review of the Swiss Research Data Day 2020 (SRDD2020): 48 experts shared their experiences on emergent approaches in Open Science
After a first edition at the Swiss Federal Institute of Technology Lausanne (EPFL) in 2016 and a second one at the Swiss Federal Institute of Technology Zurich (ETHZ) in 2018, the third edition of the Swiss Research Data Day (SRDD2020) – titled “Emergent approaches for Open Science” – took place online on 22 October 2020 during the International Open Access Week event.
SRDD2020 was organized by the Data Life-Cycle Management (DLCM) Project’s partners, (1); at the initiative of the Geneva School of Business Administration (HEG/HES-SO) together with the University of Geneva (UNIGE), and in partnership with the Zürich Hochschule für Angewandte Wissenschaften (ZHAW).
An interdisciplinary community of 301 researchers, librarians, funders, publishers and policymakers discussed the emerging technologies and approaches that contribute to the development of Research Data Management (RDM) and Open Science (OS) from both the researcher and institutional perspectives. Participants were welcomed by the launching video of OLOS.swiss, the national solution developed within the DLCM project to address archiving, long-term preservation, publication and access of research data, and accessible to all Swiss Higher Education Institutions.
Five invited speakers delivered keynote speeches at SRDD2020:
- Dr. Hrvoje Stancic, professor at the Faculty of Social Sciences and Humanities at the University of Zagreb, discussed the use of Blockchain technologies and methodologies in data management. His keynote revolved around the concepts of trustworthiness, authentication, identity and integrity of Blockchains as applied to the long-term preservation of research data.
- Dr. Patrick Furrer, coordinator of the national "Scientific Information Programme" at swissuniversities, unveiled the national Open Research Data Strategy and Action Plan to come in the next 4 years.
- Vice Rector Dr. Christine Pirinoli presented HES-SO’s Open Data Strategy, emphasizing the cultural changes institutions must achieve to properly manage research data, and the time and support required to realize this.
- Dr. Nancy McGovern, Director of Digital Preservation at the MIT, presented a 6-layer Digital Archives and Preservation (DAP) Framework to leverage cross-domain collaborations for achieving a sustainable management of research data. Such an approach emphasizes cross-domain responsibility as opposed to passive sharing, and stresses the importance of social, professional and technical inclusions to achieve effective collaborations.
- And Dr. Alberto Pace, from CERN, showcased the application of digital sovereignty to the preservation of Big Data to mitigate the risks associated with commercial software and hardware solutions and their associated costs.
During the day, 34 lectures, lighting talks, demonstrations and workshops sparked a fruitful exchange among speakers, panelists and participants. The 48 speakers, from 23 national and international institutions(2), presented various themes regrouped within eight panels:
- Panel 1 was dedicated to the proper management of Open Research Data (ORD), with (i) a demonstration of OLOS.swiss, (ii) a presentation of the professional management framework that support the identification, evaluation, and development of a portfolio of Open Data resources at SIB, (iii) a coaching program to support the implementation of a RDM strategy in the National Centre of Competence in Research (NCCR) Robotics, (iv) the handling of sensitive personal data in Leonhard Med’s secure computing environments, and (v) the development and promotion of a Data Champions community at EPFL.
- Panel 2 placed data management in the ethical, legal, financial and academical contexts, with (i) a return of experience on the implementation of the SNSF ORD policy and the required publication of research data by SNSF-funded researchers, (ii) a master thesis focusing on how to leverage copyrights in the research data context and which licenses are best suited to serve the OS movement, (iii) returns of experience on the publication of research data from 12 pilot projects in a variety of disciplines at ZHAW, and (iv) a demonstration of a web-based tool (DMLawTool) addressing the most relevant legal issues related to data management.
- Panel 3 presented uses cases supporting OS strategies, with (i) experience from the ETH Zurich’s Research Collection regarding data publication in an institutional repository, (ii) the data publication workflows of the research data repositories ERIC and EnviDat, and (iii) a presentation of UNIL’s OS Strategy and Action Plan.
- Panel 4 gathered participants in a workshop to discuss FAIR (Findable, Accessible, Interoperable and Reusable) data production in the context of a virtual research environment using the "user experience design" participatory method of the Basel-based KleioLab’s Geovistory tool.
- Panel 5 explored training in ORD, with (i) the co-creation within the DLCM project of a Massive Open Online Course (MOOC) specifically dedicated to RDM, (ii) MILOS, a microlearning prototype for OS, and Train2Dacar, a train-the-trainer approach for data curation, (iii) the promotion of the FAIR principles in data mining of population genetics using the RENKU platform, (iv) Nuvolos, a knowledge-creating platform for research and education, and (v) the promotion of a user-centered platform to make health research FAIR with the Horizon 2020. FAIR4Health project.
- Panel 6 showcased practices and experiences related to FAIR research data for OS, with (i) some observations and a workflow example of a FAIR Digital Objects (FDO) approach to facilitate data driven research across disciplines, (ii) an argumentation for research data as a new model of scholarly writing in social sciences and humanities (SSH) within the Horizon 2020 project Open Scholarly Communication in the European Research Area for Social Sciences and Humanities (Preparation OPERAS), (iii) openRDM.swiss, the data management service of ETHZ Scientific IT Services (SIS) targeting the Swiss research community based on the openBIS software platform, and (iv) recommendations and good practices to help chemists to make better chemistry data with the CHEMeDATA initiative.
- Panel 7 introduced existing solutions for the long-term preservation of research data, with (i) a presentation of the current status of the elaboration of a Swiss National ORD Strategy by a working group of swissuniversities, (ii) the Academic Output Archive (ACOUA) project, aiming at providing EPFL researchers with a service to publish and preserve their research data, (iii) a demonstration of the SWISSUbase platform, the multidisciplinary archiving service for research data based on FORS, the data service for the social sciences, (iv) Materials Cloud, the platform designed to enable open and seamless sharing of resources for computational materials science, and (v) AiiDA 1.0, the scalable computational infrastructure that automatically tracks the full provenance of data produced by workflows in the form of a directed graph.
- Panel 8 addressed specific legal questions related to data management and archiving in a workshop based on the DMLawTool.
The organization of the online event could count on 14 volunteers and resulted in more than 15 hours of video recording, split up into 34 sessions, which have been posted on the UNIGE mediaserver, publicly available at http://www.dlcm.ch/srdd2020/presentations along with the speakers’ presentation slides.
Notes
(1)DLCM is a Swiss project mandated by swissuniversities, see https://dlcm.ch
(2)Alphacruncher, European Organization for Nuclear Research (CERN), French National Centre for Scientific Research (CNRS), Geneva School of Business Administration (HEG/HES-SO), Geneva University Hospitals (HUG), KleioLab, Massachusetts Institute of Technology (MIT), Max-Planck Society, Swiss Centre of Expertise in the Social Sciences (FORS), Swiss Federal Institute for Forest, Snow and Landscape Research (WSL), Swiss Federal Institute of Aquatic Science and Technology (Eawag), Swiss Federal Institute of Technology Lausanne (EPFL), Swiss Federal Institute of Technology Zurich (ETHZ), Swiss Institute of Bioinformatics (SIB), Swiss National Science Foundation (SNSF), swissuniversities, Università della Svizzera italiana (USI), University of Applied Sciences and Arts of Western Switzerland (HES-SO), University of Geneva (UNIGE), University of Lausanne (UNIL), University of Neuchâtel (UniNE), University of Zagreb (UniZg) and Zürich Hochschule für Angewandte Wissenschaften (ZHAW).
Conférence annuelle LIBER 2020 online : compte rendu d’évènement
Piergiuseppe Esposito, Chargé de mission BCU Lausanne
Conférence annuelle LIBER 2020 online : compte rendu d’évènement
La première conférence virtuelle de LIBER s’est tenue du 22 au 26 juin 2020, sous le thème Building Trust with Research Libraries. Initialement prévue à Belgrade, la 49e conférence annuelle LIBER a été hébergée en ligne sur la plateforme AnyMeeting. Organisée en un temps record en raison de l’évolution de la situation sanitaire au printemps, la conférence a rencontré un vif succès auprès des membres de la communauté des bibliothèques européennes de recherche, avec 5’544 inscriptions de plus de 1’700 personnes, dont le personnel de 276 institutions membres de LIBER. En une semaine, plus de 50 orateurs ont animé et présenté : 1 keynote address, 2 panel sessions, 6 workshops, 10 parallel sessions et 11 posters, dont l’enregistrement et les diapositives sont disponibles sur YouTube et Zenodo via le site web de la conférence LIBER (https://liberconference.eu/liber-2020-presentations-posters/). Les grands thèmes de la conférence – Information & Research Integrity, Preservation of Collections, Leadership, Impact of Libraries, Securing Trust in Libraries, Open Knowledge – ont été abordés aussi bien sous un angle théorique que pratique, c’est-à-dire à partir de l’analyse de retours d’expérience. Une place importante a été consacrée aux sessions de questions-réponses permettant des échanges de vues et d’informations avec les spécialistes connectés, autour de divers sujets d’actualité.
«Challenging times»
Cette édition de la conférence annuelle LIBER a bien évidemment été marquée par la crise du coronavirus, qui a eu un effet disruptif sur la vie et les habitudes de travail dans le monde entier. Dans un contexte en constante mutation et face aux incertitudes liées à la crise sanitaire, les défis sont de taille pour les bibliothèques de recherche. «À quoi ressemblera l’ère post-COVID-19 ?». Dans son mot de bienvenue, la présidente de LIBER, Jeannette Frey, directrice de la BCU Lausanne, a souligné la nécessité d’ajuster et de réinventer les services selon les besoins pour refléter les restrictions liées au COVID-19. À ce propos, une enquête adressée aux institutions membres de LIBER permettra d’ici la fin de l’année 2020 de mapper la situation des bibliothèques européennes de recherche. Cette enquête ne vise pas qu’à montrer l’impact de la crise du COVID-19, mais la situation à laquelle les bibliothèques de recherche vont être confrontées dans l’année à venir (deuxième vague, post-COVID-19). Dans leurs discours d’ouverture, les trois chefs de secteurs stratégiques de LIBER – Dr Bertil F. Dorch, Dr Birgit Schmidt et Dr Giannis Tsakonas – ont réfléchi quant à eux à l’impact du COVID-19 sur la science ouverte. L’ouverture des connaissances et le partage des données primaires de la recherche sont non seulement essentiels pour comprendre et atténuer la pandémie, mais aussi un moyen d’accroître la transparence, la reproductibilité, la responsabilité et la confiance dans la recherche. De ce point de vue, les bibliothèques de recherche ont un rôle crucial à jouer dans la construction de cette confiance.
Pour aller plus loin : https://www.youtube.com/watch?v=jHc8-4lH_4U&feature=emb_logo
Retours d’expérience
À l’heure actuelle, renforcer la confiance entre les bibliothèques universitaires et la communauté scientifique est un enjeu de taille. Exemple parmi d’autres d’une collaboration fructueuse, on remarquera la présentation dans le cadre de la session Libraries as Open Innovators and Leaders de la réalisation d’un projet pilote d’édition et de publications scientifiques dénommé «Editori», basé sur le logiciel Open Journal Systems (OJS). Ce projet a été réalisé à la bibliothèque universitaire d’Helsinki en collaboration étroite avec des membres de la communauté universitaire (enseignants, doctorants) dans le cadre d’un séminaire organisé au sein d’un programme doctoral en sciences humaines et sociales. Les participants y ont été accompagnés dans toutes les étapes du processus éditorial d’une revue fictive dénommée FTY journal. Cette étude de cas illustre le rôle que peuvent jouer les bibliothèques de recherche dans le développement de compétences en matière d’édition et de publication au sein de la communauté académique. En particulier, le personnel de la bibliothèque universitaire a formé les enseignants impliqués à l’utilisation de la plateforme et a servi de support technique tout au long du séminaire. Cette expérience a permis de tirer plusieurs leçons au regard de la collaboration entre enseignants et bibliothécaires. Il en résulte trois facteurs essentiels de la réussite d’un tel projet pilote : la communication, l’implication de la bibliothèque déjà dans la phase de planification du séminaire et la collecte systématique de feedback pour l’implémentation du service.
Pour aller plus loin : https://libraryguides.helsinki.fi/editorieng
Citizen Science & SDGs
Un autre thème intéressant abordé dans le cadre de la conférence est l’émergence d’une nouvelle plateforme pour la science citoyenne. La Citizen Science a gagné en importance de façon spectaculaire ces dernières années : des milliers de projets qui intègrent le public à la recherche sont disponibles en ligne et les organismes de financement soutiennent le domaine. Du côté de LIBER, le groupe de travail Citizen Science, créé en juin 2019, s’est engagé à fournir d’ici l’année prochaine un modèle (ou une série de modèles) et à plaider en faveur d’un point de contact unique pour la science citoyenne qui pourrait être mis en place dans les bibliothèques de recherche. À travers la participation active à des projets de science citoyenne, les bibliothèques sont encouragées à œuvrer dans l’établissement d’un «BESPOC» virtuel – acronyme de Broad Engagement in Society, Point of Contact(1)– avec la collaboration de citoyens et d’autres institutions. Comme souligné dans le cadre de la session Citizen Science Supporting Sustainable Development Goals: The Possible Role of Libraries, la science citoyenne dans les bibliothèques peut en outre être considérée dans la perspective de la réalisation de l’Agenda 2030 pour le développement durable de l’ONU. À l’exemple de la bibliothèque de l’université du sud du Danemark (SDU Library) qui s’est engagée dès 2019 à améliorer son action de sensibilisation à l’échelle locale dans le cadre des 17 objectifs du développement durable (SDGs) au sein d’un Citizen Science Network.
Pour aller plus loin : https://www.sdu.dk/en/forskning/forskningsformidling/citizenscience
Notes
(1)Tiberius Ignat et Paul Ayris, “Built to last! Embedding open science principles and practice into European universities”, Insights, 33 (9), 2020, pp. 1-19 (ici p. 15).
Histoire d'une (r)évolution : l'informatisation des bibliothèques genevoises 1963-2018
Alex Boder, HEG Genève
Histoire d’une (r)évolution : l’informatisation des bibliothèques genevoises, 1963-2018
Publié en 2019, cet ouvrage, disponible en version papier et électronique, marque par son imposante densité mais également par sa qualité de mise en page.
Il constitue une somme considérable et précieuse de l’histoire de l’informatisation des bibliothèques genevoises. Près de 400 pages qui au final ne se limitent pas à la seule Genève puisqu’intelligemment il met en perspective ces développements sous un angle régional, national et parfois international.
Ces 55 ans d’histoire en onze chapitre constituent une importante et inédite contribution, qui n’a pas d’équivalent et qui représente une référence en la matière. Ce livre fourmille d’évènements, d’informations, de lieux et de personnes qui ont contribué à la mise en place et l’évolution de l’informatique documentaire. Ces 400 pages, très bien structurées, où à chaque fin de chapitre une bibliographie est ajoutée, se voient agrémentées d’outils indispensables pour une consultation aisée : profonde table des matières, liste des sigles, index des personnes citées et frise temporelle.
Cela saute aux yeux que cet ouvrage est le fruit d’un travail considérable, mené de main de maître par ses deux auteurs, porteurs d’une vaste et riche expérience : Gabrielle von Roten à qui le livre est dédié et Alain Jacquesson.
Gabrielle von Roten a dirigé le Service de coordination des bibliothèques universitaires de Genève puis a été en charge de la Coordination locale RERO (Réseau des bibliothèques de Suisse occidentales). Elle a été membre active de différents comités et commissions de bibliothèques au niveau régional et national. Elle nous a malheureusement quitté le 27 mai 2019 mais a pu transmettre ses commentaires sur les dernières épreuves de cette édition.
Alain Jacquesson, auteur de nombreuses publications de référence dans le domaine, a dirigé l’Ecole de bibliothécaires puis le réseau des Bibliothèques municipales de Genève puis enfin la Bibliothèque de Genève où il termine sa carrière en 2007.
Témoins de leur temps et surtout ayant vécu les premières informatisations réalisées dans les institutions, ils n’ont cessé de côtoyer les différents acteurs qui au cours des années ont marqué de leur empreinte les évolutions technologiques de l’informatique documentaire à Genève. Ces derniers sont chaleureusement remerciés pour l’aide apportée par leur témoignage et la documentation qu’ils ont pu fournir.
Les auteurs ont méticuleusement recueilli les éléments indispensables à la constitution de cet ouvrage. Appuyé par des sources riches et très variées, ce livre a le mérite d’en donner un sens qui nous éclaire sur ce qui a marqué l’informatisation des bibliothèques à Genève.
Cet ouvrage présente plusieurs intérêts et évite le piège d’une narration purement chronologique même si en annexe une judicieuse frise temporelle nous aide à contextualiser les événements au cours du temps dans une perspective à la fois genevoise, nationale et internationale.
Il a cette qualité de porter un regard sous plusieurs angles. De par sa valeur historique mais également scientifique par le soin apporté dans sa réalisation.
Après une introduction qui nous expose les grandes étapes marquantes, les auteurs mettent en lumière les organisations internationales établies à Genève qui ont été pionnières dans l’informatisation de leurs bibliothèques et ont continué à réaliser des solutions souvent innovantes dans ce domaine. Suit un chapitre sur les bases de données documentaires et les services qui ont été mis en place dans certaines bibliothèques pour en faciliter la constitution et la consultation. C’est au chapitre 4, le plus volumineux, que les auteurs nous détaillent les réalisations des bibliothèques scientifiques et patrimoniales. C’est finalement conséquent puisque ces bibliothèques ont été un important moteur dans la mise en place du réseau RERO qui a tant marqué les usagers des bibliothèques. Il évoque les conflits, les échecs mais également les alliances et les réussites.
La lecture publique et les bibliothèques scolaires ne sont bien entendu pas oubliées et sont traitées par la suite, après avoir dédié un chapitre sur l’impact de l’apparition de la micro-informatique au sein des institutions.
C’est d’ailleurs l’aspect technique et parfois complexe de la migration et de la retroconversion des données qui est traité dans le chapitre suivant.
Tous ces aspects techniques ne pouvaient s’expliquer sans évoquer, au neuvième chapitre, la formation à l’informatique documentaire. Les différentes écoles, cours et formations continues sont présentés avec une approche chronologique puis un sous-chapitre est consacré à la recherche, la recherche appliquée en particulier.
L’ouvrage se termine avec les deux derniers chapitres. Le dixième, qui traite des bibliothèques numériques, aborde les grands chantiers informatiques touchant périodiques, affiches, manuscrits, livres anciens, thèses, supports audio et video, logithèque, archives ouvertes, etc. mais également des services et des médiations organisés autour du numérique comme InterroGE ou Labo-Cité en exemple. Puis, l’ouvrage se termine avec le onzième et dernier chapitre sous forme de conclusion qui n’en est pas une pour nos bibliothèques puisqu’il traite de l’avenir et des immenses défis qui attendent les bibliothèques face ou avec l’informatique. Tous deux ont dorénavant un destin fortement lié lorsqu’on touche du doigt les perspectives d’avenir offertes par l’intelligence artificielle, le « deep learning » et le « big data » qui ne manqueront pas de transformer nos bibliothèques.
Il est certain que cette « Histoire d’une (r)évolution » a pour qualité de permettre à tout professionnel ou tout utilisateur (genevois) de se remémorer avec plaisir les événements, lieux ou personnes qui ont contribué à l’effort numérique des bibliothèques de Genève tout en les mettant en perspective pour aider à se forger une idée sur le futur qui les attend.
Bibliographie
JACQUESSON, Alain, VON ROTEN, Gabrielle, 2019. Histoire d'une (r)évolution : l'informatisation des bibliothèques genevoises, 1963-2018. Genève : L'Esprit de la Lettre Editions. 389 p.
ISBN 9782940587117
The No-nonsense guide to research support and scholarly communication (2020)
Thomas Pasche, Haute Ecole de Gestion, Genève
The No-nonsense guide to research support and scholarly communication (2020)
L’auteure de cet ouvrage paru en 2020, Claire Sewell, travaille au bureau de la communication scientifique de la bibliothèque de Cambridge en qualité de coordinatrice des compétences en matière de soutien à la recherche. Elle est également coordinatrice de conférence pour le conseil d’administration de la Special Librairies Association (SLA) et contributrice pour de nombreuses revues professionnelles.
L’explosion d’internet et la multiplication des plateformes de recherche auraient dû rendre le travail des chercheurs plus simple : plus d’information publiées et plus de points d’accès pour les trouver et les consulter. La réalité est tout autre : la multiplicité des sources d’informations et la prolifération des fake news et autres sources de désinformations rendent le travail des chercheurs de plus en plus compliqué, s’ajoutent à cela les coûts, souvent prohibitifs d’accès aux ressources de qualité ainsi qu’un système de publication de plus en plus restreint, tant économiquement que géographiquement. C’est dans ce contexte que le rôle du bibliothécaire chargé de la communication académique est mis en question. Quelles qualifications doit-il posséder, quelles expertises et quelle place a-t-il dans ce milieu à l’évolution rapide et souvent chaotique.
Le premier chapitre de cet ouvrage pose un cadre à cette question. Il explique le rôle que chacun se doit de jouer, explique les bases de la recherche académique tant du point de vue des chercheurs que du point de vue des bibliothécaires, brouillant parfois l’identité de ces deux rôles, le premier se retrouvant parfois à occuper le poste du second sans pour autant avoir une formation bibliothéconomique. Le rôle du bibliothécaire est par ailleurs changeant en fonction de son répondant, celui-ci ayant un besoin plus ou moins important de guidance et de soutien. Ce chapitre conclut sur le cycle de vie que toute recherche, aussi basique soit-elle, doit suivre afin d’avoir un impact et une portée maximale.
Le second chapitre fait un focus tout particulier sur les données et leur prise en charge. Tout d’abord d’un point de vue linguistique : peut-on encore parler de données lorsque son répondant travaille dans ls domaine des sciences humaines, domaine dans lequel les données vont plutôt être nommées informations. Ainsi, le bibliothécaire devra faire preuve d’adaptabilité en fonction de son répondant afin que son message soit bel et bien compris. Il aura par ailleurs la charge de faire comprendre au chercheur combien il est important d’avoir un plan de gestion des données, tant au niveau du nommage qu’en ce qui concerne leur classement, qu’il soit physique ou numérique. Les données devront ainsi être trouvables, accessibles, interopérables et réutilisables et devront être parfois maniées avec précaution, surtout si ces dernières sont des données sensibles (personnelles, médicales ou juridiques).
L’Open access est au cœur du chapitre suivant, en le définissant comme la possibilité de rendre accessibles librement les résultats de la recherche, en partie grâce à l’essor des nouvelles technologies, notamment celles du web et en s’opposant aux moyens traditionnels de publication. Ce chapitre revient également sur l’historique de l’open access, depuis l’apparition du terme au début des années 2000 et son développement dans les années qui suivirent, notamment par les trois actes fondateurs que sont : l'Initiative de Budapest en faveur de l'accès libre, la Déclaration de Bethesda sur l'édition en libre accès et la Déclaration de Berlin sur le libre accès à la connaissance dans le domaine des sciences. L’auteure aborde également les problèmes afférant à cette méthode de diffusion, en évoquant le cas de certains scientifiques qui craignent que l’open access nuise à la crédibilité de leurs travaux. Il est également question des avantages apportés par l’open access pour les chercheurs ainsi que pour le grand public. Le rôle des bibliothécaires peut être d’apporter des solutions techniques aux chercheurs, une compréhension de ce qu’est l’open access et peut également être utile dans le cadre de leurs propres recherches en leur donnant accès à un vaste volume d’informations utiles.
L’auteure évoque ensuite les méthodes de dissémination des résultats de la recherche. Il est question des différentes questions que les chercheurs doivent se poser quant au partage du résultat de leurs recherches, notamment quant au format ou aux supports servant à partager les données de la recherche : dépôt institutionnel, réseaux sociaux, plateformes dédiées, etc. Le texte met également en garde contre les « éditeurs prédateurs », des organisations qui exploitent l’open access pour un gain financier, en promettant de fournir des services spécialisés en matière de dissémination des données de la recherche, mais qui, finalement, se contentent de publier ce qui leur a été transmis sans travail supplémentaire.
Dans le cinquième chapitre, Claire Sewell évoque les critères servant à mesurer l’impact (en anglais : metrics) et la qualité de la recherche. Les bibliothécaires académiques ont ici un rôle important à jouer, dans la mesure où ils connaissent bien, en général, ces méthodes de mesures d’impact et peuvent aider les chercheurs en les soulageant de ce calcul. Dans cette partie du livre, l’auteure décrit ces différents outils de mesures et dans quelles situations les utiliser.
Le chapitre suivant se différencie des autres parties de ce livre dans la mesure où l’auteure s’adresse directement à des personnes souhaitant entamer une carrière dans le domaine de la communication académique et de l’aide à la recherche. Pour ce faire, Claire Sewell clarifie le vocabulaire propre aux offres d’emploi dans ce domaine et détaille les compétences nécessaires pour travailler dans ce domaine. Le chapitre offre également des études de cas, sous la forme de postes mis au concours dans des bibliothèques académiques et comment les décrypter.
A travers le dernier chapitre, l’auteure encourage les bibliothécaires à publier leurs propres travaux, qu’ils soient dignes de journaux revus par les pairs ou plus modestes. Il est normal pour un bibliothécaire de chercher régulièrement des solutions aux problèmes auquel il va quotidiennement être confronté et les solutions trouvées sont dignes d’être partagées avec les pairs, afin de leur permettre de résoudre des problèmes similaires. Par ailleurs, un spécialiste de l’information entreprenant ses propres recherches, quelle que soit l’ampleur de cette dernière, aura une expérience concrète lui permettant d’aider au mieux les chercheurs car il les aura également vécues. Cette expérience peut aussi ouvrir des possibilités professionnelles car elle permet d’acquérir des compétences managériales, de gestion du temps, de communication, de capacité de recul et de capacités analytiques. Cela permet aussi au chercheur en herbe de se familiariser avec les difficultés habituelles que rencontrent les chercheurs : le temps, les finances, la politique, le perfectionnisme, le manque de confiance et la motivation, pour ne citer qu’eux. Enfin, l’auteure souligne les différents moyens de diffuser le résultat de ces recherches bibliothéconomiques : conférence, poster, publication, newsletter et réseaux sociaux.
Claire Sewell conclut en mettant en avant les thèmes communs aux différents chapitres. La connaissance du domaine du support à la recherche et de ses particularités est acquise via l’expérience, et le domaine est encore pour l’instant une spécialité émergente. Aussi, à défaut de critère de recrutement précis, on préférera des qualités telles que l’adaptabilité, la capacité de communication avec divers types d’interlocuteur et enfin, la capacité de s’adapter au changement, point essentiel pour se maintenir à jour avec les dernières techniques et informations du domaine. Enfin, l’aide à la recherche ne concerne pas uniquement le domaine universitaire mais peut également être abordé plus tôt, y compris en école obligatoire : cela permet en effet de pré-former les enfants à la gestion des informations, leur utilisation et à leur sauvegarde.
En conclusion, l'ouvrage de Claire Sewell, en abordant différentes thématiques, donne un tour d'horizon clair et synthétique du domaine de l'aide à la recherche académique et montre bien comment les bibliothécaires peuvent s’impliquer utilement dans ces processus de soutien aux chercheurs. L'ouvrage comporte de nombreux exemples pratiques et concrets, permettant aux personnes déjà actives dans ce domaine, tout comme au nouveau venu de mieux cerner les enjeux de la communication académique. De plus, le livre propose une documentation fournie permettant à ceux qui le souhaitent d'explorer plus avant les différentes thématiques abordées, faisant de cet ouvrage une référence dans le domaine.
Bibliograhie
SEWELL, Claire, 2020. The No-nonsense Guide to Research Support and Scholarly Communication. London : Facet Publishing. ISBN : 9781783303939