N° 16 décembre 2015
Sommaire - N° 16, Décembre 2015
Études et recherches :
-
Le projet DLCM - Eliane Blumer et Pierre-Yves Burgi
Comptes-rendus d'expériences :
-
Aktuelle juristische Herausforderungen für Biblioteken und die wissenschaftliche Informationsversorgung - Danielle Kaufmann
-
Les archivistes comme spécialistes de la gestion de l'information: conseil et soutien des Archives de l'Etat du Valais auprès de l'Administration cantonale et des communes valaisannes - Alain Dubois et Florian Vionnet
-
Swissbib: Katalog, Datahub, Plattform - Oliver Schihin
-
Voltaire à Genève: une affaire sérieuse - Flavio Borda d'Agua et François Jacob
-
La plateforme de prêt de livres numériques e-bibliomedia - Laurent Voisard
-
La veille et l'intelligence économique dans le marché de l'emploi en Suisse romande - Raphaël Rey
Événements :
-
Compte rendu du CERN workshop sur les innovations dans la communication scientifique (OAI9), 17-19 juin 2015 - Salomé Rohr et Anne Gentil-Beccot
-
Le patrimoine : un enjeu pour les bibliothèques.. mais aussi pour le public: retour sur la 2ème école d'été internationale francophone en SIB - Hésione Guémard, Bassirou Ba et Paul Faure
Ouvrages parus en science de l'information :
-
Le crépuscule des bibliothèques, Virgile Stark - Aurélie Vieux
-
Au pays de Numerix, Alexandre Moatti - Alain Jacquesson
Editorial
Comité de rédaction
Editorial
RESSI a atteint ses 10 ans d’existence ! Le premier numéro a effectivement paru en janvier 2005, et depuis cinq ans, c’est désormais sur une périodicité annuelle que RESSI contribue à diffuser l’état de la recherche et de la pratique de la science de l’information en Suisse. Essentiellement en Suisse romande, mais aussi dans l’ensemble de la Suisse, et les pays francophones.
C’est ainsi que nous avons le plaisir de vous proposer un seizième numéro riche en contributions, et multilingue (français, anglais et allemand).
Dans la rubrique « Etudes et recherches », un article de deux chercheurs, Eliane Blumer, coordinatrice du projet, et collaboratrice scientifique à l’Université de Genève et Pierre-Yves Burgi, chef de projet, directeur suppléant de la division Systèmes et technologies de l'information et de la communication de l’Université de Genève, décrit le projet national sur la gestion du cycle de vie des données appliquées à la recherche. L’article, en anglais, intitulé Data Life-Cycle Management Project: SUC P2 2015-2018, présente les objectifs, la méthodologie et les questions de recherche de ce projet financé par la Confédération, coordonné par l’Université de Genève et réalisé en partenariat avec sept autres établissements suisses d’enseignement supérieur.
On trouvera sous la rubrique « Compte rendu d’expérience » un premier article de Danielle Kauffmann, responsable du service juridique de la bibliothèque de l’Université de Bâle. Le texte fait un état des lieux sur la révision prochaine de la loi suisse sur le droit d’auteur et les problèmes qui se posent –et actions à entreprendre-pour les bibliothèques et services d’information scientifiques. Intitulé Aktuelle juristische Herausforderungen für Bibliotheken und die wissenschaftliche Informationsversorgung, et rédigé en allemand, l‘article est accompagné d’un résumé exhaustif en français réalisé par Nicolas Prongué, assistant de recherche à la HEG-Genève
Le deuxième article de la rubrique est intitulé Les archivistes comme spécialistes de la gestion de l’information : conseil et soutien des Archives de l’Etat du Valais auprès de l’Administration cantonale et des communes valaisannes, et écrit par deux archivistes du Canton du Valais, Alain Dubois, archiviste cantonal, et Florian Vionnet, archiviste-records manager. L’article rappelle que les archivistes sont d’abord des professionnels de la gestion de l’information et fait un bilan du projet valaisan, qui grâce à la mise en œuvre de guides et d’un plan de formation, permet de positionner les archivistes comme des spécialistes reconnus de la gestion de l’information au sein des administrations communales et cantonale.
Le troisième article de la rubrique, intitulé swissbib, Katalog, data hub, Plattform, et rédigé par Oliver Schihin, responsable du projet swissbib à la bibliothèque de l’université de Bâle, décrit le méta-catalogue swissbib, qui permet d’interroger simultanément les catalogues des bibliothèques des universités suisses. Ses origines, ses composantes et ses fonctionnalités sont détaillées dans un article en allemand, précédé d’un résumé en français.
Le quatrième article de la rubrique présente un autre catalogue, le catalogue Volage, qui est le catalogue en ligne des manuscrits du Musée Voltaire à Genève. Co-écrit par le conservateur François Jacob et par l’adjoint scientifique Flávio Borda d’Àgua, tous deux rattachés au Musée Voltaire, l’article intitulé Voltaire à Genève : une affaire sérieuse, rappelle la raison d’être, l’historique du catalogue ainsi que son contenu, et est agrémenté de photos.
Le cinquième article de la rubrique «Compte rendu d’expérience», rédigé par Laurent Voisard, directeur de Bibliomedia Suisse à Lausanne, donne un bilan de la plateforme e-bibliomedia, un an après son lancement. Dans son article intitulé La plateforme de prêt de livres numériques e-bibliomedia, il décrit sa genèse, la politique d’acquisition, le lectorat, les statistiques de prêt et les principaux enseignements.
Le dernier article de cette rubrique relate les résultats d’une étude provenant d’une veille de plusieurs mois sur les offres d’emploi en veille et intelligence économique en Suisse romande. Ecrit par Raphaël Rey, assistant à la HEG de Genève, spécialisé dans les outils de veille et de KM, l’article qui a pour titre La veille et l’intelligence économique dans le marché de l’emploi en Suisse romande indique quels sont les secteurs économiques qui recrutent, quels sont les types de veille demandés, quelle est la terminologie utilisée, et quels sont les profils recherchés.
Dans la rubrique «Compte rendu d’événements», on trouvera un premier article relatant la dernière conférence du CERN sur les innovations concernant la communication scientifique. Sous la plume d’Anne Gentil-Beccot et de Salomé Rohr, bibliothécaires à la bibliothèque du CERN, intitulé Compte rendu du CERN Workshop on Innovations in Scholarly Communication (OAI9), 17-19 juin 2015, Genève, cet article, rédigé en français, donne le résumé des communications de toutes les sessions, incluant aussi bien la technique, les processus, les barrières et impacts, l’assurance de la qualité, l’institution comme maison d’édition, que le traitement et la préservation numérique d’objets scientifiques complexes.
Un dernier article relate le contenu de la deuxième école d’été internationale francophone en science de l’information et des bibliothèques. Intitulé Le patrimoine : un enjeu pour les bibliothèques… mais aussi pour le public! , co-écrit par plusieurs participants, Hésione Guémard, Bassirou Ba et Paul Faure, étudiants en Master 2 de l’ENSSIB « Politique des bibliothèques et de la documentation », l’article détaille les enjeux des projets participatifs dans la valorisation du patrimoine.
Finalement, dans la rubrique «Recensions», il est proposé deux articles, recensant deux ouvrages.
Le premier est écrit par Aurélie Vieux, adjointe scientifique à la division de l’information scientifique (DIS) de l’Université de Genève. Intitulé Le livre et les bibliothèques : c’était mieux avant il rend compte du livre polémique de Virgile Stark, « Crépuscule des bibliothèques », publié en 2015, qui prédit la fin prochaine des bibliothèques. La recension d’Aurélie Vieux résume le livre et en fait une critique sans concession.
Et le deuxième, sous la plume d’Alain Jacquesson, ancien directeur de la Bibliothèque de Genève, rend compte du livre Au pays de Numérix d’Alexandre Moatti, publié en 2015. Celui-ci décrit de manière désabusée les ratés de la politique française sur le numérique (numérisation d’ouvrages, moteur de recherche).
Nous remercions vivement les auteurs pour leurs contributions, les réviseurs, les relecteurs et ceux qui ont contribué à la relecture et la mise en ligne de RESSI, et nous vous invitons à nous soumettre des propositions d’article en tout temps.
Le Comité de rédaction
Data Life-Cycle Management Project: SUC P2 2015-2018
Eliane Blumer, Division Systèmes et technologies de l'information et de la communication (STIC), Université de Genève
Pierre-Yves Burgi, Division Systèmes et technologies de l'information et de la communication (STIC), Université de Genève
Data Life-Cycle Management Project: SUC P2 2015-2018
1. Introduction
With “datafication” of the research sector, we are living in a data deluge era and thus have to address data management before it gets completely out of control. Internationally, the trend to optimize research outcomes by providing the scientific community with access to the original data and knowledge required to reproduce published results strongly contributes to find new solutions to data management. However, caring for scientific data, ensuring their reuse in the future for yet-unknown applications, and ensuring their accessibility and understandability over time requires deep-rooted strategies and established practices and tools that appeal to the digital curation field [1], of which the key elements will be addressed in this manuscript.
Many funding agencies and publishers now impose accessibility to research data in a form that allows reproducibility, but also permits reuse of the generated knowledge. Funding bodies in Europe and USA have therefore started large programs aiming at providing researchers with institutional tools and services to manage, store and give access to their data. For instance, the Economic and Social Research Council (ESRC) in UK has a research data policy since 1995, where issues about data management are cited. In its current version, a data management plan (DMP)(1), a document describing the research project and the handling of data from collection to preservation, stipulates(2): “Planning how you will manage your research data should begin early on in the research process and Economic and Social Research Council applicants who plan to generate data from their research must submit a data management plan as part of their Joint Electronic Submissions application.” Following the same path, in 2003 the National Institutes of Health in USA has mandated data sharing for most grants receiving over $500’000 a year, as specified in its own data sharing policy(3). Moreover, the Organization for Economic Co-Operation and Development (OECD) published in April 2007 its Principles and Guidelines for Access to Research Data from Public Funding(4), a document containing directives for facilitating cost-effective access to digital research data from public funding. Over the past five years, the number of federal agencies with DMP guidelines for grant proposals has been increasing rapidly. For instance:
- 2010: the German Research Foundation mentioned the importance of accurate management of research data(5);
- 2011: the National Science Foundation in USA set up a DMP requirement for all grant proposals(6);
- 2013: the White House Office of Science and Technology Policy demanded that all agencies receiving $100 million or more in research and development funds submit policies for data sharing in order to increase the availability of the products of federally funded research(7);
- 2013: the European Commission published its Guidelines on Data Management in Horizon2020(8) and the League of European Research Universities (LERU) produced a Roadmap for Research Data, which provides a guide for research-intensive universities engaged in data-driven research(9).
- 2014: the Department of Energy in USA requires DMPs in order to apply for a grant(10).
In Switzerland, the Swiss National Science Foundation (SNSF) has not yet asked for such DMPs, but recently, its CEO (Martin Vetterli) mentioned during an Open Science Day in October 2014 at the Swiss Federal Institute of Technology – Lausanne (EPFL) that the SNFS is following the issue very closely(11).
To catch up with these still foreign but approaching trends in dealing with data management, we have set up a national project involving eight institutions (EPFL, HEG / HES-SO, UNIL, UNIBAS, UNIZH, ETHZ, UNIGE and SWITCH). After an extensive period of maturation (almost two years), on September 1st 2015 the kick-off meeting of the “Data Life-Cycle Management” project took place in Bern. This ten-million Swiss Francs and three-year long project aims first and foremost at offering new services to researchers to help them handle their research data. Given that each partner institution has major issues in data management to resolve, the SUC P2 national program provided us with the just-in-time opportunity to gather our respective forces and to grapple with this important and complex topic so as to serve the whole Swiss research community.
Before describing in more details the project, we start with some definitions of what we mean by “data life-cycle management” and what are the links with the digital curation field. We then address the researchers’ needs and discuss how the DLCM project intends to respond to these needs.
1.1. Data Life-Cycle Management in research
In the studied context, “data life-cycle management" (DLCM) refers to the various steps of a specific research process, which can be summarized as: planning, collecting, analyzing, preserving, publishing and re-using scientific data(12).In the sense that we suppose data are digital (which is not necessarily always the case), such a process is akin to digital curation [1], which deals with a set of techniques that address data management on electronic platforms with an emphasis on their maintenance and some added value to them for current and future use. In any case, data management practices cover the entire life cycle, from planning the investigation to conducting it and from backing up data as it is created and used, to long-term preservation of data after the research investigation has concluded. Well thought-out data management is therefore increasingly important due to the evolution of research practices, advances in research equipment, tools and data formats as well as new technologies, which permit sharing and collaborating on international scales(13). Recently developed concepts such as the DCC Curation Life-Cycle Model(14), help us to get a high-level overview of the topic with all the necessary stages involved in (digital) data curation [1]. DLCM is of course reminiscent of the three ages theory [2], in which data pass from the active status (data analysis and processing) to semi-active (e.g., data deposited on a repository linked to a publication), to finally end in a long-term preservation system (archived data, mainly with a passive status). The challenge resides in being able to delimit these stages in a scientific context where such archivistic notions are mainly lacking.
This is why effective data management asks for a variety of competencies provided by information specialists, information technology specialists and researchers. Furthermore, research departments, funding bodies, publishers and other partners may play an important role in data management as well [3,4,5]. Table 1 summarizes for each step the possible attributions of different roles as well as associated tasks. The main message of this table is that data life-cycle management is a teamwork effort, which is not necessarily perceived as such by researchers. That’s why, the implementation of data management asks for a cultural change as well as some flexibility and mutualization in the underlying tasks. This is not to say that research data will be curated following the archivist’s model for administrative documents. Indeed, for instance who would select the content to archive and decide their conservation duration, if not the researchers themselves? However, digital curation principles should be applied to improve the quality of the information to be preserved whenever these principles are deemed reasonable within a scientific context, with the hope that the boundaries between scientific and administrative contexts will blend in the future as researchers become more acquainted with the curation techniques. This could happen in instances where a virtual research environment (for instances in Humanities) evolves towards a digital curation center. Certainly not all scientific disciplines apply for such a transformation, but for those suitable, then data life cycle could become a common language.
Table 1: The Data Life-Cycle steps and corresponding roles [6]. Note that the tasks and responsibilities might vary from one institution to another.
|
Step |
Role |
Possible actions |
|
Plan |
Research Support
|
Keeps up-to-date with latest changes in research politics, new synergies, new obligations |
|
|
Funding Bodies |
Impose Data Policies |
|
|
Researchers |
Know the latest changes in research politics, fill in proposals |
|
|
Libraries |
Assist in filling in data management plans/proposals |
|
Collect |
Research Support |
Provides best practice guidelines |
|
|
Researchers |
Collect data according to their project |
|
|
Computing Services |
Offer infrastructure (i.e. storage) for data collection |
|
|
Industrial partners |
Offer LIMS/ELN solutions connected to repositories |
|
Analyze |
Researchers |
Analyze their data, describe them according to pre-established DMP |
|
|
Computing Services |
Offer infrastructure for data analysis, collaborate with preserving/publishing infrastructure |
|
Preserve |
Research Support |
Points to guidelines |
|
|
Researchers |
Hand data over to preserving infrastructures |
|
|
Library |
Offers expertise for submitting datasets |
|
|
Computing Services |
Offer technical infrastructure for long-term preservation |
|
Publish |
Library |
Provides visibility to published datasets, along with citation mechanisms |
|
|
Publishers |
Link data to associated publications |
|
|
Computing Services |
Offer technical infrastructures for publishing |
|
|
Researchers |
Decide on the basis of established policies the publication modalities (open vs. restricted, time period, etc.) |
|
Reuse |
Researchers |
Predispose for data re-use and sharing |
|
|
Library |
Facilitates data re-use through publication mechanisms |
2. The researchers’ needs
In preparation to the DLCM project, we wanted to identify the researchers’ primary needs at each partner institution, along with the existing solutions in place in those participating institutions. For that, all DLCM partners conducted semi-structured interviews during two months (September and October 2014). The structure of these interviews contained four major parts, namely: (1) initial data and workflow, (2) analysis and data exploration, (3) publication, archiving and long-term data management, and (4) research data in the future: challenges, risks, perspectives. Table 2 presents the compilation of all interviewed disciplines. The results of these interviews have been profusely used to orient the project’s deliverables.
Table 2: List of the interviewed disciplines during the preparation of the DLCM project.
|
Institution |
Number of interviews |
Disciplines |
|
UNIGE |
8 |
Theology, Informatics, Linguistics, German, Cognitive Neuroscience, Educational Sciences, Geomatics, Archeology, Vulnerability, Political Sciences, Medicine (Child Cancer Research), Political Sciences |
|
ETHZ |
8 |
Biosystems Science and Engineering, Seismic Networks, Sociology, Consumer Behavior, Quantum Optics Group, Scientific Computing/Photon Science, Physics |
|
UNIL |
15 |
Social Medicine, Social Sciences, Digital Humanities, Genomics, System Biology, Bio-informatics, Public Health, Imaging and Media Lab, Cancer Research |
|
EPFL |
5 |
Transport and Mobility, Quantum Optoelectronics, Supramolecular Nanomaterials and Interfaces, Audiovisual Communication Laboratory, Virology and Genetics. |
|
UNIBAS |
7 |
Biology research (Biozentrum, 2), Biology (Core facilities, 2), Molecular Psychology, Public Health (STPH), Digital Humanities |
|
UNIZH |
5 |
Law Science, Biology/Microscopy, Biology/Proteomics, University Hospital, Geosciences |
|
Total |
49 |
30 different disciplines |
2.1. Results of the interviews
Every interview was entered into a summary table, organized by discipline and dispatched in the four main interview parts with a finer classification based on similarities in the answers when applicable. On this basis, an analysis of the main trends was performed, and citations deemed representative of the researcher’s community were further extracted. This analysis shows that the outcome of the interviews are diverse, sometimes even contradictory, but clearly depend on the institutional strategies and/or research habits in the specific considered disciplines.
Generally, within the interviewed disciplines, researchers organize themselves for all matters concerned with description, sharing, storing, and publishing and archiving of research data, usually following their own appreciation and methods, as expressed by one interviewee(15): “Yes! There is a high need to centralize data management. Everyone just does it as he/she likes.” Also, the degree of organization varies from, for instance the Physics departments, which are already well organized on international, European and/or disciplinary level, emphasizing that their current system is working and doesn’t need to be changed, compared to other disciplines, such as Educational Sciences or Humanities, which are less organized and struggle with most of the DLCM issues. For instance, there can be a lack of storage possibilities, with the usage of own-bought servers stored on the floor or in inadequate rooms.
2.1.1. Initial data and workflow
Data loss is often mentioned as a main issue, as for instance an interviewee stating that “It happens a lot that we lose data, when a PhD candidate leaves.” Also, generally no formal DMP are being used, which could help to better structure the research process and its outputs, unless the funding instances require it at the time of the project application. Yet researchers become increasingly aware of them, which is a very encouraging observation.
Concerning data description and storing, unsurprisingly, there are no common guidelines shared between disciplines and thus data exist in a plurality of formats (vector, video, audio, image, text, graph, raw bit streams, and so on), proprietary or/and open, depending on the software application. Those formats are tailored to the needs of the research projects (and team) and rarely in the optics of data preservation, a fact nicely summarized by the following answer of an interviewee to the question of what happens to research data after the end of a project: “That’s the big problem. Nothing! The results are sleeping in the cupboards. We need to encourage the reflection about long-term preservation.
Yet, common description standards exist in some internationally well-organized disciplines, such as in Geography, where large volume of satellite data are processed and stored by partnering up with CERN, Swisstopo, and various other international institutions. On the contrary, in Humanities and Educational Sciences, no standards are used, with sometimes even the question of what exactly represents a “datum”, which surprisingly can in some cases remain difficult to answer.
As for data storing, in most of the cases, self-bought improvised servers are used, as institutional IT departments are often slower in providing solutions than the rate of data produced by researchers. Ad hoc infrastructures (institutional or externalized such as with Genbanks) are especially used in disciplines having to cope with huge amounts of data (like in Life Sciences). Independent of research discipline, researchers are aware of the need to back up their data, as loss of data is a recognized worrying issue. However, the organization of back-ups is not always seen as a task of the institution, but also of the individual.
The majority of the interviewed disciplines highlighted the issue of the surge of data volumes with all its underlying issues (storage cost, curation needs, etc.). This fast increase in data volumes is often cited as due to higher data quality (e.g., higher resolutions or higher sampling rates) and/or frequent versioning of those datasets (to keep trace of their processing steps).
2.1.2. Analysis and data exploration
According to the survey, both analysis and data exploration clearly depend on specific habits and software akin to the research disciplines. A very common answer is that data analysis “is work of the PhD candidate”. How they organize themselves are their responsibilities, with sometimes some “good practices” communicated, such as “don’t lose your data, back-it up”. But there are no common guidelines.
Sharing of data also depends on the disciplines’ habits, with a general tendency to agree to do it as long as it is within the same field and not against the researchers’ own interests, such as bearing prejudice on future publications and academic reputation.
Dropbox is cited as the most used solution for sharing data, but an institutional infrastructure would be preferred if available. More difficult however seems sharing of raw or processed data for a variety of reasons:
- as soon as it concerns other disciplines than their own, or targets the “public domain”;
- due to copyright issues;
- return on investment: too much efforts to do it without clear benefit, in return.
Interviewed researchers repeated the importance of incentives for data sharing. Such incentives might be, e.g. data citation or new ways of dataset peer-review, as it is increasingly appearing with the so-called “data journals”(16). A documented example on the resistance against data publication is FORS Lausanne(17). FORS aims at archiving all Social Sciences data coming from a plurality of disciplines by offering the needed infrastructure within their community. Nonetheless, so far data is not deposited deliberately; the main reason being, according to our interviewed researchers, that it takes too much time to do it relatively to the benefits one can get from it.
2.1.3. Publication, archiving and long-term data management
The end of a research project, concomitantly to the acceptation of publications describing the main project results, often represents an important milestone for data, transforming the project status from active to passive. Given that the publication of datasets is not the rule (even if some journals ask for it, i.e. in Genetics discipline), the end of a project often means the definitive loss of its research data from an institutional point of view (a more or less properly named file might still reside on the researcher’s computer). Also, the cited temporary solutions for preserving data, such as for example local storage or those based on Dropbox-like solutions, are obviously not a satisfactory answer. Yet, researchers often express the wish to keep data over longer periods, from 5 years (i.e. Computer Sciences) to forever (especially in the Humanities disciplines), with ten years representing a tangible time period for many disciplines.
In apparent contradiction with those cited periods of time, the notion of long-term preservation is generally absent in the answers. In one case an interviewee said: “However, the real problem is : will we be able to read the PDF in 30 years? I am not even able to read my own documents from 20 years ago.“ Those cases, in which former research data cannot be used because of improper description, missing context and/or technical format changes, illustrate well the problematic behind long-term preservation.
In the cases where the ingestion of data into a repository for long-term preservation is mentioned as a good solution, then comes the open question whether the repository should be at national, institutional or disciplinary levels.
2.1.4. Research data in the future: challenges, risks, perspectives
Interviewed disciplines point to an awareness of upcoming changes in research, but underline that current habits will only change if the new ones make sense and offer an academic interest. They also suggest, as expressed by one interviewee, that “funding agencies need to give money for storage as well”.
Furthermore, having additional expert staff for managing their data would be appreciated, as well as the possibility to have their research work more referenced through data citation.
One point is regularly mentioned: Researchers understand that there is no adequate answer to the question of what could and should happen to research data after the end of a project and/or after the successful publication of the scientific results. They acknowledge datasets disappear in the “office wilderness” or on unmaintained servers.
As long as researchers do not see any incentive for managing their data, they will not document neither annotate them, which render the preservation of datasets even more challenging. Yet, one interviewee acknowledges that “Standardization is needed: often, same data is reproduced, because no one knew that the other one was doing it.”
Of course, there is the possibility of enforcing research data policies at institutional and national levels, but if enforced top-down, researchers might refrain deliberately from applying such policies.
2.2. Expressed needs
Based on the aforementioned results, we have reformulated them into needs, which we intend to address with high priority in the DLCM-project. Those needs are summarized as follows:
(a) Publication of guidelines and providing support to help researchers manage their data
The interviewed disciplines, aware of upcoming changes (as several citations illustrate), would like to have access to guidelines and templates to help them elaborate DMPs, as well as tools for analysis, publication and preservation of their data. Research teams would further appreciate expert staff in data management. One interviewee nicely expressed this fact: “It would be like paradise if someone helps me organize my files, names them, etc.“
(b) Developing ad hoc short- and long-term storage, computing and data analysis solutions
These three interviewees’ citations:
“It would be convenient to have some kind of collective data storage.”
“Interesting would be an offer where data independent from the storage place could be managed ‘all in one’.“
“SNF does not fund long term storage. This is a big issue.”
are only representative out of several, but they clearly mention the need for comprehensive solutions, addressing the whole cycle of research, but also the difficulty of finding appropriate financing solutions for these services. Raw data typically go through multiple processing steps before being interpreted. The input parameters, provenance, and data workflows must therefore all be documented if (parts of) the processing workflow has to be rerun on (selected) data. Under other conditions, researchers ask for the possibility to capture snapshots of the processed data along with contextual information. These snapshots have to be automated as much as possible so as to make their capture intuitive. In all cases, processing results must be stored in a database in an adequate format so that researchers can query them through easy-to-use interfaces, and further used them for not-as-yet devised purposes. The solution must ensure that the identification and extraction of data subsets respects the donor’s consent conditions and that could potentially restrict the usage to specific field(s) of research. Furthermore, as data volumes augment, the issue of the cost of storage will have to be given special attention.
(c) Developing electronic laboratory notebooks
As the survey has shown, data analysis and its documentation in the laboratory is a major issue. Consequently, proper description is of utmost importance for research reproducibility and/or for affirming intellectual property on the research findings, yet is very difficult to put into practice. (For intellectual property reasons, “Dropbox-like tools”, in which privacy in not guaranteed, would have to be proscribed.) In the future, there is an avowedly need for Electronic Laboratory Notebooks (ELN) that will allow the storing, linking and annotating of all digital data generated during the research process, and which will also serve as a preparatory step to further submit datasets onto long-term storage infrastructures. All research fields are concerned, including those in the Humanities.
(d) Development and/or maintenance of online research data repositories
The question of what happens to data after the end of a project or the final publication of the results has not been answered, but was raised as an important issue. Data are stored wherever it seems convenient, often in an unstructured manner and left on their own with the belief that they will be available for 5, 10 and even more years. To permit effective long-term preservation, there is thus a need for OAIS-compliant data repositories(18). Ideally, each dataset should get a permanent identifier, such as a DOI (Digital Object Identifier(19)), so that it can be referenced and linked to corresponding publications in a sustainable way, which should answer the interviewee’s expressed need: “Databases take too much time and are not user-friendly to handle. We need to start to link data with publications.”
(e) Incentives for data management
Researchers will not do data management deliberately as long as they doubt the benefit in spending time and money to perform it. One interviewee nicely expressed this: “But, the only way to bring us to describe our data is to make it mandatory. Furthermore, there must be a value, as well. We are collecting and analyzing data for publications, so, if the data is not useful for this, there will be no sense to publish it.”
Incentives have to be provided, and could be, for instance, the adoption of a reference mechanism to give more visibility to data, granting money for data management into the research project proposal, improve the impact factor of a publication, etc.
3. Organization of the DLCM Project
We based the project content on the above-mentioned needs. As for the choice of the considered scientific disciplines, that is Digital Humanities and Life Sciences, it came naturally from the expertise of the project partners; and by taking into account two “distant” disciplines, we encourage the setting up of generic solutions.
The project has been divided into six complementary tracks, which are summed up in Figure 1. With the exception of track 0, which concerns the project management, we now describe each of these tracks in more details.
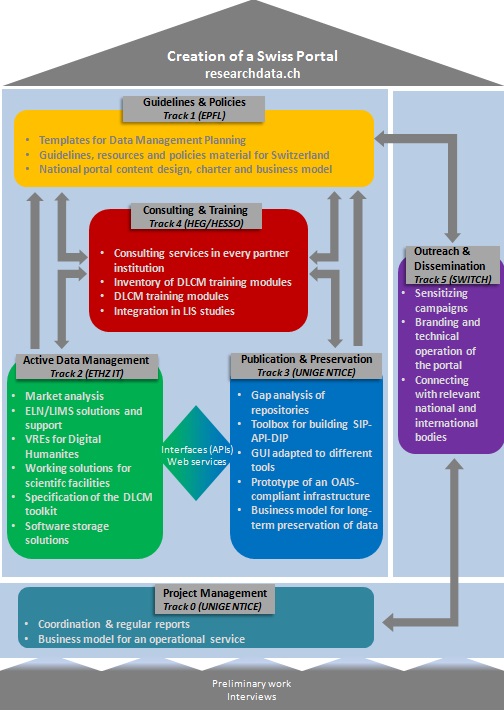
Figure 1: Project organization in 6 tracks
Track 1: Guidelines and Policies
Managed by the Swiss Federal Institutes of Technology in Lausanne (EPFL), this track shown in Figure 1 at the top of the building blocks was the first the DLCM team started to work on. Indeed, strongly connected to all other tracks, this track serves as an entry point to all future services through the setting up of a National Portal. Following the examples of national websites focusing on research data management available in the UK with the Digital Curation Center (see footnote 14), in France with the donneesdelarecherce.fr(20), or with DANS in the Netherlands(21), the proposed Swiss National Portal will provide access to customized resources, policies and guidelines regarding DLCM targeting scientific communities and information professionals based in Switzerland. The portal will also be of great importance for the whole project as it will make widely available the outputs of the different tracks of the project and a selection of a variety of external resources (e.g., training modules). At the time of this writing a first and basic version of this portal has been launched(22), which contains up-to-date information about the DLCM project and ongoing events concerning research data in Switzerland.
Besides the setting up of a National Portal, track 1 aims mainly at performing an exhaustive international literature review with which the DLCM project can build a set of best practices in terms of Data Management Plan (DMP) and policies. (The EPFL team has already worked on a similar project(23) and has therefore an up-to-date knowledge in this field.)
One of the first deliverables of this track is to provide at the Swiss level researchers and information professionals (librarians, IT engineers, etc.) with customized DMP templates regarding ongoing research projects. As previously mentioned, researchers are increasingly asked to provide DMPs when applying for research funding. As a direct consequence, the DLCM-project members are, in some cases, already facing researchers’ questions concerning such documents. In addition to providing ready-to-use templates to the research community, relevant international links to existing resources (i.e., DMPonline(24)) will be proposed on the portal so as to get a wider offer on this topic.
Focusing on the political and strategic levels, this track will allow the Swiss institutions to set out the expectations for the management and sharing of research data. It should thus help define data policies for the provision of research data management services to the community and clarify the roles and responsibilities at the institutional level. For instance, the University of Edinburgh and the Humboldt University in Berlin have both implemented a research data management policy, respectively in 2011(25) and 2014(26). However, there is yet no such example in Switzerland. Consequently, based on pre-existing policies, intended not as prescriptive but as a basic starting point, track 1 aims at proposing such policies to the Swiss institutions which could then be adapted to specific disciplinary or institutional contexts. In this context, the DLCM project is partnering up with the European Project LEARN, which intends to offer policy templates at the international level (27).
Track 2: Active Data Management
The main objective of this track, managed by the Swiss Federal Institutes of Technology in Zurich (ETHZ), is to provide to a broad spectrum of researchers concrete technologic solutions and best practices to manage their active data, with particular focus on collecting, processing and analyzing those data. Four main axes will be followed in this track:
a) Electronic laboratory notebooks (ELN) and laboratory information management systems (LIMS) solutions and support
b) Virtual Research Environment (VRE) for Digital Humanities
c) Working solutions for scientific facilities
d) Software storage solutions for active data
Concerning ELN/LIMS (part a), nowadays in Life Sciences, the majority of data produced in a scientific laboratory is stored in an electronic format, but the description of the experimental procedures used is often still recorded in conventional (paper) laboratory notebooks. In Humanities, it is very similar: the whole research process is still on paper and collection, analysis as well as temporary data storage is generally dissociated.
Systems that combine ELN and LIMS, as well as VREs for Humanities (part b), all offer solutions to this practical problem by storing and describing the experimental data in a unique place and offering the possibility to easily find data according to relevant search criteria. These tools thus will allow scientists to keep track of their experiments and to select data for future publication. Furthermore, the target is to apply a market analysis to compare existing and already implemented ELN, LIMS (i.e., sLIMS@EPFL(28)) as well as VRE (i.e., SALSAH@UNIBAS(29)) solutions, so that the selected tools fit as much as possible the researchers’ requirements and ultimately can be adapted to the Swiss research community in other disciplines than life science and digital humanities.
The main objective of part (c) is to use partners’ assets and know-how to propose and extend generic building blocks for selected use cases, particularly in medicine. Indeed, current research projects often require a contribution of multiple specialized partners and the generation of large primary datasets is often delegated to specialized platforms, so-called “core facilities”. Data provided by these core facilities are of increasing size and complexity. Moreover, they are the result of complex processing workflows consisting of multiple steps involving the integration of various files and associated metadata. Most facilities do not provide management means for the data they distribute. This delegation of data management to the researcher is possible for very simple data sets but fails to scale to modern research applications. Furthermore, facilities have neither the mandate nor the funding to manage their customers data. Also, the ETHZ, with its solid experience both with core facilities and in managing of data for distributed research consortia, has developed building blocks that address parts of the problem and has gained experience in using them. Similarly, at the University of Lausanne (UNIL), Vital-IT and IT RC(30) teams have developed know-how covering specific needs: Vital-IT has successfully managed large distributed genomic datasets for partnerships involving both academic and private companies (e.g., Imidia(31)), while IT RC implemented an Information Technology platform that will be used for the management of all UNIL cohorts(32). All these cited experiences form a strong asset for progressing on these demanding aspects of the DLCM project.
Finally, part (d) aims at developing a DLCM system that can robustly handle distributed datasets, while keeping track of data origin. As a starting point, the ETHZ openBIS system(33) will be used. This system typically associates a dataset with a single storage resource. In a further step, concepts such as distributed datasets managed by various DLCM systems, active cloud storage for enabling cloud-based analysis, actively managed caching copies and ingestions of results from cloud storage back into DLCM systems will be included into the system solution.
Track 3: Preservation and Publication
The University of Geneva (UNIGE) is heading this track, which aims at establishing a bridge between active data and long-term preservation and publication solutions. For doing so, we will base ourselves on well-established concepts, such as the Curation Life Cycle and the OAIS Model. The track is organized in five main parts:
a) Gap-analysis of repositories
b) Toolbox for building OAIS information packages (SIP-AIP-DIP)
c) GUI adapted to different tools
d) Prototype of an OAIS-compliant infrastructure
e) Business Model for Long-Term Preservation of data
The gap analysis (part a) will focus on each partner institution’s repository in use. Currently, they are at different stage of maturity and based on a large panel of technologies. For instance, the University of Zurich (UNIZH) is using ZORA(34), which is an example of a repository operated with the software Eprints(35). Eprints is a widespread open source repository software also used by the Universities of Bern and Basel. ETHZ is using Rosetta from Ex Libris(36), UNIGE, UNIL and SWITCH are using Fedora Commons(37), while EPFL’s repository is based on Invenio(38) with the intention of linking it to Zenodo(39). Consequently, it seems a logic step to assess the current status of these various systems and evaluate what is missing to comply with the Open Archival Information System (OAIS) standard, a strong requirement for guaranteeing Long-Term Preservation (LTP) of digital information.
For the methodology behind the gap analysis, we intend to exploit the evaluation tools developed by the Digital POWRR team (Preserving digital Objects With Restricted Resources)(40). They base their approach first on the National Digital Stewardship Alliance’s, which defines five functional areas (storage and geographic location, file fixity and data integrity, information security, metadata, and file formats) and four levels of digital preservation (protect, know, monitor, and repair of data) akin to digital preservation systems. Second, they developed an evaluative grid resulting from the intersection of the Digital Curation Centre’s digital curation life cycle and the OAIS Reference Model. They applied their approach on a selection of tools and services, inventoried on the Community Owned digital Preservation Tool registry(41). For the DLCM project, this methodology will be applied to the set of tools and services already used at the different partner institutions.
Based on the gap analysis, a toolbox will be proposed (part b) to allow researchers to deposit subsets of their data into a repository and/or a sustained long-term storage system. Typically, the OAIS Reference Model requires the preparation of a Submission Information Package (SIP); this process should be as transparent as possible to researchers. Tools exist to provide such microservices, as for instance Archivematica, Curator’s Workbench, etc., and will further have to be interfaced to the various outputs of track 2. In the ingest process, the SIP will then be verified, before creating an Archival Information Package (AIP) from it, to be transferred into the archival storage for long-term preservation. This approach follows the logic of the DLCM, where at some stage those researchers who are working with an active storage for processing and analyzing their scientific data might need to select a subset of these data so as to ingest them into a longer-term storage system and/or for accompanying a publication (see above the three ages theory). Motivations for researchers to accomplish this step (passing from the active to semi-active or passive status) are various and mainly include: publishers asking for sustainable access to the data used to get the results in the published paper, need of a Digital Object Identifier (DOI) (or any other permanent identifier) for openly sharing the dataset, or simply archiving data at the end of a research project. To make this step as flexible and transparent as possible, the researchers using openBIS, SLims (LIMS@EPFL) or other ELN/LIMS tools should have the possibility to push their selected data from the active storage area into a data repository (semi-active status) and/or an LTP-system (passive status) ”by a click”. The aim for the output from the Active Data Management tool is to be a generic web-based service flexible enough to be adapted to different systems. Specific user interfaces (part c) then will allow researchers to deposit and retrieve information from the repository and/or from the archived AIP. In this latter case, this will be accomplished by generating a Dissemination Information Package (DIP) delivered to the user who has requested the information.
Another important constraint of the OAIS Reference Model concerns physical storage. Storage must be highly redundant, self-correcting, resilient, and must consist of multi-copies geographically distributed, while maintaining integrity and traceability of the stored information. This will involve robust “low-level” layers for data management. There is thus a clear need of developing a novel concept for a nationally distributed storage infrastructure, OAIS compliant (part d). While each partner institution will have to decide about what architecture they will implement on the basis of the gap analysis, UNIGE (responsible for this track) will propose an implementation relying on Fedora Commons 4, coupled to a community-own network such as LOCKSS for guaranteeing (dark-archived) copies in different geographic locations, with fixity checks and mechanisms for repairing corrupted data.
Finally, also key to this work package is how to make the LTP-systems economically sustainable (part e). It is indeed intended to propose LTP-services against a fee, which must be as much as possible aligned with what users can find on the market. Typically, today a hard disk installed on a personal computer, not secured, but which can easily be configured in mirror (RAID 1) costs about 100 CHF (and thus 200 CHF in RAID 1). The proposed services will be difficult to offer at such a price level for the corresponding storage capacity and consequently will have to offer attractive value propositions to researchers; otherwise there will be few incentives for researchers to place their data onto a central storage.
Track 4: Consulting and Training
Track 4, under the management of the Haute Ecole de Gestion (HEG) and the direction of the HES-SO, is addressing on one hand the training services, found to be missing in the other tracks, and on the other hand the creation of consulting services for data management where necessary. This track is due to start once the three previous ones have produced enough know-how to build pertinent training modules.
By delivering an up-to-date list of already existing training modules and highlighting them on the National Portal, this part aims at ensuring adequate DLCM knowledge transfer through these modules. If there are missing modules, they will have to be created.
In order to facilitate the creation, centralization and exchange of internal DLCM know-how and in order to answer as best as possible every type of researchers’ questions, it is also intended to create DLCM consulting services at each partner institution, which will be coordinated by a central desk where necessary.
As a last important outcome, all acquired knowledge will be adapted to Bachelor and Master Courses in Information Science, where the freshly trained Library and Information Science students will practice and therefore ensure the sustainability of this knowledge for the future generations.
Track 5: Communication and Dissemination
Having closed the research data life cycle, there is still one important point missing. As all above mentioned topics are essential to the whole research community and should not be limited to the “biggest” players in the field, and in order to achieve the maximum possible impact of the results, a communication and dissemination track (track 5), headed by SWITCH, aims to reach institutions and other projects that are not directly involved or linked to the project.
For this, several sensitizing campaigns are planned during the whole project. Furthermore, establishing connections and links with relevant national and international bodies (i.e., RDA(42), DANS(43) etc.) will be pursued as well. One of these stakeholders is the Swiss National Science Foundation (SNSF(44)), the primary funding agency in Switzerland. Especially when it comes to DMPs, the direct involvement of the SNSF is a precondition for promoting their use.
As already mentioned, the Swiss National Portal for DLCM should become a reference website not only for researchers, but also for librarians, administrative personnel and IT staff. In order to keep the portal content as open as possible while ensuring copyright protection of its contributors, the appropriate CC (Creative Commons) license will be applied whenever feasible.
4. Conclusions
The DLCM project intends to respond to the primary researchers’ needs related to data management. It can be seen as a direct consequence of recent international initiatives concerned with scientific data management, such as Horizon2020 or the LERU Roadmap for Research Data. Researchers’ needs are various, and clearly discipline-dependent and so far no common ground between the Swiss institutions exists to provide satisfactory solutions and services. Also, after having conducted a consequent number of semi-structured interviews with researchers in different disciplines (covering about 30 different fields), five main needs could be identified, namely, (1) guidelines, (2) ad-hoc and long-term storage solutions, (3) electronic laboratory notebooks, (4) repositories for active data, and (5) development of incentives for data management. These needs set the basis for the project structure – five tracks that cover the whole data life cycle of a research project, and include training modules, and a National Portal to disseminate in a structured way as much as possible best practices in this somehow intricate field.
At the term of the project we reckon that researchers will have the appropriate tools to manage their data in a way reminiscent of digital curation methods. To be as transparent as possible, these tools will have to rely on microservices packaged into easy-to-use human-computer interaction interfaces as much as possible agnostic to the considered scientific disciplines. In any case, the challenge of closing the gap between the ways research data are managed by scientists and those in vigor in more administrative contexts managed by archivists will certainly guide us in the choices of the proposed solutions.
For any further information, please contact: pierre-yves.burgi@unige.ch or eliane.blumer@unige.ch
References
[1] H. Ross (2010) “Digital Curation: A How-To-Do-It Manual”, Neal-Schuman Publishers, Inc.
[2] G. Kern, S. Holgado, M. Cottin (2015) “Cinquante nuances de cycle de vie. Quelles évolutions possibles ? Les Cahier du Numérique, 11(2) pp.37-76. doi:10.3166/lcn.11.2.37-76
[3] S. Büttner, H.-C. Hobohm, L. Müller (2011) “Handbuch Forschungsdatenmanagement”, Bock + Herchen Verlag, Bad Honnef 2011 (p.20)
[4] H. Pampel, R. Bertelmann, H.-C. Hobohm (2010) “Data Librarianship“, Rollen, Aufgaben, Kompetenzen. In: C. Schmiedeknecht & U. Hohoff (p.166)
[5] S. Corrall, S. (2008) “Research Data Management: Professional Education and Training Perspectives”, Vortrag. 2nd DCC / RIN Research Data Management Forum. Roles and Responsibilities for Data Curation. Manchester, UK, 26-27 Nov. 2008 (p. 6)
[6] M. Eckard, C. Rodriguez (2013) "Thinking Long-Term: The Research Data Life Cycle Beyond Data Collection, Analysis and Publishing", GVSU "Big Data" Conference 2013. Grand Valley State University, Apr. 2013
Notes
(1) Examples of DMPs can be found at www.dmptool.com or dmponline.dcc.ac.uk/
(2) Economic and Social Research Council (ESRC) « Research Data Policy », March 2015: http://www.esrc.ac.uk/funding/guidance-for-grant-holders/research-data-policy/
(3) National Institutes of Health Data Sharing Policy (April 17th 2007): http://grants.nih.gov/grants/policy/data_sharing/
(4) OECD Principles and Guidelines for Access to Research Data from Public Funding, April 2007: http://www.oecd.org/sti/scitech/oecdprinciplesandguidelinesforaccesstoresearchdatafrompublicfunding.htm
(5) Pampel, Heinz. « DFG erwartet Aussagen zum Umgang mit Forschungsdaten ». wisspub.net, May 25th 2010: http://wisspub.net/2010/05/25/680/
(6) National Science Foudnation Data Management Plan Requirements, January 18th 2011 : http://www.nsf.gov/bfa/dias/policy/dmp.jsp
(7) The Interuniversity Consortium for Political and Social Research Guidelines for the Office of Science and Technology Policy Data Access Plan, February 2013: http://www.icpsr.umich.edu/icpsrweb/content/datamanagement/ostp.html
(8) European Commission, « What is Horizon 2020? », 2014:
http://ec.europa.eu/programmes/horizon2020/en/what-horizon-2020
(9) LERU Research Data Management Group. LERU Roadmap, 2013 : http://www.leru.org/files/publications/AP14_LERU_Roadmap_for_Research_data_final.pdf
(10) US Department of Energy, Office of Science. Statement on Digital Data Management, July 28th 2014: http://science.energy.gov/funding-opportunities/digital-data-management/
(11) EPFL Library. « Open research data: the future of science », October 28th 2014: http://library2.epfl.ch/conf/opendata
(12) Based on UK Data Archive: http://www.data-archive.ac.uk/create-manage/life-cycle
(13) UK Data Archive « Research Data Life-Cycle », 2015: http://www.data-archive.ac.uk/create-manage/life-cycle
(14) Digital Curation Centre, « Digital Curation Life-Cycle Model», 2015 : http://www.dcc.ac.uk/
(15) All citations have been translated into English by the authors of this manuscript and are kept anonymous.
(16) One of such a data journal is for example: http://www.nature.com/sdata/about
(18) http://www.iso.org/iso/catalogue_detail.htm?csnumber=57284
(20) http://www.donneesdelarecherche.fr/
(23) http://research-office.epfl.ch/funding/international/horizon-2020/open-research-data-pilot
(24) https://dmponline.dcc.ac.uk/
(25) University of Edinburgh, « Research Data Management Policy », May 16th 2011: http://www.ed.ac.uk/information-services/about/policies-and-regulations/research-data-policy
(26) Simukovic, Elena, « Forschungsdaten-Policy, Forschungsdatenmanagement, HU Berlin ». September 17th 2014 : https://www.cms.hu-berlin.de/de/ueberblick/projekte/dataman/policy
(27) http://cordis.europa.eu/project/rcn/194936_de.html
(28) http://www.genohm.com/slims/
(31) http://www.imi.europa.eu/content/imidia
(32)For example, Biobanque Lausanne (BIL), Swiss Kidney Project on Genes in Hypertension (SKIPOGH) http://www.skipogh.ch/index.php/Welcome_to_the_SKIPOGH_study! and the Cohorte Lausannois Study (http://www.colaus.ch).
(33) http://www.cisd.ethz.ch/software/openBIS
(35) http://www.eprints.org/uk/
(36) http://www.exlibrisgroup.com/de/category/Rosetta; see also http://dx.doi.org/10.3929/ethz-a-007362259
(37) http://fedorarepository.org/
(39) zenodo.org, launched in 2013, was created by OpenAIRE (www.openaire.eu) and CERN to provide a place for researchers to deposit datasets
(40) http://powrr-wiki.lib.niu.edu
(41) http://coptr.digipres.org
Aktuelle juristische Herausforderungen für Bibliotheken und die wissenschaftliche Informationsversorgung
Danielle Kaufmann : Rechtsdienst Universitätsbibliothek Basel Wissenschaftliche Mitarbeiterin KUB, Präsidentin AG Urheber- & Datenschutzrecht BIS
Aktuelle juristische Herausforderungen für Bibliotheken und die wissenschaftliche Informationsversorgung
Das Schweizerische Urheberrechtsgesetz wird revidiert
2012 hat Bundesrätin Simonetta Sommaruga die Arbeitsgruppe „AGUR12“ einberufen und ihr den Auftrag erteilt, Vorschläge zu unterbreiten, wie das Urheberrechtsgesetz (URG) an das Internetzeitalter angepasst werden kann. Aufgrund des Schlussberichts der AGUR12(1), der Ende 2013 vorgelegt wurde, hat der Bundesrat im Juni 2014 das Institut für Geistiges Eigentum(2) (IGE) beauftragt, einen Entwurf für ein neues URG auszuarbeiten. Dabei sollte sich die Revision eng an die Vorschläge von AGUR12 halten und damit in erster Linie die Provider mehr in die Verantwortung nehmen bezüglich der Internetpiraterie und die Verwertungsgesellschaften zu mehr Effizienz und Transparenz anhalten. Als einzige konkrete Gesetzesanpassung und aus Sicht der Bibliotheken sehr erfreulich, hat AGUR12 zudem empfohlen das sogenannte „Bestandsverzeichnis“ als neue gesetzliche Erlaubnis einzuführen, um damit den Bibliotheken und Archiven die Anreicherung ihrer Onlinekataloge zu ermöglichen.
Das IGE hat in den vergangenen Monaten nun einen Entwurf erarbeitet, der Anfang 2016 in die Vernehmlassung gehen wird. Gewisse Anzeichen sprechen dafür, dass der Entwurf weit über die Empfehlungen von AGUR12 hinausgehen wird. Bereits feststeht, dass er bedauerlicherweise die Einführung der sogenannten Verleihtantieme vorsieht. Wahrscheinlich wird er aber auch einige gute Neuerungen enthalten wie eine Regelung für verwaiste Werke und eventuell das zwingende Zweitveröffentlichungsrecht und eine Regelung für das sogenannte Text and Data Mining.
Das „Bestandsverzeichnis“ erlaubt die legale Anreicherung der Bibliothekskataloge
Dank dem Internet können die Bibliotheksnutzenden heute unabhängig von Zeit und Ort auf die Online-Kataloge zugreifen. Und gleichzeitig ermöglicht der technologischen Wandel die Anreicherung der Bibliothekskataloge mit Auszügen aus den Werken wie Coverabbildungen, Zusammenfassungen, Inhaltsverzeichnisse, Klappentexte oder auch Ausschnitte von Ton- und Filmwerken. Das wertet die Kataloge stark auf, ist aber aus juristischer Sicht heikel, wenn man davon ausgeht, dass es sich bei diesen Werkauszügen mindestens teilweise um urheberrechtlich geschützte Werke handelt, die nicht ohne Einwilligung der Rechteinhaber online zugänglich gemacht werden dürfen. Da eine solche Anreicherung der Kataloge aber auch im Interesse der Urheber und Urheberinnen ist, denn ihre Werke werden dadurch sichtbarer und besser recherchierbar, hat AGUR12 einer entsprechenden einwilligungs- und vergütungsfreien neuen gesetzlichen Erlaubnis zugestimmt. Der neue Artikel wird gemäss Schlussbericht der AGUR12 in etwa folgendermassen lauten:
Art. 24d (neu) URG: Bestandsverzeichnisse
1Öffentlich zugängliche und öffentliche Bibliotheken, Bildungseinrichtungen, Museen und Archive dürfen in den zur Erschliessung und Vermittlung ihrer Bestände nützlichen Verzeichnissen kurze Auszüge aus den in ihren Beständen befindlichen Werken oder Werkexemplaren wiedergeben, sofern dadurch die normale Verwertung der Werke nicht beeinträchtigt wird.
2Als kurze Auszüge im Sinne von Absatz 1 gelten insbesondere folgende Werkteile:
a. Bei Werken der bildenden Kunst, insbesondere der Malerei, der Bildhauerei und der
Grafik, sowie bei fotografischen und anderen visuellen Werken: Gesamtansicht der
Werke in der Form kleinformatiger Bilder mit geringer Auflösung.
b. Bei Sprachwerken: Cover als kleinformatiges Bild mit geringer Auflösung, Titel, Frontispiz, Inhalts- und Literaturverzeichnis sowie Umschlagseiten (...).
c. … (Musik- und andere akustische Werke).
d. … (Filme und andere audiovisuelle Werke).
Bezüglich der Details von Ausschnitten von Ton- und Filmwerken konnte in AGUR12 noch kein Konsens gefunden werden, es ist aber davon auszugehen, dass der in Ausarbeitung stehende Gesetzesentwurf Lösungen auch für diese Werke enthält.
Die Bibliotheken lehnen eine zusätzliche Vergütung auf die Ausleihe von Werken ab
Bisher mussten die Bibliotheken in der Schweiz für das kostenlose Ausleihen der Werke aus ihren Beständen keine Vergütung an die Urheber zahlen. Das obwohl seit Jahren die Autoren und die Verwertungsgesellschaft ProLitteris immer wieder die Einführung einer sogenannten Verleihtantieme gefordert haben. Bisher verhalte diese Forderung jeweils wieder und auch AGUR12 hat erneut eine Einführung dieser Tantieme abgelehnt. Und dennoch hat das IGE nun eine solche in den URG-Entwurf aufgenommen. Der BIS hat gemeinsam mit dem Dachverband der Urheber- und Nachbarrechtsnutzer (DUN) dem IGE gegenüber bereits seine ablehnende Haltung kundgetan. Eine zusätzliche Verleihtantieme wird – entgegen der Aussage der Autoren und Autorinnen der Schweiz (AdS) – zulasten der Bibliotheksbudgets gehen, sei es direkt oder indirekt über eine entsprechende Kürzung von kantonalen Subventionen. Im Konkreten werden die allgemeinen öffentlichen Bibliotheken schwer unter einer zusätzlichen Vergütung leiden und in der Konsequenz bei der Erwerbung von Literatur Abstriche machen müssen und so ihren Auftrag nicht mehr vollumfänglich erfüllen können. Der Profit für den einzelnen Autor, die einzelne Autorin wird dagegen eher gering ausfallen und der grösste Teil der Einnahmen aus der Tantieme wird ins Ausland abfliessen. Besonders sinnwidrig ist es, eine Vergütung für die Ausleihe von wissenschaftlichen Werken zu erheben. Die meiste wissenschaftliche Literatur wird im Rahmen eines Anstellungsverhältnisses hergestellt, eine zusätzliche Vergütung an die Autoren ist daher nicht erforderlich. Im Gegenteil würde damit die öffentliche Hand, für die von ihr selber finanzierten Werke, ein zweites Mal in Form der Verleihtantieme bezahlen. Aus Sicht von BIS und DUN stellt die Einführung einer Verleihtantieme eine indirekte Kultur- bzw. Literaturförderung dar und sollte auch als solche bezeichnet werden und gehört in diesem Sinn nicht in das Urheberrechtsgesetz.
Besonders stossend wäre eine Verleihtantieme auf e-books. Diese werden, wie die allermeisten elektronischen Medien, lizenziert und nicht gekauft. Eine Ausleihe der e-books im juristischen Sinn findet daher nicht statt, sondern den Bibliotheken wird ein Nutzungsrecht eingeräumt. Die Lizenzverträge bzw. -gebühren enthalten bereits eine Vergütung für die Nutzung der e-books durch die Bibliotheksnutzer, mit einer Verleihtantieme würde diese Nutzung zu Lasten der Bibliotheken doppelt entschädigt. Eine Verleihtantieme ist somit juristisch für e-books nicht denkbar.
Sollte die Verleihtantieme trotz Widerstand der Bibliotheken Eingang finden ins neue Urheberrechtsgesetz, wird sich der BIS zusammen mit dem DUN dafür einsetzen, dass der dannzumal auszuhandelnde Gemeinsame Tarif für die Bibliotheken fair und finanziell tragbar bleibt.
Die Nutzung von verwaisten Werken wird möglich
Verwaiste Werke sind Werke, deren Urheber nicht bekannt oder nicht auffindbar bzw. nicht kontaktierbar sind. In den Beständen der kulturellen Gedächtnisinstitutionen finden sich grosse Mengen solcher verwaister Werke, ca. 10 – 15% aller urheberrechtlich geschützter Monographien und ca. 90 – 95 % der älteren Zeitungen und Zeitschriften sowie der Fotografien aus dem 20. Jahrhundert(3) fallen unter diese Kategorie. Diese Dokumente, die heute oft nur noch in Bibliotheken und Archiven vorhanden sind, können nicht oder nur sehr eingeschränkt in Form einer Digitalisierung genutzt werden. Vor allem ein öffentliches Onlinestellen ist in aller Regel nicht zulässig. Das geltende Recht kennt mit Art. 22b URG(4) zwar eine Regelung für die Verwendung verwaister Werke, aber nur eine für verwaiste Ton- und Tonbildwerke, welche zudem in den Beständen öffentlich zugänglicher Archive bzw. Archive der Sendeunternehmen sind. Für verwaiste Schrift-, Noten- und Bildwerke gibt es keine Regelung. Eine Vervielfältigung ist somit nur äusserst eingeschränkt, nämlich nur im Rahmen eines Eigengebrauchs möglich.
Für die URG-Revision konnte der BIS dem IGE Vorschläge zur Regelung des Umgangs mit verwaisten Werken unterbreiten. Für die Nutzung, insbesondere das Veröffentlichen und Online-Zugänglichmachen einzelner Werke schlägt der BIS die Erweiterung von Art. 22b URG auf alle Werkarten und auf Bestände aller öffentlich zugänglichen Bibliotheken, Archive, Museen und Bildungseinrichtungen vor. Die Verwertung der so genutzten Werke wäre, in Übereinstimmung mit internationalem Recht und entsprechend dem bisherigen Art. 22b URG vergütungspflichtig, wobei diese Vergütung über die Verwertungsgesellschaften aufgrund eines Gemeinsamen Tarifs eingezogen würden. Das grundsätzliche Problem einer solchen Regelung bleibt jedoch bestehen, da weiterhin der jeweilige Urheber ausfindig gemacht werden muss. Hier ist jedoch noch offen, wie und unter welchen Kriterien eine solche Suche durchzuführen ist. Würde dies die gesetzliche Vorgabe sein, wäre eine Regelung, die auf der Abklärung jedes einzelnen Werkes beruht, für Digitalisierungsprojekte umfangreicher Bestände vollkommen unbrauchbar.
Aus diesem Grund hat der BIS zusätzlich eine sogenannte „Extended Collective Licensing“ (ECL), eine „erweiterte Kollektivlizenz“ nach skandinavischem Modell, vorgeschlagen. Grundlage einer ECL könnte eine gesetzliche Bestimmung im URG bieten, die es einzelnen Einrichtungen erlaubt, freiwillige Kollektivlizenzen mit Verwertungsgesellschaften abzuschliessen. Konkret würde das heissen, dass eine Bibliothek mit der jeweiligen Verwertungsgesellschaft für die Digitalisierung und das Onlinestellen eines umfangreichen Bestandes verwaister Werke einen Lizenzvertrag abschliessen könnte. Die Verwertungsgesellschaft würde dabei diese Werke kollektiv verwerten und der betroffenen Bibliothek das individuelle Verwerten und damit das Einholen einzelner Einwilligungen bei den betroffenen Urhebern und folglich das entsprechende individuelle Vergüten ersparen. Als „erweitert“ wäre die Kollektivlizenz insofern zu bezeichnen, da somit auch Werke von Urhebern und Urheberinnen verwendet werden könnten, die nicht Mitglied einer Verwertungsgesellschaft beziehungsweise unbekannt oder unauffindbar wären. Voraussetzungen für die ECL sind, dass die Verwertungsgesellschaft einerseits repräsentativ für die von der Vereinbarung erfassten Werkkategorien ist und andererseits den Nichtmitgliedern dieselbe Vergütung aus der Verwertung wie ihren Mitgliedern zukommen lässt. Bei der ECL wäre allenfalls die Möglichkeit eines sogenannten Opting outs zu prüfen, um Urhebern und Urheberinnen die Möglichkeit einzuräumen, ihre Werke von einer entsprechenden Vereinbarung auszuschliessen. Eine Verwendung im Rahmen einer ECL wäre wie die Verwertung nach Art. 22b URG vergütungspflichtig. Allerdings würde deren Höhe durch die nutzende Institution, wie auch die Art der Verwendung vertraglich ausgehandelt und nicht in einem Gemeinsamen Tarif festgesetzt.
Förderung von Open Access bedingt ein zwingendes Zweitveröffentlichungsrecht
Die Essenz in Forschung und Wissenschaft ist der rasche und offene Austausch gewonnener Erkenntnisse. Nach schweizerischem Recht übertragen Autoren und Autorinnen in der Regel die Rechte an ihren Werken einem Verlag, der die Publikation – sei es gedruckt oder auch nur digital - vornimmt. Mit dieser meist umfassenden und bedingungslosen Rechteübertragung verlieren die Autoren die Möglichkeit, ihre Werke in einem Repositorium oder auf der eigenen Homepage zusätzlich zu veröffentlichen. Zwar wäre es durchaus möglich sich im Verlagsvertrag ein Recht auf eine Zweitveröffentlichung vorzubehalten, aber da die entsprechende gesetzliche Regelung nach Art. 382 Abs. 2 und 3 OR(5) keinen zwingenden Charakter hat, können Verlage daher einem Urheber das Recht zur Zweitveröffentlichung untersagen. Dies wird durch das teilweise mangelnde Wissen der Autoren und Autorinnen und das ungleiche Machtverhältnis zwischen Urhebern und Verlagen begünstigt. Zudem ist das Publizieren in renommierten herkömmlichen Zeitschriften nach wie von entscheidender Bedeutung für eine wissenschaftliche Karriere.
In der Berliner Erklärung über den offenen Zugang zu wissenschaftlichem Wissen vom 22. Oktober 2003(6)verpflichteten sich die Schweizerischen Universitäten, die Hochschulbibliotheken und auch der Schweizerische Nationalfonds den offenen und freien Zugang zum wissenschaftlichen Wissen an ihren Einrichtungen zu fördern und zu ermöglichen. Um diese Zielsetzung durchzusetzen, braucht die Wissenschaft rechtliche Rahmenbedingungen, die eine Zweitveröffentlichung von wissenschaftlichen Werken und Forschungsdaten vertraglich unabdingbar ermöglichen. Es müsste also die bestehende verlagsvertragliche Regelung des ZGB so ausgestaltet werden, so dass das Zweitveröffentlichungsrecht des Autors, der Autorin nicht mehr vertraglich wegbedungen werden kann. Konkret könnte eine entsprechende Regelung folgendermassen lauten:
Art. 382
3bis (neu) Wissenschaftliche Werke, die ganz oder teilweise mit öffentlichen Mitteln finanziert wurden, können nach Ablauf von 3 (allenfalls nach 6 oder 12) Monaten nach der Erstpublikation vom Verlaggeber online allgemein zugänglich gemacht werden.
Eine solche Lösung zugunsten des Urhebers, der Urheberin wäre ein erster Schritt in die richtige Richtung, würde aber das Problem nicht in jedem Fall lösen, da der Urheber das Recht, aber nicht die Pflicht hätte, sein Werk zusätzlich zur Verlagspublikation zu veröffentlichen.
Um der Wissenschaft den freien Zugang zum Werk des Urhebers tatsächlich zu ermöglichen, schlägt daher die Konferenz der Schweizerischen Universitätsbibliotheken (KUB) zusammen mit dem DUN eine neue Schrankenregelung im URG vor, die es den Repositoriumsbetreibern die Möglichkeit gäbe, veröffentlichte wissenschaftliche Werke, nach einer bestimmten Embargofrist nach der Erstveröffentlichung, online frei zugänglich zu machen. Der Vorschlag der KUB lautet, mit kleinen sprachlichen Änderungen und einer verkürzten Embargofrist, in Anlehnung an Prof. Dr. Reto M. Hilty(7):
Art. xx (neu) Zweitveröffentlichungsrecht
1Wissenschaftliche Werke, die in Zeitschriften veröffentlicht und überwiegend mit öffentlichen Mitteln finanziert worden sind, dürfen nach Ablauf von 6 Monaten nach der Veröffentlichung allgemein zugänglich gemacht werden, sofern damit kein kommerzieller Zweck verfolgt wird.
2Wer Werke nach Absatz 1 zugänglich macht, schuldet dem Rechteinhaber hierfür eine Vergütung. Die Vergütungsansprüche können nur von zugelassenen Verwertungsgesellschaften geltend gemacht werden.
Der technologische Fortschritt fordert das URG weiter heraus – „Text and Data Mining“
Text and Data Mining (TDM) ist ein Prozess, mit dem Informationen aus maschinengelesenem Material abgeleitet wird. TDM funktioniert durch Kopieren von grossen Mengen an digitalen Materialien, Extraktion der Daten, Analyse und Neuzusammensetzung, um dabei Muster zu erkennen(8).
Diese Definition von LIBER und der britischen Regierung spielt vor dem Hintergrund, dass die wissenschaftliche Forschung heutzutage mehr Texte und Daten hervorbringt, als normale Wissenschaftler mit klassischen Lese- und Analysemethoden verarbeiten können. Dies betrifft zunehmend alle Forschungsgebiete, insbesondere datenintensive wie Life Sciences, Technik und andere Naturwissenschaften. Computerbasierte Methoden können viel grössere Mengen an Texten aus wissenschaftlichen Publikationen erfassen und Erkenntnisse aus Satzmustern ableiten, als ein Forscher, der traditionell eine Arbeit nach der anderen liest und in seinem Geist analysiert. Mit TDM können beispielsweise Wechselwirkungen von Proteinen über tausende von Publikationen erfasst und kartiert werden. Oder es werden neue Anwendungen von bestehenden Medikamenten systematisch festgehalten. Diese Resultate haben direkte Bedeutung für Krankheiten wie Krebs und zeigen, wie TDM den Fortschritt der Wissenschaft exponentiell beschleunigt. Voraussetzung für TDM ist, dass Forscher Zugang zu digitalen oder digitalisierten Werken haben, und die Texte und Daten wie eingangs beschrieben (mindestens vorübergehend) vervielfältigen, lokal speichern und analysieren dürfen und die daraus gewonnenen Erkenntnisse sowie Textpassagen publizieren können. Aus urheberrechtlicher Sicht geht TDM über den zulässigen Eigengebrauch hinaus und setzt die Einwilligung des Rechteinhabers an den zu nutzenden Werken und allenfalls geschützten Daten voraus. Da TDM aber in der Regel unzählige Werke umfasst, ist das Einholen von Einwilligungen gar nicht möglich. Im Weiteren werden viele der zu nutzenden Werke und Daten von wissenschaftlichen Verlagen über Lizenzen angeboten. Die entsprechenden Lizenzverträge lassen aber TDM nicht, nur beschränkt zu oder nur gegen zusätzliche Lizenzgebühren.
Aus diesem Widerspruch führt aus Sicht der Wissenschaft nur der Grundsatz: the right to read is the right to mine (Das Recht, Werke zu lesen, ist das Recht, sie mit TDM zu bearbeiten). Daher schlägt die KUB und der DUN für das Text and Data Mining eine weitere neue gesetzliche Lizenz im Urheberrechtsgesetz vor:
Art. xx (neu) Verwendung wissenschaftlicher Werke
1Werke dürfen für die wissenschaftliche Forschung vervielfältigt und bearbeitet werden.
2Die aus der Verwendung der Werke nach Abs. 1 gewonnenen Erkenntnisse und Werkbestandteile dürfen zugänglich gemacht werden.
3Wer Werke nach diesem Artikel verwendet, schuldet dem Urheber oder der Urheberin hiefür eine Vergütung. Die Vergütungsansprüche können nur von zugelassenen Verwertungsgesellschaften geltend gemacht werden.
Neuverhandlungen der Gemeinsamen Tarife 8 & 9
Nach Art. 20 Abs. 2 URG werden Nutzer und Nutzerinnen, die im Rahmen ihres Eigengebrauchs nach Art. 19 URG von veröffentlichten, urheberrechtlich geschützten Werken Vervielfältigungen herstellen, gegenüber den Inhabern der Urheberrecht vergütungspflichtig. Diese Vergütungen sollen die Urheber für die massenweise Nutzung ihrer Werke entschädigen. Geltend werden die Vergütungen durch unter Bundesaufsicht stehenden Verwertungsgesellschaften im Rahmen der sog. Gemeinsamten Tarife (GT) gemacht.. Die für Bibliotheken relevanten GT 8 und 9 sind in zahlreiche Teiltarife unterteilt. Hier von Bedeutung sind die Bibliothekstarife GT 8 II und 9 II und die Schultarife GT 8 III und 9 III. Der GT 8 regelt die Reprografie auf Papier ab gedruckter oder digitaler Vorlage und der GT 9 bezieht sich auf die Nutzung von Werke in digitaler Form in betriebsinternen Netzwerken. Um eine einfache, praktikable und berechenbare Erhebung zu ermöglichen sehen die Reprografietarife eine pauschale Vergütung für den bibliotheks- bzw. schulinternen Gebrauch je nach Anzahl an Angestellten bzw. Schülern vor. Sofern auch Reprografien im Auftrag eigenberechtigter Nutzer gemacht werden, kommt zu der pauschalen eine individuelle Vergütung hinzu, die sich an der Anzahl getätigter Kopien bzw. am Ertrag aus diesen bemisst.
Die aktuellen GT 8 und 9 laufen nach der üblichen Frist von 4 Jahren per Ende 2016 aus. Es stehen nun die Verhandlungen für die nächste Laufzeit zwischen den Urheberrechtsnutzern und den Verwertungsgesellschaften an.
Eine der zentralen Frage wird sein, ob sich der Papierverbrauch durch den technologischen Wandel tatsächlich verringert bzw. die digitale Verwendung der Werke zugenommen hat. Von dieser Frage will die zuständige Verwertungsgesellschaft ProLitteris die Festsetzung der neuen Tarifhöh abhängig machen, obwohl der Papierverbrauch bzw. der Umfang der digitalen Nutzung nicht ausschliesslich die Höhe der Tarife bestimmen. Die Festlegung der Vergütungssätze im GT 8 ist komplex konstruiert und setzt sich aus der Vergütung pro Kopie und einem prozentualen Anteil der urheberrechtlich geschützten Vorlagen in der jeweiligen Branche [sog. Branchenkoeffizient] bzw. von den Nutzern in einem Jahr angefertigten Gesamtkopienmengen zusammen. Beim GT 9 hingegen ist die Berechnung schon rein aus technischen Gründen kaum machbar, da das digitale Vervielfältigen nicht erfasst werden kann. Daher hat man sich beim GT 9 bisher darauf geeinigt, diesen als Faktor der Ansätze des GT 8 zu berechnen. Aktuell beträgt der Faktor 0,5. ProLitteris zielt auf eine Erhöhung des GT 9 ab, bei unverändertem Betrag beim GT 8. Es wird sich zeigen, ob die Nutzerseite, unter anderem der DUN, der BIS und die Erziehungsdirektorenkonferenz (EDK) sich gegen eine Erhöhung erfolgreich wehren können werden. Es bedarf wohl einer gut nachvollziehbaren Begründung, warum die Vergütung für eine digitale Kopie teurer werden sollte, nur weil die Möglichkeit besteht, allenfalls mehr Kopien herzustellen. Es ist sicherlich so, dass ein und das selbe Dokument mehrfach kopiert und gespeichert wird, sei es einmal auf einem Server, einer Wechselfestplatte zur Sicherung und schliesslich vielleicht noch in einer Cloudablage, doch würde hier eine jeweilige Vergütung bei jedem einzelnen Vervielfältigungsvorgang über das Ziel hinausschiessen. Hinzu kommt, dass bei einer Erhöhung des GT 9 folglich der GT 8 entsprechend verringert werden müsste, da man wohl davon ausgehen kann, dass weniger auf Papier kopiert werden dürfte.
Neben der Tarifhöhe geht es bei den Tarifen auch darum, für welche Verwendung im Detail die Tarife gelten und welche Nutzungsformen sie umfassen. Grundsätzlich decken die GT 8 und 9 das gesetzlich erlaubte Vervielfältigen urheberrechtlich geschützter und veröffentlichter Werke innerhalb des Eigengebrauchs gemäss Art. 19 Abs. 1 lit. b und c URG in Verbindung mit 20 Abs. 2 URG ab, wobei gemäss Art. 19 Abs. 2 URG derjenige, der zum Eigengebrauch berechtigt ist, die dazu erforderlichen Kopien auch durch Dritte, wie Bibliotheken herstellen lassen kann. Die GT erlauben aber darüber hinausgehende Nutzungen: So dürfen entgegen der gesetzlichen Regelung auch Musiknoten und Fotografien kopiert werden, allerdings nur unvollständig, was generell für alle Werke gilt, aber bei Fotografien und Musiknoten aus Sicht der Nutzer völlig unsinnig ist. Weitere zusätzliche Nutzungen, die über den Eigengebrauch hinausgehen sollen, sind zwar angesprochen, aber so unklar umschrieben, dass nicht ersichtlich wird, um welche Nutzung es sich handeln könnte. Insgesamt sollten daher bei den laufenden Tarifverhandlungen die verwendeten Begrifflichkeiten und die umschriebenen Nutzungen in den GT 8 und 9 kritisch überprüft und allenfalls korrigiert werden.
Ein weiteres wichtiges Thema der Tarife sind die sogenannten Mehrfachbelastungen. Nach Art. 19 Abs. 3bis URG sollten auf Vervielfältigungen, die beim Abrufen von legal zugänglich gemachten Werken entstehen, keine zusätzlichen Vergütungen nach GT 8 und 9 geltend gemacht werden. Dieser bei der letzten URG-Revision 2007 eingefügte Artikel bezweckt, dass der Nutzer, welcher beispielsweise im Internet mit der Einwilligung des Urhebers ein Werk in einem Download abspeichert und damit vervielfältigt, sei es gegen Entgelt oder unentgeltlich, dafür keine weitere Vergütung bezahlen muss. Diese gesetzliche Regelung ist bis anhin nie richtig umgesetzt worden, weshalb im Rahmen der laufenden URG-Revision eine Präzisierung erforderlich ist. Ziel muss insbesondere sein, dass Nutzungen von lizenzierten Werken wie e-Journals explizit von einer nochmaligen Vergütung an die Verwertungsgesellschaften ausgenommen sind, da in aller Regel mit der Bezahlung der Lizenzgebühren, die Nutzung bzw. das Downloaden bereits vergütet ist. In den aktuellen Tarifverhandlungen muss ebenfalls auf diese Problematik hingewiesen werden, auch wenn das neue URG erst im Verlauf der nächsten Laufzeit der Tarife 8 und 9 in Kraft treten wird.
Fazit
Der technologische Wandel betrifft die Bibliotheken und die wissenschaftliche Informationsversorgung auch in juristischer Hinsicht existenziell. Daher ist es von zentraler Bedeutung, dass sich alle betroffenen Institutionen aktiv und kompetent in die Vernehmlassung zum neuen Urheberrechtsgesetz anfangs 2016 einbringen. Ebenfalls wichtig ist, dass sich die Bibliotheken mit anderen kulturellen Gedächtnisinstitutionen, wie Archive und Museen, aber auch mit der Wissenschaft und Forschung vernetzen, um gemeinsam für ein neues Urheberrechtsgesetz in ihrem Interesse einzustehen.
Noten
(1) https://www.ige.ch/fileadmin/user_upload/Urheberrecht/d/Schlussbericht_der_AGUR12_vom_28_11_2013.pdf
(3) vgl. dazu Assessment of the Orphan works issue and Costs for Rights Clearance, Anna Vuopala, European Commission, DG Information Society and Media, Unit E4 Access to Information, May 2010; http://www.ace-film.eu/wp-content/uploads/2010/09/Copyright_anna_report-1.pdf
(4) Art. 22b Nutzung von verwaisten Werken
1 Die zur Verwertung von Ton- oder Tonbildträgern erforderlichen Rechte können nur über zugelassene Verwertungsgesellschaften geltend gemacht werden, wenn:
a. die Verwertung Bestände öffentlich zugänglicher Archive oder von Archiven der Sendeunternehmen betrifft;
b. die Rechtsinhaber oder -inhaberinnen unbekannt oder unauffindbar sind; und
c. die zu verwertenden Ton- oder Tonbildträger vor mindestens zehn Jahren in der Schweiz hergestellt oder vervielfältigt wurden.
2 Die Nutzer und Nutzerinnen sind verpflichtet, den Verwertungsgesellschaften die Ton- oder Tonbildträger mit verwaisten Werken zu melden.
(5) Art. 382 Verfügung des Verlaggebers
1 ...
2 Zeitungsartikel und einzelne kleinere Aufsätze in Zeitschriften darf der Verlaggeber jederzeit weiter veröffentlichen.
3 Beiträge an Sammelwerke oder grössere Beiträge an Zeitschriften darf der Verlaggeber nicht vor Ablauf von drei Monaten nach dem vollständigen Erscheinen des Beitrages weiter veröffentlichen.
(6) http://openaccess.mpg.de/Berliner-Erklaerung
(7) Hilty/Seemann, Open Access – Zugang zu wissenschaftlichen Publikationen im schweizerischen Recht, Rechtsgutachten im Auftrag der Universität Zürich, 2009, S. 96
Les archivistes comme spécialistes de la gestion de l’information : conseil et soutien des Archives de l’Etat du Valais auprès de l’Administration cantonale et des communes valaisannes
Alain Dubois, archiviste cantonal, Canton du Valais
Florian Vionnet, archiviste-records manager, Canton du Valais
Dans l’imaginaire populaire, le métier d’archiviste renvoie encore très souvent à l’archétype de l’érudit travaillant, un peu hors du monde et hors du temps, sur d’anciens (et souvent poussiéreux) documents. Pourtant, depuis plusieurs années, le monde des archives est en mutation, voire en pleine révolution. L’augmentation exponentielle de la production documentaire ces trente dernières années et le développement rapide des outils de gestion de l’information sous forme électronique poussent en effet les archivistes à repenser complètement leur manière de travailler, notamment en se positionnant toujours davantage aux côtés des producteurs des documents.
La mise en place de politiques de conseil et de soutien à ces producteurs, qu’il s’agisse d’administrations publiques ou d’organisations privées, est aujourd’hui une thématique essentielle que cet article propose d’aborder. A travers l’exemple de ce qui a été réalisé ces dernières années dans le canton du Valais, il essaiera de montrer que les archivistes, loin d’être confinés dans des tours d’ivoire ou des caves obscures, sont aujourd’hui devenus des acteurs essentiels, au cœur des administrations, et qu’un service d’archives doit devenir un véritable centre de compétences en matière de gestion de l’information, quels qu’en soient la date, le type et le support.
Les défis de l’archiviste contemporain
Pendant longtemps, la mission principale de l’archiviste était le traitement des documents « anciens » ou « historiques ». Sa matière était constituée de dossiers « clos », sans véritable utilité pour leur producteur d’origine, qu’il fallait bien souvent sauver d’une disparition quasi inévitable. L’archiviste avait alors pour tâche de collecter du mieux qu’il pouvait ces dossiers afin de les classer, de les décrire et de les mettre à la disposition du public et des chercheurs – chercheurs dont l’archiviste faisait souvent lui-même partie.
Si les bases de ce travail restent aujourd’hui inchangées, à l’exception peut-être de la recherche, le rôle et la vision de l’archiviste se sont considérablement élargis. Pour faire face aux défis de l’augmentation croissante des documents produits par les administrations et la diffusion toujours plus grande de l’information sous forme électronique, l’archiviste doit adapter ses outils et ses méthodes de travail. Ainsi, il est désormais indispensable que l’archiviste soit capable de prendre en charge les documents, quel qu’en soit le support. Si les méthodes de conservation du parchemin ou du papier sont acquises depuis longtemps, celle de l’information sous forme électronique nécessite des mesures particulières, sous peine de voir disparaître une part essentielle de l’information produite.
L’archiviste doit par ailleurs pouvoir maîtriser les documents et les dossiers sur l’ensemble de leur cycle de vie, de leur création à leur archivage ou à leur élimination contrôlée. Gérer la masse d’information produite et assurer une collecte systématique des documents suppose en effet d’être présent directement dans leurs processus de production, pour pouvoir continuer à assurer les missions essentielles de collecte et de conservation. Cet élément est d’autant plus nécessaire dans le cas des documents et données électroniques, pour lesquels l’obsolescence rapide des formats et des supports représente un risque immédiat, et implique une prise en charge beaucoup plus en amont, dès leur création.
Pour ces deux raisons, une politique de conseil et de soutien en matière de gestion des documents papier ou électroniques auprès de leurs producteurs est aujourd’hui indispensable. Elle devient de facto une nouvelle mission que doit assumer un service d’archives, en collaboration avec les autres acteurs de la gestion de l’information que sont les informaticiens ou les spécialistes des processus, à côté des missions traditionnelles de collecte, de conservation, de communication et de mise en valeur des fonds d’archives.
Les missions des Archives de l’Etat du Valais à travers les bases légales
Afin de bien comprendre cette évolution et de l’ancrer dans le cadre valaisan, il est important de prendre un peu de recul historique et d’examiner plus en détail les bases légales qui ont jalonné, en Valais, la mise en place d’une politique d’archivage et de gestion de l’information vis-à-vis de l’Administration cantonale et des communes municipales et bourgeoisiales(1).
Le premier règlement concernant les archives de l’Etat du Valais remonte à 1873 ; il donne un certain nombre d’indications sur le classement des dossiers et la typologie des documents à conserver à long terme (2). Dans la foulée, des mesures d’accompagnement des communes valaisannes sont décidées et débouchent, dès 1884, sur une série d’inspections systématiques des communes et de leurs archives, qui permettent d’établir un premier inventaire relativement complet des fonds qui y sont conservés. D’autres inspections systématiques ont lieu en 1901 et 1910. Elles sont à l’origine, en juin 1922, d’un arrêté du Conseil d’Etat sur la réorganisation des archives communales et bourgeoisiales (3). Ce dernier fixe la possibilité, pour les communes, de déposer leurs fonds d’archives auprès des Archives de l’Etat du Valais. Il octroie aussi à ces dernières un rôle de surveillance vis-à-vis des archives communales, bien que la nature et les outils de cette surveillance ne soient pas précisés. Tout au long du XXe siècle, cet arrêté servira de socle pour l’établissement de contacts réguliers entre les Archives de l’Etat du Valais et les administrations communales et l’accueil de nombreux fonds d’archives communales.
Paradoxalement, du côté de l’Administration cantonale, il faut attendre 1982(4) pour qu’un premier règlement sur les organismes des archives de l’Etat soit adopté, suite notamment à plusieurs scandales financiers. Cet acte fixe réellement, et pour la première fois, les principes de base en matière d’archivage et de gestion des documents au sein de l’Administration cantonale, notamment :
- la nécessité de gérer les documents de manière ordonnée ;
- la nécessité d’établir des principes généraux pour la constitution et le classement des archives ;
- l’obligation de verser les archives aux Archives de l’Etat du Valais ;
- l’obligation de consulter les Archives de l’Etat du Valais avant toute destruction de documents.
En 2008 est adoptée la nouvelle loi sur l’information du public, la protection des données et l’archivage (LIPDA), qui entre en vigueur dès le 1er janvier 2011(5). Si elle ne remet pas en cause les bases légales antérieures, elle permet une véritable mise à jour de la législation et réaffirme le rôle des services d’archives en matière de gestion ordonnée des documents, puisqu’elle s’applique indifféremment aux administrations cantonale et communales. Les principes généraux issues des précédentes bases légales sont repris et parfois complétés :
- nécessité pour les autorités (Etat du Valais et communes) et les employés qui en dépendent de gérer de manière ordonnée leurs documents ;
- obligation, pour les autorités, de proposer les documents aux Archives concernées ;
- rôle de surveillance des Archives de l’Etat du Valais sur les différentes archives dépendant de la loi et statut d’autorité de référence pour toute question relative à la gestion des documents et des archives, quel qu’en soit le support.
De plus, en traitant l’archivage au même niveau que l’information du public et la protection des données, la nouvelle loi permet d’ancrer un peu plus le travail des Archives de l’Etat du Valais dans une vision globale de la gestion de l’information au sein des administrations publiques.
La mise en œuvre concrète de la LIPDA au sein des Archives de l’Etat du Valais
Une des conséquences directe de la LIPDA pour les Archives de l’Etat du Valais est, en 2010, la création d’un poste à plein temps pour une personne chargée spécifiquement de la gestion des documents auprès des administrations cantonale et communales, ce qui permet de compléter les différentes postes jusqu’ici dévolus au suivi des relations avec l’Administration cantonale et les communes. Parmi les tâches confiées à cette personne, le développement et la formalisation de nouveaux guides de gestion des documents destinés aux collaborateurs des différentes administrations, ainsi qu’aux spécialistes mandatés par ces dernières.
En parallèle, il est également nécessaire pour des archivistes surtout issus du monde de l’histoire et de la recherche de mettre à niveau leurs connaissances, notamment du point de vue des normes professionnelles les plus récentes liées à la gestion des documents sous forme papier ou électronique, telles qu’ISO 15489 et 30300 ou MoReq, pour ne citer que les plus importantes. Ce travail de formation interne et d’élaboration de nouveaux outils est essentiel et permet réellement de mettre en pratique des éléments jusqu’alors relativement théoriques, voire complètement absents dans la méthode de travail des Archives de l’Etat du Valais. Le fait de disposer d’un poste spécifiquement dédié au suivi parallèle des relations avec l’Administration cantonale et les communes permet aussi de rassembler et de formaliser des approches jusqu’ici parfois séparées et de mettre en place des outils communs.
Les guides de gestion des documents et des archives
Les archives communales sont les premières à bénéficier de la mise à disposition d’un guide. Publié en 2002, le Guide pour les archives communales du Valais a pour objectif de répondre aux besoins concrets des administrations communales en matière de gestion de leurs archives. Elaboré sur mandat des Archives de l’Etat du Valais et publié par ces dernières, il contient alors les principes importants liés à l’archivage et à la conservation des documents, ainsi que des outils pratiques tels qu’un plan de classement-cade ou des délais de conservation.
Parallèlement, les archivistes chargés des relations avec l’Administration cantonale réfléchissent également, dès 2005, à la rédaction d’un guide destiné aux unités administratives de l’Etat du Valais. D’abord conçu pour intégrer toutes les procédures de travail des Archives de l’Etat du Valais, ce document est ensuite retravaillé afin de soutenir directement les employés de l’Administration cantonale dans la mise en place et la gestion quotidienne de leurs documents.
Rédigée entre 2009 et 2010, la première version finalisée du Guide de gestion des documents n’est pourtant pas publiée immédiatement et son utilisation reste essentiellement interne aux Archives de l’Etat du Valais. Dans l’intervalle, le travail d’élaboration du guide permet de lancer, dès 2012, la mise à jour de celui destiné aux communes. Après dix années d’utilisation, le besoin de refonte se fait en effet ressentir ; ce travail permet d’élaborer une version nouvelle, le Guide de gestion des documents et des archives pour les communes valaisannes, fondée sur la structure du guide destiné à l’Administration cantonale et intégrant pleinement la gestion au quotidien des documents sous forme papier et électronique.
En juin 2014, les deux guides sont finalement publiés simultanément et présentés au grand public à l’occasion d’une conférence de presse(6). Ils sont désormais accessibles en ligne sur le site Internet des Archives de l’Etat du Valais et servent de référence pour les missions de ces dernières auprès des administrations cantonale et communales(7). Bien qu’étant un peu différents dans leur forme, ces deux guides suivent la même structure et se fondent sur des approches rigoureusement identiques. Tous les deux fournissent, en plus des procédures ou des explications théoriques, une série d’outils immédiatement réutilisables par les administrations. Le cœur des guides est le cycle de vie des documents, qui pose les jalons permettant de mettre en place et de faire fonctionner un système de gestion des documents et des archives.

Fig. 1 Cycle de vie des documents
Les étapes de cette méthode sont elles-mêmes largement fondées sur la norme ISO 15489 :
- état des lieux et analyse des systèmes de gestion des documents existants ;
- élaboration de nouveaux outils : un référentiel de classement et de gestion(8), ainsi que des procédures de gestion des documents ;
- mise en œuvre des nouveaux outils et formation des collaborateurs ;
- travail quotidien avec les nouveaux outils : création et gestion des dossiers, élimination contrôlée des documents et versement des documents aux Archives ;
- traitement et conservation des archives ;
- mise à disposition du public et consultation des archives.
Les deux derniers points sont surtout détaillés dans le guide destiné aux communes, étant donné que celles-ci assument directement, au moins en partie, ces tâches. Pour l’Administration cantonale, ces dernières sont de la compétence directe des Archives de l’Etat du Valais.
Les projets de gestion des documents au sein de l’Administration cantonale
En matière de projets concrets, la situation est également un peu différente, dans la mesure où la mise en place des outils dans les communes est de la compétence de ces dernières. Si les Archives de l’Etat du Valais les encadrent et les conseillent au long des différentes étapes, elles ne peuvent conduire directement les projets, ce qu’elles font en revanche au sein de l’Administration cantonale.
Ainsi, en parallèle de la rédaction du Guide de gestion des documents, de nombreux projets visant à doter les unités administratives de référentiels de classement et de gestion sont lancés. L’accompagnement des différentes unités est aussi systématisé avec la création d’un groupe d’archivistes contacts ayant chacun la responsabilité du suivi d’un service. Un suivi qui se veut aussi complet que possible, depuis les conseils sur la gestion et le tri des dossiers courants jusqu’au traitement des fonds versés aux Archives de l’Etat du Valais, en passant par tout le travail préparatoire liés aux versements ou aux éliminations des documents, ceci aussi bien sous forme papier qu’électronique.
Des réflexions sont également lancées afin de doter l’Administration cantonale d’un outil performant permettant la gestion des documents sous forme électronique. Un groupe de travail rassemblant le Service cantonal de l’informatique, la Chancellerie d’Etat et les Archives de l’Etat du Valais est constitué et publie un premier rapport sur le cycle de vie du document électronique au sein de l’Administration cantonale dès 2008. Ce document fait un état des lieux et fixe les besoins d’un outil de gestion des documents répondant aux normes les plus récentes (ISO 15489 et MoReq notamment). Renommé ECM pour Enterprise Content Management dès 2009, le projet prévoit la généralisation de l’outil ECM au sein de l’Administration cantonale selon deux axes :
- la dématérialisation des processus centraux de l’Administration cantonale ;
- la gestion des documents électroniques (fichiers bureautiques standards) au sein des unités administratives de l’Etat.
Si la mise en œuvre généralisée et planifiée d’ECM au sein de l’Administration cantonale est refusée par le Conseil d’Etat pour des raisons budgétaires, le développement concernant les processus centraux continue. Il permet, dès 2011, la mise en place d’une gestion entièrement électronique du processus de préparation, de traitement et de diffusion des décisions du Conseil d’Etat. Par la suite, l’outil ECM se diffuse progressivement dans les unités de l’Administration cantonale. Les Archives de l’Etat du Valais mettent ainsi désormais en place ce système lors de chaque projet visant à doter une unité administrative d’un système de gestion des documents sous forme électronique. Le suivi par les archivistes contacts est également systématique et permet d’avoir une vue d’ensemble des problèmes et des projets liés à la gestion des documents et des archives au sein de l’Administration cantonale.
Une offre de formation pour les administrations
Dès la publication des nouveaux guides, notamment celui destiné aux communes, il était clair qu’une simple mise à disposition de ces outils ne pouvait suffire. Mettre en œuvre un système de gestion des documents et des archives est complexe et nécessite des ressources et une organisation adéquates. Il est aussi essentiel de pouvoir accompagner et former les collaborateurs sur des thématiques souvent assez techniques et de communiquer sur les bénéfices et avantages d’une telle approche.
C’est ainsi que, en parallèle de la préparation du Guide de gestion des documents et des archives pour les communes valaisannes, les Archives de l’Etat du Valais rédigent un concept de formation destiné aux communes. Ce dernier se concrétise avec l’élaboration, en 2015, d’un cours de formation destiné au personnel des administrations communales et aux mandataires qui travaillent habituellement pour ces dernières. Organisé sur une demi-journée, il a pour objectif de présenter les prestations et le rôle des Archives de l’Etat du Valais vis-à-vis des communes, ainsi que les étapes de mise en œuvre d’un projet de gestion des documents et des archives. Bien qu’assez largement théorique, il mobilise de nombreux exemples et offre la possibilité aux participants de discuter autour de cas pratiques.
Au sein de l’Administration cantonale, les Archives de l’Etat du Valais ont également défini un concept de formation, qui s’articule autour de trois publics différents :
- les employés de l’Administration cantonale dans leur ensemble ;
- les utilisateurs du système ECM ;
- les responsables de la gestion des documents et des archives (RGDA), soit les personnes de contact des Archives de l’Etat du Valais au sein des unités administratives.
A l’heure actuelle, les cours de formation à ECM sont les plus fréquents, puisque plusieurs dizaines ont été donnés depuis 2012. Organisés sur deux heures, ils ont pour objectif de former les futurs utilisateurs aux aspects techniques et de tester les opérations les plus courantes, telles que la création des dossiers et des documents ou la recherche des informations.
Les Archives de l’Etat du Valais ont également donné, en 2015, un cours « Quelques trucs et astuces pour mieux gérer ses documents », à travers l’offre de formation interne de l’Administration cantonale. Organisé sur une demi-journée, il vise à présenter des outils pratiques et des méthodes qui permettent une meilleure gestion quotidienne de ses documents. Des discussions autour de problèmes concrets auxquels les participants sont confrontés sont aussi organisées.
Les cours destinés aux RGDA n’ont pour l’instant pas été organisés, mais il est prévu de le faire très prochainement. Leur objectif est de former les personnes chargées du contact avec les Archives de l’Etat du Valais aux procédures spécifiques de préparation des versements et d’élimination de documents.
Un premier bilan
Les premiers retours des formations organisées pour les communes et l’Administration cantonale montrent qu’il est parfois difficile, pour les archivistes, d’être suffisamment concrets. Difficulté encore accentuée par la diversité des publics et des attentes qui peuvent être très variables. Il n’empêche que le succès rencontré par l’offre de formation, tant pour l’Administration que pour les communes (tous les cours proposés en 2015 ont dû systématiquement être dédoublés), montre l’attente et le besoin des collaborateurs des administrations dans ces domaines. Ces actions sont également importantes pour les archivistes, car elles permettent de se confronter directement aux problématiques du terrain et d’améliorer sans cesse leurs outils et leurs méthodes.
Incontestablement, ces projets ont aussi permis aux Archives et aux archivistes de modifier leur image et de se positionner progressivement comme des acteurs crédibles et essentiels de la gestion de l’information au sein des administrations. Certes, les archivistes ne sont pas les seuls spécialistes dans ce domaine, mais leurs compétences en matière de gestion et de conservation des documents et des données électroniques sont aujourd’hui reconnues.
Nul doute que cette dynamique se poursuivra dans les années à venir, car répondre aux défis actuels en matière de gestion de l’information est un travail permanent, qui nécessite de communiquer sans cesse et d’être présent au plus près des administrations et de leurs employés. Il est aujourd’hui difficile d’imaginer comment, sans ce travail de conseil et de soutien en amont et sur le terrain, les archivistes pourraient continuer à assurer leurs missions traditionnelles de collecte, de conservation, de communication et de mise en valeur, surtout dans un monde où le support électronique est devenu le support par excellence et où sa maîtrise est nécessaire durant tout le cycle de vie du document.
Notes
(1) Dans le canton du Valais, les communes bourgeoisiales existent souvent en parallèle des administrations municipales « classiques ». Ces bourgeoisies ont à leur charge la gestion d’un patrimoine dont peuvent jouir communément les « bourgeois » (forêts, vignes, patrimoine immobilier, etc.) et disposent de leur propre conseil. Dans la plupart des cas, l’administration bourgeoisiale est intégrée à celle de la commune municipale, mais certaines bourgeoisies sont complètement indépendantes. Plus d’informations sur le site web de la Fédération des Bourgeoisies valaisannes : http://www.fbvs.ch/. Dans la suite du texte, le terme de « communes » sera utilisé indifféremment pour les deux.
(2) Règlement des archives de l’Etat du 12 septembre 1873, dans Recueil des lois, décrets et arrêtés du Canton du Valais, Sion, 1874, t. XI, p. 362-370.
(3) Arrêté du 17 juin 1922 concernant la réorganisation des archives communales et bourgeoisiales, dans Recueil des lois, décrets et arrêtés du Canton du Valais, Sion, 1923, t. XXVII, p. 367-368.
(4) Règlement du 17 novembre 1982 concernant les archives des organismes de l’Etat, dans Recueil des lois, décrets et arrêtés du Canton du Valais. Année 1982, Sion, 1983, t. LXXVI, p. 218-220.
(5) Loi sur l’information du public, la protection des données et l’archivage du 9 octobre 2008. En ligne : http://www.vs.ch/Navig/navig.asp?MenuID=24420. Un règlement d’exécution est validé par le Conseil d’Etat le 16 décembre 2010 : http://www.vs.ch/Navig/navig.asp?MenuID=24421.
(6) http://www.vs.ch/Navig/navig.asp?MenuID=32342
(7) Guide de gestion des documents (Administration) : https://web.vs.ch/web/culture/guide-de-gestion-des-documents-et-des-archives-pour-l-administration-cantonale
Guide de gestion des documents et des archives pour les communes valaisannes : https://web.vs.ch/fr/web/culture/guide-de-gestion-des-documents-et-des-archives-pour-les-communes
(8) Le référentiel de classement et de gestion réunit, sous la forme d’un tableau, le plan de classement des dossiers, les règles de conservation ainsi que d’autres informations sur la gestion et l’archivage des dossiers. Il représente le cœur d’un système de gestion des documents et des archives papier et électroniques.
Swissbib : Katalog, data hub, Plattform
Oliver Schihin
Swissbib nahm Ende 2009 den Betrieb als gesamtschweizerischer Katalog auf. Die öffentlich zugängliche Suchmaschine in charakteristischem Grün ist der sichtbarste Teil einer ganzen Reihe von Daten- und Suchdiensten und, im komplexen Umfeld der schweizerischen Bibliotheks- und Verbundslandschaft, auch die „raison d'être“ dieses nationalen Projekts. In diesem Aufsatz soll ein Überblick des Projekts geboten werden. Ein erster Teil skizziert Hintergründe, Entwicklungslinien und den Projektrahmen, danach wird in drei Teilen auf den Aufbau des Angebots und gefundene Lösungen eingegangen, eng zusammenhängend mit dem Betrieb und entsprechenden Weiterentwicklungen, zuletzt werden Nutzungen dargestellt. In einem abschliessenden Kapitel sollen Ausblicke gemacht und Problembereiche skizziert werden.
Hintergründe und Ausgangspunkte
Hintergrund für swissbib bilden zwei Entwicklungslinien der Schweizer Bibliotheks- und Kataloggeschichte, einerseits verschiedene Ideen und Projekte eines schweizerischen Gesamtkatalogs sowie die wechselläufigen Bewegungen der Automatisierung und Verbundskatalogisierung seit den 1980er Jahren.
Nützlich für Bildung und Wissenschaft und im Dienste der Fernleihe etablierte sich an der Nationalbibliothek ab 1904 zuallererst ein „Schweizerischer Zeitschriftengesamtkatalog“, der bis 2002 aktiv gepflegt und danach durch ein Suchportal(1) ersetzte wurde. Das Projekt eines Gesamtkatalogs, konzeptionell ausgerichtet am entstehenden Zentralkatalog in Zürich, entwarf Hermann Escher im Jahr 1908. Vorhandene gedruckte Bandkataloge als Rohmaterial nutzend, sollte ein Zettelkatalog(2) entstehen. Umgesetzt wurde die Idee letztendlich ein Vierteljahrhundert später in reduzierter Form, der schweizerische Gesamtkatalog diente als Nachweis ausländischer Monografien. Er wurde erst vom Berufsverband gepflegt, dann von der Nationalbibliothek, und genährt durch regelmässige Sendungen von Zetteldoppeln der teilnehmenden Bibliotheken. Als „das wichtigste Arbeitsinstrument für den interbibliothekarischen Leihverkehr in der Schweiz“(3) blieb er doch an vorelektronische Techniken gebunden, der GK wurde ab 2003 nicht mehr weitergepflegt und archiviert. Als Mittel der Fernleihe war er auch ein primär bibliothekarisches Arbeitsinstrument.
In den 1970er Jahren begann auch in der Schweiz die Erschliessung und Verwaltung in Datenbanksystemen, erst in Eigenentwicklungen, ab den 1990er Jahren in Verbundsystemen, die sich auf weltweit verwendete kommerzielle Software stützen. So entstand eine äusserst vielfältige Landschaft unterschiedlicher Systeme, Anwendungsregeln und Institutionen.(4) Damit konnten Synergien genutzt werden und mit den Verbünden entstanden institutionenübergreifende Lösungen. Was fehlte, war, politisch und organisatorisch gesehen, eine „übergreifende Strategie“(5) und, katalogtechnisch gesehen, ein zentraler Katalog und eine gemeinsame Datenbasis mit einheitlichem Format, Autoritätsdateien, Formaten und Regelwerk. Gesamtkataloge liessen sich nun jedoch zumindest virtuell relativ einfach erstellen, über entsprechende Schnittstellen konnten Bibliothekare und geübte Benutzerinnen entfernte Datenbanken abfragen. Diese an verschiedenen Orten angebotene „Metasuche“ hat sicherlich dazu beigetragen, weitere Vorstösse in Richtung Zentralisierung und nationale Dienste zumindest zu bremsen. Auch wenn die Nutzerfreundlichkeit und Geschwindigkeit dieser Dienste stark eingeschränkt war, existierten sowohl für die Fremddatenübernahme in der Katalogisierung wie für die Fernleihe gute Lösungen.
Eine verbundsübergreifende Datenfusion kam, weder ganz noch in Teilen, auch mit Beginn der 2000er Jahre nicht in Frage. Doch neue technische Lösungen, als „Resource Discovery“ oder „Next Generation Library Catalogs“ bezeichnet,(6) versprachen, aus unterschiedlichen Datenquellen einen gemeinsamen Suchindex mit ansprechender Weboberfläche aufzubauen. Ein auf solcher technologischer Basis gebautes gesamtschweizerisches „Portal“ kann als Notbehelf angesichts unbeweglicher Verwaltungsstrukturen angesehen werden, aber auch als Gelegenheit, möglichst unbelastet von diesen Strukturen einen eigenen Such- und Datendienst aufbauen zu können. Inhaltlich sollte swissbib so die in den Bibliothekssystemen der Schweizer Hochschulbibliotheken und der Nationalbibliothek nachgewiesenen Bestände enthalten, erweitert um institutionelle Repositorien und digitale Bibliotheken. Ansprechen soll swissbib Kundinnen und Kunden aus dem In- und Ausland, die unbesehen von Verbundgrenzen Ressourcen und Dienste der Schweizer Bibliotheken nachfragen.
Den organisatorischen und finanziellen Rahmen für das Projekt bot ab 2008 das Innovations- und Kooperationsprojekt „e-lib.ch – Elektronische Bibliothek Schweiz“ der Schweizerischen Universitätskonferenz (SUK). Gesichert durch eine Bundesfinanzierung, vorerst für die Jahre 2008-2011, begann bald darauf ein zweiköpfiges Projektteam an der Universitätsbibliothek Basel mit dem Aufbau des Dienstes. Nach mehreren Verlängerungen und Übergangslösungen wird swissbib seit 2014 als nationales Projekt von der Schweizerischen Universitätskonferenz und swissuniversities als Teil des Programms SUK-P2 "Wissenschaftliche Information: Zugang, Verarbeitung und Speicherung" gefördert.(7) Dieses vom Bund finanzierte Programm „fördert die Bündelung und Entwicklung der heute verteilten Anstrengungen der Hochschulen für die Bereitstellung und Verarbeitung von wissenschaftlicher Information.“ Als Projekt ist swissbib bis Ende 2016 finanziert, die Programmunterstützung hat es ermöglicht, das Kernteam des Projekts auf drei Personen auszuweiten. Assoziierte Projekte haben eine weitere Verbreiterung der personellen Basis zur Folge gehabt, parallel zu einem Ausbau der Dienste und Angebote.
Aufbau und Lösungen
Seit Projektbeginn im Jahr 2008 besteht die primäre Herausforderung darin, einen heterogenen Raum aus ähnlichen, aber häufig sich unterscheidenden Daten und Systemen zu integrieren. Diese Integrationsleistung ist dabei keine einmalige Sache mit Aussicht auf spätere gemeinsame Nutzung und Pflege, sie bleibt eine dauerhafte Aufgabe, ein Nachvollzug ohne Rückwirkung zu den Quellen. Sie ist dazu mit begrenzten Mitteln zu leisten, das Team von swissbib ist nicht grösser als dasjenige eines kleinen bis mittleren Verbunds. Worin bestehen die Herausforderungen in einer detaillierteren Übersicht:
- Verwaltungssysteme: Bei Projektbeginn waren zwei grosse Systemanbieter (Exlibris Aleph / VTLS Virtua) mit etwa einem Dutzend Instanzen und Konfigurationen anzutreffen. In der Zwischenzeit hat sich die Situation weiter diversifiziert. Einerseits ist ein erster Verbund (Alexandria) auf ein cloudbasiertes SaaS-System(8) der dritten Generation (Exlibris Alma) umgestiegen, anderseits bietet sich bei mittelgrossen kantonalen und regionalen Verbünden ein noch bunteres Bild. Ebenso divers ist die Situation bei open-Access-Repositories, digitalen Bibliotheken und Systemen von Spezialsammlungen oder Archiven.
- Datenlieferung: Zwar hat sich das Datenaustauschverfahren OAI-PMH bei den meisten Partnern als Standard etabliert, doch werden einige Datenbestände auch mit anderen Verfahren wie einfachem Secure Copy (SCP) oder WebDAV geliefert. Geliefert werden die Daten in der Regel in einer XML-Codierung.
- Datenformate: Die Bibliotheken erschliessen und liefern ihre bibliografischen Daten in einem MARC-Format, jedoch in unterschiedlicher Ausprägung. Die Deutschschweizer Verbünde wenden noch bis Ende 2015 den regionalen Standard IDSMARC an, die Nationalbibliothek und der Westschweizer Verbund RERO nutzen seit langem MARC21. Ab 2016 kann mit einer gewissen Vereinheitlichung gerechnet werden, wobei Altdaten bestehen bleiben. Repositorien und digitalen Bibliotheken geben unterschiedliche Formate wie Dublin Core oder MODS aus, bei Spezialsammlungen sind eigene Implementierungen von MARC oder EAD anzutreffen.
- Regelwerke: Für die bibliothekarische Erschliessung kommen unterschiedliche Adaptionen von AACR2 zum Zug, in der Deutschschweiz sind dies die regionalen Regeln (KIDS). Diese werden Ende 2015 vom neuen internationalen Standard RDA (Resource Description and Access) abgelöst werden. Da der Westschweizer Verbund RERO erst später auf RDA umsteigen wird, bleibt eine vorerst disparate Situation erhalten. Ebenso werden nach altem Regelwerk katalogisierte Aufnahmen kaum vollständig an die Regelwerke angepasst werden, unterschiedlich ist die Lage wieder bei weiteren Datenquellen.
- Normdateien: Zwar hat sich die Situation sowohl bei der Formal- wie der Sacherschliessung in den letzten Jahren massiv verbessert. Zu Projektbeginn 2008 verwendeten beinahe alle Bibliotheken eigene Normdateien, teilweise wurden sogar in denselben Verbünden unterschiedliche Autoritäten verwendet. Zumindest in der Deutschschweiz werden 2016 die IDS-Bibliotheken und die Nationalbibliothek die Gemeinsame Normdatei (GND) einführen. Weiterhin bestehende Unterschiede in den Personenansetzungen sowie in den verwendeten Thesauri schlagen direkt auf die Benutzer- und Suchqualität durch, und sie stellen auch in anderen nationalen Projekten (wie z.B. e-rara.ch(9)) ein Hindernis dar. Es ist schwierig abzuschätzen, ob und wie neue technische Verfahren (linked data) und gemeinsame Anstrengungen der Bibliotheken und Verbünde hier die Situation zu verbessern in der Lage sein werden.
- Dedublizierung: Aus den getrennt geführten Katalogsystemen folgt eine getrennte Erschliessung identischer Ressourcen oder Titel, für ein und dasselbe Buch erhält swissbib bis zu einem Dutzend Aufnahmen. Diese sollen wenn immer möglich zusammengeführt werden, wobei entsprechende Algorithmen zum Einsatz kommen. Aktuell bezieht swissbib ungefähr 35 Millionen Titelaufnahmen, durch Zusammenführungen verbleiben noch gut 20 Millionen. Die Qualität der Zusammenführung kann als gut angesehen werden, doch gibt es keine Möglichkeit oder Bereitschaft, über technische Verfahren hinaus in den Prozess manuell einzugreifen.
- Mehrsprachigkeit: Katalogisiert wird in der Schweiz in vier Sprachen (deutsch, französisch, italienisch, englisch). Dies kann bei der angestrebten Dedublizierung durchaus zu Problemen führen, auch weil die verwendeten Sprachen nicht codiert erfasst werden. Unabhängig von diesen Katalogisierungsfragen muss eine gesamtschweizerische Benutzeroberfläche zwingend in den drei wichtigsten Landessprachen und in Englisch angeboten werden.
Swissbib erbrachte zu Beginn primär einen Suchdienst, darauf aufbauend Datendienste, und das Projekt ist im Rahmen dieses Auftrags frei in der Lösungswahl sowie unbelastet von einer Verbundverwaltung. Diese Bedingungen haben entsprechende Entscheidungen stark mitgeprägt. Eine frühe Entscheidung betraf die Architektur des Dienstes. Schon früh war offensichtlich, dass keines der auf dem Markt verfügbaren Produkte den komplexen Anforderungen alleine entsprechen kann, was sowohl für Open Source-Software wie für lizenzierte Produkte galt und immer noch gilt. Ein frühes und im Wesentlichen immer noch gültiges Anforderungsprofil lautete: „A technical solution was needed that could prepare the bibliographic data independently of the local system. Furthermore, the component for data preparation must be able to cope with the differences in cataloguing rules and must provide flexible mechanisms for deduplication and clustering. The search engine must be powerful and speedy to deliver results considerably faster than the OPACs and federated search tools while also getting the maximum out of the data with respect to multilingualism. And the user interface must be versatile and open enough to allow a connection to the local services.“(10)
In dieser Situation entschied sich das Projektteam für ein Angebot der Firma OCLC, das sowohl die einzelnen Komponenten beinhaltete wie die grundlegenden Anforderungen an die Architektur erfüllte. Wenig hat sich seither am Bau einer offenen, aus dedizierten Hosts bestehenden und durch transparente Standardschnittstellen verbundenen Softwarearchitektur verändert. Verändert haben sich im Verlauf der letzten Jahre einzelne Komponenten, die inhaltlich angepasst und verbessert oder ausgetauscht wurden. Diese wichtigsten Komponenten sollen im Folgenden kurz dargestellt werden.
Harvesting und Rohdatenspeicher
Die von den Verbundsystemen in der Regel via OAI-PMH bereitgestellten Metadaten werden von swissbib täglich bezogen. Dies garantiert, dass Löschungen, Korrekturen und Neuaufnahmen innerhalb ein bis zweier Tagen in swissbib nachgeführt sind. Zentral dabei ist eine Komponente namens „contentCollector“(11). Vor der Weiterverarbeitung werden die Daten in einem Rohdatenspeicher unverändert abgelegt. Diese Schattenkopie der bibliografischen Metadaten ermöglicht es, Korrekturen und Verarbeitungen zu tätigen, ohne die lokalen Systeme belasten zu müssen. Ein kompletter Neuaufbau der swissbib-Datenbank lässt sich so falls nötig ohne direkte Beteiligung der Lokalsysteme bewerkstelligen.
Normalisierung und Zusammenführung
Für die zentrale Aufgabe der Datenverarbeitung nutzt swissbib seit Projektbeginn die Software CBS (Central Bibliographic System) des Anbieters OCLC. CBS ist als zentrales Verbundsystem weltweit im Einsatz, unter anderem in den Verbünden mehrerer europäischer Länder oder auch in Australien. In der Regel fungiert CBS dort jedoch als zentrale Katalogisierungsdatenbank. Die Flexibilität des Systems ermöglichte es, auch automatische Verfahren zur Normalisierung, Konvertierung, Anreicherung und Clusterbildung anzuwenden. CBS bietet Transformationsroutinen mittels verketteter Skripte an und nutzt ein eigenes internes Speicherformat. Die Importprozeduren und Transformationen lassen sich je Datenquelle unabhängig konfigurieren und anpassen. Zur Dedublizierung und Clusterbildung werden zwei Verfahren angewendet:
- Matching & Merging: Nach der Normalisierung werden die Aufnahmen in einen zweistufigen Algorithmus daraufhin überprüft, ob sich sich bereits eine Aufnahme derselben Ressource in der Datenbank befindet.
- Geprüft werden lediglich Aufnahmen, deren aus dem Haupttitel gebildeter Schlüssel und / oder Identifikationsnummer (ISBN / ISSN) identisch ist. Dies verhindert einen Abgleich über den gesamten Datenbestand.
- Für die Identitätsprüfung werden Indexe der jeweiligen Aufnahme auf Übereinstimmung geprüft. Entscheidend sind Autorenansetzungen, Titel, Auflage, Erscheinungsjahr, ISBN/ISSN und Format. Vordefinierte Kategorien wie Archivmaterial oder entsprechend codierte Altbestände werden von der Zusammenführung ausgeschlossen.
Sind zwei oder mehrere Aufnahmen als identisch erkannt, kommt ein Merging-Verfahren zum Zug, in welchem eine „starke“ Aufnahme als Vorlage ausgewählt wird. Bestandsangaben, Sacherschliessungselemente und weitere Informationen werden von den anderen Aufnahmen addiert, ein erstes Anreicherungsverfahren. Dieser sogenannte „Master Record“ wird später für Indexierung und Präsentation exportiert.
- FRBR-Cluster: Neben der Zusammenführung werden auch Ähnlichkeitsprüfungen durchgeführt. Diese ermöglichen es, Aufnahmen desselben Werks in unterschiedlichen Auflagen oder Formaten zusammenzuführen. Die entsprechenden Aufnahmen werden nicht physisch zusammengeführt, sondern mittels einer entsprechenden Identifikationsnummer verbunden.
Für die Indexierung und Präsentation benötigt swissbib ein einheitliches Datenformat. Mit unterschiedlichen MARC-Derivaten konfrontiert lag es nahe, den internationalen Standard MARC21 zu wählen.(12) MARC21 ist in der Lage, sämtliche Eigenheiten auch von IDSMARC verlustfrei abzubilden, für gewisse Informationen und Erweiterungen stehen eigene swissbib-Felder zur Verfügung.(13) Mittelfristig ist zu überlegen, ob weitere Datenformate oder zusätzliche Erweiterungen notwendig sind, um Datenbestände aus Archivsystemen, Forschungs- oder Artikeldaten abzubilden.
Indexierung
Die von CBS ausgegebenen Metadaten im Format MARC21 werden in zwei Schritten für die Suchmaschine aufbereitet, angereichert und indexiert.
- Aufbereitung: In der Transformationsapplikation „content2SearchDocs“(14) werden die Aufnahmen vom Format MARC21 in ein Indexierungsformat transformiert. Im selben Ablauf werden die Metadaten angereichert, so beispielsweise mit den Texten von gescannten Inhaltsverzeichnissen oder den Nebenvarianten von Normdaten.
- Die Indexierung erfolgte für die ersten Jahre des Projekts in der mitlizenzierten Suchmaschine FAST.(15) Ab 2011 stieg swissbib erfolgreich auf die freie Suchmaschine Apache Solr/Lucene(16) um. Die von swissbib betriebenen performanten Suchmaschinencluster bilden die Basis für die Such- und Datendienste von swissbib. Ein grosser Vorteil der eingesetzten Suchmaschine besteht darin, ohne Programmierkenntnisse einfach und transparent die Indexierung von strukturierten Dokumenten steuern zu können.
Präsentation
Zu Projektbeginn verwendete swissbib die Software TouchPoint (OCLC) als Benutzeroberfläche. Diese Lösung ermöglichte eine Anbindung an den Index FAST, die Webtechnologie erlaubte ein attraktives und eigenständiges Design.(17) Dieses Design in charakteristisch leuchtendem Grün prägte swissbib über einen Systemwechsel hinaus bis ins Frühjahr 2015. Anpassungen der Software TouchPoint wurden jedoch zunehmend schwieriger und die Anbieterfirma entwickelte die Software in eine andere Richtung weiter. In dieser Situation wurde 2011 entschieden, auf das freie Discovery-System VuFind umzusatteln.(18) Dieser Entscheid erwies sich in den folgenden Jahren als richtig und wichtig für die Weiterentwicklung des Dienstes. VuFind ist ein in der Programmiersprache PHP geschriebenes Frontend für Solr/Lucene, bringt aber vor allem auch Treiber für die meisten offenen und kommerziellen Suchindexe (Primo Central, Summon, WorldCat, EBSCO) mit. Auch wurden durch die weltweite Entwicklergemeinschaft zahlreiche Anbindungen an unterschiedliche Authentifizierungsmechanismen (shibboleth, Bibliothekssysteme, LDAP) entwickelt. Die Integration von Benutzerfunktionalitäten des klassischen OPAC lässt sich relativ einfach umsetzen und erweitern, begrenzt in der Regel lediglich durch die Schnittstellen der Bibliothekssysteme selbst. Eine wachsende Nutzergemeinschaft gerade in Deutschland prägt die ursprünglich aus den USA stammende Software mit. VuFind baut auf verbreiteten Frameworks auf, was die Entwicklung erleichtert und es ermöglicht, vom Knowhow externer Entwickler profitieren zu können. Dem allgemeinem Trend folgend, führte swissbib im Frühling 2015 ein Responsive Design ein, eine Benutzeroberfläche, die sich dynamisch der Bildschirmgrösse des Endnutzers anpasst.
Schnittstellen
Neben der Benutzeroberfläche stehen bei swissbib auch maschinelle Schnittstellen zur Nutzung bereit. Aktuell handelt es sich um die bei Bibliotheken verbreiteten Technologien SRU und OAI:
- Die SRU-Schnittstelle von swissbib bietet eine performante Suche im swissbib-Bestand, die von verschiedenen Diensten genutzt werden kann.(19) Die wichtigste Anwendung, welche die SRU-Schnittstelle von swissbib aktuell nutzt, ist der Karlsruher Verbundkatalog KVK.(20) Seit kurzem wird sie auch von einer bei der Sacherschliessung verwendeten Applikation eingebunden.(21)
- Die OAI-Schnittstelle von swissbib ermöglicht es, den gesamten Datenbestand von swissbib für den Aufbau eigener Datenbanken oder Indexe zu beziehen. Entworfen wurde sie ursprünglich für das Projekt eines übergreifenden Portals von Projekten des Programms e-lib.ch, welches die Metadaten von swissbib bezog. Nach der Abschaltung dieses parallelen Suchdienstes 2014 wird OAI unterdessen vom Kartenportal verwendet, einem Fachportal der Kartensammlungen in Schweizer Bibliotheken.(22)
Bibliotheksverwaltung
Gewissermassen als Nebenprodukt eines gesamtschweizerischen Katalogs entstand ein Verwaltungsinstrument für Codes und weitere Metadaten wie Adressen, Namen und Links der beteiligten Institutionen. Seit 2012 verwendet swissbib dazu eine kleine Webapplikation, libadmin genannt.(23) Die darin gepflegten Daten stellen das wohl aktuellste und umfassendste Verzeichnis von wissenschaftlichen und weiteren öffentlichen Bibliotheken in der Schweiz dar. Verwendet werden die Daten zur Gruppierung von Institutionen und deren Bezeichnungen in der Benutzeroberfläche, auf einer entsprechenden Liste(24), verwendbar sind sie auch im Kontext von linked data.
Angebote und Nutzungen
Swissbib hat in den letzten fünf Jahren zahlreiche Angebote bereitgestellt und mit unterschiedlichen Partnern Projekte initiiert und durchgeführt. Ermöglicht wurden diese Angebote einerseits dadurch, dass mit swissbib ein einzigartiger gesamtschweizerischer bibliografischer Datenbestand existiert. Anderseits ermöglichen die freien Komponenten und die offene Architektur unterschiedliche Anknüpfungspunkte an Daten und Software. Hier soll ein kurzer Überblick der wichtigsten Dienste geboten werden.
swissbib
Zentrales Angebot von swissbib ist der nationale Katalog swissbib.ch. Er weist aktuell (Stand: Oktober 2015) mehr als 21 Millionen Aufnahmen mit gut 50 Millionen Bestandsangaben nach. Die Seite wird monatlich von gut 50'000 Benutzern aufgerufen. Ein Viertel der Anfragen werden dabei vom Karlsruher Verbundkatalog KVK generiert, diesen Besuchen geht eine Abfrage an die SRU-Schnittstelle voraus.
swissbib Basel Bern
Swissbib Basel Bern ist der gemeinsame Katalog der Hochschulbibliotheken in Basel und Bern und der Schweizerischen Nationalbibliothek. Er wurde ab 2012 aufgebaut und fungiert als primärer Katalog und als Resource Discovery-System der beiden Universitäten. Swissbib Basel Bern nutzt die Metadaten des Projekts swissbib und dieselbe Software, jedoch in einem eigenen Index und mit eigenen Instanzen für die Benutzeroberfläche. Nachgewiesen sind darin ebenso die lizenzierten E-Book-Bestände, die nicht (mehr) im Bibliothekssystem verwaltet werden. In einem zweiten Reiter der Trefferliste werden elektronische Ressourcen des Anbieters Serial Solutions / Summons angeboten. VuFind ist an das lokale Bibliothekssystem Aleph angebunden, swissbib Basel Bern bietet sämtliche verfügbaren Benutzerfunktionalitäten und Kontoinformationen.
jusbib
jusbib ist ein Metakatalog von Schweizer Rechtsbibliotheken und weiteren relevanten Beständen der juristischen Literatur. Jusbib nutzt den zentralen Suchindex von swissbib.ch, mittels eines Filters werden die entsprechenden Bestände ausgewählt. Der flexible Suchindex ermöglicht eigene Sucheinstiege und Facetten, ebenso steht eine hierarchische Suche in einer gesamtschweizerisch verwendeten juristischen Klassifikation zur Verfügung. Das Projekt wurde von der „Vereinigung der juristischen Bibliotheken der Schweiz“ gestartet und in enger Zusammenarbeit mit dem Team von swissbib durchgeführt. Es erhält eine finanzielle Unterstützung des Bundesamtes für Justiz und des Vereins eJustice.CH.
linked.swissbib
Das Projekt linked.swissbib(25) wird ebenfalls seit 2014 vom Programm P2 "Wissenschaftliche Information: Zugang, Verarbeitung und Speicherung" gefördert und gemeinsam mit den Fachhochschulen in Genf und Chur durchgeführt. Ziel ist es, den gesamtschweizerischen Katalog ins semantische Web zu integrieren, dazu werden die Metadaten in ein RDF-Datenmodell überführt und mit externen Datenquellen verlinkt. Ergebnisse sowohl im Bereich Metadaten wie in der Entwicklung und Adaption von Software sollen während der Projektlaufzeit in den Katalog swissbib integriert werden.
Kartenportal
Kartenportal.CH ist ein Fachportal für Karten in Schweizer Bibliotheken und Archiven.(26)Ursprünglich ein e-lib.ch-Projekt, wird es unterdessen als Kooperation der beteiligten Institutionen betrieben. Für die verbundsübergreifende Kartensuche stellt swissbib die Metadaten zur Verfügung, für die vollständige Anzeige wird auf swissbib zurückverlinkt. Ebenso stellt swissbib Codes und Metadaten der Schweizer Bibliotheken zur Verfügung.
WorldCat-Export
Als Teil der Zusammenarbeit mit der Firma OCLC werden die bibliografischen Metadaten des „Informationsverbunds Schweiz“ und entsprechenden Partner über die bibliografische Datenbank CBS von swissbib in den globalen Katalog WorldCat(27) exportiert. Dies erhöht die Sichtbarkeit der Bestände der Deutschschweizer Bibliotheken, eine Aktualisierung via swissbib garantiert dabei eine regelmässige wöchentliche Aktualisierung.
Metadatenmanagement Nationallizenzen
Das Projekt „Nationallizenzen“ zielt auf eine flächendeckende Versorgung des Hochschul- und Forschungsplatzes mit wissenschaftlicher Literatur durch die zentrale Lizenzierung von Backfile-Paketen grosser Verlage ab.(28) Es wird ebenfalls durch das Programm SUK-P2 finanziert. In diesem Rahmen übernimmt swissbib die Verarbeitung und Bereitstellung der gelieferten Metadaten von Artikeln und E-Books. Neben einem zentralen Sucheinstieg sollen die Metadaten auch für weitere Nutzungen durch Bibliotheken über Schnittstellen bereitgestellt werden.
Betrieb und Entwicklungen
Aus dem Betrieb und den Entwicklungen der Jahre seit dem öffentlichen Start von swissbib Anfang 2010 ergeben sich einige Punkte:
- Die als Grundkonzept festgelegte offene Softwarearchitektur funktionaler Applikationen hat sich bewährt. Swissbib ist damit stets in der Lage geblieben, auf Veränderungen in der komplexen Landschaft von Systemen und Metadaten in der Schweiz zu reagieren.
- Mit Ausnahme von CBS verwendet swissbib quelloffene Software. Auch durch die Verwendung von klar definierten Schnittstellen zwischen den einzelnen Komponenten ist so Transparenz gewährleistet. Eine Fehlersuche innerhalb von swissbib gestaltet sich technisch relativ einfach, auch wenn sie natürlich der aufwendigen Suche nach der Nadel im Heuhaufen gleichen kann. Die Verwendung von quelloffener Software garantiert überdies die mögliche Nachnutzung und spart Lizenzkosten.
- Von aussen an das Projekt getragene Anforderungen, so beispielsweise neue Authentifizierungsmechanismen oder auch das sich verändernde Suchverhalten von Nutzerinnen und Nutzern können in dieser Architektur durch gezielten Austausch oder Erweiterungen an bestehenden Komponenten gemeistert werden.
- In den ersten Jahren arbeitet swissbib stark mit der Firma OCLC zusammen. Der Dienst wurde auf Servern der Firma gehostet und drei Kernkomponenten waren darüber lizenziert. Die Zusammenarbeit mit OCLC ist weiterhin wichtig, insbesondere im Bereich des Metadatenmanagements mit CBS. In anderen Bereichen aber stützt sich swissbib neben eigenen Kräften auf unterschiedliche Partner. Für das Hosting und den Betrieb wurde eine enge Zusammenarbeit mit der Rechenzentrum der Universität Basel etabliert. Für die Pflege und Weiterentwicklung von VuFind kann swissbib sich auf Firmen in der Schweiz verlassen, welche sich rasch das notwendige Knowhow aneignen konnten. Für zahlreiche Probleme im Bereich Suche und Präsentation arbeitet das Projekt mit internationalen Entwicklungsgemeinschaften. Und selbstverständlich steht swissbib in engem Kontakt mit Kolleginnen und Kollegen in den Schweizer Verbundzentralen bereit, unverzichtbare Hilfen im Dschungel schweizerischer Bibliothekssysteme. Eigene Kompetenzen und breit abgestützte Partnerschaften verringern die Abhängigkeit von einzelnen Anbietern und erlauben zielgenaue Lösungen.
- Gleichzeitig ist der Austausch und die Erweiterung von Komponenten aufwendig. Auch wenn der Austausch eines Suchindex oder einer Transformationskomponente konzeptionell einfach vor sich geht, kann ein solches Projekt während Monaten Kräfte binden. Entsprechend müssen Entscheide dieser Art gut begründet, die Umsetzung personell und technisch gut geplant sein. Zwingend dazu ist Fachpersonal mit sowohl technischem wie bibliothekarischem Knowhow. Aktuell ist swissbib in diesem personell gut aufgestellt.
Ausblicke
Die von unterschiedlicher Seite als „stark fragmentiert“(29) bis „bizarr“(30) charakterisierte Schweizer Verbundlandschaft bringt bekannte Probleme der Datenqualität mit sich. Diese Schwierigkeiten kollidieren immer stärker mit dem Bedürfnis, Metadaten in anderen Kontexten und Formaten (externe Suchmaschinen, Fachportale, Forschungsprojekte) zu verwenden und sie mit anderen Datenbeständen zu verlinken. Erschwert werden dadurch auch grosse Projekte wie der gemeinsame Umstieg auf das neue Regelwerk RDA oder die Verwendung der Gemeinsamen Normdatei GND zur Formal- und Sacherschliessung. Jeder lokale Verbund ist mangels zentraler Möglichkeiten gezwungen, Anpassungen selbst vorzunehmen, sowohl in (halb-)automatischen wie in manuellen Teilen.
Auch hat insbesondere der stark wachsende Bestand an elektronischen Medien und die entsprechenden Anforderungen an die Verwaltung zu einer weiteren Zersplitterung der Systemlandschaft geführt. Bestehende Koordinationsgremien haben hier über den Informationsaustausch kaum Wirkung entfaltet. Eine weitere Zersplitterung ist nun bei der Einführung von Verwaltungssystemen der nächsten Generation (cloud-basierte SaaS-Systeme) bereits angelaufen. Gleichzeitig wird mit dem Projekt einer gemeinsamen „Swiss Library Service Platform“ versucht, den offensichtlichen zentrifugalen Tendenzen mit dem zentralen Betrieb eines neuen Bibliothekssystems Gegensteuer zu geben.(31) Ob und in welcher Form sich ein nationaler System- und Dienstleistungsanbieter etablieren wird, zeigt sich ab 2017 in der Phase der Implementierung. Im Bereich von open-Access-Repositories, insbesondere aber bei Archiven und Spezialsammlungen sind die Unterschiede in der Erschliessungstradition, bei Systemen und Datenformaten gross, wobei sich hier keine vorderhand keine Zentralisierung abzeichnet.
Als gesamtschweizerischer Katalog, als Suchmaschine und nationaler Datenhub wird swissbib auch in einer sich verändernden Umgebung flexibel und anpassungsfähig bleiben müssen. Die Fokussierung auf den Nachweis und als Einstiegspunkt für Such- und Datendienste hat sich hier als zielführend erwiesen. Gleichzeitig ist swissbib als technische Lösung ein Kind föderalistischer Strukturen und dezentraler Dienste. Die Qualität der angebotenen Dienste ist hoch, doch sind Fehler ohne manuelle Eingriffe unvermeidbar. Dies zeigt sich bei der Zusammenführung von Titeln aus unterschiedlichen Systemen und mit unterschiedlichen Regelwerken oder auch bei der Verlinkung mit externen Datenquellen. Eine bessere Einbindung von swissbib in die Arbeitsabläufe der Verbünde könnte zu Verbesserungen beitragen.
Für swissbib als schweizerischer Katalog und für sämtliche Such- und Datendienste sind in Zukunft zwei Dinge wichtig: Technisch müssen Verwaltungssysteme in der Lage sein, Metadaten und Zugangsinformationen vollständig über offene Schnittstellen bereitzustellen. Und organisatorisch muss ein Rahmen geschaffen werden, der einen langfristigen Betrieb und die Finanzierung über begrenzte Programme hinaus gewährleistet. Hier sollen das aktuelle Finanzierungsprogramm SUK-P2 ebenso wie die „Swiss Library Service Platform“ einen stabile Grundlage bieten.
Notes
(1) http://ead.nb.admin.ch/web/swiss-serials/psp_de.html [05.10.2015]
(2) Zur Geschichte der Zettelkataloge siehe: Krajewski, Markus. Zettelwirtschaft. Die Geburt der Kartei aus dem Geiste der Bibliothek. Berlin: Kulturverlag Kadmos, 2002.
(3) Accart, Jean-Philipp. „Der Schweizerische Gesamtkatalog (GK)“. Arbido 1–2 (2005): 28–29.
(4) Barth, Robert. „Bibliotheken in der Schweiz zwischen Tradition und Innovation“. B.I.T.online 15, Nr. 4 (2012): 333–43, S. 336-338.
(5) Dora, Cornel. „Eine Bibliotheksstrategie für die Schweiz?“ Bibliothek Forschung und Praxis 36, Nr. 1 (Januar 2012), S. 81. doi:10.1515/bfp-2012-0009.
(6) Breeding, Marshall. Next-generation library catalogs. Bd. 4. Library technology reports 43. Chicago: American Library Association ALA, 2007.
(7) http://www.swissuniversities.ch/de/organisation/projekte-und-programme/suk-p-2-wissensch-information-zugang-verarbeitung-speicherung/ [16.10.2015]
(8) https://de.wikipedia.org/wiki/Software_as_a_Service (06.10.2015).
(9) „Le manque de renvois entre les différentes formes des noms propres [...] produit du silence dans les réponses et complique la mise en oeuvre des listes alphabétiques ou des facettes.“ Zit.: Rivier, Alexis. „E-rara.ch. Une bibliothèque numérique pour les livres anciens“. Ressi No. 15 (2014).
(10) Viegener, Tobias. „Switzerland builds next-generation metacatalogue“. Research Information, Nr. August/September (2009): 18–21, S. 19.
(11) https://github.com/swissbib/contentCollector
(13) http://www.swissbib.org/wiki/index.php?title=Swissbib_marc
(14) https://github.com/swissbib/content2SearchDocs
(15) https://en.wikipedia.org/wiki/Fast_Search_%26_Transfer
(16) https://en.wikipedia.org/wiki/Apache_Solr
(17) Zur Implementierung von TouchPoint siehe v.a. Viegener, Tobias. „Switzerland builds next-generation metacatalogue“. Research Information, Nr. August/September (2009): 18–21, S. 20.
(18) https://vufind-org.github.io/vufind/
(19) Die Schnittstelle steht zur Verfügung unter http://sru.swissbib.ch. Dokumentation findet sich hier: http://www.swissbib.org/wiki/index.php?title=SRU
(20) http://www.ubka.uni-karlsruhe.de/kvk.html
(21) Siehe http://data.bib.uni-mannheim.de/malibu/isbn/suche.html [16.10.2015]
(22) http://www.kartenportal.ch/
(23) Der Quellcode ist verfügbar unter https://github.com/swissbib/libadmin
(24) Abrufbar unter https://www.swissbib.ch/Libraries, für Zugriff auf die strukturierten Daten stehen Schnittstellen bereit.
(25) Für weitere Informationen: http://linked.swissbib.ch [16.10.2015]
(26) Erreichbar unter http://www.kartenportal.ch/ [17.10.2015]
(27) http://www.worldcat.org/ [19.10.2015]
(28) http://www.swissuniversities.ch/fileadmin/swissuniversities/Dokumente/DE... [26.10.2015]
(29) Viegener, Tobias. „Die Schweizer Verbundlandschaft – ein Hemmnis für die Entwicklung der Bibliotheken?“ 027.7 Zeitschrift für Bibliothekskultur / Journal for Library Culture 1, Nr. 2 (24. September 2013). doi:10.12685/027.7-1-2-29, S. 33.
(30) Barth, Robert. „Bibliotheken in der Schweiz zwischen Tradition und Innovation“. B.I.T.online 15, Nr. 4 (2012): 333–43, S. 336.
(31) Über Projektfortschritte informiert ein Blog: http://blogs.ethz.ch/slsp/ [2. November 2015]
Voltaire à Genève : une affaire sérieuse
François Jacob, Conservateur du Musée Voltaire
Flávio Borda d’Água, adjoint scientifique au Musée Voltaire
Voltaire à Genève : une affaire sérieuse
Qu’on se le dise : rien de plus sérieux que Volage.
Volage est en effet l’acronyme de VOLtaire A GEnève et désigne le catalogue en ligne des manuscrits du Musée Voltaire. Situé dans l’ancienne demeure de Voltaire aux Délices (fig. 1), ledit musée est aujourd’hui, aux côtés de la Musicale, du Centre d’iconographie et de la maison-mère des Bastions, l’un des sites de la Bibliothèque de Genève.
Volage : pourquoi faire ?
Telle est la première question qui se pose : pourquoi établir un catalogue à part ? Pourquoi Volage n’est-il pas tout simplement reversé dans Odyssée, le catalogue en ligne des manuscrits de la Bibliothèque de Genève ? Le traitement des données archivistiques change-t-il donc de nature, selon que s’on se trouve sur la rive gauche ou sur la rive droite du Rhône ? Et faudra-t-il compter, à ce petit jeu, autant de catalogues que de sites ? La Bibliothèque de Genève, fort heureusement, se limite à quatre : que fût-il advenu, si elle s’était étendue au-delà du Pont d’Arve ou des Délices ?
Les Délices, justement : revenons-y. Si le besoin s’est fait sentir, il y a une dizaine d’années, de créer un catalogue en ligne des manuscrits du musée Voltaire (appelé jadis « Institut et Musée Voltaire », et connu comme tel dans toute la communauté scientifique depuis plus de soixante ans) on le doit à la conjonction, particulièrement perceptible en ce début de millénaire, de quatre phénomènes.
Le premier est d’ordre culturel. Voltaire fait l’objet, depuis la fin de la Seconde guerre mondiale, d’un regain d’intérêt qui a soulevé, de manière assez abrupte, la question des études philologiques liées à son œuvre. Comment exploiter la figure du patriarche à des fins idéologiques si ladite exploitation doit se contenter de slogans et ne reposer que sur de vagues études de réception ? Les Soviétiques, dès la fin de l’ère stalinienne, le comprennent fort bien et construisent, en favorisant la promotion de la Bibliothèque du philosophe à Leningrad, une véritable herméneutique de Voltaire. Les occidentaux sont quant à eux très heureux de trouver en Theodore Besterman, milliardaire anglais passionné de Voltaire (fig. 2), un porte-drapeau des plus énergiques : installé aux Délices dès 1952, Besterman fonde l’Institut et Musée Voltaire deux ans plus tard et entreprend aussitôt la publication des œuvres et de la correspondance complètes de l’écrivain.
Le deuxième phénomène est d’ordre institutionnel. Le rattachement du Musée Voltaire à la Bibliothèque Publique et Universitaire, aujourd’hui Bibliothèque de Genève, a certes des raisons historiques, le départ mouvementé de Besterman ayant laissé béante, en 1971, la question de son identité administrative : mais ladite question n’avait pu être résolue, à l’époque, qu’à l’issue d’amples débats. Un rattachement au réseau des Musées d’Art et d’Histoire n’était-il pas préférable ? Pouvait-on imaginer une autre combinaison (fondation, par exemple) ? Ne convenait-il pas, en tout cas, compte tenu de la fragilité des structures mises en place, d’autonomiser, autant que faire se pouvait, l’exploitation des fonds patrimoniaux des Délices ?
Troisième phénomène, plus actuel, celui-là : un phénomène contextuel. L’extension d’une société marchande qui ne connaît plus d’autres valeurs que celles de l’or ou du pétrole, la montée en puissance des intégrismes et jusqu’à l’oubli –peut-être concerté- de notre mémoire collective ont fait de Voltaire l’homme des recours voire des secours : « Voltaire, au secours ! » peut d’ailleurs se lire, assez régulièrement, sur les pancartes de manifestants aux objets d’indignation a priori très divers. Les événements de Paris de janvier puis novembre 2015 n’ont fait qu’accroître le phénomène : on est aujourd’hui voltairien, voltairiste, voltairophile. La mise en ligne d’un catalogue des manuscrits de Voltaire, dût-il se limiter au patrimoine de la Bibliothèque de Genève –et même à celui d’un de ses sites- ne pouvait-il alors être le lieu, ou l’occasion, d’une mise au point sur les plans historique et littéraire ? N’est-il pas temps de rappeler, au moment où explosent les demandes de consultation, que les manuscrits de Voltaire sont des objets d’étude et non des reliques ?
Quatrième phénomène enfin, d’ordre scientifique : il a été récemment décidé de concentrer les activités de recherche de la Bibliothèque de Genève sur le dix-huitième siècle. Une telle décision s’explique aisément par l’importance du patrimoine dix-huitièmiste conservé tant aux Bastions (Jean-Jacques Rousseau, François Tronchin) qu’aux Délices (Voltaire, Suard, Beaumarchais) et justifierait pleinement, à elle seule, qu’un catalogue séparé fût réservé aux manuscrits du Musée Voltaire.
Une course d’obstacles
Imaginé dès janvier 2003, Volage (qui ne trouvera son nom que quelques années plus tard, une fois diffusées les premières notices) se heurte d’emblée à plusieurs difficultés.
La première tient à l’apparente disparité des fonds manuscrits de l’Institut Voltaire et à la recherche programmée d’une plus grande cohérence avec les fonds de la maison-mère, aux Bastions. Rappelons que les fonds de l’Institut se composent pour l’essentiel de deux grands ensembles aisément identifiables, en ce que le premier réunit tous les manuscrits isolés, et physiquement rassemblés dans des classeurs adaptés, et que le second se compose, sous la seule cote MS, des recueils, factices ou non, déjà constitués et préalablement reliés.
Les cotes du premier ensemble sont très diversifiées. La série C désigne par exemple toutes les correspondances et connaît cinq déclinaisons : CA pour la correspondance active de Voltaire, CB pour sa correspondance passive, CC pour d’autres correspondances du dix-huitième siècle, CD pour les lettres jadis entrées dans le corpus bestermanien de la Correspondance définitive publiée d’abord aux Délices, puis à la Voltaire Foundation d’Oxford, et CE pour toutes les autres formes de correspondances. La série D désigne quant à elle tous autres documents manuscrits et connaît trois déclinaisons : DA pour les manuscrits des œuvres de Voltaire, qu’il s’agisse de manuscrits autographes ou de copies, DB pour les manuscrits du dix-huitième siècle sans rapport direct avec la vie ou l’œuvre du patriarche, et enfin DC pour les manuscrits d’autres époques, antérieures (seizième et dix-septième siècles) ou postérieures (nous possédons ainsi le manuscrit du livret de Zadig (fig. 3), texte de Ferdinand Hérold pour l’opéra de Jean Dupérier créé à Genève en 1938).
Si cette première série présente une certaine cohérence, la série des cotes « numériques » présente quant à elle les documents reliés dans l’ordre de leur acquisition : il importait donc que le catalogue pût créer les passerelles nécessaires au dialogue entre eux des divers documents : à titre d’exemple, les commentaires marginaux de Voltaire portés sur le compte rendu du procès d’Abbeville, lors de l’affaire du chevalier de La Barre (MS 1, fig. 4) sont à mettre en relation avec la correspondance active de Voltaire à ce sujet, consultable sous les cotes CA, CD voire BK, ces deux dernières lettres désignant les transcriptions réalisées par les secrétaires de Beaumarchais, lors de l’établissement de l’édition de Kehl, dans la décennie 1780.
La base VOLage n’a cependant pas pour objet prioritaire l’étude précise ou la mise en valeur de la documentation patrimoniale présente dans les fonds. Elle a d’abord pour mission de la faire dialoguer avec d’autres bases institutionnelles au premier rang desquelles Odyssée. Le catalogue des manuscrits de la Bibliothèque de Genève – Bastions suppose en effet, voire sous-tend une cohérence avec celui du Musée Voltaire. Il s’agit de disposer d’une vision transversale des documents voltairiens et des collections dix-huitièmistes au sein de notre institution, tous sites confondus. On se doute de l’attention requise au moment du catalogage avec, par exemple, la nécessité d’une indexation précise des personnes citées ou la systématisation du renvoi d’une unité documentaire ou d’un fonds du Musée Voltaire à une autre entité située, quant à elle, au sein des Bastions. Un tel travail permettra, une fois achevé le rétrocatalogage, de pouvoir rechercher des documents de manière transversale et d’avoir une vue synoptique des collections voltairiennes de l’ensemble de la Bibliothèque de Genève voire, dans un futur souhaitons-le proche, des collections générales de la Ville de Genève. Le gain de l’opération est triple : les chercheurs et lecteurs accèdent plus rapidement aux données qui les intéressent, nos fonds sont d’autant mieux mis en valeur qu’ils interagissent avec des fonds apparentés, et nous pouvons définir, s’agissant de la politique d’acquisition, une ligne directrice plus pertinente et plus directement centrée sur notre patrimoine.
Il ressort de la lecture des premières notices que, si les fonds de la Bibliothèque de Genève – Bastions et du Musée Voltaire sont bel et bien complémentaires, ils le sont selon des clés de répartition précises : tandis qu’en toute logique on trouve une grande partie des documents liés à la présence de Voltaire au Musée qui porte son nom et que la « vie quotidienne genevoise » se trouve quant à elle aux Bastions, certains fonds dérogent à ce principe fondateur. Tel est le cas des archives Tronchin, décrites dans Odyssée et physiquement conservées aux Bastions, alors que François Tronchin, dont on connaît le célèbre portrait de Liotard, a succédé à Voltaire dès 1765 comme résident principal des Délices où il resta d’ailleurs jusqu’à sa mort, en 1798. Même chose avec la famille Plan, sur laquelle se concentre une grande partie de la réception des Lumières en Europe au début du XXe siècle (Pierre-Paul Plan fut ainsi chargé, par Noëlle Roger, de publier la correspondance de Jean-Jacques Rousseau d’après les documents laissés par feu Théophile Dufour, son père) et dont les archives se trouvent aux Bastions. Dernier exemple : celui du fonds de la famille de Constant qui tissa jadis des relations suivies avec Voltaire et dont les archives révèlent, s’il en était besoin, l’importance de Genève dans le commerce international de l’époque, avec une implication particulière au sein de la Compagnie des Indes. Le fonds Constant et les fonds du Musée Voltaire sont pour le coup intrinsèquement liés.
Une des questions soulevées par le rétro-catalogage, et par le catalogage lui-même, dès lors qu’il s’agit de fonds spécifiques et hautement spécialisés comme le sont ceux du Musée Voltaire, est de savoir jusqu’où aller dans le détail. La politique de catalogage de l’institution doit en effet tenir compte, en matière de traitement de l’information, de ses besoins internes, mais aussi et même surtout des demandes des chercheurs. Voilà qui peut conduire à un paradoxe : il est en effet très simple de noyer une série d’informations importantes au milieu d’un océan de données.
Le Musée Voltaire a, à cet effet, concentré ses efforts, pour la correspondance, laquelle ne représente pas moins de 75 % de nos fonds manuscrits, sur l’identification des destinataires et des expéditeurs, avec en plus la mention explicite des « délocutés », ce terme désignant les personnes ou personnages mentionnés dans les lettres. Il nous a semblé important de pouvoir mettre en relief des lettres de/sur/à Voltaire se rapportant à d’autres sujets et auxquels les chercheurs n’auraient pas forcément songé. Nous avons la chance de pouvoir décrire nos manuscrits à la pièce et non pas en séries ou sous-séries comme c’est le cas dans la plupart des grandes institutions patrimoniales. Il s’agit là d’un « luxe » dont nous sommes conscients mais qui demeure nécessaire eu égard à la spécificité de nos collections.
Volage : historique
Faire l’histoire de Volage, c’est rappeler d’abord que tout ne passait pas, il y a une vingtaine d’années, par le truchement de l’ordinateur, et que les archivistes que nous fûmes maniaient encore, sinon le silex et le burin, du moins la feuille de papier et le stylo (plume, pour les plus anciens). Les premiers catalogues de manuscrits du Musée Voltaire n’ont pas dérogé à cette règle essentielle de l’évolution des media et se présentaient sous format papier : accessibles dans la salle de lecture, ils proposaient d’abord une liste récapitulative des cotes avec un descriptif sommaire de leur contenu. Suivait la description, limitée pour la plupart du temps à une présentation physique (notamment lorsqu’il s’agissait de correspondance) de l’ensemble des unités d’un même fonds. Tel le cas, par exemple, des deux mille huit cents notices descriptives du fonds BK, constitué, on s’en souvient, des copies de lettres de Voltaire réalisées entre 1780 et 1784 par les secrétaires de Beaumarchais. Soit l’équation, pour le MS BK 2438 :
L.a. à Louis François Armand du Plessis duc de Richelieu, 2 p. -4°, Ferney, 26 auguste 1773. D18528.
La référence à la version publiée de la lettre dans la Correspondance définitive éditée par Besterman, et surtout l’absence de référence à une éventuelle publication de cette même lettre dans la version antérieure de la Correspondance de Voltaire (résumée dans tous les ouvrages scientifiques par le sigle Best) font, pour le voltairiste, suffisamment sens : elles indiquent que Besterman a eu connaissance de la lettre concernée entre 1964 et 1971 : il s’agit dès lors, pour savoir où est l’original du document recopié par les secrétaires de Beaumarchais et déceler ainsi d’éventuels caviardages, de se référer à l’édition papier de la Correspondance définitive publiée par la Voltaire Foundation d’Oxford, et naturellement accessible dans la salle de lecture.
On conçoit dans ces conditions les cinq plus-values que peut apporter Volage :
- Les références à des éléments bibliographiques en ligne peuvent faire l’objet d’hyperliens permettant un accès direct.
- Une image du document, produite dans un mode suffisant pour une exploitation scientifique peut accompagner la notice et éviter ainsi tout éventuel quiproquo sur les normes de description.
- Une interaction constante avec l’ensemble du catalogue voire avec des bases voisines (Odyssée) ou lointaines (catalogues de la BNF) permet de compléter l’information recherchée par des extra auxquels le chercheur n’aurait peut-être pas songé mais qui lui seront donnés en suppléments.
- Le catalogue des manuscrits interagit de même avec les catalogues d’imprimés et les bases iconographiques disponibles en ligne.
- Volage peut enfin se nourrir des derniers acquis de la recherche, ses utilisateurs étant précisément susceptibles, par un effet de retour, de corriger telle donnée ou d’en amplifier l’écho.
Les descriptions de Volage sont établies selon la norme ISAD (International Standard Archival Description, élaborée par le Conseil international des archives), à laquelle ont été ajoutés des champs d'indexation et de gestion interne. Les informations sont encodées avec les balises de la norme EAD (Encoded Archival Description) au moyen d'un éditeur XML. Le nombre de niveaux de description varie en fonction de la complexité du fonds décrit. Cette structure est très proche de celle adoptée pour le Catalogue des manuscrits de la Bibliothèque de Genève (Odyssée).
Rappelons, sans vouloir faire un historique de ces standardisations internationales, que les normes ISAD (G), ISAD (R) et EAD ont précisément été créées afin de faciliter le travail d’encodage des données archivistiques. Le Musée Voltaire a tout de suite été concerné par ce projet une fois celui-ci mis en place par la Bibliothèque de Genève. Le plus grand défi pour des collections patrimoniales comme la nôtre était de conjuguer les attentes nées de ces standardisations avec les informations dont nous disposions préalablement. Il a fallu alors faire « entrer dans les cases » de la standardisation internationale des données qu’a priori nous considérions comme valables sur le plan scientifique mais qui présentaient, pour certaines d’entre elles, des spécificités inconciliables avec EAD. Les descriptions apparemment plus simples auxquelles nous avions recours auparavant, nous ont certes aidés dans un premier temps : il a néanmoins fallu les compléter afin de pouvoir offrir des données supplémentaires (indexation personnes, matières, lieux) et s’armer de courage pour venir à bout de difficultés inattendues. C’est ainsi que le logiciel d’encodage refuse –encore aujourd’hui- d’intégrer des italiques pour les titres, de reconnaître l’usage des guillemets, d’approuver l’emploi de formules du dix-huitième siècle ou de considérer que les accents sont une nécessité en français.
Volage est le fruit d’une réflexion impulsée, il y a une dizaine d’années, par la Bibliothèque de Genève, laquelle souhaitait créer une base par institution et par site. De là l’existence d’Odyssée (BGE-Bastions) et de Kora (Centre d’Iconographie) – encore faudrait-il parler de feue Kora puisque le Centre d’Iconographie vient de transférer l’ensemble de sa collection dans une base de données muséale : Museum+. D’entrée de jeu, Volage s’est heurté à plusieurs difficultés.
Et tout d’abord : faire correspondre autant que faire se pouvait les nouvelles normes internationales à la réalité archivistique de notre institution. Les normes internationales s’adaptent admirablement à tout fonds établi et mis en place après la Seconde Guerre mondiale mais font parfois la sourde oreille aux revendications pourtant légitimes des archivistes chargés du traitement de fonds anciens. Il a fallu, au musée Voltaire, adapter la base de données à nos propres spécificités, à nos besoins et aux attentes des chercheurs. Gageons dès lors qu’un archiviste chevronné, lorsqu’il lui prendra l’envie de se pencher sur l’architecture de la base telle que nous l’avons conçue, ou plutôt modifiée, pourrait remarquer une série d’incohérences, ou émettre quelques doutes sur la pertinence de tel ou tel choix : c’est que la hiérarchisation et le choix des notices opérés par le Musée Voltaire correspond à la réalité des fonds et surtout à la spécificité d’une institution qui œuvre principalement autour d’une seule personne, Voltaire, et d’un siècle bien particulier, les Lumières.
On pourrait suggérer un plan de classement différent, soit un seul fonds avec une répartition des documents en plusieurs séries. Pour une question de clarté et pour ne pas noyer les notices documentaires au sein de l’information proposée aux chercheurs et aux usagers, il a été convenu d’octroyer le statut de fonds à chaque «série documentaire» cohérente. Par exemple : Fonds de Correspondance définitive de Voltaire, Fonds des Manuscrits reliés, Fonds Besterman, etc. Cette solution permet à l’usager et au chercheur d’identifier plus facilement les pièces et d’orienter sa recherche de manière optimale. Le Musée Voltaire a, rappelons-le, la chance de pouvoir décrire tous ses documents au niveau de la pièce et d’offrir ainsi des descriptions détaillées qui vont au-delà de la simple identification de l’unité documentaire.
Les recherches peuvent être effectuées en plein texte, sur la base d’indexations ou à partir de la nomenclature des fonds. Dans le premier cas, il suffit de remplir avec le mot désiré la case «chercher». Cette recherche peut également se faire avec les deux onglets suivants, respectivement intitulés « recherche avancée » et « recherche multibases » et qui ont l’avantage de faire interagir les trois catalogues des fonds spécifiques de la Bibliothèque de Genève (Volage, Odyssée, Museum+).
Des fonds spécifiques
L’entrée en lice du catalogue Volage aura coïncidé, pour la correspondance de Voltaire, avec deux phénomènes d’importance sur le plan scientifique : la découverte, dans nos propres fonds, de lettres sinon totalement inconnues du moins très mal décrites, et la diffusion des résultats de la recherche menée depuis plusieurs années par André Magnan, sans doute le plus grand voltairiste actuel, à propos des lettres factices composées par Voltaire à la suite de sa rupture avec Frédéric II, roi de Prusse.
Les lettres contenues dans les séries ouvertes CA et CB ont été réunies, en 2011, dans un volume intitulé Un jeu de lettres et publié dans la collection « Hologrammes », aux éditions Paradigme. Les éditeurs en étaient, outre l’un des rédacteurs du présent article, Nicholas Cronk, directeur de la Voltaire Foundation, Olivier Ferret, professeur à l’université de Lyon II, Christiane Mervaud, professeur à l’université de Rouen, et Christophe Paillard, éminent voltairiste, aujourd’hui premier adjoint chargé de la culture à la mairie de Ferney-Voltaire.
On y trouve entre autres une très longue lettre de Mme d’Argental à Voltaire datée du 15 mai 1770 qui est, osons le mot, un des fleurons de notre collection. Elle est importante à double titre : elle nous renseigne de manière assez fiable sur les événements du 30 mai 1770, généralement baptisés, dans les chroniques de l’époque, «massacre» ou «bagarre» de la rue Royale (une compression de foule, à la suite d’un feu d’artifice, provoque la mort de plus de cent trente personnes), et elle révèle quelques-unes des modalités épistolaires qui président, à ce moment précis de leurs rapports, aux échanges de Voltaire et des époux d’Argental. L’élément le plus intéressant de la lettre est en effet le jeu constant auquel se livre Mme d’Argental sur l’identité du destinataire et sur celui du scripteur : elle laisse quasiment la plume à son mari, dans les dernières lignes, dès lors qu’il s’agit de parler d’affaires : « M. d’Argental me charge de mander à M. de Voltaire… » Cette partie de la lettre est d’ailleurs la seule qui soit véritablement destinée à Voltaire, le récit même de l’accident étant voué à être diffusé à plus large échelle. Nous sommes ici en présence d’une lettre dite «ostensible», c’est-à-dire d’une lettre dont on sait qu’elle sera d’abord lue par le « cabinet noir », service d’espionnage à la solde du roi, et dont on ne s’étonnerait pas que des éléments fussent diffusés ou publiés dans les gazettes.
À quel degré faut-il décrire, dans un cas similaire, la lettre concernée ? Et quel destinataire indiquer ? Doit-on se contenter de la mention naïve de celui à qui elle échoit physiquement, et considérer que le reste n’est que littérature ? Faut-il, à partir du moment où nous avons fait le choix d’opérer à la pièce, enrichir la notice des éléments bibliographiques susceptibles de mener le chercheur sur la voie du destinataire véritable ? À partir de quel moment le catalogueur se mue-t-il –et quel droit –a-t-il de le faire ?- en chercheur bis ?
Un autre exemple est celui des lettres de Voltaire incluses jusqu’à présent, par tous les éditeurs, dans sa correspondance, et dont André Magnan s’est aperçu, à la fin du siècle dernier, qu’elles constituaient un ensemble autonome réécrit par Voltaire à seule fin de discréditer Frédéric II, roi de Prusse. Les éditeurs successifs de Voltaire ont donc, à la suite de Voltaire lui-même, commis un faux : «On peut penser, écrit Magnan dans le n°41 de la Gazette des Délices (rubrique «Grand Salon»), que certains d’entre eux savaient ce qu’ils étaient en train de faire, c’est-à-dire dissocier un recueil premier qu’ils avaient eu entre les mains».
Or aux lettres elles-mêmes, que nous possédons pour la plupart (cotes CD et CA) et dont nous avons même les retranscriptions opérées par les secrétaires de Beaumarchais pour l’édition de Kehl s’ajoute aujourd’hui le dossier complet des investigations scientifiques qui ont permis à André Magnan d’arriver à cette découverte. Il a en effet fait don de ses archives relatives à Pamela au Musée Voltaire : cet ensemble important a été immédiatement intégré à nos « fonds spéciaux » et dûment conditionné. Son catalogage est en cours, et il pourra être mis à disposition des chercheurs dans les tout premiers jours de janvier 2016.
Le fonds le plus important, en quantité du moins –et heureusement clos- du Musée Voltaire reste toutefois le fonds Besterman. Il s’agit d’un vaste ensemble documentaire réunissant tous les échanges de correspondance de Theodore Besterman entre les années 1952 et 1973. Sont réunies près de 26'000 unités documentaires expédiées au premier directeur des Délices ou adressées par celui-ci. La difficulté majeure est, encore une fois, de savoir où arrêter la description, quelles données sélectionner et comment adapter le plan de classement initialement prévu par Besterman lui-même.
Une première étape fut de créer des dossiers par destinataires quand cela n’était pas encore fait, une deuxième de les décrire dans leur généralité en incluant quelques données biographiques ou quelques renseignements sur leur institution d’origine. Troisième étape enfin : établir une description pièce par pièce, tout en tenant compte de la législation en cours (Loi sur les Archives et Loi sur l’information au public et l’accès aux documents, dite LiPAD). Le fonds Besterman relève a priori des archives administratives du Musée Voltaire, mais il est également composé de documents établis avant la création de notre institution, et ressortit donc en partie du droit privé. Il a dès lors été convenu, après avoir fait le choix des informations susceptibles d’être reproduites dans le catalogue, d’adapter les conditions de consultation du fonds. Si tous les autres documents du Musée Voltaire sont consultables sans grande restriction, le fonds Besterman est quant à lui plus sensible et ne devrait être accessible que sur demande expresse, et argumentée, adressée au conservateur en charge du Musée Voltaire.
Le traitement des données n’en a pas moins permis de dessiner le «réseau» de Theodore Besterman et de montrer que, depuis sa création, notre institution est au cœur du monde dix-huitièmiste : Besterman n’avait-il pas d’ailleurs été l’inspirateur du premier Congrès international des Lumières ? C’est aux Délices qu’a été créée la revue des Études sur Voltaire et le Dix-Huitième Siècle, plus connue ensuite sous le titre de Studies on Voltaire and the Eighteenth Century – communément appelée SVEC – puis devenue, dès 2014, les Oxford University Studies in the Enlightenment.
Ses archives permettent également de voir comment travaillait Besterman : il a été récemment montré comment le premier conservateur des Délices était parvenu, en pleine guerre froide, à obtenir des autorités soviétiques les microfilms des manuscrits conservés à la bibliothèque Saltykov-Chtchedrine, à Leningrad. Son parcours à l’UNESCO et sa passion pour Voltaire font de lui, et par analogie la Ville de Genève et le Musée Voltaire, des pôles absolument incontournables en études dix-huitièmistes. La Bibliothèque de Genève tente aujourd’hui de garder le cap et est récemment devenue, grâce à plusieurs dons importants au premier rang desquels celui de Jean-Daniel Candaux, le plus grand centre de conservation d’œuvres et de manuscrits de Voltaire au monde.
Examinons de plus près l’information que nous avons reproduite : nous avons choisi, autant que possible, d’identifier l’expéditeur, le destinataire, le lieu de rédaction, la date d’envoi, l’importance matérielle du document, et d'en faire les données de base naturelles de la description. Viennent ensuite une indexation des personnes (correspondants et autres), une indexation des lieux et des données bibliographiques quand cela est possible. Voici, en guise d'exemple, un dossier et deux pièces type :

Volage : quels enseignements ?
Au moment de sa mise en ligne, Volage a permis une première approche des manuscrits de l’Institut et Musée Voltaire. Il offre une vision d’ensemble des collections aussi bien que des descriptifs pièce par pièce. Son but est d'en faire connaître les richesses et d’aider à formuler des questions dont la réponse sera donnée sur place, ou sous forme de courrier électronique, par les personnes en charge du catalogue.
Ce sont, après plusieurs années de réflexion et de diffusion des données, trois questions qui se posent désormais.
La première est celle de l'accès aux images. L'étape ultime du service au public serait de fournir, dans une résolution suffisante pour une consultation aisée mais insuffisante pour une publication, une image du manuscrit décrit. Mais le risque ne serait-il pas de voir ladite image se substituer à la description elle-même ? Ne pourrait-elle agir, avec des lecteurs pressés, comme un formidable miroir aux alouettes ? Et ne risquons-nous pas finalement d'inciter le lecteur à ne plus porter qu'un regard distrait sur une description pourtant indispensable à la compréhension du document ?
Une seconde question tient à l'interconnexion généralisée qui est sous-tendue par la mise en place des normes internationales et par le dialogue instauré entre les différents catalogues. Ne risquons-nous pas (et poser la question, n'est-ce pas déjà y répondre ?) de gommer la spécificité de chaque lieu, de chaque collection en voulant éradiquer, au nom d'une illusoire globalisation, ce qui fait son identité propre ? Bien des institutions ou centres de recherche, qui ont déjà perdu leur autonomie budgétaire ou leur pouvoir d'initiative, ne risquent-ils pas, à ce petit jeu, de perdre leur âme ?
Troisième question enfin : celle du lien au monde de la recherche. La richesse des fonds du Musée Voltaire appelle une coopération soutenue avec les acteurs de la recherche, qu'ils soient issus de l'Université, relèvent d'une société savante ou agissent en tant qu'individus éclairés. Nous replier sur nos seuls fonds, au nom d'on ne sait quelle efficacité, sans établir avec nos partenaires privilégiés que sont les bibliothèques-sœurs, spécialistes du même domaine et partageant des compétences similaires, des contacts privilégiés, serait un pur contresens.
Qu'on nous permette, en guise de conclusion, une petite anecdote.
Le 29 octobre 2012, les souvenirs d'Émilie du Châtelet ont été dispersés lors d'une vente spectaculaire organisée chez Christie's, à Paris. Plusieurs manuscrits d'importance ont dépassé, lors de cette vente, les estimations les plus hautes, atteignant, pour l'un d'entre eux, près d'un million d'euros. Or le Musée Voltaire fut la seule institution publique à pouvoir sauver quelques documents, au premier rang desquels un manuscrit des Examens de la Bible (fig. 5), aujourd'hui mis à la disposition des chercheurs. Les autres manuscrits de cette vente, suite à divers problèmes judiciaires, restent quant à eux inaccessibles au public.
C'est dire que notre première mission -la sauvegarde du patrimoine et, s'agissant du musée Voltaire, du patrimoine voltairien et dix-huitièmiste- nécessite tout à la fois vigilance, précision et surtout sens du service du public. C'est là toute la philosophie de Volage, et sa seule raison d'être.
Illustrations
Figure 1 : ancienne demeure de Voltaire aux Délices

Figure 2 : Theodore Besterman, milliardaire anglais passionné de Voltaire

Figure 3 : manuscrit du livret de Zadig

Figure 4 : commentaires marginaux de Voltaire portés sur le compte rendu du procès d’Abbeville

Figure 5 : manuscrit des Examens de la Bible

La plateforme de prêt de livres numériques e-bibliomedia
Laurent Voisard, Directeur de Bibliomedia Suisse, Lausanne
Bibliomedia est une fondation de droit public active dans le développement des bibliothèques et la promotion de la lecture. Elle est en quelque sorte la « bibliothèque des bibliothèques », le nœud central du réseau des bibliothèques de lecture publique suisses. Elle travaille aussi avec les bibliothèques scolaires ou directement avec les classes. Elle s'active également dans des projets de promotion de la lecture. Les trois bibliocentres de Lausanne, Soleure et Biasca proposent un large fonds de livres actuels pour tous les âges, dans toutes les langues nationales et dans plusieurs langues étrangères et un fonds d'autres médias (CD musicaux, DVD, livres audio).
Genèse
Profitant de la volonté - et des subsides - de l’Office fédéral de la culture de favoriser l'accès à la littéralité au travers de la culture numérique, la fondation Bibliomedia Suisse a contribué dès 2013 à la mise en réseau de plateformes de prêt de livres numériques. En Suisse alémanique d’abord, grâce à DIVIBIB, puis en Suisse romande par l’intermédiaire de PNB-Dilicom et la plateforme canadienne Cantook.
Les bibliothèques publiques de Suisse romande ont longtemps été éloignées du prêt de ebooks puisqu’aucune solution ne leur était proposée. La solution Numilog, choisie par quelques bibliothèques, dont la pionnière Médiathèque Valais, a été fermée à la Suisse à la fin 2013 pour des questions de droits internationaux et de géo-territorialité.
Questionné au sujet des spécificités de la territorialité pour la Suisse, Hadrieur Gardeur, PDG de Feedbooks, un serveur commercial de livres numériques situé en France, répond : « C'est un sujet très compliqué, il y a différents paramètres qui rentrent en compte:
- le fait que pour les diffuseurs papier, la Suisse est un territoire distinct alors que la France et la Belgique sont considérées comme un seul et même territoire.
- du coup, ils peuvent confier à un autre diffuseur l'activité en Suisse
- dans les flux de métadonnées, l'Europe est de plus en plus régulièrement traitée comme un seul marché (prix et disponibilité pour toute l'Europe) mais la Suisse est souvent oubliée
- certaines grosses plateformes (Amazon, Apple etc.) opèrent aussi des plateformes par pays et ont tendance à avoir des particularités vis à vis de la Suisse (pas de gestion du CHF par exemple) qui compliquent les choses
- La TVA n'est pas vraiment un problème, la Suisse est traitée comme un territoire où on vend des livres en HT au lieu de le faire en TTC (le cas est beaucoup plus complexe en Europe depuis qu'on a basculé au 1er Janvier sur une facturation selon le pays de l'acheteur).
Du fait de ces raisons, il en découle que les usagers et consommateurs en Suisse ont souvent accès à des catalogues plus limités.
Ce n’est qu’à l’automne 2014, et face à notre insistance, que PNB-Dilicom (PNB, Prêt Numérique en Bibliothèque / Dilicom, société française d'agrégation et de distribution de livres numériques), s’est enfin ouverte à la Suisse romande. e-bibliomedia, la bibliothèque numérique des bibliothèques publiques romandes, a ainsi pu être lancée en compagnie d’une quinzaine de bibliothèques avec l’objectif de desservir toutes les bibliothèques publiques et scolaires qui le souhaiteraient.
Qu’en est-il aujourd’hui ?
Avec ses 40 bibliothèques affiliées à la plateforme, et ses 1'785 usagers actifs, e-bibliomedia, dont le fonds de livres numériques se monte à ce jour 2'115 titres, a comptabilisé depuis son ouverture plus de 10'000 prêts. Un groupe de travail issu des bibliothèques affiliées s’est réuni dernièrement afin de définir les grandes lignes de la politique d’acquisition. Il ne s’agit pas à proprement parler d’un consortium étant donné que les frais de fonctionnement ne sont pas répartis entre les bibliothèques affiliées mais pris en charge par Bibliomedia. Les bibliothèques romandes bénéficient de l’infrastructure de la fondation et le montant de leur abonnement annuel est versé dans un pot commun qui sert de socle aux acquisitions. Bibliomedia complète ce fonds financier par un apport annuel substantiel d’environ 20'000 francs.
Politique d’acquisition
Au premier rang des acquisitions figurent inévitablement les fictions adultes, et en particulier les romans grand public. Utilisés en complémentarité des livres papier, les livres numériques doivent servir de solution de repli pour le lecteur en mal de disponibilité de bestsellers. Les institutions pourront d’ailleurs profiter de cette bouffée d’oxygène offerte par le numérique pour acquérir moins d’exemplaires des peu durables blockbusters, et équilibrer et diversifier leurs fonds de manière plus sereine. Parmi les genres fictionnels figurent également les bandes dessinées, dont les premiers volumes issus des fonds Casterman et Fluide glacial viennent d’arriver sur la plateforme. Précisons que ces médias en format PDF sont lisibles de préférence sur une tablette.
A la demande de certaines bibliothèques affiliées, des romans en anglais ont été acquis. Il apparaît maintenant que les ouvrages en langues étrangères sont des incontournables du prêt numérique. Il est donc question, en plus d’agrandir le fonds anglo-saxon, d’acquérir des titres dans d’autres langues, dont au moins l’allemand et l’italien. Toutes les réflexions au sujet du choix des titres sont en cours et aucun genre n’est a priori exclu.
Dans les recommandations du groupe de travail figure également la ligne à tenir concernant les ouvrages autres que les romans. Il faut acquérir des documentaires sur l’actualité brûlante, mais bien entendu aussi les genres qui fonctionnent bien, comme le développement personnel, les guides de voyage, les biographies, etc…
Un fonds jeunesse, orienté plutôt en direction des adolescents, a également fait son apparition et représente fin 2015 environ 250 titres.
Où et comment acheter des livres numériques ?
Pour prêter des livres numériques, il est nécessaire de disposer d’une plateforme dédiée à cet usage. PNB propose celle développée par l'entreprise canadienne "De Marque" et baptisée Cantook. C’est celle choisie par Bibliomedia. Il existe des solutions mises au point par des développeurs de système intégré de gestion de bibliothèque (SIGB) comme par exemple BibliOnDemand soutenu et promu par Archimed qui utilisent également l’interface de PNB-Dilicom. Mais la concurrence existe également. Outre Numilog déjà citée, nous pouvons signaler Immatériel, Bibliovox-by-Cyberlibris, Storyplayr (littérature de jeunesse), E-Fraction Diffusion et Knowledge Unlatched. On pourra lire à ce sujet l’article de SavoirCom1 dont le lien se situe au bas de cet article.
Quels lecteurs ?
Les lecteurs de la plateforme e-bibliomedia sont recrutés par les bibliothèques affiliées. Leur nombre n’est pas limité et peut donc énormément varier selon leur provenance. Actuellement et sans surprise, ce sont les plus grandes bibliothèques qui inscrivent le plus de lecteurs : Lausanne, Bienne et La Chaux-de-Fonds tiennent la corde mais les lecteurs d’Yverdon-les-Bains sont bien représentés également. En décembre 2015, sur le Canton de Genève, seule la bibliothèque municipale de Meyrin fait appel à e-bibliomedia. Charlotte Benzi, la responsable du développement de la plateforme e-bibliomedia, indique que la majorité des lecteurs se recrutent parmi les femmes de plus de 50 ans, et que la catégorie la moins représentée est celle des jeunes de 15 à 30 ans, alors que nous aurions pu attendre des « digital natives » un intérêt instinctif pour ce média en ligne. Pour la petite histoire, le doyen de la plateforme est un Chaux-de-Fonnier de 89 ans ; comme quoi les clichés sont vite dépassés.
Comment lire et à quelles conditions
L’avantage offert par PNB-Dilicom est incontestablement la possibilité pour le lecteur de pouvoir télécharger le livre numérique sélectionné sur la plateforme et le lire à l’endroit de son choix, et sur le terminal de son choix également (ordinateur, tablette, liseuse, etc). Actuellement il n’est obligé de passer par sa bibliothèque que pour son enregistrement initial. Les livres mis à disposition sur e-bibliomedia sont prêtés pour 21 jours. Chaque lecteur peut emprunter 5 ouvrages à la fois. Il a la possibilité d’effectuer un retour anticipé, ce qui lui permet de réemprunter d’autres ouvrages si son compteur était déjà parvenu à 5 titres empruntés.
Et quelles difficultés ?
Lire en numérique implique quelques manipulations pour le téléchargement que les tablettes rendent plus faciles, une fois passé l’écueil de l’identifiant "Adobe Digital Edition" (ADE). Mais les liseuses offrent un confort de lecture supérieur grâce à leur écran à encre électronique dont le rendu visuel se rapproche fortement de celui du livre papier.
Les principaux problèmes rencontrés, gérés soit au travers de l’aide en ligne e-bibliomedia ou par les responsables dans les bibliothèques affiliées, sont pratiquement tous liés au téléchargement. La version d’ADE et le modèle de liseuse y jouent un rôle crucial.
Du côté des éditeurs
Portée à bout de bras par Gallimard, l’offre des éditeurs francophones reste encore actuellement un peu décharnée, même si la situation s’est améliorée dernièrement avec l’arrivée d’éditeurs tels qu’Actes Sud, Robert Laffont ou Flammarion, car la question de la territorialité prive encore les bibliothèques de certaines ressources. De plus, un nombre important d’éditeurs ne souhaitent pas offrir l’accès numérique à leurs titres pour le prêt en bibliothèque. Ce qui explique que seuls 10’000 titres sont actuellement disponibles pour les bibliothèques suisses. L’avenir est heureusement plus séduisant puisque l’on nous annonce pas moins de 25'000 titres pour début 2016. Ce sera alors vraiment Noël pour les lecteurs romands.
La polémique est vive en France au sujet de la politique de vente de PNB-Dilicom aux bibliothèques. On critique notamment la chronodégradabilité du fonds. En effet, la majorité des titres achetés ont une durée d’emprunt de 6 ans, 3 pour Actes Sud par exemple, et après 30 prêts, l’accès à la licence doit être racheté.
Avenir pour les bibliothèques affiliées…
Dès le mois de janvier 2016, les bibliothèques affiliées à e-bibliomedia devront s’acquitter d’un abonnement annuel calculé sur la base de 2% de leur crédit d’acquisition, selon le modèle pratiqué dans les réseaux alémaniques tels que DIVIBIB (Digitale Ausleihportale für Bibliotheken) qui demandent quant à eux 5%. A noter encore que les montants récoltés serviront, dans leur intégralité, à alimenter le budget d’acquisition des livres numériques.
Et ensuite ?
Outre l’élargissement progressif du fonds avec des groupes importants d’éditeurs tels que Hachette et Immatériel, l’ajout de langues étrangères et de titres pour les jeunes publics, l’avenir passera manifestement par une valorisation et une médiation de l’outil auprès des lecteurs traditionnels de la bibliothèque. Nous souhaitons aussi toucher les non-usagers des institutions publiques qu’une telle offre, atteignable depuis leur domicile, pourrait indubitablement convaincre.
Un enjeu de taille pour les bibliothèques et e-bibliomedia, mais le succès n’arrive jamais sans effort ni créativité.
Le lecteur curieux pourra se renseigner plus en détail au sujet de la polémique française autour de PNB en consultant les liens ci-dessous :
http://www.reseaucarel.org/page/le-point-du-pnb-fevrier-2015
Au sujet du HUB Dilicom et de PNB :
La veille et l’intelligence économique dans le marché de l’emploi en Suisse romande
Raphaël Rey, Haute Ecole de Gestion, Genève
La veille et l’intelligence économique dans le marché de l’emploi en Suisse romande
1 Introduction
En Suisse romande, une part importante des dirigeants de PME (Petites et Moyennes Entreprises) affirment avoir mis en place une démarche d’intelligence économique (IE) comme en témoigne une enquête de 2014 menée par Alexandre Racine et Amanda Morina(1). Les résultats ont montré qu’un peu moins de 60% des CEO (Chief Executive Officer) interrogés se disent déjà engagés sur cette voie et que près des trois quarts des entreprises pratiquent la veille, ne serait-ce que de manière informelle.

Selon ces chiffres, une majorité d’entre elles consacreraient donc des ressources à cette question, ce qui devrait logiquement se répercuter au niveau du cahier des charges affichés dans les offres d’emploi.
Du côté des grandes multinationales, ces pratiques sont souvent anciennes et bien implantées dans la mesure où leur taille et leur zone d’activité rendent évidente l’impossibilité d’appréhender un environnement si vaste et si complexe sans y consacrer des ressources et adopter une méthode structurée. A ceci s’ajoute souvent l’influence de la culture de gestion anglo-saxonne qui a acquis depuis longtemps une sensibilité dans le domaine.
2 Objectifs
Si une majorité des entreprises en Suisse romande consacrent des ressources à l’IE et à la veille, les offres d’emploi devraient logiquement en constituer un bon indicateur avec la mention claire de tâches associées à ces domaines. Cette étude a pour principal objectif de vérifier ce fait et de proposer un panorama général du marché de l’emploi centré sur cette problématique. Il s’agira notamment de déterminer :
- les secteurs économiques qui recrutent le plus
- avec la veille ou l’IE en tâche annexe,
- avec la veille ou l’IE en tâche principale ;
- les types de veille pratiqués ainsi que la terminologie utilisée pour la désigner ;
- le rattachement au sein de l’entreprise (communication, marketing, direction générale, etc.) ;
- les profils et formations recherchées.
Ces données sont particulièrement utiles pour les acteurs de l’intelligence économique en Suisse. Elles rendent manifestes les secteurs, voire les entreprises les plus actives dans ce domaine. Elles constituent également une ressource précieuse pour le positionnement et la promotion de formations en IE afin de répondre aux besoins du marché.
Un objectif annexe à cette étude est de mettre en place un dispositif simple avec un minimum de traitement nécessaire pour relayer sur le site JVeille les annonces parues dans le domaine de l’IE : http://www.jveille.ch(2) .
3 Méthodologie
3.1 Périmètre de l’étude
Dès le début de cette étude, nous avons pris le parti de ne pas rechercher d’annonces spécifiques à l’influence (lobbying) ou à la sécurité. Outre le souci de restreindre le périmètre de récolte de données, nous voulions aussi préserver une certaine unité. En effet, la quasi-totalité des annonces observées concernant la sécurité s’adresse à des informaticiens spécialisés dans ce domaine et non à des personnes qui auraient suivi un cursus en IE. Pour le domaine de l’influence, les annonces sont peu nombreuses et difficile à distinguer des postes de relations publiques et de communication. Nous avons donc renoncé à tenter de les cibler spécifiquement.
3.2 Une recherche en trois phases
La recherche d’annonce d’emplois pour la veille et l’intelligence économique s’est déroulée en trois phases. La première avait pour but de faire différents tests de mots-clés et de sources (sites d’offres d’emplois) en vue de la mise en place d’un dispositif de surveillance permettant de détecter un maximum d’annonces en Suisse romande. Nous ciblions toutes les annonces du moment qu’elles mentionnaient des tâches même annexes en lien avec l’IE.
La seconde phase a consisté à exploiter le système mis en place et donc à récolter puis traiter les annonces détectées. Dans la dernière, nous avons davantage ciblé notre surveillance sur les offres dont la plus grande partie des tâches mentionnées relevaient directement de l’IE. Ce sont finalement surtout ces annonces-là qui permettent d’évaluer l’implantation de l’IE dans les entreprises.

3.3. Sélection des mots-clés et des sources (phases 1 et 2)
La sélection de ces derniers a été l’objet d’un choix difficile. Le terme « veille » est évidemment important, mais il désigne également l’action de « faire en sorte que » assez fréquente dans les annonces. On aurait donc pu associer ce mot-clé à des adjectifs comme « stratégique », « technologique » ou « concurrentielle », mais une exploration préliminaire nous a permis de constater que les expressions utilisées sont peu prévisibles et nous avons donc pris le parti d’accepter passablement de bruit et d’effectuer un tri manuel.
Le terme « intelligence » soulève des problèmes similaires. Fort heureusement, il n’apparaît que rarement pour désigner une caractéristique de la personne. Que ce soit dans les annonces francophones ou anglophones, il se retrouve majoritairement associé à « business » (« business intelligence »). Cette expression peut se rapporter à un champ d’activité proche de l’IE, mais dans la grande majorité des cas, il s’agit d’informatique décisionnelle. Par ailleurs, à côté d’expressions consacrées comme « competitive intelligence » tout à fait pertinentes pour notre étude, on trouve également des expressions moins caractéristiques comme « provide intelligence ». Au vu de cette diversité dans les usages nous avons donc décidé de suivre le terme « intelligence » quel que soit son contexte et de réaliser un tri par la suite.
A ces deux mots-clés, nous avons encore joint deux expressions anglophones que nous avons rencontrées à quelques reprises : « market insight » et « business insight ».
Au niveau des sources, en raison de l’abondance du bruit engendré par ces requêtes (environ 30%), nous ne pouvions naturellement pas viser l’exhaustivité. A défaut, nous avons multiplié les canaux : une agence de placement (Addeco), deux métamoteurs (Option carrière et Indeed), un réseau social (LinkedIn) et deux portails (JobUp et Monster).
Concernant le mode de récolte des données, nous avons naturellement dû nous adapter aux possibilités offertes par les différentes sources. Nous avons privilégié les flux RSS quand cela était possible, sinon nous avons recouru à des surveillances de pages de résultats en fonction de requêtes et à des alertes par email. Voici un tableau récapitulatif des surveillances :

3.4 Recentrage des surveillances (phase 3)
Après une période de surveillance où nous avons ratissé large et pu observer la diversité des annonces comportant une part d’activité en lien avec l’intelligence économique, il nous a paru pertinent de suivre sur une plus longue durée les offres beaucoup moins nombreuses avec majoritairement des tâches en lien avec l’IE.
Pour limiter le bruit et le temps de traitement, nous n’avons suivi qu’une seule source, la plus prolifique de la phase 2 : Indeed. Nous avons également pris des mesures pour réduire le bruit au risque d’un certain silence. Voici l’équation que nous avons appliqué à chaque canton romand (ou partiellement romand) :
| (veille or intelligence or "market insight" or "business insight") -"business intelligence" -"veille technologique" -"veille à" -"veiller à" -"veille au" -"veiller au" |
Parmi les points notables, nous avons par exemple rejeté l’expression « business intelligence ». En effet, la première phase de récolte a révélé que l’immense majorité des annonces comprenant cette expression n’étaient pas pertinentes par rapport à l’IE. Plus discutable peut-être, nous avons pris la décision de rejeter la veille technologique. En effet, cette tâche est mentionnée dans de très nombreuses annonces pour des postes d’ingénieurs ou d’informaticiens. Ce ne sont pas des spécialistes de la veille, mais cela fait partie de leur métier de se tenir informés sur les innovations de leur domaine. De plus, cela ne représente qu’une part très limitée de leur temps de travail.
3.5 Outils de veille utilisés
L’ensemble du dispositif a été mis en place sur le logiciel français de veille stratégique Digimind. Cet outil s’est révélé pratique pour son tableau de bord qui permettait de vérifier l’ensemble des sources de manière systématique, ainsi que pour les possibilités de capitalisation des annonces en leur associant des mots-clés en fonction de listes : formation, type de veille, secteur économique, etc.
Pour la phase 3 et la seconde collecte, nous avons également recouru à Inoreader qui permet d’exporter des flux RSS avec un paramétrage fin ainsi que des codes html pour intégrer les résultats sur un site web. Cette dernière fonctionnalité nous a permis de rediffuser les offres pertinentes sur le site JVeille.
4 Résultats
4.1 Représentation de la veille et de l’IE dans les offres d’emploi
Nous commençons l’exposition des résultats avec une rapide analyse de la présence de la veille et de l’IE dans les offres d’emploi. Pour ce faire, nous avons effectué un pointage sur toutes offres ouvertes le 10 septembre à l’aide du métamoteur Indeed et de l’équation suivante :
| (veille or intelligence or "market insight" or "business insight") -"business intelligence" -"veille à" -"veiller à" -"veille au" -"veiller au" |
Il s’agit de la même requête que celle présentée dans la section précédente à l’exception que nous n’excluons plus la veille technologique. Par commodité, nous désignerons dans les diagrammes cette équation par le sigle /veille/.
Sur l’ensemble des cantons romands à l’exclusion de Berne qui est majoritairement alémanique, nous obtenons les chiffres suivants :

On constate donc qu’en moyenne moins de 2% des offres mentionnent une activité en lien avec l’IE et cette proportion varie drastiquement selon les régions et semble diminuer à mesure que l’on s’éloigne de Genève et de l’Arc lémanique. En France, la même requête révèle qu’un peu plus de 5% des offres comportent des tâches de veille.
A titre de comparaison avec d’autres types de responsabilités ou fonctions, nous avons tenté les requêtes suivantes sur le canton de Genève :

Il ressort de ces chiffres que l’on manage à Genève au moins 8 fois plus que l’on ne fait de la veille. Une activité aussi transversale est moins demandée que des responsabilités en lien avec les ressources humaines ou la comptabilité. Quant aux ingénieurs, il n’y en a finalement qu’une partie assez faible dont l’annonce mentionne des activités de veille (9 sur 99).
Naturellement, les collaborateurs peuvent se voir confier des tâches de cet ordre, même si celles-ci ne sont pas annoncées dans l’offre. Toutefois ces chiffres semblent confirmer l’idée que les compétences en IE ne constituent que très rarement une priorité chez les recruteurs.
Ces résultats présentent une certaine stabilité dans le temps comme en témoignent deux autres sondages que nous avons effectués sur Indeed avec la même requête sur Genève (14 octobre et 4 décembre 2015).

Dans les sections suivantes, nous allons analyser plus en détail les offres repérées qui présentent tâches en lien avec l’IE.
4.2 Analyse globale des offres (juillet-août)
Sur les mois de juillet et août, nous avons retenu 277 offres comme comportant des tâches en lien avec l’IE : 24 où celles-ci occupent une place essentielle et 253 où elles sont annexes.

En plus de ces 24 offres repérées, on trouve également plusieurs stages avec des tâches relevant de l’IE prédominantes : 17 annonces dont la moitié pour des activités en lien avec le marketing. Si on cumule les chiffres pour les emplois et les stages, on constate que sur les 41 offres au total dans le domaine, 40% sont en réalité des activités non ou très peu rémunérés. Ces résultats soulèvent des questions quant à la reconnaissances des compétences propres à l’IE, si des stagiaires suffisent à couvrir une part si importante des besoins. Nous reviendrons plus loin sur ce point.

Concernant la terminologie utilisée dans les annonces pour désigner la veille, celui-ci dépend naturellement des requêtes utilisées. Néanmoins, nos équations étaient suffisamment larges pour laisser de l’intérêt à ce type d’analyse en mettant en évidence, par exemple, les termes les plus souvent associés à celui de « veille » :

En plus d’observer une grande diversité dans les domaines couverts par la veille, on ne peut que constater l’écrasante domination de la veille technologique. En effet, les offres pour des ingénieurs ou des informaticiens comportent régulièrement des tâches de veille. Celles-ci ne représentent toutefois presque jamais l’essentiel des postes.
Parmi les faits remarquables, on notera la faible représentation de la « veille stratégique » alors qu’il existe une affinité évidente entre stratégie et veille et que cette expression est très largement utilisée dans la littérature. Ces résultats tendent à montrer que la recherche d’information sert d’abord à répondre à des besoins très opérationnels.
Si on considère l’e-réputation, il n’y a que trois offres qui mentionnent cette spécialisation de l’IE (et essentiellement des entreprises françaises). Si la demande est bien marquée en France, on constate qu’elle peine à s’imposer en Suisse. Cela ne signifie pas que les organisations de ce pays ne se soucient pas de leur réputation en ligne, simplement cette tâche n’y est que rarement reconnue comme un métier en soi ou alors est désignée autrement : « analyste médias », par exemple.
En anglais, on constate une plus grande variété dans les expressions utilisées :

On observe que dans les annonces anglophones, la veille est beaucoup plus orientée sur les problématiques liées à la concurrence et à l’analyse de marché. L’influence des requêtes utilisées pour repérer les annonces est certaine, mais ne suffit pas à expliquer le fait.
A noter que « monitor(ing) » peut renvoyer à n’importe quel type de surveillance potentiellement sans aucun rapport avec de la veille (d’autres termes comme « analyse » ou « research » sont fréquents, mais non caractéristiques du type d’annonces recherchées). Les occurrences du terme « insight » sont, en revanche, très souvent pertinentes. Toutefois, il n’y a pas de combinaisons récurrentes. On trouve, par exemple, plusieurs fois des expressions comme « provide insights ».
Parmi les profils et métiers recherchés, la diversité est très importante, ce qui n’est guère surprenant dans la mesure où des besoins en veille et en IE peuvent se ressentir dans les organisations à tous les niveaux. Le diagramme suivant montre de manière sommaire pour toutes les annonces comportant des tâches de veille (prioritaires ou non) la répartition entre les différents métiers :
Premièrement, ce schéma montre la rareté des postes s’adressant spécifiquement aux spécialistes de l’information et de l’IE en Suisse romande. Nous reviendrons sur ce point par la suite.
Dans « marketing, communication, commerciaux », nous trouvons également les spécialistes des achats et les responsables de la stratégie commerciale. Ces métiers et ces fonctions n’appartiennent pas toujours à des postes différents, surtout dans les PME. Au niveau de la veille, l’ensemble de ces personnes pratique essentiellement la veille concurrentielle.
Concernant les informaticiens, une pratique de la veille est souvent attendue d’eux, mais ce n’est que très exceptionnellement que cette activité devient prioritaire par rapport au reste. Manifestement, on souhaite qu’ils mettent à jour leurs connaissances, mais cela se fait probablement le plus souvent de manière assez informelle et personnelle.
La situation est un peu différente dans les domaines commerciaux où la veille prend davantage d’importance. Toutefois elle semble également le plus souvent personnelle dans la mesure où elle sert directement les tâches que remplit le collaborateur. Par exemple, un responsable des achats va faire une veille fournisseurs.
Nous n’avons rangé parmi les « cadres dirigeants » que des directeurs généraux ou du moins des responsables de succursales. Les autres postes de cadre ont été rangés dans la catégorie correspondante à leur métier : « ressources humaines » pour un directeur des resources humaines.
Dans la catégorie « autres », nous trouvons une série de métiers comme des chefs de projet, des statisticiens, des responsables qualité, des employés administratifs, etc. Les cadres intermédiaires y sont particulièrement bien représentés.
Parmi les secteurs qui propose de plus d’emplois comportant des tâches de veille, on trouve en tête le milieu bancaire couplé à celui de la finance, ainsi que tout ce qui relève du domaine IT.

La forte présence du secteur bancaire et de la finance s’explique par le fait que ces sociétés ont un besoin important de veille à plusieurs niveaux. Ils utilisent beaucoup d’informatique et se doivent d’être absolument sécurisés à ce niveau, ce qui implique une veille technologique régulière.
D’autre part, la gestion de patrimoine représente des enjeux fiscaux et légaux importants, d’où le besoin pour une veille réglementaire. Par ailleurs, il y a aussi toute la question liée à la due diligence (devoir de vérification raisonnable) qui amène les intermédiaires financiers à enquêter sur leurs clients. Finalement, cet univers est concurrentiel comme les autres et ne peut donc pas s’épargner une veille marché.
Le deuxième secteur le plus représenté est l’IT. La veille y est surtout technologique et on la retrouve indifféremment dans de nombreux domaines d’activité : sécurité informatique, développement d’applications, solutions cloud, webdesign, gestion de systèmes d’information, etc.
On remarquera également la part importante des autres secteurs qui montre à quel point la veille, bien que rare (2% des offres environ), se retrouve dans la plupart des types d’activité.
4.3 Analyse des offres centrées sur l’IE (juillet-octobre)
Afin d’avoir davantage de données, nous avons étendu à quatre mois la période de récolte des offres qui comportent une part importante de tâches en lien avec de l’intelligence économique ou à de la veille. Dans cette partie, nous présentons donc des données datant de juillet à octobre 2015.
Nous avons retenu au total 70 offres où la part des tâches en relation directe avec l’IE nous semblait particulièrement importante. Parmi elles, la répartition des langues entre anglais et français est assez équilibrée avec un avantage pour la seconde.

La forte présence de l’anglais s’explique par la proportion significative des offres émanant de multinationales étrangères, mais pas uniquement.

Dans la section suivante, nous verrons que plusieurs secteurs d’entreprises dont le siège et l’essentiel des activités sont en Suisse proposent également des postes avec des besoins marqués en compétences IE.
Le diagramme suivant donne la répartition des offres par secteur sur les mois de juillet à octobre 2015 :

Nous pouvons tout d’abord constater une grande diversité. Après tout, le plus grand groupe est « autres secteurs » avec presque un tiers des offres. Il est toutefois intéressant de noter quelques différences avec la répartition que nous avions présentée plus haut quand nous analysions l’ensemble des annonces comportant des tâches d’IE :
- Le domaine IT a pour ainsi dire disparu ;
- Les secteurs medtech / pharma et banque / finance arrivent en tête, en particulier à cause du besoin massif de veille réglementaire ;
- La présence de cabinets de conseil que ce soit en IE, en marketing, en recrutement ou en technologie n’a rien d’étonnant dans la mesure où ce type de services requiert une recherche d’information souvent importante et actualisée ;
- Les ONG (Organisation Non-Gouvernementales) sont également bien représentées avec des tâches d'IE très diversifiées : veille médias et veille stratégique ;
- On retrouve également cette diversité dans l’horlogerie avec une dominance pour les problématiques liées au marketing.
On notera également une certaine fluctuation dans le rythme de publication des annonces. En effet, sur juillet et août, nous n’avions repéré dans le domaine de l’horlogerie aucune offre relevant majoritairement de l’IE, alors que pendant les deux mois suivants 6 paraissaient. Les autres secteurs affichent des répartitions un peu plus harmonieuses, mais le marché reste sujet à des fluctuations assez fortes.
Le diagramme suivant présente les domaines d’activité des 70 annonces retenues :

Le marketing et la conformité canalisent l’essentiel du marché de l’emploi. Ces résultats ne surprennent pas dans la mesure où le marketing est incontournable quel que soit le secteur d’activité. Quant à la conformité, elle est indispensable dans de nombreux secteurs bien représentés en Suisse romande comme les milieux bancaires ou pharmaceutiques.
La catégorie « prestation de veille » regroupe les emplois où la personne engagée n’effectue pas de la veille pour ses propres besoins ou un service donné dont elle fait partie (comme le marketing par exemple). Elle remplit au contraire un rôle de prestataire de services pour divers clients internes ou externes à l’organisation. Ces postes constituent des cibles particulièrement intéressantes pour celles et ceux qui souhaitent travailler activement dans la veille. Voici la liste des intitulés des dix annonces repérées :

A noter que pour seulement 4 de ces annonces, une formation dans le domaine de l’information est attendue (en orange dans le tableau). Quant à trois de ces offres, elles se contentent de rechercher des profils universitaires sans aucune formation spécifique à l’IE ou à la veille.
Si on ajoute encore une offre (absente de ce tableau) pour un poste à l’ONU dans le secteur des ressources humaines : JPO, HR Evaluation, Operational and Financial Analytics, il n’y a au total que 5 offres sur les 70 retenues qui expriment des attentes par rapport à une telle formation.
Comment interpréter cette situation ? On peut en déduire une certaine méconnaissance en Suisse pour les écoles et les filières qui intègrent la veille dans leur programme comme la HEG de Genève qui propose notamment un bachelor et un master en information documentaire ainsi qu’un DAS (Diploma of Advanced Studies) en intelligence économique et veille stratégique.
Toutefois, cette méconnaissance est probablement aussi le symptôme d’un manque de reconnaissance pour ce type de compétences. Parmi les emplois où la part de veille / IE est prédominante, nous avons aussi pu constater l’abondance des offres pour des stages avec près de la moitié des annonces. En particulier dans le domaine du marketing, la recherche d’information et la surveillance des médias sociaux apparaissent souvent comme des activités qu’on peut déléguer à des personnes peu formées ou du moins novices.
Pour aller au-delà de suppositions, la réalisation d’une enquête serait nécessaire. Toutefois, il est évident que pour une grande partie des travailleurs, la recherche d’information constitue une tâche quotidienne. Cette banalisation ainsi que la facilité d’accès et l’abondance de l’information masque probablement le besoin d’experts pour répondre à ces besoins. Et pourtant ceux-ci sont précieux pour coordonner les efforts d’une équipe et définir une véritable stratégie d’acquisition et de gestion de l’information. Aujourd’hui l’enjeu n’est plus tellement de trouver de l’information, mais de la trier et de cibler celle qui est véritablement utile.
5 Conclusion
Cette étude a mis en évidence un réel besoin du marché pour la veille. Avec environ 2% des offres mentionnant des tâches de ce type, il est évident que la question de l’information, de la mise à jour des connaissances est prise en compte par les recruteurs.
La plupart des secteurs d’activité sont représentés et parmi les plus demandeurs on trouve les banques, les medtechs et l'industrie pharmaceutique, puis dans une moindre mesure les ONG et l’horlogerie.
Toutefois, dans la majorité des cas, la veille ne constitue qu’une tâche annexe qui, dans les annonces, apparaît en général tout à la fin de la liste des responsabilités. Ceci est particulièrement fréquent pour les ingénieurs et les informaticiens qui comptabilisent à eux seuls un peu plus de 40% des offres repérées (112 sur 277 pour la période de juillet à août), mais uniquement dans 5 de ces offres, la veille occupe une place prédominante.
Parmi les types de veille pratiqués, l’analyse de la terminologie nous a montré qu’en français la veille technologique ou technique était très largement majoritaire (88 offres sur 277 en juillet et août), ce qui s’explique en partie par la forte proportion des annonces pour des postes d’ingénieurs ou d’informaticiens. Arrivent ensuite, la veille concurrentielle (26 sur 277) et la veille réglementaire (15 sur 277). Quant à l’e-réputation, elle n’a pas percé en Suisse malgré sa relative forte représentation en France (3 mentions dans les offres).
En anglais, la répartition est plus homogène et on trouve en tête competitive intelligence (20 sur 277) et market intelligence (12 sur 277). On ne trouve donc pas d’équivalent direct pour la veille technologique.
La présence récurrente de la veille dans les annonces constitue un premier pas, même si 2% des offres ne constitue qu’une proportion relativement faible si on la met en parallèle avec les trois quarts de dirigeants de PME qui prétendent qu’une pratique de veille existe au sein de leur entreprise (voir notre introduction).
Si une prise de conscience a eu lieu à propos de la nécessité de la veille, il s’agirait à l’avenir de généraliser et de professionnaliser sa pratique en rendant manifeste le fait que cela demande des compétences spécifiques et donc une formation.
En effet, cette étude met également en évidence un niveau d’attente très faible pour des formations en intelligence économique ou en sciences de l’information, même s’il ne fait pas de doute que des diplômes dans ces disciplines constituent un réel atout pour prétendre à des postes tels que ceux que nous avons identifiés comme comportant une part significative de tâches liées à l’IE.
Dans ce contexte, une formation telle que le DAS en intelligence économique et veille stratégique de la HEG de Genève fait particulièrement sens lorsqu’elle vient compléter un cursus dans des disciplines comme le droit, le marketing, la communication ou d’autres encore.
Néanmoins, il reste un long travail d’évangélisation à effectuer auprès des entreprises pour faire évoluer la reconnaissance des compétences d'IE et mettre en évidence l’importance d’une gestion professionnelle de l’information qui constitue aujourd’hui avec les ressources humaines, les biens les plus précieux des organisations.
Notes
(1) MORINA, Amanda., RACINE, Alexandre, 2014. Pratiques et besoins de veille dans les PME de Suisse romande. [En ligne]. Travail de bachelor. Genève : Haute école de gestion de Genève. [Consulté le 14 décembre 2015]. Disponible à l’adresse : https://doc.rero.ch/record/232941
(2) Site en lien avec l’organisation des journées franco-suisses de la veille en partenariat avec la HEG de Genève, la HE-Arc de Neuchâtel et l’Université de Franche-Comté.
Compte-rendu du CERN Workshop on Innovations in Scholarly Communication (OAI9), 17-19 juin 2015, Genève
Anne Gentil-Beccot : Bibliothèque du CERN
Salomé Rohr : Bibliothèque du CERN
Compte-rendu du CERN Workshop on Innovations in Scholarly Communication (OAI9), 17-19 juin 2015, Genève
La 9e édition de la conférence OAI a eu lieu du 17 au 19 juin 2015, à Genève, dans les locaux de l’Institut des Hautes Etudes Internationales et du Développement et du Campus Biotech de l’Université de Genève. Pour cette édition, l’Open Access était évidemment présent, mais l’accent a surtout été mis sur ce qu’il y a au-delà : Linked data, Open Data, Open Peer Review, Open Science… En effet, l’Open Access n’est pas une fin en soi ; ce sont les services que l’on construit autour qui permettent de faire évoluer la communication scientifique. Par ailleurs, il est à noter que le thème de l’institution en tant qu’éditeur scientifique s’est invité au programme pour la première fois.
Présentation d’ouverture : Au-delà de l’Open Access, par Michael Nielsen
Michael Nielsen pose d’emblée la question « L’Open Access à quoi ? ». Pour lui, l’Open Access n’est pas seulement le libre accès aux articles de journaux scientifiques ; l’enjeu se situe au-delà. « L’Open Access a le potentiel d’amplifier l’intelligence individuelle et collective », mais seulement, soutient-il, si nous développons de nouvelles formes de médias. Il cite par exemple le notebook ipython(1), qui permet d’agréger, de visualiser des données et du code, mais également de partager ses découvertes. Un tel outil permet d’augmenter le nombre de personnes qui interagissent ensemble ; le savoir devient alors d’autant plus extensible. Par conséquent, l’Open Access n’est qu'une partie d’un tout. Pour lui, les politiques d’Open Access doivent être développées de sorte que l’innovation et l’expérimentation ne soient pas inhibées.
Session technique
La première session des conférences OAI est toujours centrée sur les aspects techniques. Cette année, l’accent a été mis sur la publication des données.
Un accès durable et permettant l’interrogation aux Linked data(2), par Ruben Verborgh
Pour Ruben Verborgh, l’essentiel pour les Linked data, est qu’elles soient facilement intégrées et que l’on puisse les interroger via le web. De nombreuses données sont désormais rendues disponibles, mais la grande difficulté reste leur accessibilité. Il présente donc une nouvelle façon de publier ces données de façon à les rendre accessibles et interrogeables, tout en limitant les coûts inhérents à ces processus. Avec la technologie Triple Pattern Fragments(3), les Serveurs offrent une interface qui permet aux Clients d’exécuter des commandes complexes efficacement. Cette technologie permet des recherches fédérées avec tous types de données. Le logiciel est disponible en Open Source sur Github(4) et donc réutilisable par toute institution souhaitant mettre à disposition ses données.
Un réseau décentralisé pour publier des Linked data, par Tobias Kuhn
Tobias Kuhn souligne lui-aussi le fait que la publication scientifique aujourd’hui n’est plus centrée seulement sur l’objet ‘article’, mais doit intégrer l’ensemble des données qui sont le résultat des recherches scientifiques. Il présente quelques outils qui selon lui sont essentiels pour publier des données de façon efficace. Les nanopublications(5) (plus petites unités d’information publiables) seront désormais au centre de la communication scientifique. Ces unités seront ainsi facilement citables et réutilisables. Il présente aussi le concept des Trusty URIs(6) qui permet de citer un set de données de façon à assurer que ces données sont à tout moment vérifiables, non modifiées et pérennes. Pour lui, les nanopublications doivent être publiées de façon décentralisée(7). Enfin, il évoque le concept des Science Bots(8) qui pourraient participer au contrôle de qualité de ces processus.
“Reference rot” et annotations de liens, par Martin Klein
Martin Klein présente le projet Hiberlink[9] qui vise à quantifier le nombre de ressources citées dans des articles scientifiques mais qui ne sont plus disponibles, ce qu’il nomme Reference rots (erreurs 404, pages dont le contenu a changé, etc.). L’équipe a étudié un corpus d’articles publiés entre 1997 et 2012 sur arXiv, Elsevier et PMC ; à partir des données de cette étude, ils ont estimé que sur l’ensemble des publications en STM(10), 1 article sur 5 comporterait des références dont les liens sont brisés. Pour pallier à ce problème, il propose l’idée des Robust links(11) (liens consolidés). Le Robust Link implique plusieurs éléments : la page citée doit être archivée sur une archive web telle que archive.is(12) et le lien doit être tagué avec la date et l’heure de la version de la page citée ainsi que l’URI de la version archivée de la page.
Barrières et impacts
Dans cette session, les conférenciers nous ont présenté des outils et conseils pour tenter de briser les barrières qui s’opposent à l’Open Access et ainsi augmenter l’impact de la recherche scientifique.
L’Open Access Button, par Joseph McArthur
L’initiative “Open Access Button”(13) permet aux personnes confrontées à un paywall(14) pour accéder à un article scientifique de tenter de faire évoluer l’accès à la recherche en rapportant leurs histoires qui seront ensuite utilisées pour tenter de faire changer les systèmes de publication vers l’Open Access. Une fois l’application installée, le bouton permet aux chercheurs de signaler les paywalls et de demander l’accès au document en expliquant pourquoi il a besoin d’y accéder. Le bouton va alors en rechercher une version accessible. S’il n’en existe pas, un e-mail sera envoyé à l’auteur et la référence sera enregistrée dans la wishlist du chercheur.
Les jeunes chercheurs et l’Open Access, par Erin McKiernan
Confrontée aux problèmes d’accès à la littérature scientifique en Amérique latine, Erin McKiernan plaide en faveur de la publication en Open Access. Selon elle, les jeunes chercheurs sont préoccupés par :
- Les coûts de publication élevés : alors que certains journaux OA[15] ne font pas payer de frais ou ont des frais d’adhésion forfaitaires peu élevés ; par ailleurs, certaines institutions ou financeurs ont des fonds dédiés à la publication OA ; enfin, l’auto-archivage ne coûte rien.
- La qualité du Peer-Review : pourtant, il n’y a pas d’étude qui prouve que le Peer-Review est de moins bonne qualité dans les revues OA ; la preuve de la qualité réside dans les « Open Peer Reviews » où le chercheur peut lui-même se faire une opinion sur la rigueur du processus.
- Leur carrière : les perspectives d’emploi et les évaluations sont basées sur le facteur d’impact. Il est cependant possible de choisir des revues OA à impact modéré à élevé. L’outil Journal Selector de Cofactor(16) permet de choisir une revue en fonction aussi des critères d’accès. L’initiative DORA(17) plaide en faveur d’un changement des critères d’évaluation des chercheurs.
- L’opinion négative des co-auteurs et mentors : une explication des bénéfices et des différentes options de publication OA pourraient les faire changer d’avis.
Wikimedia et l’intégration de l’Open Access, par Daniel Mietchen
Wikimedia est étroitement liée à l’Open Access en ayant pour but de rendre la recherche librement accessible et réutilisable. Ses plateformes et outils pourraient amener les chercheurs à reconsidérer la publication de leurs articles vers un modèle ouvert. Les outils Wikimedia permettent d’intégrer du matériel Open Access et différentes interactions sont possibles, par exemple, la publication d’articles, la signalisation des sources Open Access sur Wikipédia, des liens vers des pages web archivées, les plateformes Wikimedia Commons ou Wikidata. La possibilité, notamment, de la visualisation interactive et des graphiques éditables, permet d’intégrer des éléments multimédia complexes.
Les processus en Open Science
Cette session s’est concentrée sur l’Open Science qui, au-delà de la publication en Open Access, s’intéresse à l’ouverture du processus de recherche dans sa globalité.
CHORUS : améliorer l’accès à la recherche, par Howard Ratner
L’organisation CHORUS(18) a pour but d’améliorer la communication scientifique en facilitant, normalisant et résolvant les problèmes liés aux 5 étapes du processus de recherche : identification, découverte, conformité, préservation, accès ; et ce pour tous les acteurs du processus. CHORUS se base sur des collaborations avec des outils existants, par exemple, Cross Ref’s Fund REF, ORCiD, CLOKKSS ou PORTICO. Lors du processus de soumission, l’auteur saisit les informations d’identification sur la source de financement de sa recherche. Cela permet de tagguer l’article avec les identifiants Cross Ref’s Fund REF et l’information est envoyée avec le DOI et les informations bibliographiques à Cross Ref. Les métadonnées bibliographiques des membres sont collectées par CHORUS et un tableau de bord(19), une API(20) et un moteur de recherche permettent leur recherche et exploitation.
Ouvrir les infrastructures et structures de recherche dans l’enseignement supérieur, par Tyler Walters
L’initiative SHARE(21) a pour but de créer un set de données ouvertes sur les activités de recherche tout au long de leur cycle de vie ; cela a pour but d’accélérer et d’améliorer la recherche dans l’enseignement supérieur et de permettre l’innovation. Les métadonnées sur les publications et la documentation des activités de recherche de différentes sources sont collectées à travers SHARE, normalisées et ensuite notifiées grâce à un flux RSS aux utilisateurs du service. Pour contribuer, les organisations doivent s’enregistrer pour que leurs données soient moissonnées. Des APIs permettent le partage de matériel et la recherche des données. Les challenges à relever restent l’harmonisation et la qualité des métadonnées ainsi que les questions de droits sur le partage des métadonnées et la promotion de ce partage.
Changer les processus de recherche et passer de l’Open Access à l’Open Science, par Bianca Kramer et Jeroen Bosman
Changer les processus de recherche ne concerne pas les outils, qui montrent seulement comment les chercheurs travaillent, mais les chercheurs eux-mêmes. La science s’est transformée d’un mode cyclique simple à un processus complexe multi-cyclique, multi-ordonné et multi-itératif. La transition du schéma traditionnel vers l’Open Science devrait amener à des pratiques plus honnêtes/reproductibles, efficaces et ouvertes(22). Une étude(23) est actuellement menée sur les outils utilisés par les chercheurs sur 17 activités du processus afin de voir comment la communication scientifique a changé.
Assurance de la qualité
Cette session était entièrement dédiée au processus de Peer-Review, qui comme tous les aspects de la communication scientifique se doit d’évoluer avec les nouveaux besoins et enjeux.
Gérer le processus d’évaluation par les pairs (peer review) à grande échelle, par Damian Pattinson
PLOS One(24) est une publication en libre accès multidisciplinaire ; en 2014, 32,000 articles ont été publiés. Avec un tel corpus, PLOS One est l’une des plus grandes publications scientifiques actuelles. Pour le processus d’évaluation des articles par les pairs, la revue combine le travail du bureau éditorial interne et celui, volontaire, d’éditeurs académiques et de chercheurs. Damien Pattinson fait remarquer que la recherche est de plus en plus interdisciplinaire, ce qui n’est pas forcément le cas des personnes qui évaluent les articles. Pour lui, le processus d’évaluation doit donc s’ouvrir aux lecteurs pour être plus efficace et s’adapter aux nouveaux enjeux de la recherche scientifique.
Peerage of science : une initiative issue de la communauté scientifique pour améliorer le processus d’évaluation par les pairs, par Janne-Tuomas Seppänen
Peerage of Science(25) est une initiative qui permet de rendre le processus de peer-review indépendant de la soumission à une revue. Un auteur peut en effet soumettre un article sur le site ; l’article sera révisé par un pair (dont le profil a été validé) ; et la révision elle-même sera évaluée. Le résultat est rendu disponible à toutes les revues scientifiques adhérentes à l’initiative. Un nouveau projet est en cours : my.peerageofscience.org où il est possible de visualiser les profils des pairs ainsi que leur performance et leur popularité.
Publons : donner du crédit au processus d’évaluation par les pairs, par Andrew Preston
Une initiative similaire à la précédente est Publons.com(26). Cette plateforme offre aux éditeurs les outils pour identifier et contacter les personnes qui pourront faire la révision des articles. Ces personnes trouvent un bénéfice à effectuer ce travail, car leurs évaluations sont référencées et évaluées.
L’institution comme maison d’édition
Il s’agit là d’un nouveau sujet pour la conférence OAI. Sa présence ici révèle l’importance du phénomène dans le monde académique.
Mettre le monde académique au cœur de l’édition scientifique, par Catriona Maccallum
La recherche n’est désormais plus un cycle mais un réseau dans lequel de très nombreux acteurs sont impliqués. Bien sûr, il y a l’enjeu du libre accès au contenu même des articles, mais il s’agit d’aller au-delà et d’interconnecter tous ces acteurs pour développer des services autour du contenu. En cela, les institutions ont un grand rôle à jouer, en particulier en développant la transparence à tous les niveaux (Peer-Review, coûts de publication, etc.), ce que Catriona Maccallum appelle « l’ouverture intelligente ».
Mettre l’édition scientifique au cœur du monde académique, par Ruppert Gatti
De la même manière, Ruppert Gatti dit que les centres de recherche sont très bien placés pour faire de l’édition scientifique. Parmi les nombreux avantages, il note une interaction plus directe avec l’audience recherchée. Il balaie par ailleurs les différents problèmes que l’on pourrait envisager : pour lui, l’expertise nécessaire pour faire de l’édition ainsi que les ressources sont déjà en partie présentes au sein des centres de recherche, et de nombreux outils, souvent en Open Source, sont désormais disponibles pour aider à la mise en place de tels services. Selon lui, le monde académique a tout à gagner à mettre l’édition scientifique au centre de ses activités.
L’édition universitaire en libre-accès en Europe : difficultés et opportunités dans les sciences humaines, par Victoria Tsoukala
Victoria Tsoukala s’intéresse plus particulièrement aux sciences humaines. La communication scientifique dans ce domaine diffère des STM pour de multiples raisons ; le libre accès, en particulier a du mal à prendre de l’ampleur, alors que paradoxalement de nombreuses initiatives allant dans cette direction existent. Malheureusement, le domaine souffre d’une grande fragmentation et d’une difficulté à atteindre une masse critique et donc une certaine pérennité. C’est pourquoi elle recommande qu’il y ait une meilleure coordination des services et des infrastructures au niveau européen, et que les institutions et les chercheurs eux-mêmes s’investissent d’avantage.
Traitement et préservation numérique d’objets scientifiques grands et complexes
Cette session était consacrée aux différents enjeux liés à la manipulation et à l’archivage des données scientifiques.
Le cycle de vie des données : l’exemple suisse, par Pierre-Yves Burgi(27)
Le projet DLCM(28) met d’abord un accent particulier sur 2 étapes de la gestion du cycle de vie des données pour lesquelles les chercheurs ont besoin de solutions : le traitement et l’analyse des données, appelées aussi la gestion de données actives. Un objet complexe peut être défini comme multidimensionnel : il peut être multi-format, multi-structure, multi-source, multimodal, multi-version. La taille de l’objet contribue aussi à sa complexité. Dans le cadre du projet DLCM, les efforts vont d’abord se porter sur 2 outils(29) : openBIS et SLims et, pour les humanités digitales, SALSAH. Les outils mis en place permettront aux chercheurs de travailler avec leurs données et de les documenter, puis elles seront archivées et le set de données sera référencé avec un DOI. Les challenges à relever sont, le choix d’outils génériques ou spécifiques ; comment rendre le processus intuitif ; et enfin la définition d’un business plan solide et durable.
La préservation des objets scientifiques complexes : identification et capture des données, par Andreas Rauber
La préservation est avant tout motivée par la réutilisabilité des données. Les versions des logiciels, systèmes d’exploitation, et le matériel informatique altèrent les résultats. Pour assurer la confiance en la répétabilité des données, il est nécessaire de préserver, en plus des résultats, le processus et son implémentation. Les « data management plans » doivent être remplacés par des « process management plans ». La capture du processus et de son contexte passe par la définition d’un nombre d’informations minimum à capturer de manière automatique, ré-actionnable et réutilisable par une machine. Il est aussi primordial de pouvoir précisément citer le sous-set (dynamique) de données utilisé dans une étude, tel qu’existant à un moment donné. Un groupe de travail de la RDA(30) a émis des recommandations pour rendre citables les données dynamiques, tels que l’horodatage, le versioning ou l’attribution d’un identifiant persistant à une requête.
Le traitement des données de recherche : créer des services de données (ouvertes) au CERN, par Patricia Herterich et Tibor Simko
Au CERN, les efforts se concentrent sur la préservation des données pour les expériences du CERN, l’accessibilité des données à travers le CERN Data Portal et la création de liens vers les autres plateformes utilisées au CERN pour fournir plusieurs points d’accès aux données. Au-delà du problème des petabytes de données, il est essentiel de préserver le processus d’analyse pour pouvoir le reproduire ultérieurement. Un nouveau système, basé sur le logiciel Invenio, a été développé(1) : il connecte les outils que les physiciens utilisent pour préserver les données (wiki, logiciels, ou autres) en capturant automatiquement les métadonnées techniques et sémantiques. Concernant les données ouvertes, le CERN Data Portal(32) a été créé afin de rendre des sets de données accessibles au public extérieur, après certaines périodes d’embargo définies selon les politiques des différentes expériences du CERN.
Toutes les initiatives présentées pendant les 3 jours de la conférence montrent que la communication scientifique évolue pour permettre à la science d’avoir plus d’impact et d’être plus efficace. Les différents projets, qu’ils concernent les aspects techniques, les processus ou les politiques, montrent qu’une évolution est en cours vers un nouveau paradigme de la communication scientifique, une communication « ouverte ». Ce nouveau paradigme redonne une place privilégiée au chercheur et à l’institution elle-même.
Les présentations et vidéos des sessions sont disponibles sur le site web de la conférence : https://indico.cern.ch/event/oai9
Notes
(1) http://ipython.org/notebook.html (consulté le 29.10.2015)
(2) Web de données en français
(3) http://linkeddatafragments.org (consulté le 29.10.2015)
(4) https://github.com/LinkedDataFragments (consulté le 29.10.2015)
(5) http://nanopub.org/wordpress/ (consulté le 29.10.2015)
(6) http://trustyuri.net/ (consulté le 29.10.2015)
(7) Kuhn , T.et al. Publishing without Publishers : a Decentralized Approach to Dissemination, Retrieval, and Archiving of Data arXiv:1411.2749
(8) Kuhn, T[8] Science Bots: a Model for the Future of Scientific Computation? arXiv :1503.04374
(9) http://hiberlink.org/ (consulté le 29.10.2015)
(10) Publications en science, technique et médecine
[11] http://robustlinks.mementoweb.org/spec/ (consulté le 29.10.2015)
(12) http://archive.is/ (consulté le 29.10.2015)
(13) https://openaccessbutton.org/ (consulté le 29.10.2015)
(14) Accès moyennant paiement
[15] Open Access
(16) http://cofactorscience.com/journal-selector (consulté le 29.10.2015)
(17) http://www.ascb.org/dora/ (consulté le 29.10.2015)
(18) Clearinghouse for the Open Research of the United States: http://www.chorusaccess.org/ (consulté le 29.10.2015)
(19) http://dashboard.chorusaccess.org/ (consulté le 29.10.2015)
(20) Application programming interface
(21) http://www.share-research.org/ (consulté le 29.10.2015)
(22) Modèle “G-E-O” : good, efficient, open
(23) https://101innovations.wordpress.com/ (consulté le 29.10.2015)
(24) www.plosone.org/ (consulté le 29.10.2015)
(25) https://www.peerageofscience.org/ (consulté le 29.10.2015)
(26) https://publons.com/ (consulté le 29.10.2015)
(27) Voir aussi l’article de recherche consacré à ce projet dans ce même numéro de RESSI.
(28) Data Life-Cycle Management
(29) ELN (Electronic Laboatory Notebooks) / LIMS (Laboratory Information Managing Systems)
(30) Research Data Alliance
(31) CERN Analysis Preservation : http://analysis-preservation.cern.ch/ (consulté le 29.10.2015)
(32) CERN Open Data portal : http://opendata.cern.ch/ (consulté le 29.10.2015)
Le patrimoine : un enjeu pour les bibliothèques… mais aussi pour le public ! : Retour sur la 2e École d’été internationale francophone en SIB
Hésione Guémard, École nationale supérieure des sciences de l’information et des bibliothèques
Bassirou Ba, École nationale supérieure des sciences de l’information et des bibliothèques
Paul Faure, École nationale supérieure des sciences de l’information et des bibliothèques
Entre le 22 juin et le 3 juillet 2015 s’est tenue à Villeurbanne (France, Rhône-Alpes) la 2e École d’été internationale francophone en Sciences de l’information et des bibliothèques (SIB). Un premier échange s’était déroulé en 2014 à Montréal autour du thème « Marketing et médiation numérique en bibliothèques ».
L’École nationale supérieure des sciences de l’information et des bibliothèques (Enssib) a ainsi accueilli cette année plusieurs étudiants de l’École de bibliothéconomie et des sciences de l’information (Ebsi, Québec, Montréal) et de l’École de bibliothécaires, archivistes et documentalistes (Ebad, Sénégal, Dakar). Ensemble, nous avons échangé autour du thème « Patrimoine, Numérique, Publics » pendant quinze jours. Les cours et les présentations dispensés à l’Enssib ont été ponctués de visites de bibliothèques lyonnaises permettant aux participants de confronter leurs pratiques bibliothéconomiques dans un cadre plus informel.

Les étudiants ayant participé à la 2e Ecole d'été francophone en SIB accompagnés de leurs professeurs - Copyright Enssib
Si le patrimoine désigne un ensemble de biens matériels ou immatériels, aux qualités esthétiques ou historiques certaines, appartenant à une personnalité privée ou publique, il est aujourd’hui plus que jamais convoqué pour son sens premier de bien commun hérité et fondateur de la société actuelle. Le patrimoine ne constitue plus seulement une collection réservée à une élite scientifique. Depuis de nombreuses années, Archives, musées et bibliothèques mettent en valeur leurs collections et fonds grâce à des expositions tant permanentes que temporaires. Cependant, jusqu’à l’avènement du numérique, celles-ci restaient essentiellement physiques. L’arrivée de ce nouveau canal de diffusion – concomitant du développement du Web et à l’essor d’Internet – a permis la création d’expositions virtuelles et plus globalement ouvert la voie à la valorisation numérique. Se pose aujourd’hui une nouvelle question : comment permettre au public d’enrichir quantitativement les collections et fonds et/ou de les valoriser ?
Dans ce contexte, il apparaît pertinent de s’intéresser à la rencontre entre patrimoine et publics. Si l’ensemble de la population (publics initiés, grand public et publics spécifiques) peut vouloir connaître ce qui constitue son histoire nationale, chacun d’entre nous peut désormais créer les traces que recevront les générations futures, à travers des projets participatifs.
Cet article revient sur les axes majeurs qui ont marqué les différentes interventions de l’événement, à savoir, les notions de « crowdsourcing » et de « gamification ». Ce type de projets participatifs est envisagé ici dans leur relation à la diffusion et la valorisation du patrimoine, notamment numérisé.
Projets participatifs : quels enjeux pour les bibliothèques ?
Cette partie reprend les grandes lignes de l’intervention de Raphaëlle Bats qui a introduit la première semaine de l’Ecole d’été(1).
L’essor d’Internet a permis le développement massif des projets participatifs : le partage en ligne (d’idées) et les communautés virtuelles se comptent aujourd’hui en masse. En parallèle, la numérisation du patrimoine s’est accrue et ainsi, le nombre de ressources numériques s’est amplifié. Dans le cadre d’un projet participatif, les bibliothèques rendent publiques certains documents de leurs fonds ou de leurs collections - voire les fonds eux-mêmes - et le public les visualise et les enrichit. Un projet participatif peut prendre différentes formes, physiques comme virtuelles, comme le montrent les exemples cités plus loin en forme de liens hypertexte.
Un projet participatif se décline en quatre temps : afin de répondre à un besoin, une institution ou une personne sollicite la population (sa communauté d’usagers ou le grand public) afin que celle-ci l’aide à atteindre son objectif.
Le créateur du projet donne ainsi au public les moyens de pouvoir réaliser le projet, et donc cela l’oblige à d’abord préparer tant les outils nécessaires à sa réalisation que la rédaction claire et précise de consignes à destination des futurs participants. Vient ensuite la période de la communication afin que le public puisse être informé de l’existence de ce projet. Dans un troisième temps, la population participe sur la base du volontariat. Enfin, l’initiateur du projet valide le travail effectué.
D’après Raphaëlle Bats, à travers les projets participatifs se retrouvent trois enjeux majeurs : la possibilité d’agir (« pouvoirs »), le partage de connaissances (« savoirs ») et l’expression des missions des bibliothèques (« devoirs »).
- En offrant au public la possibilité de participer à un projet de diffusion du patrimoine, les professionnels acceptent que les tâches qu’ils devraient être amenés à effectuer de par leurs compétences spécifiques soient effectuées par des personnes ne disposant pas nécessairement des mêmes compétences. Par conséquent – dans le cas plus spécifique des bibliothèques -, les « savoirs » académiques ne sont pas les seuls à être légitimes.
- La délégation à la communauté constitue une forme d’expression de la démocratie participative : les « pouvoirs » sont partagés et la mise en lumière des savoirs mobilisés par le public participe au renforcement de leur capacité d’agir dans la société.
- Les projets participatifs répondent enfin aux « devoirs » des bibliothèques. En effet, une bibliothèque doit rendre possible la consultation au plus grand nombre des ressources qu’il lui est possible d’acquérir et de conserver en vue d’une participation plus grande à la démocratie. Les projets participatifs incitent justement à un renouvellement de l’engagement des citoyens dans la sphère culturelle et publique.
Ainsi, pour reprendre les expressions employées par Raphaëlle Bats au cours de l’École d’été, une bibliothèque est donc à la fois un « lieu démocratique » et un « lieu pour la démocratie », c’est-à-dire où peut s’exprimer la démocratie.
Le crowdsourcing : un type de projet participatif
Cette partie reprend les grandes lignes des deux interventions de Pauline Moirez, conservatrice à la BnF(2).
Le principe du crowdsourcing se résume ainsi : c’est l’enrichissement ou la création de contenus par les foules (crowd). Ce procédé peut ainsi se définir comme une production participative. Les « foules », pour les bibliothèques, ce sont leurs publics et, parmi ceux-ci, majoritairement les citoyens de la ville ou du pays desservi. Un autre terme anglophone très à la mode dans les ouvrages de marketing pourrait être associé à cette idée, il s’agit du crowdfunding : un financement par les foules (en exemple, l’acquisition de l’oeuvre de Corneille de Lyon au Musée des Beaux-Arts de Lyon).
Bien que le crowdsourcing se présente sous des aspects très épars, Pauline Moirez a suggéré d’en faire une typologie. Nous vous proposons une liste des principales catégories énoncées :
- La collecte de ressources : il s’agit généralement de faire appel à une contribution collective afin d’enrichir un fonds documentaire. Les ressources populaires sont les documents les plus faciles à collecter : cartes postales, journaux, lettres, souvenirs, etc. L’un des célèbres exemples est « La Grande Collecte » qui fut organisée par la BnF et le réseau des Archives de France du 9 novembre au 16 novembre 2013 pour commémorer la Première Guerre mondiale.
- Le web collaboratif : ce projet est amorcé par les usagers, ce sont ces derniers qui sont déterminants pour la formulation des objectifs. La communauté s’impliquera pour faire vivre ses inspirations, son exemple le plus populaire est Wikimedia. En opposition, nous parlons du web participatif pour désigner les projets lancés par une institution ou un organisme.
- La géolocalisation : grâce à la participation de chacun, il s’agit de déterminer la situation géographique d’éléments, d’objets, etc. Sur ce modèle, OpenStreetMap a pour but de créer une carte libre du monde en collectant les données citoyennes.
- Le journalisme citoyen : il s’agit de collecter les témoignages ou les reportages des citoyens du monde. Ils agissent comme des journalistes sauf qu’ici les lecteurs peuvent aussi être les auteurs des publications. Le public se positionne ainsi à la source de l’information. AgorVox, le média citoyen revendique une information entièrement participative. Sa politique éditoriale et la Fondation AgoraVox offrent un cadre digne des journaux professionnels. Remarquons qu’au contraire de ces derniers, qui ont parfois de la difficulté à obtenir des commentaires sur leur site web, ici les « réactions » aux articles sont systématiques.
- Les sciences citoyennes : cette catégorie inclut les sites participatifs contribuant à l’amélioration et à l’avancement des connaissances en sciences. Ces initiatives sont souvent soutenues par un musée ou une institution publique. Parmi les sites de sciences participatifs, nous pouvons retenir Vigie Nature, un réseau de citoyens qui font avancer la science soutenu par le Muséum national d’histoire naturelle, Citizen Archivist Dashboard soutenu par U.S. National Archive et Records Administration ou encore Ancient Lives soutenu par l’Université d’Oxford. Le site anglophone Zooniverse élaboré par Citizen Sciences Alliance regroupe quant à lui une large étendue de ces projets participatifs au service de la Science.
Les projets de crowdsourcing dans le monde culturel offrent de nouvelles possibilités d’enrichissement des métadonnées. Ainsi les Archives départementales du Cantal emploient l’indexation collaborative pour la constitution d’index nominatifs ainsi que pour le découpage par année des registres paroissiaux et d’état civil. Les Archives nationales du Royaume-Uni ont lancé le projet Africathrought a lens afin d’obtenir des internautes des commentaires et des tags qui compléteront leur fonds centenaire de photographies prises en Afrique. L’Université du Michigan avec IslamicManuscripts at Michigan procède à un catalogage collectif afin d’ordonner des manuscrits islamiques. Avec Convert-a-Card sur LibCrowds, la British Library demande à la foule d’internautes d’effectuer de la rétroconversion de fichiers papiers. Mentionnons aussi la paléographie collaborative fruit d’un partenariat entre les Archives départementales des Alpes-Maritimes et Wikisource ou encore la correction collaborative de textes océrisés.
Ces procédés permettent de traiter une masse de documents en offrant un gain de temps considérable aux institutions. Toutefois le contrôle des données et le monitorat de l’enrichissement des données continueront à mobiliser le temps des professionnels.
La gamification : un vecteur fort des sites participatifs
Comme l’a expliqué Lisa Chupin au cours de son intervention(3), ces dernières années ont vu apparaître la prolifération du jeu(4) dans les pratiques tant quotidiennes que professionnelles. Gamification(5) est un terme né dans le monde anglo-saxon, il définit en premier lieu le recours au jeu dans les techniques de marketing. Toutefois dans le cadre du crowdsourcing, nous l’envisageons comme un moyen de créer de l'engagement chez un usager vis-à-vis du site participatif, afin de le fidéliser et de l’encourager à poursuivre l’enrichissement des données. Le moteur de motivation repose sur un processus de récompenses via des badges, des points ou des niveaux à monter.
Grâce au procédé de gamification, les usagers, tous publics confondus, peuvent facilement devenir adeptes du crowdsourcing.
Ainsi, parmi les sites qui se distinguent par leur usage de la gamification pour l’enrichissement des données, il est possible de citer Artigo et JocondeLAB (tag d’œuvres d’art), Building inspector (tag de plans d’architecte) et Library of Congress sur Flickr (tag de photographies).
Le fait de pouvoir librement décrire une œuvre d’art peut permettre de se divertir tout en s’introduisant un processus d’indexation. Par exemple, sur les sites précédemment cités, les œuvres ou les photographies sont souvent décrites - titre, auteur et lieu de conservation – et cette identification permet à l’internaute de connaître de nouvelles œuvres. Lorsque l’usager est interpellé par le jeu sur son centre d’intérêt, il apprécie davantage le fait de mettre ses connaissances au service de la communauté.
Pour que le crowdsourcing soit ludique, il faut que l'usager puisse facilement se donner une mission. Avec l'exemple de Anno Tate, le participant est tout d'abord invité à sélectionner un corpus selon ses goûts ou ses envies. Cette étape franchie, il a pour mission de déchiffrer un document manuscrit partiellement ou complètement. La transcription des documents devient alors un véritable défi à relever !
L’une des caractéristiques de la gamification est de permettre aux participants de jouer un rôle. Les institutions en sciences naturelles réussissent particulièrement à plonger un participant dans la peau d’un personnage comme un explorateur ou encore un biologiste. Ainsi, Science Gossip offre la possibilité aux experts comme aux novices de classifier des documents scientifiques numérisés. Pour ce projet, une série de questions sont posées sur le contenu (illustrations ou non, le type d’illustration, le texte, les mots-clés), celles-ci correspondent à des étapes à franchir et ainsi à des missions à réaliser avant de découvrir de nouvelles images. Pour sa part, Chimp & See invite le participant à surveiller des vidéos filmées en pleine nature, le but est d’identifier des animaux de passage ; le participant apprécie de jouer à « cherche et trouve » tout en découvrant ou reconnaissant différentes espèces.
Enfin, citons le projet de transcription Digitalkoot qui enthousiasma la population finlandaise grâce à son ergonomie simple et intuitive et son interface ludique.
Comment inciter le public à participer ?
Aujourd’hui, le développement d’Internet et la numérisation du patrimoine offrent à de nombreux publics l’opportunité de jouer un rôle important dans la valorisation du patrimoine. Les internautes peuvent participer de différentes manières et les professionnels deviennent chaque jour plus réceptifs à ces contributions. La mise en commun des connaissances rend possible l’émergence de projets motivants pour tous, dont notre patrimoine est le grand gagnant.
Les idées vous manquent pour captiver et attirer votre public ?
N’oubliez pas que le site Zooniverse répertorie une série de projets participatifs scientifiques pouvant constituer un excellent réservoir d’idées !
Nous vous conseillons aussi la lecture de l’ouvrage dirigé par Raphaëlle Bats, Construire des pratiques participatives dans les bibliothèques (Presses de l’enssib, collection « La Boîte à outils », septembre 2015).
Et rendez-vous en 2016 à Dakar à l’Ebad pour la 3e École d’été internationale francophone en Sciences de l’information et des bibliothèques !
Hésione GUÉMARD, Bassirou BA et Paul FAURE
Étudiants en Master 2 professionnel « Politique des bibliothèques et de la documentation » à l’Enssib ayant participé à la 2e Ecole d’été internationale francophone en SIB
Notes
(1) Raphaëlle Bats est conservatrice des bibliothèques à l’Enssib et doctorante à Paris 7, elle prépare une thèse sur la participation en bibliothèque. Lors de l’École d’été, son intervention s’est intitulée « Les projets participatifs en bibliothèques : concepts, enjeux et limites ».
(2) Ses interventions se sont intitulées « Patrimoine et crowdsourcing » et « Données et contenus dans les projets participatifs patrimoniaux ».
(3) Lisa Chupin est doctorante attachée temporaire d’enseignement et de recherche (ATER) au Conservatoire national des arts et métiers (CNAM).
Son intervention s’est intitulée « Médiation, publics et projets participatifs patrimoniaux ».
(4) Voir dans le catalogue de la bibliothèque de l’Enssib le mémoire d’étude de Marie Latour, La ludification en bibliothèque : utiliser le jeu comme médium dans la relation aux usagers (sous la direction de Guillemette Trognot, mémoire du DCB, Enssib, janvier 2015).
(5) Voir dans le Catalogue collectif de France l’ouvrage de Gabe Zichermann et Christopher Cunningham, Gamification by Design : Implementing Game Mechanics in Web and Mobile Apps (O‘Reilly Media, Inc., 2011).
Le livre et les bibliothèques : c’était mieux avant… ?
Aurélie Vieux : Université de Genève, adjointe scientifique
Le livre et les bibliothèques : c’était mieux avant… ?
Ouvrage : STARK Virgile. Crépuscule des bibliothèques. Paris : Les belles lettres, 2015. 207 p. ISBN : 978-2-251-44529-8
De l’art de clore le débat
Dès son premier chapitre intitulé « Qu’importe le flacon ? », le ton est donné. En usant du style direct, l’auteur prend à témoin ses lecteurs créant ainsi une intimité avec eux avec l’objectif de les mener à un rapprochement des points de vue. Il veut les convaincre d’adhérer à sa version des faits. Il illustre ainsi ce que le livre papier permet, c’est-à-dire une « expérience de lecture », une rencontre qui n’est possible que dans l’« espace-physique » du texte. Selon lui, la magie de la lecture et son ancrage dans la mémoire humaine ne peuvent s’opérer qu’au travers d’un « rapport sensuel» (p.23) et sensoriel liés à la réalité matérielle de l’écrit. Il ouvre alors un faux débat avec le lecteur et lui demande si, comme pour lui, la relation physique avec l’objet-livre est indispensable à l’ivresse de la lecture. Son but est d’opposer la forme « indépassable et imperfectible » du codex (p.28), cet « écrin parfait de la parole » (p. 22) qui a mis du temps à trouver sa forme définitive puisqu’il est issu d’un long processus de construction et de mutations de plusieurs siècles, à la brutalité et à la rapidité avec lesquelles le support numérique l’a déjà (presque) remplacé. Ensuite, par le biais de la technique du dialogue qu’il emprunte au théâtre, il matérialise le débat et fait s’opposer les points de vue. Il met en scène un « commercial du livre numérique » qui prône les progrès amenés avec la dématérialisation du texte et un lecteur « traditionnel » attaché à la lecture sur le papier. Selon une vision manichéenne et peu objective, il énumère les arguments du « commercial high-tech », un personnage obsédé par le progrès et les chiffres de ventes face à celui du lecteur « d’un autre âge » (p.23) crédule qui ne demande qu’à comprendre les avantages de cette nouvelle forme de lecture. Ainsi, contrairement à ce que dit Musset, dans le cas du livre où l’âme est le texte, le papier son corps, le « support n’est pas indifférent » (p.28). Le contact physique et « synesthésique » (p.24) avec le papier est indispensable à l’ivresse de la lecture. Ainsi, le débat opposant le livre papier à son homologue numérique se clôt ici.
À l’instar d’un célèbre tableau de Géricault, Stark raconte inlassablement et sur un ton dramatisant comment son radeau de la connaissance et de la mémoire humaine emporté par la vague numérique est sur le point de sombrer dans les abîmes de la « nuit noire de l’esprit » (p.18). En effet, durant les quinze autres parties du livre, l’auteur se contente de poursuivre la description fataliste et anti-progressiste d’un monde dépourvu de culture et de mémoire, car il ne dispose bientôt plus ni d’objets de connaissance, c’est-à-dire de livres physiques, ni de gardiens du savoir, les bibliothécaires, ni de lieux d’étude et de conservation de l’histoire humaine, les bibliothèques.
Du papier à l’écran, de la culture à l’acculturation
D’après l’auteur, le numérique est « l’ennemi mortel de la culture » (p.66) et ce qui est décrit comme un progrès est en fait un déclin. Il concède que la dématérialisation du texte, sa lecture sur différents écrans et sa mise en réseau facilitent et accélèrent l’accès à l’information. Cependant, le revers de la médaille est que ces soi-disant progrès techniques contribuent au désintérêt des grands textes (p.60). A plusieurs reprises, l’auteur parle d’un changement de mode de lecture induit par le support numérique. En passant du papier à l’écran, la lecture qui était un acte solitaire et concentré devient « impermanente », superficielle (p.29) et labyrinthique (p.66). Bien qu’elle offre l’avantage de favoriser les « capacités d’associations et de créativités cognitives » (p.64) par l’hypertextualité, il s’agit davantage d’un « picorage éphémère » (p.65) qui ne permet pas aux connaissances de se fixer dans la mémoire. Il trouve également une preuve de cette tendance à l’acculturation dans l’augmentation des chiffres de vente de la littérature de plage et des best-sellers ; démonstration évidente du déplacement de la lecture intelligente de livres fondamentaux au profit de « remplaçables » (p.71) dont le support privilégié, la liseuse bientôt remplacée par la tablette, se fait la complice. De même, les chiffres qui montrent qu’avec internet les gens lisent plus qu’avant doivent être relativisés. En effet, le temps n’est désormais plus consacré à la « véritable lecture » (p.53), mais au survol d’ «œuvres faciles» (p.71) et des « consternants e-mails et flux de tweets » (p.51). L’auteur voit dans cette interprétation trafiquée des chiffres un stratagème contre la lecture, une « espèce d’enfumage » (p.50) mise en place pour endormir les populations. Il ne sert plus à rien de nier, les preuves sont là. En s'inscrivant dans la lignée des futurologues, il finit par délivrer son propre pronostic : la mort du livre papier est annoncée pour 2035. Le message mensonger disant « n’espérez pas vous débarrasser du livre » se transforme en « n’espérez pas sauver les livres ».
Les livres sont voués à disparaître puisque la lecture sur support imprimé ne correspond plus aux besoins des nouvelles générations. Concurrencés par les écrans, les livres imprimés meurent « de ne pas être pas lu(s), ou lu(s) faussement par une petite élite de philistins surdiplômés » (p.52). Partant de ce constat, il remet en question les bénéfices induits par les nombreux projets de numérisation qui mettent à la portée de tous d’innombrables documents issus du patrimoine littéraire mondial (p.61). Derrière cet argumentaire, on peut remarquer une vision élitiste et réductrice de l’accès à la culture par la lecture. Il semble que, pour Stark, les connaissances culturelles s’acquièrent exclusivement par la lecture « méditative » (p.65) d’un certain type de texte sur un support imprimé.
Les bibliothécaires, des ennemis du livre ?
Parmi les autres causes qui conduisent à la mort du livre imprimé, les bibliothécaires, devenus des « techniciens enragés » tiennent un rôle prépondérant. Tantôt victime d’un endoctrinement à la technique, tantôt coupable par soumission et par peur de « passer pour un couard ou un frileux » (p.69), le bibliothécaire « embarqué sur l’onde immatérielle » (p.73) est accusé de creuser sa propre tombe.
Mais, comment l’auteur explique-il un tel investissement (p.80) dans le numérique au sein de la communauté des « gardiens du livre » ? Il répond en présentant les mécanismes d’introduction d’internet et des technologies dans le monde protégé des bibliothèques. En utilisant le champ lexical de la maladie, il présente la propagation du progrès amené avec les nouvelles technologies comme une « infection contagieuse » (p.73) qui a contaminé si profondément le milieu professionnel qu’elle a réussi à diminuer la capacité de réflexion et de recul des spécialistes de l’information. Dans le sixième chapitre intitulé « Deprogramming », (lisez « reprogrammation » ou « lavage de cerveaux »), il dénonce les techniques propagandistes (p.74) utilisées par les écoles professionnelles pour convaincre les indécis et éduquer les nouvelles générations. Pour l’auteur, nier la fin du papier et défendre la thèse de la coexistence des deux supports (p.52) relève d’une stratégie de cheval de Troie, c’est-à-dire faire tomber la méfiance, éviter la rébellion afin de rendre la mutation vers le tout-numérique moins brutale et plus définitive. Pour préparer les esprits à la « grande mue » (p.74), trois techniques ont été mises en œuvre. La première visait à « endoctriner, à rabâcher, à montrer l’exemple » (p.73) à toutes les occasions : dans les formations continues, lors de conférences ou dans des revues professionnelles. La seconde consistait à éloigner le livre papier du bibliothécaire grâce à la centralisation de la gestion des tâches bibliothéconomiques dans un système informatique. Le dernier moyen employé s’attaquait à la corde sensible du bibliothécaire, c’est-à-dire son image et sa peur de disparaître. Pour ne pas « rester sur la touche » (p.34), échapper à leur image stéréotypée, les professionnels se sont empressés de devenir « des guides de l’immatériel, des pionniers de l’Infomonde » (p.81). Au lieu d’y voir une évolution naturelle, Stark interprète cela comme une forme de soumission.
La déprogrammation est également passée par les nouveaux bibliothécaires, un public docile né avec le numérique. En usant du vocabulaire emprunté à la propagande religieuse et à la guerre, il explique comment les centres de formation et les écoles professionnelles ont formé cette « légion de précurseurs » (p.104) pour asseoir une fois pour toute la transition vers les « nouveaux métiers » (p.105) et relooker (p.34) en même temps l’image désuète de la profession. Il se moque de ce bibliothécaire moderne ; de son physique «de friend poupon et narquois » (p.104) ; de ses idées, de ses écrits (p.107) ; de ses compétences informatiques ; de ses lubies et de son langage technique qu’il assimile à un baratin assommant (p. 108). D’après l’auteur, une nouvelle profession est apparue (p.153), celle du « bibliothécaire 2.0 » (p.106) ; un « homme utile » (p.148) qui trouve ses galons dans la servitude de la masse au point de devenir un « vendeur[s] comme les autres vendant des écrans sans le moindre scrupule» (p. 69). Victimes ou acteurs, finalement peu importe. D’après Stark, la profession participe d’une stratégie clientéliste et industrielle (p.41) qui contribue à « l’indistinction des œuvres et des marchandises » (p.41).
Deux conceptions du monde professionnel s’opposent et ne peuvent coexister tout comme le livre et son avatar numérique. La guerre est déclarée entre les « deux frères ennemis » (p.113), les archaïques et les progressistes. L’un des deux camps devra gagner. Il déjà trop tard, les archéothécaires « débordés, dépassés, doublés de vitesse » par leurs successeurs sont en train de céder du terrain.
Sans lecteurs, sans livres et sans bibliothécaires, que deviennent les bibliothèques ?
Dans un monde où le public n’a plus d’intérêt pour la lecture, où l’objet-livre n’existe (bientôt) plus et dans lequel les bibliothécaires ont laissé place à des « courtisans de l’ère numérique », que deviennent alors les bibliothèques ? Quel rôle jouent-t-elles ? À quoi ressemblent-elles ? Les livres-papier y ont-ils encore une place ? Dans la continuité de son tableau apocalyptique, l’auteur répond par la négative.
L’image des bibliothèques comme « coffres à livres de papier » (p.113) n’a pas résisté au progrès. L’introduction de nouveaux services tels que le prêt de dispositifs électroniques de lecture, l’élargissement et la diversification de l’offre de contenus avec le numérique ainsi que l’installation de postes informatiques connectés à internet n’ont fait que favoriser le désintérêt du public pour le livre imprimé et la lecture traditionnelle. Il voit dans la hausse des statistiques officielles de fréquentation des espaces la preuve du nouvel usage des bibliothèques. En effet, « la population, quand elle entre dans une bibliothèque, ne vient plus chercher la culture ‒ ce labeur ingrat et peu rentable ‒, elle vient se distraire. » (p. 145). À l’occasion d’une visite dans une bibliothèque universitaire, il mesure l’ampleur de cette métamorphose qui se cristallise dans une nouvelle architecture orientée usager. Il est effaré par ce qu’il voit : une bibliothèque où on est libre de ne pas lire des livres papier, où l’on peut manger, boire, faire du bruit et utiliser les ordinateurs pour naviguer sur internet. L’apprentissage participatif, les discussions et la mutualisation ont fait fi de la lecture isolée et du silence. Ce qui le scandalise le plus est que dans ces nouveaux espaces d’apprentissage, les livres papier sont relégués au second rang : selon lui, ils ne sont là qu’à des fins décoratives pour apporter une touche « rétro » (p.132).
Les bibliothèques modernes, qu’il surnomme des « biblioparcs », se sont donc détournées du livre pour d’autres préoccupations, celles de « s’adapter à la technique et se soumettre aux diktats de la masse » (p.141). En citant de nombreux exemples de projets architecturaux ou de nouveaux services aux usagers mis en place à travers le monde, l’auteur cherche à démontrer qu’il ne s’agit pas d’une évolution positive, mais d’un travestissement. En effet, à force de vouloir séduire une clientèle (p.135) toujours plus exigeante, les bibliothèques se sont laissées vendre et se sont transformées en parcs d’attraction et en « poupothèques » (p.141). Pour Stark, en devenant conviviales et ludiques, les bibliothèques ont sacrifié leur mission culturelle et éducative. D’ailleurs, il annonce leur fin prochaine en citant des exemples de fermeture, de fusion, de diminution de budget et de suppression de postes de bibliothécaires. Ainsi, il trouve ici la preuve d’une mutation qui s’avère vaine.
Critique
Finalement, dans cette bataille opposant le livre papier à l’e-book, on pouvait s’attendre à un véritable débat ouvert et riche permettant la mise en valeur des forces et faiblesses de chacun des deux supports. On est d’autant plus confiant que l’échange est initié par un bibliothécaire, c’est-à-dire une personne au cœur de la problématique, tout à fait en mesure d’éclairer les lecteurs de manière objective. Or, dès la fin du premier chapitre, on est déçu, voire déconcerté car la discussion s’arrête net sur une idée principale : « le codex est indépassable et imperfectible, il est un chef d’œuvre adéquat à sa finalité », le livre numérique quant à lui est un « non-livre » (p.28) puisqu’il ne favorise pas une lecture linéaire et profonde, seul moyen d’acquérir de nouvelles connaissances culturelles. Avec ce postulat de départ, le débat ne peut pas avoir lieu : il est avorté avant même d’avoir véritablement commencé.
Malgré une admirable maîtrise de la langue et une aisance manifeste dans la manipulation de diverses techniques stylistiques, la faiblesse du raisonnement de Stark apparaît très rapidement : son argumentaire ne fait que tourner en rond avec la répétition des mêmes arguments dans plusieurs chapitres. Bien que l’auteur tente à plusieurs reprises de nous faire croire qu’il a essayé de trouver quelques intérêts au support numérique, on comprend qu’il ne s’agit là que d’une technique discursive dont le but ultime est de feindre l’objectivité pour mieux convaincre l’auditoire. Une lecture analytique du discours nous permet de constater qu’il utilise lui-même les techniques qu’il reproche aux documents officiels et discours politiques qu’il dénonce. D’ailleurs, il se contente de dresser un constat fataliste de la situation mais ne propose pas de véritables solutions. Ainsi, il concède peu d’atouts à la forme numérique du texte. Excepté la possibilité de grossir la taille des caractères pour permettre aux publics déficients visuels de lire les textes – mais dans ce cas-là, il faudrait plutôt appeler la liseuse une loupe (p.28) – tous les autres arguments en faveur de la lecture numérique sont critiqués et démontés sans véritables preuves et sans aucune prise de distance. L’auteur généralise tout et présente sa vision caricaturale du monde professionnel qu’il construit uniquement sur la base de quelques expériences personnelles qu’il juge négatives, notamment la rencontre avec un jeune professionnel, une visite dans un Learning center et une discussion avec des étudiants en période d’examens.
En tant que lecteur de livres papier, on aurait envie de comprendre sa colère et sa peur de voir le support imprimé avec lequel on a tous un rapport particulier, se faire concurrencer par d’autres et tomber dans l’oubli. Mais, en tant que professionnel des bibliothèques, on a une envie épidermique de refermer le livre et d’en coller les pages, notamment lorsqu’il dénigre injustement et avec condescendance les grands projets de numérisation et les efforts des bibliothécaires pour s’adapter aux nouvelles pratiques de leurs usagers. On ne peut considérer l’évolution des bibliothèques qui tend à la fois vers une ouverture démocratique et universelle aux savoirs, et une plus grande visibilité et mise en valeur de leurs collections comme un déclin.
L’auteur préfère camper sur ses positions et une conception des bibliothèques figée à l’époque du XVIIIème siècle, c’est-à-dire des lieux fermés sur eux-mêmes et réservés aux élites culturelles. On est tout autant déconcertés par le ton agressif de l’auteur lorsqu’il attaque les fonctions, le profil professionnel, mais aussi humain du bibliothécaire d’aujourd’hui. Il remplace un cliché par un autre. Ainsi et bien qu’il s’en défende, on regrette de découvrir la vision dépassée, obtuse et sans nuances d’un professionnel qui personnifie à lui seul l’ensemble des stéréotypes du bibliothécaire réfractaire à toute forme d’évolution amenée avec les technologies.
Lire ou ne pas lire Crépuscule des bibliothèques ?
Il est difficile de répondre objectivement à cette question. En effet, cet ouvrage ne laisse personne insensible par le simple fait qu’il s’intéresse à un sujet qui nous concerne tous : le texte en tant que principal vecteur de connaissances. De ce fait, il faut lui reconnaître un mérite, celui de provoquer une réaction, qu’elle soit positive ou négative, et dans une certaine mesure, de relancer la réflexion.
Cependant, cet essai n’est pas à mettre entre toutes les mains. Pour un lecteur non-averti, il peut donner une vision biaisée de la problématique et véhiculer une image négative et erronée de l’évolution du monde des bibliothèques et de l’information. Au contraire, pour un public déjà initié à cette polémique, Crépuscule des bibliothèques n’apporte rien de nouveau, bien qu’il permette de connaître les « non-arguments » des réfractaires aux e-books.
Ainsi, au-delà de ses qualités stylistiques, qui pourraient d’ailleurs être étudiées dans le cadre d’un cours d’analyse du discours dédié aux techniques argumentatives, ce texte ne présente pas beaucoup d’intérêt. Considérant tout ce qui vient d’être dit, on ne peut que recommander aux lecteurs de se dispenser de lire cet ouvrage et de réserver le temps économisé à la lecture d’autres documents qui permettent véritablement de faire avancer le débat.
MOATTI, Alexandre, 2015. Au pays de Numérix. Paris : Presses universitaires de France. 166 p. ISBN 978-2-13-063144-6
Alain Jacquesson, Ancien directeur de la Bibliothèque de Genève
MOATTI, Alexandre, 2015. Au pays de Numérix. Paris : Presses universitaires de France. 166 p. ISBN 978-2-13-063144-6
Né en 1959, Alexandre Moatti est un écrivain et éditeur scientifique français. Diplômé de l’Ecole polytechnique de Paris, il est également ingénieur des Mines. De 2002 à 2005, il est conseiller dans différents cabinets ministériels. De 2005 à 2006, il est secrétaire du comité de pilotage de la Bibliothèque numérique européenne (Europeana). Il est l’auteur de plusieurs ouvrages de vulgarisation scientifique et, notamment, d’un blog consacré aux bibliothèques numériques (http://www.bibnum.eu). A. Moatti est chercheur associé à l’Université de Paris VII-Denis Diderot.
Ce petit essai n’est pas un ouvrage à caractère scientifique, mais une oeuvre d’humeur quelque peu désabusée sur la situation du numérique en France, en particulier sur les sujets qui touchent aux sciences de l’information documentaire. Il se divise en trois chapitres.
Le premier est consacré aux bibliothèques numériques européennes qui naissent en 2005 en contrepoids au projet américain Google Livres. Il rappelle l'article de Jean-Noël Jeanneney, alors président de la Bibliothèque nationale de France : Quand Google défie l'Europe. Jeanneney, pourfendeur du projet américain, convainc le Président Chirac de lancer "un projet aussi médiatiquement alléchant que stratégiquement mal défini La bibliothèque numérique européenne" (rebatisée Europeana). Moatti démontre qu'elle est un assemblage de bibliothèques et non une entité en soi. A peine ouverte, le 20 novembre 2008, Europeana s'écroule et doit rester fermée plusieurs semaines. L'Europe ne manque pas de projets : Le moteur de recherche "Quaero" (Je cherche) doté de 250 millions d'euros sombrera dans l'oubli. L'enjeu était, selon J. Chirac de créer "la nouvelle génération de moteurs de recherche multimédia" qui devait remplacer Google, Yahoo ou Bing. Moatti montre, par de nombreux exemples, que l'on a créé de "véritables usines à gaz" en France comme en Europe, voire même à l'international (Bibliotheca universalis).
Le second chapitre est consacré à la position des intellectuels, hommes politiques et journalistes français. Ils « alertent le bon peuple de Numerix des dangers de l’Internet, de Google, de Wikipedia » Face à la révolution du numérique "Numerix, petit pays gaulois, tacherait avec mérite et témérité de résister". Une partie de ces déclarations se basent sur « l’exception culturelle » française. Si Wikipedia s'impose progressivement comme encyclopédie universelle, fruit d'une élaboration collective, Moatti ne manque pas cependant de signaler quelques "travers wikipédiens".
Le troisième chapitre est consacré à la pratique du droit d'auteur au pays de Numerix. "Le droit d'auteur à la française ne permet pas de puiser dans les archives nationales" pour illustrer le patrimoine du pays. Les deux photos officielles illustrant la page Wikipedia de "Charles de Gaulle" proviennent des Archives fédérales allemandes et l'Office of war information de la Bibliothèque du Congrès. Les institutions publiques françaises sont encore incapables de proposer des illustrations nationales librement accessibles sous "Creative Commons".
L'ouvrage de Moatti est plaisant à lire. Il abonde d'exemples, souvent amusants, qu'il a recensés grâce à sa présence dans de nombreuses commissions, ainsi que par sa veille sur les bibliothèques numériques. Publié en janvier 2015, la force de l'ouvrage est pourtant affaiblie par la position que Google prend en automne 2015 par rapport à son projet Livres(1),(2). Nombreux pensent aux Etats-Unis comme en France que la firme de Mountain Views abandonne peu à peu son projet après avoir numérisé trente millions de livres et gagné tous ses procès dans le domaine du copyright. "Selon le New Yorker, il faudrait parler « d’une sorte de limbes : ni l’enfer, certainement pas le paradis, Google Books est perdu quelque part, où même Orphée ne va pas mettre les pieds". Seule faiblesse de cet ouvrage, Moatti n'a pas pris en compte la totale indépendance d'une entreprise privée vis-vis d'un projet culturel majeur que Google peut abandonner sans l'ombre d'un regret.