N°15 décembre 2014
Sommaire - N° 15, Décembre 2014
Études et recherches :
-
Le virage Linked Open Data en bibliothèque : étude des pratiques, mise en œuvre, compétences des professionnels - Jasmin Hügi et Nicolas Prongué
-
Tests d’utilisabilité : comparaison entre une méthode avec modération en présentiel et une méthode automatisée à distance, étude de cas appliquée au site e-rara.ch - Raphael Rey et Valérie Meystre
Comptes-rendus d'expériences :
-
e-rara.ch : une bibliothèque numérique pour les livres anciens - Alexis Rivier
-
De artlibraries.net à Art Discovery Group Catalogue ou l’évolution de métacatalogues pour l’histoire de l’art et d’un réseau des bibliothèques d’art dans le monde - Véronique Goncerut Estèbe
-
Bibliothèque de Genève et Centre d’iconographie genevoise en mutation - Nelly Cauliez et Nicolas Schätti
Événements :
-
Numérique et patrimoine culturel : quels impacts ? Un condensé du Satellite Meeting IFLA Préservation et Conservation d’août 2014 - Jean-Philippe Accart
PAGE SPECIALE SATELLITE MEETING IFLA PAC GENEVE 13-14 AOUT 2014 avec toutes les communications
-
Les dilemmes éthiques dans la société de l'information : comment les codes d'éthique permettent de trouver des solutions. Une conférence conjointe du Comité FAIFE de l'IFLA et de Globethics.net au Château de Bossey, les 14 et 15 août 2014 - Amélie Vallotton Preisig
-
L’information grise : comment trouver des informations difficiles d’accès : compte-rendu de la 11ème Journée franco-suisse en intelligence économique et veille stratégique, 12 juin 2014, Haute école de gestion de Neuchâtel - Hélène Madinier et Maurizio Velletri
Ouvrage paru en science de l'information :
Editorial no 15
Editorial no 15
Nous avons le plaisir de vous proposer le 15ème numéro de RESSI, qui va fêter ses 10 ans d’existence en 2015.
Dans ce 15ème numéro, sous la rubrique Etudes et Recherches, nous vous proposons deux articles qui émanent de quatre jeunes professionnels récemment diplômés du Master en sciences de l’information de la HEG-Genève : le premier article, de Jasmin Hügi et Nicolas Prongué, respectivement bibliothécaire-système à la Coordination vaudoise à la BCU Lausanne et assistant de recherche à la HEG-Genève, s’intitule Le virage Linked Open Data en bibliothèques : Etude des pratiques, mise en œuvre et compétences des professionnels. Il explique les enjeux et l’utilité des LOD en bibliothèque (LOD que l’on traduit parfois en français par « données ouvertes et liées »), présente un mode de mise en œuvre et donne des possibilités de formation continue sur le sujet. Le 2ème article, intitulé Tests d’utilisabilité : comparaison entre une méthode avec modération en présentiel et une méthode automatisée à distance, étude de cas appliquée au site e-rara.ch émane de Raphaël Rey, assistant de recherche à la HEG et Valérie Meystre, et permet d’identifier clairement les types d’information récoltés avec chaque type de tests à partir du site e-rara.ch.
C’est précisément la description du site et plus généralement du projet e.rara.ch, que l’on trouvera dans la rubrique « Compte rendu d’expérience », sous la plume d’Alexis Rivier, conservateur à la Bibliothèque de Genève (BGE). Intitulé e-rara.ch : une bibliothèque numérique pour les livres anciens, il relate la genèse, les développements et les évolutions du projet.
Sous cette même rubrique on trouvera également la description du nouveau projet de métacatalogue Art Discovery Group Catalogue, lancé le 1er mai 2014 et permettant d’interroger les différents catalogues de bibliothèques spécialisées en art. Il est intitulé De artlibraries.net à Art Discovery Group Catalogue ou l’évolution de métacatalogues pour l’histoire de l’art et d’un réseau des bibliothèques d’art dans le monde et est rédigé par Véronique Goncerut Estèbe, conservatrice en chef et responsable du pôle bibliothèque et inventaire des Musées d’art et d’histoire de la Ville de Genève.
Un troisième article clôt cette rubrique. Intitulé Bibliothèque de Genève et Centre d’iconographie genevoise en mutation, signé par Nicolas Schätti, Conservateur responsable du Centre d’iconographie genevoise et Nelly Cauliez, Conservatrice responsable de l’Unité Régie, BGE, il décrit les actions de conservation préventive menées au Centre d’iconographie genevoise.
Ce sont également les aspects de protection du patrimoine culturel qui font l’objet du premier article de la rubrique Compte rendu d’événements, qui, sous le titre Numérique et patrimoine culturel : quels impacts ? et sous la plume de Jean-Philippe Accart, responsable de la bibliothèque de l’Ecole hôtelière de Lausanne, relate les présentations du « Satellite Meeting » de l’IFLA qui s’est tenu à Genève en août 2014.
On trouvera un deuxième compte rendu, toujours dans le cadre des réunions de l’IFLA, consacré à l’éthique. Intitulé Les dilemmes éthiques dans la société de l'information : comment les codes d'éthique permettent de trouver des solutions, et écrit par Amélie Vallotton Preisig, secrétaire du Comité FAIFE (Freedom of Access to Information and Freedom of Expression) de l'IFLA, il résume les interventions de la conférence conjointe du Comité FAIFE de l'IFLA et de Globethics.net au Château de Bossey, les 14 et 15 août 2014.
Enfin, on trouvera (comme c’est une tradition désormais) le compte-rendu de la dernière Journée franco-suisse sur la veille stratégique et l'intelligence économique, la 11ème, qui a eu lieu le 12 juin 2014 à Neuchâtel sur le thème : L’information grise : Comment trouver des informations difficiles d’accès. Signé par Maurizio Velletri, assistant de recherche à la HEG-Genève, et par Hélène Madinier, professeure à la HEG-Genève, il rend compte des interventions présentant les définitions et les enjeux liés à l’information grise, et donnant des méthodes de recherche ainsi que des exemples d’utilisation de ce type d’information.
Finalement, sous la rubrique Compte-rendu d'ouvrage en sciences de l’information, on trouvera une recension écrite par Alain Jacquesson, ancien directeur de la Bibliothèque de Genève, qui rend compte de l’ouvrage de François Vallotton, intitulé Les batailles du livre. L’édition romande, de son âge d’or à l’ère numérique et paru en 2014 aux Presses polytechniques et universitaires romandes, consacré à la place et à l’économie du livre en Suisse romande du XIXème siècle à nos jours.
Nous remercions vivement les auteurs des articles et les réviseurs qui ont contribué à ce numéro, nous vous souhaitons une bonne lecture et vous rappelons que vous pouvez, à tout moment, soumettre des propositions d’articles au Comité de rédaction de RESSI.
Le Comité de rédaction
N°19 décembre 2018
| Titre | N°19 décembre 2018 |
| Publication Type | Book |
| Year of Publication | 2018 |
Editorial
Editorial no 15
Nous avons le plaisir de vous proposer le 15ème numéro de RESSI, qui va fêter ses 10 ans d’existence en 2015.
Dans ce 15ème numéro, sous la rubrique Etudes et Recherches, nous vous proposons deux articles qui émanent de quatre jeunes professionnels récemment diplômés du Master en sciences de l’information de la HEG-Genève: le premier article, de Jasmin Hügi et Nicolas Prongué, respectivement bibliothécaire-système à la Coordination vaudoise à la BCU Lausanne et assistant de recherche à la HEG-Genève, s’intitule Le virage Linked Open Data en bibliothèques : Etude des pratiques, mise en œuvre et compétences des professionnels. Il explique les enjeux et l’utilité des LOD en bibliothèque (LOD que l’on traduit parfois en français par « données ouvertes et liées »), présente un mode de mise en œuvre et donne des possibilités de formation continue sur le sujet. Le 2ème article, intitulé Tests d’utilisabilité : comparaison entre une méthode avec modération en présentiel et une méthode automatisée à distance, étude de cas appliquée au site e-rara.ch émane de Raphaël Rey, assistant de recherche à la HEG et Valérie Meystre, et permet d’identifier clairement les types d’information récoltés avec chaque type de tests à partir du site e-rara.ch.
C’est précisément la description du site et plus généralement du projet e.rara.ch, que l’on trouvera dans la rubrique Compte rendu d’expérience, sous la plume d’Alexis Rivier, conservateur à la Bibliothèque de Genève (BGE). Intitulé e-rara.ch : une bibliothèque numérique pour les livres anciens, il relate la genèse, les développements et les évolutions du projet.
Sous cette même rubrique, on trouvera également la description du nouveau projet de métacatalogue Art Discovery Group Catalogue, lancé le 1er mai 2014 et permettant d’interroger les différents catalogues de bibliothèques spécialisées en art. Il est intitulé De artlibraries.net à Art Discovery Group Catalogue ou l’évolution de métacatalogues pour l’histoire de l’art et d’un réseau des bibliothèques d’art dans le monde et est rédigé par Véronique Goncerut Estèbe, conservatrice en chef et responsable du pôle bibliothèque et inventaire des Musées d’art et d’histoire de la Ville de Genève.
Un troisième article clôt cette rubrique. Intitulé Bibliothèque de Genève et Centre d’iconographie genevoise en mutation, signé par Nicolas Schätti, Conservateur responsable du Centre d’iconographie genevoise et Nelly Cauliez, Conservatrice responsable de l’Unité Régie, BGE, il décrit les actions de conservation préventive menées au Centre d’iconographie genevoise.
Ce sont également les aspects de protection du patrimoine culturel qui font l’objet du premier article de la rubrique Compte rendu d’événements, qui, sous le titre Numérique et patrimoine culturel : quels impacts ? et sous la plume de Jean-Philippe Accart, responsable de la bibliothèque de l’Ecole hôtelière de Lausanne, relate les présentations du « Satellite Meeting » de l’IFLA qui s’est tenu à Genève en août 2014.
A la suite de cet article, on trouvera justement un lien vers l'ensemble des communications du "Satellite Meeting" de la section IFLA Préservation et Conservation (P&C) organisé à Genève les 13 et le 14 août 2014.
On trouvera un deuxième compte rendu, toujours dans le cadre des réunions de l’IFLA, consacré à l’éthique. Intitulé Les dilemmes éthiques dans la société de l'information : comment les codes d'éthique permettent de trouver des solutions, et écrit par Amélie Vallotton Preisig, secrétaire du Comité FAIFE (Freedom of Access to Information and Freedom of Expression) de l'IFLA, il résume les interventions de la conférence conjointe du Comité FAIFE de l'IFLA et de Globethics.net au Château de Bossey, les 14 et 15 août 2014.
Enfin, on trouvera (comme c’est une tradition désormais) le compte-rendu de la dernière Journée franco-suisse sur la veille stratégique et l'intelligence économique, la 11ème, qui a eu lieu le 12 juin 2014 à Neuchâtel sur le thème: L’information grise : Comment trouver des informations difficiles d’accès. Signé par Maurizio Velletri, assistant de recherche à la HEG-Genève, et par Hélène Madinier, professeure à la HEG-Genève, il rend compte des interventions présentant les définitions et les enjeux liés à l’information grise, et donnant des méthodes de recherche ainsi que des exemples d’utilisation de ce type d’information.
Finalement, sous la rubrique Compte-rendu d'ouvrage en sciences de l’information, on trouvera une recension écrite par Alain Jacquesson, ancien directeur de la Bibliothèque de Genève, qui rend compte de l’ouvrage de François Vallotton, intitulé Les batailles du livre. L’édition romande, de son âge d’or à l’ère numérique et paru en 2014 aux Presses polytechniques et universitaires romandes, consacré à la place et à l’économie du livre en Suisse romande du XIXème siècle à nos jours.
Nous remercions vivement les auteurs des articles et les réviseurs qui ont contribué à ce numéro, nous vous souhaitons une bonne lecture et vous rappelons que vous pouvez, à tout moment, soumettre des propositions d’articles au Comité de rédaction de RESSI.
Le Comité de rédaction
Le virage Linked Open Data en bibliothèque : étude des pratiques, mise en œuvre, compétences des professionnels
Jasmin Hügi, Bibliothèque cantonale et universitaire, Lausanne
Nicolas Prongué, Haute école de gestion de Genève
Le virage Linked Open Data en bibliothèque : étude des pratiques, mise en œuvre, compétences des professionnels
1. Introduction
La thématique émergente des Linked Open Data (LOD) représente peut-être l'aube d'une révolution en bibliothèque. Avec cet article, nous avons souhaité brosser un aperçu des enjeux auxquels seront probablement bientôt confrontés les professionnels de l'information.
Tout d'abord, les concepts principaux entourant les LOD sont introduits (les termes et abréviations plus spécifiques sont définis dans un glossaire en fin d'article). Ensuite, ce texte s'attache à décrire l'utilité des LOD : pourquoi ces technologies sont-elles pertinentes et opportunes pour les bibliothèques ? Dans une troisième partie, la question est abordée d'un point de vue plus pragmatique, par la présentation d'un procédé générique de transformation de données en LOD. Ce modèle peut être réutilisé pour tout type de projet similaire. Une quatrième partie se penche ensuite sur les adaptations nécessaires des professionnels de l'information pour faire face à ces évolutions et se les approprier : quelles sont les compétences principales qu'ils devront acquérir ? Enfin, la dernière partie permet à tout un chacun d'approfondir individuellement ses connaissances sur les LOD : une formation sur la thématique y est présentée, librement accessible sur le web.
Ces divers aspects ont été traités dans trois travaux pratiques ou académiques que nous avons réalisés dans le cadre du Master en Information documentaire de la Haute école de gestion de Genève.
2. Définitions
Le terme Linked Open Data résulte de la fusion de deux concepts distincts : Linked Data et Open Data. Nous proposons ci-dessous une définition de ces deux concepts.
Linked Data est un terme créé en 2006 par Tim Berners-Lee dans le contexte du web sémantique. L'objectif du web sémantique est de briser les silos de données sur le web et de les rendre interopérables (Byrne, Goddard, 2010). Le web classique non sémantique se base sur un réseau hypertexte dans lequel des documents, les pages web, sont liés entre eux. Le web sémantique quant à lui veut créer un nouveau réseau, mais au sein duquel les données sont reliées entre elles, en plus des pages web. Pour obtenir des données liées ou des Linked Data, quatre principes doivent être respectés (Berners-Lee, 2009) :
-
Utiliser des adresses URI pour identifier les choses ;
-
Utiliser des adresses URI HTTP pour que l’on puisse consulter ces identifications ;
-
Fournir des informations utiles sous forme de standards (RDF, SPARQL) lors d’une recherche d’adresse URI ;
-
Inclure des liens vers d’autres adresses URI qui permettent de découvrir d’autres informations.
En d’autres termes, il faut donc attribuer des identifiants aux ressources sous forme d’adresses URI HTTP, les décrire en utilisant des standards du web sémantique et créer des liens vers des données externes pour créer un réseau. Si plusieurs acteurs du web utilisent les mêmes standards et les mêmes modèles, il devient plus facile d’échanger, de réutiliser et de lier les données. Mais ce scénario n'est possible qu'à condition que les données soient disponibles sous licence ouverte. C’est pour cela que les Linked Data à elles seules ne suffisent pas dans l'optique du web sémantique ; elles doivent également être des Open Data, ou données ouvertes en français.
Ce second concept est défini ainsi par l'Open Knowledge Foundation (2012) :
« Une donnée ouverte est une donnée qui peut être librement utilisée, réutilisée et redistribuée par quiconque - sujette seulement, au plus, à une exigence d’attribution et de partage à l’identique. »
Par déduction, cette définition stipule donc qu'une donnée ouverte doit pouvoir être réutilisée à des fins commerciales également.
De manière générale, pour faciliter la réutilisation des données, trois aspects doivent être pris en compte (Chignard 2012 : p. 13-14) :
-
Aspect technique : un format le plus ouvert possible
-
Aspect juridique : une licence ouverte
-
Aspect économique : des redevances nulles ou limitées
L'Open Data s'inscrit dans une mouvance plus générale d'ouverture des connaissances, incluant entre autres l'Open Source (pour les logiciels), l'Open Research Data ou encore l'Open Access (pour les ressources d'information). Le concept inclut par ailleurs l'Open Government Data, qui concerne les données produites par des institutions de droit public.
L'interopérabilité technique et la capacité sémantique des Linked Data, couplées à la libre utilisation juridique et à la gratuité de l'Open Data, forment la puissance du concept de Linked Open Data. L'aspect ouvert des données permet ainsi au web sémantique de se populariser et facilite la création de données liées en donnant accès à des jeux de données externes de manière libre.
3. Quel intérêt pour les bibliothèques ?
Les LOD représentent un thème évoqué de plus en plus fréquemment en bibliothèque, mais dont la substance est parfois difficile à saisir. L'aspect très technique qui caractérise le web sémantique, ainsi que le jargon qui l'accompagne, contribuent largement à en faire une thématique mal comprise parmi les professionnels de l'information.
Afin de concrétiser ce sujet, nous avons réalisé une étude (Hügi, Prongué, 2014), proposant une analyse de diverses applications déjà existantes et basées sur les LOD en bibliothèque. D'après les résultats de ce travail, quatre grandes catégories de plus-values ont été identifiées. Elles sont présentées ci-dessous, illustrées par des exemples réels.
3.1 Une meilleures interopérabilité des données
Les données des bibliothèques sont actuellement enregistrées sous forme de notices en format MARC. Il s'agit d'un standard métier établi dans le monde entier depuis plus de 50 ans. Néanmoins, du fait de son utilisation en bibliothèque uniquement, ce format pose certains problèmes d'interopérabilité. Les autres acteurs de l'information utilisent actuellement des standards basés sur XML ou sur d'autres formats plus modernes.
MARC s'appuie fortement sur les chaînes de caractères : trop peu de champs sont contrôlés ou utilisent des identifiants, ce qui limite le traitement automatique des données par des machines. De plus, ce format est difficilement extensible et adaptable aux évolutions. En effet, MARC est un standard ancien et répandu dans le monde entier. « [S]on adaptation à de nouveaux besoins a conduit à le complexifier et le risque d’introduire une divergence avec les données existantes freine les évolutions majeures » (Bermès, 2013 : chap. 2.1).
Les LOD se basent par contre sur RDF, un standard du web flexible et extensible. Ainsi, des données bibliographiques de structures très diverses (MARC, Dublin Core, EAD, etc.) peuvent être converties en un format unique basé sur RDF. Dans ce cas de figure, il est possible de proposer une recherche fédérée bien plus performante que lors de l'interrogation de plusieurs bases de données séparées. C’est ce qu’a réalisé avec succès la Bibliothèque nationale de France, à travers son service data.bnf.fr (http://data.bnf.fr/), qui permet de rechercher – au moyen d'une seule requête – dans le catalogue des imprimés, la bibliothèque digitale et d'autres données non issues des catalogues traditionnels.
L'utilisation d'un standard répandu sur le web et d'une licence ouverte permet également aux données des bibliothèques d'être réutilisées par des acteurs externes au domaine. Au final, cette meilleure interopérabilité peut déboucher concrètement sur des gains de temps et d'argent pour les bibliothèques.
3.2 De meilleures possibilités de recherche
Les LOD se caractérisent par des liens avec d'autres jeux de données. Grâce à ces informations externes supplémentaires, des requêtes plus précises sont rendues possibles. L'enrichissement par des données géographiques telles que latitudes et longitudes permettent ainsi la mise en place de fonctionnalités de recherche au moyen d'une carte (illustration 1).
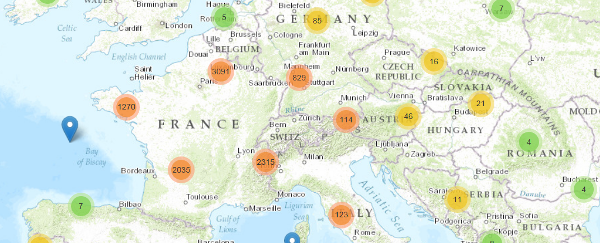
Illustration 1: Recherche géographique sur le site data.bnf.fr
Sur le même principe, des liens avec des thésaurus similaires dans d'autres langues peuvent constituer la base de fonctionnalités de recherches multilingues. Le portail The European Library (http://www.theeuropeanlibrary.org/tel4/) a implémenté une fonction de ce genre proposant des termes de recherche en trois langues à l'utilisateur. Le portail finlandais Kulttuurisampo propose quant à lui de nombreuses fonctionnalités expérimentales, parmi lesquelles la recherche de relations entre deux personnes comme les peintres Rubens et Miró (illustration 2).
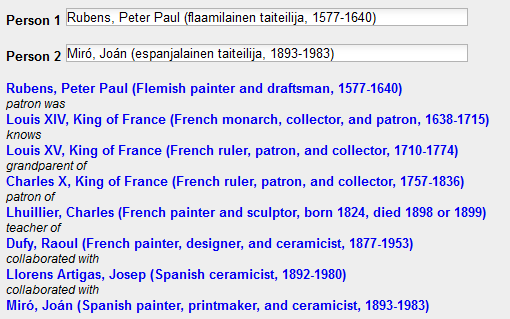
Illustration 2: Recherche de relation entre deux personnes
L’amélioration des possibilités de recherche peut élargir le rôle actuel du catalogue d’un dispositif de localisation vers un véritable outil de recherche.
3.3 Une meilleure sérendipité
Au-delà de l'amélioration des fonctionnalités de recherche, les liens vers des jeux de données externes augmentent la sérendipité de l'utilisateur. Plusieurs applications en proposent, par exemple la Deutsche digitale Bibliothek (https://www.deutsche-digitale-bibliothek.de/). Ces liens permettent de rediriger l'utilisateur vers des ressources complémentaires, comme des notices d'autorités d'autres bibliothèques ou des articles Wikipédia. VIAF (http://viaf.org/), un agrégateur de ressources de bibliothèques sur les personnes et les organisations, permet de faciliter la création de ce genre de relations.
Une institution culturelle ne possède pas que des données bibliographiques. En intégrant tous types de données au sein d'une application unique basée sur RDF, on offre la possibilité à l'utilisateur de trouver des informations qu'il ne cherchait pas forcément. Ainsi, le Centre Pompidou à Paris a converti des données de bibliothèque et de musée en un seul format, et les a reliées grâce à RDF. De cette manière, une seule recherche donne accès à des livres, des œuvres d'art numérisées, des dossiers pédagogiques ainsi que d'autres types de documents (illustration 3).

IlIllustration 3: Une seule interface pour les ressources variées du Centre Pompidou, ici sur Max Ernst
La variété des données liées ouvre des possibilités intéressantes de représentation de l'information. On s'oriente alors vers une recherche par navigation plutôt que par requêtes comme cela se fait dans les catalogues traditionnels. Dans ce sens, l'application data.bnf.fr propose la recherche géographique, mais également des représentations chronologiques des données.
Les méthodes de recherche évoluent également vers de nouvelles fonctionnalités d’auto-complétion, notamment grâce aux classes sémantiques attribuées aux données. L'application bêta d'Europeana (http://eculture.cs.vu.nl/europeana/) offre ainsi des propositions de types d'entités au cours de la saisie de la requête (illustration 4).
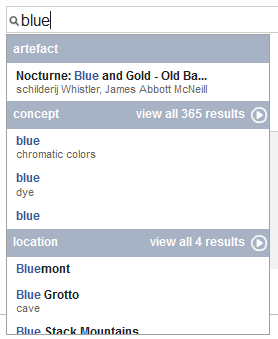
Illustration 4: Recherche par type d'entité
3.4 Une meilleure visibilité des données sur le web
Se basant sur des standards du web, les LOD proposent une interopérabilité appréciée par les moteurs de recherche, qui ont plus de facilité à indexer les contenus (Ostrowski & Pohl, 2012 : p. 272). A l'inverse, les données MARC paraissent en silos sur le web, car elles ne sont accessibles qu'au travers de portails, et ne communiquent pas avec le reste du web. L'utilisation d'identifiants uniques et pérennes pour les LOD permet de créer ces relations manquantes entre les ressources. Grâce à cela, des liens tiers pointant vers le catalogue améliorent la visibilité des données des bibliothèques. Par exemple, près de 80 % des visiteurs du service data.bnf.fr proviennent des moteurs de recherche, alors même que le catalogue traditionnel n'y est absolument pas visible (Simon & Peyrard, 2014).
4. Mise en place d'un projet Linked Open Data en bibliothèque
Les diverses plus-values présentées au chapitre précédent se basent sur les LOD, des données structurées selon le modèle RDF. Un projet LOD en bibliothèque commence donc forcément par la conversion des données préexistantes en RDF. Ce processus est présenté ci-dessous.
4.1 Les étapes d'un projet LOD
En collaboration avec RERO, le Réseau des bibliothèques de Suisse occidentale, nous avons entamé un projet de transformation des métadonnées de bibliothèque en LOD (Prongué, 2014). Sur cette base en a été déduit un processus générique composé de huit étapes. Ce processus s'inspire des bonnes pratiques issues de projets similaires, notamment au sein du réseau de bibliothèques suédois Libris (Malmsten, 2009), de la Bibliothèque nationale espagnole (Vila-Suero & Gómez-Pérez, 2013 : p. 580) ou du projet européen LOD2 (Auer, 2014 : p. 3-4).
Etape 1 : revue de la littérature
Cette première étape consiste à analyser les applications déjà existantes et les pratiques des autres bibliothèques face au web sémantique. Il s'agit également de se tenir au courant des évolutions techniques du domaine ainsi que des nouveaux standards et modèles pour les données bibliographiques. Ceci est particulièrement important dans une époque charnière comme celle-ci du point de vue des métadonnées en bibliothèque.
Etape 2 : analyse des données
Afin de déterminer précisément les données qui seront publiées en LOD, il faut les étudier. L'analyse peut se porter sur des jeux de données entiers (lesquels faut-il publier?) ou au niveau plus fin des champs de données au sein d'une base de ressources. Divers critères peuvent avoir leur importance, tels que la pertinence des données, leur qualité, leur quantité, leur normalisation, etc.
Etape 3 : modélisation
L'étape de la modélisation est cruciale, car en fonction du modèle de données retenu, des fonctionnalités différentes pourront être implémentées au sein d'une application sémantique.
Les données traditionnelles sont structurées en notices bibliographiques et en notices d'exemplaires. C'est un modèle simple, à deux niveaux, qui est dit plat. L'initiative BIBFRAME, visant à remplacer MARC, a développé un modèle innovant basé sur trois niveaux : œuvre, instance et item. Enfin, l'IFLA promeut depuis plusieurs années le modèle FRBR, structuré en quatre niveaux : œuvre, expression, manifestation, item. Chaque solution possède ses avantages et ses inconvénients. A titre d'exemple, une trop grande complexité pourrait représenter un obstacle pour la création de liens avec d'autres types de ressources, mais pourrait également permettre de construire une application plus performante.
Selon le modèle choisi, il s'agit alors de l'appliquer à ses propres données en identifiant des équivalences : quelles données correspondent à quelles entités du modèle ? La solution peut se représenter sous la forme d'un schéma de type entités-relations.
Pour être reliée, chaque ressource devra ensuite recevoir un identifiant de type URI. Une réflexion sur la forme que ces URIs doivent adopter, variant selon les types de données, est nécessaire.
Etape 4 : mapping
Une fois qu'un modèle complet et cohérent a été conçu, il faut sélectionner des vocabulaires du web sémantique pour décrire au mieux les données à publier. Il est possible de créer son propre vocabulaire, mais il en existe déjà un très grand nombre sur le web, dont certains sont devenus des standards de facto. Créer son propre vocabulaire pourrait nuire à l'interopérabilité des données, car ce nouveau langage serait utilisé uniquement dans une institution (Dunsire et al., 2012 : p. 11). Le choix des vocabulaires peut dépendre de divers critères, tels que leur pertinence, leur niveau d'utilisation en général, leur niveau d'utilisation par les bibliothèques, leur précision, etc. Les plus utilisés sur le web sont Dublin Core (DC) pour décrire des ressources bibliographiques, Friend Of A Friend (FOAF) pour des personnes et leurs relations, et Simple Knowledge Organization System (SKOS) pour des systèmes de connaissance tels que des thésaurus (Jentzsch et al., 2011). Des éléments de plusieurs vocabulaires différents peuvent être utilisés pour décrire un même jeu de données.
Quand ce cadre théorique et conceptuel est posé, des règles de conversion pour chaque élément de donnée (chaque champ) peuvent être rédigées.
Etape 5 : liens externes
Partie intégrante du processus, la génération de liens externes intervient avant ou après l'étape de la transformation. Ces liens sont créés avec des référentiels du web sémantique : il s'agit de jeux de données de référence disponibles en LOD, et généralement spécialisés dans un domaine. Ainsi, pour les descriptions de personnes et d'organisations, on créera des liens vers le référentiel VIAF, ou directement vers des fichiers d'autorités de bibliothèques. Les lieux seront par exemple reliés aux données géographiques du référentiel GeoNames, les langues à Lexvo.org, des entités diverses à DBpedia, etc.
La génération de liens externes peut se faire directement d'après les données de base, au moyen de codes ou de descripteurs contrôlés préexistants (par exemple les codes de langue MARC). Une autre méthode, plus complexe, consiste à effectuer des alignements : il s'agit de comparer les chaînes de caractères présentes dans chaque jeu de données afin d'établir des équivalences.
Etape 6 : transformation
La transformation consiste à formuler en langage informatique des règles de transformation jusqu'ici décrites en langue humaine, et à les appliquer sur les données pour les convertir.
Etape 7 : contrôle qualité
A ce stade, les premières données RDF ont été créées, mais sans doute avec des erreurs. Contrôler la qualité de l'output est donc essentiel dans le processus. Cette tâche se réalise au moyen d'échantillons représentatifs des données. Pour plus de précision, il est envisageable d'avoir un échantillon spécifique à chaque règle de transformation.
Etape 8 : publication
Lorsqu'une qualité satisfaisante a été atteinte, les données peuvent être publiées sur le web. Pour être de vraies LOD, elles doivent respecter les standards du web sémantique et posséder une licence ouverte.
La publication peut se faire de diverses manières, la plus simple étant de déposer les données en fichiers téléchargeables (nommés dumps dans le jargon) sur un serveur. Un dump doit être mis à jour périodiquement. Il est aussi possible de proposer des données RDF grâce à des interfaces pour clients informatiques (API REST ou SPARQL endpoint) ou en les intégrant dans des pages web pour les moteurs de recherche (grâce à RDFa, aux microdata ou aux microformats).
4.2 Un processus itératif
Les huit étapes mentionnées plus haut mènent à la publication de LOD, mais pas de manière linéaire (illustration 5). Il est en effet recommandé d'adopter une approche itérative pour parvenir à ses fins, comme l'affirme Martin Malmsten (2009 : chap. 1), spécialiste travaillant à la Bibliothèque royale de Suède : « a "data first" approach is better than "perfect metadata first" ». Le principe d'une telle méthode consiste à réaliser, dans une première phase, toutes les étapes du processus assez rapidement avec des éléments basiques. Ensuite, on peut perfectionner et complexifier progressivement le modèle, le mapping, les liens externes et la transformation en repassant par certaines phases du processus, autant de fois que nécessaire.
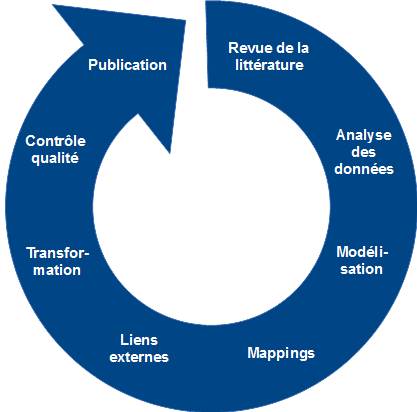
Illustration 5: Processus itératif
Après la l'étape de la publication, le processus continue. Si des dumps ou un SPARQL endpoint sont mis à disposition, les données RDF doivent être actualisées selon une périodicité régulière. Par ailleurs, le modèle et le mapping doivent être adaptés continuellement en fonction des évolutions du domaine.
4.3 Après la publication
La publication est un acte de simple mise à disposition des données afin qu'elles puissent être réutilisées librement par des tiers. Pour tirer un réel bénéfice des LOD dans une institution, il faut concevoir sur cette base une application destinée aux utilisateurs finaux. Cela peut générer des plus-values telles que celles mentionnées au chapitre 2.
Le site web data.bnf.fr illustre bien ce potentiel. Convivial, novateur, fluide et évolutif, il a déjà trouvé sa raison d'être au sein des services de la Bibliothèque nationale de France, grâce à la visibilité qu'il apporte à l'institution (Wenz, 2012 : p. 24).
Cependant, il existe aujourd'hui encore peu d'applications telles que celle-ci, basées sur les LOD et réellement innovantes. Leur conception demeure un processus complexe et peu connu, qui relève plutôt de l'expérimentation. Les technologies du web sémantique sont encore émergentes, mais possèdent un fort potentiel de développement, qui apportera sans doute bientôt de nombreuses innovations en bibliothèque.
5. Développer les compétences des professionnels de l'information
Dans les chapitres précédents, les avantages des LOD pour les bibliothèques et leurs usagers ont été présentés et les étapes d'un projet de transformation de données bibliographiques en LOD ont été expliquées. Il est évident qu'un tel projet n'est pas anodin à réaliser. De plus, la transformation de données en LOD ne représente que la moitié du chemin, car par la suite, il faut encore réussir à les exploiter. Se pose alors la question suivante : quelles sont les compétences nécessaires pour mener à bien un tel projet ? Pour y répondre, nous avons mené une étude (Hügi, Prongué, 2014) qui vise à identifier les compétences en matière de LOD pour les professionnels de l'information.
Cette étude a pour but d'informer les professionnels de l'information qui souhaitent se spécialiser dans ce domaine sur les nouvelles compétences à acquérir, apporter une aide aux managers devant engager un professionnel de l'information pour travailler sur cette thématique ou organiser des formations continues pour ses employés, ainsi que guider les responsables de plans d'études dans l'établissement de curriculums sur les LOD pour les professionnels de l'information.
5.1 Méthodologie
Afin de répondre à la question ci-dessus, nous avons décidé d'évaluer des offres d'emploi. Cette méthode permet d'avoir un aperçu des préférences en matière de compétences demandées de la part des employeurs vis-à-vis des nouveaux employés, ainsi que de leurs attentes et futurs besoins (Park et al., 2009 : p. 844). En outre, des experts ont été consultés afin de compléter les informations trouvées dans les offres d'emploi. Pour les évaluer, une analyse de contenu est préconisée par la littérature scientifique (Stanton et al., 2011 ; Marion et al., 2005 ; Orme, 2008).
Pour ce faire, une liste de plates-formes spécialisées s’adressant aux professionnels de l'information a été constituée. Seules les plates-formes couvrant un pays entier ont été retenues. Les pays suivant ont notamment été pris en considération : Suisse, Allemagne, Autriche, France, Belgique, USA. Dans les archives de chaque liste de diffusion, deux recherches par mot-clé ont été effectuées. La première avec le terme Linked et la seconde avec RDF. Seules les offres d'emploi exigeant un diplôme en science de l'information, en plus des compétences liées aux LOD, ont été retenues, pour éviter l'identification de compétences purement informatique. Ainsi, quinze offres d'emploi pertinentes ont été sélectionnées pour l'analyse de leur contenu.
En plus des offres d'emploi, nous avons décidé de nous adresser à des experts du domaine travaillant ou ayant travaillé sur un projet LOD en bibliothèque. Nous leur avons demandé quelles compétences ils exigeraient d'un professionnel de l'information pour collaborer à un projet LOD si c'était à eux d'effectuer le recrutement. Grâce aux réponses des experts, onze descriptions de compétences exigées se sont ajoutées aux quinze offres d'emploi identifiées, ce qui a permis de faire une analyse de contenu sur 26 cas en tout.
5.2 Résultats
Huit compétences clés ont pu être identifiées grâce à l'analyse de contenu de quinze offres d'emploi et onze avis d'experts sur les compétences des professionnels de l'information travaillant sur un projet LOD. Dans l'illustration 6, ces catégories sont énumérées selon le nombre de cas dans lesquels elles apparaissent. La signification de chaque catégorie est détaillée ci-après.
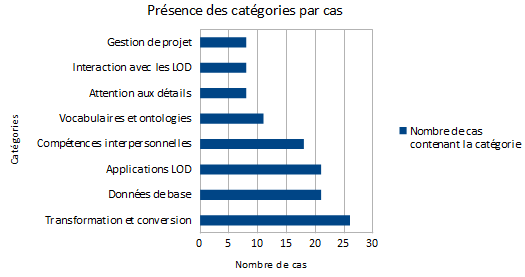
Illustration 6 : Huit compétences clés
Transformation et conversion
La catégorie Transformation et conversion comprend les compétences essentielles et nécessaires pour transformer et convertir des données en RDF afin d’en faire des Linked (Open) Data. Il s'agit donc de compétences liées à RDF et à la structure des données correspondante. Cette catégorie englobe également des compétences en lien avec les identifiants persistants, l'attribution d'URIs, la modélisation des schémas de données, etc. La maîtrise de XML est également attribuée à cette catégorie, car ce métalangage sert souvent à la transformation de données en RDF. Cette catégorie figure au premier rang, ce qui n'est guère étonnant puisqu'elle correspond au critère utilisé pour faire la sélection des offres d'emploi.
Données de base
La catégorie Données de base regroupe toutes les compétences requises pour un projet LOD ayant lieu en bibliothèque. Puisque des projets LOD peuvent avoir lieu dans d'autres contextes également, cette catégorie représente l'aspect spécifique pour les bibliothèques. Afin de pouvoir transformer et convertir des données en RDF, il est important de bien connaître les données de base. En bibliothèque, ceci implique une bonne connaissance des règles de saisie (telles que les AACR2), des formats d'enregistrement (tels que MARC) et des systèmes de saisie (tels que les SIGB). De manière plus générale, il s'agit de compétences de catalogage et d'indexation ainsi que de connaissances des standards de métadonnées bibliographiques.
Applications LOD
Cette catégorie décrit les compétences informatiques nécessaires pour la conception, le développement et la mise en route d'une application basée sur les LOD. De plus en plus de projets en bibliothèque ne se contentent pas uniquement de transformer des données bibliographiques en RDF. Leur but est de créer une réelle plus-value pour les utilisateurs à travers des applications en ligne qui se basent sur les données converties en RDF. Pour ceci, un savoir-faire par rapport à la conception, la rédaction de spécifications, l'évaluation et la mise en œuvre de tests est requis. En outre, des connaissances utiles pour la mise en ligne et la création d'interfaces ainsi que du savoir-faire en lien avec le développement web (tels que HTML, CSS, Javascript) sont exigés. Le développement d'applications nécessite quant à lui des compétences en programmation dans des langages tels que PERL, Java ou Ruby.
Compétences interpersonnelles
Cette catégorie regroupe les aptitudes de communication, de collaboration et de réseautage. La proactivité ainsi que la maîtrise de l'anglais sont également incluses dans cette catégorie.
Vocabulaires et ontologies
Cette catégorie représente des compétences en lien avec les schémas de métadonnées sous forme de vocabulaires et d'ontologies. L'utilisation et la réutilisation de vocabulaires et d'ontologies existants contribuent grandement à la création de Linked Data. Il est donc important de connaître les plus spécifiques à son propre domaine. En outre, la capacité à choisir des éléments de schémas de métadonnées pertinents pour représenter ses propres données est également considérée sous cette catégorie.
Attention aux détails
La catégorie Attention aux détails décrit des caractéristiques personnelles englobant des qualités telles que la rigueur, la précision et un esprit logique. Le sens de l'organisation est également inclus dans cette catégorie.
Interaction avec les LOD
Cette catégorie consiste à de la recherche dans des ensembles de données LOD grâce à des interfaces spécifiques (SPARQL Endpoint) en utilisant le langage de requête SPARQL. En outre, la visualisation de données disponibles en tant que LOD et la connaissance d'outils permettant cette tâche représentent également une compétence de cette catégorie.
Gestion de projet
La catégorie Gestion de projet comprend les compétences telles que la planification, l'organisation, l'implémentation et l'établissement d'un budget.
L'analyse d'offres d'emploi montre la combinaison de compétences jugées idéales pour une fonction spécifique. Cette combinaison idéale exige très souvent une double compétence en science de l'information et en informatique. Ainsi, parmi les quinze offres d'emploi analysées, six demandaient cette double compétence pour un expert LOD. Néanmoins, un projet LOD se fait rarement de manière isolée et englobe d'habitude plusieurs employés avec plusieurs profils. Il n'est donc pas forcément nécessaire de réunir toutes les compétences demandées en un seul profil. En outre, la réalité se montre souvent très différente. Dans beaucoup de bibliothèques, le budget manque pour engager du nouveau personnel et les collaborateurs se forment sur place selon les besoins pour participer à un projet LOD. Les résultats de cette étude sont à interpréter dans leur contexte ; un profil idéal y est décrit, mais cela n'empêche pas le fait que, dans la réalité, beaucoup de ces compétences sont acquises sur le terrain.
Par ailleurs, le travail avec les LOD représente une fonction en plein développement. Il sera donc important de réévaluer périodiquement les compétences requises pour ce type d'emploi. Il se peut que les tâches décrites ici soient dans un futur plus ou moins proche directement intégrées dans les SIGB avec lesquels les professionnels de l'information saisissent les métadonnées. Les critères d'embauche pourront alors se développer dans une autre direction.
Le travail avec des LOD en bibliothèque nécessite visiblement des compétences très spécifiques qui peuvent, au premier abord, sembler intimidantes. Néanmoins, les professionnels de l'information possèdent déjà plusieurs de ces compétences. Ainsi, la catégorie touchant aux ontologies et aux métadonnées qui sont utilisées pour la description des ressources a toujours fait partie des connaissances de base des professionnels de l’information. Concernant les standards de catalogage, il est inutile d’évoquer que cela appartient à la bibliothéconomie. En outre, les futurs professionnels de l'information en Suisse acquièrent des compétences de développement web et de XML.
Ce qui manque réellement en ce moment, ce sont les compétences strictement liées au web sémantique (principes, standards et technologies). Selon nous, l’enseignement de ces compétences devrait être inclus dans le curriculum des professionnels de l’information. Une introduction obligatoire à la thématique ainsi que des cours à choix devraient être dispensés au niveau bachelor, alors que les étudiants de niveau master devraient acquérir une compréhension globale de la thématique afin de pouvoir de prendre des décisions stratégiques. Par ailleurs, des cours de formation continue sont à mettre en place pour que les professionnels sur le terrain puissent, eux aussi, se former aux LOD. En effet, le web sémantique est bien plus qu'une tendance et le monde des bibliothèques ne peut se permettre d'attendre.
6.Un exemple de formation en ligne
Comme le montrent les chapitres précédents, les LOD ont dépassé le stade de simple buzz et sont devenues des pratiques établies. Parmi toutes les évolutions qui touchent les bibliothèques en ce moment, à l'instar du nouveau code de catalogage RDA ou de l'initiative BIBFRAME, les LOD ne sont pas la seule à attirer l'attention des bibliothécaires. La transformation des données bibliographiques en LOD est-elle plus importante que le passage à RDA ? Dans quel projet une bibliothèque doit-elle investir en priorité ses précieuses ressources ? Face à ces évolutions, se positionner et effectuer des choix en toute connaissance de cause est nécessaire, même si les décisions prises consistent à attendre. Le choix d'une orientation stratégique touchant à cette thématique requiert en tous les cas une compréhension minimale du fonctionnement et des enjeux des LOD, un concept qui demeure plutôt abstrait et dont la plus-value pour l'usager n'est pas évidente au premier abord.
En ce moment, il existe très peu de formations en ligne qui ne s'adressent pas à des informaticiens. C'est dans ce contexte-là qu'une formation courte en ligne a été développée (voir Hügi, 2014) sous mandat de la Bibliothèque cantonale et universitaire de Lausanne (BCUL). Le but était de transposer une formation en présentiel déjà existante (décrite dans Hügi, Schneider, 2014) dans un environnement numérique, et de permettre aux collaborateurs de la BCUL de se sensibiliser à la thématique des LOD en bibliothèque.
6.1 Méthodologie
La méthodologie ADDIE a été choisie pour la réalisation de la formation en ligne. Elle consiste en cinq phases (Herridge Group, 2004 ; Boling et al., 2011 ; Molenda, 2003) : l’analyse des besoins, la conception, le développement, l’implémentation et l’évaluation. Dans un premier temps, les besoins et les attentes des futurs apprenants et du prescripteur ont été recueillis, permettant de définir l’étendue et les objectifs de la formation, ainsi que le prérequis nécessaire pour pouvoir la suivre. Dans une deuxième phase, ces informations ont servi à concevoir le cours en ligne et à définir les modes d’accompagnement, d’interaction et d’évaluation, ainsi qu'à choisir la plate-forme en ligne. Par la suite, les supports de cours existants ont été transposés dans l’environnement numérique et complétés par de nouveaux contenus, des exercices et des tests. Dans cette étape, la structure générale et la navigation ont été créées, et une première évaluation de la formation a été effectuée. En ce qui concerne les phases de l’implémentation et de l’évaluation, qui ne sont pas couvertes par ce projet, des recommandations et un script ont été rédigés pour permettre de terminer ces étapes avec succès.
6.2 Résultats
La formation sur les LOD dans les bibliothèques est maintenant disponible sur la plate-forme Moodle de l’Université de Lausanne. Elle est constituée de quatre modules pas très techniques, qui proposent une sensibilisation et une introduction à la thématique.
Voici plus en détails le contenu couvert par les modules :
-
Module 1: L'évolution du web et son impact sur les bibliothèques
Dans ce premier module, la naissance et l'évolution du web sont retracées. Cette évolution a mené à une déclinaison du web en plusieurs versions: le web 1.0, 2.0, 3.0 et 4.0. Les caractéristiques de chacune de ces versions sont expliquées et l'on démontre comment cette évolution a impacté le monde des bibliothèques. -
Module 2: Linked Data, Open Data et Linked Open Data: définition des concepts
Dans le deuxième module, le terme Linked Open Data (données ouvertes et liées) et les concepts annexes sont définis et expliqués. Les principes de base sont présentés et des exercices donnent un premier aperçu des possibilités qu'offrent les LOD. -
Module 3: Présentation d’exemples de bibliothèques appliquant les LOD
Dans ce troisième module, des exemples concrets de bibliothèques utilisant les LOD sont donnés. Une présentation des applications de la Bibliothèque nationale de France et du Centre Pompidou est fournie, accompagnée par des articles concernant ces deux projets. -
Module 4: Les enjeux et les avantages des LOD pour les bibliothèques
Dans le quatrième module, les avantages des LOD ainsi que les enjeux de ces dernières en bibliothèque sont présentés. La plus-value pour les usagers est démontrée à travers des exemples et le potentiel des LOD à moyen et long terme est illustré.
Les contenus sont médiatisés grâce à des présentations, des articles ainsi que des vidéos. La formation est disponible en ligne sur la plate-forme Moodle de l'Université de Lausanne et ouverte à tous. Les personnes disposant d'un identifiant d'une haute école ou d'une université suisse peuvent en plus accéder à des tests de connaissances.
La formation est accessible via le lien suivant : http://moodle2.unil.ch/course/view.php?id=2960
Le cours est protégé par le mot de passe suivant : biblod
Une Licence Creative Commons « Attribution – Pas d’utilisation commerciale – Partage dans les mêmes conditions » a été attribuée à tous les contenus originaux, donc à tous les textes sur la plate-forme ainsi qu’aux présentations. Par conséquent, si quelqu'un souhaite un jour actualiser les contenus ou corriger des propos devenus obsolètes, il a le droit de le faire.
Cette formation en ligne sur les LOD en bibliothèque est la première en son genre à s'adresser aux professionnels de l'information et à être en français. Cependant, le travail ne s'arrête pas là ; il existe bien plus de contenus à enseigner, comme la logique des triplets, la structure de RDF, la modélisation des données, les différents vocabulaires, le fonctionnement d'une ontologie, etc.
Cette formation a le potentiel d'être complétée et peut faire partie d'un ensemble plus grand. Nous invitons les professionnels de l'information à la suivre, voire à la réutiliser dans un autre contexte.
7.Conclusion
Les LOD représentent une nouvelle tendance dont l'impact sur les métadonnées peut être énorme. Dans le monde entier, la communauté des bibliothèques se penche intensivement sur la question, tentant d'apprivoiser ces technologies émergentes et d'adapter ou de renouveler les standards existant, pour certains, depuis plus de 40 ans.
Cet article a tenté de faire le point sur les problématiques majeures des LOD en bibliothèque, en introduisant tout d'abord la thématique et son contexte. Ensuite, l'importance parfois méconnue des LOD pour la communauté des bibliothèques est illustrée par divers avantages, tels que des gains d'interopérabilité, de visibilité et de fonctionnalités. Une fois convaincues de l'intérêt de ces technologies, les institutions doivent alors les implémenter sur leurs propres données, en fonction de leurs propres besoins. Cet article donne un exemple type de processus à suivre pour la mise en place d'un tel projet, en huit phases clés.
Qui dit nouvelles technologies dit également nouvelles compétences. La quatrième partie de ce texte passe en revue les principaux domaines de qualification dans lesquels les professionnels de l'information devront se former pour mettre en place des initiatives LOD dans leur milieu.
Par ailleurs, nous invitons le lecteur à poursuivre sa lecture au moyen d'une formation en ligne sur le sujet. Celle-ci, présentée en fin d'article, apporte concrètement une pierre à l'édifice des LOD en bibliothèque.
Cet édifice n'en est actuellement qu'à l'étape de ses fondations. Les technologies évoluent encore et la courbe d'apprentissage pour les professionnels est raide. Pour pallier ce problème, des efforts de sensibilisation à la thématique sont nécessaires. L'intégration des LOD dans le cursus académique et au sein de la formation continue en science de l'information est une piste à considérer, tout comme l'augmentation de l'offre de formations en ligne en libre accès.
Du côté de la mise à disposition de services à valeur ajoutée, nous encourageons les acteurs à faire preuve d'audace et à se lancer dans le développement d'applications innovantes, sans forcément connaître à l'avance la forme exacte du résultat ni la plus-value pour l'utilisateur. Il s'agit alors, par l'expérimentation, de remettre en question les fondements mêmes de la recherche d'information tels qu'on les connaît actuellement. L'utilisation de méthodes de créativité ou la recherche exploratoire peuvent être de bons moyens pour découvrir des opportunités de plus-value encore ignorées que les LOD peuvent offrir aux bibliothèques.
8.Glossaire
|
AACR |
Abr. de Anglo-American Cataloguing Rules. Règles de catalogage qui donnent des directives sur la formulation des données pour la description et l’exploration des ressources. AACR2 est la version no 2. |
|
BIBFRAME |
Abr. de Bibliographic Framework. Initiative internationale, dirigée par la Library of Congress, dont le but final est le remplacement du format MARC et la création d’un nouveau modèle et d’une ontologie pour la description des données bibliographiques. |
|
Dublin Core |
Schéma de métadonnées créé pour décrire des ressources numériques. |
|
EAD |
Abr. de Encoding Archival Description. Standard qui sert à l’encodage des instruments de recherche qui se trouvent en ligne et à la description de collections et de matériaux archivistiques. |
|
FRBR |
Abr. de Functional Requirements for Bibliographic Records (spécifications fonctionnelles des notices bibliographiques). Modélisation conceptuelle des informations contenues dans les notices bibliographiques, utilisant le modèle entity-relationship. |
|
HTTP-URI |
Voir sous URI |
|
LOD |
Abr. de Linked Open Data. Données structurées en RDF qui sont disponibles sous une licence ouverte. |
|
MARC |
Abr. de MAchine Readable Cataloging. Format de catalogage qui sert à la représentation et à la communication d’informations bibliographiques et connexes. Le format se décline en plusieurs versions, parmi lesquelles MARC21, INTERMARC, UNIMARC, USMARC, etc. MARC/XML est un format basé sur le langage XML développé afin de faciliter les échanges de données. |
|
RDA |
Abr. de Resource Description & Access. Nouvelles règles de catalogage censées remplacer les AACR. |
|
RDF |
Abr. de Resource Description Framework. Recommandation du W3C proposant des spécifications pour la description conceptuelle et la modélisation d’informations issues de ressources web. RDF utilise une variété de notations, de syntaxes et de formats de sérialisation. RDF est basé sur l’idée d’identifier des choses avec des HTTP URIs et de représenter les informations sous forme de triplets. |
|
SIGB |
Abr. de Système intégré de gestion de bibliothèque. Logiciel qui permet la gestion informatique des différentes tâches et activités d’une bibliothèque. |
|
SPARQL |
Abr. de SPARQL Protocol and RDF Query Language. Langage de requête qui sert à interroger des données RDF. Un SPARQL endpoint est une interface qui accepte des requêtes SPARQL d’autres logiciels et qui renvoie des résultats dans la forme prévue par SPARQL. Un formulaire SPARQL est une interface qui permet à des êtres humains de faire des requêtes SPARQL. |
|
URI |
Abr. de Uniform Resource Identifier. Standard qui permet d’identifier des ressources web et comprend des URL pour la localisation et des URN pour l’appélation. |
|
XML |
Abr. de eXtensible Markup Language. Métalangage et spécification du W3C pour créer des documents textuels structurés. |
9.Bibliographie
9.1 Les trois études à la base de cet article
HÜGI, Jasmin, 2014. Développement d’une formation e-learning sur les Linked Open Data dans les bibliothèques. Genève : Haute école de Gestion. Disponible prochainement à l’adresse : http://doc.rero.ch/
HÜGI, Jasmin et PRONGUÉ, Nicolas, 2014. Les bibliothèques face aux Linked Open Data [en ligne]. Genève. Haute école de gestion de Genève. [Consulté le 28 octobre 2014]. Disponible à l’adresse : http://doc.rero.ch/record/209598/files/M7-2014_memoire_HUGI-PRONGUE.pdf
PRONGUÉ, Nicolas, 2014. Modélisation et transformation des métadonnées de RERO en Linked Open Data. Genève : Haute école de Gestion. Disponible prochainement à l’adresse : http://doc.rero.ch/
9.2 Autres références
AUER, Sören (éd.), 2014. Introduction to LOD2. In : AUER, Sören (éd.), Linked Open Data: creating knowledge out of interlinked data: results of the LOD2 project [en ligne]. Heidelberg : Springer International Publishing. Lecture notes in computer science, 8661. p. 1‑17. [Consulté le 8 décembre 2014]. ISBN 978-3-319-09846-3. Disponible à l’adresse : http://link.springer.com/content/pdf/10.1007%2F978-3-319-09846-3_1.pdf
BAKER, Thomas, BERMÈS, Emmanuelle, COYLE, Karen et DUNSIRE, Gordon, 2011. Library Linked Data Incubator Group Final Report [en ligne]. S.l. W3C. [Consulté le 19 juin 2014]. Disponible à l’adresse : http://www.w3.org/2005/Incubator/lld/XGR-lld-20111025/
BERMÈS, Emmanuelle, 2013. Le web sémantique en bibliothèque [en ligne]. Paris : Ed. du Cercle de la librairie. Collection bibliothèques. ISBN 978-2-7654-1417-9. Disponible à l’adresse : http://www.electrelaboutique.com/ProduitECL.aspx?ean=9782765414179
BERNERS-LEE, Tim, 2009. Linked Data. In : Design Issues [en ligne]. 18 juin 2009. [Consulté le 4 juin 2014]. Disponible à l’adresse : http://www.w3.org/DesignIssues/LinkedData.html
BOLING, Elizabeth, EASTERLING, Wylie V., HARDRE, Patricia L., HOWARD, Craig D. et ROMAN, Tiffany Anne, 2011. ADDIE: Perspectives in Transition. In : Educational Technology. 2011. Vol. 51, n° 5, p. 34 38.
BYRNE, Gillian et GODDARD, Lisa, 2010. The Strongest Link: Libraries and Linked Data. In : D-Lib Magazine [en ligne]. novembre 2010. Vol. 16, n° 11/12. [Consulté le 19 juin 2014]. DOI 10.1045/november2010-byrne. Disponible à l’adresse : http://www.dlib.org/dlib/november10/byrne/11byrne.html
CHIGNARD, Simon, 2012. Comprendre l’ouverture des données publiques. S.l. : FYP Editions. Collection entreprendre. ISBN 9782916571706
DUNSIRE, Gordon, HARPER, Corey, HILLMANN, Diane et PHIPPS, Jon, 2012. Linked Data vocabulary management: infrastructure support, data Integration, and interoperability. Information standards quarterly. 2012. Vol. 24, n° 2/3, pp. 4‑13. DOI http://dx.doi.org/10.3789/isqv24n2-3.2012.02
GANDON, Fabien, CORBY, Olivier et FARON-ZUCKER, Catherine, 2012. Le web sémantique: Comment lier les données et les schémas sur le web ? S.l. : Dunod. ISBN 9782100581405.
HERRIDGE GROUP, 2004. The Use of Traditional Inscructional Systems Desing Models for eLearning [en ligne]. 2004. S.l. : s.n. [Consulté le 17 juillet 2014]. Disponible à l’adresse : http://www.herridgegroup.com/pdfs/The%20use%20of%20Traditional%20ISD%20for%20eLearning.pdf
HÜGI, Jasmin et SCHNEIDER, René, 2014. Linked Open Data Literacy for Librarians. In : European Conference on Information Literacy. Dubrovnik : s.n. paraître 2014
JENTZSCH, Anja, CYGANIAK, Richard et BIZER, Christian, 2011. State of the LOD cloud. LOD Cloud [en ligne]. 19 septembre 2011. [Consulté le 24 juin 2014]. Disponible à l’adresse : http://lod-cloud.net/state/
MALMSTEN, Martin, 2009. Exposing library data as Linked Data. Satellite meetings IFLA 2009: Emerging trends in technology, : libraries between web 2.0, semantic web and search technology [en ligne]. Florence. 19 août 2009. [Consulté le 25 juillet 2014]. Disponible à l’adresse : http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.181.860&rep=rep1&type=pdf
MARION, Linda, KENNAN, Mary Anne, WILLARD, Patricia et WILSON, Concepción S., 2005. A Tale of two markets: employer expectations of information professionals in Australia and the United States of America. In : 71th IFLA General Conference and Council: « Libraries - A voyage of discovery » [en ligne]. Oslo : s.n. 2005. [Consulté le 4 septembre 2013]. Disponible à l’adresse : http://arizona.openrepository.com/arizona/handle/10150/105082
MOLENDA, Michael, 2003. In Search of the Elusive ADDIE Model. In : Performance Improvement [en ligne]. 2003. Vol. 42, n° 5. [Consulté le 26 mars 2014]. Disponible à l’adresse : http://search.proquest.com/eric/docview/62177054/584334380C63442EPQ/11?accountid=15920
OPEN KNOWLEDGE FOUNDATION, 2012. Le manuel de l’opendata [en ligne]. Release 1.0.0. Open Knowledge Foundation. [Consulté le 13 juin 2014]. Disponible à l’adresse : http://opendatahandbook.org/fr/
ORME, Verity, 2008. <IT>You will be</IT> …: a study of job advertisements to determine employers’ requirements for LIS professionals in the UK in 2007. In : Library Review. 5 septembre 2008. Vol. 57, n° 8, p. 619 633. DOI 10.1108/00242530810899595
OSTROWSKI, Felix et POHL, Adrian, 2012. Zur Entwicklung eines Linked-Open-Data-Dienstes für Bibliotheksdaten. In : Vernetztes Wissen: Daten, Menschen, Systeme: 5.-7. November 2012: Proceedingsband [en ligne]. Jülich : Forschungszentrum Jülich, Zentralbibliothek, Verl. 2012. pp. 271‑291. [Consulté le 3 juillet 2013]. Schriften des Forschungszentrums Jülich, Reihe Bibliothek ; Bd. 21. ISBN 978-3-89336-821-1. Disponible à l’adresse : http://hdl.handle.net/2128/4699
PARK, Jung-ran, LU, Caimei et MARION, Linda, 2009. Cataloging professionals in the digital environment: A content analysis of job descriptions. In : Journal of the American Society for Information Science and Technology. 2009. Vol. 60, n° 4, p. 844–857. DOI 10.1002/asi.21007
SIMON, Agnès et PEYRARD, Sébastien, 2014. Visibilité et web de données: réflexions autour du projet data.bnf.fr. In : SemWeb.Pro 2014 [en ligne]. Paris. 5 novembre 2014. [Consulté le 8 décembre 2014]. Disponible à l’adresse : http://semweb.pro/file/3396/raw/11-asimon.pdf
STANTON, Jeffrey M., KIM, Youngseek, OAKLEAF, Megan, LANKES, R. David, GANDEL, Paul, COGBURN, Derrick et LIDDY, Elizabeth D., 2011. Education for eScience Professionals: Job Analysis, Curriculum Guidance, and Program Considerations. In : Journal of Education for Library and Information Science. 1 avril 2011. Vol. 52, n° 2, p. 79
VILA-SUERO, Daniel et GÓMEZ-PÉREZ, Asunción, 2013. datos.bne.es and MARiMbA: an insight into Library Linked Data. In : Library hi tech. 2013. Vol. 31, n° 4, p. 575‑601. DOI 10.1108/LHT-03-2013-0031
W3C, 2013. Semantic Web. In : W3C [en ligne]. 2013. [Consulté le 14 juillet 2014]. Disponible à l’adresse : http://www.w3.org/standards/semanticweb/
WENZ, Romain, 2012. Linked Open Library Data in practice: lessons learned and opportunities for data.bnf.fr. SWIB 2012 [en ligne]. Cologne. 27 novembre 2012. [Consulté le 13 octobre 2014]. Disponible à l’adresse : http://swib.org/swib12/slides/Wenz_SWIB12_108.ppt
Tests d’utilisabilité : comparaison entre une méthode avec modération en présentiel et une méthode automatisée à distance, étude de cas appliquée au site e-rara.ch
Raphaël Rey, Haute Ecole de Gestion, Genève
Valérie Meystre, Haute Ecole de Gestion, Genève
1. Introduction
Il existe une grande diversité dans les méthodes existantes pour analyser l’utilisabilité des sites web. Les tests peuvent s’effectuer à distance ou en présentiel, avec ou sans modérateur, en recourant à un nombre de participants très variable allant de quatre ou cinq à plusieurs centaines, etc. Quand il s’agit de se lancer dans une telle démarche, il n’est donc pas aisé de choisir la méthode qui apportera les résultats les plus pertinents. L’article de Fernandez, Insfran et Abrahão (2011) illustre parfaitement cette richesse en dressant un panorama détaillé sur la base d’une sélection de 206 articles tirés d’un corpus initial de 2703 publications appartenant à ce domaine spécifique.
Pour effectuer des choix méthodologiques pertinents au sein de ce foisonnement, il existe certes des manuels qui fournissent des conseils pratiques comme celui de Barnum, Usability testing essentials (2011) où ce dernier décrit les avantages et inconvénients de la plupart des modes de test. Ces paroles d’experts sont précieuses, mais elles gagnent à être complétées et confirmées par des études de cas et notamment des études comparatives qui à l’épreuve des faits et à travers une démarche rigoureuse mettent en évidence les forces et faiblesses des différentes méthodes analysées. Le projet dont cet article se fait l’écho s’inscrit dans cette démarche.
Il se base, en effet, sur une série de tests appliqués au site e-rara.ch. Cette plateforme offre au visiteur la possibilité de consulter des imprimés anciens numérisés qui appartiennent aux collections d’un grand nombre de bibliothèques suisses partenaires. Pour évaluer l’utilisabilité du portail, nous avons d’une part recouru à un dispositif automatisé à distance et d’autre part effectué des sessions de test modérées en présentiel avec think-aloud. Le tableau suivant résume les principales différences entre les deux formes de test :
| Méthode 1 | Méthode 2 |
| A distance | En présentiel |
| Automatisée | Modérée |
| Asynchrone | Synchrone |
| Sans think aloud | Avec think-aloud |
|
Analyse quantitative et |
Analyse quantitative |
Notre objectif dans cette étude est de comparer ces deux méthodes sous les aspects : de l’efficacité et de l’efficience. Concernant l’efficacité, l’enjeu sera de déterminer quelle approche permet de repérer le plus de problèmes et si l’une d’elles permet de repérer particulièrement facilement certains types d’entre eux, ou au contraire a tendance à ignorer d’autres. La question de la fiabilité des résultats sera également abordée ainsi que celle de l’efficience qui s’intéressera à la question du coût investi, notamment en temps.
2. Etat de l’art
Les tests d’utilisabilité peuvent se mener de multiples manières différentes comme en témoigne l’abondante littérature les concernant. Mentionnons, par exemple, l’article de Bastien (2010) qui dresse un panorama général ou encore le travail imposant de Fernandez, Insfran et Abrahão qui anaylsent l’état de l’art sur le sujet à partir d’un ensemble de 206 publications sur un total initial de 2703.
Plusieurs manuels exposent les différentent méthodes et en présentent le fonctionnement, mais aussi leurs avantages et inconvénients respectifs : le livre de Barnum, Usability testing essentials : ready, set... test ! (2011), constitue à ce titre une excellente introduction et offre un aperçu assez complet de la question.
2.1. Le think-aloud, un outil aux mutiples visages
Le mode le plus traditionnel pour réaliser un test d’utilisabilité passe par le recours à un modérateur. Le participant se voit proposer une série de tâches à réaliser sur un site web et est convié à commenter à haute voix ses actions et les difficultés qu’il rencontre : il s’agit là du think-aloud dont il sera spécifiquement question dans ce chapitre.
Le manuel de Barnum et notamment son chapitre 7 définissent en détail comment utiliser cette méthode pour récolter des données (2011, p 199-237). Comme l’auteur l’explique dans son premier chapitre à la page 19, le but est de comprendre pourquoi l’utilisateur accomplit telle ou telle action : « Not only do you see the actions users take, but you also benefit from hearing why users are taking an action and what they think about the process - good and bad. When users think out loud, you don’t have to guess what they’re thinking. They tell you ». Pour une réflexion approfondie sur cette question de l’introspection et de la verbalisation de la pensée, le lecteur pourra se référer à l’article de Nielsen et al. (2002, en particulier les pages 106-107).
Afin de mieux comprendre le type de propos que l’on recueille via cette méthode, l’article de Cooke (2010) est d’un grand intérêt. A travers une comparaison entre les données d’un dispositif d’eye tracking et les propos recueillis, elle arrive à la conclusion que 58% des énoncés relèvent de la lecture et 19% de la procédure. Quant aux silences et aux paroles de remplissage des participants, ils ne traduisent pas une absence d’action. Au contraire, ils signalent souvent une difficulté ou un besoin d’analyse. Le dispositif d’eye tracking permet de repérer ce que regarde l’utilisateur dans ces moments-là et de comprendre dans une certaine mesure ses intentions. Il en ressort que le think-aloud ne donne accès qu’à une portion assez restreinte de l’activité cérébrale des utilisateurs.
Le risque principal de la pensée à voix haute est que le modérateur biaise les résultats par ses interventions ou son attitude. Barnum consacre à cette problématique les pages 207 à 218 de son ouvrage déjà mentionné (2011). Le langage corporel peut trahir des appréciations qui ensuite influencent les choix du participant. Quant aux compliments, il se doivent d’être équilibrés quel que soit le résultat de la tâche. Enfin, il faut poser des questions adéquates qui ne vont pas induire certains comportements.
Une étude de Nørgaard et Hornbæc (2006) démontre à travers l’analyse de plusieurs sessions de test avec think-aloud que les modérateurs recherchent en réalité dans leur manière d’intéragir avec les participants la confirmation de problèmes qu’ils ont déjà repérés.
Afin d’éviter ce type de biais, le plus efficace est d’intervenir le moins possible en tant que modérateur et de se contenter d’inviter le participant à verbaliser ses pensées (à ce propos voir le modèle proposé par Ericsson et Simon,1993).
Des alternatives avec davantage d’interactions ont toutefois été proposées. En 2000, Boren et Ramey constatent un décalage entre les recommandations du modèle d’Ericsson et Simon et la pratique des professionnels. Ces auteurs proposent dans un article un cadre théorique plus souple. Par exemple, si un participant estime avoir terminé une tâche et que ce n’est pas le cas, ne serait-il pas préférable de le relancer pour qu’il poursuive plutôt que de perdre une partie de ce qui aurait pu être testé? Le biais que cela induit est-il compensé par les données supplémentaires récoltées? (voir Boren et Ramey 2000, p. 273-274). Une étude de Khramer et Ummelen (2004) montre que les résultats concernant le repérage des problèmes d’utilisabilité sont à peu près équivalents, mais le confort et la performance des participants sont meilleurs avec une modération plus active. Ils ont moins le sentiment d’être « perdus » (p. 116). Zhao et McDonald (2010) arrivent à des conclusions similaires, mais soulignent le nombre plus importants d’énoncés produits grâce aux échanges avec le modérateurs sans que cela ne permettent d’améliorer la détection d’éléments problématiques. Greiner observe de même sauf pour le dernier point (2012, p. 35).
En 2014, une nouvelle étude de Zhao et McDonald auxquels vient encore s’ajouter Edwards tente une nouvelle expérience pour définir un protocole plus efficace de think-aloud. Cette fois-ci, les auteurs semblent avoir obtenu des résultats convaincants en donnant des instructions assez précises sur le type de propos qu’ils souhaitent recueillir pendant les tests. Ils ont ainsi obtenu non seulement davantage d’énoncés comme dans leur étude précédente, mais aussi davantage de contenus explicatifs. Les problèmes d’utilisabilité supplémentaires détectés par ce biais sont toutefois en général de peu d’importance.
Un mode complètement différent de recourir à la pensée à voix haute est le « retrospective think-aloud » où la personne réalise dans un premier temps le test, puis s’exprime à son propos, éventuellement en visonnant un vidéo de ses interactions avec le site. L’étude de De Jong, Schellens et van den Haak (2003) arrive à la conclusion qu’en terme de repérage des problèmes d’utilisabilité, les deux méthodes sont équivalentes. La détection s’effectue toutefois de manière différente : avec la pratique simultanée du think-aloud, les problème sont constatés surtout grâce à l’observation, tandis que si la récolte des propos se fait après la réalisation des tâches, ces derniers deviennent la source la plus importante (p. 345).
Les auteurs ont également observé une baisse des performances des participants dans la réalisation de leurs tâches lorsque ceux-ci doivent verbaliser leurs actions en prarallèle. Par conséquent, il y a un risque d’influence plus important si la tâche proposée est particulièrement complexe (p. 350).
Ces trois auteurs ont réalisé trois autres études sur des thématiques proches (2004, 2007 et 2009) et arrivent à des conclusions similaires. Ils notent toutefois l’influence du type de site testé sur l’efficacité des méthodes (voir par exemple De Jong, Schellens et van den Haak 2009, p. 201). Un article de McDonald, Zhao et Edwards (2013) estiment que ces deux approches sont complémentaires. L’usage du think-aloud pendant la réalisation des tâches permet de repérer davantage de problèmes, mais les données récoltées après coup viennent utilement confirmer ces éléments et les compléter en donnant des explications sur les difficultés rencontrées.
Même si les méthodes sont perfectibles, en particulier pour le confort des participants, l’influence du type de modération sur l’efficacité des tests semble assez négligeable, si on exclut évidemment les réels faux-pas qui biaisent les tests sans aucun profit.
2.2. Comparaison entre test en laboratoire et test à distance synchrone
Comme alternative à cette méthode traditionnelle en laboratoire, il est possible de procéder au même type de test à distance cette fois-ci. Dans ce cas, le modérateur et l’internaute se trouvent dans des lieux séparés, mais gardent un contact vocal. On parle dans ce cas de méthode à distance synchrone.
Selon Barnum, les résultats sont très similaires : « moderated, also called synchronous, remote testing is very much like lab testing » (2011, p. 42). Plusieurs études viennent confirmer ce fait : voir à ce propos Andreasen et al. (2007, p. 1413), Hartson et al. (1996, p. 234), Thompson et al. (2004, p. 136), Selvaraj (2004, p. 32). Un article de Chalil Madathil et Greenstein (2011, p. 2233) arrive à la même conclusion, mais introduit une nouvelle méthode qui semble légèrement meilleure : le laboratoire virtuel. Lors du déroulement du test, un laboratoire s’affiche à l’écran avec un navigateur partagé et deux avatars qui peuvent interagir : le participant et le modérateur. Cette méthode aurait permis de détecter davantage de problèmes de faible gravité. Ce résultat serait à confirmer.
Au niveau de l’efficience, les données montrent que les tests à distance prennent en général plus de temps (Thompson et al. 2004, p. 234 et Andreasen 2007, p. 1412), même si Slevaraj affirme que la différence qu’elle observe n’est pas suffisamment significative (2004 p. 30).
L’article de Dray et Siegel (2004, p. 12-14) mentionne trois avantages :
- Réduction des coût : toutefois, même si cela diminue par exemple les frais de déplacement ou facilite le recrutement, le gain reste faible à ce niveau.
- Liberté de l’interface : l’utilisateur peut choisir son interface et est en principe familier avec cette dernière.
- Gain de temps : il ne faut pas sous-estimer le temps nécessaire pour mettre en place le dispositif qui, à distance, peut prendre un certain temps.
Slevaraj (2004, p. 19) reprend une partie de ces éléments en ajoutant la facilité pour élargir le recrutement et mieux cibler les utilisateurs par rapport à la population cible du site. De plus, le modérateur risque moins d’influencer le déroulement, s’il est physiquement absent. Même si cela ne semble pas avoir d’impact sur les résultats, Andreasen et al. ont observé que celui-ci pouvait avoir un effet intimidant comme en témoigne ce participant au test à distance dont les auteurs rapportent les propos : « I liked this test method better than the traditional method where the test leader looks over your shoulder. » (2007, p. 1413).
En contrepartie, les données sont en général plus pauvres. Le visage de la personne qui effectue le test n’est pas toujours filmé, de plus il est assez difficile d’interprêter le langage paraverbal et non-verbal quand on n’est pas physiquement présent dans la salle (Dray et Siegel, 2004, p. 14-15). Au niveau de la satisfaction des participants, Slevaraj constate que ceux qui ont participé à un test à distance préfèrent massivement cette méthode, alors que ceux qui ont pris part à la méthode en présentiel sont beaucoup plus partagés dans leur engouement pour l’un ou l’autre dispositif (2004, p. 32-34).
2.3. Comparaison entre test synchrone et test asynchrone
Les différences au niveau de l’efficacité et de l’efficience sont plus marquées losrqu’on oppose test synchrone et test asynchrone. A noter que les études à ce propos sont assez rares, comme le font observer Rodriguez et Resnick (2010, p. 760). En 2002, un article de Tullis et al. fait le point sur la question. Il en ressort que les deux méthodes arrivent à des résultats similaires concernant le repérage des problèmes d’utilisabilité. Les plus sérieux sont toujours détectés et les utilisateurs se comportent de manière très semblable en rencontrant les mêmes difficultés dans l’un et l’autre contexte. La population plus importante des participants du test automatisé augmente la probabilité de découvrir des problèmes mineurs et constitue une source de commentaires sur les sites à la fois plus abondante et plus variée que dans une petite série de tests modérés. Ces derniers sont toutefois plus à même de découvrir certains types de problèmes, lorsque justement une observation directe est nécessaire comme dans le cas d’un scrolling excessif. Au final, l’étude conseille de combiner dans la mesure du possible les deux méthodes, même si l’une ou l’autre est suffisante s’il s’agit uniquement de repérer les problèmes les plus importants.
L’article d’Andreasen et al. déjà mentionné plus haut (2007) compare une méthode en laboratoire, une à distance modérée et deux autres automatisées (la première avec des experts et la seconde des utilisateurs ordinaires). Les conclusions sont assez défavorables pour les méthodes asynchrones qui ont permis de découvrir moins de problèmes d’utilisabilité et ont demandé plus de temps aux participants.
A noter toutefois que cette étude a effectué exactement le même nombre de tests pour chacune des méthodes (6 soit 24 au total), alors que l’intérêt des méthodes asynchrones est d’offrir la possibilité de recourir à des analyses quantitatives avec de nombreux utilisateurs comme le rappelle Bastien dans son article (2010, p. e20). Selon ce même auteur (p. e21), une des raisons de ces résultats est peut-être à chercher dans le design des tâches ou le type de site web analysé.
Schmidt a réalisé en 2013 une étude dans laquelle elle a comparé une méthode à distance automatisée et une autre en présence d’un modérateur. Les conclusions sont similaires : si les problèmes les plus sérieux sont détectés dans les deux cas, la présence d’un observateur direct donne de meilleurs résultats pour tous les autres éléments posant des difficultés. Les commentaires laissés par les participants du test automatisé sont extrêmement précieux et révèlent une part non négligeable des problèmes.
Ces résultats défavorables pour la forme asynchrone doivent toutefois être relativisé puisque le site cible de ne proposait pas d’url différentes lors du passage d’une page à l’autre ce qui rendait très difficile de suivre le parcours des internautes dans le test à distance. Les données utilisables étaient donc très incomplètes.
Notre étude se place dans la continuité de ces travaux, et, sur la base d’une nouvelle expérience, tente de confirmer ou d’infirmer ces conclusions.
3. Méthodologie
3.1. Descriptif des tests réalisés
Dans le but de limiter autant que possible les différences entre les tests, nous avons demandé aux participants de réaliser exactement les mêmes tâches dans les deux cas. Ce choix est discutable dans la mesure où en vue d’une efficacité maximale, il faudrait sans doute adapter le design de celles-ci à chacune des deux méthodes, ce qui compromettrait ensuite drastiquement les possibilités de comparaison. Par conséquent, les résultats de la comparaison des deux méthodes sont en partie liés aux tâches telles que nous les avons définies et ne peuvent donc pas être généralisés sans précaution.
La trame du test se compose d’un questionnaire préalable récoltant des informations personnelles comme l’âge et l’expertise dans l’utilisation d’Internet, des bibliothèques numériques et des livres anciens.
Arrivent ensuite cinq tâches :
- vérifier si la Bibliothèque des Pasteurs de Neuchâtel propose une partie de ses collections sur e-rara.ch ;
- trouver la liste des flux rss ;
- repérer l’ouvrage le plus ancien présent sur e-rara.ch et dont l’auteur est Erasme (moteur de recherche, index, facettes) ;
- en partant de la notice de l’Histoire naturelle des oiseaux de Buffon, déterminer quel genre d’oiseau est le griffon pour cet auteur (navigation dans un livre) ;
- dans le même ouvrage, trouver une illustration d’un faucon sort (navigation dans un livre, utilisation des vignettes).
La tâche 3 présente une différence importante selon que le test est réalisé en français ou en allemand. En effet, le système ne connaît qu’Erasmus en latin, forme qu’utilisent également les germanophones. Par contre, entrer « Erasme » dans le moteur de recherche ne retourne aucun résultat pertinent.
Dans la tâche 4, ce sont les francophones qui sont avantagés puisque le livre est en français et que dans l’énoncé nous avons traduit « griffon » par « Greif ». Ces différences linguistiques permettent de simuler une forme de test A/B avec deux versions d’un même site. Quelle méthode est la plus à même de mesurer l’impact de ces divergences ?
Une fois l’étape centrale achevée, le participant est invité à s’exprimer sur des problèmes d’utilisabilité qu’il aurait pu constater, puis arrive un test SUS quelque peu remanié et surtout raccourci sur lequel nous ne nous étendrons pas dans cet article(1).
Nous avons débuté cette étude par le test automatisé à distance. Ce choix se justifie dans la mesure où les données recueillies via la méthode avec think-aloud sont davantage qualitatives. En effet, les résultats auraient été biaisés, si nous avions à l’esprit les propos des participants du test modéré lors de l’analyse des données du test à distance, certes plus abondantes, mais plus pauvres étant donné l’absence de think-aloud.
Ce dernier a été réalisé à l’aide du logiciel Loop11 qui permet notamment d’enregistrer des flux de clics, des heatmaps(2) et de gérer des questionnaires. Nous avons recruté la grande majorité des participants grâce à la liste de diffusion Swiss-lib. Au total, 160 personnes ont démarré le test et 84 l’ont terminé avec une légère majorité pour les francophones (46 contre 38). Dans l’analyse des résultats, nous avons également pris en compte toutes les tâches effectuées dans leur intégralité, même lorsque la totalité du test n’a pas été réalisée par la suite.
Le test modéré a également été réalisé avec Loop11, mais avec en plus un enregistrement audio des commentaires des utilisateurs. Le modérateur n’a joué qu’un rôle minimal en invitant uniquement le participant à s’exprimer lorsque celle-ci cessait d’expliquer les raisons de ses actions. Comme nous l’avons vu dans notre état de l’art, le protocole du think-aloud ne possède qu’assez peu d’influence sur les résultats. Nous avons donc choisi le mode le plus simple et qui nous rapprochait le plus du test automatisé, donc sans modération. En tout, 7 personnes ont pris part au test modéré : deux germanophones et cinq francophones. Toutes avaient des affinités avec l’histoire (de par leur formation ou leur activité professionnelle).
3.2. Mode de comparaison des deux méthodes de test
A travers les questionnaires avant et après les tâches, notre objectif était de segmenter la population des participants au test automatisé en décelant des corrélations entre certains comportements et des données relatives à la personne. Par exemple, les utilisateurs plus âgés rencontreraient spécifiquement tel ou tel problème. Cette indication serait une aide ensuite pour proposer des améliorations adaptées.
Pour comparer les méthodes, nous sommes partis des problèmes qu’elles ont permis de détecter et avons regardé si un problème était clairement identifié, soupçonné ou totalement invisible. Nous avons également pris en compte la gravité des problèmes observés et la probabilité de leur observation (en fonction du nombre de participants au test). De plus, nous avons comparé l’efficience du repérage de ces problèmes en fonction de la nécessité d’une manipulation particulière des données : soit le problème pouvait être détecté via un traitement standard des données (observation directe ou commentaire de la part d’un participant pour le test modéré et analyse des questionnaires ou des flux de clics pour le test automatisé), soit le problème requérait une méthode plus complexe (par exemple le recoupement de plusieurs types de données).
Afin de systématiser cette analyse, nous avons créé une grille à l’aide de laquelle nous avons pour chacun des problèmes évalué l’une et l’autre méthode. En attribuant un score aux différents critères, il a donc été possible de comparer quantitativement les deux tests. Notre étude est toutefois également qualitative, puisque nous avons également exploité nos fiches pour catégoriser les éléments qui posaient des difficultés aux utilisateurs afin de mieux comprendre les forces et faiblesses de chacune des deux approches.
4. Résultats
4.1. Tests d’utilisabilités
Les analyses de chacune des cinq tâches nous ont permis de repérer vingt-cinq problèmes d’utilisabilité au total, toutes méthodes confondues. Il serait ici peu pertinent de les énumérer tous et nous nous contenterons de citer quelques exemples particulièrement intéressants pour notre propos.
Certaines fonctionnalités se sont montrées défectueuses : après une recherche, l’option de tri « relevance » s’affiche toujours automatiquement quand on modifie l’ordre (« croissant », « décroissant »).
Moins graves, certains éléments, comme la fenêtre de recherche, n’étaient pas toujours suffisamment visibles pour être utilisés autant qu’ils l’auraient mérité.
D’autres éléments se sont révélés peu ergonomiques à l’usage : par exemple, l’affichage des résultats manque de clareté. En effet, il n’y a pas d’étiquette pour indiquer qu’il s’agit d’un auteur, d’un titre ou d’autre chose. Le contexte permet souvent de trancher, mais pour une lecture rapide, ce n’est pas pratique.
Pareillement, la navigation dans les miniatures n’est pas aisée et le cadre rouge qui devrait servir de guide est très peu visible. Par conséquent, de nombreux utilisateurs n’ont pas pu se repérer efficacement et ont fini par se perdre dans les pages à consulter.
Pour finir, mentionnons une « fonctionnalité » manquante qui a occasionné beaucoup d’erreurs : l’absence de solution pour repérer la « bonne » variante orthographique d’un nom d’auteur (renvois, index alphabétique clair, etc.).
Nous avons également constaté de grosses différences entre les tests francophones et germanophones et avons donc pu analyser efficacement la capacité de chacune des deux méthodes à évaluer l’utilisabilité de deux versions d’un même site. Un exemple des plus emblématique est la tâche 3 (recherche d’un livre d’Erasme). Ainsi, 22% des francophones du test à distance ont réussi la tâche contre 61% des germanophones. 35% des erreurs ont été débuté avec une recherche « Erasme » au lieu du nom latin. Ce dernier étant le nom utilisé en allemand, aucun des participants germanophones n’a commis cette erreur. Ces observations se retrouvent dans le test en présentiel, mais sans qu’une analyse statistique soit pertinente : 2 francophones sur 5 ont effectués une recherche avec « Erasme ». La section suivante portera sur le comparatif des deux méthodes utilisées dans cette étude.
4.2. Evaluation et comparaison des deux méthodes
Les informations personnelles récoltées avant et après les tâches se sont révélées difficiles à exploiter. En effet, malgré nos efforts, nous n’avons pas pu déceler de corrélation significative entre plusieurs éléments (questions ou problèmes détectés). Par conséquent, ces informations ont au final été de peu d’utilité pour le test automatisé, si ce n’est pour pouvoir prouver la diversité de la population qui a pris part au test.
Lorsqu'un modérateur est présent, l’enjeu est un peu différent. Ces questions permettent de mieux cerner le participant et aident à comprendre les problèmes qu’il rencontre, sans pour autant (du moins dans notre étude) contribuer directement à la détection de problèmes.
Concernant le questionnaire post-test (similaire au SUS, mais avec uniquement six questions), le résultat du test automatisé montre qu’e-rara.ch obtient une note très moyenne de 64/100. Si ces questions avaient été déjà posées lors d’états antérieurs du site, il aurait alors été possible de suivre l’évolution du site en parallèle avec celui de son score. De plus, avant même d’entrer dans l’analyse de détail des tâches, ces informations suffisent à donner un diagnostic préalable du site. Le diagramme ci-dessous, dont les entrées de gauche constituent les critères évalués par les questions, livre un premier aperçu sur la manière dont les utilisateurs appréhendent le site.
 Résultats du questionnaire post-test
Résultats du questionnaire post-test
Dans le test modéré, les calculs quantitatifs ne sont que peu pertinents et ces questions ont surtout permis d’ouvrir la discussion et de revenir sur certains éléments du site qui ont marqué les utilisateurs. Par exemple, un participant a observé une certaine surcharge dans les contenus des pages et estimait que tous les éléments n’étaient pas utiles au même titre. Cela ne permet pas encore de définir un problème précis, mais donne malgré tout une piste intéressante.
En comparant les problèmes d’utilisabilités détectés par l’une et l’autre méthodes, nous avons pu mettre en évidence que le test automatisé révélait principalement des problèmes majeurs ou entraînant des erreurs dans la résolution des tâches (7 problèmes sur 25 relevés, dont aucun n’est passé inaperçu lors du test modéré).
")
Nombre de problèmes repérés (sans question ouverte pour le test automatisé)
Pour tout ce qui ressort d’incompréhensions de certains éléments de l’interface, d’un manque de visibilité ou d’un mauvais d’affichage et qui n’est pas directement décelable dans le flux de clic, le test modéré est clairement plus performant (19 problèmes observés, dont 12 ignorés dans l’autre test). Ce phénomène est lié d’une part au think-aloud et d’autre part à l’observation directe des interactions, qui nous apportent des éléments indispensables pour réellement comprendre le sens des actions des participants.
La question ouverte à la fin du test (propositions d’amélioration pour le site) a permis de recueillir de précieuses informations lors du test automatisé et de détecter 18 problèmes, dont 5 passés inaperçus durant le test modéré. Cette seule question est donc à l’origine de l’identification de 11 éléments, ce qui rétablit quelque peu la balance entre les deux méthodes, puisque le test modéré ne révèle alors que 6 problèmes que le test automatisé ne détecte pas.

Nombre de problèmes repérés par méthode
Cela montre bien l’importance primordiale de cette question dans le cadre du test automatisé, même si seul 40% (36 participants sur 86) y ont répondu. Dans le cas du test modéré, cette importance est nettement moindre, puisque les difficultés des participants ont été verbalisées et observées au fur et à mesure du déroulement du test. Dans notre travail, un seul problème supplémentaire a pu être détecté de cette manière.
En revanche, le nombre de participants plus important du test automatisé nous a aidé à mieux évaluer la fréquence des problèmes détectés, le taux d’échec causé par ces problèmes et l’effort nécessaire pour leur apporter une solution, point important pour décider si une modification importante est nécessaire ou si elle ne concerne finalement que peu de participants. Une faiblesse du test modéré réside dans le fait qu’il est difficile de déterminer s’il vaut la peine d’entrer dans une telle action, pouvant demander beaucoup de temps et de moyens, si elle ne concerne que 2 participants sur 7.
Par exemple, pour la tâche 3, nous avons constaté un taux de succès de 61% chez les germanophones et de seulement 22% parmi les francophones. La seule différence significative provenait du nom d’un auteur à rechercher : « Erasme » dans l’énoncé de la tâche en français et « Erasmus » dans le test germanophone. Comme le système ne reconnaît que la forme « Erasmus » (forme latine également utilisée en allemand), les participants au test francophone se voyaient proposer une tâche bien plus ardue. On peut donc affirmer que l’absence de renvois entre les diverses formes des noms d’auteur ou du moins d’un réel index alphabétique de ces derniers occasionne jusqu’à près de 40% d’échec. Ce chiffre suffit à montrer l’importance de trouver une solution à ce problème. Une telle évaluation n’aurait évidemment pas été possible avec le nombre restreint de participants à un test modéré.
Concernant le critère de l’efficacité, nos résultats n’indiquent pas une nette prééminence d’une des méthodes sur l’autre. Si on additionne le score de nos grilles relatives à chaque problème le test modéré obtient un résultat d’un peu moins de 10% supérieur.
Certains problèmes sont toutefois plus facilement détectés avec une méthode en particulier. Les phénomènes qui ne se manifestent que rarement ont peu de chance d’être mis en évidence avec le test modéré et son nombre réduit de participants. Ces faits apparaissent plus facilement dans un test à distance auquel prennent part bien plus d’utilisateurs. En revanche, le fil de clics du test à distance ne permet pas de percevoir le ressenti des usagers. Ainsi, si un problème d’utilisabilité ne provoque pas d’erreur, mais génère un désagrément, il faut que ce dernier soit exprimé dans la question ouverte en fin de test, faute de quoi il passera totalement inaperçu. Dans un test modéré, en revanche, le participant fera immédiatement part de sa frustration et de ses interrogations.
Par contre, lorsqu’il s’agit de comparer deux versions d’un même site, le test quantitatif est clairement plus performant que le test qualitatif. En effet, les statistiques permettent aisément de chiffrer l’impact de la différence entre les deux variantes, en fonction de la langue dans notre cas. Un test modéré pourrait seulement constater la présence de la difficulté sans en évaluer l’importance. De plus, la fiabilité des résultats est souvent plus faible, notamment si par exemple le fait considéré n’a été observé qu’avec un ou deux participants.
Au niveau de l’efficience, nos résultats ont montré que les deux méthodes supposent un investissement conséquent. Outre la conception du test en lui-même, l’analyse des résultats du test à distance demande un temps considérable. En effet, si le logiciel Loop11 donne différents graphiques, il est nécessaire de suivre le flux de clics de chaque participant pour bien comprendre le cheminement et les erreurs rencontrées. Quant au test modéré, il demande de planifier les rendez-vous avec les différents participants et de prévoir suffisamment de temps pour la passation de chaque test. Or, nous avons pu constater que ceux qui ont passé le test en présentiel avaient parfois tendance à s’acharner sur les différentes tâches et à vouloir absolument les mener jusqu’au bout, là où le participant à distance aurait depuis longtemps passé à la question suivante.
Au final, si l’on additionnait le temps passé par tous les acteurs (organisateurs et participants) dans la réalisation des tests, il ne fait pas de doute que le test modéré est bien plus léger. En terme de coûts réels, à l’exemple de notre étude, il est souvent possible de trouver des participants à peu de frais, mais dans le cas contraire un test automatisé avec une visée quantitative deviendrait rapidement extrêmement cher.
5. Conclusion
Même si le projet dont cet article se fait l’écho consiste en une étude de cas, plusieurs des résultats décrits précédemment peuvent dans une certaine mesure se généraliser à d’autres contextes.
Nous n’avons en effet pas opposé les deux méthodes uniquement de manière quantitative, mais défini des types de problèmes d’utilisabilité que l’une ou l’autre d’entre elles permettait de repérer plus aisément ou au contraire avait tendance à ignorer. Ces constatations restent valides quel que soit le site analysé. Naturellement, certains types de faiblesses ont pu nous échapper ou n’être tout simplement pas présent sur e-rara.ch. Par conséquent, d’autres études auraient encore tout leur sens pour confirmer et compléter nos conclusions.
Au vu des résultats décrits précédemment, le scénario idéal serait donc de recourir successivement aux deux méthodes et en cela nous rejoignons l’étude de Tullis (2002) et ce que nous en disions dans notre état de l’art. Les tests modérés permettent de repérer la plupart des problèmes et les tests automatisés à distance viendraient enrichir la liste et chiffrer de manière quantitative l'impact des éléments détectés.
Dans le cas où les ressources à disposition exigeraient de se limiter à l'une des deux méthodes, nous estimons en général plus avantageux (notamment en termes d'efficience) de recourir à un test modéré. Par contre, dans le cas où il s'agirait de comparer deux versions d'un même site, un test non modéré à distance avec de nombreux participants est largement plus intéressant. En effet, l'analyse quantitative permet de déterminer très aisément quelle variante rencontre le plus de succès ou d'échec.
Le choix dépend aussi du type de données que l’on souhaite recueillir. Si au niveau de la détection des problèmes les deux méthodes se valent environ, les caractéristiques des résultats produits sont très différentes. D’un côté, le test automatisé repose sur une part d’interprétation de l’analyste qui s’efforce de comprendre ce qui a posé des difficultés à l’utilisateur, par exemple en révisant un flux de clics. En contrepartie, des chiffres sont fournis sur la gravité des problèmes en indiquant notamment le nombre de personnes touchées, ce qui n’est pas sans intérêt pour prendre des décisions qui ont un certain coût en vue d’apporter des modifications à un site.
Quant au test modéré, il décèle les problèmes de manière explicite grâce au think-aloud, mais repose uniquement sur un nombre restreint de témoignages. Difficile donc de décider s’il s’agit de cas isolés ou d’éléments réellement importants.
L’analyste ne doit donc pas uniquement se poser la question de savoir quelle méthode permettra de détecter le plus de problèmes d’utilisabilité, mais aussi quelle forme de résultats répondra de la manière la plus adéquate aux besoins des propriétaires du site concerné.
Bibliographie
ANDREASEN, Morten Sieker, NIELSEN, Henrik Villemann, SCHRØDER, Simon Ormholt et STAGE, Jan, 2007. What Happened to Remote Usability Testing? : An Empirical Study of Three Methods. In : Proceedings of the SIGCHI Conference on Human Factors in Computing Systems [en ligne]. New York, NY, USA : ACM. 2007. pp. 1405–1414. [Consulté le 14 mars 2014]. CHI ’07. Disponible à l’adresse : http://doi.acm.org/10.1145/1240624.1240838
BARNUM, Carol M. (éd.), 2011. Usability testing essentials: ready, set... test !. Amsterdam : Elsevier. ISBN 9780123750921.
BASTIEN, J. M. Christian, 2010. Usability testing: a review of some methodological and technical aspects of the method. International Journal of Medical Informatics. avril 2010. Vol. 79, n° 4, pp. e18‑e23. DOI 10.1016/j.ijmedinf.2008.12.004.
BOREN, T. et RAMEY, J., 2000. Thinking aloud : reconciling theory and practice. IEEE Transactions on Professional Communication. septembre 2000. Vol. 43, n° 3, pp. 261‑278. DOI 10.1109/47.867942.
CHALIL MADATHIL, Kapil et GREENSTEIN, Joel S., 2011. Synchronous Remote Usability Testing : A New Approach Facilitated by Virtual Worlds. In : Proceedings of the SIGCHI Conference on Human Factors in Computing Systems [en ligne]. New York, NY, USA : ACM. 2011. pp. 2225–2234. [Consulté le 15 octobre 2014]. CHI ’11. ISBN 978-1-4503-0228-9. Disponible à l’adresse : http://doi.acm.org/10.1145/1978942.1979267
COOKE, Lynne, 2010. Assessing Concurrent Think-Aloud Protocol as a Usability Test Method: A Technical Communication Approach. IEEE Transactions on Professional Communication. septembre 2010. Vol. 53, n° 3, pp. 202‑215. DOI 10.1109/TPC.2010.2052859.
DE JONG, M. D. T., SCHELLENS, P. J. et VAN DEN HAAK, M. J., 2004. Employing think-aloud protocols and constructive interaction to test the usability of online library catalogues : a methodological comparison. Interacting with Computers. 2004. Vol. 16, n° 6, pp. 1153‑1170.
DE JONG, Menno D. T., SCHELLENS, Peter Jan et VAN DEN HAAK, Maaike J., 2003. Retrospective vs. concurrent think-aloud protocols : testing the usability of an online library catalogue. Behaviour and Information Technology. 2003. Vol. 22, n° 5, pp. 339‑351.
DRAY, Susan et SIEGEL, David, 2004. Remote Possibilities? : International Usability Testing at a Distance. interactions. mars 2004. Vol. 11, n° 2, pp. 10–17. DOI 10.1145/971258.971264.
ERICSSON, Karl Anders, 1993. Protocol analysis : verbal reports as data. Rev. ed. Cambridge Mass. [etc.] : The MIT Press. A Bradford book. ISBN 0262050471.
FERNANDEZ, Adrian, INSFRAN, Emilio et ABRAHÃO, Silvia, 2011. Usability evaluation methods for the web : A systematic mapping study. Information and Software Technology. août 2011. Vol. 53, n° 8, pp. 789‑817. DOI 10.1016/j.infsof.2011.02.007.
GREINER, Katie, 2012. A Comparison of two concurrent think-aloud protocols : Categories and relevancy of utterances [en ligne]. Thesis. [Consulté le 14 mars 2014]. Disponible à l’adresse : https://ritdml.rit.edu/handle/1850/15950
HARTSON, H. Rex, CASTILLO, José C., KELSO, John et NEALE, Wayne C., 1996. Remote Evaluation : The Network As an Extension of the Usability Laboratory. In : Proceedings of the SIGCHI Conference on Human Factors in Computing Systems [en ligne]. New York, NY, USA : ACM. 1996. pp. 228–235. [Consulté le 20 mars 2014]. CHI ’96. Disponible à l’adresse : http://doi.acm.org/10.1145/238386.238511
KRAHMER, E. et UMMELEN, N., 2004. Thinking about thinking aloud : a comparison of two verbal protocols for usability testing. IEEE Transactions on Professional Communication. juin 2004. Vol. 47, n° 2, pp. 105‑117. DOI 10.1109/TPC.2004.828205.
MCDONALD, Sharon, ZHAO, Tingting et EDWARDS, Helen M., 2013. Dual Verbal Elicitation : The Complementary Use of Concurrent and Retrospective Reporting Within a Usability Test. International Journal of Human - Computer Interaction [en ligne]. 2013. Vol. 29, n° 10. [Consulté le 16 octobre 2014]. Disponible à l’adresse : http://search.proquest.com/docview/1421973064/2BDB0E0BDC074EE2PQ/1?accountid=15920
MEYSTRE, Valérie et REY, Raphaël, 2014. Tests d'utilisabilité : comparaison de deux méthodes appliquées au site e-rara.ch [en ligne]. Haute école de gestion de Genève. [Consulté le 25 octobre 2014]. Disponible à l’adresse : http://doc.rero.ch/record/209599
NIELSEN, Janni, CLEMMENSEN, Torkil et YSSING, Carsten, 2002. Getting access to what goes on in people’s heads? reflections on the think-aloud technique. In : Proceedings of the second Nordic conference on Human-computer interaction [en ligne]. ACM. 2002. pp. 101–110. [Consulté le 15 octobre 2014]. Disponible à l’adresse : http://dl.acm.org/citation.cfm?id=572033
NØRGAARD, Mie et HORNB\A EK, Kasper, 2006. What Do Usability Evaluators Do in Practice? An Explorative Study of Think-aloud Testing. In : Proceedings of the 6th Conference on Designing Interactive Systems [en ligne]. New York, NY, USA : ACM. 2006. pp. 209–218. [Consulté le 15 octobre 2014]. DIS ’06. ISBN 1-59593-367-0. Disponible à l’adresse : http://doi.acm.org/10.1145/1142405.1142439
OLMSTED-HAWALA, Erica L., MURPHY, Elizabeth D., HAWALA, Sam et ASHENFELTER, Kathleen T., 2010. Think-aloud Protocols : A Comparison of Three Think-aloud Protocols for Use in Testing Data-dissemination Web Sites for Usability. In : Proceedings of the SIGCHI Conference on Human Factors in Computing Systems [en ligne]. New York, NY, USA : ACM. 2010. pp. 2381–2390. [Consulté le 16 octobre 2014]. CHI ’10. ISBN 978-1-60558-929-9. Disponible à l’adresse : http://doi.acm.org/10.1145/1753326.1753685
RODRIGUEZ, Ania et RESNICK, Marc L., 2010. Head to Head : Remote Usability Testing Takes on Live Usability Testing in the HFES Ultimate Fighting Challenge. Proceedings of the Human Factors and Ergonomics Society Annual Meeting. 1 septembre 2010. Vol. 54, n° 11, pp. 759‑762. DOI 10.1177/154193121005401103.
SCHMIDT, Eveline, 2013. Remote oder In-person Usability-Test ? [en ligne]. 2013. [Consulté le 3 janvier 2014]. Disponible à l’adresse : http://doc.rero.ch/record/208871?ln=fr
SELVARAJ, Prakaash, 2004. Comparative study of synchronous remote and traditional in-lab usability evaluation methodes [en ligne]. Master thesis, industrial and systems engineering. Blacksburg : Virginia Polytechnic Institute and State University. [Consulté le 16 mars 2014]. Disponible à l’adresse : http://vtechworks.lib.vt.edu/bitstream/handle/10919/9939/Thesis_Prakaash_Selvaraj.pdf?sequence=2
THOMPSON, Katherine E., ROZANSKI, Evelyn P. et HAAKE, Anne R., 2004. Here, There, Anywhere : Remote Usability Testing That Works. In : Proceedings of the 5th Conference on Information Technology Education [en ligne]. New York, NY, USA : ACM. 2004. pp. 132–137. [Consulté le 14 mars 2014]. CITC5 ’04. Disponible à l’adresse : http://doi.acm.org/10.1145/1029533.1029567
TULLIS, Tom, FLEISCHMAN, Stan, MCNULTY, Michelle, CIANCHETTE, Carrie et BERGEL, Marguerite, 2002. An Empirical Comparison of Lab and Remote Usability Testing of Web Sites. In : Usability Professionals Association Conference [en ligne]. Boston. 2002. [Consulté le 14 mars 2014]. Disponible à l’adresse : http://home.comcast.net/%7Etomtullis/publications/RemoteVsLab.pdf
VAN DEN HAAK, Maaike J., DE JONG, Menno D. T. et SCHELLENS, Peter Jan, 2007. Evaluation of an informational Web site : three variants of the think-aloud method compared. Technical Communication. 2007. Vol. 54, n° 1, pp. 58‑71.
VAN DEN HAAK, Maaike J., DE JONG, Menno D. T. et SCHELLENS, Peter Jan, 2009. Evaluating municipal websites : A methodological comparison of three think-aloud variants. Government Information Quarterly. janvier 2009. Vol. 26, n° 1, pp. 193‑202. DOI 10.1016/j.giq.2007.11.003.
ZHAO, Tingting, MCDONALD, Sharon et EDWARDS, Helen M., 2014. The impact of two different think-aloud instructions in a usability test : a case of just following orders? Behavior & Information Technology. 2014. Vol. 33, n° 2, pp. 163‑183. DOI http://dx.doi.org/10.1080/0144929X.2012.708786
ZHAO, Tingting et MCDONALD, Sharon, 2010. Keep Talking : An Analysis of Participant Utterances Gathered Using Two Concurrent Think-aloud Methods. In : Proceedings of the 6th Nordic Conference on Human-Computer Interaction : Extending Boundaries [en ligne]. New York, NY, USA : ACM. 2010. pp. 581–590. [Consulté le 16 octobre 2014]. NordiCHI ’10. ISBN 978-1-60558-934-3. Disponible à l’adresse : http://doi.acm.org/10.1145/1868914.1868979
Notes
(1) A ce propos, voir notre rapport de recherche à l’adresse http://doc.rero.ch/record/209599?ln=fr, p. 14-17.
(2) Carte représentant les points les plus cliqués pour chaque page du test.
e-rara.ch : une bibliothèque numérique pour les livres anciens
Alexis Rivier, Bibliothèque de Genève
e-rara.ch : une bibliothèque numérique pour les livres anciens
La bibliothèque numérique e-rara.ch est née dans le cadre plus général du programme d'investissement de la Bibliothèque électronique suisse, e-lib.ch, qui a financé pour la période 2008-2011 un ensemble de projets d'infrastructures pour l'information scientifique et technique(1). Elle offre aujourd'hui plus de 26'000 titres à la consultation et reçoit environ 70'000 visites par mois. Son rayonnement dépasse largement les frontières et les utilisateurs du portail situés aux États-Unis et en Allemagne sont même plus nombreux que ceux localisés en Suisse.
Désormais pérennisé, e-rara.ch est solidement implanté au sein de l'offre numérique suisse et poursuit sa croissance. Sept ans après ses débuts, un examen critique de la genèse de cette réalisation permet de montrer comment les problèmes techniques et organisationnels ont pu être surmontés.

Illustration 1. www.e-rara.ch: page d'accueil.
Le point de départ
Avant que le projet ne prenne forme en 2007, la perception générale en Suisse est que la numérisation des collections de bibliothèques n'a pas encore reçu l'attention qu'elle mérite en dehors des instances professionnelles. Les initiatives publiques piétinent, alors qu'ailleurs les grandes bibliothèques nationales passent d'une numérisation de niche à une numérisation de "masse". L'annonce du projet de Google, en décembre 2004, de numériser des collections intégrales en partenariat avec de prestigieuses bibliothèques anglo-saxonnes a fait l'effet d'un électrochoc. Marie-Christine Doffey, directrice de la Bibliothèque nationale suisse, constate avec regret dans un article que "la numérisation des bibliothèques publiques avance à pas d’escargot " et qu'"une prise de conscience et une volonté politique font encore défaut en Suisse"(2).
C'est partant d'un même constat d'absence de subventions publiques qu'Hubert Villard, directeur de la Bibliothèque cantonale et universitaire de Lausanne, annonce en 2007 l'accord passé entre l'État de Vaud et Google, portant sur la numérisation d'un lot de 100'000 volumes imprimés anciens du 17e au 19e siècle. Cela étant réalisé hors du pays, sans autres frais pour la collectivité que la mise à disposition de ressources humaines pour préparer et livrer les documents, ainsi que fournir les métadonnées nécessaires pour les signaler. Ce faisant, cette bibliothèque est devenue la première dans l'espace francophone à coopérer avec Google(3).
Le paysage numérique est alors principalement constitué de serveurs institutionnels (institutional repositories) mis en place dans le sillage du mouvement Open access, à partir desquels les bibliothèques universitaires diffusent leurs publications et leurs thèses. Ce sont essentiellement des documents numériques natifs et non des documents numérisés à partir d'un original analogique. En 2004, le consortium Rero avait ouvert un serveur original faisant office à la fois de serveur institutionnel pour ses membres et de réservoir pouvant accueillir des documents patrimoniaux numérisés, amorce d'une véritable bibliothèque numérique(4). Toutefois, celle-ci est restée modeste, proposant en été 2007 environ 5'000 documents.
À cela s'ajoute le Catalogue collectif suisse des affiches, une base iconographique qui compte alors quelque 40'000 notices accompagnées de reproductions numériques. Géré par la Bibliothèque nationale, ce serveur a reçu l'appui de la Fondation Memoriav.
La même année 2007 la Bibliothèque nationale, en collaboration avec Rero, met en place Digicoord, une plate-forme ouverte à toute institution afin de recenser les projets de numérisation existants. Digicoord offre ainsi un premier niveau de coordination, en réunissant et en partageant l'information existante sur tous les projets, qu'ils soient en cours de réalisation ou encore à l'état d'intention.
La Conférence universitaire suisse (CUS) lance alors le programme e-lib.ch. Le financement est assuré par la Confédération pour la période 2008-2011, au titre de soutien à la politique d'information scientifique et technique qui s'appuie sur les bibliothèques universitaires(5). L'objectif général d'e-lib.ch est de mettre en place un portail national facilitant le travail de la recherche et l'accès à l'information.
À côté de projets portant sur les infrastructures ou visant à faciliter l'utilisation des ressources informationnelles (comme le métacatalogue Swiss-Bib ou le portail cartographique Kartenportal), plusieurs projets de numérisation sont validés:
-
e-rara.ch: livres anciens
-
e-codices.ch: manuscrits médiévaux
-
retro.seals.ch: magazines et revues scientifiques suisses.
Après les programmes dont les sciences "dures" ont été largement bénéficiaires, notamment la coordination des ressources électroniques par le Consortium des bibliothèques universitaires suisses(6), cet accent mis sur la numérisation constitue un rééquilibrage en faveur des sciences humaines et sociales. Les documents numérisés, matériaux de base pour les chercheurs, deviendraient non seulement facilement accessibles, mais ils y permettraient de nouvelles exploitations des contenus, notamment par le biais des "humanités digitales".
L'organisation du projet
Le projet e-rara.ch se donne pour mandat d'installer et de mettre en production un serveur, afin de présenter sur Internet des contenus numérisés de livres anciens en rapport avec la Suisse, de préciser ces contenus et de coordonner la numérisation des collections des bibliothèques.
Ces objectifs correspondent aux Principes de Lund établis en 2001 par la Commission européenne pour la numérisation: créer dans chaque pays un centre de compétences, s'appuyer sur les bonnes pratiques du domaine et coordonner les initiatives.
La Bibliothèque de l'Ecole polytechnique fédérale de Zurich (ETH) prend la responsabilité du projet, auquel sont associées les bibliothèques universitaires de Bâle et de Berne, la Bibliothèque de Genève, ainsi que la Zentralbibliothek de Zurich. En Suisse les bibliothèques universitaires abritent les collections patrimoniales de leur canton respectif(7).
Les imprimés suisses du 16e siècle représentent le corpus de départ, auquel la Bibliothèque de l'ETH ajoute une collection spécifique de textes fondamentaux en histoire des sciences. A côté de la Bibliothèque de l'ETH, les quatre institutions partenaires conservent la majeure partie de cette production imprimée. De façon significative, la Bibliothèque nationale suisse n'est pas associée, du fait de sa fondation relativement récente, en 1895.
Concrétiser cette entreprise suppose d'abord de répondre à de nombreuses questions ouvertes, sous-tendues par des enjeux aussi bien techniques qu'organisationnels, ce qui fait d'e-rara.ch un projet complexe et exigeant. C'est pourquoi les tâches à accomplir ont été réparties entre quatre groupes de travail, coordonnés par la Bibliothèque de l'ETH: contenu, métadonnées, numérisation, plate-forme. Chaque groupe comprend des représentants de chaque bibliothèque partenaire.
1. Contenu
Il est question de numériser un ensemble cohérent: un exemplaire de chaque titre imprimé en Suisse au 16e siècle. À cette époque les villes ayant abrité des ateliers d'imprimerie sont peu nombreuses, et l'ensemble, évalué à 15'000 titres, est de taille raisonnable. Cette délimitation suit la pratique des grands travaux bibliographiques allemands sur les livres anciens, selon des tranches par siècles: 16e siècle, puis 17e et 18e siècles (VD16, VD17, VD18)(8).
Au cours du projet et des progrès des recensements, les quantités de livres imprimés au 16e siècle dans les différentes villes évoluent. Par ordre décroissant:
|
Bâle |
8‘200 titres |
|
Genève |
3'250 titres |
|
Zurich |
1‘626 titres |
|
Berne |
280 titres |
Autres villes romandes:
|
Fribourg |
66 titres |
|
Lausanne |
60 titres |
|
Morges |
41 titres |
|
Neuchâtel |
30 titres |
Tableau 1. Evaluation du nombre de livres produits par les imprimeurs en Suisse au 16e siècle (Recensement du groupe de travail Contenu)
Les bibliothèques cantonales conservent les principales collections de livres imprimés sur leur territoire. Le recours aux autres bibliothèques partenaires permet de combler en partie certaines lacunes.
Les corpus allemands et suisses se recoupent car VD16 inclut toute la production dans l'espace géographique de langue allemande, dont les villes de Bâle, Berne, ou Zurich, mais également Fribourg ou Pruntrut (Porrentruy). Un contact avec la Bayerische Staatsbibliothek de Munich a très vite été établi pour assurer la coordination de la numérisation entre les deux projets et mutualiser ainsi les efforts.
La Bibliothèque de Genève a pris en charge la coordination de la numérisation de toutes les impressions romandes, en prenant contact avec les bibliothèques cantonales de Fribourg, de Lausanne et de Neuchâtel.
Malgré les synergies offertes par cette dynamique de réseau, une collection numérique exhaustive du 16e siècle suisse ne pourra pas être obtenue dans les limites temporelles définies au départ. Par exemple, près de 900 impressions genevoises de cette époque ne sont connues qu'au travers d'exemplaires dispersés dans un grand nombre de bibliothèques étrangères. Une tentative d'acquisition de reproductions numériques auprès de ces institutions s'est avérée rapidement très compliquée, en raison de diverses réticences,du nombre de démarches à entreprendre et du coût.
2. Métadonnées
La description des contenus numérisés par les métadonnées réunit deux types d'information: bibliographique (fiche signalétique des documents) et structurelle (représentant le contenu du document). Ces informations fournissent autant de points d'accès à la ressource, via le moteur de recherche interne au portail et, si elles peuvent être indexées, par un moteur de recherche généraliste sur le Web.
Les métadonnées bibliographiques sont extraites des catalogues de référence des bibliothèques partenaires, au travers du système Ex Libris Aleph, qui équipe les réseaux IDS Bâle-Berne et IDS Nebis(9) ou VTLS Virtua, qui équipe le réseau Rero. S'y ajoute la base GLN15-16, base de données bibliographique exhaustive et spécialisée couvrant les impressions des 15e et 16e siècles de la Suisse romande réformée, soit Genève, Lausanne, Neuchâtel, ainsi que Morges(10).
La plate-forme de gestion numérique choisie, Visual Library de l'entreprise allemande Semantics, n'est pas conçue pour saisir directement les métadonnées bibliographiques. Un flux de données est établi avec les catalogues sources des bibliothèques au travers des protocoles d'échange automatique standards (Z39.50, OAI/PMH, SRW/SRU). Cela permet d'assurer que les notices descriptives dans e-rara.ch sont toujours à jour par rapport au catalogue de référence, dans lequel interviennent toutes les mutations. La base GLN15-16, issue d'un développement spécifique, ne permet pas l'échange automatique de données normalisées. Les informations bibliographiques doivent être importées manuellement à partir d'un fichier CSV, ainsi que les éventuelles mises à jour.
Contrairement aux métadonnées bibliographiques, les métadonnées structurelles ne sont pas préexistantes et doivent être saisies dans l'interface Visual Library. La structuration intervient après que les informations bibliographiques et l'ensemble des fichiers, sous forme de pages-images, ont été importés. Elle consiste à créer une table des matières, en regroupant les pages au sein de sections et d'éventuelles sous-sections préalablement repérées, facilitant ainsi l'usage de l'information. D'autres éléments potentiellement utiles sont également signalés, comme la page de titre ou divers éléments techniques.
Le résultat de la structuration peut être mis en forme selon des normes en vigueur, telles que METS(11) ou même TEI(12), ce qui ouvre vers des exploitations variées: fourniture de capsules d'archivage ZIP (comprenant sous forme compressée les fichiers image accompagnés de leurs métadonnées), échange ou moissonnage des métadonnées par d'autres serveurs comme par des agrégateurs (par exemple le portail Gallica).
La structuration n'est pas une opération triviale pour des textes du 16e siècle: le traitement de chaque titre prend du temps et exige des connaissances suffisantes en langues anciennes et en compréhension de l'organisation du texte. C'est pourquoi elle n'est pas toujours appliquée, notamment pour les textes courts.
Un autre écueil tient à l'absence de texte intégral généré par OCR. Ce procédé, extrêmement précieux car il facilite la "recherchabilité" de l'œuvre dans un portail ou sur Internet ainsi que le repérage de séquences de mots à l'intérieur de l'œuvre, donne des résultats mitigés pour les textes anciens. La typographie et l'orthographe de l'époque, la qualité (contraste) variable de l'impression, le jaunissement et les déformations du papier, ont un impact négatif sur le taux d'exactitude.(13) C'est pourquoi e-rara.ch a renoncé provisoirement à l'OCR. La question reste ouverte dans les plans de développement.
Illustration 2. Plate-forme e-rara.ch: interface professionnelle Visual Library Manager pour la structuration (http://dx.doi.org/10.3931/e-rara-1036)
3. Numérisation
Le groupe de travail Numérisation avait plusieurs missions: fixer les normes spécifiques pour les besoins du projet, évaluer puis acquérir deux types de scanners (manuel et automatique).
Appuyé sur les bonnes pratiques, et notamment celles de la DFG(14), le groupe considère que pour le livre ancien l'accès au contenu informationnel (texte, mais aussi schémas, équations…) ne suffit pas, la restitution de la matérialité de l'exemplaire revêt aussi une certaine importance. Les paramètres suivants sont donc adoptés:
-
Résolution optique 300/400 dpi
-
Numérisation en couleur
-
Format d'enregistrement Tiff non compressé, profil ICC attaché
-
Numérisation avec marge extérieure de 5 mm, afin de prouver l'intégrité du document
-
Numérisation intégrale, y compris pages de garde, plats extérieur et intérieur de la reliure, dos, tranche.
-
Ces normes sont complétées par des règles de nommage des fichiers, respectant l'ordre naturel de lecture(15), et un contrôle de la qualité.
Outre le respect des paramètres de numérisation susmentionnés, l'évaluation des scanners a porté particulièrement sur les critères suivants: préservation des livres anciens, qualité colorimétrique, netteté, rapidité du processus de numérisation, ergonomie. Si le scanner manuel choisi et qui a équipé chaque bibliothèque partenaire (cf. illustration 3) a globalement répondu aux attentes, les deux scanners automatiques installés dans les ateliers de Bâle et Zurich ont déçu en termes de productivité. Avec les livres anciens, dont la manipulation est délicate, le mécanisme qui tourne les pages automatiquement n'offre pas une fiabilité suffisante et implique l'intervention permanente d'un opérateur. La ZB Zurich a ainsi estimé que sa productivité réelle sur cet appareil n'était que de 2'000 scans par jour, le quart de celle annoncée par le fabricant(16).

Illustration 3. Numérisation à la Bibliothèque de Genève (photo M. Thomann, juin 2010)
Le projet e-rara.ch s'est développé durant une période où les techniques de numérisation ont considérablement évolué. D'un côté la popularité croissante des opérations de numérisation a élargi et stimulé le marché des scanners. En parallèle, les campagnes de numérisation dans les institutions se sont professionnalisées. Une prise de conscience accrue de l'importance du patrimoine a conduit à de plus grandes exigences quant aux mesures destinées à sa préservation.
L'intervention des professionnels de la conservation s'est généralisée. Ils interviennent en amont, examinant les documents à numériser et vérifiant que les contraintes mécaniques des scanners ne leur sont pas dommageables(17). Les fabricants pour leur part développent de nouveaux appareils qui visent à simplifier et à accélérer les actions de l'opérateur, tout en préservant au maximum l'intégrité matérielle des documents. La principale difficulté posée par les livres anciens est liée à l'angle d'ouverture que permet l'état du volume. Plus l'angle est réduit, moins nocive sera la numérisation. Zurich a acquis sur son propre budget un scanner nécessitant une ouverture de 30° seulement, rendant ainsi techniquement possible la numérisation de centaines de volumes supplémentaires (Illustration 4).

Illustration 4. Capter l'information dans les livres anciens exige des scanners spécialisés (Anagramm 30°)
Cette évolution de la numérisation et de la valeur attachée au patrimoine a eu des répercussions sur l'organisation générale du projet. Prévu initialement autour d'un atelier central situé à Zurich, qui aurait traité la majorité des collections des autres partenaires, le schéma a évolué vers une production plus décentralisée. Cela en raison de la complexité croissante (administrative, liée aux mesures de sécurité) du transport de livres pour la plupart rares et précieux, sans parler d'une certaine réticence des responsables au regard des risques encourus.
4. Plate-forme
Le dernier groupe devait mettre en place un système complet de "bibliothèque numérique", hébergé physiquement au centre informatique de la Bibliothèque de l'ETH. Par système complet il faut comprendre une plate-forme capable de gérer les objets numériques et de les présenter au public sur le Web. Les fonctionnalités attendues s'appliquent à ces deux volets. Pour les professionnels, cela concerne la saisie des métadonnées ainsi que le classement en collections. L'interface publique doit être orientée utilisateurs en termes de recherche, de navigation et de récupération des fichiers. L'attribution d'un identifiant à chaque document numérique assure la pérennité de l'accès à la ressource tout en permettant de la citer commodément. Le système DOI a été choisi à cet effet(18). Une interface d'échange de données standardisées permet d'intégrer le contenu d'e-rara.ch dans d'autres portails ou agrégateurs.
Le système Visual Library, développé par les entreprises Semantics et Walter Nagel, équipe plusieurs bibliothèques numériques, principalement en Allemagne. Son principe d'organisation des documents par "domaines" autonomes convenait bien aux besoins de gestion décentralisée par bibliothèques.
Un problème récurrent dans la conception des bibliothèques numériques est la dérivation, à partir des images master au format Tiff, des images numériques de moindre résolution adaptées à l'affichage Web. Cela est entièrement pris en charge par Visual Library après l'importation des fichiers (par transfert FTP ou envoi de disques durs), ainsi que la génération des fichiers PDF (totalité du document ou par chapitre), sans intervention particulière de l'opérateur du moment que celui-ci active le bouton "publication".
Après importation et publication, le système crée sur demande une "capsule ZIP", soit la réunion dans un dossier compressé d'un ensemble de fichiers images Tiff accompagnés des métadonnées issues du catalogue et de la structuration. Ces capsules ZIP sont des entités pouvant rejoindre des serveurs d'archivage numérique à long terme, tâche qui est de la responsabilité de la bibliothèque possédant le document d'origine.
L'illustration 5 montre le workflow global des opérations. Le tableau qui suit synthétise le nombre de titres et de pages intégrés chaque année. Le nombre de pages par livre varie mais représente une moyenne de 300.
Illustration 5. Workflow général du projet e-rara.ch.
|
2008 |
– |
– |
– |
|
2009 |
1'686 titres |
504'911 pages |
299 pages par titre |
|
2010 |
3'496 titres |
1'194'0905 pages |
342 pages par titre |
|
2011 |
3'323 titres |
1'128'805 pages |
340 pages par titre |
|
2012 |
6'854 titres |
2'072'486 pages |
302 pages par titre |
|
2013 |
7'156 titres |
1'660'866 pages |
232 pages par titre |
|
2014 |
6'260 titres |
1'955'137 pages |
312 pages par titre |
Tableau 2. Production pour e-rara.ch des bibliothèques partenaires en 2008-2014 (Source: Coordination e-rara.ch).
MISE EN SERVICE DU PORTAIL
E-rara.ch ouvre au public début 2010, deux ans après le lancement du projet, avec une offre initiale de 500 titres. L'intérêt suscité dès les premiers jours par cette nouvelle bibliothèque numérique se confirme par la suite, avec un nombre mensuel de visites en croissance régulière, à mesure que l'offre s'étoffe (Illustration 6).
Illustration 6. Fréquentation mensuelle du portail et nombre de titres disponibles (vue par trimestre).
Outre un bon référencement dans les moteurs de recherche, l'offre est également visible dans les métacatalogues, comme Swissbib(19), et les outils de découverte de ressources des partenaires comme Wissensportal (à Zurich)(20) ou Explore (Rero)(21). En outre le serveur est régulièrement moissonné par Gallica, la bibliothèque numérique française de référence(22), ainsi que par la base Eromm(23). Des liens réciproques vers le répertoire VD-16 pour le domaine germanique ou GLN 15-16 pour la Suisse romande sont également en place.
Les données d'accès par pays montrent clairement le rayonnement international d'e-rara.ch (illustration 7). La première place occupée par l'Allemagne n'est pas étonnante, étant donné la proportion élevée de documents provenant des bibliothèques alémaniques. L'Allemagne, les Etats-Unis, la Suisse et la France représentent presque 60% de la fréquentation totale du site.
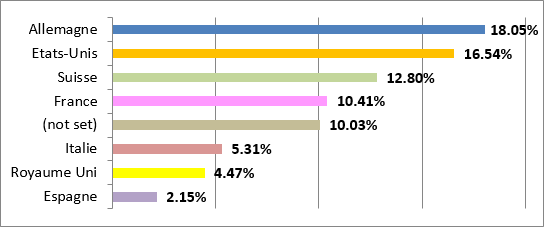
Illustration 7. Origine des internautes, janvier-septembre 2014
Évolution du projet
Contrairement à une publication imprimée qui représente l'état d'une recherche à un moment donné, un serveur Internet qui n'évoluerait pas perdrait assez rapidement son audience. Dès le début du projet l'évolution de la plateforme e-rara.ch a été envisagée, tant vis-à-vis du contenu et de son étendue que vis-à-vis du contenant, c'est-à-dire les fonctionnalités et l'ergonomie de l'interface utilisateur.
La définition des contenus éligibles pour figurer dans e-rara.ch s'est successivement élargie sur plusieurs plans:
- La période couverte
Initialement limitée au 16e siècle, elle englobe maintenant ce que les bibliothèques désignent comme livres anciens(24), soit les impressions du 15e au 19e siècle. Des livres du début du 20e siècle pourraient aussi être accueillis pour autant qu'ils soient dans le domaine public.
- Les types de documents
De nouvelles collections ont été créées pour intégrer, à côté des livres, les cartes et les partitions musicales. Si la question de traiter des périodiques ne se pose pas (d'autres plates-formes spécifiques existent(25)), inclure des estampes ("Druckgraphik") est en cours de réflexion. Le périmètre défini est celui des documents imprimés au sens large, par opposition aux manuscrits ou documents d'archives.
- Les impressions hors de Suisse
La Bibliothèque de l'ETH possède un vaste fonds patrimonial scientifique, mais peu de livres anciens imprimés en Suisse. Elle a donc contribué à la numérisation de documents édités hors de Suisse, réunis dans la collection "Textes pour l'histoire des sciences". D'autres ensembles ont suivi, comme "Poésie et prose italienne du 17e siècle" numérisée par la Biblioteca Salita dei Frati à Lugano. La seule limite fixée est que les livres doivent se trouver dans une bibliothèque suisse.
- Les contributeurs
E-rara.ch ayant élargi le périmètre des documents proposés est devenue en peu d'années une ressource incontournable au plan national. La plate-forme se prépare donc à intégrer d'autres bibliothèques qui souhaiteraient y participer.
Pour ce qui est du contenant, une étude d'utilisabilité – c'est-à-dire l'évaluation de l'efficacité des recherches et de la satisfaction de l'utilisateur – a été conduite en 2011(26). Elle a donné lieu à une refonte importante de l'interface web, mise en ligne en 2013. Grâce aux filtres par facettes, dispositif qui s'est généralisé ces dernières années, il est possible de préciser la recherche lorsque les résultats sont très nombreux. La zone de recherche elle-même est mieux mise en évidence. Un point important concerne l'abandon sur le bandeau des rubriques liées aux institutions partenaires. Elles permettaient d'afficher la liste de tous les livres conservés par une de ces bibliothèques, ce qui est compréhensible du point de vue de l'institution en quête de visibilité sur le Web, mais n'a absolument aucun sens pour l'utilisateur cherchant des contenus.
Le dynamisme technologique impose un rythme soutenu et oblige les systèmes à s'y adapter, sous peine de disparition rapide. Sur ce plan, e-rara.ch devra impérativement améliorer son interface sur les dispositifs mobiles comme les tablettes. L'absence de texte intégral généré par OCR, évoqué plus haut, sera aussi difficilement défendable à long terme.
Le manque de renvois entre les différentes formes des noms propres (Aristote en français, Aristotle en anglais, Aristoteles en allemand et parfois aussi en anglais, Aristotele en italien, etc.) produit du silence dans les réponses et complique la mise en oeuvre des listes alphabétiques ou des facettes. L'implantation d'un thésaurus établissant des équivalences a une importance particulière pour un site dédié aux imprimés anciens et devrait être réévalué (27). A moyen terme, on peut imaginer que les techniques du Web de données(28) apporteront des solutions plus légères pour intégrer ces disparités linguistiques.
Bilan et perspectives pour l'avenir
En 2009, dans un dossier traitant des politiques de numérisation, un éditorialiste soutient que la firme "Google n’accapare rien, elle profite du vide public"(29). La réalisation d'e-rara.ch est le sursaut né d'une prise de conscience politique, prouvant qu'il est possible d'occuper le terrain lorsque des moyens suffisants y sont consacrés.
La bibliothèque numérique e-rara.ch est le fruit, comme dans bien d'autres domaines, d'une utilisation pragmatique des compétences et des moyens existant dans le pays. Bien que la Bibliothèque nationale ait la mission de coordonner les initiatives liées aux bibliothèques, c'est la Bibliothèque de l'ETH qui a porté le projet d'un serveur national pour les livres anciens numérisés, dans le cadre d' e-lib.ch. Forte de plusieurs réalisations antérieures dans le domaine numérique (Consortium des bibliothèques universitaires suisses, numérisation des périodiques scientifiques), elle a pu y renforcer son rôle de leader.
Puisque le recul le permet, il est bon de rappeler les facteurs de cette réussite, même si certains d'entre eux peuvent paraître évidents:
-
La méthode projet s'est révélée très efficace. Elle a bénéficié d'un apport financier fédéral bienvenu, les partenaires mettant à disposition essentiellement des ressources en personnel. Les synergies ont été profitables à de nombreux points de vue: apport d'une masse critique pertinente de livres anciens, mise en commun des expertises, économies d'échelle pour la commande d'équipements (scanners, écrans), rigueur des évaluations.
-
Une certaine faculté d'adaptation et de redistribution des moyens a permis un grand gain de temps et une bonne cohérence dans la planification du projet. Par exemple, des équipements supplémentaires ont pu être prêtés par Zurich pour être mis à disposition à Genève, en raison de l'ampleur des collections à numériser.
-
Les exigences de qualité étaient élevées, mais raisonnablement atteignables. L'adaptation aux normes usuelles a permis de connecter immédiatement le portail à d'autres réseaux de ressources.
-
Le résultat est un portail d'envergure nationale, réunissant un vaste ensemble de documents présentés de façon identique, quelle que soit la bibliothèque de provenance.
Trop souvent en effet les institutions, par peur d'une dissolution de leur identité, tiennent à disposer de leur propre bibliothèque numérique pour mettre en valeur les richesses de leur ville ou de leur région. Cela n'apporte en fait que peu de bénéfices. Raphaële Mouren le souligne ainsi: "Les bibliothécaires savent pourtant que les portails des bibliothèques sont très peu utilisés par les internautes, et que les chercheurs, comme les autres publics, ne s’amusent pas à consulter l’un après l’autre les sites des bibliothèques pour y chercher leur bonheur: comme tout le monde, ils utilisent les moteurs de recherche."(30)
Denis Roegel, un autre chercheur grand connaisseur des bibliothèques numériques, fustige aussi la disparité des sites institutionnels(31). En outre, il met en relief un manque de réflexion préalable, rendant parfois peu pertinente l'utilisation des ressources. Une meilleure coordination entre bibliothèques, notamment pour ce qui est des critères de qualité requis, éviterait de mettre en ligne, comme c'est encore trop souvent le cas, des numérisations insuffisantes pour les chercheurs et donc finalement peu utiles.
Dans le sillage d'e-rara.ch et utilisant le même système, une nouvelle plate-forme est créée pour les manuscrits et archives: e-manuscripta.ch. Cette infrastructure, également nationale, est employée par les bibliothèques universitaires de Bâle et de Berne. L'apport principal de contenus viendra cependant de la ZB Zurich, qui avec son projet DigiTUR collabore étroitement avec l'ETH. En 2012 un financement important (près de 10 millions de francs) lui a été octroyé par le Fonds de loterie(32) (Lotteriefonds) pour la numérisation de ses collections patrimoniales(33). On peut ainsi dire que le pôle de Zurich gère une infrastructure à vocation nationale tout en répondant largement à ses propres besoins. A l'instar de Zurich, Genève, deuxième ville du pays et centre historique du livre, développe une stratégie pour intensifier la présence de son patrimoine en ligne. Les autres régions (Berne, Vaud, Valais par ex.) s'y investissent également(34).
Le programme national qui a succédé à e-lib.ch pour la période 2013-2016 est "Information scientifique: accès, traitement et sauvegarde" (CUS-P2)(35). Il prend en compte le fait que la numérisation des bibliothèques nécessite un appui financier qui s'ajoute au financement propre des institutions. Toutefois les demandes déposées dans ce cadre concernant la numérisation ont toutes été suspendues, y compris la poursuite du développement d'e-rara.ch. La direction du programme désire en effet regrouper ces requêtes sous l'autorité d'un même comité de pilotage. Souhaitons que cela permette de véritables synergies nationales, tout en gardant comme visée le bien commun: que les solutions mises en place correspondent aux besoins de toutes les institutions et répondent aux attentes des utilisateurs.
|
E-rara.ch – dates clés Août 2007 Novembre 2007 Janvier 2008 Octobre 2009 15 mars 2010 2012 Eté 2012 2013 Janvier 2013 2014 Mars 2014 Novembre 2014 Dès 2015 |
Notes
(1) Sur le projet e-rara.ch, voir: Franziska Geisser, "E-rara.ch: ein Schweizer Digitalisierungsprojekt mit internationaler Ausstrahlung", in Arbido, (3) 2011, p. 23-26. Trad. fr. par Alexis Rivier, E-rara.ch: un projet suisse de numérisation au rayonnement international. http://doc.rero.ch/record/27345
(2) Doffey Marie-Christine, in Le Temps, 4.5.2007.
(3) "La Bibliothèque cantonale et universitaire vaudoise rejoint le projet Recherche des Livres de Google", Bureau d'Information et de Communication de l'Etat de Vaud, 15.5.2007.
(4) Rero Doc, http://doc.rero.ch, bibliothèque numérique du Réseau des bibliothèques de Suisse occidentale (Rero), https://www.rero.ch.
(5) Mise en place par la Conférence universitaire suisse d'une Commission pour les bibliothèques universitaires (CBU) en 1983 et d'une Commission pour l'information scientifique dès 1985. Voir notre article, "Vingt ans de nouvelles technologies dans les bibliothèques suisses: des références aux contenus numériques", in Arbido print, (2) 2007, p. 26‑34.
(6) Coordonne la fourniture de ressources électroniques depuis 2000. http://lib.consortium.ch.
(7) Le cas est similaire en Allemagne: les bibliothèques universitaires conservent souvent le patrimoine de Länder.
(8) VD16: Verzeichnis der im deutschen Sprachbereich erschienenen Drucke des 16. Jahrhunderts (Répertoire des livres imprimés dans les pays de langue allemande au 16e siècle). Depuis 2006, la DFG (Deutsche Forschungsgemeinschaft - l'Agence allemande pour la recherche scientifique) finance la numérisation des titres recensés dans VD16. La Bayerische Staatsbibliothek de Munich, dont les collections de livres anciens sont parmi les plus étendues, est leader de ce projet. www.bsb-muenchen.de/index.php?id=1681.
Voir aussi: Sommer Dorothea, "Digitalisierung von Drucken des 17. Jahrhunderts an der Universitäts- und Landesbibliothek Halle: ein Werkstattbericht zu einem DFG-Projekt der Aktionslinie VD 16/ VD 17", in ABI-Technik, 27 (4), 2007, p. 236‑247.
(9) IDS: Informationsverbund Deutschschweiz. http://www.informationsverbund.ch.
Nebis: Netzwerk von Bibliotheken und Informationsstellen in der Schweiz. http://www.nebis.ch.
(10) Cette base est l'œuvre du bibliographe belge Jean-François Gilmont, spécialiste de l'histoire du livre au temps de la Réforme en Suisse romande. http://www.ville-ge.ch/bge/gln.
(11) Metadata Encoding and Transmission Standard. Norme gérée par la Library of Congress pour décrire dans le formalisme XML des objets numériques complexes (livres). http://www.loc.gov/standards/mets.
(12) Text Encoding and Interchange. Norme d'encodage pour les textes littéraires et l'édition scientifique. http://www.tei-c.org.
(13) On estime qu'un taux d'exactitude de 90-95% est nécessaire pour la recherche. Plusieurs projets se consacrent à l'amélioration de la qualité de l'OCR. Par ex. IMPACT (IMProving ACcess to Text), http://www.impact-project.eu et SUCCEED (Support Action Centre of Competence in Digitisation), http://www.succeed-project.eu.
eMOP (Early Modern OCR Project), http://idhmc.tamu.edu/emop.
(14) DFG-Praxisregeln "Digitalisierung", Deutsche Forschungsgemeinsschaft, 2013. Egalement en version anglaise: DFG Practical Guidelines on Digitisation. http://www.dfg.de/formulare/12_151.
(15) Pour les imprimés en hébreu notamment, la numérisation respecte l'inversion du sens de lecture. Par ex. http://dx.doi.org/10.3931/e-rara-3068.
(16) Edgar Schuler, "Die ZB ist Google für alte Schweizer Drucke", in Tages Anzeiger, 30.7.2009.
(17) Les implications de la numérisation en terme de conservation sont bien décrits dans: Anna E. Bulow et Jess Ashmon, Preparing Collections for Digitization, London, Facet Publishing, 2011.
(18) La Bibliothèque de l'ETH est agence d'attribution pour la Suisse des DOI (Digital Object Identifier). http://www.doi.org.
DOI Desk: https://www.library.ethz.ch/de/Dienstleistungen/Publizieren-registrieren-verwalten/DOI-Desk-der-ETH-Zürich.
(20) http://www.library.ethz.ch.
(22) http://gallica.bnf.fr. Les statistiques d'accès, montrent que chaque année plusieurs milliers de visites de e-rara.ch proviennent d'une recherche dans Gallica.
(23) European Register of Microform and Digital Masters. Fondée en 1994 comme catalogue collectif européen pour les copies de substitution sur microfilms, elle recense également depuis les œuvres numérisées. http://www.eromm.org.
(24) La date limite fluctue d'une institution à l'autre: 1850 ou 1900 sont usuelles.
(25) retro.seals.ch déjà mentionné plus haut pour les revues numérisées et Presse suisse en ligne pour les journaux. http://newspaper.archives.rero.ch.
(26) Eliane Blumer, Benutzerorientierte Evaluation der Webseite e-rara.ch anhand von Usability- und Blickmessungstests, Mémoire de bachelor, Genève, Haute école de gestion, 2011. http://doc.rero.ch/record/28011.
(27) Notamment mise en évidence dans une évaluation plus récente du portail e-rara.ch: Meystre Valérie, Tests d’utilisabilité: comparaison de deux méthodes appliquées au site e-rara.ch, Travail de recherche (Master), Haute école de gestion de Genève, 2014. http://doc.rero.ch/record/209599.
(28) En anglais Linked data, à rapprocher également du web sémantique. http://linkeddata.org.
(29) Nicolas Dufour, "Le grand vide public", in Le Temps, 19.9.2009.
(30) Raphaële Mouren, "Les manuscrits médiévaux dans les bibliothèques numériques en France", in Fabienne Henryot (éd.), L’historien face au manuscrit: du parchemin à la bibliothèque numérique, Louvain-la-Neuve, Presses universitaires de Louvain, 2013, p. 343-355.
(31) Denis Roegel, La numérisation durable, 21.12.2013. http://locomat.loria.fr/other/2012numerisation-durable.pdf.
(32) Le Lotteriefonds est l'organe de répartition des bénéfices de loterie pour les cantons de Suisse alémanique et le Tessin.
(33) DigiTUR. http://www.zb.uzh.ch/spezialsammlungen/digitur/index.html.de.
Communiqué de presse, canton de Zurich, 28.6.2012, Zentralbibliothek digitalisiert Zürcher Bestände, http://www.zh.ch/internet/finanzdirektion/de/aktuell.newsextern.-interne....
(34) Berne: DigiBern. http://www.digibern.ch
Vaud: Scriptorium. http://scriptorium.bcu-lausanne.ch
Valais: Vallesiana. http://www.vallesiana.ch.
(35) http://www.crus.ch/information-programmes/projets-programmes/isci.html?L=1.
De artlibraries.net à Art Discovery Group Catalogue ou l’évolution de métacatalogues pour l’histoire de l’art et d’un réseau des bibliothèques d’art dans le monde
Véronique Goncerut Estèbe, conservatrice en chef - responsable du pôle bibliothèque et inventaire des Musées d’art et d’histoire de la Ville de Genève
De artlibraries.net à Art Discovery Group Catalogue ou l’évolution de métacatalogues pour l’histoire de l’art et d’un réseau des bibliothèques d’art dans le monde
Entrée de la Bibliothèque d’art et d’archéologie (BAA) des Musées d’art et d’histoire dans artlibraries.net
Depuis la fin des années 1990, je fréquente les rencontres mondiales de la Fédération internationale des associations et institutions de bibliothèques (IFLA, http://www.ifla.org/). J’ai plusieurs fois été membre du Comité de la Section des bibliothèques d'art et grâce à cela j'ai eu l'occasion de rencontrer les professionnels des bibliothèques d'art ou de musées de Suisse, d’Europe et du monde.
C’est justement dans le cadre du Comité de la Section des bibliothèques d'art de l'IFLA, à Oslo en 2005, que j’ai pour la première fois entendu parler de artlibraries.net (http://www.artlibraries.net/index_fr.php), réseau et catalogue virtuel d’histoire de l’art, ancien Virtueller Katalog Kunstgeschichte (VKK)(1), qui permet l'interrogation simultanée des catalogues des plus importantes bibliothèques d'histoire de l'art dans le monde. À l’époque de prestigieuses bibliothèques y participaient déjà, comme celles du Metropolitan Museum à New York, du Victoria and Albert Museum à Londres, du Rijksmuseum à Amsterdam, de la Fondation Calouste Gulbenkian à Lisbonne, du Getty Research Institute à Los Angeles, de la Bibliothèque des arts décoratifs et de la Réunion des musées nationaux à Paris ou encore du Kunsthaus à Zurich.
En 2007, la bibliothèque de l’Institut suisse pour l’étude de l’art (SIK ISEA, http://www.sik-isea.ch) à Zurich songeait aussi à devenir membres d’artlibraries.net. Au moment de sa demande et avec la bibliothèque du Kunsthaus de Zurich, elles ont conjointement proposé aux responsables du réseau de contacter et d’inclure la Bibliothèque d’art et d’archéologie (BAA) des Musées d’art et d’histoire de la Ville de Genève, étant donné son importance reconnue comme la plus grande bibliothèque d’histoire de l’art et un pôle d’excellence pour tous les domaines des arts en Suisse.
C’est ainsi que le réseau artlibraries.net a approché la BAA et lui a proposé d’y entrer. Cela a été possible en 2007 encore, avec l’accord de la direction des Musées d’art et d’histoire et en raison d’un coût d’entrée et de gestion tout à fait abordable. La connexion technique et informatique de la BAA au catalogue artlibraries.net a été menée sans problème par les techniciens de l’Université de Karlsruhe qui avait déjà intégré les données du Réseau des bibliothèques de Suisse occidentale (RERO) au Kalsruher Virtueller Katalog (KVK, http://www.ubka.uni-karlsruhe.de/kvk_en.html).
Pour la BAA, les raisons de son entrée dans le catalogue sont multiples. Premièrement, ce métacatalogue met en exergue et rend public au niveau mondial l’art et le travail des artistes, des chercheurs et des scientifiques, tant genevois que suisses. Deuxièmement, il permet la diffusion et la signalisation des publications des institutions locales dans un catalogue mondial ; en cela la notion de glocal – de mettre en relation les échelles locales et mondiales – y prend également tout son sens. Finalement, il met en valeur le travail des professionnels de l’information documentaire, des bibliothèques suisses et du Réseau des bibliothèques de Suisse occidentale (RERO), en particulier.
En 2009, il m’a été demandé d’entrer au Comité d’artlibraries.net afin de pouvoir participer à l’avenir du réseau et d’informer les bibliothèques francophones participantes ou candidates. Dès ce moment et jusqu’à aujourd’hui, la vie et l’avenir du réseau a été un sujet de réflexion permanent, suscitant des rencontres, des assemblées générales et des décisions en Europe comme dans le monde.
artlibraries.net en détail
artlibrarie.net – aussi appelé Catalogue virtuel d’histoire de l’art – a été lancé en 1999 sous le nom de Virtueller Katalog Kunstgeschichte (VKK) grâce à un financement de la Deutsche Forschungsgemeinschaft dans le cadre de son programme pour les bibliothèques d’art allemandes. Tout d’abord, ce projet s’est développé en Allemagne, puis il a touché progressivement des services documentaires dans le monde entier. Il a été présenté à la conférence de l’IFLA à Glasgow en 2002.
En 2007, le site internet accueillant le moteur de recherche a été refait et le nom du catalogue a été modifié à cette occasion pour devenir artlibraries.net.
artlibraries.net est un métacatalogue international qui permet l’interrogation simultanée de notices bibliographiques et de références recensées dans des bases de données du monde entier, spécialisées en histoire de l’art. Aujourd’hui, artlibraries.net donne accès à environ treize millions de notices(2), incluant une proportion importante d’articles de périodiques, d’actes de colloques, de mélanges, de catalogues et livres d’expositions, etc., ainsi que des notices concernant des archives, des photos, des ressources en ligne.
Administration technique
artlibraries.net est une interface de recherche basée sur la technologie éprouvée du Karlsruher Virtueller Katalog (KVK), qui offre une recherche simultanée dans plusieurs catalogues accessibles sur internet. Le moteur de recherche est hébergé par la Bibliothèque universitaire de Karlsruhe (Allemagne), qui collabore à son administration.
Pour chaque nouvelle bibliothèque participante – aussi appelée système cible –, la Bibliothèque universitaire de Karlsruhe établit le fichier de description de structure CGI (Common Gateway Interface) correspondant. Actuellement, le coût d’intégration d’une nouvelle cible est de 3’000 Euros environ ; il peut être réduit de 50% s’il est possible de réutiliser un script CGI déjà existant. L’hébergement et la maintenance par la Bibliothèque universitaire de Karlsruhe sont financés par une cotisation annuelle dont le montant est établi chaque année en prenant en compte le nombre de cibles ; il s’élève à moins de 10 % du coût initial. Le Zentralinstitut für Kunstgeschichte (Munich) collecte les cotisations et les verse une fois par an à l’Université de Karlsruhe.
artlibraries.net ne développant pas de base de données propre, il repose sur la disponibilité des systèmes cibles et il produit des listes homogènes de références abrégées. Pour accéder aux références complètes des titres de documents sélectionnés, il est nécessaire de basculer dans les différents catalogues locaux des bibliothèques, avec la possibilité de bénéficier de tous les services offerts par ces catalogues, notamment l'ensemble des recherches avancées, le prêt entre bibliothèques ou la fourniture de documents à distance.
Objectifs et principes d’organisation(3)
Un des principes de base d’artlibraries.net est la complémentarité des collections d’art référencées dans chacune des bases de données. Outre la recherche d’exhaustivité pour l’ensemble des domaines couverts, le développement est également guidé par la volonté d’offrir un meilleur accès aux ressources en ligne, de multiplier et de mettre en réseau les services de fourniture de documents à distance. Outil bibliographique et documentaire, artlibraries.net a pour vocation de servir la recherche la plus spécialisée en histoire de l’art.
Les bibliothèques d’art participantes peuvent être des instituts de recherche, des établissements d’enseignement, des musées, des centres d’exposition, des collections pertinentes de bibliothèques de recherche générale, ainsi que des catalogues collectifs spécialisés, des bibliographies en ligne et des bases de données consultables sur internet.
Dans un premier temps et afin de réaliser une coopération réellement européenne au service de la communauté internationale de l’histoire de l’art, le cercle des participants s’est étendu tout particulièrement aux institutions britanniques et scandinaves, à l’Europe du Sud et aux pays de l’Europe de l’Est qui ont rejoint l’Union européenne. À l’heure actuelle, trente-huit institutions et bibliothèques d’art y participent et sont localisées en Allemagne, Australie, Autriche, Canada, Danemark, États-Unis, Finlande, France, Grande-Bretagne, Italie, Norvège, Pays-Bas, Portugal, Suède, Suisse.
Les institutions participantes reconnaissent le principe de l’open access, qui a pour objectif de rendre l’information scientifique universellement, globalement et librement accessible. Elles sont d’avis qu’artlibraries.net doit contribuer à la diffusion de ce principe. Des collaborations existent avec des centres de recherche, comme le Hathi Trust Research Center.
Sous la responsabilité commune des institutions membres agissant comme partenaires, artlibraries.net se développe sans cesse, et pas seulement en ce qui concerne les nouveaux systèmes cibles. Il est aussi important d’améliorer la quantité et la qualité des informations fournies par les participants que d’évaluer et d’optimiser l’efficacité des logiciels tant du moteur de recherche que de ses cibles. Ainsi donc, artlibraries.net est conçu comme une plate-forme associant d’importants partenaires internationaux de façon effectivement opérationnelle.
L’utilité et la valeur spécifiques d’artlibraries.net sont tout particulièrement liées au niveau de complétude, d’exhaustivité, de spécialisation et d’indexation des informations trouvées dans les systèmes cibles, ainsi qu’à la complémentarité de celles-ci. Tous les champs de l’histoire de l’art, y compris les plus récents, doivent être pris en compte et bien représentés. Les références en archéologie sont cependant en dehors des objectifs. Les articles, les comptes-rendus, les catalogues de ventes, la littérature grise, les documents non imprimés et les ressources en ligne sont couverts aussi largement que possible. Quelques cibles spécialisées offrent déjà des références de photographies, de vidéos, d’archives ou de revues de presse. artlibraries.net constitue un portail pour les catalogues internet des institutions participantes. Il ne remplace en rien leur site internet avec leurs caractéristiques et leurs services propres. Au contraire, il les rend plus visibles et plus efficaces au sein d'une fédération de coopération.
Un comité international
La tenue régulière d’assemblées générales des partenaires d’artlibraries.net et les réunions de son comité international contribuent à la réalisation de ces objectifs dans le contexte général des ressources en histoire de l’art disponibles sur internet. Toutes les décisions relatives au logiciel, à la présentation des pages web, aux formules de recherche (si elles ne découlent pas du développement général du KVK), les services supplémentaires, et tout particulièrement l’intégration de nouveaux systèmes cibles, sont prises conjointement par les membres. Actuellement, l’administration et le développement sont réalisés sans recours à une structure administrative dans un esprit de confiance et de partenariat.
Les propositions de nouveaux systèmes cibles doivent recueillir une majorité des deux tiers (un vote par système cible). L’admission d’une nouvelle institution requiert obligatoirement un vote et les demandes de participation doivent être formulées par écrit.
Les membres du comité sont des volontaires désignés par l’assemblée générale, et prêts à servir de personnes contact et à veiller, conjointement avec le coordinateur technique, aux questions relatives à la recherche et à tout autre point concernant le site internet. En outre, ces collègues peuvent assurer des missions de relations publiques et la mise en œuvre de nouveaux développements.
Membres du comité
Wendy Fish, British Architectural Library, Royal Institute of British Architects, Londres
Rüdiger Hoyer, Zentralinstitut für Kunstgeschichte, Munich
Deborah Kempe, Frick Art Reference Library, New York
Geert-Jan Koot, Rijksmuseum, Amsterdam
Paulo Leitao, Biblioteca de Arte, Fundacao Calouste Gulbenkian, Lisbonne
Michael Rocke, Biblioteca Berenson, Villa I Tatti, Florence
Kathleen Salomon, Getty Research Institute, Los Angeles
Jan Simane, Kunsthistorisches Institut in Florenz (Max-Planck-Institut), Florence
Véronique Goncerut Estèbe, Bibliothèque d'art et d'archéologie des Musées d'art et d'histoire, Genève
Administrateur technique
Uwe Dierolf, Universitätsbibliothek, Karlsruhe
De artlibraries.net à Art Discovery Group Catalogue ( OCLC)
« Because the more libraries, the more content, the more visibility. And that is what we want. » Geer-Jan Koot, Head of the Rijksmuseum Research Library, tiré de la vidéo de lancement de Art Discovery Group Catalogue (OCLC, 2014a)
À la fin de l’année 2009, le Getty Research Institute, basé en Californie et dédié à l’étude des arts visuels et à la diffusion de la connaissance sur le sujet, annonce la fin de la production et de l’édition imprimée de la Bibliographie d’histoire de l’art (BHA). Cette bibliographie centenaire, initialement publiée en France, était le fruit d’une coopération internationale. Elle a connu plusieurs autres noms et elle répertoriait les documents des domaines de l’art pour les offrir aux chercheurs et historiens(4).
En 2010 le Getty lance le projet appelé « Future of Art Bibliography (FAB)(5). Plusieurs facteurs sont à l’origine de cette nouvelle réflexion : le manque de moyens financiers pour continuer de publier une bibliographie sous forme imprimée, la difficulté de continuer le catalogage et la récolte des données de manière traditionnelle, l’inadaptation de ces formats pour leur diffusion dans les nouveaux moyens de communication électronique (internet en particulier) et l’open access, la naissance de nouvelles sources d’information (catalogues en ligne, liens électroniques), la numérisation des documents historiques et des articles de revues. Dans cette perspective, il apparaît évident que la future bibliographie d’histoire de l’art a besoin d’un nouveau format ainsi que d’un vaste réseau de coopération pour la réaliser.
Dès l’année 2010, le catalogue artlibraries.net est victime de son succès et commence à montrer des faiblesses, parfois déroutantes pour les utilisateurs : notices non uniformes en raison de la diversité des règles de catalogage, multilinguisme et complexité pour l’indexation matière. Par ailleurs, la multiplication des bibliothèques participantes et la technologie somme toute assez sommaire de l’interface rendent les recherches très lentes et la présentation des listes de résultats longues et peu commodes, classées par institution.
En juin 2011 a lieu la réunion annuelle du comité d’artlibraries.net à Institut suisse pour l’étude de l’art à Zurich. Le Getty Research Institute est également présent et des discussions sont engagées sur le sujet du futur de la bibliographie d’art.
D’emblée il apparaît que la nouvelle bibliographie doit offrir un portail d’accès aux documents numérisés et les sources d’histoire de l’art et être une archive pour les publications électroniques. Dans ce cadre précis et moyennant des aménagements, il devient évident que le catalogue artlibraries.net a la potentialité nécessaire pour devenir l’outil bibliographique le plus adapté pour réaliser le projet du Getty.
En parallèle, l’évolution technologique nécessaire pour faire de lui un catalogue orienté vers le futur commence à trouver des solutions à travers l’étude des infrastructures d’Online Computer Library Center (OCLC(6)) et de son catalogue WorldCat, ainsi qu’un rapprochement avec ces partenaires potentiels. Dès ce moment, OCLC lance le projet « Art libraries Discovery Experiment », soit un système prototype qui va permettre d’étudier si WorldCat pourra être le modèle du catalogue et de l’interface destinés aux bibliothèques d’art.
L’idée d’un rapprochement entre artlibraries.net et le catalogue OCLC/Worldcat fait son chemin. Un an plus tard, en septembre 2012 à Paris lors de la rencontre annuelle des partenaires d’artlibraries.net, des conférences d’intervenants d’OCLC présentent la possibilité de « la création sous Worldcat d’un groupement de bibliothèques spécialisées en histoire de l’art [qui] permettra de passer de la structure actuelle du métacalogue d’artlibraries.net, dont la multiplication des cibles rend longues et peu souples les procédures de recherche, à une structure appuyée sur la puissante infrastructure et sur la base de données unifiée de WorldCat. »(RAYMOND, 2012).
Art Discovery Group Catalogue (ADGC)
« The new Art Discovery Group Catalogue, a view of WorldCat that brings together items from leading art libraries around the world, was launched today [May 1st, 2014] at the Art Libraries Society of North America annual conference, in Washington, D.C.
Coordinated by artlibraries.net, an international working community of more than 100 art libraries from 16 countries, the new catalogue offers an art-focused research experience within the WorldCat environment. Art library catalogues will now be searchable alongside additional content from a multitude of online journals and databases, promising more results on a global scale. » (OCLC, 2014b)
À la suite des nombreuses discussions et essais entre partenaires, l’Art Discovery Group Catalogue est officiellement lancé le 1er mai 2014. Il est issu de la technologie utilisée dans WorldCat, coordonné par le comité d’artlibraries.net, développé dans le contexte du projet du Getty Research Institute « Future of Art Bibliography » et financé pour son développement et son lancement par la Samuel H. Kress Foundation et le Getty Research Institute.
Cette interface d’interrogation particulière du catalogue offre la possibilité de faire des recherches sur l’art seulement et dans les catalogues de bibliothèques dédiés à cette spécialité. OCLC est enthousiaste quant à cette recherche limitée à l’art, car en cas de succès il pense pouvoir lancer d’autres interfaces de recherche thématique, sur d’autres sujets.
L’avantage de l’interface est qu’elle est dédiée aux domaines de l’art et qu’elle est une sorte d’extraction thématique de la totalité de WorldCat. Si elle offre l’avantage d’associer les données bibliographiques de toutes les bibliothèques participantes, elle permet également d’accéder aux métadonnées répertoriées dans le WorldCat Central Index (OCLC, 2012), comme des collections en accès libre, environ 1900 bases de données et plus d’un million d’articles de journaux et e-books.
Le futur d’Art Discovery Group Catalogue (ADGC) et d’artlibraries.net
Le développement complet d’ADGC, interface d’interrogation des données des bibliothèques d’art, sera terminé à fin 2015. En attendant, des problèmes liés au logiciel subsistent et devront être résolus, comme l’accès aux bases de données payantes ou en accès limité, l’intégration du prêt entre bibliothèques, l’uniformisation des notices. De plus, certaines bibliothèques d’art ne sont pas prêtes à entrer dans WorldCat ou d’adhérer aux catalogues OCLC. Cela est particulièrement notable pour les bibliothèques scandinaves ou allemandes, dont certaines font partie d’artlibraries.net, mais pas d’ADGC.
En parallèle, le catalogue artlibraries.net n’est lui plus mis jour depuis deux ans, ni au niveau du logiciel, ni au niveau des informations sur les bibliothèques participantes. Il est figé et il ne grandit plus. Il présente de sérieux problèmes d’affichage des résultats des recherches. Il comporte également moins de références bibliographiques que l’ADGC et la baisse des statistiques d’utilisation laisse à penser son abandon progressif par les scientifiques et les publics intéressés.
À l’heure actuelle, il semble qu’artlibraries.net a atteint le stade final de son développement. En parallèle, ADGC présente déjà un essor intéressant, alors qu’il est toujours en construction. Mais des problématiques restent encore à résoudre, comme son efficacité en termes de recherches et son rôle pour la communauté des chercheurs et des bibliothèques d’art. Un futur site internet dédié doit mieux le présenter aux publics intéressés et le rendre accessible. Il est en cours de développement par la Fondation Calouste Gulbenkian, Lisbonne.
Dans ses conditions, tout porte à croire que le catalogue artlibraries.net cessera d’exister prochainement. Au contraire, l’ADGC deviendra l’outil bibliographique des chercheurs et des spécialistes des domaines de l’art, car il est en constante évolution technologique grâce à OCLC et il offre une interface de recherche agréable et des listes de résultats en constant accroissement.
La naissance et l’émergence de ces deux projets confirment l’intérêt pour les bibliothèques de travailler ensemble tant au niveau national qu’international, l’importance du travail des professionnels en réseau et la mise en place de catalogues partagés, ainsi que le développement des métacatalogues.
Au final pour la Bibliothèque d’art et d’archéologie, se projeter dans l’avenir et participer à la construction de métacatalogues l’a rendue plus visible aux yeux de son institution tutélaire, les Musées d’art et d’histoire de la Ville de Genève, mais aussi aux yeux de ses pairs dans le monde. L’excellence et la richesse de ses collections sont maintenant mieux mises en valeur et elle est une référence mondiale dans les domaines de l’art.
Bibliothèques participantes à Art Discovery Group Catalogue (ADGC) en novembre 2014
- Accademia di architettura - Università della Svizzera italiana (USI), Mendrisio, Suisse
- Albertina, Bibliothek, Vienne, Autriche
- Avery Architectural and Fine Arts Library, Columbia University Libraries, New York, USA
- Berenson Library, Villa I Tatti - The Harvard University Center for Italian Renaissance Studies, Florence, Italie
- Bibliothèque d'art et d'archéologie des Musées d'art et d'histoire, Genève, Suisse
- Bibliothèque des arts décoratifs, Paris, France
- Brooklyn Museum of Art Library, (NYARC), New York, USA
- Calouste Gulbenkian Foundation, Art Library, Lisbonne, Portugal
- Cleveland Museum of Art, Ingalls Library, Cleveland, USA
- Fine Arts Library, Harvard University, Cambridge, USA
- Frick Reference Art Library, (NYARC), New York, USA
- Germanisches Nationalmuseum, Bibliothek, Nuremberg, Allemagne
- Getty Research Institute Library, Los Angeles, Californie, USA
- Institut national d'histoire de l'art (INHA), Bibliothèque, Paris, France
- Institut suisse pour l’étude de l’art (SIK-ISEA), Zurich, Suisse
- Kunstbibliothek, Staatliche Museen zu Berlin - Preußischer Kulturbesitz, Berlin, Allemagne
- Kunsthaus, Bibliothek, Zurich, Suisse
- Marquand Library of Art and Archeology, Princeton University, Princeton, USA
- Museum of Modern Art Library, (NYARC), New York, USA
- National Art Library, Victoria and Albert Museum, Londres, Grande-Bretagne
- National Gallery of Art Library, Washington D.C., USA
- National Gallery of Australia Research Library, Canberra, Australie
- National Gallery of Canada, Ottawa, Ontario, Canada
- National Museum of Western Art, Research Library, Tokyo, Japon
- National Portrait Gallery of Australia Research Library, Canberra, Australie
- Philadelphia Museum of Art, Philadelphie, USA
- Rijksmuseum Research Library, Amsterdam, Hollande
- RKD (Rijksbureau voor Kunsthistorische Documentatie/Netherlands Institute for Art History), La Hague, Hollande
- Royal Institute of British Architects, Library, Londres, Grande-Bretagne
- Ryerson and Burnham Libraries, The Art Institute of Chicago, USA
- Sächsische Landesbibliothek – Staats- und Universitätsbibliothek Dresden (SLUB), Allemagne
- Sterling and Francine Clark Art Institute Library, Williamstown, USA
- Thomas J. Watson Library, Metropolitan Museum of Art, New York, USA
- Universitätsbibliothek, Heidelberg, Allemagne
- University of Texas Art Library, Austin, USA
- William Morris Hunt Memorial Library, Museum of Fine Arts, Boston, USA
Liste des trois réseaux et métacatalogues dont les notices sont accessibles au travers d’ADGC
- Kubikat, Allemagne, qui regroupe les bibliothèques suivantes :
- Kunsthistorisches Institut in Florence, Max-Planck-Institut (Florence, Italie)
- Zentralinstitut für Kunstgeschichte, Munich
- Deutsches Forum für Kunstgeschichte / Centre allemand d'histoire de l'art, Paris
- Bibliotheca Hertziana, Max Planck-Institut für Kunstgeschichte, Rome
- Gesamtkatalog der Düsseldorfer Kulturinstitute (GDK), Allemagne, qui regroupe les bibliothèques suivantes :
- Filmmuseum Düsseldorf
- Görres-Gymnasium Düsseldorf
- Goethe-Museum Düsseldorf / Anton-und-Katharina-Kippenberg-Stiftung
- Heinrich-Heine-Institut Düsseldorf
- Hetjens-Museum / Deutsches Keramikmuseum Düsseldorf
- Museum Kunstpalast Düsseldorf
- Restaurierungszentrum Düsseldorf - Schenkung Henkel
- Stadtarchiv Düsseldorf
- Stadtmuseum Düsseldorf
- Theatermuseum / Dumont-Lindemann-Archiv Düsseldorf
- Institut Français Düsseldorf
- Kunstakademie Düsseldorf
- Kunstsammlung Nordrhein-Westfalen Düsseldorf
- IRIS Consortium, Florence, Italie, qui regroupe les bibliothèques suivantes :
- Library of the Uffizi. Soprintendenza Speciale per il Patrimonio Storico, Artistico ed Etnoantropologico e per il Polo Museale della città di Firenze
- Library of the Fondazione di Studi di Storia dell'Arte Roberto Longhi
- Library of the Dutch University Institute for Art History
- Library of the Istituto Nazionale di Studi sul Rinascimento
- The «Ugo Procacci» Library, Opificio delle Pietre Dure
- Leonardiana Library, Center for Research and Documentation of Leonardo Studies
- Bill Kent Library, Monash University Prato Centre
Notes
(1) "Der "Virtuelle Katalog Kunstgeschichte" (VKK) ist eine von der Deutschen Forschungsgemeinschaft (DFG) geförderte Initiative der am System der überregionalen Literaturversorgung teilnehmenden Kunstbibliotheken in Zusammenarbeit mit der UB Karlsruhe. Ziel dieses Kataloges ist es [...] einen zentralen, übergreifenden Zugriff auf die für die Kunstgeschichte wichtigsten bzw. interessantesten maschinenlesbaren EDV-Kataloge von Kunstbibliotheken zu bieten. Dies ermöglicht die Integrierung von nicht in den Verbunddatenbanken erfaßten Bibliotheksbeständen sowie fachlicher Aufsatzliteratur. Die Teilnehmer des VKK bieten derzeit 1,6 Millionen bibliographische Nachweise, darunter zahlreiche Artikel aus Zeitschriften und Sammelbänden." Tiré de Clio-online, Fachportal für die Geschichtswissenschaften. http://www.clio-online.de/site/lang__en/ItemID__14188/mid__10308/92/default.aspx (consulté le 24 septembre 2014)
(2) Chiffres de septembre 2012
(3) Les informations contenues dans les paragraphes au sujet d’artlibraries sont librement tirées du site internet de l’organisation du même nom
(4) Le Répertoire d'art et d'archéologie publié sous la dir. du Comité français d'histoire de l'art et fondé en 1910, devient le BHA : bibliography of the history of art = bibliographie d'histoire de l'art dans les années huitante et après la fusion avec le RILA : répertoire international de la littérature de l'art = international repertory of the literature of art.
(5) Tiré de http://oclc.org/news/releases/2014/201415dublin.en.html : « About The Future of Art Bibliography. The Future of Art Bibliography (FAB) initiative was developed by The Getty Research Institute with initial funding from the Samuel H. Kress Foundation, in response to concerns among colleagues in the United States and Europe over limited funding resources for art libraries and international projects. In a series of international meetings, art librarians and historians, publishers, and information technologists reviewed current practices, took stock of changes, and developed more sustainable and collaborative ways of supporting the art history bibliography of the future. An international community-driven initiative arose from these early FAB meetings, one that envisions a global approach to an ever-evolving definition of bibliography. »
(6) Tiré de http://oclc.org/news/releases/2014/201415dublin.en.html : « About OCLC : Founded in 1967, OCLC is a nonprofit, membership, computer library service and research organization dedicated to the public purposes of furthering access to the world’s information and reducing library costs. More than 74,000 libraries in 170 countries have used OCLC services to locate, acquire, catalog, lend, preserve and manage library materials. Researchers, students, faculty, scholars, professional librarians and other information seekers use OCLC services to obtain bibliographic, abstract and full-text information when and where they need it. OCLC and its member libraries cooperatively produce and maintain WorldCat, the world’s largest online database for discovery of library resources. Search WorldCat.org on the Web. For more information, visit the OCLC website. »
Bibliographie
Art Discovery Group Catalogue [en ligne]. [Consulté le 26 novembre 2014]. Disponible à l’adresse : http://www.artlibraries.worldcat.org/
ARTLIBRARIES.NET, 2010a. Informations générales. artlibraries.net : Virtual Catalogue for Art History [en ligne]. [Consulté le 26 novembre 2014]. Disponible à l’adresse : http://www.artlibraries.net/allg_infos_fr.php
ARTLIBRARIES.NET, 2010b. Comité. artlibraries.net : Virtual Catalogue for Art History [en ligne]. [Consulté le 26 novembre 2014]. Disponible à l’adresse : http://www.artlibraries.net/allg_infos_fr.php#Comite
HOYER, Rüdiger, 2012. artlibraries.net, WorldCat and common initiatives for the future of art bibliography : IFLA, Helsinki, 2012 [en ligne]. [Consulté le 24 novembre 2014]. Publications from Art Libraries, Congress papers, Helsinky 2012, Supplementary Papers. Disponible à l’adresse : http://www.ifla.org/files/assets/art-libraries/art-ibraries-conference-papers/hoyer-2012.pdf
J. PAUL GETTY TRUST, 2010. The Future of Art Bibliography (FAB). The Getty Research Institute [en ligne]. 2010. [Consulté le 26 novembre 2014]. Disponible à l’adresse : http://www.getty.edu/research/institute/development_collaborations/fab/index.html
J. PAUL GETTY TRUST, 2010. The Getty Research Institute (GRI) [en ligne]. 2010. [Consulté le 26 novembre 2014]. Disponible à l’adresse : http://www.getty.edu/research/
OCLC, 2012. Data Integration in the Worldcat Central Index. OCLC : The World’s Libraries, Connected [en ligne]. 2012. [Consulté le 9 décembre 2014]. Disponible à l’adresse : http://www.oclc.org/content/dam/oclc/services/brochures/214567cUSF_Publisher_WorldCat_Central_Index_Info.pdf
OCLC, 2014a. Art Discovery Group Catalogue [enregistrement vidéo]. Youtube [en ligne] 26 août 2014. [Consulté le 26 novembre 2014]. Disponible à l’adresse : https://www.youtube.com/watch?v=Wzg8wqw7e58
OCLC, 2014b. New Art Discovery Group Catalogue launches. OCLC : The World’s Libraries, Connected [en ligne]. 1 mai 2014. [Consulté le 9 décembre 2014]. Disponible à l’adresse : http://oclc.org/news/releases/2014/201415dublin.en.html
RAYMOND, Hélène, 2012. 5es Rencontres artlibraries.net. Bulletin des bibliothèques de France [en ligne], n° 6, 2012 [consulté le 09 décembre 2014]. Disponible à l’adresse : http://bbf.enssib.fr/consulter/bbf-2012-06-0067-008. ISSN 1292-8399.
RIJKSMUSEUM RESEARCH LIBRARY, 2014. Art Discovery Group Catalogue. Rijksmuseum Research Library [en ligne]. Octobre 2014. [Consulté le 24 novembre 2014]. Disponible à l’adresse : http://library.rijksmuseum.nl/ArtDiscovery.htm
Samuel H. Kress Foundation, 2012 [en ligne]. [Consulté le 26 novembre 2014].Disponible à l’adresse : http://www.kressfoundation.org
Les dilemmes éthiques dans la société de l'information : comment les codes d'éthique permettent de trouver des solutions. Une conférence conjointe du Comité FAIFE de l'IFLA et de Globethics.net au Château de Bossey, les 14 et 15 août 2014
Amélie Vallotton Preisig, Comité FAIFE (Freedom of Access to Information and Freedom of Expression) de l'IFLA
Les dilemmes éthiques dans la société de l'information : comment les codes d'éthique permettent de trouver des solutions. Une conférence conjointe du Comité FAIFE de l'IFLA et de Globethics.net au Château de Bossey, les 14 et 15 août 2014
C'est dans le cadre accueillant du Château de Bossey que se sont réunis durant deux jours 28 professionnels de l'information venus de trois continents pour partager leurs réflexions éthiques.
Dans une société dite de l'information, il va de soi que les spécialistes de l'information que sont les bibliothécaires, les archivistes et les documentalistes sont au cœur de nombreux processus qui croisent leur activité et la dépassent. Ces processus informationnels s'inscrivent dans un tissu économique, juridique, politique et technique dont chacun a une connaissance limitée et sur lequel personne n'a vraiment de prise. De plus, la technologie et les pratiques évoluent plus vite que la législation, ce qui implique l'émergence de nouvelles problématiques d'ordre éthique. Dans ces conditions, le professionnel se trouve souvent démuni face à des responsabilités nouvelles.
Consciente de ces difficultés, l'IFLA a endossé en 2012 un code d'éthique international pour les bibliothécaires et les spécialistes de l'information, dont le but est d'identifier les missions centrales des spécialistes de l'information et les problématiques qui en découlent, pour ensuite tenter d'orienter la prise de décision par l'énoncé de principes propres à la profession. Il s'agit maintenant de faire en sorte que les professionnels s'approprient cet outil et s'appuient sur lui pour assumer leurs responsabilités au quotidien. C'était là l'objet de la conférence de cet été.
Suite à une première matinée de conférences plénières introductives, le groupe s'est scindé en deux ateliers, le premier portant sur les codes, leur développement et leur usage, le second se concentrant sur les situations quotidiennes impliquant des questionnements éthiques sur le lieu de travail des professionnels. De retour en plénière pour le dernier après-midi, le groupe a pu partager les réflexions des ateliers et proposer des recommandations.
Pour n'en citer que trois, il s'agirait d'encourager les associations nationales à réviser leur code, ou, le cas échéant à en développer un, pour exprimer leur spécificités locales ; à renforcer et clarifier les codes d'éthique en les associant à des collections d'études de cas ; et enfin à introduire systématiquement un module d'enseignement d'éthique professionnelle dans tous les cursus de formation. L'association suisse BIS peut être fière d'avoir été parmi les premières à revoir son code et à avoir mis en place un groupe de travail permanent consacré à l'éthique professionnelle. Par contre, notre pays est encore assez pauvre en ce qui concerne la formation, puisque seule la HEG propose un cours de déontologie.
Nous n’entrons pas ici dans le détail des interventions et des discussions, qui ont touché des thèmes aussi variés et importants que le droit d’auteur, les relations Nord/Sud, la révision du code d’éthique suisse, le droit à la vie privée en Serbie et aux Etats-Unis, la protection des mineurs en Côte d’Ivoire, etc. Dans les ateliers, les présentations de cas pratiques, locaux, ont donné lieu à des discussions très engagées et d’intérêt global. Toutes les interventions, un résumé des discussions, ainsi que les recommandations ont été publiées dans les actes de la conférence. Le livre est accessible en plein texte sur le site de Globethics.net http://www.globethics.net/fr/web/ge/publications (accès direct: http://goo.gl/wrJi7R). On peut également le commander en version papier via le même site.
Numérique et patrimoine culturel : quels impacts ? Un condensé du Satellite Meeting IFLA Préservation et Conservation d’août 2014
Numérique et patrimoine culturel : quels impacts ? Un condensé du Satellite Meeting IFLA Préservation et Conservation d’août 2014
Le Satellite Meeting de la section IFLA Préservation et Conservation (P&C)(1) organisé à Genève les 13 et le 14 août 2014 à la Bibliothèque de l’Institut des Hautes Etudes Internationales et du Développement (IHEID)(2) a été l’occasion de réunir quelque 90 professionnels suisses et du monde entier, sur un thème essentiel : « Le Patrimoine culturel à l’ère numérique ». Autour de la question du patrimoine culturel, les défis à relever sont nombreux : d’un côté, destructions, vols, pillages, catastrophes naturelles, incendie, guerres…de l’autre, préservation, archivage, conservation et numérisation.
Le patrimoine culturel apparait comme un thème éternel et abondamment traité, mais il prend un autre éclairage quand on le considère à l`ère du numérique. De nombreuses possibilités s’offrent pour sa préservation et sa conservation en recourant à un certain nombre de méthodes, à des « plans de sauvetage » quand cela s’avère indispensable, ou de techniques spécifiques selon les matériaux et leur durabilité. Conserver l’héritage culturel de l’humanité est un vrai défi à relever, auquel s’emploient de nombreux spécialistes de par le monde. En cela, le Satellite Meeting Préservation & Conservation de l’IFLA représenta un réel moment de partage et d’échange entre professionnels concernés ou sensibilisés par cette question.
Il serait difficile de retranscrire ici l’ensemble des communications et des débats durant ces deux jours. Seuls quelques aspects sont donc développés. Le programme proposé est un judicieux équilibre entre expériences suisses (à la fois genevoises, romandes et suisses-allemandes) et internationales (avec des interventions d’Australie, d’Italie, de Nouvelle-Zélande, Afrique du Sud, Algérie, Etats-Unis, Pakistan, Malaisie, Indonésie, Iran).
Deux conférences dites inaugurales ont d’entrée de jeu posé la problématique : celle d’Alex Byrne, bibliothécaire d’Etat et directeur de la bibliothèque de Nouvelle-Galles du Sud (New South Wales) en Australie(3) est centrée sur les institutions de la mémoire qui représentent un lien essentiel entre passé, présent et futur. Alexis Rivier, conservateur en charge de la bibliothèque numérique à la Bibliothèque de Genève, détaille la numérisation du patrimoine intellectuel genevois qui présente des incidences sur la conservation des documents.
D’autres conférences évoquent ensuite Genève et son riche patrimoine : celle d’Anouk Dunant Gonzenbach, archiviste, qui détaille la politique d’archivage à long terme aux Archives de l’Etat de Genève et celle de Nelly Cauliez, conservateur et responsable de l’Unité Régie de la Bibliothèque de Genève, qui prend l’angle, essentiel si ce n’est primordial, de la formation au sauvetage des collections à la Bibliothèque de Genève. Très proche est la communication de Maria Teresa Shazar, à propos du cas qui s’est présenté en automne 2013 lors de travaux à l’Abbaye de St Maurice, travaux ayant entrainé d’importants dommages aux collections entreposées. Avec Randy Silverman, conservateur à la Marriott Library de l’Université de l’Utah, il va s’agir de trouver les moyens les plus adéquats pour sauver des séismes des objets en verre ou des supports très fragiles. Christophe Jacobs, président du comité français du Bouclier bleu(4), présente quant à lui les différentes actions de cette association créée en 2001, afin de soutenir en France l’application de la convention de La Haye sur la protection des biens culturels en cas de conflit.
Un volet parallèle de cette conférence dédié au patrimoine culturel est l’aspect conservation et préservation grâce à la technologie numérique : Memoriav, exposé par Yves Niederhaüser responsable du domaine video-TV de cette organisme, est à la fois un réseau mais également une plateforme pour l’accès au patrimoine audiovisuel suisse(5); digiTUR, projet mis en place par la ville et le canton de Zürich pour sauvegarder leur patrimoine culturel(6) est présenté par Susanne Bliggenstorfer et Eva Martina Hanke, respectivement directrice et chargée de projet de la ZentralBibliothek de Zürich. La Bibliothèque nationale d’Iran (représentée par Afsaneh Teymourikhani et Saeedeh Akbari Daryan du département des Ressources numériques) développe un projet intitulé « National Persistent Identifier » afin d’identifier les objets numériques, tandis que l’Afrique du Sud numérise des collections photographiques (Nellie Somers, Université de KwaZulu-Natal). Enfin, le projet « e-manuscripta.ch », plateforme de manuscrits numérisés provenant des archives et bibliothèques suisses, est exposé par Eva Martina Hanke, chargée de projet de la ZentralBibliothek de Zürich.
D’autres aspects ont été traités, notamment les questions juridiques avec « le Traité de Marrakech visant à favoriser l’accès à la lecture aux personnes aveugles, déficientes visuelles ou ayant d’autres difficultés » (Rafael Ferrez Vasquez, OMPI)(7), mais aussi la question des archives privées dans les bibliothèques et les musées avec Kevin Racine du Musée d’histoire naturelle de Genève ; l’action de l’IFLA par rapport aux thèmes de la préservation et de la conservation avec Geneviève Clavel, de la Bibliothèque nationale suisse et par ailleurs membre du Governing Board de l’IFLA ; les programmes de formation des étudiants en sciences de l’information à la thématique numérique par Porchia Moore (Université de Caroline du Sud aux Etats-Unis). Enfin citons la troisième conférence plénière donnée par Winston Roberts de la Bibliothèque nationale de Nouvelle-Zélande, évoquant avec sensibilité et profondeur les commémorations récentes dans son pays du centenaire de la Première guerre mondiale.
Voici donc, très condensés, les thèmes principaux débattus lors du Satellite Meeting genevois. Variété, diversité, richesse des exemples et des expériences de par le monde et en Suisse sont des traits marquants de ces deux journées. Il est à souhaiter que l’IFLA s’arrête plus souvent à proximité de Genève pour renouveler l’évènement.
Notes
(1) http://www.ifla.org/preservation-and-conservation
Le meeting a été organisé en partenariat avec :
- l’Association genevoise des bibliothécaires diplômés en information documentaire (AGBD),
- the Association of International Librarians Specialists (AILIS),
- la Haute école de gestion, Département Information documentaire (HEG-ID),
- l’Association internationale francophone des bibliothécaires documentalistes (AIFBD)
- le Programme de formation continue Archives, Libraries and Information Science (ALIS) des Universités de Berne et de Lausanne
(2) http://graduateinstitute.ch/fr/home/research/library.html
(3) Cette communication fut présentée par Winston Roberts, car un vol de monnaies anciennes et précieuses eut lieu à la bibliothèque de Nouvelle-Galles du Sud avant la conférence empêchant A. Byrne de se déplacer : c’est une parfaite illustration des dangers que peut subir le patrimoine culturel
(4) http://www.bouclier-bleu.fr/
(6) http://www.zb.uzh.ch/spezialsammlungen/digitur/index.html.de
(7) Ce thème qui ne rentre pas véritablement dans le thème général de la conférence a été pris au vu de son actualité et du rôle joué par l’OMPI dont le siège est à Genève
Spécial IFLA-PAC 2014
Communications du Satellite Meeting de la section Préservation et Conservation (P&C) de l'IFLA (International Federation of Library Associations and institutions) organisé à Genève les 13 et 14 août 2014 à la Bibliothèque de l’Institut des Hautes Etudes Internationales et du Développement (IHEID).
13.08.2014 (Jour 1 / Day 1) :
- Alex Byrne: Memory institution shaping the past, present and future [presentation] / [paper]
- Alexis Rivier: Bibliothèque numérique, Bibliothèque de Genève [presentation] / [paper]
- Christophe Jacobs: Bouclier Bleu: une démarche, un réseau, des actions [presentation]
- Nelly Cauliez: La formation au sauvetage des collections à la Bibliothèque de Genève [presentation]
- Maria Teresa Shazar: Dégâts dus aux travaux: le cas de l'Abbaye de St-Maurice, automne 2013 [presentation]
- Randy Silverman: Don't break them: seism storage strategies for glass and other fragile library and archival media [presentation] / [paper]
- Saima Qutab: an investigation of conservation & preservation practices of intellectual cultural heritagge in Pakistan [paper]
- Anisur Rahman: Technical plan and strategic program of digital preservation project for long term sustainability of the old manuscripts and rare materials Dhaka University Library [paper]
- Ornella Foglieni: Something about the recent thefts in the Italian libraries [paper]
- Yves Niederhäuser: Memoriav, un réseau pour la préservation et une plate-forme pour l'accès au patrimoine audiovisuel suisse [presentation] / [paper]
- Kevin Racine: Des archives privées dans les bibliothèques et les musées : bénéfice ou charge ? [presentation]
- Susanna Bliggenstorfer et Eva Martina Hanke: digiTUR : safeguarding the cultural heritage from the City and Canton of Zurich [presentation]
- Anouk Dunant-Gonzenbach: Le patrimoine archivistique numérique : les défis de la conservation à très long terme [presentation] / [paper]
- Khedidja Oulm: La législation du patrimoine cinématographique en Algérie [presentation] / [paper]
- Rafael Vazquez: Marrakesh Treaty to Facilitate Access to Published Works for Persons Who Are Blind, Visually Impaired or Otherwise Print Disabled [presentation]
- Geneviève Clavel: Preservation and Conservation activities at IFLA: what we do and how you can get involved [presentation]
- Maurizio Lunghi: Family archives [presentation] / [paper]
- Porchia Moore: Cultural heritage informatics leadership librarians : how an American Library and Information Science Program is changing the course of preservation in digital age [presentation] / [paper]
- Afsaneh Teymourikhani and Saeedeh Akbari-Daryan: National Persistent Identifier for digital objects system of National Library and Archive of Islamic Republic of Iran : a project for ensuring the preservation of documentary heritage for future generations [presentation] / [paper]
- Nellie Sommers: Digital scanning of photographs in archival collections South Africa [presentation] [paper]
- Eva Martina Hanke: e-manuscripta.ch, the platform for digitised manuscripts from Swiss Libraries and Archives [presentation]
14.08.2014 (Jour 2 / Day 2)
- Winston Roberts: Digital access to cultural heritage information at National Library of New Zealand with a particular reference to the commemoration of the centenary of the First World War [presentation]
- Barbara Shack: IdeasBox [presentation] / [video:227 Mo !]
L’information grise : comment trouver des informations difficiles d’accès : compte-rendu de la 11ème Journée franco-suisse en intelligence économique et veille stratégique, 12 juin 2014, Haute école de gestion de Neuchâtel
Maurizio Velletri, Haute Ecole de Gestion, Genève
Hélène Madinier, Haute Ecole de Gestion, Genève
L’information grise : Comment trouver des informations difficiles d’accès : compte-rendu de la 11ème Journée franco-suisse en intelligence économique et veille stratégique, 12 juin 2014, Haute école de gestion de Neuchâtel
L’information grise, véritablement stratégique, celle qui permet à l’entreprise de prendre la bonne décision au bon moment, demeure rare, cachée, difficilement accessible : souvent de source informelle, parfois fragmentée, nécessitant une ou plusieurs étapes d’élaboration, elle constitue la matière première de l’intelligence économique.
Entre l’information « blanche » accessible à tous, et l’information « noire », secrète et interdite, l’information « grise » se définit par les difficultés à connaître son existence, à la localiser, à y accéder.
« Cette journée de réflexion visait à revisiter les fondamentaux de la recherche d’information à forte valeur ajoutée. En abordant notamment l’expertise des services de renseignements publics ou privés, ainsi que les dernières techniques des spécialistes de l’investigation à l’heure du web 2.0 ou 3.0 », résume François Courvoisier, professeur à la HEG Arc et organisateur de cette journée.
Les hautes écoles de gestion Arc et Genève ont organisé, le 12 juin 2014 à Neuchâtel, la 11ème journée franco-suisse en intelligence économique et veille stratégique en collaboration avec l’Université de Franche-Comté. Plus de 50 participants, dirigeants et responsables d’entreprises suisses et françaises ainsi que des représentants du monde académique, ont pris part à cette manifestation durant laquelle six intervenants se sont exprimés sur l’accès aux informations cachées.
Après un message d’ouverture du colloque prononcée par Olivier Kubli, directeur de la HEG Arc, ainsi qu’une allocution de Christine Gaillard, présidente du Conseil communal de la Ville de Neuchâtel, les premières interventions ont débuté.
L’information grise : définition et problématiques, par Frédéric Martinet
Frédéric Martinet, consultant et formateur en veille, propose la définition suivante, de l'ADBS : « l'information grise est de l'information licitement accessible, mais caractérisée par des difficultés dans la connaissance de son existence ou de son accès ». L'acquisition de cette information n'est pas illégale, mais pas forcément éthique. Elle peut résulter de failles de sécurité, d’inattention, de manque de sensibilisation. Elle est souvent informelle. Elle peut être implicite, déduite, calculée, devinée. Elle a souvent une valeur élevée.
Elle peut se trouver sur des espaces privés sur le web (des groupes LinkedIn par exemple) et de façon plus générale, sur des espaces non indexés par les moteurs de recherche.
Car contrairement à ce qu'on pourrait imaginer, Google n'indexe pas tout : certains contenus sont protégés, accessibles uniquement par mot de passe, ou de type multimedia, ou protégés par le droit d'auteur (DMCA), et la pratique du « cloaking » que fait Google, consistant à présenter en priorité les résultats concernant son propre pays à l'internaute ne facilite pas la recherche d'information.
Les méthodes permettant de retrouver ce type d'informations légalement sont variées et peuvent se baser sur les failles de sécurité informatiques (utiliser des informations issues d'intranets mal sécurisés indexés par les moteurs de recherche) ou sur les failles humaines (guetter ceux qui parlent trop sur les réseaux sociaux, aller écouter des conversations des concurrents dans un restaurant à la pause-déjeuner).
Savoir bien utiliser un moteur de recherche est également une méthode efficace pour recueillir des informations grises. Notamment, savoir cibler des types de sites et de fichier peut être très utile (voir par exemple des requêtes spécifiques comme "document confidentiel" site: gouv.fr ou encore prezi.com glaxosmithline confidential, Google indexant Prezi quand on crée un compte Prezi en ligne).
Attention toutefois à ne jamais franchir la ligne rouge, c’est-à-dire qu'il ne faut jamais par exemple essayer de rentrer un mot de passe.
De manière générale, avant de focaliser sur ces informations grises, il faut penser à traiter et bien exploiter l'information blanche, éviter les pratiques risquées comme l'ingénierie sociale ou le social engineering, qui consiste à rentrer en confiance avec les gens pour leur soutirer de l'information (ce qui peut relever de l'abus de confiance) et privilégier d'une part la sociabilité comme les échanges lors de rencontres, conférences, et de l'autre une exploitation fine des moteurs de recherche.
Information grise et lutte contre la contrefaçon, par Michel Arnoux
Dans son exposé intitulé Information grise et lutte contre la contrefaçon, Michel Arnoux, responsable du service anti-contrefaçon de la Fédération de l’industrie horlogère suisse a montré comment la FH utilisait des informations a priori anodines, pour identifier les fabricants de contrefaçons horlogères.
Il faut savoir que la FH compte 500 membres, et regroupe 250 marques. Elle fédère environ 50 marques dans un groupement anti-contrefaçon, qui finance cette lutte, spécifiquement sur Internet.
Les estimations de 2013 se montent à environ 33 millions de fausses pièces, alors que 29 millions de montres suisses ont été produites.
L'équipe en charge de la lutte contre la contrefaçon collecte les informations grises qui vont lui permettre de faire des liens et reconstituer des réseaux.
Les recherches d'informations se basent d'abord sur des données douanières : nombre de saisies aux frontières, types de produits, origine.
La FH procède à des investigations en faisant des achats-tests sur Internet. Il faut ensuite garder le paquet et s'adresser au service de livraison UPS pour obtenir les adresses correspondant à ceux qui ont payé le colis, rechercher ces adresses sur Google, et puis de fil en aiguille, identifier le grossiste.
L'examen des fausses montres permet de comparer et d'identifier des familles de contrefaçons. c'est ainsi que l'examen de bracelets, qui comportaient un composant chimique volatile utilisé dans l'industrie automobile, a permis d'identifier les fabricants.
Enfin, sur Internet, un logiciel va comparer les adresses de sites donnés en se basant sur l'identification du gestionnaire de domaine.
Toutes ces informations sont ensuite enregistrées dans une base de données.
Cet exposé a clairement montré combien il était utile de savoir rechercher ces informations d'accès difficile, mais légal (informations grises) puis de les traiter.
Deux exposés, plus axés sur la sécurité, ont ensuite été présentés.
Information grise et sécurité, par André Duvillard
Le premier, d'André Duvillard, délégué de la Confédération suisse et des cantons au Réseau national de sécurité a présenté le réseau national de sécurité qui permet de réagir aux menaces et aux dangers relevant de la politique de sécurité. Le délégué coordonne l'action des cantons et de la confédération, et il a au-dessus de lui deux conseillers fédéraux et deux conseillers d'Etat. Ses principes d’action sont la légalité, la proportionnalité et l'opportunité.
Le réseau peut bien entendu procéder à des écoutes téléphoniques préventives, et la meilleure source de renseignement est clairement le renseignement humain (HUMINT).
Le traitement de la source humaine, par Bruno Migeot
C'est précisément le renseignement humain, ce type d'information grise spécifique, qu'a présenté Bruno Migeot, ancien officier de la gendarmerie nationale responsable de l’antenne Intelligence économique de la région de gendarmerie de Franche-Comté.
Partant également du constat que le renseignement humain est essentiel, Bruno Migeot a expliqué qu’il faut trouver les méthodes adéquates pour obtenir les renseignements souhaités. D'autre part il est nécessaire de disposer de plusieurs sources pour confirmer une information (« one source, no source »). L'humain est fragile et on peut agir sur lui de différentes façons : le flatter, avancer masqué (scinder la recherche d’information en plusieurs sujets) et de façon générale utiliser un des moyens MICES : M : Money, I : Ideology, C : Compromission, E : Ego, S : Sex.
Pour obtenir la confiance d'une personne, l'ingénierie sociale est indiquée.
Il s'agit ensuite de faire preuve de convivialité, de ténacité, de discrétion et de diplomatie, et de façon plus classique en veille, rédiger un plan de renseignement et de recherche, puis consigner les informations recueillies dans des notes d'étonnement et coter les différentes sources.
Trouver l’information grise dans un environnement B2B hautement concurrentiel, par Annette Siegl
Annette Siegl a ensuite présenté le cas de la recherche d'informations grises à Faurecia, entreprise de sous-traitance pour l'automobile, dans le cadre de la recherche et développement. Faurecia compte environ 94'000 employés et 30 centres de recherche et développement. La veille est ici effectuée pour la section Faurecia automotive exteriors, qui compte 7'000 employés. Il s'agit de veille technologique.
Ce qui est utile ici, c'est de savoir qui travaille avec qui, avec quels matériaux, et quelles sont les innovations et brevets déposés.
Pour cela, Annette Siegl, qui est seule pour faire sa veille, utilise les sources d'informations grises suivantes, à savoir : les réseaux sociaux, les blogs, les forums, les sites de photos et de vidéos, les sites comme Slideshare et Docstoc, les sites d'évaluation d’entreprise comme Kununu (pour la région DACH) et Glassdoor (US), ainsi que des salons professionnels et des banques de données spécialisées externes comme A2Mac1 et Espacenet, pour la recherche de brevets.
Elle utilise également des sources d'informations blanches comme les sites de presse généraliste et spécialisé, et les sites les sites internet de concurrents, clients, fournisseurs.
Voici quelques exemples d'informations grises identifiées à partir de ces sources :
- le profil d’un professionnel sur LinkedIn qui donne des informations très précises sur son travail chez un concurrent ;
- une vidéo d’un essai crash sur YouTube, et en particulier le nombre de gens qui l'ont vue (72'000, ici) et surtout les commentaires ;
- une vidéo sur la production, l’intérieur, la logistique, les processus et le personnel de l’usine d’un concurrent ;
- le Forum de discussion motortalk.de ;
- le site d'évaluation Kununu, qui donne des opinions des collaborateurs.
Par ailleurs, il faut aussi savoir qu’on trouve de l’information technologique utile dans les manuels d’utilisation et de réparation.
Bien entendu, il est nécessaire de disposer des compétences ad hoc pour évaluer et traiter ensuite ces informations.
Luxe, pharma et chocolat : comment utiliser l’information grise comme outil stratégique ? par Stéphanie Perroud
C'est enfin Stéphanie Perroud, Directrice associée chez Pélissier & Perroud, Service d’information et de veille professionnelle, qui a présenté la manière dont P&P utilise l'information grise. Celle-ci est utilisée au quotidien, que ce soit par le moyen du réseau d’experts de P&P, dans 60 pays du monde, ou par l'accès à des banques de données spécialisées.
P&P couvre tous les domaines et fait tout type de veille. L'entreprise identifie trois niveaux de sources d'information :
- les sources d'informations publiques,
- les sources à accès restreint,
- l'appel direct auprès d’une personne qui détient l’information (avec un prétexte).
Par exemple, dans le domaine de la pharmacie, l'entreprise devait trouver des données de marché, des volumes de stockage et des prix, ce qui a pu être obtenu avec un appel -avec prétexte-. Dans le domaine du chocolat, P&P a mis en veille les concurrents d’un client dans divers pays émergents, en surveillance la presse internationale et en faisant appel aux partenaires locaux en Asie et Europe de l’Est.
Depuis 2007, les demandes faites par les clients ont passablement évolué. Elles sont passées d’une simple revue de presse mensuelle sur une société à une surveillance quotidienne de la presse sur une société avec des mots-clés précis. A l’heure actuelle, les demandes se complexifient : différents types de veille (concurrentielle, sectorielle, brevets, etc.), des études de marchés, recherche de fournisseurs dans des domaines techniques, etc.
Dans tous les cas P&P suit la loi sur la protection des données (principes de licéité, bonne foi et proportionnalité) et s'assure que ses partenaires locaux agissent avec légalité.