N°14 décembre 2013
Sommaire - N°14, Décembre 2013
Etudes et recherches :
- Projektbericht: Connecting Open Library Systems and Sugar - Brigitte Lutz, Karsten Schuldt
Comptes-rendus d'expériences :
- La gouvernance des documents électroniques dans l’administration cantonale genevoise : genèse et mise en œuvre - Anouk Dunant Gonzenbach
Evénements :
- Veille et marketing de l’innovation : outils et méthodes pour explorer les marchés de demain : compte-rendu de la 10ème journée franco-suisse sur la veille stratégique et l’intelligence économique, 6 juin 2013, Haute Ecole de Gestion. Genève - Hélène Madinier, Maurizio Velletri
- Les humanités numériques et les spécialistes en information documentaire : compte-rendu de la 1re Digital Humanities Summer School, 26-29 juin 2013, Berne - Mathilde Panes, Igor Milhit
- Journée d'étude « Les données en bibliothèques, les enjeux des linked open data », Lausanne 1er octobre 2013 - Pierre Boillat
Ouvrages parus en science de l'information :
- Barrelet, Jean-Marc (éd.). Entre lecture, culture et patrimoine. La Bibliothèque de la Ville de la Chaux-de-Fonds 1838-2013 - Alain Jacquesson
Editorial no 14
Editorial no 14
Nous avons le plaisir de vous proposer le 14ème numéro de RESSI, seule revue électronique suisse en science de l’information.
Le Comité de rédaction de RESSI a été en partie renouvelé cette année : Michel Gorin et René Schneider ont quitté le Comité, alors qu’Alain Jacquesson, Basma Makhlouf Shabou, Stéphanie Pouchot, et Igor Milhit l’ont rejoint. Nous remercions les deux partants pour le travail effectué et souhaitons la bienvenue aux nouveaux.
Dans ce 14ème numéro, sous la rubrique Etudes et Recherches, vous trouverez un article en allemand de Karsten Schuldt et Brigitte Lutz, tous deux adjoint scientifiques à l'Institut des sciences de l'information de la HTW de Coire. Ils décrivent le projet COLISu, «Connecting Open Library System and Sugar », s’inscrivant lui-même dans le projet OLPC (One laptop per child/un PC portable par enfant) qui vise à offrir des ordinateurs, appelés XO, coûtant moins de 100 dollars et fonctionnant avec des logiciels libres et une interface graphique simple, « Sugar ». COLISu décrit les connexions possibles entre Sugar et des logiciels libres de gestion de bibliothèques, notamment Koha et ABCD.
Sous la rubrique « Compte rendu d’expérience », vous trouverez deux articles, émanant tous les deux de services d’archives cantonaux.
Le premier émane d’Anouk Gonzenbach, archiviste aux Archives d’Etat de Genève. Intitulé La gouvernance des documents électroniques dans l’administration cantonale genevoise : genèse et mise en œuvre, il relate le projet d’élaboration d’une politique de gouvernance des documents électroniques au sein de l’administration genevoise, projet mené en collaboration avec les services informatiques et les différents métiers de l’administration.
L’article d’Alain Dubois, archiviste-paléographe aux Archives cantonales du Valais, intitulé quelle qualité pour les archives électroniques ? Réflexions et retour d’expérience autour du processus décisionnel du Conseil d’Etat valaisan, détaille la méthodologie, les outils et techniques mis en œuvre pour optimiser la gestion des documents relevant du processus décisionnel du Conseil d’Etat valaisan (tous les documents produits ou reçus à l’occasion de ce processus). Cette approche fidèle à la norme OAIS-ISO 14721 met l’accent sur la nécessité de développer plusieurs types de métadonnées pour mieux contextualiser l’activité administrative.
Dans la rubrique Evénements, on trouvera tout d'abord le compte-rendu de la dernière Journée franco-suisse sur la veille stratégique et l'intelligence économique (la 10ème) qui a eu lieu le 6 juin 2013 à Genève, sur le thème: Veille et marketing de l’innovation : outils et méthodes pour explorer les marchés de demain. Signé par Maurizio Velletri, assistant à la HEG-Genève, et par Hélène Madinier, professeure à la HEG-Genève, il rend compte des interventions relatant les différentes méthodes d’exploration des marchés, parmi lesquelles la prise en compte des idées de clients/partenaires possibles, la rapidité d’action et l’écoute permanente de son environnement.
On trouvera ensuite un article signé Igor Milhit et Mathilde Panes, assistants à la HEG- Genève, intitulé Les humanités numériques et les spécialistes en information documentaire : compte rendu de la 1ère Digital Humanities Summer School, 26-29 juin 2013, Berne et synthétisant par thématique les diverses interventions, cours, ateliers et « non-conférences » (unconferences) ayant eu lieu à cette première école d’été suisse sur le sujet. L’article développe aussi les liens entre les humanités digitales et le métier de spécialiste en information documentaire.
On trouvera finalement un dernier compte rendu, intitulé Journée d'étude 2013 : les données en bibliothèques, les enjeux des linked open data. Signé par Pierre Boillat, bibliothécaire principal aux Conservatoire et Jardin botaniques de la Ville de Genève, il présente les différents projets exposés le 1er octobre 2013 à Lausanne sur le web des données libres (traduction de « linked open data ») et leurs implications sur le métier de professionnel de l’information.
Enfin, sous la rubrique Compte-rendu d'ouvrage, on trouvera deux recensions : la première, écrite par Alain Jacquesson, ancien directeur de la Bibliothèque de Genève – et nouveau membre du comité de rédaction de RESSI- rend compte de l’ouvrage Entre lecture, culture et patrimoine. La Bibliothèque de la Ville de la Chaux-de-Fonds 1838-2013 édité par Jean-Marc Barrelet. Cet ouvrage illustré, paru à l’occasion du 175ème anniversaire de la bibliothèque contient dix-sept contributions retraçant l’histoire de la bibliothèque de la Chaux-de-Fonds et la plaçant dans un contexte suisse et international.
La deuxième recension est signée Eric Thivant, docteur ingénieur en sciences de l’information à l’IAE de Lyon et enseignant à l’Université de Lyon 3, et résume l’ouvrage dirigé par Tom D. Wilson Theory in Information Behaviour Research. Cet ouvrage collectif paru en 2013, disponible en format électronique, contient huit essais sur des approches théoriques utilisées pour l’analyse des pratiques informationnelles en contexte.
Nous remercions les auteurs des articles et les réviseurs qui ont contribué à ce numéro et nous invitons les lecteurs à proposer des articles pour les prochains numéros.
Le Comité de rédaction
Projektbericht: Connecting Open Library Systems and Sugar
Brigitte Lutz, Schweizerisches Institut für Informationswissenschaft, HTW Chur
Karsten Schuldt, Schweizerisches Institut für Informationswissenschaft, HTW Chur
Projektbericht: Connecting Open Library Systems and Sugar
1. Projektbeschreibung
Das Projekt COLiSu besteht grundsätzlich aus zwei Teilbereichen: erstens den technischen Fragestellungen und zweitens den Nicht-Softwarebezogenen Fragestellungen, die sich aus der vorgeschlagenen Verbindung ergeben. In Kapitel 1 wird Sugar eingeführt (1.1), anschliessend Freie Bibliothekssysteme besprochen (1.2) sowie die Forschungsfrage des Projektes formuliert (1.3).
1.1 Sugar
Eine der beiden technischen Komponenten des COLiSu-Projektes stellt die Lernoberfläche Sugar dar, welche im Folgenden vorgestellt wird. Sie wurde in der ersten Version für den One Laptop Per Child (OLPC) Computer entwickelt, kann aber auch ohne diesen Rechner verwendet werden. Der von der OLPC-Stiftung - gegründet als Ausgliederung aus einem Forschungsprojekt des Massachusetts Institute of Technology - entwickelte Rechner soll grundsätzlich die Bildungschancen in Ländern des globalen Südens verbessern. (Bashi (2011), Ashling (2010), Riem (2010), Pal (2010), One Laptop per Child (Ohne Jahr)) Dazu wurden an diesen Rechner mehrere Anforderungen gestellt:
- Er soll gleichzeitig möglichst kostengünstig und robust sein. Angestrebt – wenn auch bislang nicht ganz erreicht – wurden Endkosten von 100 US-Dollar. Weiterhin soll der Rechner unter klimatisch und gesellschaftlich schwierigen Bedingungen eingesetzt werden können. So kam der Rechner seit 2007, dem ersten Jahr seines Masseneinsatzes, unter anderem in ländlichen Gegenden Nigerias, der Mongolei, Brasilien und Haitis zur Verwendung.
- Der Rechner soll alle Möglichkeiten moderner Hard- und Softwartechnologie bieten, gleichzeitig möglichst umweltfreundlich hergestellt werden. Dies bedeutet unter anderem, dass explizit Materialien verwendet wurden, die keine geplante Obsoleszenz (Verfall) beinhalteten.
- Grundsätzlich sollen die Rechner ohne weitere Infrastruktur betrieben werden können: Sie können ohne einen Anschluss an das Internet autonom benutzt werden, gleichzeitig wurden Möglichkeiten entwickelt, sie unabhängig vom Stromnetz, beispielsweise mit kleinen Solarzellen oder handbetriebenen Generatoren mit Energie zu versorgen.
Die Entwickler stellten sich vor, dass diese Rechner in einem weit von urbanen Zentren entfernten Gebiet im globalen Süden - zum Beispiel über einem Dorf im brasilianischen Urwald - abgeworfen und dort direkt von den Kindern und Jugendlichen eingesetzt werden können. Ein solches Gedankenexperiment bringt zahlreiche Aufgabenstellungen für die Konstruktion des Rechners, die gelöst werden müssen. OLPC nimmt für sich in Anspruch, diese Probleme grundsätzlich mit dem ersten Modell des Rechners (XO-1) gelöst zu haben, arbeitet allerdings intensiv weiter an der Hardware. Angekündigt ist eine vierte Version (XO-4), erhältlich ist ausserdem ein Tablet. Da die OLPC-Rechner als Teil einer Bildungsinitiative genutzt werden, sind diese weniger im normalen Handel erhältlich, sondern werden überwiegend durch Regierungen verschiedener Staaten in grösseren Stückzahlen abgenommen und im Rahmen von Bildungsprogrammen eingesetzt. Ziel dieser Programme ist es, dass alle beteiligten Schülerinnen und Schüler einen solchen Rechner zur freien Verfügung erhalten und dieser in Schul- und andere Veranstaltungen eingebunden wird. Nur eine kleine Zahl dieser Rechner ist in Ländern des globalen Nordens verbreitet. (Beuermann et al. (2012), Cristia et al. (2012), Barack (2008), Hettich (2008)) Dennoch kann auf der Software dieser Rechner aufgebaut werden.
Die Software des OLPC-Rechners ist den Ansprüchen des Rechners gemäss gestaltet:
- Die Software geht nicht davon aus, dass die Nutzerinnen und Nutzer mit den grundlegenden Konzepten von Betriebssystemen (beispielsweise dem Unterschied zwischen Software und Datei, dem Konzept des Speicherns u.a.) vertraut sind. Gleichzeitig setzt die Software keine vorgängige Alphabetisierung voraus.
- Die Software ist eine Lernsoftware, die auf konstruktivistischer Pädagogik aufbaut. Der Konstruktivismus geht davon aus, dass das Wissen im Lernprozess von den Lernenden selber hergestellt wird und dieser Prozess durch Lehrende und Infrastruktur nur unterstützt, nicht aber vollständig gesteuert werden kann. Die Lernenden selber generieren Wissen, schliessen an schon vorhandenes Wissen an, übersetzen gegebene Informationen und Übungen in ihr eigenes Wissen. Diese Pädagogik stellt die Lernenden und ihre Arbeitsprozesse in den Mittelpunkt. Der Unterricht besteht deshalb vor allem in aktiver Kommunikation, dem eigenständigen Durcharbeiten von Themen und Problemen, zudem gilt die Motivation der Lernenden als Voraussetzung für jeden Lernerfolg.
- Die Software des OLPC-Rechners ist vollständig Open Source. Dies bedeutet auch, dass der Quellcode frei zugänglich ist, sodass es grundsätzlich möglich ist, die Software beliebig fortzuschreiben und anzupassen.
- Die Software funktioniert vereinfacht gesprochen als Oberfläche, die auf einem Betriebssystem aufgesetzt werden kann. Sie ist kein eigenständiges Betriebssystem. In der ersten Version wurde die Oberfläche Sugar auf Basis des Linux-OS geschrieben, welches weiterhin zumeist als Grundlage verwendet wird. Gleichzeitig lässt sich Sugar auch auf Windows, Mac-OS und Android installieren. Die Software ist nicht an die OLPC-Rechner gebunden, sondern kann auf jedem Rechner, auch älteren Datums, laufen. Dies ermöglicht auch, dass sie in Ländern des globalen Nordens mit anderen Rechnern als dem XO in mehreren Projekten in Schulen eingesetzt wurde.
Sugar bietet einige unkonventionelle Lösungen, die aus der Aufgabenstellung heraus leicht verständlich sind.
- Sugar bietet keine spezifischen Programme, sondern Aufgaben. So existiert beispielsweise keine Office-Suite, sondern die Aufgabe “Schreiben”, die bei jedem Aufruf ein Textdokument öffnet, welches direkt bearbeitet werden kann. Analog gibt es Aufgaben wie “Lesen”, “Browsen”, “Malen”, “Aufnehmen” etc. Ebenso kennt Sugar nicht die Funktion des Speicherns. Vielmehr werden alle einmal geöffneten Dokumente im letzten Zustand aufgehoben und können über ein Journal aufgerufen werden. Dieses Vorgehen soll im Vergleich zu konventionellen PC-Programmen dem Denken von Lernenden eher entsprechen – es kann damit verglichen werden, dass ein Text, den man zu schreiben begonnen hat, temporär auf dem Schreibtisch liegen bleibt, um ihn zu einem späteren Zeitpunkt weiter zu schreiben.
- Sugar kann ohne einen Internetanschluss betrieben werden und setzt – obgleich ein Browser vorhanden ist – auf lokale, ad hoc hergestellte Netzwerke aller in Reichweite befindlichen Rechner (MeshNetzwerke). Diese bieten unter anderem den Vorteil, dass sie „selbstheilend“ sind. Das bedeutet, dass die Rechner so vernetzt sind, dass Daten um eine blockierte Verbindung umgeleitet werden, sodass das Netzwerk nach wie vor betriebsfähig bleibt. So ist zum Beispiel die Chatfunktion darauf ausgerichtet, dass sich die Schülerinnen und Schüler in einem Klassenraum vernetzen, wobei die einzelnen Rechner ein eigenes Netzwerk aufbauen. Dies ist in Regionen ohne oder mit schlechter Internetanbindung äusserst sinnvoll, bietet aber auch in anderen Regionen pädagogische Vorteile. So kann eine Schulklasse ohne jede weitere Software kollaborativ arbeiten.
- Die gesamten Funktionen von Sugar sind in einfachen Symbolen dargestellt und bedürfen keiner Schriftkenntnis. Sie sollen sofort von allen Menschen verstanden werden, so dass im Idealfall die Lernenden sich den Umgang mit dem Rechner eigenständig erarbeiten können.
- Obwohl Sugar explizit als Software designt wurde, welche im pädagogischen Kontext benutzt werden soll, gibt es keine Trennung zwischen expliziter Lern- und anderer Software. Vielmehr wird in einer Anzahl von Aufgaben versucht, Spiel und Lerneffekte zu verbinden.
Die Verbreitung von OLPC-Rechnern sowie der Sugar-Plattform ist beachtlich. Das Projekt selber spricht von über 2.4 Millionen verteilten Rechnern. Es existieren in zahlreichen Staaten Communities, die sich mit OLPC und Sugar befassen. (One Laptop per Child (ohne Jahr))
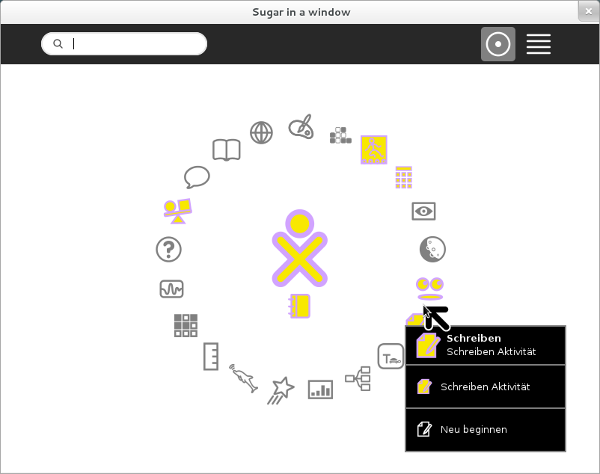
Abbildung 1: Screenshot Sugar, mit der hervorgehobenen Aktivität "Schreiben". Das Journal kann unter der Figur (welche einen Nutzer / eine Nutzerin repräsentiert) aufgerufen werden.
Die Ergebnisse einiger Studien zum Einsatz der Rechner sind hingegen durchwachsen. (Favivar (2012), Kornberger (2010), Meneweger (2010), Luyt (2008), Kenney (2006)) Grundsätzlich kommen sie alle zum Ergebnis, dass der Einsatz von Sugar und OPLC-Rechnern möglich ist und keine negativen Folgen hat. Die grossen Hoffnungen, welche das OLPC-Projekt an den Rechner und seine Wirkungen stellte, scheinen sich allerdings bislang nicht zu erfüllen. Dies hat indes auch damit zu tun, dass mehrere ähnliche Projekte gestartet wurden. (Vergleiche für eine Übersicht über ähnliche Projekte Trucano (2013).) Dennoch sind OLPC-Rechner und Sugar die verbreitetste Hard- und Software, was nicht zuletzt darauf zurückzuführen ist, dass sich dieOLPC-Stiftung äusserst aktiv in der Verbreitung des Rechners zeigt. Da zudem die Entwicklung von Sugar durch die Community vorangetrieben wird (Sugarlabs (ohne Jahr)), ist nicht auszuschliessend, dass es in Zukunft zu einer gesteigerten Nutzung kommen kann.
1.2 Freie Bibliothekssysteme
Innerhalb der letzten Jahre ist eine Anzahl von freien Bibliothekssystemen, also Open Source Lösungen, entstanden. Diese Systeme bieten, wie proprietäre Bibliothekssysteme auch, integrierte Lösungen für alle bibliothekarischen Aufgaben - angefangen vom Bestandsmanagement über die Katalogisierung bis hin zur Ausleihverwaltung, Gestaltung des Internetauftritts und Management von elektronischen Medien. (Macan, Fernández, Stojanovski (2013), Taylor et al. (2013), Vimal, Jasimudeen (2012), Kamble, Raj, Sangeeta (2012) Singh, Sanaman (2012))
Anders als zum Beispiel in der Schweiz sind diese Systeme in vielen Ländern des globalen Südens weit verbreitet. Ebenso findet sich eine Anzahl von Staaten im globalen Norden, in denen diese freien Bibliothekssysteme in den meisten Bibliotheken genutzt werden, insbesondere Koha, welches direkt aus dem neuseeländischen Bibliothekssystem stammt. (Koha (ohne Jahr), Koha Community (ohne Jahr)) Freie Bibliothekssysteme werden dabei nicht nur als billige Lösung von Etat-schwachen Bibliotheken eingesetzt. Eine Reihe von grösseren Bibliothekssystemen, sowohl im öffentlichen als auch wissenschaftlichen Bereich sowie eine Anzahl von Nationalbibliotheken, hat sich für solche Systeme entschieden. Zu nennen sind vor allem die beiden erfolgreichen Systeme Koha, NewGenlib und das von der UNESCO finanzierte ABCD. (Koha (ohne Jahr), Koha Community (ohne Jahr), NewGenLib (ohne Jahr), NewGenLib Forum (ohne Jahr), Dhamdhere (2011))
Die Vorteile dieser Systeme sind neben den geringen Kosten, die sich vor allem auf die technische Infrastruktur beziehen, ihre allgemeine Flexibilität, die Offenheit der Software und die klare Dokumentation ihrer Schnittstellen. Gleichzeitig haben sich um diese Systeme, vor allem um NewGenlib und Koha, Communities gebildet, die wie bei anderer Open Source Software schnelle Beratungen untereinander ermöglichen. (Koha Community (ohne Jahr), NewGenLib Forum (ohne Jahr))
Gleichzeitig bietet solche Software die Möglichkeit, relativ professionell und mit verhältnismäßig wenig Arbeit eigene kleine Bibliotheken zu betreiben. Die Systeme können auf einfachen Servern installiert und betrieben werden, sie führen durch die unterschiedlichen bibliothekarischen Aufgaben und übernehmen Verwaltungsarbeiten, die ansonsten zum Beispiel in Bibliotheken in abgelegenen Schulen von einem nicht-bibliothekarisch ausgebildeten Personal improvisiert durchgeführt würden.
1.3 Projektfrage
Das Projekt COLiSu schlägt vor, diese beiden Softwarekomponenten – Sugar und freie Bibliothekssysteme – miteinander zu verbinden. Dies soll ermöglichen, die Vorteile beider Lösungen produktiv nutzbar zu machen. Über eine technische Verbindung soll aus Sugar direkt auf freie Bibliothekssysteme in verschiedenen Varianten zugegriffen werden können. Dies könnte ein neues Zusammenspiel von Schulen und Bibliotheken bedingen. Im folgenden Abschnitt (2.) werden kurz die zu lösenden technischen Fragen einer solchen Kombination besprochen, anschliessend (Abschnitt 3.) Anwendungsszenarien und inhaltliche Implikationen dieser Kombination vorgestellt.
2. Technische und inhaltliche Fragen
Im Projekt COLiSu stellen sich voneinander zu differenzierende Fragen. Dieser Unterteilung folgt der Abschnitt 2., indem der zuerst die technischen Aspekte (2.1) und anschliessend die inhaltlichen Aspekte (2.2) des Projektes bespricht.
2.1 Technische Aspekte
Die grundlegenden technischen Aspekte des Projektes sind – verglichen mit anderen technisch ausgelegten Projekten – relativ gering. Beide zu verbindende Komponenten sind als Open Source gestaltet, die Schnittstellen sind allgemein gut dokumentiert. So liegen zum Beispiel für Sugar explizit Vorgaben dazu vor, wie Aktivitäten programmtechnisch gestaltet werden sollen. (Anonym (2008)) Ähnliches lässt sich für die freien Bibliothekssysteme sagen. Das dies so einfach erscheint, ist im Konzept von Open Source Software angelegt. Diese Software soll anderen aktiv ermöglichen, in den Code des jeweiligen Projektes direkt Einblick zu nehmen, diesen zu verbessern oder anzupassen. Gleichzeitig soll die Kollaboration zwischen unterschiedlichen Communities gefördert werden. COLiSu schlägt diesbezüglich nur vor, diese Verbindung zwischen bestimmten Communities explizit zu fördern.
Hinzu tritt, dass der Austausch bibliographischer Daten, der eine der wichtigsten Funktionen der vorgeschlagenen Sugar-Aktivitäten darstellen soll, über das standardisierte Austauschformat Machine-Readable Cataloging (MARC) beziehungsweise seine Dialekte funktioniert. Dieser Standard ist in Bibliotheken etabliert und wird von allen freien Bibliothekssystemen genutzt. (Seikela, Steeleb (2011))
Der konkrete Programmierungsaufwand für die einzelnen Komponenten ergibt sich aus den unterschiedlichen Anwendungsszenarien. Deshalb wird im Abschnitt 3. jeweils auf diesen Aufwand der einzelnen Szenarien eingegangen. Festzuhalten ist jedoch, dass sich die Lösungen in allen Fälle grösstenteils auf schon vorhandene Komponenten stützen werden.
Eine interessante Einschränkung, die sich in allen Szenarien stellt, ist der Fakt, dass nicht von einer kontinuierlichen Internetverbindung ausgegangen werden kann. Wie unter 1.1 erwähnt ist Sugar für Rechner gedacht, die keine andauernde Verbindung mit dem Internet voraussetzen. Softwareprojekte in Ländern des globalen Nordens gehen hingegen zumeist davon aus, dass eine solche Verbindung existiert, indem zum Beispiel bei Kataloganfragen auf eine funktionierende Server-Client-Verbindung gesetzt wird.
2.2 Inhaltliche Aspekte und Fragen
Interessant sind beim COLiSu-Projekt die inhaltlichen Fragen: Was passiert, wenn den Schülerinnen und Schülern Zugriff über Sugar auf bibliothekarische Daten und Angebote gegeben wird? Dabei lässt sich nicht nur an Zugriff auf Kataloge, sondern zum Beispiel auch auf Sondersammlungen – zuerst von Lernmaterialien – denken. Wird der Unterricht dadurch für die Lernenden aktiver, da sie neben dem Input der Lehrpersonen weitere Quellen zur Information nutzen und dies direkt im Unterricht einbringen können? Was passiert, wenn freie Bibliothekssysteme und Sugar verbunden werden? Hier drängt sich die Vorstellung auf, dass die technischen Möglichkeiten auch in kleinen, abgelegenen Schulen genutzt werden können, um Schulbibliotheken vergleichsweise professionell zu führen und zu nutzen.
Es sei daran erinnert, dass Sugar vor allem für den Einsatz im globalen Süden entwickelt wurde; dort stellen sich auch weiterreichende Fragen: Schliesst man mit einer solcher Verbindung von Sugar und Bibliothekssystemen Schülerinnen und Schüler, die bislang nicht von Bibliotheken erreicht wurden, an diese Bibliotheken an? Müssen Bibliotheken beginnen, sich Gedanken über die Ausleihe in abgelegene Gebiete zu machen? Wird es Aufgabe von Bibliotheken, besondere Sammlungen von elektronischen Lernmaterialien bereitzustellen und zu pflegen? Motiviert der Einsatz von freien Bibliothekssystemen ein Wachstum von Schulbibliotheken in kleinem Rahmen, die aber relativ hohe bibliothekstechnische Standards haben? Wenn ja, welche Auswirkungen hat dies?
Gleichwohl wird Sugar auch in Schulen des globalen Nordens eingesetzt. (Kornberger (2010), Meneweger (2010)) Zudem kann aus den Ergebnissen anderer Staaten auch für reiche Länder wie die Schweiz gelernt werden. Grundsätzlich eröffnet das Projekt COLiSu zahlreiche Anschlussfragen und potentielle Folgeprojekte. So wäre es zum Beispiel sinnvoll, die Implementation der vorgeschlagenen Verbindung von Sugar und freien Bibliothekssystemen in unterschiedlichen Gebieten aktiv zu begleiten, um die tatsächlichen Konsequenzen zu eruieren. Auch stellen sich pädagogische Fragen, die nur in Zusammenarbeit mit den Erziehungswissenschaften bearbeitet werden können.
3. Anwendungsszenarien und Implikationen
Im Folgenden werden vier Anwendungsszenarien beschrieben, welche auf den im COLiSu-Projekt vorgeschlagenen Verbindungen von Sugar und freien Bibliothekssystemen basieren.
3.1 Szenario: Zugriff auf eine Schulbibliothek
Das erste, einfachste Szenario geht davon aus, dass Schülerinnen und Schüler auf die Bestände einer lokalen Schulbibliothek zugreifen können, die mit freier Bibliothekssoftware betrieben wird. Hierfür notwendig ist neben den Rechnern, welche Sugar nutzen, ein schuleigener Server, auf welchem ein freies Bibliothekssystem betrieben wird. Dies ist allerdings relativ billig und einfach zu bewerkstelligen. Alle dieser Systeme sind daraufhin angelegt, auf einfacher Software zu laufen. Für alle existieren zum Beispiel Anleitungen, wie sie durch ein unkompliziertes Verfahren installiert werden können.
In einem einfachen Anwendungsfall ist dieser Zugriff nur dann ermöglicht, wenn die Schülerinnen und Schüler sich auch in der Schule befinden. Hier wird der Zugriff auf die Daten des Servers in der Schulbibliothek durch das lokale Mesh-Netzwerk hergestellt. Im erweiterten Anwendungsfall wird den Schülerinnen und Schülern ermöglicht, auf den Katalog auch ausserhalb der Schulen zuzugreifen. Dabei ist es nicht möglich, auf eine funktionierende Internetverbindung zu vertrauen. Vielmehr wird ein System entwickelt werden müssen, welches bei Verbindung mit dem Server die notwendigen Daten auf den einzelnen Sugar-Rechner lädt, dort vorhält und zum Beispiel durchsuchbar macht, gleichzeitig Such- und Bestellvorgänge ermöglicht und zu einem späteren Zeitpunkt, wenn wieder eine Verbindung mit dem Bibliotheksserver hergestellt wird – zum Beispiel weil die Schülerin oder der Schüler wieder die Schule besucht – ausführt.
Neben dieser zu lösenden technischen Aufgabe stellt sich die Herausforderung, eine Such-Oberfläche für den Bibliothekskatalog zu gestalten, welche den anderen Aktivitäten von Sugar entspricht und dennoch möglichst komplexe Zugriffe auf die Mediendaten im Katalog ermöglicht. Denkbar ist auch, mehrere Aktivitäten zu gestalten, die mehr oder weniger komplexe Suchmöglichkeiten bieten.
Im Alltag bietet dieses Szenario den Schülerinnen und Schülern die Möglichkeit direkt auf die Medien ihrer Schulbibliothek zuzugreifen, Katalogrecherchen durchzuführen und Leihbestellungen aufzugeben. Sugar ist als zentrales Lern- und Arbeitswerkzeug gestaltet, insoweit bedeutet eine Einbindung des Katalogs einer Schulbibliothek als, neben den anderen Aktivitäten, gleichberechtigtes Element, auch eine direkte Einbindung der Bibliotheken in den Schulalltag. Lehrerinnen und Lehrer können somit Unterrichtsaufgaben auf diese Möglichkeit hin ausrichten.
Zu lösen sind für dieses Szenario folgende technische Probleme:
- Gestaltung einer Aktivität, die den Zugriff auf die Katalog- und Ausleihfunktionen der freien Bibliothekssysteme ermöglicht und sich gleichzeitig in Sugar integriert.
- Diese Aktivität sollte die Speicherung der Rechercheergebnisse ermöglichen.
- Unter Umständen eine Zusammenstellung mehrerer Aktivitäten, welche dies erfüllen, mit unterschiedlichen Komplexitäten (einfache Suche, Expertensuche, starke Facettierung etc.).
- Lokale Speicherung von Katalogdaten, Rechercheergebnissen und Leihanfragen. Aktualisierung dieser Daten und Push – d.h. der automatisch vom Systeme ausgelösten Übertragung – von Leihanfragen, wenn der Rechner sich wieder mit dem Server in einem gemeinsamen Netzwerk befindet.
- Zudem muss eine Möglichkeit der Identifikation der einzelnen Schülerinnen und Schüler im Bibliothekssystem geschaffen werden. Denkbar ist zwar der Zugang über Passwörter, andere Möglichkeiten – beispielsweise die automatisch Identifikation – würden die Nutzungsbarrieren abbauen und die Aktivitäten stärker in die normale Arbeit mit Sugar einbinden.
3.2 Szenario: Betrieb einer Schulbibliothek
Während das erste Szenario davon ausgeht, dass die betreffende Schulbibliothek getrennt von Sugar mit der jeweiligen freien Bibliothekssoftware betrieben wird, lässt sich auch ein Szenario entwerfen, in dem die Schülerinnen und Schüler in die Verwaltung der jeweiligen Bibliothek einbezogen sind.
Grundsätzlich ist bei allen Bibliothekssystemen die Möglichkeit gegeben, Rollen zu definieren. Diese Rollen ermöglichen es, für unterschiedliche Nutzerinnen und Nutzer bestimmte Rechte zu verteilen. So kann festgelegt werden, dass einige Personen nur die Ausleihverwaltung betreiben dürfen, während andere nur die Verwaltung der Medien erledigen können. Hierbei unterscheiden sich die freien Bibliothekssysteme nicht von anderen Bibliothekssystemen. In diesem Szenario sollen eine oder mehrere Aktivitäten entworfen werden, die auf diesen Rollenzuweisungen aufbauen und es zum Beispiel ermöglichen, Schülerinnen und Schülern zu ermöglichen, mit ihren Sugar-Rechnern Aufgaben in der Bibliothek zu übernehmen. Diese Mitarbeit von Lernenden in Schulbibliotheken ist an sich verbreitet; Aufgabe wäre es, diese auch technisch zu ermöglichen.
Grundsätzlich baut dieses Szenario technisch auf dem ersten Szenario auf. Zudem sind folgende Probleme zu lösen:
- Aktivitäten erstellen und gestalten, die auf unterschiedliche Funktionen der freien Bibliothekssysteme zugreifen und es ermöglichen, zum Beispiel die Ausleihe oder die grundlegende Katalogisierung von Sugar aus zu übernehmen.
- Der Zugriff auf die Funktionen der Bibliothekssysteme ist, im Gegensatz zu Katalogdaten, nicht standardisiert. Insoweit werden die Aktivitäten auf den Schnittstellen der unterschiedlichen Systeme aufbauen müssen. Aus diesem Grund lässt sich, zumindest für die erste Programmierung, die Konzentration auf die beiden verbreiteten freien Bibliothekssysteme Koha und NewGenLib begründen. (ABCD ist zwar von seiner Trägerinstitution her interessant, aber wenig in realen Bibliotheken verbreitet.)
3.3 Szenario: Verbindung zu Öffentlicher Bibliothek
Im dritten Szenario wird eine Verbindung von Sugar-Rechnern zu Angeboten einer Öffentlichen Bibliothek vorgeschlagen. Denkbar ist dies nur, wenn zumindest zeitweise eine Verbindung zu dieser Bibliothek – entweder über Internetverbindungen oder die Einspeisung der Bibliotheksdaten in lokale Netzwerke, zum Beispiel über einen Server innerhalb der Schule – hergestellt werden kann. Zudem soll in diesem Stadium davon ausgegangen werden, dass die Öffentliche Bibliothek ein freies Bibliothekssystem verwendet, was allerdings im globalen Süden oft der Fall ist. Da Katalogdaten per MARC ausgetauscht werden lässt sich aber auch daran denken, dass perspektivisch andere Bibliothekssysteme verwendet werden können.
Grundsätzlich ist das dritte Szenario eine Erweiterung des ersten Szenarios. Allerdings integriert es die Öffentliche Bibliothek in das pädagogische Netzwerk der Schule selber. Dadurch würde es zur Aufgabe der Öffentlichen Bibliotheken, Leihbedingungen für Fernleihen in entlegene Schulen zu installieren, Sondersammlungen für die Nutzung in Schulen oder von Schülerinnen und Schülern in deren Freizeit aufzubauen. Grundsätzlich kann man sich vorstellen, dass Öffentliche Bibliotheken, wenn Sugar-Rechner in einer Region verstärkt eingesetzt werden, die Verantwortung übernehmen, die Schulen dieser Region durch eine aktive Bestandspflege zu unterstützen. Eine sinnvolle Erweiterung wird die Pflege von Sammlungen digitaler Lehrmaterialien darstellen.
Zusätzlich zu den im ersten Szenario genannten sind folgende technische Probleme zu klären:
- Die Aktivität sollte, wenn elektronische Medien angeboten werden, die direkte Nutzung dieser Medien ermöglichen. Hierfür stehen andere Aktivitäten – zum Beispiel “Read” für E-Books – zur Verfügung. Zu schaffen wäre eine direkte Verbindung zwischen diesen Aktivitäten.
- Die Aktivität muss die automatische, gleichwohl platzsparende Speicherung dieser elektronischen Medien ermöglichen.
3.4. Szenario: schulinterne Digitale Bibliothek
An das erste und dritte Szenario anschliessend wäre auch eine schulinterne digitale Bibliothek, die von Sugar aus benutzt, ergänzt und gepflegt würde, denkbar. So kann die Schulbibliothek mit elektronischen Medien ergänzt werden, wobei vor allem die Nutzung von Open Educational Ressources sinnvoll erscheint. Eine solche digitale Bibliothek kann sich auch aus anderen Quellen speisen und beispielsweise bei seltener und nie vorhandener Internetverbindung den Schülerinnen und Schülern eine Auswahl elektronischer Medien zur Verfügung stellen. Gleichzeitig kann eine solche Sammlung das Einspeisen von selbst erstellten elektronischen Medien durch die Schülerinnen und Schüler aber auch durch Lehrpersonen oder Bibliotheksverantwortliche motivieren. Angesichts dessen, dass Sugar auf konstruktivistischen pädagogischen Annahmen aufbaut und das eigenständige, spielerische Tun der Lernenden in den Mittelpunkt stellt, wäre eine solche Möglichkeit eine sinnvolle Ergänzung. Möglich wird dieses Szenario nur durch den Betrieb eines eigenen Servers für elektronische Medien in der Schule selber. Allerdings ist auch dies relativ einfach und mit einem geringen finanziellen Aufwand umzusetzen.
Das Szenario vereinigt technisch gesehen das erste und zweite Szenario. Hinzu tritt folgendes zu lösendes Problem:
- In Sugar-Aktivitäten erstellte elektronische Medien müssen schnell und einfach in die schulinterne Digitale Bibliothek integriert werden können.
4. Fazit und zukünftige Entwicklungsmöglichkeiten
Im COLiSu-Projekt wird vorgeschlagen, die Lernplattplattform Sugar technisch mit freien Bibliothekssystemen zu verbinden und die Möglichkeiten dieser Verbindungen zu untersuchen. Grundsätzlich scheint diese Verbindung technisch relativ einfach herzustellen. Interessant sind die sich daraus ergebenden praktischen Fragen für den Einsatz von Sugar und freien Bibliothekssystemen.
Problematisch ist, wie bei vielen anderen Projekten, die finanzielle Frage des Projektes. Während der mögliche Einfluss leicht sichtbar ist, gibt es wenige Töpfe für eine solche Programmarbeit. So sind die meisten Stiftungen in der Schweiz, die sich mit Bildungsfragen oder der Entwicklungshilfe beschäftigen zumeist auf direkt helfende Projekte beschränkt. Dies ist sinnvoll, da die wenigen Mittel zweckmäßig eingesetzt werden sollen, zeigt aber eine gewisse Schwachstelle der Finanzierungsmöglichkeiten. Offenbar ist es nicht vorstellbar, dass mit einer relativ geringen Programmierarbeit, dem Anschluss an schon vorhandene Projekte und einer Unterstützung bei Implementation der Neuerungen, eine grosse Palette von Möglichkeiten zur Verbesserung von Bildungsaktivitäten für zahlreiche Schülerinnen und Schüler weltweit zur Verfügung stehen könnte.
Sollte die Finanzierungshürde genommen werden können, ergeben sich für die Zukunft zahlreiche Anschlussfragen, die in weiteren Projekten bearbeitet werden könnten.
- Die Begleitung der Implementation der Aktivitäten und der damit möglichen Veränderungen in unterschiedlichen Gebieten und für die unterschiedlichen Szenarien.
- Die Untersuchung der tatsächlichen Effekte dieser Implementationen in Schulen, Schulbibliotheken, Bibliotheken und Communities.
- Die Begleitung des Aufbaus von Programmen von Bibliotheken zur Unterstützung von abgelegenen Schulen. Dabei ginge es weniger darum, die Bibliotheken zu verändern, sondern eher die Stellung der Bibliotheken in den Communities zu untersuchen und sie dabei zu unterstützen, diese Stellung zu verändern.
- Die Begleitung des Aufbaus und des Betriebs von Schulbibliotheken oder digitalen Sammlungen.
- Die Frage, wie diese Möglichkeiten im globalen Norden genutzt werden können.
- Die Ausweitung auf andere Bibliothekssysteme oder Lernplattformen.
Literatur
[Letzter Aufruf der URLs: 08.10.2013]
Anonym (2008) / Activity Handbook: How to get started with software development for the OLPC XO. (Ohne Ort): OLPC Austria, http://wiki.sugarlabs.org/images/5/51/Activity_Handbook_200805_online.pdf
Ashling, Jim (2010) / Laptops Bridge Gap in Structured Learning. In: InformationToday 27 (2010) 8, 22-23
Barack, Lauren (2008) / My Daughter Meets the XO. In: School Library Journal, http://www.schoollibraryjournal.com/slj/printissuecurrentissue/859515-42...
Bashi, Pantea (2011) / Digitale Ungleichheit? : One Laptop Per Child: Anspruch und Wirklichkeit. München : AVM, 2011
Beuermann, Diether W. ; Cristia, Julián P. ; Cruz-Aguayo, Yyannu ; Cueto, Santiago ; Malamud, Ofer (2012) / Home Computers and Child Outcomes : Short-Term Impacts from a Randomized Experiment in Peru (IDB Working Paper Series, 382). (Ohne Ort) : Inter-American Development Bank, 2012
Cristia, Julián P. ; Ibarrarán, Pablo ; Cueto, Santiago ; Santiago, Ana ; Severín, Eugenio (2012) / Technology and Child Development : Evidence form the One Laptop per Child Program (IDB Working Paper Series, 304). (Ohne Ort) : Inter-American Development Bank, 2012
Dhamdhere, Sangeeta Namdev (2011) / ABCD, an open source software for modern libraries. In: Chinese Librarianship: an International Electronic Journal, (2011) 32, http://www.iclc.us/cliej/cl32dhamdhere.pdf
Dent, Valeda Frances (2006) / Modeling the rural community library : Characteristics of the Kitengesa Library in rural Uganda. In: New Library World 107 (2006) 1220/1221, 16-30
Farivar, Cyrus (2012) / Step 1: give every kid a laptop. Step 2: learning begins?. In: arstechnica.com, 09.02.2012, http://arstechnica.com/business/the-networked-society/2012/02/step-one-g...
Hettich, Nils (2008) / Internetzugang für Schulen in Entwicklungsländern : In Verbindung mit der Initiative „One Laptop Per Child“. Saarbrücken : VDM Verlag, 2008
Kamble, V.T: ; Raj, Hans ; Sangeeta, Sangeeta (2012) / Open Source Library Management and Digital Library Software. In: DESIDOC Journal of Library & Information Technology 32 (2012) 5, 388-392
Kenney, Brian (2006) / One Child, One Laptop : Is this our chance to help change the world?. In: School Library Journal 52 (2006) 8, 11
Koha (ohne Jahr) / http://www.koha.org/
Koha Community (ohne Jahr) / http://koha-community.org/
Kornberger, Angelika (2010) / Das OLPC-Projekt (‘One Laptop per Child‘) unter dem besonderen Aspekt des Mathematikunterrichts (Eingereicht an der Pädagogischen Hochschule Steiermark zur Erlangung des akademischen Grades Bachelor of Education (Bed)). Graz : Pädagogische Hochschule Steiermark, 2010
Luyt, Brendan (2008) / The One Laptop Per Child project and the negotiation of technological meaning. In: First Monday 13 (2009) 6, http://firstmonday.org/htbin/cgiwrap/bin/ojs/index.php/fm/article/viewAr...
Macan, Bojan ; Fernández, Gladys Vanesa ; Stojanovski, Jadranka (2013) / Open source solutions for libraries: ABCD vs Koha. In: Program: electronic library and information systems, 47 (2013) 2, 136 – 154
Meneweger, Magdalena (2010) / Das OLPC-Projekt (‘One Laptop per Child‘) unter dem besonderen Aspekt des Deutschunterrichts (Eingereicht an der Pädagogischen Hochschule Steiermark zur Erlangung des akademischen Grades Bachelor of Education (Bed)). Graz : Pädagogische Hochschule Steiermark, 2010
NewGenLib (ohne Jahr) / http://www.verussolutions.biz/web/
NewGenLib Forum (ohne Jahr) / http://forums.newgenlib.org/
One Laptop per Child (ohne Jahr) / http://one.laptop.org/
Pal, Joyojeet (2012) / The machine to aspire to: The computer in rural south India. In: First Monday 17 (2012) 2, http://www.firstmonday.org/htbin/cgiwrap/bin/ojs/index.php/fm/article/vi...
Riem, Ulrich (2010) / One Laptop per Child: Überlegungen zum entwicklungspolitischen Anspruch einer technischen Innovation und ihrer Governance. In: Aichholzer, Georg ; Bora, Alfons ; Bröchler, Stephan ; Decker, Michael ; Lattzer, Michael (Hrsg.) / Technology Governance : Der Beitrag der Technikfolgenabschätzung (Gesellschaft – Technik – Umwelt, Neue Folge, 13). Berlin : edition sigma, 2010, 129-141
Seikela, Michele ; Steeleb, Thomas (2011) / How MARC Has Changed: The History of the Format and Its Forthcoming Relationship to RDA. In: Technical Services Quarterly Volume 28 (2011) 3, 322-334
Singh, Manisha ; Sanaman, Gareema (2012) / Open source integrated library management systems: Comparative analysis of Koha and NewGenLib. In: The Electronic Library 30 (2012) 6, 809 - 832
Stranger-Johannessen, Espen (2009) / Student Learning through a Rural Community Library : A case study from Uganda (Master of Philosophy in Comparative and International Education). Oslo : University of Oslo, 2009. http://eprints.rclis.org/bitstream/10760/13127/1/Espen%27s_thesis_finish...
Sugarlabs (ohne Jahr) / http://sugarlabs.org/
Taylor, Sally; Jacobi, Kristin; Knight, Elizabeth; Foster, Dale (2013) / Cataloging in a Remote Location: A Case Study of International Collaboration in the Galapagos Islands. In: Cataloging & Classification Quarterly51 (2013) 1-3, 168-178
Trucano, Michael (2013) / Big educational laptop and tablet projects -- Ten countries to learn from. In: EduTech, http://blogs.worldbank.org/edutech/big-educational-laptop-and-tablet-pro...
Vimal, Kumar V. ; Jasimudeen, S. (2012) / Adoption and user perceptions of Koha library management system in India. In: Annals of Library and Information Studies (ALIS), 59 (2012) 4, http://eprints.rclis.org/18198/
La gouvernance des documents électroniques dans l’administration cantonale genevoise : genèse et mise en œuvre
Anouk Dunant Gonzenbach, Archives d'État de Genève
La gouvernance des documents électroniques dans l’administration cantonale genevoise : genèse et mise en œuvre
Le patrimoine informationnel d'une institution confirme les droits des personnes physiques ou morales, répond aux obligations légales, renseigne sur des questions essentielles, permet la prise de décision et appuie la réflexion et l'analyse. En bref, il permet une bonne gouvernance de l'Etat. Dans l’administration genevoise, les documents sous forme papier sont adéquatement traités, classés et conservés grâce aux outils de gestion de l'information mis en place par les archivistes de département et les Archives d'Etat.
Mais aujourd'hui, les processus de travail ont changé: les documents papier deviennent électroniques et ne sont plus systématiquement imprimés. Ils sont classés dans des systèmes de gestion électronique de documents (GED), des arborescences ou des systèmes d’information métier et conservés sur les serveurs de l'Etat. Néanmoins, l'administration doit pouvoir retrouver facilement ces documents et les traiter tout en garantissant leur authenticité pendant tout leur cycle de vie. La protection des données personnelles et la sécurité de l'information doivent également être assurées. Comment répondre à ces nouveaux défis? C'est le sujet de cet article, qui est une première synthèse de ce projet que nous continuons de poursuivre. Il présentera tout d'abord les Archives d'Etat de Genève, leur implication dans le projet de gestion des documents électroniques et enfin la politique de gouvernance des documents électroniques de l'administration cantonale.
1. Les Archives d'Etat de Genève
Les Archives d'Etat de Genève, institution d'archives cantonales, ont pour mission de veiller à la constitution, à la gestion et à la conservation des archives publiques dans leur ensemble et plus particulièrement à celles des archives historiques, et de les mettre à la disposition du public (chercheurs, généalogistes, journalistes, historiens, étudiants, politiques, etc.).
Au sein de leurs trois dépôts principaux, dont le principal est l'Ancien Arsenal, en face de l'hôtel de Ville, les Archives d'Etat conservent, du plus ancien au plus récent: les archives du Moyen Age provenant de l'époque précédant la Réforme, où les seigneuries exerçaient le pouvoir aussi bien temporel que spirituel dans la ville et dans ses possessions de la campagne, les mandements; les archives de l'ancienne République de Genève, depuis 1536 jusqu'en 1798; les archives de l'époque du Département du Léman, de 1798 à 1813 et enfin les archives du canton de Genève, dès 1814, issues des trois pouvoirs, législatif, exécutif et judiciaire. A cela s'ajoutent les documents de provenance privée, soit des archives de familles, de sociétés, d'associations ou d'entreprises.
Ces documents représentent un volume d'environ 29 km linéaires, depuis le plus ancien, daté de 913 jusqu'à aujourd'hui. Les Archives sont ouvertes gratuitement au public.
Une bibliothèque consultative abondamment fournie en ouvrages sur l’histoire de Genève et l'histoire régionale permet de faciliter les recherches et complète l’offre documentaire, avec comme autre point fort l'histoire de la Réforme.
2. La problématique des archives nées numériques
La transition vers le numérique est désormais effectuée. Aujourd'hui, l'information est créée, enregistrée et transmise électroniquement; les formats numériques remplacent les supports traditionnels tels que le papier. Or la conservation de l'information sous forme numérique est beaucoup plus complexe que la conservation sous forme papier ou microfilm. Les documents électroniques ont une grande vulnérabilité au temps et ont pour caractéristique les formats et supports les moins durables de l'histoire. Un cd par exemple a une durée de vie d’une dizaine d’années. On peut affirmer aujourd’hui qu'un objet numérique créé sans précautions particulières ne pourra plus être lu d'ici une quinzaine d'années.
La mission des Archives d'Etat, elle, n'a pas changé: les documents électroniques qui ont une valeur juridique, patrimoniale, économique ou historique doivent être conservés sur le très long terme. C’est un défi que doivent relever les Archives d’Etat, à l’instar de toutes les institutions d’archives. C’est ainsi qu’est né le projet Gal@tae.
3. Le projet Gal@atae d'archivage à long terme des documents électroniques
Les Archives d'Etat ont mené entre 2011 et 2013 un projet pilote d'archivage électronique à très long terme, nommé Gal@tae (Genève : archivage à long terme d’archives électroniques). L'objectif de ce projet était de mettre en place tous les éléments permettant un archivage électronique pérenne des documents, de la création dans un système d’information métier de paquets de données électroniques à archiver au dépôt sur la plate-forme de pérennisation des Archives fédérales suisses, en passant par les étapes de transfert et de contrôle de qualité aux Archives d’Etat. Ce projet pilote a permis de développer les compétences en matière d'archivage électronique pour les Archives d'Etat et les informaticiens, de mettre en place les procédures et processus permettant d'assurer cet archivage pérenne et de tester la solution technique. Il s'est conclu avec succès et la prochaine étape est la mise en production de la solution(1).
4. De l'archivage électronique à long terme à la gouvernance des documents
L'objectif de l'archivage à long terme des documents électroniques a été défini par l'ensemble des institutions d'archives suisses faisant partie du Centre de coordination pour l'archivage à long terme des documents électroniques (CECO): il s’agit de "[…] faire en sorte que les documents électroniques restent durablement compréhensibles et que leur authenticité, leur intégrité et leur accessibilité soient garanties"(2). Pour recevoir de la part de l'administration des documents et données électroniques archivables, c’est-à-dire intègres, authentiques, fiables et exploitables, intervenir en amont de la production documentaire est indispensable. En effet, il est important de s’assurer que les éléments nécessaires à la prise en charge du cycle de vie du document lors des étapes postérieures (de sa création à son archivage définitif en passant par sa modification et sa validation) sont pris en compte et complétés à chacune de ces interventions. Le rattrapage a posteriori s’avère lourd, parfois impossible. Le suivi de ces exigences tout au long du cycle de vie du document en facilitera grandement l’archivage définitif. Ce projet a donc mis en évidence l'importance de gérer correctement les documents et données électroniques dès leur création et de réfléchir au cycle de vie des documents dès la mise en place d’un nouveau système d'information.
Ainsi le projet d’archivage à très long terme des Archives d'Etat, prévu dans un but patrimonial et de recherche avec le souci d'assurer la conservation des sources électroniques pour l'avenir, a fait aborder l'angle du gestionnaire : comment l'Etat doit-il traiter ses données électroniques? Le document électronique, qu'il soit archivé ou non à la fin de son cycle de vie, doit être géré et conservé correctement pendant sa durée de vie dans l'administration. Les problématiques se recoupent en effet pour le moyen et le long terme: l'intégrité, l'authenticité, la gestion des droits d'accès, etc.
Les Archives d'Etat de Genève ont ainsi fait le choix de s'impliquer tout au long du cycle de vie du document, de la création des systèmes d'information à l'archivage des documents électroniques.
Genèse du projet
Pour mener à bien le projet d'archivage électronique Gal@tae, les Archives d'Etat ont décidé de travailler avec des groupes ayant des compétences et des responsabilités en matière de systèmes d'information. Elles ont ainsi fait valider chacune des étapes de leur projet par le Collège spécialisé des systèmes d'information, un organe de haut niveau réunissant les directeurs informatiques de chaque département, présidé par le directeur de la Direction générale des systèmes d'information de l’Etat (DGSI). Lorsque ce collège a mandaté un groupe de travail pour réfléchir aux questions liées à la GED dans l'administration, il l'a placé assez naturellement sous la présidence de l'archiviste d'Etat au vu des travaux précédents. Ce groupe de travail, composé d'archivistes et d'informaticiens, a reçu un cahier des charges dont l’un des objectifs initiaux était de réfléchir à un nouvel outil de GED. Il lui est cependant vite apparu qu'avant de fournir des solutions et des réponses techniques, il était indispensable d'établir un cadre général pour la gestion des documents électroniques au sein de l'administration cantonale.
5. La politique de gouvernance des documents électroniques
C'est ainsi qu'a été rédigée la politique de Bonne gouvernance des documents électroniques au sein de l'administration. Nous avons souhaité avoir la garantie que ce document soit conforme aux pratiques professionnelles en vigueur, c'est pourquoi nous l'avons soumis au comité Records Management de l'Association eCH, au comité Records Management de l'Association des archivistes suisses ainsi qu’au Centre suisse de coordination pour l'archivage à long terme des documents électroniques. Ces trois instances ont reconnu la conformité de ce document, qui a été validé en février 2013 par le Collège spécialisé des systèmes d'information. Depuis lors, l'administration cantonale est dotée d'une politique de gouvernance des documents électroniques.
Ce document définit tout d’abord plusieurs termes. En effet, le vocabulaire dans le domaine des systèmes et applications de gestion des documents électroniques est encore volatile et les prestataires de service et de solutions n'utilisent pas forcément les mêmes définitions que les professionnels en science de l'information ou les juristes. Ainsi en est-il du mot "archivage", utilisé couramment dans le domaine informatique pour signifier une durée de vie d'une dizaine d'années ou du mot « copie » qui n’a pas le même sens pour un juriste ou un informaticien.
La Gouvernance des documents électroniques a pour but d'exposer les objectifs d'une bonne gestion des documents électroniques pendant leur durée de vie administrative et légale (autrement dit de leur création à leur sort final, qui est la conservation ou l'élimination définitive). Elle vise également à démontrer les avantages liés à de bonnes pratiques ainsi que les risques encourus si celles-ci ne sont pas appliquées. Ce document présente le cadre légal et normatif ainsi que les éléments fondamentaux en matière de gestion des documents électroniques et en décrit le processus général. Nous allons détailler ces points ci-dessous. Il est également important de préciser que les exigences fonctionnelles et les directives techniques sont exclues du document mais en constituent des annexes, et que le texte ne se réfère pas à un outil existant.
Les objectifs sont formulés de la manière suivante:
- rendre l'administration plus performante
- faciliter le travail des collaborateurs
- garantir la valeur légale des documents qui le nécessitent
- répondre aux exigences légales.
Le cadre légal
Le cadre légal en matière de document numérique provient de différentes sources : le droit fédéral, le droit cantonal (dont la loi sur la protection des données) et les lois et règlements spécifiques aux métiers. Pour ce qui est de la valeur légale -ou probante- du document électronique, on se réfère aujourd'hui au code civil suisse, essentiellement aux articles 130 et 177 (accessoirement 139 et 143) qui définissent qu’un document électronique est recevable à titre de preuve. Ainsi, de facto, le document électronique possède la même valeur probante qu’un document papier. Dans l’Ordonnance concernant la tenue et la conservation des livres de comptes (OLICO), le législateur a consacré au niveau fédéral la valeur légale du document électronique, pour autant que certaines conditions soient remplies. Il faut retenir parmi ces conditions, et nous y reviendrons, l'importance de la documentation des processus, l'authenticité, la fiabilité et l'intégrité du document électronique.
Le cadre normatif
Il existe plusieurs normes relatives à la gestion des documents électroniques, dont trois sont essentielles: la norme ISO 15489 de records management, le recueil d’exigences MoReQ (Modular Requirements for Records Systems) spécifiant les exigences fonctionnelles pour un système d’archivage électronique à valeur probante et enfin la norme ISO 14641 sur l'archivage électronique, entendu ici comme archivage pendant la durée de vie légale d'un document. Les standards eCH en matière de cyberadministration suisse doivent également être pris en compte. Ces normes et standards sont brièvement exposés dans le document et détaillés dans une annexe.
Le processus général
La garantie de l'authenticité d'un document repose plus sur la qualité des procédures et processus mis en place, autrement dit de l'organisationnel, que sur l'outil technique. Il faut ainsi prévoir les processus dès le départ et éviter la tentation de choisir un outil et de se reposer entièrement sur lui. Il est néanmoins nécessaire de préciser que tous les documents n’ont pas la même portée. Ils ne relèvent donc pas tous des mêmes exigences légales et, par conséquent, des mêmes obligations en matière de conservation. Un travail d'analyse préalable pour chaque série de documents est indispensable.
Le processus général, qui doit être adapté à chaque besoin métier, peut de manière simplifiée se schématiser ainsi: le service produit et reçoit numériquement des documents électroniques ou dématérialise des dossiers papier. A la création du document, des métadonnées (dont la durée d'utilisation administrative et légale et le sort final) sont associées à ce document électronique; cette opération est généralement automatisée. A sa validation (stade définitif d'élaboration), le document est nommé correctement et son format transformé en un format d'archivage. S'il faut conserver à ce document sa valeur probante, il est alors transféré dans un coffre-fort électronique. Au terme de sa durée d'utilité administrative et légale, le document est soit détruit, soit versé aux Archives d'Etat, selon le sort final qui lui a été attribué.
6. Les clés d'une bonne gestion des documents électroniques
Notre document met en exergue les clés d'une bonne gestion des documents électroniques. Chaque point fait l'objet d'une directive, qui constitue une annexe.
Le calendrier de conservation
Le calendrier de conservation est un outil essentiel pour gérer le cycle de vie des documents. Il s'agit fondamentalement d'une liste déterminant pour chaque série de documents une durée de conservation et un sort final (destruction ou versement aux archives définitives). En déterminant ces deux éléments, le calendrier permet de libérer de la place dans les espaces de stockage et de répondre aux exigences de la Loi sur l'information du public, l'accès aux documents et la protection des données personnelles (LIPAD, A 2 08), qui requiert que les documents contenant des données personnelles sensibles soient détruits au terme de leur durée d'utilité légale.
Les métadonnées
Les Archives d'Etat et le secteur Environnement documentaire et collaboratif de la DGSI ont élaboré une liste de métadonnées résultant des besoins liés à la bonne gestion des documents électroniques dans l'administration et de ceux liés à l'archivage électronique à long terme. Cette liste comporte un jeu de vingt-neuf métadonnées dont huit sont obligatoires (parmi elles, la durée de conservation et le sort final); elle offre parallèlement la possibilité d'ajouter des métadonnées supplémentaires pour les besoins métier particuliers. Ces métadonnées sont conformes aux normes de Records Management et le format de date exigé répond à la norme ISO 8601. Ce "recueil de métadonnées Etat de Genève" est en vigueur depuis le mois d'octobre 2011; depuis lors, il est utilisé lors de tout nouveau projet de GED.
Les formats
La question des formats est critique, car elle constitue un point particulièrement difficile à résoudre dans la perspective de la conservation à moyen et à long terme de l'information. Les évolutions techniques sont si rapides qu'il est difficile de présager la solution qu'il faudra adopter. C'est pourquoi il est raisonnable de conserver les données dans des formats répondant à des critères définis. Les documents numériques doivent être enregistrés dans des formats les plus pérennes possibles dès leur production; ils seront ensuite au besoin migrés régulièrement. Les Archives d'Etat ont produit une liste de formats de fichiers adaptés à l'archivage électronique à moyen et long terme. Le nombre de formats acceptés est restreint. En effet, un petit nombre de formats soigneusement sélectionnés et contrôlables garantit de manière plus sûre leur lisibilité sur le long terme qu'une grande quantité de formats dont l'entretien sera complexe et onéreux. Les formats choisis dans notre liste correspondent principalement aux critères d'ouverture et d'indépendance. Un format ouvert doit avoir une documentation complète et accessible à tous. C'est à partir de cette documentation qu'il sera possible d'écrire un programme pour lire les données ou les convertir vers un autre format.
Le nommage des fichiers et des répertoires
Les contraintes d'ordre technique ainsi que l'utilisation d'arborescences informatiques communes ont permis de montrer les enjeux liés au choix du nom de dossier et de fichier. Des règles de nommage précises sont nécessaires pour repérer et identifier plus facilement les documents recherchés, éviter les problèmes lors de transfert et de partage et permettre leur conservation à moyen et long terme. Un nom doit être unique et significatif. Des règles doivent donc s'appliquer pour permettre à un document d'être reconnu dans les différents environnements existants et d'être identifiable (ce qui signifie qu'il n'est pas nécessaire d'ouvrir un document pour savoir de quoi il s'agit).
Nous avons alors établi une liste de règles et de recommandations découlant des objectifs suivants: garantir l'accessibilité du document, éviter les problèmes techniques, faciliter la recherche et assurer une bonne gestion des documents. Par exemple: éviter les caractères spéciaux, ne pas utiliser de mots vides comme "le, la, une", ne pas utiliser les signes diacritiques, choisir un nom court et significatif, etc.
Nous avons également produit une typologie des séries des principaux documents de l'administration genevoise en proposant une abréviation pour chacune (A pour "arrêté", AP pour « avant-projet », etc.).
La liste des recommandations peut être adaptée, et chaque département est libre de préconiser ses propres pratiques dans ce cadre.
Il faut relever ici que la validation de cette liste de règles et de recommandations par le Collège des directeurs informatiques a soulevé certaines réticences, notamment lorsqu'il s'est agi d'imposer le format de dates ISO (AAAAMMJJ ou AAAA_MM_JJ). Cette question touche des pratiques quotidiennes qu'il n'est pas facile de modifier ou de faire évoluer.
Le coffre-fort électronique
Le coffre-fort électronique est la seule façon d’assurer l’authenticité, la fiabilité et l'intégrité du document électronique, et donc sa valeur probante.
On entend par :
- authenticité : il peut être prouvé que le document est bien ce qu’il prétend être, qu’il a bien été créé ou envoyé par la personne qui l’a créé ou envoyé et qu’il a bien été créé ou envoyé à la date indiquée
- fiabilité : le document est bien la représentation complète et fidèle de l’opération ou des opérations qu’il atteste (traçabilité)
- intégrité : le document est complet, non altéré et protégé contre toute modification non autorisée ; il n’est pas modifié sans qu’on puisse le constater.
Tous les documents ne nécessitent pas de telles conditions de sécurité, c’est pourquoi l'évaluation des séries documentaires est indispensable. Il est important de bien comprendre ici la différence entre un système d'information métier ou une GED et coffre-fort électronique:
Un système d'information métier / une GED:
- permet la modification des documents, la production et la gestion de plusieurs versions
- permet des mises à jour constantes (données non figées)
- peut permettre la destruction des documents
- peut comprendre un contrôle des durées de conservation
- peut comprendre une structure organisée de stockage, sous le contrôle des utilisateurs
- est a priori dédié à la gestion quotidienne des documents pour la conduite des affaires
- ne garantit pas la valeur probatoire des documents.
Un coffre-fort électronique:
- interdit la modification des documents une fois ceux-ci validés
- contient des données figées
- interdit la destruction des documents
- comprend obligatoirement un contrôle rigoureux des durées de conservation
- comprend obligatoirement une structure rigoureuse de classement (plan de classement) gérée et contrôlée par l'administrateur
- garantit l'authenticité des documents et leur traçabilité.
Les fonctionnalités que doit couvrir un coffre-fort électronique sont décrites dans la norme ISO 14641-1.
Dématérialisation, chaîne de numérisation et mise en GED
Les processus de dématérialisation des documents et leur mise en GED doivent être documentés pour éviter tout conflit ultérieur et toutes les opérations doivent être tracées. Il est ainsi nécessaire de rédiger des procédures et protocoles couvrant toute la chaîne de numérisation afin de s'assurer que les dossiers sont intégralement numérisés et que le processus de numérisation est fiable dans son entier. Cette documentation doit être rassemblée au même endroit et tenue à jour.
Analyse des risques liés au document électronique et à sa sécurité
Les aléas auxquels sont exposés l'information et les systèmes de gestion des documents sont particulièrement nombreux. Afin de définir précisément ces risques, d'identifier leurs causes et de proposer des actions visant à les contrer ou à les limiter, nous avons établi, en collaboration avec le contrôle interne du département de la sécurité, une cartographie des risques liés au document électronique à tous les stades de son cycle de vie. Ces risques relèvent notamment des atteintes potentielles à la confidentialité, à l'intégrité, à la disponibilité et à l'authenticité des documents et données et cette cartographie met en évidence les enjeux financiers, légaux et d'image liés à ces risques.
7. La question de la valeur probante des documents électroniques
Une question récurrente se pose désormais pour la plupart des projets de gestion des documents : « mon service souhaite dématérialiser les processus et les documents et numériser les dossiers papier. Pouvons-nous ensuite détruire les documents papier pour gagner de la place ? » A ce stade, ni les Archives d’Etat ni la DGSI ne pouvaient répondre à cette question, qui sous-entend celle de la valeur probante des documents numérisés et nés-numériques. C’est pourquoi la DGSI a mandaté une société externe pour obtenir une évaluation de l’existant, en lui donnant la mission de valider la conformité des processus et procédures générales et des outils mis en place par rapport aux exigences légales et normatives en matière de numérisation et d’archivage électronique à valeur probante et, si nécessaire, de recommander les évolutions fonctionnelles, techniques et organisationnelles à mettre en œuvre.
Cette étude a permis de mettre en évidence que la plate-forme de dématérialisation et de GED de l’administration offre en standard une couverture fonctionnelle très complète qui répond parfaitement aux besoins métiers mais s’avère insuffisante pour garantir la valeur probante des documents à forte valeur légale. En effet, cette valeur probante ne peut être assurée en l’état que par l’utilisation d’une fonction de « coffre-fort électronique ». La conclusion de cette étude rappelle également l’importance de documenter les procédures et processus et de conserver soigneusement cette documentation, que ce soit la documentation technique ou les processus et la documentation métier.
Les résultats de cette étude, rendus en septembre 2013, ne sont au final que peu surprenants et confirment les besoins mis en évidence dans la Bonne gouvernance des documents électroniques. Il s’agit maintenant de mettre en œuvre ses recommandations afin de pouvoir garantir un archivage à valeur probante dans l’administration genevoise.
Il est nécessaire de relever à nouveau que ce niveau de sécurité n’est pas nécessaire pour toutes les séries documentaires produites et qu’il est donc important d’évaluer pour chacune s’il est nécessaire ou non de mettre en place de telles mesures.
8. Communication liée au projet de gouvernance des documents électroniques
Tout au long du projet, nous avons informé les différents intervenants des nouveaux documents mis à disposition (recueil de métadonnées, catalogue des formats d’archivage, etc.). Des séances ont eu lieu avec les chefs de projets de la DGSI. La problématique a fait l’objet de présentations devant divers publics : forum des archivistes genevois, Centre suisse de coordination de l’archivage (CECO), Groupe de coordination de l’archivage, Commission consultative LArch-LIPAD.
Retours sur les documents produits
Au fil des réunions et des échanges avec les chefs de projets, il ressort que ces derniers sont satisfaits de disposer des documents relatifs à la gestion des documents électroniques. Le recueil de métadonnées, par exemple, répondait à un besoin avéré et évite aux chefs de projets de se poser les mêmes questions lors de chaque projet et de chaque fois réinventer la roue.
Check-list relative à la gestion des documents électroniques
Pour simplifier le travail des chefs de projets et pour les orienter sur toutes ces questions, notre groupe de travail a produit à leur intention une liste de points relatifs à la gestion des documents électroniques. La méthode de gestion des projets dans le domaine des technologies de l'information utilisée à l'Etat de Genève est la méthode Hermès, développée par la Confédération. Nous avons obtenu qu'à un stade précis du développement du projet, au point dit "de cohérence", le chef de projet doive répondre aux questions posées par cette liste (par exemple: l'archiviste de département et/ou les AEG ont-ils été consultés sur ce projet? Le système d'information (SI) peut-il garantir l'authenticité, la fiabilité, l'intégrité et l'exploitabilité des documents à forte valeur légale? Les documents et/ou données concernés par le SI sont-ils pourvus de délais de conservation? Les métadonnées obligatoires sont-elles implémentées? Les Archives d'Etat ont-elles été consultées pour déterminer si le SI contient des documents et/ou données qui devront être conservés à long terme?).
9. La suite de nos travaux
Nous avons constaté qu’il n’est pas forcément évident pour un chef de projet informatique de définir les besoins en matière de gestion des documents électroniques lors de la mise en place d’un projet. C’est pourquoi nous nous attelons à la rédaction d’un vade-mecum rassemblant de manière très succincte l’ensemble des questions auxquelles un chef de projet est confronté lors de la mise en place d’un nouveau système d’information. Ce guide devra également permettre d’exprimer les besoins métier de manière claire et de choisir une solution adaptée aux besoins du service qui en fait la demande.
Il est également nécessaire de fournir un modèle de documentation de procédures de chaînes de dématérialisation et de mise en GED. En effet cette documentation est l’un des points principaux pour garantir la valeur probatoire d’un document et, à notre connaissance, il n’existe pas de modèle de ce type en Suisse, ou en tous les cas pas dans une administration cantonale.
Conclusion
En tant qu’institution cantonale d’archives, notre démarche relative à la conservation à très long terme des documents électroniques nous a donc conduits à la problématique de la gestion des documents électroniques au sein de l’administration. Ces réflexions, au départ théoriques, ne sont pas des priorités, il faut l’avouer, d’autant qu’il s’agissait au départ de questionnements sur des aspects qui ne posaient pas encore problème. Les premières réactions à nos actions, qui se voulaient anticipatrices, étaient plutôt de dire « on verra bien ». Il a fallu convaincre nos interlocuteurs.
Puis les chefs de projets informatiques se sont trouvés face à des problèmes concrets, notamment la question de la valeur probante des e-documents, et les ont relayées à leurs directeurs informatiques, qui se sont alors tournés vers nous. Des synergies se sont ainsi peu à peu créées et la compréhension de la problématique s’est propagée.
Une fois les acteurs convaincus de l’importance de gérer correctement les documents électroniques, il reste ensuite la question du financement, puisque la mise en place de la fonction de coffre-fort électronique représente un certain coût. Une analyse de risque doit maintenant être accomplie et des budgets devront alors peut-être être trouvés.
De tels projets doivent être menés de manière interdisciplinaire entre les métiers (services de l’administration), les juristes, les services informatiques et les Archives ; il n’est pas possible de travailler dans des silos séparés. En tant qu’institution d’archives, nous avons également dû réfléchir à notre positionnement – agir traditionnellement en bout de chaîne uniquement ? Notre choix s’est porté sur une présence durant toute la vie du document et même plus largement, depuis la création même des systèmes d’information. Nous pensons que c’est une question à laquelle toutes les institutions d’archives devront répondre ces prochaines années.
Notes
(1) Anouk Dunant Gonzenbach (coll. Emmanuel Ducry), « L’archivage des documents électroniques à Genève, aspects organisationnels et techniques : le projet Gal@tae », in Françoise Hiraux ( dir.), De la préservation à la conservation. Stratégies pratiques d'archivage, Louvain-la-Neuve, Academia, à paraître.
(2) Exigences de base en matière d'archivage électronique, version 1.0 du 28.09.2009, Centre de coordination à long terme de documents électroniques, Berne.
Bibliographie
CONSEIL FÉDÉRAL SUISSE, 2002. Ordonnance concernant la tenue et la conservation des livres de comptes (Olico) du 24 avril 2002 [en ligne]. 24 avril 2002. [Consulté le 26 novembre 2013]. Disponible à l’adresse : http://www.admin.ch/opc/fr/classified-compilation/20001467/index.html
DLM FORUM FOUNDATION, 2011. MoReq2010: modular requirements for records systems [en ligne]. [Consulté le 26 novembre 2013]. Disponible à l’adresse : http://moreq2010.eu/pdf/MoReq2010-Core+Plugin(v1-0).pdf
ETAT DE GENÈVE. ARCHIVES D’ÉTAT, [sans date]. Politique de gouvernance des documents électroniques à l’Etat de Genève. République et canton de Genève [en ligne]. [Consulté le 26 novembre 2013]. Disponible à l’adresse : http://etat.geneve.ch/dt/archives/politique_gouvernance_documents_electroniques_etat_genave-66-5414-13734.html
GRAND CONSEIL DE LA RÉPUBLIQUE ET CANTON DE GENÈVE, 2000. Loi sur les archives publiques (LArch) du 1er décembre 2000 [en ligne]. 1 décembre 2000. [Consulté le 26 novembre 2013]. Disponible à l’adresse : http://www.geneve.ch/legislation/rsg/f/s/rsg_b2_15.html
GRAND CONSEIL DE LA RÉPUBLIQUE ET CANTON DE GENÈVE, 2001. Loi sur l’information du public, l’accès aux documents et la protection des données personnelles (LIPAD) du 5 octobre 2001 [en ligne]. 5 octobre 2001. [Consulté le 26 novembre 2013]. Disponible à l’adresse : http://www.ge.ch/legislation/rsg/f/s/rsg_a2_08.html
ORGANISATION INTERNATIONALE DE NORMALISATION, 2001. Information et documentation: « records management ». 1ère éd. 2001-09-15. Genève : ISO. Norme internationale ISO, 15489.
ORGANISATION INTERNATIONALE DE NORMALISATION, 2004. Éléments de données et formats d’échange -- Échange d’information -- Représentation de la date et de l’heure. 1ère éd. 1988. Genève : ISO. Norme internationale ISO, 8601.
ORGANISATION INTERNATIONALE DE NORMALISATION, 2012. Electronic archiving = Archivage électronique. 1st ed. 2012-02-01. Genève : ISO. International standard ISO, 14641-1.
Quelle qualité pour les archives électroniques ? Réflexions et retour d’expérience autour du processus décisionnel du Conseil d’Etat valaisan
Alain Dubois, Archives de l'État du Valais
En guise de préambule – quelques réflexions sur la qualité des archives électroniques
Une hypothèse de travail simple a guidé toute la réflexion des Archives de l’État du Valais en matière d’archivage électronique : la qualité des archives électroniques est étroitement liée à la qualité des données et des métadonnées qui sont extraites ou héritées des systèmes de gestion des documents, qu’il s’agisse d’une structure arborescente gérée par un système d’exploitation, d’un système de gestion électronique des documents ou d’un système de records management électronique(2). Les systèmes de gestion des documents et les plates-formes de pérennisation et d’archivage constituent en effet les deux faces d’une même médaille, dont l’avers dépend de la qualité du revers et réciproquement. C’est ainsi qu’il me paraît possible, en y ajoutant néanmoins une palette de nuances, de dégager trois niveaux de qualité. Et ces niveaux de qualité peuvent se mesurer à l’aune des normes de description du Conseil international des Archives, qui de facto répondent aux trois questions suivantes : Quoi ? Il s’agit de décrire le contenu des dossiers et des documents, ainsi que des données, sur la base de la norme ISAD(G)(3). Qui ? Il s’agit d’identifier et de décrire les producteurs des dossiers, des documents et des données, sur la base de la norme ISAAR (CPF)(4). Comment ? Il s’agit de documenter la manière dont se sont progressivement constitués les dossiers d’affaires, qui résultent toujours d’un processus d’activité, sur la base de la norme ISDF(5). Sur cette base, il est ainsi possible de distinguer :
- un niveau de qualité minimal. L’archiviste a peu de contrôle sur le(s) système(s) qui produi(sen)t les données et les métadonnées avant leur versement aux Archives. Il est dès lors très fortement tributaire de la qualité des systèmes de gestion des documents mis en place, notamment des attributs du système paramétrés par défaut qui lui permettent d’extraire les métadonnées qui décrivent le contenu des dossiers. Il lui sera néanmoins très difficile de garantir a posteriori une qualité qui a fait défaut initialement. Ce niveau de qualité, qui apporte des renseignements sur le quoi, se retrouve, entre autres, dans les structures arborescentes gérées par un système d’exploitation.
- un niveau de qualité intermédiaire. L’archiviste a la possibilité d’extraire des systèmes de gestion des documents des métadonnées qui décrivent le contenu des dossiers et renseignent sur les utilisateurs ou les groupes d’utilisateurs qui ont accès aux dossiers. Ce niveau de qualité, qui apporte des renseignements sur le quoi et le qui, se retrouve, entre autres, dans les systèmes de gestion électronique des documents et dans les systèmes de records management électronique.
- un niveau de qualité maximal. L’archiviste a la possibilité d’extraire des systèmes de gestion des documents des métadonnées qui décrivent le contenu des dossiers et renseignent non seulement sur les utilisateurs et les groupes d’utilisateurs, mais également sur la manière dont ont été progressivement constitués les dossiers. Ce niveau de qualité, qui apporte des renseignements sur le quoi, le qui et le comment, se retrouve dans les systèmes de gestion des affaires, qui intègrent à la fois la gestion par processus d’activités et le records management électronique.
Le niveau de qualité des archives électroniques est donc directement influencé par le système qui gère les données et les documents avant leur versement sur une plate-forme de pérennisation et d’archivage. A ce stade, il me paraît néanmoins nécessaire d’ajouter une seconde variable : le degré d’implication des archivistes dans la conception des systèmes de gestion des documents. En effet, plus l’archiviste participe à la définition et à l’implémentation des systèmes de gestion des documents, meilleures seront les chances d’en extraire des archives électroniques de qualité. Il est ainsi tout à fait possible d’augmenter la qualité des archives électroniques qui proviennent d’une structure arborescente issue d’un système d’exploitation, en y ajoutant nativement certaines métadonnées descriptives, de même que la qualité des archives électroniques extraites d’un système de gestion des affaires pourra être médiocre en raison d’une absence de paramétrage de certaines métadonnées descriptives dans le système d’origine. La prise en compte de ces deux variables milite donc clairement en faveur de l’intervention des archivistes durant tout le cycle de vie des documents et des données électroniques dans une perspective de gestion continue des documents ou de records continuum. Ce sont en tous les cas ces réflexions – cette intime conviction, serais-je tenté de dire – qui ont guidé et nourri l’action des Archives de l’État du Valais au cours des cinq dernières années en matière de gestion des documents et d’archivage électronique.
Le retour d’expérience présenté dans le cadre de cet article, qui sous-tend la réflexion décrite ci-dessus, porte sur un projet pilote mené en 2012-2013 sur l’archivage du processus décisionnel du Conseil d’État valaisan. Il s’agit certes de la description d’une situation idéale, où les Archives de l’État du Valais ont été étroitement associées à la définition et à la mise en œuvre du système qui gère ce processus et ont pu, par incidence, obtenir un niveau de qualité élevé du point de vue des archives électroniques versées, mais qui devrait néanmoins tendre à devenir la norme à l’avenir. Surtout, ce retour d’expérience veut démontrer tous les bénéfices et toutes les potentialités d’un travail certes exigeant, mais susceptible d’apporter des plus-values décisives par rapport à un archivage sous forme papier.
1. Les conditions cadres nécessaires à un archivage électronique
Trois prérequis ont été nécessaires pour mener un tel projet pilote.
Disposer d’un système de gestion des documents tout d’abord. Avant de mettre en place un tel système, les Archives de l’État du Valais ont d’abord dû définir une méthode de travail à l’interne. Synthétisée dans un Guide de gestion des documents, cette dernière présente les différentes étapes nécessaire à l’implémentation d’un système de gestion des documents de sa conception à sa réalisation concrète selon les principes de la gestion de projet(6). Les Archives de l’État du Valais ont ensuite travaillé – et travaillent actuellement – à la mise en œuvre concrète du système de gestion des documents à travers le projet Enterprise Content Management ou projet ECM, qui a pour objectif non seulement de dématérialiser progressivement les processus d’activités de l’État du Valais qui ne sont pas gérés par des outils métier spécifiques, mais également de mettre en œuvre des projets de records management électronique à proprement parler. C’est ainsi que sont aujourd’hui entièrement dématérialisés le processus décisionnel du Conseil d’État, que je présenterai plus en détail ci-dessous, et le processus des dossiers soumises à la signature des chefs du Département de la santé, des affaires sociales et de la culture et du Département des transports, de l’équipement et de l’environnement. Des systèmes de records management électronique ont, dans le même temps, été mis en œuvre ou le seront prochainement auprès de la Chancellerie d’État et du Service parlementaire, de l’état-major de la cheffe du Département de la santé, des affaires sociales et de la culture, du Service de la culture et du Service de l’agriculture.
Disposer d’une plate-forme d’archivage électronique ensuite. Dans le cadre d’un projet mené au niveau du Service de la culture, qui visait à assurer la conservation à long terme des collections numériques et numérisées des Archives de l’État du Valais, de la Médiathèque Valais et des Musées cantonaux, les Archives de l’État du Valais ont contribué à la mise en place d’une plate-forme de pérennisation et d’archivage conforme aux normes et standards internationaux en la matière. Cette plate-forme, mise en service en mai 2011, accueille également les publications officielles produites par les autorités cantonales et communales et les dossiers des ouvrages d’art exécutés à la demande du Service des routes, transports et cours d’eau. Elle accueillera prochainement les pièces justificatives numérisées par le Service des registres fonciers et de la géomatique(7).
Disposer d’une interface d’échange entre le système de gestion des documents et la plate-forme d’archivage électronique enfin. C’est le Matterhorn METS Profile, publié en novembre 2012 auprès de la Bibliothèque du Congrès à Washington qui, aujourd’hui, assure ce rôle(8). Ce profil, décrit ci-dessous, est un modèle qui présente les données et documents électroniques ainsi que les métadonnées qui s’y rapportent selon les principes d’un document METS.
C’est ainsi qu’au cours des dernières années et à travers ces différents projets, les Archives de l’État du Valais ont progressivement mis en place les outils qui permettent de gérer tout le cycle de vie d’un document depuis sa création dans un système de records management jusqu’à sa conservation à long terme sur une plate-forme dédiée.
2. L’archivage du processus décisionnel du Conseil d’État
Mises progressivement en place, ces conditions cadres ont finalement permis la réalisation du projet pilote d’archivage du processus décisionnel du Conseil d’État valaisan.
2.1. Le processus décisionnel du Conseil d’État
Conduit à la fois sous forme papier et électronique, le processus de préparation, de traitement et de notification des décisions du Conseil d’État, processus central de l’Administration cantonale valaisanne, apportait un certain nombre de contraintes, liées notamment à la gestion hybride des documents, auxquelles il s’agissait de remédier. Décision a donc été prise de le dématérialiser, non seulement afin d’améliorer la rapidité, la fluidité et la traçabilité du processus, ainsi que la gestion et l’accès aux dossiers et aux documents, mais également de garantir la conservation à long terme des dossiers. Le projet a été conduit entre juin 2010 et décembre 2011 par la direction opérationnelle du projet ECM, composée de représentants des Archives de l’État du Valais (gestion des documents), de la Chancellerie d’État (analyse des processus) et du Service cantonal de l’informatique (implémentation de l’outil), et de représentants des unités administratives directement concernées par le processus (états-majors des chefs de département et services centraux). Les séances du Conseil d’État se déroulent ainsi sous forme entièrement électronique depuis le début avril 2011. Ce sont près de 250 personnes qui participent au traitement hebdomadaire de 150 dossiers en moyenne.
Résumé dans le schéma suivant(9), le processus se déroule comme suit :
01. Préparation
Le Service qui souhaite soumettre un dossier à l’approbation du Conseil d’État prépare un projet de décision, auquel il joint toutes les pièces utiles à la prise de décision (correspondance, rapport, recours ou dossier de procédure, par exemple). Une fois validé, le chef de service transmet le dossier au secrétariat du chef de département.
02.01. Analyse formelle
Le secrétariat du chef de département examine le dossier d’un point de vue formel (complétude du dossier et saisie des différents champs obligatoires). Cas échéant, il peut le retourner au service émetteur pour correction ou complément. Une fois validé, le dossier est transmis au chef de département pour prise de connaissance.
02.02. Pré-validation / Validation
Le chef de département examine le dossier du point de vue du contenu. Cas échéant, il peut soit le retourner au service émetteur pour demander des compléments ou des adaptations, soit le retirer. Une fois validé, le dossier est transmis soit aux services centraux pour préavis (étape 02.03. Préavis), soit à la Chancellerie d’État pour inscription à l’ordre du jour de la prochaine séance du Conseil d’État (étape 03. Consolidation).
02.03. Préavis
Un préavis des services centraux est requis dans les cas suivants : dossiers en lien avec les ressources humaines (préavis du Service des ressources humaines et de l’Administration cantonale des finances), dossiers ayant une incidence financière (Administration cantonale des finances), projets d’actes législatifs (Chancellerie d’État) et renouvellement des commissions administratives (Secrétariat à l’égalité et à la famille). Un préavis peut être favorable, défavorable ou formulé avec des réserves. Le service central peut également refuser de se prononcer sur le projet de décision.
02.04. Validation
Une fois préavisé, le dossier est retourné chez le chef de département qui décide de la suite à donner en fonction du type de préavis reçu. Si le préavis est positif, le dossier est transmis à la Chancellerie d’État pour inscription à l’ordre du jour de la prochaine séance du Conseil d’État. Si le préavis est négatif ou formulé avec des réserves ou si le service central ne se prononce pas, le chef de département prend contact avec le service émetteur pour décider de la suite à donner (retrait du projet de décision ou compléments apportés au dossier).
03. Consolidation
Une fois transmis à la Chancellerie d’État, le dossier est une nouvelle fois examiné du point de vue formel par la secrétaire du protocole (contrôle de la présence des préavis des services centraux et de la liste de distribution). Cas échéant, il peut être retourné au département émetteur pour correction ou adaptation. Si le dossier est complet, il est inscrit au bordereau de la prochaine séance du Conseil d’État.
04. États-majors
A ce moment-là, le dossier est libéré auprès des états-majors des chefs de département pour analyse et commentaires en prévision de la séance du Conseil d’État.
05. Séance
Le dossier est traité au cours de la séance du Conseil d’État. Un dossier peut être validé ou refusé, modifié, non traité pour des questions de temps ou mis en attente pour des raisons stratégiques ou politiques.
06. Diffusion
Une fois validé par le Conseil d’État, le dossier est transmis au département émetteur pour notification. Ce dernier est ensuite chargé de le transmettre au service émetteur. Le dossier est alors conservé dans le système pendant plusieurs années avant d’être versé sur la plate-forme de pérennisation et d’archivage.
2.2. L’archivage du processus décisionnel du Conseil d’État
En préambule, il me paraît essentiel de rappeler une évidence : l’archivage d’un dossier sous forme électronique ne conduit pas à des changements majeurs dans le travail d’évaluation effectué par l’archiviste. Les fondamentaux restent identiques, même s’il est nécessaire d’effectuer quelques adaptations méthodologiques. Dans le cadre de l’archivage d’un dossier papier, l’archiviste dispose de l’état du dossier tel qu’il est à la clôture de l’affaire. Il dispose par ailleurs d’informations sur le contenu et les acteurs de ce dernier (le quoi et le qui évoqués précédemment), mais plus rarement sur le processus qui est à l’origine de sa création (le comment). Dans le cadre de l’archivage d’un dossier électronique, l’archiviste dispose également de l’état du dossier tel qu’il est à la clôture de l’affaire. Par contre, selon la nature du système de gestion des documents mis en œuvre, il dispose d’un vaste réservoir de métadonnées qui peut le renseigner non seulement sur le contenu et les acteurs d’un dossier, mais aussi sur le processus qui en découle. C’est donc à l’archiviste de sélectionner les métadonnées qui lui paraissent utiles et nécessaires à la compréhension de la manière dont s’est progressivement constitué le dossier jusqu’à sa clôture. En somme de rendre intelligible le contexte de création de ce dernier pour une personne étrangère au domaine concerné. D’où la nécessité d’intervenir en amont de la chaîne documentaire pour paramétrer dans le système de gestion des documents les éléments d’information nécessaires à la conservation à long terme du dossier électronique. C’est donc à ce niveau que, de mon point de vue, réside la différence majeure entre archivage papier et archivage électronique : décrire a posteriori un dossier pour l’un, identifier a priori les renseignements nécessaires à la compréhension d’un dossier par les générations futures pour l’autre. Sans parler, bien évidemment, de la possibilité de représenter ces derniers de manière dynamique et de les traiter automatiquement.
2.2.1. La sélection des documents nécessaires à la compréhension d’une affaire
Débutons par un aspect du métier qui ne change pas. A l’instar du monde papier, l’archiviste doit tout d’abord se charger de l’évaluation du contenu du dossier. Il va ainsi sélectionner les documents qu’il juge nécessaires à la bonne compréhension de l’affaire. Dans le cadre du processus décisionnel du Conseil d’État, l’archiviste dispose d’un modèle de dossier d’affaires qui se compose des éléments suivants :
Le dossier « 1 – Rapports » contient le ou les rapports qui soutiennent le projet de décision, tandis que le dossier « 2 – Préavis » contient les préavis requis auprès des services centraux et le dossier « 3 – annexes » toutes les autres pièces nécessaires à la prise de décision (procédure d’adjudication ou dossier de recours, par exemple). Le dossier « 4 – interne », accessible uniquement aux différents états-majors des chefs de département (en l’occurrence l’état-major de la présidence du Conseil d’État), contient des notes qui étayent les prises de position des chefs de département. Enfin, à la racine du dossier, se trouve(nt) le(s) projet(s) de décision.
Ont ensuite été définis la typologie et le cycle de vie des documents :

L’évaluation des documents a abouti aux décisions suivantes :
- conservation définitive de tous les documents contenus dans les dossiers « 1 – Rapports », « 2 – Préavis » et « 3 – Annexes » ;
- conservation définitive du projet de décision du Conseil d’État soumis par le service émetteur au département, du projet de décision présenté par le département au Conseil d’État et de la décision validée par le Conseil d’État ;
- élimination des dossiers « 4 – interne » ;
- élimination des certificats médicaux et des notes internes.
2.2.2. La sélection des métadonnées nécessaires à la compréhension de l’affaire
Poursuivons notre travail d’évaluation par un élément nouveau, susceptible d’un point de vue qualitatif d’améliorer notablement la description des archives. A la différence du monde papier, en effet, l’archiviste dispose dans le monde électronique d’un réservoir presque inépuisable d’informations à travers les métadonnées produites par les systèmes de gestion des documents. Son travail consiste dès lors à sélectionner dans ce vaste ensemble les informations qui documentent en toute transparence la constitution progressive d’un dossier d’affaires. Ces informations sont de deux types : les métadonnées de description, qui renseignent sur le contenu même du dossier, et les métadonnées de pérennisation, qui permettent de gérer le dossier sur le long terme. En écho aux trois standards du Conseil international des Archives évoqués ci-dessus, elles répondent aux trois questions suivantes :
- que contient le dossier ?
- qui est intervenu sur le dossier ?
- comment le dossier s’est-il progressivement constitué ?
C’est ainsi que, comme nous le montre la copie d’écran suivante, la page d’accueil d’un dossier soumis à l’approbation du Conseil d’État valaisan permet de répondre à ces trois questions :
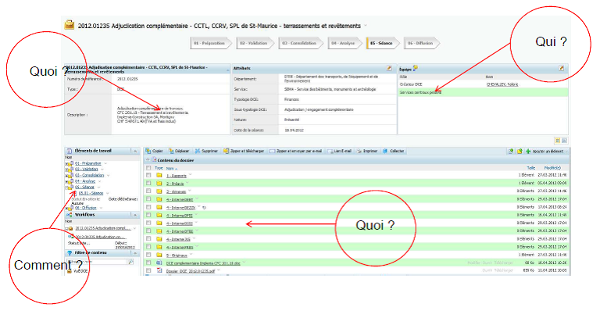
Que contient un dossier ?
Dans le cadre du processus décisionnel du Conseil d’État, les métadonnées qui décrivent le contenu d’un dossier sont de deux types :
- les métadonnées qui décrivent le dossier d’affaires en tant que tel ;
- les métadonnées qui décrivent les sous-dossiers et les documents en tant que tels.
Sur la base d’une analyse très détaillée du système de gestion des décisions du Conseil d’État, les Archives de l’État du Valais ont ainsi décidé de sélectionner 15 métadonnées qui décrivent le dossier en tant que tel(10), 3 métadonnées(11) qui décrivent le répertoire et 5 métadonnées qui décrivent le document(11).
Qui est intervenu sur le dossier d’activité ?
Dans le cadre du processus décisionnel du Conseil d’État, chaque utilisateur est identifié non pas au niveau individuel, mais en fonction du ou des rôles qu’il exerce tout au long du processus. Il est ainsi rattaché à un ou plusieurs groupes d’utilisateurs, ce qui permet par ailleurs de gérer les droits d’accès aux documents.
Comment le dossier s’est progressivement constitué ?
Un système de gestion des affaires présente l’avantage de renseigner les différentes étapes de constitution d’un dossier d’affaires sous forme d’événement. Dans ce cas idéal, l’archiviste n’a bien évidemment pas le devoir de conserver tous les événements qui affectent un dossier jusqu’à sa clôture, mais bien d’en conserver les principaux. Dans le cadre du processus décisionnel du Conseil d’État, les Archives de l’État du Valais ont ainsi décidé de conserver les événements suivants :
- 01 Préparation
- lancer le workflow du dossier
- 02.01 Analyse formelle
- accepter (opération qui permet de passer à l’étape suivante « 02.02 Pré-validation »). En revanche, les autres événements de cette étape ne sont pas conservés, dans la mesure où il ne s’agit que de contrôles formels qui n’ont pas d’influence sur le contenu même du dossier.
- 02.02 Pré-validation / Validation
- accepter (opération qui permet de passer à l’étape suivante (soit « 02.03. Préavis », soit « 03 Consolidation »))
- retourner pour adaptation du dossier auprès de l’émetteur
- retirer le dossier
- requérir un préavis de la part des services centraux (Administration cantonal des finances, Service des ressources humaines, Chancellerie d’État et Secrétariat à l’égalité et à la famille)
- 02.03 Préavis
- préavis (type de préavis (favorable, défavorable, avec réserve, ne se prononce pas), auteur, date)
- 02.04 Validation
- accepter (opération qui permet de passer à l’étape suivante « 03 Consolidation »)
- retourner pour adaptation du dossier auprès de l’émetteur
- retirer le dossier
- 03 Consolidation
- Faire suivre (opération qui permet de passer à l’étape suivante « 04 Analyse »). En revanche, les autres événements de cette étape ne sont pas conservés, dans la mesure où il ne s’agit que de contrôles formels qui n’ont pas d’influence sur le contenu même du dossier.
- 04 Analyse
- Les événements de cette étape ne sont pas conservés.
- 05 Séance
- Décision du Conseil d’État (Accepté, refusé, mis en attente)
- Compte-rendu de la décision
- Report du dossier à une autre séance (non traité)
- Faire suivre (opération qui permet de passer à l’étape suivante « 06 Diffusion » et de transmettre le dossier au service émetteur)
- 06 Diffusion
- Faire suivre (opération qui permet de transmettre le dossier au service émetteur)
2.2.3. La modélisation des (méta)données dans le format du Matterhorn METS Profile
Une fois effectué le travail d’analyse et de sélection du contenu du dossier et des métadonnées qui s’y rapportent, il s’est agi tout d’abord de créer un WebReport pour les extraire du système de gestion des décisions du Conseil d’État, puis de les intégrer dans un modèle de données. Dans le cadre des Archives de l’État du Valais, c’est le Matterhorn METS Profile qui a été choisi. Ce modèle de données permet, en effet, de restituer dans un fichier .zip :
- le contenu (dossiers et documents) ;
- les métadonnées encodées dans un fichier mets.xml qui se compose des éléments suivants :
- information de description (en EAD)
- information de préservation (en PREMIS)
- informations sur la structure du dossier (relations entre les sous-dossiers, les documents et les métadonnées)
2. 4. Le modèle de données développé pour le processus décisionnel du Conseil d’État
J’illustrerai mon propos à travers l’exemple d’un dossier d’adjudication complémentaire validé par le Conseil d’État en 2012 pour les travaux de terrassement et de revêtement de la place de stockage des poids lourds sur le site d’un centre de contrôle autoroutier. Le dossier est tout d’abord extrait du système de gestion des décisions du Conseil d’État sous la forme d’un SIP (Submission Information Package), qui se base sur la structure d’analyse présentée ci-dessus (fichier .zip composé d’un dossier qui regroupe les documents de l’affaire en question et d’un fichier mets.xml).
Le contenu du dossier, subdivisé en sous-dossiers et en documents, est présenté conformément à la structure définie ci-dessus suite à l’évaluation des documents :

Quant au fichier mets.xml, il permet de présenter toutes les métadonnées extraites du système de gestion des décisions du Conseil d’État en relation avec le dossier d’adjudication complémentaire(13).

Ces métadonnées sont présentes dans plusieurs sections du fichier.
La section <METS:dmdSec>
Cette section contient, d’une part, les métadonnées qui décrivent le dossier d’adjudication complémentaire en tant que tel. Les métadonnées sont encodées en EAD (Encoded Archival Description)(14) , déclinaison XML de la norme de description ISAD(G) :

Cette section contient, d’autre part, les métadonnées qui décrivent les sous-dossiers (répertoires) et les documents (fichiers) du dossier d’adjudication complémentaire. Ainsi en est-il, par exemple, du projet de décision du Conseil d’État soumis par le service émetteur :
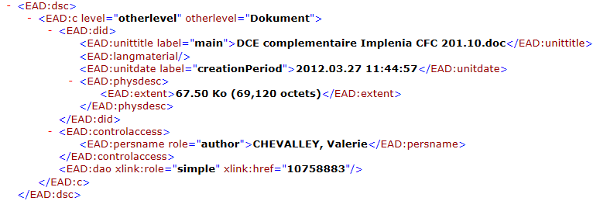
La section <METS:amdSec>
Cette section contient les métadonnées qui permettent de pérenniser un dossier. Ces métadonnées de préservation sont décrites selon le standard PREMIS, qui se compose de quatre sections(15):

La section « Objet » (section <PREMIS:object>)
Cette section contient des informations qui permettent de garantir la conservation à long terme des documents électroniques. Elle comporte notamment des informations sur les formats de fichier utilisés, ainsi que leur version, de même que les sommes de contrôle effectuées. Voici, à titre d’exemple, les métadonnées extraites de la décision validée par le Conseil d’État :
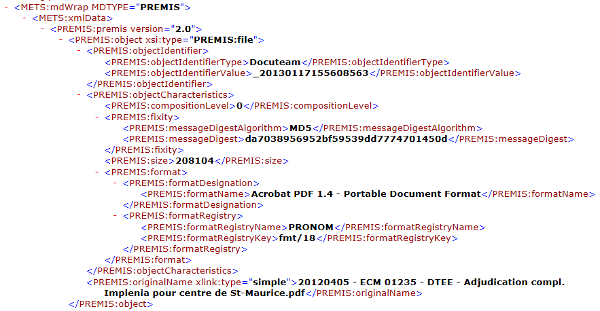
La section « Evénement » (section <PREMIS:event>)
Cette section contient les informations relatives aux différentes étapes du processus. J’illustrerai mon propos à travers l’exemple du passage du dossier d’adjudication de l’étape « 01. Préparation » à l’étape « 02.01. Analyse formelle » ; il s’agit du moment où le dossier a été transmis par le Service des bâtiments, monument et archéologie au secrétariat du chef du Département des transports, de l’équipement et de l’environnement :
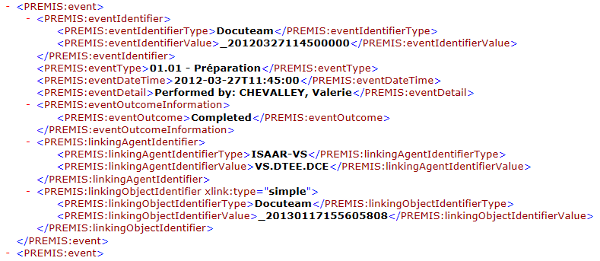
La section « Agent » (section <PREMIS:agent>)
Cette section contient les informations relatives aux différents groupes d’utilisateurs qui sont intervenus au cours du processus. Dans le cadre du processus décisionnel du Conseil d’État, les groupes d’utilisateurs sont relativement importants, dans la mesure où ce sont eux qui permettent de gérer les droits d’accès à tout ou partie d’un dossier lorsque ce dernier n’est pas encore accessible pour le public – le délai de protection des documents contenant des données sensibles et des profils de la personnalité est, par exemple, de 100 ans(16). J’illustrerai mon propos avec le groupe d’utilisateurs de l’Administration cantonale des finances chargé de donner un préavis aux projets de décision qui ont une incidence financière. Ce groupe d’utilisateurs est défini comme suit dans le fichier METS :

La section « Droits » (section <PREMIS:rights>)
Cette section contient les informations relatives aux droits dont disposent les différents groupes d’utilisateurs qui interviennent au cours du processus sur les objets qu’ils créent, modifient, éliminent ou simplement auxquels ils accèdent. Dans le cadre du processus décisionnel du Conseil d’État, cette section est relativement importante, dans la mesure où elle permet d’accorder aux groupes d’utilisateurs les mêmes droits dont ils disposaient dans le système de gestion des documents et ce jusqu’à l’échéance du délai de protection. J’illustrerai mon propos avec les droits attribués au groupe de la Chancellerie d’État, qui dispose du droit de voir et de voir le contenu des dossiers et des documents, mais non de les créer, de les modifier et/ou de les éliminer. Ce droit est défini comme suit dans le fichier METS :

Vers une conclusion
Le projet mené par les Archives de l’État du Valais visait à démontrer non seulement la faisabilité de l’extraction d’un SIP depuis un système de gestion des documents, mais surtout l’exploration et l’exploitation des possibilités offertes par la sélection des métadonnées dans les systèmes de gestion des documents pour enrichir la description archivistique et assurer, par voie de conséquence, un archivage de qualité.
Le test a été mené sur un échantillon pour lequel les informations de description et de préservation étaient riches. Ce niveau de qualité maximal a été rendu possible par l’intégration dans le système de gestion des décisions du Conseil d’État de métadonnées qui donnaient des renseignements sur le contenu d’un dossier progressivement constitué au cours d’un processus parfaitement connu et dont les acteurs étaient clairement identifiés. A terme, il ne pourra toutefois être déployé que dans les systèmes de gestion des affaires. Dans les systèmes de records management électronique traditionnels, par contre, il faudra accepter un niveau de qualité intermédiaire, qui renseigne avant tout sur le contenu et les acteurs, mais pas sur le processus qui a documenté la constitution progressive d’un dossier. Par contre, là où les données et les métadonnées ne sont pas clairement gérées avant leur versement sur une plate-forme de pérennisation et d’archivage, il sera difficile de garantir a posteriori une qualité qui a fait défaut initialement. C’est ainsi que ce retour d’expérience démontre de manière claire, me semble-t-il, que les archivistes, s’ils souhaitent disposer d’archives électroniques de qualité, doivent intervenir en amont de la chaîne documentaire et participer très activement aux projets de records management électronique et de dématérialisation des processus d’activités. C’est en effet au moment de la conception des systèmes d’information que se définit – et, partant, se joue – la bataille de la qualité des données et des documents, ainsi que des métadonnées, qui sont destinés à être conservés sur le long terme. Il en va finalement de la transmission de notre mémoire aux générations futures.
Notes
(1)Il convient de préciser à ce propos que les résultats présentés dans le cadre de cet article ont été rendus en partie possibles grâce à la fructueuse collaboration conclue depuis plusieurs années en matière d’archivage électronique entre les Archives de l‘État du Valais et l’entreprise Docuteam GmbH, en particulier Tobias Wildi.
(2)Les Archives de l’État du Valais ont du reste eu l’occasion d’approfondir cette notion de qualité dans le cadre du projet « Définition et mesure des qualités des archives et documents électroniques publics (QADEPs) » dirigé par Basma Makhlouf Shabou, professeur d’archivistique à la Haute Ecole de gestion de Genève, filière Information documentaire, et réalisé en partenariat avec l’Université de Berne, les Archives fédérales, les Archives d’État de Genève et Docuteam GmbH.
(3)La Norme générale et internationale de description archivistique a été publiée officiellement par le Conseil international des Archives en 1994 ; la seconde et dernière version date de 1999. Se référer à http://www.icacds.org.uk/fr/ISAD(G).pdf [Consulté le 8 novembre 2013].
(4)La Norme internationale sur les notices d’autorité archivistiques relatives aux collectivités, aux personnes et aux familles a été publiée en 1995 ; la seconde et dernière version date de 2004. Se référer à http://www.icacds.org.uk/fr/ISAAR(CPF).htm [Consulté le 8 novembre 2013].
(5)La Norme internationale pour la description des fonctions a été publiée en février 2008. Se référer à www.ica.org/download.php?id=1150 [Consulté le 8 novembre 2013].
(6)Actuellement disponible sous forme papier, le Guide de gestion des documents sera mis à la disposition du public sous forme électronique au cours de l’année 2014 sur le nouveau site Internet des Archives de l’Etat du Valais. Tout projet de gestion des documents se déroule en cinq phases : définition du projet, analyse de la gestion des documents, conception du nouveau système de gestion des documents, dont le référentiel de classement et de gestion, qui synthétise en un seul document le plan de classement, le calendrier de conservation et les droits d’accès, constitue la pierre angulaire, implémentation concrète du système, utilisation de ce dernier au quotidien et révision périodique.
(7)A l’heure actuelle, la plate-forme de pérennisation et d’archivage conserve près de 375 000 objets pour un volume de 20 TB. Un article de synthèse à paraître en 2014 en présentera du reste la genèse : Alain Dubois, « Une plate-forme pour la pérennisation du patrimoine valaisan », dans Des institutions au service du patrimoine culturel, changement et continuité. La contribution valaisanne.
(8)Ce profil, conjointement développé par les Archives de l’État du Valais et Docuteam GmbH, est disponible ici : http://www.loc.gov/standards/mets/profiles/00000041.xml [Consulté le 8 novembre 2013].
(9)Schéma extrait d’ECM DCE. Manuel d’utilisation du logiciel de gestion du processus décisionnel du Conseil d’État, version 1.5 du 21 février 2011, p. 2.
(10)"Il s’agit des métadonnées suivantes : numéro de référence, nom du créateur, titre, description, type, date de création, département émetteur, service émetteur, personne de référence, typologie DCE, sous-typologie DCE, nature, nom du collaborateur (dossier RH), prénom du collaborateur (dossier RH) et commune (si applicable).
(11)"Il s’agit des métadonnées suivantes : doc ID (identifiant unique), titre du dossier et date d’enregistrement.
(12)"Il s’agit des métadonnées suivantes : doc ID (identifiant unique), auteur, titre du document, date d’enregistrement et format.
(13)Un document METS se compose de différentes sections :
- un en-tête <METS:metsHdr>
- une section qui contient les métadonnées descriptives METS:dmdSec>
- une section qui contient les métadonnées de préservation <METS:amdSec>
- une section de fichiers <METS:fileSec>
- une carte de structure <METS:structMap>
Pour plus d’information sur le profil METS, se référer à http://www.loc.gov/standards/mets/ [Consulté le 8 novembre 2013].
(14)Sur l’EAD, se référer à http://www.loc.gov/ead/ [Consulté le 8 novembre 2013].
(15)Pour plus d’information sur le standard PREMIS (PREservation Metadata : Implementation Strategies), se référer à http://www.loc.gov/standards/premis/ [Consulté le 8 novembre 2013].
(16)Art. 43, al. 2 de la Loi sur l’information du public, la protection des données et l’archivage (LIPDA) du 9 octobre 2008.
Veille et marketing de l’innovation : outils et méthodes pour explorer les marchés de demain : compte-rendu de la 10ème journée franco-suisse sur la veille stratégique et l’intelligence économique, 6 juin 2013, Haute Ecole de Gestion. Genève
Hélène Madinier, Haute Ecole de Gestion de Genève
Maurizio Velletri, Haute Ecole de Gestion de Genève
Veille et marketing de l’innovation : outils et méthodes pour explorer les marchés de demain : compte-rendu de la 10ème journée franco-suisse sur la veille stratégique et l’intelligence économique, 6 juin 2013, Haute École de Gestion. Genève.
Cette 10ème journée franco-suisse s’est proposée d’explorer les méthodes et les outils qui peuvent être mobilisés dans les situations d’innovation de rupture, en faisant le lien entre les pratiques d’étude de marché et les outils de la veille, et en s’intéressant à la façon dont la recherche d’information peut être construite afin d’accompagner les avancées du processus d’innovation. On a pu voir notamment l’importance de l’action, des compétences sociales et de l’écoute de son environnement pour identifier ses marchés.
Tout d’abord, Nicolas Walder, maire de Carouge, a prononcé un discours de bienvenue aux quelque 60 participants présents. Il a mis l’accent sur le souhait de la ville de poursuivre ses actions en faveur du développement durable et de la formation. La directrice de la HEG, Claire Baribaud a ensuite pris la parole en se réjouissant de la collaboration fructueuse entre les 3 institutions co-organisatrices (Université de Franche-Comté, HEG de Genève, HEG Arc de Neuchâtel) et en rappelant que la HEG Genève est la seule Haute école en Suisse Romande à proposer une formation axée sur la veille stratégique et l’intelligence économique.
Marché découvert ou marché construit ? La logique d’action des entrepreneurs innovateurs, par Philippe Silberzahn
M. Silberzahn explique comment naît une idée et de quelle manière se déroule un processus complet de création, comprenant la création d’un produit, d’un marché ainsi que d’une entreprise. Pour ce faire, il prend l’exemple des hôtels en glace imaginés par la société Jukkas AB. A travers cet exemple, il met en évidence la capacité de l’entrepreneur à se tourner vers son environnement pour trouver une idée ou une solution à un problème ; la création et l’émergence de nouvelles idées étant donc des processus extrêmement sociaux. Ainsi, la capacité à avoir de nouvelles idées n’est pas indispensable pour un entrepreneur. En revanche, les compétences sociales le sont.
M. Silberzahn souligne également le fait que la prédiction rend l’entrepreneur fragile, car l’avenir n’est pas calculable ! Celui-ci doit passer d’une logique de prédiction à une logique de contrôle de son environnement tout en délaissant la logique des probabilités : « l’incertitude c’est la liberté ». Aucune tendance n'est inéluctable, les prévisions et les scenarios peuvent être pris au contrepied.
En veille, il n’est pas suffisant de se contenter de la position d’observateur. S’adapter à son environnement suppose forcément un retard sur cet événement. La personne chargée de veille autant que l’entrepreneur doivent se positionner en tant qu’acteurs de leur environnement. C’est bien l’action qui produit la pensée et l’idée et non l’inverse.
Finalement, il conseille à chaque entrepreneur d’être patient en ce qui concerne le chiffre d’affaires et impatient concernant le profit. Un entrepreneur se doit d’agir en termes de « perte acceptable » plutôt qu’en « retour attendu ».
Comment Colorix Sàrl a découvert ses marchés et créé ses domaines d’application, par David Maurer
M. Maurer explique les grandes phases qui ont jalonné la vie de sa société durant ces dix dernières années. Il a commencé avec un prototype d’appareil lisant la couleur et est parvenu à l’invention et la mise sur le marché de Colorcatch. David Maurer a su se diversifier pour proposer un produit innovant et faisant gagner énormément de temps (et d’argent) à l’industrie de la peinture. Il va s’attaquer également à l’imprimerie, au graphisme, au contrôle qualité, carrosserie de voiture, etc. Cette success story ne s’est pas faite facilement. Après une première désillusion, il n’abandonne pas, il s’adapte aux réalités du marché et entre dans un parc technologique ; il y gagne une formation à Boston lors d’un concours d’entrepreneurs. A son retour, il emprunte de l’argent pour la création de son entreprise et les premières ventes en Suisse se font, puis il attaque le marché européen.
La force de Colorcatch est d’être en constante évolution, et de s’adapter à notre société numérique (connecteur USB, applications mobiles) ainsi qu’aux besoins spécifiques de ses utilisateurs (appareil petit, précis, avec des possibilités de mises à jour). En 2011, c’est la consécration, il gagne le prix de l'innovation de la banque centrale Neuchâteloise (BCN) : 500 000 CHF ! Il prévoit dès lors l’embauche de 33 personnes d’ici 2015.
M. Maurer tient tout particulièrement à encourager et soutenir le développement économique de sa région ; pour cela, 90% des fournisseurs de Colorix se trouvent à Neuchâtel. Il conclut en soulignant le fait qu’il est très important d’écouter ses clients, et d’ainsi permettre à l’idée de départ de se transformer, s’adapter et s’améliorer. Bref, « ne jamais lâcher le morceau ! »
La recherche de signaux de routines comme contribution à la veille créative, par Stéphane Goria
Stéphane Goria nous présente la manière d’identifier les signaux de routines(1) grâce à des représentations de stratégies de marché sur un support de jeu. Il s’agit de partir d'un panel d'objets (photos), en faire une description normée, avec un lexique de synonymes : on voit ainsi ressortir ce qui est commun, constant et stable, c’est-à-dire une routine. Exemple : les manettes de jeu entre la 6ème et la 7ème génération 2001 – 2004 : le câble a disparu, le reste est conforme : cela signifie, qu’il faut être attentif, qu’un acteur risque de faire une innovation. Ces signaux de routine peuvent se trouver dans le design des objets, dans la tactique ou dans la stratégie. Par exemple le nouveau design de manette de jeu avec la Wii provient de l'évolution subite de la forme des manettes, en «croissant» depuis longtemps.
Les jeux de guerre sont utilisés pour simuler des situations auxquelles les entreprises peuvent faire face et doivent apprendre à réagir, comme l’apparition de nouveaux acteurs sur le marché.
La mise en place de stratégies basées sur les mouvements de l’adversaire, ou les actions de concurrents, est facilitée par la simulation de jeu. Utiliser cette approche permet d’apprendre à anticiper les actes de l’autre, et à préparer une stratégie de réponse.
Il est donc intéressant de recourir à ces outils pour contribuer à la veille créative, une veille qui doit donner des idées et orienter l’innovation (par exemple : occuper un terrain encore en friche). Elle n’est pas seulement intuitive, elle stimule l’imagination également.
Explorer et exploiter de nouveaux marchés dans un marché existant, par Jean-Marc Hilfiker
Jean-Marc Hilfiker présente Fongit, un incubateur de start-up dans des domaines tels que les cleantech et les medtech. Il apporte une aide à la fondation, à l'hébergement et au développement de start-up. Sa mission est de créer de la valeur économique dans le high-tech (nouvelles technologies).
Le point de départ de cette structure est la mise au jour de deux problématiques majeures pour le marché de l'innovation aujourd'hui. Tout d'abord, les start-up ont de réels problèmes d'intégration dans le marché et doivent donc être mises en relation avec les clients. De plus, les clients potentiels ont des difficultés à formuler leurs besoins et surtout veulent avoir une vision globale sur les technologies de niche. Ils souhaitent donc avoir des éléments afin d'orienter leur stratégie d'investissement.
Les besoins du marché de l'innovation sont donc de qualifier et de positionner les acteurs industriels ainsi qu'une identification des investisseurs potentiels. Un mapping des besoins stratégiques des différents partenaires est également nécessaire. Enfin, un mapping des start-up répondant aux besoins du marché actuel doit se faire.
L’exemple de Tegona, fournisseur de solutions d’identification et d’authentification, par Geoffroy Raymond
Geoffroy Raymond présente sa société Tegona, fondée en 2009, qui est incubée à Fongit. Elle propose le développement de logiciels pour les consommateurs. Tegona s'est penchée sur le marché de la remittance (transfert d'argent) qui se chiffre à 514 milliards de dollars par an dont 400 milliards dans les pays en développement. Le numéro 1 sur ce marché est Western Union qui compte 7000 employés dans un peu plus de 150 pays.
Un dernier schéma pour le transfert d'argent est celui du « mobile money » dont un des exemples les plus connus est M-Pesa. Il a été développé au Kenya, pour une population non bancarisée et qui souhaitait déposer son argent quelque part (suite à la guerre civile). De nombreux copycats ont éclos dans les pays émergents. Aujourd'hui, un millier de start-up essayent de rentrer sur ce marché très mature.
Tegona s’est démarqué et a innové en s’intéressant au pourquoi, à la raison qui poussent des personnes à faire des transferts d’argent à des personnes non bancarisées. Le premier motif invoqué est de pouvoir payer des frais médicaux; or dans plus de 40% des cas (Western Union), l’argent n’est pas utilisé à ces fins. Il veut donc s’assurer que l’argent soit bien utilisé à des fins de santé et c’est ainsi qu’il a développé un projet-pilote dans 2 pays d’Afrique, la carte Nafi, qui est une carte prépayée de santé qui permet de régler une facture médicale. Il n’y a donc pas de liquidités et une garantie que l’argent est bien utilisé.
Pour cela, Tegona est parti du réseau de valeur en essayant de satisfaire tous les acteurs : les compagnies d'assurance, les professionnels de santé, les services points (emplois créés sur place), l’uitlisation de la chaîne traditionnelle d’émission (extension aux opérateurs GSM, aux outils classiques des banques)
Son business model s’appuie sur un taux prélevé sur chargement des cartes, ainsi que sur la négociation de réductions sur les soins de santé.
La perspective d'un centre de R&D : la valorisation des technologies, par Marie-Noëlle Dessinges
Marie-Noëlle Dessinges présente le centre de recherche technologique du commissariat à l'énergie atomique et aux énergies alternatives (CEA). Le bureau d'étude marketing s'occupe essentiellement du marketing de l'innovation. Le business model du CEA (env. 15000 personnes) est d’une part de développer des technologies et dans un deuxième temps de les valoriser en les vendant à des industriels.
Au sein du service marketing, tous les employés possèdent une double compétence : ingénierie et marketing dans le but d’avoir un langage commun entre scientifiques et entrepreneurs. Un des cas d'école les plus connus du CEA est ST Microelectronics qui est l'un des leaders mondiaux de la fabrication de semi-conducteurs.
Le CEA utilise une boîte à outil méthodologique systématique pour toute étude de marché. La première étape est celle de l'analyse documentaire, qui permet de comprendre le marché. Puis le CEA passe par une phase de terrain (avec collecte et analyse des données) et finalement propose une synthèse des différentes informations. Des interviews de toutes les personnes sont menées tout au long de la chaine de valeur afin de savoir qui est le prescripteur.
La bibliométrie et le benchmarking sont également importants pour se positionner face aux concurrents ainsi que pour connaitre les niches technologiques ou les marchés exploitables.
Le CEA trouve les idées et cherche des personnes qui pourraient les appliquer, un marché qui pourrait absorber une telle technologie.
L'intermédiation dans le marché émergent de l'impression 3D : l'exemple de la start-up PrintaBit, par Stéphane Madoeuf
Stéphane Madoeuf présente PrintaBit, start-up fondée par 3 personnes. Elle est spécialisée dans l’impression en 3 dimensions, type d’impression qui représente une nouvelle révolution industrielle.
Il est possible d'imprimer sur tout type de support : métal, aliments, biologie (organes).... Cette technologie ne nécessite aucun assemblage, aucun délai, aucune compétence. Il est possible de répliquer tous les objets physiques, dans toutes les tailles et toutes les couleurs.
PrintaBit se positionne, dans le marché de l'impression 3D, sur l'art, le design et la mode. Cette plateforme sera bi-versant : elle sera ouverte aux designers qui souhaitent mettre leurs produits en vente, aux utilisateurs et aussi aux makers (personnes qui souhaitent fabriquer quelque chose).
C’est grâce à une veille méthodique que PrintaBit a choisi d’être un intermédiaire sur ce marché : c’est en identifiant les tendances et les besoins des clients possibles, aussi bien en participant à des salons qu’en structurant sa veille avec un grand nombre d’outils de veille à bas coût ou gratuits ; c’est ainsi que les 3 fondateurs de PrintaBit ont donc élaboré un portail Netvibes pour la recherche d'actualités, des flux RSS et des alertes Google, ils ont organisé la gestion de leurs signets avec Pearltrees et gèrent leurs informations via un compte Dropbox et Evernote. De plus, PrintaBit a développé Printabase, une base de données interne sur l'impression 3D. La communication au sein de l'équipe se pratique avec Google Plus. PrintaBit utilise également des outils pour gérer les projets (Basecamp) et les relations clients (Highrise).
Conclusion
La prise en compte des idées de clients/partenaires possibles, l’écoute permanente, la rapidité d’action –sans passage obligé par les études de marché-, la persévérance malgré les obstacles, ainsi que l’identification précise des failles et absences de ses concurrents sur certains segments, -avec l’aide par exemple, des jeux de stratégie- : voici quelques-unes des méthodes permettant d’identifier ses marchés actuels et futurs, méthodes qui ont été illustrées par des exemples vivants, concrets, et variés lors de cette 10ème journée franco-suisse sur la veille.
Même si la rapidité d’action est décisive, les start-up auront recours avec profit aux différents types d’incubateurs existants pour les aider dans l’identification de leur marché : que ce soit des incubateurs externes, spécialisés sur un domaine d’activité, comme la Fongit à Genève, ou internes à une organisation, comme le bureau d’études marketing (BEM) du CEA à Grenoble, ces organismes allient une méthodologie rigoureuse à une longue expérience.
Notes
(1) Eléments qu'on retrouve systématiquement sur une longue période, sur lesquels il n'y a pas d'innovation.
Les humanités numériques et les spécialistes en information documentaire : compte-rendu de la 1re Digital Humanities Summer School, 26-29 juin 2013, Berne
Mathilde Panes, Haute Ecole de Gestion, Genève
Igor Milhit, Haute Ecole de Gestion, Genève
Les humanités numériques et les spécialistes en information documentaire : compte-rendu de la 1re Digital Humanities Summer School, 26-29 juin 2013, Berne
Les Digital Humanities, un terme en vogue actuellement, suscitent la curiosité d’une partie des professionnels des sciences humaines et de l'information, font l'objet de nombreux articles et ont eu droit à leur première école d'été en Suisse. Organisé par infoclio.ch (Infoclio 2013), cet événement a eu lieu du 26 au 29 juin 2013 à l'Université de Berne (Natale 2013a).
La jeunesse de cette discipline induit une certaine liberté de définition. En effet, les acteurs des Digital Humanities n'ont pas encore formulé une définition établie de ce domaine, mais plutôt des esquisses. Lors de son intervention durant l'école d'été, Susan Schreibman, professeur au Département des Humanités numériques du Trinity College de Dublin (Trinity College Dublin 2011), interroge l'audience : les humanités numériques sont-elles un domaine, un outil, une discipline ? Tout cela à la fois ? Ou encore autre chose ? La question reste en suspens. Wikipédia, l'encyclopédie libre en ligne, présente les digital humanities de la manière suivante : elles « sont un domaine de recherche, d'enseignement et de création concernés par le croisement entre l'informatique et les disciplines des sciences humaines. » (Humanités numériques 2013). L'expression digital humanities se traduit en français par « humanités numériques » ou encore « humanités digitales » (Clivaz 2012). Nous utiliserons dans ce texte ces trois expressions indifféremment.
Si la plupart des chercheurs travaillent dans un environnement numérique, l'utilisation des nouvelles technologies pour élargir et mettre en valeur les sciences humaines en est à ses balbutiements, ou alors, selon le point de vue, à sa redécouverte. Comme le mettent en évidence les deux graphiques ci-dessous, l'expression Digital Humanities semble apparaître au début des années 2000. Le terme "Humanities computing" est son prédécesseur, ce qui souligne que les sciences humaines, comme la plupart des sciences, se sont intéressées à l'ordinateur il y a quelques décennies déjà. L'outil Google Trends met en avant l'émergence du terme Digital humanities à partir de 2006.
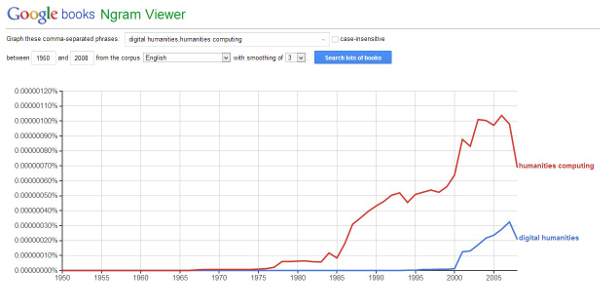
Graphique 1 - Comparaison des termes "Humanities computing" et "digital humanities", selon leurs occurences dans un corpus de l'outil Ngram Viewer de Google - http://goo.gl/RJ7Ycb
Graphique 2 - Evolution des recherches effectuées sur Google utilisant le terme "digital humanities", avec l'outil Google Trends - http://goo.gl/6Fmyr0
Dans cet article, nous esquissons les ponts qui rapprochent le domaine des humanités numériques, où beaucoup reste à explorer, et celui de l'information documentaire, à la recherche de convergences prometteuses.
Le programme, serré mais bien équilibré, de ces trois jours d'école d'été a permis d'aborder le sujet de manière conceptuelle et pratique. Les deuxième et troisième journées ont été rythmées par une alternance entre cours et ateliers, la dernière demi-journée ayant été consacrée à des mini unconferences : dans un mode horizontal de collaboration, les participants ont pu proposer des sujets de discussions, dont une partie a été sélectionnée par l'assemblée par une procédure de vote. Ces sujets ont ensuite été approfondis de manière informelle par tous les participants intéressés. La collaboration et la communication ont été facilitées par l'usage d'un outil de prise de notes collectives et par l'échange de tweets grâce au hashtag #dhch.
Des mécanos pour l'humaniste
Parmi les concepts et les outils abordés lors de l'école d'été, nous avons choisi une sélection susceptible d'intéresser, voire d'impliquer les métiers de l'information documentaire.
Analyse textuelle avec des outils en ligne
Le cours de Susan Schreibman a offert un regard rétrospectif sur les digital humanities et avancé quelques définitions. Il a mis en évidence que l'analyse textuelle et l'édition critique a, dès les années 50, rencontré l'informatique (Roberto Busa 2013). Schreibman a par ailleurs animé un atelier (Natale 2013b), qui a permis de découvrir un certain nombre d'outils en ligne pour accompagner l'analyse de texte, des services web qui ont l'avantage d'être relativement simples à utiliser. Simples, parce qu'ils ne nécessitent pas de prendre en charge l'installation de logiciels sur un ordinateur, ni l'apprentissage d'un langage de programmation ou de manipulation des données. Nous sommes d’avis que l’analyse textuelle est un domaine que peuvent s’approprier les spécialistes de l’information, et ce grâce à leurs connaissances des mécanismes de recherche d’information à travers les moteurs de recherche. En effet, les moteurs de recherche font subir plusieurs traitements synchrones et asynchrones aux requêtes formulées et au corpus indexés pour pouvoir être le plus efficaces possibles. Nous pensons qu'un des nouveaux rôles des bibliothèques académiques est d'initier les chercheurs intéressés à ces outils. Aussi, les compétences spécifiques à ces enseignements doivent être représentées au sein de l'équipe.
Nous constatons que certains des exemples présentés par Schreibman ne sont pas inconnus de nos professions. Le fameux Google Ngram Viewer, cité plus haut, est un des outils de recherche, mis à disposition par Google, que les spécialistes de la recherche connaissent. Il exprime graphiquement le nombre d’occurrences d'un terme ou d'une expression dans le corpus de livres numérisés par Google. Celui-ci est certainement l'un des plus conséquents disponible à ce jour. Néanmoins, il est important de garder à l'esprit qu'il est circonscrit aux collections qui ont été numérisées, et qu'il ne représente pas la "littérature mondiale". L'univers anglo-saxon y est par exemple surreprésenté. De plus, l'algorithme qu'utilise Google n'est pas public, ce qui empêche d'utiliser Ngram Viewer de manière scientifique, en reproduisant la méthodologie utilisée. Lors de l'atelier, il a été remarqué qu'il n'est pas toujours évident de comprendre comment fonctionne le lissage (smoothing) de la courbe. Google Ngram Viewer ne permet pas d'ajouter des données pour les analyser, l'utilisateur est contraint de se servir du corpus proposé, même si celui-ci est impressionnant. Il est toutefois possible de sélectionner une langue particulière ou de définir une échelle temporelle.
IBM offre également un outil en ligne très intéressant pour la visualisation de données : Many Eyes (IBM 2007). Il est possible de charger ses propres données, par exemple grâce à l'export d'un tableur en CSV, ou tout simplement une œuvre littéraire sous la forme d'un fichier TXT. Ce fichier peut être le résultat de l'OCR d'un livre numérisé, ou un fichier trouvé dans une bibliothèque numérique comme Projet Gutenberg, Internet Archive ou encore Wikisources. Différents types de visualisations sont possibles : créer un nuage de mots tout en sélectionnant une racine particulière (stemming), ou observer une structure du contexte d'un terme particulier, ou le réseau qui peut exister entre deux termes mis en relation de diverses manières. Par contre, Many Eyes ne s'adapte pas très bien aux textes francophones : l'outil d'IBM ne reconnaît pas les caractères accentués et les signes diacritiques.
De ce point de vue, Voyant est un service bien plus utile pour l'utilisateur non anglophone (Sinclair, Rockwell 2013; Lincoln Logarithms: Finding Meaning in Sermons : Text Mining with Voyant 2013). Il s'utilise sans création de compte. Il suffit de copier-coller le texte à analyser, ou de charger sur le site un fichier TXT. Une fois les données disponibles, Voyant affiche plusieurs cadres. Le cadre central est constitué par le texte lui-même, dans lequel il est possible de naviguer. Un nuage de mots est proposé, ainsi que des statistiques générales sur le texte : le nombre total de mots, de mots uniques, les mots les plus fréquents. Si on sélectionne un mot dans le texte, alors s'affiche un graphique représentant la fréquence de ce terme, ainsi que le contexte de ce terme. Chacun de ces cadrans peut être configuré, et c'est là que l'outil devient très intéressant. Il est en effet possible de choisir dans des listes prédéfinies de stop words – tous les mots non significatifs, comme les déterminants – en fonction de la langue utilisée, mais également d'ajouter ou de retirer tel ou tel terme de la liste sélectionnée.
Figure 1 - Interface de Voyant
Nous pouvons constater que les outils à disposition offrent des possibilités intéressantes, mais le chercheur peut vite en rencontrer les limites. Par ailleurs, comme c'est toujours le cas pour les services en ligne, la question de la sécurité et de la confidentialité des données se pose, surtout selon la nature de la recherche. De plus, ces outils d'analyses ne se substituent pas à une analyse classique, mais viennent la compléter. Enfin, selon les besoins, il peut être intéressant de mettre en œuvre un tel outil d'analyse textuelle au moyen des logiciels libres disponibles (moteurs de recherche, outils d'analyse des données, outils de visualisation, etc.), afin de pouvoir les paramétrer avec une plus grande liberté.
Encodage de manuscrits
Avec Elena Pierazzo (Pierazzo 2012), nous nous sommes penchés sur l'édition de textes (Natale 2013c), et plus particulièrement sur l'édition de textes à partir de manuscrits. Cette activité relève d'une tradition ancienne et marquée par une exigence d'exactitude, condition nécessaire à la pratique de l'analyse littéraire, de l'étude philosophique ou des sciences historiques. Quel est l'apport du numérique dans ce domaine ? Représenter un texte sur un écran revient-il au même que de le faire sur du papier ?
Au-delà des difficultés qui ne peuvent être résolues que par des compétences précises en littérature, histoire, paléographie, etc., retranscrire un manuscrit consiste à rendre compte de la « matérialité » de l'écrit, de sa disposition sur un support. De sa temporalité également : par rapport à un texte imprimé, un manuscrit reflète l'activité de la pensée qui n'est pas aussi linéaire que ce que l'imprimé suggère trop facilement (Grandjean 2013). Du point de vue de ces particularités de l'édition du manuscrit, il s'agit à la fois d'être en mesure de transcrire cette matérialité sur un écran, et de pouvoir utiliser la puissance de calcul de l'ordinateur pour retranscrire le côté dynamique de la pensée. Le « Proust Prototype » est un exemple pertinent de cette démarche (Pierazzo, André 2012). La retranscription du texte se superpose au fac-similé numérique et le lecteur peut soit suivre la chronologie de l'écriture, soit celle de la lecture.
Le codage de textes imprimés pour un support numérique, se fait au moyen d'un standard particulier, mis au point par la Text Encoding Initiative (TEI). Il s'agit d'un ensemble de directives constituant un format XML, dont l'objectif est de transcrire un texte imprimé pour que la machine puisse le traiter, en encodant à la fois la structure et les métadonnées. Aussi le TEI, jusqu'à récemment, ne permettait pas de retranscrire un document, avec ses aspects physiques, comme la page, la disposition du texte sur la page ou les ratures. C'est dans le but de pouvoir le faire que s'est constitué le TEI Manuscript Special Interest Group (Schreibman, Pierazzo, Vanhoutte 2013). Le groupe s'est attelé au développement d'un nouveau module dédié à l'édition critique de manuscrits et à la critique génétique (Génétique des textes 2013). L'atelier de l'après-midi a été l'occasion de pratiquer cette méthode d'encodage, à partir d'un court extrait d'un manuscrit de Jane Austen, dont on peut admirer, non pas les résultats de l'atelier, mais l'édition officielle à l'URL suivante : http://www.janeausten.ac.uk/manuscripts/pmwats/b1-4.html.
Cette évolution de la TEI est certainement en mesure d’interpeller les professionnels de l'information documentaire, dans la mesure où, historiquement, elle est apparue au début de l'aventure des bibliothèques numériques. D'autant que cette technique offre la possibilité de pousser encore plus loin la mise en valeur des collections de manuscrits numérisés, ajoutant à l'image scannée une transcription du texte qui respecte la matérialité du document.
RDF pour un retour dans le futur
Frédéric Kaplan (EPFL 2013) a présenté le projet Venice Time Machine, qui a pour but d'offrir aux chercheurs et au public des outils de visualisation de l'histoire de Venise. Il s'agit donc de récolter des données et de leur faire porter du sens grâce à des modèles sémantiques (Natale 2013d, 2013e).
Pour la première étape, l'acquisition des données, il est question de numériser la totalité des archives de Venise : 80 km de documents d'archives, sur une surface temporelle de plus de 1000 ans. Kaplan pense qu'en optimisant les techniques de numérisation, il est possible de parvenir à traiter 450 volumes par jour, afin de numériser le tout en dix ans. Quant à l'OCR, c'est un fait connu qu'actuellement le taux de réussite de la reconnaissance optique des caractères appliquée sur des manuscrits atteint, au mieux, 80 %. Ce taux peut sembler élevé, or il signifie que le cinquième de chaque volume doit être corrigé à la main, par des personnes capables de lire de telles écritures. Ce qui rend le projet de numérisation impossible. Kaplan pense que l'on aborde la question de l'OCR des manuscrits par un angle qui n'est pas des plus pertinents. La recherche actuelle s’attelle à produire des algorithmes capables de reconnaître des écritures manuelles quels que soient les contextes. Il se trouve que si l'on tient compte de ce contexte – est-ce un livre de droit, écrit à Venise au XVIe siècle, une chronique du XIIe ? –, alors il est possible de réduire considérablement le type de langues, de phrases, de mots, voire de formes de caractères, qui sont vraisemblablement utilisés dans un corpus précis. Aussi faudrait-il produire autant d'algorithmes que de corpus particuliers, et, selon Kaplan, par cette méthode il est possible de parvenir à un bien meilleur taux de réussite.
En imaginant que le point de la numérisation, y compris de l'OCR, soit résolu, reste à donner du sens à cette énorme masse de données, et que ce sens soit accessible au traitement automatique par les machines. C'était le propos de l'atelier Semantic Modelling for Humanities (Natale 2013e). Celui-ci a abordé les différentes méthodes connues jusqu'ici pour enregistrer et structurer des données. La méthode la plus simple est d'utiliser un tableur (Microsoft Excel, LibreOffice Calc, etc.). On dispose ainsi d'éléments sémantiques : l'intitulé des colonnes. Bien entendu, avec une telle méthode les requêtes de recherche possibles sont relativement limitées, et les logiciels actuels ne permettent pas de dépasser un nombre fixe de colonnes.
L'étape suivante consiste à utiliser un système de bases de données relationnelles (par exemple SQL). Le problème de la limite des colonnes se contourne par la création de nouvelles tables qui relient les informations entre elles. Et dans un tel contexte, la complexité de requêtes est bien plus élevée et donne lieu à des résultats plus approfondis. En revanche, alors que la quantité des données évolue, il sera peut-être nécessaire de migrer d'un schéma de base de données à un autre, ce qui peut vite devenir complexe et pénible.
Pour se libérer de ces contraintes, il est souhaitable d'utiliser non plus seulement les données, mais les métadonnées. Plus s'ajoutent des données, plus s'enrichissent les métadonnées, qui sont une manière de structurer les données, et qui offrent des possibilités de requêtes très développées. C'est lors de cette étape qu'intervient le RDF (Resource Description Framework 2013): il s'agit de relier des données au moyen de métadonnées. Avec cette solution, les éléments sémantiques sont nombreux, puisque les relations entre les données donnent justement du sens à celles-ci. Structurer revient à définir, et inversement. De plus, cette structure n'est ni figée ni limité par un logiciel (les limites d’un tableur comme Excel) ou par un schéma (le schéma d'une base de données), mais évolue et se développe simplement en ajoutant des données et des relations entre elles.
Ce type de projet rencontre un certain scepticisme à la fois des chercheurs en sciences humaines et des spécialistes de l'information documentaire, principalement concernant le volet de la numérisation et de « l'OCRisation » de telles masses de documents d'archives, le plus souvent manuscrits. Pourtant, comme cela a souvent été le cas dans l'histoire récente, c'est du monde des ingénieurs que des évolutions significatives sont venues modifier de manière fondamentale les méthodes à la fois des sciences humaines et des sciences de l'information. Mais, au-delà de ce scepticisme bien compréhensible, il est indéniable que les spécialistes de l'information documentaire ont des compétences à faire valoir, que ce soit en termes de projets de numérisation, de traitement de textes anciens et de gestion des métadonnées, voire de leur mise à disposition justement dans le but de construire de grands ensembles sémantiques de données (voir par exemple Hügi, Prongué 2013).
Un nouveau souffle pour les ID
Au-delà de l'intégration des spécialistes de l'information documentaire (ID) dans le développement des humanités numériques, l'émergence de ce nouveau domaine peut être une source d'inspiration pour les professionnels de l'ID. En effet, nous pensons tout d'abord que le rapport entre le passé, la tradition et la transition vers le monde numérique est un processus similaire, qu'il se déroule dans les sciences humaines ou dans l'information documentaire. L'adoption des nouvelles technologies est inéluctable. Les humanistes et les professionnels de l'information documentaire doivent identifier les méthodes et le savoir-faire propres à leurs disciplines et les utiliser dans un contexte numérique. Dans les deux cas, cela nécessite d’importantes capacités d'introspection et d’adaptation.
Par ailleurs, le poids de la tradition joue un rôle que nous percevons comme potentiellement contre-productif. L'image d'une profession ou d'une discipline véhiculée auprès des autres communautés professionnelles, du grand public et des détenteurs des cordons de la bourse, ainsi qu'auprès des acteurs du domaine eux-mêmes, peut freiner l'évolution vers la modernité. Assurément, un déficit en termes d'image entraîne une crédibilité réduite lorsqu'il s'agit de débuter des projets audacieux.
Lors de la participation à l'école d'été des humanités numériques, nous avons pu saisir l'enthousiasme bouillonnant qui va de pair avec la naissance des nouvelles idées et de nouveaux concepts, soutenus par les nouvelles technologies. Cet enthousiasme se traduit par une utilisation accrue d'outils informatiques, parfois imparfaits ou non-standards, ainsi que par la collaboration à la création de nouveaux instruments. Le site infoclio.ch en est un exemple : il rassemble de nombreux outils (informationnels, techniques, méthodologiques) à destination des professionnels des sciences historiques.
Sans oublier les fondations de leurs disciplines respectives, ni mettre de côté un regard critique et questionnant, les participants à la Summer School ont naturellement adopté une posture favorisant les échanges, et donc l'innovation. Comme nous l'avons évoqué en introduction, la création d'un espace collaboratif pour la prise de notes (DHCH 2013) a permis à l'audience de s'impliquer. Les unconferences (non-conférences), qui ont eu lieu lors de la dernière demi-journée, ont été un autre indicateur d'une communication transversale qui ne se formalise pas du statut de chacun. Dans un contexte si dynamique, la prise de parole par chacun est encouragée. Ce contexte précis pourrait bénéficier au domaine de l'information documentaire pour la construction de concepts novateurs et de nouveaux paradigmes. Aujourd'hui, l’effervescence qui a eu cours dans le milieu ID lors du début de l'informatisation des catalogues est retombée, et une association avec les humanistes est l'occasion de donner un nouveau souffle à l'engouement pour l'innovation technologique en matière de traitement de l'information.
La combinaison de l'ancien et du neuf donne lieu à des associations inédites : l'histoire et la visualisation de données, la philologie et l'encodage de texte ou l'information documentaire et la curation de données. Pour ce faire, il est nécessaire de définir les compétences métiers intrinsèques à une discipline, puis de mener une réflexion concernant les outils qui serviront le mieux cette discipline. Une fois les premiers pas effectués, une communication adéquate sur les projets est nécessaire. En cela, il est important que les chercheurs s'entendent sur une définition concertée des humanités numériques. Tout comme les professionnels de l'information tentent constamment de définir « l'information documentaire ».
Une place à prendre
Dans ce contexte, quels peuvent être les rôles des professionnels de l'information documentaire dans les humanités numériques ? En préambule à ce point, il n'est peut-être pas inutile de rappeler que si les humanités numériques sont nées de la confrontation des sciences humaines avec l'informatisation généralisée, la science de l'information est souvent située à l'intersection des sciences de l'ingénieur et des sciences humaines. Ici, la question de la double ou triple compétence est centrale. En effet, dans les humanités numériques, l'équation est la suivante : sujet (littérature du XVIe siècle, manuscrits médiévaux, etc.) ET technique (encodage de textes, visualisation des données, fouille de données textuelles, etc.) ET utilisation des outils documentaires informatisés (gestion des références bibliographiques avec, par exemple, Zotero, système de gestion de contenu, wiki, etc.). Dans ce cadre, il y a donc toujours un sujet, plus ou moins spécifique, avec ses particularités et ses concepts fondamentaux, ainsi qu'une couche technique. Les professionnels de l'information documentaire sont plus ou moins familiers avec cette partie technique, car, avec l'évolution de leurs métiers, ils sont souvent versés dans l'utilisation d'outils informatiques.
Traditionnellement, les professionnels ID sont en mesure d'appréhender des sujets pour lesquels ils n'ont pas forcément d'expertise. Par exemple, lors de l'indexation, le bibliothécaire sélectionne les mots-matières adéquats sans comprendre le contenu du livre dans son intégralité. Il est simplement capable d'en extraire assez d'informations pour pouvoir rendre le livre accessible via une recherche. Si nous transposons cette pratique dans le cadre des humanités digitales, le professionnel ID devra appliquer les techniques de gestion de l'informatique numérique à des sujets relatifs aux sciences humaines. Il pourra apporter une aide concrète, plutôt technique, sans devoir être un spécialiste, par exemple, de la correspondance de tel écrivain du XVIIIe siècle.
Pour saisir les enjeux des humanités numériques, un spécialiste de l'information devrait comprendre les méthodologies et les compétences spécifiques au domaine des humanistes, en faisant appel à ses capacités d'adaptation et d'apprentissage ou en privilégiant l'échange de connaissances. Le niveau d’expertise du spécialiste dépend principalement des exigences d'un employeur qui pourrait souhaiter qu'une double ou triple compétence soit déjà acquise par la personne qu'il emploie. En partant du principe que les humanités numériques ne sont pas encore circonscrites, les emplois et les compétences qui s'y rapportent ne sont pas encore clairement définis. En clair, les humanistes n'ont pas encore déterminé quels étaient leurs besoins pour une transition vers le numérique, les professionnels ID peuvent être intégrés au sein de ces terrains mouvants.
Si la summer school de 2013 a permis de mettre en évidence qu'une partie des chercheurs en sciences humaines ont acquis des compétences certaines à la fois dans les domaines de l'informatique (outil de visualisation basé sur la maîtrise de langages) et des sciences de l'information (Zotero, RDF), ce n'est de loin pas le cas de toute la communauté. Or, ces mêmes chercheurs vont de plus en plus se tourner vers ce type d'outils. Et si les professionnels de l'information documentaire leur apportent déjà une aide pour s'emparer des outils de recherches existants (OPAC, banques de données commerciales, recherche sur le Web, logiciel de gestion de références bibliographiques), ils peuvent certainement étendre ce rôle. Notamment parce que les projets de recherche impliquent aujourd'hui des équipes d'une certaine ampleur, des productions de documents importantes, ainsi que la gestion de volumes de données non négligeables. De ce point de vue, les compétences ID sont d'évidence des ressources utiles dans l'accompagnement des usagers, la structuration de l'information ainsi que le développement d'interfaces et d'outils de recherche permettant de soutenir les efforts des chercheurs et l'exploitation future des données.
À cela s'ajoute que la position particulière des professionnels de l'information documentaire est tout à fait intéressante. Nos métiers, nous l'avons déjà mentionné, ont une longue tradition de services offerts aux chercheurs, professeurs et étudiants en sciences humaines. Mais, depuis quelques décennies au moins, nous avons été confrontés avec le monde de l'informatique. Comme le travail des chercheurs, même en sciences humaines, implique de gérer de l'information, avec les moyens et les contraintes de l'informatique, les professionnels de l'information documentaire doivent développer les compétences nécessaires pour soutenir les chercheurs dans leur travail. Nous pensons, par exemple, aux exigences pointues qui sont de plus en plus imposées aux chercheurs en matière d'archivage électronique des données de la recherche.
Dans ce sens, nous pensons qu'il est essentiel que les spécialistes ID puissent, d'une part, intervenir très tôt dans le cursus universitaire, comme c'est d'ailleurs la tendance, non seulement pour former les étudiants à la recherche d'information, à la citation et la rédaction de bibliographies, mais également pour introduire des notions de gestion de l'information, ne serait-ce que la maîtrises des sauvegardes, ou le choix de formats offrant de meilleures assurances d'archivage. D'autre part, nos métiers doivent accompagner les chercheurs, et ce dès la phase de conception d'un projet de recherche, afin d'apporter toute l'aide nécessaire à la digital curation des données de la recherche, ou à la manipulation de certains outils d'analyse (comment préparer un corpus de texte pour que des outils d'analyse puissent les traiter, par exemple).
Bibliographie
CLIVAZ, Claire, 2012. «Humanités Digitales»: mais oui, un néologisme consciemment choisi! Suite. Digital Humanities Blog [en ligne]. 13 septembre 2012. [Consulté le 16 décembre 2013]. Disponible à l’adresse : http://claireclivaz.hypotheses.org/114
DHCH, 2013. Framapad Lite [en ligne]. [Consulté le 16 décembre 2013]. Disponible à l’adresse : http://lite.framapad.org/p/DHCH
EPFL, 2013. Frédéric Kaplan. EPFL [en ligne]. 2013. [Consulté le 16 décembre 2013]. Disponible à l’adresse : http://personnes.epfl.ch/frederic.kaplan
Génétique des textes, 2013. Wikipédia [en ligne]. [Consulté le 16 décembre 2013]. Disponible à l’adresse : https://fr.wikipedia.org/wiki/Génétique_des_textes
GRANDJEAN, Martin, 2013. #dhch Manuscript edition « Sometimes there is no text! » @epierazzo (non linear examples) pic.twitter.com/cCEoy3h1oc. @GrandjeanMartin [en ligne]. 10 AM - -06-27 2013. [Consulté le 25 novembre 2013]. Disponible à l’adresse : https://twitter.com/GrandjeanMartin/status/350164196094255104
HÜGI, Jasmin et PRONGUÉ, Nicolas, 2013. Marc contre Élodie, ou les avantages des Linked Open Data en bibliothèque. Recherche d’ID : carnet de recherche des étudiants du master en information documentaire de la Haute école de gestion de Genève [en ligne]. 10 décembre 2013. [Consulté le 16 décembre 2013]. Disponible à l’adresse : http://recherchemid.wordpress.com/2013/12/10/marc-contre-elodie/
Humanités numériques, 2013. Wikipédia [en ligne]. [Consulté le 2 décembre 2013]. Disponible à l’adresse : https://fr.wikipedia.org/wiki/Humanités_numériques
IBM, 2007. Many Eyes. Many Eyes [en ligne]. 2007. [Consulté le 8 décembre 2013]. Disponible à l’adresse : http://www-958.ibm.com/software/data/cognos/manyeyes/
INFOCLIO, 2013. infoclio.ch. infoclio.ch : le portail professionnel des sciences historiques en Suisse [en ligne]. 2013. [Consulté le 2 décembre 2013]. Disponible à l’adresse : http://www.infoclio.ch/
Lincoln Logarithms: Finding Meaning in Sermons: Text Mining with Voyant, 2013. Emory Libraries : Digital Scholarship Commons [en ligne]. [Consulté le 8 décembre 2013]. Disponible à l’adresse : http://disc.library.emory.edu/lincoln/voyant/
NATALE, Enrico, 2013a. First DH Summer School : Switzerland, June 26-29, 2013, University of Bern. [en ligne]. 2013. [Consulté le 2 décembre 2013]. Disponible à l’adresse : http://www.dhsummerschool.ch/
NATALE, Enrico, 2013b. Text Analysis with online Tools. dhsummerschool [en ligne]. 4 juillet 2013. [Consulté le 16 décembre 2013]. Disponible à l’adresse : http://www.dhsummerschool.ch/?page_id=358
NATALE, Enrico, 2013c. Course: Pierazzo. dhsummerschool [en ligne]. 4 juillet 2013. [Consulté le 8 décembre 2013]. Disponible à l’adresse : http://www.dhsummerschool.ch/?page_id=283
NATALE, Enrico, 2013d. Course: Kaplan. dhsummerschool [en ligne]. 4 juillet 2013. [Consulté le 16 décembre 2013]. Disponible à l’adresse : http://www.dhsummerschool.ch/?page_id=335
NATALE, Enrico, 2013e. Semantic Modelling for the Humanities. dhsummerschool [en ligne]. 4 juillet 2013. [Consulté le 16 décembre 2013]. Disponible à l’adresse : http://www.dhsummerschool.ch/?page_id=364
PIERAZZO, Elena et ANDRÉ, Julie, 2012. Autour d’une séquence et des notes du Cahier 46 : enjeu du codage dans les brouillons de Proust. Proust Prototype [en ligne]. 2012. [Consulté le 8 décembre 2013]. Disponible à l’adresse : http://research.cch.kcl.ac.uk/proust_prototype/
PIERAZZO, Elena, 2012. Elena Pierazzo. Elena Pierazzo [en ligne]. 17 novembre 2012. [Consulté le 8 décembre 2013]. Disponible à l’adresse : http://www.elenapierazzo.org/
Resource Description Framework, 2013. Wikipédia [en ligne]. [Consulté le 16 décembre 2013]. Disponible à l’adresse : https://fr.wikipedia.org/wiki/Resource_Description_Framework
Roberto Busa, 2013. Wikipedia, the free encyclopedia [en ligne]. [Consulté le 2 décembre 2013]. Disponible à l’adresse : https://en.wikipedia.org/wiki/Roberto_Busa
SCHREIBMAN, Susan, PIERAZZO, Elena et VANHOUTTE, Edward, 2013. TEI: Manuscripts SIG. TEI : Text Encoding Initiative [en ligne]. 7 mars 2013. [Consulté le 8 décembre 2013]. Disponible à l’adresse : http://www.tei-c.org/Activities/SIG/Manuscript/
SINCLAIR, Stéfan et ROCKWELL, Geoffrey, 2013. Voyant Tools: Reveal Your Texts. [en ligne]. 2013. [Consulté le 8 décembre 2013]. Disponible à l’adresse : http://voyant-tools.org/
TRINITY COLLEGE DUBLIN, 2011. School of English : Trinity College Dublin, The University of Dublin, Ireland. [en ligne]. 2011. [Consulté le 2 décembre 2013]. Disponible à l’adresse : http://www.tcd.ie/English/staff/academic-staff/susan-schriebman.php
Journée d'étude « Les données en bibliothèques, les enjeux des linked open data », Lausanne 1er octobre 2013
Pierre Boillat, Conservatoire et Jardin botaniques de la Ville de Genève
L'importance des données ne va faire que s'accroître ces prochaines années. Les professionnels de l'information documentaire de Suisse romande ne s'y sont pas trompés en s'inscrivant en nombre à la journée d'étude du 1er octobre 2013 à Lausanne sur le web des données libres (en anglais les linked open data) en lien avec les bibliothèques. Septante-deux inscrits ont conduit les organisateurs, la filière Information documentaire de la Haute école de gestion de Genève, à déplacer le lieu de la rencontre afin de recevoir tous les participants dans de bonnes conditions.
La journée s'est organisée autour de six exposés présentés par des intervenants du monde des bibliothèques provenant de plusieurs pays européens et ayant, pour la plupart, une solide expérience de la pratique du web des données libres. En guise d'introduction, Madame Emmanuelle Bermès, du Centre Pompidou (Paris), a dressé un tableau synthétique de la problématique du web sémantique en abordant notamment le Resource description framework (RDF)1. Elle a insisté sur l'importance du partage des données, qui doit primer sur la possession de données en elle-même (le succès du libre accès – l'open access – en est un brillant exemple). Cet échange passe par le renouvellement des normes et standards. MARC et ses dérivés nationaux ou internationaux ne peuvent plus convenir à une société qui échange globalement et fait fi des barrières des métiers. L'utilisateur du web n'a que faire de nos catalogues ou portails documentaires bridés par leurs formats limités, il veut l'information directement. De nouveaux standards au-delà de l'environnement des bibliothèques (tels que MARC) émergeront et les bibliothèques devront se battre pour rester dans la course. Ce combat ne réussira que si les bibliothèques s'unissent ; si une association faîtière telle que l'IFLA peut apparaître peu réactive au premier abord face aux métamorphoses continues des pratiques du web, elle dispose néanmoins de compétences humaines véritables par sa section dédiée au web sémantique (cf. infra). Les initiatives suivantes ont été citées : W3C Library Linked Data Incubator Group2 (qui a cessé ses activités en avril 2012), Dublin Core Metadata Initiative3, Resource Description and Access (RDA)4, Bibliographic Framework Transition Initiative (BIBFRAME)5, Linked Open Data in Libraries, Archives & Museums (LODLAM)6, Schema Bib Extend Community Group (W3C Community and Business Groups)7 ou encore le Semantic Web Special Interest Group de l'IFLA8.
Ces concepts se sont concrétisés avec la communication de Monsieur Stefan Gradmann, professeur au Département de l'art de la Katholieke Universiteit Leuven (Louvain) et directeur de la bibliothèque universitaire de cette université. M. Gradmann nous a donné à voir une application en bibliothèque du web des données libres à travers la bibliothèque numérique européenne Europeana et son Europeana data model. Europeana data model est un modèle de représentation du patrimoine culturel dans Europeana. Il montre bien les relations entre les données internes à Europeana et celles récupérées dans d'autres bases de données ou catalogues de référence tels que le Virtual International Authority File (VIAF)9 pour les autorités, le Getty Thesaurus of Geographic Names10 pour les noms de lieu, la Library of Congress pour les noms de langues, etc. Europeana data model est un modèle valable autant pour les bibliothèques, que pour les archives ou les musées. Il pourrait devenir un standard même si pour l'heure aucun logiciel commercial ne l'utilise. Par ailleurs, et d'une manière générale, la masse des ressources en ligne constitue un vrai défi pour les chercheurs qui doivent développer de nouvelles stratégies d'utilisation de l'information à l'aide d'outils encore à créer. Les bibliothèques ont ici une opportunité à saisir pour se mettre en avant. Ce développement s'accompagne aussi d'une nouvelle terminologie que le bibliothécaire doit apprivoiser. Dans ce contexte, Europeana, qui est devenu une source majeure des humanités numériques et qui propose une nouvelle manière de rechercher l'information, permet aux bibliothécaires de se positionner au même niveau que les chercheurs (ou presque).
Un autre exemple nous a été présenté par Monsieur Romain Wenz, conservateur à la Bibliothèque nationale de France (BnF), avec l'outil « data.bnf.fr ». Lancé en 2011, « data.bnf.fr » réutilise les données contenues dans les différents catalogues de la BnF (à ce jour 5,5 millions de documents sont concernés, soit 40% des notices de catalogues) et les présente aux utilisateurs, à l'aide des outils du web sémantique, d'une manière synthétique et originale (voir les graphiques par frises chronologiques pour les différentes éditions d'une œuvre) alors qu'elles étaient jusque-là dispersées dans lesdits catalogues. « data.bnf.fr » est indexé par les moteurs de recherche. Ainsi, l'internaute accède à l'information sans passer par les catalogues. Ces données sont complètement libres de droit. Cette approche novatrice permet de mettre en exergue des auteurs peu connus ou des contributions peu visibles des grands auteurs. Le succès est au rendez-vous avec plus de 70'000 visiteurs uniques par mois, dont 80% passent par l'entremise des moteurs de recherche.
Le CERN est un grand producteur de données et Monsieur Jens Vigen, chef du Service d'information scientifique dudit CERN, a présenté les défis d'une institution qui rencontre déjà des problèmes de lecture de données vieilles d'à peine dix ans ! Aux projets d'open access pour les publications que le CERN a mis en oeuvre avec succès depuis déjà un certain temps, s'ajoutent ceux concernant les données scientifiques. Monsieur Vigen s'est réjoui que l'accès aux données soit une priorité reconnue par les instances politiques. Il a cité le rapport remis en octobre 2010 par le High Level Expert Group on Scientific Data à la Commission européenne, document qui présente une vision de la problématique des données scientifiques à l'horizon 203011.
Le Réseau des bibliothèques de Suisse occidentale (RERO) est un acteur régional majeur dans le monde des bibliothèques. Monsieur Miguel Moreira, chef de projet à RERO, a présenté les implications actuelles et potentielles du web des données libres sur le réseau romand. Le web sémantique est une priorité pour RERO comme en témoigne son inscription au plan stratégique 2013-2017 sous le chiffre 1.512. La bibliothèque numérique RERO DOC apparaît comme le plus bel exemple d'une valorisation des données par RERO. L'adhésion en 2010 de RERO à VIAF a constitué une étape forte vers le web de données libres. Les projets s'articulent autour du passage au RDF et au choix « des vocabulaires et métadonnées à adopter pour les relations ».
La dernière présentation, un duo mené par Madame Jasmin Hügi et Monsieur Nicolas Prongué, tous deux étudiants en Master en science de l'information à la Haute école de gestion de Genève, s'est divisée en deux parties. D'une part, ils ont décrit les cinq exemples suivants d'applications existantes dans le web des données libres en bibliothèque : lobid.org (Linking Open Bibliographic Data)13, British National Bibliography14, VIAF15, Centre Pompidou16 et « data.bnf.fr ». Ils ont relevé qu'en Suisse, rien n'a encore dépassé le stade du projet. Néanmoins, des recherches sont menées par la Bibliothèque nationale suisse, le CERN, RERO et Swissbib. D'autre part, ils ont effectué une étude des compétences requises pour les professionnels de l'information documentaire souhaitant œuvrer dans le web des données libres en bibliothèque. Ils ont analysé huit offres d'emploi et ont pris contact avec dix experts dans le domaine. Leurs résultats leur permettent d'esquisser trois axes de compétence des candidats : transformation de données bibliographiques en linked open data, publication des linked open data et accès en ligne et, finalement, collaboration. Ils émettent aussi deux constats généraux : le premier sur la nécessaire métamorphose du travail des catalogueurs tel qu'il se pratique aujourd'hui et, le deuxième, sur l'importance de la veille et du suivi des évolutions métier.
Cette journée a ouvert une fenêtre sur l'évolution de nos catalogues de bibliothèque ou plutôt a permis de démontrer que les innombrables données qu'ils contiennent ont un avenir. Des générations de bibliothécaires se sont succédées pour les alimenter et les développer. Il est heureux de savoir que les outils du web des données libres accroissent encore les possibles de leur utilisation. Peut-être devrons-nous, bibliothécaires, faire le deuil du contrôle du contenu de « nos » notices ; les relations entre ressources estomperont les limites des réservoirs des uns et des autres. Et ces applications permettron d'offrir aux utilisateurs des accès à l'information en phase avec leurs demandes, en adéquation avec les besoins de la société. Toute nécessité indispensable à l'inscription pérenne des bibliothèques dans notre temps.
Notes
Barrelet, Jean-Marc (éd.). Entre lecture, culture et patrimoine. La Bibliothèque de la Ville de la Chaux-de-Fonds 1838-2013. Neuchâtel : Ed. Alphil, 2013. 241 p., ill., 29 cm. ISBN 9782940489237
Alain Jacquesson, Ancien directeur de la Bibliothèque de Genève
Barrelet, Jean-Marc (éd.). Entre lecture, culture et patrimoine. La Bibliothèque de la Ville de la Chaux-de-Fonds 1838-2013. Neuchâtel : Ed. Alphil, 2013. 241 p., ill., 29 cm. ISBN 9782940489237
Ont contribué à l'ouvrage : Jean-Frédéric Jauslin, Jean-Marc Barrelet, Jacques Ramseyer, Sylvie Béguelin, Jacques-André Humair, Josiane Cetlin, Clara Grégori, Catherine Corthésy, Philippe Schindler, Michel Schlup, Jean-Henry Papilloud, Yolande Estermann Wiskott, Michel Gorin, Alain Jacquesson, Christian Gaiser.
A l'occasion de son 175ème anniversaire, la Bibliothèque de la Ville de la Chaux-de-Fonds a publié en janvier 2013 un ouvrage volumineux retraçant son histoire. Les dix-sept contributions mettent en perspective cette bibliothèque par rapport aux évolutions politiques, sociales et culturelles qui caractérisent la fin du XIXe siècle. L'ouvrage évoque la naissance de la bibliothèque dans un environnement scolaire (1838), puis son ouverture aux adultes vers 1901. Elle devient alors Bibliothèque de la Ville. Son développement est freiné par la crise horlogère des années trente, puis par la guerre. L'introduction du libre-accès est une étape importante. Progressivement sous la houlette de Fernand Donzé, son nouveau directeur, la Bibliothèque devient l'une des bibliothèques de lecture publique les plus en vue dans notre pays. Dans les années quatre-vingt, outre ses missions traditionnelles, l'institution intègre la conservation du patrimoine des montagnes neuchâteloises. Dès les années quatre-vingt, la Bibliothèque intègre les documents audio-visuels, l'informatique et le numérique.
Dès sa création l'institution s'est préoccupée de rassembler et organiser des fonds d'archives provenant de personnalités neuchâteloises, artistes, horlogers ou savants. A partir de 1910, la Bibliothèque acquit, par dons ou par legs, des fonds comprenant la bibliothèque et les manuscrits de personnalités de la ville. De nombreux écrivains, journalistes, artistes, hommes politiques, ainsi que de nombreuses sociétés (musique, commerce, sport) y déposèrent aussi leurs fonds. Le fonds bibliophilique de la bibliothèque est constitué d'éditions originales, d'éditions illustrées (Blaise Cendrars par Sonia Delaunay, par exemple), de livres d'artistes, de revues d'artistes, mais aussi d'incunables, de livres illustrés ou d'éditions d'imprimeurs prestigieux de la Renaissance. La Bibliothèque des jeunes ouverte en 1953 connaîtra une dynamique reconnue dans la Suisse entière. La Bibliothèque récolte des documents audio-visuels dès la fin des années soixante-dix. Une loi de 1981 la charge du Dépôt légal cantonal dans ce domaine. Ses fonds diversifiés, provenant de privés comme d'entreprises, n'ont pas d'équivalents en Suisse romande si ce n'est peut-être en Valais. L'informatisation se fait en deux temps, tout d'abord en local avec le système ALS, puis en rejoignant le réseau RERO. La Bibliothèque est également à l'origine du Bibliobus neuchâtelois qui fonctionne depuis 1974 dans les montagnes de la région. Le Réseau des bibliothèques neuchâteloises et jurassiennes (RBNJ), une structure administrative simple créée en 2002, vise à améliorer les services au public et de coordonner la gestion et la valorisation du patrimoine dont elle a la charge, agissant ainsi beaucoup plus largement que la coordination informatique.
La Bibliothèque a également adopté un programme PAC (Preservation And Conservation) tel qu'il a été mis en oeuvre dans le réseau romand, compte tenu de deux services aux missions contradictoires : la communication et la conservation. Le traitement de certains documents peut s'appuyer sur des structures fédérales comme Memoriav (Association dont la mission est la sauvegarde du patrimoine audiovisuel suisse).
Une contribution est consacrée à la formation et plus spécifiquement à la création en 1995 des Hautes écoles spécialisées (HES) et leurs conséquences sur la formation des bibliothécaires, des documentalistes et des archivistes, ainsi que des nouveaux métiers liés à l'évolution des sciences de l'information. Les titres qu'elles décernent (Bachelor, Master) sont désormais reconnus au niveau fédéral. Un dernier chapitre cherche à savoir quelle sera la place des bibliothèques dans un monde qui progressivement bascule vers le numérique. L'informatique a permis dans un premier temps de faire évoluer les catalogues sur fiches cartonnées vers des bases de données bibliographiques régionales (RERO), suisses (SwissBib) et planétaires (WorldCat), accessibles à tout un chacun depuis son domicile ; cette dernière réalisation permet de localiser théoriquement 1,9 milliard d'ouvrages dont ceux de la Chaux-de-Fonds. La nouvelle révolution concerne le numérique ; certains domaines de l'édition ont totalement basculé vers le numérique (physique, sciences de la vie). L'évolution est moins rapide dans les sciences humaines et la lecture loisir, mais le mouvement est lancé. On publie désormais sous forme immatérielle (ebooks) et on numérise des fonds entiers de bibliothèques patrimoniales. La gigantesque opération lancée par Google Livres (23 millions de volumes numérisés en 2013) met en évidence un nouveau danger : les fonds imprimés des bibliothèques étaient dans le domaine public et accessibles à tous, sous forme numérique ils retournent au secteur privé. Pour les bibliothèques les défis sont multiples ; ils touchent notamment les technologies, la conservation du patrimoine numérique, l'évolution des législations, les bouleversements commerciaux.
L'ouvrage publié par la Bibliothèque de la Ville de La Chaux-de-Fonds est remarquable par plusieurs aspects. Son graphisme, sa typographie, ses illustrations sont autant d'atouts qui mettent en valeur les textes. Tous les auteurs ont pris soin de placer les réalisations de la Chaux-de-Fonds dans un contexte plus général, suisse voire international. A l'occasion de cet anniversaire, ce livre rend hommage aux générations de professionnels qui ont œuvré au développement de cette bibliothèque. Un exemple pour tous.
Wilson, Tom D. (dir.). Theory in Information Behaviour Research. Sheffield : Eiconics limited at Smashwords, 2013, 182 p. ISBN 9780957495708
Eric Thivant, IAE Lyon - Université Lyon 3
Wilson, Tom D. (dir.). Theory in Information Behaviour Research. Sheffield : Eiconics limited at Smashwords, 2013, 182 p. ISBN 9780957495708. - Disponible à l'adresse : https://www.smashwords.com/books/view/336724
Ont contribué à l’ouvrage : Gérald Benoit, Andrew Cox, Jannica Heinstrom, Elena Macevicuite, Agusta Palsdottir, Rebecca Reynolds, Reijo Savolainen
Ce livre destiné aux chercheurs et aux étudiants en Sciences de l’Information présente huit essais sur des approches théoriques prometteuses utilisées pour l’analyse des pratiques informationnelles en contexte. Pour chaque approche, les auteurs rappellent à chaque fois succinctement le cadre théorique utilisé, propose une liste bibliographique complète sur une théorie et montre comment cette théorie a pu ou peut être mobilisée en Sciences de l’Information. L’idée initiale de cet ouvrage était de faire appel aux auteurs d’articles scientifiques intéressants de la revue « Information research » pour qu’ils présentent en approfondissant les théories qu’ils avaient utilisées et montrent leurs intérêts dans le domaine des pratiques informationnelles.
Cet ouvrage est complémentaire et non concurrent à d’autres livres théoriques qui font aussi le point sur les pratiques informationnelles comme le livre de D. Case « Looking for Information : A Survey of Research on Information Seeking, Needs and Behavior » publié en 2002 ou le livre de K.E. Fisher, S Erdelez & E.F McKechnie, intitulé « theories of Information Behaviour », qui présentent de façon plus large, les cadres théoriques, les méthodologies et/ou les modèles développés à partir de ces théories.
Cet ouvrage n’a pas la prétention d’être exhaustif, il ne recense que sept théories utilisés par des chercheurs en sciences de l'information : la théorie de l'activité décrite par T.D Wilson, la théorie critique présentée par G. Benoit, la théorie du construit personnel expliquée par Rebecca Reynolds, la théorie de la personnalité par Jannica Heinstrom, la théorie de la pratique (ou pragmatique) par Andrew Cox, la théorie socio-cognitive par Agusta Palsdottir et la phénoménologie sociale par T.D Wilson et R. Savolainen. Et E. Macevicuite nous dresse un rapide panorama dans un dernier chapitre des études qui ont été menées en Europe Centrale et Orientale et en Russie et qui complètent les travaux des chercheurs occidentaux.
Toutes ces théories peuvent être utiles aux étudiants et aux chercheurs pour guider leurs travaux, réfléchir sur leurs collectes de données et analyser leurs résultats. Ces théories proposent comme nous l’indique T.D. Wilson des explications alternatives des phénomènes sociaux observés en contexte et non des prédictions sur des futurs comportements informationnels. Chaque chapitre est réalisé suivant le schéma suivant : présentation de la théorie choisie (histoire et principe) et ses applications dans la littérature sur les pratiques informationnelles en sciences de l’Information. Ainsi à titre d’exemple, nous commenterons les premiers trois chapitres de cet ouvrage.
Dans le premier chapitre, T.D. Wilson s’intéresse à la genèse et rappelle les principaux principes de la théorie de l’activité ou « activity theory » développée par L. S. Vygotsky et les dimensions culturelles et historiques de l’activité avec A.N. Leont’ev et Y. Engeström dans une première partie. Puis dans une seconde partie, T.D. Wilson nous dresse un inventaire des recherches menées actuellement sur les pratiques informationnelles qui mobilisent notamment cette théorie, par exemple par C. Khulthau lorsqu’elle évoque le concept de la zone d’intervention ou encore par le groupe de recherche AIMTech à l’Université de Leeds qui l’applique dans des contextes variés. Une bibliographie et une webographie complètent la présentation de cette théorie et de ses applications.
Dans le chapitre suivant, G. Benoît nous présente l’origine et le développement de la « Critical Theory » appelée aussi « théorie critique », issue de l’Ecole de Francfort, depuis la première génération de penseurs du début du 20ème siècle, avec M. Horkheimer, T. Adorno, jusqu’à la seconde génération avec K-O. Appel, H. Joas, A. Honneth, J. Habermas. Le modèle de J. Habermas est présenté ainsi qu’un rapide recensement des travaux en Sciences de l’information issus de ce courant.
Nous évoquerons également le troisième chapitre rédigé par R. Reynolds sur la théorie du construit personnel. Cette théorie a été développée par G. Kelly en 1963 et a été utilisée notamment par C. Kuhlthau pour conceptualiser le processus de recherche d’information et les effets de l’incertitude. Les travaux de C. Kuhlthau restent parmi les plus cités dans la communauté des chercheurs qui travaillent sur les pratiques informationnelles et cet ouvrage permet de faire le point sur la théorie sous-jacente utilisée.
Nous laissons au lecteur le soin de lire les derniers chapitres et de découvrir les théories suivantes comme la théorie de la personnalité, la théorie de la pratique, la théorie sociocognitive qui peuvent permettre de comprendre également ces comportements et pratiques informationnels.
En conclusion nous pensons que cet ouvrage est un bon point de départ pour des jeunes chercheurs ou des chercheurs confirmés qui souhaitent s’appuyer sur des textes de référence théorique et qui est révélateur des derniers travaux des chercheurs de cette communauté.